

An Entity Linking Algorithm Derived from Graph Convolutional Network and Contextualized Semantic Relevance

Abstract
:1. Introduction
- A novel strategy for building entity graphs that drastically explores the semantic space consistency among the candidate entities is presented. This not only reduces the time needed to build an entity graph, but also enhances the coherence of the finally built graph.
- The asymmetric graph convolutional network is used to learn entity embeddings, which improves discriminative signals of the entities by fully exploring the asymmetric structural features of the entity graphs. In addition, the final EL features combine the contextual information and the prior probability as well.
- Experiments with benchmark datasets demonstrate the superior performance of our approach compared with the state-of-the-art EL methods. Our experimental studies also illustrate the influences of the key features.
2. Related Work
2.1. Individual Entity Linking
2.2. Collective Entity Linking
3. Preliminaries
3.1. Entity Linking
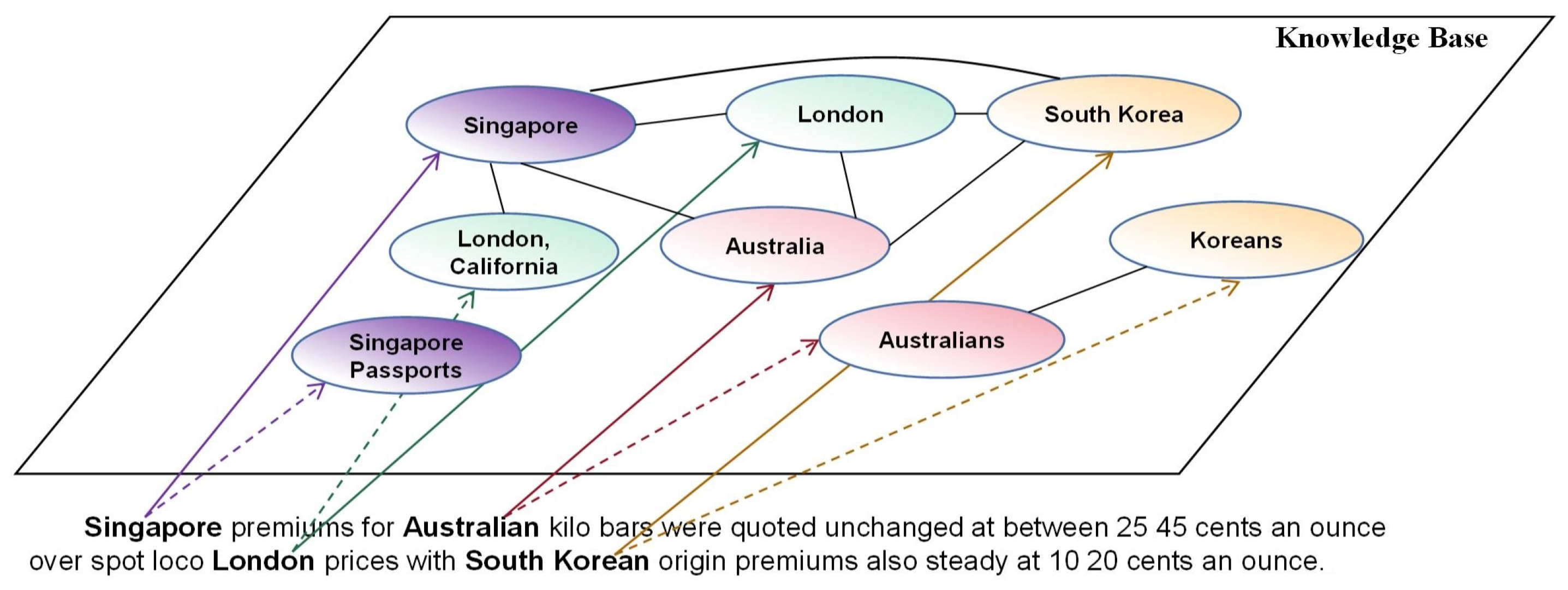
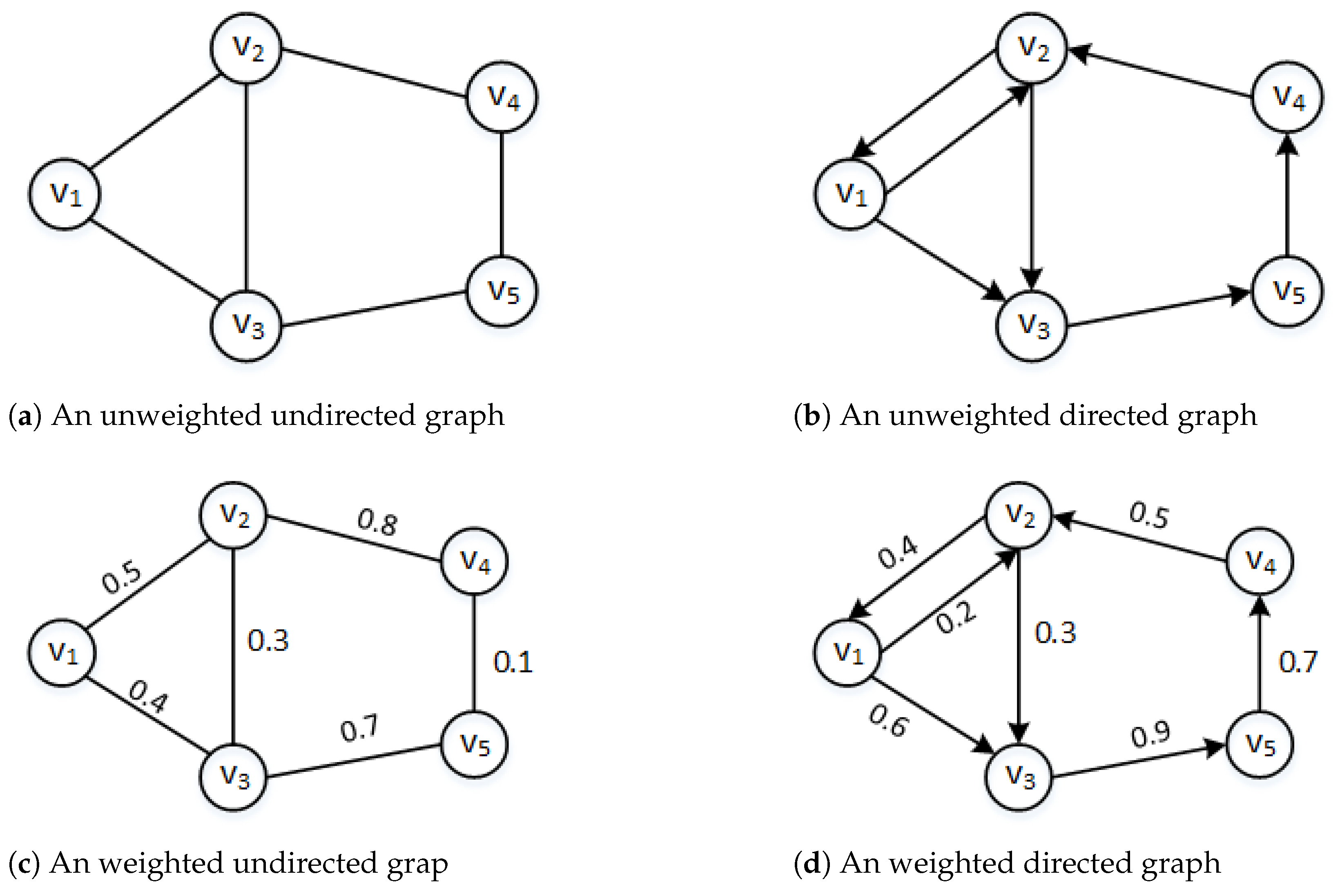
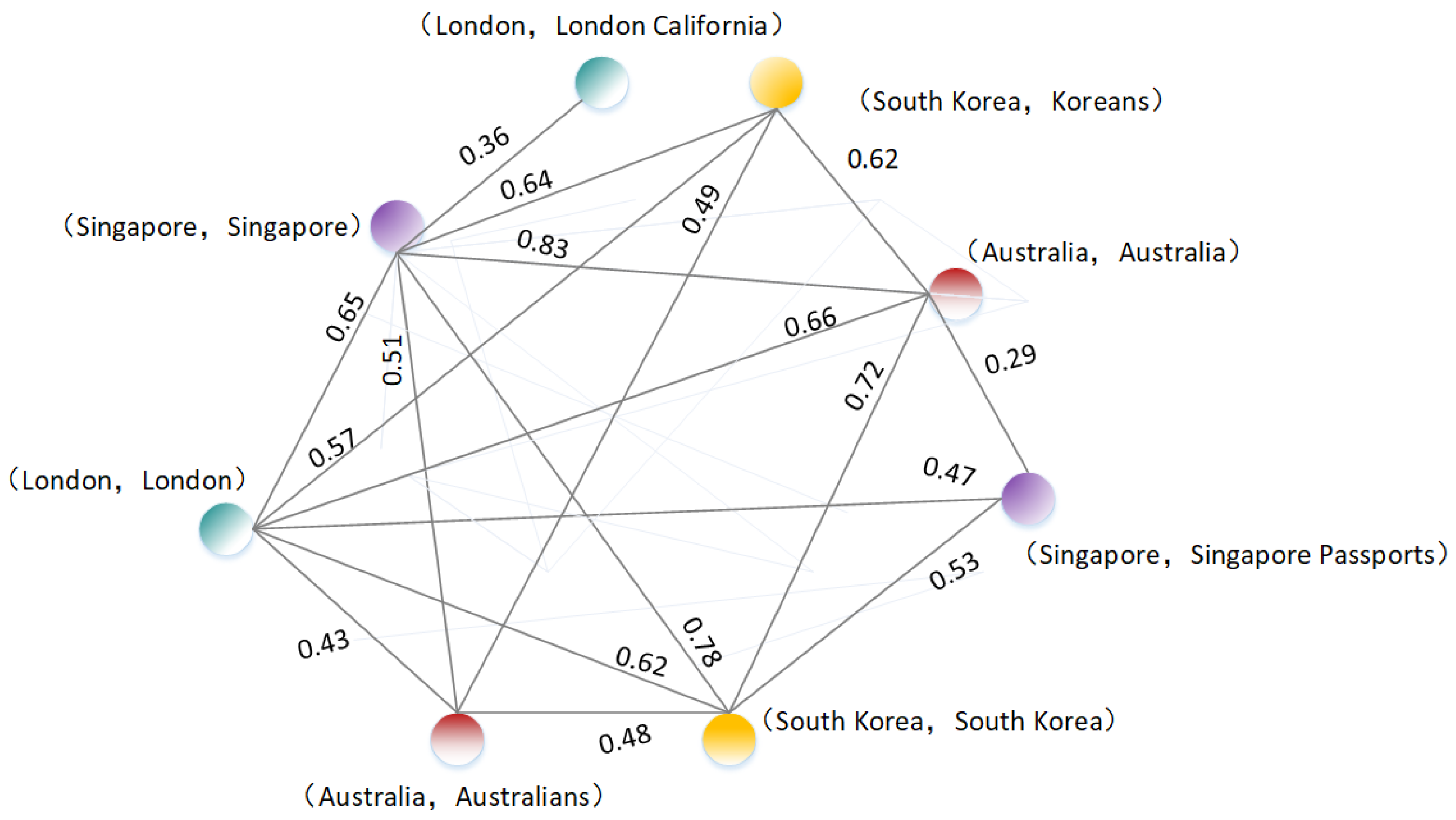
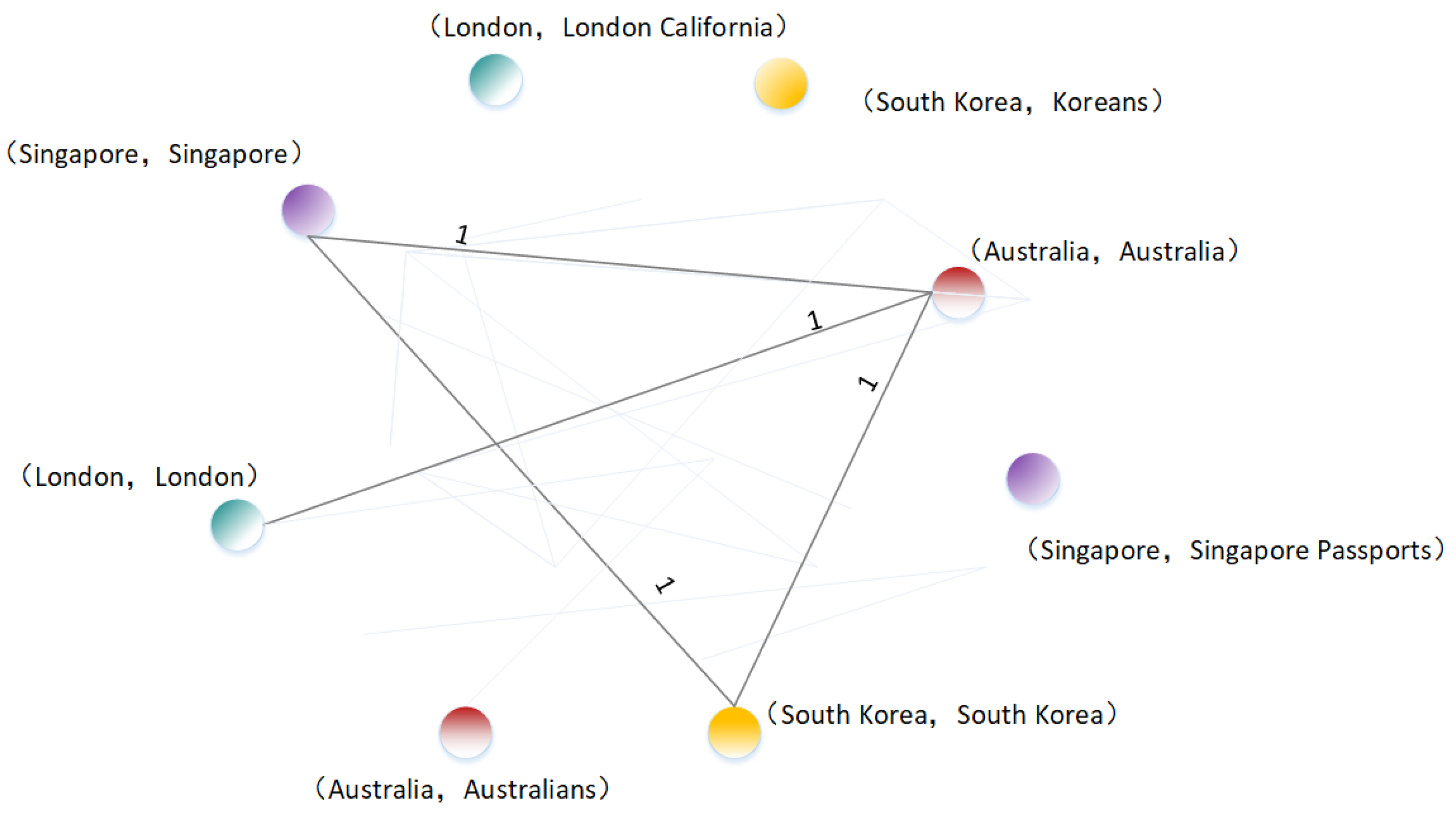
3.2. Entity Graph
3.2.1. Normalized Google Distance-Based Entity Graph
3.2.2. Link-Based Entity Graph
3.2.3. Embedding-Based Entity Graph
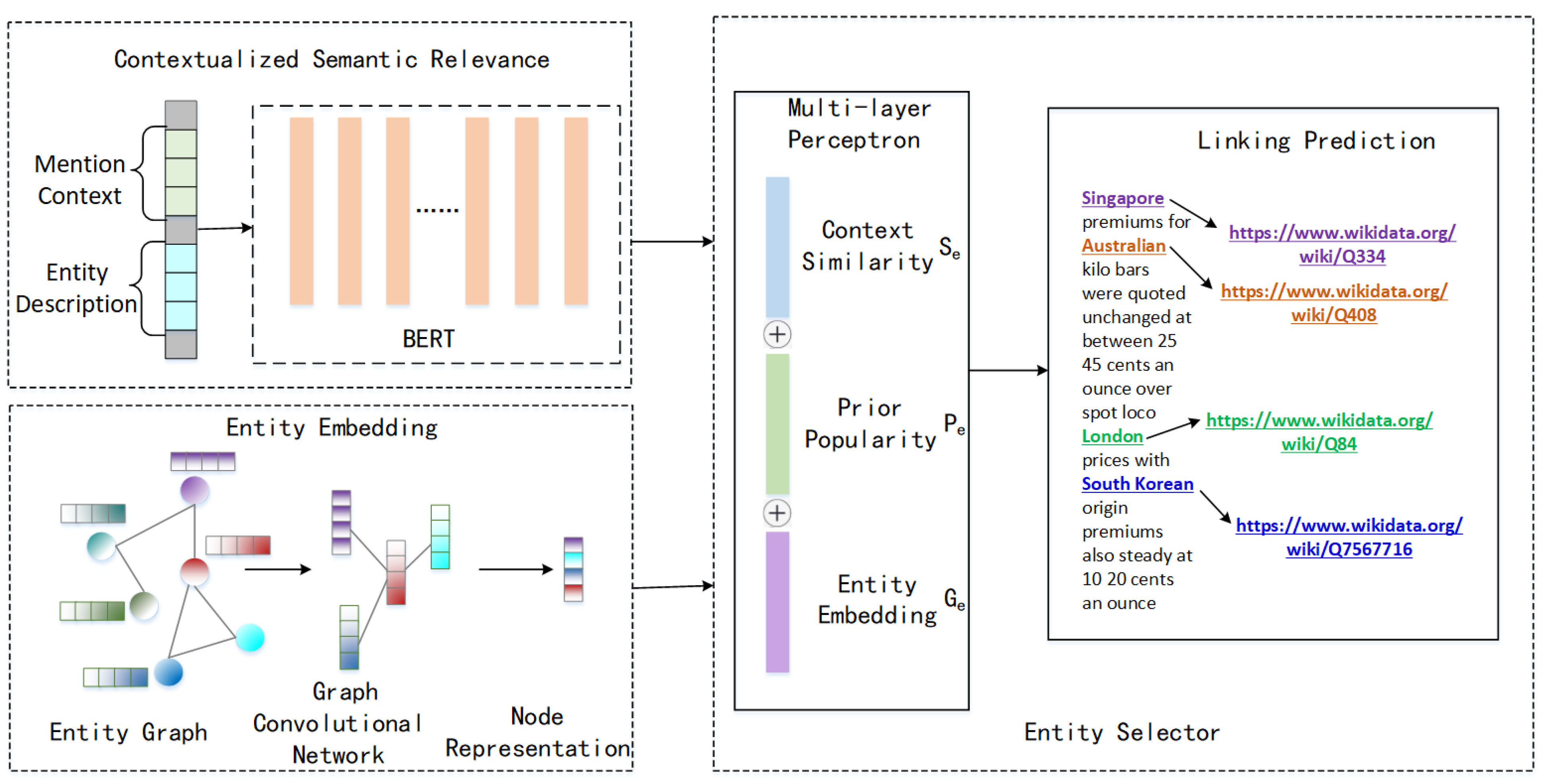
4. Proposed Model
4.1. Contextualized Semantic Relevance with BERT
4.2. Entity Embedding with Asymmetric Graph Convolutional Network
4.3. Entity Selector with Multiple Features
5. Experiment
5.1. Experimental Settings
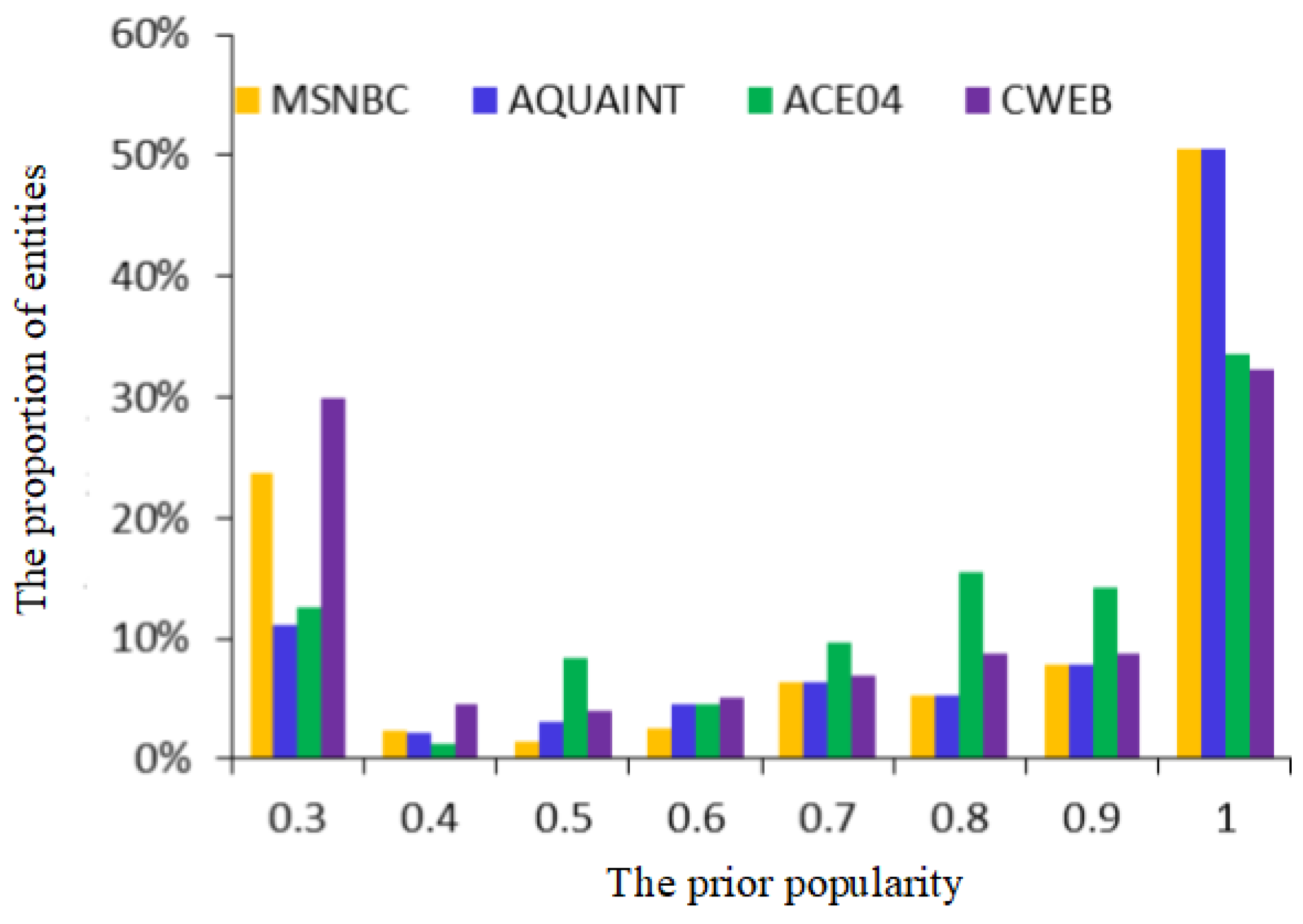
5.1.1. Datasets
5.1.2. Parameters
5.1.3. Complexity Analysis
5.2. Evaluation Metric
5.3. Result and Discussion
5.4. Impact of Different Modules
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef] [Green Version]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Guo, S.; Chang, M.W.; Kiciman, E. To link or not to link? A study on end-to-end tweet entity linking. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 1020–1030. [Google Scholar]
- Nie, F.; Cao, Y.; Wang, J.; Lin, C.Y.; Pan, R. Mention and entity description co-attention for entity disambiguation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5908–5915. [Google Scholar]
- He, Z.; Liu, S.; Li, M.; Zhou, M.; Zhang, L.; Wang, H. Learning entity representation for entity disambiguation. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 30–34. [Google Scholar]
- Guo, Z.; Barbosa, D. Robust named entity disambiguation with random walks. Semant. Web 2018, 9, 459–479. [Google Scholar] [CrossRef]
- Xie, T.; Wu, B.; Jia, B.; Wang, B. Graph-ranking collective Chinese entity linking algorithm. Front. Comput. Sci. 2020, 14, 291–303. [Google Scholar] [CrossRef]
- Lamurias, A.; Ruas, P.; Couto, F.M. PPR-SSM: Personalized PageRank and semantic similarity measures for entity linking. BMC Bioinform. 2019, 20, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rama-Maneiro, E.; Vidal, J.C.; Lama, M. Collective disambiguation in entity linking based on topic coherence in semantic graphs. Knowl. Based Syst. 2020, 199, 105967. [Google Scholar] [CrossRef]
- Deng, Z.; Li, Z.; Yang, Q.; Liu, Q.; Chen, Z. Improving Entity Linking with Graph Networks. In International Conference on Web Information Systems Engineering; Springer: Cham, Switzerland, 2020; pp. 343–354. [Google Scholar]
- Li, Q.; Li, F.; Li, S.; Li, X.; Liu, K.; Liu, Q.; Dong, P. Improving Entity Linking by Introducing Knowledge Graph Structure Information. Appl. Sci. 2022, 12, 2702. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Fauceglia, N.R.; Rodriguez-Muro, M.; Hassanzadeh, O.; Gliozzo, A.; Sadoghi, M. Joint Learning of Local and Global Features for Entity Linking via Neural Networks. In Proceedings of the COLING, Osaka, Japan, 13–16 December 2016; pp. 2310–2320. [Google Scholar]
- Gupta, N.; Singh, S.; Roth, D. Entity Linking via Joint Encoding of Types, Descriptions, and Context. In Proceedings of the EMNLP, Copenhagen, Denmark, 7–11 September 2017; pp. 2681–2690. [Google Scholar]
- Tang, Y.; Pedrycz, W. Oscillation-bound estimation of perturbations under Bandler-Kohout subproduct. IEEE Trans. Cybern. 2021, 52, 6269–6282. [Google Scholar] [CrossRef]
- Tang, Y.; Pedrycz, W.; Ren, F. Granular symmetric implicational method. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 6, 710–723. [Google Scholar] [CrossRef]
- Mendes, P.N.; Jakob, M.; García-Silva, A.; Bizer, C. DBpedia spotlight: Shedding light on the web of documents. In Proceedings of the 7th International Conference on Semantic Systems, Graz, Austria, 7–9 September 2011; pp. 1–8. [Google Scholar]
- Sun, Y.; Lin, L.; Tang, D.; Yang, N.; Ji, Z.; Wang, X. Modeling Mention, Context and Entity with Neural Networks for Entity Disambiguation. In Proceedings of the IJCAI, Buenos Aires, Argentina, 10–13 August 2015; Volume 15, pp. 1333–1339. [Google Scholar]
- Sun, Y.; Ji, Z.; Lin, L.; Wang, X.; Tang, D. Entity disambiguation with memory network. Neurocomputing 2018, 275, 2367–2373. [Google Scholar] [CrossRef]
- Cao, Y.; Huang, L.; Ji, H.; Chen, X.; Li, J. Bridge text and knowledge by learning multi-prototype entity mention embedding. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 1–4 August 2017; pp. 1623–1633. [Google Scholar]
- Hoffart, J.; Yosef, M.A.; Bordino, I.; Fürstenau, H.; Pinkal, M.; Spaniol, M.; Taneva, B.; Thater, S.; Weikum, G. Robust disambiguation of named entities in text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–29 July 2011; pp. 782–792. [Google Scholar]
- Moro, A.; Raganato, A.; Navigli, R. Entity linking meets word sense disambiguation: A unified approach. Trans. Assoc. Comput. Linguist. 2014, 2, 231–244. [Google Scholar] [CrossRef]
- Ganea, O.E.; Hofmann, T. Deep joint entity disambiguation with local neural attention. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–9 September 2017; Association for Computational Linguistics. pp. 2619–2629. [Google Scholar]
- Cao, Y.; Hou, L.; Li, J.; Liu, Z. Neural Collective Entity Linking. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 675–686. [Google Scholar]
- Fang, Z.; Cao, Y.; Li, R.; Zhang, Z.; Liu, Y.; Wang, S. High quality candidate generation and sequential graph attention network for entity linking. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 640–650. [Google Scholar]
- Bunescu, R.; Pasca, M. Using encyclopedic knowledge for named entity disambiguation. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics, Sydney, Australia, 17–21 July 2006; pp. 117–126. [Google Scholar]
- Zheng, Z.; Li, F.; Huang, M.; Zhu, X. Learning to link entities with knowledge base. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 483–491. [Google Scholar]
- Shen, L.; Joshi, A.K. Ranking and reranking with perceptron. Mach. Learn. 2005, 60, 73–96. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Qin, T.; Liu, T.Y.; Tsai, M.F.; Li, H. Learning to rank: From pairwise approach to listwise approach. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 129–136. [Google Scholar]
- Francis-Landau, M.; Durrett, G.; Klein, D. Capturing semantic similarity for entity linking with convolutional neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Berlin, Germany, 7–12 August 2016; pp. 1256–1261. [Google Scholar]
- Sukhbaatar, S.; Weston, J.; Fergus, R. End-to-end memory networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1–9. [Google Scholar]
- Zhang, S.; Lou, J.; Zhou, X.; Jia, W. Entity Linking Facing Incomplete Knowledge Base. In International Conference on Web Information Systems Engineering; Springer: Cham, Switzerland, 2018; pp. 325–334. [Google Scholar]
- Yamada, I.; Shindo, H.; Takeda, H.; Takefuji, Y. Joint learning of the embedding of words and entities for named entity disambiguation. In Proceedings of the 26th International Conference On Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 250–259. [Google Scholar]
- Moreno, J.G.; Besançon, R.; Beaumont, R.; D’hondt, E.; Ligozat, A.L.; Rosset, S.; Tannier, X.; Grau, B. Combining word and entity embeddings for entity linking. In Proceedings of the European Semantic Web Conference, Vienna, Austria, 21–25 October 2017; Springer: Cham, Switzerland, 2–5 May 2017; pp. 337–352. [Google Scholar]
- Han, X.; Sun, L.; Zhao, J. Collective entity linking in web text: A graph-based method. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 765–774. [Google Scholar]
- Ratinov, L.; Roth, D.; Downey, D.; Anderson, M. Local and global algorithms for disambiguation to wikipedia. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 1375–1384. [Google Scholar]
- Alhelbawy, A.; Gaizauskas, R. Graph ranking for collective named entity disambiguation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 75–80. [Google Scholar]
- Guo, Z.; Barbosa, D. Robust entity linking via random walks. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 499–508. [Google Scholar]
- Pershina, M.; He, Y.; Grishman, R. Personalized page rank for named entity disambiguation. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 238–243. [Google Scholar]
- Zwicklbauer, S.; Seifert, C.; Granitzer, M. Robust and collective entity disambiguation through semantic embeddings. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 425–434. [Google Scholar]
- Globerson, A.; Lazic, N.; Chakrabarti, S.; Subramanya, A.; elRingaard, M.; Pereira, F. Collective entity resolution with multi-focal attention. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 621–631. [Google Scholar]
- Yang, Y.; Irsoy, O.; Rahman, K.S. Collective entity disambiguation with structured gradient tree boosting. arXiv 2018, arXiv:1802.10229. [Google Scholar]
- Phan, M.C.; Sun, A.; Tay, Y.; Han, J.; Li, C. NeuPL: Attention-based semantic matching and pair-linking for entity disambiguation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1667–1676. [Google Scholar]
- Phan, M.C.; Sun, A.; Tay, Y.; Han, J.; Li, C. Pair-linking for collective entity disambiguation: Two could be better than all. IEEE Trans. Knowl. Data Eng. 2018, 31, 1383–1396. [Google Scholar] [CrossRef] [Green Version]
- Le, P.; Titov, I. Improving entity linking by modeling latent relations between mentions. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1595–1604. [Google Scholar]
- Le, P.; Titov, I. Distant learning for entity linking with automatic noise detection. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 4081–4090. [Google Scholar]
- Le, P.; Titov, I. Boosting entity linking performance by leveraging unlabeled documents. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1935–1945. [Google Scholar]
- Yamada, I.; Washio, K.; Shindo, H.; Matsumoto, Y. Global Entity Disambiguation with BERT. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Washington, DC, USA, 10–15 July 2022; pp. 3264–3271. [Google Scholar]
- Ma, Q.; Fan, Z.; Wang, C.; Tan, H. Graph Mixed Random Network Based on PageRank. Symmetry 2022, 14, 1678. [Google Scholar] [CrossRef]
- Zhu, J.; Mao, G.; Jiang, C. DII-GCN: Dropedge Based Deep Graph Convolutional Networks. Symmetry 2022, 14, 798. [Google Scholar] [CrossRef]
- Guo, Q.; Xie, H.; Li, Y.; Ma, W.; Zhang, C. Social Bots Detection via Fusing BERT and Graph Convolutional Networks. Symmetry 2021, 14, 30. [Google Scholar] [CrossRef]
- Shen, W.; Li, Y.; Liu, Y.; Han, J.; Wang, J.; Yuan, X. Entity linking meets deep learning: Techniques and solutions. IEEE Trans. Knowl. Data Eng. 2021. Early Access. [Google Scholar] [CrossRef]
- Sevgili, Ö.; Shelmanov, A.; Arkhipov, M.; Panchenko, A.; Biemann, C. Neural entity linking: A survey of models based on deep learning. Semant. Web 2022, 13, 527–570. [Google Scholar] [CrossRef]
- Fang, Z.; Cao, Y.; Li, Q.; Zhang, D.; Zhang, Z.; Liu, Y. Joint entity linking with deep reinforcement learning. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 438–447. [Google Scholar]
- Hu, L.; Ding, J.; Shi, C.; Shao, C.; Li, S. Graph neural entity disambiguation. Knowl.-Based Syst. 2020, 195, 105620. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, R.; Mao, Y.; Guo, H.; Soflaei, M.; Huai, J. Dynamic graph convolutional networks for entity linking. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 1149–1159. [Google Scholar]
- Jia, N.; Cheng, X.; Su, S.; Ding, L. CoGCN: Combining co-attention with graph convolutional network for entity linking with knowledge graphs. Expert Syst. 2021, 38, e12606. [Google Scholar] [CrossRef]
- Xue, M.; Cai, W.; Su, J.; Song, L.; Ge, Y.; Liu, Y.; Wang, B. Neural collective entity linking based on recurrent random walk network learning. arXiv 2019, arXiv:1906.09320. [Google Scholar]
- Jia, B.; Yang, H.; Wu, B.; Xing, Y. Collective entity disambiguation based on hierarchical semantic similarity. Int. J. Data Warehous. Min. (IJDWM) 2020, 16, 1–17. [Google Scholar] [CrossRef]
- Adel, H.; Dahou, A.; Mabrouk, A.; Abd Elaziz, M.; Kayed, M.; El-Henawy, I.M.; Alshathri, S.; Amin Ali, A. Improving crisis events detection using distilbert with hunger games search algorithm. Mathematics 2022, 10, 447. [Google Scholar] [CrossRef]
- Cucerzan, S. Large-scale named entity disambiguation based on Wikipedia data. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 708–716. [Google Scholar]
- Milne, D.; Witten, I.H. Learning to link with wikipedia. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 509–518. [Google Scholar]
- Jia, B.; Wu, Z.; Zhou, P.; Wu, B. Entity Linking Based on Sentence Representation. Complexity 2021, 2021, 8895742. [Google Scholar] [CrossRef]
- Cheng, X.; Roth, D. Relational inference for wikification. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Washington, DC, USA, 18–21 October 2013; pp. 1787–1796. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Model | Input | Knowledge Base | Mention | Entity | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| na | ctx | tl | ds | enl | pr | cg | ||||
| Individual entity linking | DBpedia Spotlight [16] | document | DBpedia Wikipedia | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ |
| CNNContex [17] | document | Wikipedia | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | |
| MemNet(C+L) [18] | document | Wikipedia | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | |
| MPME [19] | document | Wikipedia | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | |
| Collective entity linking | AIDA [20] | document | Yago Wikipedia | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ |
| Babelfy [21] | document | BabelNet | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | |
| L2R-WNED [6] | document | Wikipedia | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ | |
| Deep-ed [22] | document | Yago Wikipedia | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | |
| NCEL [23] | document | Wikipedia | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | |
| SeqGAT [24] | document | Wikipedia | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | |
| Model | MSNBC | AQUAINT | ACE04 | CWEB |
|---|---|---|---|---|
| Prior | 0.89 | 0.83 | 0.84 | 0.70 |
| AIDA [20] | 0.79 | 0.56 | 0.80 | 0.58 |
| RI [63] | 0.90 | 0.90 | 0.86 | 0.68 |
| DoSeR [39] | 0.91 | 0.84 | 0.91 | - |
| GCNCS | 0.91 | 0.90 | 0.94 | 0.74 |
| Model | MSNBC | AQUAINT | ACE04 | CWEB |
|---|---|---|---|---|
| BiLSTM | 0.56 | 0.44 | 0.62 | 0.48 |
| BERT | 0.74 | 0.57 | 0.77 | 0.58 |
| GCNBL | 0.78 | 0.77 | 0.82 | 0.71 |
| GCNCS | 0.91 | 0.90 | 0.94 | 0.74 |
| Model | MSNBC | AQUAINT | ACE04 | CWEB |
|---|---|---|---|---|
| GCNLJ | 0.69 | 0.56 | 0.72 | 0.52 |
| GCNEB | 0.83 | 0.78 | 0.84 | 0.65 |
| GCNLR | 0.84 | 0.84 | 0.90 | 0.67 |
| GCNCS | 0.91 | 0.90 | 0.94 | 0.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, B.; Wang, C.; Zhao, H.; Shi, L. An Entity Linking Algorithm Derived from Graph Convolutional Network and Contextualized Semantic Relevance. Symmetry 2022, 14, 2060. https://doi.org/10.3390/sym14102060
Jia B, Wang C, Zhao H, Shi L. An Entity Linking Algorithm Derived from Graph Convolutional Network and Contextualized Semantic Relevance. Symmetry. 2022; 14(10):2060. https://doi.org/10.3390/sym14102060
Chicago/Turabian StyleJia, Bingjing, Chenglong Wang, Haiyan Zhao, and Lei Shi. 2022. "An Entity Linking Algorithm Derived from Graph Convolutional Network and Contextualized Semantic Relevance" Symmetry 14, no. 10: 2060. https://doi.org/10.3390/sym14102060
APA StyleJia, B., Wang, C., Zhao, H., & Shi, L. (2022). An Entity Linking Algorithm Derived from Graph Convolutional Network and Contextualized Semantic Relevance. Symmetry, 14(10), 2060. https://doi.org/10.3390/sym14102060