
Image Segmentation via Multiscale Perceptual Grouping

Abstract
:1. Introduction
2. Related Works
3. The Proposed Model
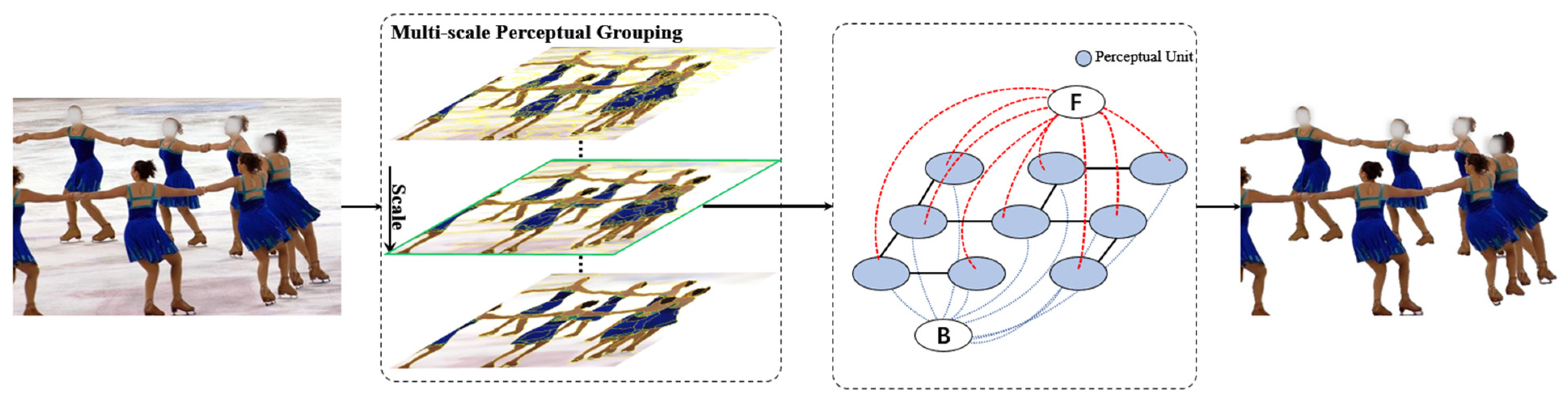
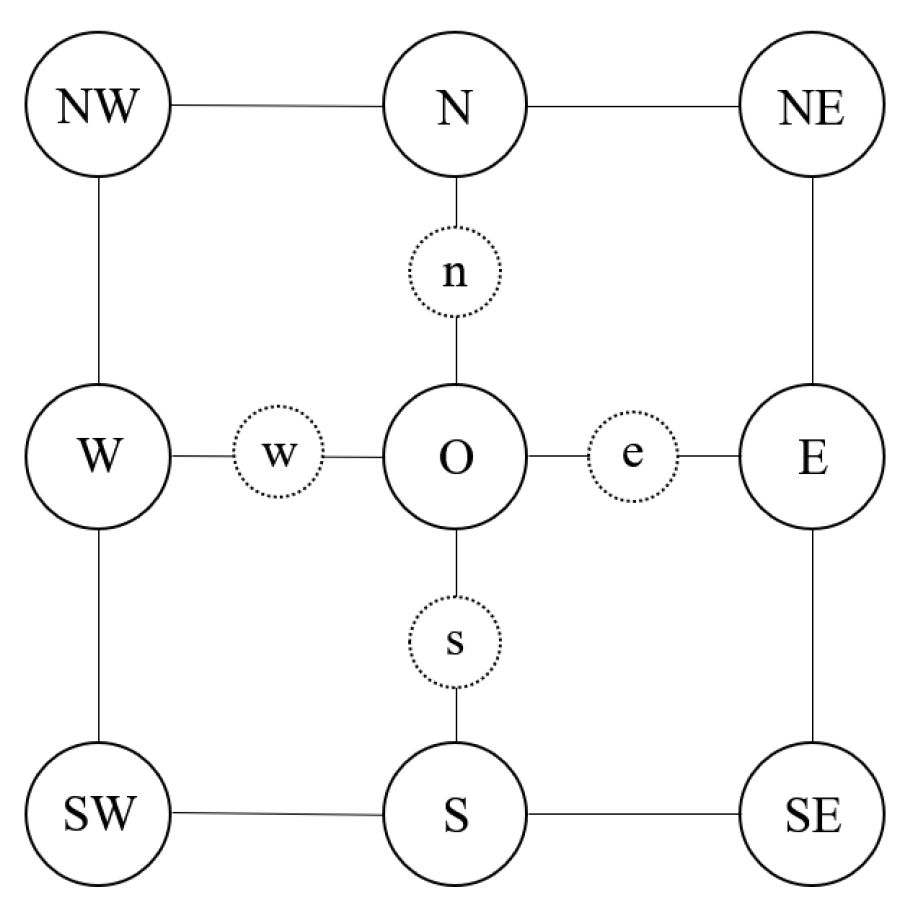
3.1. Multiscale Perceptual Grouping
| Algorithm 1: Require: the initial image and the threshold . |
| 1: Initialize and . |
| 2. Divide the image into perceptual units by using the watershed method [27]. |
| 3: Compute the smoothed image using Equation (7). |
| 4: Divide the smoothed image into perceptual units by using the watershed method [27]. |
| 5: If the larger than , go back to Step 3. |
| 6. Output the perceptual units . |
3.2. Perceptual-Unit-Based Graph-Cut Method
| Algorithm 2: Require: and using bounding box , the perceptual units s, and the threshold of combination . |
| 1: Initialize x. |
| 2: Construct each perceptual unit as a Gaussian distribution. |
| 3: Compute the term using Equation (15). |
| 4: Estimate the number of background and foreground regions by combining s with the threshold . |
| 5: Estimate the initial using EM. |
| 6: N = 1 |
| 7: For N ≤ 5: |
| 8: Update , given the current using the graph cut. |
| 9: Update , given the current using EM |
| 10: Compute the term using Equation (17) for s. |
| 11: End. |
| 12: Output the foreground . |
4. Numerical Experiments
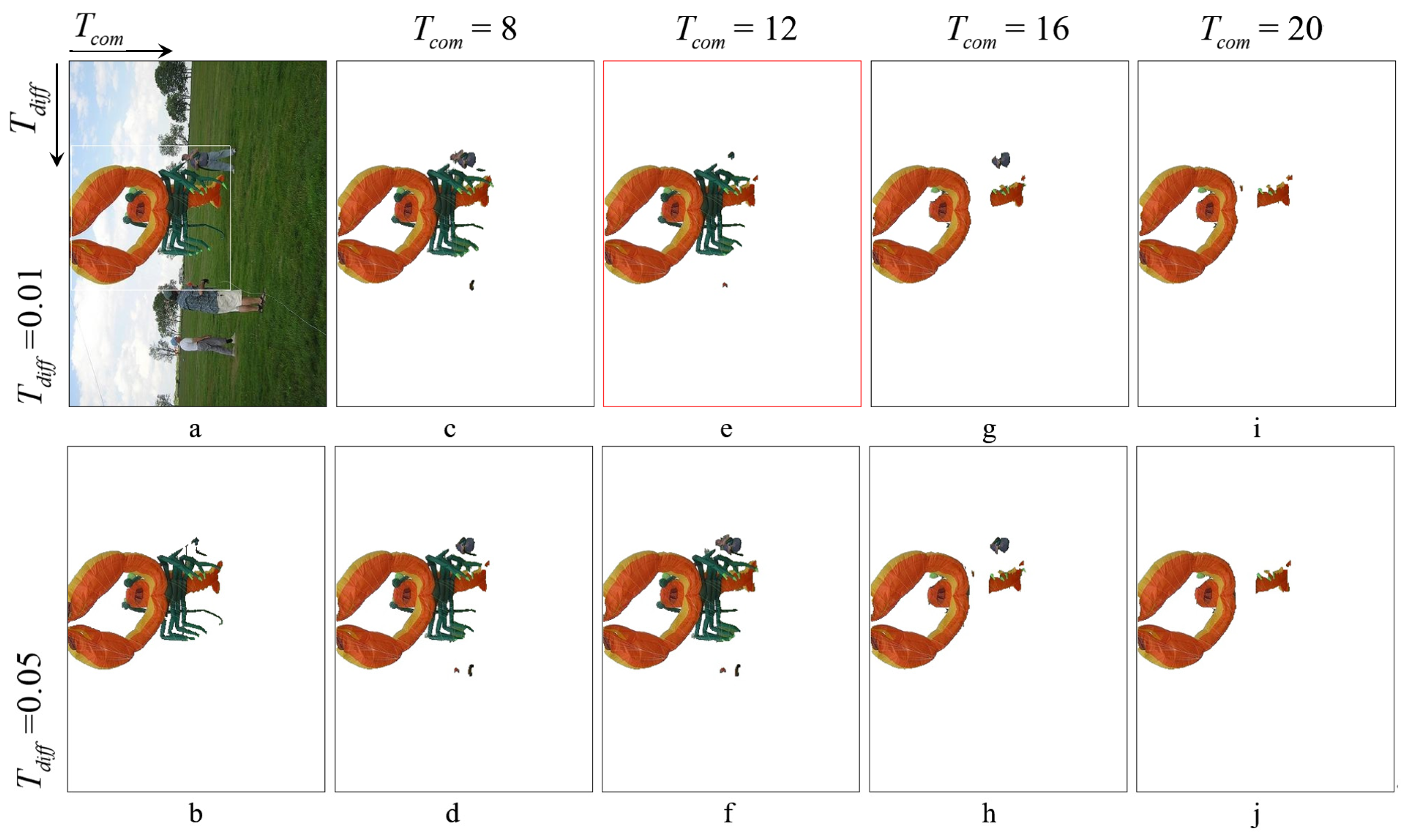
4.1. Parameter Discussion
4.2. Comparison and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

References
- Wang, L.; Chen, G.; Shi, D.; Chang, Y.; Chan, S.; Pu, J.; Yang, X. Active contours driven by edge entropy fitting energy for image segmentation. Signal Process. 2018, 149, 27–35. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Wang, L.; Deng, S.; Zhou, C. Color image segmentation using adaptive hierarchical-histogram thresholding. PLoS ONE 2020, 15, e0226345. [Google Scholar] [CrossRef] [PubMed]
- Tong, J.; Zhao, Y.; Zhang, P.; Chen, L.; Jiang, L. MRI brain tumor segmentation based on texture features and kernel sparse coding. Biomed. Signal Process. Control 2019, 47, 387–392. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. arXiv 2021, arXiv:2001.05566. [Google Scholar] [CrossRef]
- Li, Y.; Feng, X. A multiscale image segmentation method. Pattern Recognit. 2016, 52, 332–345. [Google Scholar] [CrossRef]
- Tang, M.; Gorelick, L.; Veksler, O.; Boykov, Y. GrabCut in One Cut. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV 2013), Sydney, Australia, 1–8 December 2013; pp. 1769–17761. [Google Scholar] [CrossRef]
- Tunga, P.P.; Singh, V. Extraction and description of tumour region from the brain MRI image using segmentation techniques. In Proceedings of the 2016 IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 20–21 May 2016; pp. 1571–1576. [Google Scholar]
- Kumar, S.; Pant, M.; Kumar, M.; Dutt, A. Colour image segmentation with histogram and homogeneity histogram difference using evolutionary algorithms. Int. J. Mach. Learn. Cybern. 2018, 9, 163–183. [Google Scholar] [CrossRef]
- Xu, N.; Price, B.; Cohen, S.; Yang, J.; Huang, T. Deep grabcut for object selection. arXiv 2017, arXiv:1707.00243. [Google Scholar]
- Grady, L. Random walks for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [Green Version]
- Tsai, A.; Yezzi, A.; Willsky, A.S. Curve evolution implementation of the Mumford-Shah functional for image segmentation, denoising, interpolation, and magnification. IEEE Trans. Image Process. 2001, 10, 1169–1186. [Google Scholar] [CrossRef] [Green Version]
- Boykov, Y.Y.; Jolly, M.P. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. In Proceedings of the eighth IEEE international conference on computer vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume 1, pp. 105–112. [Google Scholar]
- Lu, Y.; Chen, Y.; Zhao, D.; Chen, J. Graph-FCN for image semantic segmentation. In International Symposium on Neural Networks; Springer: Cham, Switzerland, 2019; pp. 97–105. [Google Scholar]
- Jesson, A.; Arbel, T. Brain tumor segmentation using a 3D FCN with multi-scale loss. In International MICCAI Brainlesion Workshop; Springer: Cham, Switzerland, 2017; pp. 392–402. [Google Scholar]
- Villa, M.; Dardenne, G.; Nasan, M.; Letissier, H.; Hamitouche, C.; Stindel, E. FCN-based approach for the automatic segmentation of bone surfaces in ultrasound images. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 1707–1716. [Google Scholar] [CrossRef] [PubMed]
- Tang, W.; Zou, D.; Yang, S.; Shi, J.; Dan, J.; Song, G. A two-stage approach for automatic liver segmentation with Faster R-CNN and DeepLab. Neural Comput. Appl. 2020, 32, 6769–6778. [Google Scholar] [CrossRef]
- Yeo, S.Y.; Xie, X.; Sazonov, I.; Nithiarasu, P. Segmentation of biomedical images using active contour model with robust image feature and shape prior. Int. J. Numer. Methods Biomed. Eng. 2014, 30, 232–248. [Google Scholar] [CrossRef] [Green Version]
- Chan, T.F.; Vese, L.A. Active contours without edges. IEEE Trans. Image Process. 2001, 10, 266–277. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Liu, F.; Liu, S. Active contours driven by normalized local image fitting energy. Concurr. Comput. Pract. Exp. 2014, 26, 1200–1214. [Google Scholar] [CrossRef]
- Miao, J.; Huang, T.Z.; Zhou, X.; Wang, Y.; Liu, J. Image segmentation based on an active contour model of partial image restoration with local cosine fitting energy. Inf. Sci. 2018, 447, 52–71. [Google Scholar] [CrossRef]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut” interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. TOG 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Wu, S.; Nakao, M.; Matsuda, T. SuperCut: Superpixel based foreground extraction with loose bounding boxes in one cutting. IEEE Signal Process. Lett. 2017, 24, 1803–1807. [Google Scholar] [CrossRef]
- Chan, T.F.; Osher, S.; Shen, J.H. The Digital TV Filter and Nonlinear Denoising. IEEE Trans. Image Process. 2001, 10, 231–241. [Google Scholar] [CrossRef] [Green Version]
- Antman, S.S.; Marsden, J.E.; Sirovich, L. Mathematical Problems in Image Processing: Partical Differential Equations and the Calculus of Variations; Springer Science Business Media, LLC: Berlin/Heidelberg, Germany, 2006; pp. 70–72. [Google Scholar]
- Vincent, L.; Soille, P. Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef] [Green Version]
- Batra, D.; Kowdle, A.; Parikh, D.; Luo, J.; Chen, T. icoseg: Interactive co-segmentation with intelligent scribble guidance. In Proceedings of the 2010 IEEE computer society conference on computer vision and pattern recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3169–3176. [Google Scholar]
- Pont-Tuset, P.; Marques, F. Supervised Evaluation of Image Segmentation and Object Proposal Techniques. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1465–1478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Rijsbergen, C. Information retrieval: Theory and practice. In Proceedings of the Joint IBM/University of Newcastle upon Tyne Seminar on Data Base Systems, Newcastle upon Tyne, UK, 4–7 September 1979; pp. 1–14. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | IOU | F-Measure | ||||
|---|---|---|---|---|---|---|
| Min | Mean | Max | Min | Mean | Max | |
| The CMU-Cornell iCoseg database | ||||||
| This method | 0.328 | 0.790 | 0.995 | 0.579 | 0.882 | 0.997 |
| SuperCut [24] | 0.253 | 0.764 | 0.994 | 0.540 | 0.841 | 0.997 |
| Deep GrabCut [11] | 0.254 | 0.752 | 0.984 | 0.537 | 0.836 | 0.992 |
| GrabCut [23] | 0.221 | 0.763 | 0.996 | 0.525 | 0.841 | 0.998 |
| Multiscale level-set method [7] | 0.0 | 0.599 | 0.975 | 0.200 | 0.725 | 0.987 |
| Methods | Figure 3a | Figure 3b | Figure 3c | Figure 3d | Figure 3e |
|---|---|---|---|---|---|
| 332 × 500 | 500 × 332 | 500 × 372 | 500 × 372 | 500 × 372 | |
| This method | |||||
| Precision | 0.966 | 0.995 | 0.930 | 0.959 | 0.936 |
| Recall | 0.993 | 0.965 | 0.984 | 0.981 | 0.991 |
| F-measure | 0.979 | 0.980 | 0.957 | 0.970 | 0.963 |
| IOU | 0.959 | 0.960 | 0.917 | 0.941 | 0.928 |
| Computational cost(s) | 2.138 | 12.39 | 12.68 | 10.35 | 13.80 |
| SuperCut [24] | |||||
| Precision | 0.974 | 0.986 | 0.919 | 0.830 | 0.917 |
| Recall | 0.998 | 0.972 | 0.978 | 0.983 | 0.989 |
| F-measure | 0.986 | 0.979 | 0.947 | 0.900 | 0.952 |
| IOU | 0.972 | 0.959 | 0.899 | 0.818 | 0.908 |
| Computational cost(s) | 4.950 | 9.442 | 12.29 | 5.665 | 9.609 |
| Deep GrabCut [11] | |||||
| Precision | 0.927 | 0.963 | 0.830 | 0.779 | 0.969 |
| Recall | 0.999 | 0.995 | 0.968 | 0.991 | 0.848 |
| F-measure | 0.961 | 0.979 | 0.894 | 0.872 | 0.904 |
| IOU | 0.926 | 0.958 | 0.808 | 0.773 | 0.825 |
| Computational cost(s) | 3.215 | 3.175 | 3.501 | 3.447 | 2.993 |
| GrabCut [23] | |||||
| Precision | 0.968 | 0.962 | 0.506 | 0.813 | 0.911 |
| Recall | 0.999 | 0.988 | 0.991 | 0.992 | 0.994 |
| F-measure | 0.978 | 0.975 | 0.670 | 0.894 | 0.951 |
| IOU | 0.959 | 0.951 | 0.504 | 0.808 | 0.907 |
| Computational cost(s) | 3.610 | 8.001 | 10.94 | 4.279 | 8.359 |
| The multiscale level-set method [7] | |||||
| Precision | 0.993 | 0.611 | 0.750 | 0.693 | 0.812 |
| Recall | 0.973 | 0.976 | 0.844 | 0.949 | 0.956 |
| F-measure | 0.983 | 0.752 | 0.794 | 0.801 | 0.878 |
| IOU | 0.966 | 0.602 | 0.659 | 0.668 | 0.783 |
| Computational cost(s) | 4.116 | 2.106 | 7.132 | 7.250 | 7.074 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, B.; He, K. Image Segmentation via Multiscale Perceptual Grouping. Symmetry 2022, 14, 1076. https://doi.org/10.3390/sym14061076
Feng B, He K. Image Segmentation via Multiscale Perceptual Grouping. Symmetry. 2022; 14(6):1076. https://doi.org/10.3390/sym14061076
Chicago/Turabian StyleFeng, Ben, and Kun He. 2022. "Image Segmentation via Multiscale Perceptual Grouping" Symmetry 14, no. 6: 1076. https://doi.org/10.3390/sym14061076
APA StyleFeng, B., & He, K. (2022). Image Segmentation via Multiscale Perceptual Grouping. Symmetry, 14(6), 1076. https://doi.org/10.3390/sym14061076