

Determination of Air Traffic Complexity Most Influential Parameters Based on Machine Learning Models

 ,
,  , ,
, ,  ,
, 
Abstract
:1. Introduction
- Determination of the most important variables in an objective way, using artificial intelligence applications. Dynamic feature weight selection made it possible to identify which variables are more important in the complexity definition, without being based on human bias.
- Possibility of capturing different behaviours and trends, due to the different nature of the ATC sectors. This is also possible thanks to the application of machine learning algorithms.
- Ability to adapt and capture changes in results over time as new operational data are added to the model.
2. Materials and Methods
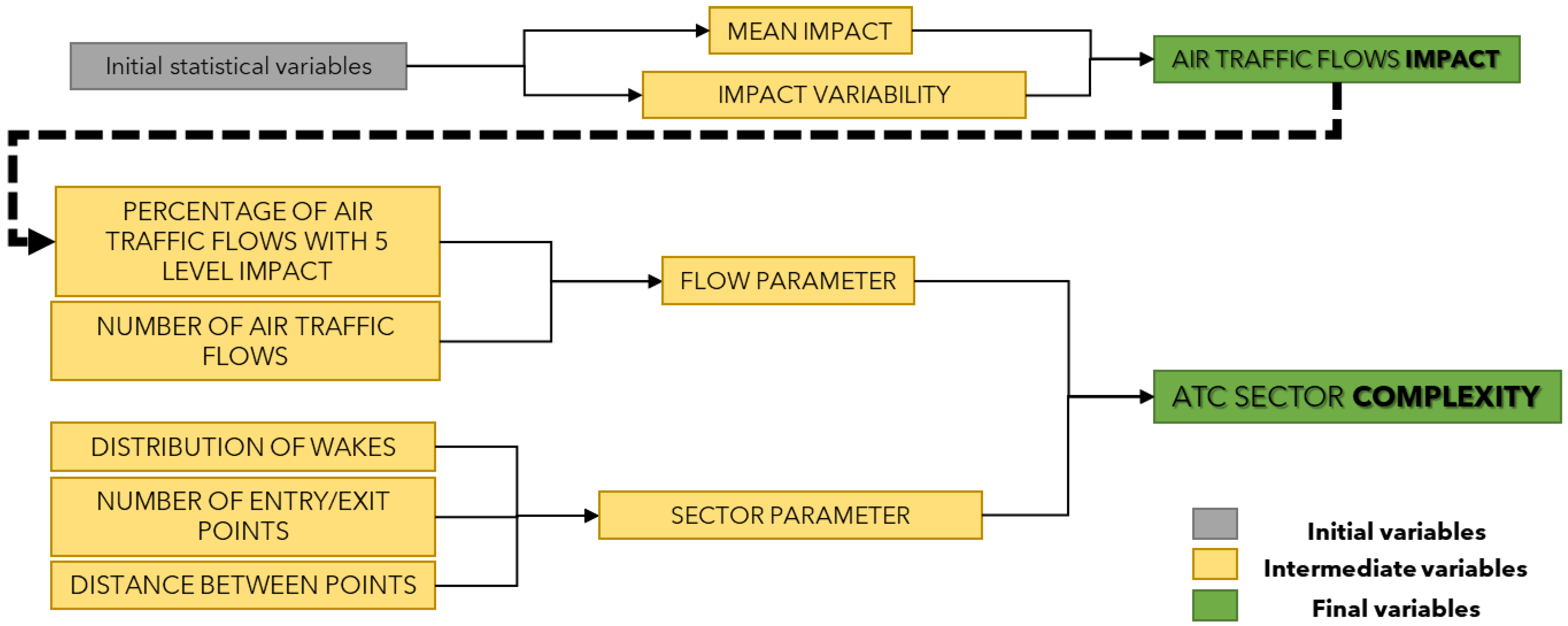
- Definition of complexity: To be able to estimate the variables that make the airspace more complex, it is first necessary to define what complexity is.
- Identification of the most important variables: Once the complexity has been defined, it is appropriate to identify which variables are the most influential.
2.1. Complexity Definition
- Mix of aircraft wake turbulence categories in the sector: Aircraft mix is traffic dependent but is considered within the structural aspects of the sector as this will vary depending on the geographical location and the type of operations and routes within the sector. For this reason, it has been considered a structural aspect of the sector.
- Number of entry and exit points: The number of aircraft entry and exit points is a structural aspect of the sector which gives an idea of the complexity of traffic within the sector. If there are many points, the operation will be more complex.
- Distance between entry and exit points: It is not only the number of points that is important, but also their concentration. If the points are further apart, the operation in the ATC sector will be more uniform and simpler than if the points are concentrated in certain areas of the sector.
- Air traffic density: Traffic density is the variable most closely related to complexity in the literature. For this reason, it is the first area to be considered and its importance is expected to be high.
- Vertical air traffic density: To know the complexity of airspace, it is also necessary to know how aircraft occupy this airspace vertically. The distribution of aircraft per FLs is also a variable that is widely considered in the literature.
- Time Distribution: This field studies the percentage of hours and days that the flows were open. This area may also be of interest.
- ATFCM Regulations: Regulations appear when the capacity of the ATC system cannot cope with the aircraft demand. For this reason, regulations will appear in the most complex airspaces. The relationship between these regulations and complexity may also be of great interest.
- Daily number of Aircraft in the air traffic flow: As the air traffic flow is data provided by the CRIDA company, and the exact time of entry and exit to the sector is also available, a count of aircraft belonging to each flow is made each day.
- Hourly number of Aircraft in the air traffic flow: As for the previous variable, it is easy to perform a count of aircraft entering the sector by a concrete flow each hour. To maintain the daily time horizon, all hourly counts on the same day are averaged.
- Maximum aircraft in an hour in the air traffic flow: Starting from the hourly counts of a given day for each flow, the maximum of the sample is taken. This is taken because the peak hourly traffic is just as important as the average hourly traffic.
- Percentage of changing FL Aircraft in the air traffic flow: Information on the average flight level of all aircraft, and the standard deviation is taken. If the standard deviation of the FL is different from zero, it is because the aircraft has changed FL at some point. All aircraft with a standard deviation of FL different from 0 are divided by the total number of aircraft each day.
- Number of Ascending/Descending aircraft in the air traffic flow: Data are available for the vertical speed of aircraft in the sector. If this vertical speed is other than 0, the aircraft is ascending/descending. The ascents and descents are combined because one case is equally complex for the ATCOs as the other. To obtain this variable, a count is made of all aircraft per day and per flow that have a vertical speed different from 0.
- Number of Cruise aircraft in the air traffic flow: Complementary to the previous variable, this variable is obtained by counting all aircraft per day and per flow that have a vertical speed of 0.
- Number of Occupied FL in the air traffic flow: Information is available on the flight levels of the aircraft within each sector. Information is also available on the flows to which each aircraft belongs. With this, a count is made of the different flight levels that appear each day in the flow. This variable will be the total number of different flight levels.
- Number of Aircraft per FL in the air traffic flow: With the above information, it is also easy to make a count of how many aircraft are in each flight level per flow per day. With the number of aircraft in each flight level, an arithmetic mean is made.
- Days that the air traffic flow is occupied within a year: A flow does not necessarily have aircraft every day of the year. With the information on the entry and exit of the aircraft sector of each flow, the day of entry is considered. This is used to calculate which days there will be aircraft and which days there will not. The number of days on which there will be aircraft is divided by 365 to give the percentage. These data will be unique for each flow during the whole period, contrary to the rest of the parameters, but are still considered as they give very useful information.
- Hours that the air traffic flow is occupied within a day: Like the previous variable, the time of the entry of the aircraft is used, and the flow to which they belong. In this case, the specific time is considered, and a count is made of the hours during which the flow will have aircraft. The total of these hours is calculated and divided by 24 to make the percentage.
- Percentage of regulated aircraft in the air traffic flow: Another piece of information is the number of regulations affecting each flight. All those aircraft in the flow each day with a non-zero number of regulations have been divided by the total number of aircraft in the flow on that day.
- Mean regulations in the air traffic flow: Of all aircraft in each flow on the analysis day, the arithmetic means of the regulations are calculated.
- Mean regulations based on regulated aircraft in the air traffic flow: Of all aircraft with several regulations greater than zero (regulated aircraft) in each flow on the analysis day, the arithmetic mean of the regulations is calculated. This variable is also considered because the meaning is different from the previous variable. It is not the same to see which regulations affect on average, being strongly influenced by unregulated aircraft, as it is to see the average regulations only when knowing that they are regulated.
- Percentage of delayed aircraft in the air traffic flow: This is also available for each aircraft. The number of aircraft with a delay greater than zero on a day in a flow is divided by the number of total aircraft on that day in that flow.
- Mean delay in the air traffic flow: From all aircraft in each flow on the analysis day, the arithmetic mean delay is calculated.
- Mean delay based on regulated aircraft in the air traffic flow: From all regulated aircraft in each flow on the analysis day, the arithmetic mean of the delay is calculated.
- Number of air traffic flows in the ATC sector: The number of flows into which the airspace is distributed is provided by CRIDA.
- Percentage of air traffic flows with 5-level impact: Of the total flows present in the airspace on the day of analysis, the impact is calculated as described above. The number of flows with 5-level impact is divided by the total number of flows.
- Distribution of wake turbulence categories in the ATC sector: The most complex situation for the ATC service is that there is an equal number of aircraft of the different wake turbulence categories. The simplest situation is when all aircraft are in the same wake turbulence category. Therefore, the most complex situation will be 5 of the overall variables, and the simplest will be 1. The percentage of aircraft in each wake turbulence category is therefore calculated on the day of operation, and the deviation from these two extremes is measured.
- Number of points where Aircraft enter/exit the ATC sector: All air traffic flows will have a sector entry and exit point. However, the entry or exit points of several flows may coincide. Therefore, the number of entry or exit points may be 2·number of flows or less. The number of entry or exit points is calculated and divided by (2·number of flows). This will result in a parameter between 0 and 1.
- Distance between points where Aircraft enter/exit the ATC sector: The distance in km between the different entry or exit points is calculated. The arithmetic mean is then calculated.
- The model determines the impact of flows, and the complexity of the sector, based on simple statistical variables. These variables are representative.
- The division of the variables is accurate and based on a correct analysis of the literature.
- The definition of impact and complexity is based on weighted sums, which is good for a machine learning model to obtain relative importance and be representative.
2.2. Most Important Variables Identification
2.3. Evaluation of Machine Learning Models
3. Results
- Low Sectors: These sectors are sectors where aircraft are in evolution (climbing/descending) and at a low flight level (FL). These ATC sectors are the sectors immediately above the terminal maneuvering area (TMA) of the airports. Available examples of these sectors are Castejón Low (LECMCJL) and Gran Canaria Northeast (GCCCRNE).
- Upper Sectors: These ATC sectors are occupied by aircraft flying at high FLs and in a cruising regime. There is usually much less variability in operation. They are more stable sectors. The sectors selected as a sample, in this case, are Pamplona Upper (LECMPAU) and Domingo Upper (LECMDGU).
- Integrated Sectors: These are sectors where enroute operation is combined with arrival and departure operation. They are normally operational at night as there are fewer aircraft. As there is more variability in the operation, they are only operational when traffic is lower so that the same ATCOs can take care of the operation in cruise and evolution. The integrated sectors to be studied are Teruel Zaragoza Integrated (LECMTZI) and Toledo Integrated (LECMTLI).
- To assess the suitability of the methodology for sectors operating differently from each other and whether it can detect the most important variables under different operating conditions.
- To verify whether the sectors classified in the different groups are similar in nature and whether the methodology can capture this.
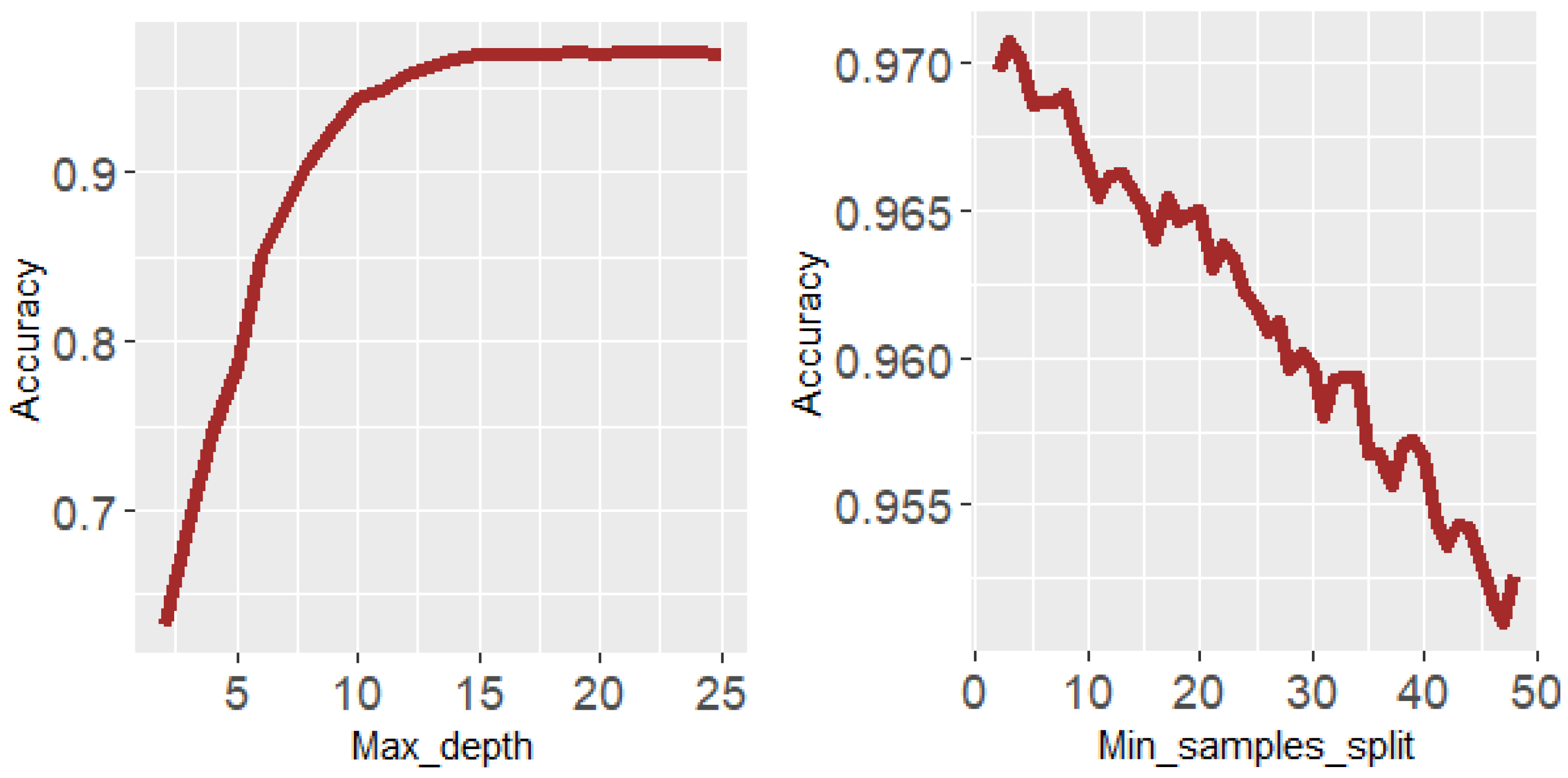
3.1. Hyperparameters of Machine Learning Models
- N_estimators: Total number of trees to be constructed in the forest [49].
- Max_features: Used for denoting the maximum number of variables used in independent trees [49].
- Max_depth: The maximum number of times that the trees will be divided.
- Min_samples_split: The minimum number of samples necessaries to split the branch of the tree.
3.2. Evaluation of Machine Learning Models
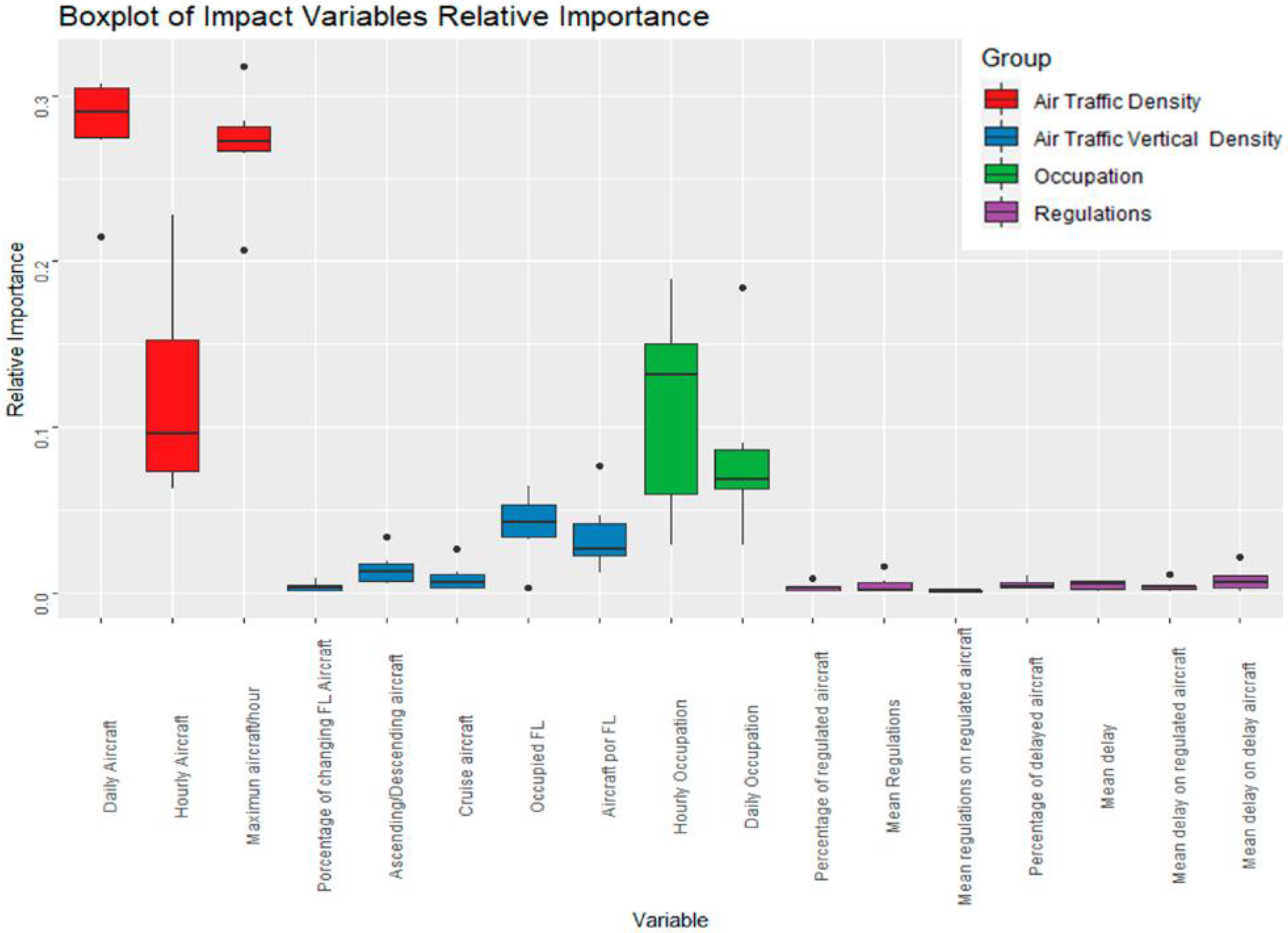
3.3. Analysis of the Impact Most Important Variables
- In the upper sectors (LECMDGU and LECMPAU) the importance of the number of aircraft per hour is lower than in the rest of the ATC sectors. Conversely, in these sectors, the importance of occupancy is more important (the number of hours that the flows are open in LECMPAU and the number of days that the flows are open in LECMDGU). Moreover, in these sectors, the importance of delays is higher here than in the rest of the ATC sectors, although lower than estimated by expert opinion.
- The integrated sectors (LECMTLI and LECMTZI) give less importance to occupancy, in favour of the number of aircraft in the flows per hour, and a more uniform distribution in the rest of the variables. It can be seen how, especially in LECMTLI, the distribution of aircraft in the different FLs is quite important, above that estimated by expert opinion. This does make sense from an operational point of view. Since the occupancy of these ATC sectors will always be at night, occupancy will not be such an influential variable on the impact of the flows. Conversely, by mixing enroute operation with climb/descent operation, the vertical distribution of aircraft becomes more important.
- The low sectors, on the other hand, differ more from each other. In GCCCRNE, the model gives a high importance to aircraft per hour in the flows, and a higher importance to regulations in their flows. In contrast, occupancy is not as important. LECMCJL gives less importance to hourly aircraft in the flows. In contrast, the overall importance of occupancy is higher. This sector is the only one where the importance of the percentage of aircraft climbing/descending is higher than the one proposed by expert opinion. This is because this sector is where the aircraft that take off or land at Madrid airport pass through. Therefore, the aircraft on climb/descent is higher than in the rest of the sector.
3.4. Analysis of the Complexity Most Important Variables
- The upper sectors have the most similar behaviour. The number of flows in the sector is by far the most important variable, approximately 60% more important than predicted by expert opinion. The distance between entry and exit points to the sector is also more important than in the rest of the sectors, and slightly more important than predicted by expert opinion. On the other hand, the rest of the variables have minimal relative importance, less than 0.1 in all cases. This relative importance is below that predicted by expert opinion in the three remaining cases. The relative importance in LECMPAU and LECMDGU is very similar, so it can be concluded in this case that the upper sectors have a complexity mainly determined by the amount of air traffic flows and by the distribution of aircraft entry and exit points in the sector.
- The low and integrated sectors have disparate trends, and it is not possible to find similarities between the different groups. For the LECMTLI and GCCCRNE sectors, the complexity depends to a large extent on the percentage of flows with 5-level impact and the distribution of wake turbulence categories in the sector, as well as the number of entry and exit points. LECMTZI and LECMCJL have similar relative importance to the upper sectors, with the main indicator of complexity being the number of air traffic flows.
4. Conclusions and Future Works
- Firstly, when testing the methodology in different types of sectors, it has been found that there are certain common characteristics. However, there are also differences between sectors that need to be considered. Thanks to the use of machine learning models, the results are adapted to each sector. That the results were different in different sectors is logical, as the sectors are very different in nature and being able to capture this makes the model very interesting. On the other hand, that the model can find similarities in sectors of the same type means that there are indeed similarities between them, which is expected. This duality is captured by the model and makes the methodology robust.
- Related to the previous conclusion, it is important to note that this methodology can be applied now with more sectors or in the future with new data. At present, there is a large diversity of data. Despite this, the methodology will remain the same and can be applied with data from different sources as long as they provide the minimum necessary information. Moreover, without the need to change the methodology, it can be applied to ATC sectors or to different time horizons, as the presence of machine learning models makes the methodology adaptable.
- The results arrived at by applying this methodology have been based on expert opinion. However, expert opinion is merely a starting point, and the model is supposed to arrive at the same results regardless of the starting point. This makes dynamic feature weight selection independent of human bias.
- In this case, data for a full year, which is 2019, have been used. However, if the data used to apply the methodology were from a different time horizon, the results would be different. Since the methodology is adapted to the nature of the sectors, it can also be adapted to the desired time horizon.
- Furthermore, thanks to the division into two different models, it has been possible to analyse the sector’s operations in detail. It has been possible to establish that the complexity at a high tier depends on the behaviour of its flows, but it is also possible to analyse in more detail what determines the behaviour of the flows. This modularity is also considered an advantage of the model.
- Additionally, the computational cost of the developed models is minimal. In most cases, stability is reached in less than 10 iterations, the time of an iteration being in the order of less than a minute on a normal computer. Therefore, in a time of 15 min, a complete analysis can be obtained for any sector.
- 7.
- First, this model will be applied to more sectors of different types. The objective is to see if the similarities analysed here hold in other sectors and see if air traffic behaviour is symmetrical in different ATC sectors. The application to more sectors will also allow us to obtain other possible variables that may be important in the determination of impact or complexity in different scenarios.
- 8.
- Further literature review to find additional variables that may be of interest for the calculation of impact and complexity. It is expected that by considering different variables, the patterns found will change and the relative importance will be different. Drawing conclusions with additional variables may be of great interest to the development of the methodology.
- 9.
- An attempt will also be made to make a subsequent model by eliminating the variables that have been considered less relevant here. In doing so, it is hoped to clarify the patterns in the operation.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ATM | Air Traffic Management |
| ATC | Air Traffic Control |
| ATCO | Air Traffic Controller |
| ATFCM | Air Traffic Flow Capacity Management |
| RI | Relative Importance |
| TMA | Terminal Maneuvering Area |
| LECMCJL | Castejon Low ATC sector |
| GCCCRNE | Northeast Canary Island ATC sector |
| LECMPAU | Pamplona Upper ATC sector |
| LECMDGU | Domingo Upper ATC sector |
| LECMTLI | Toledo Integrated ATC sector |
| LECMTZI | Teruel Zaragoza Integrated ATC sector |
| FL | Flight Level |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| DD | Dynamic Density |
References
- Lee, K.; Feron, E.; Pritchett, A. Describing Airspace Complexity: Airspace Response to Disturbances. J. Guid. Control Dyn. 2009, 31, 210–222. [Google Scholar] [CrossRef]
- Antulov-Fantulin, B.; Juričić, B.; Radišić, T.; Çetek, C. Determining Air Traffic Complexity–Challenges and Future Development. Promet 2020, 32, 475–485. [Google Scholar] [CrossRef]
- Xu, Y.; Camargo, L.; Prats, X. Fast-Time Demand-Capacity Balancing Optimizer for Collaborative Air Traffic Flow Management. J. Aerosp. Inf. Syst. 2021, 18, 583–595. [Google Scholar] [CrossRef]
- Delahaye, D.; García, A.; Lavandier, J.; Chaimatanan, S.; Soler, M. Air Traffic Complexity Map Based on Linear Dynamical Systems. Aerospace 2022, 9, 230. [Google Scholar] [CrossRef]
- Gorripaty, S.; Liu, Y.; Hansen, M.; Pozdnukhov, A. Identifying similar days for air traffic management. J. Air Transp. Manag. 2017, 65, 144–155. [Google Scholar] [CrossRef]
- Han, K.; Shah, S.H.H.; Lee, J.W. Holographic Mixed Reality System for Air Traffic Control and Management. Appl. Sci. 2019, 9, 3370. [Google Scholar] [CrossRef] [Green Version]
- Tan, X.; Sun, Y.; Zeng, W.; Quan, Z. Congestion Recognition of the Air Traffic Control Sector Based on Deep Active Learning. Aerospace 2022, 9, 302. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, M.; Ge, J.; Dong, X.; Chen, H. Learning Air Traffic as Images: A Deep Convolutional Neural Network for Airspace Operation Complexity Evaluation. Complexity 2021, 2021, 1–16. [Google Scholar] [CrossRef]
- Gianazza, D. Airspace configuration using air traffic complexity metrics. In Proceedings of the 7th FAA/Europe Air Traffic Management Research and Development Seminar, Barcelona, Spain, 2–5 July 2007. [Google Scholar]
- Brázdilová, S.L.; Cásek, P.; Kubalčík, J. Air traffic complexity for a distributed air traffic management system. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2011, 225, 665–674. [Google Scholar] [CrossRef]
- Laudeman, I.V.; Shelden, S.G.; Branstrom, R.; Brasil, C.L. Dynamic Density: An Air Traffic Management Metric; NASA: San José, CA, USA, 1998.
- Standfuss, T.; Rosenrow, J. Applicability of Current Complexity Metrics in ATM Performance Benchmarking and Potential Benefits of Considering Weather Conditions. In Proceedings of the 2020 AIAA/IEEE 39th Digital Avionics Systems Conference (DASC) Proceedings, San Antonio, TX, USA, 11–15 October 2020. [Google Scholar]
- Wee, H.J.; Lye, S.W.; Pinheiro, J.-P. A Spatial, Temporal Complexity Metric for Tactical Air Traffic Control. J. Navig. 2018, 71, 1040–1054. [Google Scholar] [CrossRef]
- Marchitto, M.; Benedetto, S.; Baccino, T.; Cañas, J.J. Air traffic control: Ocular metrics reflect cognitive complexity. Int. J. Ind. Ergon. 2016, 54, 120–130. [Google Scholar] [CrossRef]
- Juntama, P.; Delahaye, D.; Chaimatanan, S.; Alam, S. Hyperheuristic Approach Based on Reinforcement Learning for Air Traffic Complexity Mitigation. J. Aerosp. Inf. Syst. 2022, 19, 633–648. [Google Scholar] [CrossRef]
- Pejovic, T.; Netjasov, F.; Crnogorac, D. Relationship between Air Traffic Demand, Safety and Complexity in High-Density Airspace in Europe. MATEC Web Conf. 2020, 314, 01004. [Google Scholar] [CrossRef]
- Isufaj, R.; Koca, T.; Piera, M.A. Spatiotemporal Graph Indicators for Air Traffic Complexity Analysis. Aerospace 2022, 8, 364. [Google Scholar] [CrossRef]
- Dmochowski, P.A.; Skorupski, J. Air Traffic Smoothness. A New Look at the Air Traffic Flow Management. Transp. Res. Procedia 2017, 28, 127–132. [Google Scholar] [CrossRef]
- An, Z.; Wang, X.; Li, B.; Xiang, Z.; Zhang, B. Robust visual tracking for UAVs with dynamic feature weight selection. Appl. Intell. 2022, 1–14. [Google Scholar] [CrossRef]
- Diamalech, M.; Jahromi, M.Z. A general feature-weighting function for classification problems. Expert Syst. Appl. 2017, 72, 177–188. [Google Scholar]
- Gianazza, D.; Guittet, K. Selection and Evaluation of Air Traffic Complexity Metrics. In Proceedings of the 2006 IEEE/AIAA 25TH Digital Avionics Systems Conference, Portland, Oregon, 15–19 October 2006; pp. 1–12. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Yu, Q.; Tang, C.; Lu, Z.; Yang, Y. Application of Feature Selection Based on Multilayer GA in Stock Prediction. Symmetry 2022, 14, 1415. [Google Scholar] [CrossRef]
- Molčan, S.; Smiešková, M.; Bachratý, H.; Bachratá, K. Computational Study of Methods for Determining the Elasticity of Red Blood Cells Using Machine Learning. Symmetry 2022, 14, 1732. [Google Scholar] [CrossRef]
- Algehyne, E.A.; Jibril, M.L.; Algehainy, N.A.; Alamri, O.A.; Alzahrani, A.K. Fuzzy Neural Network Expert System with an Improved Gini Index Random Forest-Based Feature Importance Measure Algorithm for Early Diagnosis of Breast Cancer in Saudi Arabia. Big Data Cogn. Comput. 2022, 6, 13. [Google Scholar] [CrossRef]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A comparison of random forest variable selection methods for classification prediction modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef]
- Andraši, P.; Radišić, T.; Novak, D.; Juričić, B. Subjective Air Traffic Complexity Estimation Using Artificial Neural Networks. Promet–Traffic Transp. 2019, 31, 377–386. [Google Scholar] [CrossRef] [Green Version]
- Gianazza, D.; Guittet, K. Evaluation of air traffic complexity metrics using neural networks and sector status. In Proceedings of the 2nd International Conference on Research in Air Transportation, Belgrade, Serbia and Montenegro, 24–28 June 2006; pp. 113–122. [Google Scholar]
- Li, B.; Du, W.; Zhang, Y.; Chen, J.; Tang, K.; Cao, X. A Deep Unsupervised Learning Approach for Airspace Complexity Evaluation. IEEE Trans. Intell. Transp. Syst. 2021, 23, 1–13. [Google Scholar] [CrossRef]
- Oktal, H.; Yaman, K. A new approach to air traffic controller workload measurement and modelling. Aircr. Eng. Aerosp. Technol. 2011, 83, 35–42. [Google Scholar] [CrossRef]
- Moreno, F.P.; Comendador, V.F.G.; Jurado, R.D.-A.; Suárez, M.Z.; Janisch, D.; Valdes, R.M.A. Dynamic model to characterise sectors using machine learning techniques. Aircr. Eng. Aerosp. Technol. 2022; ahead-of-print. [Google Scholar] [CrossRef]
- Sridhar, B.; Sheth, K.; Grabbe, S. Airspace complexity and its application in air traffic management. In Proceedings of the 2nd USA/Europe Air Traffic Management R&D Seminar, Orlando, FL, USA, 1–4 December 1998. [Google Scholar]
- Comendador, V.F.G.; Valdés, R.M.A.; Diaz, M.V.; Parla, E.P.; Zheng, D. Bayesian Network Modelling of ATC Complexity Metrics for Future SESAR Demand and Capacity Balance Solutions. Entropy 2019, 21, 379. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiao, M.; Zhang, J.; Cai, K.; Cao, X. ATCEM: A synthetic model for evaluating air traffic complexity. J. Adv. Transp. 2016, 50, 315–325. [Google Scholar] [CrossRef] [Green Version]
- Sutherland, H.; Recchia, G.; Dryhurst, S.; Freeman, A.L. How People Understand Risk Matrices, and How Matrix Design Can Improve their Use: Findings from Randomized Controlled Studies. Risk Anal. 2022, 42, 1023–1041. [Google Scholar] [CrossRef]
- Ball, D.J.; Watt, J. Further Thoughts on the Utility of Risk Matrices. Risk Anal. 2013, 33, 2068–2078. [Google Scholar] [CrossRef]
- Comendador, V.F.G.; Valdés, R.M.A.; Vidosavljevic, A.; Cidoncha, M.S.; Zheng, S. Impact of Trajectories’ Uncertainty in Existing ATC Complexity Methodologies and Metrics for DAC and FCA SESAR Concepts. Energies 2019, 12, 1559. [Google Scholar] [CrossRef]
- Jardines, A.; Soler, M.; García-Heras, J. Estimating entry counts and ATFM regulations during adverse weather conditions using machine learning. J. Air Transp. Manag. 2021, 95, 102109. [Google Scholar] [CrossRef]
- Tambake, N.R.; Deshmukh, B.B.; Patange, A.D. Data Driven Cutting Tool Fault Diagnosis System Using Machine Learning Approach: A Review. J. Phys. Conf. Ser. 2021, 1969, 012049. [Google Scholar] [CrossRef]
- Patange, A.D.; Jegadeeshwaran, R. A machine learning approach for vibration-based multipoint tool insert health prediction on vertical machining centre (VMC). Measurement 2021, 173, 108649. [Google Scholar] [CrossRef]
- Chen, Y.-T.; Piedad, J.E.; Kuo, C.-C. Energy Consumption Load Forecasting Using a Level-Based Random Forest Classifier. Symmetry 2019, 11, 956. [Google Scholar] [CrossRef] [Green Version]
- Yan, L.; Liu, Y. An Ensemble Prediction Model for Potential Student Recommendation Using Machine Learning. Symmetry 2020, 12, 728. [Google Scholar] [CrossRef]
- Kuhn, K.D. A methodology for identifying similar days in air traffic flow management initiative planning. Transp. Res. Part C Emerg. Technol. 2016, 69, 1–15. [Google Scholar] [CrossRef]
- Alduailij, M.; Khan, Q.W.; Tahir, M.; Sardaraz, M.; Alduailij, M.; Malik, F. Machine-Learning-Based DDoS Attack Detection Using Mutual Information and Random Forest Feature Importance Method. Symmetry 2022, 14, 1095. [Google Scholar] [CrossRef]
- Geron, A. Hands-On Machine Learning with Scikit-Learn & TensorFlow; O’Reilly: Newton, MA, USA, 2017. [Google Scholar]
- Luque, A.; Carrasco, A.; Martín, A.; Lama, J.R. Exploring Symmetry of Binary Classification Performance Metrics. Symmetry 2019, 11, 47. [Google Scholar] [CrossRef] [Green Version]
- Aghdam, M.; Tabbakh, S.K.; Chabok, S.M.; Kheyrabadi, M. Optimization of air traffic management efficiency based on deep learning enriched by the long short-term memory (LSTM) and extreme learning machine (EML). J. Big Data 2021, 8, 54. [Google Scholar] [CrossRef]
- ENAIRE. Available online: https://insignia.enaire.es/ (accessed on 11 July 2022).
- Bernard, S.; Heutte, L.; Adam, S. Influence of Hyperparameters on Random Forest Accuracy. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 171–180. [Google Scholar] [CrossRef]
- George, S.; Sumathi, B. Grid Search Tuning of Hyperparameters in Random Forest Classifier for Customer Feedback Sentiment Prediction. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 173–178. [Google Scholar]
- Koca, T.; Piera, M.A.; Radanovic, M. A Methodology to Perform Air Traffic Complexity Analysis Based on Spatio-Temporal Regions Constructed Around Aircraft Conflicts. IEEE Access 2019, 7, 104528–104541. [Google Scholar] [CrossRef]
- Flener, P.; Pearson, J.; Ågren, M.; Garcia-Avello, C.; Çeliktin, M.; Dissing, S. Air-traffic complexity resolution in multi-sector planning. J. Air Transp. Manag. 2007, 13, 323–328. [Google Scholar] [CrossRef] [Green Version]
- Lehouillier, T.; Soumis, F.; Omer, J.; Allignol, C. Measuring the interactions between air traffic control and flow management using a simulation-based framework. Comput. Ind. Eng. 2016, 99, 269–279. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Air Traffic Density | Air Traffic Vertical Density | Time Distribution | ATFCM Regulations |
|---|---|---|---|
| Daily number of aircraft in the air traffic flow (0.4297) | Percentage of changing FL aircraft in the air traffic flow (1) | Days that the air traffic flow is occupied within a year (0.5833) | Percentage of regulated aircraft in the air traffic flow (0.0755) |
| Hourly number of aircraft in the air traffic flow (0.2714) | Number of ascending/descending aircraft in the air traffic flow (0.4206) | Hours that the air traffic flow is occupied within a day (0.9914) | Mean regulations in the air traffic flow (0.0163) |
| Maximum aircraft in an hour in the air traffic flow (0.4) | Number of cruise aircraft in the air traffic flow (0) | Mean regulations based on regulated aircraft in the air traffic flow (0) | |
| Number of occupied FL in the air traffic flow (0.75) | Percentage of delayed aircraft in the air traffic flow (0.0189) | ||
| Number of aircraft per FL in the air traffic flow (0.3305) | Mean delay in the air traffic flow (0.0008) | ||
| Mean delay based on regulated aircraft in the air traffic flow (0.0151) | |||
| Mean delay based on delayed aircraft in the air traffic flow (0.0047) |
| Flow Parameter | Sector Parameter |
|---|---|
| Percentage of air traffic flows with 5-level impact (2.043) | Distribution of wake turbulence categories in the ATC sector (2.965) |
| Number of air traffic flows in the ATC sector (3.046) | Number of points where aircraft enter/exit the ATC sector (1.5) |
| Distance between points where aircraft enter/exit the ATC sector (2.011) |
| Machine Learning Model | N_estimators | Max_features | Max_depth | Min_samples_split |
|---|---|---|---|---|
| Impact | 100 | sqrt | 15 | 2 |
| Complexity | 100 | sqrt | 15 | 35 |
| Impact Level | Precision | Recall | f1-Score |
|---|---|---|---|
| 2 | 0.97 | 0.97 | 0.97 |
| 3 | 0.98 | 0.97 | 0.97 |
| 4 | 0.96 | 0.97 | 0.97 |
| 5 | 0.96 | 0.96 | 0.97 |
| Complexity Level | Precision | Recall | f1-Score |
|---|---|---|---|
| 2 | 0.95 | 0.97 | 0.96 |
| 3 | 0.99 | 0.97 | 0.98 |
| 4 | 1 | 1 | 1 |
| ATC Sector | Number of Machine Learning Model Iterations |
|---|---|
| GCCCRNE | 5 |
| LECMCJL | 4 |
| LECMDGU | 4 |
| LECMPAU | 12 |
| LECMTLI | 7 |
| LECMTZI | 7 |
| ATC Sector | Number of Machine Learning Model Iterations |
|---|---|
| GCCCRNE | 7 |
| LECMCJL | 6 |
| LECMDGU | 5 |
| LECMPAU | 4 |
| LECMTLI | 5 |
| LECMTZI | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez Moreno, F.; Gómez Comendador, V.F.; Delgado-Aguilera Jurado, R.; Zamarreño Suárez, M.; Janisch, D.; Arnaldo Valdés, R.M. Determination of Air Traffic Complexity Most Influential Parameters Based on Machine Learning Models. Symmetry 2022, 14, 2629. https://doi.org/10.3390/sym14122629
Pérez Moreno F, Gómez Comendador VF, Delgado-Aguilera Jurado R, Zamarreño Suárez M, Janisch D, Arnaldo Valdés RM. Determination of Air Traffic Complexity Most Influential Parameters Based on Machine Learning Models. Symmetry. 2022; 14(12):2629. https://doi.org/10.3390/sym14122629
Chicago/Turabian StylePérez Moreno, Francisco, Víctor Fernando Gómez Comendador, Raquel Delgado-Aguilera Jurado, María Zamarreño Suárez, Dominik Janisch, and Rosa María Arnaldo Valdés. 2022. "Determination of Air Traffic Complexity Most Influential Parameters Based on Machine Learning Models" Symmetry 14, no. 12: 2629. https://doi.org/10.3390/sym14122629
APA StylePérez Moreno, F., Gómez Comendador, V. F., Delgado-Aguilera Jurado, R., Zamarreño Suárez, M., Janisch, D., & Arnaldo Valdés, R. M. (2022). Determination of Air Traffic Complexity Most Influential Parameters Based on Machine Learning Models. Symmetry, 14(12), 2629. https://doi.org/10.3390/sym14122629