
Preemptive Prediction-Based Automated Cyberattack Framework Modeling




Abstract
:1. Introduction
2. Related Research
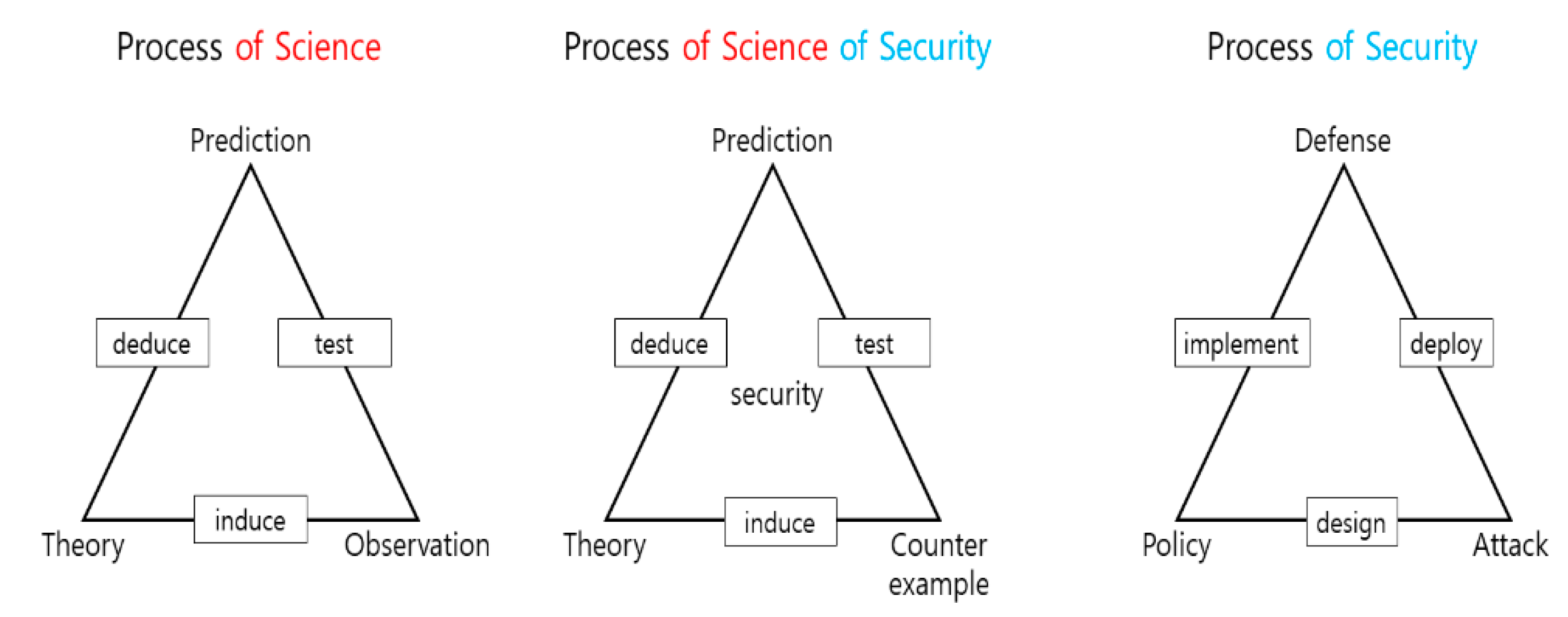
2.1. Science of Security (SoS)
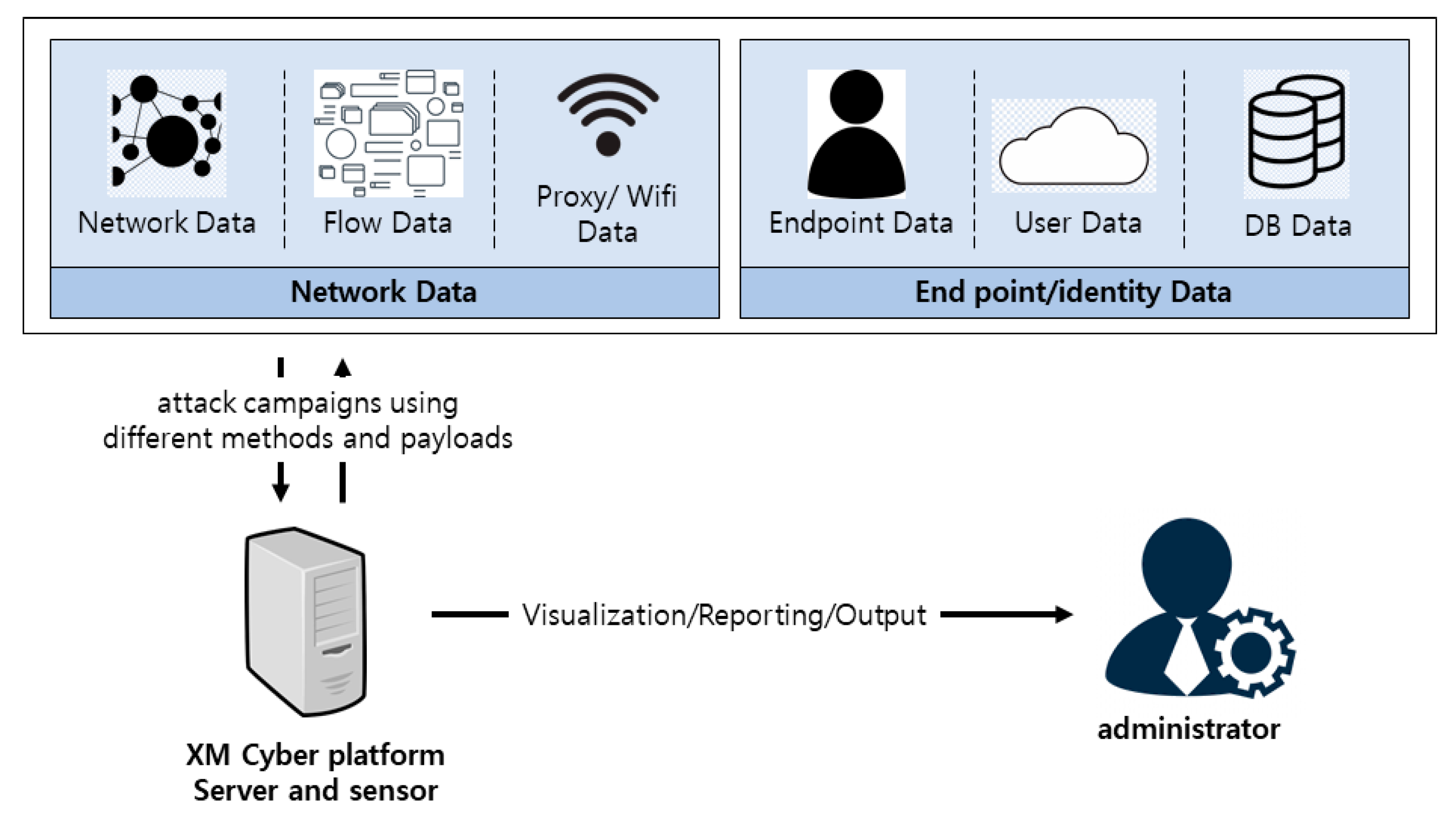
2.2. Breach and Attack Simulation (BAS)
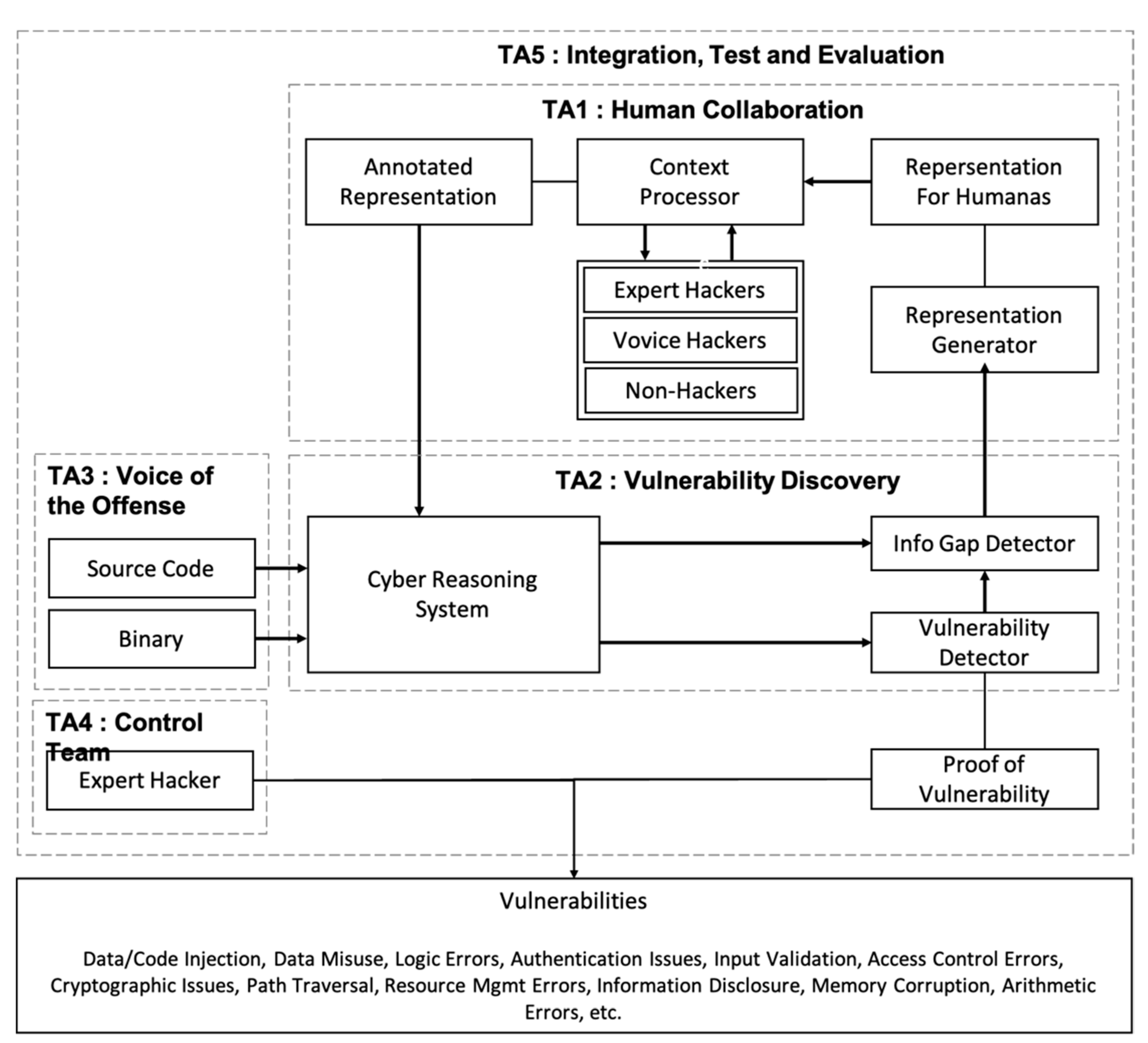
2.3. CHESS (Computers and Humans Exploring Software Security)
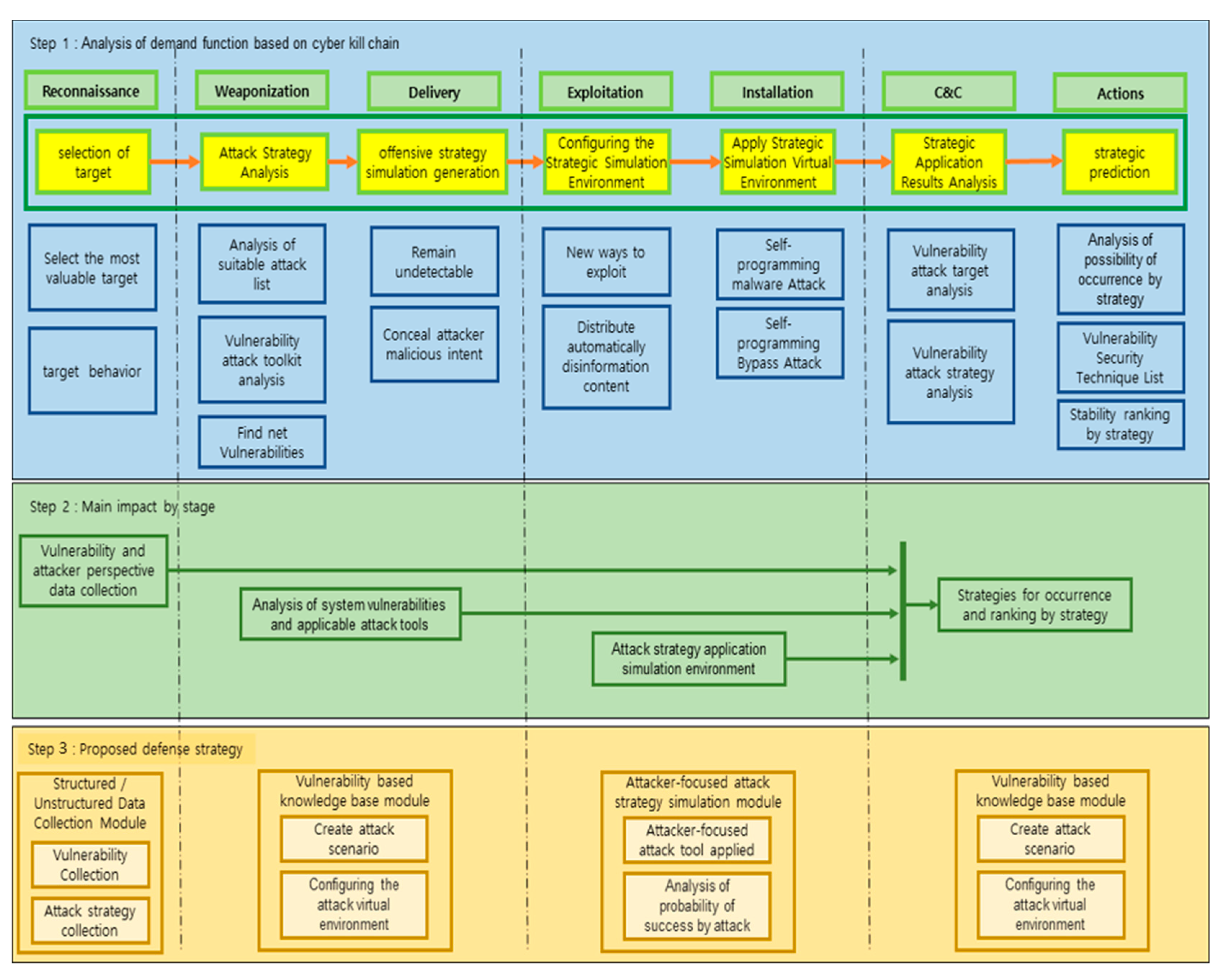
2.4. Cyber Kill Chain
2.5. Analysis of Related Research Trend
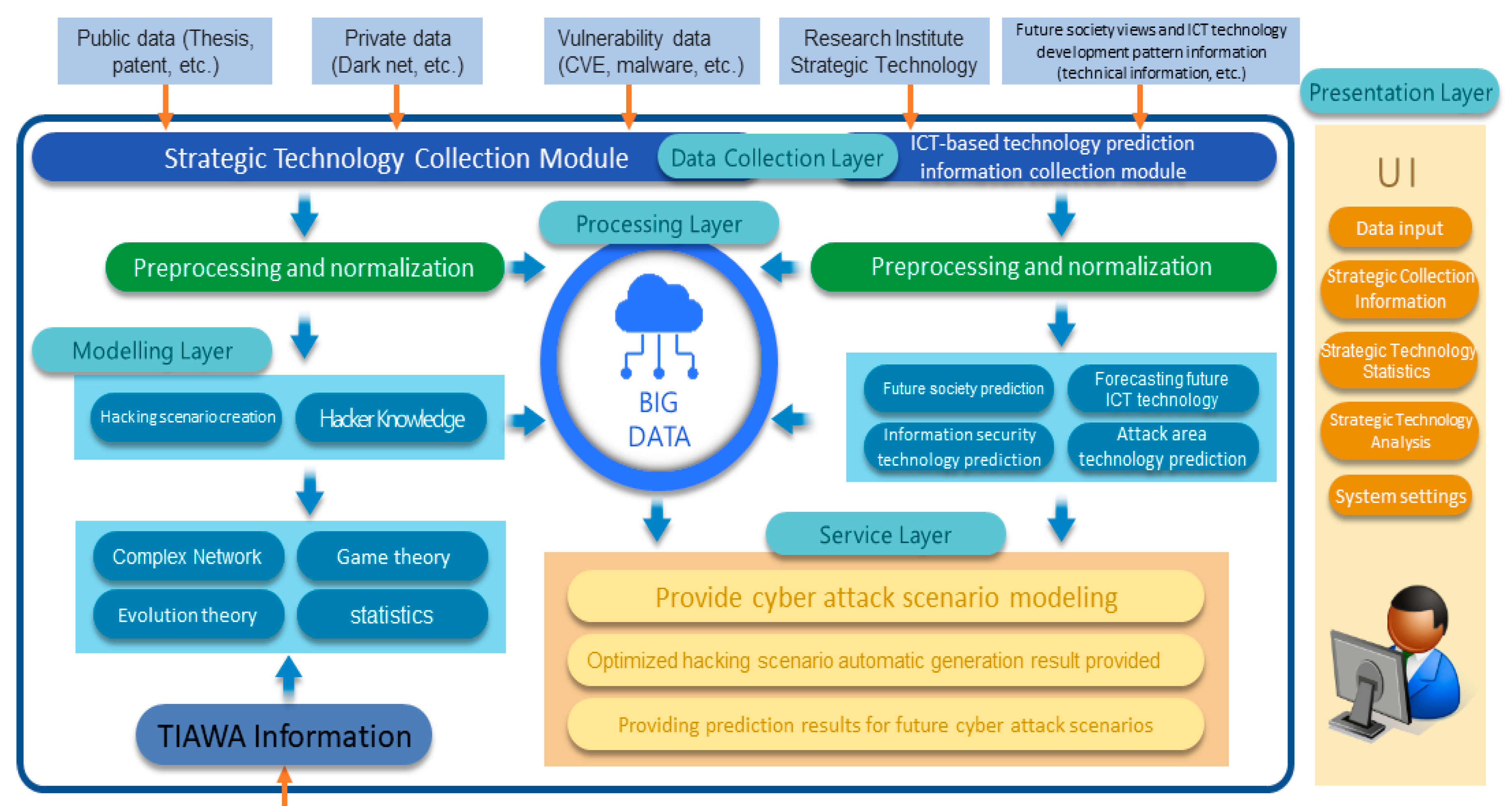
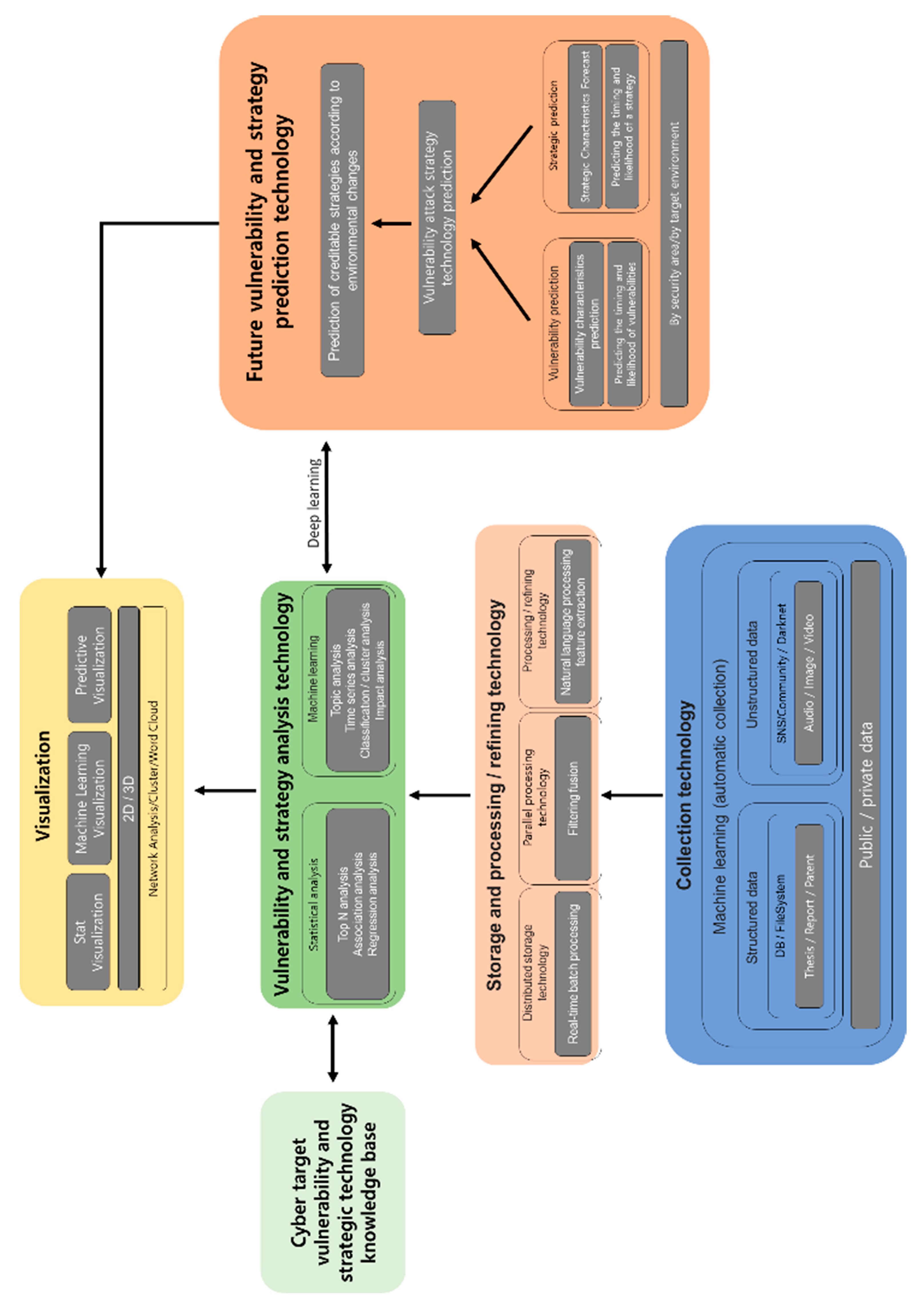
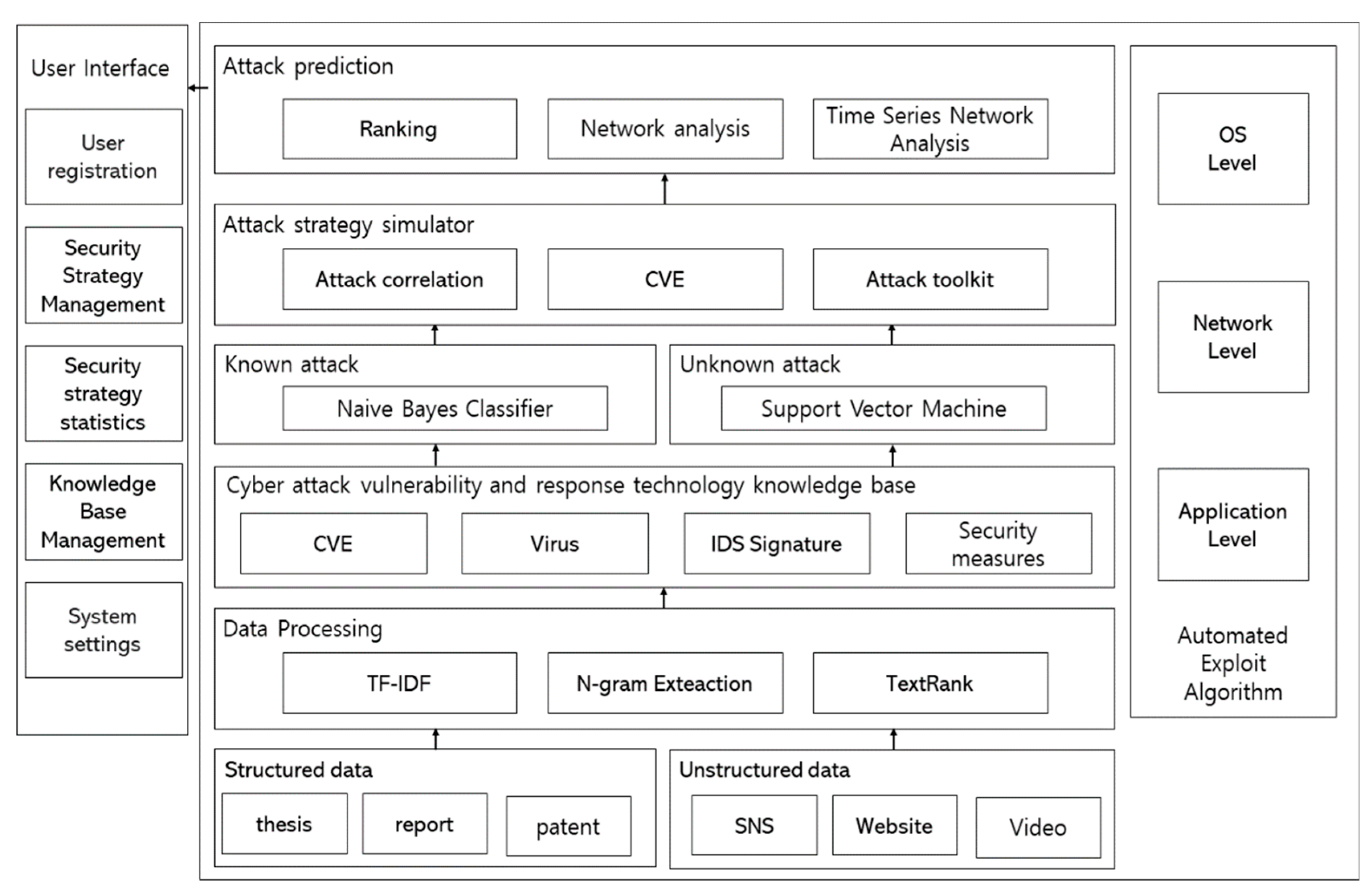
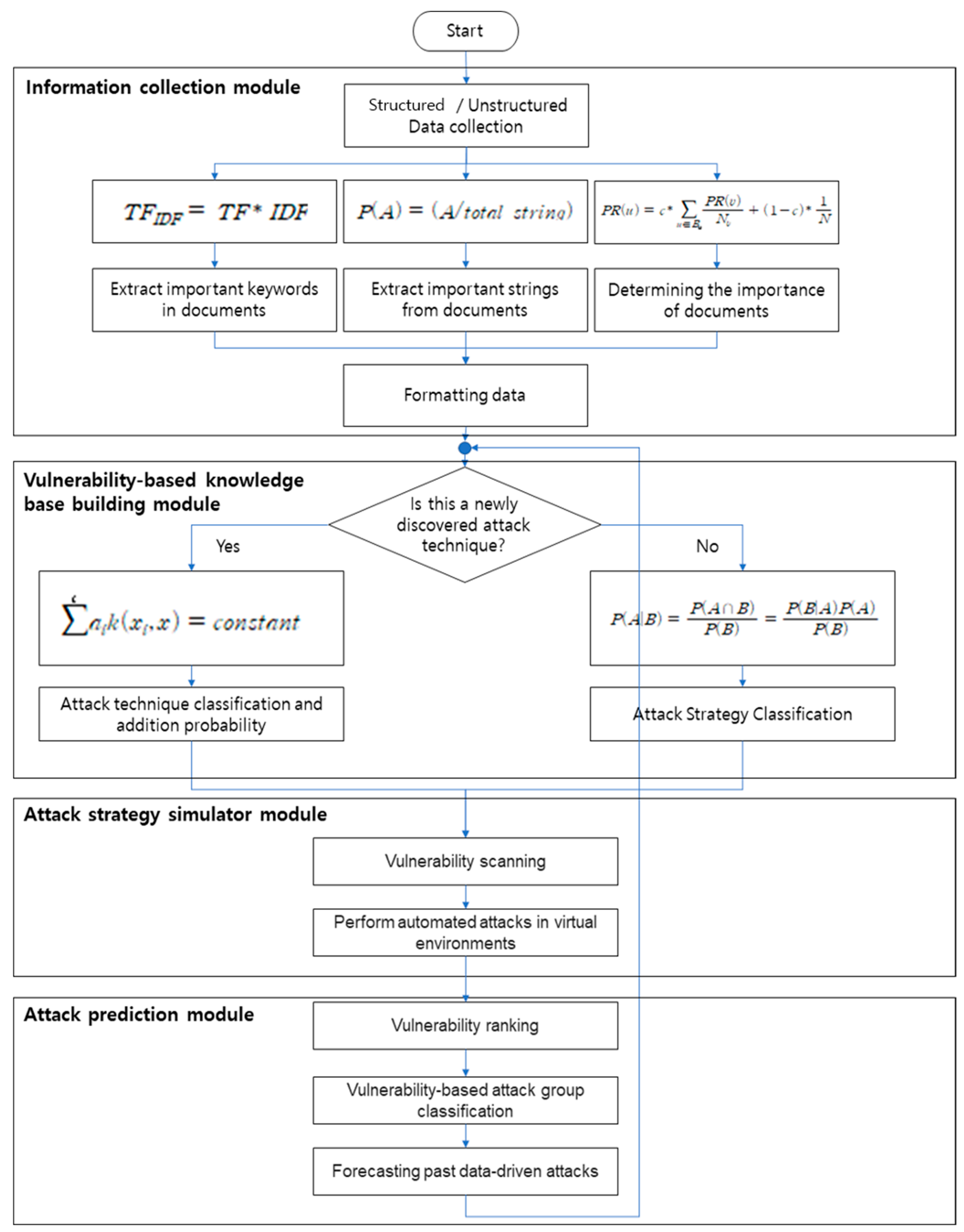
3. Proposed Preemptive Prediction-Based Automated Cyberattack Framework
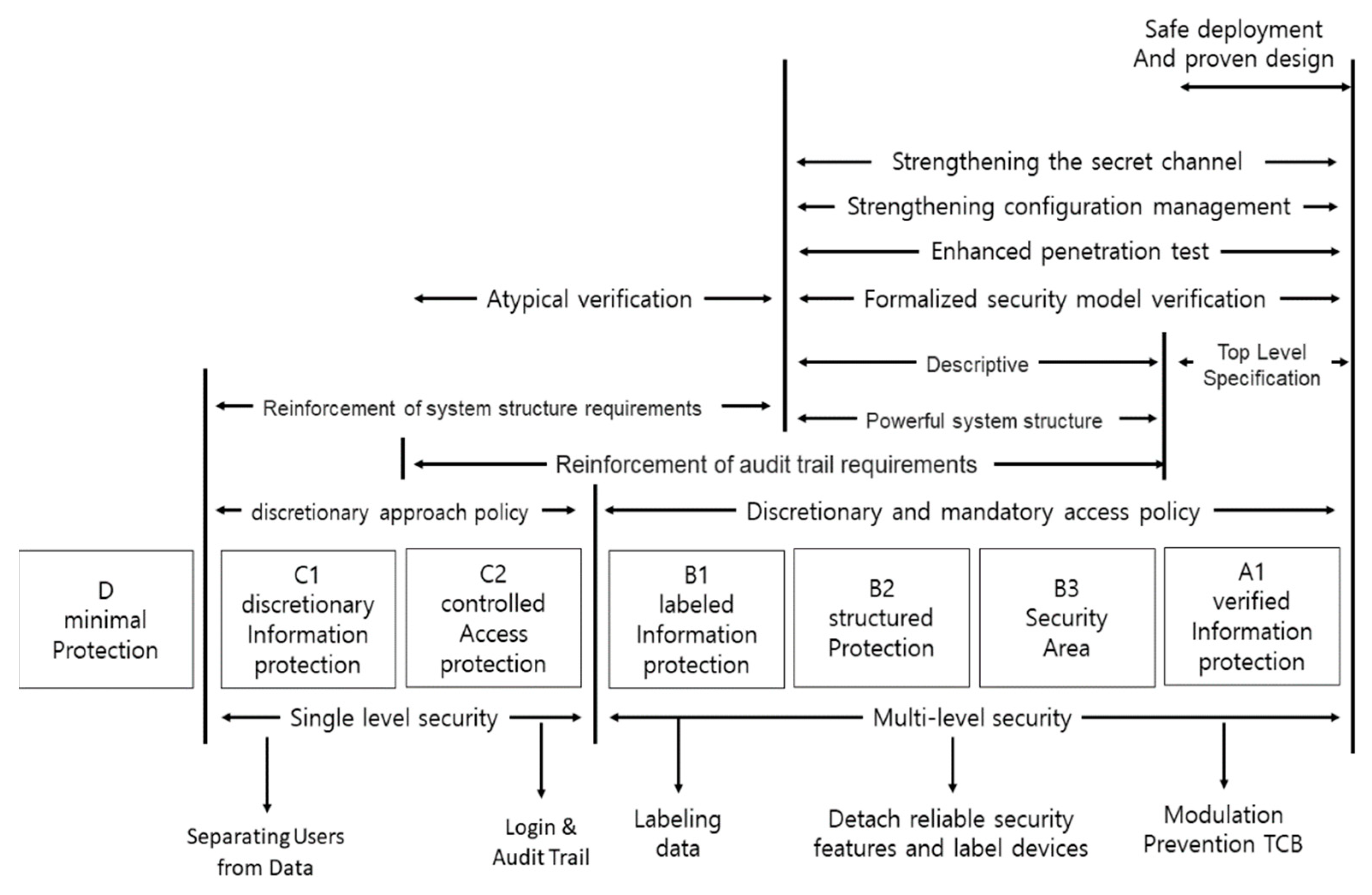
3.1. Analysis of Security Requirements for Target System
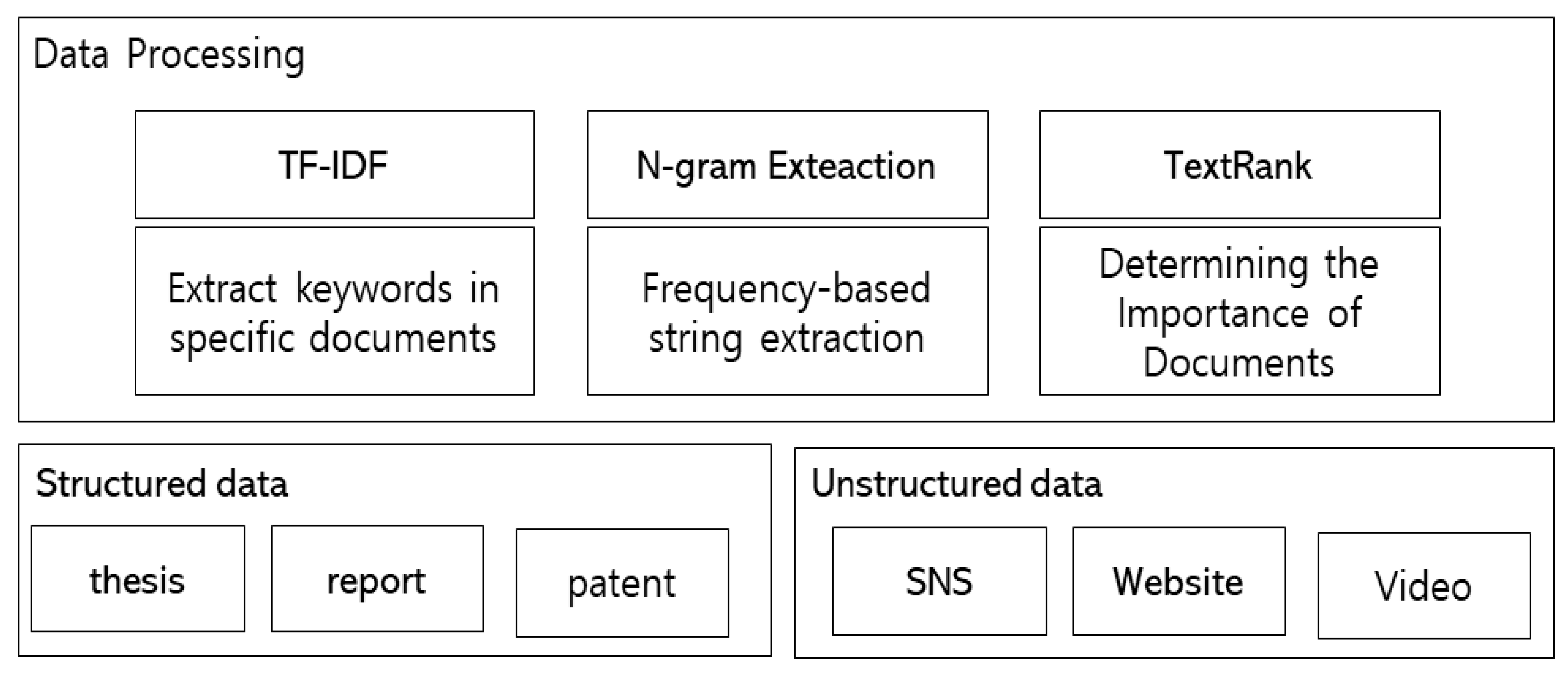
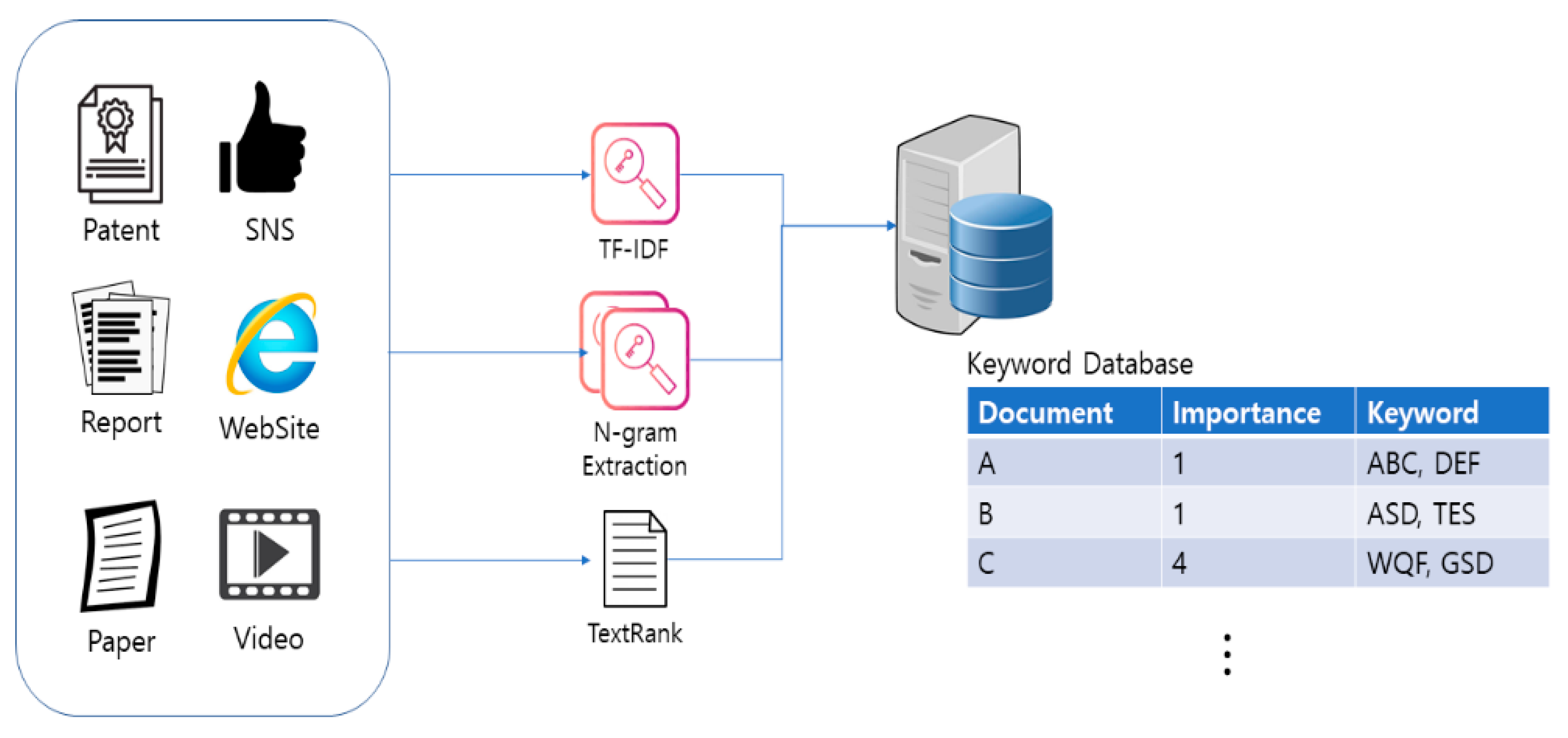
3.2. Structured/Nonstructured Data Collection Module
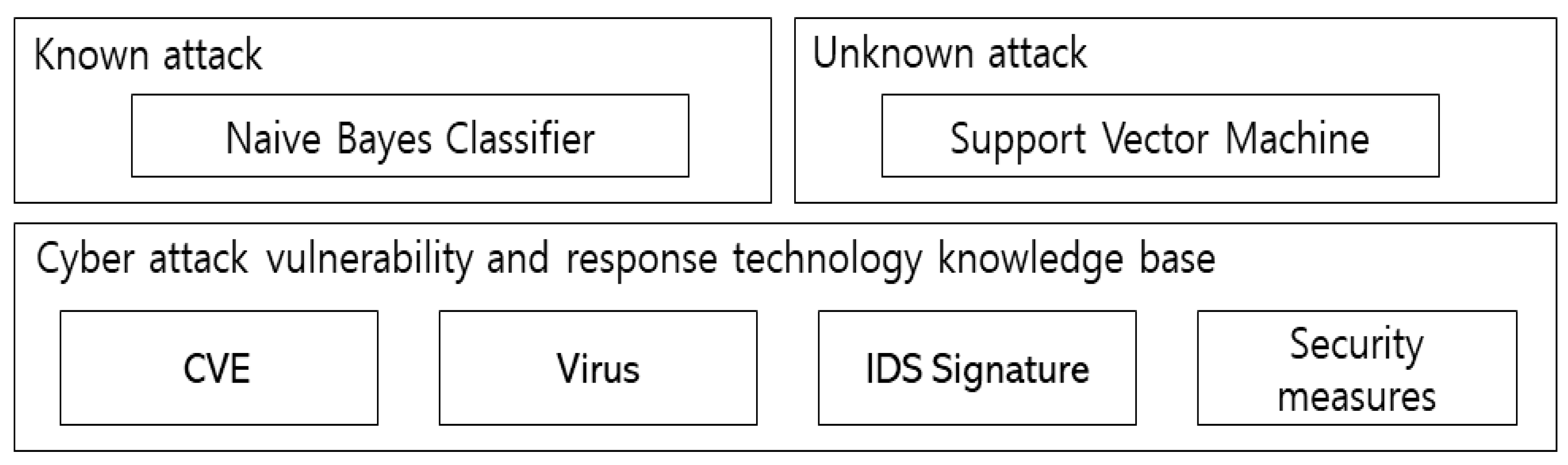
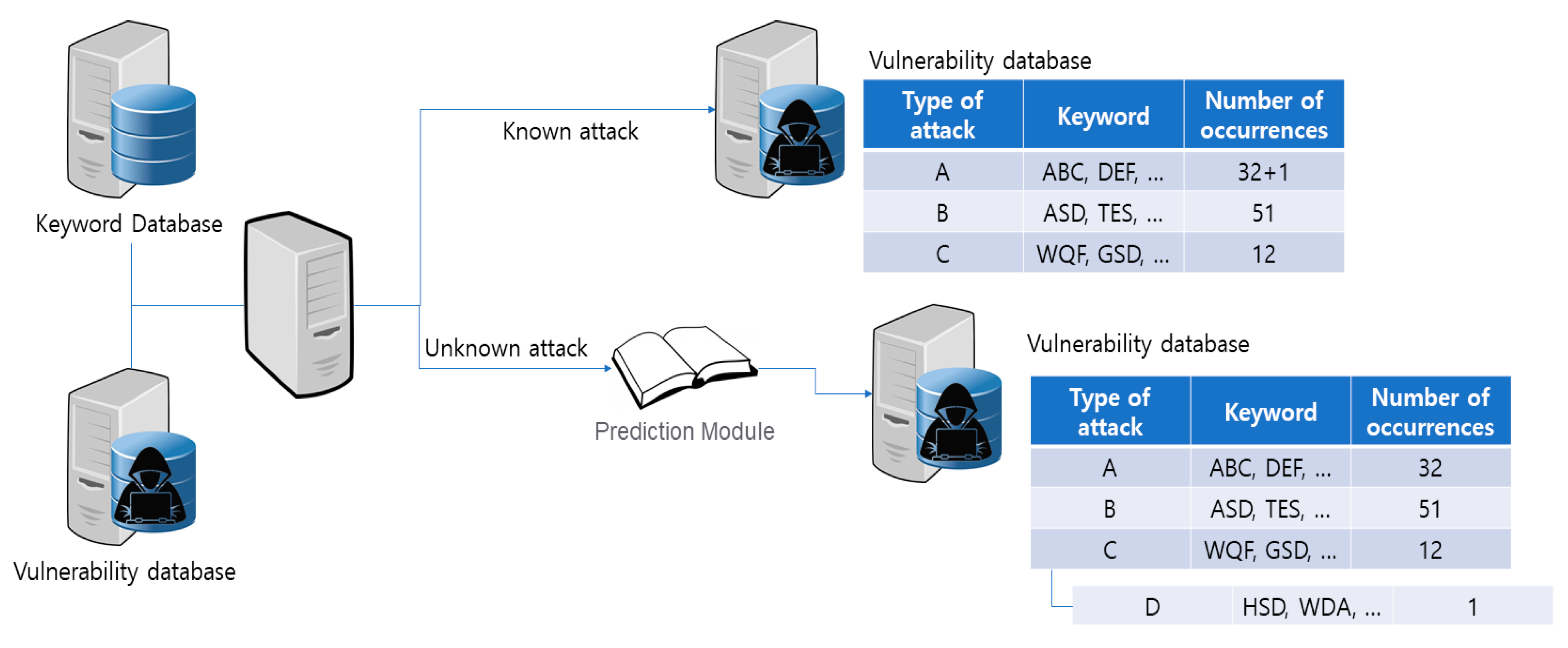
3.3. Vulnerability-Based Knowledgebase Module
3.4. Attacker-Oriented Attack Strategy Simulation Module
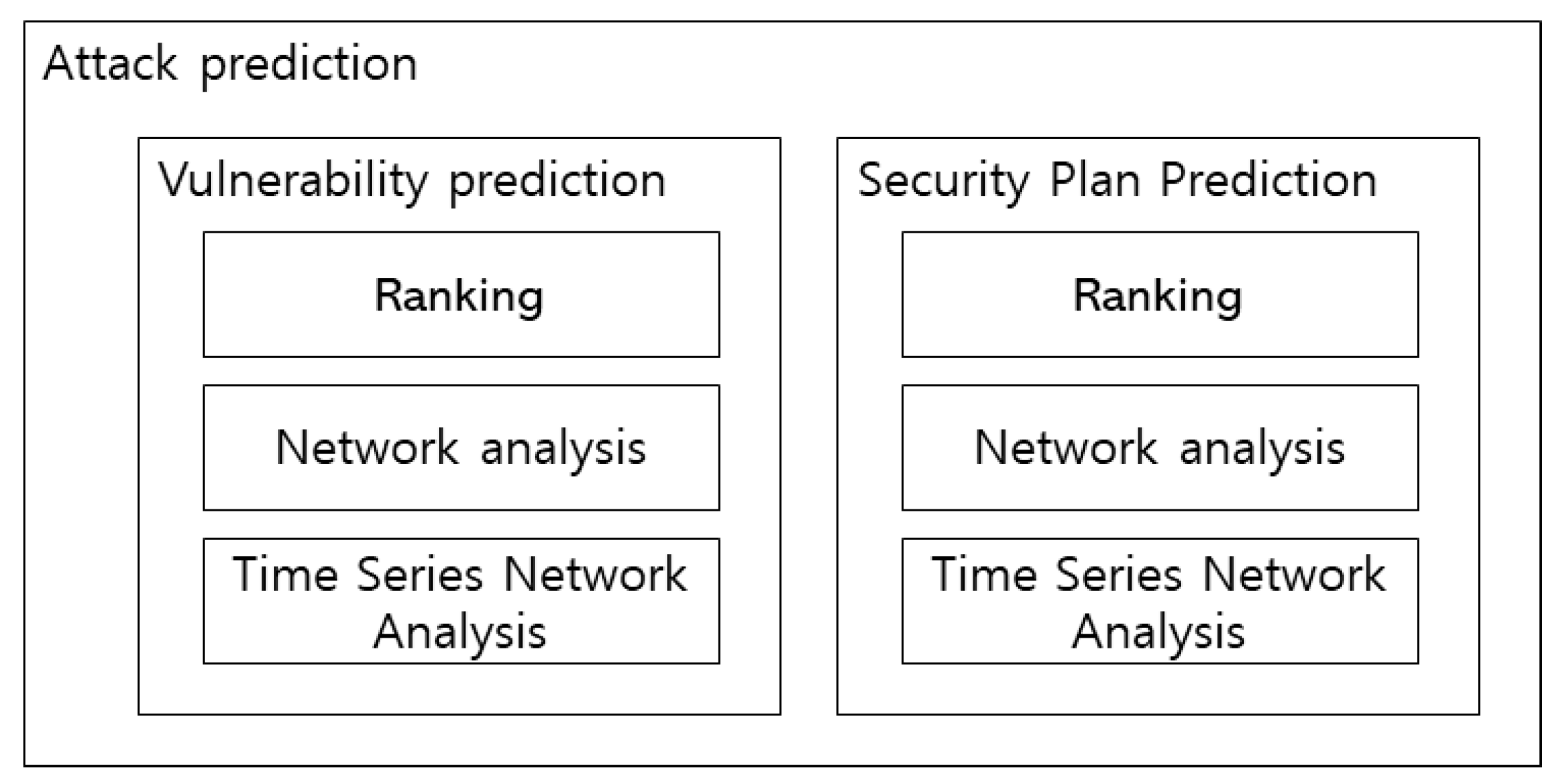
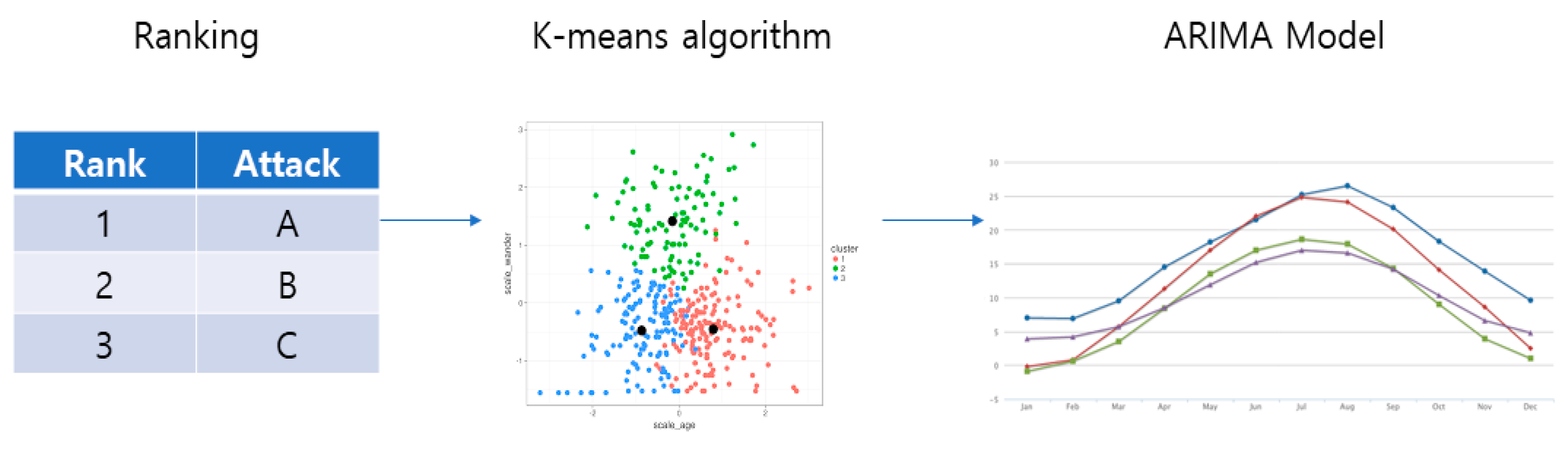
3.5. Attack Prediction Module
4. Comparative Analysis of Cyberattack Strategy Frameworks Using the Cyber Kill Chain Method
5. Conclusions and Future Plans
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yasasin, E.; Prester, J.; Wagner, G.; Schryen, G. Forecasting IT security vulnerabilities—An empirical analysis. Comput. Secur. 2020, 88. [Google Scholar] [CrossRef]
- Caporale, G.M.; Kang, W.-Y.; Spagnolo, F.; Spagnolo, N. Non-linearities cyber attacks and cryptocurrencies. Financ. Res. Lett. 2020, 32. [Google Scholar] [CrossRef]
- Park, N.; Lee, D. Electronic identity information hiding methods using a secret sharing scheme in multimedia-centric internet of things environment. Pers. Ubiquitous Comput. 2018, 22, 3–10. [Google Scholar] [CrossRef]
- Kim, J.; Park, N. Lightweight knowledge-based authentication model for intelligent closed circuit television in mobile personal computing. Pers. Ubiquitous Comput. 2019, 1–9. [Google Scholar] [CrossRef]
- Kiwia, D.; Dehghantanha, A.; Cho, K.K.R.; Slaughter, J. A cyber kill chain based taxonomy of banking Trojans for evolutionary computational intelligence. Comput. Sci. 2018, 27, 394–409. [Google Scholar] [CrossRef] [Green Version]
- Noor, U.; Anwar, Z.; Amjad, T.; Cho, K.K.R. A machine learning-based FinTech cyber threat attribution framework using high-level indicators of compromise. Future Gener. Comput. Syst. 2019, 96, 227–242. [Google Scholar] [CrossRef]
- Science of Security. Available online: https://www.nsa.gov/What-We-Do/Research/Science-of-Security/ (accessed on 20 April 2021).
- Smith, C.L.; Brooks, D.J. Security Science: The Theory and Practice of Security; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Lee, J.; Moon, D.S.; Kim, I.K. Technological trends in cyber attack simulations. Electron. Telecommun. Trends 2020, 35, 34–48. [Google Scholar]
- Lee, D.; Park, N. Blockchain based privacy preserving multimedia intelligent video surveillance using secure Merkle tree. Multimed. Tools Appl. 2020, 1–18. [Google Scholar] [CrossRef]
- Khan, P.W.; Bryun, Y.-C.; Park, N. A Data verification system for CCTV surveillance cameras using blockchain technology in smart cities. Electronics 2020, 9, 484. [Google Scholar] [CrossRef] [Green Version]
- Yadav, T.; Rao, A.M. Technical aspects of cyber kill chain. Commun. Comput. Inf. Sci. 2015, 536, 438–452. [Google Scholar]
- Fox, D.B.; Arnoth, E.I.; Skorupka, C.W.; McCollum, C.D.; Bodeaou, D.J. Enhanced Cyber Threat Model for Financial Services Sector (FSS) Institutions; The Homeland Security Systems Engineering and Development Institute: McLean, VA, USA, 2018. [Google Scholar]
- Lee, D.; Park, N.; Kim, G.; Jin, S. De-identification of metering data for smart grid personal security in intelligent CCTV-based P2P cloud computing environment. Peer-Peer Netw. Appl. 2018, 11, 1299–1308. [Google Scholar] [CrossRef]
- Hassanzadeh, A.; Burkett, R. SAMIIT: Spiral attack model in IIoT mapping security alerts to attack life cycle phases. In Proceedings of the 5th International Symposium for ICS & SCADA Cyber Security Research 2018 (ICS-CSR 2018), Hamburg, Germany, 29–30 August 2018. [Google Scholar]
- Computers and Humans Exploring Software Security. Available online: https://www.darpa.mil/program/computers-and-humans-exploring-software-security (accessed on 28 April 2021).
- Kim, J.; Park, N.; Kim, G.; Jin, S. CCTV video processing metadata security scheme using character order preserving-transformation in the emerging multimedia. Electronics 2019, 8, 412. [Google Scholar] [CrossRef] [Green Version]
- Park, N.; Sung, Y.; Jeong, Y.; Shin, S.-B.; Kim, C. The analysis of the appropriateness of information education curriculum standard model for elementary school in Korea. Int. Conf. Comput. Inf. Sci. 2018, 1–15. [Google Scholar] [CrossRef]
- Hahn, A.; Thomas, R.K.; Lozano, I.; Cardenas, A. A multi-layered and kill-chain based security analysis framework for cyber-physical systems. Int. J. Crit. Infrastruct. Prot. 2015, 11, 39–50. [Google Scholar] [CrossRef]
- Yadav, T.; Rao, A.M. Technical aspects of cyber kill chain. In International Symposium on Security in Computing and Communication. Security in Computing and Communications; Springer: Cham, Switzerland, 2015; pp. 438–452. [Google Scholar]
- Lee, D.; Park, N. Geocasting-based synchronization of Almanac on the maritime cloud for distributed smart surveillance. Supercomputing 2017, 73. [Google Scholar] [CrossRef]
- Kim, J.; Park, N. Role-based Access Control Video Surveillance Mechanism Modeling in Smart Contract Environment. In Transactions on Emerging Telecommunications Technologies; John Wiley & Sons, Inc.: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Park, N.; Kang, N. Mutual authentication scheme in secure internet of things technology for comfortable lifestyle. J. Sens. 2015, 16, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Samtani, S.; Chinn, R.; Chen, H.; Nunamaker, J.F., Jr. Exploring emerging hacker assets and key hackers for proactive cyber threat intelligence. J. Manag. Inf. Syst. 2017, 34, 1023–1053. [Google Scholar] [CrossRef]
- Fang, Y.; Liu, Y.; Huang, C.; Liu, L. FastEmbed: Predicting vulnerability exploitation possibility based on ensemble machine learning algorithm. PLoS ONE 2020, 15, e0228439. [Google Scholar] [CrossRef] [PubMed]
- Kaloudi, N.; Li, J. The AI-based cyber threat landscape: A survey. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Paul, K. Multi-level security requirements for hypervisors. In Proceedings of the 21st Annual Computer Security Applications Conference, Tucson, AZ, USA, 5–9 December 2005. [Google Scholar]
- Park, N.; Kwak, J.; Kim, S.; Won, D.; Kim, H. WIPI mobile platform with secure service for mobile RFID network environment. J. Adv. Web Netw. Technol. Appl. 2006, 741–748. [Google Scholar] [CrossRef]
- Xu, M.; Jiang, X.; Sandhu, R.; Zhang, X. Towards a VMM-based usage control framework for OS kernel integrity protection. In Proceedings of the 12th ACM Symposium on Access Control Models and Technologies, Sophia Antipolis, France, 20–22 June 2007; pp. 71–80. [Google Scholar]
- Kim, J.; Lee, D.; Park, N. CCTV-RFID enabled multifactor authentication model for secure differential level video access control. Multimed. Tools Appl. 2020, 79, 23461–23481. [Google Scholar] [CrossRef]
- Park, N.; Kim, M. Implementation of load management application system using smart grid privacy policy in energy management service environment. Clust. Comput. 2014, 17, 653–664. [Google Scholar] [CrossRef]
- Park, N.; Bang, H.C. Mobile middleware platform for secure vessel traffic system in IoT service environment. Secur. Commun. Netw. 2016, 9, 500–512. [Google Scholar] [CrossRef]
- Park, N.; Hu, H.; Jin, Q. Security and privacy mechanisms for sensor middleware and application in internet of things (IoT). J. Distrib. Sens. Netw. 2016, 12. [Google Scholar] [CrossRef] [Green Version]
- Keyword Eextraction and Key Sentence Extraction using TextRank (Implementation and Experiment). Available online: https://lovit.github.io/nlp/2019/04/30/textrank/ (accessed on 28 April 2021).
- Figueiredo, L.N.L.; de Assis, G.T.; Ferreira, A.A. DERIN: A data extraction method based on rendering information and n-gram. Inf. Process. Manag. 2017, 53, 1120–1138. [Google Scholar] [CrossRef]
- Park, N.; Kim, B.G.; Kim, J. A Mechanism of masking identification information regarding moving objects recorded on visual surveillance systems by differentially implementing access permission. Electronics 2019, 8, 735. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Park, N. Blockchain-Based Data-Preserving AI Learning Environment Model for AI Cybersecurity Systems in IoT Service Environments. Appl. Sci. 2020, 10. [Google Scholar] [CrossRef]
- Park, N.; Park, J.; Kim, H. Inter-Authentication and Session Key Sharing Procedure for Secure M2M/IoT Environment. Int. Inf. Inst. (Tokyo) Inf. 2015, 18, 261–266. [Google Scholar]
- Kotu, V.; Deshpande, B. Autoregressive integrated moving average. Data Sci. 2019. [Google Scholar] [CrossRef]
- Park, J.; Kim, J.; Gupta, B.B.; Park, N. Network Log-Based SSH Brute-Force Attack Detection Model. CMC-COMPUTERS MATERIALS & CONTINUA 2021, 68, 887–901. [Google Scholar] [CrossRef]
- Kim, J.; Park, N. A Face Image Virtualization Mechanism for Privacy Intrusion Prevention in Healthcare Video Surveillance Systems. Symmetry 2020, 12. [Google Scholar] [CrossRef]
- Park, N. The implementation of open embedded S/W platform for secure mobile RFID reader. J. Korean Inst. Commun. Inf. Sci. 2010, 35, 785–793. [Google Scholar]
- Park, N. Secure data access control scheme using type-based re-encryption in cloud environment. In International Conference on Hybrid Information Technology; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Park, N. Secure UHF/HF dual-band RFID: strategic framework approaches and application solutions. In International Conference on Computational Collective Intelligence; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Park, N.; Song, Y. Secure RFID application data management using all-or-nothing transform encryption. In International Conference on Wireless Algorithms, Systems, and Applications; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Park, N.; Kim, S.; Won, D.; Kim, H. Security analysis and implementation leveraging globally networked RFIDs. In IFIP International Conference on Personal Wireless Communications; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
| Security Requirements | Description |
|---|---|
| User authentication | User classification and authentication through electronic signature Notification of illegal access to the administrator |
| Access control | ACL control of key information Mandatory access control according to sensitivity of resources in the system Mandatory control of user IP, available time, period, service |
| Authority management | Account management for authorized users Separation of roles and authorities between system administrators and security managers |
| Confidentiality | Detection and blocking of intrusion of malignant codes Blocking of unauthorized users and unauthorized works |
| Integrity | Blocking of attacks through the obtaining of the authority of a system administrator Prevention of unauthorized modification by an unauthorized user or work |
| Vulnerability Scanning | Penetration Testing | Proposed Framework | |
|---|---|---|---|
| Scope | Identify all potential vulnerabilities | Identity attackable vulnerabilities | Identity attackable vulnerabilities |
| Vulnerabilities | Classify vulnerabilities based on standardized theoretical information | Check vulnerabilities to specific network resources | Check vulnerabilities to specific network resources |
| Usefulness of checking results | Identify and provide vulnerabilities that cannot be false-positive or exploited | Identify and attack vulnerabilities that actually threaten | Identify and attack vulnerabilities that actually threaten |
| Network connection check | No connections revealed among network components | Exploit a trust relationship among network components | Check a trust relationship between network components |
| Improvement support | Provide lists of vulnerabilities | Evaluate potential risk of a specific vulnerability that can be exploited, and prioritize vulnerabilities that require caution and immediate processing | Predict specific vulnerabilities with high probability of occurrence |
| Inspection on security investment | Does not provide virtual attacks | Carry out actual attacks to check if it normally operates | Carry out actual attacks to assess probability and level of threat |
| Security risk evaluation | Identify patches that are not applied only. Actual security risk cannot be evaluated. | Assess risk based on actual threats through imitating hackers or worms’ acts | Assess risk based on substantial threats using attackers’ attack strategies |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, S.; Kim, J.; Park, N.; Seo, Y. Preemptive Prediction-Based Automated Cyberattack Framework Modeling. Symmetry 2021, 13, 793. https://doi.org/10.3390/sym13050793
Ryu S, Kim J, Park N, Seo Y. Preemptive Prediction-Based Automated Cyberattack Framework Modeling. Symmetry. 2021; 13(5):793. https://doi.org/10.3390/sym13050793
Chicago/Turabian StyleRyu, Sungwook, Jinsu Kim, Namje Park, and Yongseok Seo. 2021. "Preemptive Prediction-Based Automated Cyberattack Framework Modeling" Symmetry 13, no. 5: 793. https://doi.org/10.3390/sym13050793
APA StyleRyu, S., Kim, J., Park, N., & Seo, Y. (2021). Preemptive Prediction-Based Automated Cyberattack Framework Modeling. Symmetry, 13(5), 793. https://doi.org/10.3390/sym13050793