
An Improved Evaluation Methodology for Mining Association Rules


Abstract
:1. Introduction
- (1)
- This paper firstly expounds several aspects of association rules and then makes a summary of relevant research results on the objective interestingness measure of association rules. At the same time, we find that all have some defects and problems by discussing and comparing the various measurement methods of association rules.
- (2)
- Then, we proposed four more effective measurement methods of association rules (Bi-support, Bi-lift, Bi-improvement, and Bi-confidence) based on the improvement of some methods. The Bi-confidence method makes an adjustment to the non-occurrence possibility of an antecedent based on the Confidence.
- (3)
- Through the experimental analysis, we propose a novel measure framework (Bi-support and Bi-confidence framework) to improve the traditional one.
2. A Review of Relevant Research on Association Rules
2.1. Algorithm of Association Rules
2.2. Application of Association Rules
2.3. Evaluation Method of Association Rules
2.4. Evaluation Method and Framework of Association Rules
3. Review on Interestingness Measure Indicators for Association Rules
3.1. Support and Confidence
3.2. Lift
3.3. Validity
3.4. Conviction
3.5. Improvement
3.6. Chi-Square Analysis
4. The Improvement of Objective Interestingness Measures
4.1. Bi-Support
- (1)
- Supp() min supp.;
- (2)
- Supp() min supp.
4.2. Bi-Lift
4.3. Bi-Improvement
4.4. Bi-Confidence
5. The Bi-Directional Measure Framework of Association Rules and Experimental Analysis
5.1. Numerical Analysis of Simulated Data Sets
- (a)
- Support conditions (Bi-support):
- (b)
- Confidence conditions:
- (c)
- Bi-confidence conditions:
| Algorithm 1: Pseudocode of the proposed measure framework. |
| INPUT: Shopping lists OUTPUT: High value association rules Step1: Calculate frequent 1-itemsets L1. Step2: Find frequent 2-itemsets L2 with L1: l1 ⋈ l2, namely ); Step3: Calculate the Bi-support of the association rules: (1) SuppSupport threshold (min Supp.) (2) Supp(Support threshold (min Supp.) Step4: Calculate the Confidence of the association rules, namely Conf): ConfConfidence threshold (min Conf.) Step5: Calculate the Bi-confidence of the association rules, namely Bi-conf): Bi-confBi-confidence threshold (min Bi-conf.) Step6: Output the high value association rules. |
- (1)
- The traditional Support-Confidence framework can exclude most of the irrelevant association rules. When the Support threshold and Confidence threshold are low, it can bring about the combination explosion, and with low constraints, it can also give rise to a number of frequent patterns which have little correlation with it, and can even produce some rules which are either negatively correlated or totally wrong. On the contrary, when the Support threshold and Confidence threshold are high, some interesting rules and fresh knowledge that users show great interest in will be filtered out because of data sparsity.
- (2)
- The Validity (Val.) is not effective and differs greatly from other measurement methods. There are eight rules whose values are incorrectly estimated by the Validity method in Table 5. Rules F→J (val. = 0.3) and F→R(val. = 0.3) are in fact irrelevant, while rules, such as F→G (val. = 0.3), G→N (val. = 0.2), G→F (val. = 0.2), and N→G (val. = 0.1), may have some restraining influences. The Validity of rule I→F and rule M→F are both 0, but they are actually positively related.
- (3)
- As the value domain of Conviction (conv.) is the value of Conviction being “1” implies that “A” have no relation with “B”, and, here, “1” means independence. Additionally, the greater the value of Conviction is, the higher Interest the rule will have. Values in [0, 1) represent a negative correlation; thus, lots of valuable association rules will be excluded. For example, in Table 1, < 1 and < 1 both have a low value of Conviction, but, in fact, it is still possible to find high interest in the rule and the rule . Moreover, it is supposed to meet the requirement of at the same time, and thus, the values of many rules cannot be calculated.
- (4)
- The evaluation result of Lift is satisfactory. However, obviously, Lift puts event A and event B in equivalent positions, that is to say, Lift() is equivalent to Lift(). Once we accept rule , rule should also be accepted, which is sometimes against the fact. Thus, under such circumstances, we propose Bi-lift to solve this problem. However, Bi-lift also has its own problem since it has to satisfy two conditions. One is , and the other is that both A and B are not a certain event or an impossible event. Its value domain is .
- (5)
- Shortcomings of Improvement (Imp.) are obvious. Firstly, it is hard to figure out what level of improvement is needed to make a difference. Secondly, the probability of the antecedent’s occurrence will greatly affect the Improvement evaluation in such a way that when it is high, the value of Improvement will be very small all the time. Thus, it is difficult to distinguish valuable rules, and it is likely to make an inaccurate value evaluation. Chi-square analysis (Csa.) is proposed based on the Improvement (Imp.). However, the evaluation results indicate that it eventually fails to solve the problem of improvement, and its evaluation performance is not as good as that of Bi-improvement. Therefore, this paper puts forward Bi-Improvement aimed at evaluating the value of rules in a more accurate way.
- (6)
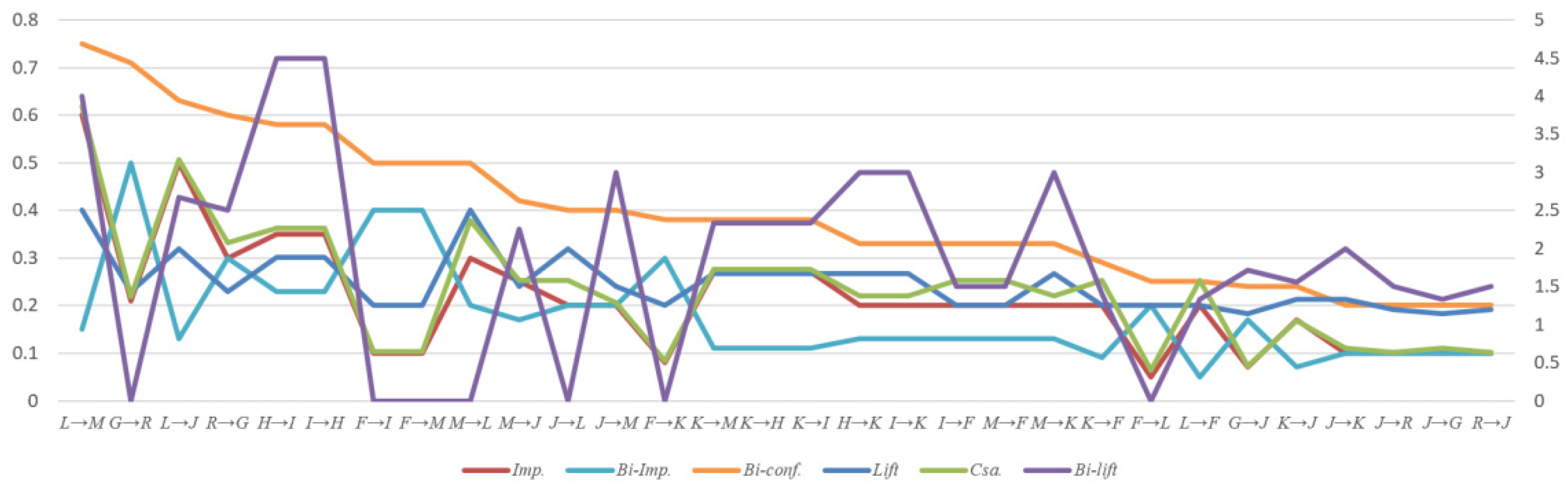
- The evaluation results of the author’s “Bi-confidence”, which is adjusted by the nonoccurrence probability of the antecedent, will increase the differentiation and accuracy. The novel Bi-support and Bi-confidence framework is more efficient than the traditional Support-confidence framework. The comparative results of the two different frameworks are shown in Table 7. There are nine rules that are useless (five rules have a negative correlation, and four rules have no correlation) in the Support-confidence framework. The new framework retains 12 high-value association rules of the old framework and reduces 32 non-value association rules. The high-value association rules are shown in Table 8 and Table 9. Evaluation results and comparisons of Improvement (Imp.), Bi-improvement (Bi-Imp.), Bi-confidence (Bi-conf.), Lift, Chi-square analysis (Csa.), and Bi-lift are shown in Figure 1.
5.2. Verification Analysis of Public Data Sets
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Herawan, T.; Dens, M. A Soft Set Approach for Association Rules Mining. Knowl.-Based Syst. 2011, 24, 186–195. [Google Scholar] [CrossRef]
- Kaushik, M.; Sharma, R.; Peious, S.; Shahin, M.; Yahia, S.; Draheim, D. A Systematic Assessment of Numerical Association Rule Mining Methods. SN Comput. Sci. 2021, 2, 348. [Google Scholar] [CrossRef]
- Zhao, Z.; Jian, Z.; Gaba, G.; Alroobaea, R.; Masud, M.; Rubaiee, S. An improved association rule mining algorithm for large data. J. Intell. Syst. 2021, 30, 750–762. [Google Scholar] [CrossRef]
- Wang, H.; Gao, Y. Research on parallelization of Apriori algorithm in association rule mining. Procedia Comput. Sci. 2021, 183, 641–647. [Google Scholar] [CrossRef]
- Telikani, A.; Gandomi, A.; Shahbahrami, A. A survey of evolutionary computation for association rule mining. Inf. Sci. 2020, 524, 318–352. [Google Scholar] [CrossRef]
- Fowler, J.H.; Laver, M. A Tournament of Party Decision Rules. J. Confl. Resolut. 1998, 52, 68–92. [Google Scholar] [CrossRef]
- Varija, B.; Hegde, N.P. An Association Mining Rules Implemented in Data Mining. Smart Innov. Syst. Technol. 2021, 225, 297–303. [Google Scholar]
- Srikand, B.R. Mining generalized association rules. Future Gener. Comput. Syst. 1997, 13, 161–180. [Google Scholar] [CrossRef]
- Arour, K.; Belkahla, A. Frequent Pattern-growth Algorithm on Multi-core CPU and GPU Processors. J. Comput. Inf. Technol. 2014, 22, 159–169. [Google Scholar] [CrossRef] [Green Version]
- Tseng, M.C.; Lin, W.Y.; Jeng, R. Incremental Maintenance of Generalized Association Rules under Taxonomy Evolution. J. Inf. Sci. 2008, 34, 174–195. [Google Scholar] [CrossRef]
- Marijana, Z.S.; Adela, H. Data Mining as Support to Knowledge Management in Marketing. Bus. Syst. Res. 2015, 6, 18–30. [Google Scholar]
- Chen, M.C. Ranking Discovered Rules from Data Mining with Multiple Criteria by Data Envelopment Analysis. Expert Syst. Appl. 2007, 33, 1100–1106. [Google Scholar] [CrossRef]
- Toloo, M.; Sohrabi, B.; Nalchigar, S. A New Method for Ranking Discovered Rules from Data Mining by DEA. Expert Syst. Appl. 2009, 36, 8503–8508. [Google Scholar] [CrossRef]
- Geng, L.; Hamilton, H.J. Interestingness Measures for Data Ming: A Survey. ACM Comput. Surv. 2006, 38, 9–es. [Google Scholar] [CrossRef]
- Hoque, N.; Nath, B.; Bhattacharyya, D.K. A New Approach on Rare Association Rule Mining. Int. J. Comput. Appl. 2012, 53, 297–303. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Wang, Y.; Feng, J. Attribute Index and Uniform Design Based Multiobjective Association Rule Mining with Evolutionary Algorithm. Sci. World J. 2013, 1, 1–16. [Google Scholar] [CrossRef]
- Pal, A.; Kumar, M. Distributed synthesized association mining for big transactional data. Sadhana 2020, 45, 169. [Google Scholar] [CrossRef]
- Huo, W.; Fang, X.; Zhang, Z. An Efficient Approach for Incremental Mining Fuzzy Frequent Itemsets with FP-Tree. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2016, 24, 367–386. [Google Scholar] [CrossRef]
- Liu, L.; Wen, J.; Zheng, Z.; Su, H. An improved approach for mining association rules in parallel using Spark Streaming. Int. J. Circuit Theory Appl. 2021, 49, 1028–1039. [Google Scholar] [CrossRef]
- Islam, M.R.; Liu, S.; Biddle, R.; Razzak, I.; Wang, X.; Tilocca, P.; Xu, G. Discovering dynamic adverse behavior of policyholders in the life insurance industry. Technol. Forecast. Soc. Change 2021, 163, 120486. [Google Scholar] [CrossRef]
- Yang, D.; Nie, Z.T.; Yang, F. Time-Aware CF and Temporal Association Rule-Based Personalized Hybrid Recommender System. J. Organ. End User Comput. 2021, 33, 19–36. [Google Scholar] [CrossRef]
- Sanmiquel, L.; Bascompta, M.; Rossell, J.M.; Anticoi, H.F.; Guash, E. Analysis of Occupational Accidents in Underground and Surface Mining in Spain Using Data-Mining Techniques. Int. J. Environ. Res. Public Health 2018, 15, 462. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Yu, W.; Ma, X.; Ogura, H.; Ye, D. Multi-Objective Optimization for High-Dimensional Maximal Frequent Itemset Mining. Appl. Sci. 2021, 11, 8971. [Google Scholar] [CrossRef]
- Song, K.; Lee, K. Predictability-based collective class association rule mining. Expert Syst. Appl. 2017, 79, 1–7. [Google Scholar] [CrossRef]
- Heechang, P. A Proposal of Symmetrically Balanced Cross Entropy for Association Rule Evaluation. J. Korean Data Anal. Soc. 2018, 20, 681–691. [Google Scholar]
- Shaharanee, I.; Hadzic, F. Evaluation and optimization of frequent, closed and maximal association rule based classification. Stat. Comput. 2014, 24, 821–843. [Google Scholar] [CrossRef]
- Silverstein, C.; Brin, S.; Motwani, R. Beyond Market Baskets: Generalizing Association Rules to Dependence Rules. Data Min. Knowl. Discov. 1998, 2, 39–68. [Google Scholar] [CrossRef]
- Ma, L.; Jie, W. Research on Judgment Criterion of Association Rules. Control. Decis. 2003, 18, 277–280. [Google Scholar]
- Brin, S.; Motwani, R.; Ullman, J.D.; Tsur, S. Dynamic Itemset Counting and Implication Rules for Market Basket Data. In Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data, Tucson, AZ, USA, 11–15 May 1997; pp. 255–264. [Google Scholar]
- Li, Y.; Wu, C.; Wang, K. A New Interestingness Measures for Ming Association Rules. J. China Soc. Sci. Tech. Inf. 2011, 30, 503–507. [Google Scholar]
- Bao, F.; Wu, Y.; Li, Z.; Li, Y.; Liu, L.; Chen, G. Effect Improved for High-Dimensional and Unbalanced Data Anomaly Detection Model Based on KNN-SMOTE-LSTM. Complexity 2020. [Google Scholar] [CrossRef]
- Lenca, P.; Meyer, P.; Vaillant, B. On Selecting Interestingness Measures for Association Rules: User Oriented Description and Multiple Criteria Decision Aid. Eur. J. Oper. Res. 2008, 184, 610–626. [Google Scholar] [CrossRef] [Green Version]
- Ju, C.; Bao, F.; Xu, C.; Fu, X. A Novel Method of Interestingness Measures for Association Rules Mining Based on Profit. Discret. Dyn. Nat. Soc. 2015, 1, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Xiang, K.; Xu, C.; Wang, J. Understanding the Relationship Between Tourists’ Consumption Behavior and Their Consumption Substitution Willingness Under Unusual Environment. Psychol. Res. Behav. Manag. 2021, 14, 483–500. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Liu, W. Understanding the adoption of mobile social payment? From the cognitive behavioral perspective. Int. J. Mob. Commun. 2022; in press. [Google Scholar] [CrossRef]
- Xu, C.; Ding, A.S.; Zhao, K. A novel POI recommendation method based on trust relationship and spatial-temporal factors. Electron. Commer. Res. Appl. 2021, 48, 101060. [Google Scholar] [CrossRef]
- Xu, C.; Liu, D.; Mei, X. Exploring an Efficient POI Recommendation Model Based on User Characteristics and Spatial-Temporal Factors. Mathematics 2021, 9, 2673. [Google Scholar] [CrossRef]
- Tang, Z.; Hu, H.; Xu, C. A federated learning method for network intrusion detection. Concurr. Comput. Pract. Exp. 2022, e6812. [Google Scholar] [CrossRef]
- Xu, C.; Ding, A.S.; Liao, S.S. A privacy-preserving recommendation method based on multi-objective optimisation for mobile users. Int. J. Bio-Inspired Comput. 2020, 16, 23–32. [Google Scholar] [CrossRef]
- Chen, Y.; Thaipisutikul, T.; Shih, T.K. A Learning-Based POI Recommendation with Spatiotemporal Context Awareness. IEEE Trans. Cybern 2020, 99, 1–14. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
| Tid | E | F | G | H | I | J | K | L | M | N | R | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 8 |
| 2 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 8 |
| 3 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 5 |
| 4 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 8 |
| 5 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 6 |
| 6 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 6 |
| 7 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 4 |
| 8 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 5 |
| 9 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 4 |
| 10 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 4 |
| Total | 10 | 8 | 7 | 4 | 4 | 5 | 3 | 2 | 4 | 6 | 5 | 58 |
| Occur | Not Occur | Total | |
|---|---|---|---|
| occur | 50 | 30 | 80 |
| not occur | 20 | 0 | 20 |
| Total | 70 | 30 | 100 |
| Total | |||
|---|---|---|---|
| occur | 825 | 75 | 900 |
| not occur | 50 | 50 | 100 |
| Total | 875 | 125 | 1000 |
| D Occur | D Not Occur | Total | |
|---|---|---|---|
| C occur | 345 | 55 | 400 |
| C not occur | 385 | 215 | 600 |
| Total | 730 | 270 | 1000 |
| Rules | Supp. | Conf. | Lift | Val. | Conv. | Imp. | Csa. | Bi-lift | Bi-imp. | Bi-conf. |
|---|---|---|---|---|---|---|---|---|---|---|
| M→J | 0.3 | 0.75 | 1.5 | 0.1 | 2 | 0.25 | 1.58 | 2.25 | 0.16 | 0.42 |
| M→G | 0.3 | 0.75 | 1.08 | 0.1 | 1.2 | 0.05 | 0.35 | 1.13 | 0.03 | 0.08 |
| J→G | 0.4 | 0.8 | 1.14 | 0.1 | 0.75 | 0.1 | 0.69 | 1.33 | 0.1 | 0.2 |
| I→H | 0.3 | 0.75 | 1.88 | 0.2 | 2.4 | 0.35 | 2.26 | 4.5 | 0.23 | 0.58 |
| I→F | 0.4 | 1 | 1.25 | 0 | / | 0.2 | 1.58 | 1.5 | 0.13 | 0.33 |
| H→F | 0.3 | 0.75 | 0.95 | −0.2 | 0.8 | −0.05 | −0.4 | 0.9 | −0.03 | −0.08 |
| R→G | 0.5 | 1 | 1.42 | 0.3 | / | 0.3 | 2.1 | 2.5 | 0.3 | 0.6 |
| N→G | 0.4 | 0.67 | 0.95 | 0.1 | 0.9 | −0.03 | −0.21 | 0.89 | −0.05 | −0.08 |
| R→F | 0.4 | 0.8 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| N→F | 0.5 | 0.83 | 1.04 | 0.2 | 1.2 | 0.03 | 0.24 | 1.11 | 0.05 | 0.08 |
| M→F | 0.4 | 1 | 1.25 | 0 | / | 0.2 | 1.58 | 1.5 | 0.13 | 0.33 |
| J→F | 0.4 | 0.8 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| G→F | 0.5 | 0.71 | 0.89 | 0.2 | 0.7 | −0.09 | −0.71 | 0.71 | −0.21 | −0.28 |
| J→M | 0.3 | 0.6 | 1.5 | 0.2 | 1.5 | 0.2 | 1.29 | 3 | 0.2 | 0.4 |
| G→J | 0.4 | 0.57 | 1.14 | 0.3 | 1.17 | 0.07 | 0.44 | 1.71 | 0.18 | 0.24 |
| H→I | 0.3 | 0.75 | 1.88 | 0.2 | 2.4 | 0.35 | 2.26 | 4.5 | 0.23 | 0.58 |
| F→I | 0.4 | 0.5 | 1.25 | 0.4 | 1.2 | 0.1 | 0.65 | / | 0.4 | 0.5 |
| G→R | 0.5 | 0.71 | 1.42 | 0.5 | 1.75 | 0.21 | 1.33 | / | 0.49 | 0.71 |
| G→N | 0.4 | 0.57 | 0.95 | 0.2 | 0.93 | −0.03 | −0.19 | 0.86 | −0.07 | −0.1 |
| F→R | 0.4 | 0.5 | 1 | 0.3 | 1 | 0 | 0 | 1 | 0 | 0 |
| F→N | 0.5 | 0.63 | 1.04 | 0.4 | 1.07 | 0.03 | 0.19 | 1.25 | 0.12 | 0.13 |
| F→M | 0.4 | 0.5 | 1.25 | 0.4 | 1.2 | 0.1 | 0.65 | / | 0.4 | 0.5 |
| F→J | 0.4 | 0.5 | 1 | 0.3 | 1 | 0 | 0 | 1 | 0 | 0 |
| F→G | 0.5 | 0.63 | 0.89 | 0.3 | 0.8 | −0.07 | −0.48 | 0.63 | −0.28 | −0.38 |
| M→L | 0.2 | 0.5 | 2.5 | 0.2 | 0.64 | 0.3 | 2.37 | / | 0.2 | 0.5 |
| Rules | Supp. AB | Supp. | Conf. | Lift | Imp. | Csa. | Bi-lift | Bi-Imp. | Bi-conf. |
|---|---|---|---|---|---|---|---|---|---|
| F→I | 0.4 | 0.2 | 0.50 | 1.25 | 0.10 | 0.65 | / | 0.40 | 0.50 |
| F→K | 0.3 | 0.2 | 0.38 | 1.25 | 0.08 | 0.52 | / | 0.30 | 0.38 |
| F→L | 0.2 | 0.2 | 0.25 | 1.25 | 0.05 | 0.40 | / | 0.20 | 0.25 |
| F→M | 0.4 | 0.2 | 0.50 | 1.25 | 0.10 | 0.65 | / | 0.40 | 0.50 |
| G→J | 0.4 | 0.2 | 0.57 | 1.14 | 0.07 | 0.45 | 1.71 | 0.17 | 0.24 |
| G→R | 0.5 | 0.3 | 0.71 | 1.43 | 0.21 | 1.36 | / | 0.50 | 0.71 |
| H→I | 0.3 | 0.5 | 0.75 | 1.88 | 0.35 | 2.26 | 4.50 | 0.23 | 0.58 |
| H→K | 0.2 | 0.5 | 0.50 | 1.67 | 0.20 | 1.38 | 3.00 | 0.13 | 0.33 |
| I→K | 0.2 | 0.5 | 0.50 | 1.67 | 0.20 | 1.38 | 3.00 | 0.13 | 0.33 |
| J→K | 0.2 | 0.4 | 0.40 | 1.33 | 0.10 | 0.69 | 2.00 | 0.10 | 0.20 |
| J→L | 0.2 | 0.5 | 0.40 | 2.00 | 0.20 | 1.58 | / | 0.20 | 0.40 |
| J→M | 0.3 | 0.4 | 0.60 | 1.50 | 0.20 | 1.29 | 3.00 | 0.20 | 0.40 |
| J→R | 0.3 | 0.3 | 0.60 | 1.20 | 0.10 | 0.63 | 1.50 | 0.10 | 0.20 |
| K→M | 0.2 | 0.5 | 0.67 | 1.67 | 0.27 | 1.72 | 2.33 | 0.11 | 0.38 |
| L→M | 0.2 | 0.6 | 1.00 | 2.50 | 0.60 | 3.87 | 4.00 | 0.15 | 0.75 |
| I→F | 0.4 | 0.2 | 1.00 | 1.25 | 0.20 | 1.58 | 1.50 | 0.13 | 0.33 |
| K→F | 0.3 | 0.2 | 1.00 | 1.25 | 0.20 | 1.58 | 1.40 | 0.09 | 0.29 |
| L→F | 0.2 | 0.2 | 1.00 | 1.25 | 0.20 | 1.58 | 1.33 | 0.05 | 0.25 |
| M→F | 0.4 | 0.2 | 1.00 | 1.25 | 0.20 | 1.58 | 1.50 | 0.13 | 0.33 |
| J→G | 0.4 | 0.2 | 0.80 | 1.14 | 0.10 | 0.69 | 1.33 | 0.10 | 0.20 |
| R→G | 0.5 | 0.3 | 1.00 | 1.43 | 0.30 | 2.07 | 2.50 | 0.30 | 0.60 |
| I→H | 0.3 | 0.5 | 0.75 | 1.88 | 0.35 | 2.26 | 4.50 | 0.23 | 0.58 |
| K→H | 0.2 | 0.5 | 0.67 | 1.67 | 0.27 | 1.72 | 2.33 | 0.11 | 0.38 |
| K→I | 0.2 | 0.5 | 0.67 | 1.67 | 0.27 | 1.72 | 2.33 | 0.11 | 0.38 |
| K→J | 0.2 | 0.4 | 0.67 | 1.33 | 0.17 | 1.05 | 1.56 | 0.07 | 0.24 |
| L→J | 0.2 | 0.5 | 1.00 | 2.00 | 0.50 | 3.16 | 2.67 | 0.13 | 0.63 |
| M→J | 0.3 | 0.4 | 0.75 | 1.50 | 0.25 | 1.58 | 2.25 | 0.17 | 0.42 |
| R→J | 0.3 | 0.3 | 0.60 | 1.20 | 0.10 | 0.63 | 1.50 | 0.10 | 0.20 |
| M→K | 0.2 | 0.5 | 0.50 | 1.67 | 0.20 | 1.38 | 3.00 | 0.13 | 0.33 |
| M→L | 0.2 | 0.6 | 0.50 | 2.50 | 0.30 | 2.37 | / | 0.20 | 0.50 |
| Framework | Conditions | High Value | Low Value | No Value | Total |
|---|---|---|---|---|---|
| support-confidence | min supp. (AB) = 0.2, and min conf. (AB) = 0.5 | 9 | 7 | 9 | 25 |
| support-confidence | min supp. (AB) = 0.2, and min conf. (AB) = 0.2 | 12 | 22 | 32 | 66 |
| Bi-support and Bi-confidence | min supp. (AB) = 0.2, min supp. ) = 0.2, min conf. (AB) = 0.2, and Bi-conf. (AB) = 0.2 | 12 | 18 | 0 | 30 |
| Rules | Supp. AB | Supp. | Conf. | Lift | Imp. | Csa. | Bi-lift | Bi-Imp. | Bi-conf. |
|---|---|---|---|---|---|---|---|---|---|
| L→M | 0.2 | 0.6 | 1.00 | 2.50 | 0.60 | 3.87 | 4.00 | 0.15 | 0.75 |
| G→R | 0.5 | 0.3 | 0.71 | 1.43 | 0.21 | 1.36 | 0.50 | 0.71 | |
| L→J | 0.2 | 0.5 | 1.00 | 2.00 | 0.50 | 3.16 | 2.67 | 0.13 | 0.63 |
| R→G | 0.5 | 0.3 | 1.00 | 1.43 | 0.30 | 2.07 | 2.50 | 0.30 | 0.60 |
| H→I | 0.3 | 0.5 | 0.75 | 1.88 | 0.35 | 2.26 | 4.50 | 0.23 | 0.58 |
| I→H | 0.3 | 0.5 | 0.75 | 1.88 | 0.35 | 2.26 | 4.50 | 0.23 | 0.58 |
| M→L | 0.2 | 0.6 | 0.50 | 2.50 | 0.30 | 2.37 | 0.20 | 0.50 | |
| F→I | 0.4 | 0.2 | 0.50 | 1.25 | 0.10 | 0.65 | 0.40 | 0.50 | |
| F→M | 0.4 | 0.2 | 0.50 | 1.25 | 0.10 | 0.65 | 0.40 | 0.50 | |
| M→J | 0.3 | 0.4 | 0.75 | 1.50 | 0.25 | 1.58 | 2.25 | 0.17 | 0.42 |
| J→L | 0.2 | 0.5 | 0.40 | 2.00 | 0.20 | 1.58 | 0.20 | 0.40 | |
| J→M | 0.3 | 0.4 | 0.60 | 1.50 | 0.20 | 1.29 | 3.00 | 0.40 |
| Rules | Supp. | Conf. | Lift | Imp. | Csa. | Bi-lift | Bi-imp. | Bi-conf. |
|---|---|---|---|---|---|---|---|---|
| G→R | 0.5 | 0.71 | 1.42 | 0.21 | 1.33 | / | 0.49 | 0.71 |
| R→G | 0.5 | 1 | 1.42 | 0.3 | 2.1 | 2.5 | 0.3 | 0.6 |
| I→H | 0.3 | 0.75 | 1.88 | 0.35 | 2.26 | 4.5 | 0.23 | 0.58 |
| H→I | 0.3 | 0.75 | 1.88 | 0.35 | 2.26 | 4.5 | 0.23 | 0.58 |
| F→I | 0.4 | 0.5 | 1.25 | 0.1 | 0.65 | / | 0.4 | 0.5 |
| F→M | 0.4 | 0.5 | 1.25 | 0.1 | 0.65 | / | 0.4 | 0.5 |
| M→L | 0.2 | 0.5 | 2.5 | 0.3 | 2.37 | / | 0.2 | 0.5 |
| M→J | 0.3 | 0.75 | 1.5 | 0.25 | 1.58 | 2.25 | 0.16 | 0.42 |
| J→M | 0.3 | 0.6 | 1.5 | 0.2 | 1.29 | 3 | 0.2 | 0.4 |
| Framework | Conditions | High Value | Low Value | No Value | Total |
|---|---|---|---|---|---|
| support-confidence | min supp. (AB) = 0.05, and min conf. (AB) = 0.2 | 10 | 14 | 48 | 72 |
| Bi-support and Bi-confidence | 10 | 5 | 0 | 15 |
| Rules | Supp. AB | Conf. | Bi-conf. | |
|---|---|---|---|---|
| Beer→Frozen meat | 0.29 | 0.57 | 0.58 | 0.39 |
| Frozen meat→beer | 0.30 | 0.57 | 0.56 | 0.39 |
| Frozen meat→Canned vegetables | 0.30 | 0.56 | 0.57 | 0.39 |
| Canned vegetables→Frozen meat | 0.30 | 0.56 | 0.57 | 0.39 |
| Beer→Canned vegetables | 0.29 | 0.57 | 0.57 | 0.38 |
| Canned vegetables→beer | 0.30 | 0.57 | 0.55 | 0.37 |
| Candy→wine | 0.27 | 0.58 | 0.52 | 0.32 |
| Wine→candy | 0.28 | 0.58 | 0.50 | 0.32 |
| Fish→Fruits and vegetables | 0.29 | 0.55 | 0.50 | 0.28 |
| Fruits and vegetables→fish | 0.29 | 0.55 | 0.48 | 0.28 |
| Beer→Frozen meat | 0.29 | 0.57 | 0.58 | 0.39 |
| Frozen meat→beer | 0.30 | 0.57 | 0.56 | 0.39 |
| Framework | Conditions | High Value | Low Value | No Value | Total |
|---|---|---|---|---|---|
| support-confidence | min supp. (AB) = 0.02, and min conf. (AB) = 0.1 | 59 | 37 | 18 | 114 |
| Bi-support and Bi-confidence | min supp. (AB) = 0.02 min supp. ) = 0.02, min conf. (AB) = 0.1 and Bi-conf. (AB) = 0.1 | 50 | 7 | 0 | 57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, F.; Mao, L.; Zhu, Y.; Xiao, C.; Xu, C. An Improved Evaluation Methodology for Mining Association Rules. Axioms 2022, 11, 17. https://doi.org/10.3390/axioms11010017
Bao F, Mao L, Zhu Y, Xiao C, Xu C. An Improved Evaluation Methodology for Mining Association Rules. Axioms. 2022; 11(1):17. https://doi.org/10.3390/axioms11010017
Chicago/Turabian StyleBao, Fuguang, Linghao Mao, Yiling Zhu, Cancan Xiao, and Chonghuan Xu. 2022. "An Improved Evaluation Methodology for Mining Association Rules" Axioms 11, no. 1: 17. https://doi.org/10.3390/axioms11010017
APA StyleBao, F., Mao, L., Zhu, Y., Xiao, C., & Xu, C. (2022). An Improved Evaluation Methodology for Mining Association Rules. Axioms, 11(1), 17. https://doi.org/10.3390/axioms11010017