
Forecasting Crude Oil Prices with Major S&P 500 Stock Prices: Deep Learning, Gaussian Process, and Vine Copula



Abstract
:1. Introduction
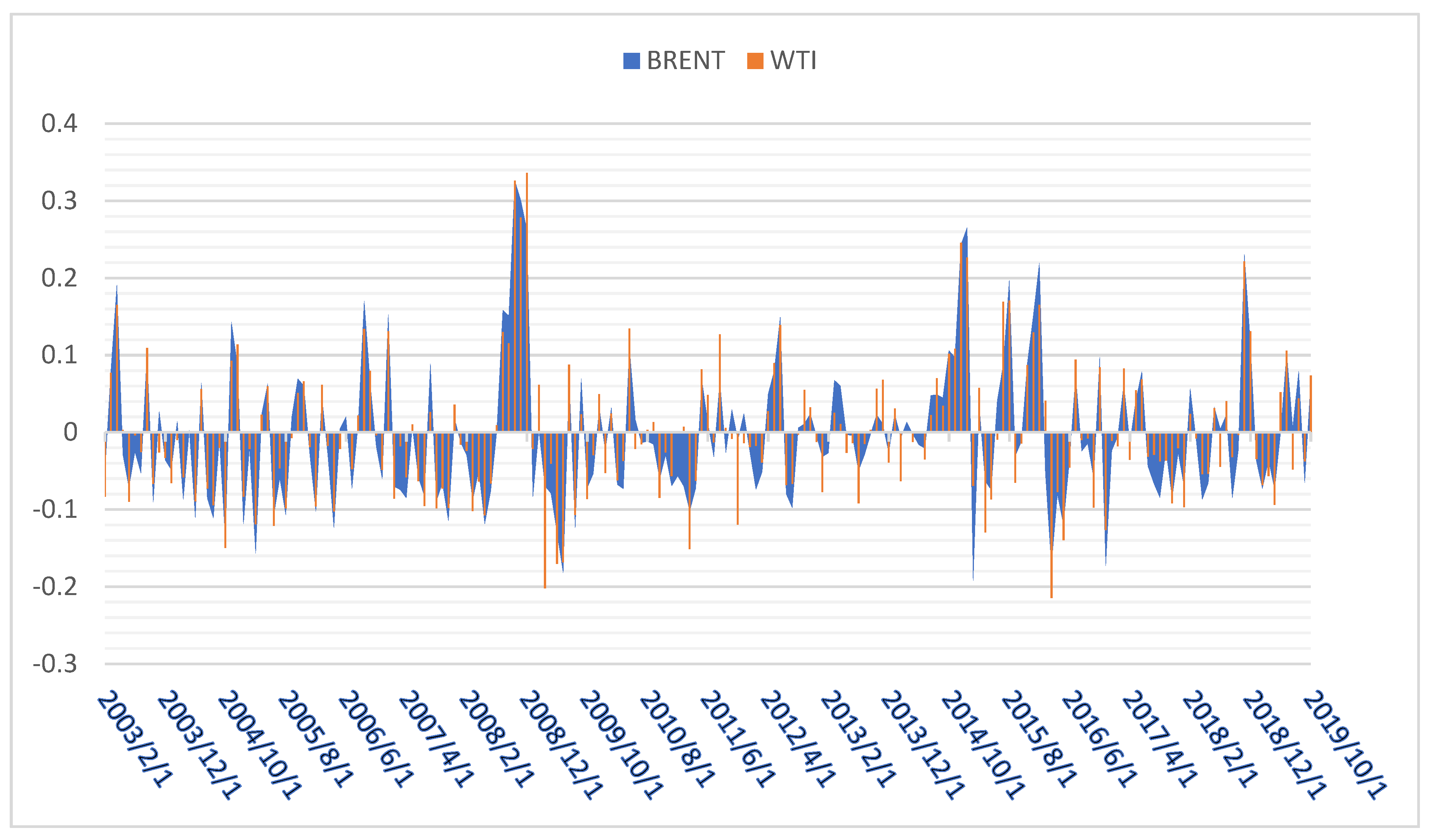
2. Summary Statistics
3. Statistical Methods
3.1. Gaussian Process (GP) Model
3.2. Copulas
3.3. Deep Learning
3.4. Bayesian Variable Selection
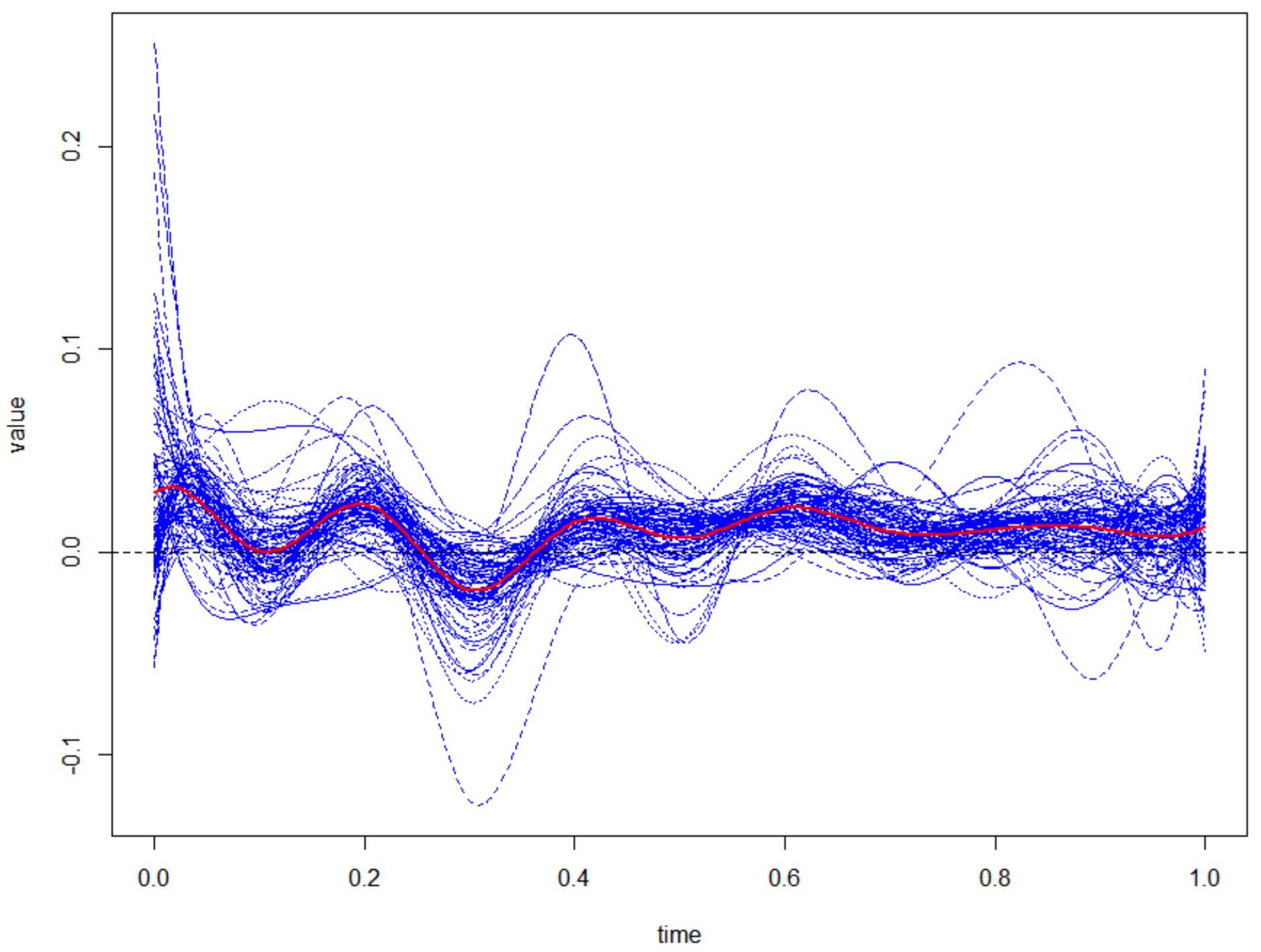
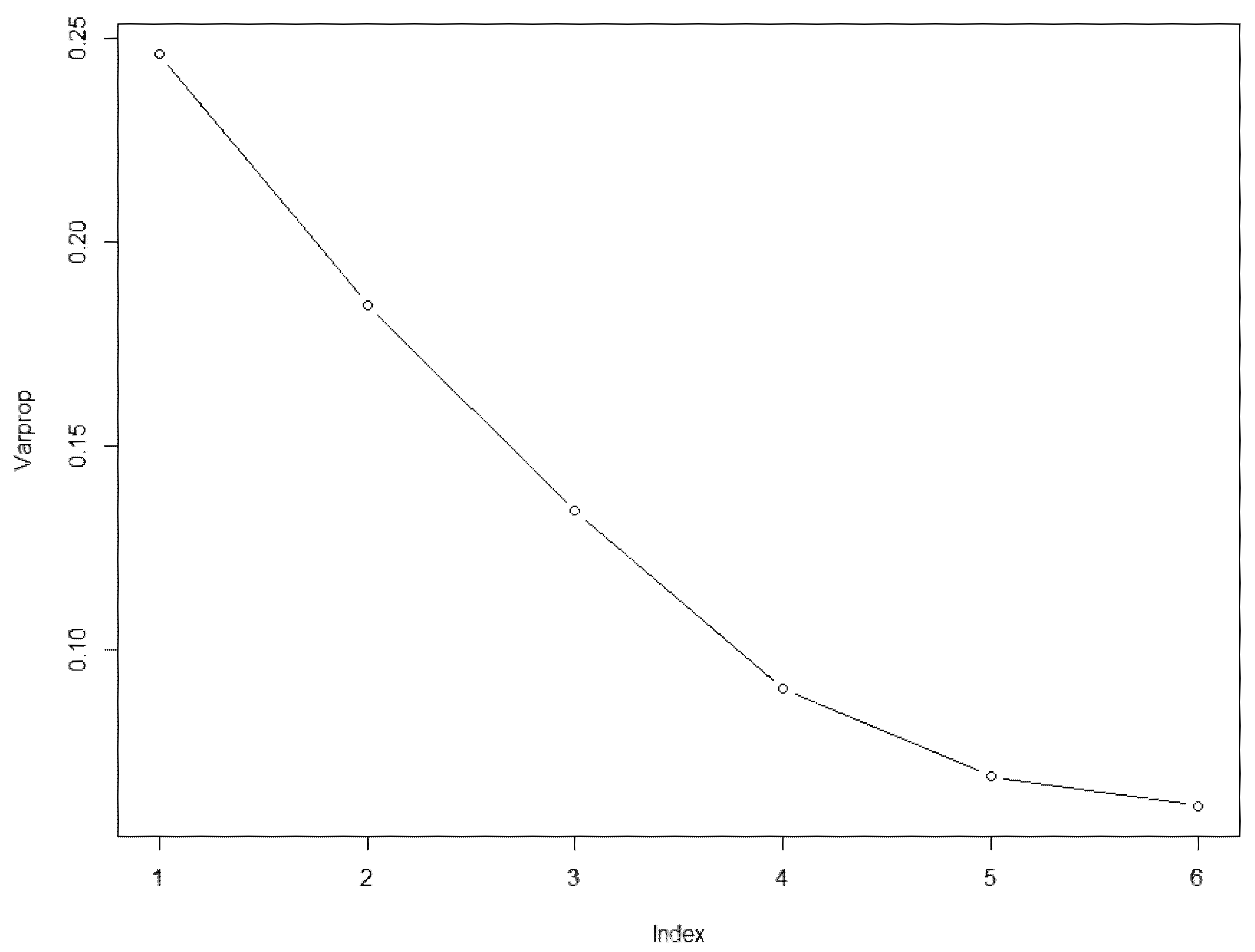
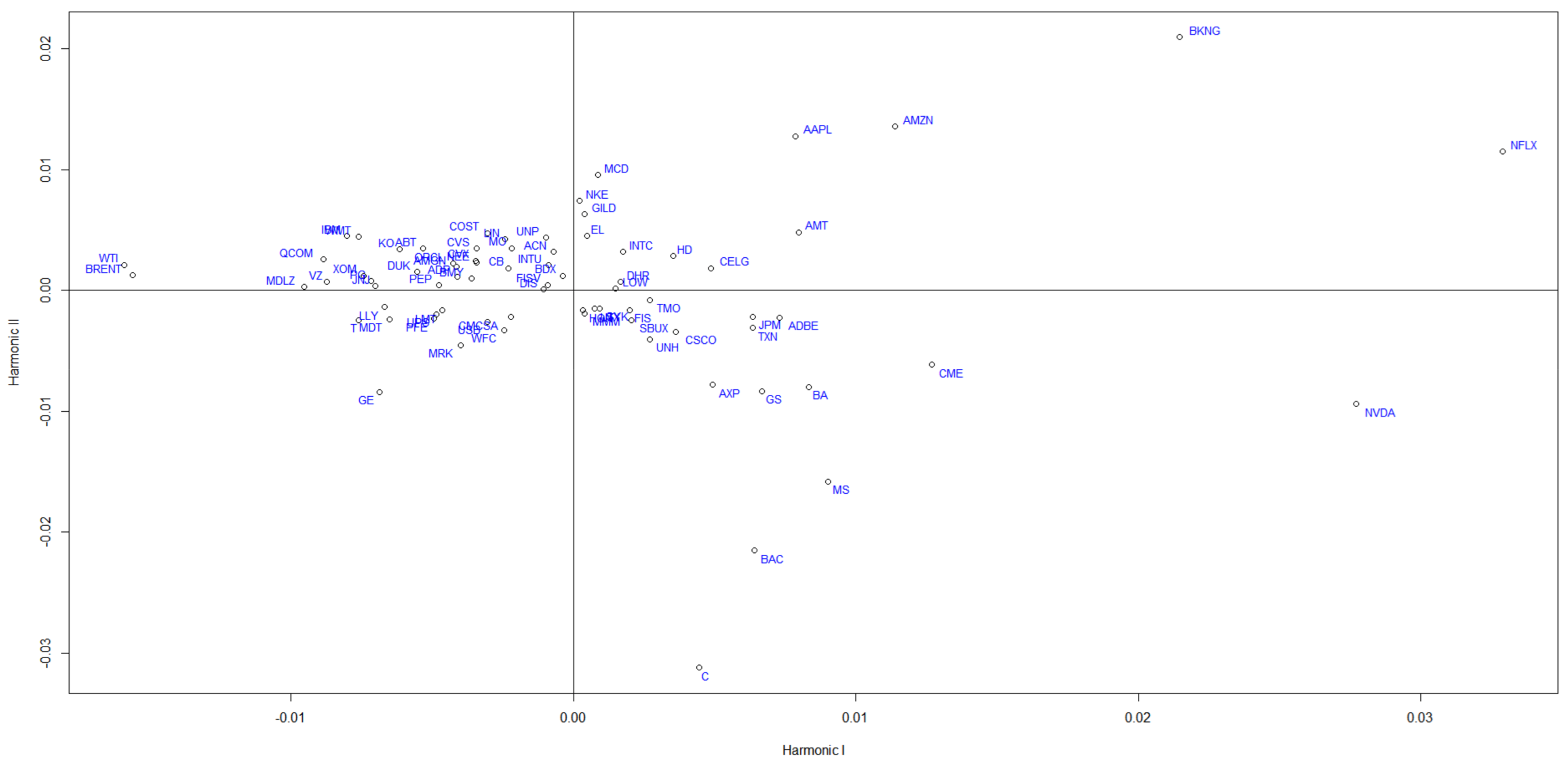
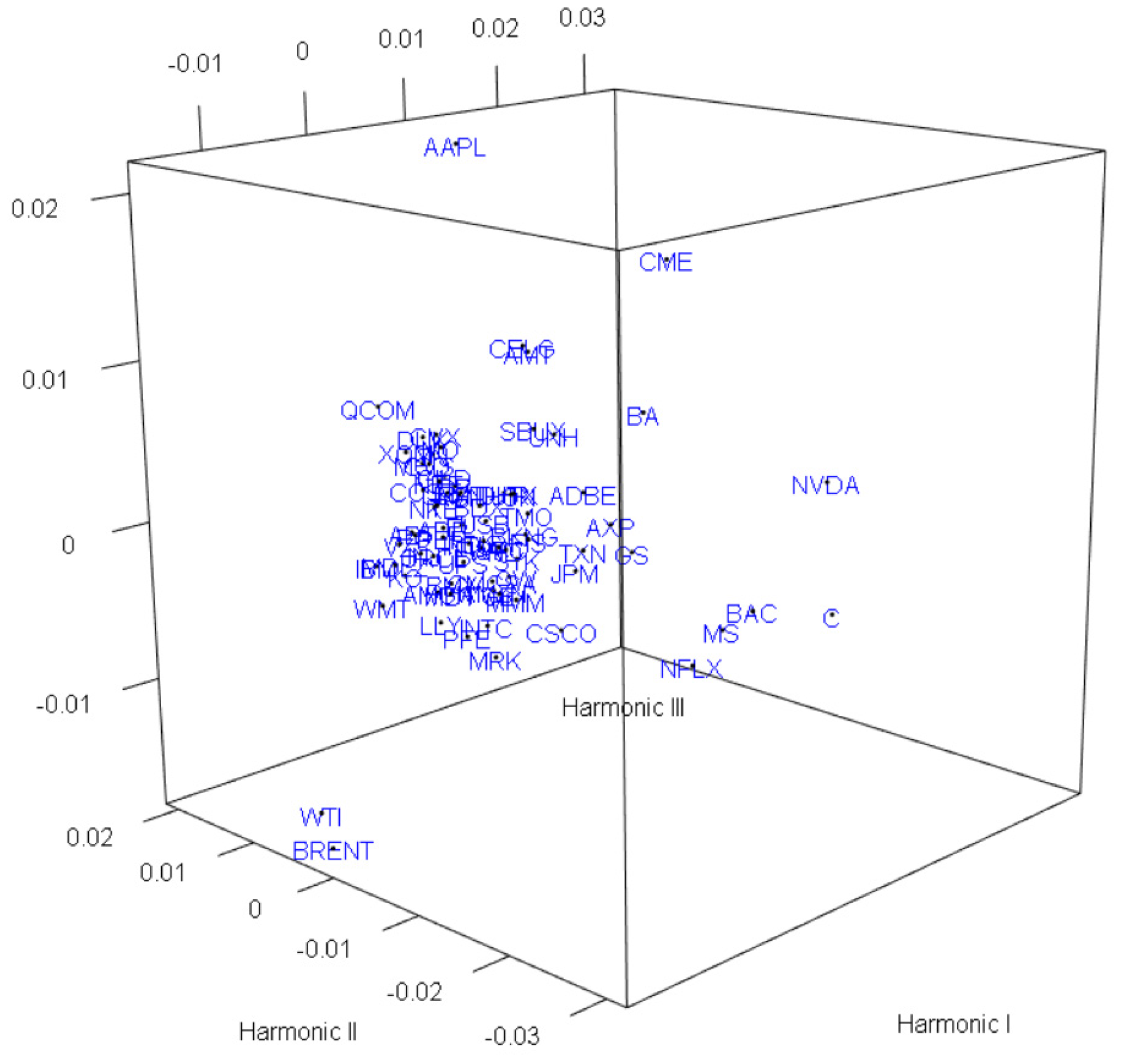
3.5. Nonlinear PCA
4. Data Analysis
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Name |
|---|---|
| BRENT | Brent Crude |
| WTI | Western Texas Intermediate |
| AAPL | Apple, Inc. |
| ABT | Abbott Laboratories |
| ACN | Accenture Plc |
| ADBE | Adobe, Inc. |
| ADP | Automatic Data Processing, Inc. |
| AMGN | Amgen, Inc. |
| AMT | American Tower Corp. |
| AMZN | Amazon.com, Inc. |
| AXP | American Express Co. |
| BA | The Boeing Co. |
| BAC | Bank of America Corp. |
| BDX | Becton, Dickinson & Co. |
| BKNG | Booking Holdings, Inc. |
| BMY | Bristol-Myers Squibb Co. |
| C | Citigroup, Inc. |
| CB | Chubb Ltd. |
| CELG | Celgene Corp. |
| CMCSA | Comcast Corp. |
| CME | CME Group, Inc. |
| COST | Costco Wholesale Corp. |
| CSCO | Cisco Systems, Inc. |
| CVS | CVS Health Corp. |
| CVX | Chevron Corp. |
| DHR | Danaher Corp. |
| DIS | The Walt Disney Co. |
| DUK | Duke Energy Corp. |
| EL | The Estée Lauder Companies, Inc. |
| FIS | Fidelity National Information Services, Inc. |
| FISV | Fiserv, Inc. |
| GE | General Electric Co. |
| GILD | Gilead Sciences, Inc. |
| GS | The Goldman Sachs Group, Inc. |
| HD | The Home Depot, Inc. |
| HON | Honeywell International, Inc. |
| IBM | International Business Machines Corp. |
| INTC | Intel Corp. |
| INTU | Intuit, Inc. |
| JNJ | Johnson & Johnson |
| JPM | JPMorgan Chase & Co. |
| KO | The Coca-Cola Co. |
| LIN | Linde Plc |
| LLY | Eli Lilly & Co. |
| LMT | Lockheed Martin Corp. |
| LOW | Lowe’s Cos., Inc. |
| MCD | McDonald’s Corp. |
| MDLZ | Mondelez International, Inc. |
| MDT | Medtronic Plc |
| MMM | 3M Co. |
| MO | Altria Group, Inc. |
| MRK | Merck & Co., Inc. |
| MS | Morgan Stanley |
| NEE | NextEra Energy, Inc. |
| NFLX | Netflix, Inc. |
| NKE | NIKE, Inc. |
| NVDA | NVIDIA Corp. |
| ORCL | Oracle Corp. |
| PEP | PepsiCo, Inc. |
| PFE | Pfizer Inc. |
| PG | Procter & Gamble Co. |
| QCOM | QUALCOMM, Inc. |
| SBUX | Starbucks Corp. |
| SYK | Stryker Corp. |
| T | AT&T, Inc. |
| TMO | Thermo Fisher Scientific, Inc. |
| TXN | Texas Instruments Incorporated |
| UNH | UnitedHealth Group, Inc. |
| UNP | Union Pacific Corp. |
| UPS | United Parcel Service, Inc. |
| USB | U.S. Bancorp |
| UTX | United Technologies Corp. |
| VZ | Verizon Communications, Inc. |
| WFC | Wells Fargo & Co. |
| WMT | Walmart, Inc. |
| XOM | Exxon Mobil Corp. |
| Grp. | Symbol | Security | GICS Sector | GICS Sub Industry | |
|---|---|---|---|---|---|
| 1 | AAPL | Apple Inc. | Information Technology | Technology Hardware, Storage and Peripherals | Brent |
| 1 | AMT | American Tower Corp. | Real Estate | Specialized REITs | |
| 1 | AMZN | Amazon.com Inc. | Consumer Discretionary | Internet and Direct Marketing Retail | |
| 1 | BKNG | Booking Holdings Inc | Consumer Discretionary | Internet and Direct Marketing Retail | Brent |
| 1 | CELG | Celgene | Health Care | Biotechnology | WTI removed: 21 November 2019 |
| 1 | DHR | Danaher Corp. | Health Care | Health Care Equipment | |
| 1 | EL | Estee Lauder Cos. | Consumer Staples | Personal Products | WTI |
| 1 | GILD | Gilead Sciences | Health Care | Biotechnology | |
| 1 | HD | Home Depot | Consumer Discretionary | Home Improvement Retail | Brent, WTI |
| 1 | INTC | Intel Corp. | Information Technology | Semiconductors | |
| 1 | LOW | Lowe’s Cos. | Consumer Discretionary | Home Improvement Retail | |
| 1 | MCD | McDonald’s Corp. | Consumer Discretionary | Restaurants | |
| 1 | NFLX | Netflix Inc. | Communication Services | Movies and Entertainment | |
| 1 | NKE | Nike | Consumer Discretionary | Apparel, Accessories, and Luxury Goods | |
| 2 | ABT | Abbott Laboratories | Health Care | Health Care Equipment | |
| 2 | ACN | Accenture plc | Information Technology | IT Consulting and Other Services | |
| 2 | ADP | Automatic Data Processing | Information Technology | Internet Services and Infrastructure | |
| 2 | AMGN | Amgen Inc. | Health Care | Biotechnology | |
| 2 | BDX | Becton Dickinson | Health Care | Health Care Equipment | Brent, WTI |
| 2 | BMY | Bristol-Myers Squibb | Health Care | Health Care Distributors | Brent |
| 2 | CB | Chubb Limited | Financials | Property and Casualty Insurance | |
| 2 | COST | Costco Wholesale Corp. | Consumer Staples | Hypermarkets and Super Centers | |
| 2 | CVS | CVS Health | Health Care | Health Care Services | |
| 2 | CVX | Chevron Corp. | Energy | Integrated Oil and Gas | Brent, WTI |
| 2 | DIS | The Walt Disney Company | Communication Services | Movies and Entertainment | |
| 2 | DUK | Duke Energy | Utilities | Electric Utilities | Brent |
| 2 | FISV | Fiserv Inc | Information Technology | Data Processing and Outsourced Services | |
| 2 | IBM | International Business Machines | Information Technology | IT Consulting and Other Services | WTI |
| 2 | INTU | Intuit Inc. | Information Technology | Application Software | |
| 2 | JNJ | Johnson & Johnson | Health Care | Pharmaceuticals | |
| 2 | KO | Coca-Cola Company | Consumer Staples | Soft Drinks | |
| 2 | LIN | Linde plc | Materials | Industrial Gases | Brent, WTI |
| 2 | MDLZ | Mondelez International | Consumer Staples | Packaged Foods and Meats | |
| 2 | MO | Altria Group Inc | Consumer Staples | Tobacco | Brent, WTI |
| 2 | NEE | NextEra Energy | Utilities | Multi-Utilities | |
| 2 | ORCL | Oracle Corp. | Information Technology | Application Software | |
| 2 | PEP | PepsiCo Inc. | Consumer Staples | Soft Drinks | WTI |
| 2 | PG | Procter & Gamble | Consumer Staples | Personal Products | Brent, WTI |
| 2 | QCOM | QUALCOMM Inc. | Information Technology | Semiconductors | Brent, WTI |
| 2 | UNP | Union Pacific Corp | Industrials | Railroads | WTI |
| 2 | VZ | Verizon Communications | Communication Services | Integrated Telecommunication Services | |
| 2 | WMT | Walmart | Consumer Staples | Hypermarkets and Super Centers | WTI |
| 2 | XOM | Exxon Mobil Corp. | Energy | Integrated Oil and Gas | |
| 3 | CMCSA | Comcast Corp. | Communication Services | Cable and Satellite | |
| 3 | GE | General Electric | Industrials | Industrial Conglomerates | |
| 3 | LLY | Lilly (Eli) & Co. | Health Care | Pharmaceuticals | Brent |
| 3 | LMT | Lockheed Martin Corp. | Industrials | Aerospace and Defense | |
| 3 | MDT | Medtronic plc | Health Care | Health Care Equipment | |
| 3 | MRK | Merck & Co. | Health Care | Pharmaceuticals | Brent, WTI |
| 3 | PFE | Pfizer Inc. | Health Care | Pharmaceuticals | WTI |
| 3 | T | AT&T Inc. | Communication Services | Integrated Telecommunication Services | |
| 3 | UPS | United Parcel Service | Industrials | Air Freight and Logistics | |
| 3 | USB | U.S. Bancorp | Financials | Diversified Banks | |
| 3 | WFC | Wells Fargo | Financials | Diversified Banks | |
| 4 | ADBE | Adobe Systems Inc | Information Technology | Application Software | |
| 4 | AXP | American Express Co | Financials | Consumer Finance | |
| 4 | BA | Boeing Company | Industrials | Aerospace and Defense | |
| 4 | BAC | Bank of America Corp | Financials | Diversified Banks | |
| 4 | C | Citigroup Inc. | Financials | Diversified Banks | |
| 4 | CME | CME Group Inc. | Financials | Financial Exchanges and Data | |
| 4 | CSCO | Cisco Systems | Information Technology | Communications Equipment | Brent, WTI |
| 4 | FIS | Fidelity National Information Services | Information Technology | Data Processing and Outsourced Services | Brent, WTI |
| 4 | GS | Goldman Sachs Group | Financials | Investment Banking and Brokerage | Brent |
| 4 | HON | Honeywell Int’l Inc. | Industrials | Industrial Conglomerates | Brent |
| 4 | JPM | JPMorgan Chase & Co. | Financials | Diversified Banks | |
| 4 | MMM | 3M Company | Industrials | Industrial Conglomerates | |
| 4 | MS | Morgan Stanley | Financials | Investment Banking and Brokerage | WTI |
| 4 | NVDA | Nvidia Corporation | Information Technology | Semiconductors | Brent, WTI |
| 4 | SBUX | Starbucks Corp. | Consumer Discretionary | Restaurants | |
| 4 | SYK | Stryker Corp. | Health Care | Health Care Equipment | |
| 4 | TMO | Thermo Fisher Scientific | Health Care | Life Sciences Tools and Services | |
| 4 | TXN | Texas Instruments | Information Technology | Semiconductors | |
| 4 | UNH | United Health Group Inc. | Health Care | Managed Health Care | WTI |
| 4 | UTX | United Technologies | Industrials | Aerospace and Defense |
References
- Reboredo, J.C.; Ugolini, A. Quantile dependence of oil price movements and stock returns. Energy Econ. 2016, 54, 33–49. [Google Scholar] [CrossRef]
- Narayan, P.K.; Gupta, R. Has oil price predicted stock returns for over a century? Energy Econ. 2015, 48, 18–23. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.-S. Forecasting crude oil price movements with oil-sensitive stocks. Econ. Inq. 2014, 52, 830–844. [Google Scholar] [CrossRef]
- Han, L.; Lv, Q.; Yin, L. Can investor attention predict oil prices? Energy Econ. 2017, 66, 547–558. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, F.; Wang, Y. Forecasting crude oil prices with a large set of predictors: Can LASSO select powerful predictors? J. Empir. Financ. 2019, 54, 97–117. [Google Scholar] [CrossRef]
- Kim, J.-M.; Jung, H. Dependence Structure between Oil Prices, Exchange Rates, and Interest Rates. Energy J. 2018, 39, 259–280. [Google Scholar] [CrossRef] [Green Version]
- Kamalov, F.; Smail, L.; Gurrib, I. Stock price forecast with deep learning. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Online, 8–9 November 2020; pp. 1098–1102. [Google Scholar]
- Anand, C. Comparison of Stock Price Prediction Models using Pre-trained Neural Networks. J. Ubiquitous Comput. Commun. Technol. (UCCT) 2021, 3, 122–134. [Google Scholar]
- Sharma, A.; Tiwari, P.; Gupta, A.; Garg, P. Use of LSTM and ARIMAX Algorithms to Analyze Impact of Sentiment Analysis in Stock Market Prediction. In Intelligent Data Communication Technologies and Internet of Things. Lecture Notes on Data Engineering and Communications Technologies; Hemanth, J., Bestak, R., Chen, J.Z., Eds.; Springer: Singapore, 2021; Volume 57. [Google Scholar] [CrossRef]
- Chen, Z. Gaussian Process Regression Methods and Extensions for Stock Market Prediction. Ph.D. Thesis, University of Leicester, Leicester, UK, 2017. [Google Scholar]
- Bisht, A.; Chahar, A.; Kabthiyal, A.; Goel, A. Stock Prediction using Gaussian Process Regression. In Proceedings of the 6th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 29–31 March 2022; pp. 693–699. [Google Scholar] [CrossRef]
- Erickson, C.B.; Ankenman, B.E.; Sanchez, S.M. Comparison of Gaussian process modeling software. Eur. J. Oper. Res. 2018, 266, 179–192. [Google Scholar] [CrossRef] [Green Version]
- Sacks, J.; Welch, W.J.; Mitchell, T.J.; Wynn, H.P. Design and Analysis of Computer Experiments. Stat. Sci. 1989, 4, 409–423. [Google Scholar] [CrossRef]
- Erickson, C. GauPro: Gaussian Process Fitting. R Package Version 0.2.2. 2017. Available online: https://CRAN.R-project.org/package=GauPro (accessed on 19 March 2021).
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Available online: www.GaussianProcess.org/gpml (accessed on 19 March 2021).
- Kim, J.-M.; Kim, D.H.; Jung, H. Modeling Non-normal Corporate Bond Yield Spreads by Copula. N. Am. J. Econ. Financ. 2020, 53, 101210. [Google Scholar] [CrossRef]
- Kim, J.-M.; Jung, H. The impacts of COVID-19 on the dependence structure of the stock market. Appl. Econ. Lett. 2022, 1–6. [Google Scholar] [CrossRef]
- Kim, J.-M.; Jung, H.; Yang, B. A revisit to size anomalies in U.S. bank stock returns by panel copula. Appl. Econ. Lett. 2022, 29, 750–754. [Google Scholar] [CrossRef]
- Sklar, M. Fonctions de Répartition À N Dimensions et Leurs Marges; Université Paris 8: Paris, France, 1959. [Google Scholar]
- Joe, H. Multivariate Models and Dependence Concepts; Chapman & Hall: London, UK, 1997. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas, 2nd ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Nagler, T.; Schepsmeier, U.; Stoeber, J.; Brechmann, E.C.; Graeler, B.; Erhardt, T. VineCopula: Statistical Inference of Vine Copulas. In R Package, VineCopula; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Jang, H.; Kim, J.-M.; Noh, H. Vine Copula Granger Causality in Mean. Econ. Model. 2022, 109, 105798. [Google Scholar] [CrossRef]
- Kim, J.-M.; Ha, I.D. Deep Learning-Based Residual Control Chart for Count Data. Qual. Eng. 2022, 34, 370–381. [Google Scholar] [CrossRef]
- Rong, X. Deep Learning Toolkit in R. In R Package, Deepnet; R Foundation for Statistical Computing: Vienna, Austria, 2015. [Google Scholar]
- Bayarri, M.J.; Berger, J.O.; Forte, A.; García-Donato, G. Criteria for Bayesian model choice with application to variable selection. Ann. Stat. 2012, 40, 1550–1577. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Donato, G.; Forte, A.; Vergara-Hernández, C. Bayes Factors, Model Choice and Variable Selection in Linear Models. In R Package, BayesVarSel; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Schölkopf, B.; Smola, A.; Müller, K.-R. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef] [Green Version]
- Karatzoglou, A.; Smola, A.; Hornik, K.; National ICT Australia; Maniscalco, M.A.; Teo, C.H. Kernel-Based Machine Learning Lab. In R Package, Kernlab; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]





| Mean | Median | Minimum | Maximum | St.D | Skewness | Kurtosis | |
|---|---|---|---|---|---|---|---|
| BRENT | −0.003 | −0.015 | −0.192 | 0.326 | 0.089 | 0.968 | 4.476 |
| WTI | −0.002 | −0.014 | −0.215 | 0.336 | 0.088 | 0.897 | 4.728 |
| Prob. | HPM | MPM | |
|---|---|---|---|
| CB | 0.54 | * | |
| HD | 0.61 | * | * |
| HON | 0.65 | * | * |
| LIN | 0.73 | * | * |
| PG | 0.56 | * | * |
| Prob. | HPM | MPM | |
|---|---|---|---|
| HD | 0.58 | * | |
| HON | 0.57 | * | |
| LIN | 0.61 | * | * |
| PG | 0.44 | * | |
| UNP | 0.68 | * | * |
| Theta | |
|---|---|
| CB | 6.1 |
| HD | 0.87 |
| HON | 2.07 |
| LIN | 9.58 |
| PG | 2.51 |
| Nugget = 0.244 | |
| RMSE = 0.088 | |
| N = 170 | |
| Theta | |
|---|---|
| HD | 24.8 |
| HON | 8.08 |
| LIN | 25 |
| PG | 112 |
| UNP | 2.86 |
| Nugget = 0.546 | |
| RMSE = 0.0797 | |
| N = 170 | |
| Method | Deep Learning | Gaussian Process | Vine Copula | |||||
|---|---|---|---|---|---|---|---|---|
| RMSE | ALL | BVS | NLPCA | ALL | BVS | NLPCA | BVS | NLPCA |
| Brent | 0.087 | 0.090 | 0.088 | 0.100 | 0.078 | 0.077 | 0.079 | 0.072 |
| WTI | 0.085 | 0.084 | 0.084 | 0.086 | 0.080 | 0.073 | 0.077 | 0.069 |
| MAD | ALL | BVS | NLPCA | ALL | BVS | NLPCA | BVS | NLPCA |
| Brent | 0.075 | 0.078 | 0.076 | 0.080 | 0.060 | 0.058 | 0.060 | 0.060 |
| WTI | 0.072 | 0.071 | 0.072 | 0.073 | 0.064 | 0.059 | 0.061 | 0.057 |
| LOSS | Deep Learning | ||
|---|---|---|---|
| LOSS1 | ALL | BVS | NLPCA |
| Brent | (0.0048, 0.0106) | (0.0048, 0.0107) | (0.0049, 0.0107) |
| WTI | (0.0044, 0.0098) | (0.0042, 0.0096) | (0.0042, 0.0096) |
| LOSS2 | ALL | BVS | NLPCA |
| Brent | (0.0588, 0.0926) | (0.0591, 0.0929) | (0.0591, 0.0930) |
| WTI | (0.0549, 0.0884) | (0.0540, 0.0870) | (0.0540, 0.0871) |
| LOSS | Gaussian Process | ||
| LOSS1 | ALL | BVS | NLPCA |
| Brent | (0.0048, 0.0151) | (0.0023, 0.0099) | (0.0025, 0.0101) |
| WTI | (0.0040, 0.0109) | (0.0022, 0.0095) | (0.0029, 0.0109) |
| LOSS2 | ALL | BVS | NLPCA |
| Brent | (0.0566, 0.1025) | (0.0414, 0.0793) | (0.0483, 0.0826) |
| WTI | (0.0550, 0.0904) | (0.0462, 0.0794) | (0.0488, 0.0856) |
| LOSS | Vine Copula | ||
| LOSS1 | ALL | BVS | NLPCA |
| Brent | NA | (0.0018, 0.0108) | (0.0022, 0.0082) |
| WTI | NA | (0.0019, 0.0101) | (0.0019, 0.0076) |
| LOSS2 | ALL | BVS | NLPCA |
| Brent | NA | (0.0402, 0.0796) | (0.0448, 0.0753) |
| WTI | NA | (0.0434, 0.0793) | (0.0418, 0.0714) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-M.; Han, H.H.; Kim, S. Forecasting Crude Oil Prices with Major S&P 500 Stock Prices: Deep Learning, Gaussian Process, and Vine Copula. Axioms 2022, 11, 375. https://doi.org/10.3390/axioms11080375
Kim J-M, Han HH, Kim S. Forecasting Crude Oil Prices with Major S&P 500 Stock Prices: Deep Learning, Gaussian Process, and Vine Copula. Axioms. 2022; 11(8):375. https://doi.org/10.3390/axioms11080375
Chicago/Turabian StyleKim, Jong-Min, Hope H. Han, and Sangjin Kim. 2022. "Forecasting Crude Oil Prices with Major S&P 500 Stock Prices: Deep Learning, Gaussian Process, and Vine Copula" Axioms 11, no. 8: 375. https://doi.org/10.3390/axioms11080375
APA StyleKim, J.-M., Han, H. H., & Kim, S. (2022). Forecasting Crude Oil Prices with Major S&P 500 Stock Prices: Deep Learning, Gaussian Process, and Vine Copula. Axioms, 11(8), 375. https://doi.org/10.3390/axioms11080375