1. Introduction
Chinese traditional ancient architecture bears witness to China’s excellent historical culture and glorious historical achievements; it carries the historical development of the Chinese nation and the local area and has irreplaceable cultural, social, and artistic value. Most of this historical architecture is widely distributed and is scattered in remote villages; it gradually disappeared with urban development and change, bringing irreparable losses to China’s history, culture, economy, etc. Therefore, it is very necessary to study and protect Chinese traditional ancient architecture. Different ancient architectural communities represent different cultures and also need different protection methods. Among them, the accurate recognition of ancient architecture is an important prerequisite for formulating targeted ancient architecture protection measures. Traditional methods, such as relying on human experience and judgment, are inefficient, error-prone, and highly dependent on personal experience and professional skills; thus, they are not suitable for large-scale promotion and application. Therefore, the development and maturity of deep learning, image processing, and other technologies provide new ideas and efficient means for the recognition and classification of ancient architecture. The combination of deep learning and other technologies with the identification and protection of ancient architecture can give better play to the advantages of cutting-edge technologies and can push the protection of ancient architecture to a new and higher level [
1].
The feature extraction of traditional ancient architecture mainly depends on the architecture’s color and structure. For some ancient architectures with a roughly similar appearance, due to the influence of different factors, such as light angle, shooting angle, and the building’s weathering degree during the image acquisition process, the recognition efficiency and accuracy will be greatly reduced by labor that has weak professional knowledge. In view of this issue, one common method is to extract features from ancient architectural images, calculate the distance between the extracted features and the features in the scale map, and then use this as the basis for classification to judge the types of buildings. For example, Wang et al. [
2] proposed a building recognition algorithm that combines local features with shape contour-matching, which has a good recognition effect in terms of different angles, different scales, and different lighting conditions. Wu [
3] proposed an automatic classification algorithm for ancient Buddhist buildings, based on local features, which can reasonably segment Buddhist building images and can finally achieve a good recognition result. Hasan M et al. [
4] used four different feature detection methods to realize the identification of the architectural age of three types of era for the ancient and heritage buildings of the Indian subcontinent. Zhang et al. [
5] proposed an ancient architecture image-annotation method based on the visual attention mechanism and the graph convolution network, which can effectively improve the annotation accuracy of ancient Chinese architecture and enrich the semantic information. Yang Song et al. [
6] proposed a building recognition method based on the improved histogram features of gradient direction. Freeman et al. [
7] proposed a direction-controlled filter, which shows great advantages in terms of image edge detection and texture analysis.
The deep convolutional neural network is another effective means of building-type recognition. In terms of the convolution layer structure, such a network has a variety of structures, such as conventional convolution, atrous convolution [
8], depthwise separable convolution [
9], etc. Classical convolutional neural network structures mainly include LeNet [
10], AlexNet [
11], VGGNet [
12], ResNet [
13], InceptionNet [
14], and so on. LeNet [
10] is the earliest convolutional network that was used for image classification tasks, including 7 convolutional layers; AlexNet [
11] expands the network structure to 8 layers, becoming much larger in scale than LeNet, and introduces the ReLU activation function and image enhancement; the symmetric convolutional network, VGGNet [
12], is increased to 16 layers and 19 layers, and is deeper than AlexNet but is simpler in form; the symmetric convolutional network, ResNet [
13], is 8 times deeper than VGGNet but has lower complexity and strong characterization ability, which solves the problem of gradient disappearance through a residual structure. Compared with the way that VGGNet vertically stacks the convolution layer, InceptionNet [
14] adopts a completely different approach, i.e., it improves the network capacity by horizontally increasing the network width and uses “global average pooling + full connection layer” to greatly reduce the parameter scale. In recent years, with the continuous development and application of convolutional neural networks, various classical network models have been constantly improved and can be applied to many different fields. For example, in the AlexNet network, some scholars changed the network framework by increasing the network depth, replacing the FC layer, and changing the intranet network by adding a BN layer and LRN layer, which ultimately improved the network’s accuracy and training speed [
15]. Abhronil Sengupta et al. [
16] proposed a new weighting normalization technique to ensure that the actual spiking neural network operation was in the loop during the conversion phase. This work, which was aimed at optimizing the ratio of synaptic weights to neuronal firing thresholds, ultimately demonstrated the effectiveness of the architecture for complex visual recognition problems; it can be used in the VGG and ResNet architectures, bringing better accuracy than the most advanced techniques. Ayesha Younis et al. [
17] used the VGG 16 architecture as the main network to generate a convolutional feature map. An effective method using MRI to detect brain tumors was developed and improved, which was superior to the current traditional brain tumor detection method. It can be seen that all kinds of convolutional neural networks are constantly improving, progressing, and developing.
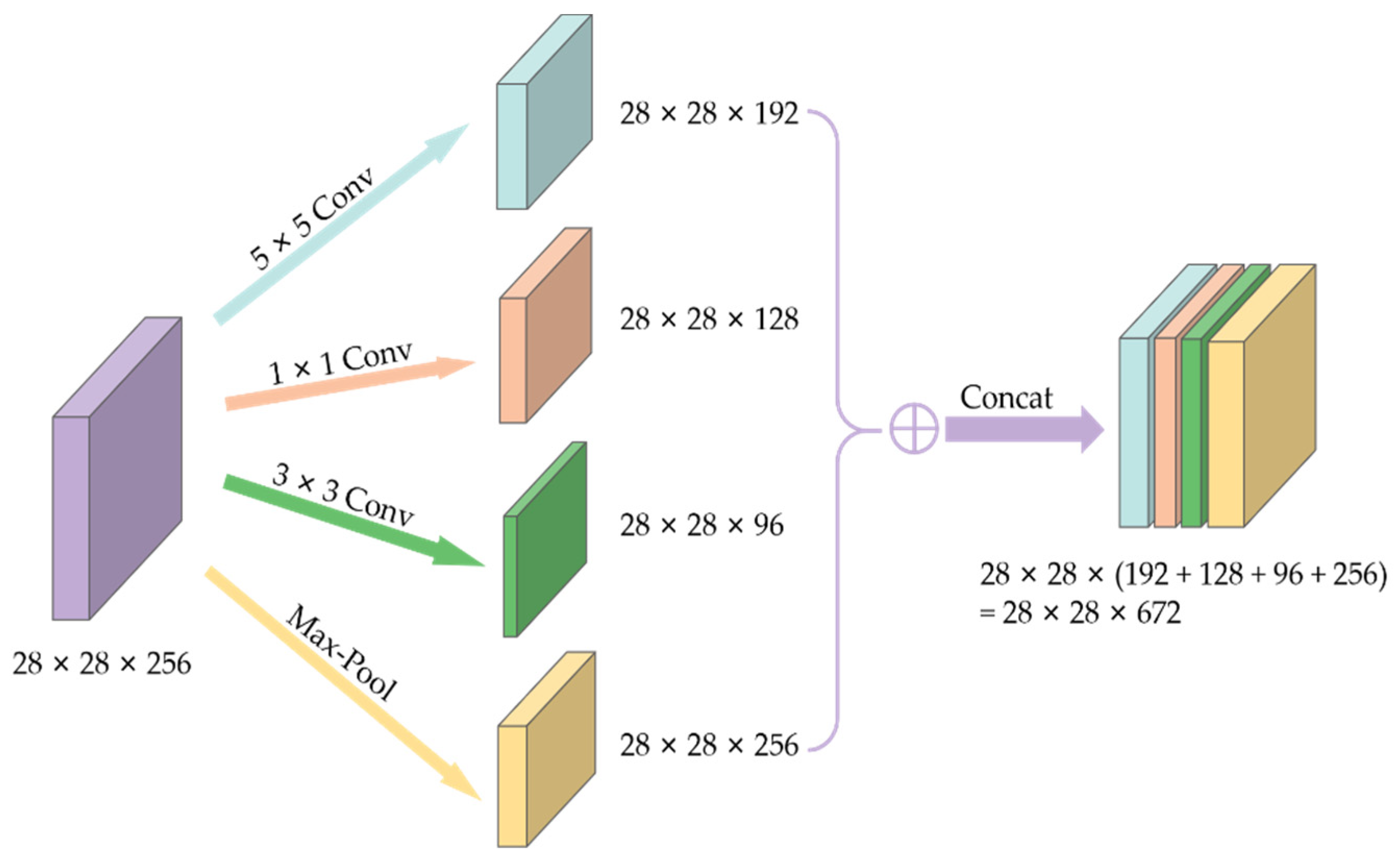
However, different convolution layer structures define the different feature extraction methods, so that the convolution neural network can fully extract the image features. In terms of neural network structure, the connection mode between layers and the size of the convolution kernel are important factors affecting the accuracy of model recognition. Previous studies have shown that using a larger convolution kernel will achieve better results [
18]. It can be seen that the convolutional neural network has more room for development in building-type recognition. For example, Professor Xiao [
19], from the South China University of Technology, proposed an automatic recognition and classification algorithm based on ResNet152, which is applicable to a large number of traditional village status maps; the overall recognition accuracy reached 83.4%. Guo et al. [
20] applied a convolutional neural network to building style image classification, designed a shallow classification model and deep classification model, respectively, from aspects of network structure design and parameter optimization, and improved model generalization capability via DropConnect. Building identification methods based on deep convolutional neural networks have high identification efficiency and accuracy, which is helpful for improving the archiving and management efficiency of ancient architecture [
21]. In addition, in recent years, transfer learning has been widely used in the image classification tasks of convolutional neural networks. By retaining the weight and bias of the original model, some layers of the neural network are trained to improve model training efficiency [
22]. For example, Wang et al. [
23] used the pre-trained VGG16 network for transfer learning, to improve the recognition effect. At the same time, they proposed an adaptive feature fusion method to fuse the features extracted from the VGG16 network for prediction and obtained a satisfactory recognition effect. However, the above methods have some shortcomings, such as too-deep network layers, the huge scale of model training parameters, a slow training process, etc. Moreover, due to the small number and scattered distribution of ancient architectures, it is easy to experience an over-fitting phenomenon caused by insufficient training samples, and there is a lack of recognition models specifically intended for ancient architectures.
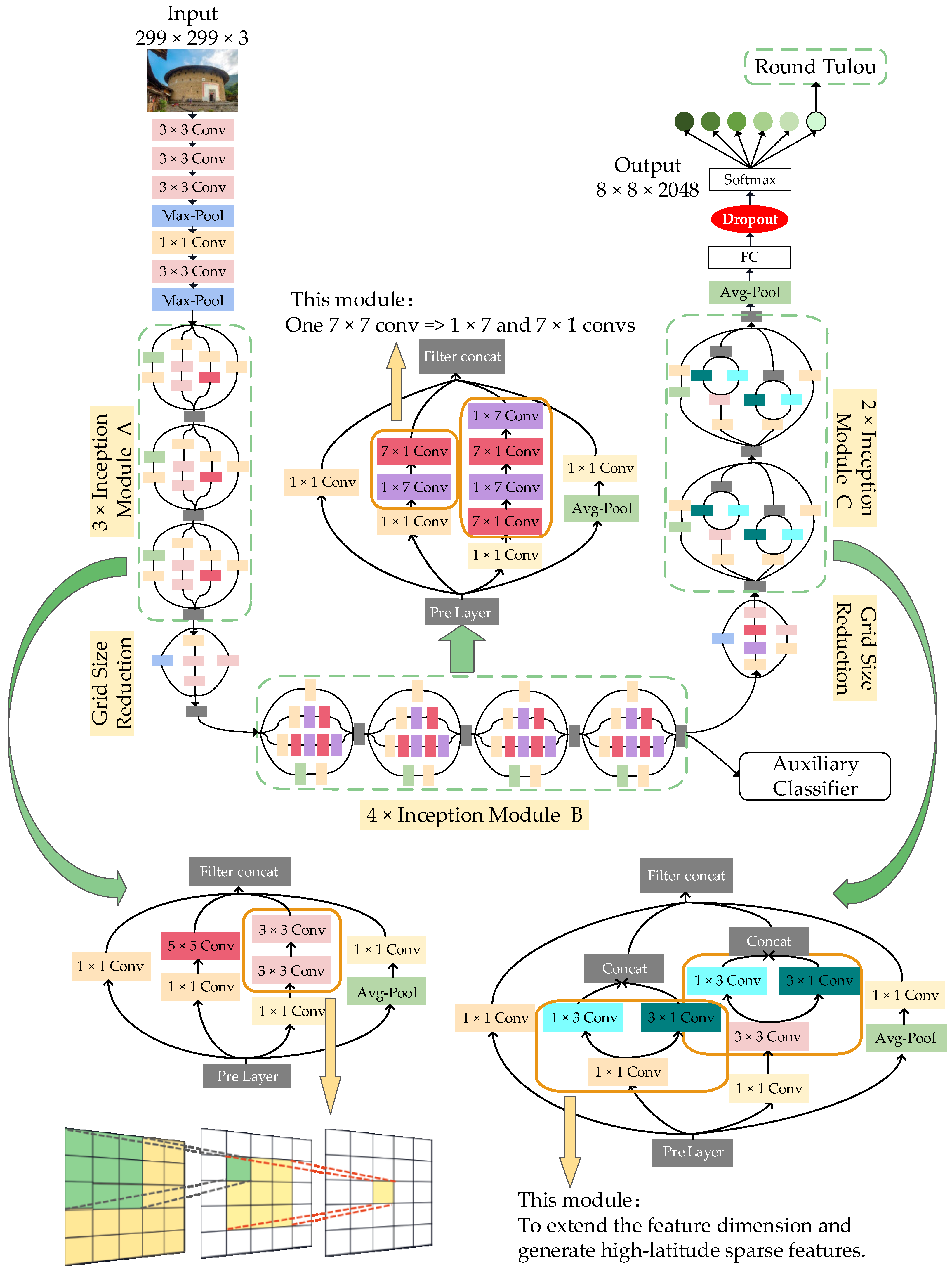
In view of the above reasons, this paper adopts the improved Inception V3 [
14] model to identify ancient architectures. The Inception V3 model decomposes large convolution kernels into small convolution kernels and has excellent parallel convolution ability and strong model expression ability. It supports high-performance computing, based on dense matrices, and can process more and richer spatial features. However, if the Inception V3 model is directly applied to ancient architecture type identification, it will lead to overfitting, low training efficiency, and other problems, so the model needs to be further improved. This paper fully combines the advantages of the Inception V3 model, such as decomposing large convolution kernels into small convolution kernels with strong expression ability, supporting parallel convolution, and the advantages of the dropout layer’s strong ability to prevent overfitting, to propose an improved Inception V3 model with a dropout layer. In this paper, comparative experiments are carried out, after which the best and most effective method is used to preprocess the self-built ancient architecture dataset, then transfer learning technology is introduced. Finally, the overfitting phenomenon in the model training process is alleviated, and the model training efficiency is improved; in addition, the model calculation efficiency is increased, and the model recognition accuracy is improved. It provides a useful reference scheme for the accurate identification of traditional Chinese ancient architecture, based on deep learning technology.
The rest of this paper is organized as follows.
Section 2 describes and pre-processes the ancient building dataset.
Section 3 introduces the improved Inception V3 model.
Section 4 explains our methodology.
Section 5 verifies the effectiveness of our proposed method by means of experiments.
Section 6 concludes this paper.
4. Methodology
4.1. Loading the Pre-Training Model
Because of the small sample size of the ancient architecture dataset, in order to improve the model’s training efficiency and model recognition accuracy, this paper adopts a model-based transfer learning technique, which means transferring and applying the Inception V3 model, trained on the ImageNet dataset, to the ancient architecture-type recognition task. In order to implement the model transfer, the Inception V3 pre-training model needs to be loaded first, namely, training the Inception V3 model on the ImageNet dataset to obtain a pre-training model with the model’s parameters. Since the feature extraction methods of the data in ImageNet are similar but not identical to those of the ancient architecture dataset, in this paper, all layers in the Inception V3 model are added to the training process to achieve better recognition results.
4.2. Training Process of the Model
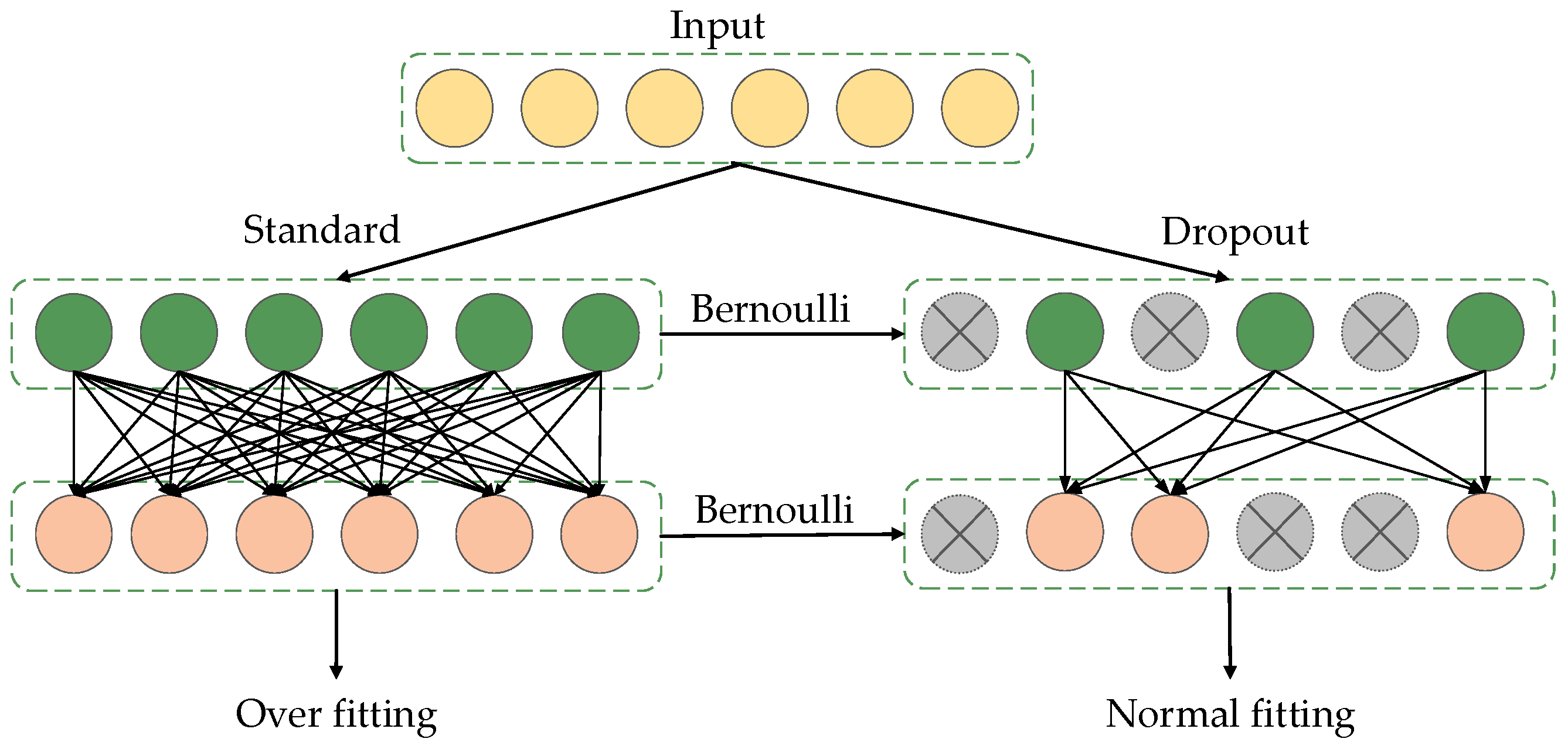
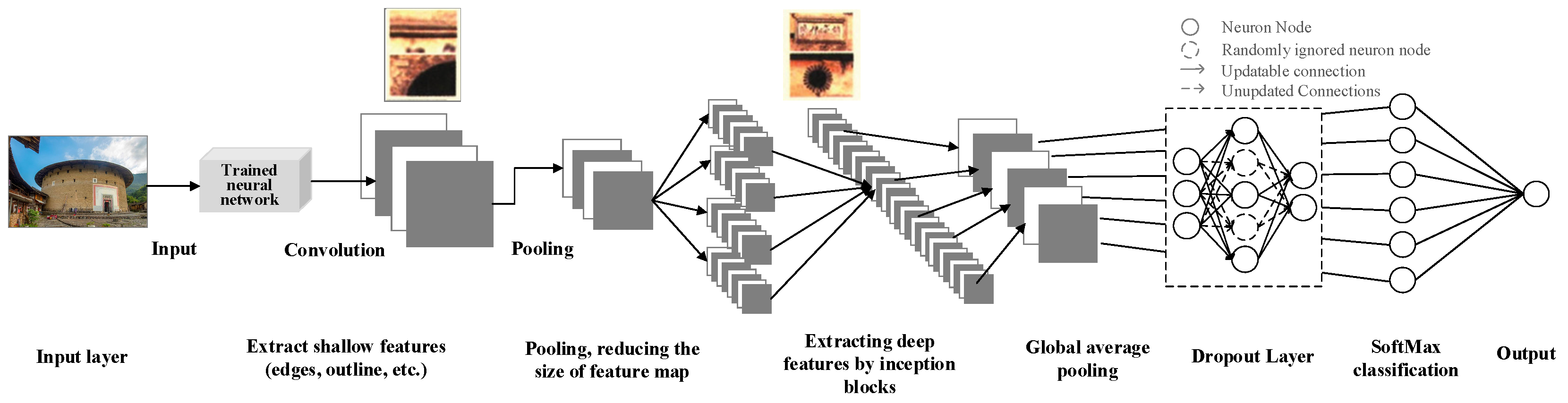
Figure 7 shows the training process of the improved Inception V3 model. The ancient architecture images in the training set are input into the pre-trained Inception V3 model, and the shallow features of the images are extracted via convolution in the first few layers of the model and pooled to reduce the feature map size, so as to further extract the deep features in the Inception block. The Inception block extracts feature maps of different sizes via parallel convolution layers; these feature maps are merged at the end of each Inception block and then input to the next layer. Then, all the extracted features are input into the global average pooling layer, and the dropout layer is added before the results of the global average pooling layer are input to the SoftMax classification layer, i.e., some neuron nodes are randomly ignored at a certain ratio (but the input layer and output layer are not changed). The SoftMax classification layer outputs the classification results and, thus, completes a forward propagation process. After the forward propagation is completed, the parameters in Inception V3 are updated according to the backpropagation algorithm (the ignored neuron nodes are not updated), thus completing an iterative process. The above steps are repeated until the end of the training process.
4.3. Settings of Model Hyperparameters
In the process of model training, the main hyperparameters, such as learning rate, epoch, batch size, optimizer, loss function, and evaluation metrics need to be optimized and tuned.
Learning rate: The learning rate determines how fast the objective function converges and has a substantial impact on the learning speed. When the learning rate is too large, the learning speed is fast, but the model parameters may not converge; if the learning rate is too small, the learning speed will be slow, which will lead to slow model convergence. After several tests, the empirical value of the learning rate is finally taken to be 0.001.
Epoch: This refers to the iteration times of the neural network. In this paper, the number of iterations is set to 20.
Batch size: This refers to the number of images input into the neural network at one time during training. If the batch size is too large, the memory will be overloaded; if the batch size is too small, the computing resources cannot be fully utilized, resulting in more waste. After testing, it is most appropriate to set the batch size to 16.
Optimizer: Since the Adam optimizer has the advantages of fast convergence and easy parameter tuning, as well as the ability to automatically adjust the learning rate, Adam is utilized as the optimizer for updating the parameters of the model in this paper. The update formula for the Adam parameters is as follows:
where
and
are two hyper-parameters;
controls the first-order momentum and
controls the second-order momentum. The initial values of
and
are 0.9 and 0.999, respectively. At the same time, Adam can adaptively optimize the learning rate, taking the decay rate epsilon = 1 × 10
−7.
Loss function: For multi-category neural network models, the cross-entropy loss function is usually applied, and its formula is shown in Formula (11):
where
represents the sample,
represents the real label,
represents the predicted output, and
represents the total number of samples.
Metric evaluation criteria: Since the task of this paper is to identify 6 types of ancient buildings, the traditional top 1 and top 5 accuracies cannot objectively measure the model’s recognition effect. Therefore, the 1st and 5th accuracy rates are used as model evaluation criteria in this paper:
- (1)
1st Accuracy: This represents the maximum value of top1 accuracy during 20 rounds of model training;
- (2)
5th Accuracy: This represents the 5th largest value of top1 accuracy during 20 rounds of model training.
5. Experimental Verification and Result Analysis
The experiment environments are as follows:
- (1)
Experiment hardware environments: Intel(R) Xeon(R) Gold 5120 CPU @ 2.20GHz × 32 cores, NVIDIA Tesla T4 GPU, 1005 MHZ core frequency, 10,000 MHZ memory frequency, and a total of four video memories with each 15 GB of storage.
- (2)
Experiment software environments: Linux x86_64 operating system, driver version: 440.118.02.
- (3)
Network training environments: CUDA10.2, Python3.8.5, Tensorflow-gpu2.2.0.
5.1. Comparison and Analysis of Different Pre-Processing Methods
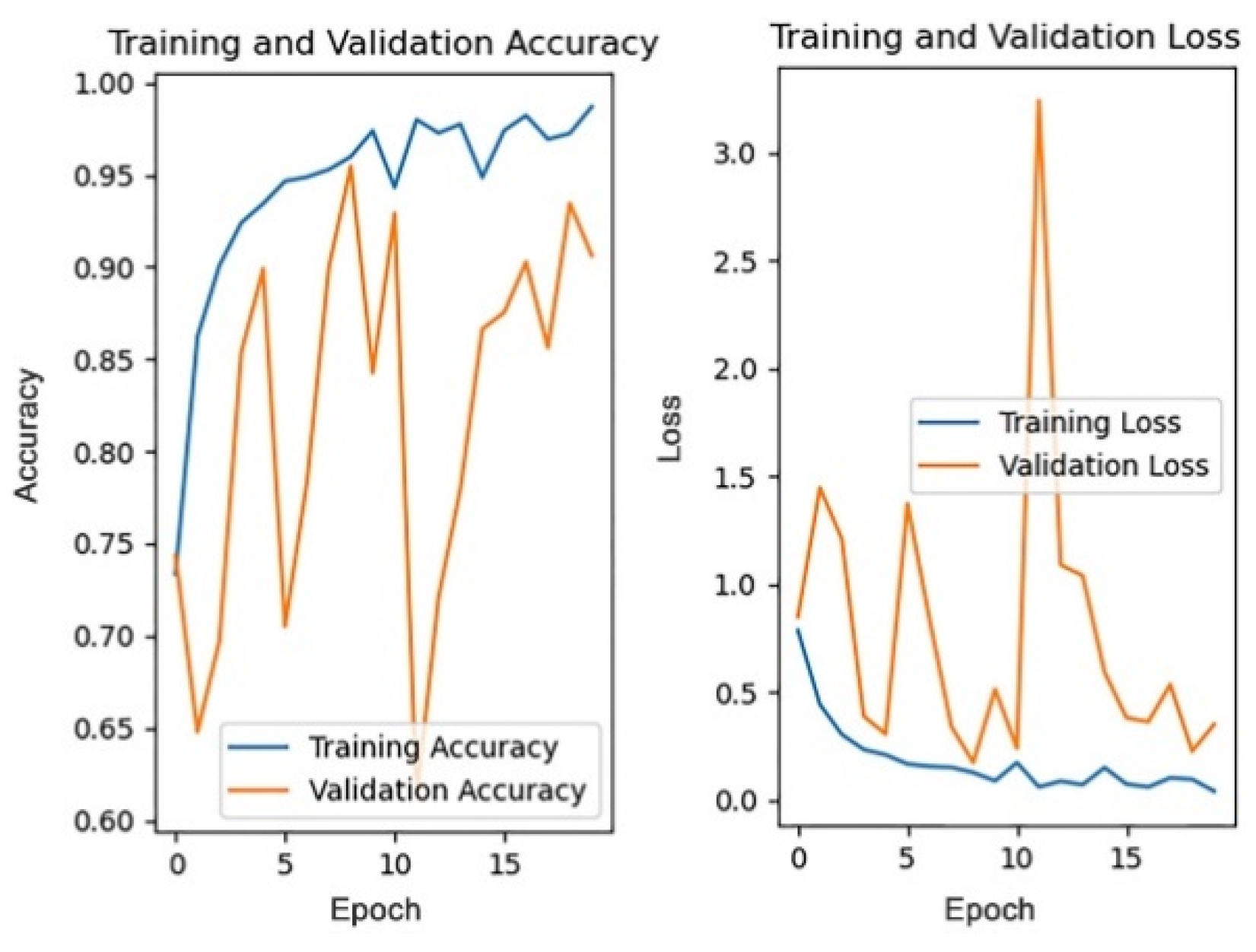
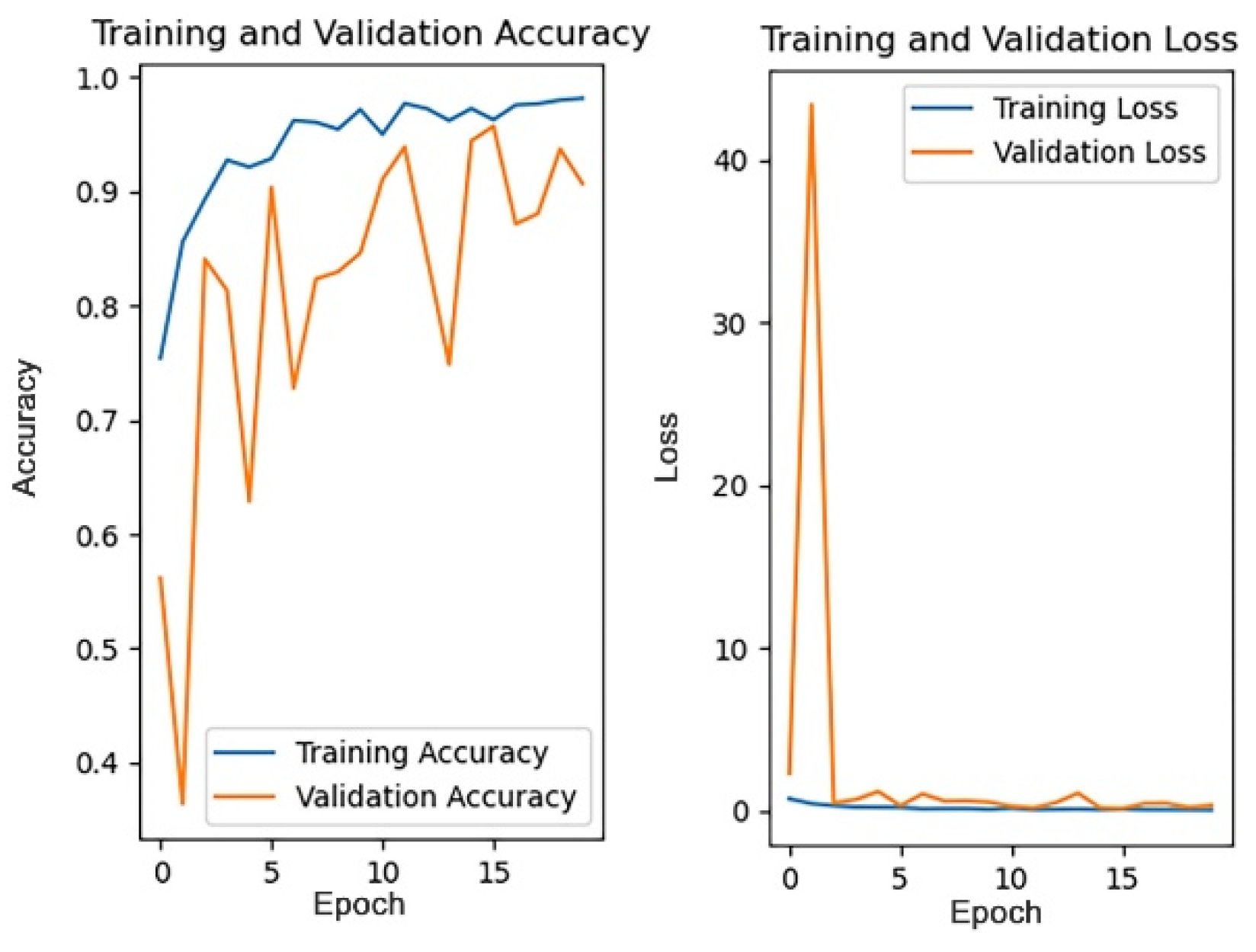
Data pre-processing methods have an important impact on the model’s training results, and this section will compare and analyze the effects of different data pre-processing methods. Among them, the model training results after directly modifying the size without considering the aspect ratio of the image are shown in
Figure 8, the model training results after center cropping according to the short side are shown in
Figure 9, and the model training results after filling according to the long side are shown in
Figure 10.
The 1st accuracy and 5th accuracy obtained by training the models according to three preprocessing methods are shown in
Table 4.
Because the 1st accuracy is accidental, in order to more objectively measure the model training results of each pre-processing method, this paper takes both the 1st accuracy and the 5th accuracy as the evaluation indicators of the model training effect. According to the above results, it can be observed that the 1st and 5th accuracies of the model obtained by the filling pre-processing method are higher than the other two pre-processing methods. Therefore, this paper finally chooses filling as the data pre-processing method for the ancient architecture recognition task. The most likely reasons for the above results are: (1) the pre-processing method of directly modifying the image size does not take into account the aspect ratio of the image, and some images may thus be distorted, which leads to the distortion of the feature map obtained by convolution, thus affecting the accuracy of the model; (2) although the pre-processing method of center cropping will not compress the image and cause distortion, for some specific buildings, their features may just be located at the edge of the image, and these features may just be clipped off, thus affecting the model recognition effect; (3) the pre-processing method of filling will not cause image distortion, nor will it lose some features due to clipping. Therefore, the filling pre-processing method is superior to the former two methods in both performance and results.
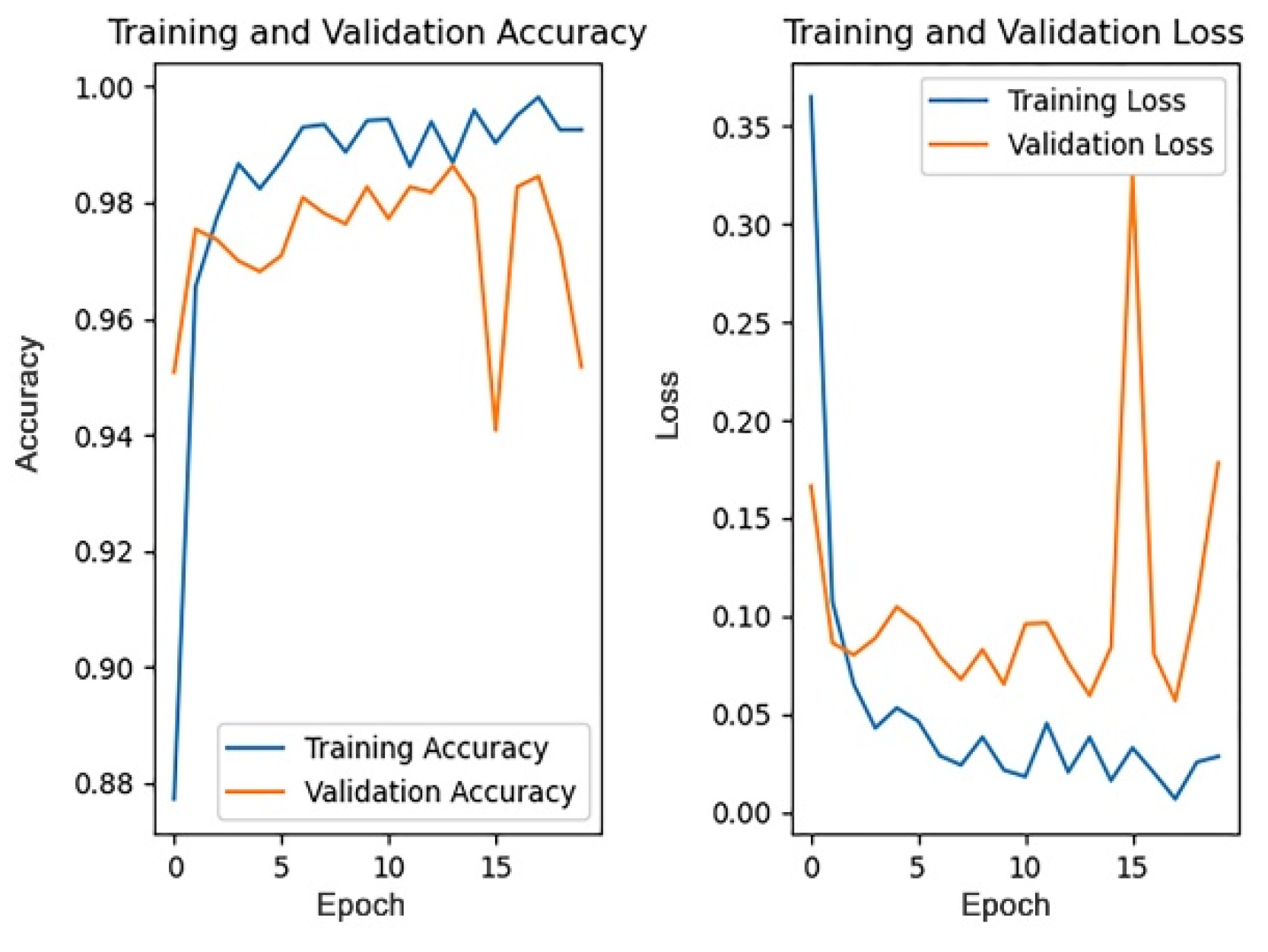
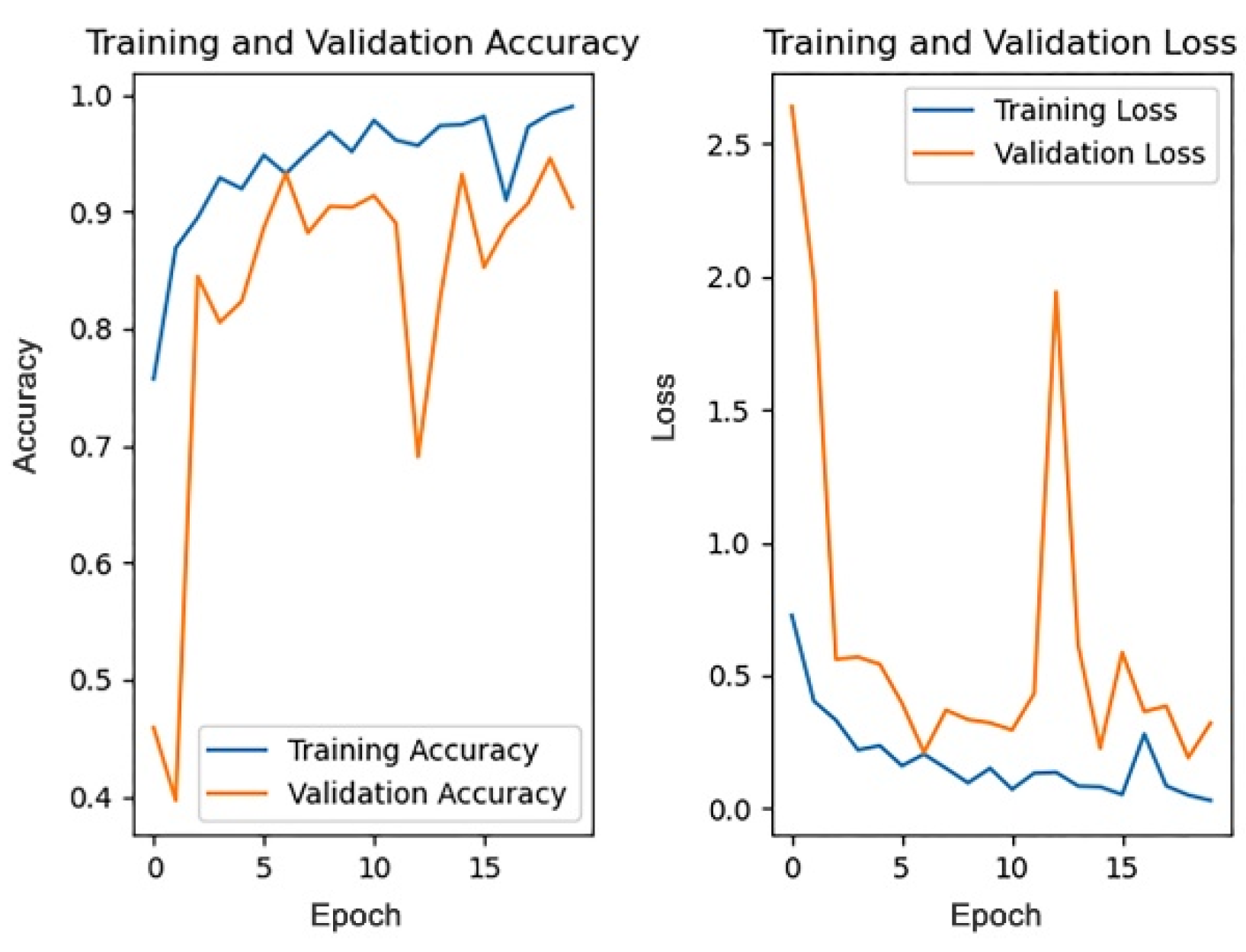
5.2. Comparison and Analysis of the Different Dropout Rates
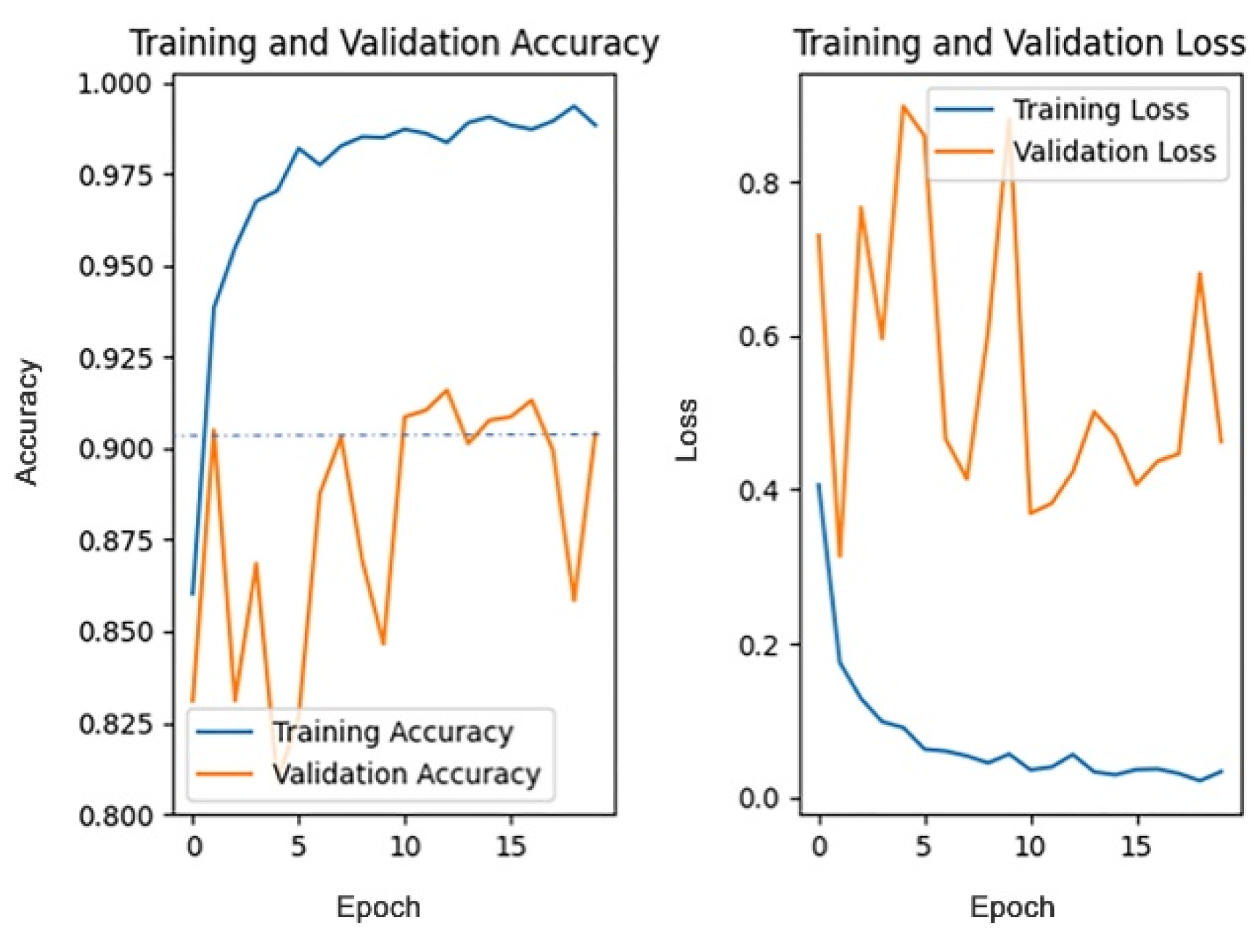
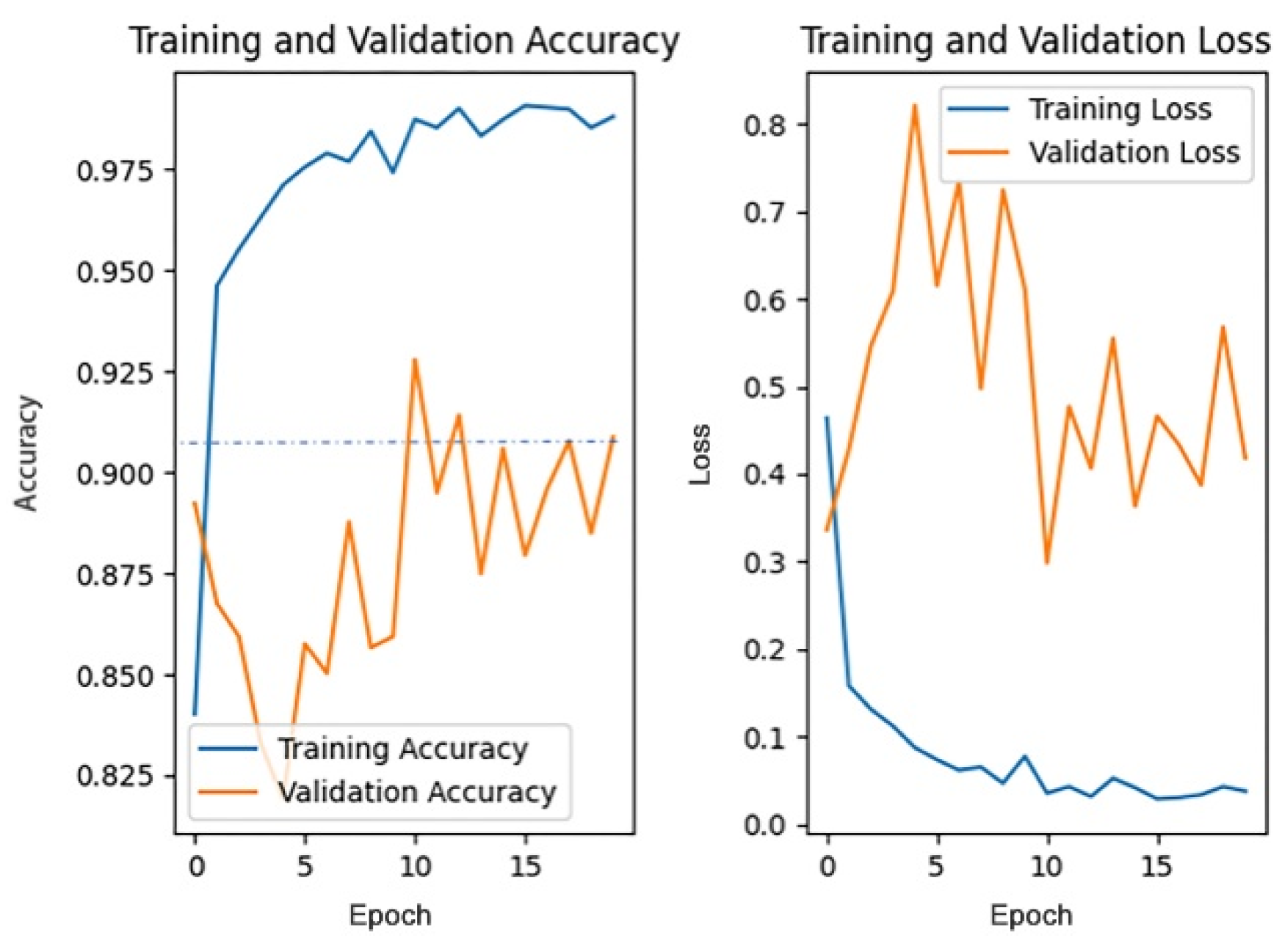
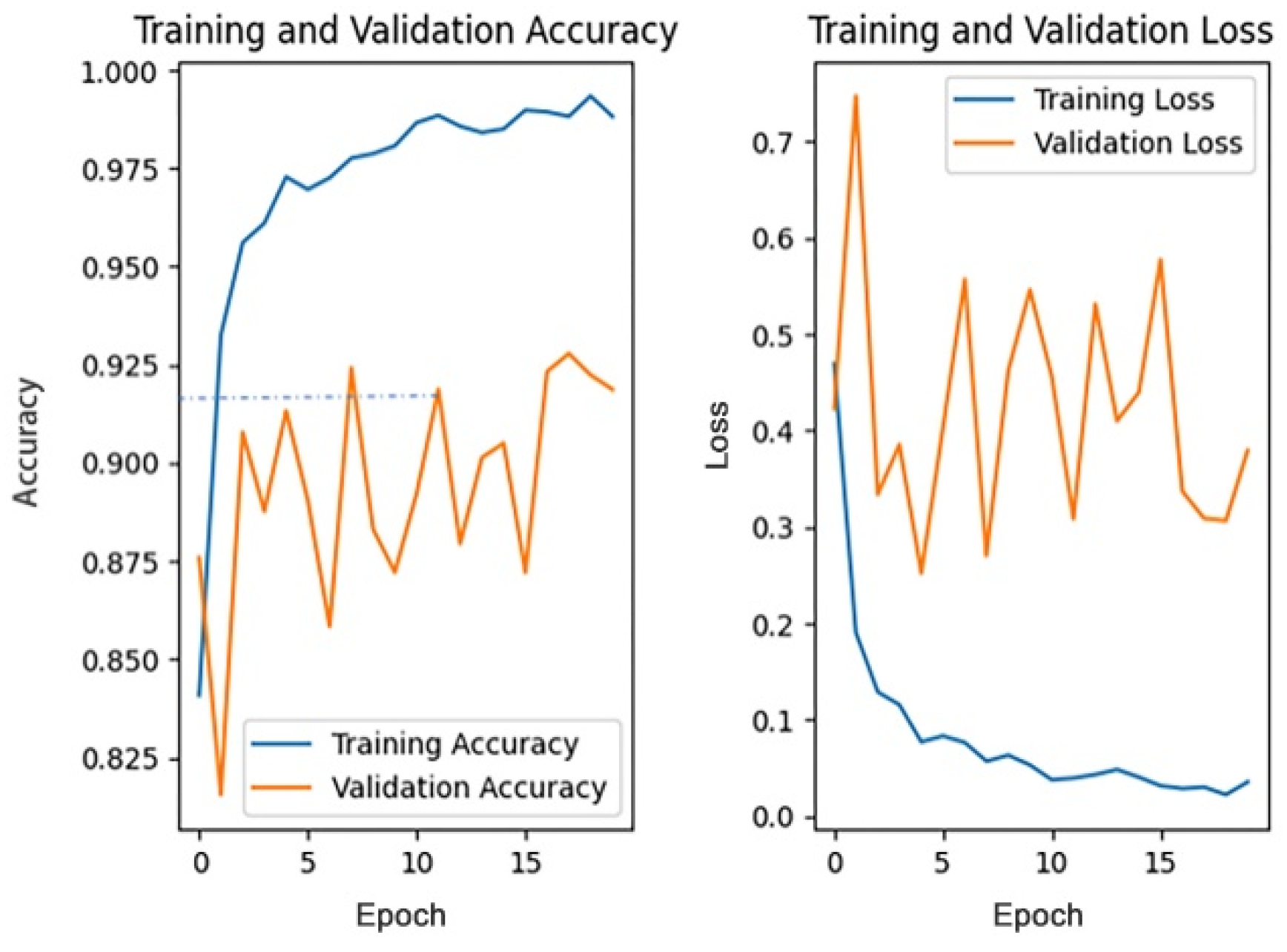
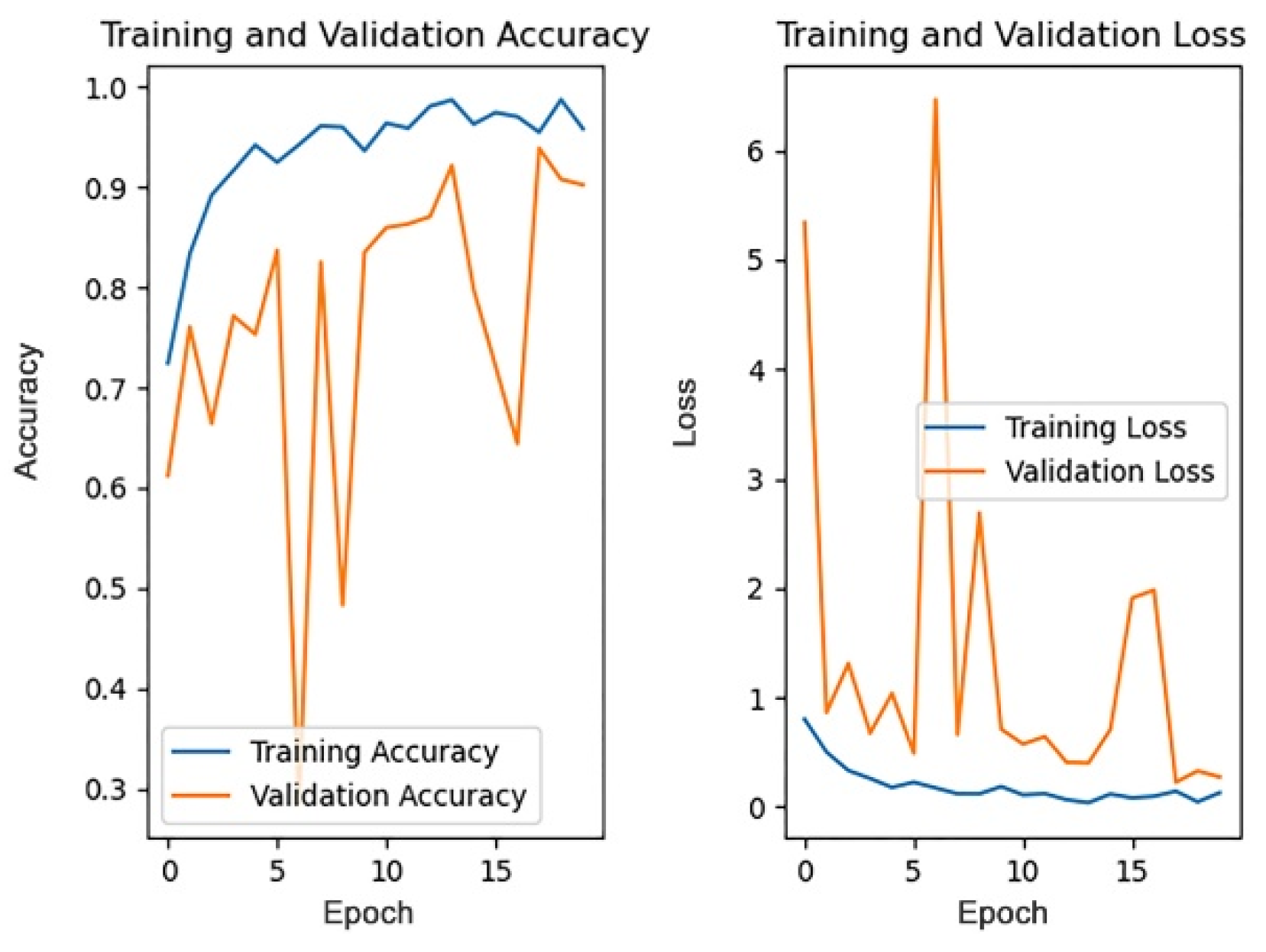
This section discusses the impact of different dropout rates on the model training effect under the data pre-processing mode, based on filling, while other parameters remain unchanged. The dropout rate is generally no more than 0.5. This paper trains the model when the dropout rate is 0, 0.1, 0.2, 0.3, 0.4, and 0.5. The training process of the different dropout rates is shown in
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
Figure 16.
Since the 1st accuracy value may have some deviation and contingency, likewise, the 1st accuracy and the 5th accuracy are also selected as the evaluation criteria.
Table 5 shows the 1st and 5th accuracies under different dropout rates.
From the above results, it can be seen that the recognition accuracy is the highest when the dropout rate is 0.3. In general, the dropout rate, as a hyper-parameter, is mainly used for regularization and there is no definite standard for its value. According to cross-validation experience, the effect is best when the dropout rate is 0.5. However, in this paper, the recognition accuracy is highest when the dropout rate is 0.3. One possible explanation is that buildings are usually tall and complex and contain more details. Therefore, the model will extract numerous features in the training process. For an object composed of a large number of features, when the dropout rate is too high, the model may ignore some important features in the training process, thus affecting the accuracy of the model recognition results. Therefore, when the dropout rate is 0.3, the accuracy is instead higher than that when the dropout rate is 0.5.
5.3. Comparison and Analysis of the Training Efficiency of Different Network Models
To verify the performance of the improved Inception V3 model proposed in this paper when on the ancient architecture recognition task, this paper finally chooses three classic convolutional neural networks, i.e., VGGNet19 [
12], ResNet50 [
13], and ResNet152 [
19], to conduct a comparative analysis with the improved Inception V3 model.
The pre-trained weights on the ImageNet dataset are loaded into the four models, respectively, with each model trained for 20 rounds, then the accuracy of each model on the test dataset and the average training time are compared.
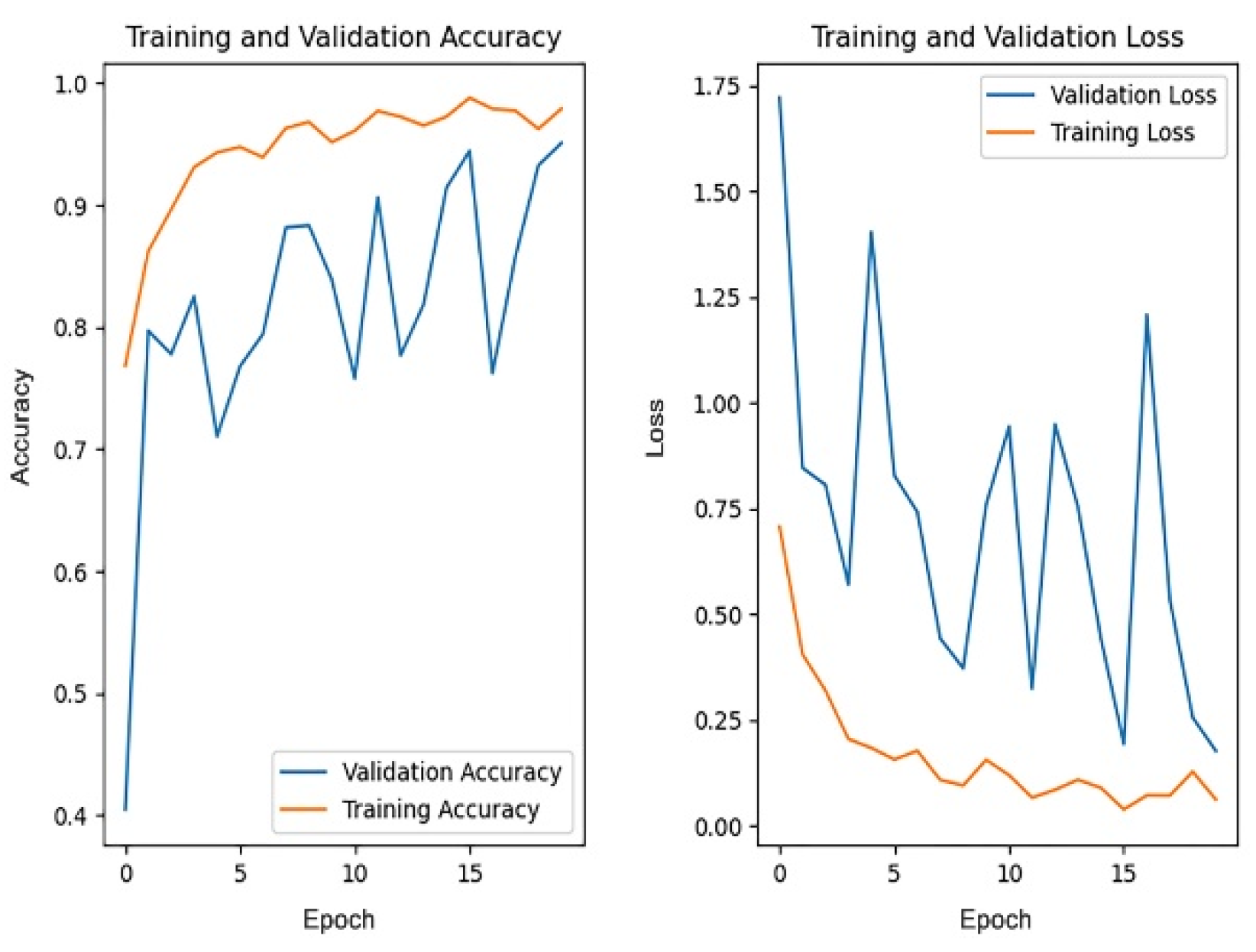
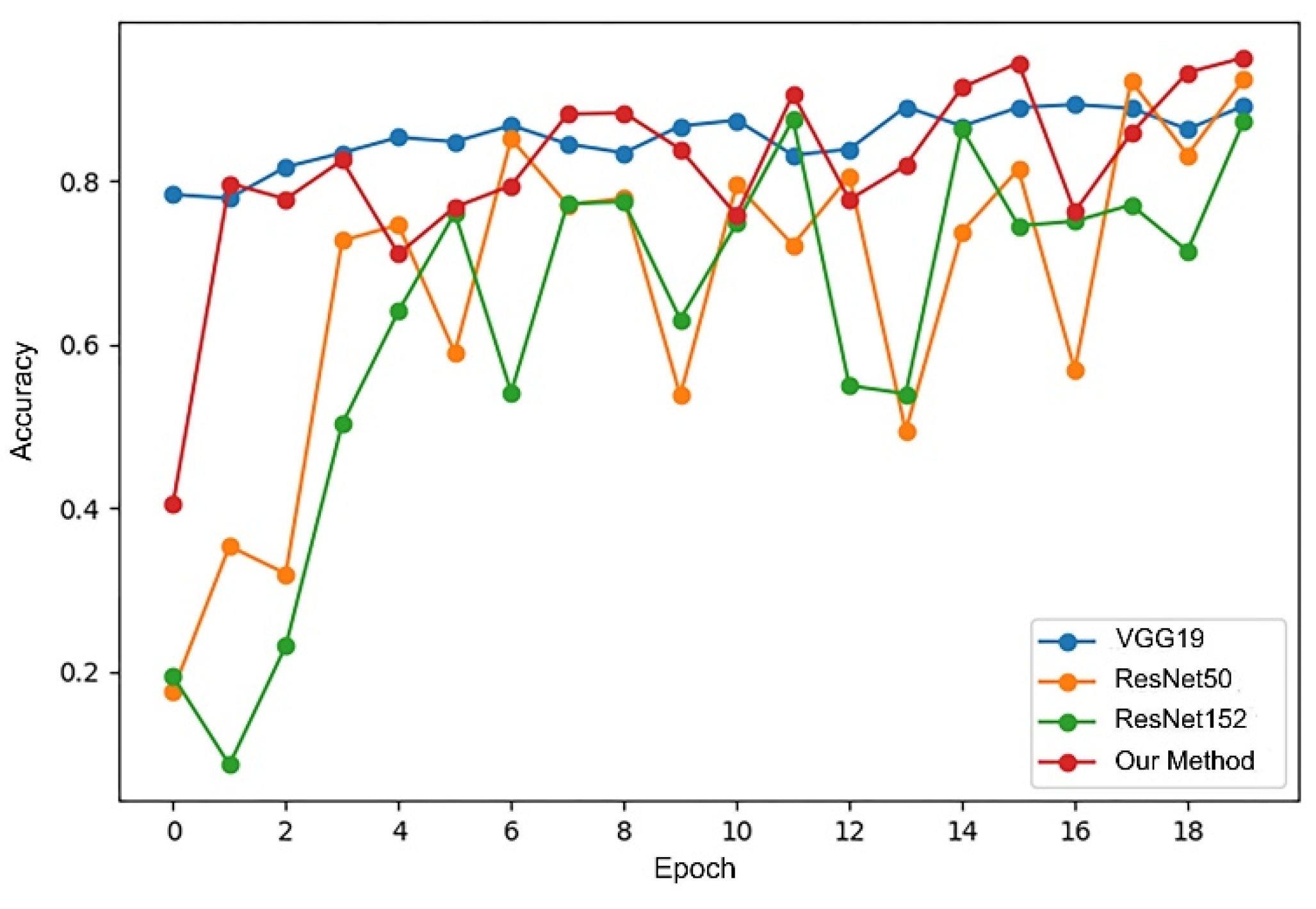
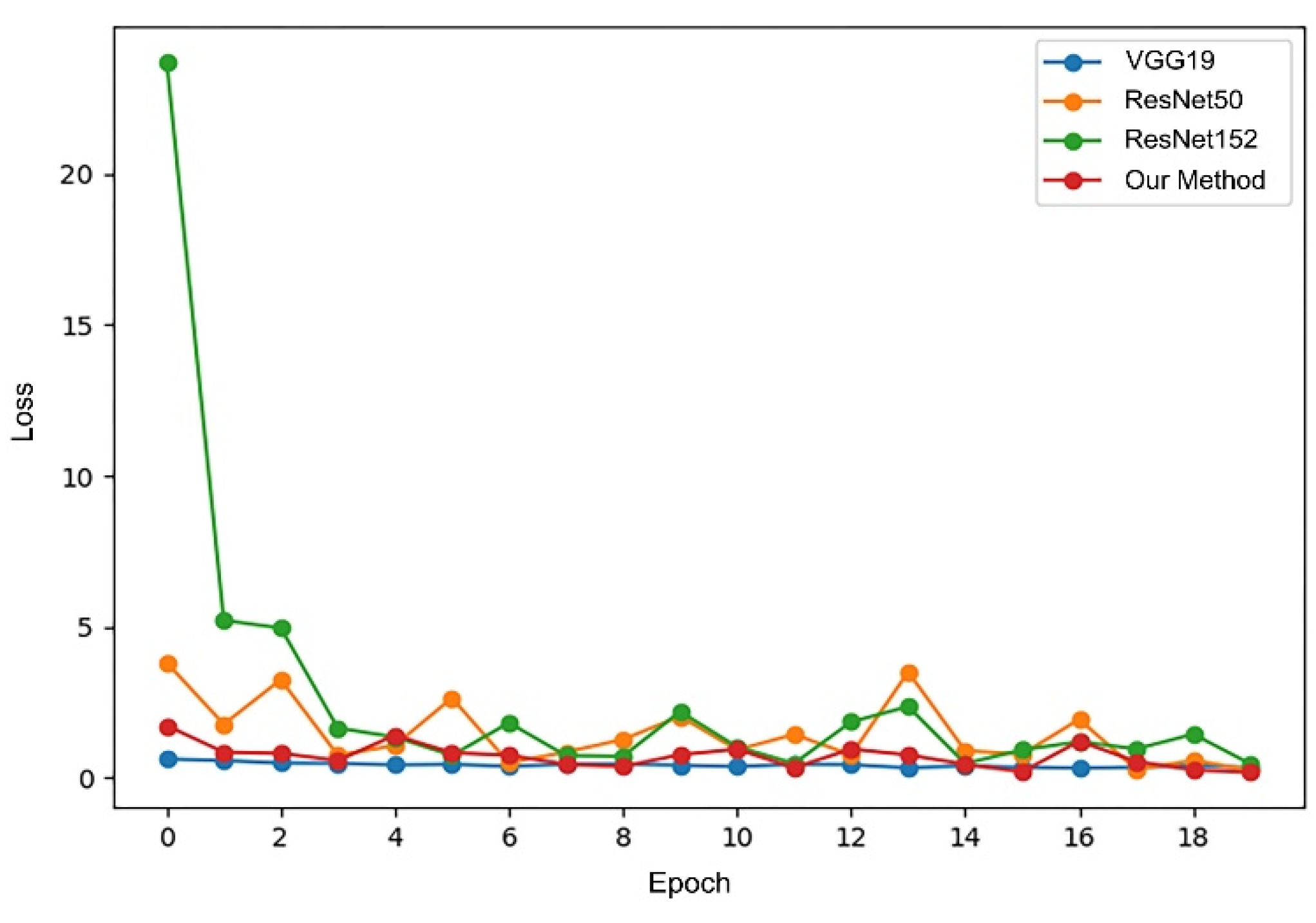
Figure 17 and
Figure 18, respectively, show the changes in accuracy and loss during the training process of four models.
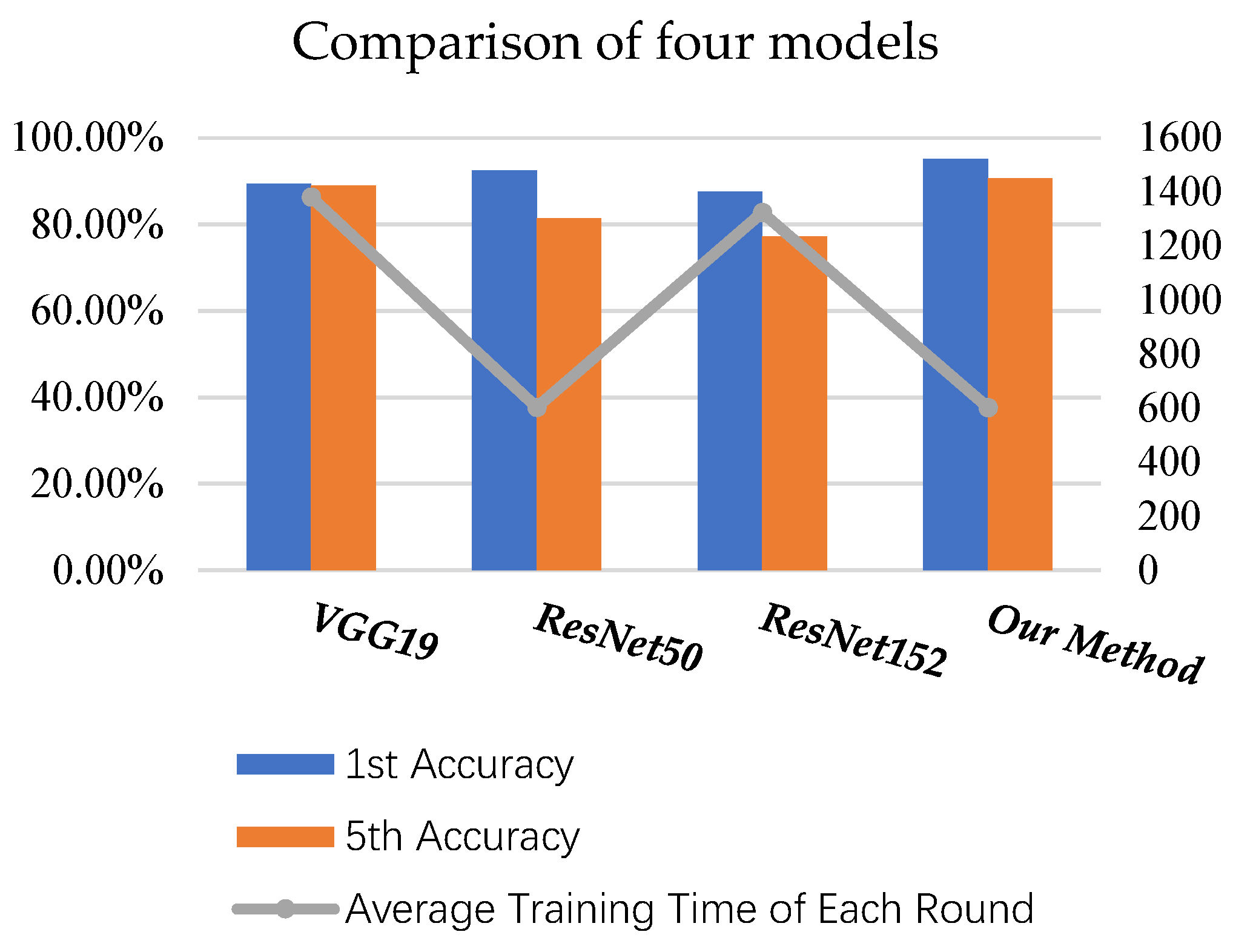
Similarly, we use the 1st accuracy and the 5th accuracy as the evaluation criteria. The 1st accuracy and the 5th accuracy on the test dataset and the average training time of the four models are shown in
Figure 19 and
Table 6, respectively.
It can be seen from the above results that the 1st and 5th accuracies of the improved Inception V3 both show the highest values, while the average training time is also the shortest with the same hardware resources, showing that it performs the best, comprehensively. The cause for this lies in the fact that the last layers of the VGGNet19, ResNet50, and ResNet152 networks use the full connection layer, inevitably increasing the network training parameter scale. In comparison, there is no full connection layer in the improved Inception V3 model, and it has a higher training speed. In addition, because the ResNet152 model contains 152 layers and has the deepest structure, it is more prone to overfitting, and the training time is longer. To sum up, compared with the discussed models, the improved Inception V3 model adopted in this paper has the best results when performing the ancient architecture recognition task.
5.4. Realization of Recognition System
In this paper, we adopt SoftMax as the activation function, formulated as follows:
where
is the score given when one image belongs to type
i after feature extraction and weight addition, while
is the probability that the image belongs to type
i. After being processed by the SoftMax activation function, the scores given when images belong to each type are converted to the corresponding probabilities, and the type with the highest probability value is the most likely type to which an ancient building belongs. In order to eliminate the interference of other images, it is only when the probability value of the highest probability type is greater than 60% that it can be determined that the building belongs to the corresponding category; otherwise, it will be included in other categories, namely, types other than the square-shaped Tulou, Canton ancestral hall, Leiqiong folk house, San-Jian Liang-lang folk house, Hakka walled village, and round Tulou.
Based on the identification model in this paper, our team has developed the B/S architecture and C/S architecture ancient building recognition system, which improved the work efficiency of the research team and the professionals. The running system is shown in
Figure 20, where left subfigure and right subfigure represent the recognition results under the C/S architecture and B/S architecture respectively.
6. Discussion
The automatic identification of ancient building types has important research significance and application value for studying the development of society and cultural civilization and is also the application of an asymmetric system. In order to improve the accuracy of the machine vision recognition of ancient buildings, based on the convolutional neural network model, this paper proposes an improved Inception V3 model for ancient building recognition. The automatic recognition model proposed in this paper is mainly improved in the following aspects: (1) a dropout layer is added after the global average pooling layer of the Inception V3 model, which effectively alleviates the overfitting problem in the model learning process; (2) on the one hand, the integration of transfer learning and the ImageNet dataset into the training process of the model speeds up the training speed of the model, while on the other hand, it can further alleviate the overfitting problem caused by insufficient training due to a small sample size; (3) this paper also optimizes the network super-parameters of the recognition model through ablation experiments: the recognition effect of the model is the best when the data preprocessing method is set to the filling mode, and the dropout rate is set to 0.3 at this time. The data set of ancient buildings, independently constructed by the team of the South China University of Technology, is taken as the experimental data; then, the recognition effects of several convolutional network models, i.e., VGGNet19, ResNet50, and ResNet152, are compared and analyzed. The experimental results show that the accuracy of the improved Inception V3 model, proposed in this paper to identify ancient buildings, reaches 98.64% at the highest level. Compared with other classical models, the recognition model proposed in this paper has the best recognition accuracy and the least model training time, which validates the effectiveness of promoting performance in the ancient building recognition task of our proposed method.
The research in this paper provides a new idea and method for the recognition of ancient buildings, based on convolution. In future research, we will further carry out the recognition of ancient building materials and other features and will further improve the recognition effect by combining data enhancement, target recognition, and other methods.



 ,
, 




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















