In the present paper, we generalize these probability distributions by introducing two new inputs, which are the following:
3.1. Random Solution and Random Approximations of Deterministic Partial Differential Equation
The purpose of this section is based of the following fundamental remark: the solution u to the variational problem (VP), except for particular cases, is totally unknown (being impossible to calculate it analytically); this motivates the numerical schemes one will choose to implement.
This inability to determine, in most cases, the exact solution u is mainly due to the complexity of the involved PDE’s operator; it indeed depends on complex combinations of integrals, partial derivatives and boundary conditions, as well as on the bent geometrical shape of the domain of integration . All of these ingredients hence participate in the incapability to analytically determine exact solution u as their relationship with u is inextricable and unknown.
As a consequence, this lack of knowledge and information regarding the dependency between these ingredients and solution u motivates us to consider u as a random variable, as well as any function of u. This paper is dedicated to the approximation error of , considered as a random variable.
In this frame, we view solution u with respect to variational formulation (VP) defined by (1) in the same manner as it normally is viewed to consider the trajectory and contact point with the ground of any solid body that is thrown, i.e., as random. Indeed, in this case, due to the lack of information concerning the initial conditions of the trajectory of the body, the solution of the concerned inverse kinematic operator is inaccessible and is, thus, observed as a random variable.
In the case analyzed in this paper, the situation is much worse. Indeed, we investigate a general variational formulation (VP) where the analog of the inverse kinematic operator is too complex to enable us to analytically determine the corresponding solution of (VP) by any mathematical expression. It is one of the reasons that motivate us to view solution u and its approximation as random variables, since the corresponding approximate operator conserves the complexity of the original one described above.
3.2. The Probabilistic Distribution of the Relative Finite Elements Accuracy
In the previous section, we expressed the reason for why we consider solution u and its approximation as random variables.
In order to complete the description of the randomness feature of approximation error , we also remark that since the manner a given mesh grid generator will produce any mesh is random, the corresponding approximation is random too.
For all of these reasons, based on the error estimate (12) and (13), we can only affirm that the value of approximation error is somewhere within interval .
As a consequence, we decide to view norm as a random variable defined as follows.
Let
and
p be fixed. We introduce the random variable
defined by the following.
Thus, space product plays the role of the usual probability space introduced in this context.
Now, regarding the absence of information concerning the more likely or less likely values of norm
within interval
, we assume that random variable
is uniformly distributed over interval
with the following meaning.
Equation (18) means that if one slides interval anywhere in , the probability of event does not depend on where interval is located in , but only on its length; this corresponds to the property of uniformity of random variable .
Let us now consider two families of Lagrange finite elements and corresponding to a set of values such that .
The two corresponding inequalities given by (12) and (13), assuming that solution
u to (
VP) belong to
, are as follows:
where
and
, respectively, denote
and
Lagrange finite element approximations of
u and
as defined by (13).
Remark 2. If one considers a given mesh for finite element that contains that of , then for the particular class of problems where is equivalent to a minimization formulation (see for example [11]), one can show that the approximation error of the finite element is always smaller than that of , and is more accurate than for all values of the mesh size h. Therefore, in order to avoid this situation, for a given value of h, we consider two independent meshes built by a mesh generator for and . Now, usually, in order to compare the accuracy between these two finite elements, one asymptotically considers inequalities (19) and (20) to conclude that, when h proceeds to zero, is more accurate than , since proceeds faster to zero than .
However, for a given application, h has a given and fixed value; thus, this method of comparison is not valid anymore. For this reason, our purpose is to determine the relative accuracy between two finite elements and for a fixed value of h corresponding to two independent meshes.
Moreover, since we chose to consider two random variables as uniformly distributed on their respective interval of values , we also assume that they are independent. This assumption is, once again, the result of the lack of information which led us to model the relationship between these two variables as independent, since any knowledge is available for more precisely localizing the value of if the value of was known and vice versa.
By the following result, we establish the density of probability of the random variable Z defined by the following: .
Theorem 1. Let be the two uniform and independent random variables defined by (16) and (17): , where is defined by (13).
Then, random variable Z defined on has the following density of probability. Proof. Let us now remark that since the support of two random variables is , the support of density is, therefore, , which corresponds to (21).
Let us consider the case where .
If
denotes the density of probability defined on
associated to each random variable
, since we assume that they are independent variables, density
is given by the following:
where
and
is the indicator function of the interval
.
Furthermore, due to the definition (27) of the density for each variable
the integrand of (26) can be expressed as follows:
As a consequence, , which leads one to consider the five following cases corresponding to the significant relative positions between intervals and :
Let us assume that . If , then and , which is again a result of (21);
We consider now the values of z such that and .
If
, then
and by (26) we obtain the expected expression of (25) since we have the following.
The following case concerns the values of
z such that
and
. If
, then
and we obtain (23) since the following is the case.
If and , then , which is impossible since .
We consider now the values of z such that and .
If
, then
and since we have the following:
we obtain the expected expression of (22).
Finally, if , then and , which corresponds to (21).
The other cases corresponding to can be deduced by using the same arguments. □
From Theorem 1, one can infer the entire cumulative distribution function
defined by the following.
However, since we are interested in determining the more likely finite element between and , we focus the following corollary to the value of , which corresponds to .
Corollary 1. Let be the two uniform and independent random variables defined by (16)–(17): , where is defined by (13). Then, we have: Proof.
- —
Let us consider the case where
. Then, by definition (33) of the entire cumulative distribution function
, at
, we have the following:
where we used the values of the density
given by (22) and (23).
- —
In the same manner, when
, we have the following.
□
We can now explicate the probability distribution of event given by (34) and (35) as a function of the mesh size h.
To this end, we remark that, since each has two possible values depending on the relative position between h and defined by (14), the probability distribution we are looking for must be splitted in the corresponding cases as well.
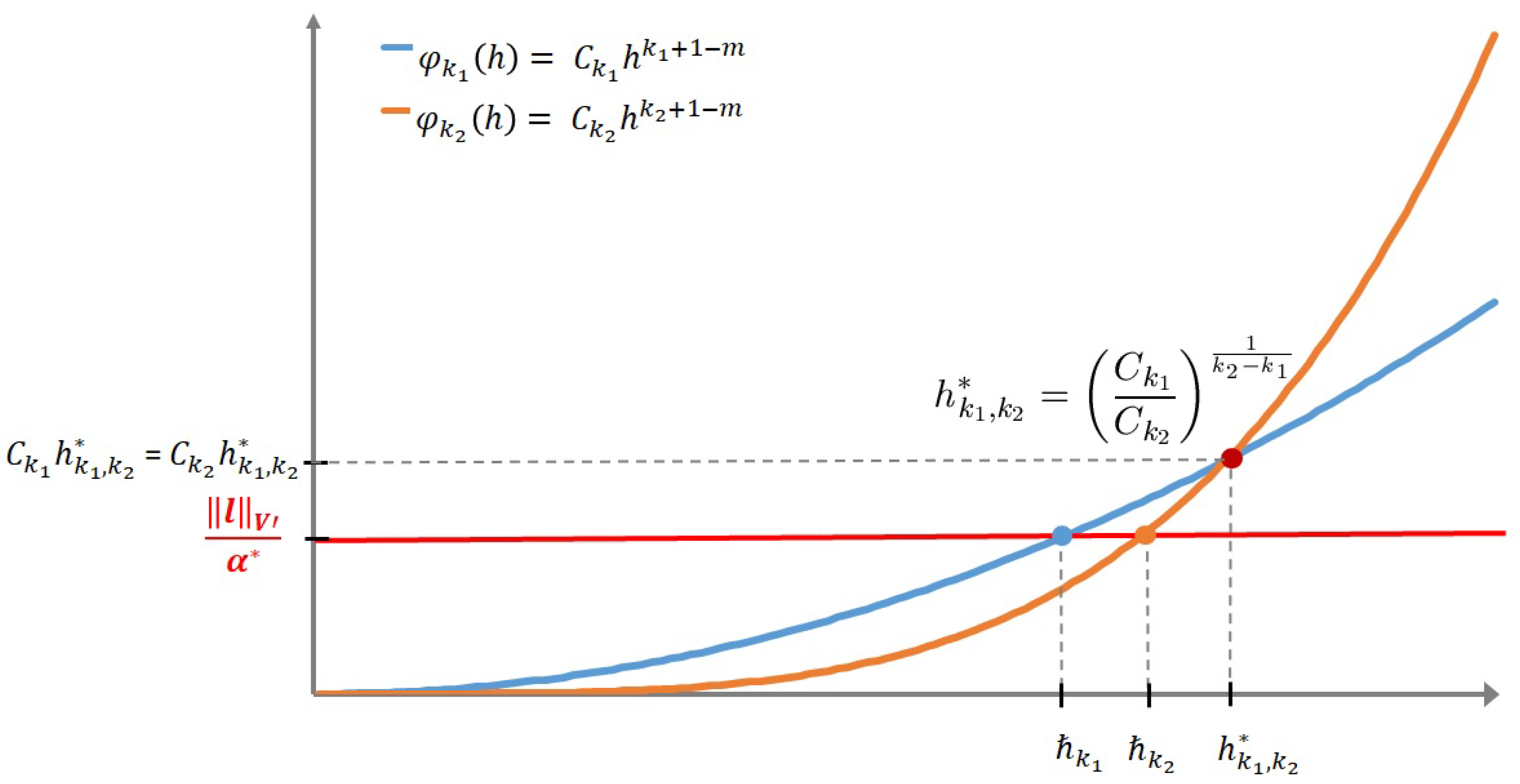
Let us, hence, introduce constants
defined by the following:
and the specific value
of
h which corresponds to the intersection of the curves
defined by
(see
Figure 1).
Then, we have the following.
We notice that and strongly depend on m and p, since and depend on these two parameters as well. As a consequence, in the following theorem, the different formulas of will contain this dependency on m and p.
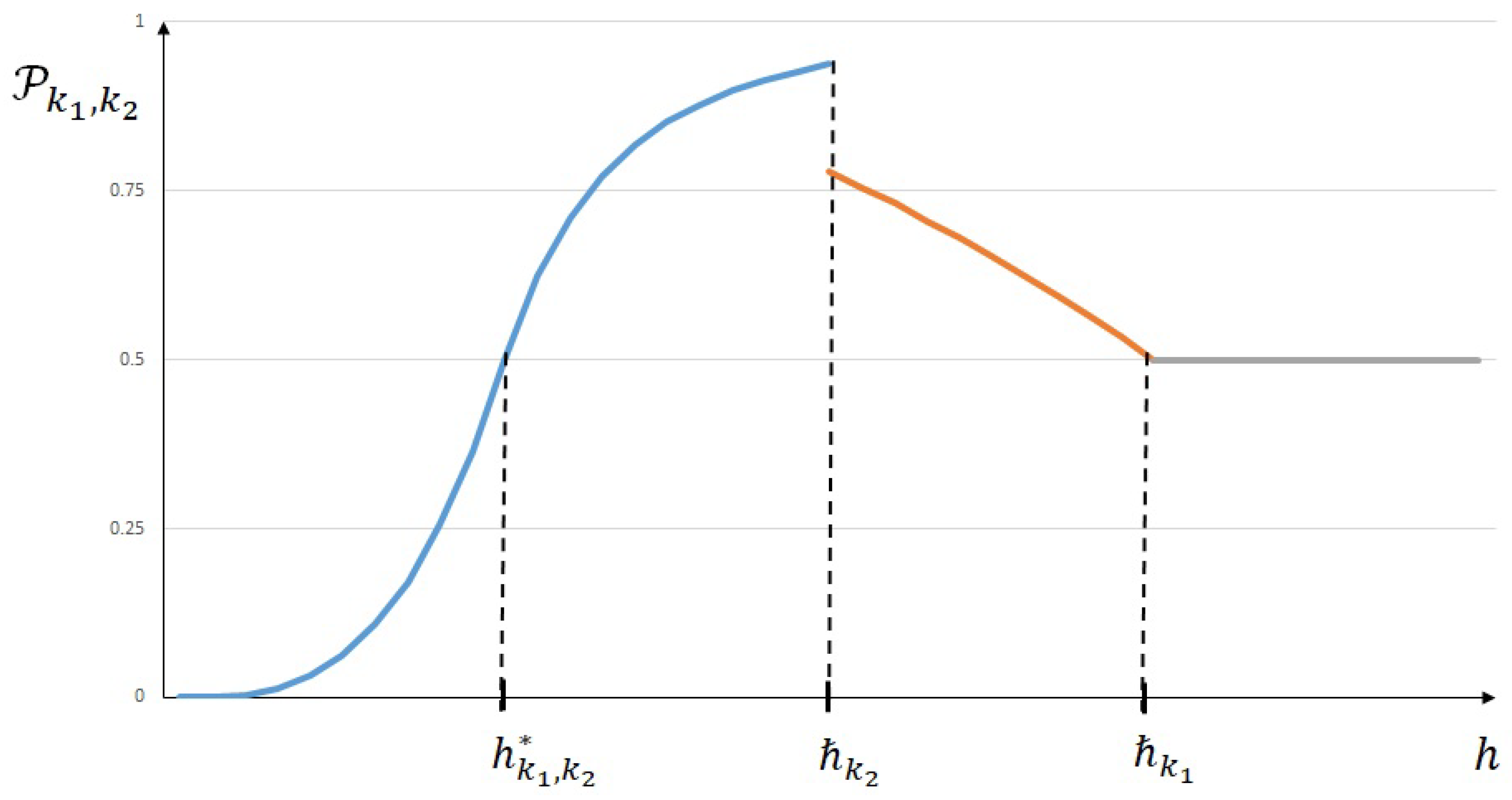
Theorem 2. Let be the two uniform and independent random variables defined by (16) and (17). Then, is determined by the following.
If , then and we have: If , then and the following. Proof. In order to establish the proof of Theorem 2, we will consider a geometrical interpretation of error estimate (19) and (20).
These two inequalities can indeed be geometrically viewed with the help of the relative position between the two curves
introduced above and the horizontal line defined by
(see
Figure 1).
Then, depending on the position of the horizontal line with particular value we have to consider the two following cases:
- —
If , then ;
- —
If , then .
Thus, let us consider the first case when or equivalently . Therefore, due to the relative positions between the three curves and , we have the following results:
and with . Then, from (35), we obtain (40);
and with and . Then, again from (35), we obtain (41);
and . Then, from (34) or (35), we obtain (42);
and . Then, again from (34) or (35), we also obtain (42).
We now consider the case where which corresponds to . Therefore, using once again the relative positions between curves and , we deduce the following results:
and with . Then, from (35), we obtain (43);
and with . Then, from (34), we obtain (44);
and with and . Then, again from (34), we obtain (45);
and . Then, from (34) or (35), we obtain (46).
□
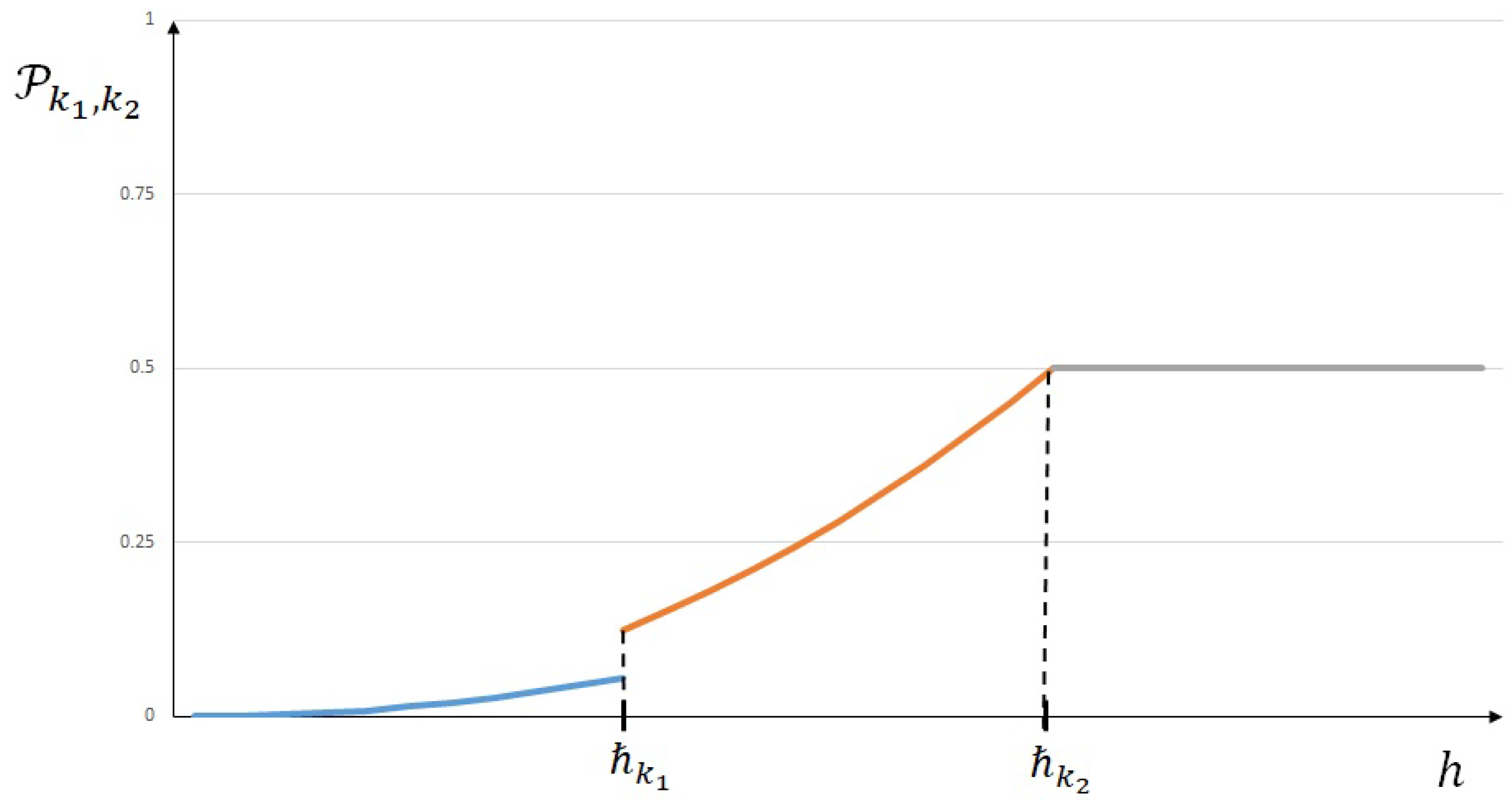
Remark 3. We notice that the probability distribution given by Theorem 2 generalizes those that we found in [1,6]. Indeed, when we derived probability distribution without taking into account the a priori estimates (2) and (4), we obtained the following. In this case, we showed in [12] two numerical examples based on PDE’s formulation where exact solutions may be computed to illustrate probabilistic law (47) and (48). In particular, we highlighted the statistical methodology that enabled us to determine a statistical estimator of the threshold given by (39).
Based on this study, one may adapt it in order to obtain applications that will illustrate the new probabilistic value we derived in Theorem 2.
Moreover, in Theorem 2, the contribution of a priori estimates (2) and (4) modifies the probability distribution given by (47) and (48), since the horizontal line interferes with the two polynomials (see Figure 1). This phenomenon will be analyzed in the following section.


{kind=link}
{kind=link}
{kind=link}
{kind=link}



