

Detecting Compressed Deepfake Images Using Two-Branch Convolutional Networks with Similarity and Classifier


Abstract
:1. Introduction
- A two-branch convolutional network for robust compressed deepfake detection is proposed based on symmetry of an image and its compressed image.
- The proposed method can determine the authenticity of a raw image or its various compressed images. In other words, our method is robust to the compression factor.
- A joint loss function is introduced to train the similarity-learning branch and binary-classification branch simultaneously, which can extract the common features under image compression and identify the authenticity of the image.
- Various experiments are conducted to test our method and compare it with state-of-the-art deepfake detection methods.
2. Related Works
2.1. Deepfake Detection Methods
2.2. Similarity Learning
3. Analysis and Method
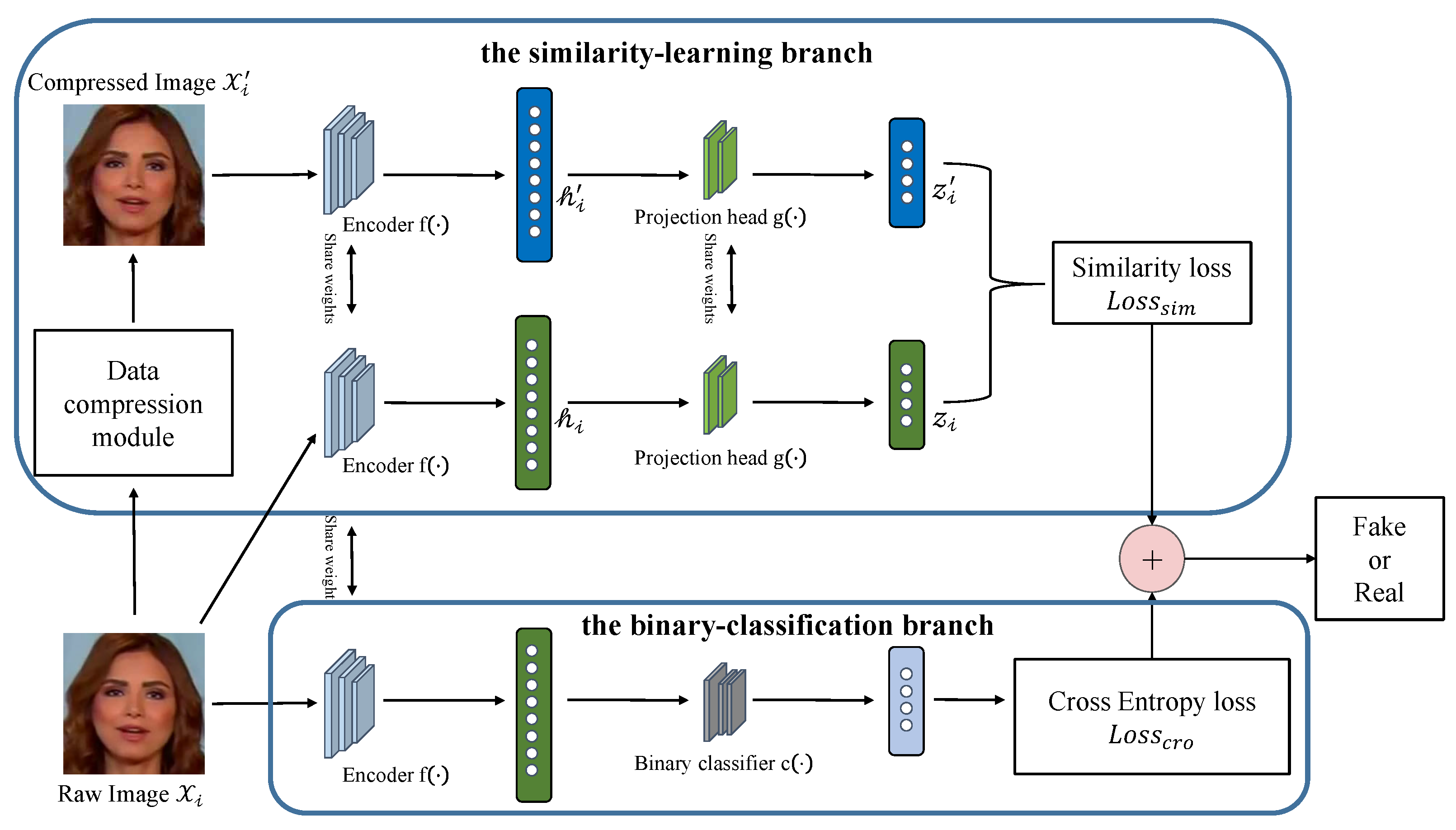
3.1. Architecture
| Algorithm 1: Main algorithm in the similarity-learning branch |
 |
| Algorithm 2: Main algorithm in the binary-classification branch |
 |
3.2. Loss Function
4. Experiment and Evaluation
4.1. Experimental Setting
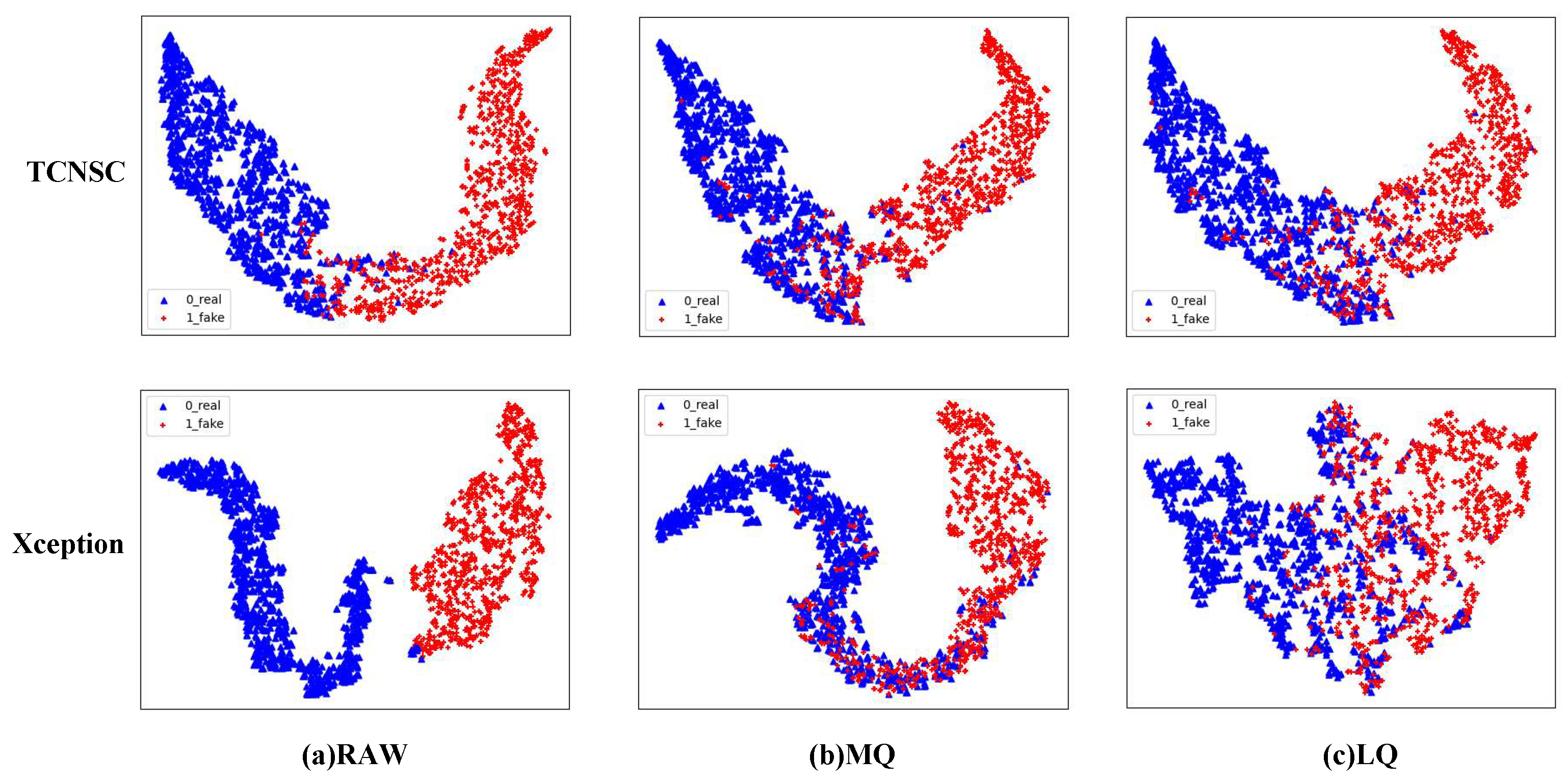
4.2. Evaluation
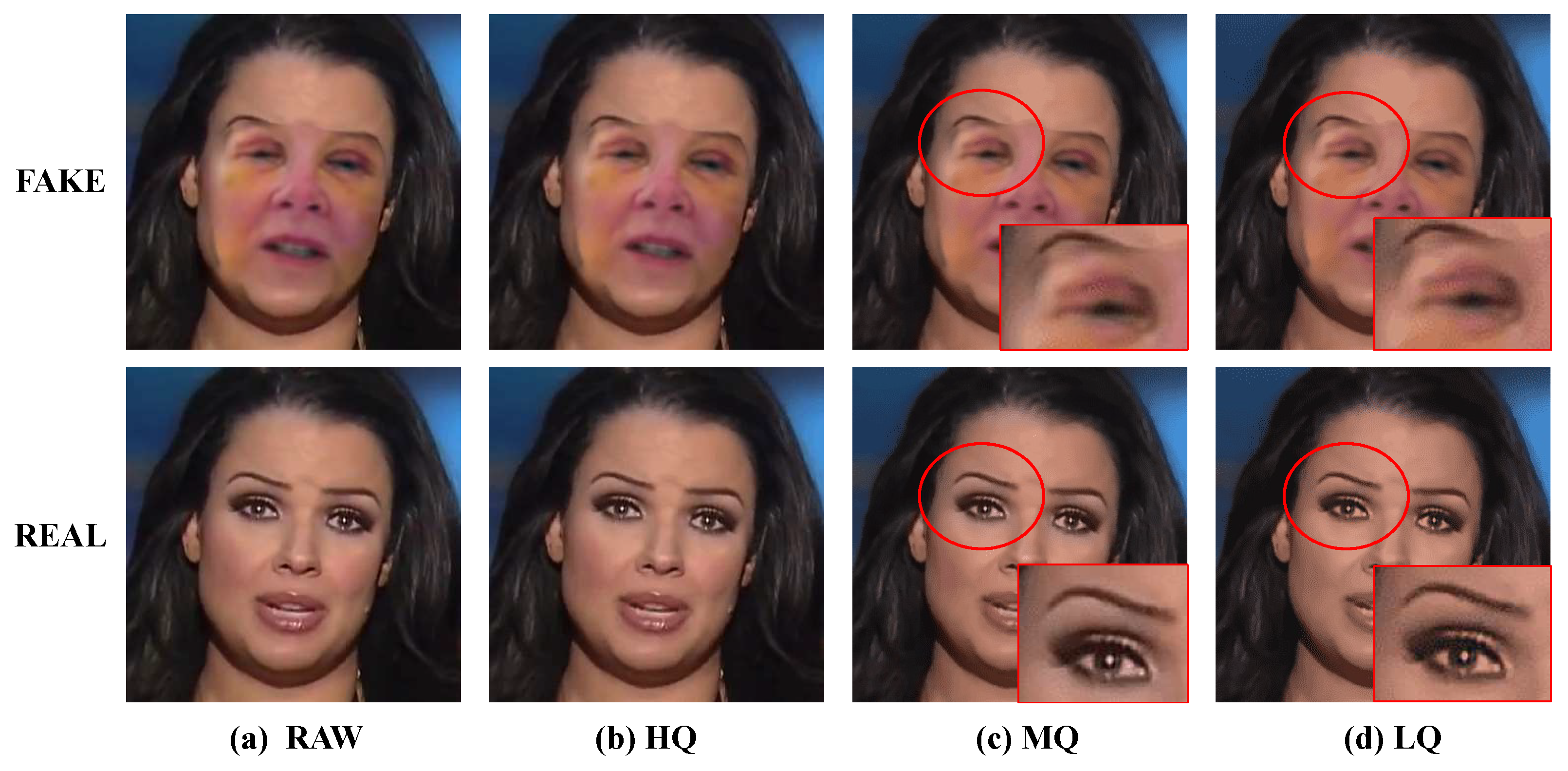
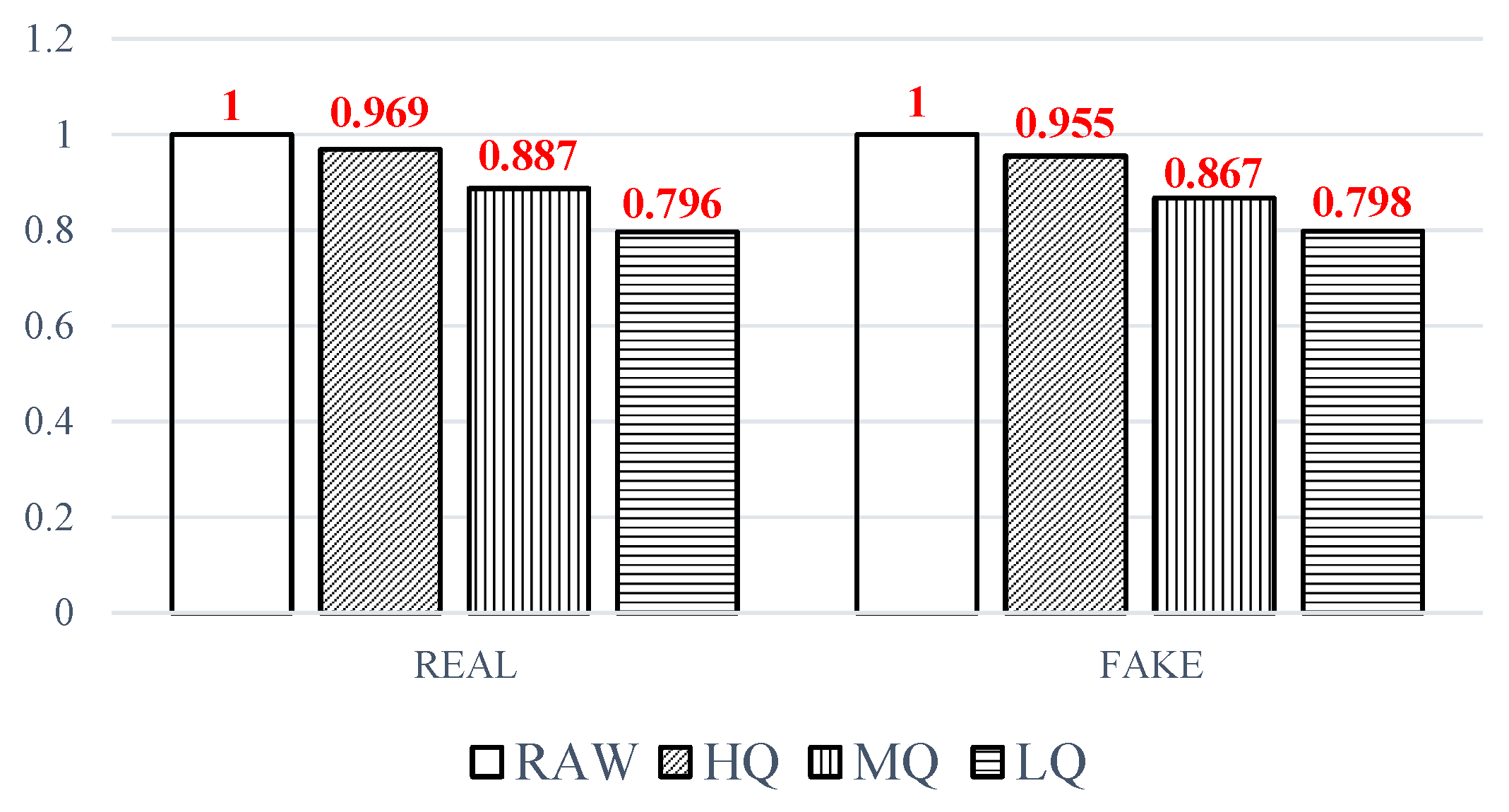
4.2.1. Impact of Compression Factor
4.2.2. Ablation Study
4.2.3. Comparisons with Other Deepfake Detection Methods
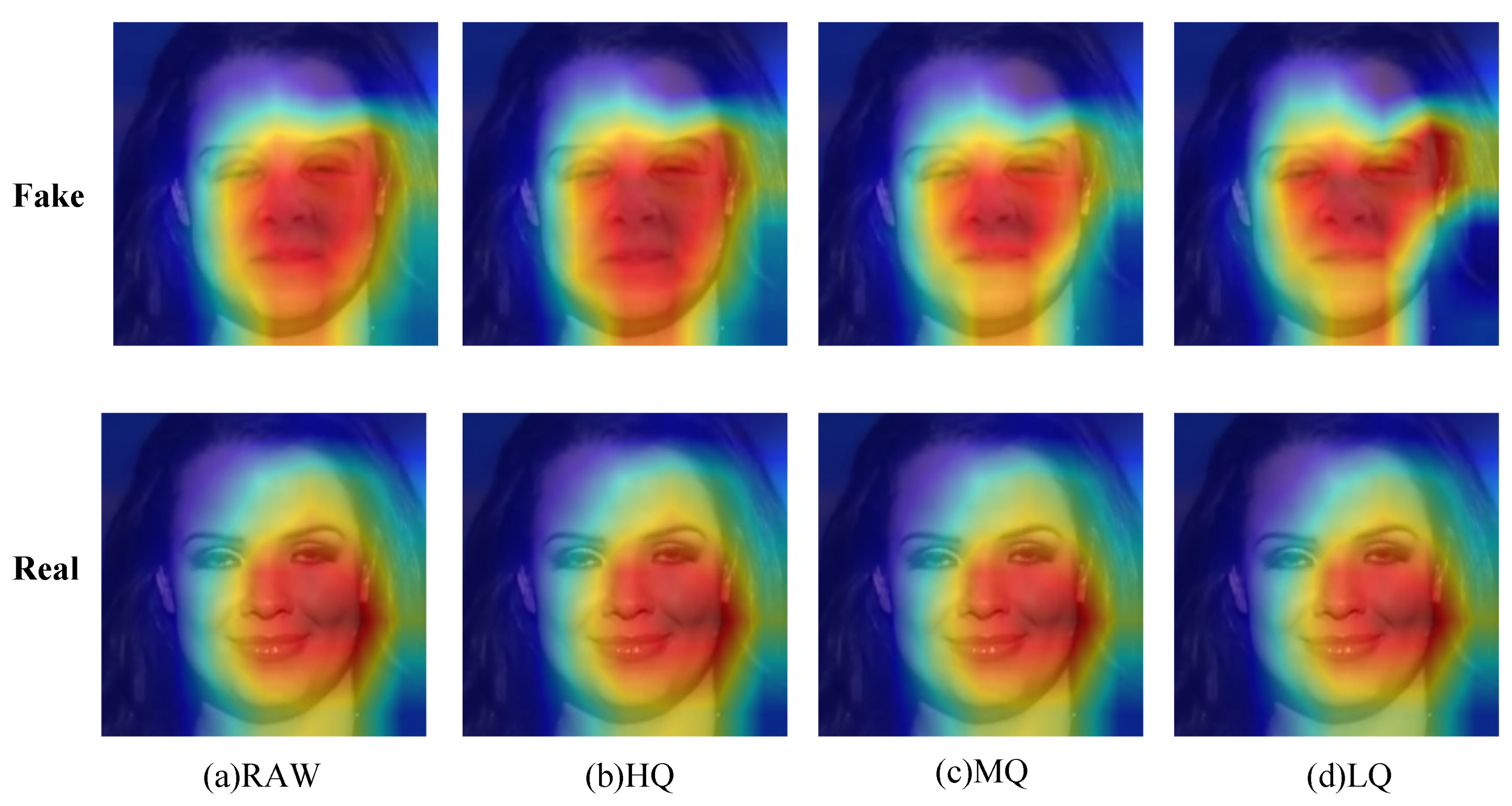
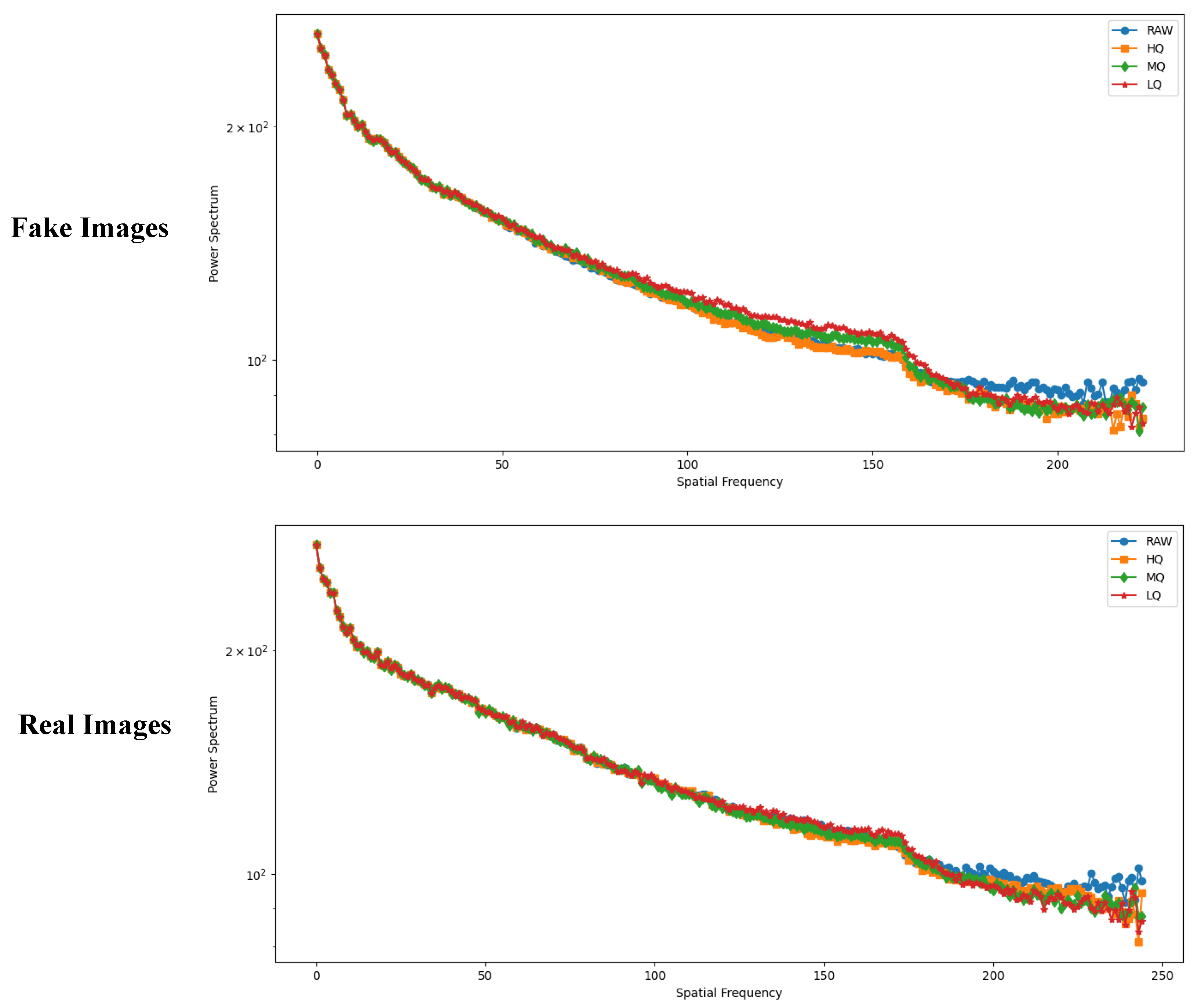
4.3. Discussion
5. Conclusions and Future work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Chen, S.; Yao, T.; Chen, Y.; Ding, S.; Li, J.; Ji, R. Local relation learning for face forgery detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1081–1088. [Google Scholar]
- Gu, Q.; Chen, S.; Yao, T.; Chen, Y.; Ding, S.; Yi, R. Exploiting fine-grained face forgery clues via progressive enhancement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; Volume 36, pp. 735–743. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2185–2194. [Google Scholar]
- LIY, C.M.; InIctuOculi, L. ExposingAICreated FakeVideosbyDetectingEyeBlinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1–11. [Google Scholar]
- Li, Y.; Lyu, S. Exposing DeepFake Videos By Detecting Face Warping Artifacts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Sun, K.; Yao, T.; Chen, S.; Ding, S.; Li, J.; Ji, R. Dual contrastive learning for general face forgery detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; Volume 36, pp. 2316–2324. [Google Scholar]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging frequency analysis for deep fake image recognition. In Proceedings of the International Conference on Machine Learning, Virtually, 13–18 July 2020; pp. 3247–3258. [Google Scholar]
- Jung, T.; Kim, S.; Kim, K. Deepvision: Deepfakes detection using human eye blinking pattern. IEEE Access 2020, 8, 83144–83154. [Google Scholar] [CrossRef]
- Gu, Z.; Chen, Y.; Yao, T.; Ding, S.; Li, J.; Ma, L. Delving into the local: Dynamic inconsistency learning for deepfake video detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtually, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Deepfakes. Available online: https://github.com/deepfakes/faceswap (accessed on 24 February 2022).
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- FaceSwap. Available online: https://github.com/MarekKowalski/FaceSwap (accessed on 24 February 2022).
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Yin, X.; Liu, X. Multi-task convolutional neural network for pose-invariant face recognition. IEEE Trans. Image Process. 2017, 27, 964–975. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ginesu, G.; Pintus, M.; Giusto, D.D. Objective assessment of the WebP image coding algorithm. Signal Process. Image Commun. 2012, 27, 867–874. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Durall, R.; Keuper, M.; Pfreundt, F.J.; Keuper, J. Unmasking deepfakes with simple features. arXiv 2019, arXiv:1911.00686. [Google Scholar]
- Durall, R.; Keuper, M.; Keuper, J. Watch your up-convolution: Cnn based generative deep neural networks are failing to reproduce spectral distributions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7890–7899. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Dataset | Test Dataset | ||||
|---|---|---|---|---|---|
| RAW | HQ | MQ | LQ | WEBP | |
| (RAW, HQ) | 96.8 | 94.5 | 92.6 | 90.4 | 89.2 |
| (RAW, MQ) | 96.4 | 94.3 | 92.1 | 90.2 | 89.3 |
| (RAW, LQ) | 97.6 | 95.3 | 93.4 | 91.8 | 92.7 |
| (LQ, MQ) | 93.2 | 92.1 | 91.4 | 91.1 | 89.1 |
| Model | Test Dataset | ||||
|---|---|---|---|---|---|
| RAW | HQ | MQ | LQ | WEBP | |
| model A | 51.8 | 51.7 | 51.7 | 51.7 | 51.7 |
| model B | 98.8 | 96.2 | 83.7 | 71.3 | 82.6 |
| dual-branch model | 97.6 | 95.3 | 93.4 | 91.8 | 92.7 |
| Methods | RAW | HQ | MQ | LQ | WEBP |
|---|---|---|---|---|---|
| Xception-RAW Xception-C23 Xception-C40 [10] | 99.7 99.3 81.3 | 91.2 90.6 86.0 | 83.3 86.7 87.9 | 74.9 82.1 88.3 | 82.6 85.2 86.5 |
| MesoInception Meso4 [16] | 91.7 89.1 | 57.4 51.3 | 57.4 50.8 | 57.2 50.4 | 57.2 51.4 |
| Capsule [14] | 94.47 | 89.2 | 81.3 | 64.8 | 78.5 |
| FWA [3] | 81.6 | 76.8 | 67.2 | 58.1 | 68.4 |
| DSP-FWA [11] | 93.4 | 87.6 | 83.1 | 75.6 | 82.8 |
| Ours | 97.6 | 95.3 | 93.4 | 91.8 | 92.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Xu, M.; Wang, X. Detecting Compressed Deepfake Images Using Two-Branch Convolutional Networks with Similarity and Classifier. Symmetry 2022, 14, 2691. https://doi.org/10.3390/sym14122691
Chen P, Xu M, Wang X. Detecting Compressed Deepfake Images Using Two-Branch Convolutional Networks with Similarity and Classifier. Symmetry. 2022; 14(12):2691. https://doi.org/10.3390/sym14122691
Chicago/Turabian StyleChen, Ping, Ming Xu, and Xiaodong Wang. 2022. "Detecting Compressed Deepfake Images Using Two-Branch Convolutional Networks with Similarity and Classifier" Symmetry 14, no. 12: 2691. https://doi.org/10.3390/sym14122691
APA StyleChen, P., Xu, M., & Wang, X. (2022). Detecting Compressed Deepfake Images Using Two-Branch Convolutional Networks with Similarity and Classifier. Symmetry, 14(12), 2691. https://doi.org/10.3390/sym14122691