1. Introduction
Internet of Things (IoT) is a network composed of many devices, such as physical gadgets, domestic appliances and microcontrol equipment. A large number of resource-constrained embedded devices are used in the IoT. The data generated by these devices cannot use traditional encryption algorithms that require large computing resources to ensure confidentiality. Therefore, lightweight encryption algorithms are required to ensure data security in resource-constrained devices. The existing blockciphers have limitations on block length. To design an encryption algorithm that accepts plaintext input of any length without selecting an encryption mode is more suitable for the IoT with diverse data, limited computing power and storage space.
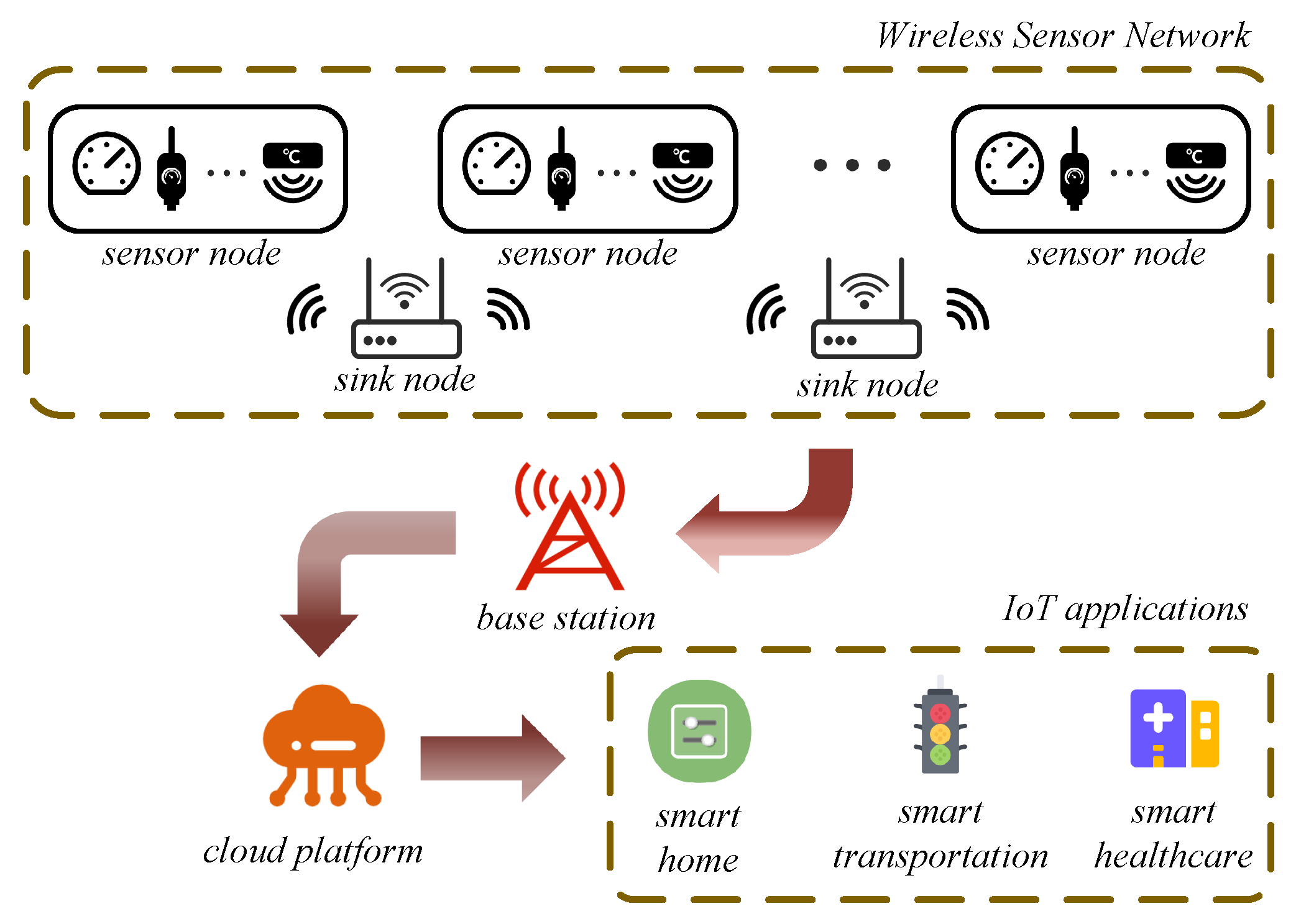
The structure of IoT can be divided into the perception layer, the network layer and the application layer. As shown in
Figure 1, wireless sensor networks (WSNs) play an important role in the perception layer. This has already been applied in many areas of the IoT, such as smart transportation, smart homes and smart healthcare. WSNs collect, process and transmit the information of the perceived area through a large number of sensor nodes.
For example, in a smart home, sensor nodes in a WSN collect the private data of the house and transmit them to the sink node. Sink nodes upload the sensing information to an IoT cloud server. Users can download and view private family data by using mobile phones when they leave home. Data containing personal privacy may be transmitted through an untrusted network layer or stored in untrusted cloud services. The confidentiality of sensitive data is potentially subject to cyber attacks [
1,
2]. In addition, the perception layer also has the risk of being attacked [
3]. Hence, the perception layer requires security measures for information acquisition in the IoT [
4].
However, the cost and performance of protecting data in the perception layer are critical issues that must be considered in combination. Due to the limited computing capabilities and power of components in WSNs, ensuring the communication security of WSNs requires high performance costs [
5]. For example, the main frequency of the remote terminal unit (RTU) used as the sink node in smart transportation is only 48 Mhz, and the memory is only 1 M byte.
Standard encryption algorithms used in RTU can provide high security, such as symmetric encryption algorithm (e.g., AES) and asymmetric encryption algorithm (e.g., Elliptic Curve Cryptography). Since these algorithms involve a great deal of computation, the limited processing and storage capacity of sensors cannot effectively support them. This fact drives the demand for more secure, less computational and more flexible encryption algorithms.
A variety of lightweight symmetric block ciphers have been designed. Lightweight symmetric cryptography in resource-constrained devices is a hotspot in current research of information safety [
6]. However, existing lightweight symmetric cryptography research mainly focuses on the optimization of single-block encryption. The processing methods between blocks with a large impact on efficiency and security have not been emphasized. The traditional processing methods for encrypting a long message are composed of encryption modes and length-preserving-encryption algorithms.
The classic encryption modes include Electronic Codebook (ECB), Cipher Block Chaining (CBC), Cipher Feedback (CFB), Output Feedback (OFB) and Counter mode (CTR) in the DES modes of operations [
7]. Generally, the bit length of plaintext is not an integer multiple of the block length. The ciphertext is longer than the plaintext if a mode similar to ECB is used. It means that more storage and transmit space is needed to temporarily store these data on embedded devices. In addition, it cannot meet the existing security requirements if the CTR mode is used.
The classic length-preserving-encryption algorithms include Arbitrary Block Length Mode (ABL) [
8], a Variable-Input-Length Enciphering Mode (HCTR) [
9] and the Extended Codebook Mode (XCB) [
10], which allow devices to store the ciphertext without additional storage space. For example, XCB can be used to encrypt an arbitrary block length and provide the best possible security in the light of disk-block encryption. However, such methods are devised for common devices but not resource-constrained devices.
Therefore, the problems come from two aspects. One is how to ensure that as much data as possible can be stored on the resource-constrained devices, the other is how to make the encryption algorithm for processing large amounts of data run efficiently in such devices. Focusing on these questions, we design a scheme that uses length-preserving-encryption algorithms to provide a variety of optional input lengths and reduce pressure on data transmission in the IoT. In addition, by converting the existing length-preserving-encryption algorithm, a lightweight version can be obtained, which reduces the consumption of computing resources.
We propose a lightweight length-preserving symmetric enciphering algorithm (LILP), which is based on the Lai–Massey [
11] structure. LILP accepts any plaintext whose length is greater than or equal to the length of two blocks. LILP consists of a compression function, a counter mode (CTR), whitening key additions and S-boxes. Specifically, the main contributions of LILP in this paper are as follows.
The decryption process of LILP can reuse its encryption process because it uses symmetric structures and involuntary components.
A lightweight compression function (LCF) is carefully designed for running on 32-bit platforms, which gives LILP an advantage over existing length-preserving-encryption algorithms in terms of speed and cost.
LILP can accept different bit-level input sizes so that the caller has flexibility in choosing the size of the encrypted data.
The remainder of this paper is organized as follows. In
Section 2, we introduce the LILP. In
Section 3, the security of LILP is discussed. In
Section 4, we present the software implementation results of LILP. Finally, we conclude our work in
Section 5.
2. The Proposed Encryption Algorithm
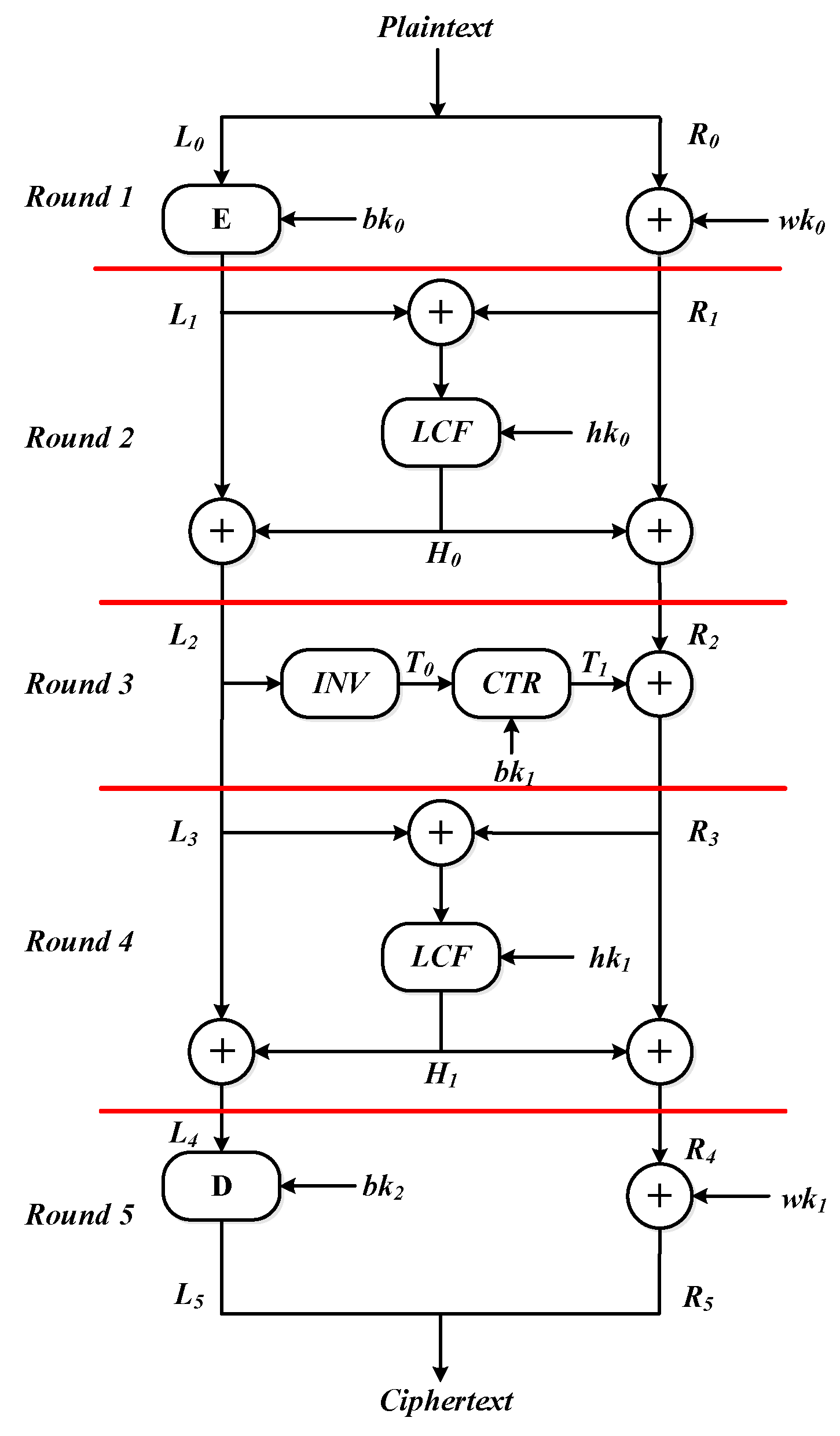
LILP is a lightweight encryption algorithm that generates multiple subkeys from one master key for use by various components. The length of the master key is designed as double the key size of an underlying block encryption algorithm. LILP uses a symmetrical structure, which can be divided into five layers in total—namely, two XOR layers, two Lai–Massey layers and a CTR layer.
Figure 2 shows the encryption of LILP.
2.1. Encryption Algorithm
The description of the notation used in the proposed LILP is listed in
Table 1. LILP makes use of a pair of block encryption and decryption algorithms and a specific compression function
H. Suppose that the blockcipher is
, then
is
where
. Algorithm 1 shows
in detail.
| Algorithm 1 The proposed LILP encryption |
Input:
Output: C- 1:
- 2:
- 3:
- 4:
- 5:
- 6:
- 7:
- 8:
- 9:
- 10:
- 11:
return:
|
We provide a concrete instance that takes the Piccolo [
12] block cipher as the underling block encryption algorithm. A variable-input-length block cipher that accepts message sizes larger than or equal to 128 bits is created. Piccolo is a variant of a generalized Feistel network. It supports 64-bit block size with 80-bit and 128-bit keys through 25 and 31 rounds, respectively.
The 80-bit key version of Piccolo was chosen in our design. Thus, a 160-bit master key, twice key size of Piccolo, is used to generate a series of subkeys. The length of plaintext is at least 128 bits. A plaintext P is divided into two parts and , in which is the first 64 bits of the plaintext while is the remainder of the plaintext. Then, five layers of operations continue to perform.
In the first layer,
is obtained from running a block encryption on
.
is obtained by XOR
with whitening key
at the same time. The whitening key
is obtained by iteratively using Piccolo with reduced rounds. The detailed process is expressed by the formula as follows:
The Lai–Massey structure is applied in the second layer, which is characterized by involution.
is first filled by padding zero bits. The length of
after filling is equal to the length of
. Then, a result of XOR is input into
. Assuming that the value generated by compression function is
, then
and
is XOR with
and
, respectively. An operation similar to filling
needs to be performed on
before the XOR operation with
. The process of the second layer is represented by the formula as follows:
In the third layer, a initial vector
is formed by inputting
into the nonlinear component
. It refers to sixteen identical and involutive S-boxes. Enough intermediate state
is formed after
is input into the
layer. A partial input
of the next round is obtained from
and
. The detailed process of the third layer is shown by the formula as follows:
The operation in the fourth layer is similar to the second layer. The XOR of left and right parts is input into the compression function to obtain a 64-bit compression value. The value is mixed into the left and right parts. The process of the fourth layer is expressed by the formula as follows:
The block decryption algorithm
D and whitening key addition are used in the fifth layer. The output of the block decryption algorithm and the results of XORing
with whitening key
are spliced together to obtain the final ciphertext
C. The process of the last layer is formulated as follows:
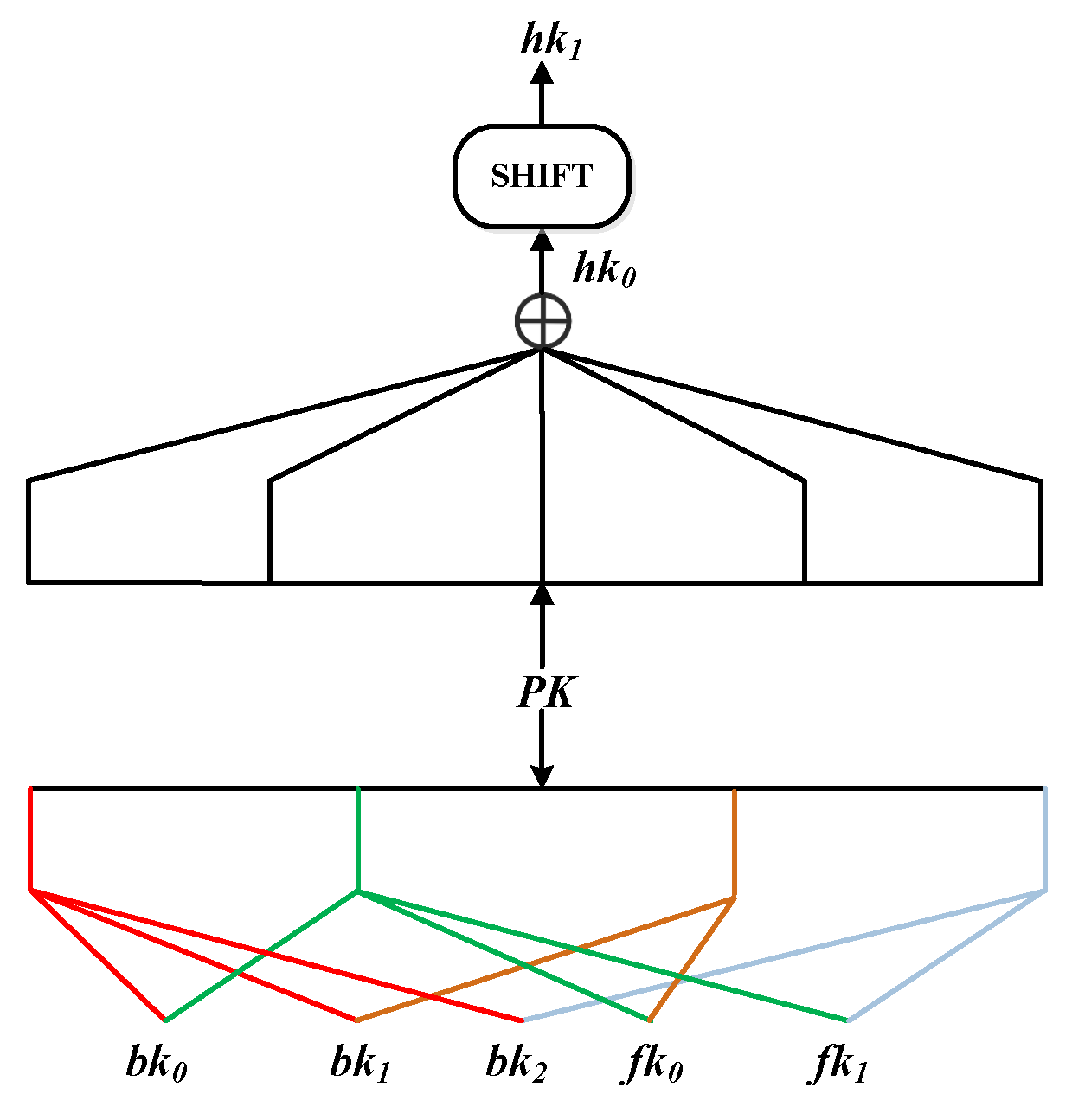
2.2. Key Schedule
As shown in
Figure 3, the key schedule divides a 160-bit primary key
into four 40-bit subkeys
, which provides three
and two
as follows:
In order to generate the keys required for the compression function,
is denoted as five 32-bit subkeys
as
. Then, the generation method of
and
is expressed by the formula as follows:
A variable-length whitening key is generated by using a reduced-round block cipher . The so-called reduced-round block cipher refers to a block cipher that reduces the number of encryption rounds. can be divided into m groups according to 64 bits as a group. The last group, if less than 64 bits, are also counted as a group. A constant block is encrypted by using the reduced-round block cipher . is a 64-bit string of 0s.
The results of the encryption are used as the first part of whitening key. The remaining parts of the whitening key are obtained from performing iterative encryption. The parameter
i of
refers to number of generation reduction rounds. The value is recommended as 3 during our experiments. We use
to append 0s to turn the bit length of
X into 64. The specific process of the generating whitening key
is as follows:
The process of generating
is essentially the same as
. The difference is that
in
is used instead of
in calculation. A different subkey
is also used.
2.3. LCF
The execution flow of LCF is presented in
Figure 4. The design inspiration of LCF comes from the Murmurhash2B function. Diffusivity is the main indicator to be considered when modifying the Murmurhash2B function to achieve the LCF. The implementation cost of LCF is also concerned. Currently, many embedded chips have multipliers. However, there are still many MCUs that do not have multipliers due to cost constraints. Multiplication needs to be implemented through addition and shift instead. In short, the advantage of using addition outweighs multiplication in terms of the cost and performance.
Therefore, we suggest replacing certain multiplication operators in the Murmurhash2B function with the modular addition of a lightweight component. A search algorithm is devised to realize the above idea. This algorithm attempts to use as many modular addition operations as possible in LCF, rather than multiplication operations. The search algorithm is described as Algorithm 2.
| Algorithm 2 The search algorithm |
- 1:
for 7 do - 2:
- 3:
for 7 do - 4:
- 5:
- 6:
for do - 7:
- 8:
- 9:
for do - 10:
if then - 11:
- 12:
if then - 13:
- 14:
else - 15:
- 16:
- 17:
- 18:
- 19:
- 20:
|
The goal of the search algorithm is to make the function LCF obtain a better diffusion rate when processing data of different lengths. The results of the search algorithm are constants that can be used in LCF. Constants within a certain range are searched in Algorithm 2 to make the diffusion rate of LCF reach the target for each data length. In other words, LCF can choose different constants according to the length of the data.
In our experiment, suppose that the multiplication operations can be reduced by 4 to 14 times. represents the number of multiplication used in LCF. The data lengths processed by LCF range from 64 bits to 1927 bits, and these will be divided into eight groups.
Each group is characterized by the same results when the elements in the group are treated with mod 8. For each group, constants from 0x5b000000 to 0x5c000000 are sought when the number of multiplication operations used is determined. The function is used to record the group number, constant and lower limit of the diffusivity if the constant makes all points in a group meet the diffusivity condition. is used to record the number of constants in each group that meet the conditions. is used to check the constant results for each group after searching the eight groups.
It is possible to use modular addition instead of multiplication if all eight groups have results. A constant is selected from the numerous constants after the search algorithm is completed. Not only can this make the LCF obtain an equilibrium diffusion rate but it can also deduce other constants from it. In other words, the selected constants can make the diffusion effect of LCF independent of the data length.
Finally, the fourteen multiplication operations in Murmurhash2B are simplified into four multiplication operations through experiments. The corresponding constants are analyzed to obtain the constant 0x5be5e995 used to design LCF. The selected constant can make the lower limit of diffusivity for LCF reach 0.47. In particular, the diffusivity of LCF can reach 0.5 when LCF uses eight times the data. In conclusion, the proposed LCF processes data faster and more cheaply than Murmurhash2B. The performance comparison between LCF and other functions is in
Section 4. LCF is described in Algorithm 3.
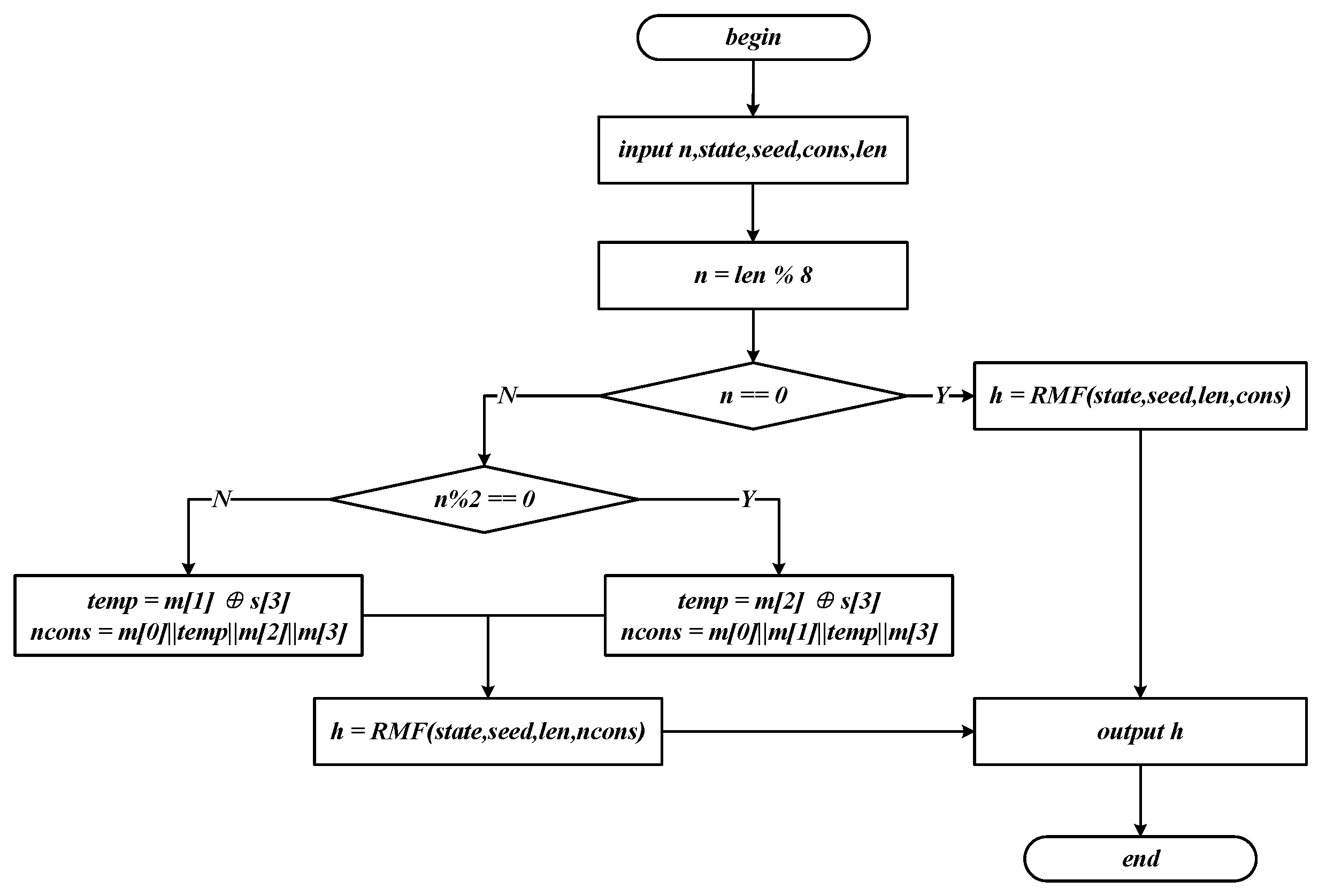
LCF receives two parameters: key () and data (). A seed is provided by the key processing function, which is divided into four words. The bit length of each word is 8 bits. The bit length of the state and seed together determine the constant to be used when calling function RMF in LCF. can evolve 32 values under different conditions. This is used directly as an argument to RMF when the bit length of state is an integer multiple of 8. A conditional judgment is executed in other cases. The first or second word in is changed to create a new constant () after the condition is determined. is generated by XOR operation on the third byte of and . LCF has a 64-bit compressed value by calling RMF after determining the constant. RMF is described in Algorithm 4.
Each basic operation processes 32-bit data in RCF.
and
are generated by processing every eight bytes of the state through modulo addition, shift and XOR operations. The first four bytes of a group with less than eight bytes are processed similarly to the previous step. The last three bytes are connected and added to
. Then,
and
are mixed by XOR, shift and multiplication operations. The final value
is the combination of
and
.
| Algorithm 3 The lightweight compress function LCF |
Input:
Output: h- 1:
- 2:
- 3:
- 4:
- 5:
ifthen - 6:
if then - 7:
- 8:
- 9:
else - 10:
- 11:
- 12:
- 13:
else - 14:
- 15:
return:h
|
| Algorithm 4 The revised murmurhash2B function RMF |
Input:
Output: - 1:
- 2:
- 3:
- 4:
whiledo - 5:
- 6:
- 7:
- 8:
- 9:
- 10:
- 11:
- 12:
- 13:
ifthen - 14:
- 15:
- 16:
- 17:
- 18:
- 19:
- 20:
- 21:
- 22:
- 23:
- 24:
- 25:
return:
|
2.4. Decryption Algorithm
The shared key between the encrypting party and the decrypting party can be exchanged through a secure key exchange protocol. There are many such key exchange protocols, such as those proposed in [
13,
14,
15]. The encryptor sends the
to the receiver of the ciphertext through a secure key exchange protocol. The receiver of the ciphertext uses the
to generate a series of subkeys for decryption. The decryption operation of the proposed LILP is the same as the encryption operation. However, each subkey needs to be applied in reverse order when decrypting. Assuming that the order of keys used in encryption is
, and then the order of keys used in decryption is
.
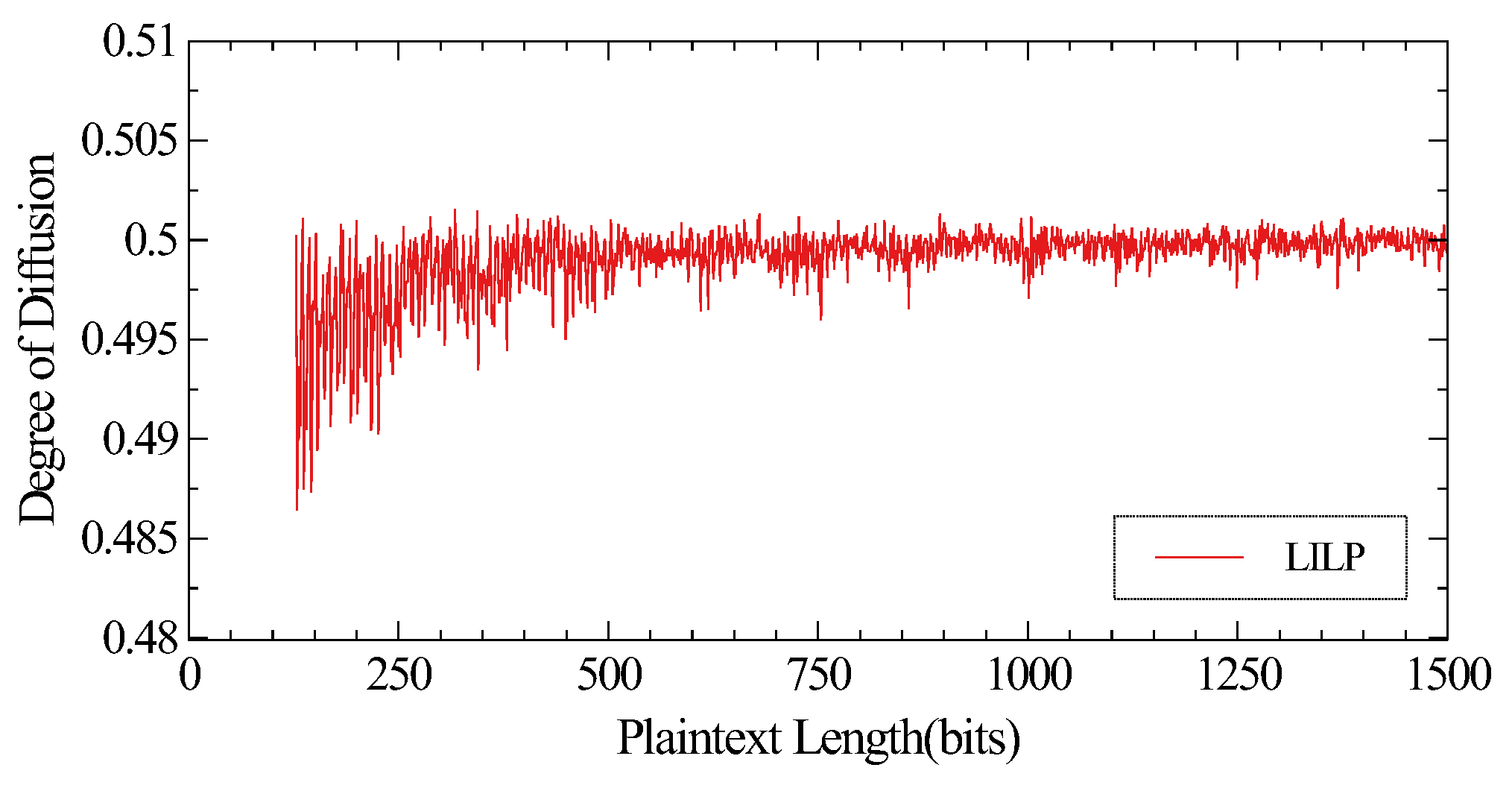
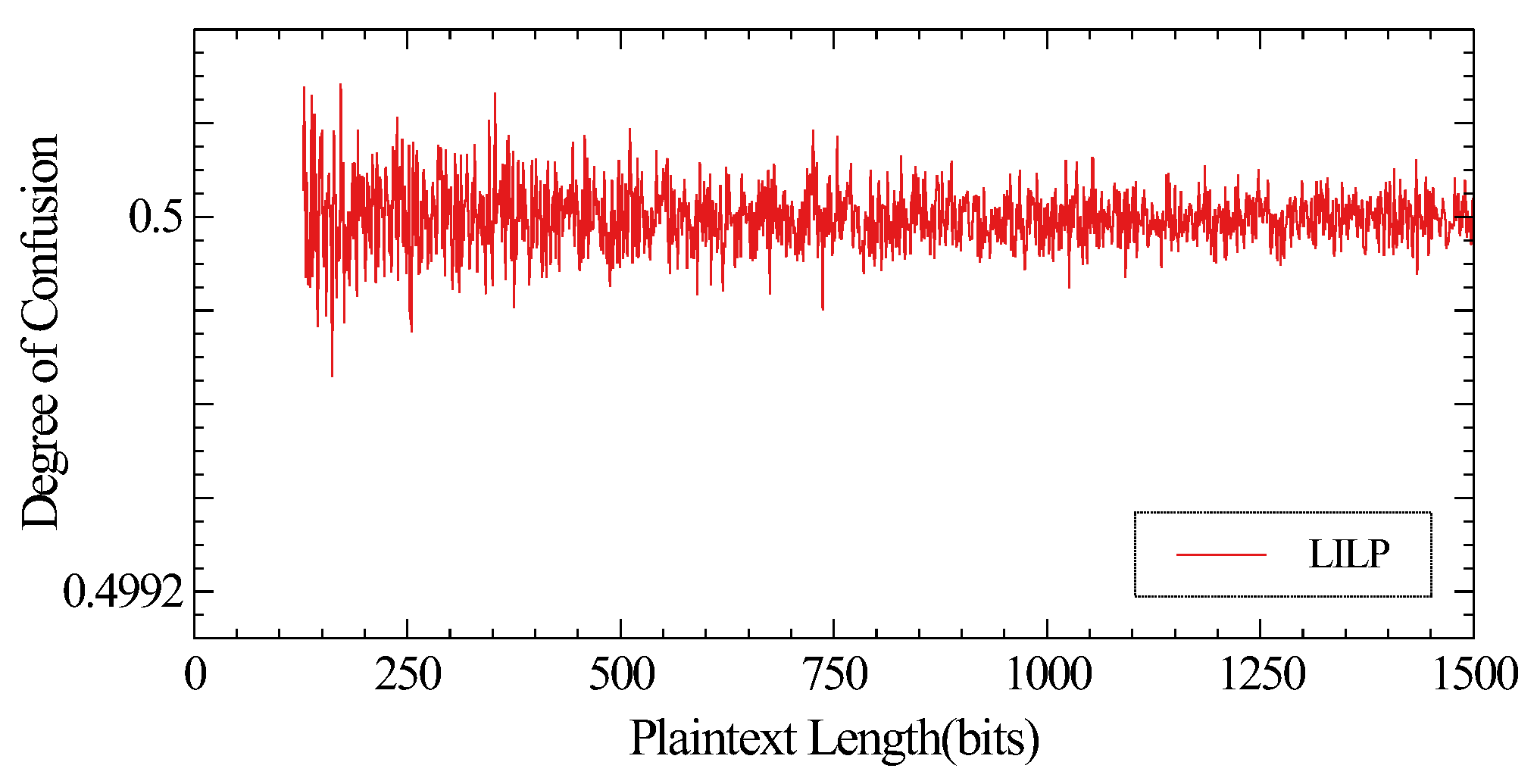
4. Performance Analysis
4.1. Overall Comparison
As shown in
Table 2, length-preserving-encryption algorithms can accept input of any length. Some components of the length-preserving algorithms can be operated in parallel. In addition, algorithms using the Luby–Rackoff structure do not input the entire plaintext into the compression function, which affects the diffusion effect of the algorithms. The Lai–Massey structure adopted by LILP can solve this problem. It is worth noting that the GHash-like compression functions used by ABL, XCB and HCTR need to implement multiplication over finite fields. A simple implement of multiplication is much slower than one AES call [
17]. However, the compression function LCF used by LILP does not require such a large computational cost. In order to adapt to resource-constrained devices, LCF also takes cost, security and performance into consideration comprehensively.
We implemented LILP on the 1.6 GHz Intel(R) Core i5-8250U CPU, which uses the Intel C++ compiler to run a 64 bit operating system. In addition, there are devices used for data acquisition, control and communication functions in the perception layer. They often have more abundant computing resources and storage resources when compared with sensor nodes, such as RTU [
18]. The frequency range of the embedded processing chips typically used is from tens of MHZ to hundreds of MHZ [
19,
20,
21]. Compared with the dominant frequency of GHZ on the server, the data processing capability is still relatively weak. Therefore, we also implemented LILP on RTU, which uses a 32-bit 48 MHz ARM processor with 32 single byte general-purpose registers, 1 M byte SRAM and 8 M byte programmable flash memory.
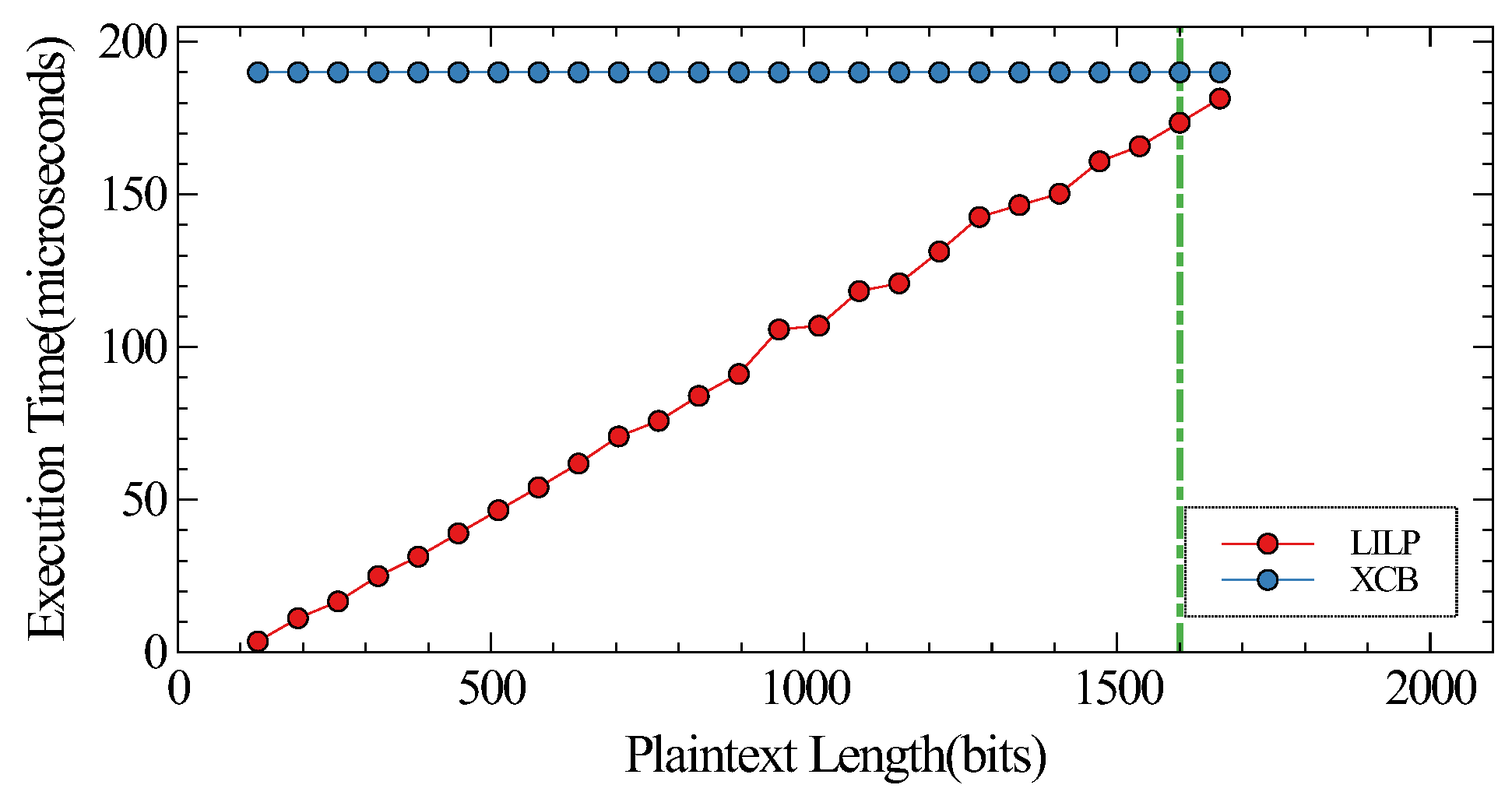
First of all, LILP is a lightweight and improved version of XCB. We compare the encryption and decryption speed of LILP with XCB. We prepare 10 GB and 1 GB of data for each plaintext length on PC and RTU, respectively, to calculate the average running time of LILP and XCB. The comparison results are shown in
Figure 7, and these indicate that LILP is faster than XCB in processing data on both PC and RTU.
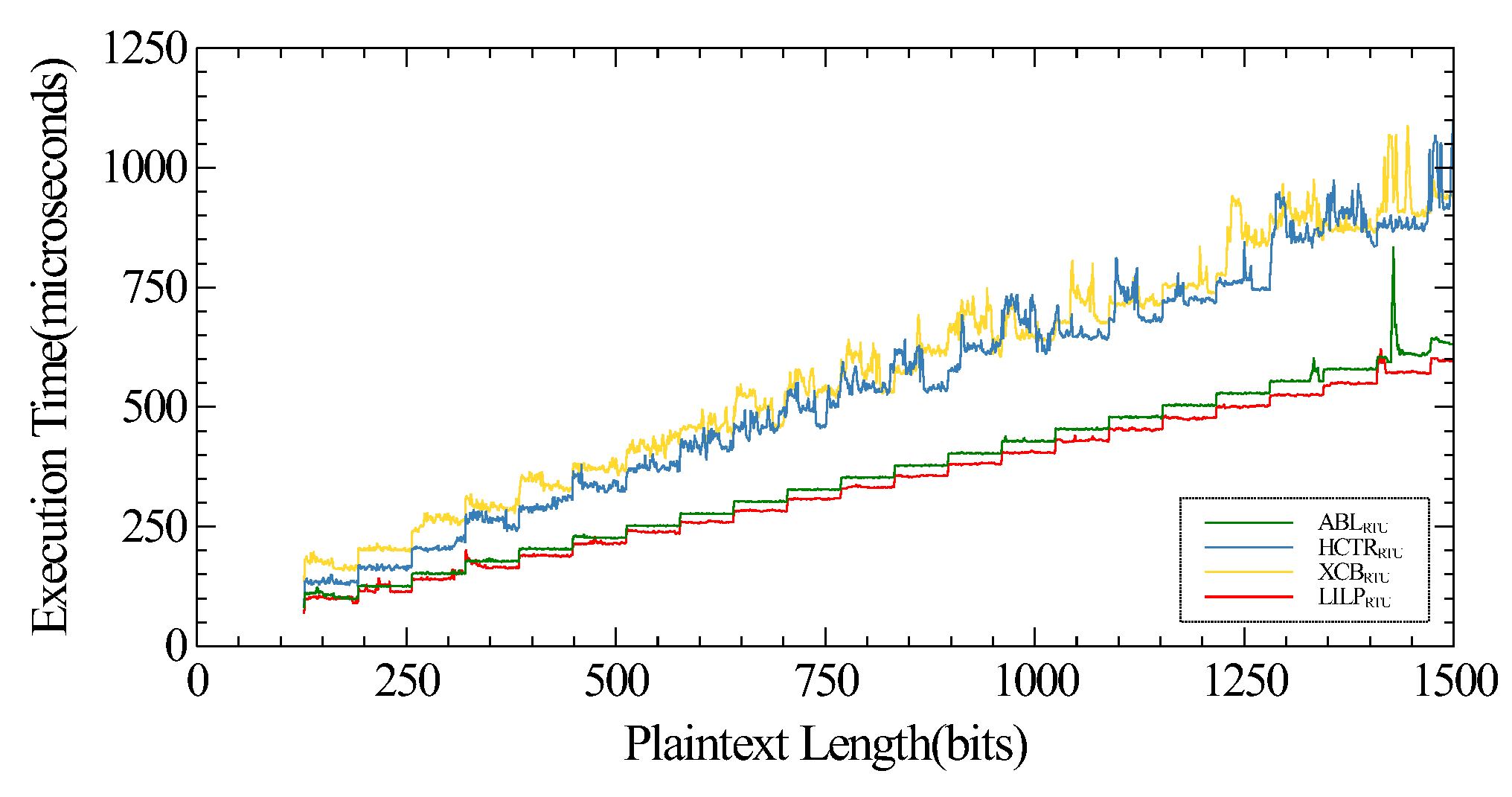
In addition, we select several existing length-preserving-encryption algorithms of the same type as LILP to compare the encryption and decryption speed. Since algorithms, such as ABL and HCTR, do not have a specific key schedule function, for the sake of fairness, all keys required by the algorithm are prepared in advance. The running time of the algorithm on RTU is also calculated and compared. As shown in
Figure 8, we observed that LILP shows better performance to achieve length-preserving encryption of 128-bit to 1499-bit data. The comparison with other ciphers for encrypting 1000-bit plaintext is shown in
Table 3. In terms of the throughput, LILP is faster than ABL, HCTR and XCB.
4.2. Comparison of the Key Schedule
We suppose that the underlying block encryption algorithm can generate 64-bit ciphertext by using 80-bit keys after 25 rounds of transformation. The key schedule algorithm of XCB uses an 80-bit master key to generate a 64-bit and three 80-bit subkeys. The 64-bit subkey is ciphertext generated by encrypting all zero constants with a block cipher. The 80-bit subkeys are results of encrypting different constants by calling the block encryption algorithm twice. The advantage of XCB using such a key schedule is to save space for storing keys.
However, if such a key schedule is used in resource-constrained embedded devices, it requires seven times the block encryption algorithms to generate four subkeys, which will undoubtedly reduce the operating efficiency of the entire system. Therefore, it is necessary to run a simple and fast key schedule function on resource-constrained embedded devices to ensure a certain degree of security.
In this paper, the reduced round block encryption algorithm is used to generate the whitening keys. The keys required for the block encryption algorithm and compression function are realized through the operations of grouping, splicing and shifting. The time required to generate a whitened key varies with the length of plaintext. The advantage of using the reduction round method is to reuse existing components. In addition, whitening keys can be generated safely and quickly when plaintext of a certain length range is encrypted.
For example, compared with the large amount of time spent on the XCB key schedule, the time for LILP to complete the key schedule in the case of plaintext lengths from 448 to 640 bits is equivalent to the time of calling the block cipher twice. It can be seen from
Figure 9 that, when the plaintext length is less than 1600 bits, the execution time of LILP is significantly shorter than XCB in the key schedule. Some security risks may be hidden in a length-preserving-encryption algorithm without a key schedule function. For example, the ciphertext generated by HCH [
17] encryption does not have strong randomness without processing a master key.
4.3. Comparison of Compression Function
Since the choice of compression function has a great impact on the performance and security of the proposed LILP, it is necessary to analyze and compare compression functions. The specific results of analysis and comparison are as follows. First, the performance of three compression algorithms—namely, AXUHash, GHash and Murmurhash2B are compared. A special AXU (AlmostXorUniversal) function can accept
X of any length by dividing
X into
. If the length of
is less than
n, then enough 0 bits are filled in the end of
to make the bit length of
equal to
n.
refers to the bit length of
X.
h is a parameter similar to the key that needs to be specified separately. A special AXUHash is defined as follows:
This compression function is based on multiplication and addition over finite fields. A fixed-length value is formed by dividing input into blocks for absorption. The advantage of the above compression functions is that it can be implemented efficiently on a high-performance server. However, its disadvantage is also obvious. If the platform uses 32-bit or less algorithms, there is no data type long enough to effectively implement operations over finite fields. Therefore, the implementation of multiplication is more complicated, which will greatly reduce the operational efficiency of this compression function. Similar to AXUHash, GHash is also based on polynomial operations over finite fields. The specific calculation details of GHash are shown in [
8].
In addition, the influence of different compression functions on the diffusion effect of the algorithm is also studied. When all inputs are 0, AXUHash and GHash will not work, which means that the compressed value will also be 0 or a simple value. This is because any element in a finite field multiplied by 0 will be 0.
The experimental results show that Murmurhash2B has a good diffusion effect. It uses XOR, shift, normal addition and multiplication to obtain a 64-bit value [
22]. The running time of these three compression functions is tested multiple times with 5 GB data. The average running time obtained is shown in
Table 4. In addition, the advantage of using Murmurhash2B is that it can directly process the byte stream submitted by the bottom layer. The byte stream needs to be formatted before using GHash and AXUHash, which reduces the running efficiency of the whole algorithm to a certain extent.
4.4. Application
The proposed LILP is applied to protect sensor data in WSNs. In addition, a lightweight key exchange security framework [
23] is used for key transmission. WSNs consist of sensor nodes, such as temperature sensors, soil sensors, humidity sensors, light sensors and soil pH sensors. These sensor nodes are installed manually on the WSN to collect environmental data before transmission to the sink node. Then, the sink node transmits the data to the user through a common channel.
Users make choices and take necessary actions on sensor data property based on the environmental facts obtained. RTU is used to collect sensor data in a monitoring area with 100 monitoring points. Each monitoring point uses temperature and humidity sensors, light sensors and carbon dioxide sensors to monitor the environmental information of the crops. The sensor data is encrypted on the RTU and transmitted to the cloud server through the 4G network.
We stipulate that the temperature and humidity information occupies 4 bytes, the light information occupies 3 bytes, the carbon dioxide information occupies 2 bytes, and the location code occupies 1 byte. When RTU reads sensor data from 100 nodes, the data size to be encrypted is 1000 bytes. The experimental results show that it takes 0.02 s to call LILP to encrypt such sensor data. The advantage of LILP in encryption speed makes it have less impact on other services running in the RTU. In addition, LILP has the advantage of adapting to sensor data of different lengths. For example, sometimes adding monitoring nodes or damaging sensors will cause changes in the amount of data.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}