
Construction and Application of a Knowledge Graph for Gold Deposits in the Jiapigou Gold Metallogenic Belt, Jilin Province, China

 ,
,
Abstract
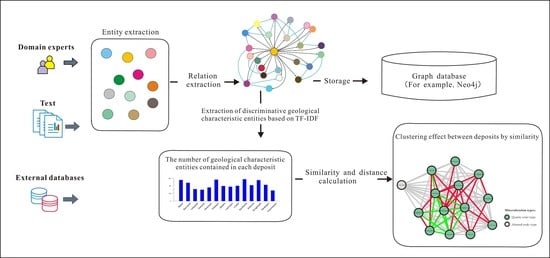
:
1. Introduction
2. Geological Settings
3. Related Work
3.1. Named Entity Recognition (NER)
3.2. Relation Extraction
3.3. Entity Alignment
3.3.1. Edit Distance Similarity
3.3.2. Vector Similarity
3.4. Visualization of KGs
4. Construction of KG for Ore Deposits
4.1. Basic Ideas and Algorithm Flow
4.2. Entity Extraction
4.3. Relation Extraction
4.4. Knowledge Fusion
4.5. The Application of the KG
5. Application of the KG in the JGMB
5.1. Visualization of the KG
5.2. Extraction of Key Geological Characteristic Entities
5.3. Similarity and Distance between Deposits
5.4. Visualization of the Regional Metallogenic Model Based on the KG
6. Discussion
6.1. Benefits
6.2. Limitations
6.3. Compared with the Previous Work
6.4. Future Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Han, J.L.; Sun, J.G.; Liu, Y.; Zhang, X.T.; He, Y.P.; Yang, F.; Chu, X.L.; Wang, L.L.; Wang, S.; Zhang, X.W.; et al. Genesis and age of the Toudaoliuhe breccia-type gold deposit in the Jiapigou mining district of Jilin Province, China: Constraints from fluid inclusions, H-O-S-Pb isotopes, and sulfide Rb-Sr dating. Ore Geol. Rev. 2020, 118, 103356. [Google Scholar] [CrossRef]
- Miao, L.C.; Qiu, Y.M.; Fan, W.M.; Zhang, F.Q.; Zhai, M.G. Geology, geochronology, and tectonic setting of the Jiapigou gold deposits, southern Jilin Province, China. Ore Geol. Rev. 2005, 26, 137–165. [Google Scholar] [CrossRef]
- Deng, J.; Yang, L.Q.; Gao, B.F.; Sun, Z.S.; Guo, C.Y.; Wang, Q.F.; Wang, J.P. Fluid Evolution and Metallogenic Dynamics during Tectonic Regime Transition: Example from the Jiapigou Gold Belt in Northeast China. Resour. Geol. 2009, 59, 140–152. [Google Scholar] [CrossRef]
- Zeng, Q.D.; Wang, Z.C.; He, H.Y.; Wang, Y.B.; Zhang, S.; Liu, J.M. Multiple isotope composition (S, Pb, H, O, He, and Ar) and genetic implications for gold deposits in the Jiapigou gold belt, Northeast China. Miner. Deposita 2014, 49, 145–164. [Google Scholar] [CrossRef]
- Zhang, X.T. Research on Geology, Geochemistry and Metallogenesis of the Gold Deposits of the Jiapigou Ore Field in the Continental Margin of Northeast China. Ph.D. Thesis, Jilin University, Changchun, China, 2018. [Google Scholar]
- Yang, L.Y.; Yang, L.Q.; Yuan, W.M.; Zhang, C.; Zhao, K.; Yu, H.J. Origin and evolution of ore fluid for orogenic gold traced by D-O isotopes: A case from the Jiapigou gold belt, China. Acta Petrol. Sin. 2013, 29, 4025–4035, (In Chinese with English Abstract). [Google Scholar]
- Deng, J.; Yuan, W.M.; Carranza, E.J.M.; Yang, L.Q.; Wang, C.M.; Yang, L.Y.; Hao, N.N. Geochronology and thermochronometry of the Jiapigou gold belt, northeastern China: New evidence for multiple episodes of mineralization. J. Asian Earth Sci. 2014, 89, 10–27. [Google Scholar] [CrossRef]
- Goldfarb, R.J.; Groves, D.I. Orogenic gold: Common or evolving fluid and metal sources through time. Lithos 2015, 233, 2–26. [Google Scholar] [CrossRef]
- Li, L.; Sun, J.G.; Men, L.J.; Chai, P. Origin and evolution of the ore-forming fluids of the Erdaogou and Xiaobeigou gold deposits, Jiapigou gold province, NE China. J. Asian Earth Sci. 2016, 129, 170–190. [Google Scholar] [CrossRef]
- Mao, J.W.; Zhang, Z.H.; Wang, Y.T.; Jia, Y.F.; Kerrich, R. Nitrogen isotope and content record of Mesozoic orogenic gold deposits surrounding the North China craton. Sci. China Ser. D 2003, 46, 231–245. [Google Scholar] [CrossRef]
- Dai, J.Z.; Wang, K.Y.; Cheng, X.M. Geochemical features of ore-forming fluids in the Jiapigou gold belt, Jilin province. Acta Petrol. Sin. 2007, 23, 2198–2206. [Google Scholar]
- Yu, J.J.; Wang, F.; Xu, W.L.; Gao, F.H.; Tang, J. Late Permian tectonic evolution at the southeastern margin of the Songnen-Zhangguangcai Range Massif, NE China: Constraints from geochronology and geochemistry of granitoids. Gondwana Res. 2013, 24, 635–647. [Google Scholar] [CrossRef]
- Wu, F.Y.; Zhao, G.C.; Sun, D.Y.; Wilde, S.A.; Yang, J.H. The Hulan Group: Its role in the evolution of the Central Asian Orogenic Belt of NE China. J. Asian Earth Sci. 2007, 30, 542–556. [Google Scholar] [CrossRef]
- Li, C.D.; Zhang, F.Q.; Miao, L.C.; Jie, H.Q.; Hua, Y.Q.; Xu, Y.W. Reconsideration of the Seluohe Group in Seluohe area, Jilin Province. J. Jilin Univ. Earth Sci. Ed. 2007, 37, 841–847, (In Chinese with English Abstract). [Google Scholar]
- Zeng, Q.D.; Wang, Z.C.; Zhang, S.; Wang, Y.B.; Yang, Y.H.; Liu, J.M. The ore-forming epoch of the Jiapigou gold belt, NE China: Evidences from the zircon LA–ICP–MS U–Pb dating of the intrusive rocks. Acta Geol. Sin. 2014, 88 (Suppl. S2), 1029–1030, (In Chinese with English Edition). [Google Scholar] [CrossRef]
- Sarker, I.H.; Hoque, M.M.; Uddin, M.K.; Alsanoosy, T. Mobile Data Science and Intelligent Apps: Concepts, AI-Based Modeling and Research Directions. Mobile Netw. Appl. 2021, 26, 285–303. [Google Scholar] [CrossRef]
- Singhai, A. Introducing the Knowledge Graph: Things, Not Strings. Available online: https://blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 16 May 2012).
- Ma, X.G.; Ma, C.; Wang, C.B. A new structure for representing and tracking version information in a deep time knowledge graph. Comput. Geosci. 2020, 145, 104620. [Google Scholar] [CrossRef]
- Wang, C.S.; Hazen, R.M.; Cheng, Q.M.; Stephenson, M.H.; Zhou, C.H.; Fox, P.; Shen, S.Z.; Oberhansli, R.; Hou, Z.Q.; Ma, X.G.; et al. The Deep-Time Digital Earth program: Data-driven discovery in geosciences. Natl. Sci. Rev. 2021, 8, nwab027. [Google Scholar] [CrossRef]
- Cheng, B.J.; Zhang, J.; Liu, H.; Cai, M.L.; Wang, Y. Research on Medical Knowledge Graph for Stroke. J. Healthc. Eng. 2021, 2021, 5531327. [Google Scholar] [CrossRef]
- Yu, C.M.; Wang, F.; Liu, Y.H.; An, L. Research on knowledge graph alignment model based on deep learning. Expert Syst. Appl. 2021, 186, 115768. [Google Scholar] [CrossRef]
- Zhu, Y.Q.; Zhou, W.W.; Xu, Y.; Liu, J.; Tan, Y.J. Intelligent Learning for Knowledge Graph towards Geological Data. Sci. Program. 2017, 2017, 5072427. [Google Scholar] [CrossRef]
- Qiu, Q.J.; Xie, Z.; Wu, L.; Tao, L.F. Automatic spatiotemporal and semantic information extraction from unstructured geoscience reports using text mining techniques. Earth Sci. Inform. 2020, 13, 1393–1410. [Google Scholar] [CrossRef]
- Wang, C.B.; Ma, X.G.; Chen, J.G.; Chen, J.W. Information extraction and knowledge graph construction from geoscience literature. Comput. Geosci. 2018, 112, 112–120. [Google Scholar] [CrossRef]
- Wang, C.B.; Ma, X.G.; Chen, J.G. Ontology-driven data integration and visualization for exploring regional geologic time and paleontological information. Comput. Geosci. 2018, 115, 12–19. [Google Scholar] [CrossRef]
- Li, S.; Chen, J.P.; Xiang, J. Prospecting Information Extraction by Text Mining Based on Convolutional Neural Networks—A case study of the Lala Copper Deposit, China. IEEE Access 2018, 6, 52286–52297. [Google Scholar]
- Holden, E.J.; Liu, W.; Horrocks, T.; Wang, R.; Wedge, D.; Duuring, P.; Beardsmore, T. GeoDocA–Fast analysis of geological content in mineral exploration reports: A text mining approach. Ore Geol. Rev. 2019, 111, 102919. [Google Scholar] [CrossRef]
- Enkhsaikhan, M.; Holden, E.J.; Duuring, P.; Liu, W. Understanding ore-forming conditions using machine reading of text. Ore Geol. Rev. 2021, 135, 104200. [Google Scholar] [CrossRef]
- Wang, Z.W.; Pei, F.P.; Xu, W.L.; Cao, H.H.; Wang, Z.J.; Zhang, Y. Tectonic evolution of the eastern Central Asian Orogenic Belt: Evidence from zircon U-Pb-Hf isotopes and geochemistry of early Paleozoic rocks in Yanbian region, NE China. Gondwana Res. 2016, 38, 334–350. [Google Scholar] [CrossRef]
- Wu, F.Y.; Sun, D.Y.; Ge, W.C.; Zhang, Y.B.; Grant, M.L.; Wilde, S.A.; Jahn, B.M. Geochronology of the Phanerozoic granitoids in northeastern China. J. Asian Earth Sci. 2011, 41, 1–30. [Google Scholar] [CrossRef]
- Zhang, X.T.; Sun, J.G.; Yu, Z.T.; Song, Q.H. LA-ICP-MS zircon U-Pb and sericite Ar-40/Ar-39 ages of the Songjianghe gold deposit in southeastern Jilin Province, Northeast China, and their geological significance. Can. J. Earth Sci. 2019, 56, 607–628. [Google Scholar] [CrossRef]
- Han, J.L.; Deng, J.; Zhang, Y.; Sun, J.G.; Wang, Q.F.; Zhang, Y.M.; Zhang, X.T.; Liu, Y.; Zhao, C.T.; Yang, F.; et al. Au mineralization-related magmatism in the giant Jiapigou mining district of Northeast China. Ore Geol. Rev. 2022, 141, 104638. [Google Scholar] [CrossRef]
- Huang, Z.X.; Yuan, W.M.; Wang, C.M.; Liu, X.W.; Xu, X.T.; Yang, L.Y. Metallogenic epoch of the Jiapigou gold belt, Jilin Province, China: Constrains from rare earth element, fluid inclusion geochemistry and geochronology. J. Earth Syst. Sci. 2012, 121, 1401–1420. [Google Scholar] [CrossRef]
- Zhang, X.T.; Sun, J.G.; Han, J.L.; Feng, Y.Y. Genesis and ore-forming process of the Benqu mesothermal gold deposit in the Jiapigou ore cluster, NE China: Constraints from geology, geochronology, fluid inclusions, and whole-rock and isotope geochemistry. Ore Geol. Rev. 2021, 130, 103956. [Google Scholar] [CrossRef]
- Alokaili, A.; Menai, M.E. SVM ensembles for named entity disambiguation. Computing 2020, 102, 1051–1076. [Google Scholar] [CrossRef]
- Bikel, D.M.; Schwartz, R.; Weischedel, R.M. An algorithm that learns what’s in a name. Mach. Learn 1999, 34, 211–231. [Google Scholar] [CrossRef]
- Lu, J.L.; Kato, M.P.; Yamamoto, T.; Tanaka, K. Entity Identification on Microblogs by CRF Model with Adaptive Dependency. IEICE Trans. Inf. Syst. 2016, E99d, 2295–2305. [Google Scholar] [CrossRef]
- He, C.H.; Zhang, C.; Hu, S.Z.; Tan, Z.; Zhu, H.M.; Ge, B. Chinese News Text Classification Algorithm Based on Online Knowledge Extension and Convolutional Neural Network. In Proceedings of the 2019 16th International Computer Conference on Wavelet Active Media Technology and Information Processing, Chengdu, China, 14–15 December 2019; pp. 204–211. [Google Scholar]
- Qin, Y.; Shen, G.W.; Zhao, W.B.; Chen, Y.P.; Yu, M.; Jin, X. A network security entity recognition method based on feature template and CNN-BiLSTM-CRF. Front. Inf. Technol. Electron. Eng. 2019, 20, 872–884. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Yang, G.; Xu, H.Z. A Residual BiLSTM Model for Named Entity Recognition. IEEE Access 2020, 8, 227710–227718. [Google Scholar] [CrossRef]
- Tian, G.; Wang, Q.B.; Zhao, Y.; Guo, L.T.; Sun, Z.L.; Lv, L.Y. Smart Contract Classification With a Bi-LSTM Based Approach. IEEE Access 2020, 8, 43806–43816. [Google Scholar] [CrossRef]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Quillen, D. Learning Hand-Eye Coordination for Robotic Grasping with Large-Scale Data Collection. Int. J. Robot. Res. 2017, 1, 173–184. [Google Scholar]
- Majumdar, A. Graph structured autoencoder. Neural Netw. 2018, 106, 271–280. [Google Scholar] [CrossRef] [PubMed]
- Yu, T.Z.; Guo, C.X.; Wang, L.F.; Xiang, S.M.; Pan, C.H. Self-Paced AutoEncoder. IEEE Signal Process. Lett. 2018, 25, 1054–1058. [Google Scholar] [CrossRef]
- Lei, J.P.; Ouyang, D.T.; Liu, Y. Adversarial Knowledge Representation Learning Without External Model. IEEE Access 2019, 7, 3512–3524. [Google Scholar] [CrossRef]
- Qiu, Q.J.; Xie, Z.; Wu, L.; Tao, L.F.; Li, W.J. BiLSTM-CRF for geological named entity recognition from the geoscience literature. Earth Sci. Inform. 2019, 12, 565–579. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, C.J.; Li, T.X.; Wu, H.; Zhao, X.; Ye, K.; Liao, J. Named entity recognition from Chinese adverse drug event reports with lexical feature based BiLSTM-CRF and tri-training. J. Biomed. Inform. 2019, 96, 103252. [Google Scholar] [CrossRef] [PubMed]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–14 June 2016; pp. 260–270. [Google Scholar]
- Enkhsaikhan, M.; Liu, W.; Holden, E.J.; Duuring, P. Auto-labelling entities in low-resource text: A geological case study. Knowl. Inf. Syst. 2021, 63, 695–715. [Google Scholar] [CrossRef]
- Gao, X.; Tan, R.; Li, G.H. Research on text mining of material science based on natural language processing. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; p. 768072094. [Google Scholar]
- Choi, Y.; Ryu, P.M.; Kim, H.; Lee, C. Extracting Events from Web Documents for Social Media Monitoring Using Structured SVM. IEICE Trans. Inf. Syst. 2013, E96d, 1410–1414. [Google Scholar] [CrossRef]
- Huang, W.; Shao, Z.F.; Luo, M.Y.; Zhang, P.; Zha, Y.F. A novel multi-loss-based deep adversarial network for handling challenging cases in semi-supervised image semantic segmentation. Pattern Recogn. Lett. 2021, 146, 208–214. [Google Scholar] [CrossRef]
- Quan, C.Q.; Wang, M.; Ren, F.J. An Unsupervised Text Mining Method for Relation Extraction from Biomedical Literature. PLoS ONE 2014, 9, e102039. [Google Scholar] [CrossRef]
- Brin, S. Extracting Patterns and Relations from the World Wide Web; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1590, pp. 172–183. [Google Scholar]
- Hasegawa, T.; Sekine, S.; Grishman, R. Discovering relations among named entities from large corpora. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 415–422. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Zheng, S.C.; Hao, Y.X.; Lu, D.Y.; Bao, H.Y.; Xu, J.M.; Hao, H.W.; Xu, B. Joint entity and relation extraction based on a hybrid neural network. Neurocomputing 2017, 257, 59–66. [Google Scholar] [CrossRef]
- Li, P.F.; Mao, K.Z. Knowledge-oriented convolutional neural network for causal relation extraction from natural language texts. Expert Syst. Appl. 2019, 115, 512–523. [Google Scholar] [CrossRef]
- Ru, C.S.; Tang, J.T.; Li, S.S.; Xie, S.X.; Wang, T. Using semantic similarity to reduce wrong labels in distant supervision for relation extraction. Inform. Process. Manag. 2018, 54, 593–608. [Google Scholar] [CrossRef]
- Zeng, D.J.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Ren, X.; Wu, Z.Q.; He, W.Q.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J.W. CoType: Joint Extraction of Typed Entities and Relations with Knowledge Bases. In Proceedings of the 26th International Conference on World Wide Web (Www’17), Perth, Australia, 3–7 April 2017; pp. 1015–1024. [Google Scholar]
- Huang, Y.Y.; Wang, W.Y. Deep residual learning for weakly-supervised relation extraction. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 27 July 2017. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching Machines to Read and Comprehend. Adv. Neural Inf. Process. Syst. 2015, 28, 1693–1701. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. Adv. Neural Inf. Process. Syst. 2015, 28, 577–585. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.Y.; Xu, B. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Zgank, A.; Kacic, Z. Predicting the Acoustic Confusability between Words for a Speech Recognition System using Levenshtein Distance. Elektron Elektrotech. 2012, 18, 81–84. [Google Scholar] [CrossRef]
- Yan, Z.Q.; Wu, Q.; Ren, M.; Liu, J.Q.; Liu, S.W.; Qiu, S. Locally private Jaccard similarity estimation. Concurr. Comput. Pract. Exp. 2019, 31, e4889. [Google Scholar] [CrossRef]
- Ye, J. Improved cosine similarity measures of simplified neutrosophic sets for medical diagnoses. Artif. Intell. Med. 2015, 63, 171–179. [Google Scholar] [CrossRef] [Green Version]
- Hong, T.P.; Lin, C.W.; Yang, K.T.; Wang, S.L. Using TF-IDF to hide sensitive itemsets. Appl. Intell. 2013, 38, 502–510. [Google Scholar] [CrossRef]
- Alammary, A.S. Arabic Questions Classification Using Modified TF-IDF. IEEE Access 2021, 9, 95109–95122. [Google Scholar] [CrossRef]
- Larabi-Marie-Sainte, S.; Alnamlah, B.S.; Alkassim, N.F.; Alshathry, S.Y. A new framework for Arabic recitation using speech recognition and the Jaro Winkler algorithm. Kuwait J. Sci. 2022, 49. [Google Scholar] [CrossRef]
- Volz, J.; Bizer, C.; Gaedke, M.; Kobilarov, G. Discovering and Maintaining Links on the Web of Data. Lect. Notes Comput. Sci. 2009, 5823, 650–665. [Google Scholar]
- Vrandecic, D.; Krotzsch, M. Wikidata: A Free Collaborative Knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Niu, X.; Rong, S.; Wang, H.F.; Yu, Y. An effective rule miner for instance matching in a web of data. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October 2012; pp. 1085–1094. [Google Scholar]
- Zhang, D.K.; Yin, J.; Zhu, X.Q.; Zhang, C.Q. Network Representation Learning: A Survey. IEEE Trans. Big Data 2020, 6, 3–28. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, Kdd’16, San Francisco, CA, USA, 13 August 2016; pp. 855–864. [Google Scholar]
- Li, G.H.; Luo, J.W.; Wang, D.C.; Liang, C.; Xiao, Q.; Ding, P.J.; Chen, H.L. Potential circRNA-disease association prediction using DeepWalk and network consistency projection. J. Biomed. Inform. 2020, 112, 103624. [Google Scholar] [CrossRef] [PubMed]
- Bordes, A.; Usunier, N.; Garcia Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 5–10 December 2013; pp. 2787–2795. [Google Scholar]
- Ji, G.L.; Liu, K.; He, S.Z.; Zhao, J. Knowledge graph completion with adaptive sparse transfer matrix. In Proceedings of the 30th Association for the Advancement of Artificial Intelligence Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 985–991. [Google Scholar]
- Lin, Y.K.; Liu, Z.Y.; Sun, M.S.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Zhu, J.Z.; Jia, Y.T.; Xu, J.; Qiao, J.Z.; Cheng, X.Q. Modeling the Correlations of Relations for Knowledge Graph Embedding. J. Comput. Sci. Technol. 2018, 33, 323–334. [Google Scholar] [CrossRef]
- Li, S.Y.; Pan, R.; Luo, H.Y.; Liu, X.; Zhao, G.S. Adaptive cross-contextual word embedding for word polysemy with unsupervised topic modeling. Knowl.-Based. Syst. 2021, 218, 106827. [Google Scholar] [CrossRef]
- Wang, B.L.; Sun, Y.Y.; Chu, Y.H.; Yang, Z.H.; Lin, H.F. Global-locality preserving projection for word embedding. Int. J. Mach. Learn. Cybern. 2022, 13, 2943–2956. [Google Scholar] [CrossRef]
- Pan, F.Y.; Li, S.K.; Ao, X.; He, Q. Relation Reconstructive Binarization of word embeddings. Front. Comput. Sci. 2022, 16, 162307. [Google Scholar] [CrossRef]
- Wang, X.Z.; Zhang, H.; Liu, Y. Sentence Vector Model Based on Implicit Word Vector Expression. IEEE Access 2018, 6, 17455–17463. [Google Scholar] [CrossRef]
- Basirat, A.; Nivre, J. Real-valued syntactic word vectors. J. Exp. Theor. Artif. Intell. 2020, 32, 557–579. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation. Read. Cogn. Sci. 1988, 323, 318–362. [Google Scholar]
- Santos, R.; Murrieta-Flores, P.; Calado, P.; Martins, B. Toponym matching through deep neural networks. Int. J. Geogr. Inf. Sci. 2018, 32, 324–348. [Google Scholar] [CrossRef]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Zhou, C.H.; Wang, H.; Wang, C.S.; Hou, Z.Q.; Zheng, Z.M.; Shen, S.Z.; Cheng, Q.M.; Feng, Z.Q.; Wang, X.B.; Lv, H.R.; et al. Prospects for the research on geoscience knowledge graph in the Big Data Era. Sci. China Earth Sci. 2021, 64, 1105–1114. [Google Scholar] [CrossRef]
- Pillai, S.G.; Soon, L.K.; Haw, S.C. Comparing DBpedia, Wikidata, and YAGO for Web Information Retrieval. Lect. Note Netw. Syst. 2019, 67, 525–535. [Google Scholar]
- Farber, M.; Bartscherer, F.; Menne, C.; Rettinger, A. Linked Data Quality of DBpedia, Freebase, OpenCyc, Wikidata, and YAGO. Semant. Web 2018, 9, 77–129. [Google Scholar] [CrossRef]
- Das, A.; Mitra, A.; Bhagat, S.N.; Paul, S. Issues and Concepts of Graph Database and a Comparative Analysis on list of Graph Database tools. In Proceedings of the 2020 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 22–24 January 2020; pp. 353–358. [Google Scholar]
- Vigo, M.; Matentzoglu, N.; Jay, C.; Stevens, R. Comparing ontology authoring workflows with Protege: In the laboratory, in the tutorial and in the ‘wild’. J. Web Semant. 2019, 57, 100473. [Google Scholar] [CrossRef]
- Chen, C.M.; Hu, Z.G.; Liu, S.B.; Tseng, H. Emerging trends in regenerative medicine: A scientometric analysis in CiteSpace. Expert Opin. Biol. Ther. 2012, 12, 593–608. [Google Scholar] [CrossRef]
- Gong, F.; Wang, M.; Wang, H.F.; Wang, S.; Liu, M.Y. SMR: Medical Knowledge Graph Embedding for Safe Medicine Recommendation. Big Data Res. 2021, 23, 100174. [Google Scholar] [CrossRef]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Hao, Y.C.; Zhang, Y.Z.; Liu, K.; He, S.Z.; Liu, Z.Y.; Wu, H.; Zhao, J. An End-to-End Model for Question Answering over Knowledge Base with Cross-Attention Combining Global Knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Acl 2017), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 221–231. [Google Scholar]
- Gajendran, S.; Manjula, D.; Sugumaran, V. Character level and word level embedding with bidirectional LSTM—Dynamic recurrent neural network for biomedical named entity recognition from literature. J. Biomed. Inform. 2020, 112, 103609. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Grishman, R. Relation Extraction: Perspective from Convolutional Neural Networks. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 31 May 2015; pp. 39–48. [Google Scholar]
- Zhang, D.X.; Wang, D. Relation Classification via Recurrent Neural Network. arXiv 2015, arXiv:1508.01006v1. [Google Scholar]
- Wang, Z.H.; Wang, D.; Li, Q. Keyword Extraction from Scientific Research Projects Based on SRP-TF-IDF. Chin. J. Electron. 2021, 30, 652–657. [Google Scholar]
- Sun, G.; Lv, H.Z.; Wang, D.Y.; Fan, X.P.; Zuo, Y.; Xiao, Y.F.; Liu, X.; Xiang, W.Q.; Guo, Z.Y. Visualization Analysis for Business Performance of Chinese Listed Companies Based on Gephi. Comput. Mater. Contin. 2020, 63, 959–977. [Google Scholar]
- Wutiepu, W.; Yang, Y.C.; Han, S.J.; Guo, Y.F.; Nie, S.J.; Liu, C.; Fan, W.L. Zircon U-Pb age, Hf isotope, and geochemistry of Late Permian to Triassic igneous rocks from the Jiapigou gold ore belt, NE China: Petrogenesis and tectonic implications. Geol. J. 2020, 55, 501–516. [Google Scholar] [CrossRef]
- Hovy, E.; Lin, C. Automated text summarization and the SUMMARIST system. In Proceedings of the TIPSTER ‘98, Baltimore, MD, USA, 13–15 October 1998; pp. 197–214. [Google Scholar]
- Piantadosi, S.T. Zipf’s word frequency law in natural language: A critical review and future directions. Psychon. B Rev. 2014, 21, 1112–1130. [Google Scholar] [CrossRef] [Green Version]
- Ye, T.Z.; Lv, Z.C.; Pang, Z.S.; Zhang, D.H.; Liu, S.Y.; Wang, Q.M.; Liu, J.J.; Cheng, Z.Z.; Li, C.L.; Xiao, K.Y.; et al. Metallogenic Prognosis Theories and Methods in Exploration Areas, 1st ed.; Geological Publishing House: Beijing, China, 2014; pp. 1–703. (In Chinese) [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Category | Beginning of an Entity | Inside of an Entity | Number of Entities in Training Dataset | Number of Entities in Validation Dataset | Number of Entities in Test Dataset |
|---|---|---|---|---|---|
| Deposit type | B-deposit_type | I-deposit_type | 278 | 6 | 19 |
| Dyke | B-dyke | I-dyke | 1326 | 139 | 176 |
| Extrusive rock | B_extrusive_rock | I-extrusive_rock | 129 | 18 | 6 |
| Fault character | B-fault_character | I-fault_character | 672 | 50 | 83 |
| Formation | B-formation | I-formation | 196 | 33 | 24 |
| Geological time scale | B-geological_time_scale | I-geological_time_scale | 1600 | 302 | 165 |
| Geotectonic location | B-geotectonic_location | I-geotectonic_location | 620 | 163 | 66 |
| Group | B-group | I-group | 340 | 36 | 33 |
| Intrusive rock | B-intrusive_rock | I-intrusive_rock | 1050 | 239 | 71 |
| Location | B-location | I-location | 1014 | 91 | 113 |
| Metallogenic stage | B-metallogenic_stage | I-metallogenic_stage | 120 | 2 | 29 |
| Metamorphic rock | B-metamorphic_rock | I-metamorphic_rock | 1451 | 200 | 90 |
| Mineral | B-mineral | I-mineral | 2705 | 191 | 482 |
| Name of the deposit | B-deposit | I-deposit | 2296 | 185 | 340 |
| Orebody shape | B-orebody_shape | I-orebody_shape | 1040 | 44 | 228 |
| Pluton | B-pluton | I-pluton | 112 | 8 | 4 |
| Regional fault | B-regional_fault | I-regional_fault | 110 | 27 | 22 |
| Secondary fault | B-secondary_fault | I-secondary_fault | 264 | 45 | 17 |
| Sedimentary rock | B-sedimentary | I-sedimentary | 105 | 18 | 13 |
| Wall rock alteration | B-wall_rock_alteration | I-wall_rock_alteration | 797 | 48 | 136 |
| Operating System | Windows 10 |
|---|---|
| CPU | Intel Core i9-10900F @ 2.80 GHz |
| GPU | Nvidia GeForce RTX 3080 (10 GB) |
| Python | 3.6 |
| Pytorch | 1.7.0 |
| Hyperparameters | Value |
|---|---|
| Batch size | 128 |
| Learning rate | 0.001 |
| Epochs | 250 |
| Character embedding dimension | 100 |
| The number of hidden units | 128 |
| Dropout rate | 0.5 |
| Optimizer | Adam |
| Model | ACC (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| MHH | 95.32 | 66.26 | 80.17 | 72.55 |
| CRF | 99.16 | 94.62 | 93.25 | 93.93 |
| Bi-LSTM | 99.09 | 91.70 | 94.65 | 93.15 |
| Bi-LSTM-CRF | 99.27 | 97.01 | 96.83 | 96.92 |
| Relation Category | Number of Triples | ||
|---|---|---|---|
| Training Dataset | Validation Dataset | Test Dataset | |
| associated_with | 23 | 4 | 3 |
| belongs_to | 86 | 8 | 17 |
| contains | 565 | 86 | 97 |
| controls | 93 | 15 | 10 |
| deposit_type | 60 | 8 | 9 |
| dyke | 557 | 81 | 90 |
| extrusive_rock | 3 | 1 | 3 |
| fault_character | 276 | 48 | 56 |
| formation | 86 | 10 | 11 |
| formed_in | 244 | 35 | 42 |
| geologic_time_scale | 422 | 64 | 53 |
| geotectonic_location | 120 | 16 | 15 |
| Group | 131 | 22 | 22 |
| intrusive_rock | 177 | 37 | 39 |
| located_in | 46 | 11 | 12 |
| metallogenic_stage | 45 | 11 | 9 |
| metamorphic_rock | 302 | 53 | 55 |
| Mineral | 584 | 101 | 97 |
| occurs_in | 543 | 94 | 85 |
| orebody_shape | 118 | 22 | 17 |
| Other | 55,057 | 9206 | 9195 |
| pluton | 24 | 4 | 5 |
| regional_fault | 26 | 6 | 2 |
| secondary_fault | 153 | 24 | 21 |
| wall_rock_alteration | 259 | 44 | 35 |
| Hyperparameters | Value |
|---|---|
| Batch size | 32 |
| Learning rate | 0.001 |
| Epochs | 100 |
| Word embedding dimension | 50, 100, 200 |
| Size of hidden state | 256 |
| Size of position embedding | 50 |
| Dropout_rate | 0.5 |
| Optimizer | adadelta |
| Word Embedding Dimension | Model | ACC (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|
| 50 | CNN | 97.95 | 88.96 | 82.21 | 85.46 |
| 100 | 98.19 | 87.18 | 88.81 | 87.99 | |
| 200 | 98.27 | 87.15 | 90.30 | 88.70 | |
| 50 | Bi-LSTM + Pooling | 98.25 | 86.82 | 90.92 | 88.82 |
| 100 | 98.40 | 89.84 | 89.05 | 89.44 | |
| 200 | 98.36 | 87.16 | 92.04 | 89.53 | |
| 50 | Att-Bi-LSTM | 98.59 | 90.06 | 90.17 | 90.12 |
| 100 | 98.48 | 88.21 | 92.16 | 90.15 | |
| 200 | 98.67 | 90.73 | 91.29 | 91.01 |
| Name | Labeled Dataset | Unlabeled Dataset | Total |
|---|---|---|---|
| Number of entities | 20,187 | 25,514 | 45,701 |
| Number of relations | 80,011 | 101,049 | 181,060 |
| Number of predefined relations | 6553 | 8803 | 15,356 |
| Number of sentences | 7014 | 8802 | 15,816 |
| Number of characters | 527,449 | 671,489 | 1,198,938 |
| Model | Threshold | ACC (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|
| Edit distance | 0.670 | 93.14 | 95.15 | 97.53 | 96.32 |
| Word vector | 0.965 | 85.94 | 92.18 | 92.53 | 92.36 |
| The proposed method | 0.670 | 93.21 | 95.03 | 97.72 | 96.36 |
| Number | TF-IDF | Deposit | Geological Characteristics Entities |
|---|---|---|---|
| 1 | 0.632 | Songjianghe | Seluohe Group, Jurassic, Permian, ductile fault, Jinyinbie fault, Proterozoic, Dunhua City, schist, Triassic, brittle–ductile fault |
| 2 | 0.446 | Banmiaozi | Diorite, Zhenzhumen Formation, Diaoyutai Formation, fault breccia, Jiapigou block, diabase, marble, granite, Jiapigou fault, Huadian City |
| 3 | 0.432 | Laoniugou | Jiapigou block, gneiss, Laoniugou Formation, Archean, granulite, amphibolite, Sandaogou Formation, granite, diorite, quartzite |
| 4 | 0.431 | Liupiye | Granite, brittle–ductile fault, Archean, diorite, diabase, Jiapigou block, gabbro, Jurassic, Mesozoic, Biotite |
| 5 | 0.403 | Yuanchaogou | Pyrite, quartz vein, galena, Au-bearing quartz vein, sphalerite, Huadian City, Jiapigou block, Laoniugou Formation, lamprophyre, chalcopyrite |
| 6 | 0.399 | Damiaozi | Granite, Jiapigou fault, Huadian City, Jiapigou block, ductile fault, Sandaogou Formation, granodiorite, Archean, lamprophyre, breccia |
| 7 | 0.393 | Daxiangou | Archean, Jiapigou granite-greenstone belt, lenticular, ductile fault, diorite, granite porphyry, brittle fault, Jiapigou block, Daxiangou syncline, vein |
| 8 | 0.390 | Xiaobeigou | Gneiss, Jiapigou block, granite, quartz vein-type, quartz vein, Archean, ductile fault, quartz, Jiapigou fault, Jiapigou Group |
| 9 | 0.385 | Erdaogou | Diorite, quartz vein, gneiss, quartz, Archean, Jiapigou block, zircon, quartz vein-type, granodiorite, granite |
| 10 | 0.370 | Jiapigou | Archean, Mesozoic, granite, ductile fault, Jiapigou block, Jiapigou fault, quartz vein, Huadian City, quartz, gneiss |
| 11 | 0.353 | Caiqiangzi | Schist, mylonite, Jiapigou fault, compressional structure, Huadian City, diabase, Archean, granite, silicification, granodiorite |
| 12 | 0.351 | Bajiazi | Granite porphyry, pyrite, quartz, diorite, zircon, Triassic, quartz vein, granite aplite, quartz vein-type, Biotite |
| 13 | 0.344 | Sidaocha | Quartz vein, Archean, Au-bearing quartz vein, quartz vein-type, granite porphyry, gneiss, Jiapigou fault, diorite, amphibolite, Sandaogou Formation |
| 14 | 0.313 | Sandaocha | Brittle fault, granite porphyry, quartz vein, diorite, quartz vein-type, quartz, ductile fault, Archean, pyrite, Jiapigou fault |
| Deposit | Jiapigou | Liupiye | Songjianghe |
|---|---|---|---|
| Country rocks | Gneiss, hornblende, mylonite, TTGs | Gneiss, mylonite, TTGs | Mylonite, gneiss, hornblende, TTGs |
| Intrusive rocks and dykes | Granite, quartz vein, diorite, granite porphyry, granite pegmatite, granodiorite, Au-bearing quartz vein | Granite, diorite, diabase dyke, gabbro, granodiorite, granodiorite, granite porphyry, Au-bearing quartz vein | Granite porphyry, diorite, granite, granodiorite |
| Structures | Jiapigou fault, Huiquanzhan fault, Jinyinbie fault, Xing’antun circular structure | Jiapigou fault, Xing’antun circular structure | Jinyinbie fault, Jiapigou fault, Langcaihe anticline |
| Mineralization types | Quartz vein-type | Altered rock-type | Altered rock-type |
| Metal minerals | Pyrite, sphalerite, galena, chalcopyrite, magnetite | Pyrite, chalcopyrite, galena | Pyrite, molybdenite, chalcopyrite, sphalerite |
| Ore body shapes | Vein, stratiform-like, lenticular | Vein | Vein |
| Wall rock alterations | Silicification, sericitization, chloritization, potassium, pyritization | Pyritization, clayization, carbonatization, sericitization, potassium, mylonitization | Silicification, sericitization, mylonitization, carbonatization, chloritization, epidotization, potassium, pyritization, boilerization |
| Main metallogenic stages | Quartz-pyrite stage, polymetallic sulfide stage | Quartz-pyrite stage, polymetallic sulfide stage | Quartz-pyrite stage, polymetallic sulfide stage |
| Regional Prospecting Criteria | |
|---|---|
| Country rocks | TTGs, amphibolite, gneiss, Mesozoic granite. |
| Wall rock alterations | Silicification, carbonation, sericitization, chloritization, pyritization |
| Dykes | Syenite porphyry, lamprophyre, diabase, diorite, diorite porphyrite |
| Minerals | Natural gold, pyrrhotite, pyrite, chalcopyrite, galena, sphalerite |
| Strata | Jiapigou Group, Seluohe Group |
| Structures | Jiapigou fault, Jinyinbie fault |
| Ore body shape | Vein |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pei, Y.; Chai, S.; Li, X.; Samuel, J.C.; Ma, C.; Chen, H.; Lou, R.; Gao, Y. Construction and Application of a Knowledge Graph for Gold Deposits in the Jiapigou Gold Metallogenic Belt, Jilin Province, China. Minerals 2022, 12, 1173. https://doi.org/10.3390/min12091173
Pei Y, Chai S, Li X, Samuel JC, Ma C, Chen H, Lou R, Gao Y. Construction and Application of a Knowledge Graph for Gold Deposits in the Jiapigou Gold Metallogenic Belt, Jilin Province, China. Minerals. 2022; 12(9):1173. https://doi.org/10.3390/min12091173
Chicago/Turabian StylePei, Yao, Sheli Chai, Xiaolong Li, Jofrisse Cremilda Samuel, Chengyou Ma, Haonan Chen, Renxing Lou, and Yu Gao. 2022. "Construction and Application of a Knowledge Graph for Gold Deposits in the Jiapigou Gold Metallogenic Belt, Jilin Province, China" Minerals 12, no. 9: 1173. https://doi.org/10.3390/min12091173
APA StylePei, Y., Chai, S., Li, X., Samuel, J. C., Ma, C., Chen, H., Lou, R., & Gao, Y. (2022). Construction and Application of a Knowledge Graph for Gold Deposits in the Jiapigou Gold Metallogenic Belt, Jilin Province, China. Minerals, 12(9), 1173. https://doi.org/10.3390/min12091173