
Deepfake Video Detection Based on MesoNet with Preprocessing Module



Abstract
:1. Introduction
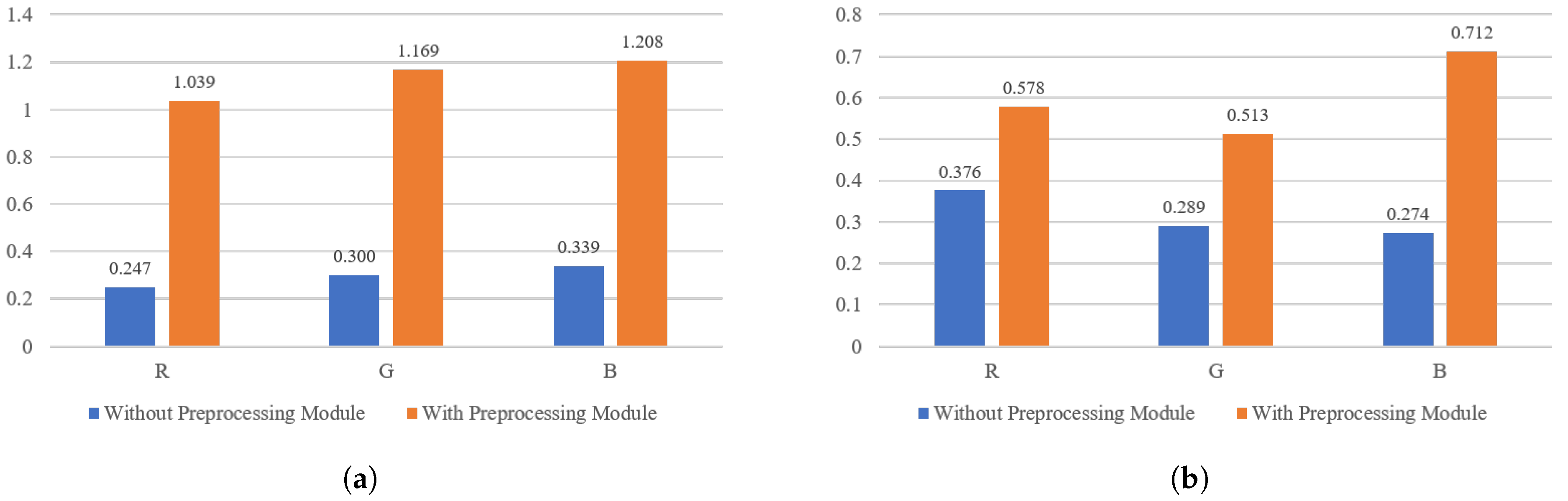
- We propose a new preprocessing module to filter low-frequency signals in images and retain high-frequency signals, and therefore increasing the discrimination between Deepfake generated and real images. The effectiveness of the preprocessing module is verified in the ablation experiment.
- We propose a new Deepfake detection method by combining the classic MesoNet with preprocessing module. In the case of heavy compression, it can still maintain good robustness; the accuracy of our proposed method is still higher than 88%.
- The performance of our method is verified among numerous baseline datasets. Extensive experimental evaluations demonstrate that the proposed method performs well on Celeb-DF and FaceForensics++. Our method outperforms some SOTA methods on the Celeb-DF. In addition, the AUC of our proposed method is 0.965 and 0.843 on the UADFV and DFD datasets, respectively.
2. Related Works
2.1. Deepfake Video Detection Method Based on Hand-Crafted
2.2. Deepfake Video Detection Method Based on Deep Learning
2.2.1. Frame-Level Detection Methods
2.2.2. Video-Level Detection Methods
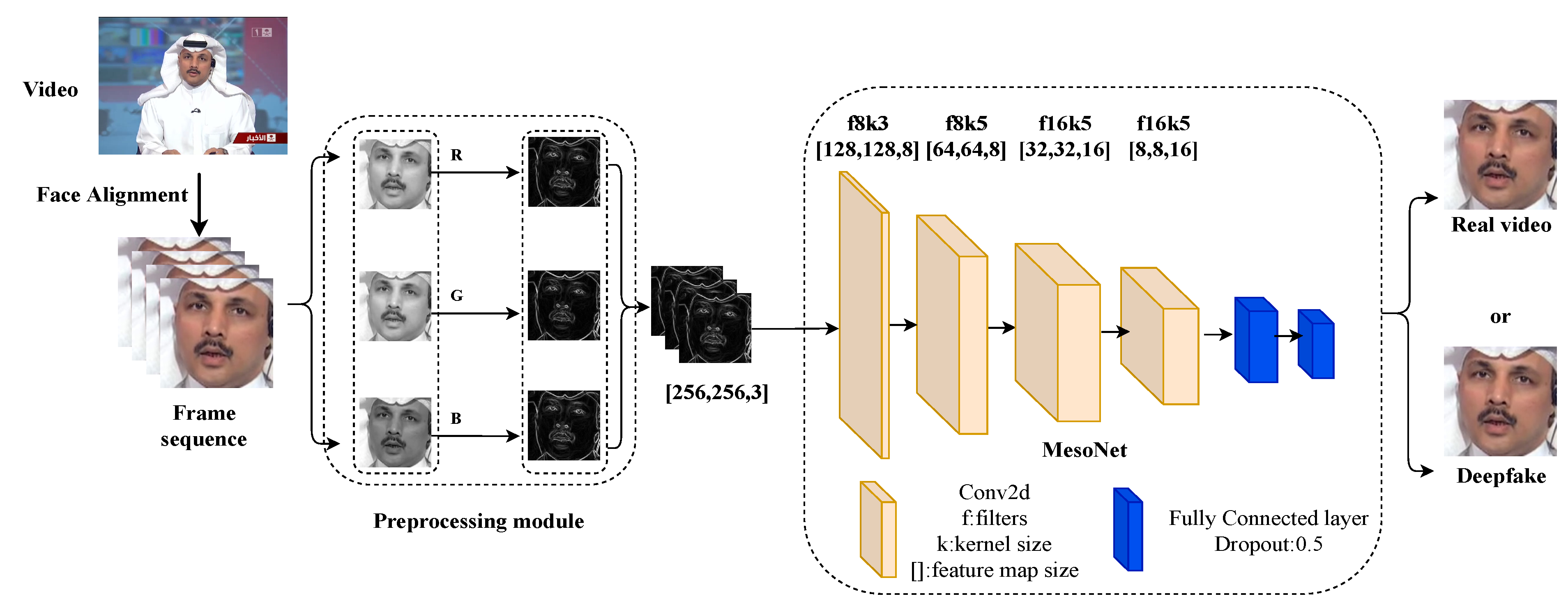
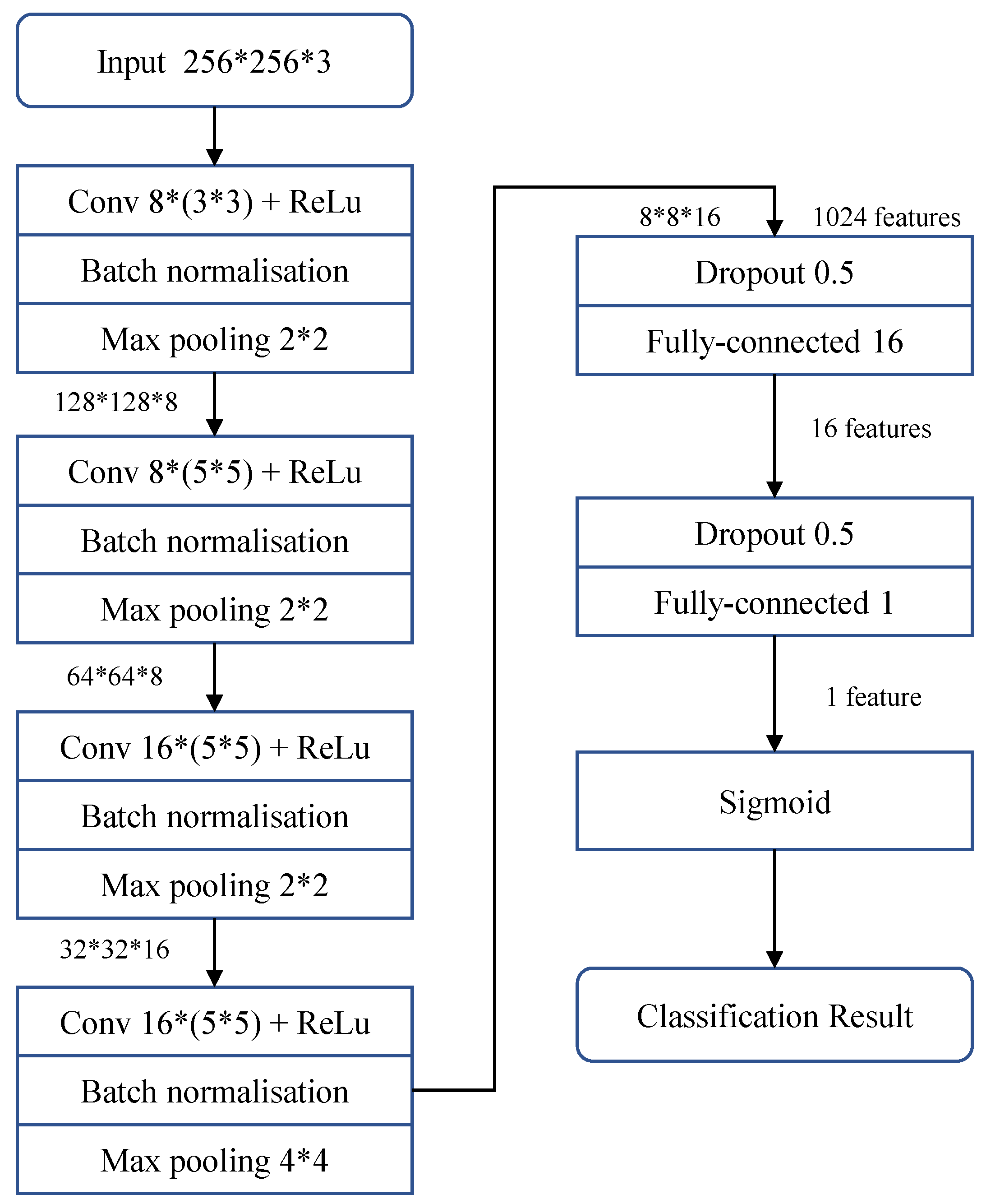
3. Proposed Method
3.1. Preprocessing Module
3.2. MesoNet
4. Experiments
4.1. Dataset
4.2. Experiment Settings
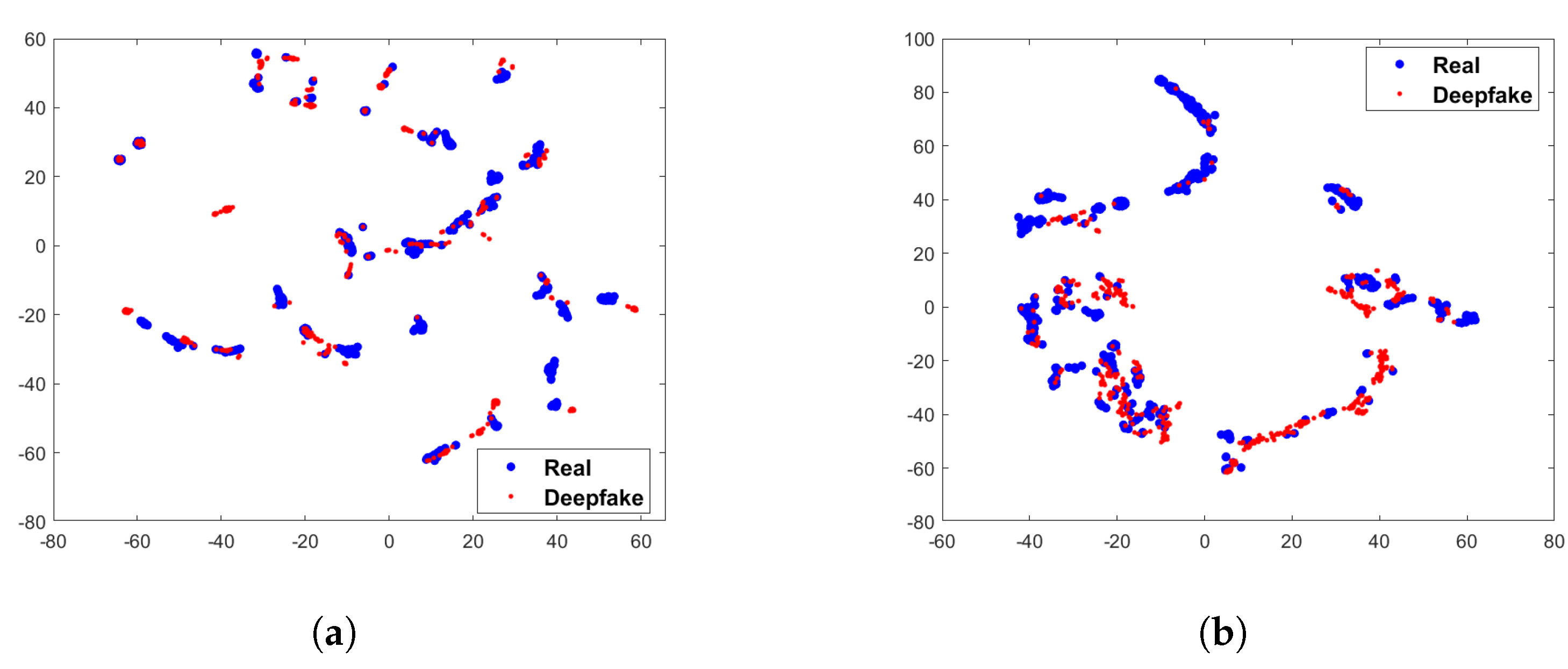
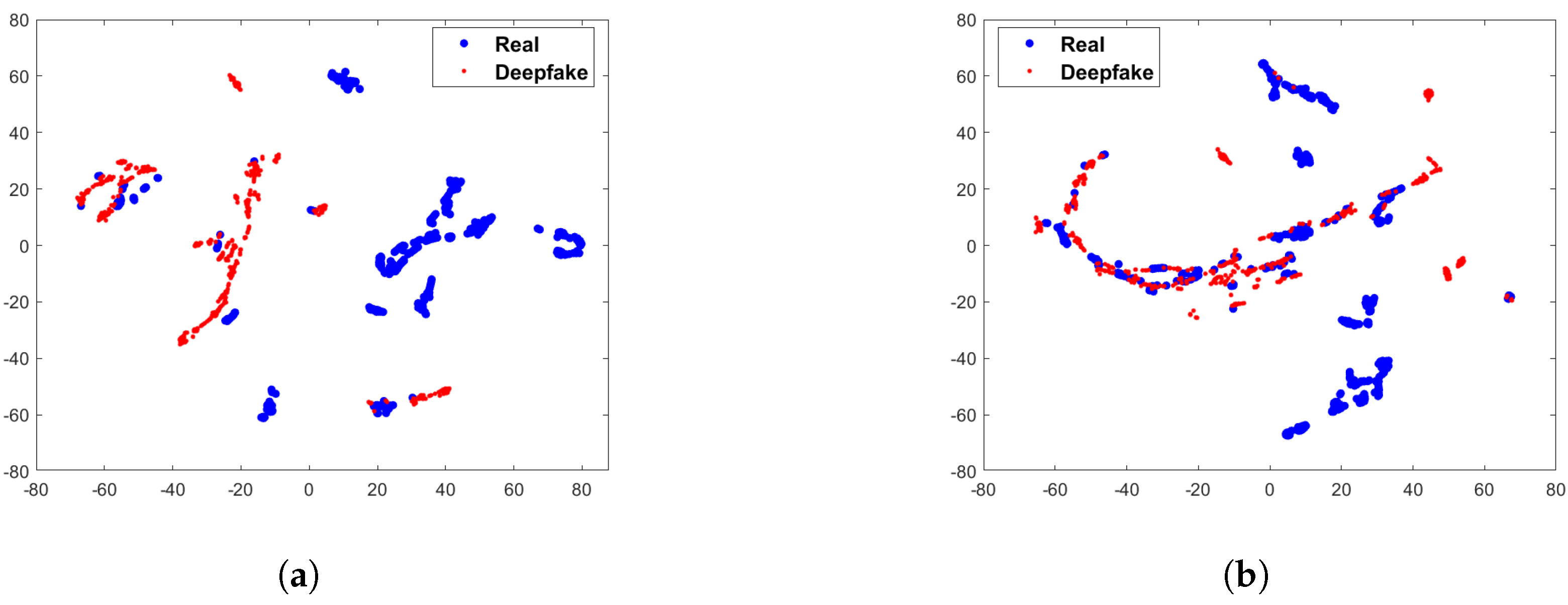
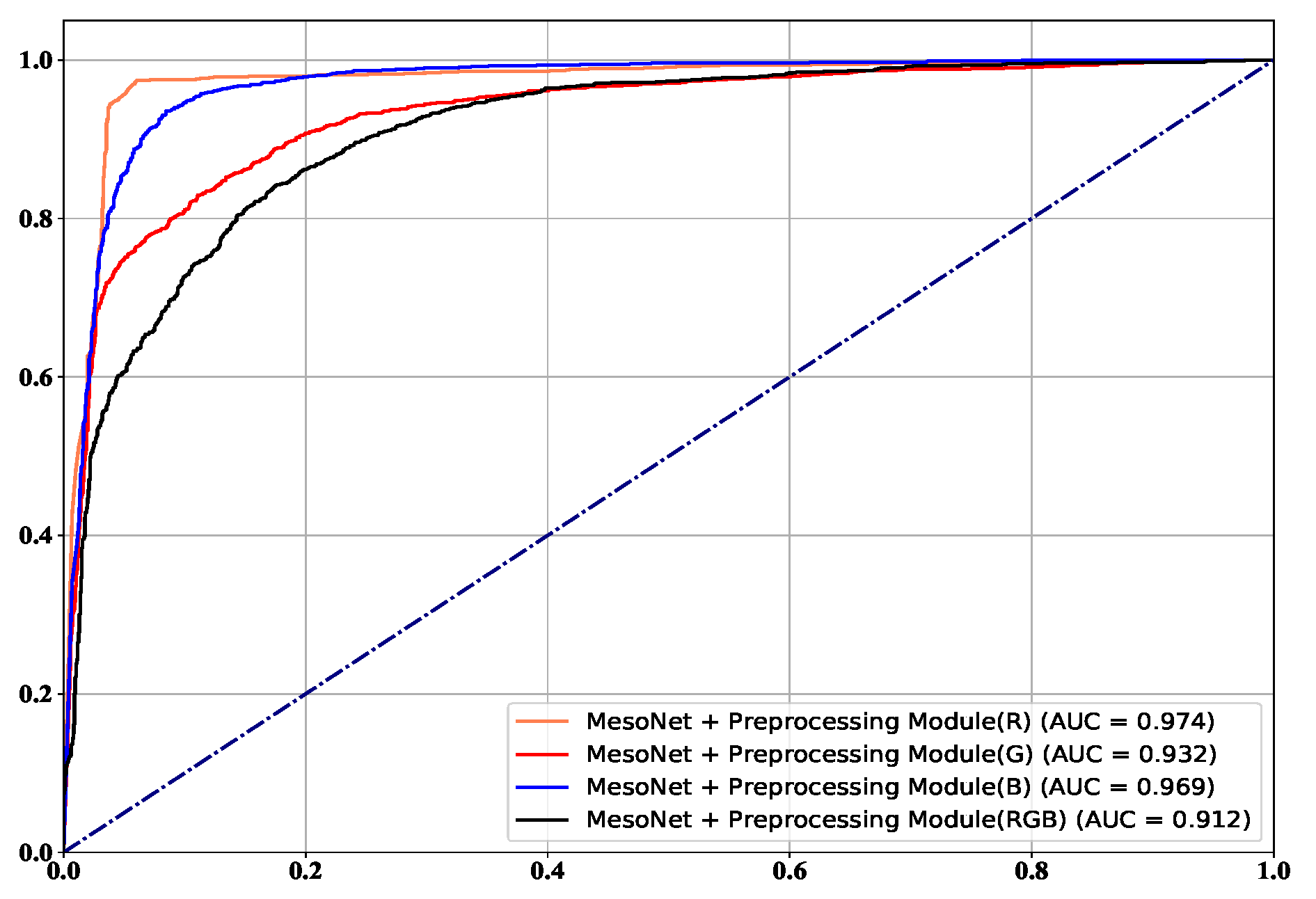
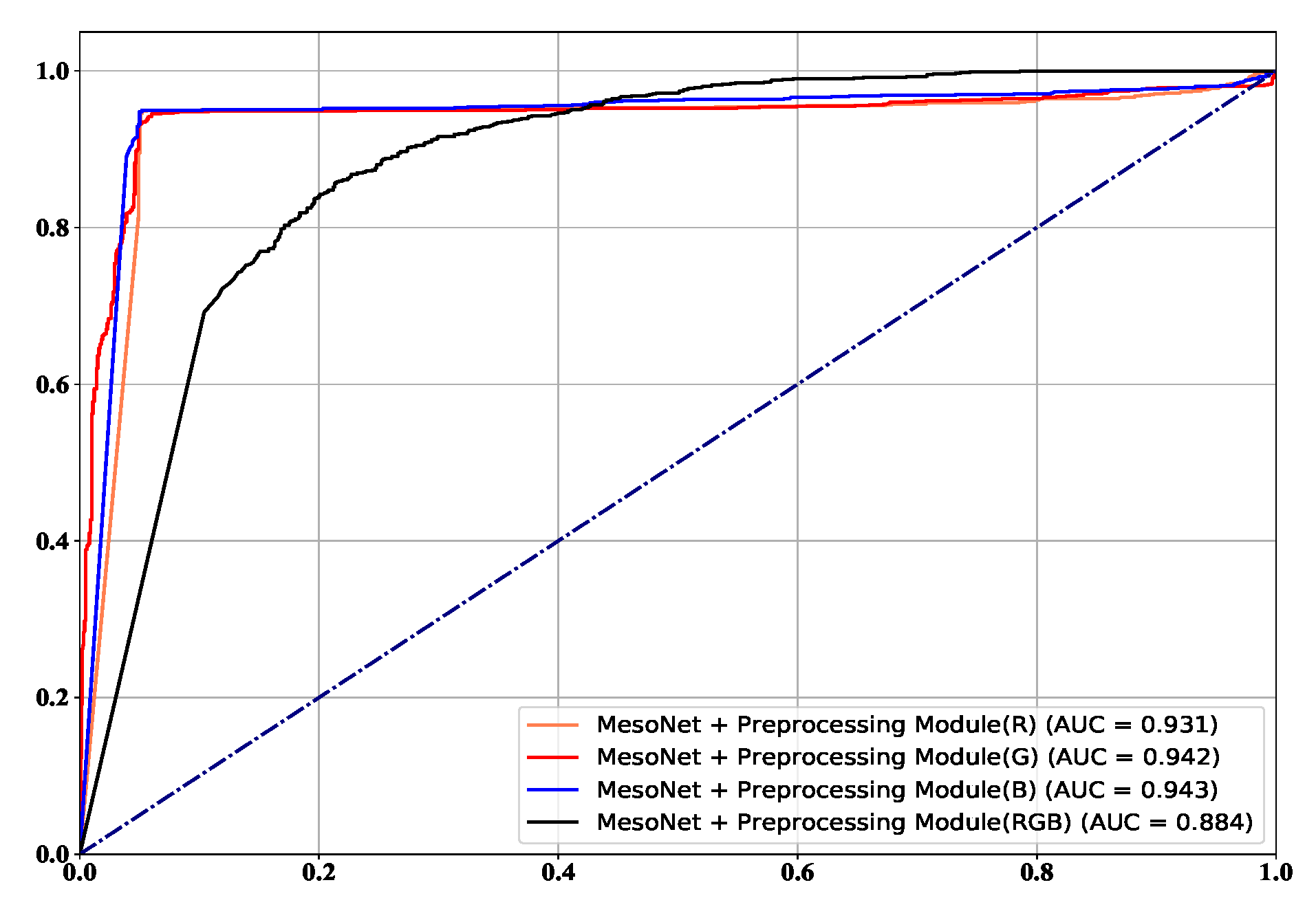
4.3. Ablation
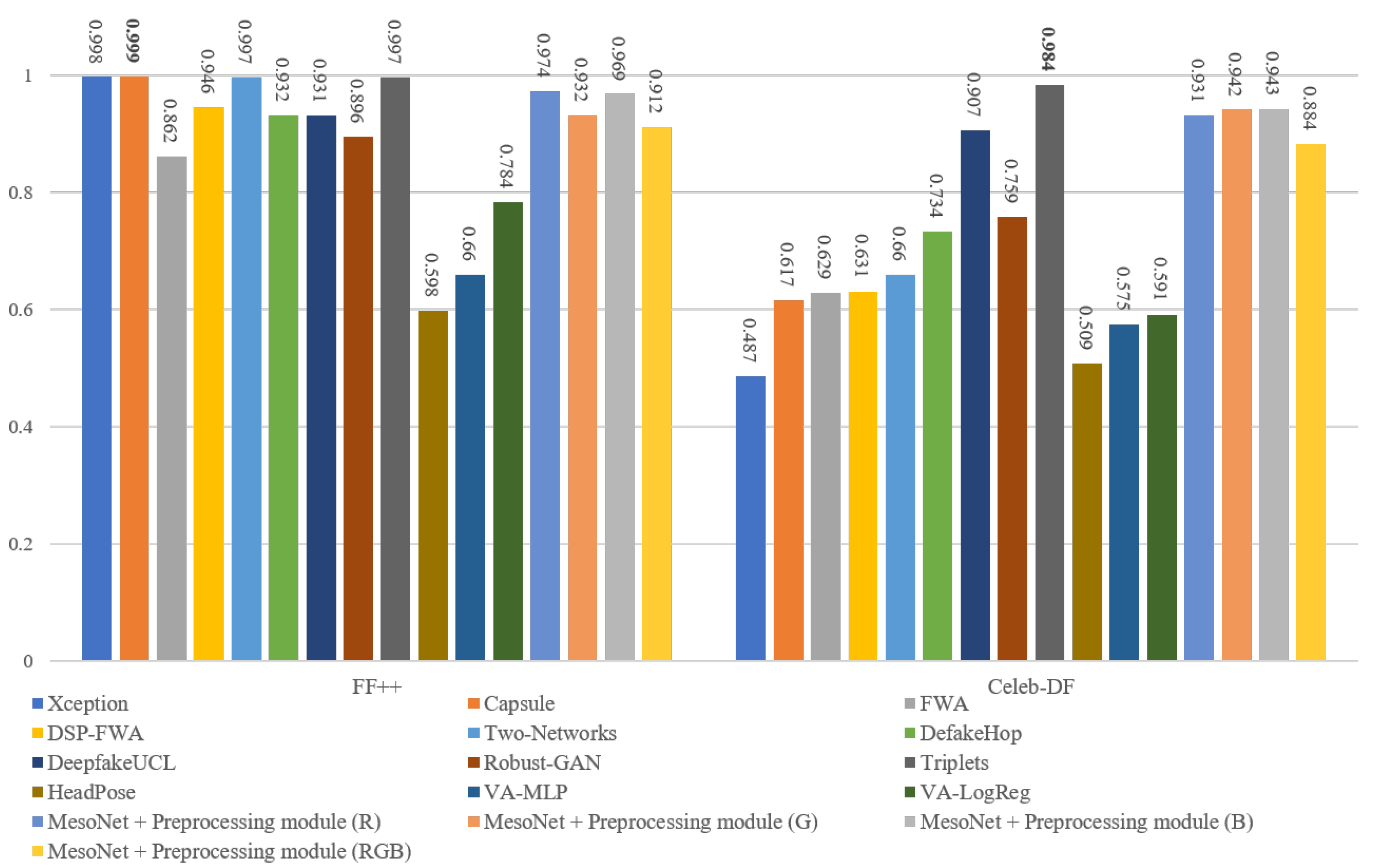
4.4. Comparison with Previous Methods
4.5. Detecting Different Types of Deepfake Videos
4.6. Robustness
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Khichi, M.; Yadav, R.K. A Threat of Deepfakes as a Weapon on Digital Platform and their Detection Methods. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–8. [Google Scholar]
- Yu, P.; Xia, Z.; Fei, J.; Lu, Y. A survey on deepfake video detection. IET Biom. 2021, 10, 607–624. [Google Scholar] [CrossRef]
- Lukáš, J.; Fridrich, J.; Goljan, M. Detecting digital image forgeries using sensor pattern noise. In Proceedings of the Security, Steganography, and Watermarking of Multimedia Contents VIII, San Jose, CA, USA, 15 January 2006; Volume 6072, pp. 362–372. [Google Scholar]
- Amerini, I.; Galteri, L.; Caldelli, R.; Del Bimbo, A. Deepfake video detection through optical flow based cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Koopman, M.; Rodriguez, A.M.; Geradts, Z. Detection of deepfake video manipulation. In Proceedings of the 20th Irish machine vision and image processing conference (IMVIP), Ulster University, Ulster, Northern Ireland, 29–31 August 2018. [Google Scholar]
- Lugstein, Florian and Baier, Simon and Bachinger, Gregor and Uhl, Andreas PRNU-based Deepfake Detection. In Proceedings of the 2021 ACM Workshop on Information Hiding and Multimedia Security, Virtual, 22–25 June 2021; pp. 7–12.
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging frequency analysis for deep fake image recognition. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 13–18 July 2020; pp. 3247–3258. [Google Scholar]
- Kharbat, F.F.; Elamsy, T.; Mahmoud, A.; Abdullah, R. Image feature detectors for deepfake video detection. In Proceedings of the 2019 IEEE/ACS 16th International Conference on Computer Systems and Applications (AICCSA), Abu Dhabi, United Arab Emirates, 3–7 November 2019; pp. 1–4. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the 2017 IEEE conference on computer vision and pattern recognition workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE international workshop on information forensics and security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1–11. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for DeepFake Forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Hu, J.; Liao, X.; Liang, J.; Zhou, W.; Qin, Z. FInfer: Frame Inference-based Deepfake Detection for High-Visual-Quality Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2022; 1–9, in press. [Google Scholar]
- Nirkin, Y.; Wolf, L.; Keller, Y.; Hassner, T. DeepFake detection based on discrepancies between faces and their context. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2185–2194. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent convolutional strategies for face manipulation detection in videos. Interfaces (GUI) 2019, 3, 80–87. [Google Scholar]
- Montserrat, D.M.; Hao, H.; Yarlagadda, S.K.; Baireddy, S.; Shao, R.; Horváth, J.; Bartusiak, E.; Yang, J.; Guera, D.; Zhu, F.; et al. Deepfakes detection with automatic face weighting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 668–669. [Google Scholar]
- Hu, J.; Liao, X.; Wang, W.; Qin, Z. Detecting Compressed Deepfake Videos in Social Networks Using Frame-Temporality Two-Stream Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1089–1102. [Google Scholar] [CrossRef]
- Agarwal, S.; Farid, H.; Gu, Y.; He, M.; Nagano, K.; Li, H. Protecting World Leaders Against Deep Fakes. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–21 June 2019; Volume 1. [Google Scholar]
- Wu, X.; Xie, Z.; Gao, Y.; Xiao, Y. Sstnet: Detecting manipulated faces through spatial, steganalysis and temporal features. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2952–2956. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-branch recurrent network for isolating deepfakes in videos. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 667–684. [Google Scholar]
- Li, H.; Li, B.; Tan, S.; Huang, J. Identification of Deep Network Generated Images Using Disparities in Color Components. Signal Process. 2020, 174, 107616. [Google Scholar] [CrossRef]
- Qiao, T.; Shi, R.; Luo, X.; Xu, M.; Zheng, N.; Wu, Y. Statistical model-based detector via texture weight map: Application in re-sampling authentication. IEEE Trans. Multimed. 2018, 21, 1077–1092. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Chen, H.S.; Rouhsedaghat, M.; Ghani, H.; Hu, S.; You, S.; Kuo, C.C.J. DefakeHop: A Light-Weight High-Performance Deepfake Detector. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Fung, S.; Lu, X.; Zhang, C.; Li, C.T. DeepfakeUCL: Deepfake Detection via Unsupervised Contrastive Learning. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Chen, B.; Liu, X.; Zheng, Y.; Zhao, G.; Shi, Y.Q. A robust GAN-generated face detection method based on dual-color spaces and an improved Xception. IEEE Trans. Circuits Syst. Video Technol. 2021. [Google Scholar] [CrossRef]
- Kumar, A.; Bhavsar, A.; Verma, R. Detecting deepfakes with metric learning. In Proceedings of the 2020 8th international workshop on biometrics and forensics (IWBF), Porto, Portugal, 29–30 April 2020; pp. 1–6. [Google Scholar]
- LIY, C.M.; InIctuOculi, L. Exposing AI Created Fake Videos by Detecting Eye Blinking. In Proceedings of the 2018 IEEE InterG national Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018. [Google Scholar]
- Dufour, N.; Gully, A. Contributing data to deepfake detection research. Google AI Blog 2019, 1, 3. [Google Scholar]
- Fridrich, J.; Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef] [Green Version]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Recasting residual-based local descriptors as convolutional neural networks: An application to image forgery detection. In Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security, Philadelphia, PA, USA, 20–22 June 2017; pp. 159–164. [Google Scholar]
- Bayar, B.; Stamm, M.C. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Vigo, Spain, 20–22 June 2016; pp. 5–10. [Google Scholar]
- Rahmouni, N.; Nozick, V.; Yamagishi, J.; Echizen, I. Distinguishing computer graphics from natural images using convolution neural networks. In Proceedings of the 2017 IEEE Workshop on Information Forensics and Security (WIFS), Rennes, France, 4–7 December 2017; pp. 1–6. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Color Channel | FaceForensics++ | Celeb-DF | ||
|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | ||
| MesoNet | R | 0.912 | 0.922 | 0.711 | 0.831 |
| G | 0.884 | 0.891 | 0.645 | 0.747 | |
| B | 0.893 | 0.917 | 0.755 | 0.834 | |
| RGB | 0.885 | 0.902 | 0.731 | 0.837 | |
| MesoNet + Preprocessing module | R | 0.941 | 0.974 | 0.936 | 0.931 |
| G | 0.896 | 0.932 | 0.941 | 0.942 | |
| B | 0.939 | 0.969 | 0.949 | 0.943 | |
| RGB | 0.916 | 0.912 | 0.899 | 0.884 | |
| Type | R | G | B | |||
|---|---|---|---|---|---|---|
| ACC | AUC | ACC | AUC | ACC | AUC | |
| Deepfakes | 0.941 | 0.974 | 0.896 | 0.932 | 0.939 | 0.969 |
| FaceSwap | 0.951 | 0.959 | 0.849 | 0.914 | 0.857 | 0.923 |
| Face2Face | 0.969 | 0.974 | 0.885 | 0.956 | 0.865 | 0.939 |
| NeuralTexture | 0.921 | 0.942 | 0.937 | 0.960 | 0.932 | 0.963 |
| Method | UADFV | FF++ | Celeb-DF | DFD |
|---|---|---|---|---|
| MesoNet+Preprocessing module(R) | 0.948 | 0.974 | 0.931 | 0.816 |
| MesoNet+Preprocessing module(G) | 0.965 | 0.932 | 0.942 | 0.828 |
| MesoNet+Preprocessing module(B) | 0.952 | 0.969 | 0.943 | 0.843 |
| Methods | c0 | c23 | c40 |
|---|---|---|---|
| Steg.Features [38] | 97.63% | 70.97% | 55.98% |
| MesoNet [11] | 95.23% | 83.10% | 70.47% |
| Cozzolino et al. [39] | 98.57% | 78.45% | 58.69% |
| Bayar et al. [40] | 98.75% | 82.97% | 66.84% |
| Rahmouni et al. [41] | 97.03% | 79.08% | 61.18% |
| MesoNet+Preprocessing module | 94.12% | 91.97% | 88.51% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, Z.; Qiao, T.; Xu, M.; Wu, X.; Han, L.; Chen, Y. Deepfake Video Detection Based on MesoNet with Preprocessing Module. Symmetry 2022, 14, 939. https://doi.org/10.3390/sym14050939
Xia Z, Qiao T, Xu M, Wu X, Han L, Chen Y. Deepfake Video Detection Based on MesoNet with Preprocessing Module. Symmetry. 2022; 14(5):939. https://doi.org/10.3390/sym14050939
Chicago/Turabian StyleXia, Zhiming, Tong Qiao, Ming Xu, Xiaoshuai Wu, Li Han, and Yunzhi Chen. 2022. "Deepfake Video Detection Based on MesoNet with Preprocessing Module" Symmetry 14, no. 5: 939. https://doi.org/10.3390/sym14050939
APA StyleXia, Z., Qiao, T., Xu, M., Wu, X., Han, L., & Chen, Y. (2022). Deepfake Video Detection Based on MesoNet with Preprocessing Module. Symmetry, 14(5), 939. https://doi.org/10.3390/sym14050939