1. Introduction
The complicated retrovirus (lentivirus) family, known as human immunodeficiency virus (HIV), is a virus that usually threatens human life, resulting in patient death when treatment is not adequately followed or commences early as prescribed by experts in the clinical field. The destruction of the immune system is the major concern of the virus. As a result of this virus attack, medical researchers developed the current antiretroviral therapy (ART) drug that will reduce and stop the further replication of the virus. Currently, the ART drug is the one that is capable and reliable in handling both HIV-1 and HIV-2 cases [
1].
Several researchers have used different statistical models to predict its epidemiology, such as HIV/AIDS-related cases and their development, which have resulted in the current achievement of undetectable and non-transmissible outcomes among people living with the virus [
2,
3,
4]. Some researchers used logistic regression to predict the influence of the early risk factors of SARS-CoV-2 ART associated with the advancement of the disease, and the findings showed that vaccination and early treatment with antivirals have significantly reduced the risk of disease progression. Similarly, the chi-square test and stepwise regression to investigate the longer duration of ART in overcoming barriers to long-term adherence, improving the survival of adolescents and young adults with HIV, and the results supported the global goals for HIV prevention and treatment. Zalla et al. [
3] employed binomial distribution to examine the differences in race and ethnicity among people entering HIV care for ART medication, and the results indicated no significant difference in ART medication according to race or ethnicity, but Black and Hispanic patients showed a significant difference compared with White patients receiving ART. Torres et al. [
5] used a chi-square analysis and a
t test to evaluate the frequency incidence difference between S68G and K65R mutations on the basis of the different types of HIV-1.
Similarly, Kiyingi et al. [
6] confirmed that the regression analysis results showed that women living with HIV have a high risk of human papillomavirus infection. However, Hameiri-bowen et al. [
7] concluded that there was a significant delay in prevalence and associated factors of ART launching among people living with HIV on the basis of the PCA and logistic regression results. Chaula et al. [
8] confirmed that the PCA findings showed there was no sustained medication interruption after examining the effect of azithromycin on the illustration of plasma-soluble biomarkers in adults and children who had chronic lung disease. Jin et al. [
9] employed logistic regression and PCA to determine whether the HIV-antibody repertoire can be used to predict the viral reservoir, and the PCA results showed that there was a correlation between the DNA of HIV patients and western blot kits; in addition, the variables were associated with the prevalence, according to the clustered indicators.
Camargo et al. [
10] confirmed that the study utilized by MCA demonstrated a relationship between variables related to HIV/AIDS patients’ failure to adhere to ART. Bayon et al. [
11] investigated the serum levels of amylase and CD4 in newly diagnosed people living with HIV by using a chi-square test and MLR, and the results suggested that opportunistic infections caused by low CD4 counts could be the primary cause of pancreatic damage. Soogun et al. [
12] applied LG and CA to forecast the multidrug support of a staphylococcus aureus nasal isolate with clonal complex in HIV-treated patients, and the CA demonstrated positive associations. Chaula et al. [
13] employed correlation and a mixed-effects statistical model to predict the early duration of ART treatment to stabilize the growth of viral reservoirs in HIV-1 patients, and the results showed that early treatment can to some extent decrease the viral load. Alanzi et al. [
14] presented factors related to high viral load by using MCA and RF, and the outcomes showed that MCA was the tool that best meets the UNAIDS 95–95–95 target goal in achieving viral load suppression in that the study identified a high proportion of individuals with a lower viral load.
However, several scholars have used AI models to predict the achievement and progress of patients surviving HIV/AIDS. Other such as Rodriguez et al. [
15] used RF machine-learning techniques to forecast the history of HIV-treated breastfeeding mothers, and the result showed that RF gave a higher accuracy performance. Besides, artificial neural networks (ANNs) was employed to estimate prokaryotic genomes’ important genes, and the findings revealed that an ANN is the most efficient model. Dimopoulos et al. [
16] used the deep-learning method to evaluate empathic conduct in a social dynamic condition, and the results showed that the proposed method surpasses other popular ML methods and did so with high maximum accuracy. Vapnik, et al. [
17] developed the conceptual overview of AI based SVM theory and logistic regression, and the results showed that ML techniques such as SVM surpassed logistic regression. In addition, Farhat [
18] utilized the radial basis function, SVM, product unit and sigmoid unit to investigate the typology of HIV-treated patients receiving ART medication, and the results showed that radial basis neural networks demonstrated the best performance accuracy.
This study aims to integrate four AI-based models and CA techniques to predict the outcomes of HIV/AIDS patients receiving ART at Federal Teaching Hospital in Gombe state, Nigeria. The proposed AI algorithm was designed to compare the performance of three nonlinear (ANN, ANFIS and SVM) models and one linear (MLR) model. The main purpose of employing AI is to evaluate the influence and effect of taking ART medication for a longer duration while the CA is employed, to examine the visual positioning and contributions of each row and column term as dimensions of the success for the ART medication. The authors have not yet seen any related paper combining artificial intelligence models and correspondence analysis.
Section 2 of this paper contains the presentation of material and methods connected to HIV/AIDS examination. This is followed by a discussion of the proposed approach in
Section 3 and a conclusion in
Section 4.
4. Conclusions
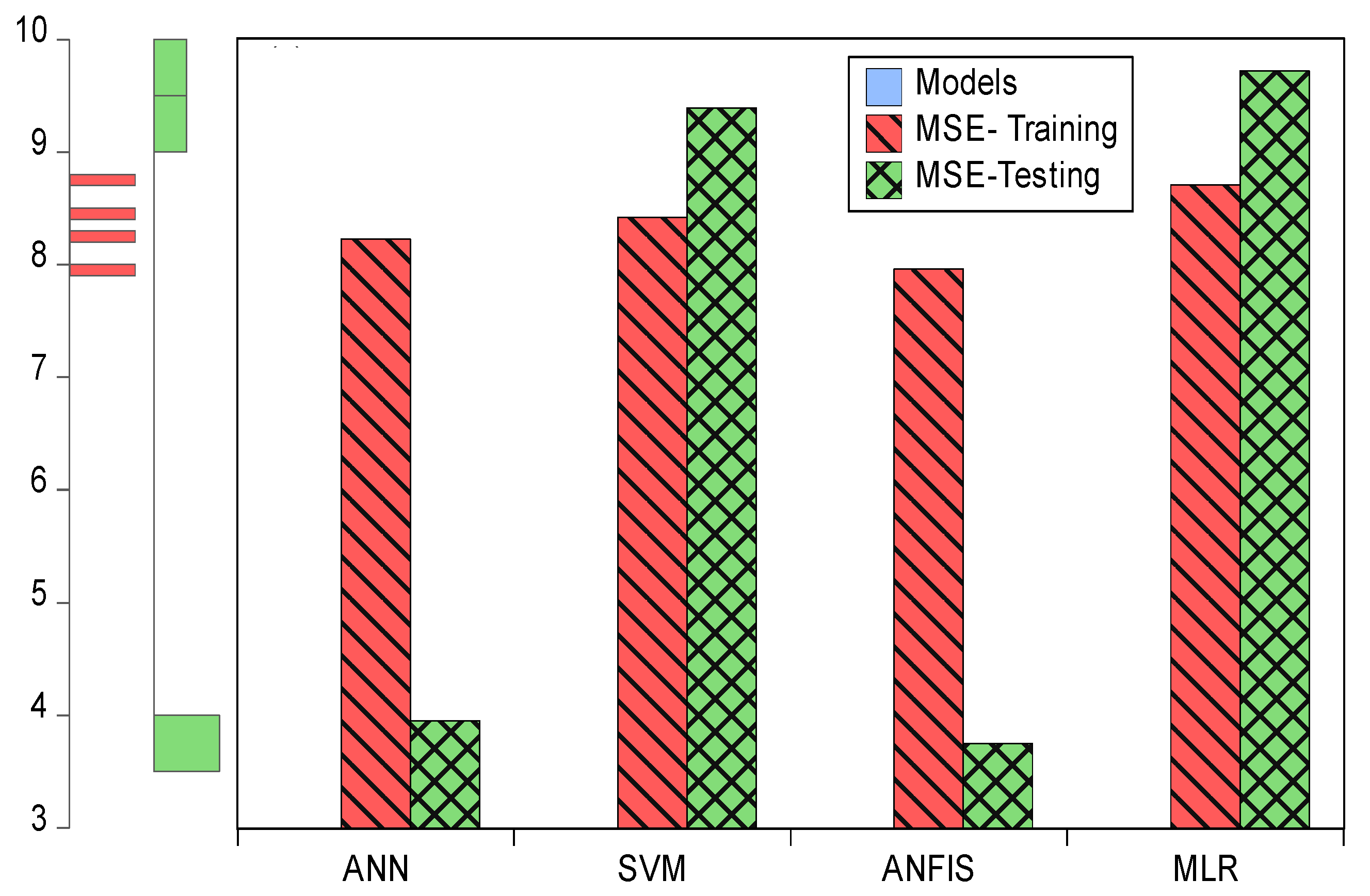
A combination of artificial intelligence models and correspondence analysis techniques was employed in this study to predict and examine HIV/AIDS-treated patients at the Federal Teaching Hospital in Gombe state. The single nonlinear model and linear models (ANN, ANFIS, SVM and MLR), including CA, were measured by using evaluation index criteria terms such as R2, MSEs, percentages of inertia, dimensions, active margins, p-values and chi-square tests. The comparison results for the study showed that ANFIS R2 (0.903 and 0.904) with MSE (7.961 and 3.751) outperformed the remaining models in both training and testing. This revealed that patients’ lives become safer and healthier as their time on ART medicine increases. The descriptive results showed that ABC-DDI-LPV/r (682) was the most prescribed drug for the patients. Marital status for those that were married (1703) recorded a high number of patients in attendance; hospital status showed alive patients (2407) on treatment were doing well in that only a few deaths were recorded while patients received ART treatment; a state visit showed that Gombe (1576) has the highest number of patients in attendance; and the 30 to 39 age group (956 patients) was the group most committed to undergoing treatment.
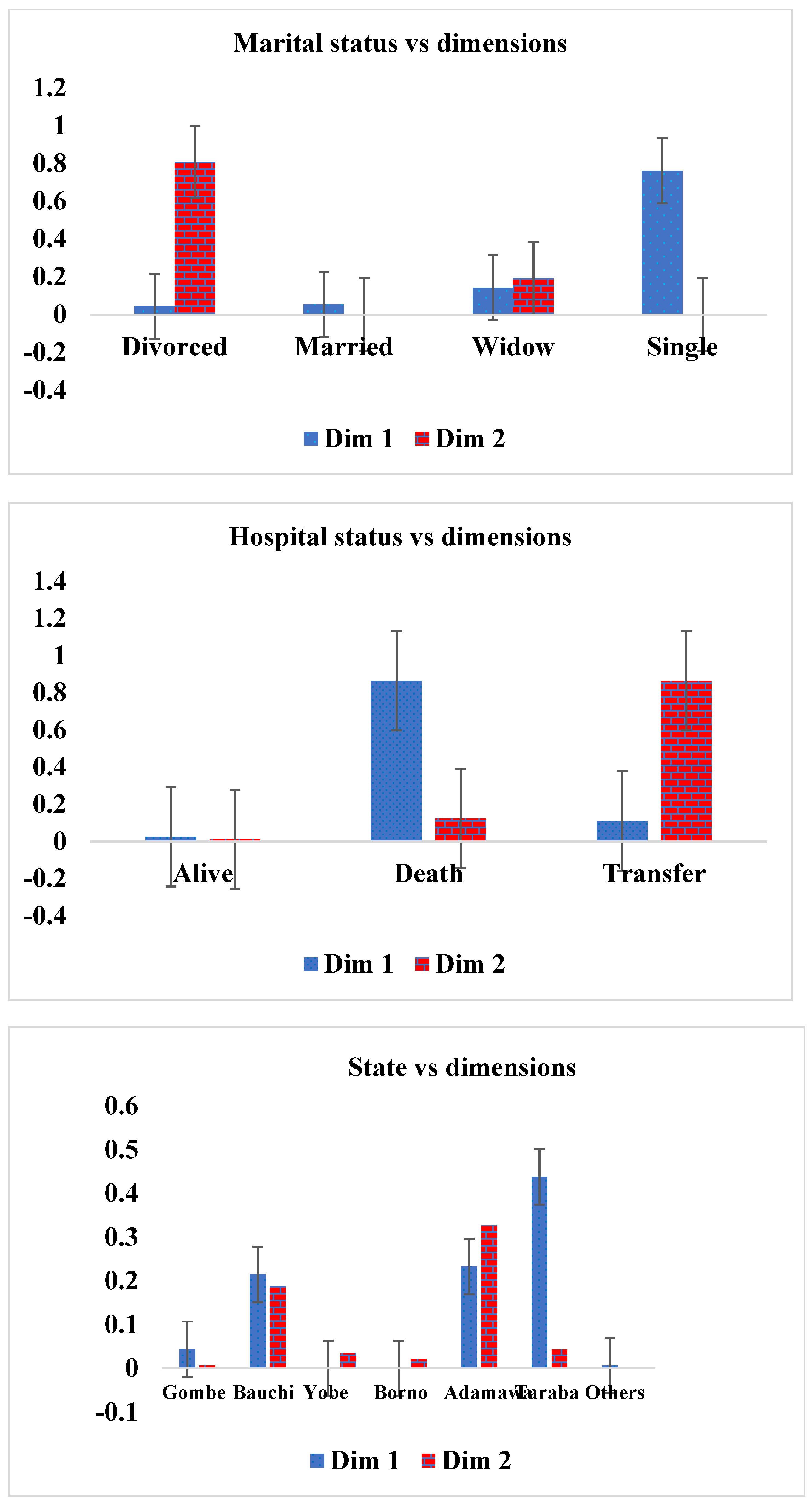
The results from the dimensions showed that drugs AZT-3TC-NPV (0.001), TDF-3TC-EFV (0.000), TDF-3TC-LPV/r (0.001) and TDF-FTC-NPV (0.000) contributed more according to marital status, in row I, compared with the remaining drugs, while in row II, drugs ABC-DDI-LPV/r (0.003), AZT-3TC-EFV (0.005) TDF-3TC-ATV/r (0.001) and TDF-3TC-EFV (0.005) contributed more to marital status than the other drugs did. Subsequently, in row I, AZT-3TC-ATV/r (0.001), AZT-3TC-LPV/r (0.001), TDF-3TC-EFV (0.001), TDF-3TC-NPV (0.000), TDF-FTC-ATV/r (0.007) and TDF-FTC-NPV (0.000) contributed more according to hospital status compared with the other drugs, while AZT-3TC-EFV (0.007), AZT-3TC-NPV (0.004) and TDF-3TC-ATV/r (0.005) contributed more according to hospital status, in row II, compared with the remaining drugs.
Next, ABC-DDI-LPV/r (0.007), AZT-3TC-EFV (0.000), AZT-3TC-LPV/r (0.002) and TDF-FTC-ATV/r (0.000) contributed more according to various state visits to the hospital, in row I, compared with the remaining drugs, while ABC-DDI-LPV/r (0.000), AZT-3TC-NPV (0.004), TDF-FTC-EFV (0.006) and TDF-FTC-LPV/r (0.001) contributed more according to state visits, in row II. Finally, AZT-3TC-EFV (0.005), TDF-3TC-NPV (0.008), TDF-FTC-ATV/r (0.000) and TDF-FTC-LPV/r (0.000) contributed more according to age groups, in row I, while in row II, AZT-3TC-LPV/r (0.002), TDF-3TC-EFV (0.005), TDF-3TC-NPV (0.000), TDF-FTC-EFV (0.003) and TDF-FTC-LPV/r (0.002) contributed more according to age groups compared with the remaining drugs.
However, the dimension results showed that divorced (0.004) and married (0.053) patients were doing better on drugs than the remaining marital statuses, in column I, while in column II, married (0.001) and single (0.000) patients were doing better on the drug compared with the remaining marital statuses. Alive patients (0.025), in column I and column II (0.012), were doing better on drugs than the remaining hospital statuses were. State visit data showed that Yobe state (0.000), Borno state (0.000) and other states (0.007) were doing better on the drug, in column I, compared with the remaining states, while Gombe state (0.007) and other states (0.000), in column II, were doing well on the drug compared with the remaining states. The age-group category revealed that age group 10–19 (0.007), in column I, and age group 30–39 (0.006), in column II, were doing better on the drug than the remaining age groups. The CA and the chi-square test yielded similar results, revealing that only the relationship between drug and age group was significant ( = 68.733, p = 0.026, and R2 = 79.4%), but in terms of performance, the relationship between drugs and marital status (93.7%) explained a higher percentage of variation compared with what the remaining variables could. A combination of different AI models and multivariate exploratory analysis techniques are required in future studies to evaluate epidemiological data other than HIV data.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}