1. Introduction
Diabetic cases, and specifically diabetic retinopathy cases, have been on the rise globally [
1] leading to a major cause of blindness for young adults as well as older individuals (20–70 years) [
2]. Even as a developed country, the U.S. has 93 million patients suffering from diabetic retinopathy (DR), and the number of such patients is increasing [
2,
3]. Diabetic retinopathy occurs as a result of retinal vascular diseases and abnormal blood flow in the retina. DR is usually characterized using four distinct levels for the disorder, including mild, moderate, severe, and proliferative diabetic retinopathy (PDR). Moreover, the mild, moderate, and severe DR categories are regarded as non-proliferative diabetic retinopathy (NPDR) whereas the neovascularization disorder is linked to PDR. The levels of DR are determined based on the difference in the ratio of diseases present, including microaneurysms, intraretinal hemorrhages (dot/blot), hard exudates, cotton wool spots, venous beading, and intraretinal microvascular abnormalities [
2].
The motivation for various researches on medical images is purely related to the contribution to the diagnostic healthcare systems. Advances in the diagnosis for various diseases have been developed along with machine learning techniques based on medical images [
4]. This is due to the requirement of a modern point-of-care (PoC) screening to promptly and exactly diagnose diseases outside the laboratory. Various applications installed in high-performance smart phones also have provided healthcare services to monitor the conditions of human body [
5]. Such high-performance electronic devices and computer-aided programs make it possible for us to diagnose DR using deep learning techniques.
To prevent DR globally, various multipurpose diagnosis systems based on machine learning have already been proposed [
6,
7,
8]. Initially, researchers used retinal fundus photographs for the detection of various eye diseases, using traditional machine learning methods including support vector machine (SVM), K-neighbor mapping, and random forest [
9]. However, these algorithms are not general and lead to low accuracies as they require manual feature extraction. In contrast, deep convolutional neural networks (CNN) addressed the feature extraction problem; for large scale datasets, they also exhibited tremendous success in solving complex problems, including object detection, segmentation, and image translation [
10]. CNNs also led to extraordinary achievements in the medical field, for the early diagnosis of diseases, tumors, and cancers in the human body [
4].
In the past few years, numerous promising studies have been conducted on retinal image analysis. For this purpose, in [
11], authors designed an algorithm to classify various retinal diseases with a relatively smaller database using a deep learning model called VGGNet. In [
11], authors designed a system for types of diseases other than DR. Therefore, this technique allows a lot of room for error. Recently, Carson et al. used a deep learning model named GoogleNet for the detection of retinal lesions based on patches of input images [
12]. In this work, each patch size was 128 × 128 × 3, which slowed it down tremendously in the training and inference process. Varadarajan et al. extracted completely novel information from retinal images using the ResNet architecture [
13]. In [
14], authors shared the performance of their automated detection system for DR and other eye diseases using deep learning. In addition, Gulshan et al. also used CNNs for the sole classification of DR for two different datasets producing state-of-the-art outcomes [
15]. In [
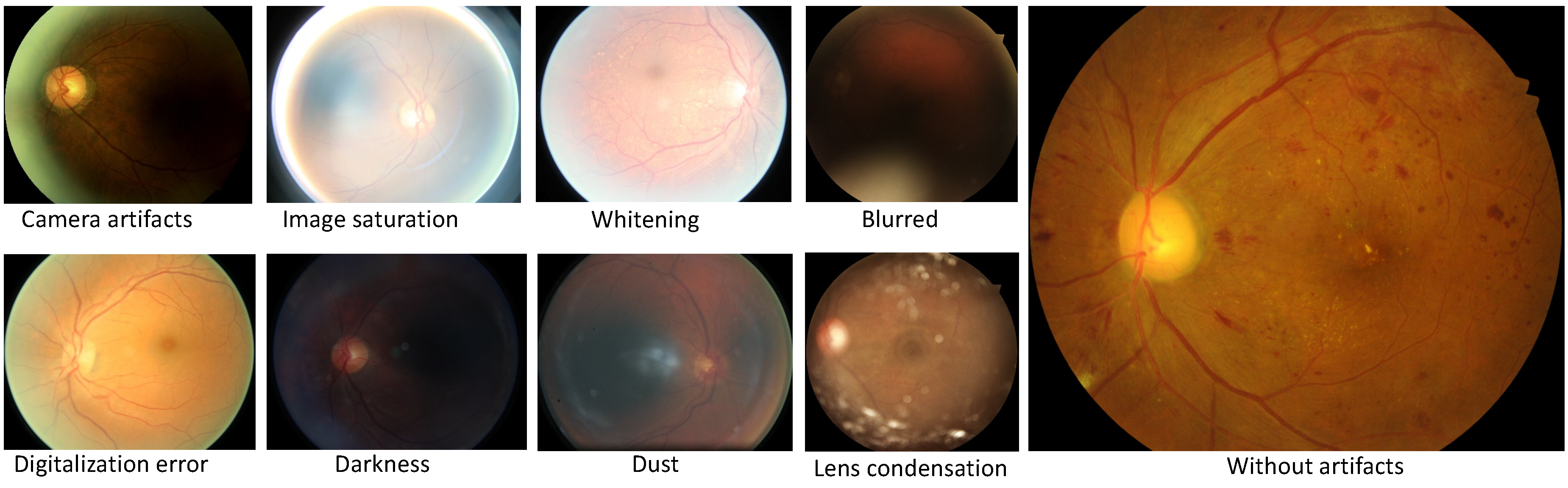
6], authors present a novel and cutting-edge system based on Inception V3. With this algorithm, researchers offer solutions for predicting various biometric factors from the retina including age, gender, body mass index (BMI), blood pressure, and smoker status. Generally, these articles faced common challenges in the analysis of retinal images. Indeed, a large number of uncertainty factors including blurriness, contrast, focus, distortion, whitening, and blankness [
16] can create problems while training deep learning models, aiming at convergence.
1.1. Our Contribution
In this study, for the first time, we have used densely connected neural networks for the classification of DR. The motivation behind our approach was to deploy networks with more deep supervision to extract comprehensive feature maps from fundus images. In the literature, many research groups worldwide, including Google and Stanford, have already introduced VGGNet, GoogleNet, InceptionsNets, and ResNets, with fundus images for the classification of various diseases [
6,
9,
11,
13,
14,
15]. These articles indicate that every new deep learning model produced state-of-the-art outcomes in various domains of fundus images. Hence, for the first time, we introduce the idea of exploring deep and densely connected networks for the classification of DR, which further improves the performance of computer-assisted diagnosis for retinal images.
We propose a unique preprocessing step for the datasets for training and inference. Before the special preprocessing, we cleaned the messidor-2 and Kaggle datasets and similarly rearranged wrongly labeled data based on instructions of their websites [
17,
18]. Preprocessing also includes steps such as cropping window, data generation, and data normalization. We optimized densely connected neural networks (DenseNets) [
19] to train on EyePACS images and test on messidor-2. We trained the models from scratch with an input resolution of 32 × 32 × 3. In the end, our idea improved the performance of the DR diagnosis system even for very-low-resolution images. Furthermore, we calculated the confusion matrix for class accuracy and performance.
1.2. Article Structure
The remaining article details are following: the preliminary steps, including data cleaning, rearranging, and data preprocessing, are discussed in
Section 2. Data preprocessing involves three stages, namely the cropping window for efficient training, data generation to overcome class imbalance and overfitting, and data normalization.
Section 3 illustrates the methodology in our approach to explore DenseNets with implementations. The results with confusion matrices, area under the curve (AUC), and a comparison table are reported in
Section 4. A discussion on the results is presented in
Section 5, and the conclusions of the study are presented in
Section 6.
3. Methodology
In this article, we exploited publicly available datasets including the messidor-2 and EyePACS, for the classification of DR status [
17,
18]. To achieve this goal, for the very first time, we evaluated a multiclass deep and densely connected model [
19];
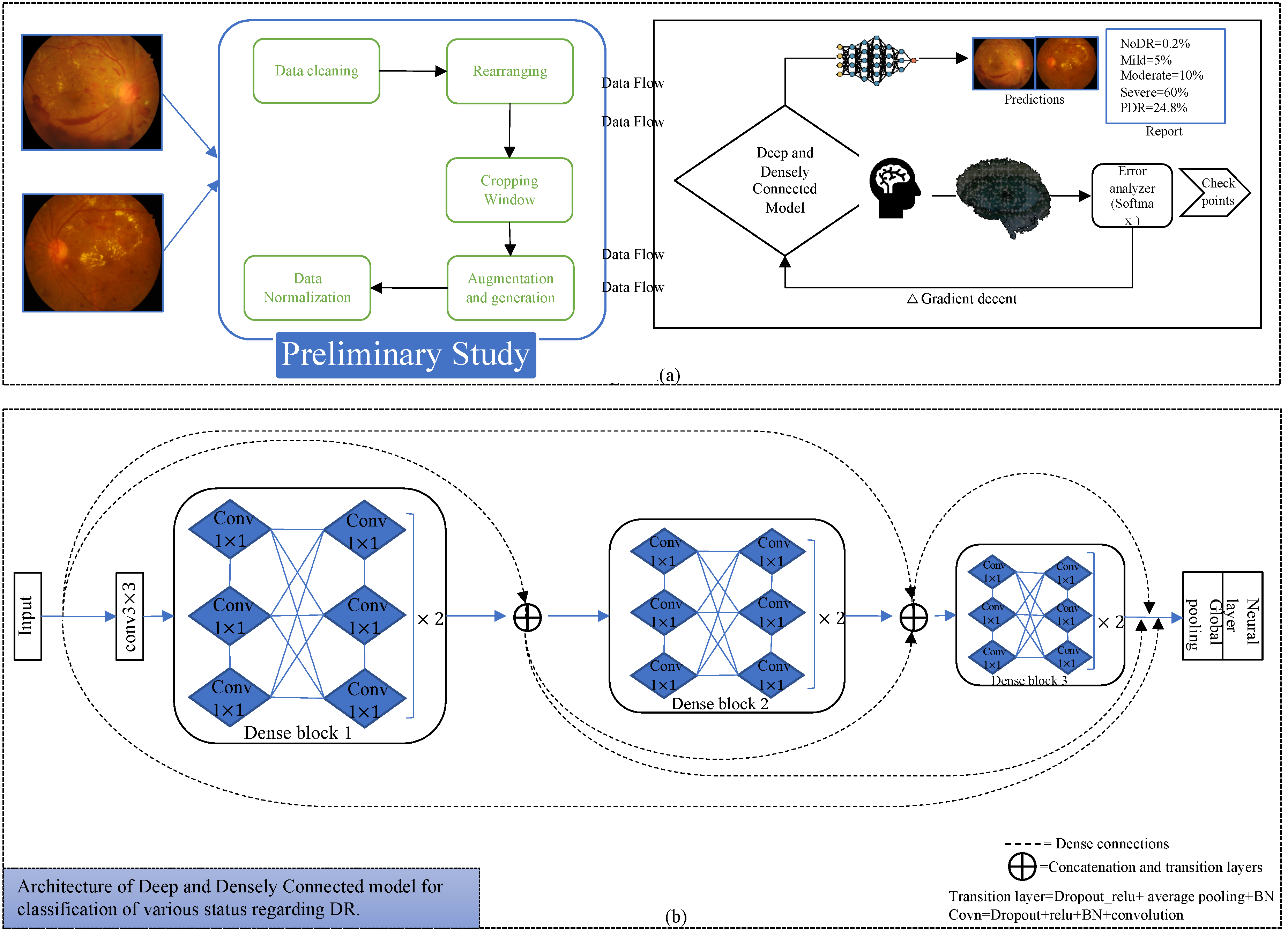
Figure 2 indicates the process diagram for such models. Similarly, to initiate training and inference, we followed the following key steps.
3.1. Data Preparation
This proposed deep learning network for the required conversion of original raw data of fundus images to useable form. Therefore, to run simulations using our approach, we first needed to follow preliminary steps including data cleaning, rearranging, implementation of cropping windows, augmentation and data generation, and data normalization. Following these steps, to initiate the training and validation processes for the deep and densely connected model, we split the data into respective sets. This constitutes the first block for starting an implementation procedure in the process diagram.
3.2. Deep and Densely Connected Networks
Deep and densely connected networks [
19] are the successors of ResNets [
23], but they contain a distinctive connectivity in the deeper layers referred to as dense connections.
Figure 2 also represents the dense connectivity patterns between the layers of the CNN. In [
19], authors explained the many advantages of such networks over ResNets [
23] and InceptionNets [
24], especially for deeper supervision, reduced complexity, parametric efficiency, lower computational power requirements, and higher accuracy.
Deep and densely connected networks [
19] comprise various dense blocks, and each block contains combinations of many 1 × 1 and 3 × 3 convolutional layers (conv) with dense connectivity. Our model consists of three dense blocks, each having twelve convolutional layers. A transition block is another essential element in the implementation of such networks; it includes batch normalization [
25], relu activation [
26], 1 × 1 conv, 2 × 2 average pooling layer, and concatenation layers. A transition layer is implemented after every dense block; in addition, before the first dense block, we also implemented a 3 × 3 conv layer as in the original article. After the last dense block, we implemented a global average pooling, fully connected or conventional neural network layer which also known as the dense layer, and a softmax layer as a loss function.
Selection of Hyperparameters
The optimization of deep learning models requires an efficient tuning of hyperparameters. A model depends on these parameters, and these can be different across models. The common hyperparameters for DenseNets are the growth-rate (K), dropout, depth of network, number of dense blocks, learning rate, learning decay ratio, weight decay, compression factor, bottleneck layer activation, optimizer, momentum, epochs, batch size, and weight regularization. To optimize our network for the training over fundus images, we used K = 12, depth of network = 40, batch size = 64, epoch = 350, and three dense blocks. We set the learning rate = 1 × 10
−3, learning decay ratio = 0.1, weight decay = 1 × 10
−4, and L2 regularization on weights. The compression factor and bottleneck layer activation are also implemented in our designed network. To optimize the weights of the model, we implemented a stochastic gradient descent optimizer having a momentum of 0.9 with Nesterov mode. We kept the dropout at 0.2, to reduce overfitting [
27].
3.3. Implementation
The execution of dense blocks with various hyperparameters allows us to move further in the implementation process. The details are as follows:
3.3.1. Training and Inference
The training is performed on the EyePACS dataset after the preliminary steps. We trained the deep and densely connected networks on 71,913 balanced fundus images and validated on 17,979 images. Training continued on an Nvidia GPU GTX 1080ti with described setting of parameters. During training, the first conv layer extracts initial feature maps which are further manipulated in the first dense block to extract low-level features with a 32 × 32 × 168 resolution. Only two transition layers with average pooling are employed after the first and second dense block. The first transition layer performs the down sampling for low-level features to 16 × 16 × 168. After every conv layer the feature maps grow with a factor of twelve within the dense block and concatenation helps combine all of them. Likewise, the second dense block extracts mid-level 16 × 16 × 312 features maps, and the final transition layer, with the help of average pooling, down samples them to 8 × 8 × 312. The final dense block generates high-level features for the fundus images 8 × 8 × 456 feature maps. In the end, the global average pooling and neural layer (dense) are applied and the softmax loss function helps to learn representative predictions for fundus images. The training and validation losses are 0.163 and 0.265, respectively, for fundus images to classify five levels of DR.
We evaluated the performance of the dense block-based model on the messidor-2 dataset with 1747 images and the EyePACS dataset with 17,978 images.
3.3.2. Threefold Cross Validation, Checkpoints, and Graphs
In machine learning, trained models can be overfitted for deeper networks. Therefore, we applied threefold cross validation at the time of training [
28]. In the architecture of the network, we applied a dropout factor for every conv layer with a 0.2 dropout rate [
27]. The threefold validation and dropout assist the relatively deeper networks and thereby prevent them from overfitting. Moreover, the purpose of checkpoints is to save the best weights at the time of training with respect to loss and accuracy curves. During cross validation, our algorithm generates checkpoints after every five epochs on the basis of model loss and accuracy. Furthermore, the saved weights facilitate the inference process on new datasets. In the end, the proposed approach calculates the graphs of the loss function, accuracy, and performance of the model on new datasets by storing history of the models and tensor-board.
3.4. Calculation of Performance
In this study, we were able to calculate the confusion matrix for each class at the time of inference. Moreover, our algorithm extracts sufficient information from the testing data, such as area under the curve with average and as well as per class AUC. The next section provides the results in the form of confusion matrix and AUC.
4. Results
The model evaluates the outcome on messidor-2 and EyePACS images in the form of a confusion matrix; furthermore, it evaluates the performance table including precision, sensitivity, specificity, F
1 score that means 2×(precision×recall)/(precision+recall), and AUC.
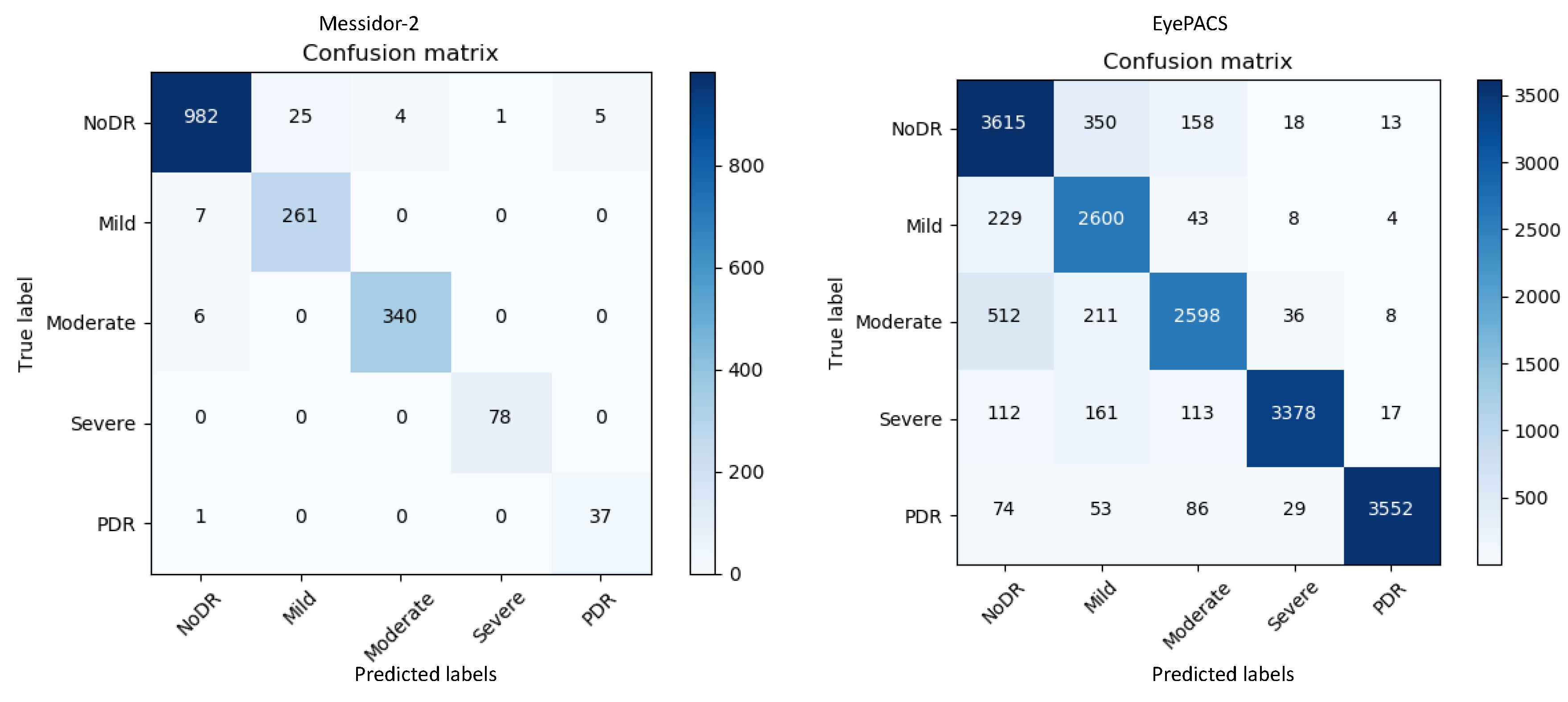
Figure 3 represents the confusion matrices for both datasets. The confusion matrices in
Figure 3 show that for messidor-2, the model yields adequate results compared with those for EyePACS as it is a tiny and clean dataset. By contrast, EyePACS is sharply noisy, unclean, and contains a large number of images; therefore, the model underperforms slightly there. Moreover, the proposed method can generate a report table that delivers important information regarding each class in the retinal datasets to support comprehensive analysis.
Table 1 describes the performance of the proposed model on the messidor-2 datasets; it uses various mathematical equations to evaluate the report on the input data.
Table 1 and
Figure 3 provide key information on the retinal images for messidor-2 specifically; mild-DR indicates that there is a less than 5% chance to contract the DR disease, hence a normal image and a mild-DR are shared almost similar features, a promising potential reason behind the relatively lower precision.
Applying the same method, a report for the EyePACS data is reported in
Table 2. Precision, sensitivity, and specificity are the key metrics for checking the accuracy of a model. For our method, we evaluate the F1-score, which checks the accuracy of the test data in the form of harmonic average specifically for imbalance datasets.
In this study, we assessed the performance metrics with a five-class dataset; therefore, to describe the mathematical equations for each parameter, let us consider a generic 5 × 5 matrix, as given below:
It represents any confusion matrix with five classes from one to five. The x-axis and y-axis represent the predicted and actual class information, respectively. It first performs calculations for overall accuracy in Equation (1). The ratio of correct predictions over the aggregate number of data points is known as the overall accuracy, and the overall accuracies for messidor-2 and EyePACS are 0.97 and 0.88, respectively. Similarly, precision is defined as the ratio of true positive (T
P) values for a specific class with the combination of true positive and false positive (F
P) values from the confusion matrix. F
P is the total sum of all elements in a column related to a specific class.
The final equation for precision can be written as in Equations (2) and (3):
From the matrix, to find the precision specially for class 3, T
P is A
3,3 and F
P is the combination of all the elements in the third column of matrix, specifically A
1,3, A
2,3, A
4,3, and A
5,3, excluding T
P. After applying this formula, the algorithm evaluates the precision for all classes and computes the average values of 0.95 and 0.88 for messidor-2 and EyePACS, respectively. Furthermore, sensitivity is another essential metric that conveys the accuracy of a machine learning model. It is the ratio of T
P and sum of T
P with false negatives (F
N). In contrast with F
P, it is the sum of all the elements in the row of the target class excluding T
P. Equations (4) and (5) represent the sensitivity, also known as true positive rate (TPR).
Equation (4) is a generic formula to determine the sensitivity or
TPR (Recall) and Equation (5) describes the sensitivity for class three only. Similarly, after calculating the sensitivity for messidor-2 and EyePACS, the average values are found to be 0.98 and 0.94, respectively. Specificity is another metric representing the accuracy of a machine learning model, and it is calculated by dividing the true negative (T
N) by the combination of T
N and false positive (F
P), as in Equation (6). T
N is sum of all the elements except the row and column of the specific class. Similarly, let us consider a scenario where we attempt to find the specificity for class 3;
is the true negative rate for class 3, it is shown in Equation (7) and FP is the same as Equations (3) and (4). It is also known as the true negative rate (TNR). The average specificities for messidor-2 and EyePACS are 0.98 and 0.97, respectively. Furthermore, precision and sensitivity help evaluate the F1 score which is another crucial metric for expressing the accuracy of unbalanced datasets. This is expressed in Equation (9), as follows:
The average values of the F1 score for messidor-2 and EyePACS are 0.97 and 0.88, respectively. The results indicate that the model provides relatively low results for [
18]; this could be attributed to the fact that the first three classes share almost the same features.
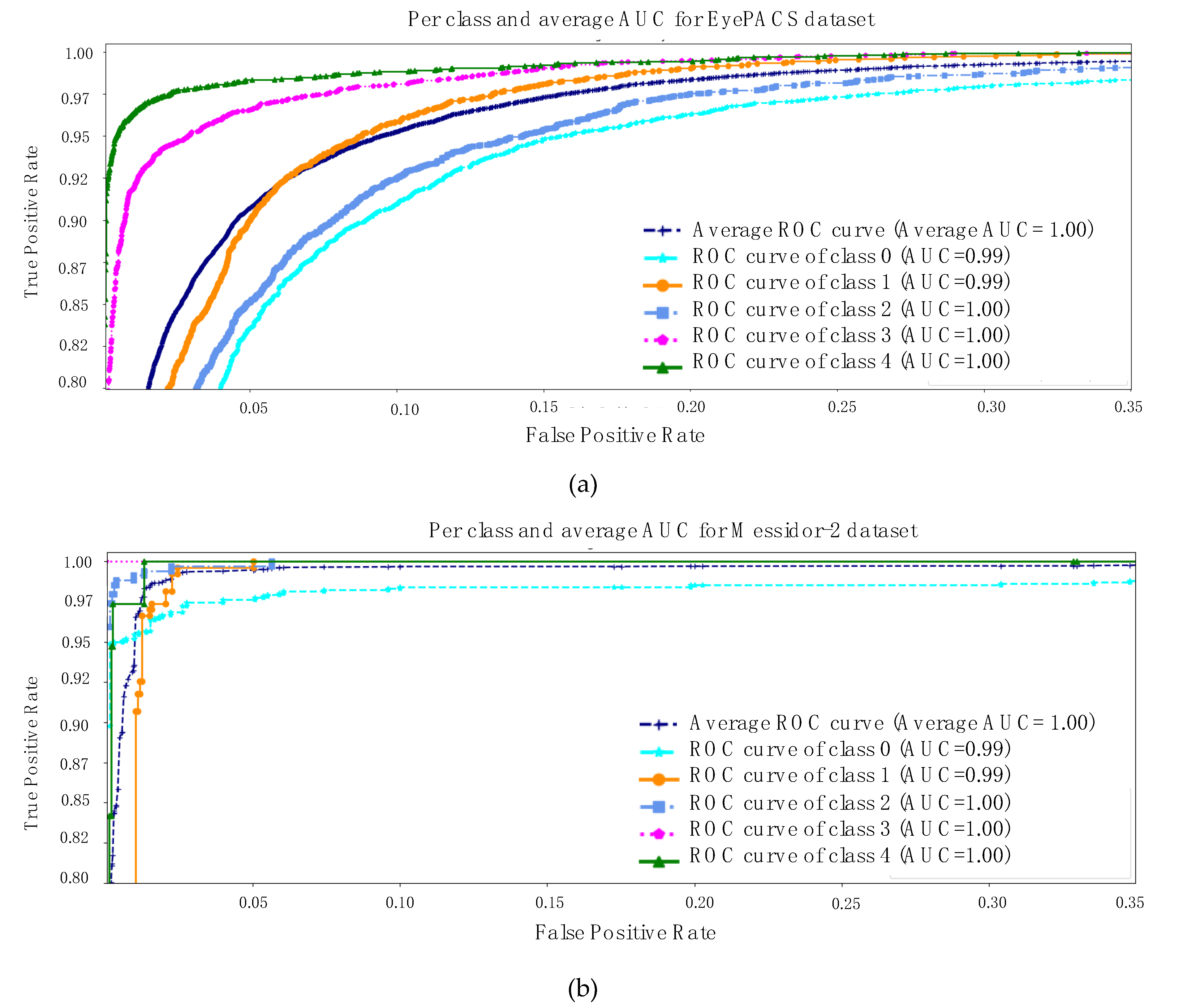
The equations above and various representations to express the results are all equally important. However, at the final stage, the model calculates the area under the curve (AUC) for each class and its average as well. The rationale for checking the AUC for every individual class is linked to the analysis of the impact of the trained model on each class. AUC is computed using a receiver operating characteristic (ROC) curve, which is a graph conveying the performance of a classification model. The ROC curve plots involve two metrics such as
TPR and false positive rate (
FPR). We already have TPR, but
FPR is computed using Equation (10), as follows:
Finally, AUC stands for area under the ROC curve. Therefore,
Figure 4 is describing the AUC for both datasets [
17,
18]. The same key points are highlighted, specifically messidor-2 is a simpler and smaller retinal dataset than EyePACS and the first three classes of each dataset are sharing a few similar features. With all the evidence, the model exhibits an average AUC of 1 and 0.98 for both datasets separately.
5. Discussion
In this study, we investigated the classification of the cases of DR disease, using deeper and dense networks. This method can perform diagnosis based on the various status of the DR images. To reach this goal, we trained deep and densely connected networks with distinct sets of hyper parameters, as discussed in
Section 3 (Methodology). During the training process, the method determines the graphs for the model’s loss and accuracy for 350 epochs.
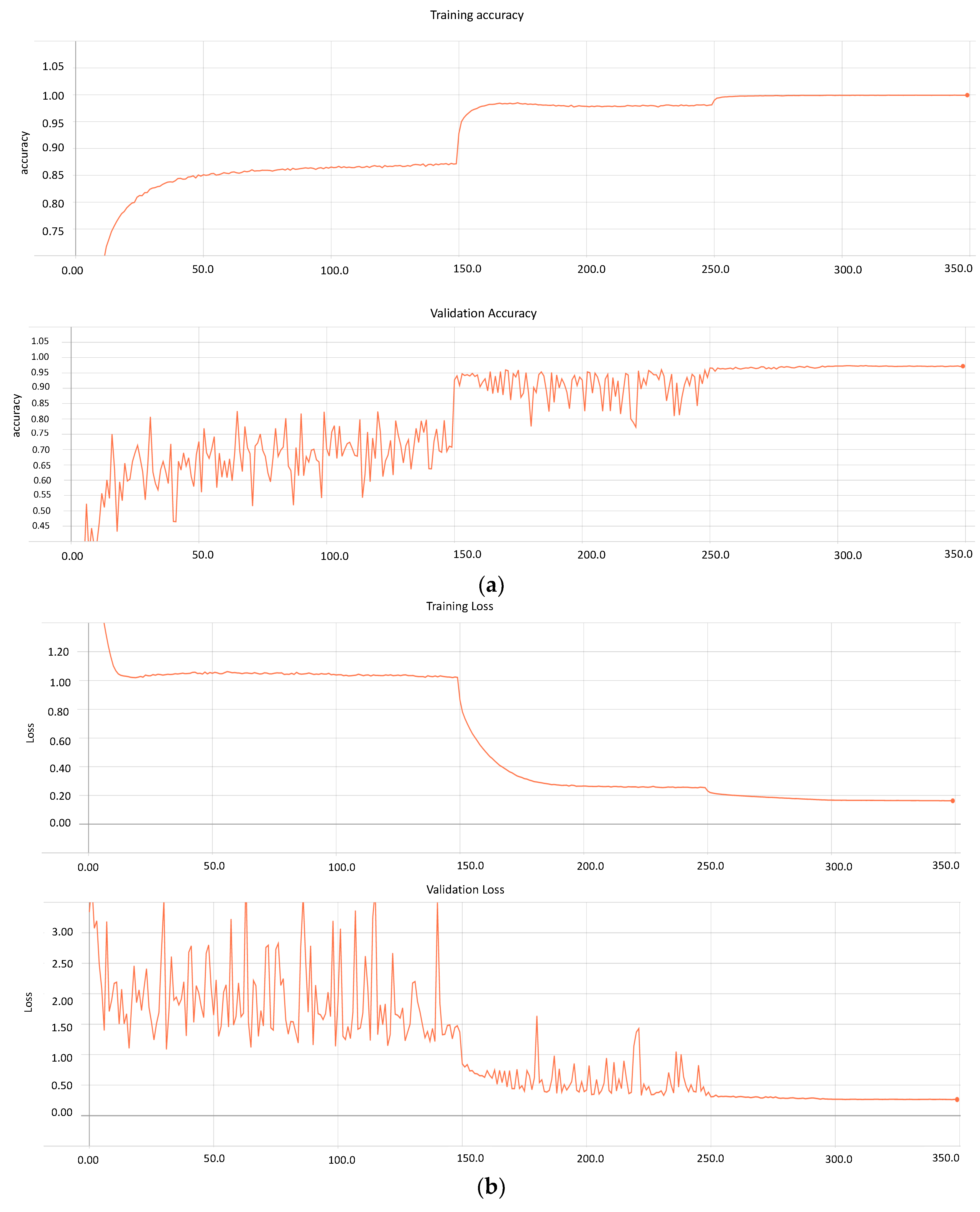
Figure 5a,b presents both metrics for the trained model.
Similarly, the model performs training on 71,913 images and validation on 17,979. Furthermore, based on the graphs, it can be seen that after 300 epochs, the model loss and accuracy remain constant, which can result in overfitting. Therefore, our approach stores various weights at distinct learning rates with a loss of 0.163 and 0.265 for the training and validating data, respectively. Conversely, the accuracy of the model on messidor-2 and EyePACS is 0.99 and 0.97, respectively.
6. Conclusions and Future Research
This paper introduced a state-of-the-art deep learning model for the classification of DR from images. In this work, we also proved that deep and densely connected networks have the potential to yield deeper supervision, which further secures the more relevant feature maps alone. Based on this, the accuracy improves across a wide range; for instance, in messidor-2, our model provides the highest AUC, sensitivity, and specificity. Another key aspect of our approach is the data scrubbing and the special cropping windows; both help the model to learn quickly with discriminant features regarding each abnormality. Moreover, this method also supplies deep and comprehensive analysis for each class of images by providing a confusion matrix and generating reports with various representations of essential parameters. Finally, it indicates that our method improves accuracy and reduces the loss; the performance gains are clearly visible from the comparison table as well. As a result, we can assert that we pioneered the use of deep and densely connected models for the diagnosis of DR by analyzing retinal images.
In the future, we plan to examine various datasets for the detection of lesions to highlight damaged pixels in the images, which can be flagged as a segmentation problem instead of a classification one. Furthermore, we have already assembled a fully connected deep and densely connected network, which will be a new tool leading to a single segmentation model for all types of lesion detection. Although the current work is related to the classification of DR, in the near future, this research will be helpful to design a general deep learning model that can exactly detect defective areas or abnormal pixels on the retinal images. In order to reduce the complexity, traditional works have used specific datasets that are targeted at similar types of diseases. In this work, we have proposed to make a common dataset that can segment various diseases with only one model. This method could be useful for early state PoC screening services in the future.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}