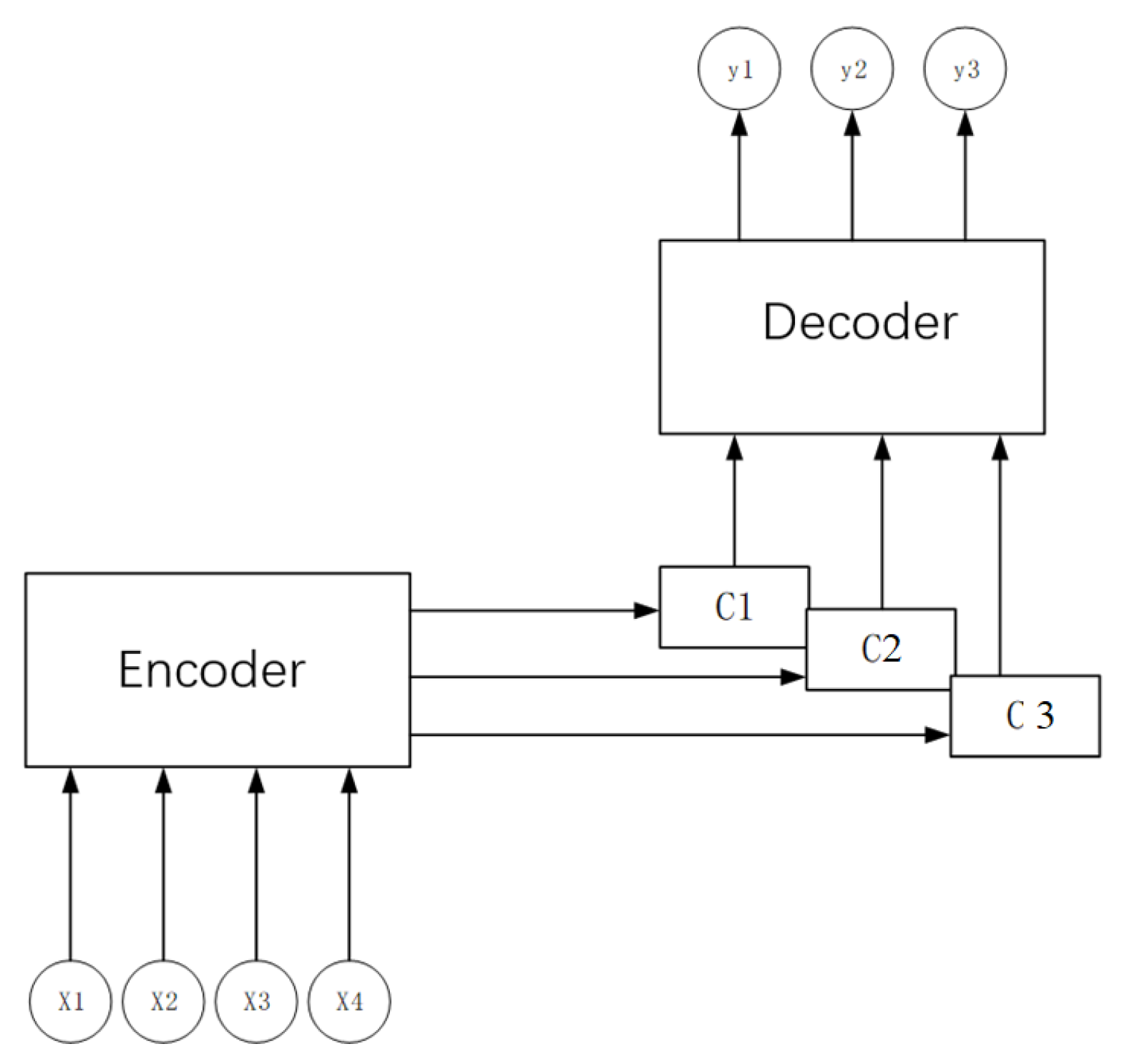
The goal of this paper was to simply demonstrate that a functioning capsule network should reduce the number of parameters required in a text classification model by better embedding information due to its inherent ability. The proposed method was tested in an experimental environment to evaluate its accuracy compared to traditional convolutional neural networks and similar methods. To this end, three commonly used text datasets were used to test the proposed method based on network evaluation: the IMDB, MPQA, and MR datasets. All the experiments showed that capsule networks with self-attention mechanisms can achieve better results than other comparable methods.
4.1. Experimental Dataset and Preprocessing
This study conducted experiments on three benchmark datasets, which specific details and parameter statistics are shown in
Table 3. In the table, Dataset refers to the dataset name; Train corresponds to the number of training set samples; Valid refers to the number of validation set samples; Test corresponds to the number of samples in the test set; Class refers to the number of target categories; Arg.T represents the average length of the sample sentences; Max.T represents the maximum length of the sample sentence; and Vocabsize represents the size of the vocabulary.
- (1)
IMDB Available online:
https://www.imdb.com/interfaces/ (accessed on 5 April 2024) dataset [
47]: This was an IMDB English film review dataset integrated internally by Keras. The experiment used a labeled dataset containing 50,000 IMDB film reviews with significant bias, specifically for emotional analysis. The 25,000 reviews marked with a training set did not include movies in the 25,000 reviews test set. Among these movies, 25,000 were used as training sets and 25,000 were used as testing sets, and the labels used were pos (positive) and neg (negative). In addition, the positively and negatively labelled reviews were equal in number.
- (2)
MPQA Available online:
https://mpqa.cs.pitt.edu/ (accessed on 5 April 2024) dataset [
48]: This was a binary dataset that mostly consisted of various English news articles. Among these articles, there were a total of 3311 positive tendencies and 7293 negative tendencies. During the experiment, 80% of the data were used to form a training set and the remaining 20% were used as a testing set.
- (3)
MR Available online:
http://www.cs.cornell.edu/people/pabo/movie-review-data/ (accessed on 5 April 2024) dataset [
49]: This was a binary dataset that was mostly sourced from short texts from professional English film review websites containing the emotional tendencies of “positive” and “negative”, with the dataset containing 5331 entries each in these categories. In this study, the dataset segmentation method used was the same as that used in the MPQA dataset.
Comparing these three different datasets, the sample sentences in the IMDB dataset were relatively long; the average length is 238 words [
47]. While those in the MPQA and MR datasets were relatively short; the average length is 20 words [
48,
49].
The specific experimental details and parameter statistics are shown in
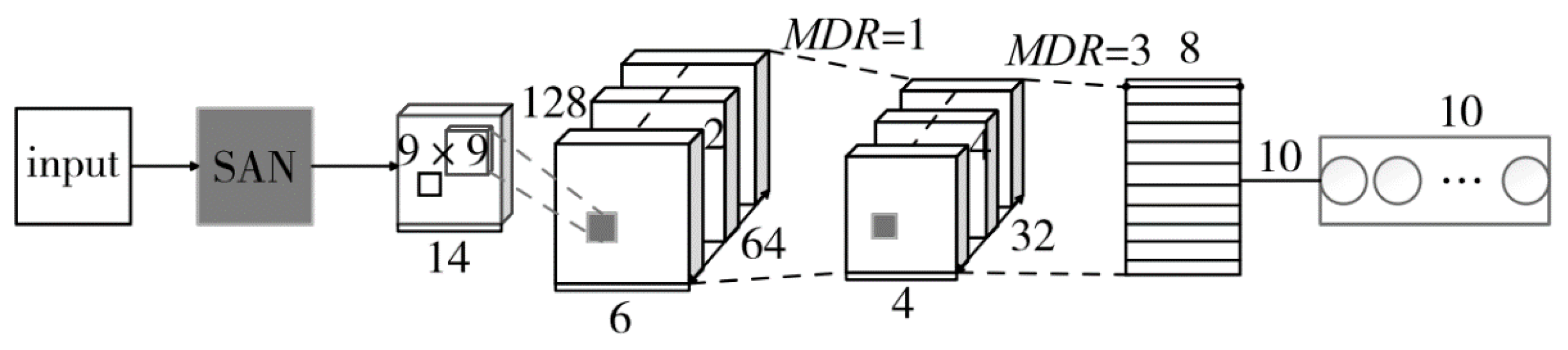
Table 4. As can be seen, the Activation parameter corresponds to the extrusion function using ReLU; Optimizer corresponds to the optimizer Adam; Loss corresponds to the loss function Margin; Input_ Size corresponds to a batch size of 200; n layers correspond to four layers of the stack; Total params corresponds to the total parameter quantity of 3,452,864; EPS corresponds to a neural network learning rate of 10
−7; and Epoch represents the number of training rounds.
After determining the dataset, it is necessary to preprocess the text data when transmitting it to the network. As the data in this study were segmented comments, it was necessary to first segment the text data. After tokenization is performed, the words need to be converted into numbers in order to form a vector matrix that is transmitted to the network one number at a time. In this study, words were converted into numbers using the subscript of the word in the dictionary as the number representing the word. Through this process, the text data were transformed into vector data, and then the vector data were all normalized to the same length. We chose the maximum length of the vectors, while vectors less than the specified length were filled with 0. In addition, this study treated all punctuation marks, special characters, and other language symbols that appeared in the dataset as spaces and changed all uppercase letters in the dataset to lowercase letters. Further to this, during the process of building the vocabulary, words that only appeared once in the dataset were deleted.
4.3. Ablation Experiment
Next, to verify the advantages of the SA-CapsNet model, the study conducted relevant experiments on the model’s self-attention network and capsule layer structures, as well as on the fusion of the two. These experiments were conducted by mapping self-attention networks with different structures to feature extraction layers of capsule networks, and the experimental results are shown in
Table 6.
As can be seen from the above results, when using the self-attention module (SA) as the basic unit in constructing a self-attention network, increasing the number of SA layers achieved a better fit and model data training results, up until three SA layers were used. When three layers were used, overfitting gradually occurred as the training parameters increased, leading to a decrease in classification accuracy. At present, pooling operations can cause extracted features to lose some spatial information. Indeed, when the pooling operations were reduced once in these experiments, the classification accuracy was improved. However, without pooling operations, a model’s accuracy will decrease due to there being redundant information in the features. Therefore, a self-attention network structure was ultimately used to add one layer of pooling to a three-layer SA. To verify the effectiveness of this proposed model, ablation experiments were conducted, as shown in
Table 7.
Comparing the results of experiments 1, 2, 3, and 4, it can be seen that mapping the self-attention module to the feature extraction layer of the capsule network improved the classification accuracy of the model. Additionally, it can be seen that increasing the middle capsule layer and reducing the dimensionality of the capsule not only reduced the number of parameters but also improved the performance of the model.
4.4. Comparative Experiment
Next, a comparison experiment was performed. In this experiment, three classic networks, namely, the CNN, RNN, and LSTM network, were tested on the three datasets. The classification accuracy results for these three networks and the capsule network used in this study are shown in
Table 8.
Firstly, a CNN is mainly composed of convolutional layers and pooling layers. Because convolutional operations can effectively extract image feature information, CNNs are widely used by researchers. In most cases, researchers use them on image datasets, and they are commonly employed in image classification, image segmentation, and other tasks; they can also be used for text classification. In this study, a CNN was used on text datasets. The performance accuracy of this model on the three datasets was 78.86%, 73.52%, and 70.36%, respectively, meaning its performance was relatively poor. This is because CNNs have a small field of view problem, with their perception actually being the size of the convolutional kernel, which is often set to five or three. Although their perception can be increased by stacking convolutional layers, CNNs may also encounter other problems, such as gradient disappearance or gradient explosion, so the use of CNNs is therefore not suitable for text datasets.
RNNs are specifically designed to process data with temporal characteristics. The output of an RNN’s neurons is not only transmitted to the next layer, but also retains a hidden state, which is passed on to the next neuron until it is changed in subsequent divine elements. This hidden state gives subsequent neurons the opportunity to see the state preserved by previous neurons far away from them; this is very important in text classification as such classification involves a section of a sentence being analyzed. Usually, the subject of the sentence appears at the beginning, and the meaning or verb conveyed by the sentence often appears in the middle. The implicit state of an RNN is conducive to the network identifying the sentences in the later part while connecting these with the subject appearing at the beginning in order to make judgments. In this study, the performance accuracy of the RNN on the four datasets was 80.98%, 74.98%, and 71.36%, respectively. Therefore, compared to the CNN, the RNN achieved a higher accuracy, owing to its unique hidden state.
The LSTM network is a recurrent neural network based on the short-term memory model. It is based on RNNs and has characteristics that match its name, being designed to solve long-distance problems. In addition to the hidden characteristic possessed by RNNs, the LSTM network adds three additional gate attributes, termed the forgetting gate, memory gate, and output gate. The forgetting gate is used to calculate the information to be forgotten, the memory gate is used to calculate the information to be memorized, and the output gate combines the previously obtained information to calculate the output information. The three gate attributes complement each other, enabling the LSTM network to remember words that are far away from the current position. At the same time, the presence of the forgetting gate allows the network to ignore some unimportant information. The performance accuracy of the LSTM network on the three datasets was 82.28%, 76.36%, and 72.68%, respectively. Therefore, compared to the RNN, its text classification accuracy was better, thanks to its ability to remember long and short distance feature information.
As a comparison with the original experiment, CapsNet was also tested on the three datasets. CapsNet, also known as the capsule network, was developed in order to solve the problems faced by CNNs. It was first applied to image classification and has gradually achieved good performance results in some classification task experiments. The capsule network is applied to text classification models and proposed two structures: the first uses single-scale features in the convolutional layer, and the second uses multi-scale features in the convolutional layer. Their experiments showed that multi-scale features are superior to single-scale features, as these contain richer and more diverse grammatical information. However, this finding ignores the fact that the various scale features corresponding to words within a text should not be equally important. In this study, the performance accuracy of CapsNet on the three datasets was 83.64%, 79.92%, and 74.95%, respectively.
Finally, SA-CapsNet had a performance accuracy of 84.72%, 80.31%, and 75.38%, respectively, on the three datasets. Therefore, compared to the other three models, SA-CapsNet’s accuracy was superior by more than 2%; this was thanks to its unique self-attention mechanism capsule attribute.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}