“PhysIt”—A Diagnosis and Troubleshooting Tool for Physiotherapists in Training



Abstract
:1. Introduction
2. Related Work
2.1. Diagnosis
2.2. Troubleshooting
2.3. Summary and Our Contribution
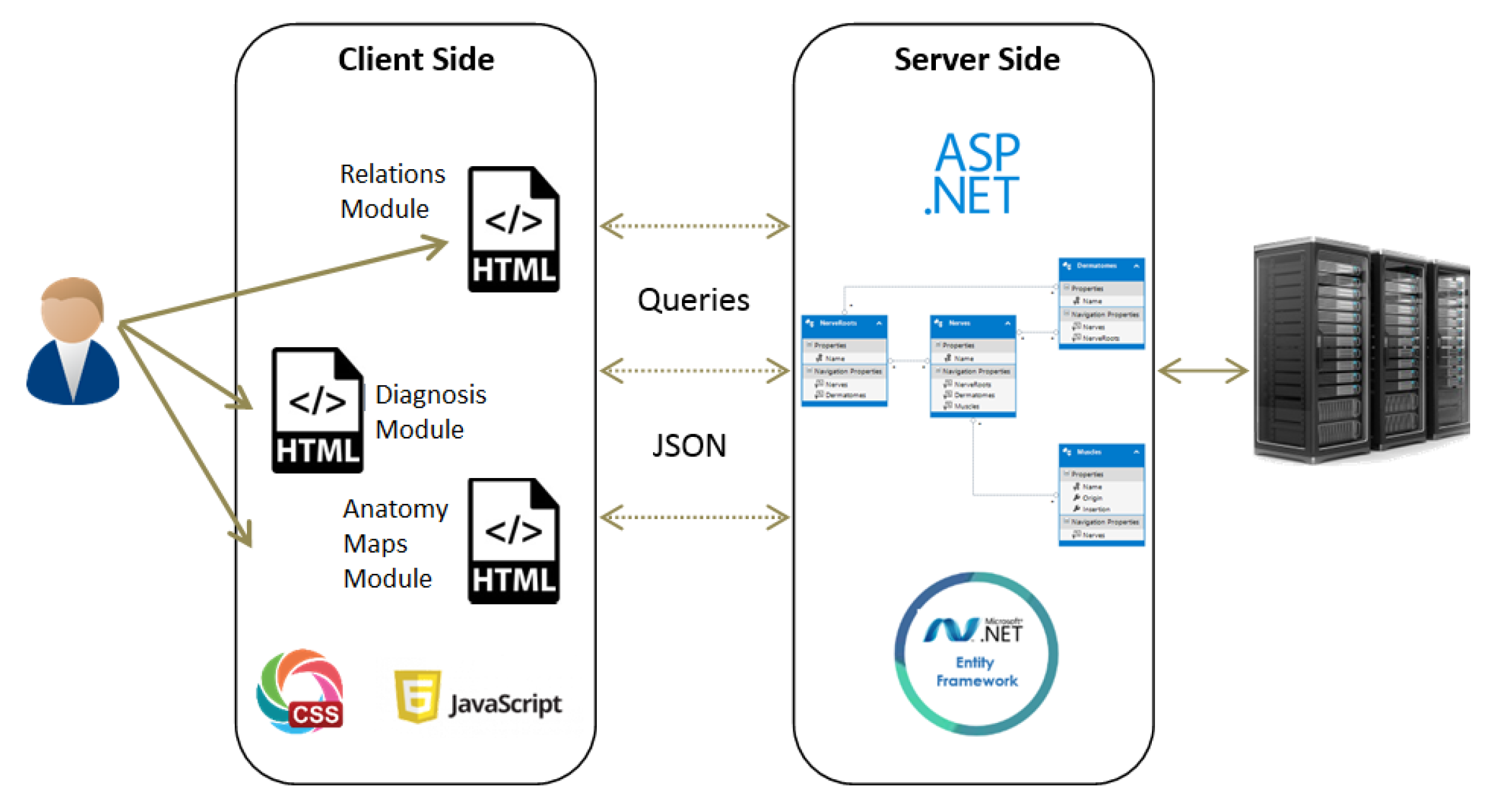
3. Architecture and Interface
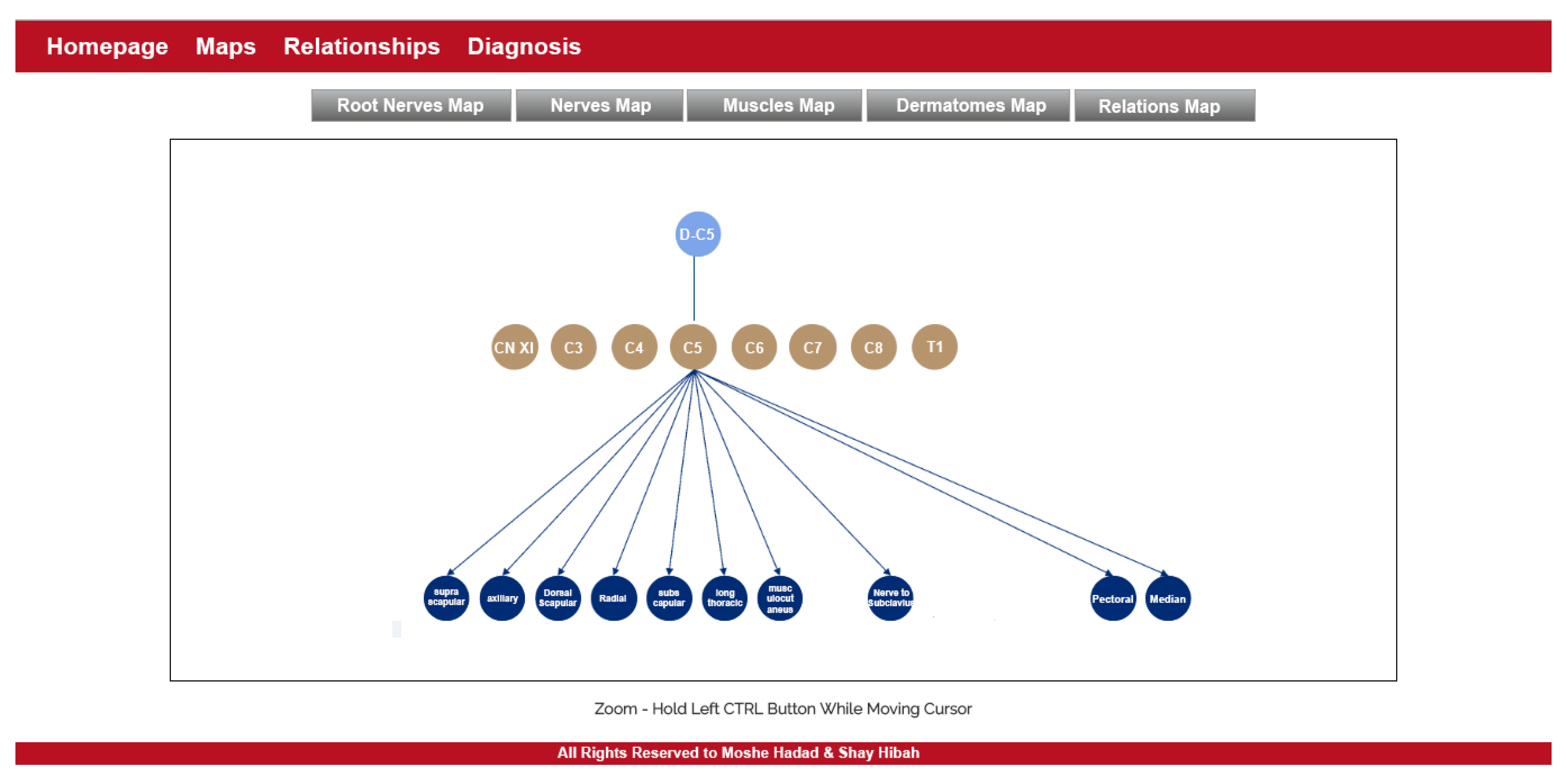
- Maps
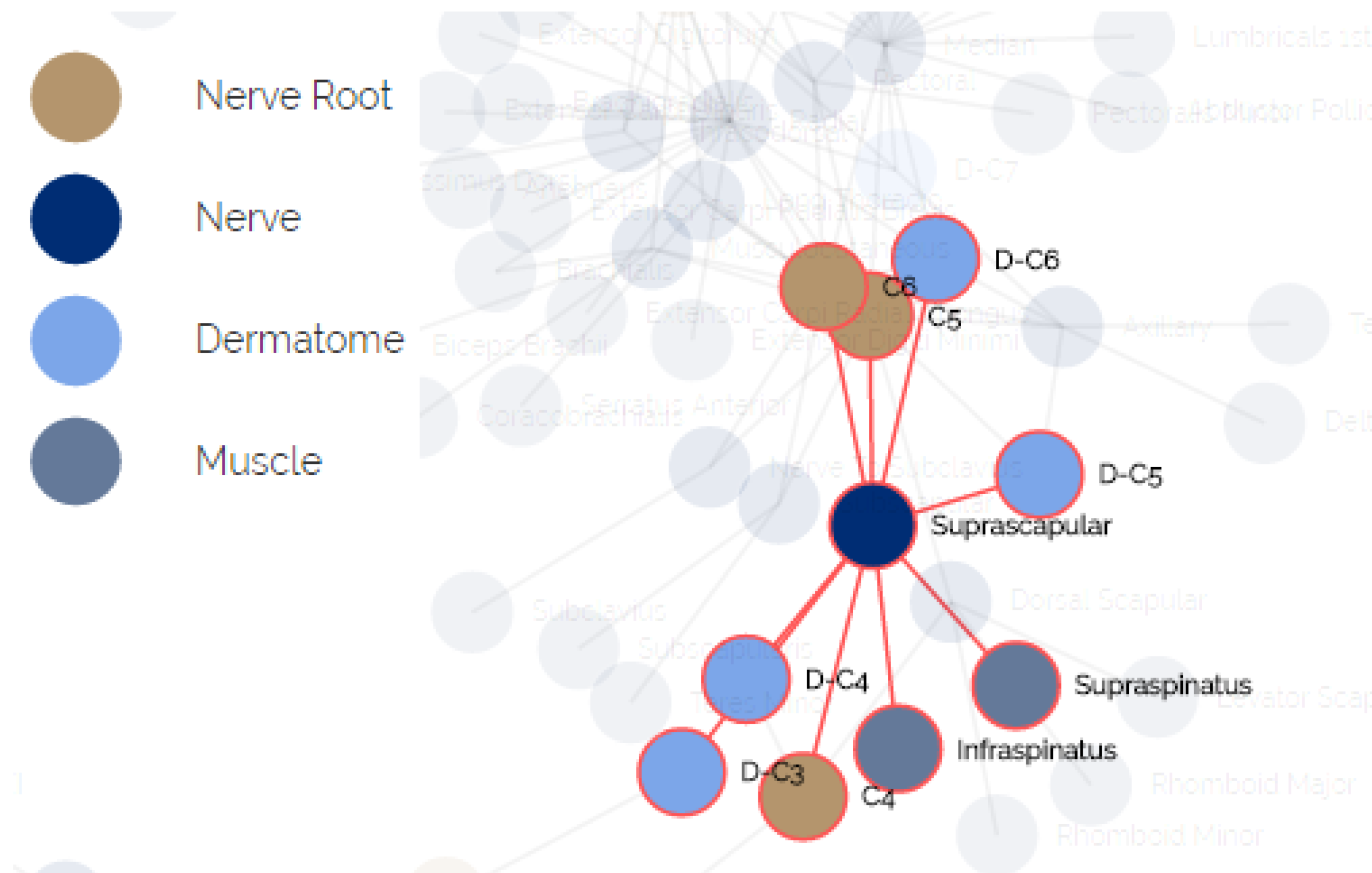
- The purpose of this module is to provide visualization of the anatomical entities in the human body, while allowing to focus on different structures. This module contains an inner navigation bar, to choose between one of several views: root nerves, nerves, muscles, dermatomes and relations. All maps but the latest focus on different component types and present the names of the relevant components on an illustration. The relations map is a hierarchical representation of the connections between the different entities. It is similar to the relationships graph in the relationships module, but its visualization focuses only on a specific component at a time. An example of this representation is shown in Figure 2. Clicking on one of the nodes constructs a graph of the dependencies of this node.
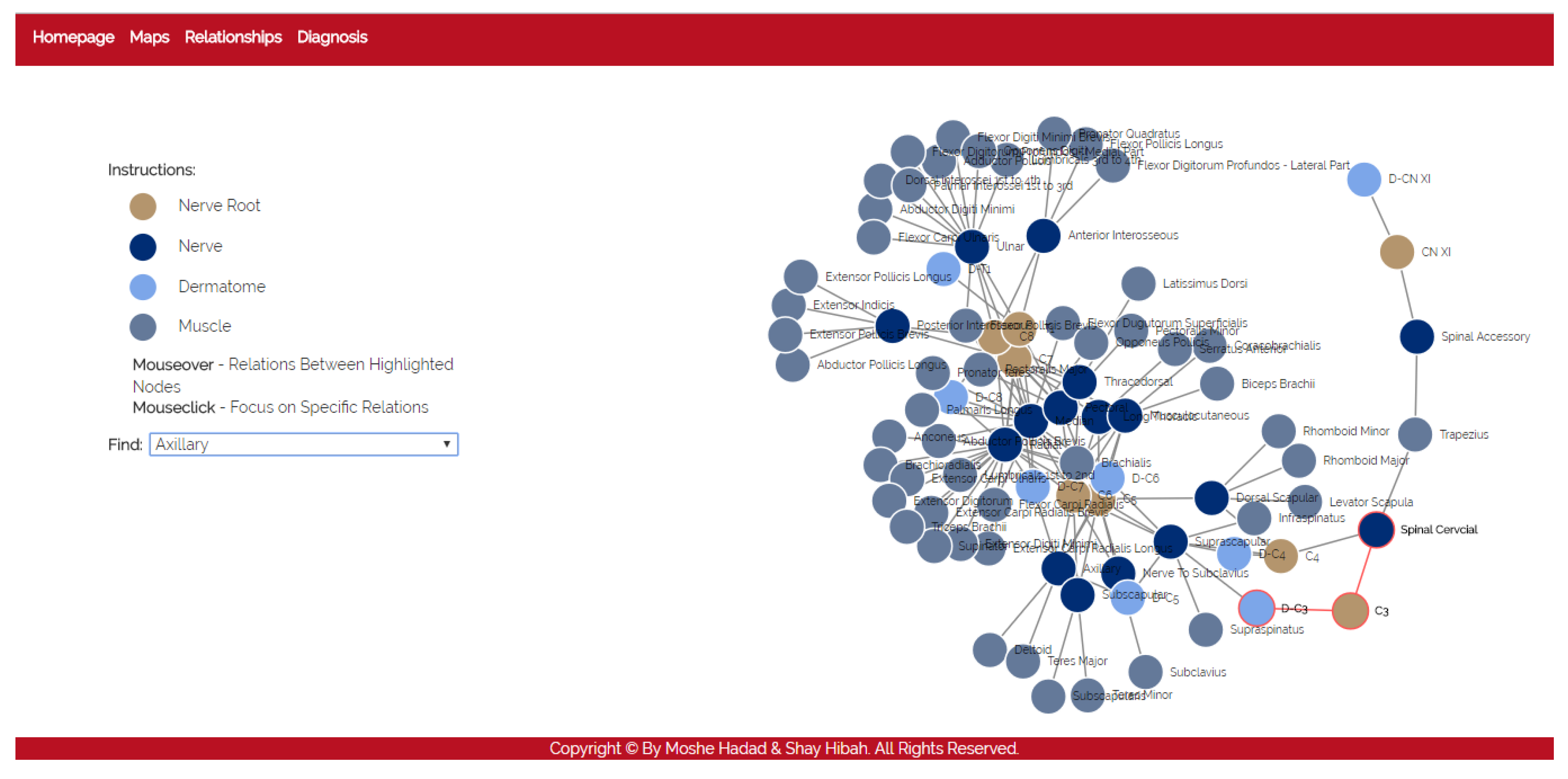
- Relationships
- The purpose of this module is to allow a thorough investigation of the relations between the different components of the body. The navigation through the different components can be performed either by using a drop-down list and choosing a specific item from it, or by clicking directly on a node in the graph. The complete relationship graph is presented in Figure 3. This module enables to dynamically navigate from one node to another, a feature which allows the PT to investigate causal connections.
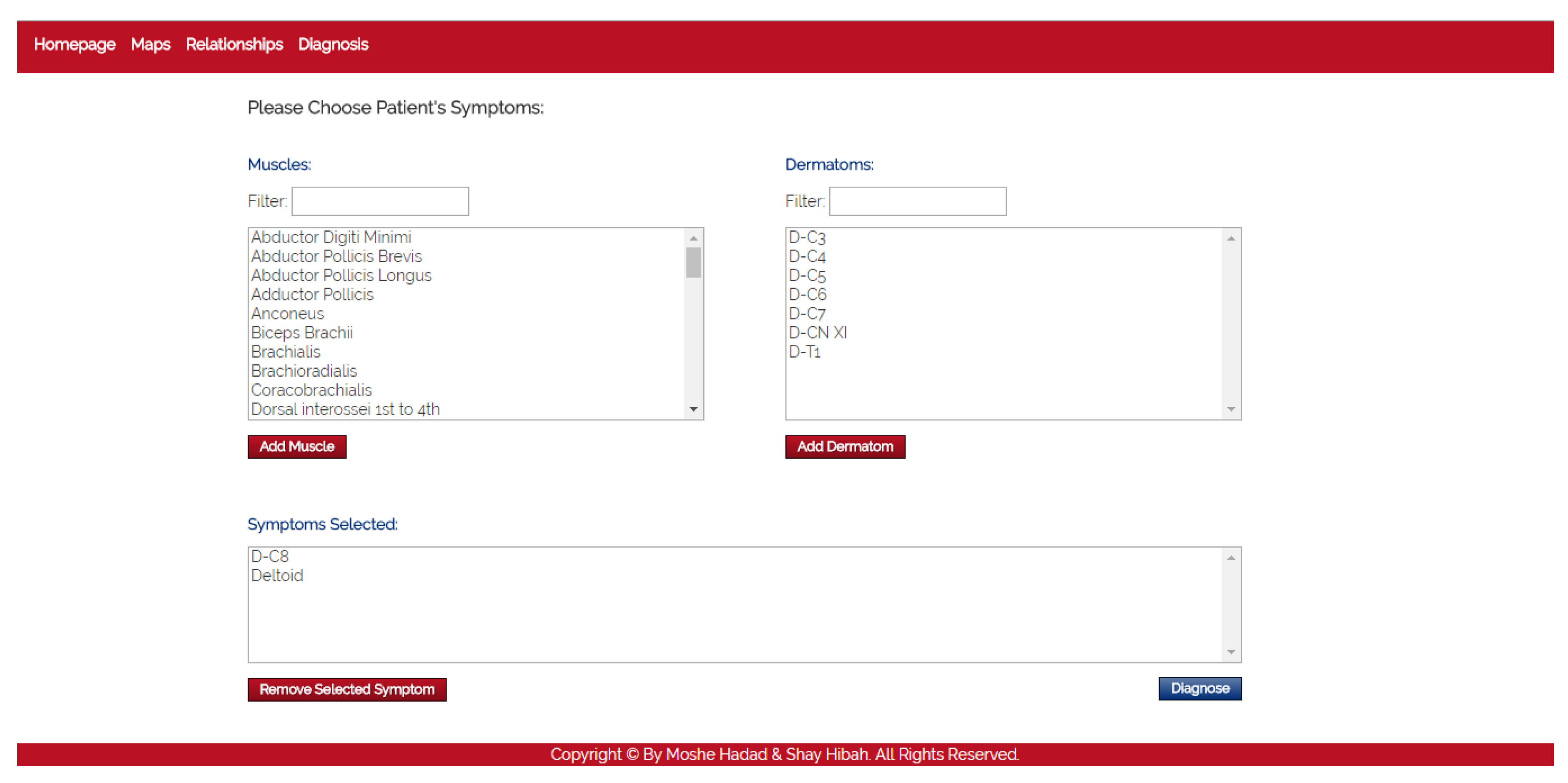
- Diagnosis
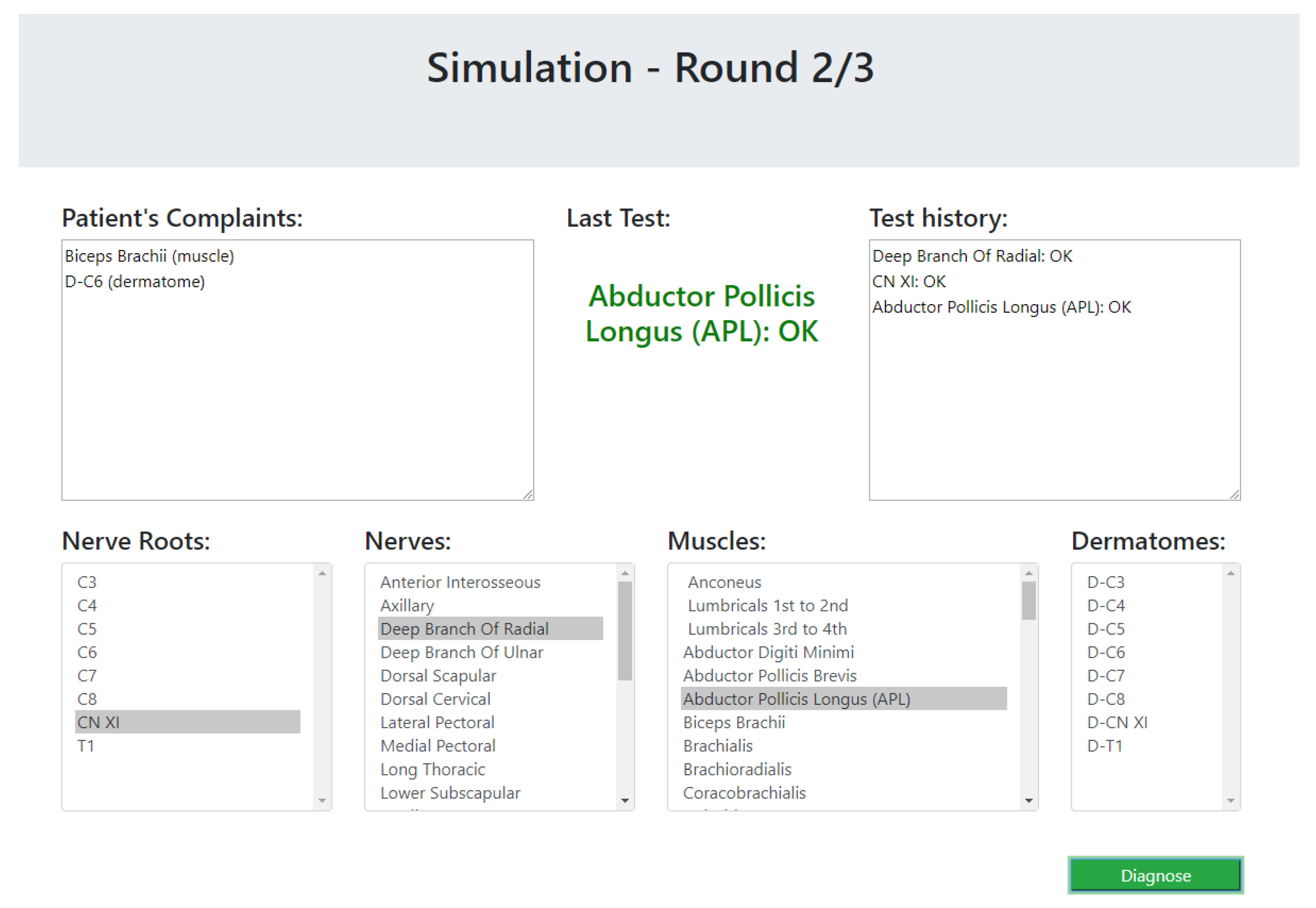
- The purpose of this module is to diagnose the patient, given a list of symptoms. The initial screen of this module is shown in Figure 4. This screen contains two lists of possible symptoms—muscles and dermatomes—which can be added by the PT. When the PT finishes adding initial symptoms, a click on the “Diagnose” button will trigger a recommendation for the next component to check, and then the system requests the PT to update whether the test passed or failed (the component works as expected or not). At any point, the PT can choose to stop this process and receive a list of the remaining diagnoses.
4. Technical Description
4.1. Model Description
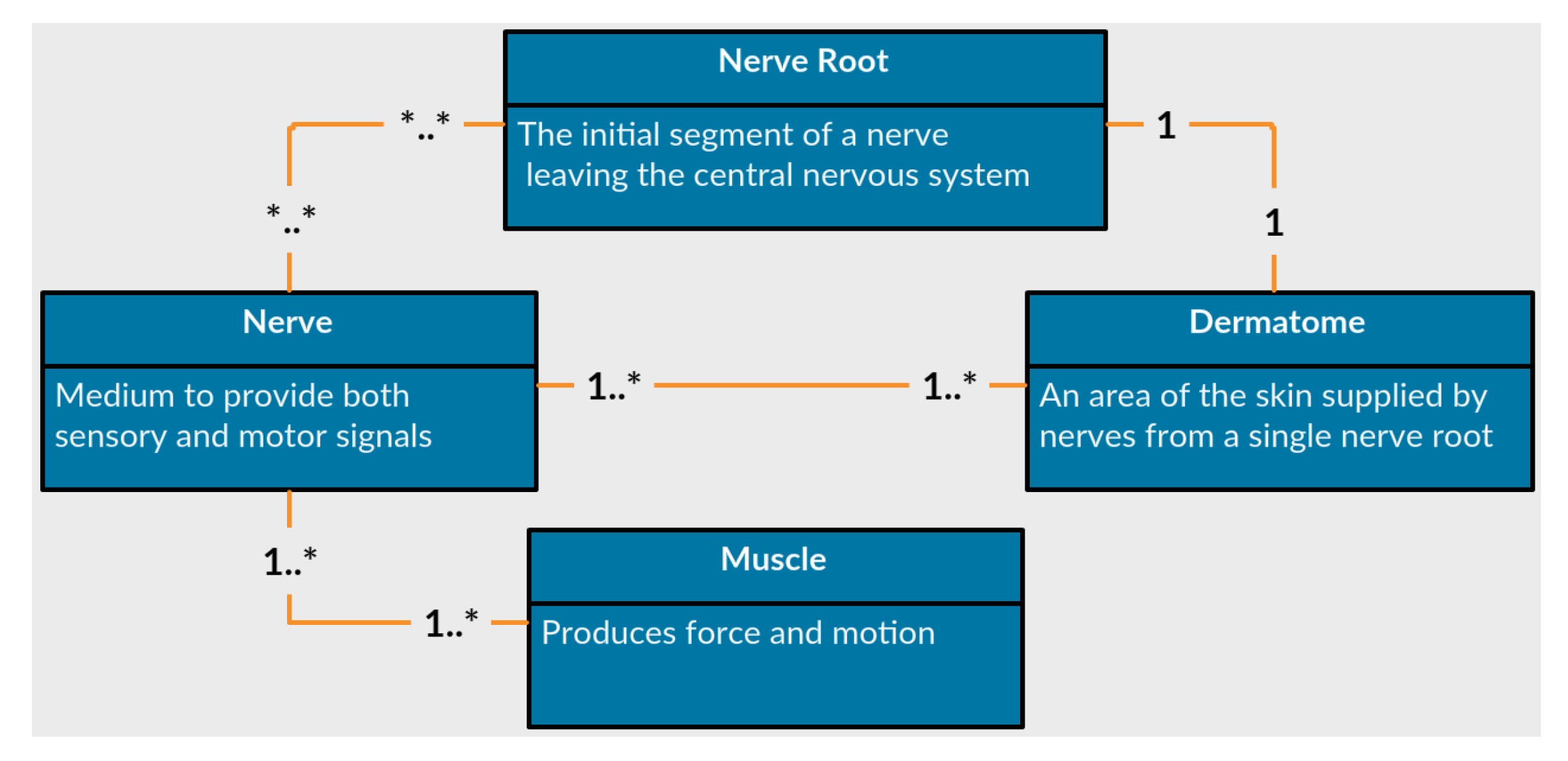
- Nerves
- are the common pathway for messages to be transmitted to peripheral organs. A damaged nerve can cause paralysis, pain or numbness in the innervated organs.
- Nerve Roots
- are the initial segments of a nerve affected by the central nervous system. They are located between the vertebrae and process all signals from the nerves. A damaged nerve root can cause paralysis, weakened movement, pain or numbness in vast areas of the body.
- Muscles
- are soft tissues that produce force and movement in the body. A damaged muscle can cause weakness, reduced mobility and pain.
- Dermatomes
- are sensory areas along the skin, which are traditionally divided according the relevant nerve roots that stimulate them. A damaged dermatome is usually caused by a scar or burn and can cause pain, numbness or lack of sense.
- The observations are symptoms or cues, reported by the patient or by the PT.
- Each observation is a signal that can be influenced by more than one component in the system. For example, a tingling sensation in the plantar side of the thumb is a signal from a specific dermatome called DC−6, which can be influenced by a problem in the respective root nerve C−6, or from a nerve called radial.
- The health state of a component cannot be directly evaluated, but must be inferred from observations. Thus, to test the radial nerve described above, the PT will try to cause a tingling sensation in the thumb or to find weakened movement in the hand extensor.
- The outcome of a test does not always directly implies the health state of a component, but can be masked by other components in the system. For example, inability to perform shoulder extension is a signal related to the deltoid muscle, but even when the deltoid is healthy, the extension might fail due to a problem in the radial nerve or the nerve root C−6.
4.2. The Diagnosis Process
4.2.1. COMPS
4.2.2. OBS
4.2.3. SD
- Transitivity: for a given component c, if (1) and (2) every component that affects c () is healthy () and (3) the inputs of are proper ), then it must hold that .
- Weak Fault Model (WFM): in this model we describe only the healthy behaviour of a component rather than its faulty modes. Thus, we cannot conclude anything about the success of a test () in case the component is faulty (). In addition, in case a test passed successfully, we cannot conclude that the component checked by this test is healthy. Only in case that a test failed, we can conclude that the tested component or one of its antecedents is faulty.
4.3. The Troubleshooting Process
| Algorithm 1: Probing Process |
 |
5. Performance Analysis
5.1. Scenario Simulator
5.2. Results
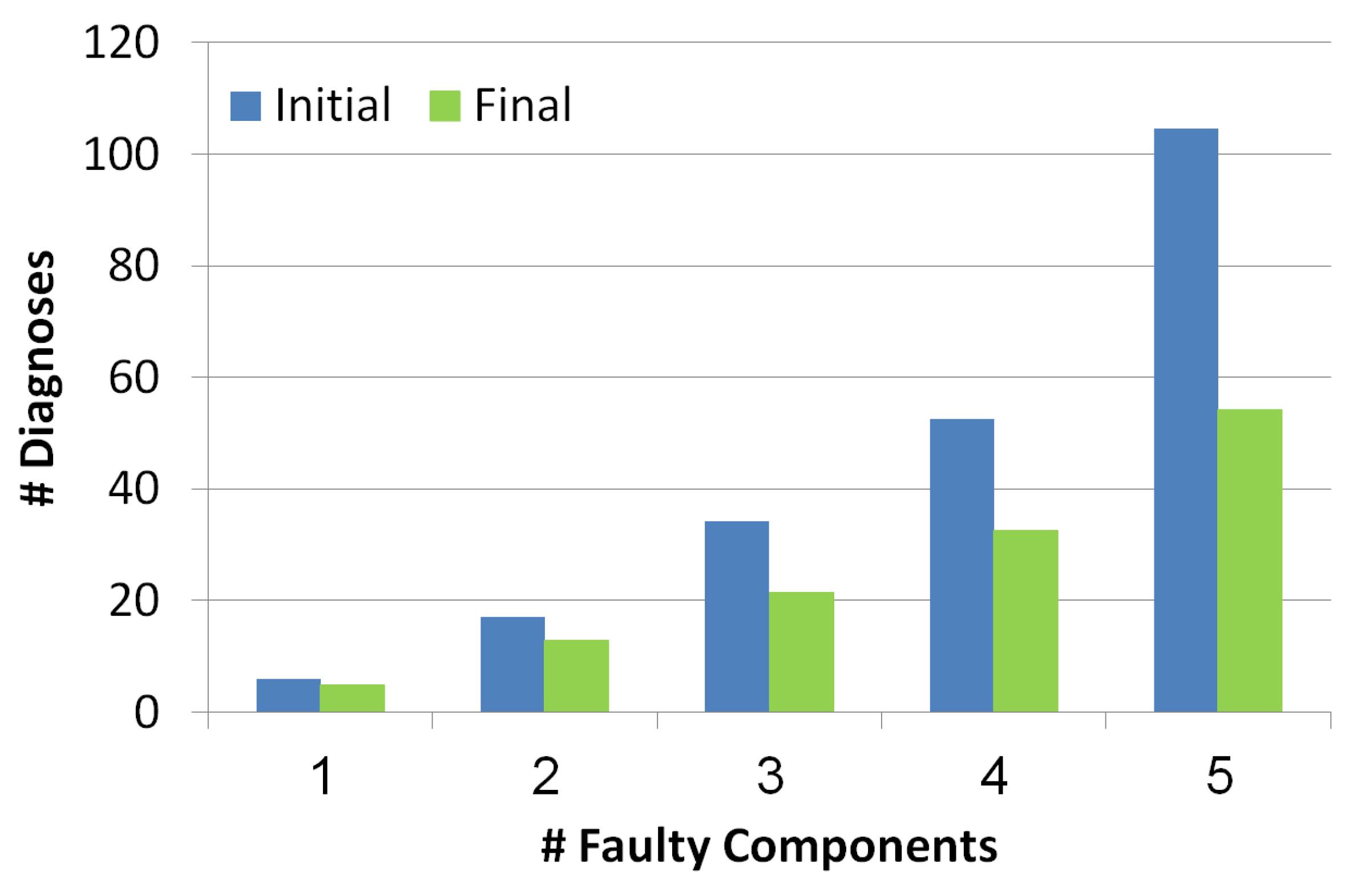
5.2.1. Diagnosis Set Size
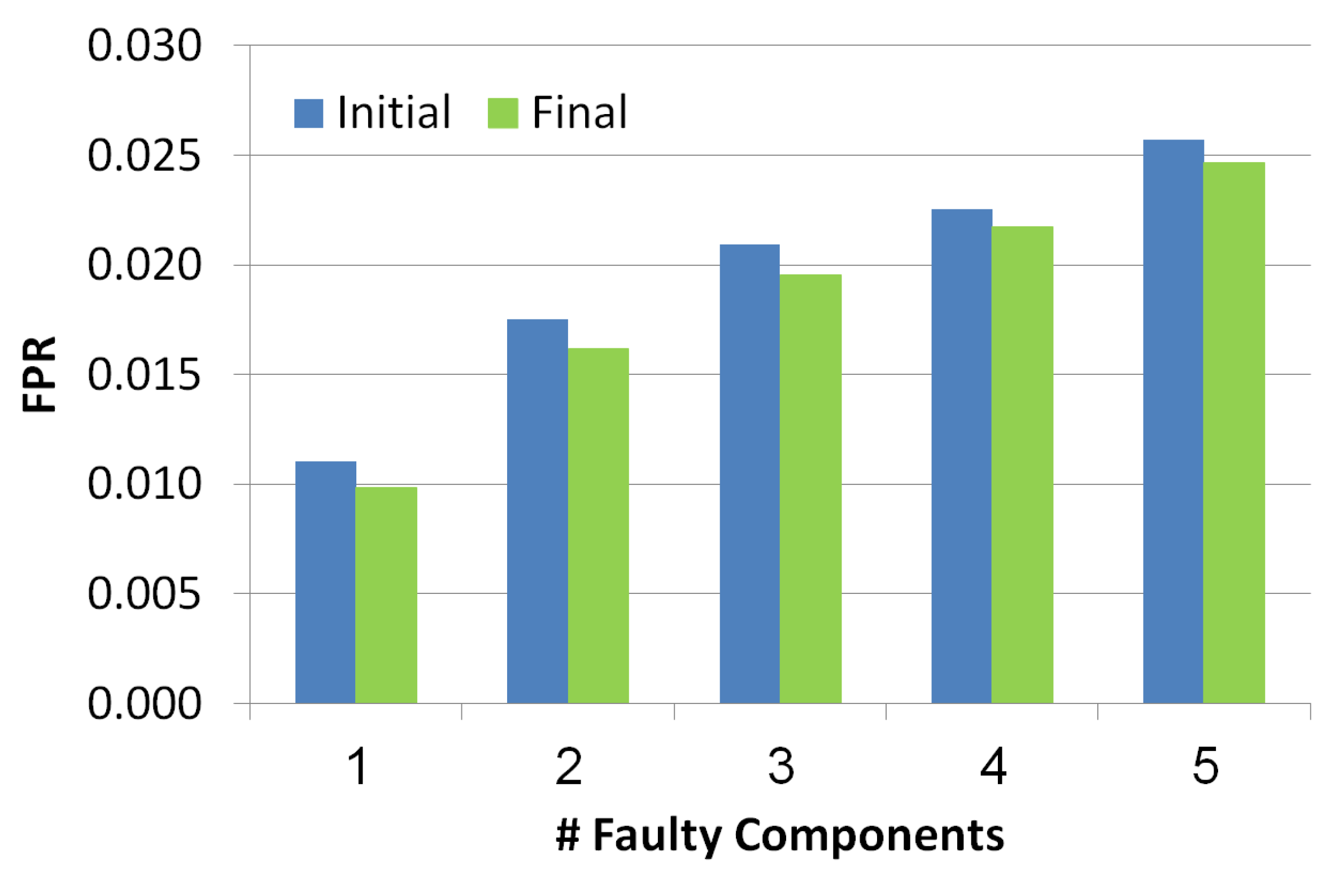
5.2.2. False Positive Rate (FPR)
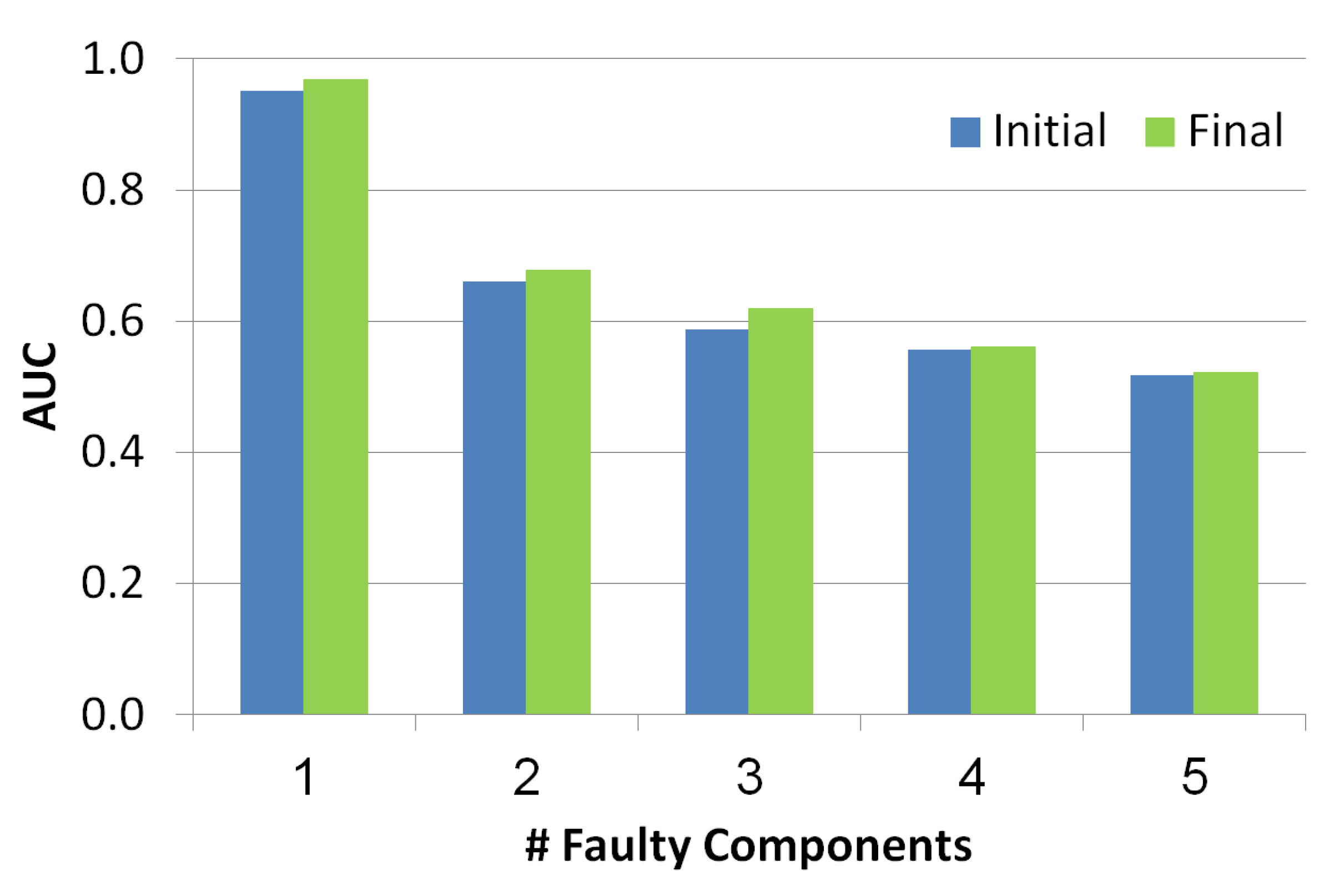
5.2.3. Area Under the Curve (AUC)
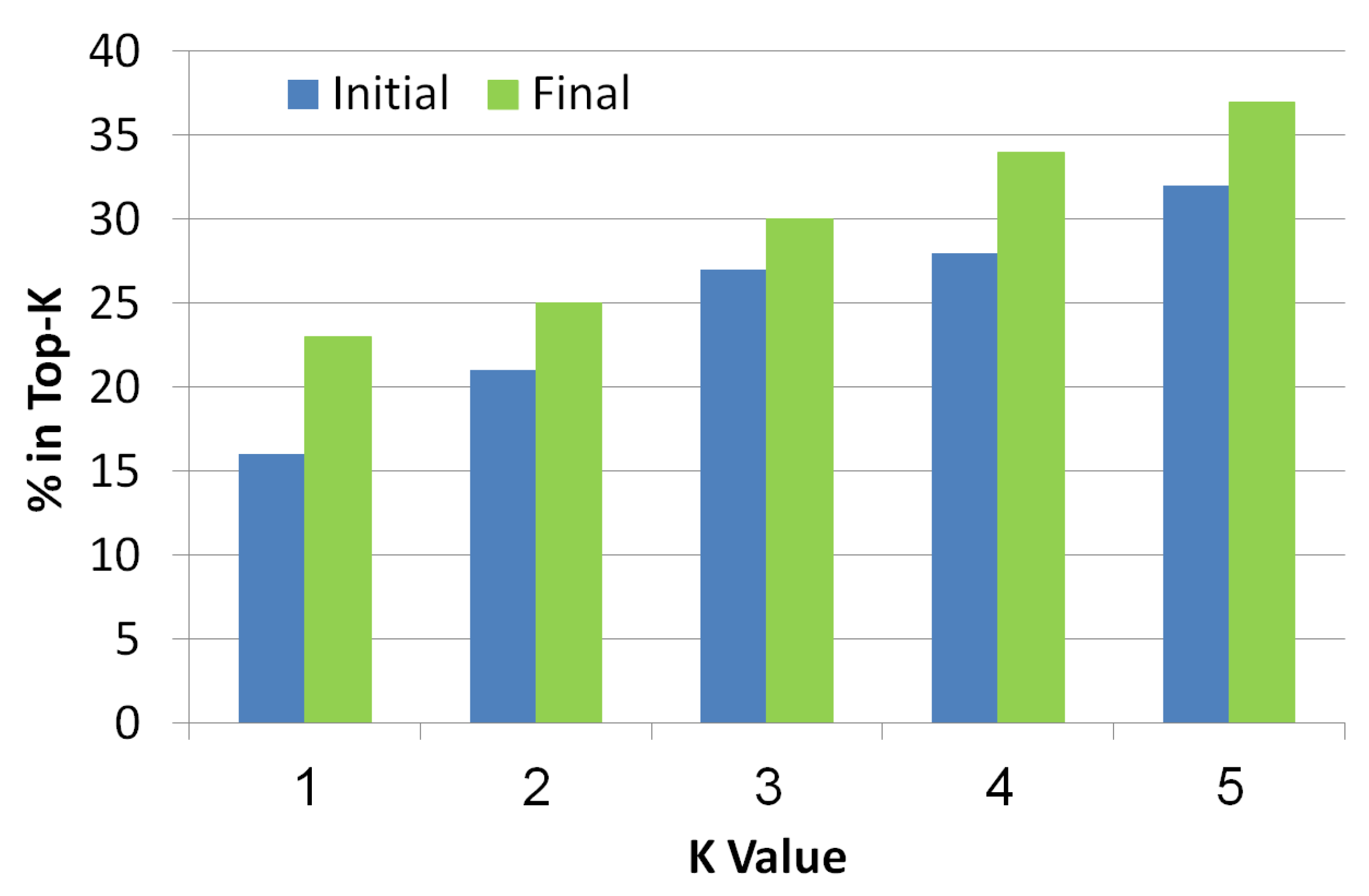
5.2.4. Top-K
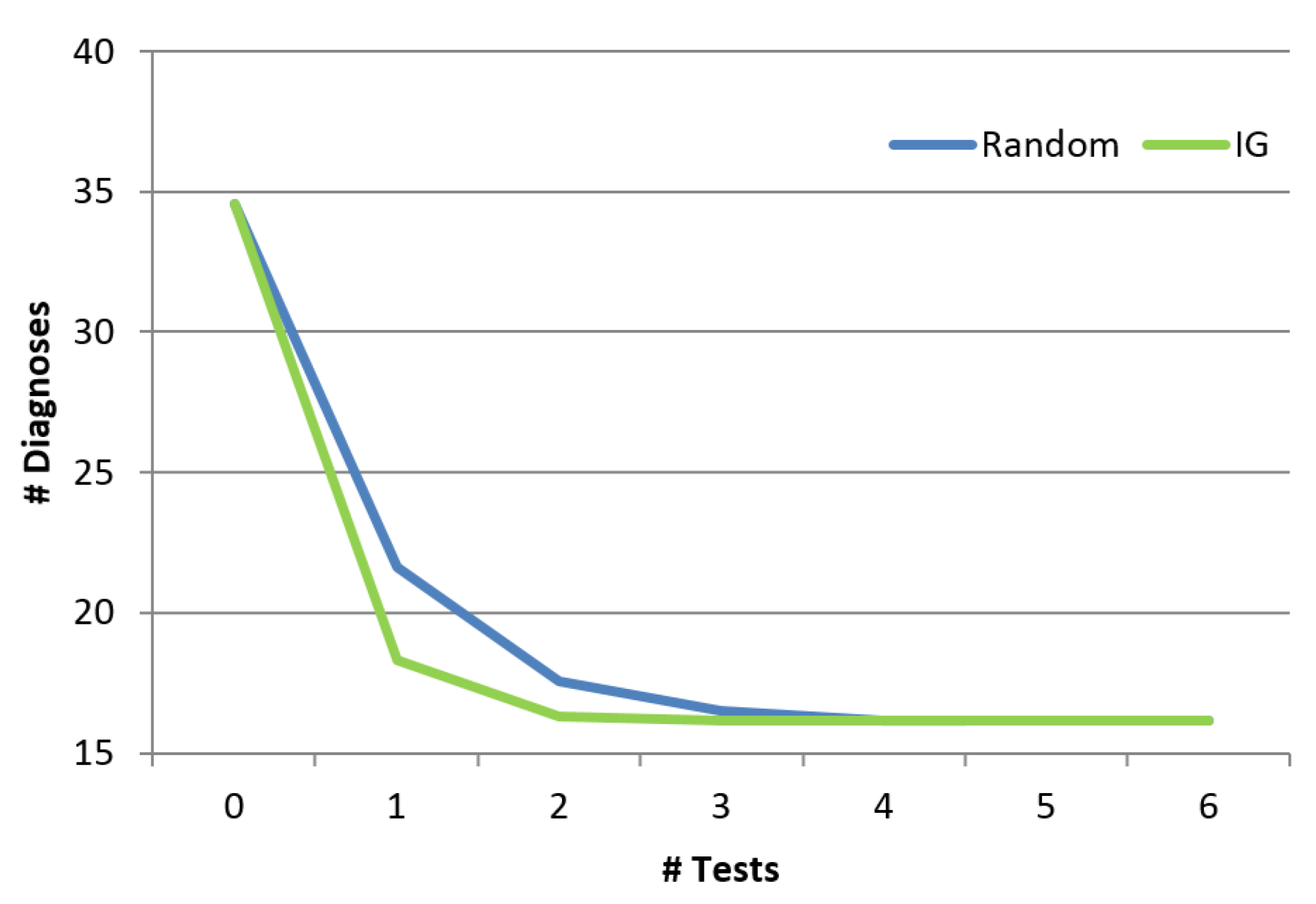
5.2.5. Comparing to Random
5.3. Real-World Scenarios
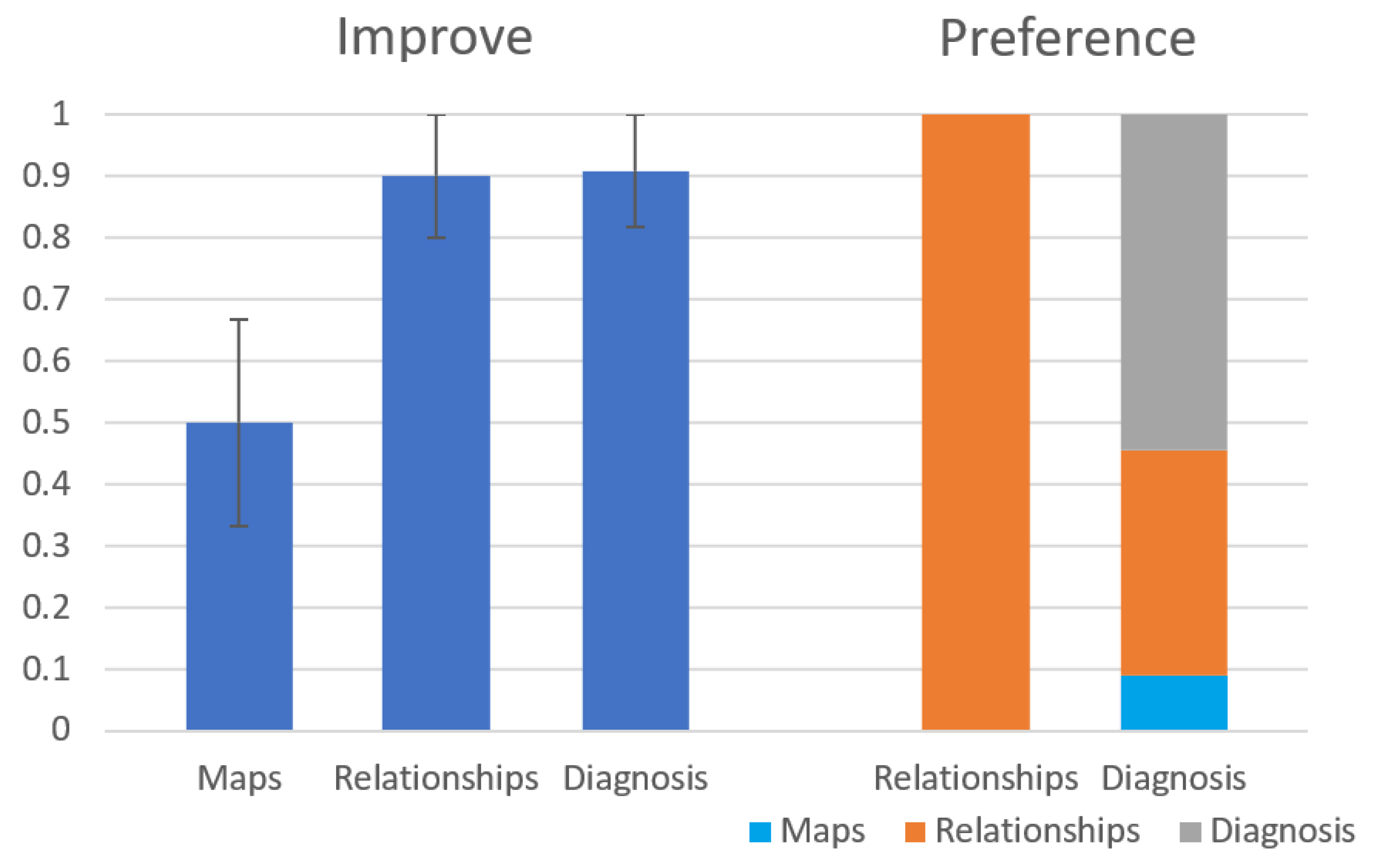
6. User Study
Experimental Setup
| 1. | Improve: | Did the system improve your choice of tests to perform? |
| (yes/no) | ||
| 2. | Clear: | Was the system easy to understand? |
| (5-point scale) | ||
| 3. | Use: | Was the system easy to use? |
| (5-point scale) | ||
| 4. | Preference: | Which of the components did you use the most? |
| (choice between available components) | ||
| 5. | Open: | In your opinion, was there something that was missing in the system? |
| (open question) |
7. Conclusions and Future Work
- A malfunction in the muscle is usually reported by the patient as a mobility issue. Identifying the relevant muscle based on motion disability or pain is part of the clinical evaluation, which is not presented in our model. We intend to extend the system to include “movement” entities and their relations to muscles and nerves.
- In practice, most tests do not output a binary result and a component can have more states rather than and . We wish to augment probabilities in our model - both to represent a degree of “faultiness” and to be able to evaluate the impact of batches of tests.
- As shown in previous papers, abduction with a model of abnormal behaviour is a much better way to deal with medical diagnosis. To this aim we plan to achieve more information about the abnormal behaviour of components and integrate it in our model in order to discard redundant diagnoses.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jones, M.A.; Jensen, G.; Edwards, I. Clinical reasoning in physiotherapy. Clin. Reason. Health Prof. 2008, 3, 117–127. [Google Scholar]
- de Kleer, J.; Williams, B.C. Diagnosing Multiple faults. Artif. Intell. 1987, 32, 97–130. [Google Scholar] [CrossRef]
- Reiter, R. A theory of diagnosis from first principles. Artif. Intell. 1987, 32, 57–95. [Google Scholar] [CrossRef]
- Stern, R.T.; Kalech, M.; Feldman, A.; Provan, G.M. Exploring the Duality in Conflict-Directed Model-Based Diagnosis. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Metodi, A.; Stern, R.; Kalech, M.; Codish, M. A Novel SAT-Based Approach to Model Based Diagnosis. J. Artif. Intell. Res. (JAIR) 2014, 51, 377–411. [Google Scholar] [CrossRef] [Green Version]
- Feldman, A.; Provan, G.; van Gemund, A. A model-based active testing approach to sequential diagnosis. J. Artif. Intell. Res. (JAIR) 2010, 39, 301. [Google Scholar] [CrossRef]
- Wagner, W.P. Trends in expert system development: A longitudinal content analysis of over thirty years of expert system case studies. Expert Syst. Appl. 2017, 76, 85–96. [Google Scholar] [CrossRef]
- Patel, S.; Patel, H. Survey of data mining techniques used in healthcare domain. Int. J. Inf. 2016, 6, 53–60. [Google Scholar] [CrossRef]
- Lucas, P.J.F.; Orihuela-Espina, F. Representing Knowledge for Clinical Diagnostic Reasoning. In Foundations of Biomedical Knowledge Representation: Methods and Applications; Hommersom, A., Lucas, P.J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 35–45. [Google Scholar] [CrossRef]
- Stern, R.; Kalech, M.; Rogov, S.; Feldman, A. How Many Diagnoses Do We Need? In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI’15, Austin, TX, USA, 25–30 January 2015; pp. 1618–1624. [Google Scholar]
- Stern, R.; Kalech, M.; Rogov, S.; Feldman, A. How Many Diagnoses Do We Need? Artif. Intell. 2017, 248, 26–45. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis; Wiley Online Library: Hoboken, NJ, USA, 2005. [Google Scholar] [CrossRef]
- Isermann, R. Model-based fault detection and diagnosis: Status and applications. In Proceedings of the 16th IFAC Symposium on Automatic Control in Aerospace, St. Petersburg, Russia, 14–18 June 2004; pp. 71–85. [Google Scholar]
- Economou, G.P.; Lymberopoulos, D.; Karavatselou, E.; Chassomeris, C. A new concept toward computer-aided medical diagnosis-a prototype implementation addressing pulmonary diseases. IEEE Trans. Inf. Technol. Biomed. 2001, 5, 55–65. [Google Scholar] [CrossRef]
- Sánchez-Garzón, I.; González-Ferrer, A.; Fernández-Olivares, J. A knowledge-based architecture for the management of patient-focused care pathways. Appl. Intell. 2014, 40, 497–524. [Google Scholar] [CrossRef]
- Akerkar, R.A.; Sajja, P.S. Knowledge-Based Systems; Jones and Bartlett Publishers: Burlington, MA, USA, 2010. [Google Scholar]
- Wagholikar, K.B.; Sundararajan, V.; Deshpande, A.W. Modeling paradigms for medical diagnostic decision support: A survey and future directions. J. Med. Syst. 2012, 36, 3029–3049. [Google Scholar] [CrossRef]
- Arya, C.; Tiwari, R. Expert system for breast cancer diagnosis: A survey. In Proceedings of the 2016 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 7–9 January 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Ambilwade, R.; Manza, R.; Gaikwad, B.P. Medical expert systems for diabetes diagnosis: A survey. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2014, 4, 647–652. [Google Scholar]
- Tomar, D.; Agarwal, S. A survey on Data Mining approaches for Healthcare. Int. J. Bio-Sci. Bio-Technol. 2013, 5, 241–266. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bonato, P.; Sherrill, D.M.; Standaert, D.G.; Salles, S.S.; Akay, M. Data mining techniques to detect motor fluctuations in Parkinson’s disease. In Proceedings of the 26th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Francisco, CA, USA, 1–5 September 2004; Volume 2, pp. 4766–4769. [Google Scholar]
- Zorman, M.; Masuda, G.; Kokol, P.; Yamamoto, R.; Stiglic, B. Mining diabetes database with decision trees and association rules. In Proceedings of the 15th IEEE Symposium on Computer-Based Medical Systems (CBMS 2002), Maribor, Slovenia, 4–7 June 2002; pp. 134–139. [Google Scholar]
- Lucas, P.J. Model-based diagnosis in medicine. Artif. Intell. Med. Spec. Issues 1997, 10. [Google Scholar] [CrossRef]
- Reggia, J.A.; Nau, D.S.; Wang, P.Y. Diagnostic expert systems based on a set covering model. Int. J. Man-Mach. Stud. 1983, 19, 437–460. [Google Scholar] [CrossRef]
- Cruz, J.; Barahona, P. A causal-functional model applied to EMG diagnosis. In Conference on Artificial Intelligence in Medicine in Europe; Springer: Berlin/Heidelberg, Germany, 1997; pp. 247–260. [Google Scholar]
- Console, L.; Dupré, D.T.; Torasso, P. A Theory of Diagnosis for Incomplete Causal Models. In Proceedings of the Eleventh International Joint Conference (IJCAI-89), Detroit, MI, USA, 20–25 August 1989; pp. 1311–1317. [Google Scholar]
- Sebastiani, P.; Abad, M.M.; Ramoni, M.F. Bayesian Networks. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2005; pp. 193–230. [Google Scholar] [CrossRef]
- de Kleer, J. An assumption-based truth maintenance system. Artif. Intell. 1986, 28, 127–162. [Google Scholar] [CrossRef]
- Downing, K.L. Physiological applications of consistency-based diagnosis. Artif. Intell. Med. 1993, 5, 9–30. [Google Scholar] [CrossRef]
- Gamper, J.; Nejdl, W. Abstract temporal diagnosis in medical domains. Artif. Intell. Med. 1997, 10, 209–234. [Google Scholar] [CrossRef] [Green Version]
- Weiss, S.M.; Kulikowski, C.A.; Amarel, S.; Safir, A. A model-based method for computer-aided medical decision-making. Artif. Intell. 1978, 11, 145–172. [Google Scholar] [CrossRef] [Green Version]
- Citro, G.; Banks, G.; Cooper, G. INKBLOT: A neurological diagnostic decision support system integrating causal and anatomical knowledge. Artif. Intell. Med. 1997, 10, 257–267. [Google Scholar] [CrossRef]
- Wainer, J.; de Melo Rezende, A. A temporal extension to the parsimonious covering theory. Artif. Intell. Med. 1997, 10, 235–255. [Google Scholar] [CrossRef]
- Peng, Y.; Reggia, J.A. Abductive Inference Models for Diagnostic Problem-Solving; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Patel, V.L.; Arocha, J.F.; Zhang, J. Thinking and reasoning in medicine. Camb. Handb. Think. Reason. 2005, 14, 727–750. [Google Scholar]
- Brusoni, V.; Console, L.; Terenziani, P.; Dupré, D.T. A spectrum of definitions for temporal model-based diagnosis. Artif. Intell. 1998, 102, 39–79. [Google Scholar] [CrossRef]
- Pukancová, J.; Homola, M. Abductive Reasoning with Description Logics: Use Case in Medical Diagnosis. In Description Logics; Journal of Artificial Intelligence Research: El Segundo, CA, USA, 2015. [Google Scholar]
- Console, L.; Torasso, P. On the co-operation between abductive and temporal reasoning in medical diagnosis. Artif. Intell. Med. 1991, 3, 291–311. [Google Scholar] [CrossRef]
- Huang, Y.; McMurran, R.; Dhadyalla, G.; Jones, R.P. Probability based vehicle fault diagnosis: Bayesian network method. J. Intell. Manuf. 2008, 19, 301–311. [Google Scholar] [CrossRef]
- Mengshoel, O.J.; Chavira, M.; Cascio, K.; Poll, S.; Darwiche, A.; Uckun, S. Probabilistic model-based diagnosis: An electrical power system case study. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2010, 40, 874–885. [Google Scholar] [CrossRef] [Green Version]
- Steinder, M.; Sethi, A.S. Probabilistic fault localization in communication systems using belief networks. IEEE/ACM Trans. Netw. 2004, 12, 809–822. [Google Scholar] [CrossRef]
- Hood, C.S.; Ji, C. Probabilistic network fault detection. In Proceedings of the GLOBECOM’96, 1996 IEEE Global Telecommunications Conference, Communications: The Key to Global Prosperity, London, UK, 18–28 November 1996; Volume 3, pp. 1872–1876. [Google Scholar]
- Schvaneveldt, R.W. Pathfinder Associative Networks: Studies in Knowledge Organization; Ablex Publishing: New York, NY, USA, 1990. [Google Scholar]
- Nathwani, B.N.; Clarke, K.; Lincoln, T.; Berard, C.; Taylor, C.; Ng, K.; Patil, R.; Pike, M.C.; Azen, S.P. Evaluation of an expert system on lymph node pathology. Hum. Pathol. 1997, 28, 1097–1110. [Google Scholar] [CrossRef]
- Velikova, M.; Dutra, I.; Burnside, E.S. Automated Diagnosis of Breast Cancer on Medical Images. In Foundations of Biomedical Knowledge Representation: Methods and Applications; Hommersom, A., Lucas, P.J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 47–67. [Google Scholar] [CrossRef] [Green Version]
- Andreassen, S.; Woldbye, M.; Falck, B.; Andersen, S.K. MUNIN: A causal probabilistic network for interpretation of electromyographic findings. In Proceedings of the 10th International Joint Conference on Artificial Intelligence, Milan, Italy, 23–29 August 1987; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1987; Volume 1, pp. 366–372. [Google Scholar]
- Suojanen, M.; Andreassen, S.; Olesen, K.G. A method for diagnosing multiple diseases in MUNIN. IEEE Trans. Biomed. Eng. 2001, 48, 522–532. [Google Scholar] [CrossRef]
- Mcilraith, S.A. Towards a Theory of Diagnosis, Testing and Repair. In Proceedings of the Fifth International Workshop on Principles of Diagnosis; Morgan Kaufmann: New Paltz, NY, USA, 1994; pp. 185–192. [Google Scholar]
- Sampath, M.; Lafortune, S.; Teneketzis, D. Active diagnosis of discrete-event systems. IEEE Trans. Autom. Control. 1998, 43, 908–929. [Google Scholar] [CrossRef]
- Haar, S.; Haddad, S.; Melliti, T.; Schwoon, S. Optimal Constructions for Active Diagnosis. In Proceedings of the IARCS Annual Conference on Foundations of Software Technology and Theoretical Computer Science, FSTTCS, Guwahati, India, 12–14 December 2013; pp. 527–539. [Google Scholar]
- Cassez, F.; Tripakis, S. Fault Diagnosis with Static and Dynamic Observers. Fundam. Inform. 2008, 88, 497–540. [Google Scholar]
- Debouk, R.; Lafortune, S.; Teneketzis, D. On an optimization problem in sensor selection. Discret. Event Dyn. Syst. 2002, 12, 417–445. [Google Scholar] [CrossRef]
- Mirsky, R.; Stern, R.; Gal, Y.; Kalech, M. Sequential Plan Recognition. In Proceedings of the International Joint Conference of Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016. [Google Scholar]
- McSherry, D. Sequential Diagnosis in the Independence Bayesian Framework. In Soft-Ware 2002: Computing in an Imperfect World: First International Conference, Soft-Ware 2002 Belfast, Northern Ireland, April 8–10, 2002 Proceedings; Bustard, D., Liu, W., Sterritt, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 217–231. [Google Scholar] [CrossRef]
- Heckerman, D.; Breese, J.S.; Rommelse, K. Decision-theoretic troubleshooting. Commun. ACM 1995, 38, 49–57. [Google Scholar] [CrossRef]
- de Kleer, J.; Raiman, O. Trading off the Costs of Inference vs. In Probing in Diagnosis. In Proceedings of the IJCAI 1995, Montreal, QC, Canada, 20–25 August 1995; pp. 1736–1741. [Google Scholar]
- McSherry, D. Interactive case-based reasoning in sequential diagnosis. Appl. Intell. 2001, 14, 65–76. [Google Scholar] [CrossRef]
- Xudong, W.; Biswas, G.; Weinberg, J. MDS: An integrated architecture for associational and model-based diagnosis. Appl. Intell. 2001, 14, 179–195. [Google Scholar]
- Brodie, M.; Rich, I.; Ma, S. Intelligence Probing: A Cost-Effective Approach to Fault Diagnosis Computer Networks. IBM Syst. J. 2002, 41, 372–385. [Google Scholar] [CrossRef]
- Zamir, T.; Stern, R.; Kalech, M. Using Model-Based Diagnosis to Improve Software Testing. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Landi, C.; van Gemund, A.; Zanella, M. Heuristics to Increase Observability in Spectrum-based Fault Localization. In Proceedings of the European Conference on Artificial Intelligence (ECAI), Prague, Czech Republic, 18–22 August 2014; pp. 1053–1054. [Google Scholar]
- Nica, I.; Pill, I.; Quaritsch, T.; Wotawa, F. The Route to Success: A Performance Comparison of Diagnosis Algorithms. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, IJCAI ’13, Beijing, China, 3–9 August 2013; pp. 1039–1045. [Google Scholar]
- Williams, B.C.; Ragno, R.J. Conflict-directed A* and its role in model-based embedded systems. Discret. Appl. Math. 2007, 155, 1562–1595. [Google Scholar] [CrossRef] [Green Version]
- Torta, G.; Torasso, P. The Role of OBDDs in Controlling the Complexity of Model Based Diagnosis. In Proceedings of the 15th International Workshop on Principles of Diagnosis (DX04), Carcassonne, France, 23–25 June 2004; pp. 9–14. [Google Scholar]
- Darwiche, A. Decomposable Negation Normal Form. J. ACM 2001, 48, 608–647. [Google Scholar] [CrossRef]
- Metodi, A.; Stern, R.; Kalech, M.; Codish, M. Compiling Model-Based Diagnosis to Boolean Satisfaction. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Rutenburg, V. Propositional truth maintenance systems: Classification and complexity analysis. Ann. Math. Artif. Intell. 1994, 10, 207–231. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Netter, F.H.; Colacino, S. Atlas of Human Anatomy; Ciba-Geigy Corporation: Basel, Switzerland, 1989. [Google Scholar]
- Netter’s 3D Anatomy. 2018. Available online: http://netter3danatomy.com/ (accessed on 28 January 2020).
- Healthline Human Body Maps. 2005. Available online: https://www.healthline.com/human-body-maps (accessed on 28 January 2020).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| FPR | 0.11 | 0.08 | 0.06 | 0.03 | 0.04 |
| AUC | 0.01 | 0.05 | 0.05 | 0.01 | 0.03 |
| Wasted Effort | 0.15 | 0.25 | 0.42 | 0.44 | 0.54 |
| Top-5 | 0.05 | 0.24 | 0.67 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mirsky, R.; Hibah, S.; Hadad, M.; Gorenstein, A.; Kalech, M. “PhysIt”—A Diagnosis and Troubleshooting Tool for Physiotherapists in Training. Diagnostics 2020, 10, 72. https://doi.org/10.3390/diagnostics10020072
Mirsky R, Hibah S, Hadad M, Gorenstein A, Kalech M. “PhysIt”—A Diagnosis and Troubleshooting Tool for Physiotherapists in Training. Diagnostics. 2020; 10(2):72. https://doi.org/10.3390/diagnostics10020072
Chicago/Turabian StyleMirsky, Reuth, Shay Hibah, Moshe Hadad, Ariel Gorenstein, and Meir Kalech. 2020. "“PhysIt”—A Diagnosis and Troubleshooting Tool for Physiotherapists in Training" Diagnostics 10, no. 2: 72. https://doi.org/10.3390/diagnostics10020072
APA StyleMirsky, R., Hibah, S., Hadad, M., Gorenstein, A., & Kalech, M. (2020). “PhysIt”—A Diagnosis and Troubleshooting Tool for Physiotherapists in Training. Diagnostics, 10(2), 72. https://doi.org/10.3390/diagnostics10020072