1. Introduction
The new generation of information and communication technology has produced profound changes to the manufacturing industry. Industry 4.0 has become a major factor in the future competitiveness of enterprises, and the use of sensors, data collection and analysis, information technology infrastructure, and mobile terminals are considered important basic technologies [
1]. Digitization and networking make the acquisition, sharing, and use of data faster and cheaper, and massive amounts of data are generated in the entire lifecycle of mechanical products [
2,
3]. With high information density and utilization value, these data can be combined with emerging intelligent technologies such as finite element simulation, machine learning, and artificial intelligence. These data provide broad prospects for intelligent manufacturing, with considerable application potential in various product lifecycles, spanning design, manufacturing, operation, maintenance, etc. [
4,
5].
However, because of the lack of effective integration methods, these data are usually isolated or fragmented, hindering further empowerment of intelligent manufacturing [
6]. This means that stakeholders such as designers, manufacturers, and maintainers still cannot obtain the data generated in other stages and then cannot conduct manual or intelligent analysis to improve the current link. Although digital threads provide data transmission, methods and technologies such as simulations can use the acquired data for analysis, the connection, that is, the integrated modeling of product data, is still missing. For example, Wuest et al. [
7] indicated that machine learning, which can be used to process high-dimensional problems and data to discover implicit knowledge, etc., has application advantages in manufacturing, but the acquisition of relevant data is still a common challenge. The integration of product data and the fusion of virtual models and physical entities are considered the foundations of product smart and sustainable manufacturing. In this context, digital twin is recognized as a key approach and has received substantial attention from scholars and the industry. In 2012, digital twin was included in the “Modeling, Simulation, Information Technology and Processing Roadmap” released by NASA [
8]. For four consecutive years since 2016, Gartner [
9], one of the world’s most authoritative information technology research and consulting companies, listed digital twins as one of the top ten strategic technology development tendencies. A comment by Tao et al. about digital twins published in
Nature pointed out that the virtual model could boost smart manufacturing by simulating decisions and optimization, from design to operations [
10].
However, modeling as a foundation technology for digital twin implementation still has many challenges to be solved. In the field of mechanical product digital twins, most of the models currently developed are partial mappings oriented toward specific purposes, or just real-time data and intelligent algorithm-added simulation models. Although they can meet the current needs, their application scope and scalability are limited. The existing PLM system has realized the integration of many product data and can serve as the foundation of functional and effective digital twins, but it still needs development in terms of cyber-physical integration and rapid iteration [
11,
12]. In addition, many characteristics of mechanical products, such as hierarchy, have not been fully utilized in existing research on digital twin modeling. Therefore, a model framework that has the ability to integrate all heterogeneous data from products and to iterate it quickly is needed. Although not all data may be used in a specific requirement, the model framework provides the possibilities for various applications.
In accordance with the above, this study provides the following contributions:
A native full-element digital twin modeling method for mechanical products is proposed.
The developed model could serve as a data center for the entire lifecycle of the product or could be combined with existing data management systems, integrating the previously isolated, fragmented, and scattered data on various platforms into a unified data architecture.
The model utilizes the structural characteristics of mechanical products and is developed as a hierarchical digital mapping to better meet the application requirements.
The model is easy to implement and can quickly iterate its structure to meet the response needs of cyber-physical systems flexibly, so the proposed method has the potential to be used by a series of emerging technologies, thereby enabling smart manufacturing.
The remainder of this paper is organized as follows. In
Section 2, a review of product digital twins and related enabling technologies, including ontology and graph databases, is provided. The detailed proposed methodology is illustrated in
Section 3. Based on the methodology proposed, a case for the development of a digital twin model about a helicopter and some of its transmission parts is presented in
Section 4. Further discussions on the method and the case are provided in
Section 5, and concluding remarks and an analysis of the limitations and future research directions are presented in
Section 6.
3. Methodology
In this study, a hierarchical integrated modeling method for a digital twin is proposed in response to the need for full-element data fusion of mechanical products. The method provides a phased framework for digital twin modeling, and its goal is to build a comprehensive digital model that integrates various data in the entire lifecycle of mechanical products.
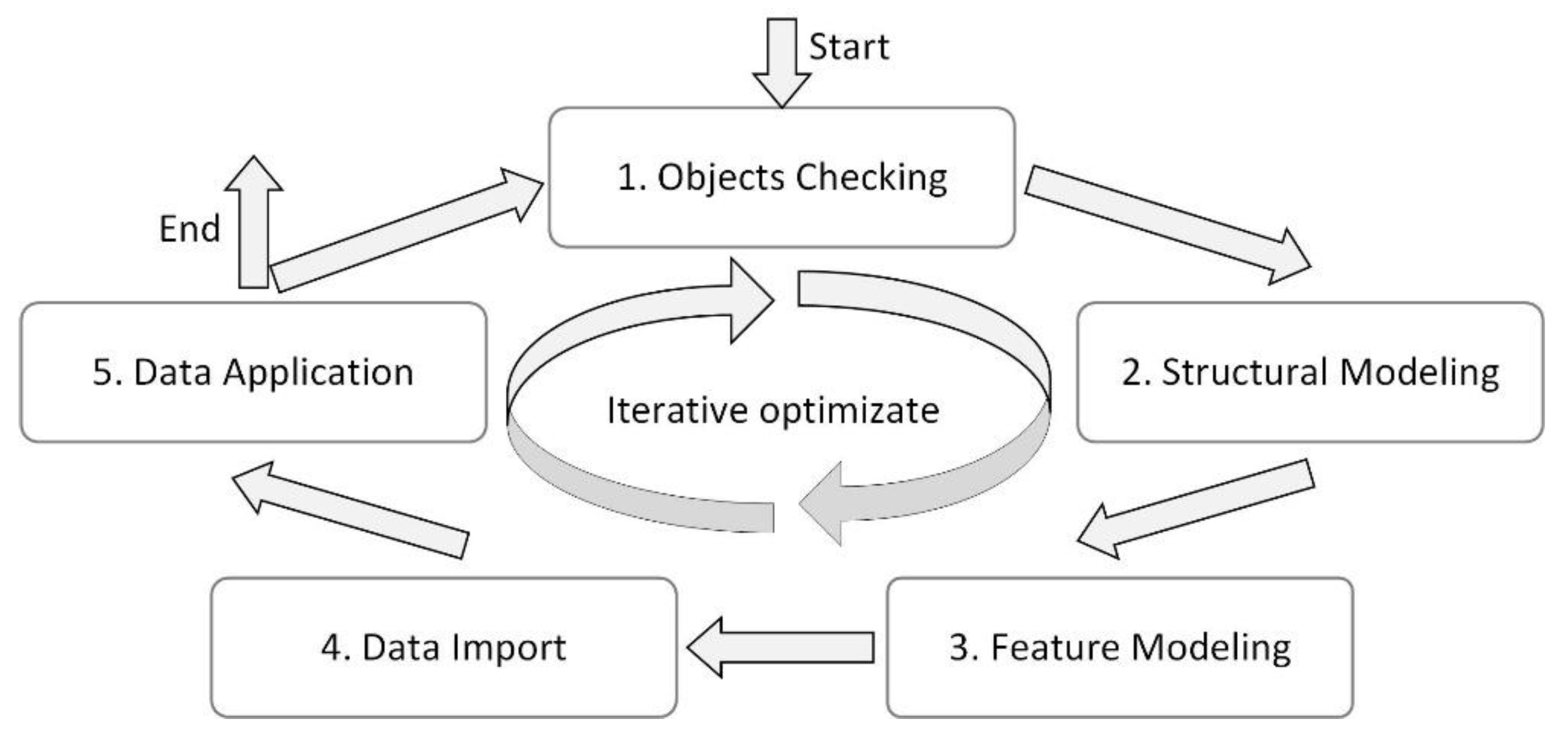
Figure 1 shows the main process of the method, including object checking, structural modeling, feature modeling, data import, and data application. The method starts from Phase 1; to meet the dynamic and scalable needs of digital twins, the modeling process in this method is not a one-time process but could continue to iteratively optimize the digital twin model as the entity evolves until the iteration process ends at Phase 5.
3.1. Objects Checking
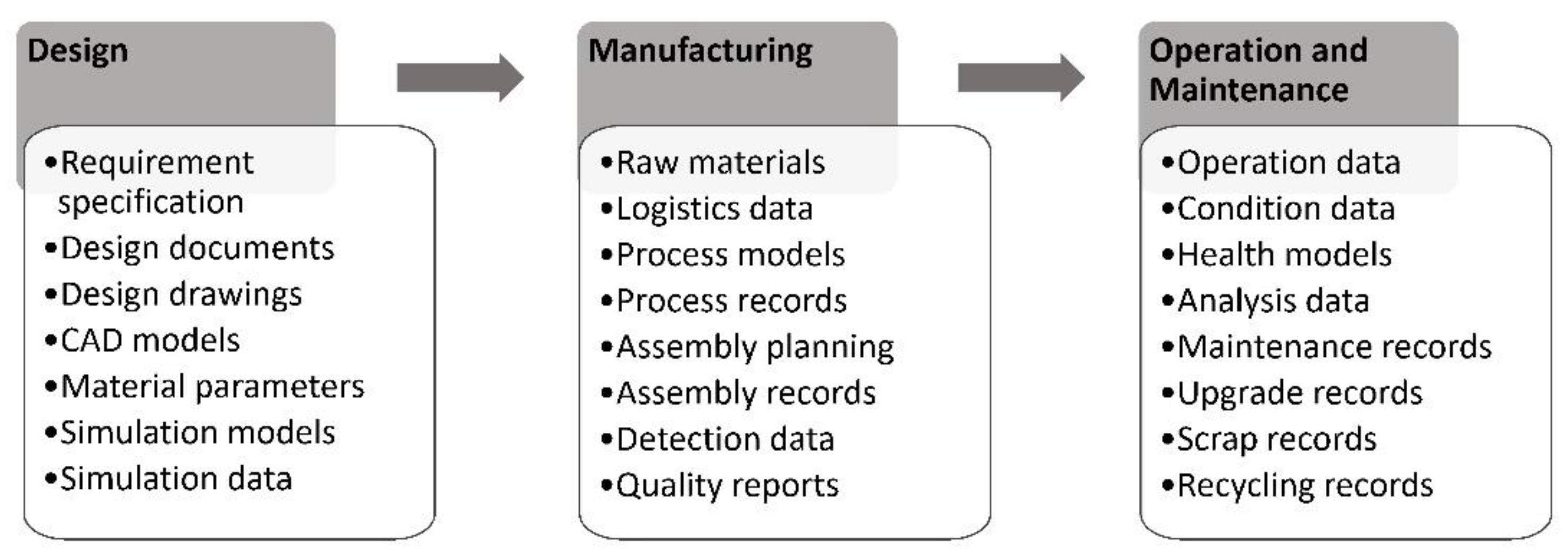
In the first phase, we clarify the modeling scope of the digital twin according to the needs of mechanical products and collect the corresponding data. The digital twin model, as a digital mapping of the product entity in the entire lifecycle, may include various data generated in the design, manufacturing, operation, and maintenance stages, as shown in
Figure 2.
The goal of the digital twin approach is to develop a full-element map of the product, but this does not mean that all data must be included at the beginning. The development of a digital twin model is a dynamic and iterative process. The data that are temporarily not included in the current digital model can be improved in future optimizations. When this phase is finished, the modeling objects are checked, laying an important foundation for the subsequent steps.
3.2. Structural Modeling
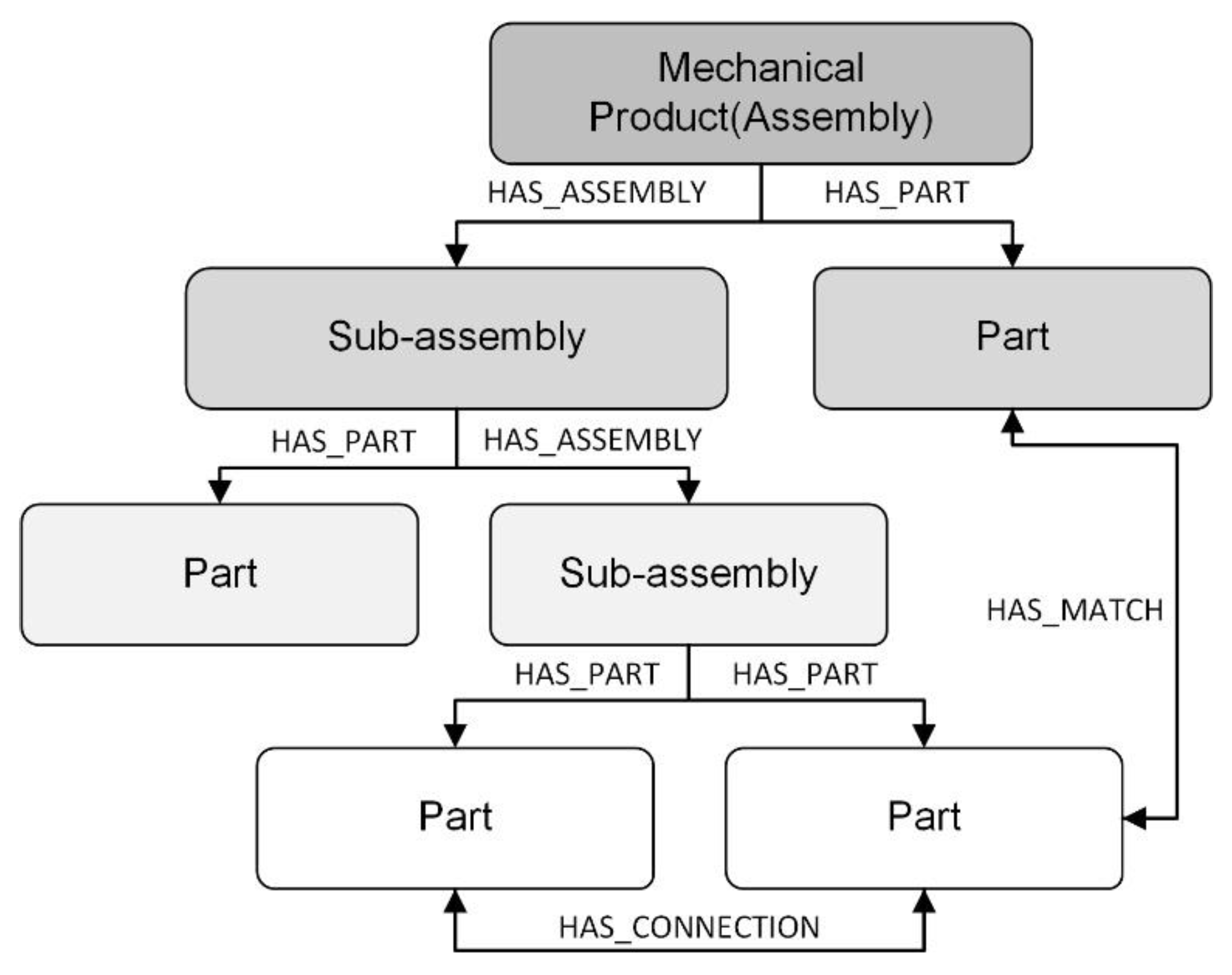
The objective of the second phase is to use the mechanical product assembly structure to develop a hierarchical digital model as the fundamental structure of the entire digital twin model. First, we build a corresponding knowledge model based on the ontology method. The ontology model includes classes and instances. A class is a concept in a domain that represents a collection of instances of a certain type in the domain. An instance is a formal description of an individual in the field, including the name, class to which it belongs, and corresponding description. Owing to the need for design, manufacturing, and maintenance, mechanical products usually have a clear assembly structure, which is particularly evident in complex mechanical equipment. In view of this characteristic, they are classified into two classes: parts and assemblies. A part refers to the smallest decomposition unit of a mechanical product structure in the digital twin, whereas an assembly is composed of multiple parts. The specific part or assembly instance in each mechanical product is defined as a corresponding instance.
Subsequently, orientation relationships are developed between the parts and assemblies. In an ontology model, the attribute relationship is the predicate connection of the class–class relationship or the instance–instance relationship, which functions as a logical rule definition. In generic mechanical products, the structural relationships mainly include composition, connection, and matching relationships. In view of these characteristics, the internal structural relationships of mechanical products are defined. The composition relationship from the assembly to the sub-assembly or part is defined as a “has assembly” or a “has parts” relationship, respectively. Connection and matching relationships include the “has connection” and “has match” relationships between assemblies and parts. A schematic of the hierarchical ontology model is shown in
Figure 3.
Furthermore, combined with the characteristics of the graph database using graph theory to store the relationship between instances, the developed ontology model is mapped into a graph database. First, the assembly and part are created as two types of nodes in the graph database. Then, the mechanical product and its sub-assemblies and parts are mapped to the nodes of the corresponding type. The relationships between the attributes in the ontology model are mapped to the directional relationships between nodes: “has assembly”, “has part”, “has connection”, and “has match” relationships are created between the developed assembly and part nodes. When the second phase is finished, all components of the mechanical product are mapped to the graph database hierarchically according to the assembly structure, and the corresponding structural relationships are defined using the edges between the nodes. Due to the objectivity of the mechanical product structure, the consistency of this part of the model can be guaranteed naturally. The developed structural model serves as the foundational architecture for the entire digital twin model.
3.3. Feature Modeling
The objective of the third phase is to model the feature data of the product on the basis of the developed structural model and to complete the construction of the digital twin model architecture. In this paper, feature refers to the product quality or characteristic to be modeled, parameter refers to specific data, and attribute is the term in ontology or the graph database.
In the first phase, the objects to be modeled are checked and the corresponding data are collected. According to the relationships between features and mechanical structure, these features can be divided into three categories: (1) features that belong to specific parts or assemblies and are directly related to the mechanical structure. For example, if a component is part of an assembly, then its corresponding two-dimensional or 3D drawing is also part of the drawing of the assembly; (2) features that independently belong to specific parts or assemblies are not related to the others, such as the name, number, or other basic data of a component; and (3) features that are public information, which are indirectly related to each part or assembly through transition attributes. For example, specific data such as the density, elastic modulus, or Poisson’s ratio of a material are only indirectly related to corresponding parts or assemblies by the features of “has material.”
Among the various features included in the digital twin of mechanical products, some can be clearly classified into the above three categories, such as basic information, 3D drawings, and material parameters. Others can be further decomposed into more sub-features. For example, the simulation model usually includes a 3D model, material parameters, and working condition parameters. These composited features can be decomposed and modeled in the above manner.
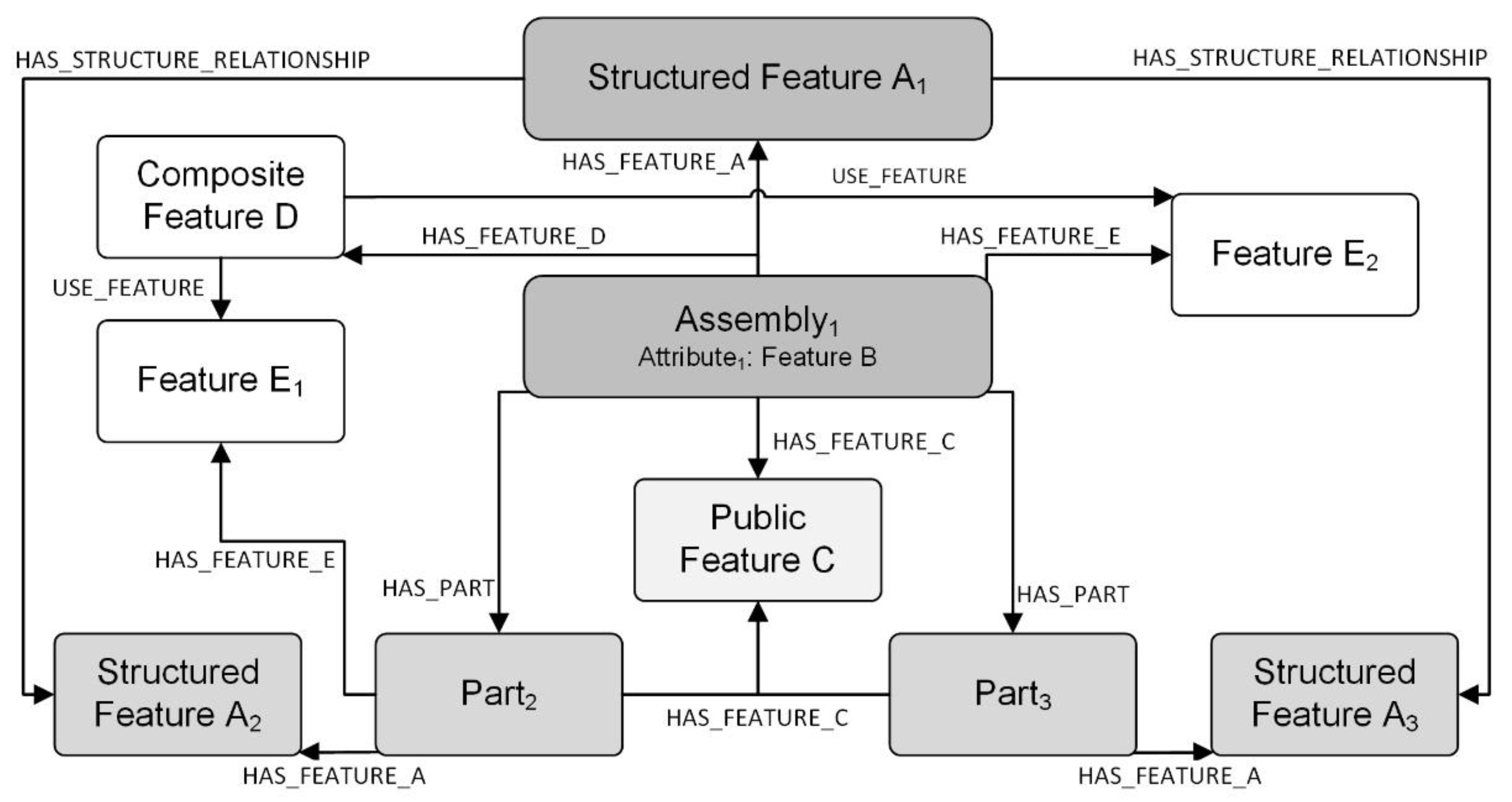
For the above three categories of features, different approaches are proposed for modeling, as shown in
Figure 4. For the features of the first category, because of the structured logic inside the feature data, their attribute classes are defined in the ontology model. Relationships between instances in different levels of features are developed through attribute relationships, and then, they are similarly associated with corresponding assemblies or parts, as shown in Structured Feature A in
Figure 4. Furthermore, they are mapped to the corresponding nodes and directional relationships between the nodes in the graph database. For the second category of features, as the feature data are only associated with a specific part or assembly, these features are added as attributes in the definition of the class of the corresponding part or assembly in the ontology model, such as the internal attribute Feature B of Assembly 1, as shown in
Figure 4. This reduces the model complexity and modeling cost. Furthermore, they are mapped as attributes of the corresponding parts or assembly nodes in the graph database. The features of the third category are defined as independent attribute classes in the ontology model, and the data are stored in these public classes. This meets the need for public reuse of feature data and improves model consistency and storage efficiency. The parts or assemblies that use the feature data are associated with the public class through the “has...characteristic” attribute relationship, as Public Feature C is jointly owned by Assembly1, Part2, and Part3, as shown in
Figure 4. Moreover, the public features are mapped to the corresponding feature nodes in the graph database, and orientation relationships are developed between the part or assembly nodes and the created feature nodes. The composite features are decomposed into the above three categories and then modeled. Composite Feature D in
Figure 4 can be decomposed into two related Features E1 and E2, and then, an association with Assembly1 is developed, whereas Features E1 and E2 are also related to Part2 and Assembly1, respectively. Since a feature may have multiple expressions, in order to improve the consistency of the model, the terminology should be proofread and confirmed before adding operations to avoid adding the same feature repeatedly based on different descriptions. When the third phase is completed, the product digital twin model architecture is completed.
3.4. Data Import
The objective of the fourth phase is to import the corresponding data into the built product digital twin model architecture, that is, to store various feature data in the created nodes or attributes. Feature data can be divided into three categories according to the format. The first category of data can be stored directly as fields in the node attributes. For example, for material parameters including density and elastic modulus, relevant attribute fields can be directly designed in the material nodes and the corresponding data can be stored in them. For the second category of data, as their formats do not conform to the field types in a graph database, they need to be structured in conjunction with external resources to be converted into field types that can be directly stored. For example, drawings of mechanical products can be stored in resources such as external servers or cloud disks. Then, the storage address is transferred to the corresponding field in the graph database as a uniform resource locator. The third category of data, such as design condition data or simulation results, can be stored in created nodes or attribute fields in a graph database. However, the data may form a mature management mode in external resources such as PLM systems, or their formats may be more suitable for other databases (e.g., relational databases). This category of data can also be processed for reference using the approach of the second category: first, it stores the data in suitable external resources, and then, it links the locator in a uniform manner. In addition, if the product feature data include unstructured data, it can be preprocessed first to improve the model quality of the digital twin. For example, transforming the obtained scans of drawings into original electronic digital ones through information recognition, converting image format documents into digital files, sorting or preprocessing various working condition data according to specific rules, and compressing files in complex formats.
Through the discussed approaches, the data collected in the first phase are imported to complete the storage of the feature data in the nodes and attribute relationships. When the fourth phase is completed, the modeling of all of the mechanical product data is completed and the digital twin model of a mechanical product in a graph database is developed as expected.
3.5. Data Application
The development of a product digital twin model consists of effectively integrating and fusing the originally isolated and fragmented data in mechanical products, thereby empowering smart manufacturing. Therefore, the objective of this phase is to develop corresponding application tools according to the requirements and to combine them with various emerging intelligent technologies to fully utilize the value of product data. For example, we used a 3D model and real-time operating data in a digital twin to develop a visual interface to show the operating status of the product for real-time monitoring and scheduling by technicians. Alternatively, the simulation model and historical operating data in the digital twin are combined with artificial intelligence algorithms to perform health management and predictive maintenance of the product.
The development of a product digital twin model is a continuous iterative optimization process. If it is found that the current scope of data is not sufficiently large or that the structure is unreasonable and further applications are restricted during usage, the modeling process cycle can be restarted from the first phase according to the new needs, such that the product digital twin model can be continuously improved.
4. Case Study
To verify the feasibility and effect of implementing the proposed method, the development process of a digital twin model prototype of an actual helicopter is presented in this section. The research background of this project is that aeronautical engineers already have plenty of data about the helicopter, including structural information, drawings, working condition data, simulation models, etc. However, these data are heterogeneous and scattered, so it is difficult to be directly used to map the physical entity. They also do not have much intention of deploying a PLM system from scratch because the organization already has an internal data archiving system, and now they just want to integrate the product data for mapping and analysis. Therefore, a lightweight and flexible modeling method is expected for the development of the helicopter digital twin model and the effective integration of heterogeneous data.
The goal of this case was to develop a hierarchical structure model that included the main systems of a helicopter and to develop a twin model containing feature data for some parts and assemblies to fully illustrate the details of the method. The developed digital twin model needs to integrate various heterogeneous data of the helicopter and its components to be directly used for further analysis, such as simulation. In this section, we conducted modeling strictly based on the steps of the proposed method and recorded the implementation process and the effects of each phase in detail.
4.1. Process and Results of Object Checking
In the first phase, the modeling scope of the product digital twin was clarified, and the relevant data were collected. Its implementation process corresponds to Phase 1 in the method. According to the goal of the case, the specific objects of the digital twin model of a helicopter developed in this section are listed in
Table 3. In terms of assemblies and parts, 26 assemblies and two parts, including five main systems, were selected. In terms of feature data, seven types of features, including basic information, 3D drawings, finite element simulation models, simulation results, historical data, materials, and working conditions, and 10 specific pieces of data were selected.
4.2. Process and Results of Structural Modeling
The target of the second phase was to develop a digital hierarchical structure model of a helicopter based on its assembly structure. Its implementation process corresponds to Phase 2 in the method. In the process of ontology modeling, two classes of assembly and parts were defined. The 26 assemblies, including helicopters, transmission systems, and rotor systems, were created as instances of assemblies, and the inner and outer rings of the two parts were created as instances of parts. Then, according to the relationships between the assemblies and parts, the attribute relationships “has assembly,” and “has part,” were defined. Corresponding relationships were developed between the matching assembly and the part instances. Subsequently, a structural knowledge model for the helicopter was obtained.
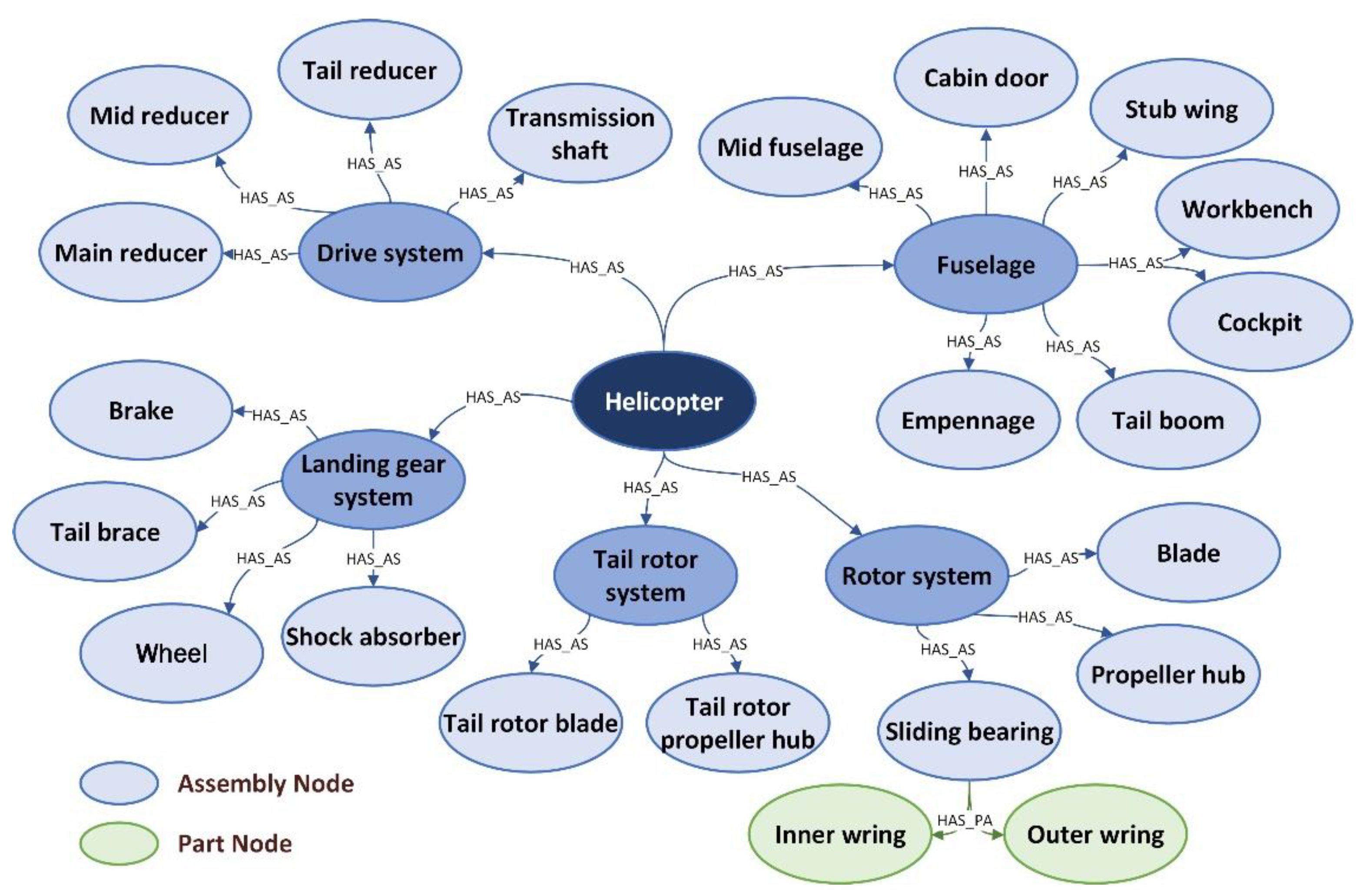
Based on this, the ontology model developed was mapped to a graph database. As the graph database uses graph theory to store the relationships between instances, its structure is very similar to that of the ontology model. First, the assembly and the part were created as two node types, and then, 26 assemblies and two parts were mapped to the corresponding types of nodes. Then, the attribute relationships in the ontology model were mapped to the orientation edges between the nodes, that is, the relationships “has assembly,” and “has part,” were created between the corresponding assembly and part nodes, which were abbreviated as “HAS_AS,” and “HAS_PA,”, respectively. The implementation results of the second phase are shown in
Figure 5, and the different levels of assembly are represented by colors from dark blue to light blue. At this time, a hierarchical structure model of a helicopter was created in a graph database. As shown in the figure, the assembly helicopter was in the first level; the transmission system, rotor system, and some other assemblies were in the second level; the main reducer, sliding bearing, and remainder assemblies were at the third level; and the inner ring and outer ring were at the fourth level.
4.3. Process and Results of Feature Modeling
The objective of the third phase was to create the containers required for storage of the various feature data collected in the first phase and to complete the construction of the digital twin model architecture for a helicopter. The features were classified and processed according to the third phase of the proposed method, as shown in
Table 4.
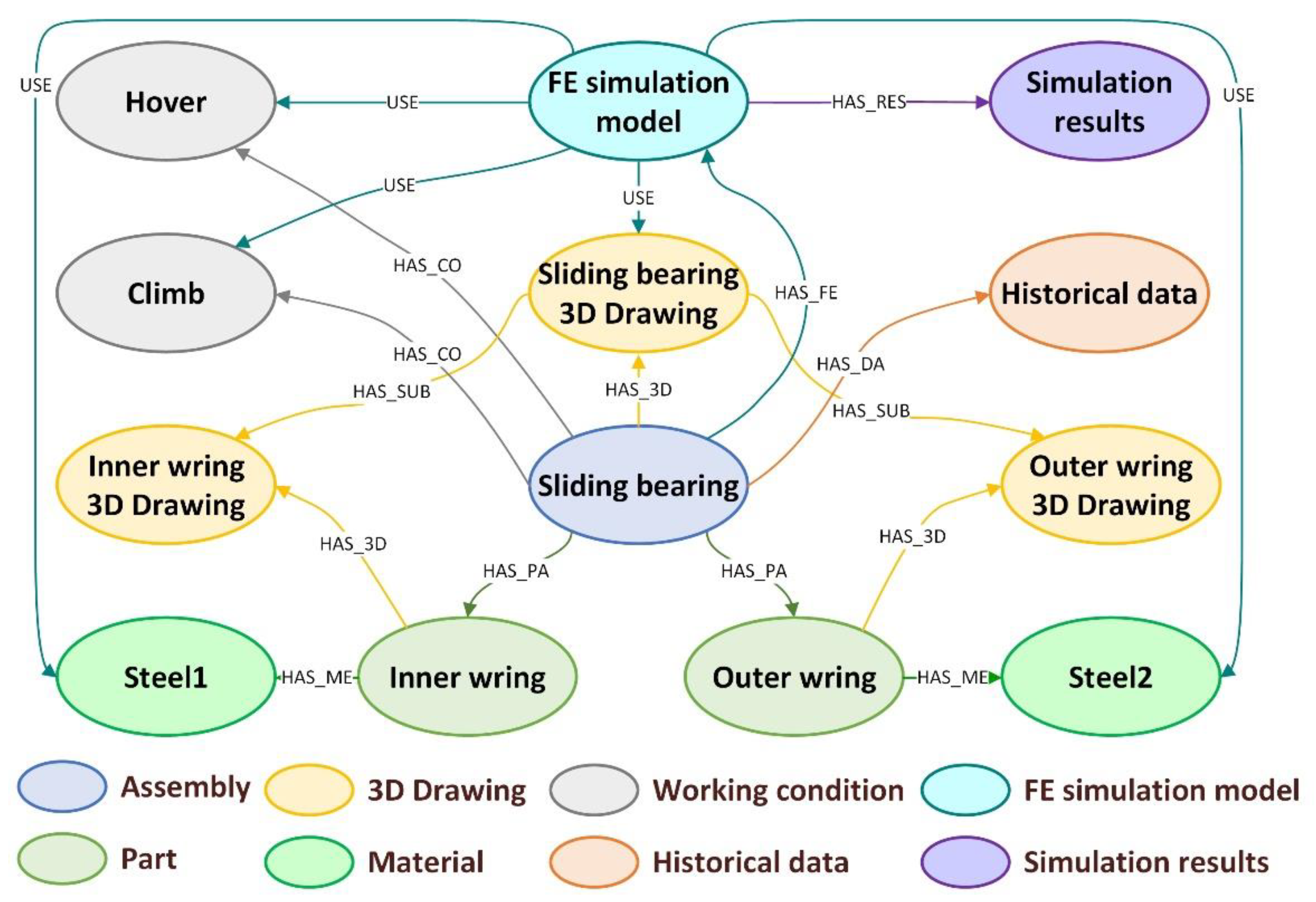
The first category contains the features associated with the mechanical structure, including the 3D drawings in this case. Three-dimensional drawing was defined as an attribute class, and sliding bearing 3D drawing, inner ring 3D drawing, and outer ring 3D drawing were created as the corresponding three instances. These three instances had the relationships “has 3D model” with the corresponding assembly and parts; in addition, according to the structural relationships between the sliding bearing, inner wring, and outer wring, corresponding subordination relationships were also provided between the three drawing instances.
The second category contained features that belonged to an assembly or part alone, including the basic information in this case. These data could be directly stored as an attribute of the corresponding assembly or part, without the need to create additional instances or relationships.
The third category contained common features that could be associated with multiple assemblies or parts, including the materials, working conditions, and historical data. In the ontology model, these three features were defined as attribute classes, and their specific content, including two materials, two working conditions, and one historical data, were created as instances. They were then associated with one or more corresponding assembly or part instances.
The composite features were decomposed and modeled, such as the finite element simulation model. The specific content of the finite element simulation model object was decomposed into 3D drawings, materials, working conditions, and simulation results. Among them, the classes and instances corresponding to the first three items were created in the preceding steps. As the simulation results might have multiple uses, the items were processed as a common feature to separately define a class and to create the corresponding instances. On this basis, the finite element simulation model was created as an attribute class, the simulation model of the sliding bearing was created as an instance, and the relationships between this instance and other decomposed instances were established.
The developed ontology model was mapped to a graph database, and the results are shown in
Figure 6. After finishing this phase, the digital twin model architecture of the helicopter was completely developed.
4.4. Process and Results of Data Import
The objective of the fourth phase was to import data into the developed digital twin model architecture. Thus, various feature data were classified and processed.
The first category contained data that could be directly stored in the nodes, including the basic information and material parameters. Fields were added, and contents were stored in the assembly, part, and material nodes.
The second category contained data that could not be directly stored in the graph database because of their formats, including 3D drawings, finite element simulation models, and simulation results. These data were first stored in an external server or cloud disk, and then, the storage address was imported into the corresponding field of the nodes in the form of a uniform resource locator. For more complex application scenarios, dynamic interfaces with external resources can be designed. These data were integrated into the developed product digital twin model to meet the requirements of unified storage and recall.
The third category contained data that could be directly imported or processed with external resources, including historical data and working conditions. These data had a simple list format, and it was feasible to store them directly in the node. However, these data were stored in external resources such as PLM systems in advance, and relational databases are more mature and efficient in managing these data. These data were stored on the server or cloud disk and could be called in the form of uniform resource locators, which conformed to the integrity of the digital twin model and improved the efficiency of data management.
The above data were stored in the product digital twin model in a graph database. After finishing this phase, the development of a digital twin model for a helicopter was completed.
4.5. Process and Results of Data Application
The objective of the fifth phase was to develop application tools based on the digital twin model and to use the integrated data. Its implementation process corresponds to Phase 5 in the method. In this case, the need for engineers to quickly and conveniently perform finite element simulation on the sliding bearing according to the working condition data to obtain its force situations was urgent. The developed digital twin model integrates all of the data needed for simulation, such as product 3D drawings, material parameters, and working condition data. In this context, a simulation application tool with a graphical interface was further developed based on the digital twin model and was associated with the simulation software to perform calculations, as shown in
Figure 7.
The simulation tool developed could automatically call the relevant data, enabling the original data with different formats and scattered storage to obtain a higher value after fusion. This avoids tedious work for engineers to manually collect data and develop simulation models, and lays the foundation for artificial intelligence, machine learning, and other algorithms to assist simulation optimization.
Thus, the objective of the case was achieved. A hierarchical digital model including the main systems of the helicopter containing characteristic data for some key components was developed. The model integrates various heterogeneous data of the helicopter and its components and can be directly used for further analysis, such as simulations. Compared with the existing PLM system, its characteristics include: (a) it could simulate and map the state of the product physical entity with input parameters; (b) focusing on the product itself, it could quickly and lightly realize the integration and fusion of heterogeneous data, without the need for a customized software system; (c) it could easily respond and iterate. If the product structure or feature changes, engineers will track by adjusting the nodes or edges in the graph database, thereby recalling the required data.
5. Discussion
The digitization and intelligence of mechanical products face many new challenges. Massive amounts of new data are collected during product design, manufacturing, and operation, but their isolation and fragmentation restrict further mining of their value. The integration of these data has become a key issue to be solved in the information era. With the development of digital twins, full-element reconstruction in virtual space is regarded as an important data fusion approach. This is theoretically reasonable, but the implementation of digital twin technology requires further study. In this context, a hierarchical modeling method for digital twin models of mechanical products was proposed in this study.
First, this method provides a feasible modeling framework and develops a full-element digital twin model for mechanical products. Compared with some partial models or frameworks for respective needs in the existing literature, such as computational virtual abstraction of complex manufacturing phenomena [
28] and digital twin-oriented assembly model [
35], this is a native product digital twin modeling method rather than an extension of the original simulation model. This method uses ontology to structure various types of data into computer-understandable descriptions. For example, in this case, various data including complex structural relationships between assemblies and parts, drawings, models, parameters, and other feature data with completely different formats were transformed into attribute instances and their relationships through ontology modeling. In order to elaborate on the modeling process in an appropriate space, some typical features were selected and connections between systems were simplified to links in the case study. In actual projects, more data types and interfaces are usually necessary, which requires more case-based research work in the future. This is also the main reason why the developed model is called a digital twin prototype. Overall, the developed model serves as a data center for the entire lifecycle of the product or is integrated into existing data management systems, integrating the previously isolated, fragmented, and scattered data on various platforms into a unified data architecture. By abstracting the essential content and relationships of data, a formally unified and computer-understandable model was developed, which provides feasibility for data fusion and further applications.
Second, the digital model developed in this method is hierarchical and more suitable for mechanical products. The product digital twin modeling methods in the existing literature, such as generic cyber-physical system architecture [
30] and heterogeneous data model for product development and manufacturing [
31], are for general products and do not utilize the structural characteristics of mechanical products. In addition, the general domain model based on ontology is typically flat and decentralized in these studies. However, for mechanical products, data calling requirements are often clustered in the structural dimension. For example, in the case of a sliding bearing finite element simulation, the required data mainly include various feature data related to the assembly and its parts. Cross-domain calls in the structural dimension rarely occur. For example, for the sliding bearing simulation of the rotor system, the data of the landing gear in another system are generally not used. In order to describe the model clearly and concisely, the main systems of the helicopter and related parts of the sliding bearing are modeled in this case. As not many components were involved, quantitatively comparing efficiency improvements is difficult, which needs to be further expanded in future research based on software engineering. All in all, the model developed by the proposed method utilizes the structural characteristics of mechanical products, and hierarchical digital mapping can better meet the application requirements.
Third, this method stores the developed ontology model in a graph database, which is simple, direct, and efficient. In the existing research, owing to the limitation of the development stage of information technology, scholars have been devoted to studying how to store ontology models based on text or relational databases for a long time, such as ManuService ontology [
46] and the ontology-based CAD model retrieval method [
47]. However, the ontology model is essentially a graph model, and the inherent structure of the two-dimensional table restricts the representation of complex semantics in the ontology and the efficient storage of large amounts of data. With the rapid development of new non-relational databases, using graph databases to directly store ontology models has become possible, but their application is still rare in the field of digital twins. This method proposes a means to map the developed ontology model to the graph database and to demonstrate it in this case. Although the underlying structure of the existing graph databases are similar, many differences still exist in specific operations, which should be noted by researchers who need to replicate and apply this method. In general, the results show that the graph database can support the storage and management of the product digital twin model using this method.
In addition, compared with the common large-scale or customized software in the field of product data management, the proposed method is lightweight, flexible, and easy to implement. Following these steps, engineers with programming capabilities can quickly and accurately develop the required product digital twin model in a graph database, thereby integrating the existing isolated, fragmented data. The integrated data can be efficiently connected and used in computer programs and can be further used for digital or intelligent applications such as monitoring, simulation, and forecasting. Additionally, this method can be iteratively optimized, and its scalability can meet the dynamic and evolutionary requirements of the digital twin model. The development of the product digital twin model is not a one-time process but a continuous expansion and optimization as the received data and usage requirements change. This method realizes looping and iteration from the framework level, and the selected ontology and graph database have good dynamic expansion performances. When the product digital twin model needs to integrate more data to serve new needs and to add corresponding nodes, relationships, and attributes according to this method, the digital twin model is updated to the new state of the physical entity.
From the management perspective, the data integration and iterative optimization supported by this method can also provide some inspiration for the management and sharing of product data. The ideal product digital twin model is unique and dynamic; in its entire life cycle, only one digital model continuously evolves and integrates all data, rather than multiple isolated models of various stages assembled. The product digital twin model developed by this method, as a digital map integrating all elements, can be used as the only digital model in the entire lifecycle. From design and manufacturing to operation and maintenance, different participants only need to add new elements to the same digital twin model in the graph database for updating. In this context, the data flow between the original isolated models is no longer a problem because they have been aggregated into a digital model at this time, breaking the barriers between data islands. For participants at various stages, such as designers, processors, and maintainers, they no longer transfer data but cooperate to develop a complete product digital model.
6. Conclusions and Future Works
With the development of information and communication technology, a large amount of multi-source heterogeneous data with high information density and utilization value are generated, but isolated and fragmented data are difficult to use effectively. In this context, digital twins have been increasingly researched as they enable the user to rebuild all of the elements of a physical entity in a virtual space. However, the development of a digital twin model is still in its infancy, and most of the models currently developed are partial mappings oriented to specific needs and do not take advantage of the characteristics of mechanical products. In this study, a hierarchical integrated modeling method for digital twin models of mechanical products is proposed. By combining it with ontology technology, this method develops a native, full-element digital twin model for mechanical products. The model could serve as a data center for the entire lifecycle of the product or can be integrated with existing data management systems, integrating the previously isolated, fragmented, and scattered data on various platforms into a unified data architecture. In addition, the model utilizes the structural characteristics of mechanical products and is developed as a hierarchical digital mapping to better meet the application requirements. The proposed method has the potential to be used by more data technologies, thereby enabling smart manufacturing.
Although the proposed method can realize the development of a digital twin model at the theoretical level and prototype system, it still has some limitations, and the related enabling technologies need to be further studied in the future. For example, during the evolution of the digital twin model, direct modification or deletion in the ontology model may result in data loss and difficulty in traceability. To meet the high reliability and traceability requirements of mechanical data, a model evolution and version management mechanism must be studied. Another example is that the stakeholders of a mechanical product usually do not completely trust each other. Therefore, the development of a secure cooperative modeling mechanism for a single digital model remains to be explored. In addition, further research is required to explore how SysML or other modeling languages can be used to standardize the expression of product digital twins and, for data that cannot be stored directly in a graph database but temporarily imported by a link, a more efficient integrated interface to achieve better fusion can be developed.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}