
Multi-Contrast MRI Image Synthesis Using Switchable Cycle-Consistent Generative Adversarial Networks

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. MRI Data
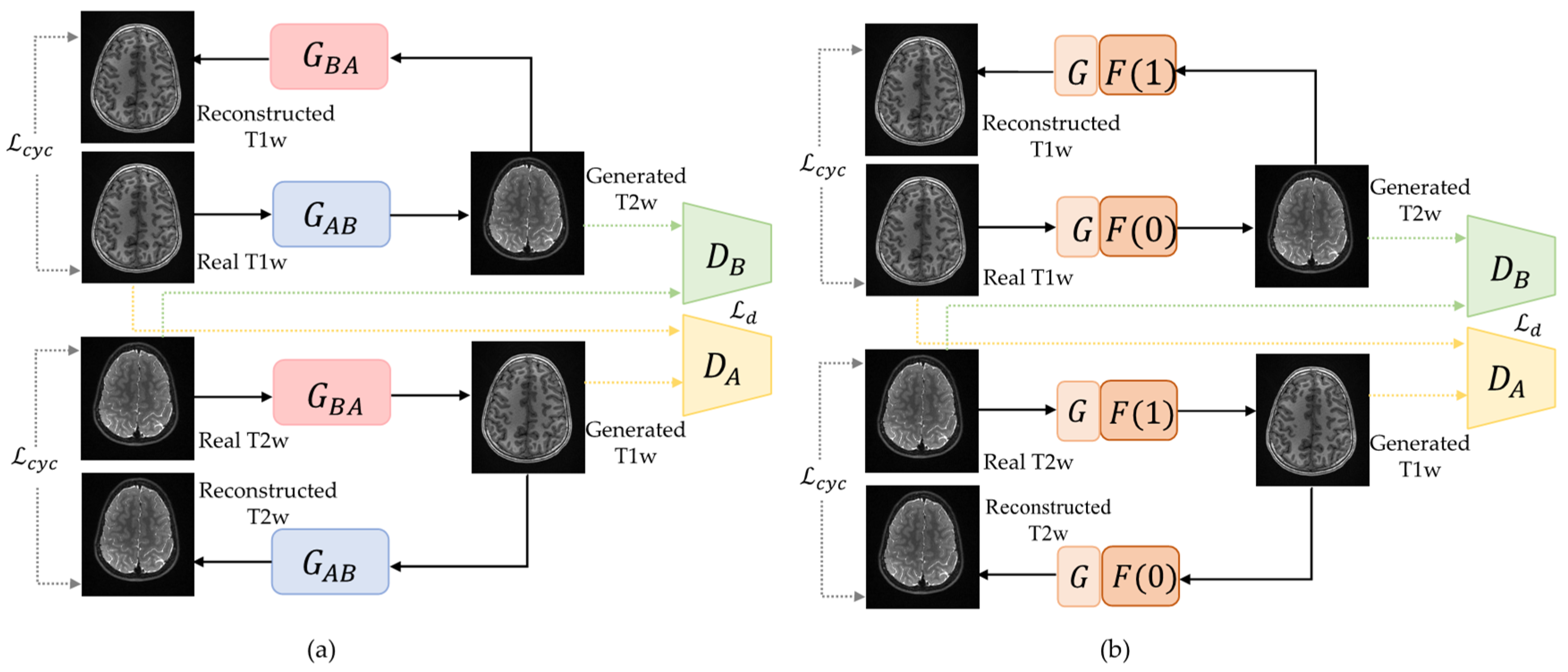
2.2. Overview of Switchable CycleGAN
2.3. Network Architecture of Switchable CycleGAN
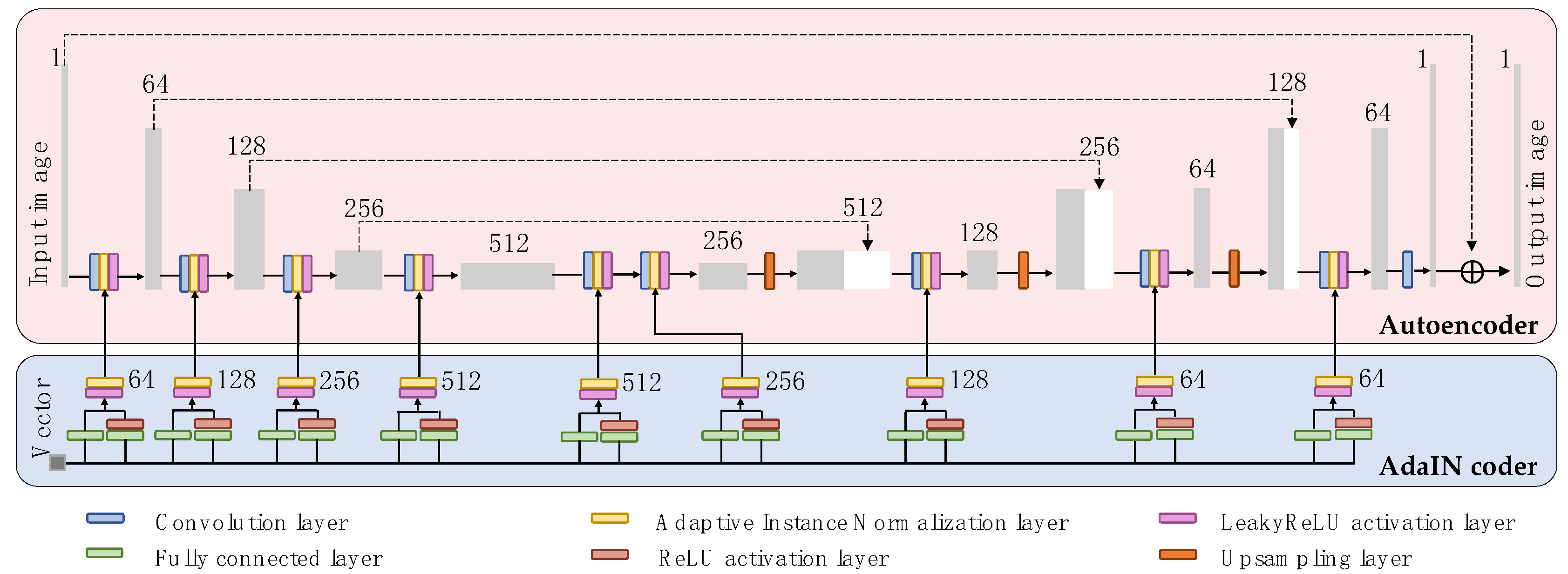
2.3.1. Generator
Autoencoder Module
AdaIN Coder Module
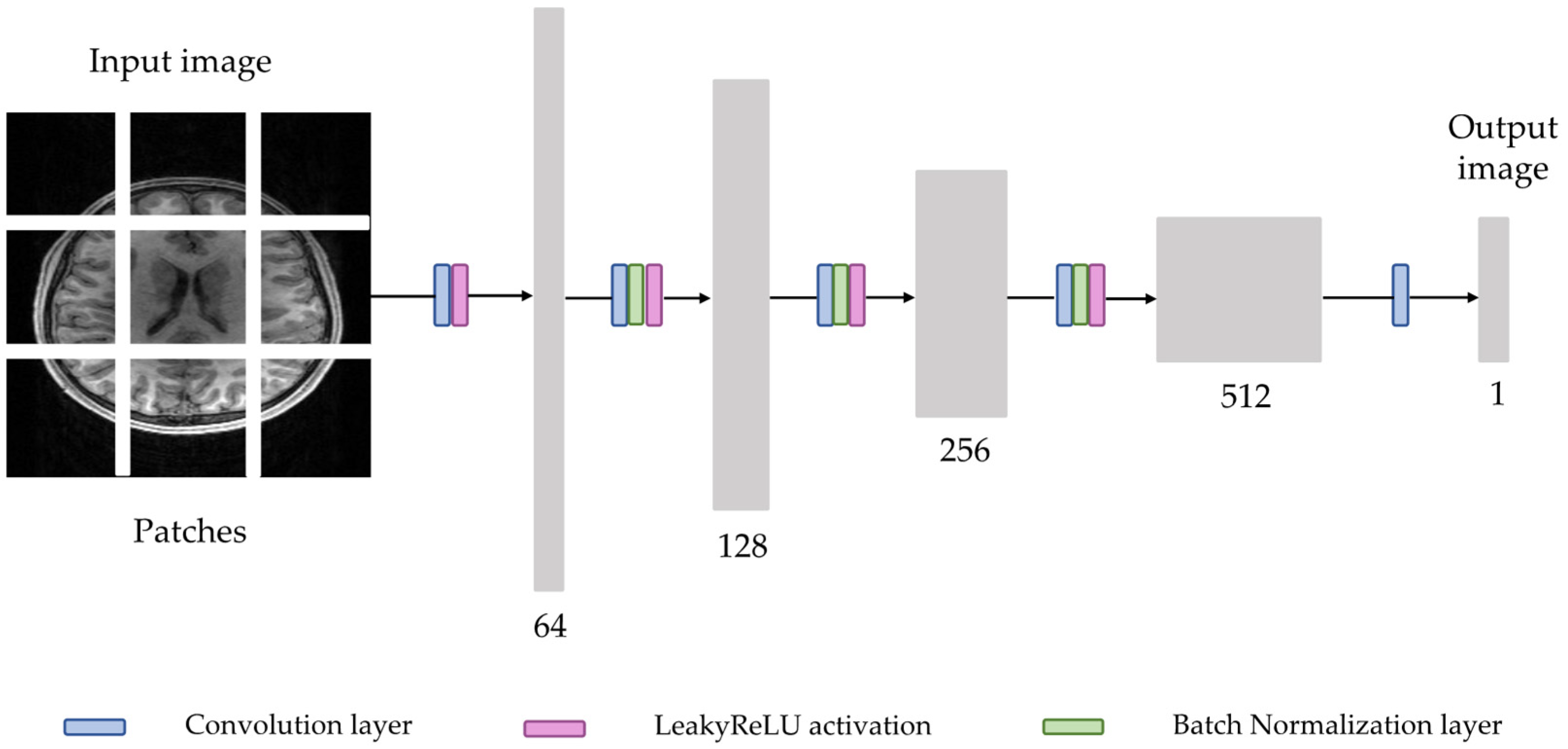
2.3.2. Discriminator
2.4. Model Training
2.5. Implementation Details
2.6. Model Evaluation and Statistical Analysis
3. Results
3.1. Quantitative Comparison between CycleGAN and Switchable CycleGAN
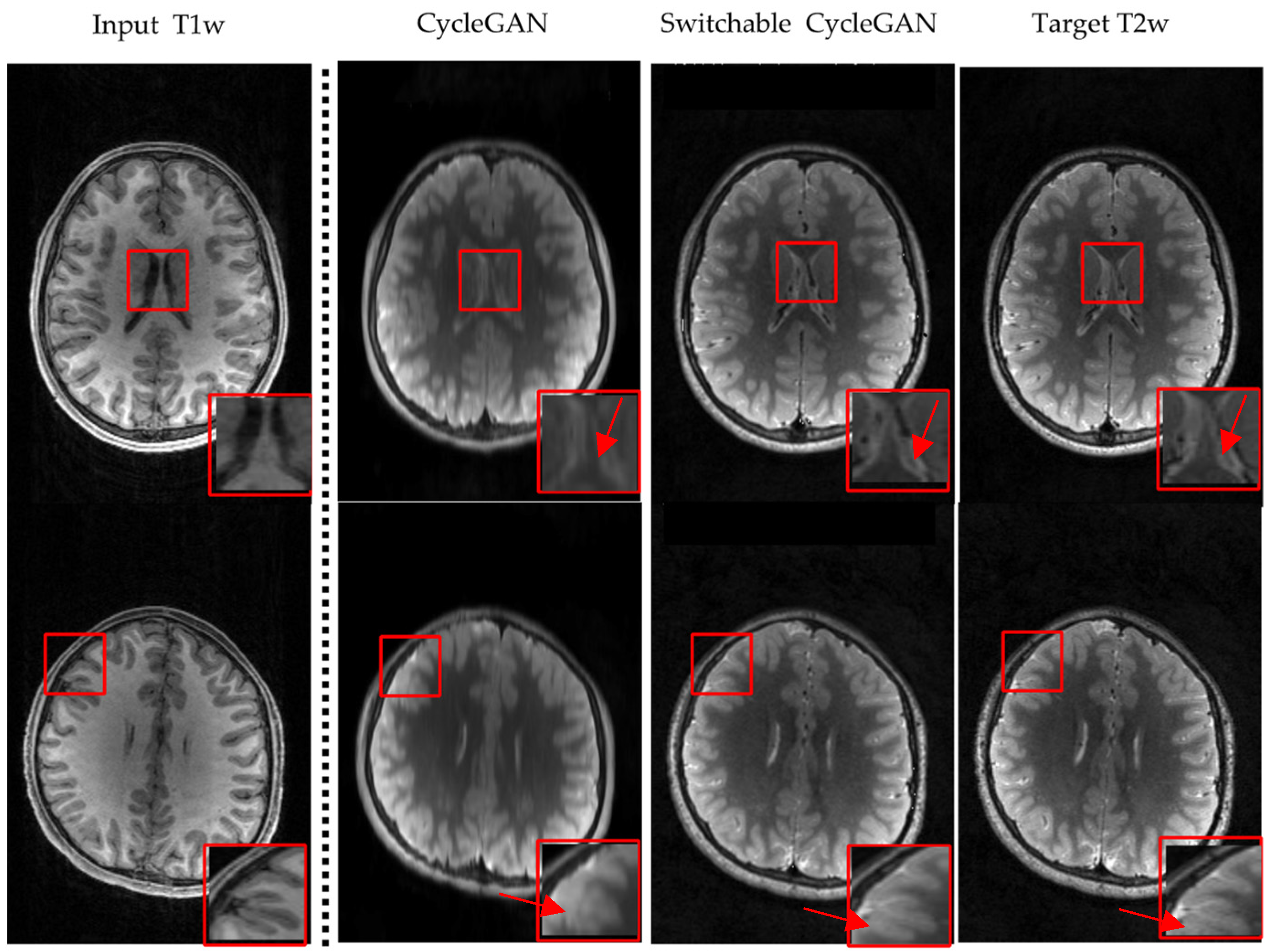
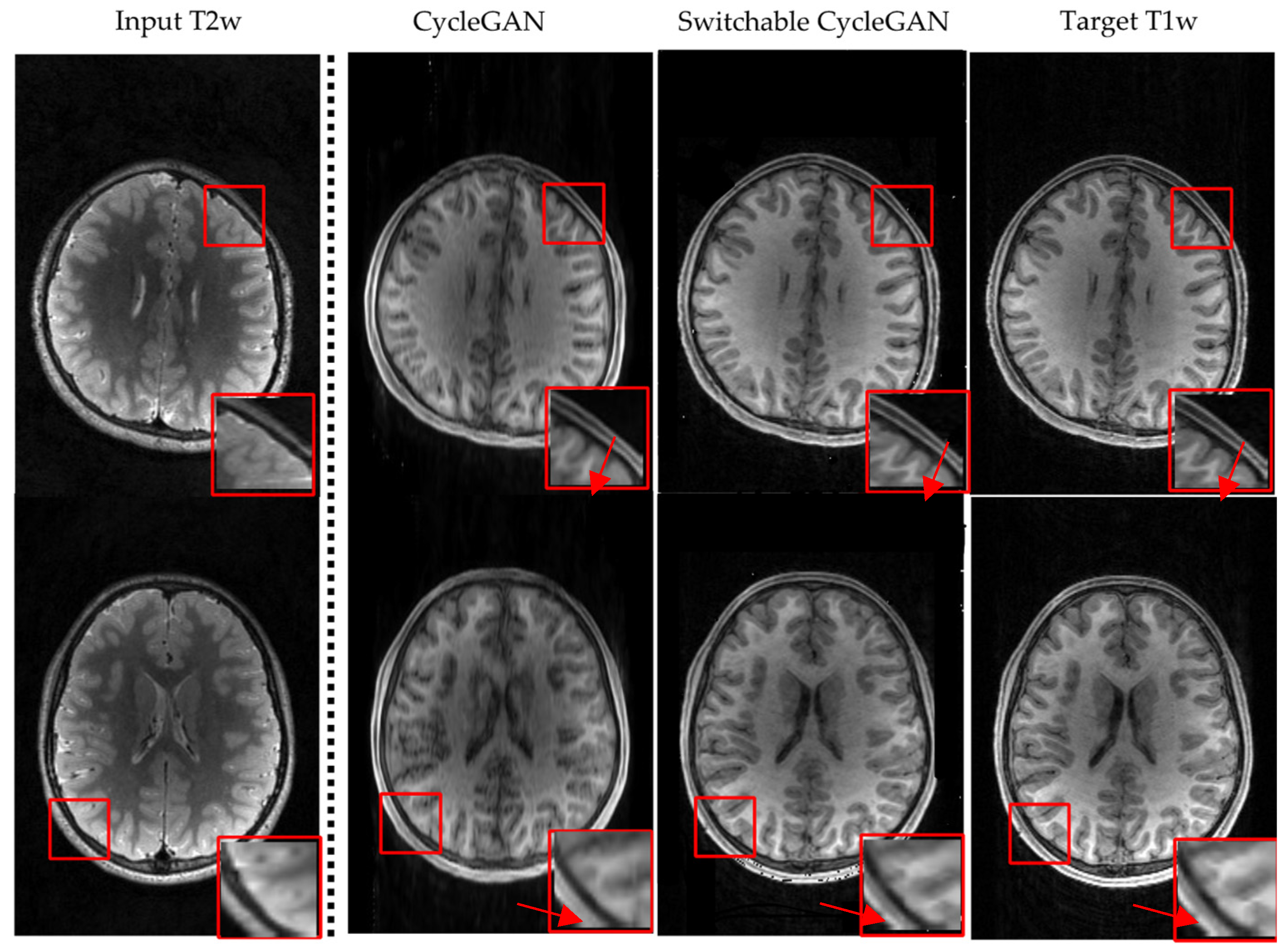
3.2. Visualization
3.3. Robustness to Small Dataset
3.4. Time Efficiency
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vlaardingerbroek, M.T.; Boer, J.A. Magnetic Resonance Imaging: Theory and Practice; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Krupa, K.; Bekiesińska-Figatowska, M. Artifacts in magnetic resonance imaging. Pol. J. Radiol. 2015, 80, 93. [Google Scholar] [PubMed] [Green Version]
- Loddo, A.; Buttau, S.; Di Ruberto, C. Deep learning based pipelines for Alzheimer’s disease diagnosis: A comparative study and a novel deep-ensemble method. Comput. Biol. Med. 2022, 141, 105032. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.; Ullah, Z.; Gwak, J. Mri-based brain tumor classification using ensemble of deep features and machine learning classifiers. Sensors 2021, 21, 2222. [Google Scholar] [CrossRef] [PubMed]
- Loddo, A.; Pili, F.; Di Ruberto, C. Deep Learning for COVID-19 Diagnosis from CT Images. Appl. Sci. 2021, 11, 8227. [Google Scholar] [CrossRef]
- Putzu, L.; Loddo, A.; Ruberto, C.D. Invariant Moments, Textural and Deep Features for Diagnostic MR and CT Image Retrieval. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Nicosia, Cyprus, 28–30 September 2021; pp. 287–297. [Google Scholar]
- Rzedzian, R.; Mansfield, P.; Doyle, M.; Guilfoyle, D.; Chapman, B.; Coupland, R.; Chrispin, A.; Small, P. Real-time nuclear magnetic resonance clinical imaging in paediatrics. Lancet 1983, 322, 1281–1282. [Google Scholar] [CrossRef]
- Han, X. MR-based synthetic CT generation using a deep convolutional neural network method. Med. Phys. 2017, 44, 1408–1419. [Google Scholar] [CrossRef] [Green Version]
- Xiang, L.; Wang, Q.; Nie, D.; Zhang, L.; Jin, X.; Qiao, Y.; Shen, D. Deep embedding convolutional neural network for synthesizing CT image from T1-Weighted MR image. Med. Image Anal. 2018, 47, 31–44. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Processing Syst. 2014, 27, 1–9. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kawahara, D.; Nagata, Y. T1-weighted and T2-weighted MRI image synthesis with convolutional generative adversarial networks. Rep. Pract. Oncol. Radiother. 2021, 26, 35–42. [Google Scholar] [CrossRef]
- Emami, H.; Dong, M.; Nejad-Davarani, S.P.; Glide-Hurst, C.K. Generating synthetic CTs from magnetic resonance images using generative adversarial networks. Med. Phys. 2018, 45, 3627–3636. [Google Scholar] [CrossRef]
- Sohail, M.; Riaz, M.N.; Wu, J.; Long, C.; Li, S. Unpaired multi-contrast MR image synthesis using generative adversarial networks. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Shenzhen, China, 13 October 2019; pp. 22–31. [Google Scholar]
- Olut, S.; Sahin, Y.H.; Demir, U.; Unal, G. Generative adversarial training for MRA image synthesis using multi-contrast MRI. In Proceedings of the International Workshop on Predictive Intelligence in Medicine, Granada, Spain, 16 September 2018; pp. 147–154. [Google Scholar]
- Wang, G.; Gong, E.; Banerjee, S.; Martin, D.; Tong, E.; Choi, J.; Chen, H.; Wintermark, M.; Pauly, J.M.; Zaharchuk, G. Synthesize high-quality multi-contrast magnetic resonance imaging from multi-echo acquisition using multi-task deep generative model. IEEE Trans. Med. Imaging 2020, 39, 3089–3099. [Google Scholar] [CrossRef] [PubMed]
- Dar, S.U.; Yurt, M.; Karacan, L.; Erdem, A.; Erdem, E.; Çukur, T. Image synthesis in multi-contrast MRI with conditional generative adversarial networks. IEEE Trans. Med. Imaging 2019, 38, 2375–2388. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yurt, M.; Dar, S.U.; Erdem, A.; Erdem, E.; Oguz, K.K.; Çukur, T. mustGAN: Multi-stream generative adversarial networks for MR image synthesis. Med. Image Anal. 2021, 70, 101944. [Google Scholar] [CrossRef] [PubMed]
- Wolterink, J.M.; Dinkla, A.M.; Savenije, M.H.; Seevinck, P.R.; van den Berg, C.A.; Išgum, I. Deep MR to CT synthesis using unpaired data. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Quebec, QC, Canada, 10 September 2017; pp. 14–23. [Google Scholar]
- Hiasa, Y.; Otake, Y.; Takao, M.; Matsuoka, T.; Takashima, K.; Carass, A.; Prince, J.L.; Sugano, N.; Sato, Y. Cross-modality image synthesis from unpaired data using CycleGAN. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Lima, Peru, 4 October 2018; pp. 31–41. [Google Scholar]
- Chartsias, A.; Joyce, T.; Dharmakumar, R.; Tsaftaris, S.A. Adversarial image synthesis for unpaired multi-modal cardiac data. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Quebec, QC, Canada, 10 September 2017; pp. 3–13. [Google Scholar]
- Oh, G.; Sim, B.; Chung, H.; Sunwoo, L.; Ye, J.C. Unpaired deep learning for accelerated MRI using optimal transport driven cycleGAN. IEEE Trans. Comput. Imaging 2020, 6, 1285–1296. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ben-Cohen, A.; Klang, E.; Raskin, S.P.; Amitai, M.M.; Greenspan, H. Virtual PET images from CT data using deep convolutional networks: Initial results. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Quebec, QC, Canada, 10 September 2017; pp. 49–57. [Google Scholar]
- Bi, L.; Kim, J.; Kumar, A.; Feng, D.; Fulham, M. Synthesis of positron emission tomography (PET) images via multi-channel generative adversarial networks (GANs). In Molecular Imaging, Reconstruction and Analysis of Moving Body Organs, and Stroke Imaging and Treatment; Springer: Berlin/Heidelberg, Germany, 2017; pp. 43–51. [Google Scholar]
- Yang, S.; Kim, E.Y.; Ye, J.C. Continuous Conversion of CT Kernel using Switchable CycleGAN with AdaIN. IEEE Trans. Med. Imaging 2021, 40, 3015–3029. [Google Scholar] [CrossRef]
- Gu, J.; Ye, J.C. AdaIN-Switchable CycleGAN for Efficient Unsupervised Low-Dose CT Denoising. arXiv 2020, arXiv:2008.05753. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. arXiv 2018, arXiv:1812.04948. [Google Scholar]
- Hagler, D.J., Jr.; Hatton, S.; Cornejo, M.D.; Makowski, C.; Fair, D.A.; Dick, A.S.; Sutherland, M.T.; Casey, B.; Barch, D.M.; Harms, M.P. Image processing and analysis methods for the Adolescent Brain Cognitive Development Study. Neuroimage 2019, 202, 116091. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Mathieu, M.; Couprie, C.; LeCun, Y. Deep multi-scale video prediction beyond mean square error. arXiv 2015, arXiv:1511.05440. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from simulated and unsupervised images through adversarial training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2107–2116. [Google Scholar]
- Avants, B.B.; Tustison, N.J.; Song, G.; Cook, P.A.; Klein, A.; Gee, J.C. A reproducible evaluation of ANTs similarity metric performance in brain image registration. Neuroimage 2011, 54, 2033–2044. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murugan, P. Hyperparameters optimization in deep convolutional neural network/bayesian approach with gaussian process prior. arXiv 2017, arXiv:1712.07233. [Google Scholar]
- Hinz, T.; Navarro-Guerrero, N.; Magg, S.; Wermter, S. Speeding up the hyperparameter optimization of deep convolutional neural networks. Int. J. Comput. Intell. Appl. 2018, 17, 1850008. [Google Scholar] [CrossRef] [Green Version]
- Mahmood, F.; Chen, R.; Durr, N.J. Unsupervised reverse domain adaptation for synthetic medical images via adversarial training. IEEE Trans. Med. Imaging 2018, 37, 2572–2581. [Google Scholar] [CrossRef] [Green Version]
- Costa, P.; Galdran, A.; Meyer, M.I.; Niemeijer, M.; Abràmoff, M.; Mendonça, A.M.; Campilho, A. End-to-end adversarial retinal image synthesis. IEEE Trans. Med. Imaging 2017, 37, 781–791. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; pp. 694–711. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Mroueh, Y. Wasserstein style transfer. arXiv 2019, arXiv:1905.12828. [Google Scholar]
- Dalmaz, O.; Yurt, M.; Çukur, T. ResViT: Residual vision transformers for multi-modal medical image synthesis. arXiv 2021, arXiv:2106.16031. [Google Scholar]
- Korkmaz, Y.; Dar, S.U.; Yurt, M.; Özbey, M.; Cukur, T. Unsupervised MRI reconstruction via zero-shot learned adversarial transformers. IEEE Trans. Med. Imaging 2022, 13, 27. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR | SSIM | ||
|---|---|---|---|---|
| T2w | T1w | T2w | T1w | |
| CycleGAN [11] | 1.296 | 0.620 | 0.150 | 0.113 |
| pix2pix GAN [23] | 1.443 | 0.544 | 0.131 | 0.120 |
| Switchable CycleGAN | 1.813 | 0.169 | 0.128 | |
| Data Size | CycleGAN [11] | Switchable CycleGAN | ||
|---|---|---|---|---|
| T2w | T1w | T2w | T1w | |
| 30,000 | 0.150 | 0.113 | 0.169 | 0.128 |
| 3000 | 0.214 | 0.146 | 0.156 | 0.130 |
| 300 | 0.126 | 0.158 | 0.136 | 0.135 |
| Method | Training Time (Number of Hour of 200 Epochs) |
|---|---|
| CycleGAN [11] | 74.4 |
| Switchable CycleGAN | 36.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Li, H.; Dillman, J.R.; Parikh, N.A.; He, L. Multi-Contrast MRI Image Synthesis Using Switchable Cycle-Consistent Generative Adversarial Networks. Diagnostics 2022, 12, 816. https://doi.org/10.3390/diagnostics12040816
Zhang H, Li H, Dillman JR, Parikh NA, He L. Multi-Contrast MRI Image Synthesis Using Switchable Cycle-Consistent Generative Adversarial Networks. Diagnostics. 2022; 12(4):816. https://doi.org/10.3390/diagnostics12040816
Chicago/Turabian StyleZhang, Huixian, Hailong Li, Jonathan R. Dillman, Nehal A. Parikh, and Lili He. 2022. "Multi-Contrast MRI Image Synthesis Using Switchable Cycle-Consistent Generative Adversarial Networks" Diagnostics 12, no. 4: 816. https://doi.org/10.3390/diagnostics12040816
APA StyleZhang, H., Li, H., Dillman, J. R., Parikh, N. A., & He, L. (2022). Multi-Contrast MRI Image Synthesis Using Switchable Cycle-Consistent Generative Adversarial Networks. Diagnostics, 12(4), 816. https://doi.org/10.3390/diagnostics12040816