1. Introduction
For more than three decades, the multicriteria ordinal classification (also called multicriteria sorting) problem has captured the attention of the multicriteria decision-making research community. In multicriteria sorting, decision actions (alternatives, objects), which are described by multiple assessment criteria, must be assigned to predefined and ordered classes (or categories). In this type of decision problem, we must pay attention to two fundamental issues: (i) the way in which the preferences of the decision-maker (DM) are modelled, and (ii) the way in which the classes are characterized.
There are three main paradigms for modelling the preferences of the decision-maker regarding his/her preferences for an action over another:
- -
Using a value or utility function (the functional paradigm; e.g., [
1]), such that the function provides a numeric representation of the DM’s desirability toward the alternatives.
- -
Building a binary preference or outranking relation (the relational paradigm; e.g., [
2]), where the preference relation between pairs of alternatives can be determined.
- -
The symbolic paradigm, mainly related to the use of Rough Sets to create a system of decision rules (e.g., [
3]).
On the other hand, classes can be characterized through reference actions, known as profiles, in one of the following ways:
- -
Using limiting profiles that describe the boundaries between classes [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13], such that the profiles can be exploited to discern two consecutive classes (e.g., [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13]).
- -
Through representative or characteristic profiles used to symbolize a typical action in the corresponding class (e.g., [
8,
14,
15,
16,
17,
18,
19]).
- -
The profiles (either limiting or characteristic) may be seen as actions, since they are characterized by their impacts on the criteria. The set of assignments examples provided by the DM may not only be used to characterize classes, but also to infer the parameters of a functional or relational decision model (e.g., [
20,
21]). This approach to obtain parameters indirectly is also known as preference disaggregation analysis (PDA). PDA methods use regression-like techniques to “learn” the decision model that represents the underlying assignment policy, which is manifested in the assignment examples given or approved by the DM [
25].
In this paper, our interest is restricted to the relational paradigm. Within this, the most popular multicriteria-sorting methods belong to those in the ELECTRE family. The first, ELECTRE TRI (later renamed ELECTRE TRI-B), describes classes through a single limiting profile. The authors in [
16] proposed ELECTRE TRI-C, in which categories are described by a single characteristic (“central”) profile. Both methods use an outranking relation to compare actions with profiles. Subsequently, the previous ELECTRE TRIs were extended to handle several profiles in ELECTRE TRI-nC and ELECTRE TRI-nB [
11,
17]. These methods were also extended by [
10].
Relational-based ordinal classification methods were recently generalized by [
26,
27]. Using either a reflexive or an asymmetric general preference relation, Fernández et al. proposed methods that characterize classes through either limiting or representative profiles. These methods fulfill the fundamental properties previously discussed by [
5] for ELECTRE TRI-B and revisited by [
16] for ELECTRE TRI-C. The proposals by [
26,
27] are a wide generalization of the relational paradigm applied to ordinal classification.
Using ELECTRE methods, the direct parameter elicitation can be a difficult task [
28]. Typically, the DM finds severe difficulty in defining parameter values whose meaning is confusing to her/him. This is particularly true when setting veto thresholds, as the veto concept is unfamiliar to most DMs. The direct elicitation task is even more complex in the case of ordinal classification methods where categories are described by several limiting profiles, the existence of which is subject to question in many real problems [
15,
16], and where several preference-based separability conditions involving parameter values must be fulfilled. The strong requirements in the proposal by [
26] contribute to making the direct elicitation of parameters and profiles a very big concern.
Indirect elicitation is a suitable alternative. In this approach, the DM typically uses his/her holistic judgments to provide/accept a set of assignment examples that inherently contain his/her underlying assignment policy. This can be less cognitively demanding for the DM due to any of the following reasons: (i) the DM often feels more comfortable making decision assignments than justifying/explaining them; (ii) the DM can provide decision assignments that were previously provided/accepted by her/him; (iii) the DM can provide assignments of a set of fictitious examples that can be easily classified; (iv) the DM can make decision assignments on a subset of actions, for which the she/he feels comfortable.
Under some strong simplifications, the inference of outranking model parameters in ELECTRE TRI-B was approached through classical mathematical programming techniques in [
29]. However, such an indirect way of obtaining parameter values becomes a very complex optimization problem when veto thresholds must be inferred. These thresholds become real-valued decision variables. Inferring all the parameters of ELECTRE-based methods simultaneously involves addressing non-linear optimization problems with non-convex constraints [
29,
30]. There are some works that have assessed the effectiveness of different optimization methods to infer the parameters of ELECTRE-based methods simultaneously (e.g., [
31]); their general conclusion is that in such cases, evolutionary algorithms should be used as in [
25]. The authors in [
32] proposed an evolutionary algorithm to infer the whole ELECTRE TRI-nB model, including preference parameters and limiting profiles. Less sophisticated heuristic approaches may be used when the preference model does not include veto, as in [
33]. A satisfiability-based approach to learn the parameters of a non-compensatory sorting model was proposed by [
34].
With respect to ELECTRE TRI-nC, obtaining representative profiles directly is less cognitively demanding than obtaining the limiting profiles in ELECTRE TRI-nB. The same happens when the methods with limiting and representative profiles proposed by [
26,
27] are compared. As a consequence, in a direct elicitation framework, most DMs should prefer a method based on representative profiles. However, in an indirect elicitation framework, the cognitive effort required by the DM consists basically of the creation of the set of assignment examples. Therefore, the DM should prefer the method that provides more “learning” capacity. Such capacity might depend on (i) the way that it is used to characterize the ordered classes; (ii) the number of assignment examples provided by the DM and (iii) the type of preference relation, namely, reflexive or asymmetric, that is used to compare actions with profiles.
Contributions
This paper presents a method to infer the parameter values and profiles of the methods in the proposals of both [
26,
27]. The first of these proposals is based on limiting profiles while the second one is based on characteristic profiles. In both cases, the outranking relation of ELECTRE TRI is used [
2]; both methods can be used with either a reflexive preference relation or its asymmetric version. [
32] The non-linear optimization problem maximizes an agreement measure between the model and the assignment examples and is addressed using a genetic algorithm. Variants of the genetic algorithm have been successfully used in several works by the authors [
30,
31,
32,
35], and have shown to be considerably more effective than other metaheuristics [
31] in similar contexts (that is, in terms of the elicitation procedures of ELECTRE-inspired model parameters). Therefore, one of our main interests in this work is to analyze if the genetic algorithm with specific characteristics for the current problem continues to be as effective as in those works. We intend to answer the following research questions:
- (1)
What are the learning capabilities of the proposal for each method, and for which of these methods is the inference process more effective?
- (2)
Similarly, how does the effectiveness of the proposal behave regarding the type of relation (reflexive or asymmetric)?
- (3)
To what extent is the “learned” model able to represent the underlying DM’s assignment policy when new actions are classified?
- (4)
How does this capacity depend on the number of assignment examples provided by the DM?
- (5)
How does this capacity depend on the number of classes and the number of criteria?
The first two questions are specially interesting. One could hypothesize that the method based on limiting profiles can make the proposal to learn with higher levels of effectiveness because of its ability to identify the boundaries of each class; however, the experiments showed that this is not the case: the highest levels of effectiveness were achieved in the context of the method based on characteristic profiles. Similarly, since an asymmetric relation has more inherent information than a reflexive relation, one might think that using the former should yield better results. However, the experiments also showed that it was actually in the context of the reflexive relation that the proposal achieved the best effectiveness.
In this paper, extensive computational experiments are performed to respond to the above questions.
The structure of the paper is as follows:
Section 2 provides a brief background to the proposal, including the description of the multicriteria-sorting methods.
Section 3 explains the generalities of the proposed methodology, while
Section 4 presents the details for inferring the parameter values of the ELECTRE-based methods proposed in [
26,
27]. Finally,
Section 5 assesses the robustness of the proposal and
Section 6 concludes this paper.
2. Some Background
2.1. A Theoretical Insight
The family of ELECTRE (
ELimination Et Choix Traduisant la REalité, ELimination and Choice Expressing the REality) methods exploit the so-called outranking relation [
36,
37,
38] that represents the assertion “action
x is at least as good as action
y”. These family of methods is particularly useful when the decision problem includes at least three criteria to assess the actions and when either the actions are evaluated on an ordinal scale or there is a lot of heterogeneity or compensation among the criteria [
37]. Depending on the type of decision problem (choosing, ranking, sorting), the family of ELECTRE methods offers subsets of methods able to address the problem; the ELECTRE TRI methods are within the subset of multicriteria-sorting methods.
The ELECTRE TRI methods share several consistency properties, namely, homogeneity, unicity, independence, monotonicity, conformity, and stability [
5,
16,
39]. There are, however, some important differences. ELECTRE TRI-nC and its extensions are based on two (ascending and descending) rules, which are symmetric via the transposition operation. Such an operation consists of simultaneously inverting the order of the categories and the sense of preference in all the assessment criteria. According to [
9,
40], all relational-based multicriteria-sorting methods should fulfill symmetry in terms of the transposition operation, as carried out by ELECTRE TRI-C, ELECTRE TRI-nC and its extensions [
16,
39]. However, ELECTRE TRI-B and its extensions do not fulfill this symmetry property [
9,
40]. As [
9] state, this lack of symmetry is a consequence of the way ELECTRE TRI-B defines the categories as closed from below.
ELECTRE TRI-B and ELECTRE TRI-nB are composed of two procedures, namely, the pseudo-conjunctive and pseudo-disjunctive rules. In the pseudo-conjunctive procedure, an outranking relation
S is used to compare actions against limiting profiles (
xSy denotes “action
x is at least as good as action
y”), while the pseudo-disjunctive procedure uses the asymmetric preference relation
P, which is the asymmetric part of
S. Ref. [
9] (respectively, [
12]) proposed to replace the conjoint use of the pseudo-conjunctive and pseudo-disjunctive procedures of ELECTRE TRI-B (resp., ELECTRE TRI-nB) by descending and ascending rules, which use
S and are symmetric in terms of the transposition operation. However, in these proposals, the limiting profiles are fictitious actions, which do not belong to any category; to a large extent, this contradicts the conformity requirement, which states that the limiting profiles have to be assigned to the categories to which they belong.
The conflict between conformity and correspondence through the transposition operation was solved by [
26]. They proposed to describe the limiting boundary
Bk between classes
Ck and
Ck+1 by two “layers”; namely,
BUk and
BLk.
Ck+1 is closed from below by
BLk, while
Ck is closed by
BUk. Based on a general reflexive (respectively, asymmetric) binary preference relation
S (resp.
P), the method in [
26] fulfills the whole set of consistency properties required by [
5] and is symmetric in terms of the transposition operation. However, this theoretical advance required imposing strong conditions on the set of limiting profiles, which constitutes the main obstacle for the method in [
26].
The outranking relation of the ELECTRE family and its extensions are particular cases of the relation on which the method in [
26] is based. In the following, we call ELECTRE TRI-nB-2 to this method when
S is the outranking relation as in ELECTRE TRI-B or ELECTRE III [
2].
Regarding the relational methods that characterize classes through representative profiles, a similar generalization was proposed by [
27]. Any reflexive preference relation
S (or its asymmetric part
P) can be used by two assignment rules that are equivalent through the transposition operation. If
S is the outranking relation as in ELECTRE TRI-nC, the rules suggest assigning actions to ranges of possible categories containing the classes suggested by that former method.
Thus, both proposals in [
26,
27] fulfill the desirable properties. As discussed in the introduction, in a direct elicitation framework, the use of “characteristic” or representative profiles requires less effort from the DM. However, in a PDA approach, the cognitive demand depends only on the number of assignment examples. Given several assignment examples, it is interesting to illustrate (i) which way describing classes should be preferred and (ii) which preference relation (
S or
P) provides better results.
2.2. A Brief Description of the ELECTRE TRI-nB-2
ELECTRE Tri-nB-2 is a particular case of the method proposed in [
26] when
S is the outranking relation of ELECTRE TRI. The boundary
Bk that separates the classes
Ck and
Ck+1 is described by a set of limiting profiles
bk,j (
j = 1, …,
card (
Bk)),
Bk = {
bk,j}, and is made up of two “layers”, called
BLk and
BUk, which are disjoint sets.
BLk is composed of profiles belonging to
Ck+1, while
BUk by other limiting profiles belonging to
Ck. So,
Ck+1 is closed from below by
BLk, and
Ck is closed from above by
BUk.
Let us denote by P the asymmetric part of S and by D the Pareto dominance relation. In ELECTRE TRI-nB-2, the profiles should fulfill the following requirements:
There is no (w,z) belonging to BLk × BLk such that wPz;
There is no (w,z) belonging to BUk × BUk such that wPz;
There is no (w,z) in BUk × BLk fulfilling wSz;
There is no (w,z) in Bk × Bh (h > k) fulfilling wSz;
For all z in BUk there is y in BLk−1fulfilling zSy;
For all z in BLk there is y in BUk + 1 that fulfills ySz;
For all z in BUk there is w in BUk + 1that fulfills wDz;
For all z in BUk there is w in BUk−1that fulfills zDw;
For each z in BLk there is y in BLk−1that fulfills zDy;
For all z in BLk there is y in BLk + 1 that fulfills yDz.
The authors in [
26] proposed two assignment rules, namely, primal and dual, which are symmetric in terms of the transposition operation; these rules should be used conjointly. They are based on a relation
S between actions and boundaries, defined as: (i)
xSBk if, and only if, there is
y ∈
BLk such that
xSy and there is no
w ∈
Bk fulfilling
wPx; (ii)
BkSx if, and only if, there is
y ∈
BUk such that
ySx and there is no
w ∈
Bk fulfilling
xPw.The primal rule is a descending procedure that assigns the action x to Ck+1, where k is the subscript of the first limiting boundary fulfilling xSBk. On the other hand, the dual rule is an ascending procedure that assigns x to Cj, where j is the first subscript fulfilling BjSx. All the categories in the range between Cj and Ck (or vice versa) are possible assignments for x.
2.3. The Methods Based on Comparing Actions against Representative Profiles
The authors in [
27] proposed alternative multicriteria-sorting methods, one based on
S and one based on
P.
In both methods, each category Ck is characterized by a subset Rk of representative profiles, rk,j, j = 1,…, card (Rk), which must fulfill several demands. For the S-based method, these demands are the following:
For all ordered pairs (k, h) (h > k), for k = 1, …, M-1, for each y in Rh, there is no z in Rk, fulfilling zSy;
For all ordered pairs (k, h) (h > k), for k = 1, …, M-1, for each y in Rk, there is a z in Rh, fulfilling zSy;
For all ordered pairs (k, h) (k > h), for k = 2, …, M, for each y in Rk, there is a z in Rh fulfilling ySz.
For all ordered pairs (k, h) (h > k), for k = 1, …, M-1, for each y in Rk, there is a z in Rh, fulfilling zDy;
For all ordered pairs (k, h) (k > h), for k = 2, …, M for each y in Rk, there is a z in Rh, fulfilling yDz.
The S-relation between actions and subsets of profiles is defined as
xSRk if and only if there is a y belonging to Rk, that fulfills xSy;
RkSx if and only if there is a y in Rk, fulfilling ySx;
Like ELECTRE TRI-nC, [
27] proposed two assignment rules, which are symmetric via the transposition operations. The descending rule finds the first subscript
k for which
xSRk, and
x is assigned to
Ck or
Ck+1. In the ascending rule, the first
h such that
RhSx is identified, and then
x is assigned to
Ch−1 or
Ch. The conjoint assignment rule suggests assigning
x to a class within the range
Ch-
Ck (or vice versa).
For the P-based method, the requirements are the same as above—replacing S by P, but adding (vi). For k = 1,…, M, there is no pair (z, w) in Rk × Rk that fulfills zPw. This requirement forces profiles to be central in order to achieve a good characterization of their related category (a central profile is a characteristic action representative of a class). The relation P between actions and subsets of profiles is defined as the relation S, but with P instead of S. The descending and ascending rules are similar, but replacing xSRk with xPRk, and RhSx with RhPx. The conjoint assignment rule is identical to that of the S-based method.
3. The Proposed Methodology
The proposed methodology is based on a set of reference examples. This set is built by the decision-maker according to his/her own system of preferences/decision policy; then, based on a given decision model able to assess xSy (from which, xPy can be derived), the proposed methodology intends to define the model’s parameter values such that the decision model can reproduce the reference examples as accurately as possible.
Even when this work exploits the proposed methodology in the context of the ELECTRE TRI models [
26,
27], the methodology is general enough to work with virtually any decision model (not only those based on ELECTRE methods) whose complexity requires the optimization stage to be an evolutionary algorithm. Other examples of decision models that can fulfill such a condition are those based on value functions with veto conditions (e.g., [
41]), the ELECTRE methods with interactions between criteria [
42], the extended ELECTRE method to handle reinforced preferences and counter-veto effects [
43], the hierarchical version of the ELECTRE methods [
44], and the interval outranking approach by [
45,
46].
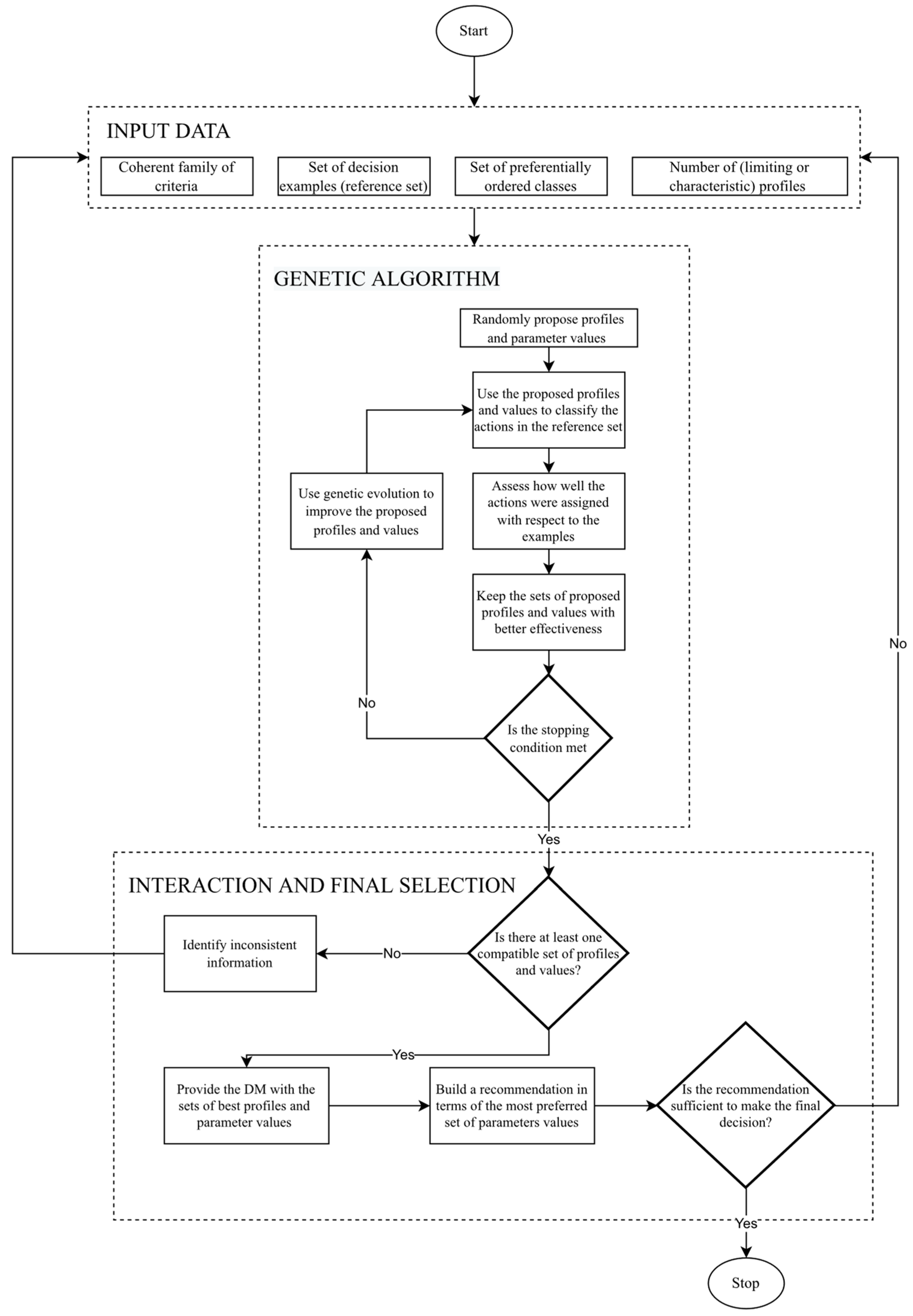
Figure 1 shows an insight into the proposed approach.
3.1. Input Data
As shown in
Figure 1, the input data of the proposed approach are composed by a coherent family of criteria, a set of decision examples, a set of preferentially ordered classes, and a set of (limiting or characteristic) profiles for each class.
3.1.1. A Coherent Family of Criteria
The set of criteria must be established based on three characteristics: (1) no redundancy (each criterion is considered only once); (2) completeness (the criteria characterize all the significant objectives for the decision problem); and (3) consistency, which involves the DM’s preference to be consistent with the comprehensive assessment.
3.1.2. A Set of Assignment Examples
Let
x and
y be decision alternatives, each of them characterized by its scores on the family of criteria. The assignment examples provided by the DM are of the form “
x should be assigned to class
Ci”. These decisions may be past decisions or new easy-to-make decisions (that can even include fictitious alternatives). In each of these situations, the examples provide instances about the judgment policy of the DM as well as his/her system of preferences; furthermore, the examples provided can influence the preference model defined by the proposal. Therefore, it is important for the DM to carefully express his/her holistic preference on the basis of all the criteria defined in
Section 3.1.1.
3.1.3. A Sequence of Preferentially Ordered Classes
Let C1, C2, …, CM, be a sequence of classes such that each class denotes intensity of preference, thus the decision alternatives assigned to Ci are not worse than those assigned to Cj for i > j.
3.1.4. The Number of (Limiting or Characteristic) Profiles
As stated in the introduction, classes may be characterized by limiting profiles that describe the boundaries between classes or by representative (central) profiles. Each of these profiles is characterized through scores on the family of criteria (as decision alternatives). The proposal expects the DM to provide the number of profiles to be defined by the approach.
3.2. A Genetic Algorithm to Select the Most Convenient Set of Parameter Values
A genetic algorithm is used to infer representative profiles and parameter values compatible with the decision examples provided. The canonic version of a genetic algorithm was used to define the most convenient parameter values. The description of this genetic algorithm is provided in
Section 4.3.
3.3. Interaction with the DM and Final Selection of the Parameter Values
Finally, the approach identifies the set of parameter values and profiles most compatible with the decision examples provided by the DM; if the DM is not satisfied with this set, then he/she should adjust the information provided as the input. This information is always consistent, and there should always be at least one set of parameter values and profiles compatible with the decision examples. If the DM is comfortable and approves the recommendation, the inference process ends; otherwise, the input information should be revised and adjusted.
4. Eliciting the Preference Models
As explained above, the proposed methodology can work with virtually any decision model. Here, we describe the components used to infer the sets of parameter values and profiles of either ELECTRE TRI-nB-2 or the method based on comparing actions against representative profiles. In both cases, the outranking relation of ELECTRE TRI is used (cf. [
2]). The degree of credibility of the outranking relation, σ(
x,
y), is built on
A ×
A, where
A is a set of actions described on the basis of
N criteria (without loss of generality, we assume that the performance on these criteria should be maximized). The output of σ(
x,
y) denotes the degree of credibility of the assertion “
x is at least as good as
y” from the perspective of the DM. The steps to calculate σ(
x,
y) can be followed from [
2].
The relative importance of each criterion is called weight and reflects its voting power; the weight
wi of each criterion
gi must fulfill
wi > 0 and, for convenience, ∑
wi = 1. The procedure described in [
2] to calculate σ(
x,
y) uses an indifference threshold,
qi(
gi(
x)) ≥ 0, and a preference threshold for each criterion
gi fulfilling
pi(
gi(
x)) ≥
qi(
gi(
x)). It also uses veto thresholds,
vi(
gi(
x)), to reflect the veto power of some criteria toward the hypothesis that the outranking relation is met. The authors in [
47] advanced this procedure to also consider pre-veto thresholds,
ui(
gi(
x)). For readability purposes, we use
qi,
pi,
vi,
ui to denote these concepts. Finally, if there is enough evidence to accept that “
x is at least as good as
y” and there is no enough evidence that opposes the assertion, then it is accepted that “action
x outranks action
y”, which is denoted by
xSy.
xSy can be assessed using the outranking relation and a credibility threshold, λ. Formally,
Note that these parameters depend on the decision policy of the decision-maker; thus, decision models with different sets of parameter values can lead to different decisions. Our proposal consists of inferring the parameter values that best restore the reference decisions provided by the DM.
4.1. Inferring an ELECTRE TRI-nB-2 Model
According to previous discussions, the information that must be inferred to fully operationalize the ELECTRE TRI-nB-2 method is the following:
Weights: wi for i = 1, …, N;
Veto thresholds: vi for i = 1, …, N;
Pre-veto thresholds: ui for i = 1, …, N;
Majority threshold: λ.
Limiting profiles:
Bk =
BLk ∪
BUk, where each element in
BLk and each element in
BUk are characterized by their assessments on the
N criteria. The set of profiles
Bk (made up by the disjoint sets
BLk and
BUk) that separates the classes
Ck and
Ck+1, and whose cardinality is given by the DM, must fulfill the conditions described in
Section 2.2.
Let C = {C1, C2, …, CM} be the set of classes defined by the DM, such that Ci + 1 is preferred over Ci, and T be the set of actions used in the decision examples provided by the DM, such that each has been assigned by the DM to a class Cj ∈ C. Each of these decision examples contains holistic information about the preferences of the DM. Therefore, the goal of the inference process is to assign values to the parameters so the ELECTRE TRI-nB-2 method can reproduce the decision examples.
The inferred information that is most appropriate to fit the examples provided by the DM,
, is the one that minimizes the number of inconsistencies with respect to the expressed decisions. Each
is assigned by the DM to a range of classes through his/her own system of preferences, say
; similarly, the ELECTRE TRI-nB-2 method can use
to assign each
to a range of classes. Thus, let
be the set of classes to which the DM has assigned
and let
be the set of inferred classes. Since
is not necessarily assigned to only one class but to a range of classes, the so-called F
1-score [
48] is exploited here. The authors in [
49] use the concepts of
precision,
Q, and
recall,
R, to define this measure: F
1-score = 2
QR/(
Q + R). The authors in [
33] use such a procedure to define
in the following non-linear optimization problem:
Note that the decision variables in Problem (1) are those listed at the beginning of this Section.
4.2. Inferring a Model for the Representative-Profiles-Based Methods
A set of assignment examples is also used to define the information required by the methods that use representative profiles. The information that must be inferred in this case is the same as in the case of the ELECTRE TRI-nB-2 model except for the case of the profiles since now the profiles that must be inferred are representative of each class.
Let
be the set of assignment examples such that each
is assigned by the DM to a range of elements of the set of classes
. Since both the DM and the method described in
Section 2.3 assign each action
to a range of classes, the F
1-score is also used in the context of representative profiles to determine the most convenient set of profiles and parameter values,
. Following the intuition of the notation used in the previous section, the fitness function is defined as follows:
Note that the decision variables in Problem (1) are those listed at the beginning of
Section 4.1, except for
Rk that substitutes
Bk.
4.3. A Genetic Algorithm to Address Equations (1) and (2)
Note that the optimization problems resulting from Equations (1) and (2) are non-linear optimization problems with non-convex constraints given that the whole sets of parameters mentioned in
Section 4.1 are being inferred simultaneously [
29]. Therefore, following evidence from other works [
25,
31], we use an evolutionary algorithm to address these problems. Particularly, we use a genetic algorithm inspired by those described in works that are similar to a certain extent [
27,
30,
31,
32,
35]; we use similar genetic operators with different representations of individuals.
Evidently, using a decision model different to that used here (an ELECTRE-based decision model) implies some changes to the procedure described below; particularly, different parameters require a different structure of the individuals.
In the case of Problem (1), the algorithm uses a real-valued vector composed of
genes to denote each individual (where
is the number of profiles used to separate each pair of classes and
n is the number of criteria), as shown in
Figure 2; in this figure,
gi(
bk,j) is the impact of profile
bk,j ∈
Bk on the
ith criterion. In the case of Problem (2), the algorithm also uses a real-valued vector but is now composed of
, where
is the number of profiles used to characterize each class, as shown in
Figure 3.
The initial population of the genetic algorithm contains individuals that are generated randomly but that fulfill the constraints established by the DM/analyst pair. The selection of the parents in the algorithm is performed using binary tournament, while the crossover is at one point of the individuals. To facilitate consistency, the genes related to the weights form an inseparable unit. Only one offspring individual is created from each pair of parent individuals; then, a given probability is assigned to the possible mutation of the offspring individual. This mutation involves the random generation of a randomly selected gene (or set of genes, in the case of the weights) in such a way that the mutated offspring fulfills the constraints. This way, a number of offspring individuals equal to the number of individuals in the population is generated (say, pop_size), and all the (parent and offspring) individuals are inserted into a pool from which pop_size-1 individuals are randomly selected to create the population in the next iteration of the algorithm. Each individual’s fitness is calculated using Problems (1) or (2). When the stopping criterion is met, the best individuals found so far compose the set of best solutions in the current execution of the algorithm. A centroid of such a set is calculated using the average values of the parameters in the set. Such a centroid is considered as the best solution when it achieves the best-known fitness value, otherwise, the solution closest to the centroid is chosen (in terms of the Euclidean distance). Furthermore, to ensure robustness, twenty executions of the algorithm are performed.
The control parameters of the genetic algorithm are defined following the results of previous works by the authors [
30,
31,
32,
35,
50]. In those works, similar optimization problems have been addressed through the genetic algorithm; its parameters had been previously determined using a classical configuration technique, ParamILS [
51]. Assessing the neighborhood of such values helped us to determine the specific control parameters used in this work in preliminary experimentation. The control parameters used by the algorithm are size of the population, number of generations, probability of crossover, and probability of mutation. The values are, respectively, 200, 200, 60% and 2%.
This procedure is formalized in Algorithm 1.
| Algorithm 1. Genetic Algorithm proposed to address Problems (1) and (2). |
| Require: A set of reference examples, |
| Ensure:, individual representing the population with the best fitness values |
| 1: |
| 2: |
| 3: |
| 4: create-Initial-Population () |
| 5: for do |
| 6: create-Offspring (, selection, crossover, mutation) |
| 7: generate-Population ( |
| 8: |
| 9: end for |
| 10: find-Best () |
| 11: find-Centroid () |
| 12: if is-best () |
| 13: |
| 14: else |
| 15: find-closest () |
5. Assessing the Robustness of the Inference Procedure
This section details the experimentation performed to assess the robustness of the inference approach.
5.1. Experimental Design
The basic experimentation consists of the following steps:
Simulate the preference model of a decision-maker and some limiting (respectively, characteristic) profiles that are all compatible with the model that uses limiting (respectively, characteristic) actions; this way, both the parameter values of the preference model and the set of profiles are known.
Use the known preference model to assign a set of reference actions to ordered classes.
Exploit Algorithm 1 to infer the parameter values of the preference model.
Simulate actions different to the ones used as reference.
Assign the new actions to ordered classes using the simulated preference model; also assign them using the inferred parameter values.
Obtain an out-of-sample effectiveness, measuring the proportion of coincidences between the assignments made on points 4 and 5.
To improve the soundness of the experimentation, the procedure described above is performed twenty times and, for each of these, the experiment setup uses a wide variety of values, as shown in
Table 1.
Four profiles were used (per class/per boundary) in all scenarios. The mean values of the results are used below and, since there are large numbers of experiments being carried out, following the Central Limit theorem, it can be assumed that such mean values are normally distributed. Therefore, two-sample t-tests with a significance level of 0.05 are used to assess the null hypothesis of “two mean values are equal”.
5.2. Results
First, we identify the type of method (based on central or limiting profiles) that displays higher performance using the reflexive S relation (since it presents milder requirements); then, we make a deeper analysis of the results provided by such a method.
In
Table 2, the fourth column compares the out-of-sample effectiveness of the classification method based on central objects in terms of a different number of training objects per class (2, 4, and 6). For each number of criteria (
N) and classes (
M), the effectiveness is compared according to the number of reference objects per class. The group that showed a statistically significant difference with respect to the others is marked in red. If there are two rows marked in red (for example, in the row with
N = 3 and
M = 2), it means that those values are better than the rest, but they do not have a significant difference between themselves.
The sixth column reflects the same process but for the method based on limiting profiles. The blue color indicates the row that shows a statistically significant difference with respect to the others.
Remarkably, all the values in column 4 are significantly higher than the corresponding values in column 6. The method based on representative profiles is clearly superior to the method based on limiting profiles for all N, M, and the number of training objects.
Table 3 integrates the information considering the number of criteria
N as a separation variable. In column 2 of this table, the value that shows a statistically significant difference with the others in the same column is marked in red. In column 4, the highest value (with a significant difference) is marked in blue.
Table 4 shows similar information in the context of the number of classes
M.
Since it is evident that the method based on representative profiles was more effective than the one based on limiting profiles, we proceed to deepen in the results provided by the former.
Table 5 compares the effectiveness obtained using the method based on representative objects first with the reflexive relation
S and then with the asymmetric relation
P. Only the effectiveness in the triples (
N,
M,
nclass) is shown in this table, where the difference between the treatment with
S and the treatment with
P showed significant differences. The treatment that was superior is marked in red.
Table 6 reproduces the results of
Table 5 but with a focus on the number of criteria. A significant difference is marked in red.
Similarly,
Table 7 focuses on the number of classes to compare the effectiveness of the method based on representative profiles using the relation
S and using the relation
P.
5.3. Discussion
The proposed methodology is very general; it can be exploited to infer virtually any multicriteria decision model that is complex enough that the optimization process must be performed through metaheuristics. An important advantage of this work consists of the practical value of the experiments. Given a multicriteria-sorting problem, the experiments answer the following questions: which of the considered sorting methods can the decision-maker choose? Should he/she use representative or limiting profiles to identify the classes? Should he/she use an asymmetric preferential relation, or a reflexive relation is enough to reach high levels of effectiveness? How many reference objects/assignment examples should he/she provide?
The experiments assessed the robustness of the proposed methodology by using many diverse scenarios, including the number of criteria, the number of classes, the number of reference objects (assignment examples) per class, the decision policy of the simulated decision-maker providing the examples, and the type of sorting method and preference relation. It is easy for the decision-maker to provide the reference examples required by the proposed methodology. According to the results of the experiments, only a limited number of examples can be enough to obtain sufficiently high levels of effectiveness in the definition of the parameter values.
It can be seen from
Table 2 that, when there are only two classes and the method based on characteristic profiles is used, then two or four objects per class is enough to reach maximum effectiveness; so, little cognitive effort is required from the DM in this case. However, this effect is not appreciated with the method based on limiting profiles, where, even with the minimum number of criteria (three) and classes (two), the highest level of effectiveness is only achieved using the maximum number of objects per class (six). It can be seen from this table that, when there are more than two classes, increasing the number of objects per class most of the time improves the capacity to learn the reference examples.
The range of effectiveness values in
Table 2 for the method based on characteristic profiles is 0.82–0.97, with an average value of 0.89. As expected, the lowest effectiveness levels are seen in the highest complexities of the problem, where nine criteria and five classes are considered; although, even in this case, increasing the number of objects per class almost always increased the effectiveness. All this is also true for the method based on limiting profiles, whose range of effectiveness in
Table 2 is 0.57–0.89 (with significative lower values than those produced using characteristic profiles, respectively). Another interesting result from this table is that effectiveness seems to be more affected by the number of classes than by the number of criteria; for example, for the method based on reference profiles, the average effectiveness when
N = 3 and
M = 5 is 0.88, while the average effectiveness when
N = 5 and
M < 4 is greater than 0.88. Very similar results can be seen for the method based on limiting profiles and for other combinations of
N,
M. This assertion is confirmed by
Table 3 and
Table 4; the former shows that increasing the number of criteria does not necessarily decrease effectiveness, while the latter clearly shows that increasing the number of classes decreased effectiveness.
Unequivocally,
Table 2,
Table 3 and
Table 4 show higher learning abilities when using representative profiles over using limiting profiles, both with the reflexive relation
S. This is an outstanding result since the method based on comparing actions against representative profiles demands the fulfillment of fewer conditions compared to those of the method based on limiting profiles. Therefore, future works relying on the proposed inference process should follow a methodology based on representative profiles.
Table 5,
Table 6 and
Table 7 show that, in most cases, the effectiveness of the method based on representative profiles using the reflexive relation
S is significatively greater than that when the asymmetric relation
P is used; this is particularly true when there are three and five criteria (
Table 6) and when there are four and five classes (
Table 7).
On the other hand, it appears that using
S provides higher effectiveness in the presence of lower numbers of objects per class, since
Table 5 shows that using
P was better only once when there were two objects (in the case
N =
M = 3); however, further experiments are required to provide deeper insights in this regard.
6. Conclusions and Future Work
The full operationalization of recent multicriteria-sorting methods has been achieved. These methods can use either a reflexive or an asymmetric general preference relation and either limiting or representative profiles; furthermore, they fulfill all the fundamental properties commonly required from multicriteria-sorting methods (see [
5,
16]); therefore, they constitute some of the widest generalizations of the relational paradigm applied to ordinal classification. However, the methods require the definition of many parameter values (common in outranking-based methods), which is arduous work for the decision-maker that can lead to counterintuitive results.
This paper has described a complete methodology to infer the most convenient parameter values based on sets of decision examples provided by the decision-maker. The proposed inference methodology addresses the specific characteristics of the sorting methods through an accuracy measure that defines the effectiveness of the inference process. The optimization of this measure is performed through evolutionary algorithms given the non-convexity of the search space, which is caused by inferring all the parameters of the methods simultaneously.
The main conclusion of the results is that, for all the tested scenarios in the context of the multi-criteria aggregation of preferences from ELECTRE III, the highest effectiveness values of the inference process were obtained when using the method based on representative profiles. Since such a method is also the one with the mildest requirements, the decision-maker–decision-analyst pair should concentrate on this sorting method. On the other hand, using such a method with the reflexive relation S was apparently more effective than using it with the asymmetric relation P; however, this result was not conclusive, since using the relation P seems to outperform the former in presence of lower numbers of classes; so, further experiments should be performed to test this hypothesis. The good performance of the reflexive relation regarding its asymmetric counterpart could be a result of milder conditions. Note that the condition imposed to the method when it is using the relation P implies that the profiles must be central. By not constraining the method to such a condition when it is using S, perhaps the profiles can better represent the class. Theoretical (more than practical) studies will be performed in future work to discover the real causes.
The results shown in
Table 2 indicate that, when two classes are used in the sorting process, then only two and sometimes four objects per class are enough to reach the highest effectiveness. However, when there are more than two classes in the problem, then, regarding a number of criteria and a number of classes, the highest effectiveness can be achieved with the highest number of objects per class (six). Therefore, an interesting future research line is to determine if this is the highest achievable effectiveness, or if such an effectiveness can be increased by increasing the number of objects per class. Of course, if the latter is true, deciding to increase the effectiveness of the inference process is dependent on the decision-analyst–decision-maker pair, and it should be considered that the effectiveness of most scenarios of
Table 2 is considerably high. Other results indicate that increasing the number of classes decreased the effectiveness of the methodology, but increasing the number of criteria does not necessarily provoke this effect.
It is important to remark that these conclusions are valid for models based on ELECTRE III. Analyses with other ways to aggregate preferences are pending and will be addressed in future work. More research is needed to compare our results and validate our conclusions using other metaheuristic approaches.







{kind=link}
{kind=link}
{kind=link}