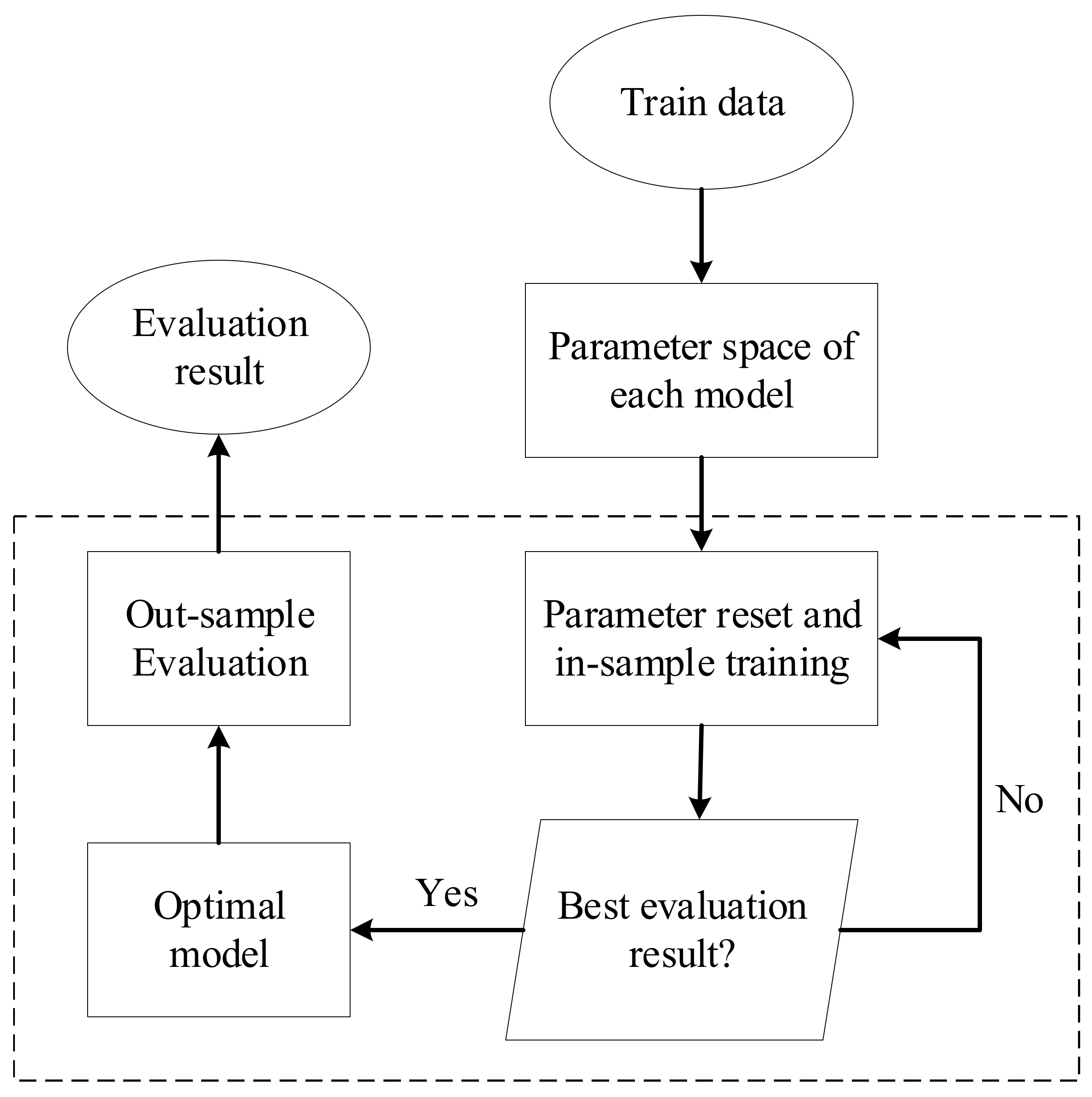
In this section, we first present 6 machine learning models for predicting crude oil price. Then, we describe the metrics used to evaluate their predictive performance. Finally, we introduce the SHAP method used in this study to interpret the prediction results of the models.
4.1. Machine Learning Models
Multiple linear regression is a commonly used statistical analysis method for estimating the marginal effects of selected independent variables on explanatory dependent variables. In multiple linear regression, the ordinary least squares (OLS) method is a simple method for estimating the relationship between the independent variable and the explanatory variable. The model can be expressed as:
where
is the expected value at the moment t,
denotes the regression constant,
represent the regression coefficients,
are the explanatory variables at the moment t, and
is the random error term at the moment t.
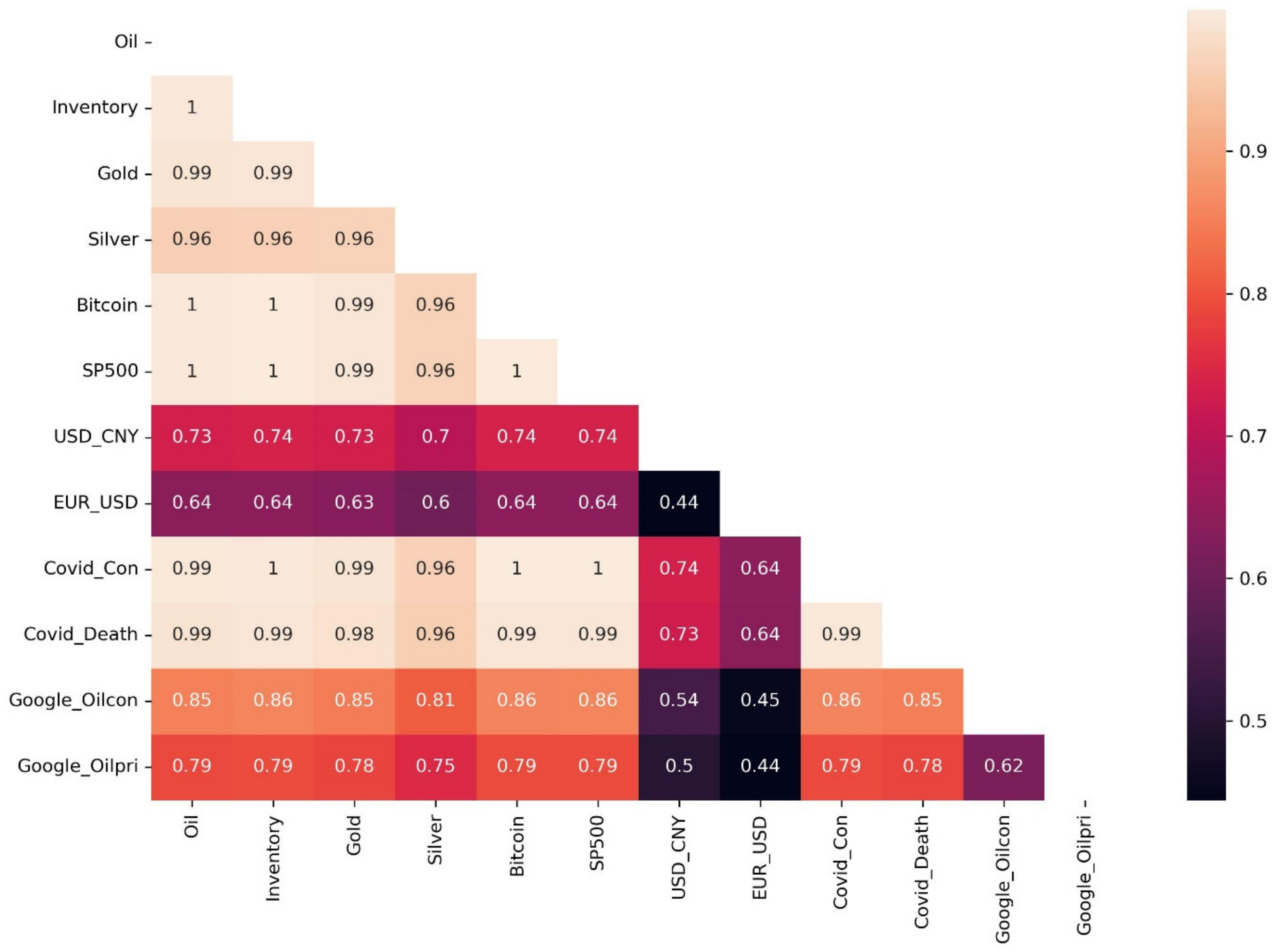
Multiple linear regression is the simplest, most commonly used and most fundamental regression model that can fit the time series observational data well. It can be used for short or simple time series or smooth time series. Part of the literature has revealed the correlation between oil price and other price in financial markets [
28,
29] and assessed the accuracy of linear and nonlinear models in predicting daily crude oil price [
30].
Nearest neighbor is a classical concept in machine learning. It was first proposed as a classifier: given an unlabeled sample, it can find its K most similar (closest) labeled samples and use most of their classes to predict the category of unlabeled samples. Subsequently, this classical idea has been rapidly extended to the field of regression, and the related method is known as K-nearest neighbor regression (KNN) [
31]. In this regression context, samples have relevant predictive target values rather than class- or category-based data. The basic idea can be summarized as follows: given a sample with an unknown predicted value
, the target values of its
K nearest neighbors are pooled, e.g., by averaging or taking the median to predict the unknown target value. Here, we use Euclidean distance to measure the similarity between different samples, as shown in Equation (3):
where
denotes the distance between samples
x and
y,
represents the feature vector of sample
x, and
is the feature vector of sample
y.
The application of KNN algorithms for forecasting in various fields is becoming more and more widespread. The KNN model is used to forecast crude oil price, while comparing with NNAR and ARIMA [
31,
32]. The results have all indicated that the proposed KNN model has a higher forecasting accuracy.
The random forests algorithm was proposed by Breiman in 2001, and consists of a number of deep and uncorrelated decision trees built on different samples of the entire data [
33]. It is a popular tree-based regression method designed to reduce the variance of statistical models, model the variability of the data by randomly extracting bootstrap samples from a single training set and aggregate predictions of new records [
33,
34]. In general, the basic steps can be summarized as follows: (1) randomly generate a subset of samples based on the bootstrap method; (2) use the idea of a random subspace, randomly extract features, split nodes, and construct regression sub-decision trees; (3) repeat the above steps to construct T regression decision sub-trees and form a random forest; (4) for the predicted values of T decision sub-trees, take the mean value as the final prediction result.
Recently, several studies have shown its effectiveness in economics and finance (see [
35,
36,
37]). RF has been widely used in recent years due to its more robust performance compared to other traditional models [
26].
The XGB algorithm was proposed in 2016 and is a relatively new approach [
38]. In recent years, it has been applied to various disciplines such as energy [
39,
40], security [
41] (Parsa et al., 2020), commodities [
26] and credit scoring [
42]. XGB is an integrated classification and regression tree (CART) using the boosting method integration model. It has the advantages of fast training and high prediction accuracy. The result of XGB is the sum of the prediction scores of all CART (Chen and Guestrin, 2016), as shown in Equation (4):
where
denotes the number of trees in the model,
represents each CART tree and
is the predicted outcome.
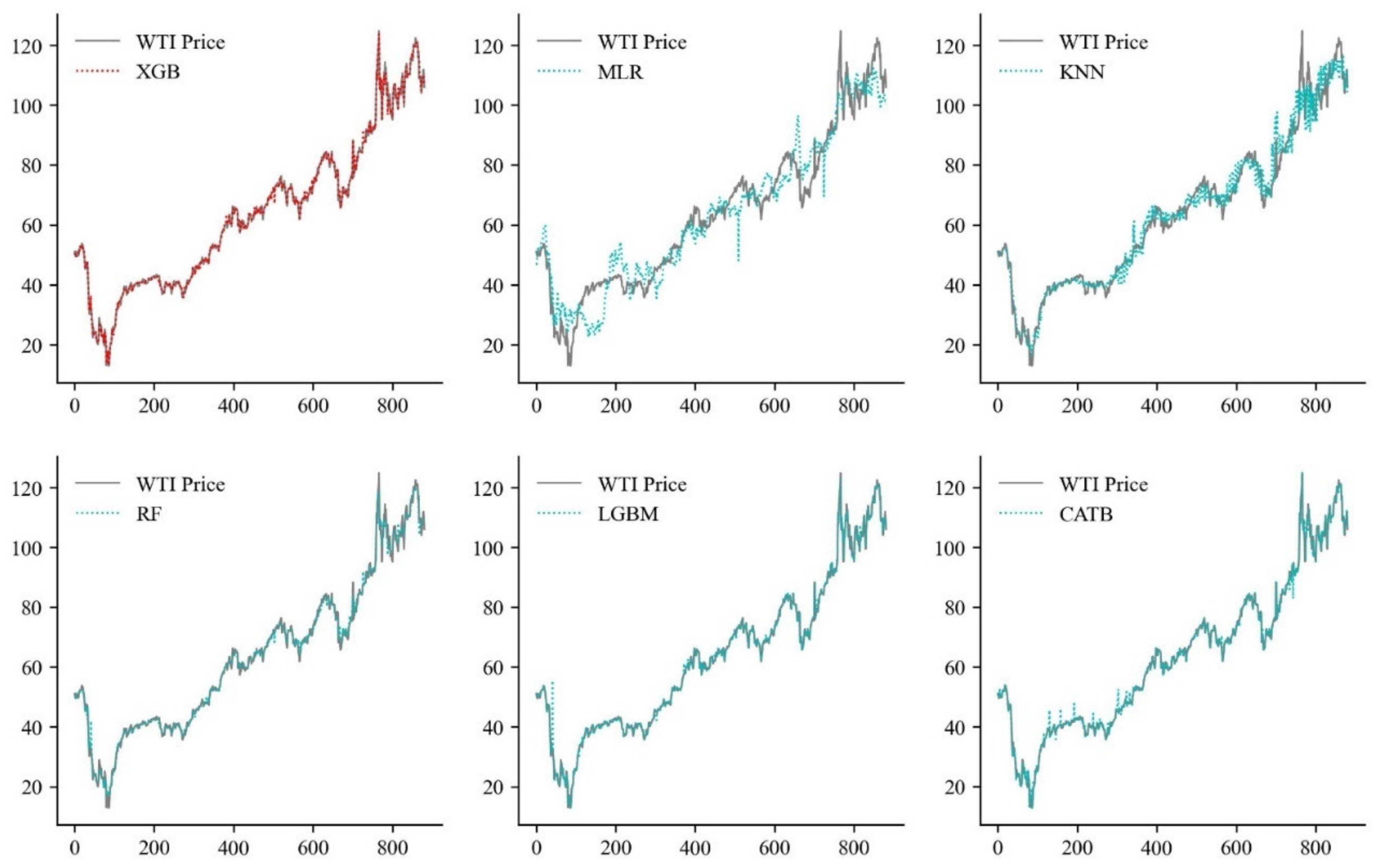
The introduction of the XGB method for oil price prediction not only improves the accuracy of the prediction, but also takes more influencing factors into account [
43]. These studies on crude oil price involved making predictions using variables such as green energy resources, the stock market, and bitcoin during the COVID-19 outbreak [
21,
44]. The results showed that the XGB model outperformed the traditional model.
Light gradient boosting machine (LGBM) is a novel gradient boosting framework proposed by Ke et al. in 2017 to address the efficiency and scalability problems of GBDT and XGB when applied to problems with high-dimensional input features and large data volumes [
45]. According to Wen et al. [
46], LGBM outperforms other gradient enhancement methods in terms of training speed and prediction accuracy because it combines gradient-based one-side sampling (GOSS) and exclusive feature bundling (EFB). Specifically, the estimation function of LGBM is defined as follows:
where
is the regression tree and
T denotes the number of regression trees.
Several previous studies have concluded that LGBM exhibits higher efficiency and accuracy in ML tasks compared to other advanced algorithms [
26,
46]. As a decision tree-based model, LGBM has the additional advantage of being robust to multicollinearity. Therefore, the inclusion of correlated independent variables, which is very common in economics data, is not a consideration for the LGBM.
Catboost is a novel gradient boosting algorithm that has been proposed in recent years to handle categorical features efficiently and reasonably well with fewer parameters, with an ability to match categorical variables and a high accuracy [
47]. It uses gradient boosting of decision trees to classify categorical data. The decision tree is created by dividing the training dataset into similar parts. To better handle categorical features, Catboost uses ordered boosting and innovative algorithms to process the data, outperforming other boosting techniques in terms of performance. In addition, Catboost makes the data distribution free from noise and low frequencies by adding prior distribution terms, as shown in Equation (6):
where
is the prior term and
is the weight of the prior term.
Catboost computes the node values of existing leaves, circumventing the direct computation of multiple dataset alignments, which can handle the classification feature problem well and can effectively reduce the overfitting problem [
48]. Since the introduction of Catboost, there has been ample research applying it to crude oil price forecasting. Jabeur et al. predicted oil price during the COVID-19 pandemic using Catboost [
21]. Hancock and Khoshgoftaar gave a systematic review of the application of Catboost in the field of big data [
48].
4.3. Interpretation of Results
Model interpretability is a major challenge for the application of machine learning methods, and a considerable amount of research in computer science has been devoted to it. However, not enough attention has been paid to the use of ML methods for predicting financial/economic data. To improve the interpretation of machine learning models, Lundberg and Lee proposed the SHAP method in 2017, which assigns a value to each input variable that reflects its importance to the prediction model [
50].
For each subset
of features of the input (where F represents the set of all features), two models are trained separately to extract the impact of feature i. The first model
is trained with feature i as an input, while the other model
is trained without feature i as an input, where
and
are the input features. Then, for each possible subset
,
is computed and the Shapely value of each feature i is obtained as follows.
However, a major limitation of Equation (10) is that the computational cost will grow exponentially as the number of features increases. To address this issue, Lundberg et al. in 2020 proposed an easy-to-handle computational tree model (such as XGB used in this paper) interpretation method, TreeExplainer [
51]. The TreeExplainer method makes it more efficient to compute SHAP values for local and global feature factors.
SHAP combines optimal assignment and local interpretation using classical Shapley values. It will help the user to trust the prediction model—not only what the prediction is, but also why and how it is made. Thus, the SHAP interaction value can be calculated as the difference between the Shapley value with factor
i and no factor
j in Equation (13):
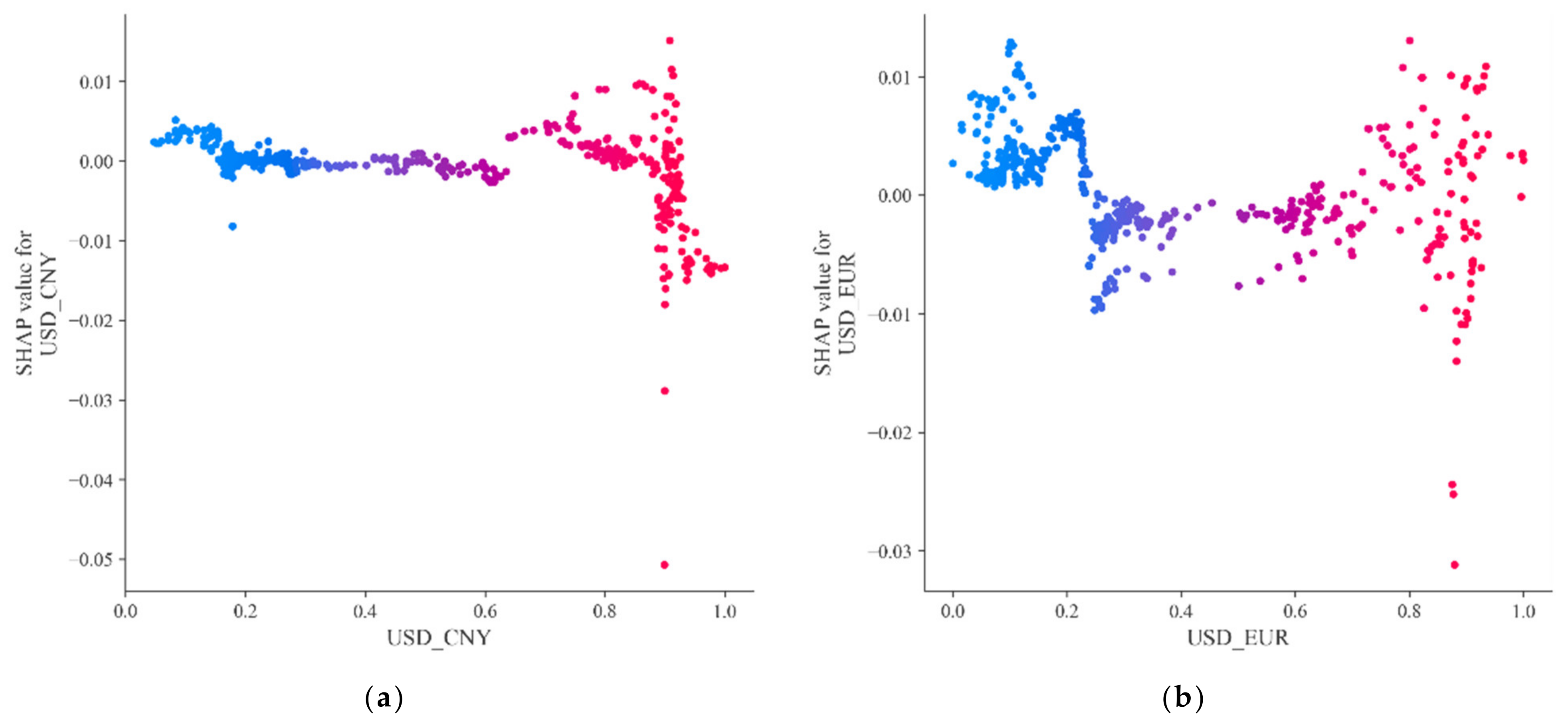
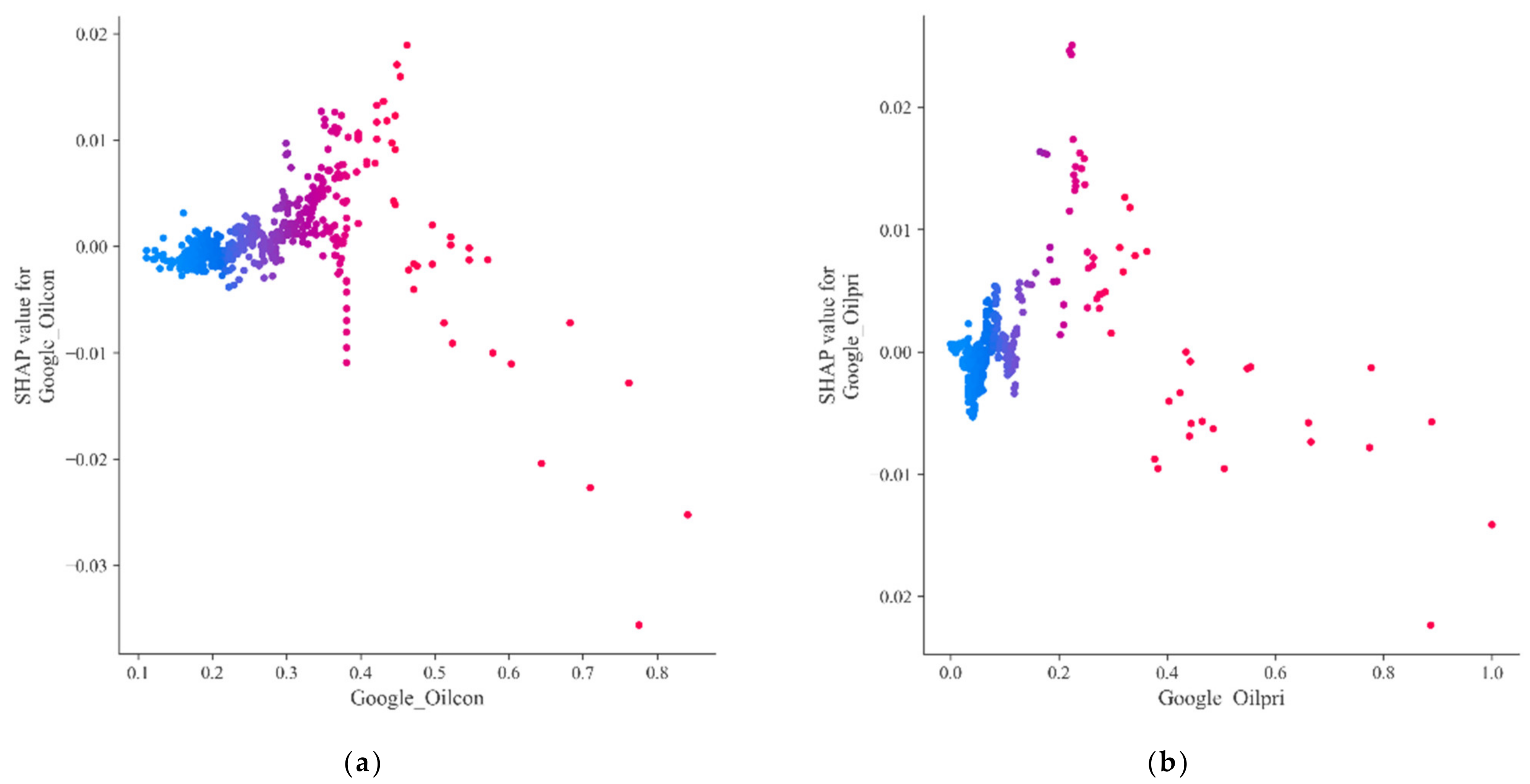
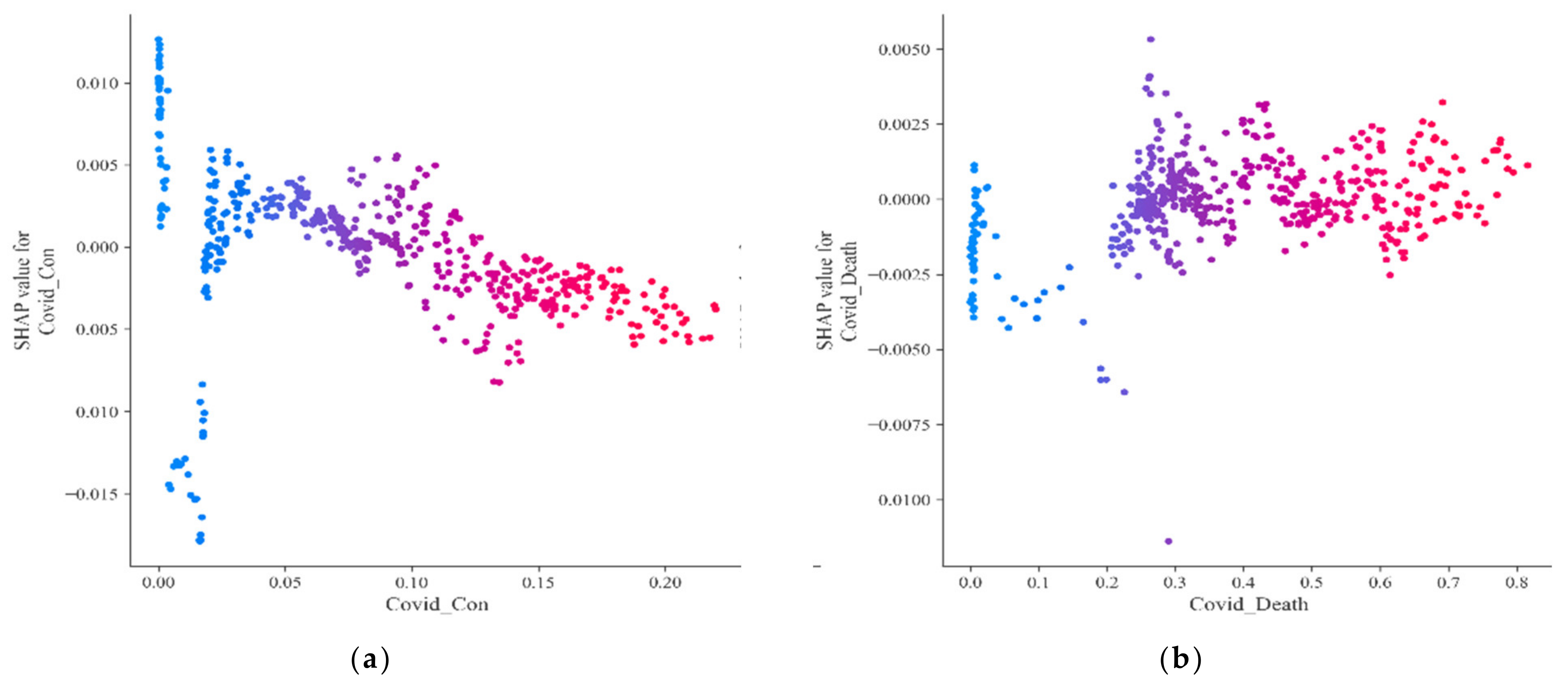
Based on this advantage, we used it to interpret the decision-tree-based XGB model with to the objective of discovering the predictive impact of different features of students on their final destination. Thus, compared with existing methods (e.g., feature importance in random forest methods), SHAP not only ranks feature importance, but also shows the positivity and negativity of feature influence results, thus improving the explanatory power of the model output.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}