1. Introduction
In the drive for continual improvement in vehicle engineering design, optimised structures and components with lower safety margins and greater reliability are sought [
1]. Advances in computational design such as finite element analysis and dynamic modelling combined with fatigue prediction have furthered this goal tremendously during the design phase. Nevertheless, there is still a need to dynamically test physical prototypes or existing designs in a controlled laboratory environment. For the analysis to be worthwhile the excitation of the structure in the laboratory environment must induce responses in the structure as though it were being tested under real-world operating conditions. The end goal is to enable Accelerated Destructive Testing (ADT) of the structure. In ADT, a vehicle’s chassis is mounted with its suspension system on a set of hydraulic actuators. The hydraulic actuators then excite the system vertically. Laterally acting forces are simulated with additional actuators. An example of an ADT set-up is shown in
Figure 1.
The structure’s excitation is then carried out for extended periods, allowing for the degradation of the structure to be measured in a controlled environment [
1]. The structure is not typically excited until catastrophic failure, but rather until the degradation measured as vibration or noise has met a specified threshold [
2]. This indicates possible failure points of the system and a means of predicting the component’s healthy lifespan. Other insights can be gained from dynamic testing, such as a better understanding of the system dynamics, vibration isolation [
1] and vibration severities for passenger ride comfort [
3].
The biggest hurdle with ADT is that the inputs to the system, such as the displacements or the forces acting on the vehicle’s tyres, are difficult or impossible to measure directly in the field. This means the problem must be cast as an inverse modelling or response reconstruction problem [
4]. In inverse problems, the outputs of the system
Z are used in conjunction with model parameters
to determine the inputs
U, i.e.,
There are two possible choices for creating a model of the system. A mapping of the system can be constructed so that the system’s inputs are used to predict the outputs of the system. This is referred to as the forward problem. The forward problem is then inverted. If the model used to map the problem is nonlinear, an iterative optimisation scheme is employed to invert the system. However, the optimisation scheme may be prone to local minima. The second approach is to create a direct inverse of the model whereby the system’s outputs are used to predict the inputs of the system. The inverse method has an inherent stability check since the solution will only be obtained if the direct inverse model is stable [
1]. However, we quickly find that most inverse problems are ill-posed. For a problem to be well-posed it needs to meet the following criteria: the solution is unique, the global solution exists for all data and the solution to the problem is continuously dependent on the given data [
5]. The first criterion is normally the offending culprit since it is easy to construct a forward problem where two different inputs result in the same output. Therefore, the inverse solution is typically not unique. This introduces an asymmetry into the problem whereby the assumption of an one-to-one mapping is broken. If the problem is ill-posed we may use regularisation techniques to cast the problem as a more well-behaved problem. Regularisation techniques include: cross validation, SVD, iterative methods, data filtering and Tikhonov regularisation [
4].
Most common reconstruction techniques are implemented in the frequency domain [
6], whereby the discrete Fourier response is multiplied by an inverse or pseudoinverse frequency response function [
7]. Raath’s Ph.D. thesis [
1] highlighted the then known issues of using frequency response techniques in accelerated fatigue testing. It was shown that the frequency response was inaccurate for several reasons, that include:
Assuming that the input and output signals are periodic when often they were not. These include sharp impulses from random impacts.
Being unable to model nonlinear models since frequency response analyses assume a linear model.
Requiring long time signals of the order of hours as opposed to minutes or seconds needed for the time domain. This ties in with the issue that low frequency information is easily lost due to spectral leakage where the energy in the lower frequencies is spread over to higher frequencies.
Failing to capture the sequence or causal effects which play an important role in crack propagation.
Various time-domain techniques have been developed to overcome this. However, they have been shown to be slow or inaccurate [
8]. The vehicle structures of interest typically contain many nonlinear components such as springs and pneumatic dampers. Typical control systems will overcome this issue by linearising the system around the operation point. It is then assumed that the system will experience small perturbations around this point. However, it is expected that the system will experience impact loadings and large displacements, which will force the system out of its linear region [
1]. Another issue associated with response reconstruction is that of model mismatch, whereby the identified system does not truly represent the physical test rig. In response reconstruction the misrepresentation occurs when the physical test rig is taken from the real-world and recreated and simulated in the laboratory environment. Typically the degrees of freedom are not fully represented in the laboratory or the test rig parameters, such as mass, may vary. In this laboratory environment, the process of system identification occurs; therefore, we will have mapped a domain that differs from the real-world domain. When the real-world outputs need to be recreated we may find that the mapped inverse model may be forced to extrapolate into regions in the mapped domain to find a solution. In other words, the inverse model has over-fitted to the laboratory domain and generalises poorly with regard to the real-world domain. Regularisation can be employed to minimise this error [
9]. A related field to response reconstruction is force identification whereby the inputs of the system are of interest. However, the inputs of the system for a given output are not unique [
10]. Force identification tackles this problem by enforcing some prior knowledge of the system dynamics to constrain the inputs to reasonable solutions. Bayesian methods have become prevalent in force identification literature since they allow the experimenter to systematically incorporate prior knowledge [
11]. Another benefit of incorporating Bayesian methods is that it provides for confidence intervals on the input predictions and model parameters [
12]. A noticeable distinction in force identification literature is that a known finite element model of the structure is typically assumed, i.e., a known forward model.
The approach taken in this paper of solving the issue of non-uniqueness of the input is mitigated by
not focusing on the reconstructed input accuracies.
using cross validation of the system’s reconstructed outputs to determine whether a given inverse model of the system is satisfactory i.e., using a forward pass through the physical system in each cross validation step to determine the model accuracy.
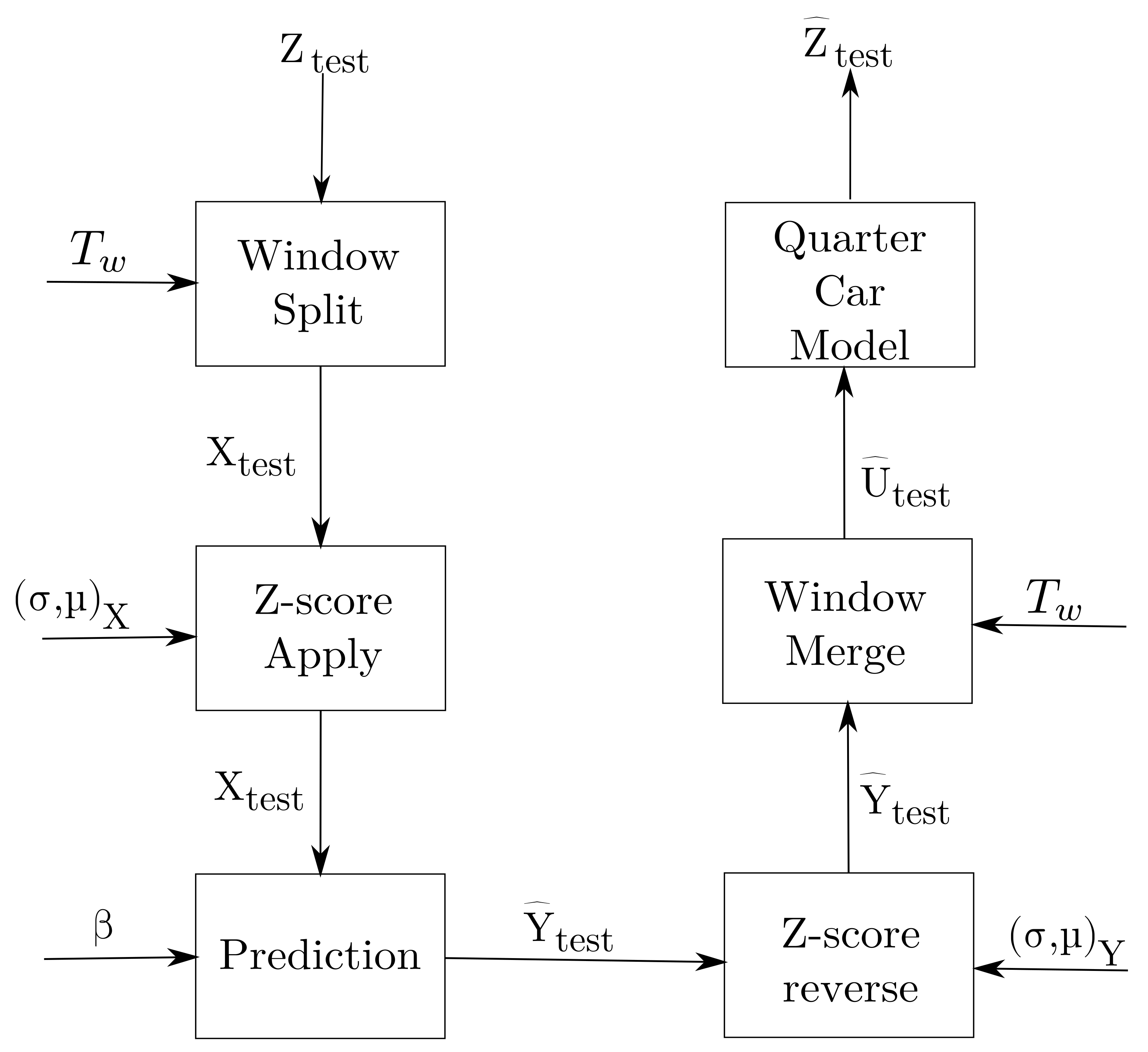
A potential drawback to this approach is that, if implemented naively, the cross validation can induce undue stress on the system before any ADT occurs. An overview of the response reconstruction methodology used in this paper is given in
Figure 2.
This paper focuses on linear regression methods for mapping the relationship between the outputs
X and inputs
Y for response reconstruction, i.e.,
. The core contribution of this paper is the proposed method of extending the capabilities of said linear regression methods by introducing overlaps and merging them using averaging in a process called AntiDiagonal Averaging (ADA), encapsulated in Equation (
12). We show that ADA is closely related to FIR methods. We benchmark ADA in terms of its response reconstruction ability as well as its performance against the related FIR methods. We focus on Tikhonov regularisation with cross validation through the use of Ridge Regression (RR) to regularise the inversion of the system. Any suitable linear regression method can be employed with ADA; however, RR is needed for the FIR methods we cover.
We first give a brief overview of RR and how it enforces regularisation. The theory behind ADA is then introduced and compared against related FIR methods. The design of the investigation is then given with an overview of the numerical quarter car model, with which the reconstruction methods are benchmarked. The results of the benchmarks are then discussed. Finally, an illustrative comparison of the different regression methods is conducted showing the performance of the regression method on a challenging response reconstruction problem.
1.1. Ridge Regression
As opposed to discretely truncating the singular values, RR instead smoothly decays the singular values through the use of a regularisation matrix
which results in the solution
where
is typically chosen as a scaling of the identity matrix though the use of the regularisation constant
, i.e.,
. RR has the solution in terms of the SVD of
X [
13]
where the entries of the diagonal matrix
D are given by
and are the left and right singular vectors of X, respectively, with the corresponding singular values .
1.2. ADA
Windowing methods are needed to represent the responses Z as the predictor matrix and the inputs U as the target matrix in any suitable linear regression method. This is achieved by windowing said signals and treating each window as an observation. The original input and response measurements are given by and where m is the original sequence length in samples and q and o are the number of actuator and sensor channels, respectively.
In ADA we introduce overlap between these observations. The overlap sample length
is defined by a proportion
of the proposed window sample length
, i.e.,
where
is the window sample length given by the desired window length in seconds
multiplied by the sampling frequency
The stride of the window,
, is then given by
This occurs for each time sequence for either an actuator or sensor signal, being appended column-wise, resulting in
and the number of rows or observations,
n, equal to
We set the amount of overlap to the extreme such that the stride is one sample, i.e.,
. This results in the following windowed target matrix
YThe windowed predictor matrix
X takes on a similar form (not shown). We can simply average over the anti-diagonals of the windowed data matrix
to reconstruct the approximated input
. To compute the average response
we average all the anti-diagonal terms of
, such that
for which
and
is the number of elements in the anti-diagonal. This process is known as Hankelization which is the same process followed in Singular Spectral Analysis (SSA) [
14]. The corresponding windowed matrix is referred to as the trajectory matrix. This is known as the embedding step in SSA. The windowed matrix is then decomposed using SVD. In this case, we are merely borrowing the ADA concept from SSA for the regression problem, whereas SSA typically uses this process for autoregressive models.
An example signal with
samples and window length
and windowed with ADA results in the following equation
Here
z is the response signal used to predict the inputs
u. The linear coefficients
are computed using any suitable linear regression method. To gain insight into the workings of ADA we can write out the set of equations that infer
, i.e.,
We can then average over all the
predictions to obtain the final prediction of
If we rewrite the average of the
multiplying with a particular
z term as a new constant, e.g.,
, we obtain
Here we note that the ADA emphasises the middle term with decreasing emphasis placed on proceeding and preceding terms. It in effect creates a triangular windowing function. If we add a corresponding weight term
w, e.g.,
we can rewrite the equation generally as
This result demonstrates that ADA is an indirect method of creating a weighted moving average filter. In system identification this is known as a Finite Impulse Response (FIR) model. More specifically this an example of a non-causal weighted FIR model. The weights can be arbitrary and are a prior design choice. If we forgo the ADA method and use the weighted FIR model, we can be more creative with the weighting.
1.3. FIR Models
In FIR models the current output of the system is a function of past inputs such that
This is in contrast to other models such as Autoregressive eXogenous (ARX) which includes output feedback as well, i.e.,
This paper focuses on non-causal inverse implementations of FIR models, where the current input is a function of both past and future outputs, written as
By using the FIR model, the predictor matrix
X takes on the form
with the corresponding target matrix
Y written as
It is worth noting that we lose the first and last samples of the target matrix Y since we shifted the inputs to make the system non-causal.
The lack of feedback means that FIR methods are inherently stable. This is suitable and sometimes sought after if the system under consideration is stable. However, if the system is unstable, it will only approximate the instability for a short period before diverging [
15]. FIR models come with the cost of needing significantly more terms than what output feedback models need to map the same system [
15]. A similar approach to ADA can be achieved through the use of FIR models combined with Tikhonov regularisation. Using Tikhonov regularisation, the
coefficients can be penalised and thus shaped by choice of the
matrix in Equation (
2). To this end three options for the
matrix are implemented in this paper, namely: Finite Impulse Response with TriangularWeighting (FIR-T), Finite Impulse Response with Difference Smoothing and Triangular Weighting (FIR-DT) and Finite Impulse Response with Ridge Regression (FIR-RR).
In FIR-T, the coefficients relating to the outputs further away from the required input (both forwards and backwards in time) are penalised. This is achieved by setting
where
W is an inverted triangular set of penalty weights, given as
and
scales the amount of regularisation we wish to impose. This should ideally mimic the weighting function achieved by ADA in Equation (
20). FIR-DT further modifies the triangular weighting matrix through the use of a first difference matrix
A, given as
The first difference matrix ensures that the difference between each successive
coefficient is small [
16]. The difference matrix is then combined with the weighting matrix
W to obtain the final form of the regularisation matrix such that
This weighting scheme was initially implemented and developed for a causal FIR system where the penalty weights increased linearly further back in time [
16]. Finally, the last choice of penalty matrix
is that of FIR-RR, i.e.,
where we only limit the magnitude of the weights to act as a reference. This enables us to determine whether the regularisation of
contributes to the accuracy of the response reconstruction.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
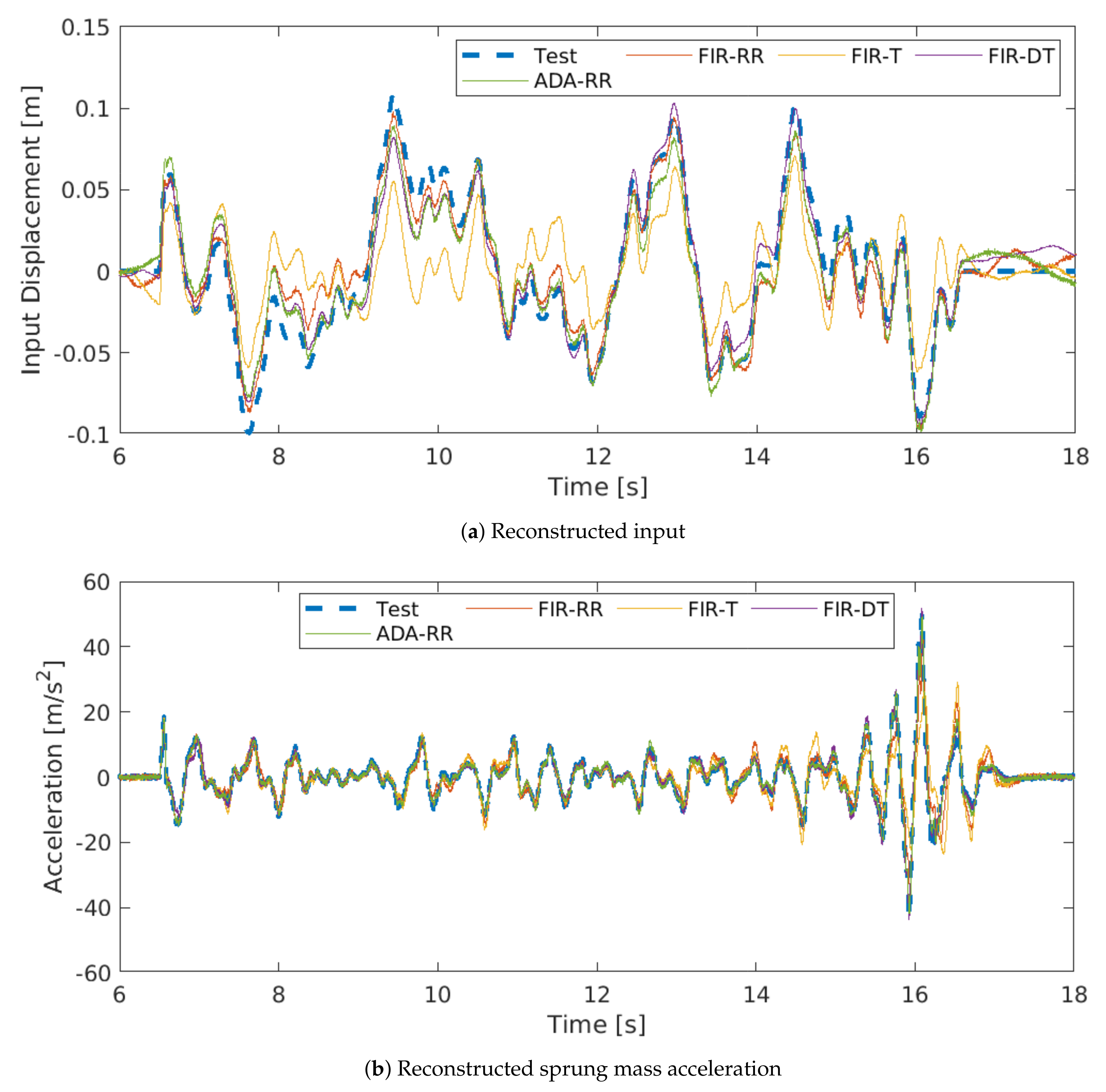{kind=link}
{kind=link}