1. Introduction
Since it was proposed in the 1930s, the Ornstein–Uhlenbeck model has been used in many areas of application, including, but not limited to, fields such as health care [
1], nanotechnology/thermodynamics [
2], geophysics [
3] and finance [
4,
5,
6]. Unlike its original proposition, which involved a Brownian motion as its background driving process, there have been many extensions or modifications to it in order to truly capture the behavior of data sets, which otherwise could not be modeled rightly with Brownian motions [
7,
8]. Empirical results have shown evidence of non-Brownian behavior in many real-world complex systems [
5,
9,
10]. In fact, according to [
9], statistics of the Lévy type is a ubiquitous phenomenon observed in a wide variety of areas, including physics, seismology, engineering to mention a few. Lévy motions constitute one of the important and fundamental families of random motions, which, unlike Brownian motions, have stationary and independent increments.
Being able to understand and predict future behaviors of stock markets will, without any doubt, be beneficial to individual investors and economic policymakers. It is for this reason that there is always ongoing research into improving the forecasting models of financial stock markets [
3,
5,
10,
11]. It is also of little surprise that there arise some dependencies within stock markets. In studying market trends, one would realize more often than not a positive relationship in the movements of stock portfolios, such as the Dow Jones, the NASDAQ, the Russell, and the S&P500. With the knowledge of these dependencies, we model a stochastic system of equations driven by Lévy processes to predict future trends of the stock market from two different portfolios.
Earthquakes, rock slides, and volcanic eruptions are known to be deadly disasters, which, if not forecasted correctly in order for cities to take safety measures, can result in unprecedented losses to life and property. The 1989–1990 Eruption of Mount Redoubt in Alaska was reported to have caused damages worth USD 160 million plus an additional USD 80 million for two planes that flew over it [
12]. Meanwhile, the 1964 rock slide of Mt Toc, Italy, was estimated to have destroyed property worth USD 200 million and the loss of 2000 lives [
13]. The more recent earthquake in Tohoku, Japan, was believed to have resulted in 18,000 deaths. Knowing the possibility of such devastating losses explains the many research works devoted to forecasting such phenomena [
10,
13,
14,
15,
16,
17]. This work includes an application of the model using volcanic eruption data obtained from the Bezymianny seismic station.
In January 2020, the first case of COVID-19 infection was reported in the United States of America, and since then, the entire year of 2020 and parts of 2021 were devoted to battling the spread of the COVID-19 virus, which plagued the entire world for the entirety of the year 2020. In the wake of this unprecedented pandemic, many researchers around the world sought to model the spread of the COVID-19 virus in order to help officials understand the severity of the situation as well as enact preventive measures to control the spread [
18,
19,
20,
21]. In reading the literature on these models, we observed that most of these models were in the class of compartmental models, which are mostly deterministic. Introducing the stochasticity in the prediction of the spread of the COVID-19 disease has the advantage of causing the disease to die out in scenarios where deterministic models predict disease persistence.
The Ornstein–Uhlenbeck model and its variants have been used to analyzed various data sets in the literature [
22,
23,
24]. In this work, we extend its application by developing an intrafield and interfield coupled system with both
and
background driving processes. In our model, we have also used the R package
[
25] to estimate the volatility parameters, which we use in the coupled Ornstein–Uhlenbeck system of equations.
A common factor among the data sets being analyzed are their direct impact on human lives and properties. A financial crush has the potential of crippling economies and increasing poverty; a volcanic eruption affects human lives and property; and a disease outbreak affects human lives. In [
26], authors showed that how complexity science is essential in modeling these events, which translates to the saving of human lives and property.
In this work, we applied a coupled system of Ornstein–Uhlenbeck stochastic differential equations (SDE) driven by Lévy processes (BDLP) to model three different areas of application. The applications presented include applications to financial data, volcanic eruptions data, and the U.S.A. COVID-19 data. For the financial data, we consider the Dow Jones, the NASDAQ, the S&P500, and the Russel. The volcanic eruptions data were obtained from the Bezymianny seismic station and the COVID-19 data from the New York Times database.
Using the three data sets, we model four different applications. The first three we term as intra-dependent field applications, which implies modeling two data sets collected from the same field. The last application we term as an interdependent field application deals with modeling a combination of two different fields, which in this paper refers to modeling the financial data with the COVID-19 data. Various works in the literature have shown the occurrence of such phenomena, where the actions of one event trigger specific behaviors in another. In [
13], the author presented scenarios where volcanic eruptions preceded an earthquake from up to 120 miles away. It goes without saying that the financial market was greatly affected in the wake of the COVID-19 pandemic. Our model derives the correlation parameter, which shows the correlation between the COVID-19 daily cases and deaths with the stock market, thus helping us model the two different fields of data sets with one system of SDE.
For the BDLP, we consider two Lévy processes, namely the process and the IG(a,b) process. This affords us the ability to compare model performance based on the choice of BDLP to ascertain the desirable option.
The outline of the paper is as follows, we introduce the coupled system of Ornstein–Uhlenbeck equations in
Section 2 in addition to the
and the inverse Gaussian(a,b) process. In
Section 3, we present the data used in addition to the estimation of relevant parameters from the data.
Section 4 deals with the four different applications of our model and presents results from running simulations on the data using the model. We show the estimated errors when our model is used for predictions. In
Section 5, we discuss the results observed from our simulation in
Section 4, and finally, in
Section 6, we present some conclusions as well as possible future works based on the current work and its results.
2. Model
Assume two stochastic (
,
) processes relative to two time series data collected within a specified time period. Suppose the data sets have some correlation, i.e., their correlation coefficient is non-zero. We further assume the stochastic processes to be Lévy driven and simulate the model using either a
process or an IG(a,b) process for comparison purposes. Then, we can model a coupled system of Ornstein–Uhlenbeck SDE as shown below in Equations (
1) and (
2)
where
and
are the intensity parameters,
and
determine volatility, and
and
describe the correlation between the data sets. Now, we observe that when
, we end up with a decoupled system and thus conclude that the two occurrences do not have any correlation. When
, we end up with a decoupled deterministic system, and each equation can be solved independently.
and
are the background driving Lévy processes for the system; we assume both
and
are either
processes or IG(a,b) processes.
In matrix form, the system of the OU equation can be written as
where
and
The solution to this system was obtained in [
5] with a clear step-by-step proof, and hence the proof is omitted in this work. The solution is thus given as
2.1. and IG(a,b) Process
In this section, we briefly define the process and the IG(a,b) process.
2.1.1. Process
Definition 1. The gamma process is a stochastic process X = with parameters a and b which satisfies the following conditions:
.
The process has independent increments.
For , the random variable has a distribution.
A random variable X has a gamma distribution with rate and shape parameters, and , respectively, if its density function is given by 2.1.2. IG(a,b) Process
Definition 2. The IG process is defined as the stochastic process satisfying the following properties:
has independent increments.
follow an inverse Gaussian distribution for all .
Here, is a monotone increasing function and IG(a,b), denotes the IG distribution with probability density function, The inverse Gaussian distribution is infinitely divisible, thus we redefine IG(a,b) as a stochastic process X with parameters a,b to be the process that starts at zero and has independent and stationary increments such that 5. Discussion
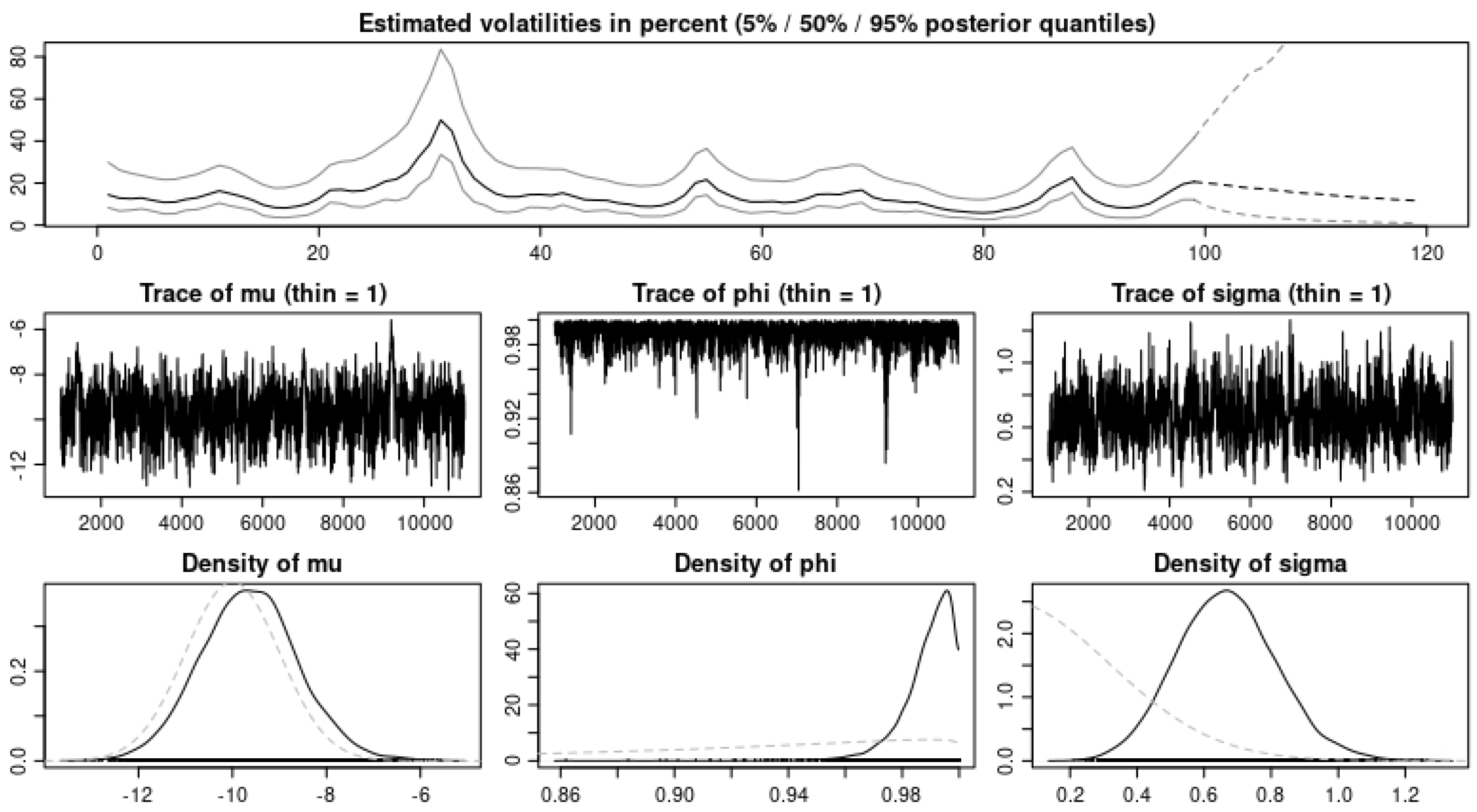
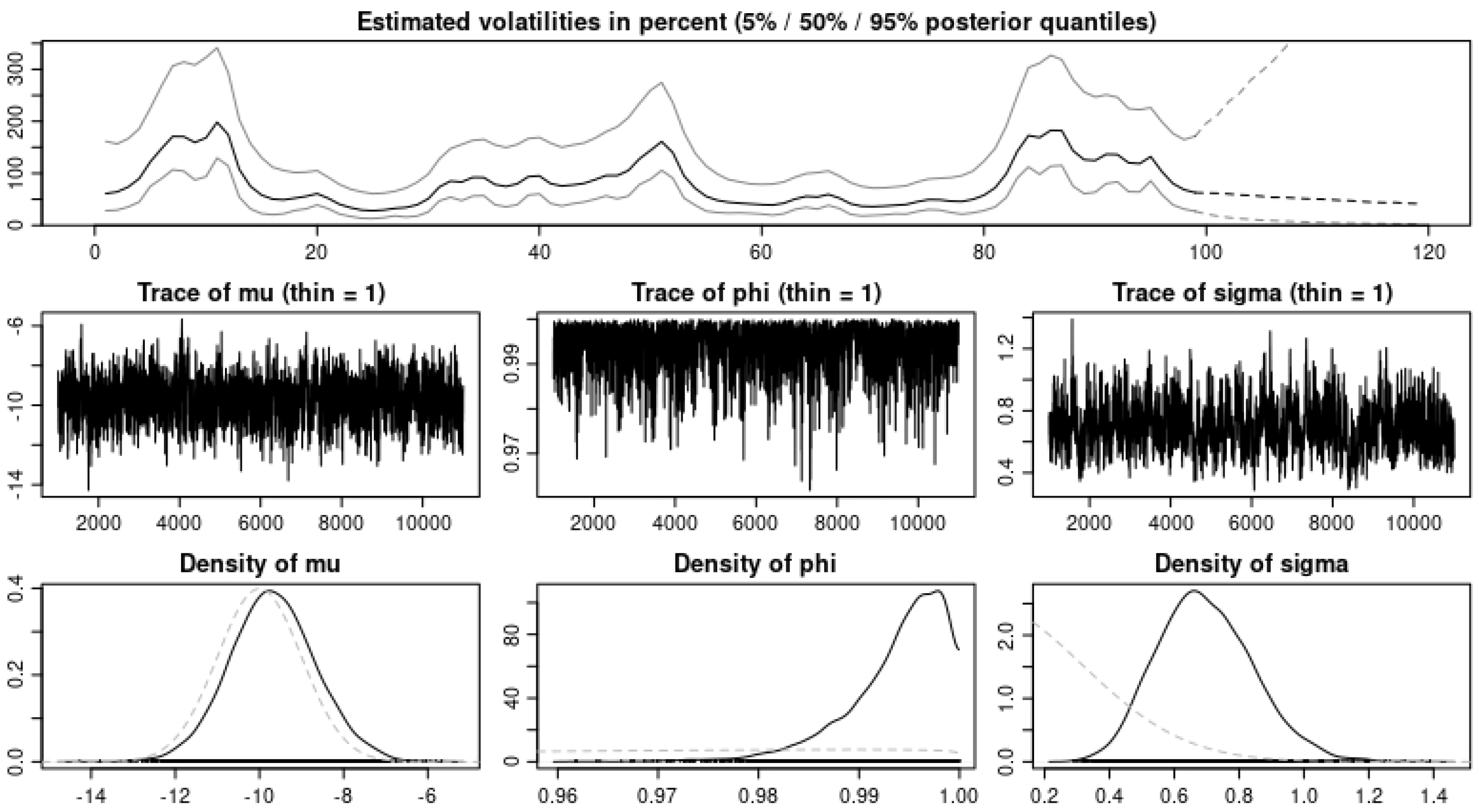
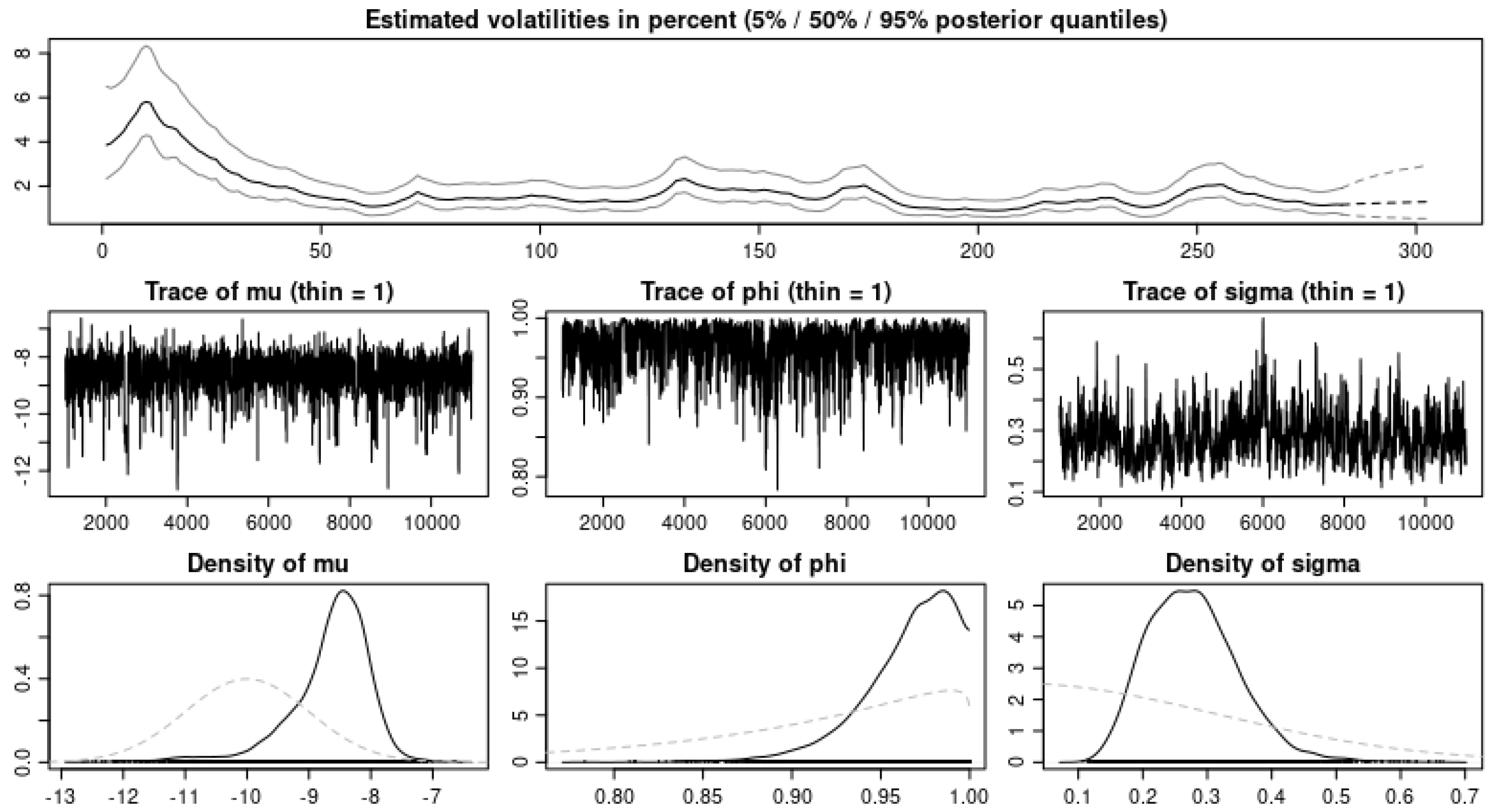
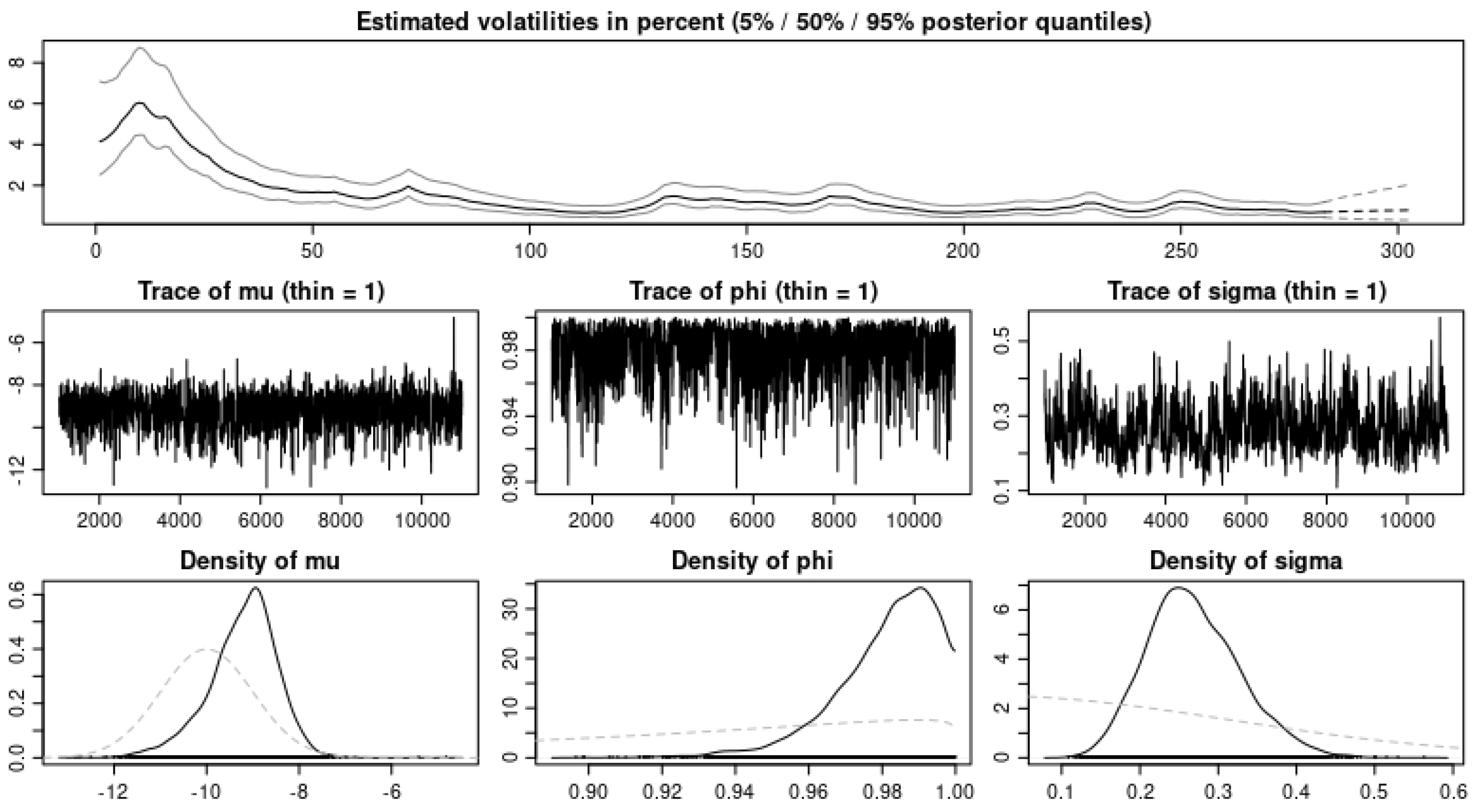
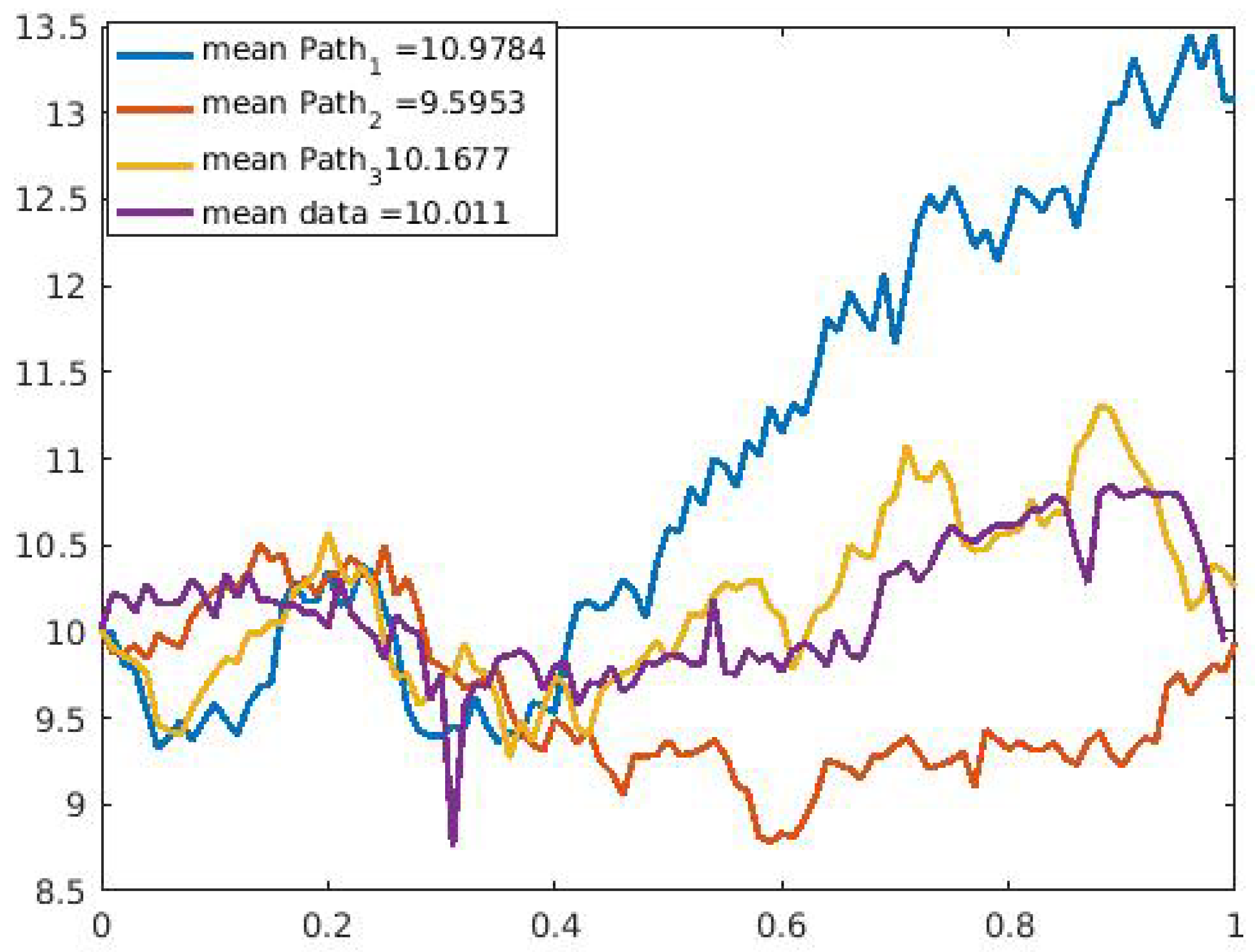
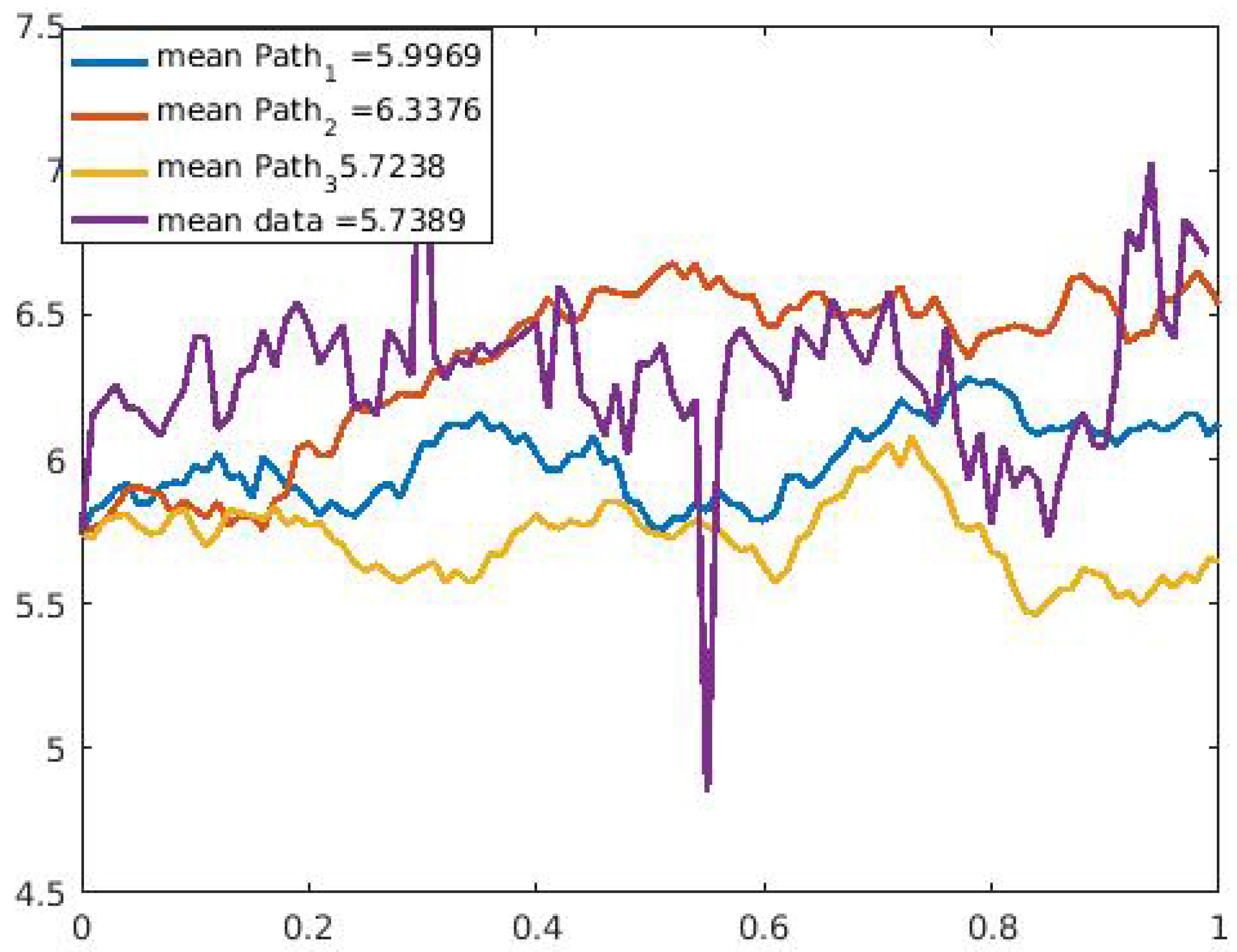
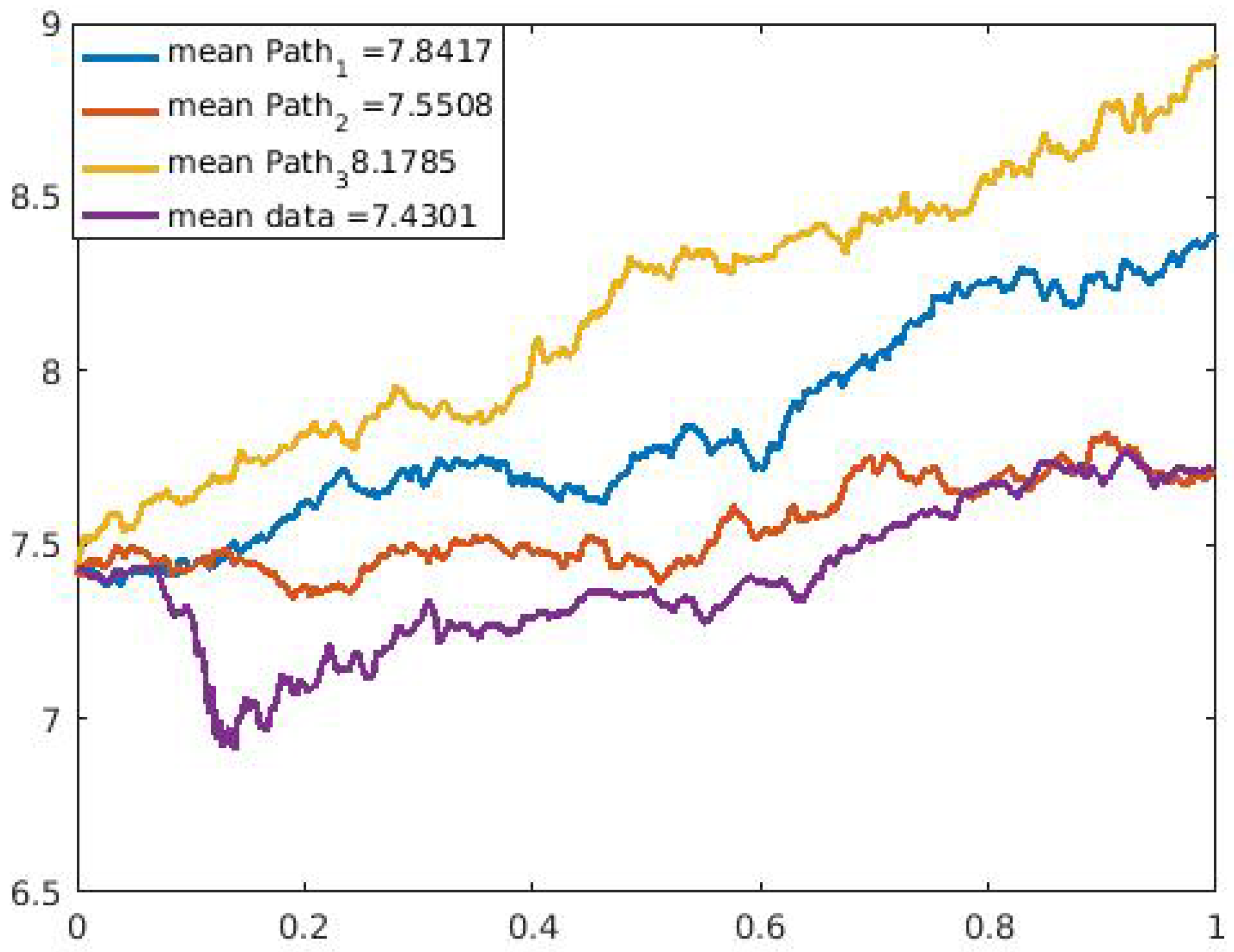
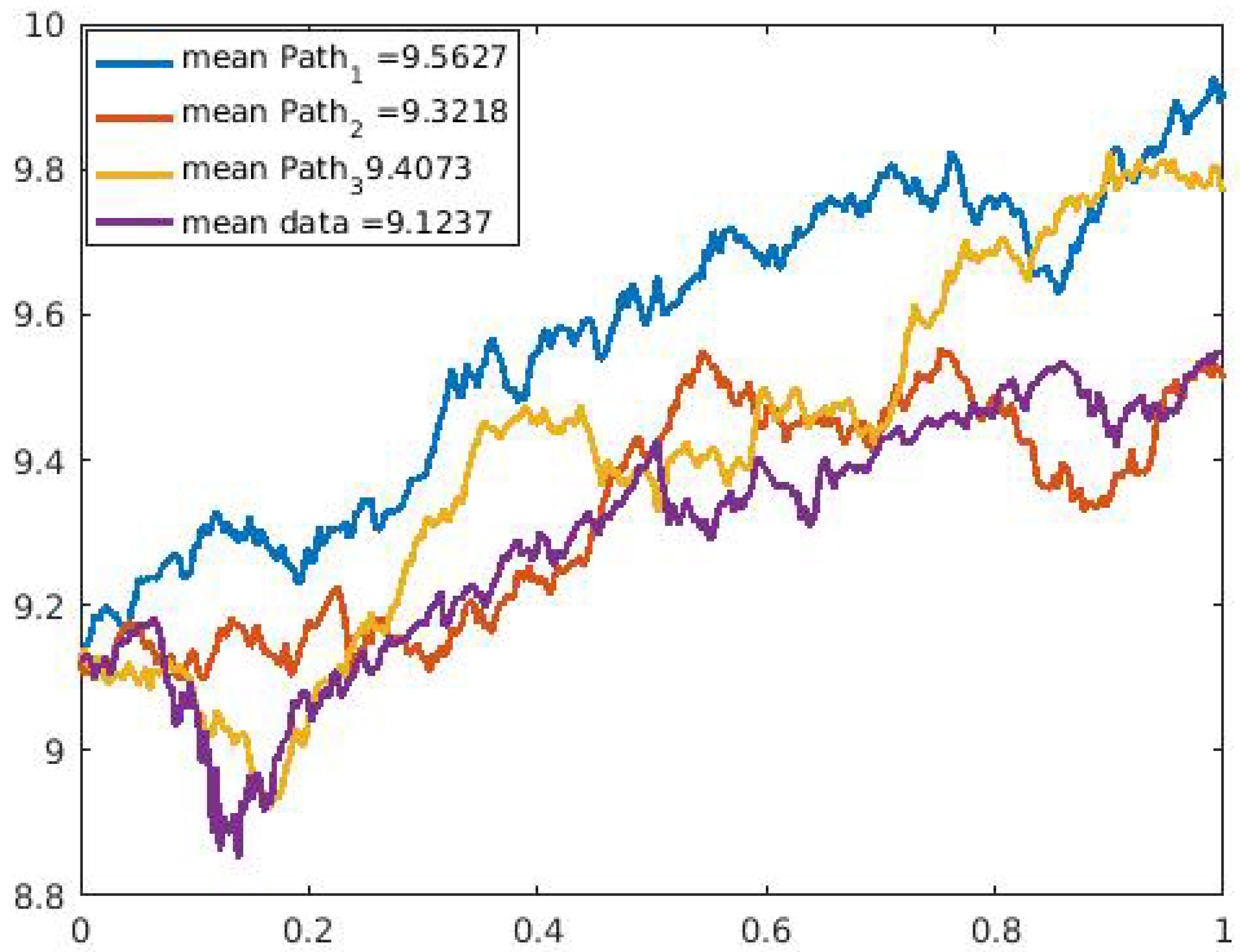
We ran our model simulation with four different applications and showed that with the data sets modeled, our model prediction gives a good fit for the data sets when we observe the values obtained from the error estimates. In
Table 6 and
Table 7, we observe an improvement in the MAPE, MAE, and ARPE error estimates with all three eruptions when the BDLP is an IG(a,b) process. However, we observe that the RMSE for eruption 4 with the
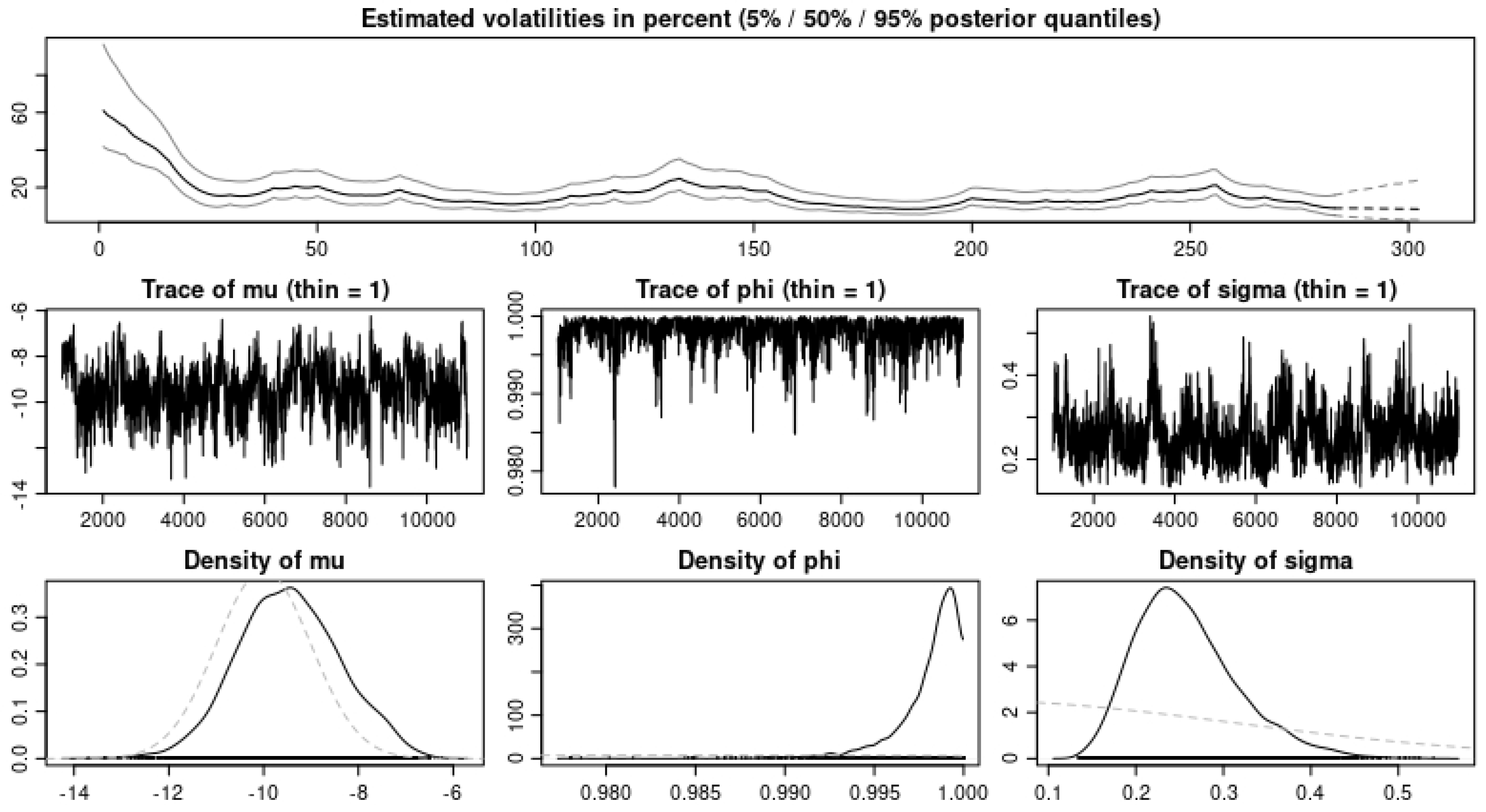
process gave better results. For the application to the financial data, we observe in
Table 8 and
Table 9 from the error estimates that for the IG(a,b) as BDLP, our predictions are slightly better compared to those of the
. In
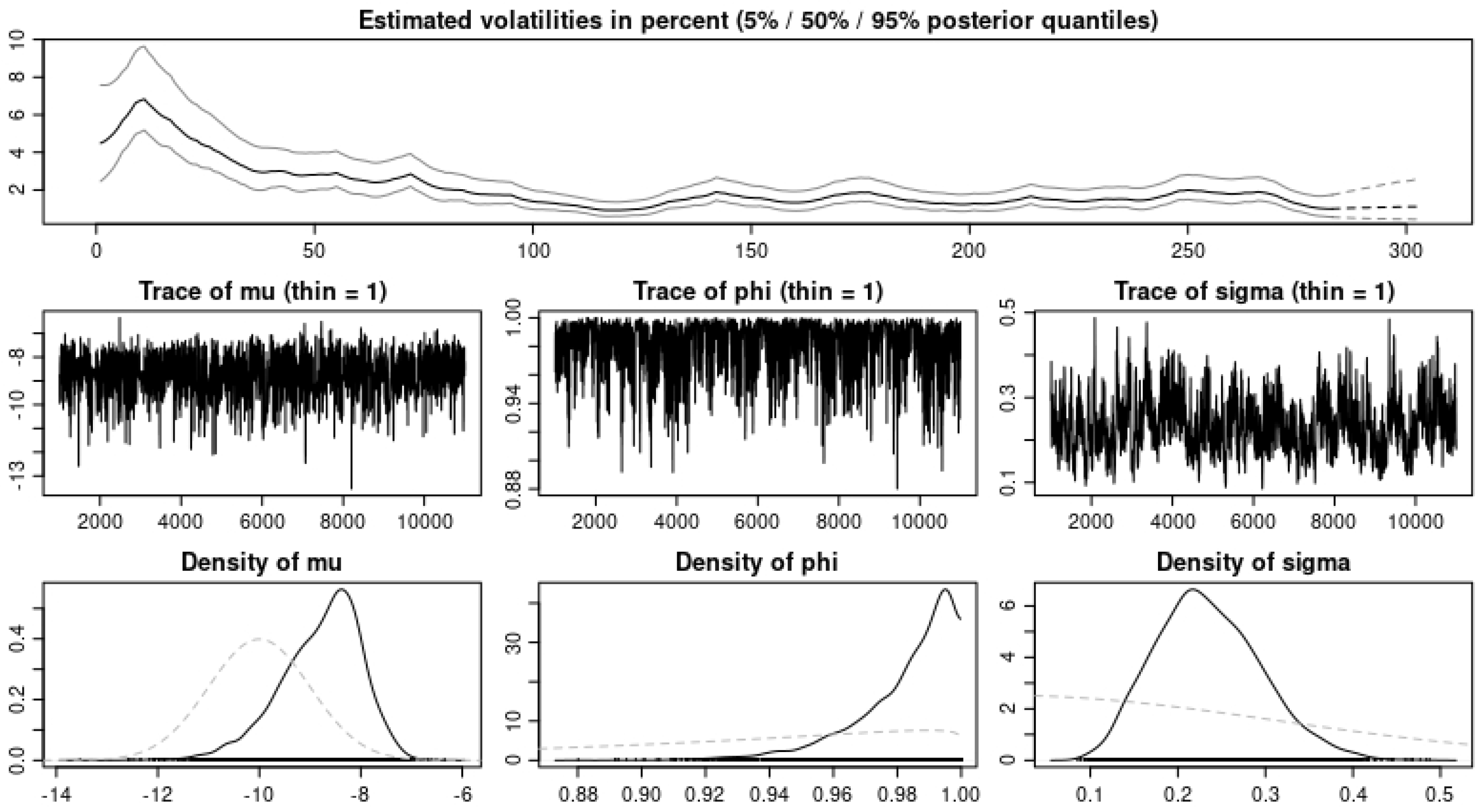
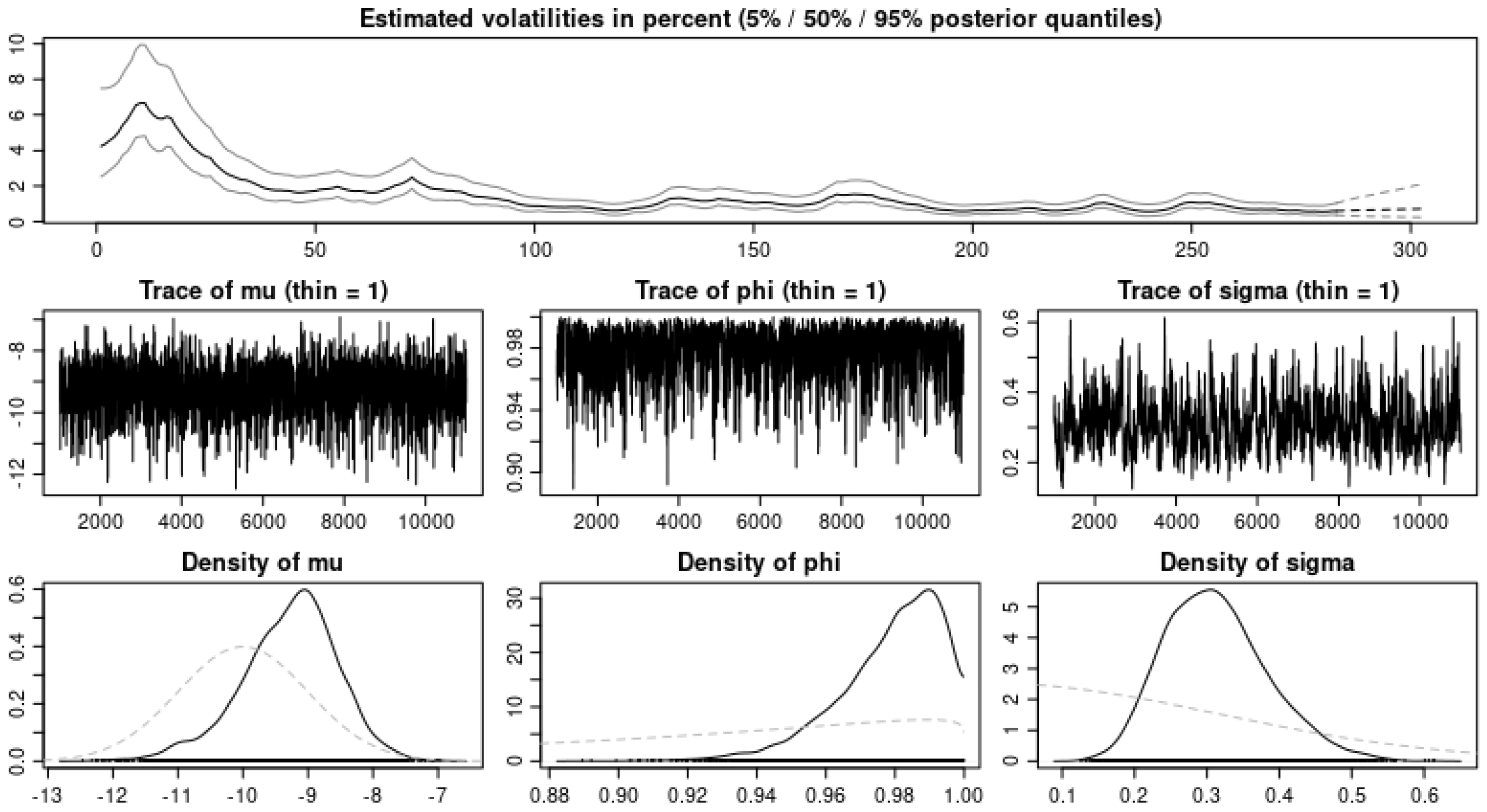
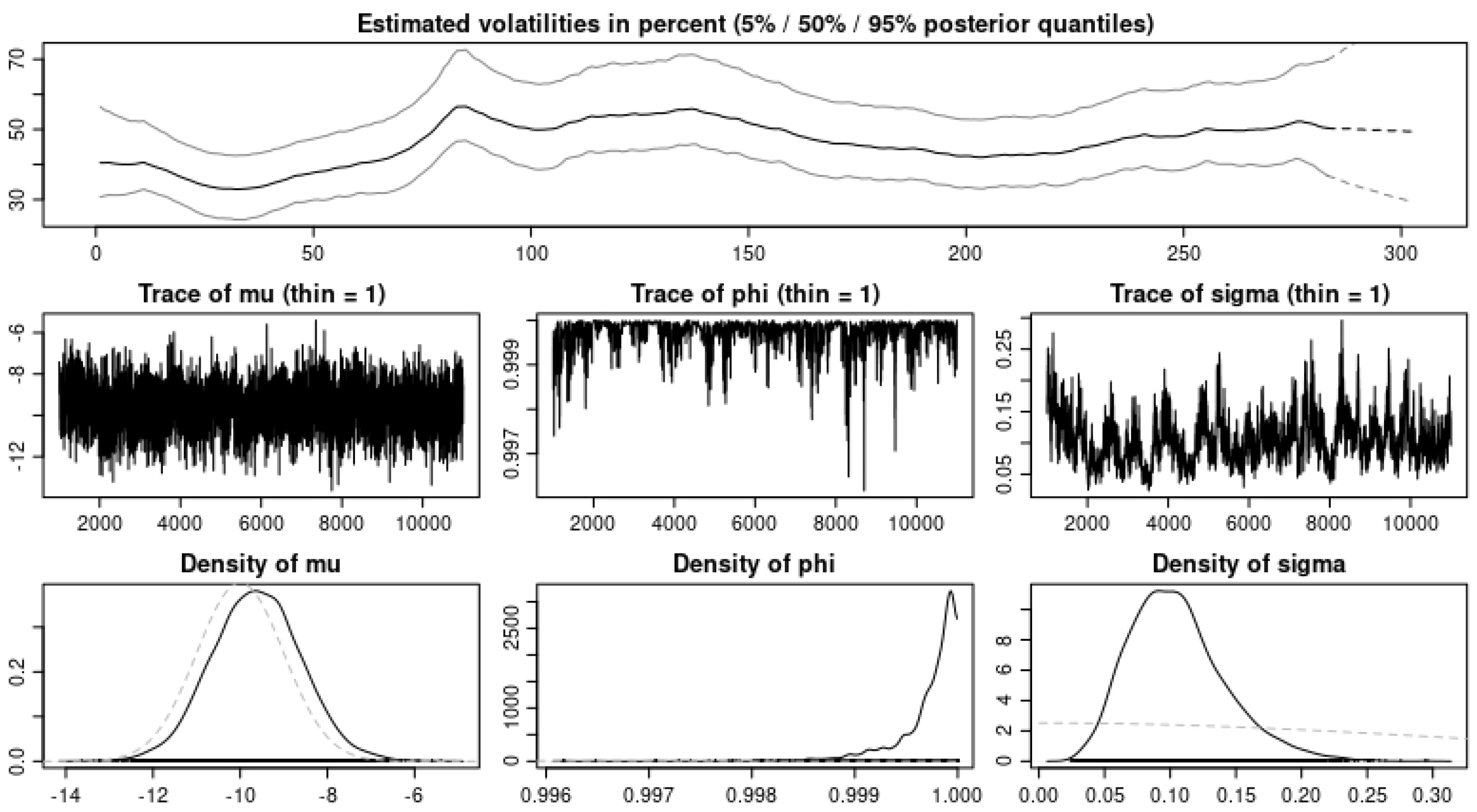
Table 10 and
Table 11, where we model the U.S. COVID-19 cases and deaths, we observe in
Table 11 and
Table 12 that we obtain the same error estimates with the IG(a,b) and the
as BDLPs when we consider the daily cases; however, for the daily deaths, the IG(a,b) BDLP gives a better error estimate. Finally, when we consider
Table 12,
Table 13,
Table 14 and
Table 15, we observe good estimates for both IG(a,b) and
BDLP when the financial data were modeled with the U.S. COVID-19 cases compared to when they were modeled with the U.S. COVID-19 deaths. This is explained from the strong correlation observed in
Table 4 between the financial data and the daily US COVID-19 cases compared to that of the financial data and the daily U.S. COVID-19 deaths. In addition, the three sample paths shown in
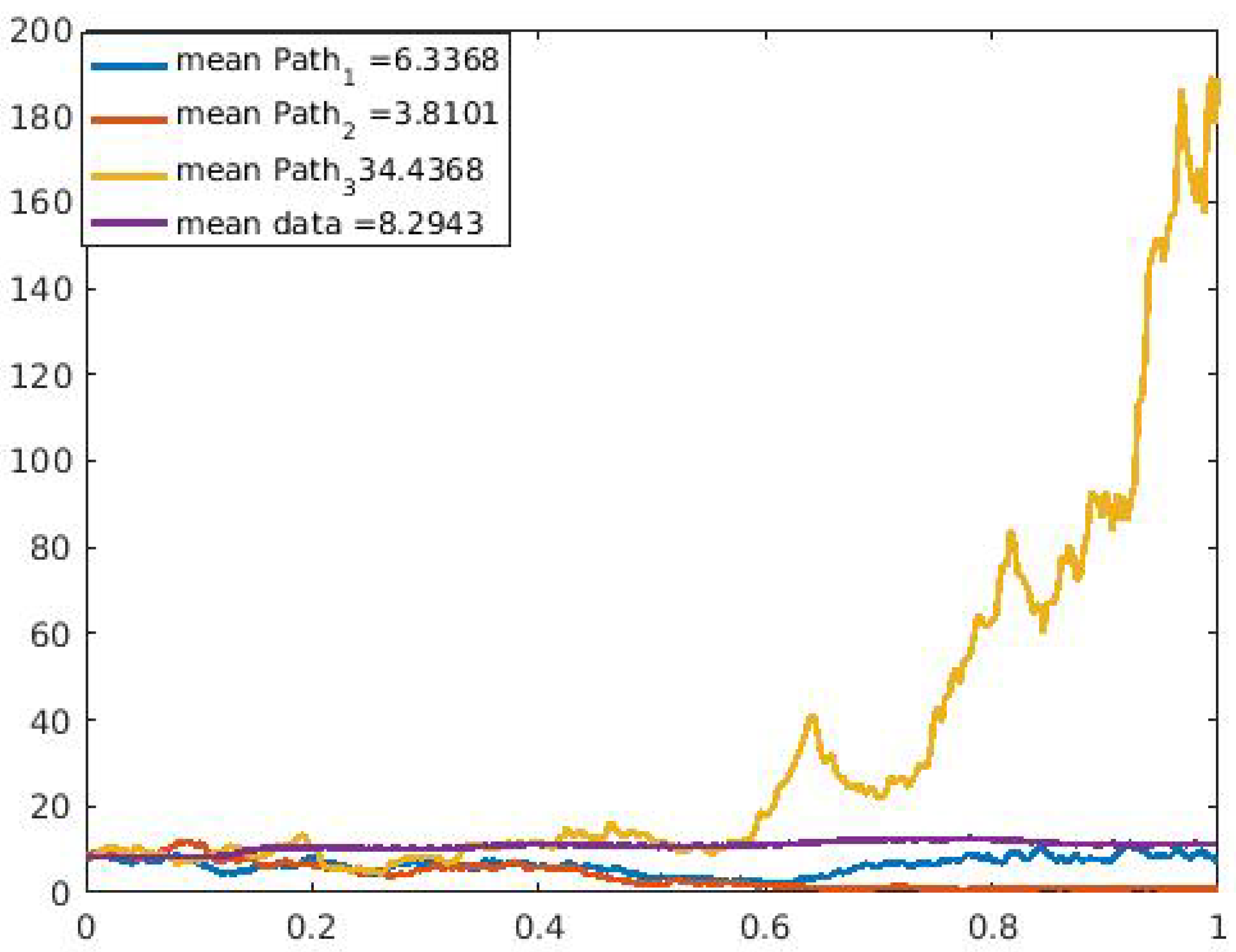
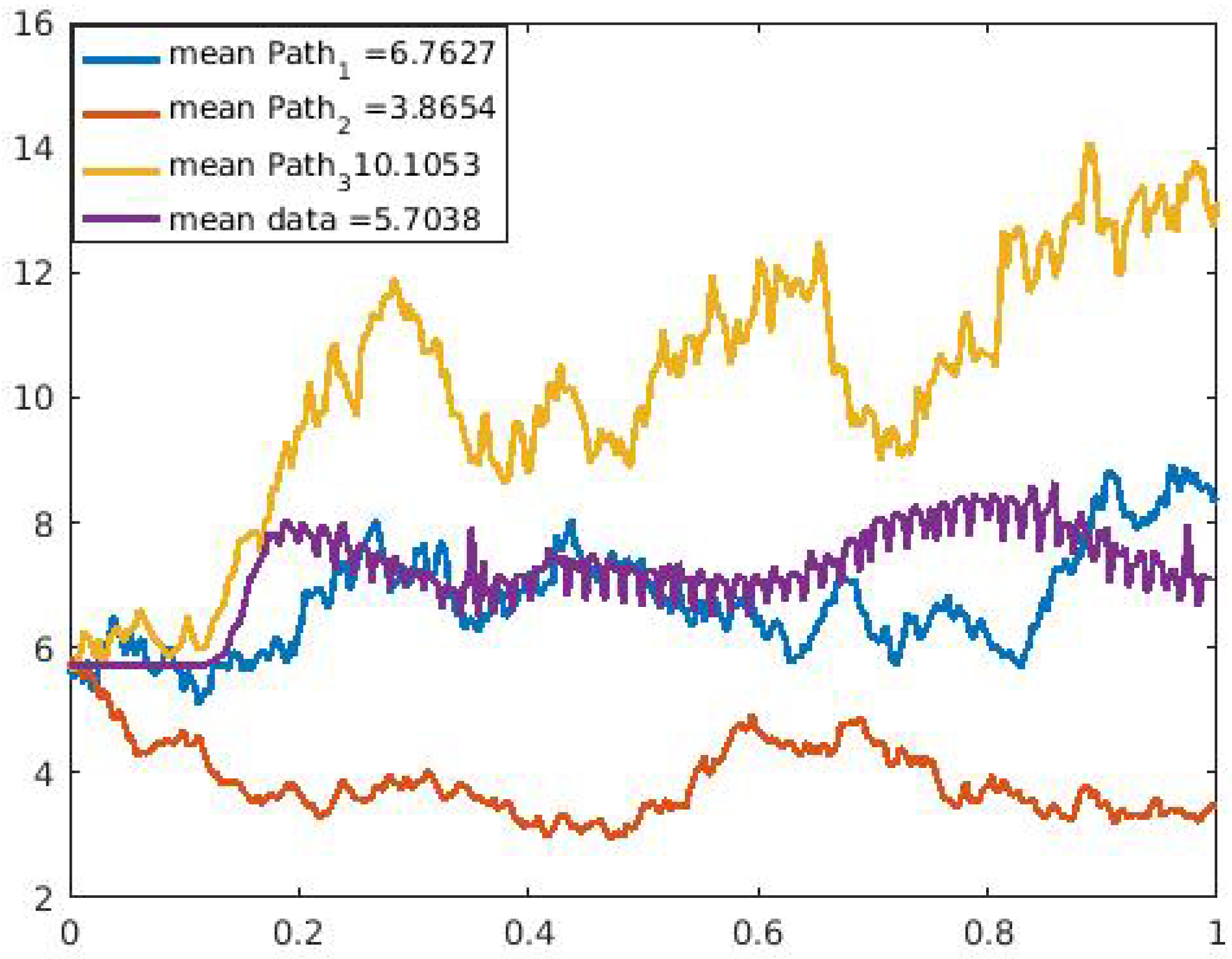
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13 and
Figure 14 for the selected data sets show expected discontinuous paths, making the choice of a Lévy process as the BDP the proper choice. Comparing the sample paths to the original time series, we observe the solution path that best models the data with a mean comparatively closer to that of the time series data. In addition, by modeling the U.S. COVID-19 data using a stochastic SDE, we observe from the three sample paths drawn in
Figure 13 and
Figure 14 that the disease would potentially die out at some point after it has peaked (both reported cases and deaths) once or multiple times, thus showing that there exist scenarios where the disease will die out.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}