1. Introduction
The importance of statistical theory comes from modeling real-world events. Lifetime data modeling and analysis are crucial in a variety of fields, including medicine, engineering, insurance, and finance. It is common practice to analyze lifespan data sets using statistical probability distributions, as well as their expansions. The addition of one or two parameters to the basic distributions encourages novel distribution theory modeling ideas. In recent years, generalized distributions have been a popular way to construct flexible distributions that can suit actual data. Statisticians are constantly on the lookout for novel statistical models to fit data sets from a variety of fields. Statistical models can be used to describe and forecast real-world phenomena. In recent years, many distributions have been widely used. For more reading, see [
1,
2,
3].
Now, we are facing a huge pandemic affecting the whole world; this pandemic is known as the COVID-19 virus. We are studying the mortality rate in many countries through the mortality number every day. The behavior of the shock was simulated, and it was determined that the effect of COVID-19 on the financial system in 2020 will continue to negatively affect domestic credit provided to the private sector by banks for about five years; see [
4,
5,
6]. Many authors have conducted studies on mortality rates; for instance, see [
7,
8,
9].
Currently, scientists are conducting substantial investigation into this event. However, obtaining the correct facts and figures is important in order to do all that is possible to block COVID-19. It is always critical to provide the most accurate description of the data being analyzed when studying and using big data sciences. Recent research has shown how statistical distributions can be used to describe data in applied disciplines, such as medicine. See, for example, Refs. [
10,
11,
12].
Vaccines debuted by the end of August 2021, bolstering the fight against the epidemic. Today, several nations have zero active instances of COVID-19 infection. The situation appears to be under control in the majority of countries, and others hope that the COVID-19 pandemic will end soon. Many authors have conducted studies on vaccination process and studied the effect of the spreading. See, for example, Refs. [
13,
14,
15].
This work investigates new distributions to model COVID-19 deaths. The purpose of this research is to investigate the point estimate of unknown PHD parameters using conventional estimation methods. A statistical comparison of these approaches is performed using simulation to evaluate their performance and investigate how these estimators behave for various sample sizes and parameter values. We also studied the existence and uniqueness of the likelihood function, see
Section 6. We can see that the estimates provided are maximum points and represent the global maximum. At the end of the application section, we added graphs that demonstrate the flexibility and the superiority of the proposed distribution among all its rivals; for this, we used the proposed distribution for data analysis for COVID-19 data.
The rest of this paper is organized as follows. In
Section 2, we define the PHD distribution. PHD, PDF and CDF are obtained. In
Section 3, the associated properties and equations of the PHD are derived mathematically.
Section 4 describes the methods and techniques used in the estimation. In
Section 5, a simulation study is conducted to compare the performance of these estimation methods. One real data set of COVID-19 from different life applications is used in
Section 6 to prove the efficiency of the PHD distribution compared to other distributions. Finally, conclusions and major findings are given in
Section 7.
2. Model Formulation
Haq [
16] presented a one-parameter distribution called Haq distribution (HD), where its cumulative distribution function (CDF) is defined as follows:
and its corresponding probability density function (PDF) is defined as follows:
Now, by adding an extra parameter to HD by using the power transformation
, we have a new statistical model know as the power Haq distribution (PHD). The CDF and PDF of the PHD are defined, respectively, as follows:
It is possible to draw the conclusion that the HD is a specific case of the PHD when
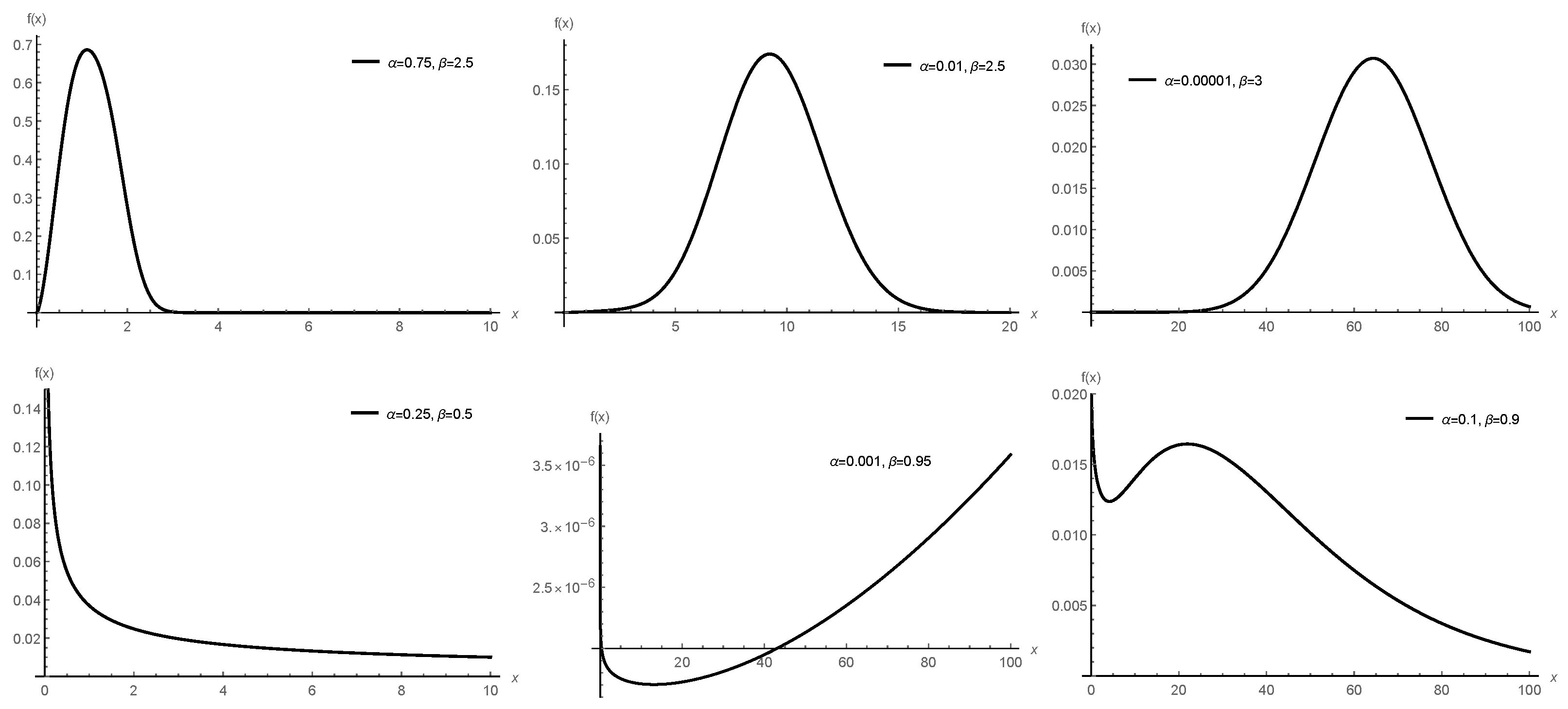
. The many shapes that the PHD’s PDF may take are seen in
Figure 1. The PDF of the PHD may clearly assume a variety of shapes, including decreasing, bathtub, unimodal (left skewed, right skewed and symmetric), and decreasing–increasing–decreasing shapes.
Reliability Functions
The survival function (
) and hazard rate function
of the PHD are defined, respectively, as follows:
On display in
Figure 2 are the several possible plots of the
of the PHD, such as bathtub, increasing–decreasing–increasing, increasing and decreasing shapes.
3. Statistical Properties
3.1. Mode
The mode of the PHD is determined by two steps, firstly, we determine the first derivative of the PDF with respect to
x of the PHD as follows:
then equating the previous equation to zero and solving it for
x, we have the PHD modes as follows:
3.2. Moments
For PHD, its
r-th moments are derived as follows:
The first four moments of PHD are obtained using the values of r = 1, 2, 3, and 4 in the last equation, and these moments are then used to determine the skewness and kurtosis coefficients, respectively.
Additionally, by using moments around the origin, we can determine the
central moment of
X as follows:
The moment generating function of the PHD is derived as follows:
3.3. Incomplete Moments
The
rth incomplete moment of the PHD is derived as follows:
where
.
When , we obtain the first incomplete moment, which is crucial for constructing the Lorenz and Bonferroni curves, which are, respectively, defined as and . Additionally, it is used to determined the mean residual life () , and the mean waiting time .
3.4. Order Statistics
The
order statistic for the PDF and CDF of PHD are derived, respectively, as follows:
where
is a regularized hyper geometric function.
4. Estimation of PHD Parameters
The traditional PHD parameter estimate methods are covered in this section. By maximizing or minimizing an objective function, this estimator is produced.
By maximizing the following equation, the parameter estimation for the PHD is obtained using maximum likelihood estimation (MLE):
By minimizing the following equation, the parameter estimation for the PHD is obtained using Anderson–Darling estimation (ADE):
By minimizing the following equation, the parameter estimation for the PHD is obtained using the right-tail Anderson–Darling estimation (RADE):
By minimizing the following equation, the parameter estimation for the PHD is obtained using the left-tailed Anderson–Darling estimation (LTADE):
By minimizing the following equation, the parameter estimation for the PHD is obtained using the Cramér–von Mises estimation (CVME):
By minimizing the following equation, the parameter estimation for the PHD is obtained using least-squares estimation (LSE):
By minimizing the following equation, the parameter estimation for the PHD is obtained using the weighted least-squares estimation (WLSE):
By maximizing the following equation, the parameter estimation for the PHD is obtained using the maximum product of spacing estimation (MPSE):
By minimizing the following equation, the parameter estimation for the PHD is obtained using the minimum spacing absolute distance estimation (MSADE):
By minimizing the following equation, the parameter estimation for the PHD is obtained using the minimum spacing absolute-log distance estimation method (MSALDE):
5. Numerical Simulation
All of the estimating methods covered in the previous part will be used in this section to identify estimators of our proposed model using data sets produced at random. In this study, we want to investigate the behavior of the model estimators as well as the performance of these estimating approaches. Additionally, we will use a variety of measurements to gauge the success of these methods, such as average of bias (BIAS) , mean squared errors (MSE), , mean relative errors (MRE) , average absolute difference () , maximum absolute difference () , and average squared absolute error (ASAE) , where are the ascending ordered observations, and . Additionally, using the R programming language, we calculate the coverage probability (CP) and percentile bootstrap confidence intervals length (CIL) for all parameter combinations for both small and big sample sizes.
The simulation may be used to determine the most accurate approach for estimating the model parameters. In our simulation, we produced (
) samples with the following sizes
n = 30, 70, 150, and 350. In
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5, the numerical outcomes of simulations are shown. The power value displays a technique’s comparative effectiveness to all other procedures.
Table 6 lists the partial and total ranks of our estimators. The following conclusions may be drawn from the simulation’s findings and the ranking table:
The PHD estimators’ values show the consistency property.
All measures in the simulation tables decrease, as the sample size increases, except for the CP.
is always smaller than .
The maximum spacing product is the estimation method that is most preferred according to the ranking table.
6. Real Data Analysis
In this part, we illustrate the flexibility of the distribution by using data taken from the real world. The PHD is shown to be applicable by an empirical demonstration using the modeling of the COVID-19 actual data set. The COVID-19 data set pertains to 53 patients’ survival periods in China during the first two months of the year 2020 when they were in critical circumstances. The duration of time was measured beginning with hospitalization and ending with death, and it was studied by [
17].
In order to demonstrate the adaptability of the model that we presented, we will compare it with other, more established models. The specifications of each of the models that will be compared are as follows: Haq distribution (HD), Frechet distribution (FD), exponential distribution (ED), Lindley distribution (LD), Lomax distribution (LD), Maxwell distribution (MD), Rayleigh distribution (RD), Weibull distribution (WD), and gamma distribution (GD). We use the MLE method to compute all model estimates via Wolfram Mathematics Software Version 12.0, especially by using the NMaximize function, which attempts to find the global solution.
We make use of a series of analytical criteria, such as the Akaike information criterion (), the correct Akaike information criterion (), Bayesian information criterion (), and Hannan information criterion (). In addition, we base our decision on a number of other statistics on the goodness-of-fit of the model, such as Anderson–Darling (), Cramér–von Mises () and Kolmogorov–Smirnov () with its p-value (). In order to choose the model that is going to be the best fit for the COVID-19 data set, we take into consideration all previous measures.
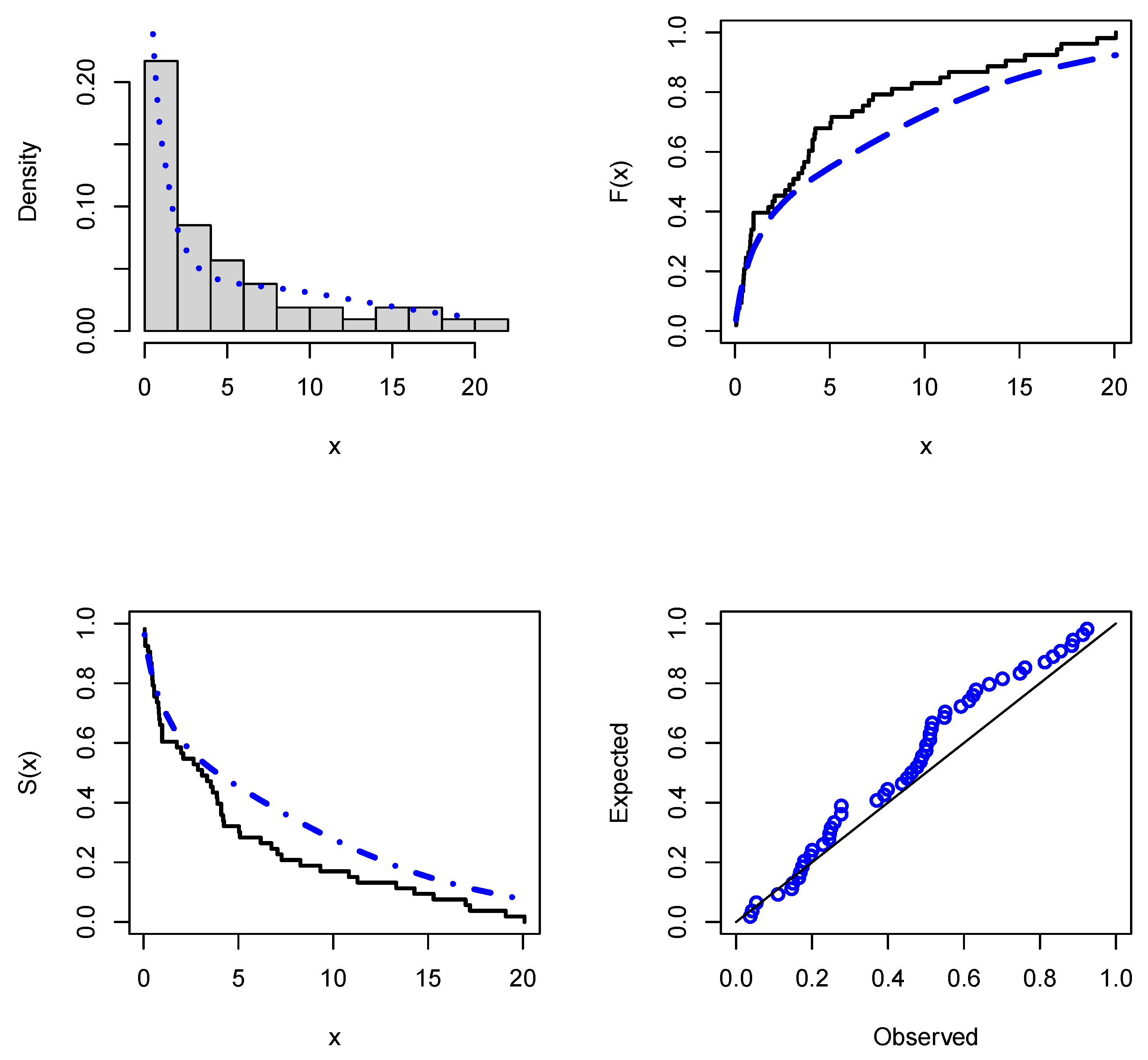
As can be seen in
Table 7, the analytical measures, as well as the related MLE and standard errors (SE), are supplied for the COVID-19 data set, which was considered for assessment. As a consequence of this, we may draw the conclusion that the PHD performs noticeably better than the other models that are equivalent. The P-P plot as well as the estimated PDF, CDF, and SF plots are used in order to demonstrate that the PHD is a good match for the COVID-19 data set that is shown in
Figure 3. Using the COVID-19 data set, it is shown that the proposed model provides a satisfactory match.
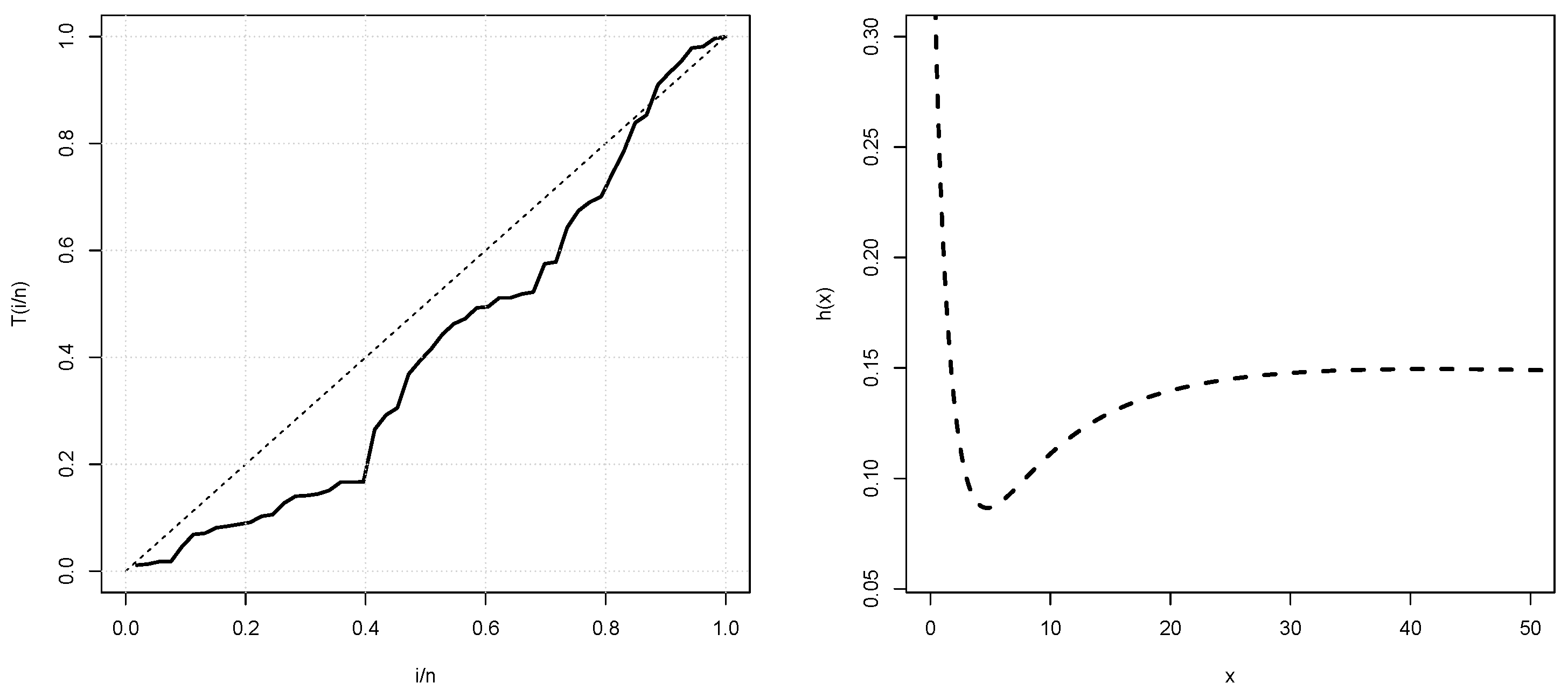
Figure 4 displays the TTT as well as an estimated HRF of the PHD plots for the COVID-19 data set.
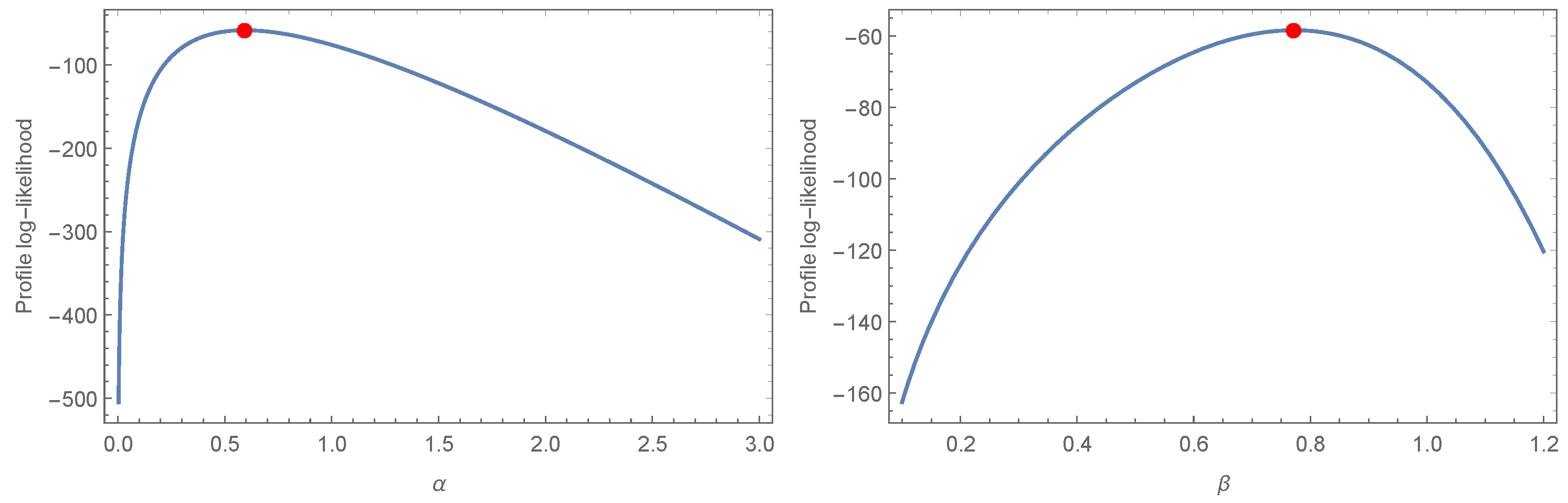
Figure 5 depicts the behavior of the log-likelihood function with estimated parameters for the COVID-19 data set, which is a unimodal function.
7. Conclusions
We create a relatively novel statistical model for the purpose of this study. This model is an extension of the HD, which is explained in further detail elsewhere. Its PDF has a number of distinct forms, including those that are skewed to the left or right, symmetrical, decreasing, bathtub, and others. Additionally, its
exhibits a variety of forms. A mathematical investigation is carried out in order to study some of its most important statistical properties. The PHD parameters are estimated with the use of 10 different conventional estimation approaches. We find out that the MPSE is the best estimator depending on the overall rank seen in
Table 6. The findings of the simulations show that the PHD estimators have very high performance levels. In addition, the practical application of the PHD is addressed by the use of a real-world data set, which reveals that it offers a superior match in comparison to well-known competitors.
Author Contributions
Conceptualization, Y.T.; methodology, M.E.B.; software, E.H.; validation, A.M.G. and M.M.H.; investigation, A.M.G.; resources, M.M.A.E.-R. All authors have read and agreed to the published version of the manuscript.
Funding
This study was funded by Researchers Supporting Project number (RSP2023R488), King Saud University, Riyadh, Saudi Arabia.
Data Availability Statement
All data are available in the paper.
Acknowledgments
This study was funded by Researchers Supporting Project number (RSP2023R488), King Saud University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Alshanbari, H.M.; Abd El-Bagoury, A.A.H.; Gemeay, A.M.; Hafez, E.H.; Eldeeb, A.S. A flexible extension of pareto distribution: Properties and applications. Comput. Intell. Neurosci. 2021, 2021, 9819200. [Google Scholar] [CrossRef] [PubMed]
- Alshanbari, H.M.; Gemeay, A.M.; El-Bagoury, A.A.A.H.; Khosa, S.K.; Hafez, E.H.; Muse, A.H. A novel extension of fréchet distribution: Application on real data and simulation. Alex. Eng. J. 2022, 61, 7917–7938. [Google Scholar] [CrossRef]
- Saber, M.M.; Shishebor, Z.; Raouf, M.M.; Hafez, E.H.; Aldallal, R. Most effective sampling scheme for prediction of stationary stochastic processes. Complexity 2022, 2022, 4997675. [Google Scholar] [CrossRef]
- Ashraf, B.N. Economic impact of government interventions during the COVID-19 pandemic: International evidence from financial markets. J. Behav. Exp. Financ. 2020, 27, 100371. [Google Scholar] [CrossRef] [PubMed]
- Sansa, N.A. The impact of the COVID-19 on the financial markets: Evidence from China and USA. Electron. Res. J. Soc. Sci. Humanit. 2020, 2. [Google Scholar] [CrossRef]
- Zhang, D.; Hu, M.; Ji, Q. Financial markets under the global pandemic of COVID-19. Financ. Res. Lett. 2020, 36, 101528. [Google Scholar] [CrossRef] [PubMed]
- Almetwally, E.M.; Abdo, D.A.; Hafez, E.H.; Jawa, T.M.; Sayed-Ahmed, N.; Almongy, H.M. The new discrete distribution with application to COVID-19 data. Results Phys. 2022, 32, 104987. [Google Scholar] [CrossRef] [PubMed]
- Alsuhabi, H.; Alkhairy, I.; Almetwally, E.M.; Almongy, H.M.; Gemeay, A.M.; Hafez, E.H.; Aldallal, R.A.; Sabry, M. A superior extension for the lomax distribution with application to COVID-19 infections real data. Alex. Eng. J. 2022, 61, 11077–11090. [Google Scholar] [CrossRef]
- Bo, W.; Ahmad, Z.; Alanzi, A.R.; Al-Omari, A.I.; Hafez, E.H.; Abdelwahab, S.F. The current COVID-19 pandemic in china: An overview and corona data analysis. Alex. Eng. J. 2022, 61, 1369–1381. [Google Scholar] [CrossRef]
- Almetwally, E.M.; Alharbi, R.; Alnagar, D.; Hafez, E.H. A new inverted topp-leone distribution: Applications to the COVID-19 mortality rate in two different countries. Axioms 2021, 10, 25. [Google Scholar] [CrossRef]
- Almongy, H.M.; Almetwally, E.M.; Aljohani, H.M.; Alghamdi, A.S.; Hafez, E.H. A new extended rayleigh distribution with applications of COVID-19 data. Results Phys. 2021, 23, 104012. [Google Scholar] [CrossRef] [PubMed]
- Alzeley, O.; Almetwally, E.M.; Gemeay, A.M.; Alshanbari, H.M.; Hafez, E.H.; Abu-Moussa, M.H. Statistical inference under censored data for the new exponential-x fréchet distribution: Simulation and application to leukemia data. Comput. Intell. Neurosci. 2021, 2021, 2167670. [Google Scholar] [CrossRef] [PubMed]
- Benati, I.; Coccia, M. Global analysis of timely COVID-19 vaccinations: Improving governance to reinforce response policies for pandemic crises. Int. J. Health Gov. 2022. ahead-of-print. [Google Scholar]
- Jiménez-Rodríguez, P.; Muñoz-Fernández, G.A.; Rodrigo-Chocano, J.C.; Seoane-Sepúlveda, J.B.; Weber, A. A population structure-sensitive mathematical model assessing the effects of vaccination during the third surge of COVID-19 in italy. J. Math. Anal. Appl. 2022, 514, 125975. [Google Scholar] [CrossRef] [PubMed]
- Malik, A.A.; McFadden, S.M.; Elharake, J.; Omer, S.B. Determinants of COVID-19 vaccine acceptance in the us. EClinicalMedicine 2020, 26, 100495. [Google Scholar] [CrossRef] [PubMed]
- Ahsan-ul Haq, M. Statistical analysis of haq distribution: Estimation and applications. Pak. J. Stat. 2022, 38, 473–490. [Google Scholar]
- Afify, A.Z.; Al-Mofleh, H.; Aljohani, H.M.; Cordeiro, G.M. The marshall–olkin–weibull-h family: Estimation, simulations, and applications to COVID-19 data. J. King Saud Univ.-Sci. 2022, 34, 102115. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}