
Deep Learning Algorithms in the Automatic Segmentation of Liver Lesions in Ultrasound Investigations

 ,
,  ,
, 
Abstract
:1. Introduction
2. Materials and Methods
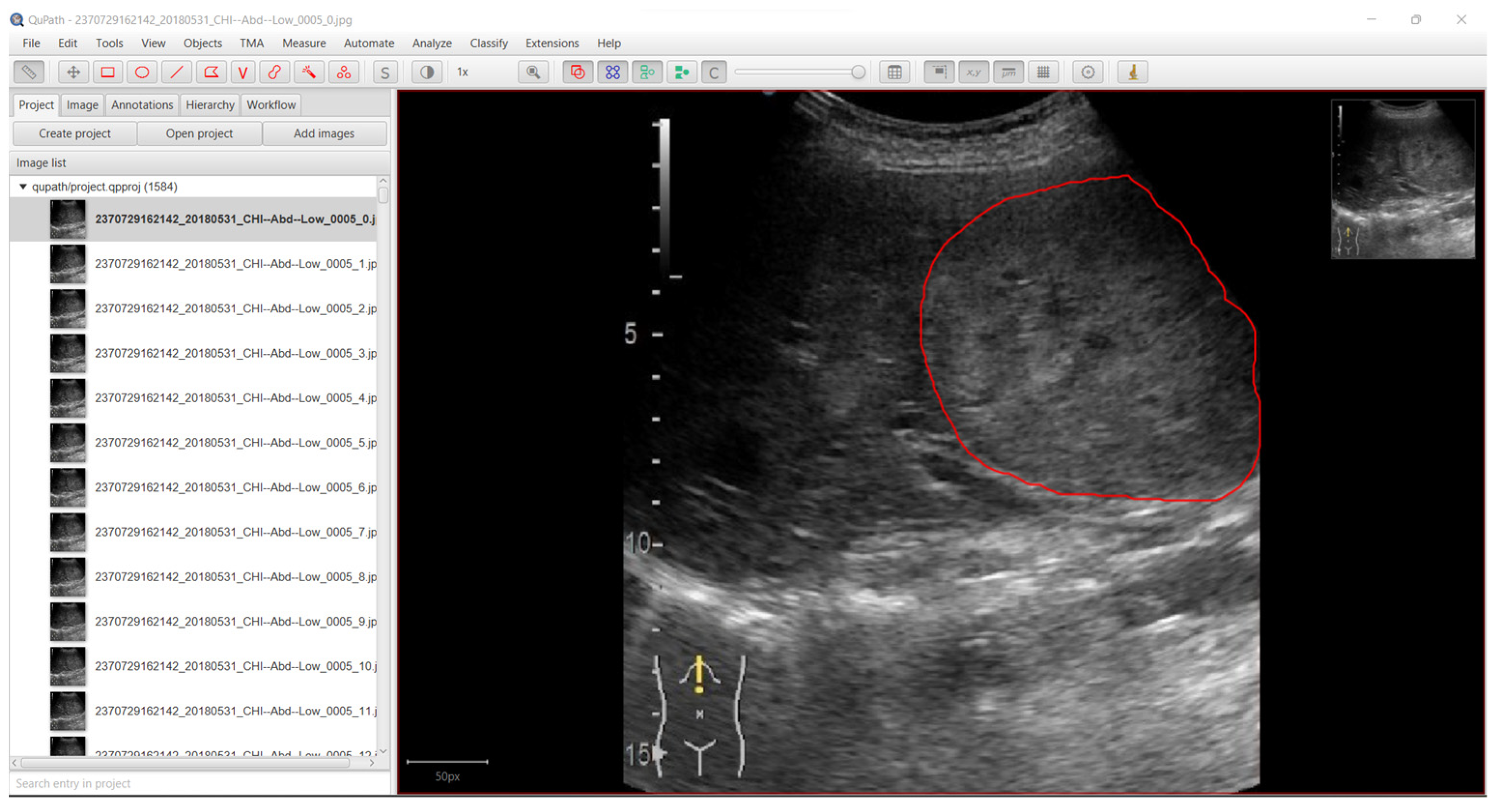
2.1. Data Acquisition
2.2. Data Preprocessing
| Algorithm 1. Extracting frames from the video examination |
| fps ← 0 ultrasound_device ← ultrasound_device_characteristics_object fps ← ultrasound_device.getFPS() frame_height ← read frame height of the video examination frame_width ← read frame width of the video examination b_mode_x_min ← ultrasound_device.b_mode_x_min b_mode_x_max ← ultrasound_device.b_mode_x_max b_mode_y_min ← ultrasound_device.b_mode_y_min b_mode_y_max ← ultrasound_device.b_mode_y_max |
| while video examination file still has frames do: frame_id ← get the frame id from the video file frame ← get the frame from the video file if frame_id % fps == 0 do: //Proccess the frame and save it to disk. Cropped_frame ← frame[b_mode_x_min: b_mode_x_max, b_mode_y_min, b_mode_y_max] save cropped_frame to disk else: continue //ignoring the current frame |
| Algorithm 2. Mask creation (binary image) | |
| current_image ← obtain current image while current_image is not null do: mask ← new Image(current_image.width, current_image.height, values = 0) for each object in annotation_list do: roi ← object.getROI() roi.fill(values = 1) mask ← mask bitwise and roi mask_filename ← string concatenation (current_image.name, “-mask”) save image to disk (mask, mask_filename) | |
2.3. Neural Network Model
2.4. Hyperparameters and Loss Function
2.5. Experimental Setup
2.6. Assessing the Performance of the Deep Neural Network Model
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hu, J.; Zhou, Z.-Y.; Ran, H.-L.; Yuan, X.-C.; Zeng, X.; Zhang, Z.-Y. Diagnosis of Liver Tumors by Multimodal Ultrasound Imaging. Medicine 2020, 99, e21652. [Google Scholar] [CrossRef] [PubMed]
- Birch, M.S.; Marin, J.R.; Liu, R.B.; Hall, J.; Hall, M.K. Trends in Diagnostic Point-of-Care Ultrasonography Reimbursement for Medicare Beneficiaries Among the US Emergency Medicine Workforce, 2012 to 2016. Ann. Emerg. Med. 2020, 76, 609–614. [Google Scholar] [CrossRef] [PubMed]
- Hata, J. Point-of-Care Abdominal Ultrasound. Masui 2017, 66, 503–507. [Google Scholar] [PubMed]
- Lencioni, R.; Piscaglia, F.; Bolondi, L. Contrast-Enhanced Ultrasound in the Diagnosis of Hepatocellular Carcinoma. J. Hepatol. 2008, 48, 848–857. [Google Scholar] [CrossRef] [Green Version]
- Jacobsen, N.; Nolsøe, C.P.; Konge, L.; Graumann, O.; Dietrich, C.F.; Sidhu, P.S.; Piscaglia, F.; Gilja, O.H.; Laursen, C.B. Contrast-Enhanced Ultrasound: Development of Syllabus for Core Theoretical and Practical Competencies. Ultrasound Med. Biol. 2020, 46, 2287–2292. [Google Scholar] [CrossRef]
- Dietrich, C.F.; Nolsøe, C.P.; Barr, R.G.; Berzigotti, A.; Burns, P.N.; Cantisani, V.; Chammas, M.C.; Chaubal, N.; Choi, B.I.; Clevert, D.-A.; et al. Guidelines and Good Clinical Practice Recommendations for Contrast-Enhanced Ultrasound (CEUS) in the Liver–Update 2020 WFUMB in Cooperation with EFSUMB, AFSUMB, AIUM, and FLAUS. Ultrasound Med. Biol. 2020, 46, 2579–2604. [Google Scholar] [CrossRef]
- Streba, C.T. Contrast-Enhanced Ultrasonography Parameters in Neural Network Diagnosis of Liver Tumors. World J. Gastroenterol. 2012, 18, 4427. [Google Scholar] [CrossRef]
- Zhang, Q.; Du, Y.; Wei, Z.; Liu, H.; Yang, X.; Zhao, D. Spine Medical Image Segmentation Based on Deep Learning. J. Healthc. Eng. 2021, 2021, 1917946. [Google Scholar] [CrossRef]
- Yu, F.; Zhu, Y.; Qin, X.; Xin, Y.; Yang, D.; Xu, T. A Multi-Class COVID-19 Segmentation Network with Pyramid Attention and Edge Loss in CT Images. IET Image Process. 2021, 15, 2604–2613. [Google Scholar] [CrossRef]
- Sammouda, R.; El-Zaart, A. An Optimized Approach for Prostate Image Segmentation Using K-Means Clustering Algorithm with Elbow Method. Comput. Intell. Neurosci. 2021, 2021, 4553832. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Oktay, O.; Schlemper, J.; Le Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Araújo, J.D.L.; da Cruz, L.B.; Diniz, J.O.B.; Ferreira, J.L.; Silva, A.C.; de Paiva, A.C.; Gattass, M. Liver Segmentation from Computed Tomography Images Using Cascade Deep Learning. Comput. Biol. Med. 2022, 140, 105095. [Google Scholar] [CrossRef] [PubMed]
- Nowak, S.; Mesropyan, N.; Faron, A.; Block, W.; Reuter, M.; Attenberger, U.I.; Luetkens, J.A.; Sprinkart, A.M. Detection of Liver Cirrhosis in Standard T2-Weighted MRI Using Deep Transfer Learning. Eur. Radiol. 2021, 31, 8807–8815. [Google Scholar] [CrossRef] [PubMed]
- Hiransakolwong, N.; Hua, K.A.; Khanh, V.; Windyga, P.S. Segmentation of Ultrasound Liver Images: An Automatic Approach. In Proceedings of the 2003 International Conference on Multimedia and Expo—ICME ’03 (Cat. No.03TH8698), Baltimore, MD, USA, 6–9 July 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 1–573. [Google Scholar]
- Jain, N.; Kumar, V. Liver Ultrasound Image Segmentation Using Region-Difference Filters. J. Digit. Imaging 2017, 30, 376–390. [Google Scholar] [CrossRef]
- Gupta, D.; Anand, R.S.; Tyagi, B. A Hybrid Segmentation Method Based on Gaussian Kernel Fuzzy Clustering and Region Based Active Contour Model for Ultrasound Medical Images. Biomed. Signal. Process. Control 2015, 16, 98–112. [Google Scholar] [CrossRef]
- Ciocalteu, A.; Iordache, S.; Cazacu, S.M.; Urhut, C.M.; Sandulescu, S.M.; Ciurea, A.-M.; Saftoiu, A.; Sandulescu, L.D. Role of Contrast-Enhanced Ultrasonography in Hepatocellular Carcinoma by Using LI-RADS and Ancillary Features: A Single Tertiary Centre Experience. Diagnostics 2021, 11, 2232. [Google Scholar] [CrossRef]
- Bankhead, P.; Loughrey, M.B.; Fernández, J.A.; Dombrowski, Y.; McArt, D.G.; Dunne, P.D.; McQuaid, S.; Gray, R.T.; Murray, L.J.; Coleman, H.G.; et al. QuPath: Open Source Software for Digital Pathology Image Analysis. Sci. Rep. 2017, 7, 16878. [Google Scholar] [CrossRef] [Green Version]
- Cheng, D.; Lam, E.Y. Transfer Learning U-Net Deep Learning for Lung Ultrasound Segmentation. arXiv 2021, arXiv:2110.02196. [Google Scholar]
- Jia, S.; Despinasse, A.; Wang, Z.; Delingette, H.; Pennec, X.; Jaïs, P.; Cochet, H.; Sermesant, M. Automatically Segmenting the Left Atrium from Cardiac Images Using Successive 3D U-Nets and a Contour Loss. In Statistical Atlases and Computational Models of the Heart. Atrial Segmentation and LV Quantification Challenges; Springer: Cham, Switzerland, 2018. [Google Scholar]
- González Sánchez, J.C.; Magnusson, M.; Sandborg, M.; Carlsson Tedgren, Å.; Malusek, A. Segmentation of Bones in Medical Dual-Energy Computed Tomography Volumes Using the 3D U-Net. Phys. Med. 2020, 69, 241–247. [Google Scholar] [CrossRef]
- Wu, J.; Yang, S.; Gou, F.; Zhou, Z.; Xie, P.; Xu, N.; Dai, Z. Intelligent Segmentation Medical Assistance System for MRI Images of Osteosarcoma in Developing Countries. Comput. Math. Methods Med. 2022, 2022, 7703583. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tversky, A. Features of Similarity. Psychol. Rev. 1977, 84, 327–352. [Google Scholar] [CrossRef]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Butaru, A.E.; Mămuleanu, M.; Streba, C.T.; Doica, I.P.; Diculescu, M.M.; Gheonea, D.I.; Oancea, C.N. Resource Management through Artificial Intelligence in Screening Programs—Key for the Successful Elimination of Hepatitis C. Diagnostics 2022, 12, 346. [Google Scholar] [CrossRef] [PubMed]
- Google Colab. Available online: https://colab.research.google.com/ (accessed on 3 October 2022).
- Milletari, F.; Ahmadi, S.-A.; Kroll, C.; Plate, A.; Rozanski, V.; Maiostre, J.; Levin, J.; Dietrich, O.; Ertl-Wagner, B.; Bötzel, K.; et al. Hough-CNN: Deep Learning for Segmentation of Deep Brain Regions in MRI and Ultrasound. Comput. Vis. Image Underst. 2017, 164, 92–102. [Google Scholar] [CrossRef] [Green Version]
- Milletari, F.; Ahmadi, S.-A.; Kroll, C.; Hennersperger, C.; Tombari, F.; Shah, A.; Plate, A.; Boetzel, K.; Navab, N. Robust Segmentation of Various Anatomies in 3D Ultrasound Using Hough Forests and Learned Data Representations. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015; pp. 111–118. [Google Scholar]
- Taha, A.A.; Hanbury, A. Metrics for Evaluating 3D Medical Image Segmentation: Analysis, Selection, and Tool. BMC Med. Imaging 2015, 15, 29. [Google Scholar] [CrossRef] [Green Version]
- Florescu, L.M.; Streba, C.T.; Şerbănescu, M.-S.; Mămuleanu, M.; Florescu, D.N.; Teică, R.V.; Nica, R.E.; Gheonea, I.A. Federated Learning Approach with Pre-Trained Deep Learning Models for COVID-19 Detection from Unsegmented CT Images. Life 2022, 12, 958. [Google Scholar] [CrossRef]
- Dietrich, C.; Ignee, A.; Hocke, M.; Schreiber-Dietrich, D.; Greis, C. Pitfalls and Artefacts Using Contrast Enhanced Ultrasound. Z. Gastroenterol. 2011, 49, 350–356. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X Min | X Max | Y Min | Y Max |
|---|---|---|---|
| 0 | 400 | 78 | 525 |
| α | β1 | β2 | ε |
|---|---|---|---|
| 0.0001 | 0.9 | 0.999 | 10−8 |
| Parameters | IoU | Recall | Precision |
|---|---|---|---|
(Dice coefficient) (Training/Validation) | 0.8392/0.7129 | 0.8911/0.8256 | 0.9334/0.8448 |
0.75 (Training/Validation) | 0.7990/0.6572 | 0.8171/0.7735 | 0.9635/0.8192 |
| Model | Minimum Inference (Milliseconds) | Maximum Inference (Milliseconds) | Average Inference (Milliseconds) | Loading Time (Seconds) |
|---|---|---|---|---|
(Dice coefficient) | 32.50 | 56.48 | 41.76 | 294.29 |
0.75 | 32.15 | 59.70 | 43.04 | 373.16 |
| Model | Minimum Inference (Milliseconds) | Maximum Inference (Milliseconds) | Average Inference (Milliseconds) | Loading Time (Seconds) |
|---|---|---|---|---|
(Dice coefficient) | 48.76 | 77.59 | 59.68 | 5.86 |
0.75 | 51.90 | 76.43 | 61.15 | 7.89 |
| Metric | Value | Unit |
|---|---|---|
| FLOPs | 43.2433 | MFLOPs |
| Memory requirement (GPU) | 0.9291 | GB |
| Total number of parameters | 414,401 | N/A |
| Variable | n 1 (%) |
|---|---|
| Gender | M-63.26% F-36.74% |
| Age (mean value ± SD) | 69.57 ± 10.65 |
| Age Wise Classification of Samples | |
| Age group | Number of patients |
| <40 | 2 |
| 40–49 | 2 |
| 50–59 | 7 |
| 60–69 | 17 |
| 70+ | 21 |
| Underlying liver disease | |
| 1. Liver cirrhosis | 36.73% |
| 2. Chronic viral hepatitis | HBV-6.12% HCV-10.20% |
| History of previous malignancy | 22.44% |
| Tumor size (mm), mean value | 51.65 |
| Final diagnosis | |
| Hepatic hemangioma | 10.16% |
| Liver cysts | 8.47% |
| Focal nodular hyperplasia | 1.69% |
| Liver adenoma | 1.69% |
| Liver abscess | 1.69% |
| Hepatocellular carcinoma | 40.67% |
| Liver metastases | 25.42% |
| Cholangiocarcinoma | 6.77% |
| Malignant liver adenoma | 1.69% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mămuleanu, M.; Urhuț, C.M.; Săndulescu, L.D.; Kamal, C.; Pătrașcu, A.-M.; Ionescu, A.G.; Șerbănescu, M.-S.; Streba, C.T. Deep Learning Algorithms in the Automatic Segmentation of Liver Lesions in Ultrasound Investigations. Life 2022, 12, 1877. https://doi.org/10.3390/life12111877
Mămuleanu M, Urhuț CM, Săndulescu LD, Kamal C, Pătrașcu A-M, Ionescu AG, Șerbănescu M-S, Streba CT. Deep Learning Algorithms in the Automatic Segmentation of Liver Lesions in Ultrasound Investigations. Life. 2022; 12(11):1877. https://doi.org/10.3390/life12111877
Chicago/Turabian StyleMămuleanu, Mădălin, Cristiana Marinela Urhuț, Larisa Daniela Săndulescu, Constantin Kamal, Ana-Maria Pătrașcu, Alin Gabriel Ionescu, Mircea-Sebastian Șerbănescu, and Costin Teodor Streba. 2022. "Deep Learning Algorithms in the Automatic Segmentation of Liver Lesions in Ultrasound Investigations" Life 12, no. 11: 1877. https://doi.org/10.3390/life12111877
APA StyleMămuleanu, M., Urhuț, C. M., Săndulescu, L. D., Kamal, C., Pătrașcu, A. -M., Ionescu, A. G., Șerbănescu, M. -S., & Streba, C. T. (2022). Deep Learning Algorithms in the Automatic Segmentation of Liver Lesions in Ultrasound Investigations. Life, 12(11), 1877. https://doi.org/10.3390/life12111877