
Q-Learning with the Variable Box Method: A Case Study to Land a Solid Rocket

 , , and
, , and
Abstract
:1. Introduction
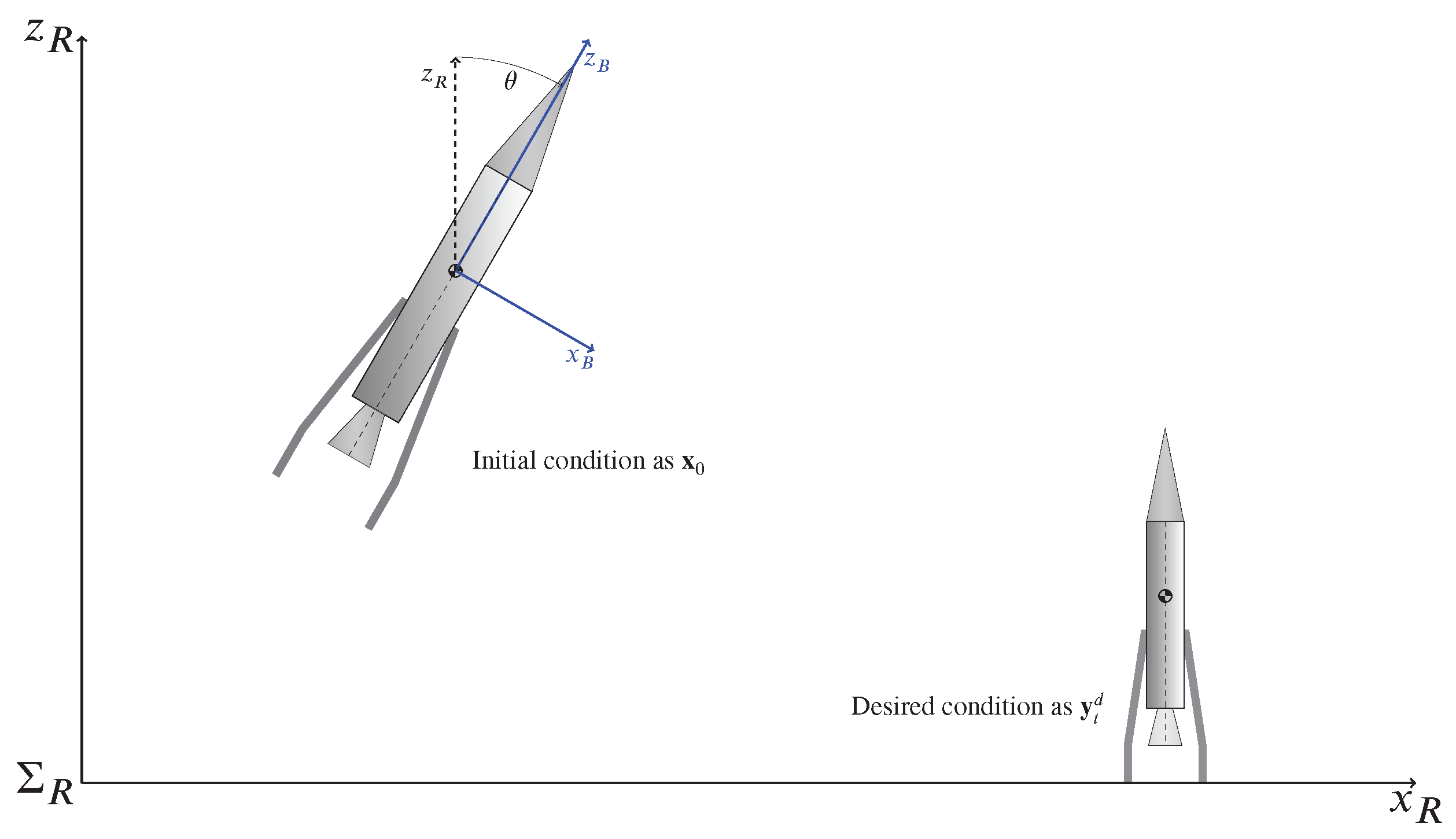
2. Problem Statement
- 1.
- nonlinear (superposition theorem does not apply);
- 2.
- underactuated (there exist more degrees of freedom than control inputs);
- 3.
- non-affine in the control input u (since cannot be written as for a given input matrix).
3. Box Methods in RL algorithms
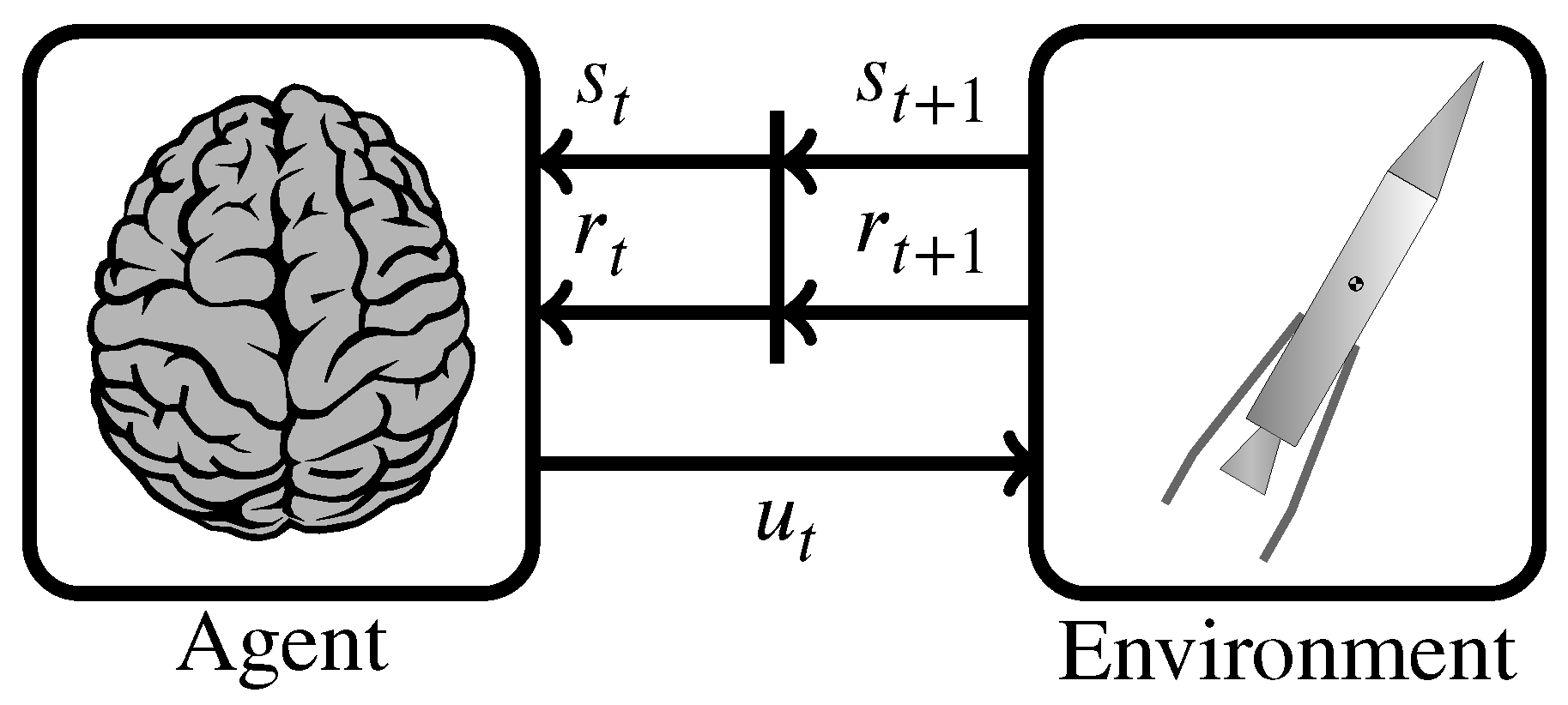
3.1. Brief Background of Reinforcement Learning
3.2. Classical Box Method
- -
- Finite State-Number Space. Let be the index vector of the finite state-number space for , whose elements are the state numbers codified by ’s elements. Then, models a vector of the integer numbers’ range as elements of a tensor of N-axes, coding the state number into to finally relate the indexed output vector to and then to .
- -
- Finite Action Space. Aiming at obtaining a finite action space for the bounded action (control) variable represented by m-boxes of width each, then . Each element is indexed by the m-th action agent from an arbitrary policy. Note that a high number of u values is suggested to enable more state-number explorations. However, this may lead to an unfeasible explosion of dimensions, or the curse of dimensionality.
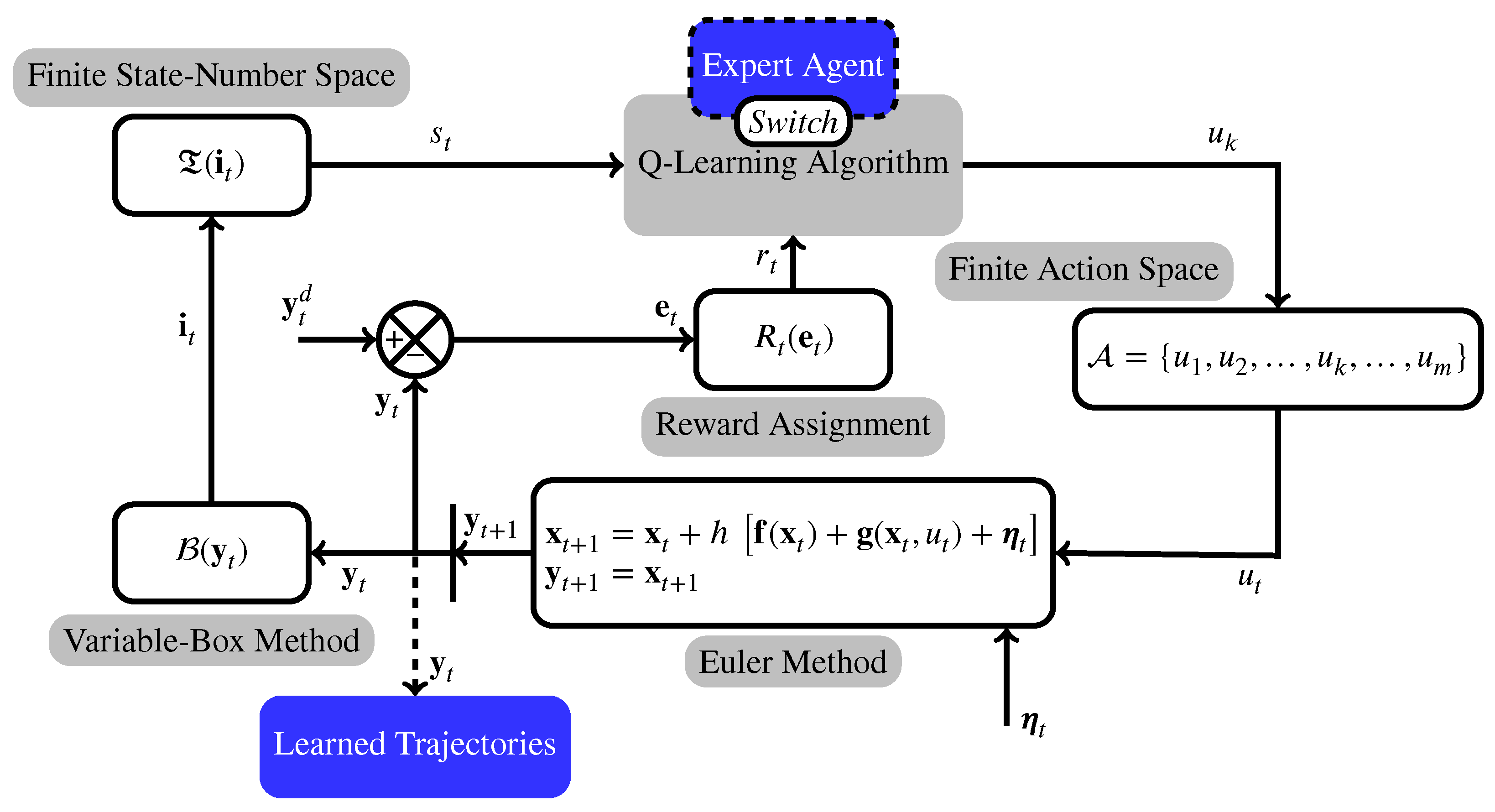
3.3. The Proposed Variable Box Method
- a.
- a faster reaction for larger errors;
- b.
- a constant box dimension; the remaining boxes are enlarged (shrank) when is reduced (expanded), like an accordion of a fixed length;
- c.
- continuous action-taken history and influence [14], with smooth transitions between state numbers.
| Algorithm 1: The proposed variable box method enables higher resolution near the goal but lower resolution away from it to avoid exploiting dimensionality |
 |
3.4. How to Deal with the Curse of Dimensionality
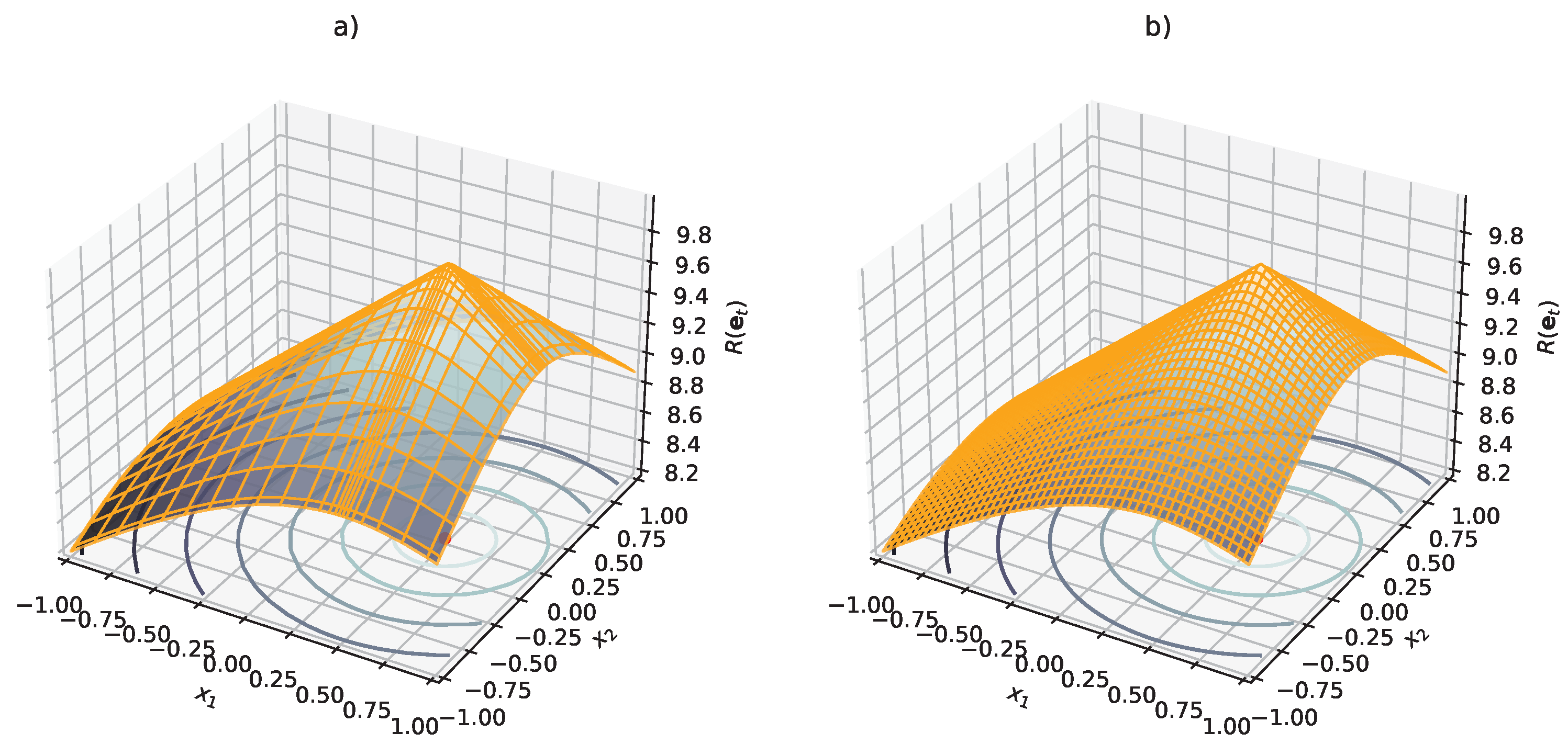
3.5. Reward Assignment
4. A Case Study: Rocket Landing
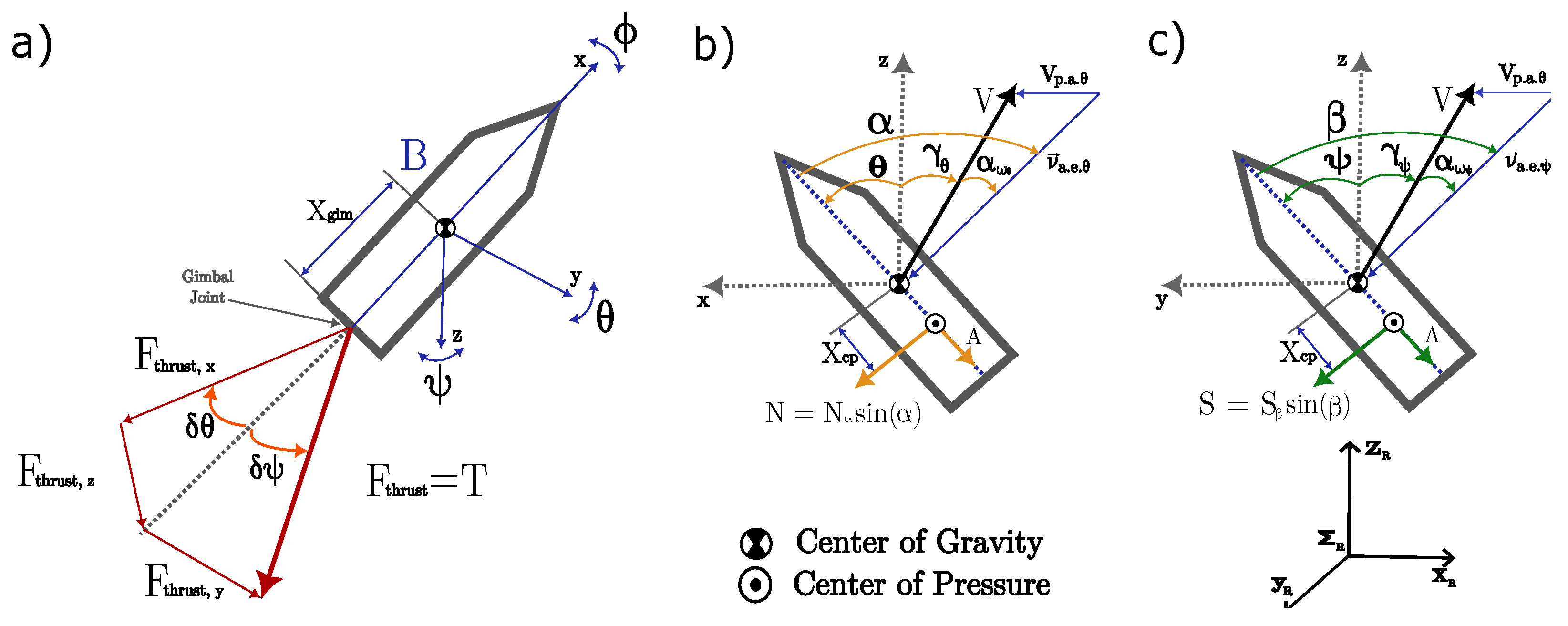
4.1. Dynamical Model
4.1.1. Translational Dynamics
4.1.2. Rotational Dynamics
4.1.3. Rotational Kinematics
4.2. Two-Dimensional Aerodynamic Rocket Model
4.3. Simulation Study
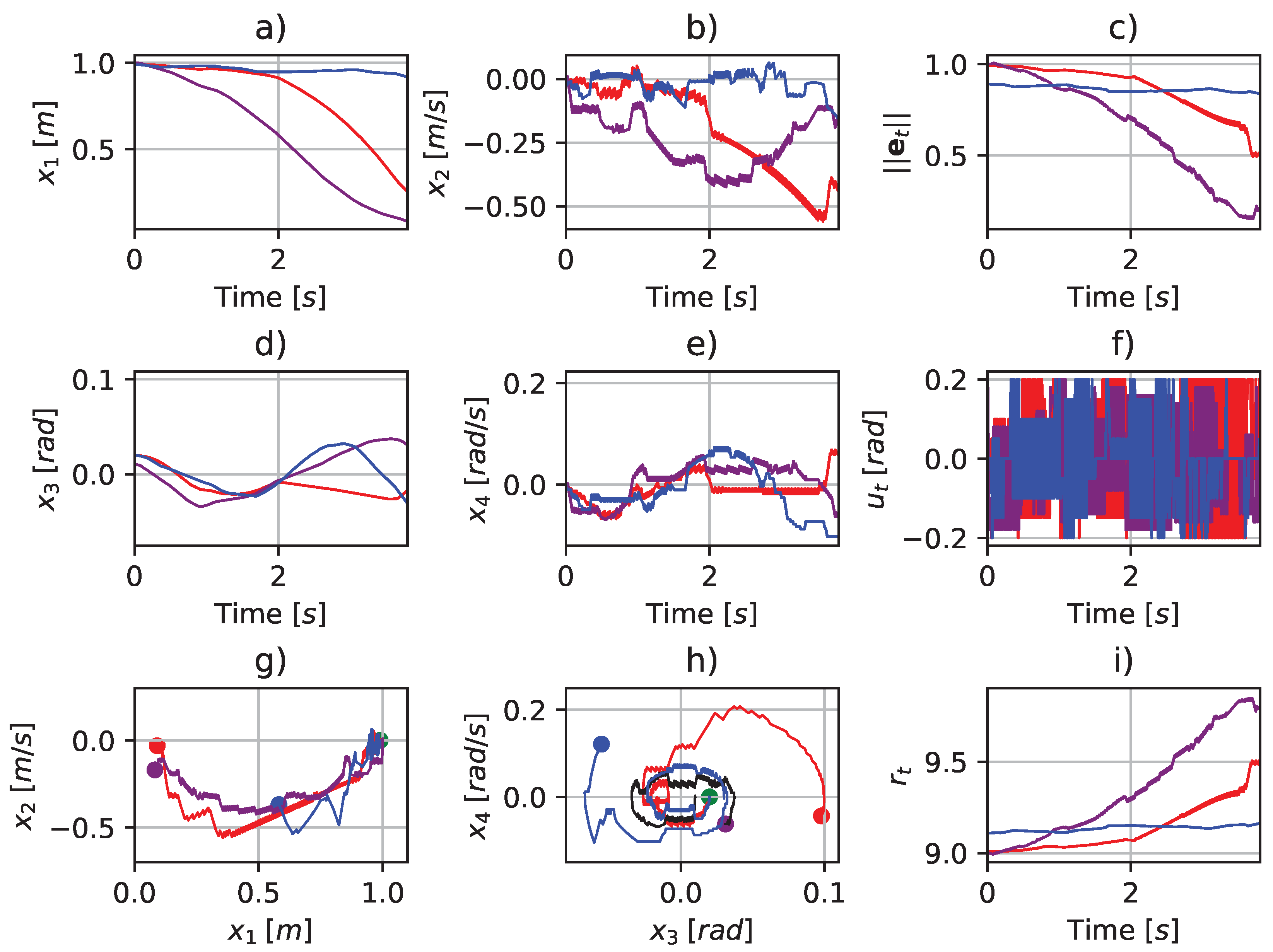
- 1.
- shows the comparative performance of the classical and variable box methods for the same output limits, action space, and number states but with different resolutions.
- 2.
- shows the comparative performance considering the same goal-box resolution and state-space dimension for the variable box method.
- 3.
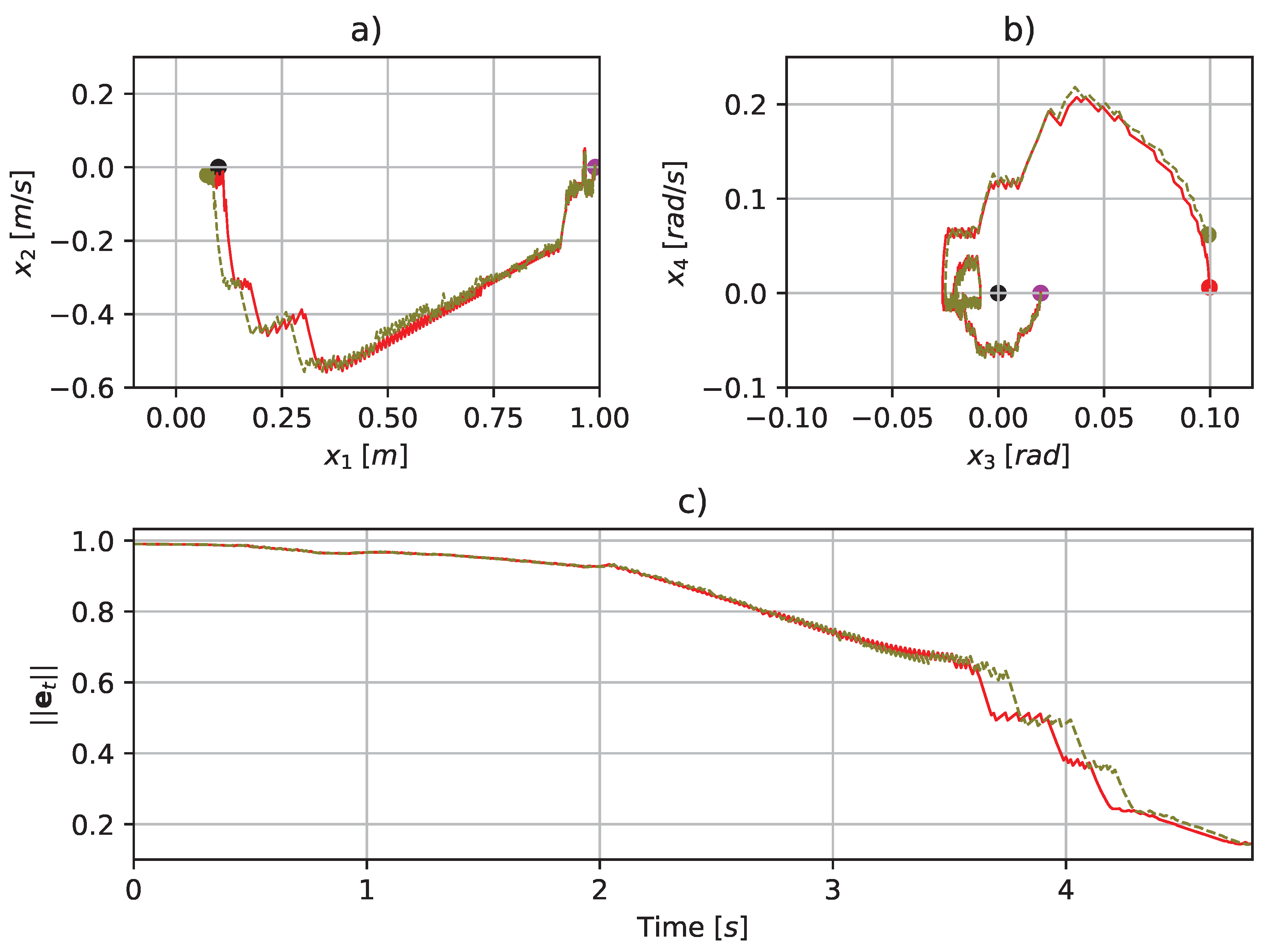
- shows the rocket landing trajectories when the rocket is subject to a Gaussian disturbance.
4.4. Rocket and Learning Parameters
4.5. Simulation A: Comparative Performance
4.6. Simulation B: Comparative Performance
4.7. Rocket Subject to Disturbances
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. The Standard Q-Learning Algorithm
| Algorithm A1: The classical Q-learning |
 |
References
- Nebylov, A.; Nebylov, V. Reusable Space Planes Challenges and Control Problems. IFAC-PapersOnLine 2016, 49, 480–485. [Google Scholar] [CrossRef]
- Ünal, A.; Yaman, K.; Okur, E.; Adli, M.A. Design and Implementation of a Thrust Vector Control (TVC) Test System. J. Polytech. Politek. Derg. 2018, 21, 497–505. [Google Scholar] [CrossRef]
- Oates, G.C. Aerothermodynamics of Gas Turbine and Rocket Propulsion, 3rd ed.; American Institute of Aeronautics and Astronautics: Washington, DC, USA, 1997; ISBN 978-1-56347-241-1. [Google Scholar]
- Chen, Y.; Ma, L. Rocket Powered Landing Guidance Using Proximal Policy Optimization. In Proceedings of the 4th International Conference on Automation, Control and Robotics Engineering, Shenzhen, China, 19–21 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Yuan, H.; Zhao, Y.; Mou, Y.; Wang, X. Leveraging Curriculum Reinforcement Learning for Rocket Powered Landing Guidance and Control. In Proceedings of the China Automation Congress, Beijing, China, 22–24 October 2021; pp. 5765–5770. [Google Scholar] [CrossRef]
- Sánchez-Sánchez, C.; Izzo, D. Real-Time Optimal Control via Deep Neural Networks: Study on Landing Problems. J. Guid. Control Dyn. 2018, 41, 1122–1135. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, Z.; Wang, J.; Huang, Z. Rocket Image Classification Based on Deep Convolutional Neural Network. In Proceedings of the 10th International Conference on Communications, Circuits and Systems, Chengdu, China, 22–24 December 2018; pp. 383–386. [Google Scholar] [CrossRef]
- Stengel, R.F. Flight Dynamics; Princeton University Press: Princeton, NJ, USA, 2004; ISBN 978-1-40086-681-6. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; A Bradford Book: Cambridge, MA, USA, 2018; ISBN 978-0-262-03924-6. [Google Scholar]
- Michie, D.; Chambers, R.A. Boxes: An Experiment in Adaptive Control. Mach. Intell. 1968, 2, 137–152. [Google Scholar]
- Davies, S. Multidimensional Triangulation and Interpolation for Reinforcement Learning. In Proceedings of the 9th International Conference on Neural Information Processing Systems, Denver, CO, USA, 3–5 December 1996; pp. 1005–1011. [Google Scholar] [CrossRef]
- Dayan, P.; Hinton, G.E. Feudal Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems 5, Denver, CO, USA, 30 November–3 December 1992; pp. 271–278. [Google Scholar] [CrossRef]
- Barto, A.G.; Sutton, R.S.; Anderson, C.W. Neuronlike Adaptive Elements that Can Solve Difficult Learning Control Problems. IEEE Trans. Syst. Man Cybern. 1983, SMC-13, 834–846. [Google Scholar] [CrossRef]
- Munos, R.; Moore, A. Variable Resolution Discretization in Optimal Control. Mach. Learn. 2002, 49, 291–323. [Google Scholar] [CrossRef]
- Moore, A.W. Variable Resolution Dynamic Programming: Efficiently Learning Action Maps in Multivariate Real-valued State-spaces. In Proceedings of the 8th International Conference of Machine Learning, Evanston, IL, USA, 1 June 1991; pp. 333–337. [Google Scholar] [CrossRef]
- Zahmatkesh, M.; Emami, S.A.; Banazadeh, A.; Castaldi, P. Robust Attitude Control of an Agile Aircraft Using Improved Q-Learning. Actuators 2022, 11, 374. [Google Scholar] [CrossRef]
- Sutton, R.S. First Results with Dyna, an Integrated Architecture for Learning, Planning and Reacting. In Neural Networks for Control; Miller, W.T., Sutton, R.S., Werbos, P.J., Eds.; The MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Tewari, A. Atmospheric and Space Flight Dynamics; Modeling and Simulation in Science, Engineering and Technology; Birkhäuser Boston: Boston, MA, USA, 2007; ISBN 978-0-81764-437-6. [Google Scholar] [CrossRef]
- Martínez-Perez, I.; Garcia-Rodriguez, R.; Vega-Navarrete, M.A.; Ramos-Velasco, L.E. Sliding-mode based Thrust Vector Control for Aircrafts. In Proceedings of the 12th International Micro Air Vehicle Conference, Puebla, Mexico, 16–20 November 2021; pp. 137–143. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Box Method | Code | |||||
|---|---|---|---|---|---|---|
| Classical | CBM1 | 28,224 | 0.6304 | 9.3787 | 4.88 | |
| Variable | VBM1 | 28,224 | 0.1381 | 9.8618 | 4.82 | |
| Variable | VBM3 | 18,225 | 0.1519 | 9.8480 | 4.93 | |
| VBM2 | 51,984 | 0.1458 | 9.8541 | 3.7 | ||
| VBM4 | 51,984 | 0.0867 | 9.9132 | 3.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tevera-Ruiz, A.; Garcia-Rodriguez, R.; Parra-Vega, V.; Ramos-Velasco, L.E. Q-Learning with the Variable Box Method: A Case Study to Land a Solid Rocket. Machines 2023, 11, 214. https://doi.org/10.3390/machines11020214
Tevera-Ruiz A, Garcia-Rodriguez R, Parra-Vega V, Ramos-Velasco LE. Q-Learning with the Variable Box Method: A Case Study to Land a Solid Rocket. Machines. 2023; 11(2):214. https://doi.org/10.3390/machines11020214
Chicago/Turabian StyleTevera-Ruiz, Alejandro, Rodolfo Garcia-Rodriguez, Vicente Parra-Vega, and Luis Enrique Ramos-Velasco. 2023. "Q-Learning with the Variable Box Method: A Case Study to Land a Solid Rocket" Machines 11, no. 2: 214. https://doi.org/10.3390/machines11020214
APA StyleTevera-Ruiz, A., Garcia-Rodriguez, R., Parra-Vega, V., & Ramos-Velasco, L. E. (2023). Q-Learning with the Variable Box Method: A Case Study to Land a Solid Rocket. Machines, 11(2), 214. https://doi.org/10.3390/machines11020214