1. Introduction
A hand gesture is simply defined as “the known movement of a single or both hands”. A Gesture usually conveys a precise single message. For example, waving a hand is to say ‘Good Bye’, and waving both hands shows excitement [
1]. For humans, the eyes capture the hand movement, and the brain processes the image to recognize a gestural movement. In this process, the combination of sharp vision and right visibility produces a perfect picture in the brain. This results in accurate human gesture recognition. Similarly, machines require complete and clear input information for accurate vision-based gesture recognition. In addition, an efficient embedded system is required to extract meaningful information from the environment.
In a vision-based gestural system, expressive input is required to recognize gestures with human-like accuracy. The input types used for vision-based gesture recognition technology are static and dynamic gestures. A static gesture image contains the hand in a static state. This means that the posture of the hand, its position, and shape remain the same. On the other hand, a dynamic gesture comprises a sequence of still photos that have been acquired frame by frame. Dynamic gestures can match the characteristics of actual hand movement by having different images express the gestural movement from start to finish. The accuracy of the dynamic gestural recognition system relies on an accurate static gesture recognition model [
2]. This is because factors that affect the static gesture recognition process ultimately affect dynamic gesture recognition.
Image noise is one such factor that reduces the accuracy of the recognition system. Noise is defined as the undesired information that comes along with the input image. An example of this is the variation of brightness level within an image. This illumination variation occurs either because of the image sensor or the image surroundings. The change in the number of lumens (lm) emitted by the lighting device is referred to as brightness variation. More lumens mean brighter light, fewer lumens mean dim light, and in between is ambient or general lighting. Usually, rooms and kitchens are set to general lighting, whereas bathrooms have brighter lighting and bedrooms have dim lighting. Real-time recognition becomes complex when the user is moving around the house in different lighting conditions where the brightness level varies unexpectedly. Hence, image enhancement is necessary for accurate recognition.
Many researchers have proposed different image enhancement techniques to improve the feature extraction and overall gestural recognition process. Some of the applications, such as sign language recognition, need a high level of precision and reliability in detecting the hand and recognizing gestures. Therefore, distinguishing characteristics need to be identified for this purpose. However, the vast majority of efforts have only looked at a single lighting scenario to recognize the gesture pattern, so there is still a lot of room for improvement in the area of gesture recognition under varying lighting scenarios. In this study, symmetric patterns and a related luminosity-based filter are considered for use in gesture recognition. The main contributions of this paper are as follows:
Firstly, we proposed a symmetry-pattern-based gesture recognition framework that works well in diverse illumination lighting effects.
Secondly, the dataset is created based on 26 American Sign Language (ASL) hand gesture images under diverse illumination conditions. Then, an efficient method for gesture feature extraction is used that is based on luminosity-based grey-scale image conversion and perimeter feature extraction.
Thirdly, segmentation and identifying the significant points to enhance the number of Scale-Invariant Feature Transform (SIFT) key points and minimized the time taken for key point localization within features.
Then, the gesture recognition process is validated by different Artificial Neural Network (ANN) architectures to enhance the recognition accuracy rate and avoid any uncertainty management in decision-making.
Finally, a comparison has been performed between our work and other available researchers’ published work in a similar domain to show the efficiency of our proposed framework process.
The organization of the paper is as follows in different sections:
Section 2 literature review.
Section 3 briefly explains the proposed hand gesture recognition framework with mathematical modelling.
Section 4 demonstrated the testbed environment and results. Finally,
Section 5 discussed the conclusion and possible future work.
2. Literature Review
This section reviews the most relevant state-of-the-art literature on gesture detection in a variant illuminated background environment, considering its application in ASL. Researchers [
3,
4,
5,
6] have proposed different techniques to address the illumination variation problem in vision-based hand gesture recognition systems. For sign language recognition covering languages of their origin, that may affect image recognition. In a study [
7], the approach of pattern recognition for surface electromyography (sEMG) signals of nine different finger movements is described. The authors in [
8] proposed log-spiral codes of symmetric patterns in the unique method that was developed to identify human hands and understand motions from video streams using long spiral codes. In a recent study [
9], the authors present a symmetric CNN called HDANet. This CNN is built on the self-attention mechanism of the Transformer and makes use of symmetric convolution in order to capture the relationships of image information in two dimensions, specifically spatial and channel. In research [
10], using a generative adversarial network to capture the implicit relationship between glyphs from Oracle Bone Characters and modern Chinese characters was the basis of a research project that proposed a method for image translation from Oracle Bone Characters to modern Chinese characters. This method could translate images from Oracle Bone Characters to modern Chinese characters. Another research [
11] presents a collaborative surgical robot system for percutaneous treatment directed by hand gestures and supplemented by an AR-based surgical field. The use of hand gestures to instruct the surgical robot improved needle insertion accuracy in experiments. Whereas [
12] proposed a depth-based palm biometrics system. The technology splits the user’s palm and retrieves finger dimensions from the depth picture. In addition, studies [
13,
14,
15] present a thorough review of hand gesture techniques to eliminate the effect of illumination variations. Some of the most common classifiers proposed by the researchers include k-NN, presented in [
12], the SVM classifier discussed in [
16], and the tree-based random forest classifier elaborated in [
17].
The authors in [
18] presented a novel recognition algorithm based on a double-channel convolutional neural network, which separates the varying illumination from the gesture. The study [
19], recognized sign language gestures in seven categories using visibility, shape, and orientation of the hand features. At the preprocessing step, they applied skin detection using colour properties in the HSV domain to form a uniform linear binary pattern. The multiclass Support Vector Machine classifier classified the images from the dataset of 3414 signs corresponding to 37 Pakistan Sign Language alphabets with good categorization results. Chen et al. [
20] proposed an event-based system that uses a biologically inspired neuromorphic vision sensor, an encoding process to identify objects, and a flexible system to classify hand movements. According to [
21], the fitness function for gamma correction preserves the brightness and details of the image of both brighter and low-contrast images. Particle Swarm Optimization can be applied to make the gamma correction adaptive by calculating the optimal gamma values.
As shown by [
22], a method for compensating for the poor ambient illumination in the scene is by balancing it against incident illumination. Demonstrated by [
23], details about imaging hardware, the collection procedure, the organization of the database, several potential uses of the database, and how to obtain the database. The study collected a database of over 40,000 images of 68 people. Each person is captured in 13 different poses, under 43 different illumination conditions, and with 4 different expressions. In another study [
24], a large-scale dataset was collected with various illumination variations to evaluate the performance of the Remote Photo Plethysmography (RPG) algorithm. The study also proposed a low-light enhancement solution for remote heart rate estimation under low-light conditions. In a recent study [
25], fine perceptive generative adversarial networks (FP-GANs) are proposed to construct super-resolution (SR) MR images from low-resolution equivalents. FP-GANs use a divide-and-conquer strategy to process low-and high-frequency MR image components individually and in tandem. In another study [
26] mild cognitive impairment and Alzheimer’s disease are assessed using a tensorizing GAN with high-order pooling. The proposed model can benefit from brain structure by tensorizing a three-player cooperative gaming framework. By introducing high-order pooling into the classifier, the suggested model can employ second-order MRI statistics (MRI). The study [
27] proposed state-of-the-art XAI algorithms for EMG hand gesture classification to understand the outcome of machine learning models with respect to physiological processes to recognise hand movements by mapping and merging synergic muscle activity.
The systematic review shown in
Table 1 that highlights the potential related research focused on diverse illumination variation factors is given by.
3. Materials and Methods
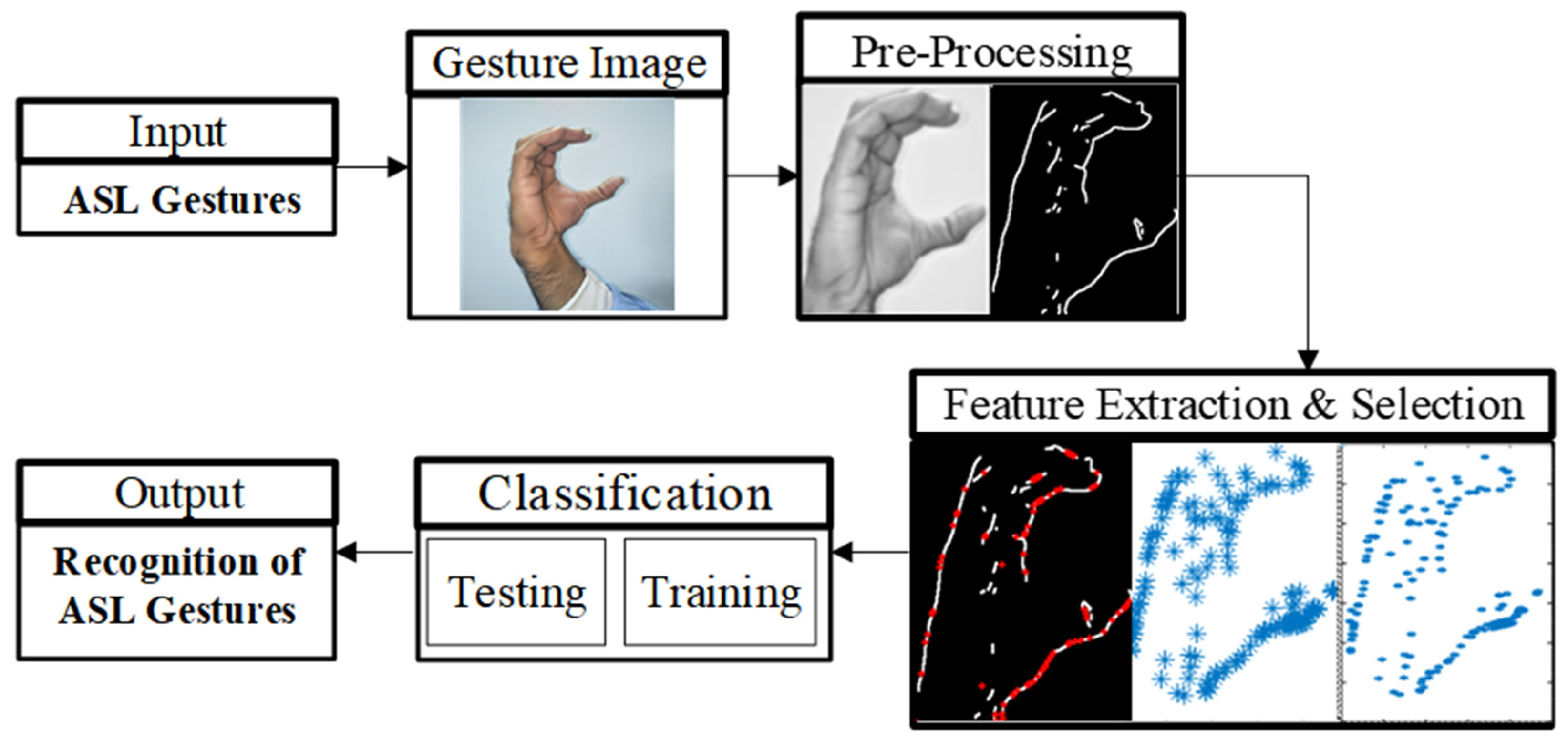
This section proposed a framework of sensor-based sign language gesture recognition which consists of the following main phases, i.e., acquiring the image, image preprocessing, feature extraction, and classification, as shown in
Figure 1.
The recognition process starts with the acquisition of depth images using the Kinect sensor. Each pixel in a depth image reflects the distance between the image plane and an RGB image object. Following that, hand shapes are precisely segmented in order to locate and track the hands’ shapes, similar to the human’s communication approach. To develop the datasets, ASL-based gesture images are stored in a database and converted into PNG format. The next step is the pre-processing of the acquired images to transform the captured image into a uniform level of brightness. For that, the system performs the luminosity method based on the grey-scale conversion of the input image. Grayscale conversion reduces complexity and is much easier to work with a variety of tasks such as image segmentation problems. Greyscale conversion is carried out through the weighted method, also called the luminosity method. The main reason for proposing the luminosity method is to equalize the weights of red, green, and blue according to their wavelengths. The luminosity method is a better version of the average method. As discussed in [
35], luminosity-based greyscale conversion can be calculated as follows:
where R, G, and B represent red, green, and blue colours, respectively.
The next step is to extract the appropriate features and their selection. The selection of the number of features is a critical step because more features consume additional space and computational time. Fewer features affect the accuracy. For that, the SIFT method is proposed to select and extract the appropriate features from acquired data. The proposed method extracts four significant features (perimeter, hand size, centre of hand and finger distance) from a given input image.
To define the shape of the hand and calculate the perimeter value, the perimeter feature extraction (PFE) technique is used to detect the edges and boundaries of the human hand by counting the pixels having values of 1 and 0 for neighboring pixels while skipping the grey shades. The shape is calculated by finding the projection of the hand that provides the size of the hand. For that, vertical and horizontal values are calculated by adding up all the values of rows and columns as follows:
where
v and
h represent the vertical and horizontal positions, and
r and
c represent the row and column, respectively, of pixel
P in an image. In Equation (2), the letter “n” stands for the maximum “height” value, which is the vertical side of a hand. In Equation (3), the letter “n” stands for the maximum “width” value, which is the horizontal side of a hand.
The hand size feature is useful to recognize the change in the size of a hand because hand size differs from person to person. The size component of a hand represents the hand size at a specific time. To calculate the hand size, we define the function,
Mi(r, c) as in Equations (4) and (5).
where
r and
c represent the row and column, respectively, of pixel
P in an image. Then, the area
Ai is measured in pixels and indicates the relative size of the hand.
The centre of the hand feature recognizes the orientation and position of the hand. Finding the centre of the object is important for detecting any change in hand shape, palm position, and movement of the hand or fingers. We can define the centre of hand by the pair (
) for rows and columns, respectively, measured as follows:
where both
r and
c represent the row and column, respectively, of pixel
P in an image, and
Mi(r, c) is a size function.
Finally, the fingers position is calculated by finding the distance between two open or closed fingers. The finger’s distance feature helps define the gesture. It can be carried out by counting the continuous pixel having a value of 0 until a neighboring pixel with a value of 1. The significant points can be calculated as follows:
where
Sp is a significant point plotted on the plane averaging 5-pixel values along the
x-axis and
y-axis, respectively,
sx is the starting point along the
x-axis averaging the next five values,
sy is the starting point along the
y-axis averaging the next five-pixel values. Additionally,
b is a bias that gives the neural network an extra parameter to tune by initializing non-zero random values.
After that, extracted features are combined into the form of a feature vector set
, the data is displayed in the form of these symmetric patterns. To measure the boundary, size, and orientation of the hand for a particular gesture defined as
where
where the letter “
n” denotes the total number of extracted ‘feature points’ for each defined feature (
F1,
F2,
F3, and
F4) for a hand gesture. The symmetric feature set enables the description of symmetric patterns such as the perimeter, center, finger position, and the size of the hand. Where ‘perimeter features’ outline the physical shape of the hand, ‘size feature’ extracts features for comparison of scale variation of the hand, ‘center of hand’ handles the orientation of the hand, and ‘finger position’ feature measures the distance between two fingers. The feature set created in matrix form shows all the features combined in Equation (15).
where each pixel corresponds to a matrix element value. “0” and “1” represent pixel values, with 1 indicating the presence of a feature point and 0 indicating its absence. Finally, the SIFT technique is employed, which was proposed by Lowe, D.G. [
36] and later the anatomical structure was discussed by the authors in their work [
37]. The SIFT technique extracts features and identifies the significant key points of ASL-based images with their relevant features in diverse illumination conditions. The SIFT algorithm is formulated as follows in Algorithm 1.
| Algorithm 1: SIFT Keypoints Generation |
1: Gaussian scale-space computation
2: Input: i image
3: Output: s scale-space |
4: Difference of Gaussians (DoG)
5: Input: s scale-space
6: Output: d DoG |
7: Finding keypoints (extrema of DoG)
8: Input: d DoG
9: Output: {(rd, cd, αd)} list of discrete extrema (position and scale) |
10: Keypoints localization to sub-pixel precision
11: Input: d DoG and {(rd, cd, αd)} discrete extrema
12: Output: {(r, c, α)} extreme points |
13: Filter unstable extrema
14: Input: d DoG and {(r, c, α)}
15: Output: {(r, c, α)} filtered keypoints |
16: Filter poorly localized keypoints on edges
17: Input: d DoG and {(r, c, α)}
18: Output: {(r, c, α)} filtered keypoints |
19: Assign a reference orientation to each keypoint
20: Input: (∂mv, ∂nv) scale-space gradient and {(r, c, α)} list of keypoints
21: Output: {(x, y, α, θ)} list of oriented keypoints |
22: SIFT Feature descriptor generator
23: Input: (∂mv, ∂nv) scale-space gradient and {(x, y, α, θ)} list of keypoints
24: Output: {(r, c, 1: α, θ, f)} list of described keypoints |
4. Experimentation and Results
To prove the concept, a workable testbed has been developed in the laboratory by using the Microsoft Kinect sensor to capture the images and convert them into depth images for acquiring the diverse resolution data, as shown in
Figure 2.
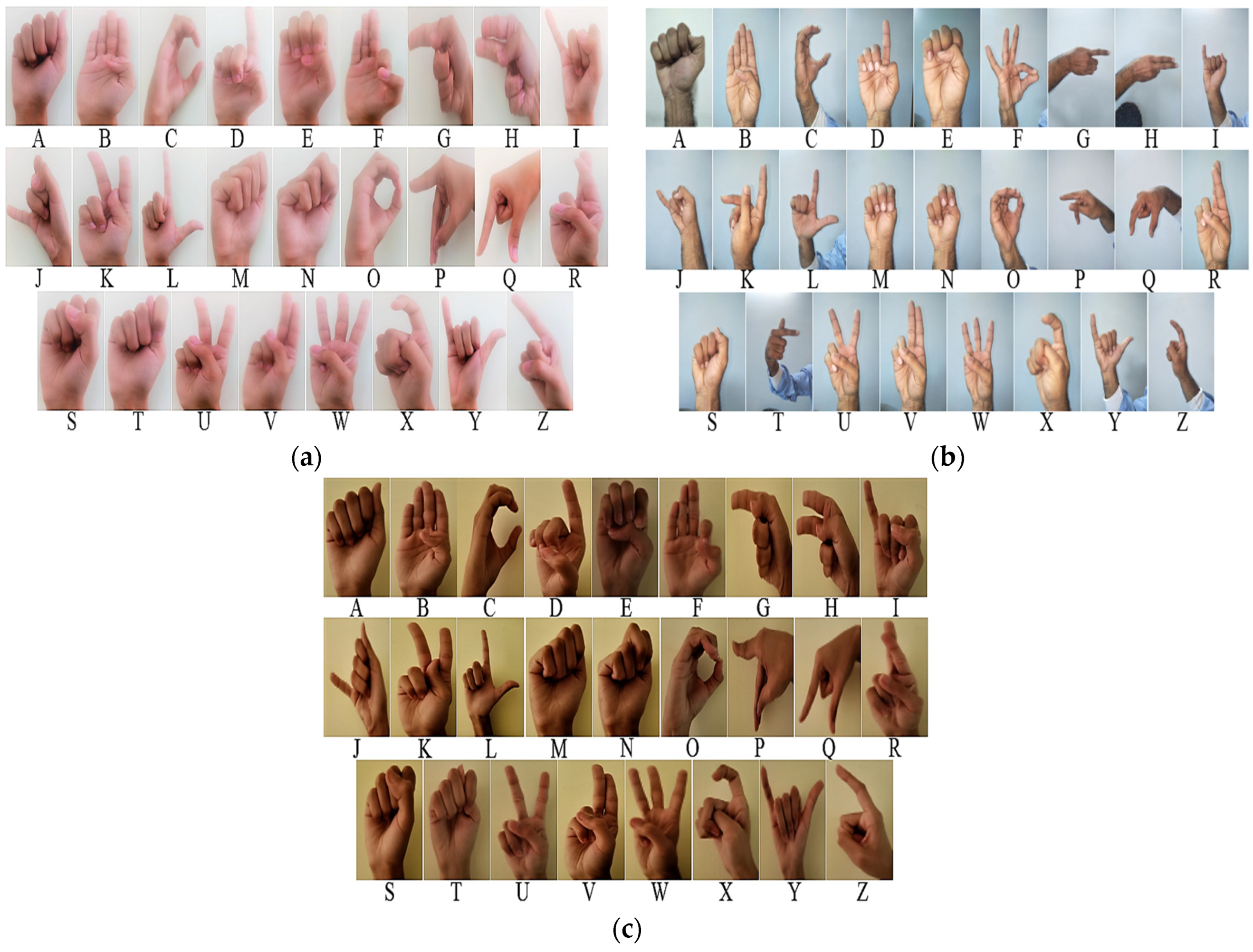
For the development of a case study, a total of three subjects were considered to acquire the data in diverse illuminated conditions and save it into PNG format according to Equation (1), as shown in
Figure 3.
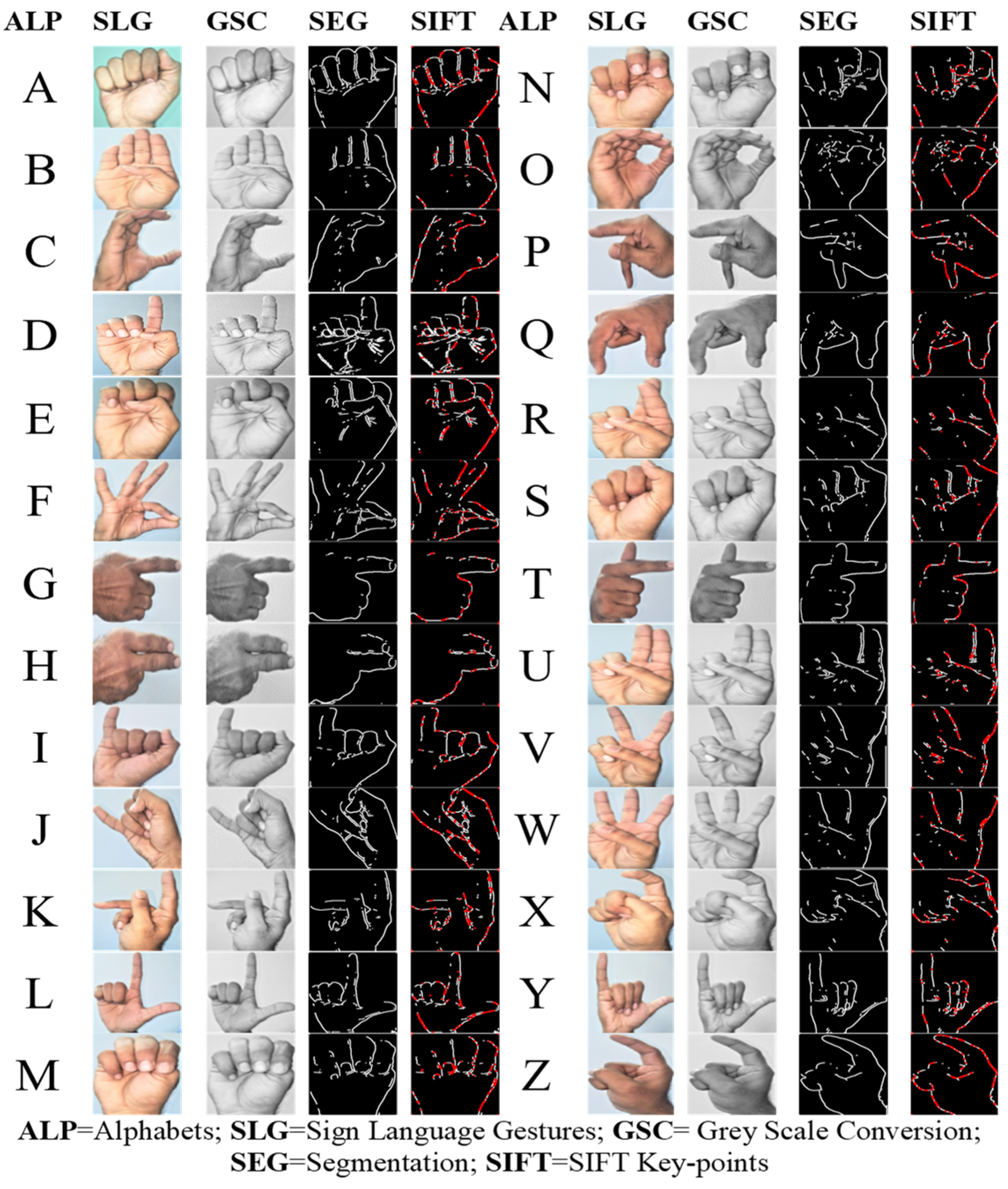
The subsequent step is to convert the ASL images into grayscale for the segmentation to separate the hand object from its background, as shown in
Figure 4. The next stage is to calculate the SIFT points from the segmented hand objects to identify the feature points as mentioned in Equation (15). A feature descriptor method is used to process the significant image points from identified feature points to convert them into significant vector points. For that, the Matlab tool is used to extract the required feature point values and convert them into significant points using the SIFT algorithm from 26 letters of the alphabets.
After calculating the SP using SIFT, the average processing time of every step is calculated under different lighting conditions and resolution rates as shown in the following
Table 2. As we can observe from
Table 2, the reasonable processing time is at a 1024 × 768-resolution rate in ambient light conditions, which is a good resolution rate for analysis. It is noticed that higher resolution rates consume more processing time. Therefore, we will consider the 1024 × 768 resolution rate at the next stage.
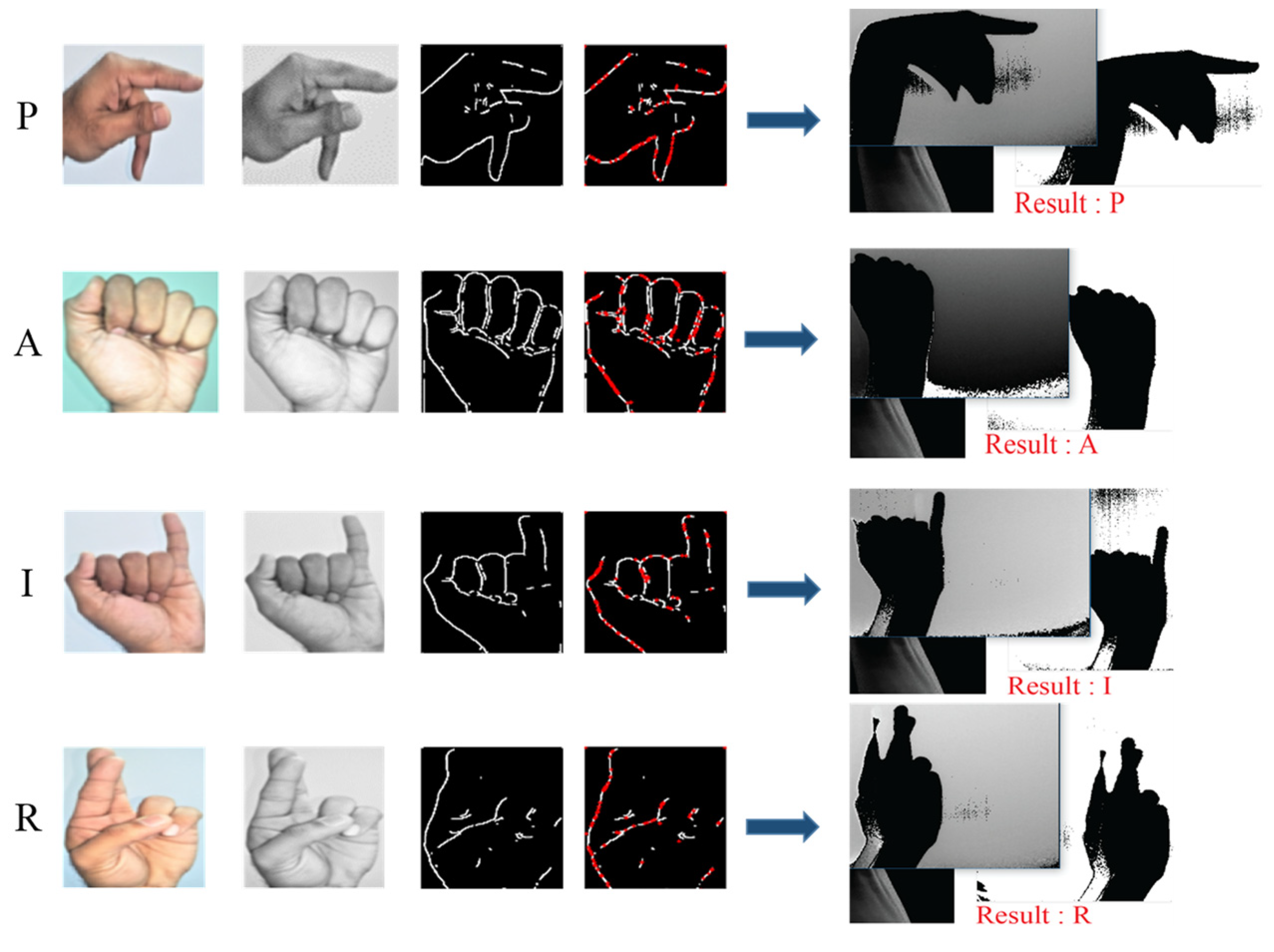
After converting the 26 alphabets into grayscale, segmentation and significant point calculation of A–Z, four letters are considered to show the efficiency of the proposed framework. Letters “P”, “A”, “I”, and “R” are used for segmentation, SIFT, and measure the significant points of the hand gesture as shown in the following
Figure 5.
Referring to Equation (15), and
Figure 6, we considered the mean (
), standard deviation (σ), variance (µ) and average deviation (AD) values against each feature of selected SP and converted them into the compact form of featured SP, respectively. The details are shown in
Table 3.
Selection of applicable gesture features is a key task as inputs of ANN for training to measure the accuracy from acquired data and it may indistinct the network structure. However, the right feature selection improves the efficiency of the ANN network, and training time may also be reduced by adopting the right ANN hidden layer architecture according to the input and output. In classification and data processing, ANN learning accommodates a variety of conditions better than any other classification technique [
38]. In this paper, we have chosen four different features as inputs
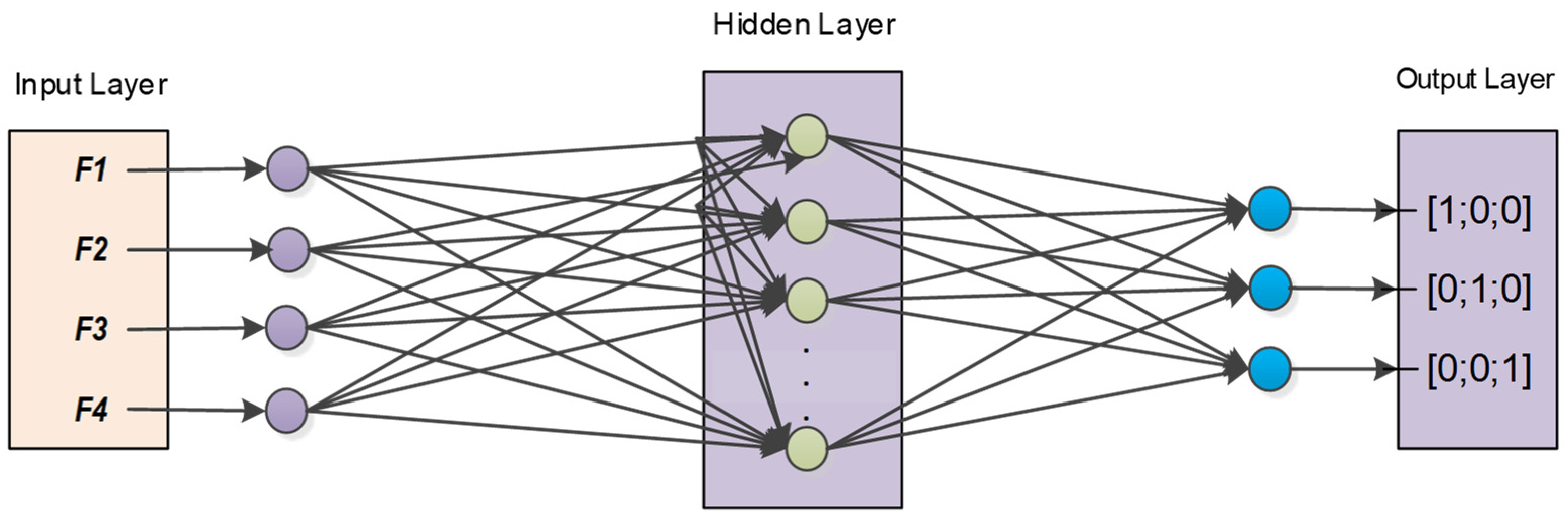
for each layer of neurons. Each network consists of one hidden layer that contains multiple neurons according to the inputs. The number of hidden layer neurons has a reliable impact on the performance of the ANN model. Therefore, the selection of a number of the hidden layer neurons depends on ANN accuracy in primary trials. For the target output, a vector of classes to recognize the hand gesture is written as follows:
[1; 0; 0]: Hand Natural Position;
[0; 1; 0]: Hand Gestural Position;
[0; 0; 1]: Hand Unknown Position.
A multi-layer Feedforward Neural Network (FFNN) method is used in this paper for the recognition of hand gestures from datasets. The proposed architecture of ANN for a single hand gesture is presented in
Figure 7.
Based on the same ANN training process, we used a similar classification architecture for the recognition of multiple hand gestures as objects. Every hand gesture feature’s vector class was used as input data and classified through a similar network architecture. The output layer in
Figure 6 presents the current state of the gesture. It contains a total of four NN input nodes, and the hidden layer activation function
is employed for every proposed output. All object feature values in
Table 3 were stored in the
Mat extension file and assigned these values with each hand gesture and divided all features into sub-features. The training goal is set at 0.01 target value and the Back Propagation (BP) learning method is adopted for training.
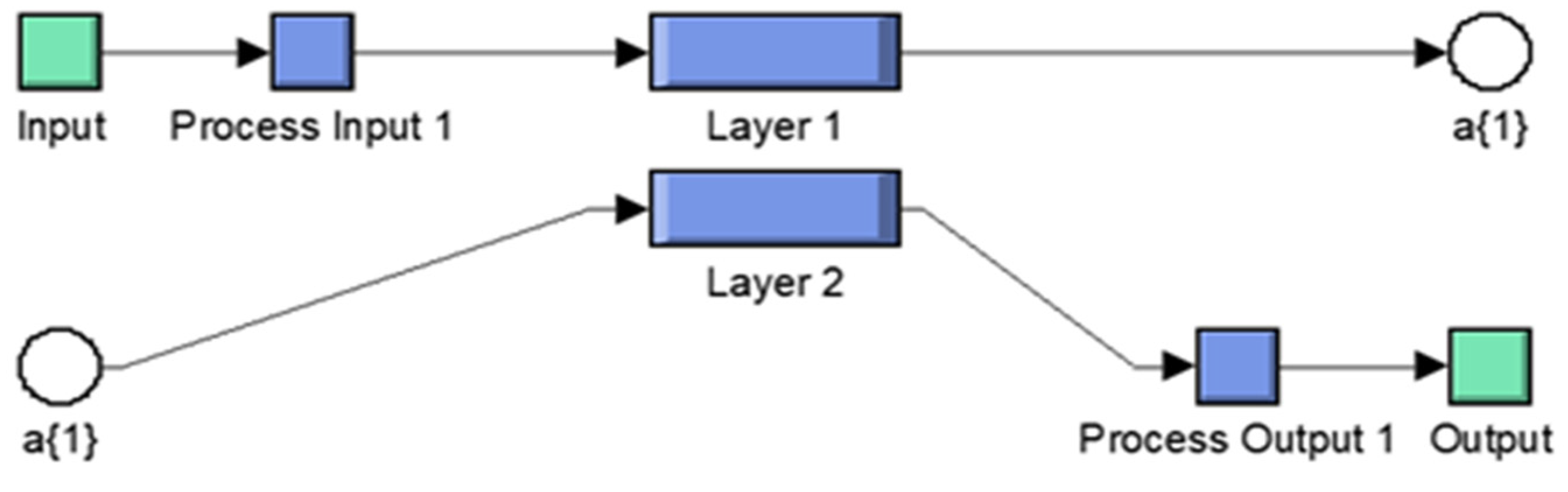
Figure 7 presents the inside architecture of each neural network for each hand object.
After initializing the ANN model for non-linear system modelling, specific ANN data must be assessed targeting nodes precedents. The hidden layer neurons and transfer function are set up to compute the training objective. Then, the layer weight is set for output.
Table 4 shows the brief explanation and ANN layer setup information.
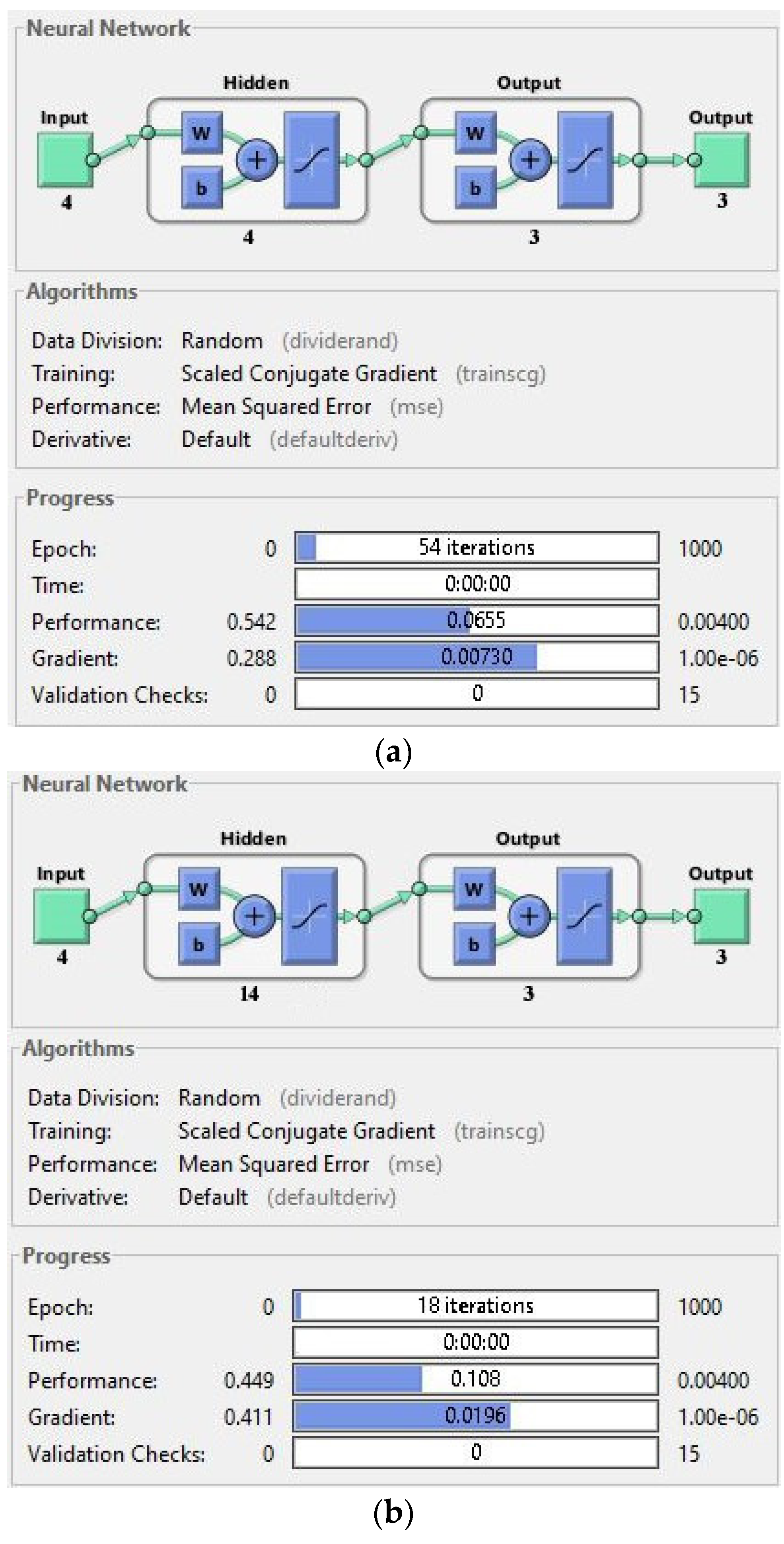
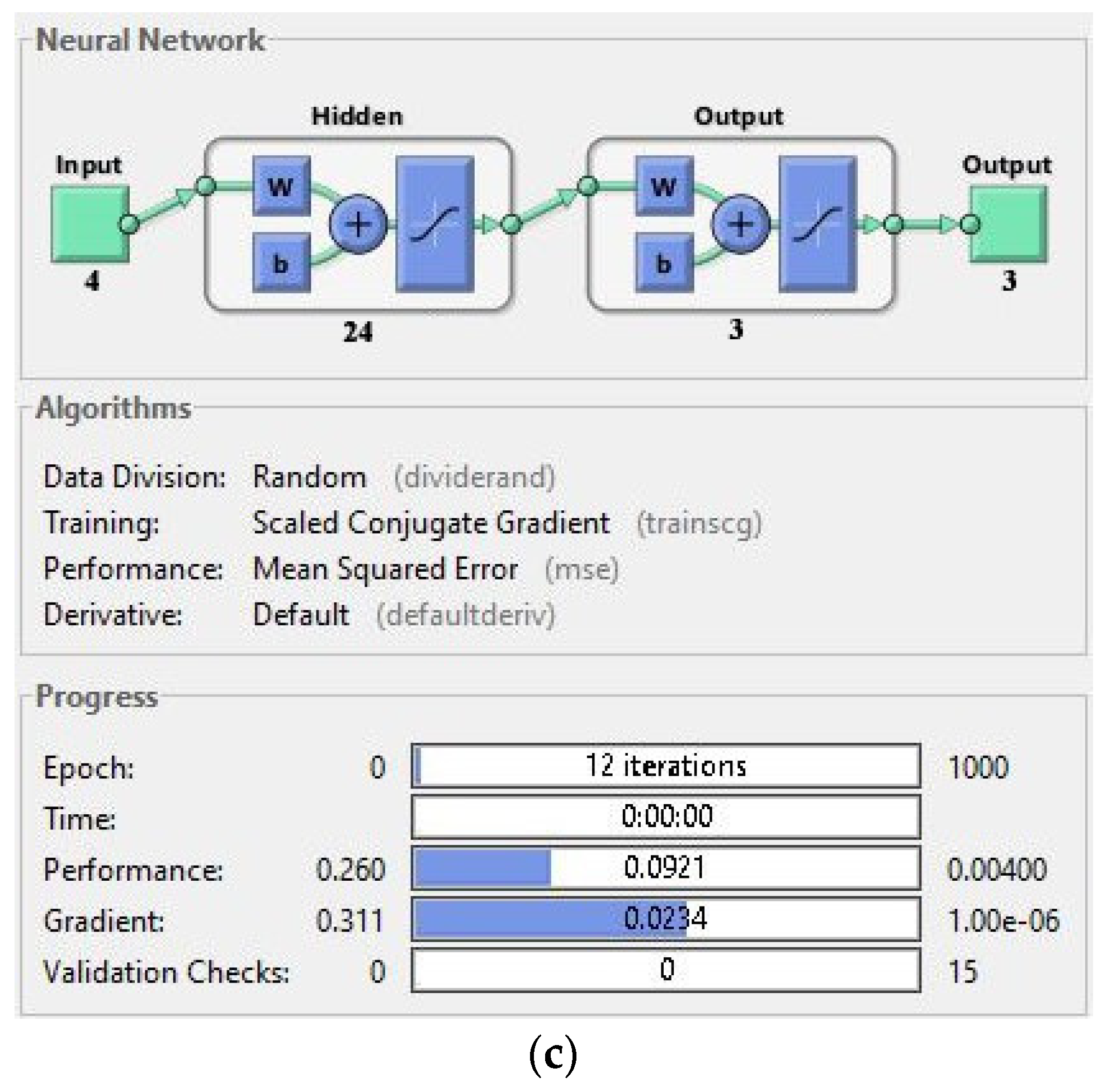
For the selection of suitable hidden layer neurons architecture, three types of ANN architecture (the [4 × 4 × 3], [4 × 14 × 3] and [4 × 24 × 3]) were tested in this paper for training purposes, as shown in
Figure 8. To alter the weights of the hidden layer until the targeted output was achieved at reasonable epoch numbers with less error rate, as shown in
Table 5.
Table 4.
Description of the implemented ANN.
Table 4.
Description of the implemented ANN.
| NN Steps | Artificial Neural Network Structure for Performance Matrices |
|---|
| Network Mode | FFNN |
| Learning Pattern | Back Propagation |
| Training Goal | 0.001 |
| Input data | Four inputs of 1D ANN matrix where all data were placed in each image’s class for recognition process index |
| No. of neurons in hidden layer | Diverse N architectures are used with different values of neurons inside hidden layer. For example, [4 × 4 × 3], [4 × 14 × 3] and [4 × 24 × 3] (see Figure 9). |
| Vector of classes for the target outputs | Mathematical matrices refer to the classified vector classes with value 0 or 1. |
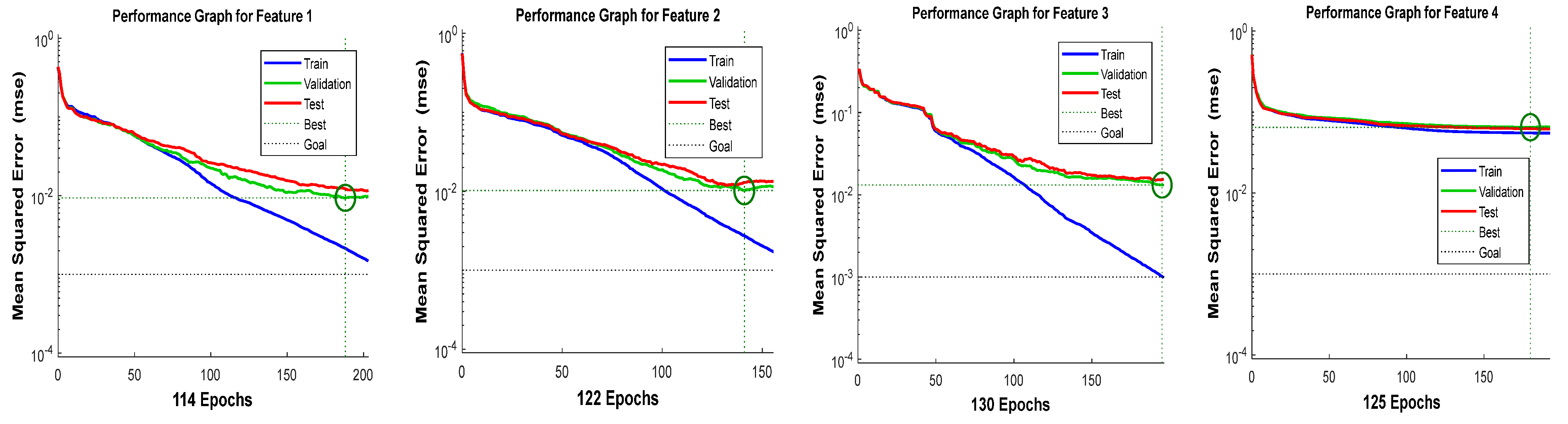
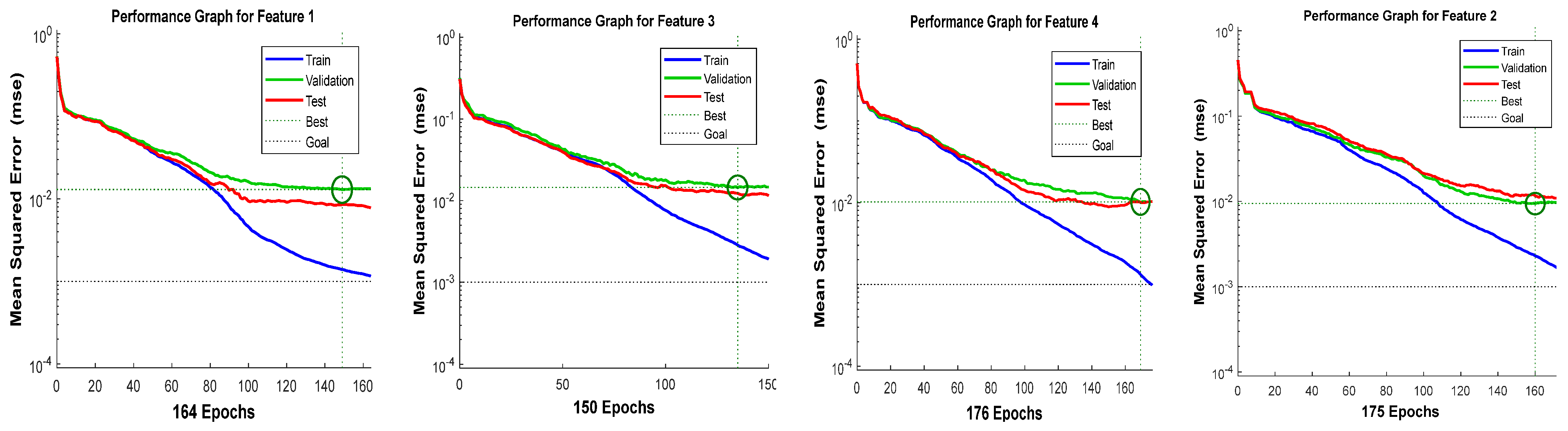
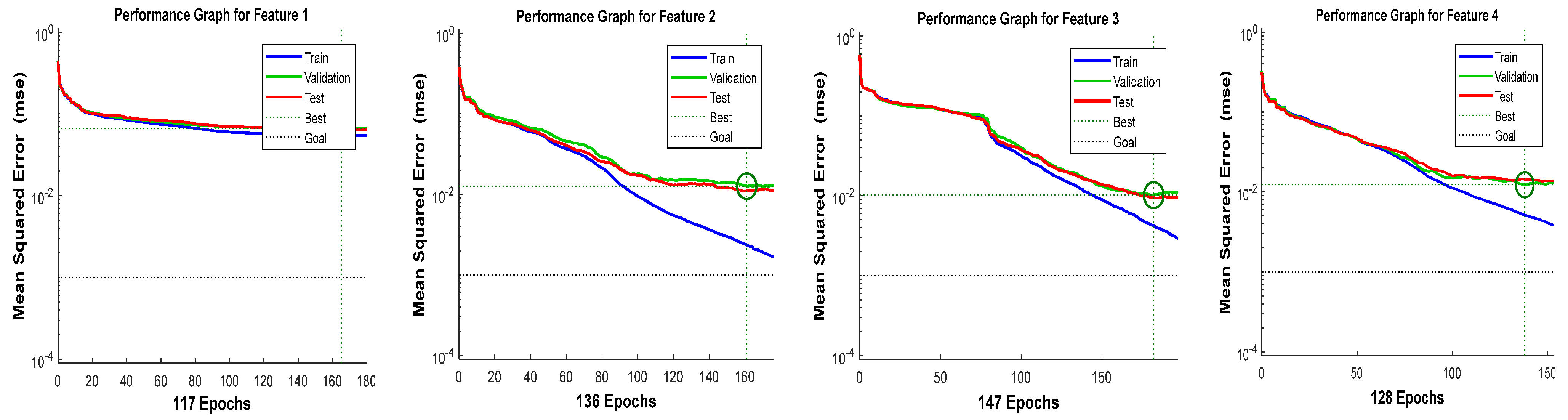
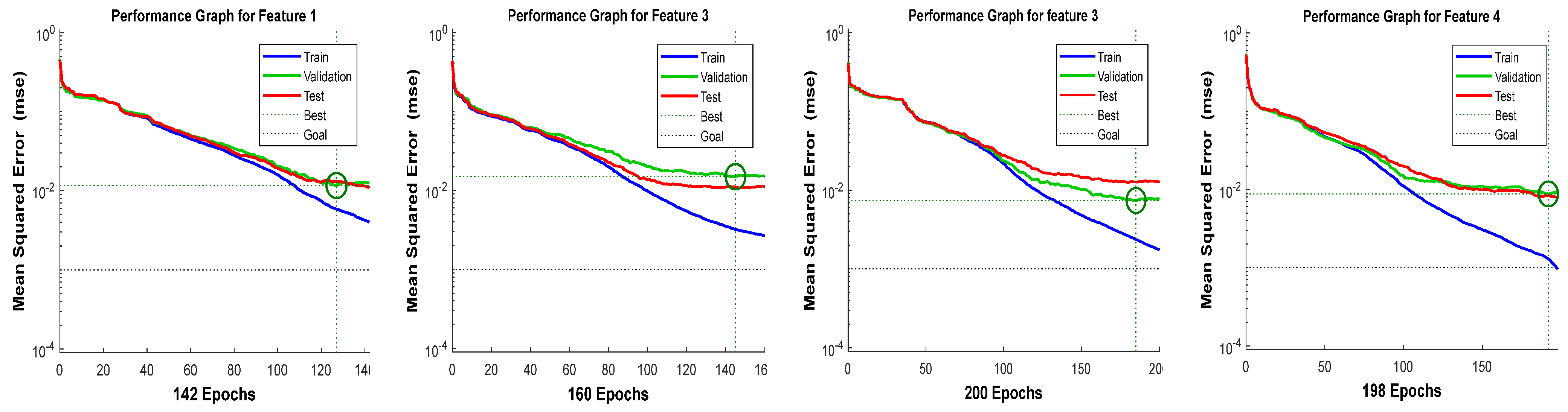
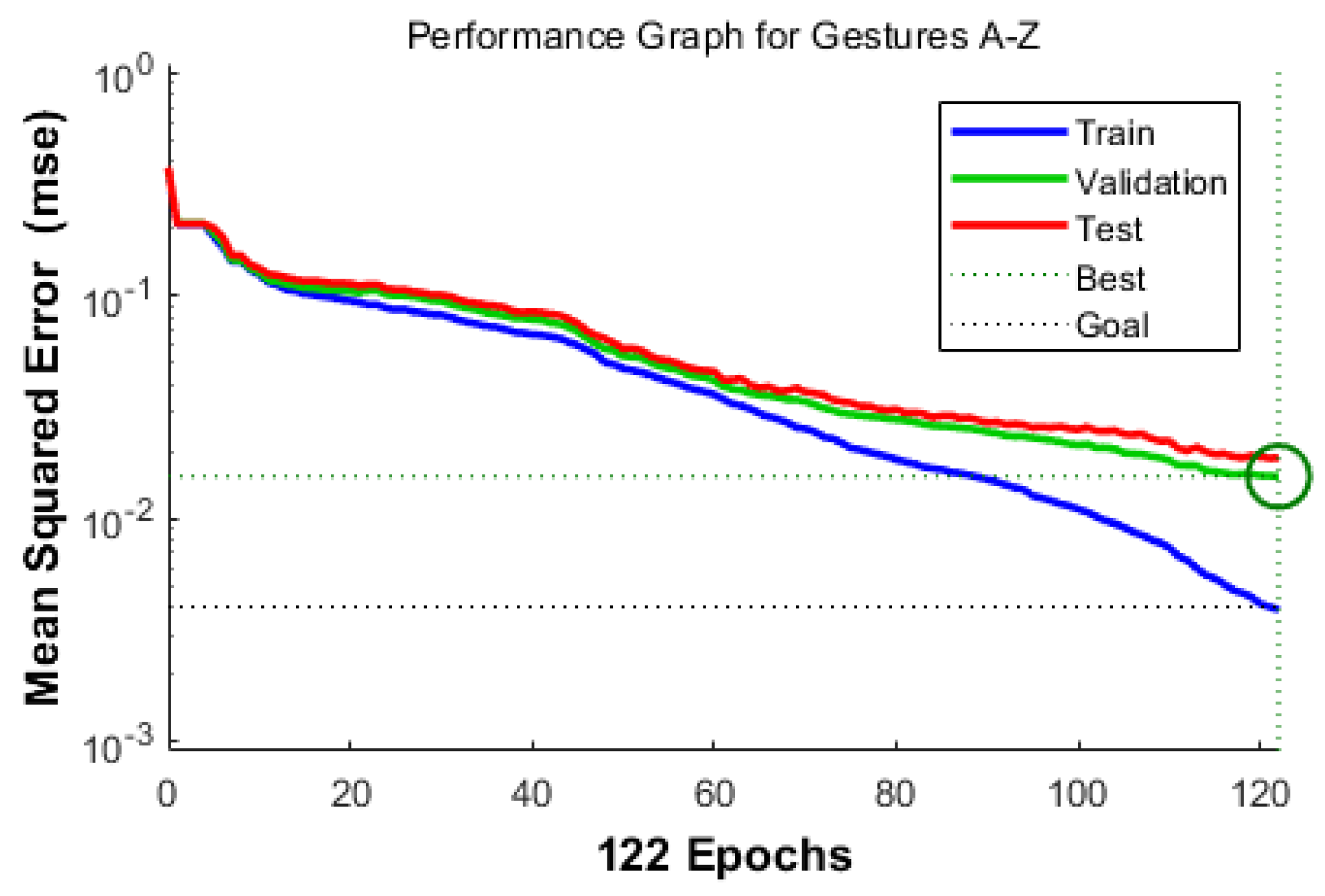
It can be observed from
Table 5 that the selected architecture [4 × 14 × 3] has presented better mean squared error (MSE) performance with reasonable epoch numbers and error rate than other ANN architectures. The next process is to measure the validation of acquired features in
Table 2.
Figure 9,
Figure 10,
Figure 11 and
Figure 12 show the training performance graph of the ANN architecture [4 × 14 × 3], which attained a good and considerable performance result during ANN testing.
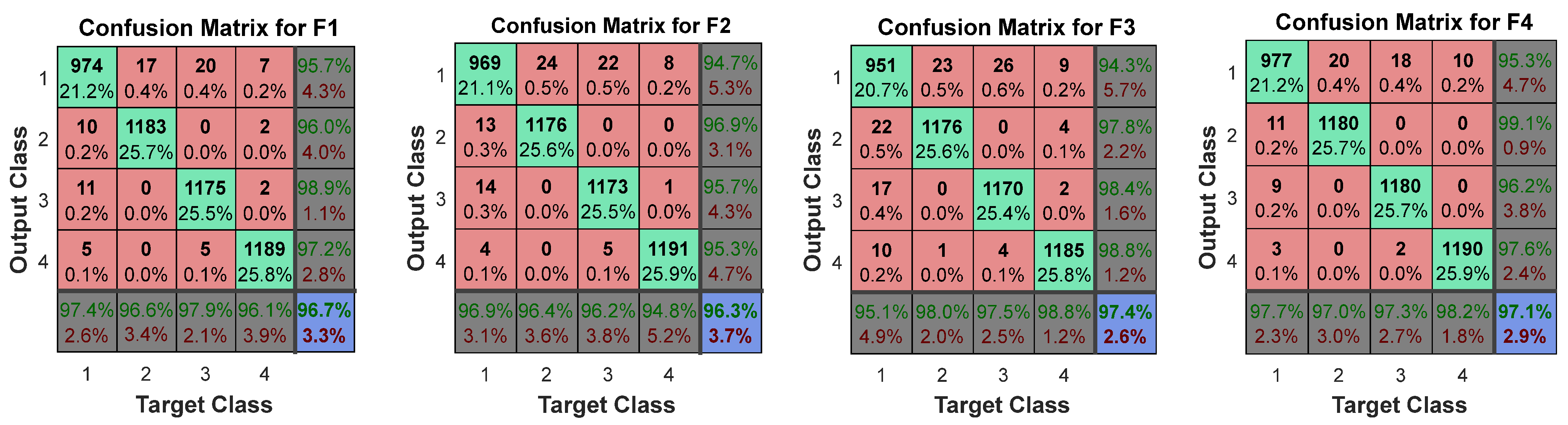
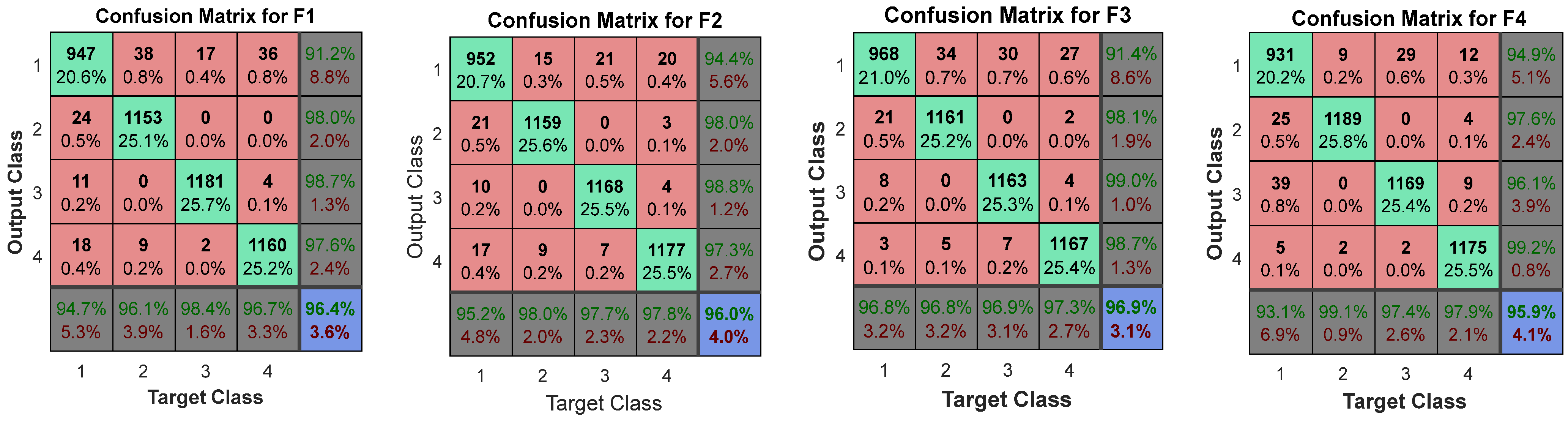
After measuring and testing the performance graph of the ANN architecture [4 × 14 × 3], the next stage of validation is to calculate the accuracy by calculating the Confusion Matrix (CM). To construct the CM, the four features input
values are inserted into ANN architecture in
Figure 7 by adjusting the height of the hidden layer. The combined confusion matrices of all features against each character of the
PAIR word are shown in
Figure 13,
Figure 14,
Figure 15 and
Figure 16.
In
Figure 13,
Figure 14,
Figure 15 and
Figure 16 above, each corner cell shows the accurately tested pattern cases of gestures through the proposed ANN architecture [4 × 14 × 3] to decide the recognition of the right-hand gesture. In the confusion matrices graph, the confusion grid holds the features processed training data between the target and output classes, consisting of three procedural stages: preparing, testing, and training of the gesture recognition and individually measuring the performance of the ANN architecture.
To perform these procedural stages, four horizontal target and vertical output classes were defined to demonstrate the precise data validation testing process to reflect all possible targeted sample values of feature sets. The green cells in the CM grid graphs show those data groups that are accurately classified and have completed a successful training process. Each grey corner cell in horizontal position shows those data groups of targeted classes that are accurately classified and complete the testing phase in the training process. The red cell presents those data sets that are wrongly classified or might not be properly validated in the testing phase. Finally, the blue cell presents the overall percentage of correctly classified gesture test cases from datasets. From confusion matrix diagrams, we can easily observe that each class has been tested under 1200 test cases and show percentages in green cells to observe the targeted class output parentage with error rates which are accurately classified during the testing phase with less than 1% wrongly classified in all trained datasets. Overall, a maximum 97.4% accurate rate of the word “PAIR” was achieved in the blue cell with only a 2.6% error rate, which shows the overall efficiency of the ANN architecture in terms of processing time.
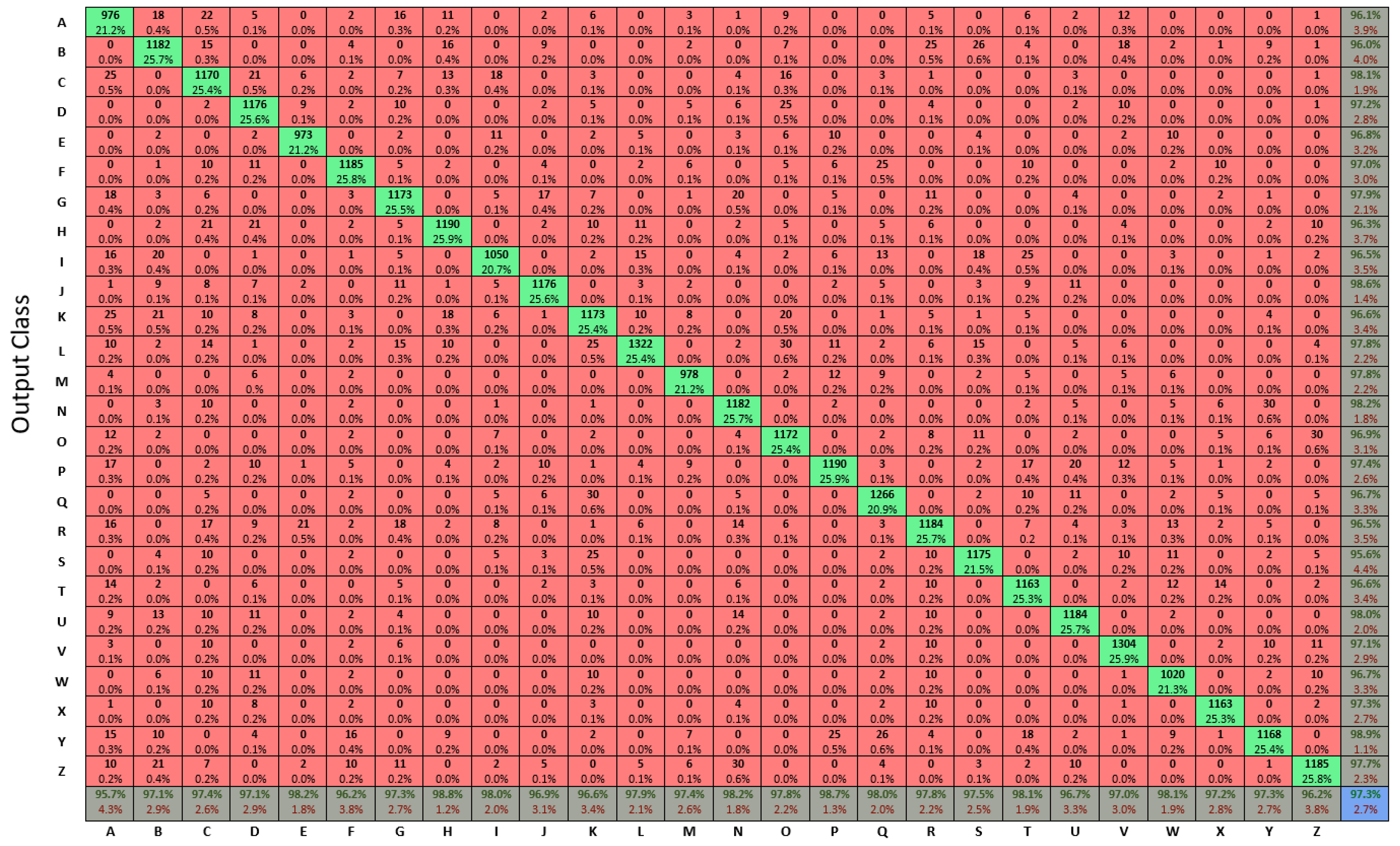
After measuring, testing, and calculating the accuracy of four selected features, the next step is to measure the accuracy of the whole dataset (A–Z). For that, the same ANN architecture [4 × 14 × 3] is utilized with the previous configuration settings that were used in the case study.
Figure 17 shows the training performance graph of ANN architecture [4 × 14 × 3], NN testing produced an excellent and significant performance result. The combined confusion matrix of all chosen features against each character (A–Z) word is shown in
Figure 17. From
Figure 18, we can certainly perceive that each class has been tested under 1400 test cases from trained datasets to observe the accurately classified target output class and only less than 1% are wrongly classified in all trained datasets. Overall, a maximum of 97.3% accuracy rate of all 26 alphabets was achieved in the blue cell with only a 2.7% error rate, which shows the overall efficiency of the adopted NN architecture [4 × 14 × 3] in terms of processing time.
Finally, a comparison has been performed between our work and other researcher’s published works in a similar domain to show the efficiency of our proposed framework process.
Table 6 compares the performance of our and other works based on gesture image datasets and recognition methods in terms of the number of gestures, frame resolution, response time, recognition approaches, and accuracy rate with an error rate under various illuminated conditions. The combination of preprocessing process, PFE, segmentations, significant point extraction, and utilising multiple ANN architectures for classification to reduce the error rate and achieve the high accuracy rate in gesture recognition is the reason for achieving the high accuracy rate compared with others.
5. Conclusions
This paper presented an efficient framework to improve the performance of gesture recognition under variant illumination using the luminosity method. Symmetric patterns and a related luminosity-based filter are considered for use in gesture recognition. The proposed framework consists of four main phases, i.e., acquiring the image, image pre-processing, feature extraction, and classification. To develop the datasets, a workable testbed has been developed in the laboratory by using two Microsoft Kinect sensors to capture the depth images for the purpose of acquiring diverse resolution data. ASL-based gesture images are stored in the database and converted into PNG format. The next step is the pre-processing of the acquired images to transform the captured image into a uniform level of brightness. For that, the system performs the luminosity method based on the grey-scale conversion of the input image. Grayscale conversion reduces complexity and is much easier to work with a variety of tasks such as image segmentation problems. Greyscale conversion was carried out through the weighted method. The next step is to extract the appropriate features and make their selection. It is a critical step because more appropriate features consume additional space and computational time. For that, the SIFT method is proposed to select and extract the appropriate features from acquired data. The proposed method extracts four significant features (perimeter, hand size, centre of hand, finger distance) from a given input image. After that, extracted features are combined into the form of a feature vector set to measure the boundary, size, and orientation of the hand for a particular gesture. Then, SIFT algorithm is to identify the significant key points of ASL-based images with their relevant features in diverse illuminated conditions. A feature descriptor method is used to calculate the significant image points from identified feature points and convert them into significant vector points. From the results, we can observe that the reasonable processing time is at a 1024 × 768 resolution rate, which is a good resolution rate for analysis. It is also noticed that higher resolution rates consume higher processing time and are shown in tabular form. Finally, we have chosen four different features as inputs for each layer of neurons. Each network consists of one hidden layer that contains multiple neurons with NN architectures ([4 × 4 × 3], [4 × 14 × 3], and [4 × 24 × 3]), respectively. After training, it is identified that the architecture [4 × 14 × 3] presented a better mean squared error (MSE) performance with reasonable epoch numbers and error rate among other NN architectures. From confusion matrix diagrams, we can easily observe that each class has been tested under 1200 test cases and show percentages in green cells to observe the targeted class output parentage with error rates which are accurately classified during the testing phase with less than 1% wrongly classified in all trained datasets. Overall, a maximum 97.4% accurate rate of the word “PAIR” was achieved with only a 2.6% error rate, which shows the overall efficiency of the NN architecture.
Future development would be extended toward the incorporation of complex depth images with more gesture angles in other languages (regional sign language) by using multiple high-resolution camera modules. Further complexity in recognition can be created to select more features at multiple angles and lighting conditions in outdoor environments.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


















