
Operator Smith Algorithm for Coupled Stein Equations from Jump Control Systems


Abstract
:1. Introduction
- We introduce the operator defined asThis operator formulation enables us to adapt the Smith iteration [4,11,22] to an operator version, denoted as the operator Smith algorithm (OSA). By doing so, the iteration maintains quadratic convergence for computing the symmetric solution of CDSEs (1). Our numerical experiments demonstrate that the OSA outperforms existing linearly convergent iterations in terms of both the CPU time and accuracy.
- To address large-scale problems, we structure the OSA in a low-ranked format with twice truncation and compression (TC). One TC applies to the factor in the constructed operator (2), while the other TC applies to the factor in the approximated solution. This approach effectively reduces the column dimensions of the low-rank factors in symmetric solutions.
- We redesign the residual computation to suit large-scale computations. We incorporate practical examples from industries [23] to validate the feasibility and effectiveness of the presented low-ranked OSA. This not only demonstrates its practical utility but also lays the groundwork for exploring various large-scale structured problems.
2. Operator Smith Iteration for CDSEs
2.1. Iteration Scheme
2.2. Examples
3. Structured Algorithm for Large-Scale Problems
3.1. Structured Iteration Scheme
3.2. Truncation and Compression
3.3. Computation of Residuals
3.4. Large-Scale Algorithm and Complexity
| Algorithm 1: Algorithm OSA_lr. Solve large-scale CDSEs with low-ranked |
Inputs: Sparse matrices , low-rank factors for , probability matrix , truncation tolerance , upper bound and the iteration tolerance . Outputs: Low-ranked matrix and the kernel matrix with the solution . 1. Set and for . 2. For until convergence, do 3. Compute and as in (8). 4. Truncate and compress as in (10) with accuracy . 6. Compute and as in (9). 7. Truncate and compress as in (10) with accuracy . 9. Evaluate the relative residual Rel_Res in (19). 11. If Rel_Res , break, End. 12. ; 14. End (For) 18. Output , . |
3.5. Error Analysis
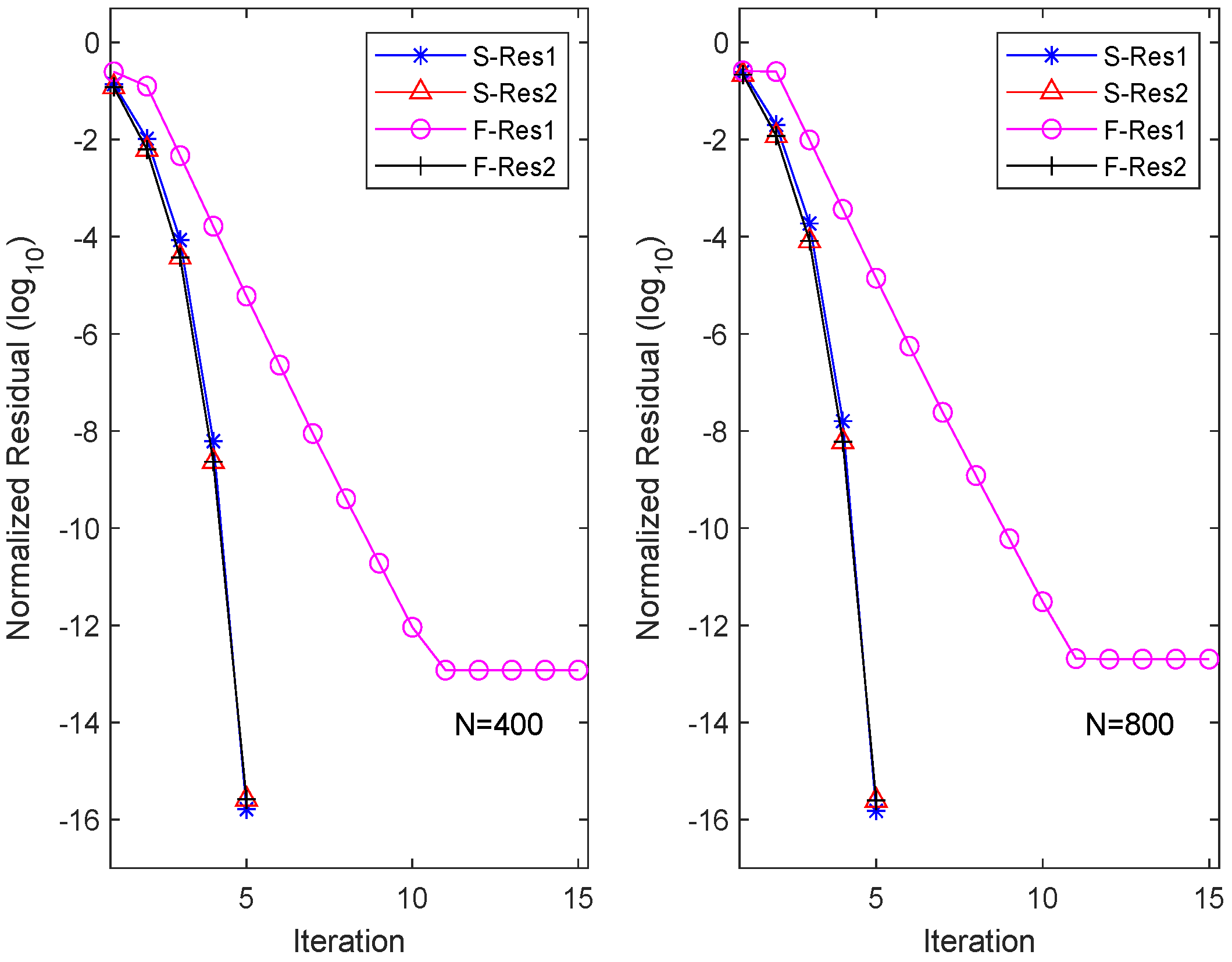
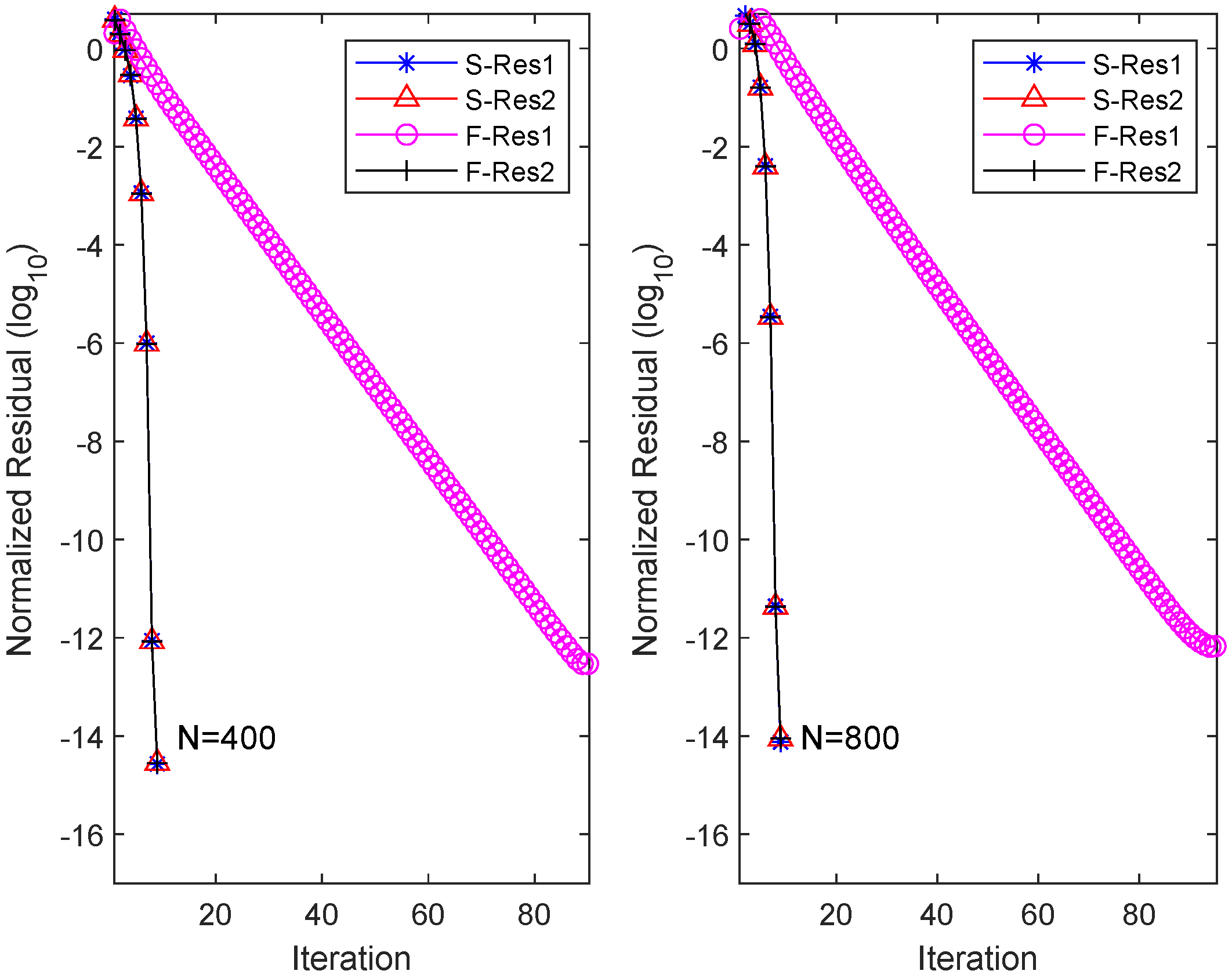
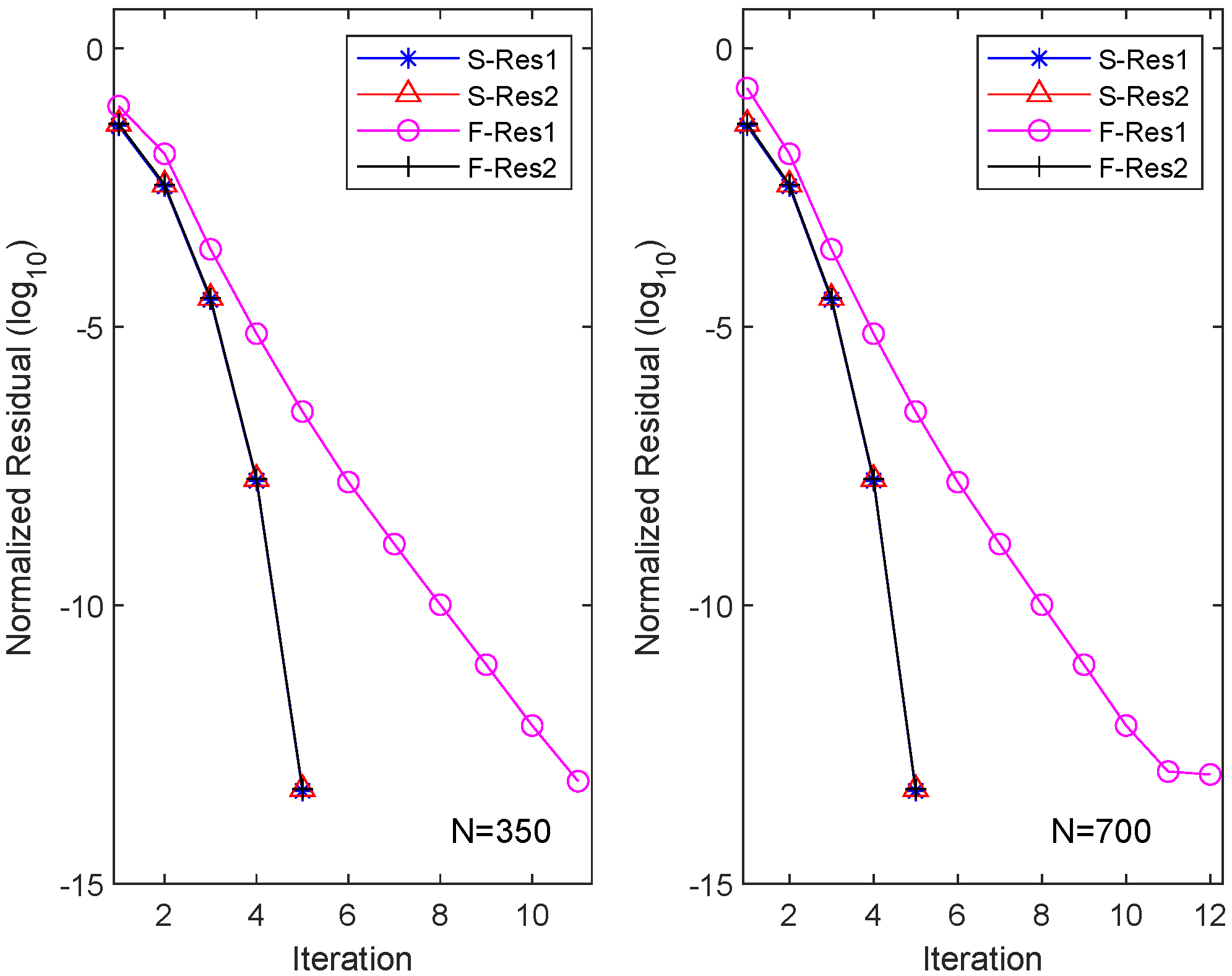
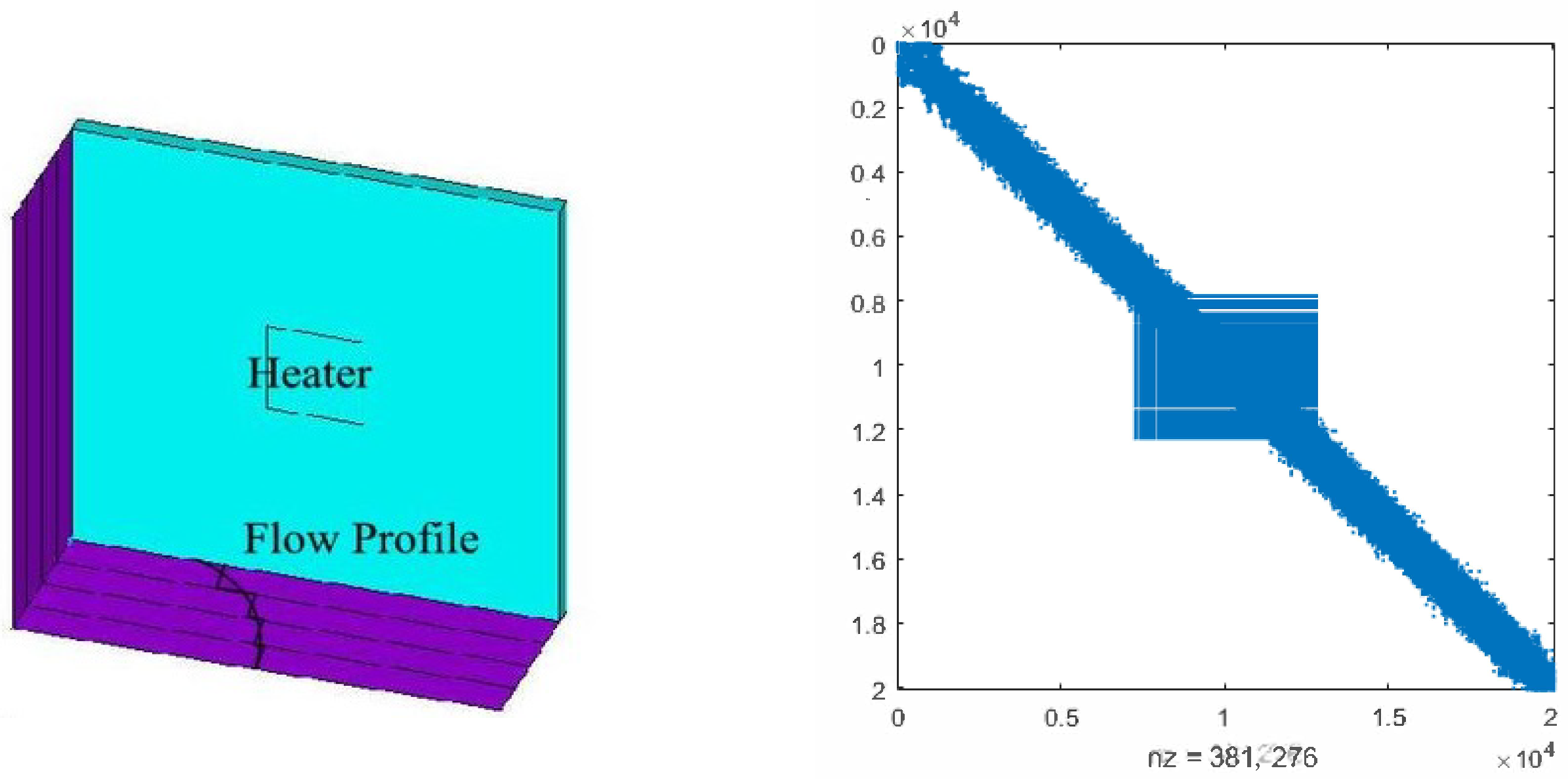
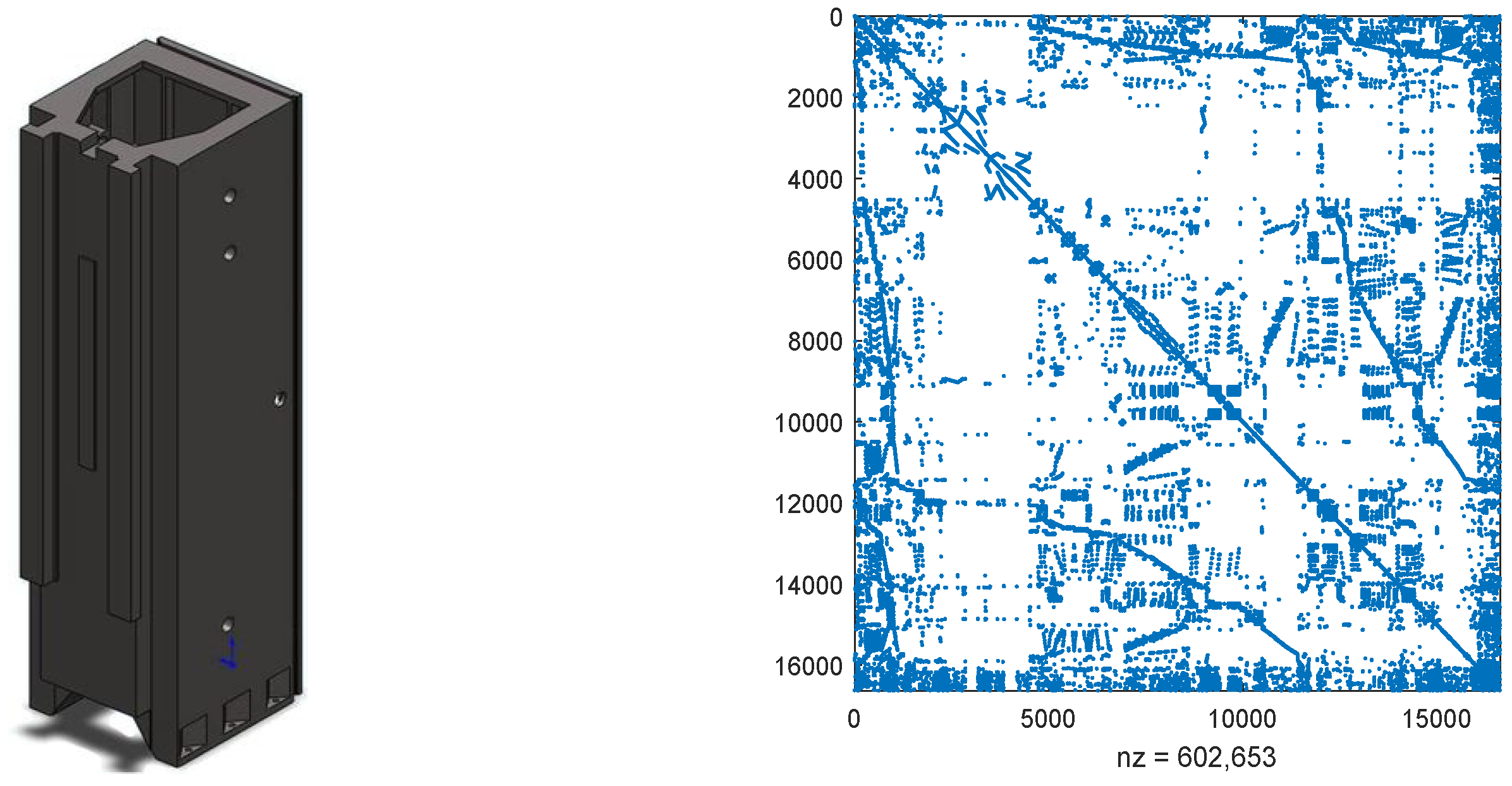
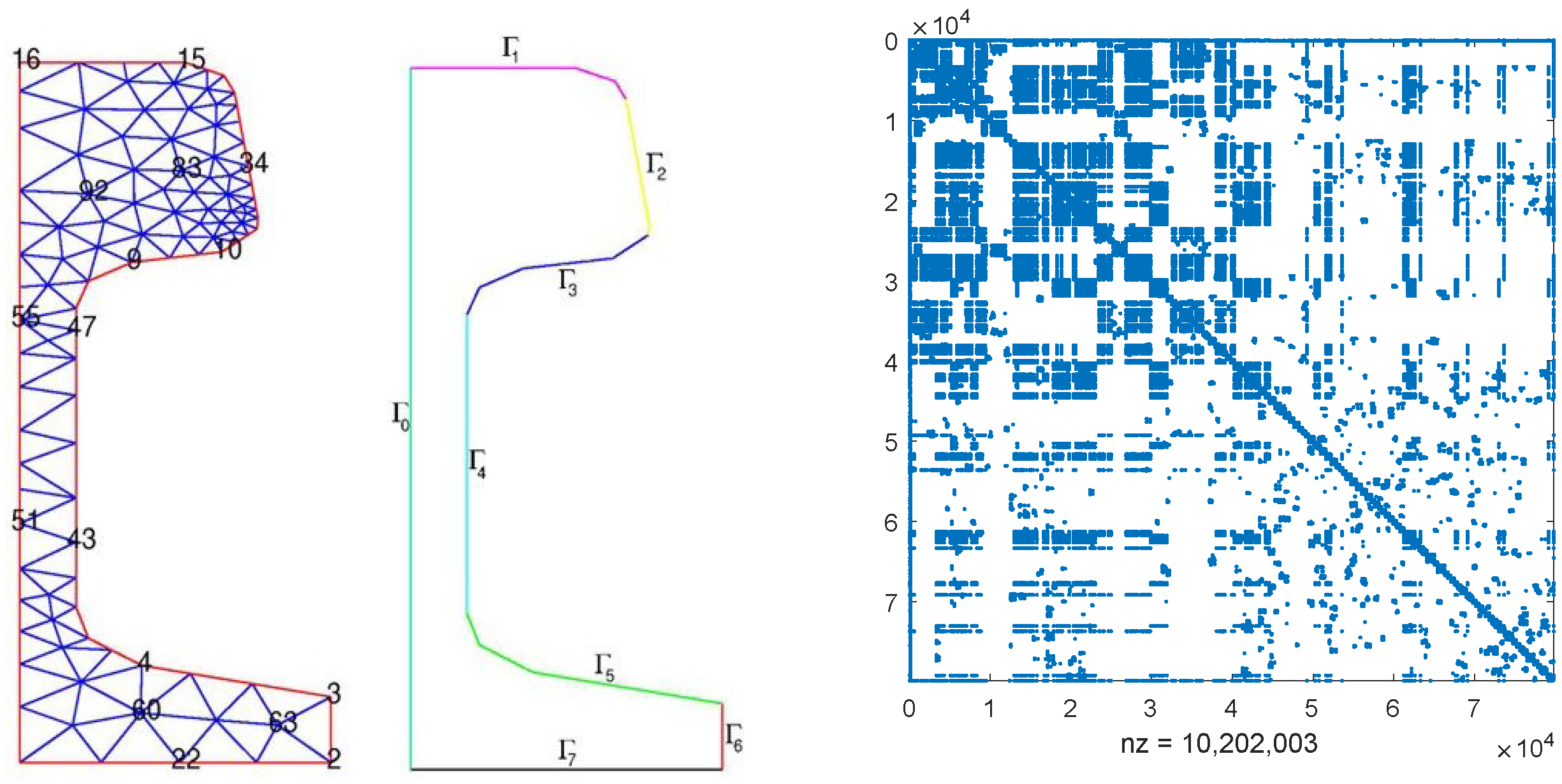
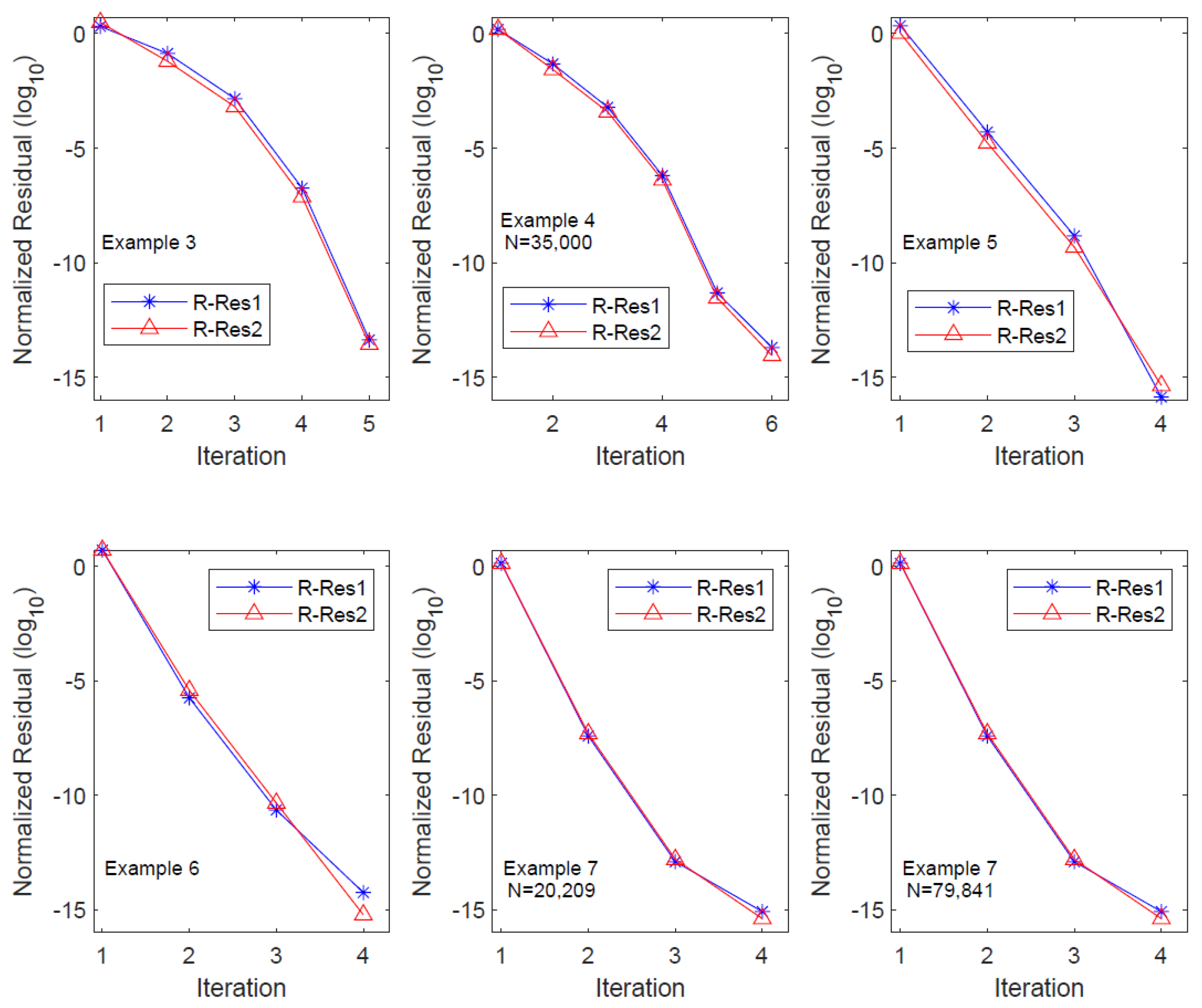
4. Numerical Examples

5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, C.-T. Linear System Theory and Design, 3rd ed.; Oxford University Press: New York, NY, USA, 1999. [Google Scholar]
- Betser, A.; Cohen, N.; Zeheb, E. On solving the Lyapunov and Stein equations for a companion matrix. Syst. Control Lett. 1995, 25, 211–218. [Google Scholar] [CrossRef]
- Hueso, J.L.; Martínez, G.; Hernández, V. A systolic algorithm for the triangular Stein equation. J. VLSI Signal Process. Syst. Signal Image Video Technol. 1993, 5, 49–55. [Google Scholar] [CrossRef]
- Li, T.-X.; Weng, P.C.-Y.; Chu, E.K.-W.; Lin, W.-W. Large-scale Stein and Lyapunov Equations, Smith Method, and Applications. Numer. Algorithms 2013, 63, 727–752. [Google Scholar] [CrossRef]
- Fan, H.-Y.; Weng, P.C.-Y.; Chu, K.-W. Numerical solution to generalized Lyapunov/Stein and rational Riccati equations in stochastic control. Numer. Algorithms 2016, 71, 245–272. [Google Scholar] [CrossRef]
- Yu, B.; Dong, N.; Tang, Q. Factorized squared Smith method for large-scale Stein equations with high-rank terms. Automatica 2023, 154, 111057. [Google Scholar] [CrossRef]
- Borno, I.; Gajic, Z. Parallel algorithm for solving coupled algebraic Lyapunov equations of discrete-time jump linear systems. Comput. Math. Appl. 1995, 30, 1–4. [Google Scholar] [CrossRef]
- Wu, A.-G.; Duan, G.-R. New Iterative algorithms for solving coupled Markovian jump Lyapunov equations. IEEE Trans. Auto. Control 2015, 60, 289–294. [Google Scholar]
- Zhou, B.; Duan, G.-R.; Li, Z.-Y. Gradient based iterative algorithm for solving coupled matrix equations. Syst. Control. Lett. 2009, 58, 327–333. [Google Scholar] [CrossRef]
- Li, Z.-Y.; Zhou, B.; Lam, J.; Wang, Y. Positive operator based iterative algorithms for solving Lyapunov equations for Itô stochastic systems with Markovian jumps. Appl. Math. Comput. 2011, 217, 8179–8195. [Google Scholar] [CrossRef]
- Yu, B.; Fan, H.-Y.; Chu, E.K.-W. Smith method for projected Lyapunov and Stein equations. UPB Sci. Bull. Ser. A 2018, 80, 191–204. [Google Scholar]
- Sun, H.-J.; Zhang, Y.; Fu, Y.-M. Accelerated smith iterative algorithms for coupled Lyapunov matrix equations. J. Frankl. Inst. 2017, 354, 6877–6893. [Google Scholar] [CrossRef]
- Li, T.-Y.; Gajic, Z. Lyapunov iterations for solving coupled algebraic Riccati equations of Nash differential games and algebraic Riccati equations of zero-sum games. In New Trends in Dynamic Games and Applications; Olsder, G.J., Ed.; Annals of the International Society of Dynamic Games; Birkhäuser: Boston, MA, USA, 1995; Volume 3. [Google Scholar]
- Wicks, M.; De Carlo, R. Solution of Coupled Lyapunov Equations for the Stabilization of Multimodal Linear Systems. In Proceedings of the 1997 American Control Conference (Cat. No.97CH36041), Albuquerque, NM, USA, 4–6 June 1997; Volume 3, pp. 1709–1713. [Google Scholar]
- Ivanov, I.G. An Improved method for solving a system of discrete-time generalized Riccati equations. J. Numer. Math. Stoch. 2011, 3, 57–70. [Google Scholar]
- Qian, Y.-Y.; Pang, W.-J. An implicit sequential algorithm for solving coupled Lyapunov equations of continuous-time Markovian jump systems. Automatica 2015, 60, 245–250. [Google Scholar] [CrossRef]
- Costa, O.L.V.; Aya, J.C.C. Temporal difference methods for the maximal solution of discrete-time coupled algebraic Riccati equations. J. Optim. Theory Appl. 2001, 109, 289–309. [Google Scholar] [CrossRef]
- Costa, O.L.V.; Marques, R.P. Maximal and stabilizing Hermitian solutions for discrete-time coupled algebraic Riccati equations. Math. Control Signals Syst. 1999, 12, 167–195. [Google Scholar] [CrossRef]
- Ivanov, I.G. Stein iterations for the coupled discrete-time Riccati equations. Nonlinear Anal. Theory Methods Appl. 2009, 71, 6244–6253. [Google Scholar] [CrossRef]
- Bai, L.; Zhang, S.; Wang, S.; Wang, K. Improved SOR iterative method for coupled Lyapunov matrix equations. Afr. Math. 2021, 32, 1457–1463. [Google Scholar] [CrossRef]
- Tian, Z.-L.; Xu, T.-Y. An SOR-type algorithm based on IO iteration for solving coupled discrete Markovian jump Lyapunov equations. Filomat 2021, 35, 3781–3799. [Google Scholar] [CrossRef]
- Penzl, T. A cyclic low-rank Smith method for large sparse Lyapunov equations. SIAM J. Sci. Comput. 1999, 21, 1401–1408. [Google Scholar] [CrossRef]
- Korvink, G.; Rudnyi, B. Oberwolfach Benchmark Collection. In Dimension Reduction of Large-Scale Systems; Benner, P., Sorensen, D.C., Mehrmann, V., Eds.; Lecture Notes in Computational Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2005; Volume 45. [Google Scholar]
- Wang, Q.; Lam, J.; Wei, Y.; Chen, T. Iterative solutions of coupled discrete Markovian jump Lyapunov equations. Comput. Math. Appl. 2008, 55, 843–850. [Google Scholar] [CrossRef]
- Mathworks. MATLAB User’s Guide; Mathworks: Natick, MA, USA, 2020; Available online: https://www.mathworks.com/help/pdf_doc/matlab/index.html (accessed on 15 March 2024).
- Ober, R.J. Asymptotically Stable All-Pass Transfer Functions: Canonical Form, Parametrization and Realization. IFAC Proc. Vol. 1987, 20, 181–185. [Google Scholar] [CrossRef]
- Chahlaoui, Y.; Van Dooren, P. Benchmark examples for model reduction of linear time-invariant dynamical systems. In Dimension Reduction of Large-Scale Systems; Springer: Berlin/Heidelberg, Germany, 2005; Volume 45, pp. 379–392. [Google Scholar]
- Chu, E.K.-W.; Weng, P.C.-Y. Large-scale discrete-time algebraic Riccati equations—Doubling algorithm and error analysis. J. Comput. Appl. Math. 2015, 277, 115–126. [Google Scholar] [CrossRef]
- Higham, N.J. Functions of Matrices: Theory and Computation; SIAM: Philadelphia, PA, USA, 2008. [Google Scholar]
- Chahlaoui, Y.; Van Dooren, P. A collection of benchmark examples for model reduction of linear time invariant dynamical systems. Work. Note 2002. Available online: https://eprints.maths.manchester.ac.uk/1040/1/ChahlaouiV02a.pdf (accessed on 15 March 2024).
- Moosmann, C.; Greiner, A. Convective thermal flow problems. In Dimension Reduction of Large-Scale Systems; Lecture Notes in Computational Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2005; Volume 45, pp. 341–343. [Google Scholar]
- Lang, N. Numerical Methods for Large-Scale Linear Time-Varying Control Systems and Related Differential Matrix Equations; Logos-Verlag: Berlin, Germany, 2018. [Google Scholar]
- Schmidt, A.; Siebert, K. Design of Adaptive Finite Element Software—The Finite Element Toolbox ALBERTA; Lecture Notes in Computational Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2005; Volume 42. [Google Scholar]
- Harper, C.A. Electronic Packaging and Interconnection Handbook; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| It. | Rel_Res | Rel_Res | |||||
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| OSA | 3 | ||||||
| 4 | |||||||
| 5 | |||||||
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| FIX | 6 | ||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| 10 | |||||||
| 11 |
| It. | Rel_Res | Rel_Res | |||||
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| OSA | 3 | ||||||
| 4 | |||||||
| 5 | |||||||
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| FIX | 6 | ||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| 10 |
| Items | Flops | Memory |
|---|---|---|
| QR * | ||
| Compressed | ||
| — | ||
| — | ||
| QR * | ||
| Compressed |
| It. | Res1 | Rel_Res1 | Res2 | Rel_Res2 | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 3 | ||||||
| 2 | 9 | 9 | ||||||
| 3 | 21 | 21 | ||||||
| 4 | 46 | 46 | ||||||
| 5 | 109 | 109 |
| It. | Res1 | Rel_Res1 | Res2 | Rel_Res2 | ||||
|---|---|---|---|---|---|---|---|---|
| N = 21,000 | ||||||||
| 1 | 3 | 3 | ||||||
| 2 | 7 | 7 | ||||||
| 3 | 15 | 15 | ||||||
| 4 | 31 | 31 | ||||||
| 5 | 157 | 157 | ||||||
| 6 | 908 | 908 | ||||||
| N = 28,000 | ||||||||
| 1 | 3 | 3 | ||||||
| 2 | 7 | 7 | ||||||
| 3 | 15 | 15 | ||||||
| 4 | 31 | 31 | ||||||
| 5 | 147 | 147 | ||||||
| 6 | 908 | 908 | ||||||
| N = 35,000 | ||||||||
| 1 | 3 | 3 | ||||||
| 2 | 7 | 7 | ||||||
| 3 | 15 | 15 | ||||||
| 4 | 31 | 31 | ||||||
| 5 | 161 | 161 | ||||||
| 6 | 908 | 908 |
| It. | Res1 | Rel_Res1 | Res2 | Rel_Res2 | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | 10 | 10 | ||||||
| 2 | 22 | 22 | ||||||
| 3 | 46 | 46 | ||||||
| 4 | 112 | 112 |
| It. | Res1 | Rel_Res1 | Res2 | Rel_Res2 | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 3 | ||||||
| 2 | 7 | 7 | ||||||
| 3 | 25 | 25 | ||||||
| 4 | 119 | 119 |
| It. | Res1 | Rel_Res1 | Res2 | Rel_Res2 | ||||
|---|---|---|---|---|---|---|---|---|
| N = 20,209 | ||||||||
| 1 | 12 | 12 | ||||||
| 2 | 24 | 24 | ||||||
| 3 | 48 | 48 | ||||||
| 4 | 96 | 96 | ||||||
| N = 79,841 | ||||||||
| 1 | 12 | 12 | ||||||
| 2 | 24 | 24 | ||||||
| 3 | 48 | 48 | ||||||
| 4 | 96 | 96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, B.; Dong, N.; Hu, B. Operator Smith Algorithm for Coupled Stein Equations from Jump Control Systems. Axioms 2024, 13, 249. https://doi.org/10.3390/axioms13040249
Yu B, Dong N, Hu B. Operator Smith Algorithm for Coupled Stein Equations from Jump Control Systems. Axioms. 2024; 13(4):249. https://doi.org/10.3390/axioms13040249
Chicago/Turabian StyleYu, Bo, Ning Dong, and Baiquan Hu. 2024. "Operator Smith Algorithm for Coupled Stein Equations from Jump Control Systems" Axioms 13, no. 4: 249. https://doi.org/10.3390/axioms13040249
APA StyleYu, B., Dong, N., & Hu, B. (2024). Operator Smith Algorithm for Coupled Stein Equations from Jump Control Systems. Axioms, 13(4), 249. https://doi.org/10.3390/axioms13040249