
Knowledge Extraction and Quality Inspection of Chinese Petrographic Description Texts with Complex Entities and Relations Using Machine Reading and Knowledge Graph: A Preliminary Research Study

 ,
,
Abstract
:1. Introduction
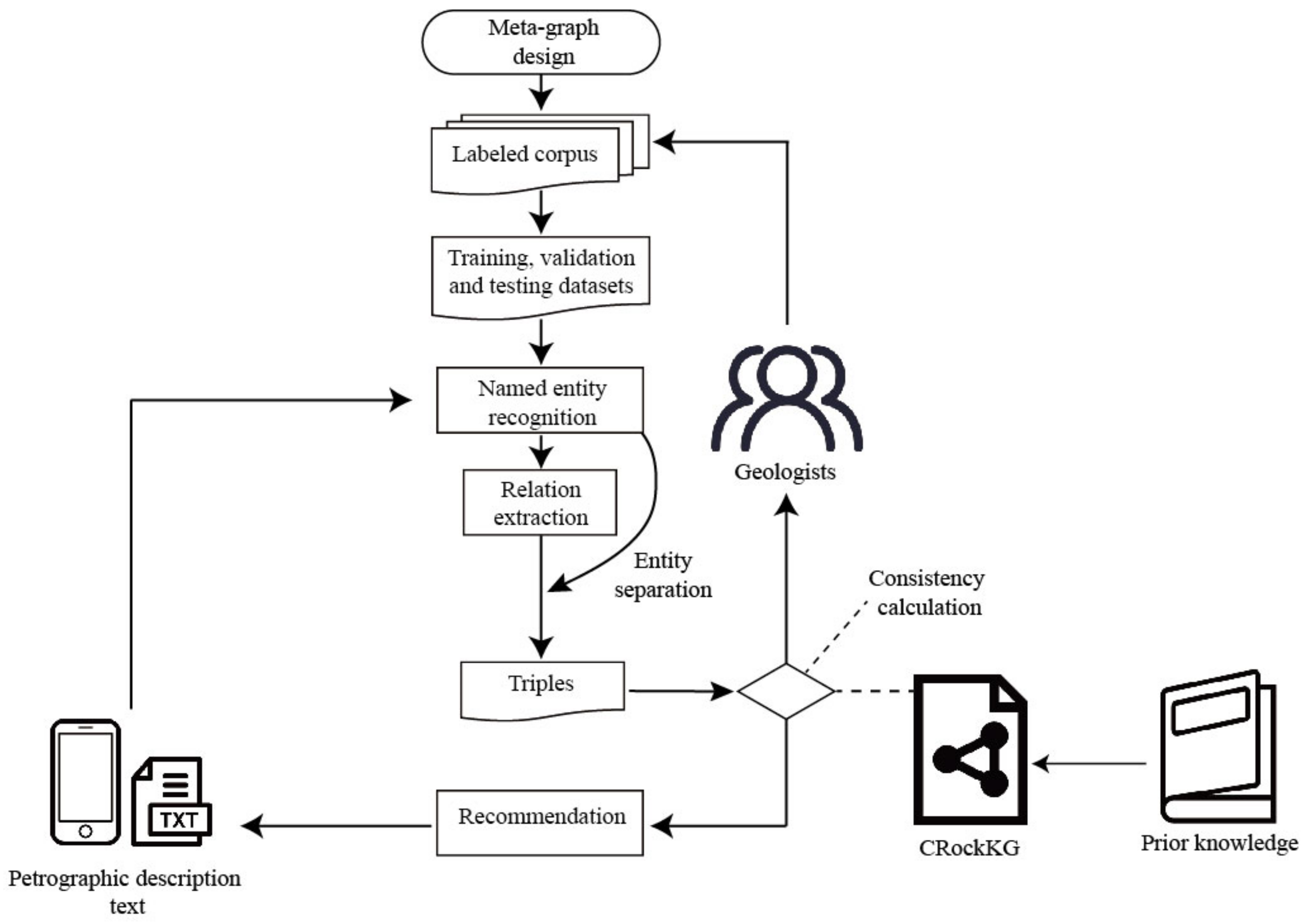
2. Knowledge Extraction and Quality Inspection Framework
2.1. Predefinition of Named Entities and Relations Based on Prior Petrographic Knowledge
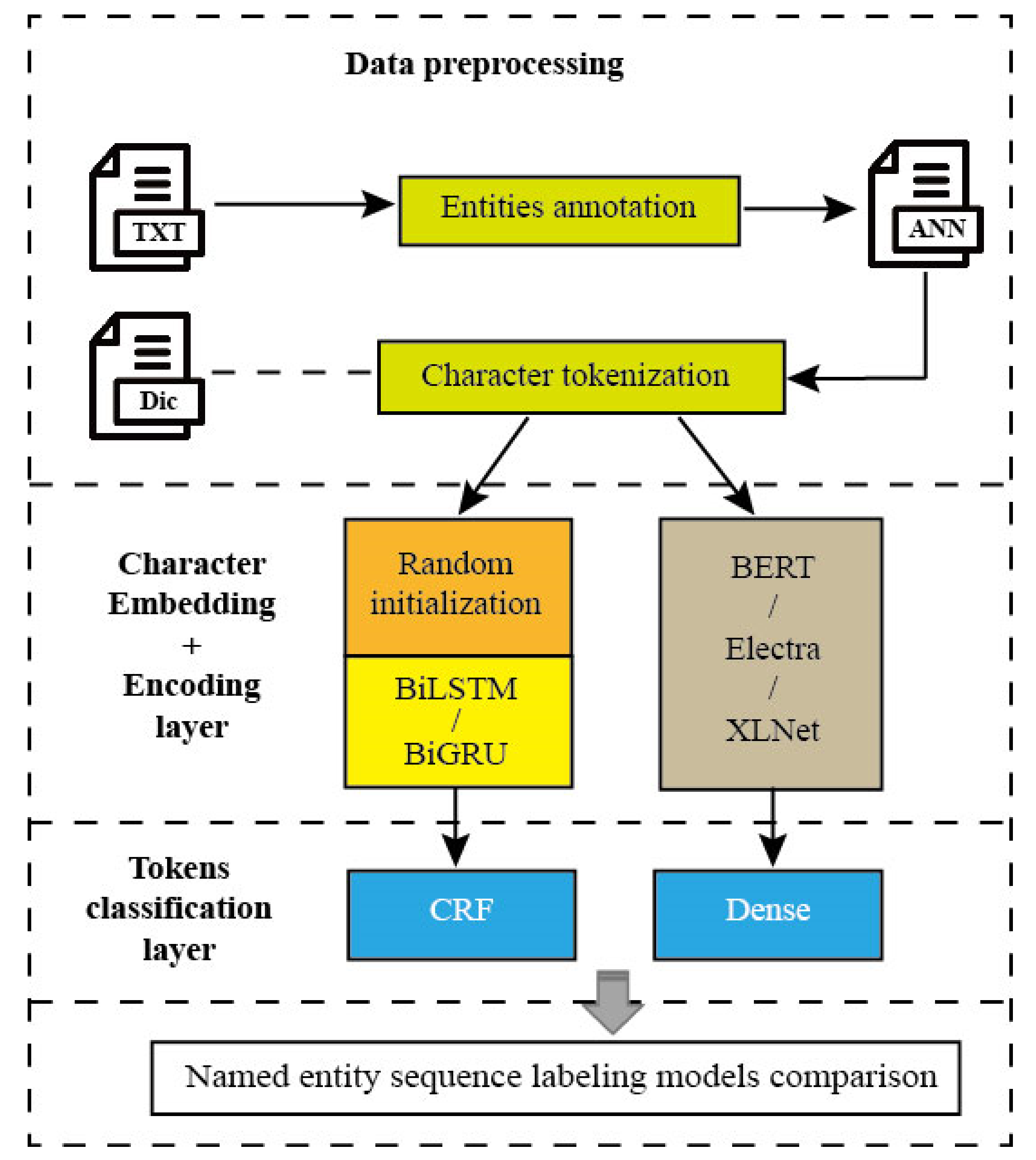
2.2. Petrographic Named Entity Recognition Based on Sequence Labelling Model
2.3. Petrographic Relation Extraction Based on Enriching R-Transformer Model
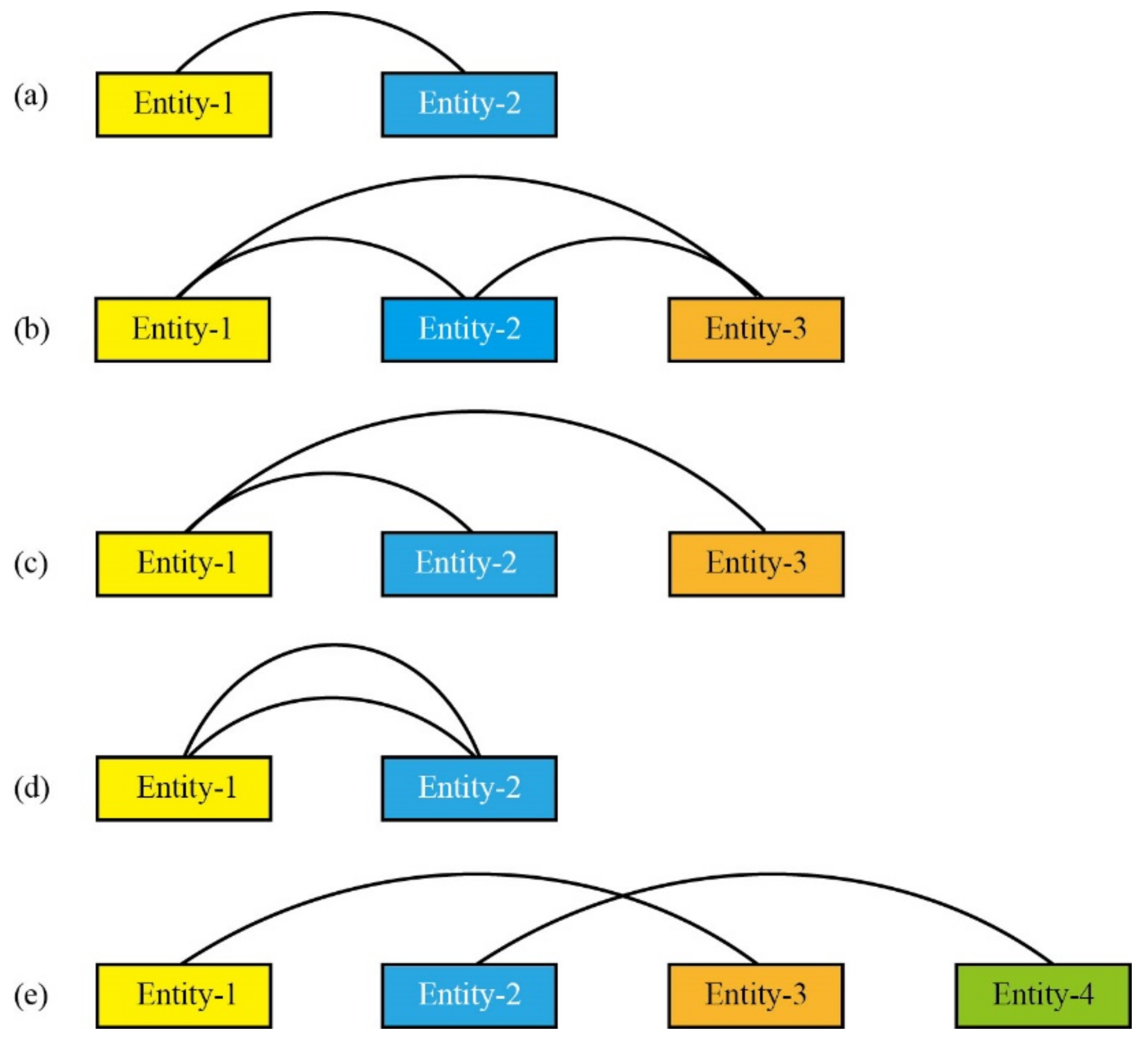
2.4. Rule-Based Complex Entity Separation
| Algorithm 1. Complex entity separation algorithm. |
| Input: a complex entity Output: entities separated 1: input complex entity containing the entity type 2: if entity type is Texture 3: if entity is blastic texture and len (entity) > 7 4: execute extraction of grain size, minor and major mineral textures 5: else if entity type is Structure 6: if concatenation characters are present in entity 7: execute entity separation based on the concatenation character 8: return entities |
3. Experimental Results
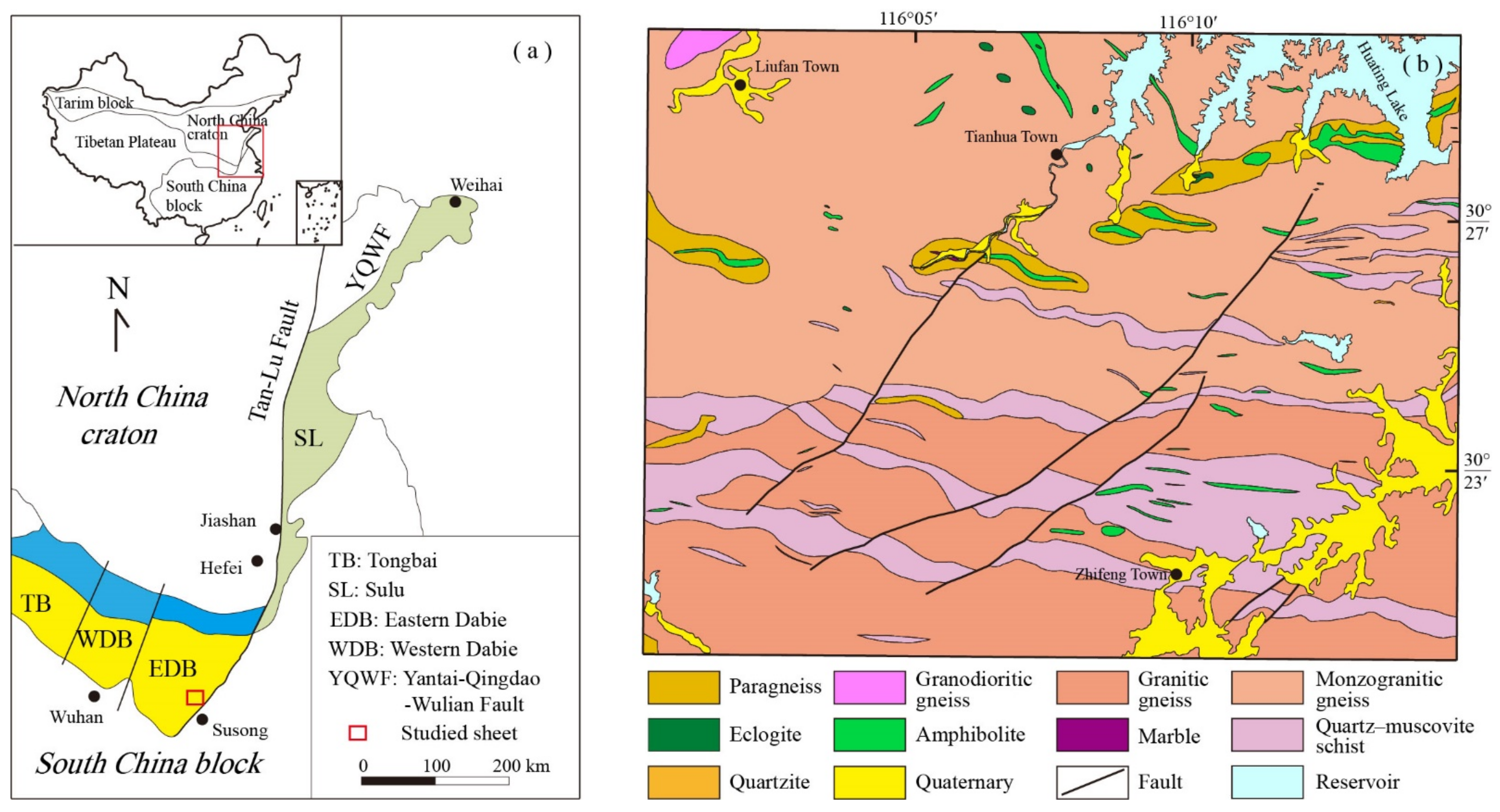
3.1. Construction of the Prior Petrographic KG
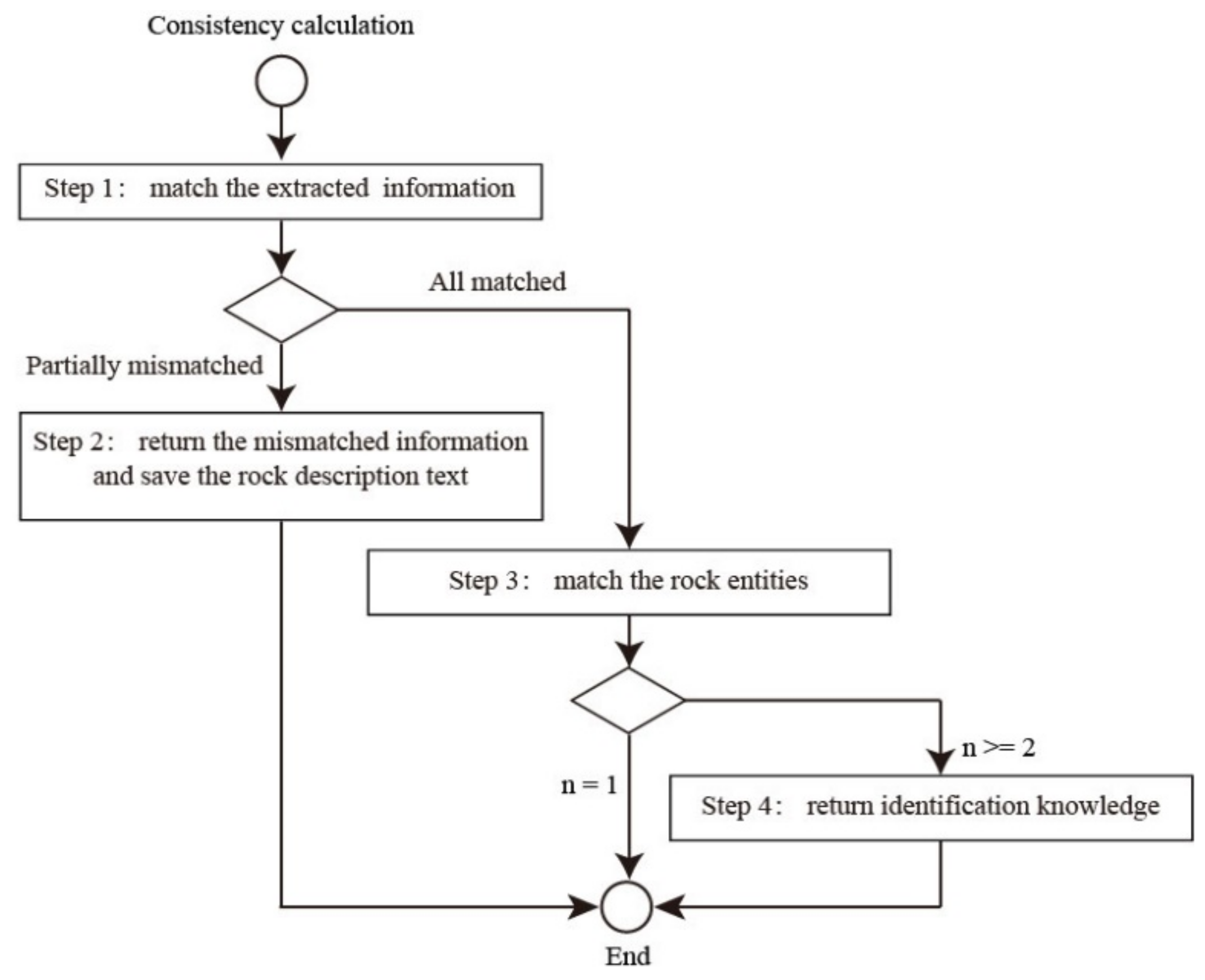
3.2. Knowledge Extraction and Quality Inspection
4. Discussion
4.1. Error Transformation in Pipeline Mode
4.2. Integration of Variant Data and Specifications
4.3. Knowledge Recommendation and Knowledge Reasoning
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Karpatne, A.; Ebert-Uphoff, I.; Ravela, S.; Babaie, H.A.; Kumar, V. Machine Learning for the Geosciences: Challenges and Opportunities. IEEE Trans. Knowl. Data Eng. 2019, 31, 1544–1554. [Google Scholar] [CrossRef]
- Zhou, Y.Z.; Zuo, R.G.; Liu, G.; Yuan, F.; Mao, X.C.; Guo, Y.J.; Xiao, F.; Liao, J.; Liu, Y.P. The great-leap-forward development of mathematical geoscience during 2010–2019: Big Data and artificial intelligence algorithm are changing mathematical geoscience. Bull. Mineral. Petrol. Geochem. 2021, 40, 556–573. [Google Scholar]
- Sun, Z.; Sandoval, L.; Crystal-Ornelas, R.; Mousavi, S.M.; Wang, J.; Lin, C.; Cristea, N.; Tong, D.; Carande, W.H.; Ma, X.; et al. A Review of Earth Artificial Intelligence. Comput. Geosci. 2022, 159, 105034. [Google Scholar] [CrossRef]
- Bergen, K.J.; Johnson, P.A.; De Hoop, M.V.; Beroza, G.C. Machine Learning for Data-Driven Discovery in Solid Earth Geoscience. Science 2019, 363, eaau0323. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine Learning in Geosciences and Remote Sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef]
- Jia, L.; Yang, M.; Meng, F.; He, M.; Liu, H. Mineral Photos Recognition Based on Feature Fusion and Online Hard Sample Mining. Minerals 2021, 11, 1354. [Google Scholar] [CrossRef]
- Sun, G.; Huang, D.; Cheng, L.; Jia, J.; Xiong, C.; Zhang, Y. Efficient and Lightweight Framework for Real-Time Ore Image Segmentation Based on Deep Learning. Minerals 2022, 12, 526. [Google Scholar] [CrossRef]
- Chow, B.H.Y.; Reyes-Aldasoro, C.C. Automatic Gemstone Classification Using Computer Vision. Minerals 2022, 12, 60. [Google Scholar] [CrossRef]
- McCoy, J.T.; Auret, L. Machine Learning Applications in Minerals Processing: A Review. In Minerals Engineering; Elsevier Ltd.: Amsterdam, The Netherlands, 2019; pp. 95–109. [Google Scholar]
- Zhou, G.Y.; Zhang, M.M.; Shen, L.; Zhang, S.H.; Yuan, F.; Li, X.H.; Ji, B.; Zhou, Y.Z. Data mining of deep geological spatial information of the Yaojialing Zinc-gold polymetallic deposit. Geotecton. Metallogenia 2020, 44, 242–250. [Google Scholar]
- Zhou, C.H.; Wang, H.; Wang, C.S.; Hou, Z.Q.; Zheng, Z.M.; Shen, S.Z.; Cheng, Q.M.; Feng, Z.Q.; Wang, X.B.; Lv, H.R.; et al. Prospects for the Research on Geoscience Knowledge Graph in the Big Data Era. Sci. China Earth Sci. 2021, 64, 1105–1114. [Google Scholar] [CrossRef]
- Gil, Y.; Pierce, S.A.; Babaie, H.; Banerjee, A.; Borne, K.; Bust, G.; Cheatham, M.; Ebert-Uphoff, I.; Gomes, C.; Hill, M.; et al. Intelligent Systems for Geosciences: An Essential Research Agenda. Commun. ACM 2019, 62, 76–84. [Google Scholar] [CrossRef]
- Jiang, S.J.; Zheng, Y.; Solomatine, D. Improving AI System Awareness of Geoscience Knowledge: Symbiotic Integration of Physical Approaches and Deep Learning. Geophys. Res. Lett. 2020, 47, e2020GL088229. [Google Scholar] [CrossRef]
- Wagener, T.; Dadson, S.J.; Hannah, D.M.; Coxon, G.; Beven, K.; Bloomfield, J.P.; Buytaert, W.; Cloke, H.; Bates, P.; Holden, J.; et al. Knowledge Gaps in Our Perceptual Model of Great Britain’s Hydrology. Hydrol. Process. 2021, 35, e14288. [Google Scholar] [CrossRef]
- Sherlock, M.J.; Hasan, M.; Samavati, F.F. Interactive Data Styling and Multifocal Visualization for a Multigrid Web-Based Digital Earth. Int. J. Digit. Earth 2021, 14, 288–310. [Google Scholar] [CrossRef]
- Kase, S.E.; Hung, C.P.; Krayzman, T.; Hare, J.Z.; Rinderspacher, B.C.; Su, S.M.M. The Future of Collaborative Human-Artificial Intelligence Decision-Making for Mission Planning. Front. Psychol. 2022, 13, 1246. [Google Scholar]
- Enkhsaikhan, M.; Holden, E.-J.; Duuring, P.; Liu, W. Understanding Ore-Forming Conditions Using Machine Reading of Text. Ore Geol. Rev. 2021, 135, 104200. [Google Scholar] [CrossRef]
- Berardi, M.; Amato, L.S.; Cigna, F.; Tapete, D.; de Cumis, M.S. Text Mining from Free Unstructured Text: An Experiment of Time Series Retrieval for Volcano Monitoring. Appl. Sci. 2022, 12, 3503. [Google Scholar] [CrossRef]
- Grishman, R. Twenty-Five Years of Information Extraction. Nat. Lang. Eng. 2019, 25, 677–692. [Google Scholar]
- Kopperud, B.T.; Lidgard, S.; Liow, L.H. Text-Mined Fossil Biodiversity Dynamics Using Machine Learning. Proc. R. Soc. B Biol. Sci. 2019, 286, 20190022. [Google Scholar] [CrossRef]
- Abu-Salih, B. Domain-Specific Knowledge Graphs: A Survey. J. Netw. Comput. Appl. 2021, 185, 103076. [Google Scholar] [CrossRef]
- Liu, C.; Chen, J.; Li, S.; Qin, T. Construction of Conceptual Prospecting Model Based on Geological Big Data: A Case Study in Songtao-Huayuan Area, Hunan Province. Minerals 2022, 12, 669. [Google Scholar] [CrossRef]
- Ma, X.G. Knowledge Graph Construction and Application in Geosciences: A Review. Comput. Geosci. 2022, 161, 105082. [Google Scholar] [CrossRef]
- Wang, B.; Ma, K.; Wu, L.; Qiu, Q.J.; Xie, Z.; Tao, L.F. Visual Analytics and Information Extraction of Geological Content for Text-Based Mineral Exploration Reports. ORE Geol. Rev. 2022, 144, 104818. [Google Scholar] [CrossRef]
- Peters, S.E.; Zhang, C.; Livny, M.; Ré, C. A Machine Reading System for Assembling Synthetic Paleontological Databases. PLoS ONE 2014, 9, e113523. [Google Scholar] [CrossRef] [Green Version]
- Peters, S.E.; Husson, J.M.; Wilcots, J. The Rise and Fall of Stromatolites in Shallow Marine Environments. Geology. 2017, 45, 487–490. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, W.; Xu, Y.; Liu, J.; Tan, Y. Intelligent Learning for Knowledge Graph towards Geological Data. Sci. Program. 2017, 2017, 5072427. [Google Scholar] [CrossRef]
- Wang, C.; Ma, X.; Chen, J.; Chen, J. Information Extraction and Knowledge Graph Construction from Geoscience Literature. Comput. Geosci. 2018, 112, 112–120. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef]
- Grohe, M.; Lindner, P. Infinite Probabilistic Databases. Log. Methods Comput. Sci. 2022, 18, 34. [Google Scholar] [CrossRef]
- Ceylan, I.I.; Darwiche, A.; Van den Broeck, G. Open-World Probabilistic Databases: Semantics, Algorithms, Complexity. Artif. Intell. 2021, 295, 103474. [Google Scholar] [CrossRef]
- Amarilli, A.; Ceylan, I.I. The Dichotomy of Evaluating Homomorphism-Closed Queries on Probabilistic Graphs. Log. Methods Comput. Sci. 2022, 18, 2. [Google Scholar] [CrossRef]
- Liu, W.C.; Zhang, C.J.; Wang, C.; Zhang, X.Y.; Zhu, Y.Q.; Jiao, S.T.; Lu, Y.X. Geological time information extraction from Chinese text based on BiLSTM-CRF. Adv. Earth Sci. 2021, 36, 211–220. [Google Scholar]
- Fan, R.; Wang, L.; Yan, J.; Song, W.; Zhu, Y.; Chen, X. Deep Learning-Based Named Entity Recognition and Knowledge Graph Construction for Geological Hazards. ISPRS Int. J. Geo-Inf. 2019, 9, 15. [Google Scholar] [CrossRef]
- Qi, H.; Dong, S.C.; Zhang, L.L.; Hu, H.; Fan, J.X. Construction of earth science knowledge graph and its future perspectives. Geol. J. China Univ. 2020, 26, 2–10. [Google Scholar]
- Zhou, Y.Z.; Zhang, Q.L.; Huang, Y.J.; Yang, W.; Xiao, F.; Ji, J.J.; Han, F.; Tang, L.; Ouyang, C.; Shen, W.J. Constructing knowledge graph for the porphyry copper deposit in the Qingzhou Hangzhou area: Insight into knowledge graph based mineral resource prediction and evalution. Earth Sci. Front. 2021, 28, 67–75. [Google Scholar]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Melbourne, VIC, Australia, 2018; pp. 506–514. [Google Scholar]
- Yang, M.L.; Xue, L.F.; Ran, X.J.; Sang, X.J.; Yan, Q.; Dai, J.H. Intelligent mineral geological survey method: Daqiao-Yawan area in Gansu Province as an example. Acta Petrol. Sinica 2021, 37, 3880–3892. [Google Scholar]
- Wang, Z.G.; Wen, H.Y.; Lu, Q.; Shen, H.K. Joint extraction of open entity relation in geological field. Comput. Eng. Design 2021, 42, 996–1005. [Google Scholar]
- Zhang, X.Y.; Ye, P.; Wang, S.; Du, M. Geological entity recognition method based on deep belief networks. Acta Petrol. Sinica 2018, 34, 343–351. [Google Scholar]
- Chu, D.P.; Wan, B.; Li, H.; Fang, F.; Wang, R. Geological entity recognition based on ELMO-CNN-BiLSTM-CRF model. Earth Sci. 2021, 46, 3039–3048. [Google Scholar]
- Xie, X.J.; Xie, Z.; Ma, K.; Chen, J.G.; Qiu, Q.J.; Li, H.; Pan, S.Y.; Tao, L.F. Geological entity recognition based on BERT and BiGRU-Attention-CRF model. Geological Bulletin of China. 2021. Available online: https://kns.cnki.net/kcms/detail/11.4648.p.20210913.1040.002.html (accessed on 12 March 2022).
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Networks Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef]
- Chen, Z.L.; Yuan, F.; Li, X.H.; Zhang, M.M. Based on BERT-BiLSTM-CRF model the named entity and relation joint extration of Chinese lithological description corpus. Geol. Rev. 2022, 68, 742–750. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting Pre-Trained Models for Chinese Natural Language Processing. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 657–668. [Google Scholar]
- Stenetorp, P.; Pyysalo, S.; Topíc, G.; Ohta, T.; Ananiadou, S.; Tsujii, J. BRAT: A Web-Based Tool for NLP-Assisted Text Annotation. In Proceedings of the Demonstrations at the 13th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2012, Avignon, France, 23–27 April 2012; Association for Computational Linguistics (ACL): Avignon, France, 2012; pp. 102–107. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling Relations and Their Mentions without Labeled Text BT. In Machine Learning and Knowledge Discovery in Databases; Balcázar, J.L., Bonchi, F., Gionis, A., Sebag, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 148–163. [Google Scholar]
- Zhao, L.; Xu, W.; Gao, S.; Guo, J. Cross-Sentence N-Ary Relation Classification Using LSTMs on Graph and Sequence Structures. Knowl.-Based Syst. 2020, 207, 106266. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, J.; Lin, H.; Wang, X.; Yang, Z.; Zhang, Y. Biomedical Cross-Sentence Relation Extraction via Multihead Attention and Graph Convolutional Networks. Appl. Soft Comput. 2021, 104, 107230. [Google Scholar] [CrossRef]
- Wang, X.; Guo, J.; Tao, W.; Jiang, L.; Deng, J.; Ma, C. Paleoproterozoic Tectonic Evolution of the Yangtze Craton: Evidence from Magmatism and Sedimentation in the Susong Area, South China. Precambrian Res. 2021, 365, 106390. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, Y.-C.; Li, Y.; Groppo, C.; Rolfo, F. Zircon U-Pb Dating and Petrogenesis of Multiple Episodes of Anatexis in the North Dabie Complex Zone, Central China. Minerals 2020, 10, 618. [Google Scholar] [CrossRef]
- Qiu, X.-F.; Tong, X.-R.; Jiang, T.; Khattak, N.U. Reworking of Hadean Continental Crust in the Dabie Orogen: Evidence from the Muzidian Granitic Gneisses. Gondwana Res. 2021, 89, 119–130. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rock Type | Texture | Structure | Major Minerals | Minor Minerals | Accessory Minerals |
|---|---|---|---|---|---|
| Monzogranitic gneiss (二长花岗质片麻岩) | Lepidoblastic texture (鳞片变晶结构), granoblastic texture (花岗变晶结构), porphyroclastic texture (碎斑结构), blastogranitic texture (变余花岗结构), coarse-grained blastic texture (粗粒变晶结构), medium-grained blastic texture (中粒变晶结构) | Gneissic structure (片麻状构造), massive structure (块状构造), weak gneissic structure (弱片麻状构造), ophthalmitic structure (眼球状构造), streaky structure (条纹状构造), banded structure (条带状构造) | Quartz (石英), plagioclase (斜长石), k-feldspar (钾长石) | Biotite (黑云母), muscovite (白云母), epidote (绿帘石) | Zircon (锆石), sphene (榍石), magnetite (磁铁矿), garnet (石榴子石) |
| Granitic gneiss (花岗质片麻岩) | Lepidoblastic texture (鳞片变晶结构), granoblastic texture (花岗变晶结构), blastogranitic texture (变余花岗结构), fine-grained blastic texture (细粒变晶结构) | Gneissic structure (片麻状构造) | Quartz (石英), k-feldspar (钾长石), plagioclase (斜长石) | Biotite (黑云母), muscovite (白云母) | Zircon (锆石), apatite (磷灰石), rutile (金红石), ilmenite (钛铁矿), magnetite (磁铁矿), garnet (石榴子石) |
| Granodioritic gneiss (花岗闪长质片麻岩) | Blastogranitic texture (鳞片变晶结构), porphyroclastic texture (碎斑结构) | Gneissic structure (片麻状构造), massive structure (块状构造) | Quartz (石英), plagioclase (斜长石), k-feldspar (钾长石) | Biotite (黑云母), hornblende (角闪石) | Magnetite (磁铁矿), sphene (榍石), zircon (锆石) |
| Description text in Chinese | 点南为灰白色厚层状花岗质片麻岩, 细粒鳞片花岗变晶结构, 片麻状-块状构造, 主要矿物斜长石50%, 钾长石20%,石英20%, 他形粒状,少量黑云母. | ||
| Description text | The south of the point is greyish-white, thick, layered granitic gneiss; fine-grained and lepidoblastic-granoblastic structure, gneissic-mass structure; major minerals: plagioclase 50%, k-feldspar 20%, quartz 20%, xenomorphic crystal, a small amount of biotite. | ||
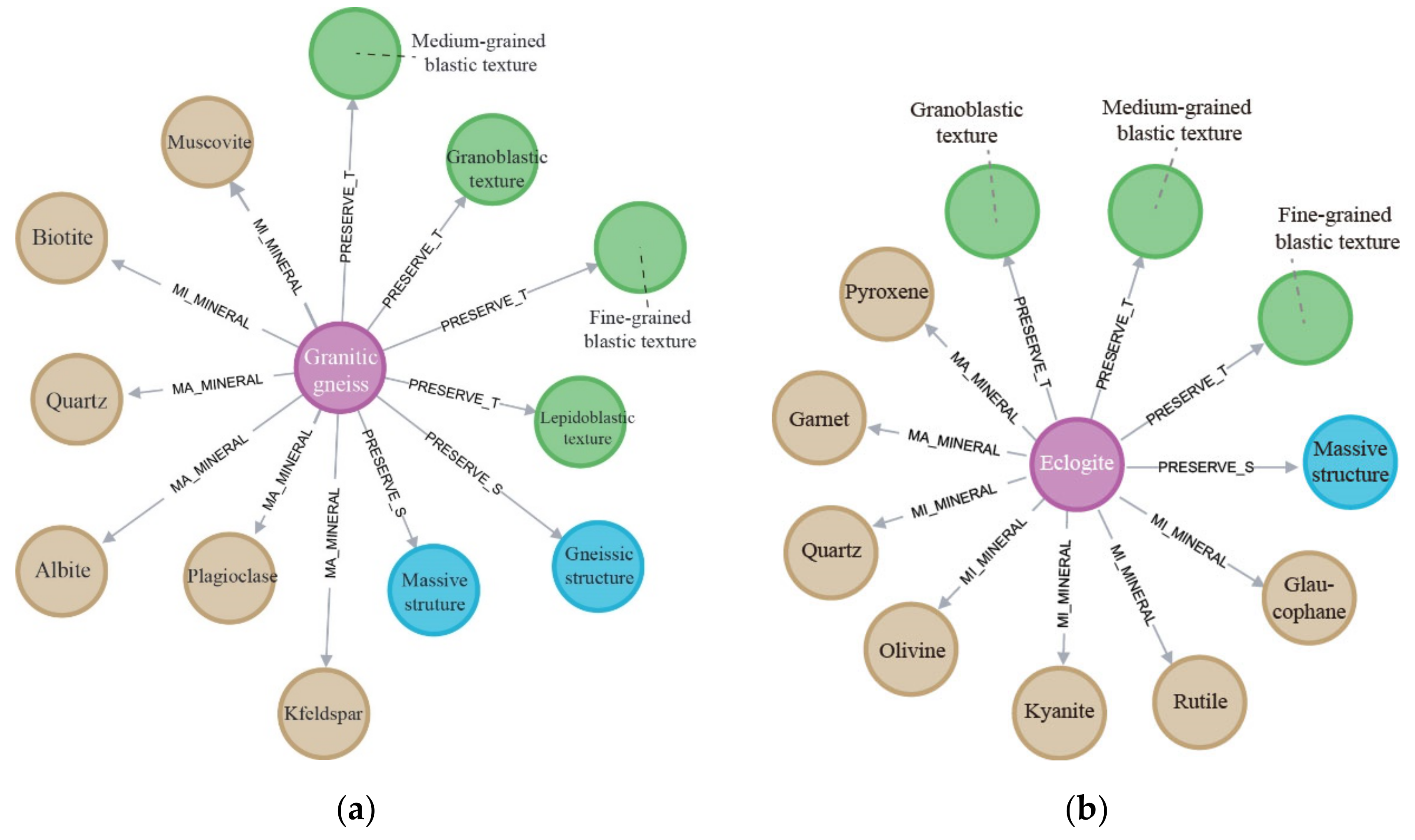
| Structure | Gneissic structure (片麻状构造), massive structure (块状构造) | Texture | Fine-grained blastic texture (细粒变晶结构), lepidoblastic texture (鳞片变晶结构), granoblastic texture (花岗变晶结构) |
| Major mineral | Plagioclase (斜长石), k-feldspar (钾长石), quartz (石英) | Minor mineral | Biotite (黑云母) |
| Extracted rock entity | Granitic gneiss (花岗质片麻岩) | ||
| Description text in Chinese | 点北为榴辉岩, 灰绿色, 细粒变晶结构, 块状构造, 主要由石榴子石30%, 辉石70%组成, 矿物颗粒较细小, 多在0.5 mm左右, 石榴子石多风化呈红褐色圆粒状. | ||
| Description text | The north of the point is eclogite. Grey-green, fine-grained blastic texture, mass structure, mainly composed of garnet 30%, pyroxene 70%. Mineral particles are small, mostly around 0.5 mm. Weathered garnet is mahogany and has a rounded grain. | ||
| Structure | Massive structure (块状构造) | Texture | Fine-grained blastic texture (细粒变晶结构) |
| Major mineral | Garnet (石榴子石), pyroxene (辉石) | Minor mineral | |
| Extracted rock entity | Eclogite (榴辉岩) | ||
| Indicator | BiLSTM-CRF | BiGRU-CRF | BERT | XLNet | ELECTRA | |
|---|---|---|---|---|---|---|
| Entity | p | 97.81 | 97.14 | 97.57 | 95.38 | 97.38 |
| R | 97.81 | 98.33 | 98.51 | 97.63 | 97.81 | |
| F1 | 97.81 | 97.74 | 98.04 | 96.49 | 97.60 | |
| Relation | p | - | - | 91.77 | 91.15 | 90.84 |
| R | - | - | 94.71 | 93.32 | 90.56 | |
| F1 | - | - | 93.22 | 92.22 | 90.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Yuan, F.; Li, X.; Wang, X.; Li, H.; Wu, B.; Chen, Y. Knowledge Extraction and Quality Inspection of Chinese Petrographic Description Texts with Complex Entities and Relations Using Machine Reading and Knowledge Graph: A Preliminary Research Study. Minerals 2022, 12, 1080. https://doi.org/10.3390/min12091080
Chen Z, Yuan F, Li X, Wang X, Li H, Wu B, Chen Y. Knowledge Extraction and Quality Inspection of Chinese Petrographic Description Texts with Complex Entities and Relations Using Machine Reading and Knowledge Graph: A Preliminary Research Study. Minerals. 2022; 12(9):1080. https://doi.org/10.3390/min12091080
Chicago/Turabian StyleChen, Zhongliang, Feng Yuan, Xiaohui Li, Xiang Wang, He Li, Bangcai Wu, and Yuheng Chen. 2022. "Knowledge Extraction and Quality Inspection of Chinese Petrographic Description Texts with Complex Entities and Relations Using Machine Reading and Knowledge Graph: A Preliminary Research Study" Minerals 12, no. 9: 1080. https://doi.org/10.3390/min12091080
APA StyleChen, Z., Yuan, F., Li, X., Wang, X., Li, H., Wu, B., & Chen, Y. (2022). Knowledge Extraction and Quality Inspection of Chinese Petrographic Description Texts with Complex Entities and Relations Using Machine Reading and Knowledge Graph: A Preliminary Research Study. Minerals, 12(9), 1080. https://doi.org/10.3390/min12091080