1. Introduction
Machine tool accuracy may degrade significantly due to thermal effects resulting partly from heat generated by the drives and the motions of rotary axes [
1]. One way to reduce these errors is real time compensation to cancel TCP deviation at an arbitrary point in the work space by adjusting its command position [
2]. Mayr et al. stated that precise predictions of thermal errors through models are fundamental for effective real time compensation [
3]. The higher the predictability of the thermal error models, the more accurate the compensation will be.
Brecher et al. developed first and second order transfer functions between the thermal volumetric errors (TVEs) of a three-axis machine tool as outputs and the internal control data (rotational speeds and motor currents) and environment temperature as inputs [
4]. Horejs et al. compensated thermal displacements in the y and z directions of the TCP through thermal transfer functions that were achieved using Matlab’s System Identification Toolbox. The inputs are the temperatures from inside the main spindle, ram and base of the horizontal milling machine, ambient temperature and spindle speed and the outputs are the thermal displacements [
5]. Liu at al. modelled thermally induced volumetric errors based on the 21 geometric error components and nine thermal drift errors for milling and boring machine using rigid body kinematics. Only volumetric error in the z direction identified as the main error was compensated with Programmable Logic Controller and the machine’s computer numerical controller (CNC) [
6]. Mayr et al. found compensation values for individual thermal errors of rotary axis and main spindle from a gray box model using cooling power as input [
7]. Yu et al. investigated the dependence of volumetric errors on spindle speed and temperature at pre-defined points through polynomial regression model. The model with closest predictability to the measured outputs is chosen [
8]. Bitar-Nehme and Mayer developed first order transfer functions with delay terms to predict individual machine geometric errors as output from power consumptions as input. The machine table thermal expansion was also predicted [
1]. Baum et al. modeled thermally induced volumetric error from the 21 geometric errors components for a three-axis machine tool through rigid body kinematics. Error components were measured with integral deformation sensors in the training process and the R-test based procedure in the testing process [
9]. Liu et al. established a mechanism-based error model to identify three thermally induced error terms of linear axes X, Y, and Z as functions of time and positions. With spindle system, they modelled relationship between two angular thermal errors yaw and pitch, two thermally translational errors in x and y directions, and spindle elongation with temperatures of critical key locations by multivariate linear regression analysis [
10].
The above models show their ability to predict the TVEs (data sequence) of the machine tools. However, the volume and variety of data become bigger; the model has more clues to predict outputs better, but the calculation cost and internal parameters increase. In some cases are over the capability of manual analysis [
11,
12]. Elaborate training of the model is expected to be able to guarantee reliable results in the long term [
13]. Deep learning technique enables learning complex relations and is a new approach for these problems. LSTM and GRU networks have attracted attention in recent time and Liang et al. proved that they have a better quality than Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) for processing sequence data and avoiding overfitting problem [
14]. Ngoc et al. [
11] applied LSTM to predict multi step ahead data of thermally induced geometric errors, which define the errors between and within individual machine axes, from activity cycles involving the two rotary axes B and C of a five-axis machine tool. Others [
15,
16,
17,
18] presented the efficiency of LSTM networks for modelling the thermal behaviors of a machine tool. Refs. [
15,
16] modeled the thermal elongation of spindle as a function of rotational speed. Ref. [
17] used thermal elongation of spindle in the z direction as output and temperature at key locations as inputs. Ref. [
18] found the relationship between thermal errors of ball screws and temperature of the feed drive system. While in [
11] thermally induced geometric errors (TGEs) were predicted using SLSTM, the current paper applies SLSTM and SGRU to directly predict the TVEs without the use of a rigid body kinematic model. This avoids having to develop the machine kinematic model and may be able to model error sources that a kinematic model may not consider. Calculating them from predicted TGEs does not consider errors that cannot be explained with the estimated geometric errors [
1,
19]. TVEs directly relate to compensation values of the thermal errors of paths to move the tool to target positions in the working space of the machine tool. These predictions are more difficult than doing TGEs because the predictors need to realize not only the change of thermal behavior of machine, but also the positions we want to move the tool to. Therefore, the input data include not only the power consumptions of axes B and C, but also the machine linear and rotary axis positions. Increasing the number of inputs also increases the calculation cost. With a multivariate and multi-layer network, it may be trapped within multiple local minima; Sagheer and Kotb suggest having a suitable optimizer to facilitate the training of deep learning models [
20]. Stochastic optimization is successfully applied in Deep learning [
21] and Adam [
22] is a popular optimizer. Adaptive moment with decoupled weight decay (AdamW) optimizer [
23] is a modification of Adam with flexible learning rate, decoupling the weight decay from the gradient update, is expected to make the networks converge faster and improve accuracy. The proposed scheme is presented in six sections:
Section 1 reviews previous works.
Section 2 describes the experimental process.
Section 3 presents the neural network configurations of the SLSTMs and SGRUs models.
Section 4 shows the training and predicting processes. The results and discussion are in
Section 5 and the conclusion follows in
Section 6.
2. Experiment Process
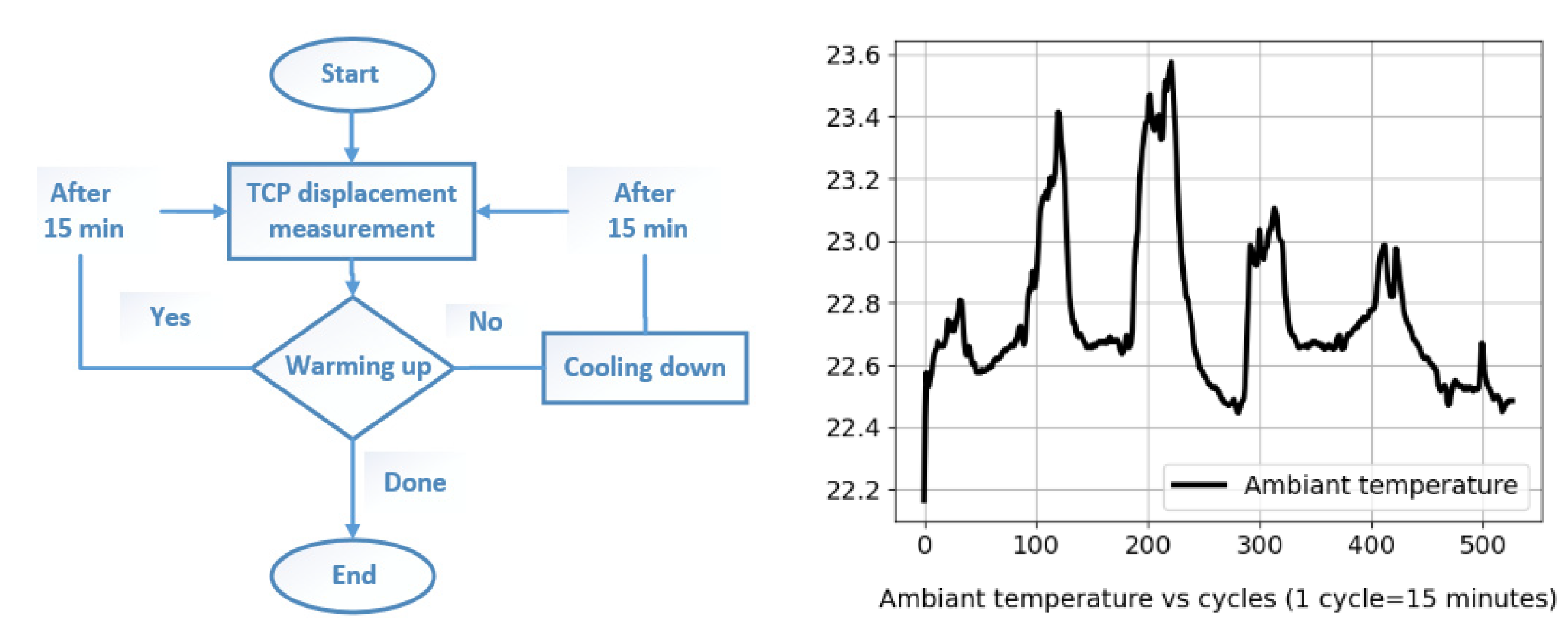
Motion sequences for machine axes were designed to warm up the machine tool without any machining [
1,
24], while measuring the TVEs, or TCP displacements between a contactless R-test device (sensor nest) [
25] and ball artefacts on a Mitsui-Seiki HU40T horizontal machining center with wCBXfZY(S)t topology as described in [
1].
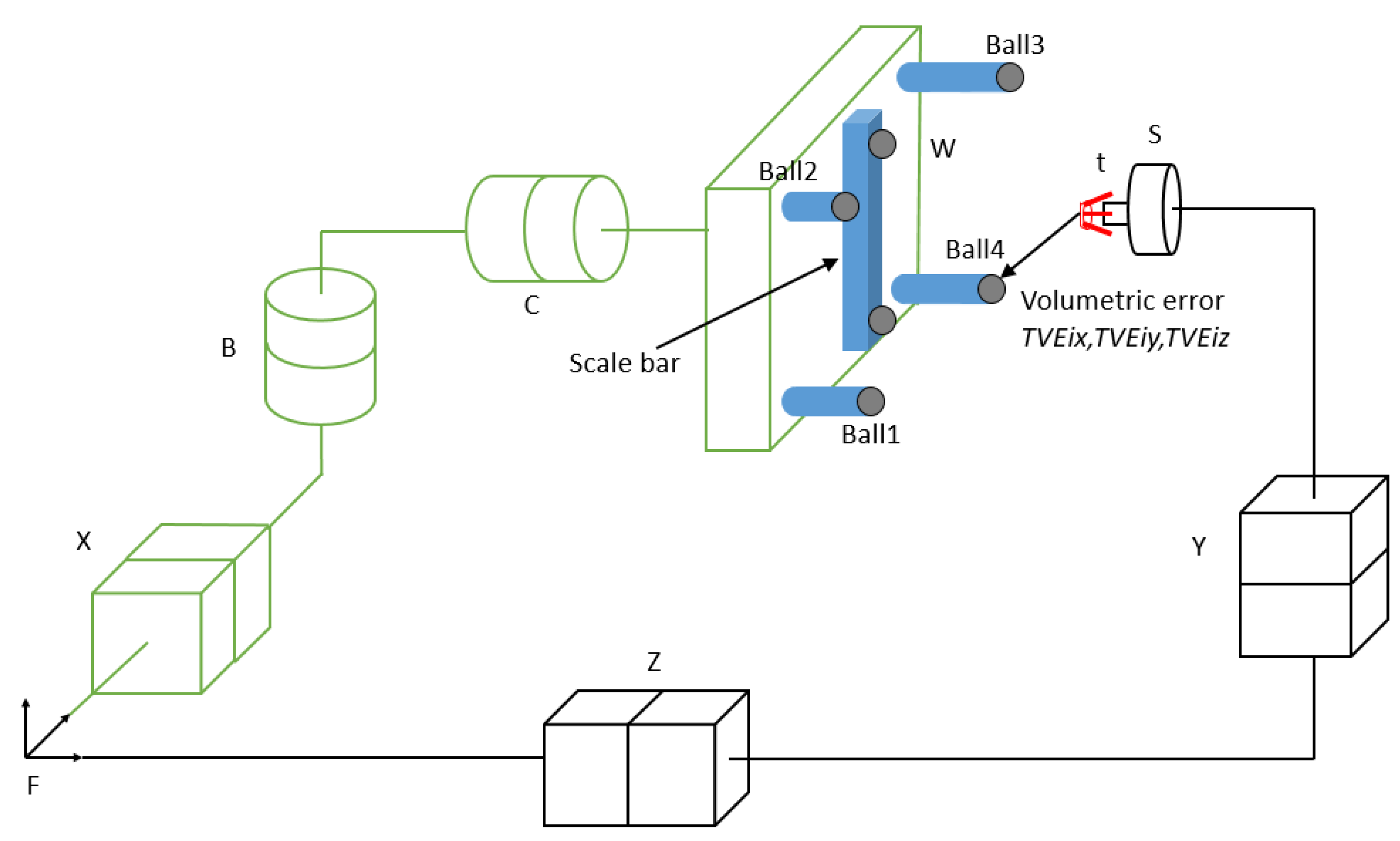
Figure 1 illustrates the experimental setup. Four separate artefact balls are fixed on stems with different lengths and a scale bar made of Invar with two balls separated by a calibrated distance on the workpiece side, while the sensor nest is mounted in the spindle on tool side.
Heating (rotary axes’ motions at different speeds) and cooling (machine stopped) cycles are shown in
Figure 2 (on the left).
Figure 2 (on the right) illustrates ambient temperature controlled between 22.1 and 23.5 Celsius degrees in 132 h (528 cycles) training process.
The activity sequences are implemented using a machine tool G-code. TCP positions are measured at 15 min intervals for both training and testing processes. TVEs, estimated by the Scale And Master Ball Artefact (SAMBA) method [
26] in both processes in the x, y, and z directions, are the subtractions of the initial value from all subsequent values to avoid the effect of machine quasi-static geometric errors as given by Equation (1).
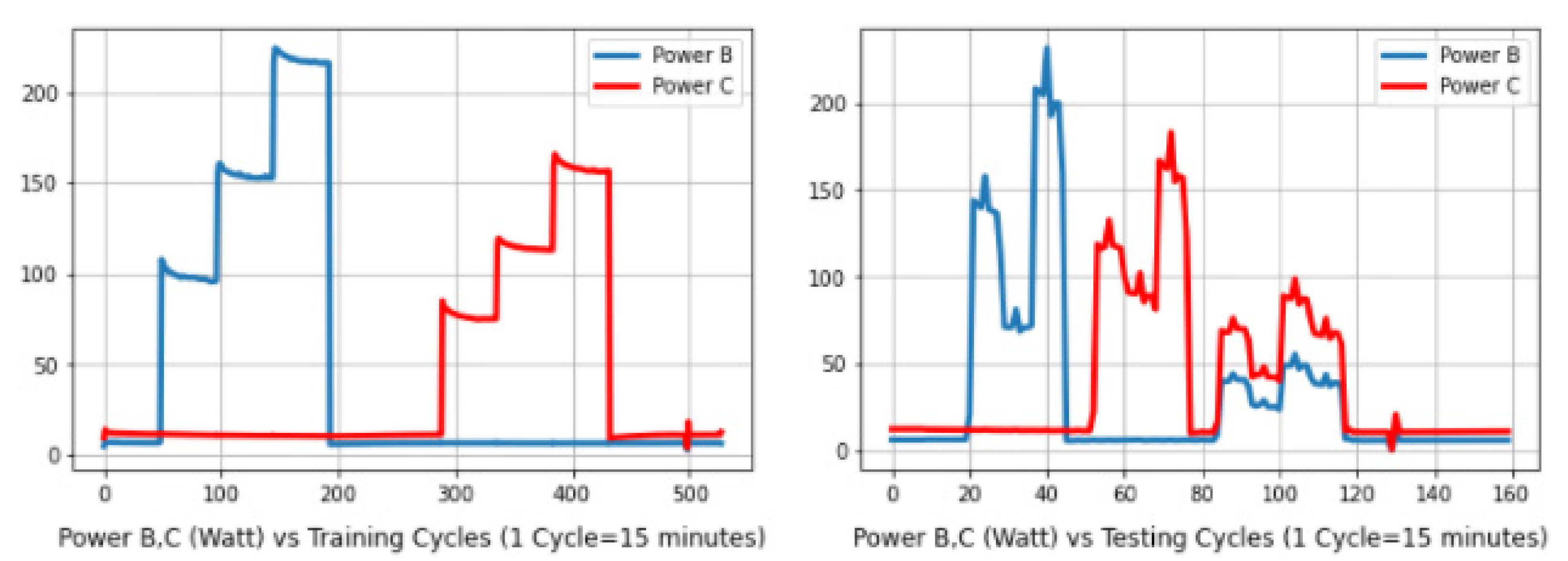
Figure 3 on the left shows the long process of activity with different measured powers of the B and C rotary axes lasting 132 h. In this process, each axis is exercised separately to capture their individual effect on the behavior of the machine tool.
Figure 3 on the right shows the short process lasting 40 h with individual and simultaneous motions of rotary axes, which was run after some days and with similar starting condition to the long process. The short process is different from the long process and includes individual axis motions as well as combined axis motions as would be likely during a machining process.
3. Stacked LSTMs and GRUs
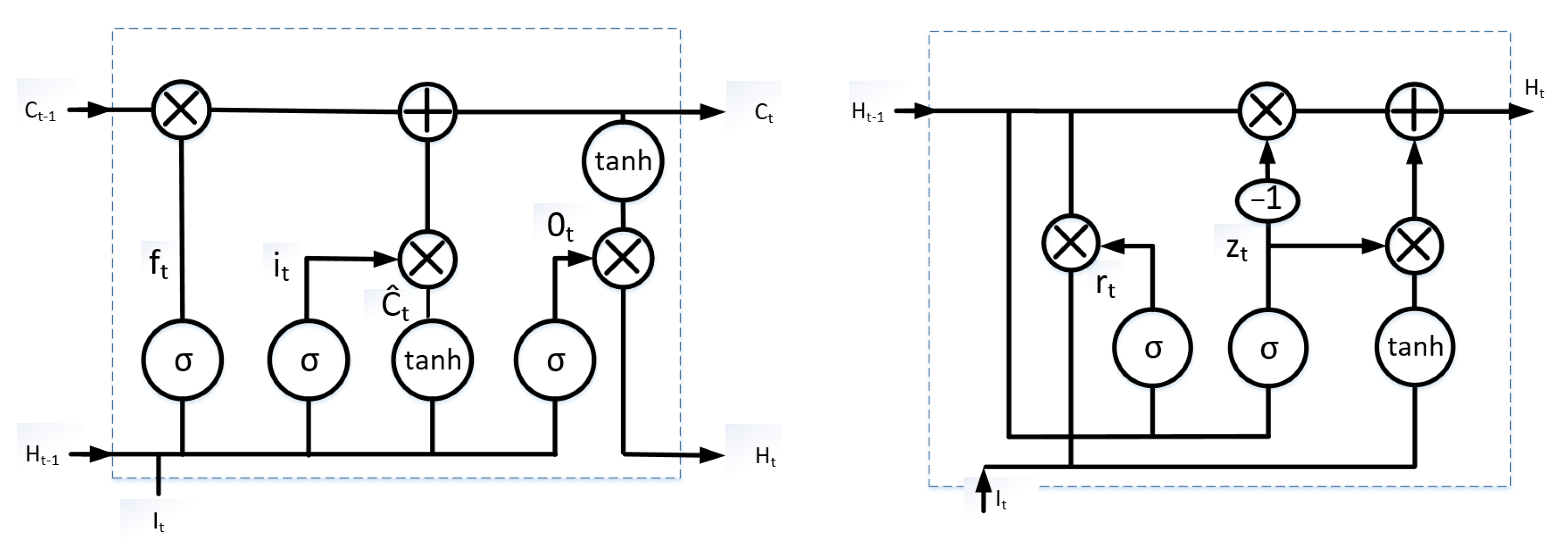
An LSTM unit has three gates: an input gate (i
t), an output gate (0
t) and a forget gate (f
t) as shown in
Figure 4 (on the left).
The function of the LSTM unit is to remove or add information to the cell state that is carefully regulated by these three gates. represents new information that can be applied to cell state . is the hidden state; and are sigmoid and tangent activation functions, respectively.
Gated recurrent unit (GRU) [
27] is also working by a gating mechanism. GRU unit contains a reset gate
and an update gate
. GRU does not have an output gate
and long-term memory unit
as the LSTM unit. Both of them have the ability to eliminate the vanishing gradient problem by keeping the relevant information and passing it to the next time steps of the network.
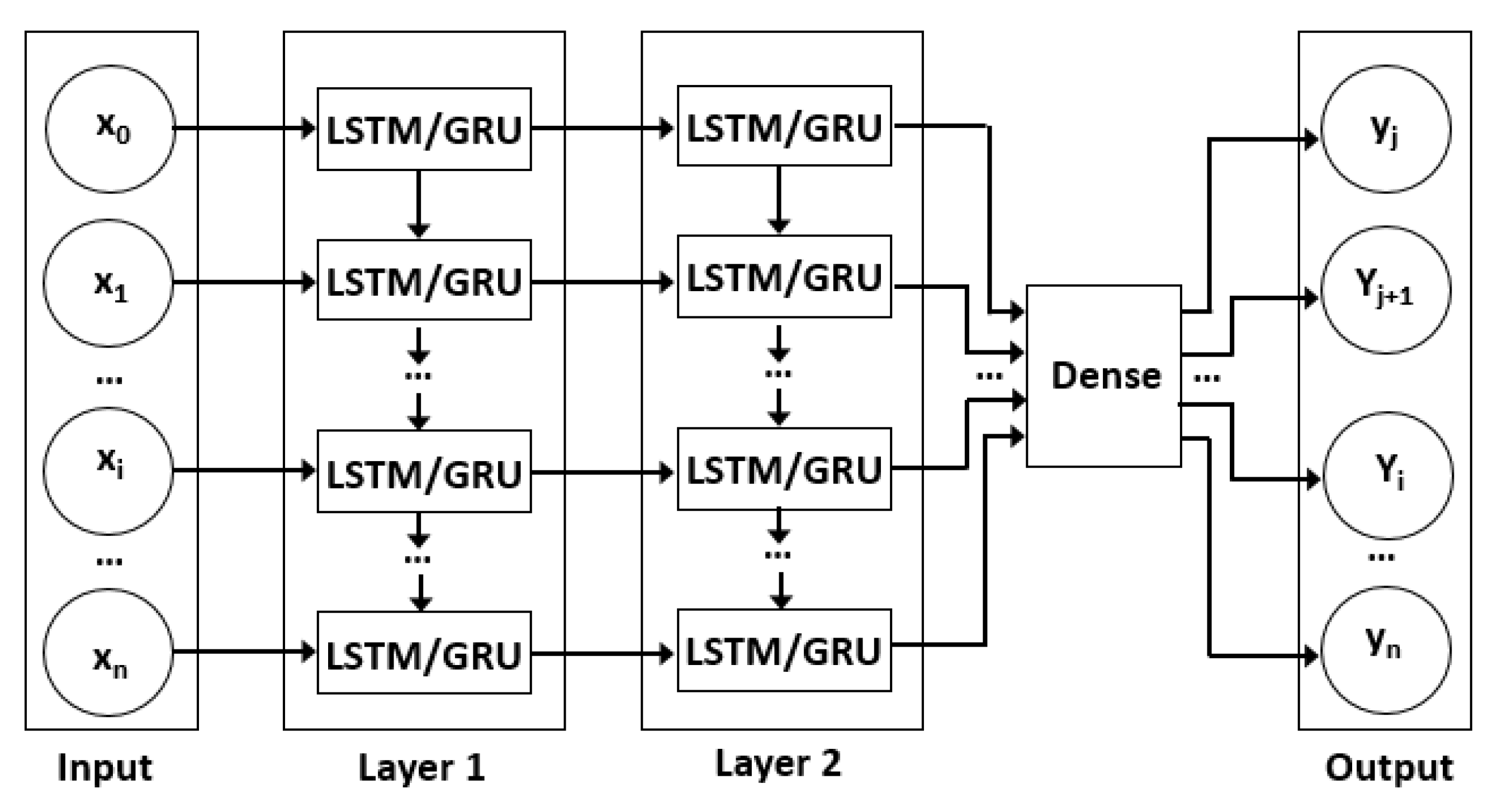
SLSTM/SGRUs in
Figure 5 consists of stacked layers of LSTMs/GRUs and the output layer makes a prediction [
20]. The SLSTMs/SGRUs run when the first LSTM/GRU layer takes the input sequence and every LSTM/GRU layer feeds hidden states to the next LSTM/GRU in the stack. SLSTMs/SGRUs calculates only one error signal at the final output layer, and then back propagates it through all previous layers [
20]. This structure is programmed with Pytorch library in Python using torch.nn.LSTM/GRU.
4. Training and Testing Processes
The machine schematic in
Figure 6 shows TVEs measured at four artefact balls. The workpiece and tool branches are illustrated in green and black colors, respectively.
The TVEs have three positioning error components as described in Equation (2). These error components may change with activities of the B- and C-axis, positions, and indexations.
where N is the number of measured positions.
In the training phase, the SLSTMs/SGRUs models are built using long process data, as illustrated in
Figure 7, and TVE
s in 24 positions of the artefact balls 1, 2, and 3, shown in
Table 1, are used as targets. The power consumptions of the axes B and C, the 24 linear axis positions used to move the sensor nest to the ball artefacts and the nine (B, C) indexations, or rotary axis positions, are used as inputs.
The testing phase will consider two cases: long test data consisting of TVEs at seven positions of artefact ball 4 as well as the short test data of all 31 positions at all four artefact balls.
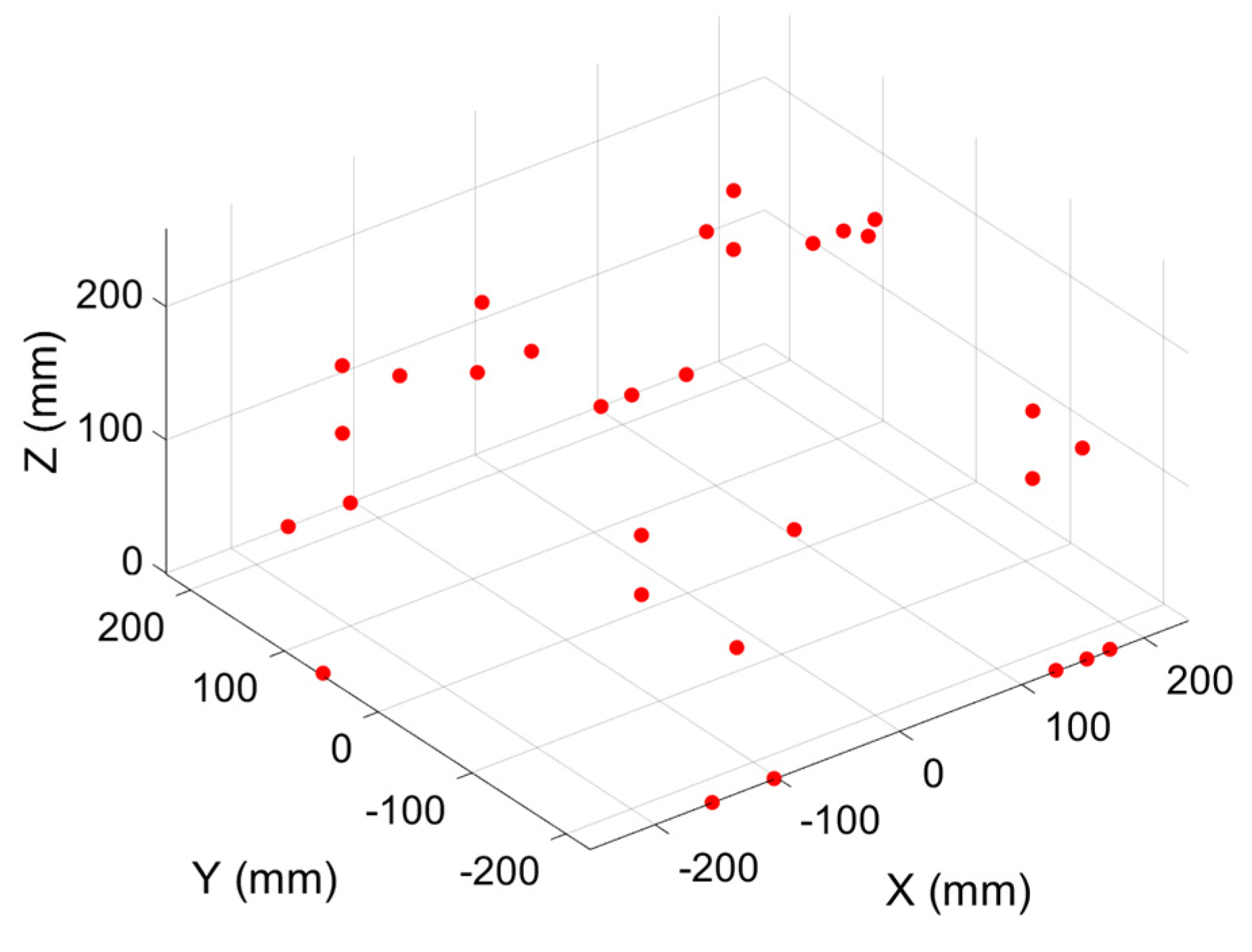
The 31 linear axis positions are shown in
Figure 8. These positions are pre-determined by calculations based on the indexations of B and C axes and the artefact’s positions in the machine frame. They are used for the G-code to move the sensor nest to the four artefact balls.
SLSTMs/SGRUs [
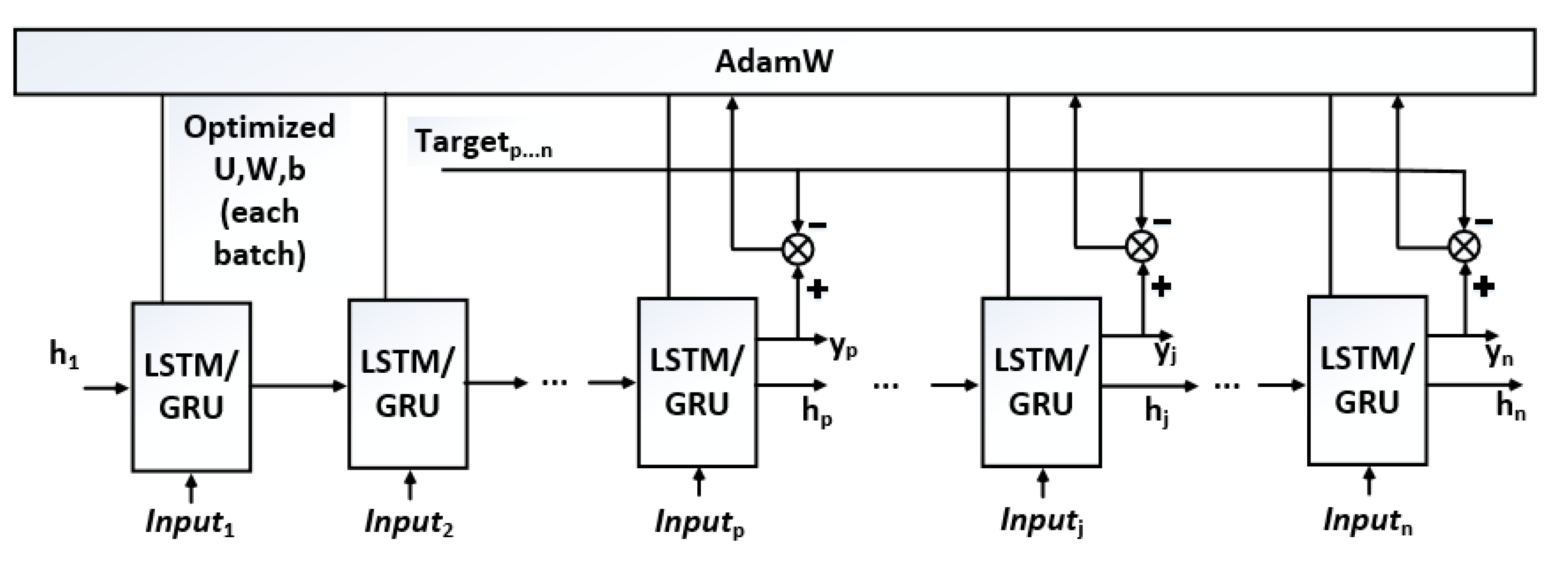
28] are capable of capturing longer patterns in sequential data. AdamW optimizer is used to generate the optimized weights and biases based on the outputs of the SLSTMs\SGRUs and the measured TVEs at 24 different positions. In
Figure 7,
with
; p is the number of inputs in one sample = 8;
is the number of training data = 528 × 24 = 12,672, corresponding to 24 position measurements or observations at each of the 528 measurement cycles;
is the desired
of SLSTMs/SGRUs equal to the measured
TVEj;
;
U,
W and
b are weight and bias that need to be updated after each batch (number of training samples) in the training process as Equations (3)–(5) [
29]
where
is the learning rate,
= 10
−8,
and
are bias-corrected first and second moment estimates and
is the rate of the weight decay per step.
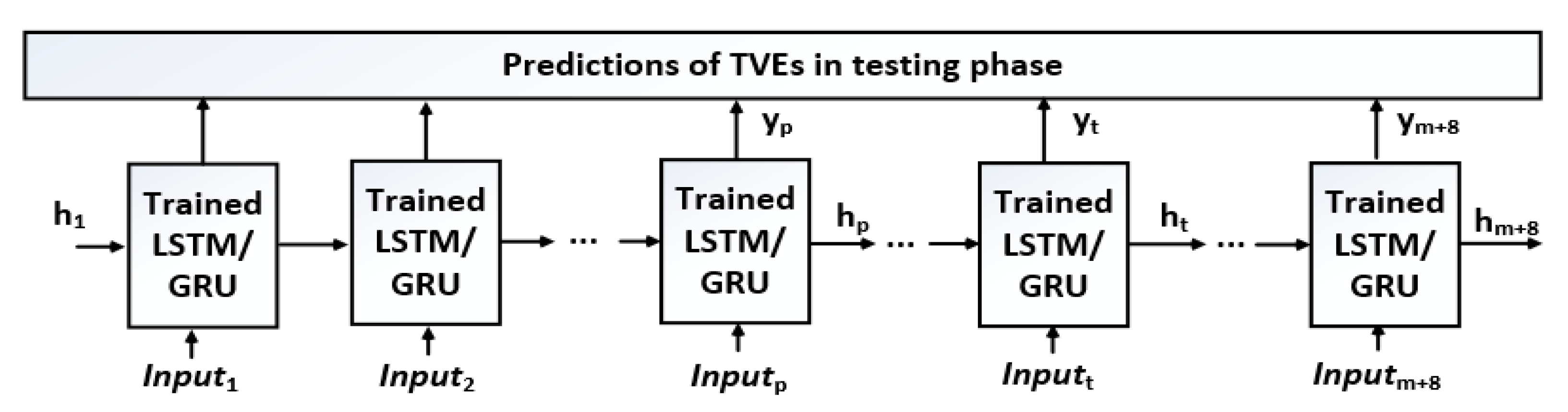
The diagram in
Figure 9 shows the testing procedure applying multistep predictions with the trained SLSTMs/SGRUs and inputs without using measured TVEs as targets. In this phase, to match the initial conditions, eight first states with values of zeros are added to the data sequence, as Ngoc et al. conducted this in [
11].
In
Figure 9:
,
,
= 528 and 160 cycles in the long and short processes, respectively; and
.
5. Results and Discussions
In this section, the prediction ability of the trained SLSTMs for all TVEs are shown before some the best and worst cases are chosen to compare with the SGRUs’. In the training phase, three Stacked LSTMs are used to build the models for TVEx, TVEy and TVEz separately. Data of the thermal behaviors of the machine in 24 positions (31 positions of
Table 1 less positions 5, 8, 14, 17, 20, 25, and 29 of ball 4) were put in series.
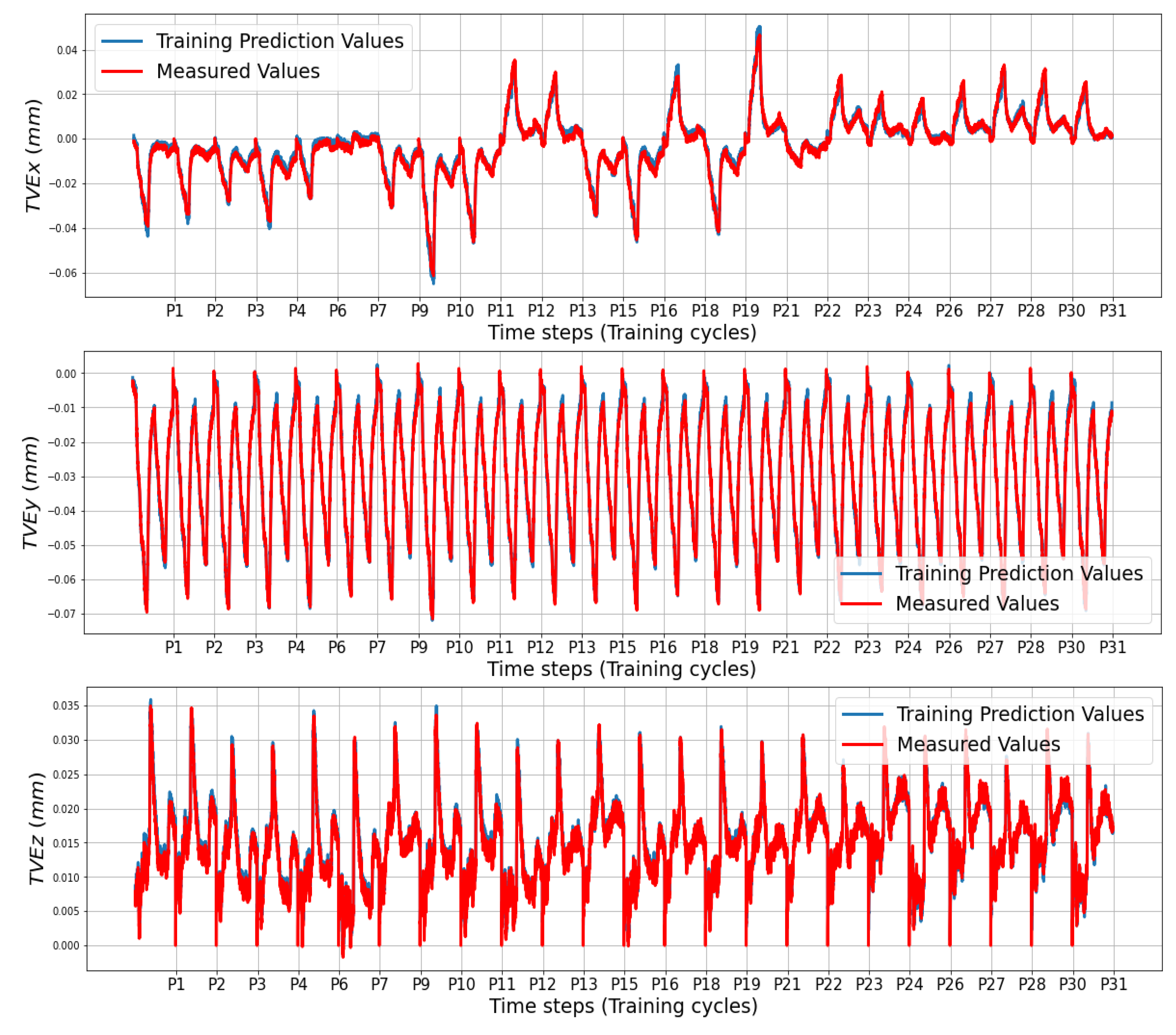
Figure 10 shows the measured and predicted thermal volumetric errors (TVEs) for each of the 24 balls’ positions where for each position, 528 measuring and prediction cycles are conducted. The results for each position are concatenated horizontally, so the timeline of the abscissa repeats for every position (Pi) for compactness of presentation.
The B axis has a greater impact on volumetric errors (TVEs) than the C axis. In fact, B axis activity dominates almost all of the TVEx. However, the influence of C axis activity relative to the B axis increases for TVEy and TVEz.
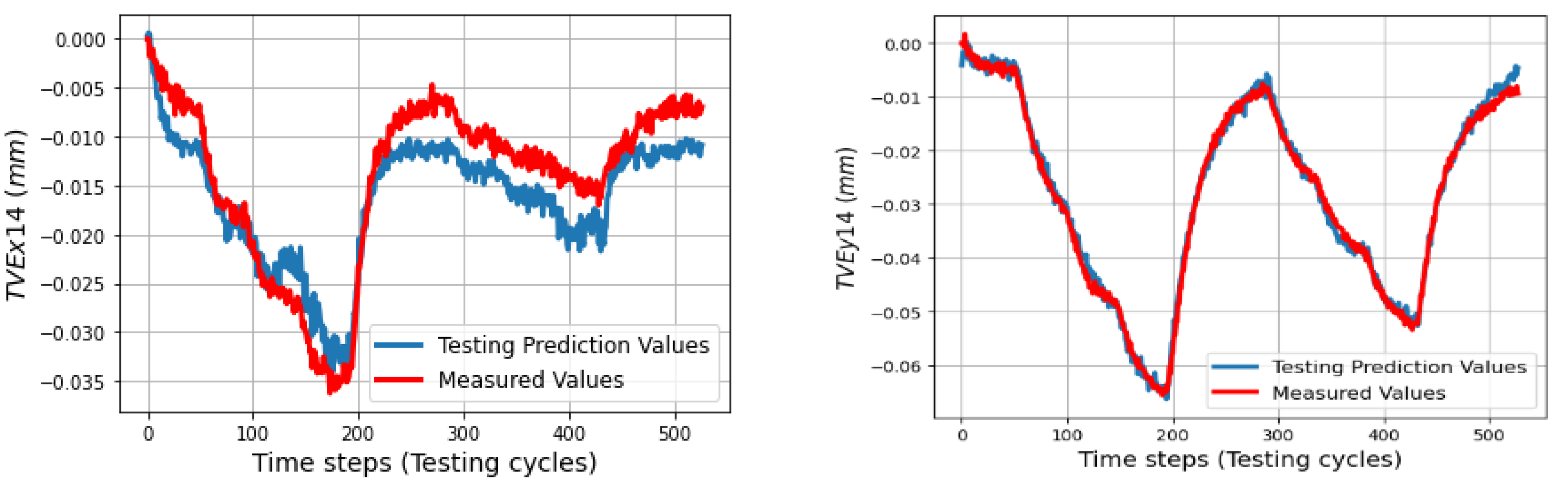
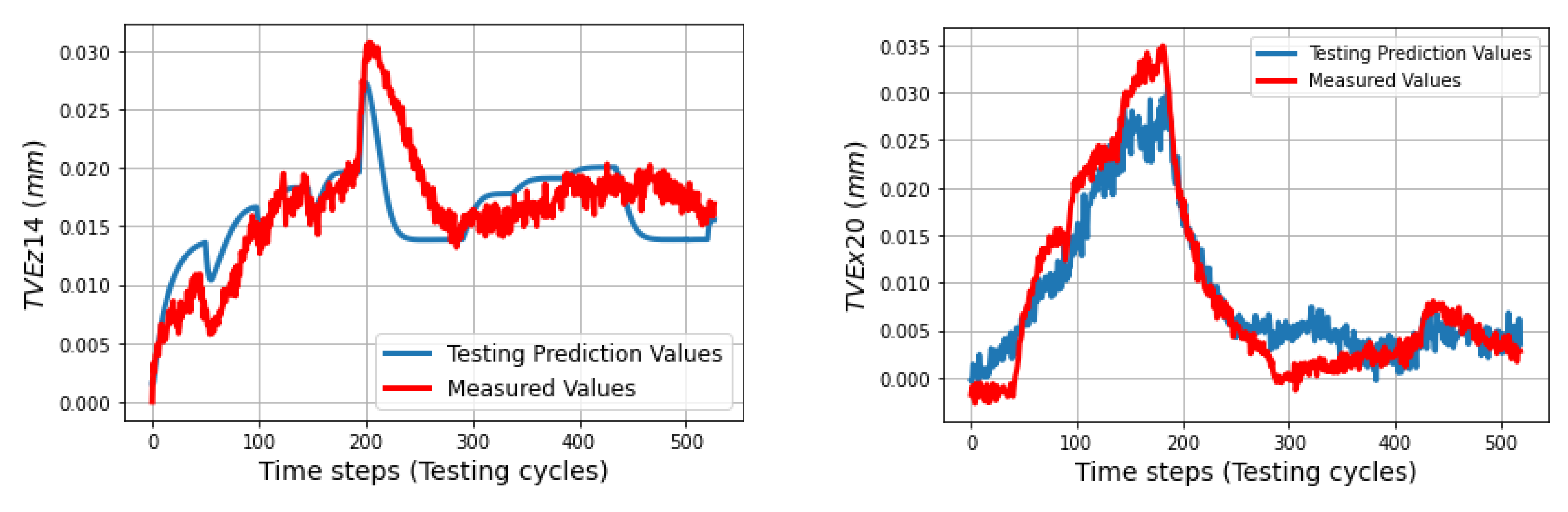
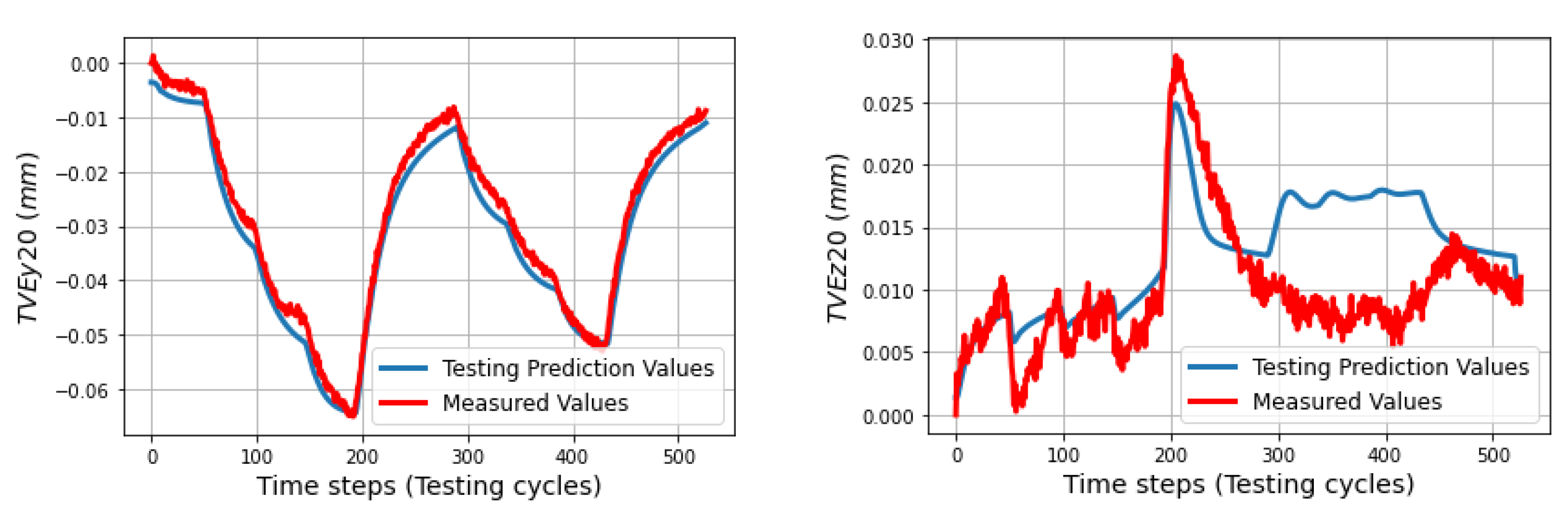
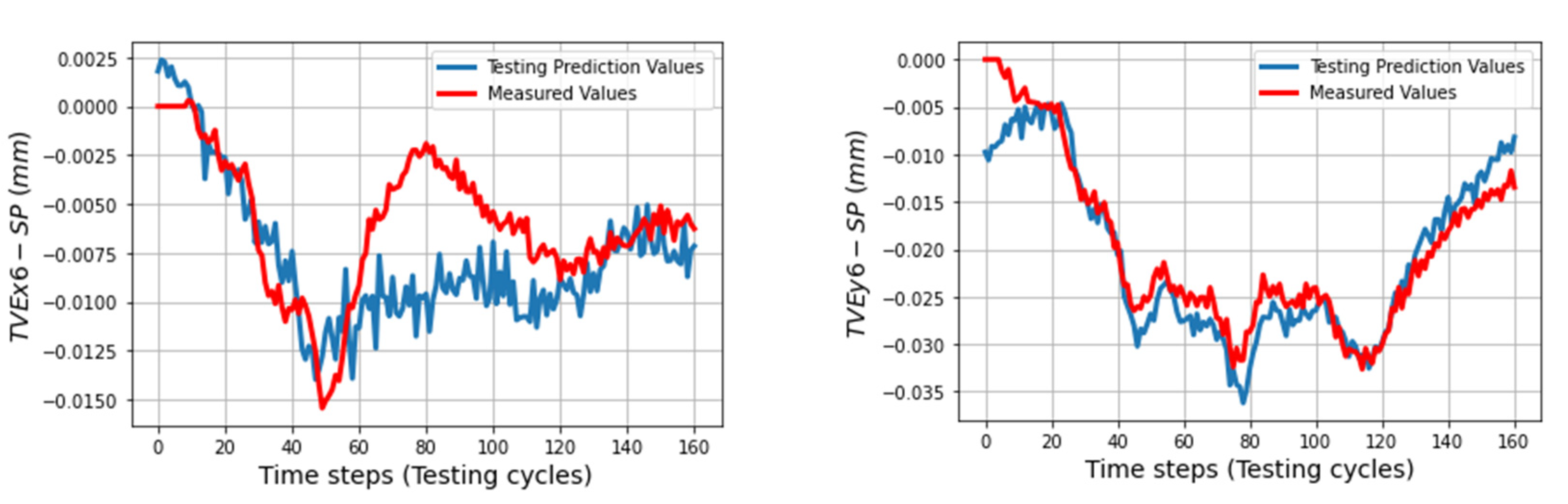
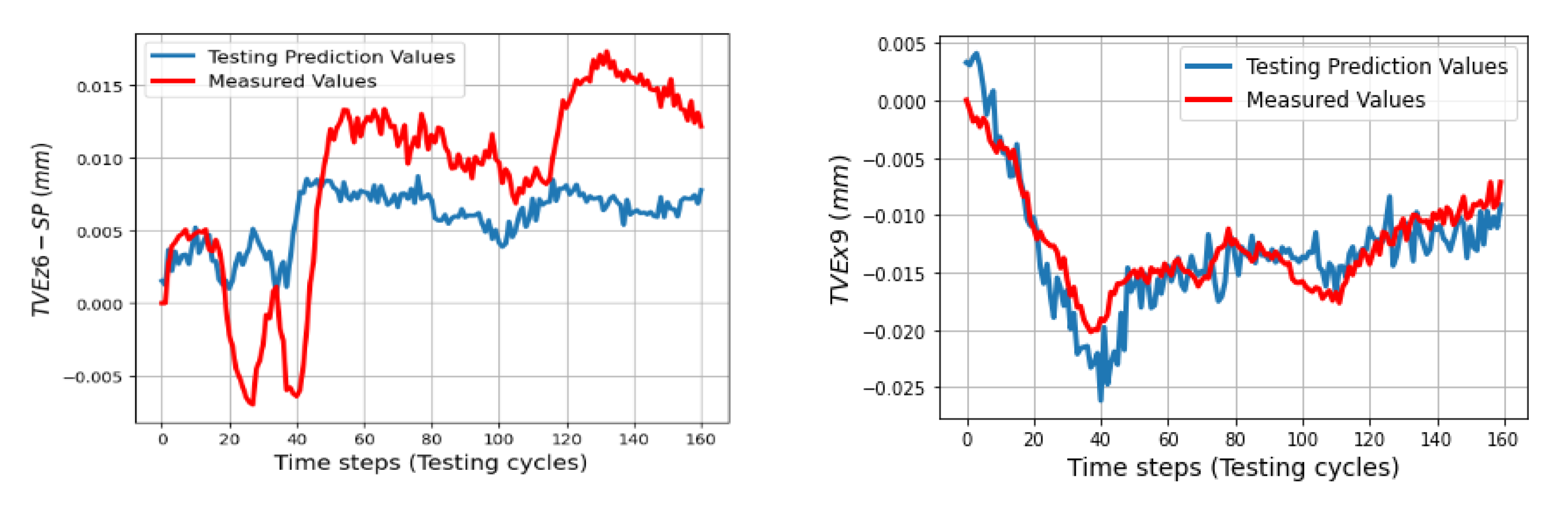
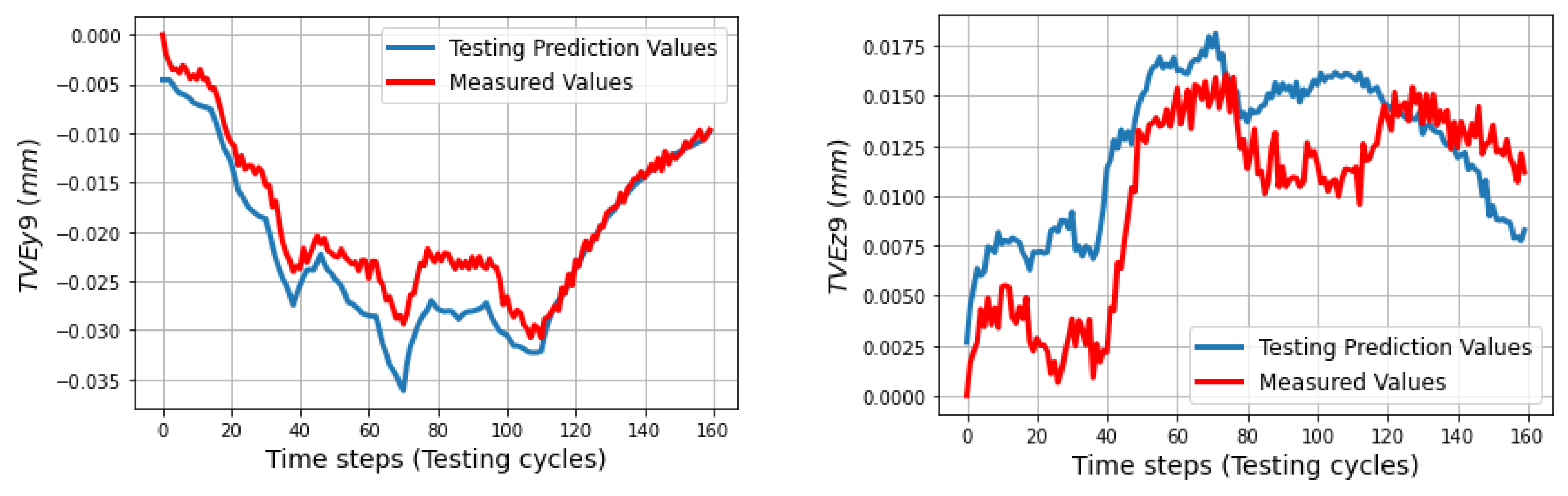
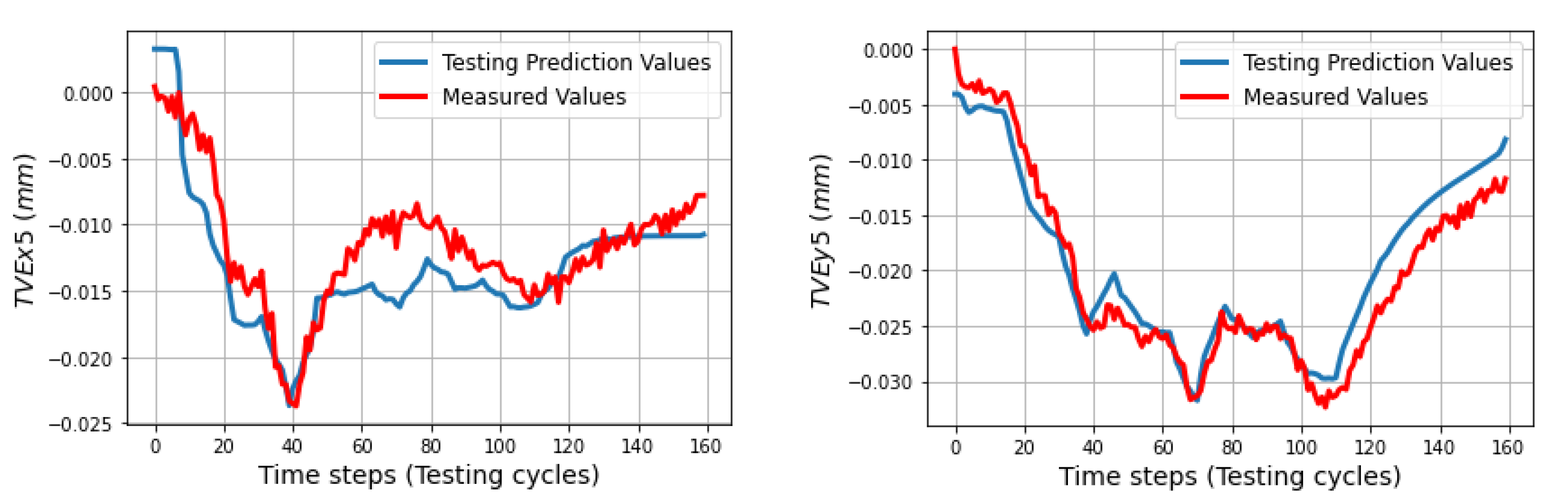
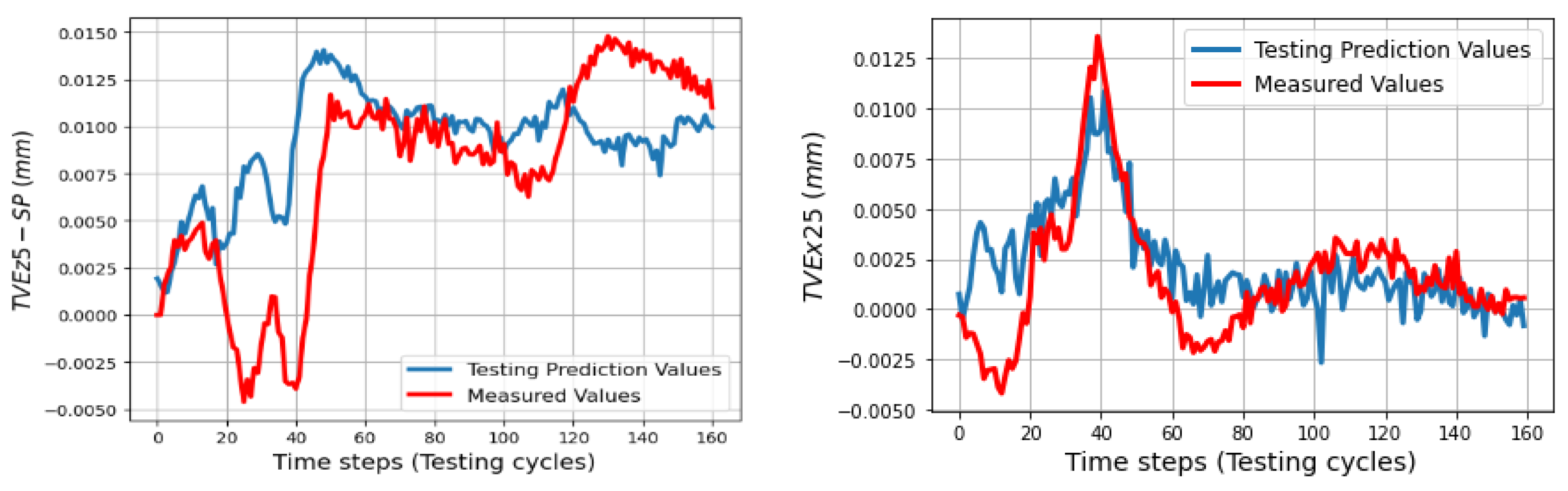
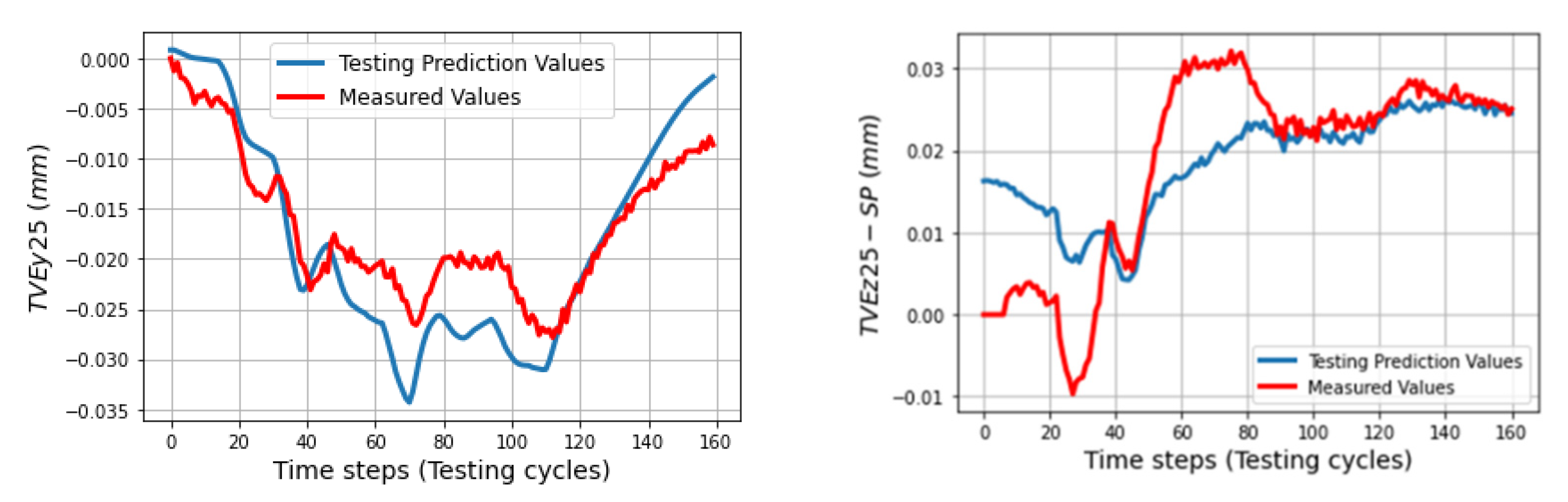
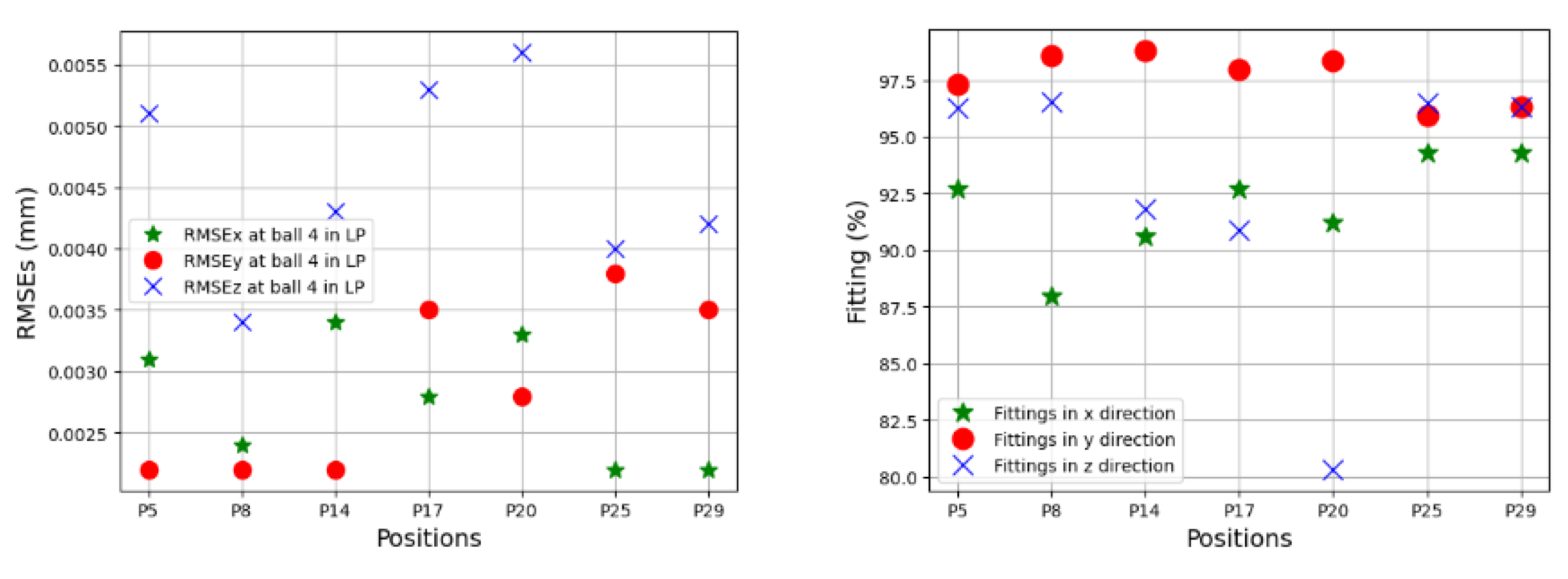
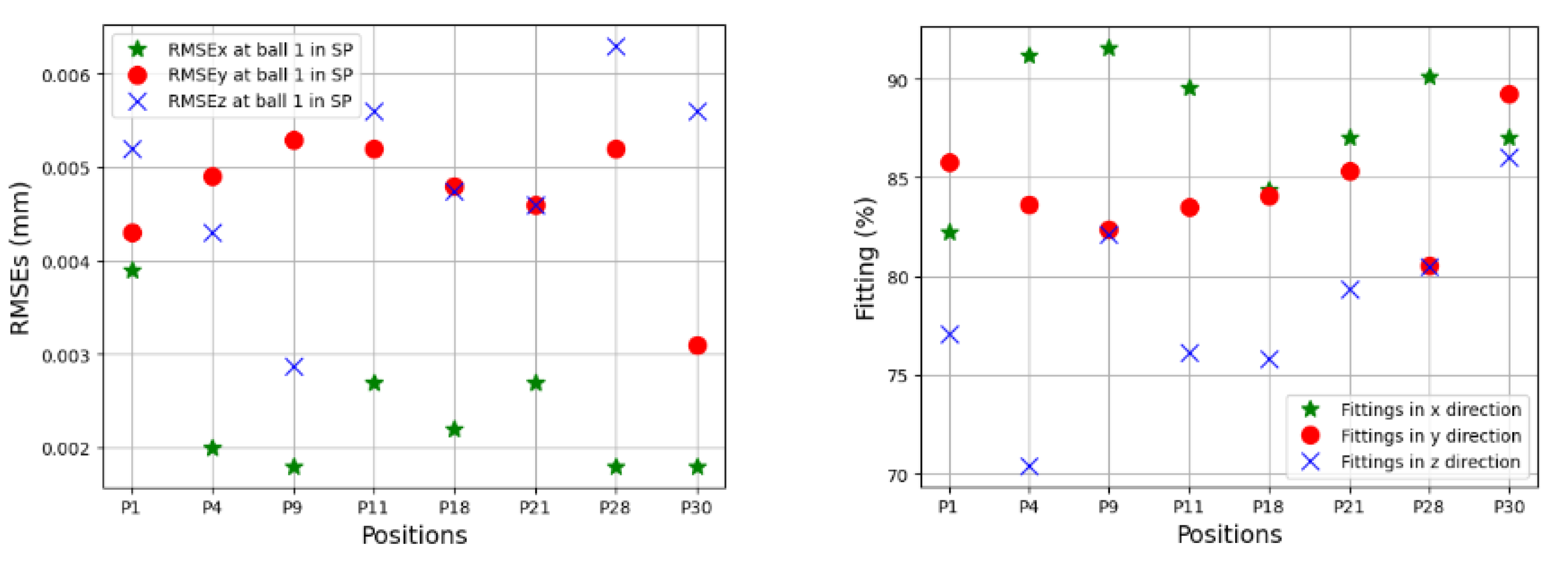
In the testing phase, three sets of volumetric errors were considered to test the ability of the trained model: data of seven positions at ball 4 in the long process (different positions in workspace but same process with training data), and data of 31 positions in the short process which is divided in two sets: the first set with 24 positions at balls 1, 2, 3 (same positions but different process) and the second set with seven positions of ball 4 (different positions and process). Due to the limitation of space, some of the best and the worst predictions of the TVEs in each set are presented. Multistep predictions (528 steps (cycles)) for positions P14 and P20 in the long process are computed and illustrated from
Figure 11,
Figure 12 and
Figure 13. In the short process, 160 prediction steps are shown from
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18 and
Figure 19 for positions P4, P5, P9, and P25.
The trained model appears to have difficulty predicting TVEz20 from cycles 300 to 450, as its parameters tend to rely heavily on the patterns observed in the training data and do not adjust well to changes in TVEz20 during the testing process. As a result, the model’s predictions for TVEz20 during this period are likely to be inaccurate. Conversely, TVEz14 tends to be better predicted during this time. The model is able to adapt more easily to changes in TVEz14.
The changes of TVEs depend on the inputs: powers of rotary axes, durations of activities, positions, and indexations. The trained models have capability to predict TVEs, respectively illustrated from
Figure 11 to
Figure 24 and
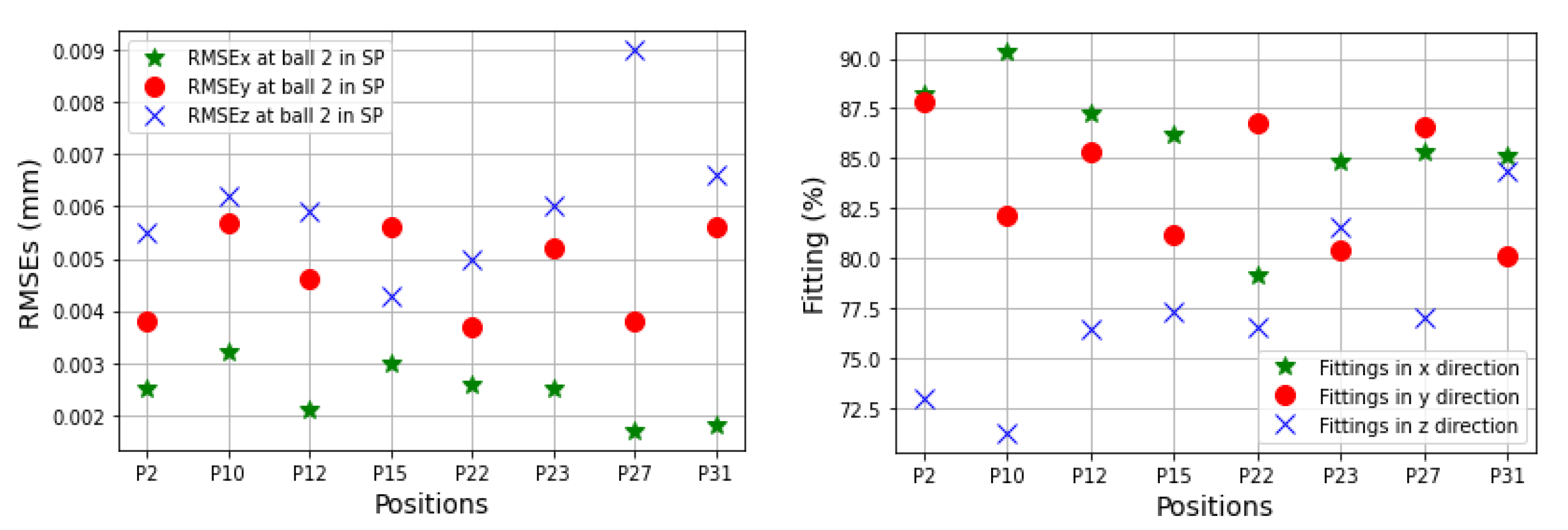
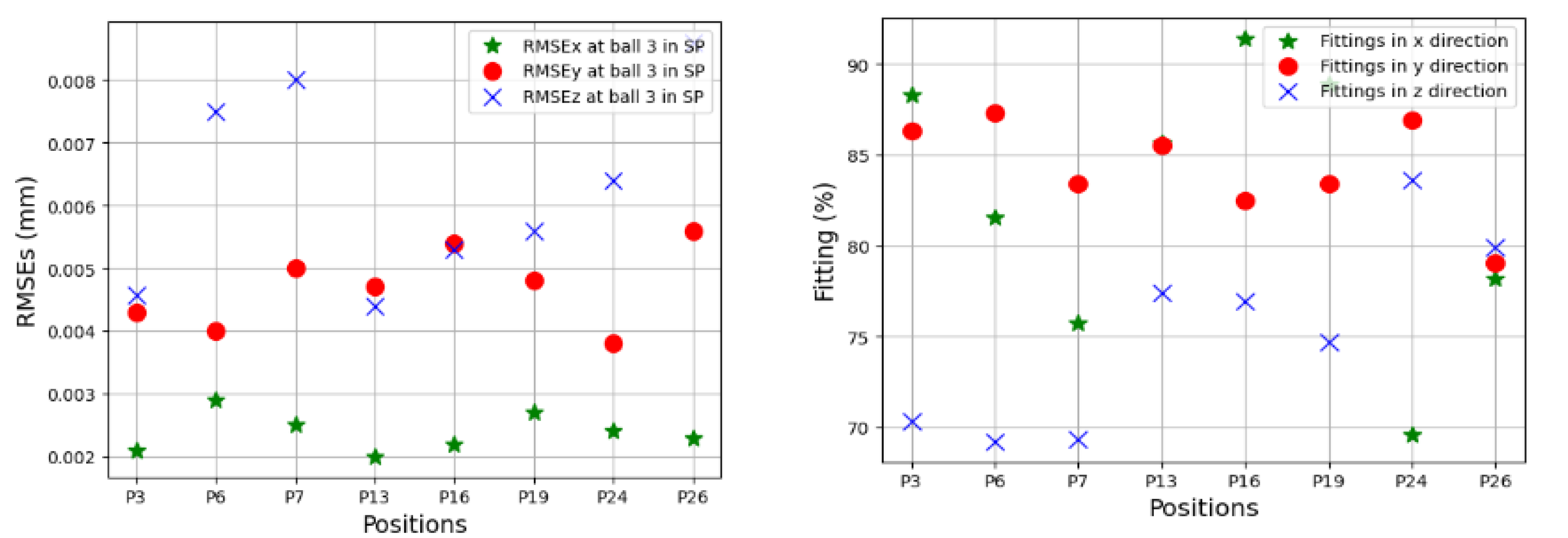
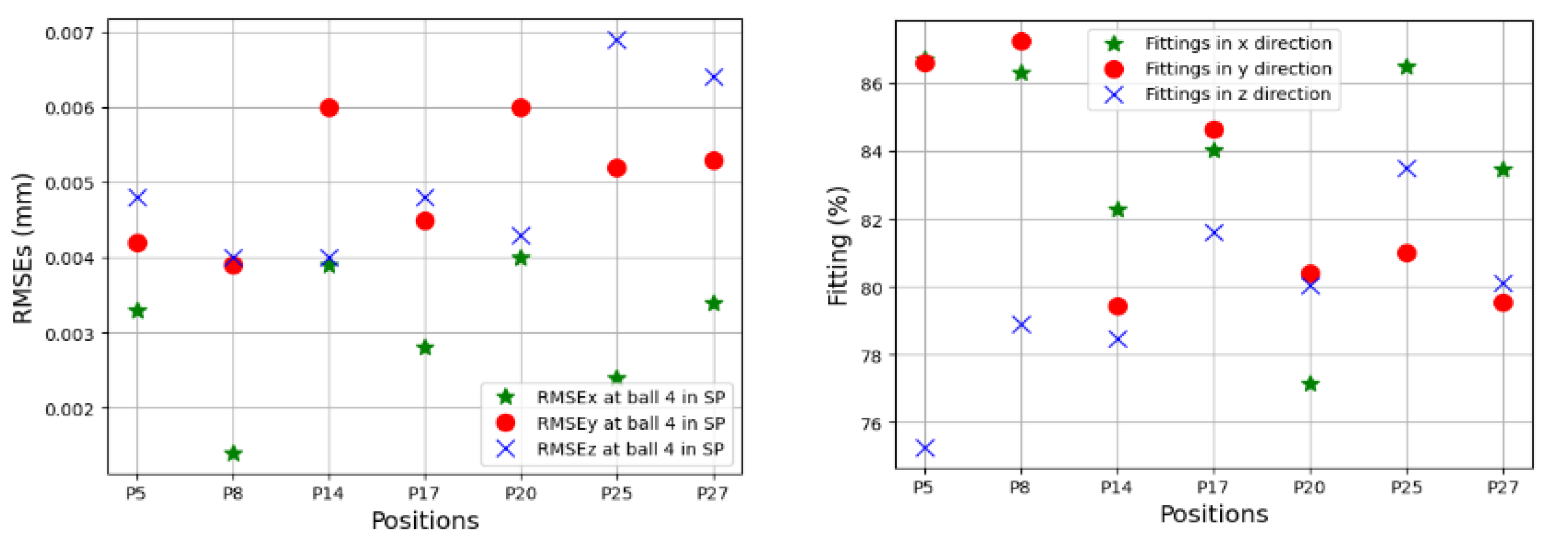
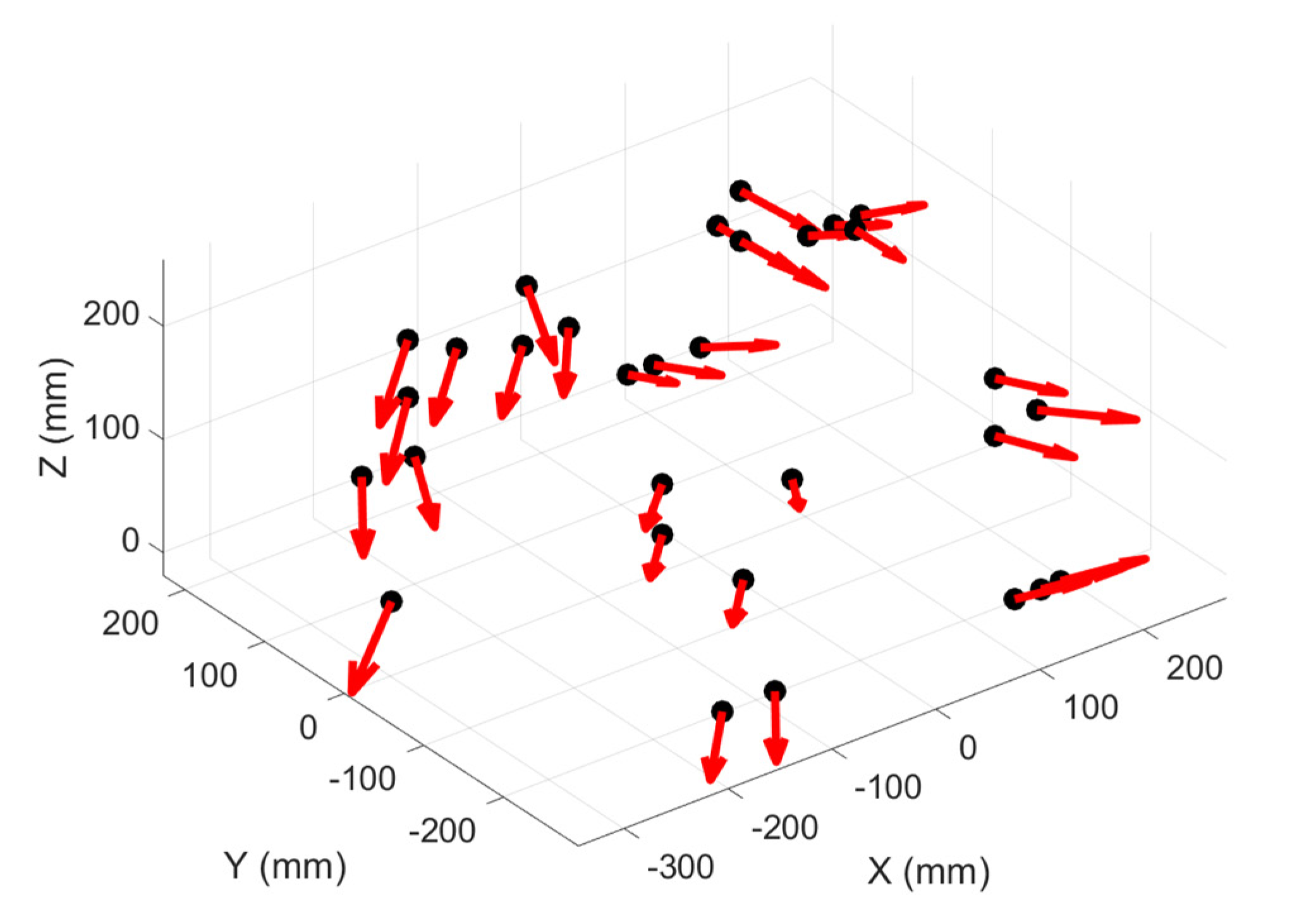
Figure 25 presents a set of TVE
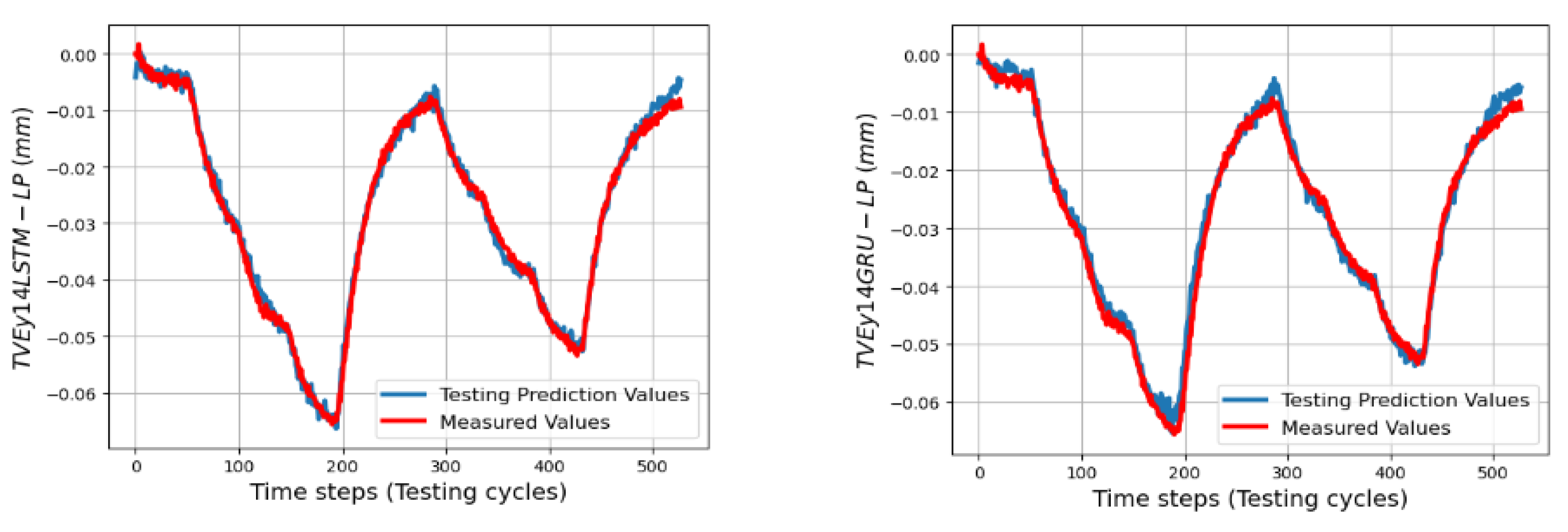
s in 33 linear axis positions with directional components of TVEx, TVEy, and TVEz at one cycle in the testing process. Predictions of TVEs of seven positions at ball 4 in the long process can reach very high fitting with RMSE = 2.2 μm (fitting = 98.8%) for TVEy14, while the lowest proportion of fitting in this process is for TVEz20 with RMSE = 5.6 μm (fitting = 80.3%).
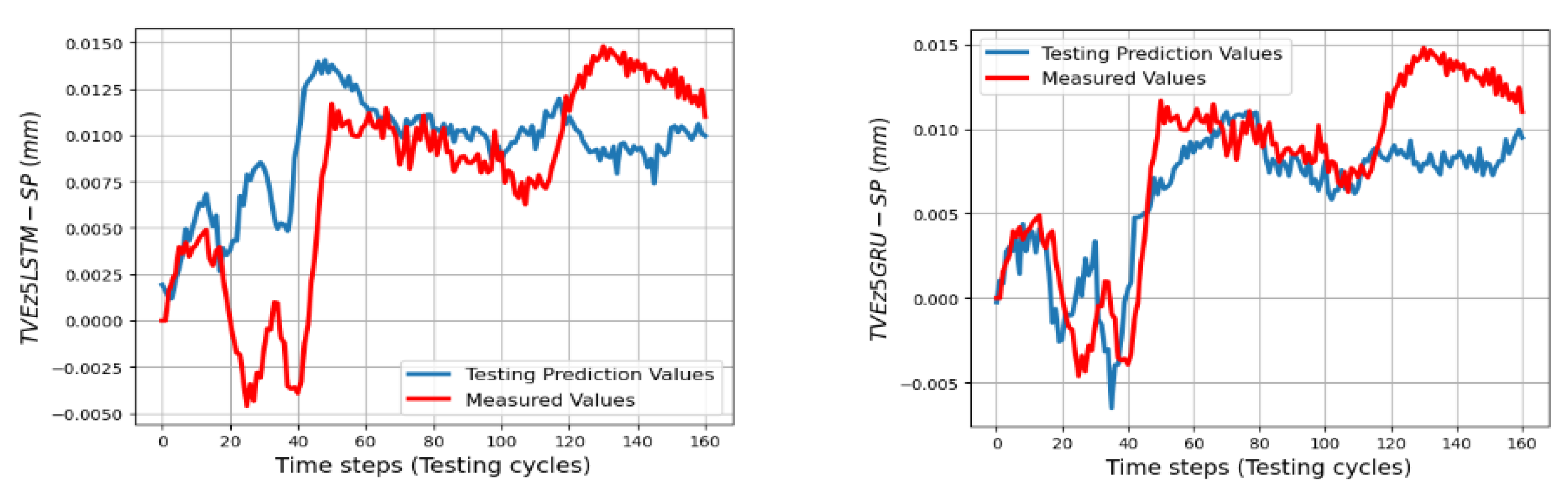
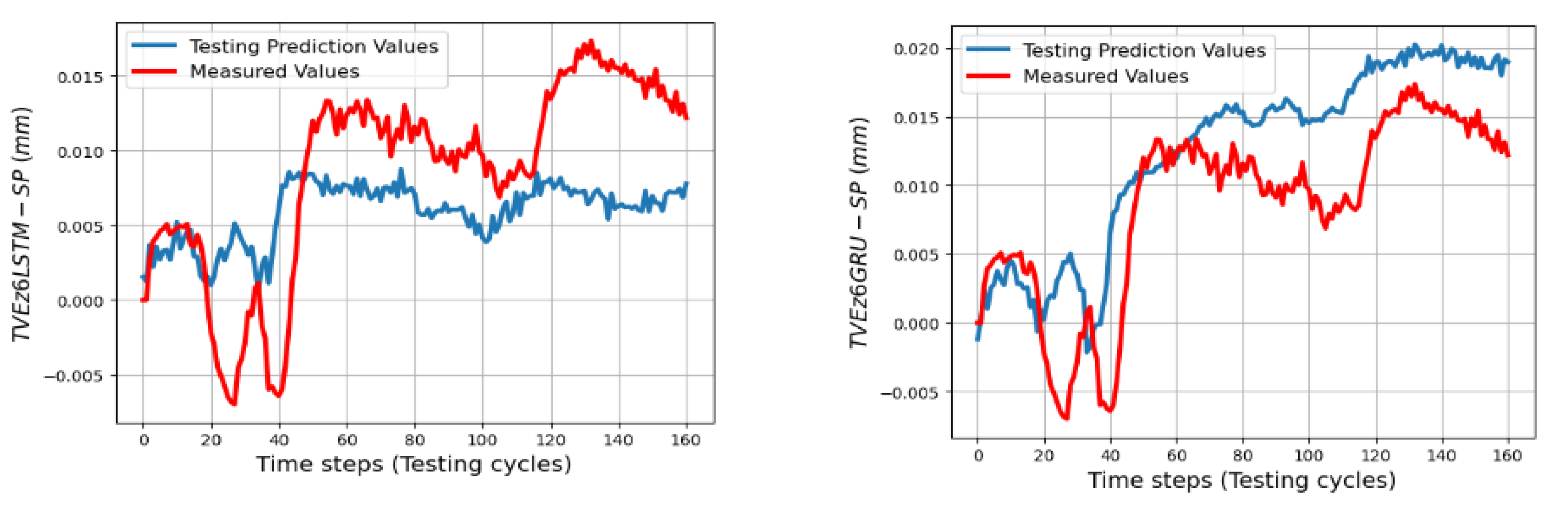
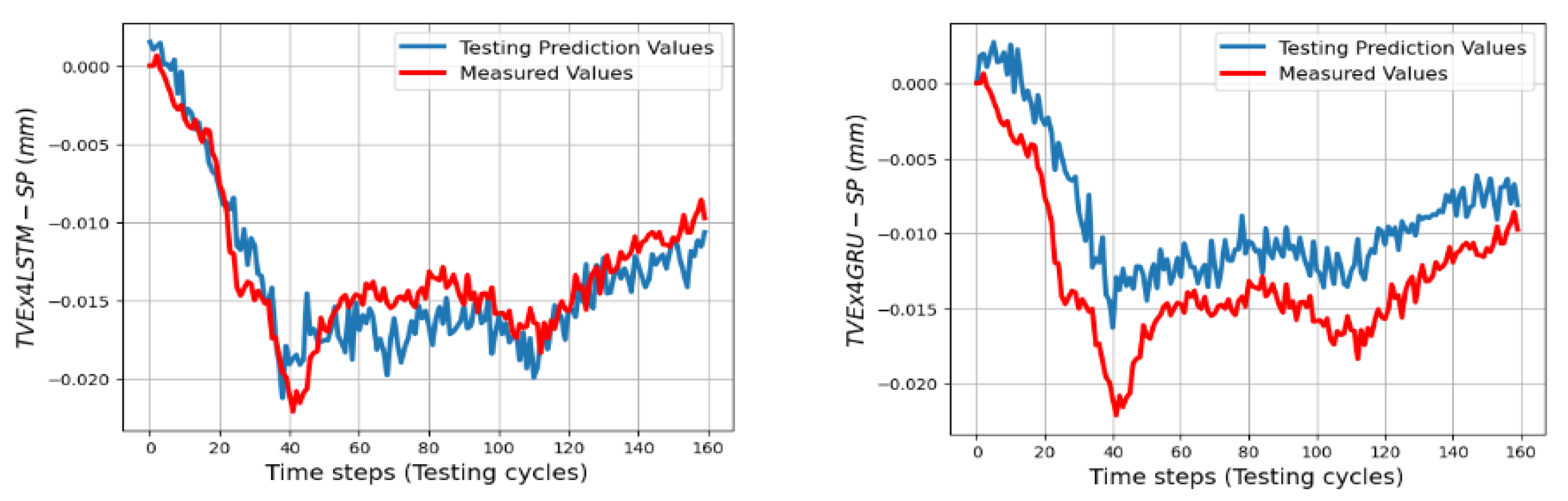
The trained models gave less quality when they predict TVEs at 7 positions at ball 4 in the short testing process as shown by RMSEs from 3.3 μm (86.7% fitting) for TVEx5 to 4.8 μm (75.27% fitting) for TVEz5. The predictions are good for positions at ball 1, 2, and 3 in the short testing process with the highest fitting 91.6% (1.8 μm) for TVEx9, and the worst case in this process with 69.2% (7.5 μm) for TVEz6. The results also indicate that the model gives the highest capability of prediction for TVE
y and the worst for TVE
z. These situations happened in [
11], with geometric errors relating to y and z components. There are some over responses of the trained model in the beginning of the short process for all TVEs, but the predictions gradually improve to closely track the measured values for the rest of the process.
Figure 20,
Figure 21,
Figure 22,
Figure 23 and
Figure 24 reveal an interesting finding: for the positions located at the artifact ball four, TVEy tends to have a higher fitting than TVEx and TVEz. On the other hand, for the positions located at the artifact balls one, two, and three, TVEx tends to dominate the others.
The SLSTMs model showed its ability to predict thermally induced volumetric errors of the machine tool based on the motor powers of the rotary axes. GRU unit was invented after LSTMs with a simpler structure for time series application. The question is: which one is better for data sequences? To answer this question, this work continues by taking some cases including the best and worst predictions of SLSTMs and uses SGRUs to train model and predict these thermally induced volumetric errors with similar structure, learning rate, and weight decay.
SLSTMs predict TVEy14, TVEx4 better than SGRUs as shown in
Figure 26,
Figure 27,
Figure 28 and
Figure 29 with RMSEs = 2.2 μm, 2 μm and 2.4 μm, 4.4 μm, respectively. For TVEz5, 6, SGRUs performs better with RMSEs = 3.2 μm and 6.6 μm, while SLSTMs have RMSEs turnoff 4.8 μm and 7.5 μm. Both the SLSTMs and SGRUs proved that they have potential to predict the sequence data. The results in this section partly prove the ability of SLSTMs and SGRUs to predict TVEs at the 40 h process with different activities and inputs.
This study has several limitations that should be taken into account. Firstly, the heat sources are limited to the rotary axes, which may affect the quality of predictions of TVEz. To improve the accuracy of the predictions, it may be beneficial to include more information on the activities of the linear axes and temperatures as inputs. Additionally, the ambient temperature should not be overlooked as it can directly affect the change in temperature of the axes following a sequence of activities.
6. Conclusions
In this study, an approach using SLSTM/SGRU for directly predicting thermally induced volumetric errors without the use of a kinematic model with geometric error parameters was proposed. SLSTMs\SGRUs+AdamW are used for modelling and predicting the sequential data. The training and testing data sets used different positions and different B- and C-axis exercise cycles. The SLSTMs model’s best prediction in the long process reached RMSE of 2.2 μm (98.8% fitting to the experimental measurement), while in a short testing process, it achieved 1.8 μm (91.6%). The worst case predicted by the model in processes is 7.5 μm (69.2% fitting). This work gives a potential solution in practice to predict the thermal volumetric errors at different positions in the workspace directly over an extended period of 40 h without the need for remeasuring the thermal errors, which allows sufficient time for the machining of most workpieces.
A comparison between two popular deep learning models for sequential data, SLSTMs and SGRUs, is carried out for some outstanding TVEs. The purpose is to determine which one is better for this application. Their capabilities were similar.
Future work can focus on exploring the heat sources associated with the activities of five-axis machine tools, as well as examining the robustness of deep learning models when faced with variations in ambient temperature.


































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}