
Self-Supervised Learning Methods for Label-Efficient Dental Caries Classification

 , ,
, ,  , and
, and
Abstract
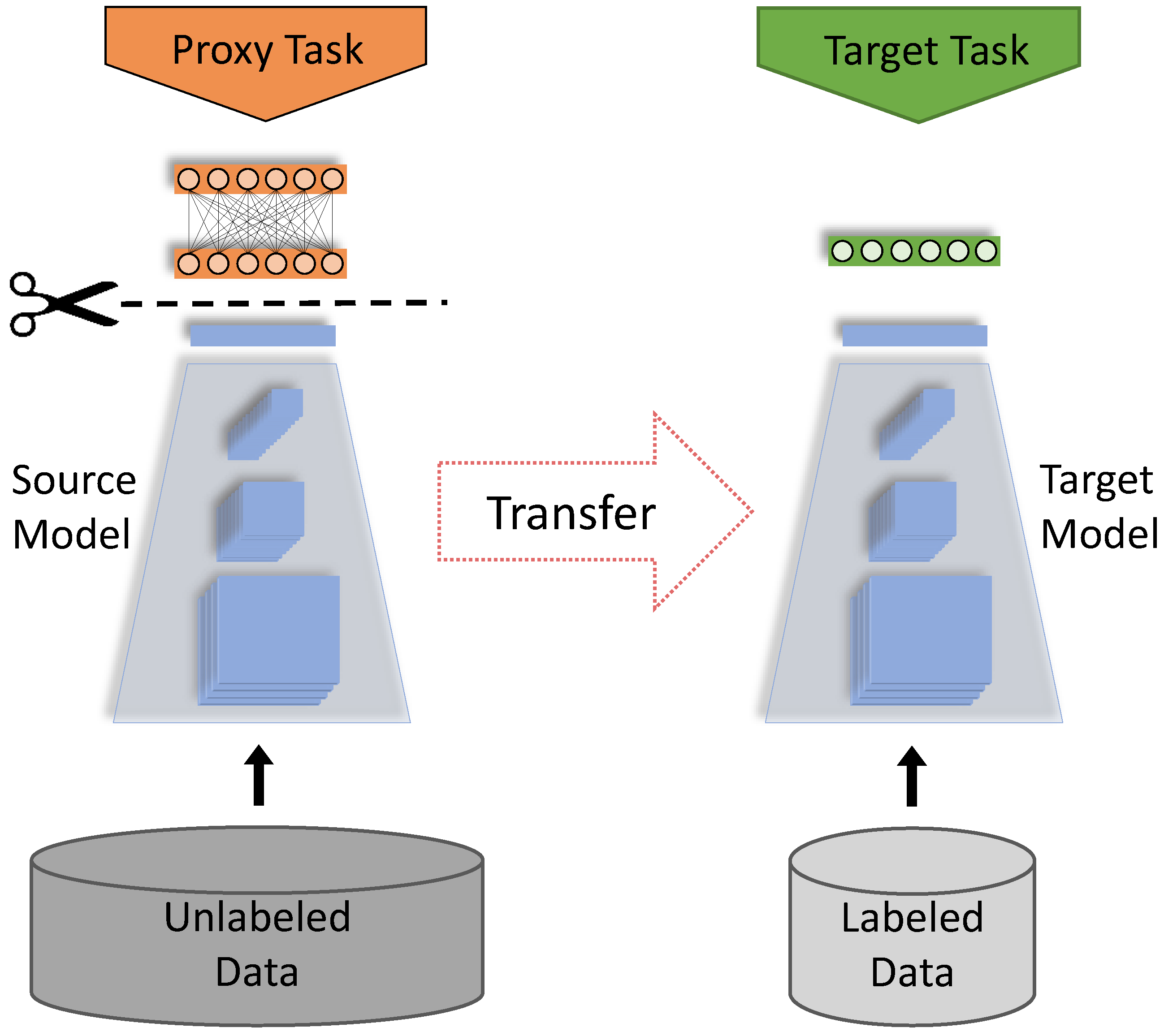
:1. Introduction
- Does pretraining of models with self-supervision improve the diagnostic performance of the model?
- Does self-supervision reduce the amounts of annotations required, i.e., improves label-efficiency?
- Does oversampling of the positive class (here, caries are present) improve the diagnostic performance of the classifier?
2. Materials and Methods
2.1. Dataset
2.2. Self-Supervised Learning Algorithms
2.2.1. SimCLR
- The image dataset is processed in batches, where same-views and others-views are created from each batch.
- For each input image, a pair of same-views is created using image augmentations. The others-views are then the remaining images in the batch.
- All images are then processed by the encoder network, to produce a vector representation for each image. We employ CNNs for encoder architecture, but other architectures are possible. During training, the encoder is replicated to process pairs of samples, constituting a Siamese architecture [44].
- Each representation is then processed by a small projection head, which is a non-linear multi-layer perceptron (MLP) with one hidden layer.
- Finally, the NCE loss computes the cosine similarity across all samples. This loss encourages the similarity between same-views to grow larger (attracts their representation vectors in the embedding space), and the similarity to others-views to become smaller (repels their representations in the embedding space).
2.2.2. BYOL
- The first online network is trained to predict the representations of the other target network.
- The weights of the target network are an exponential moving average of the online network.
- This means that the actual parameter updates, i.e., gradients of the loss, are applied on the online network only. This is ensured by a “stop gradient” technique on the target network, which has been found, empirically, to be essential [46] to avoid collapsed representations.
- The training loss is the mean squared error (MSE) between the predictions of online and target networks. Note that both networks use a projection head similar to SimCLR’s.
2.2.3. Barlow Twins
- Assuming a batch of images. Two sets of augmented views are created by different augmentations.
- These views are processed concurrently with a Siamese encoder. Similar to SimCLR, the encoder weights are replicated, and the representations are projected with a projection head.
- The cross-correlation matrix of the two sets of representations is computed. Each entry of this matrix encodes the correlation between the corresponding representation entries.
- Finally, the loss is defined as the difference between the cross-correlation and the identity matrices. The intuition behind this is that it encourages the representations of same image views to be similar, while minimizing the redundancy between their components.
2.3. Image Augmentations in Self-Supervised Training
- Random resized cropping between 50–100% of input size.
- Random horizontal flip with 50% probability.
- Color adjustments (probabilities): Brightness (20%) and Contrast (10%), and Saturation (10%).
- Random rotation angles between −20 to 20.
2.4. Implementation Details
3. Results
3.1. Fine-Tuning on Pretrained Models
3.2. Data-Efficiency by Successively Increasing the Size of the Training Set
3.3. Oversampling of the Positive Class
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BWR | Bitewing Radiograph |
| EHR | Electronic Health Records |
| SimCLR | Simple Framework for Contrastive Learning of Visual Representations |
| BYOL | Bootstrap Your Own Latent |
| MSE | Mean Squared Error |
| ROC-AUC | Receiver Operating Characteristic—Area Under Curve |
| sens. | Sensitivity |
| spc. | Specificity |
| p.p. | Percentage Points |
| 30K | 30 Thousands |
| CI | Confidence Interval |
| NCE | Noise Contrastive Estimation |
References
- Grünberg, K.; Jimenez-del Toro, O.; Jakab, A.; Langs, G.; Salas Fernandez, T.; Winterstein, M.; Weber, M.A.; Krenn, M. Annotating Medical Image Data. In Cloud-Based Benchmarking of Medical Image Analysis; Springer International Publishing: Cham, Switzerland, 2017; pp. 45–67. [Google Scholar]
- Schwendicke, F.; Krois, J. Data Dentistry: How Data Are Changing Clinical Care and Research. J. Dent. Res. 2022, 101, 21–29. [Google Scholar] [CrossRef] [PubMed]
- Khanagar, S.B.; Al-ehaideb, A.; Maganur, P.C.; Vishwanathaiah, S.; Patil, S.; Baeshen, H.A.; Sarode, S.C.; Bhandi, S. Developments, application, and performance of artificial intelligence in dentistry—A systematic review. J. Dent. Sci. 2021, 16, 508–522. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, H.S.; Song, I.S.; Jung, K.H. DeNTNet: Deep Neural Transfer Network for the detection of periodontal bone loss using panoramic dental radiographs. Sci. Rep. 2019, 9, 17615. [Google Scholar] [CrossRef] [PubMed]
- Setzer, F.; Shi, K.; Zhang, Z.; Yan, H.; Yoon, H.; Mupparapu, M.; Li, J. Artificial Intelligence for the Computer-aided Detection of Periapical Lesions in Cone-beam Computed Tomographic Images. J. Endod. 2020, 46, 987–993. [Google Scholar] [CrossRef]
- Charles, M. UNSCEAR Report 2000: Sources and effects of ionizing radiation. J. Radiol. Prot. 2001, 21, 83. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Jeyaseelan, L.; Li, Q.; Chiang, J.N.; Wu, Z.; Ding, X. Embracing imperfect datasets: A review of deep learning solutions for medical image segmentation. Med. Image Anal. 2020, 63, 101693. [Google Scholar] [CrossRef] [Green Version]
- Xu, J. A Review of Self-supervised Learning Methods in the Field of Medical Image Analysis. Int. J. Image Graph. Signal Process. (IJIGSP) 2021, 13, 33–46. [Google Scholar] [CrossRef]
- Liu, X.; Sinha, A.; Unberath, M.; Ishii, M.; Hager, G.D.; Taylor, R.H.; Reiter, A. Self-supervised Learning for Dense Depth Estimation in Monocular Endoscopy. arXiv 2018, arXiv:1806.09521. [Google Scholar]
- Li, H.; Fan, Y. Non-rigid image registration using self-supervised fully convolutional networks without training data. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; IEEE: Washington, DC, USA, 2018; pp. 1075–1078. [Google Scholar]
- Zhang, P.; Wang, F.; Zheng, Y. Self supervised deep representation learning for fine-grained body part recognition. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017; IEEE: Melbourne, Australia, 2017; pp. 578–582. [Google Scholar]
- Jamaludin, A.; Kadir, T.; Zisserman, A. Self-supervised Learning for Spinal MRIs. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 294–302. [Google Scholar] [CrossRef] [Green Version]
- Yan, K.; Wang, X.; Lu, L.; Zhang, L.; Harrison, A.P.; Bagheri, M.; Summers, R.M. Deep Lesion Graph in the Wild: Relationship Learning and Organization of Significant Radiology Image Findings in a Diverse Large-Scale Lesion Database. In Deep Learning and Convolutional Neural Networks for Medical Imaging and Clinical Informatics; Springer International Publishing: Cham, Switzerland, 2019; pp. 413–435. [Google Scholar] [CrossRef]
- Ye, M.; Johns, E.; Handa, A.; Zhang, L.; Pratt, P.; Yang, G. Self-Supervised Siamese Learning on Stereo Image Pairs for Depth Estimation in Robotic Surgery. In Proceedings of the Hamlyn Symposium on Medical Robotics, London, UK, 25–28 June 2017; pp. 27–28. [Google Scholar] [CrossRef]
- Bai, W.; Chen, C.; Tarroni, G.; Duan, J.; Guitton, F.; Petersen, S.E.; Guo, Y.; Matthews, P.M.; Rueckert, D. Self-Supervised Learning for Cardiac MR Image Segmentation by Anatomical Position Prediction. In Medical Image Computing and Computer-Assisted Intervention; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 541–549. [Google Scholar]
- Roß, T.; Zimmerer, D.; Vemuri, A.; Isensee, F.; Bodenstedt, S.; Both, F.; Kessler, P.; Wagner, M.; Müller, B.; Kenngott, H.; et al. Exploiting the potential of unlabeled endoscopic video data with self-supervised learning. Int. J. Comput. Assist. Radiol. Surg. 2017, 13, 925–933. [Google Scholar] [CrossRef] [Green Version]
- Spitzer, H.; Kiwitz, K.; Amunts, K.; Harmeling, S.; Dickscheid, T. Improving Cytoarchitectonic Segmentation of Human Brain Areas with Self-supervised Siamese Networks. In Medical Image Computing and Computer-Assisted Intervention; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 663–671. [Google Scholar]
- Tajbakhsh, N.; Hu, Y.; Cao, J.; Yan, X.; Xiao, Y.; Lu, Y.; Liang, J.; Terzopoulos, D.; Ding, X. Surrogate Supervision for Medical Image Analysis: Effective Deep Learning From Limited Quantities of Labeled Data. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1251–1255. [Google Scholar]
- Jiao, J.; Droste, R.; Drukker, L.; Papageorghiou, A.T.; Noble, J.A. Self-Supervised Representation Learning for Ultrasound Video. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1847–1850. [Google Scholar]
- Zhou, Z.; Sodha, V.; Rahman Siddiquee, M.M.; Feng, R.; Tajbakhsh, N.; Gotway, M.B.; Liang, J. Models Genesis: Generic Autodidactic Models for 3D Medical Image Analysis. In Medical Image Computing and Computer-Assisted Intervention; Springer International Publishing: Cham, Switzerland, 2019; pp. 384–393. [Google Scholar]
- Taleb, A.; Loetzsch, W.; Danz, N.; Severin, J.; Gaertner, T.; Bergner, B.; Lippert, C. 3D Self-Supervised Methods for Medical Imaging. Adv. Neural Inf. Process. Syst. 2020, 33, 18158–18172. [Google Scholar]
- Taleb, A.; Lippert, C.; Klein, T.; Nabi, M. Multimodal Self-supervised Learning for Medical Image Analysis. In Information Processing in Medical Imaging (IPMI); Feragen, A., Sommer, S., Schnabel, J., Nielsen, M., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 661–673. [Google Scholar]
- Zhuang, X.; Li, Y.; Hu, Y.; Ma, K.; Yang, Y.; Zheng, Y. Self-supervised Feature Learning for 3D Medical Images by Playing a Rubik’s Cube. In Medical Image Computing and Computer-Assisted Intervention; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 420–428. [Google Scholar]
- Chen, L.; Bentley, P.; Mori, K.; Misawa, K.; Fujiwara, M.; Rueckert, D. Self-supervised learning for medical image analysis using image context restoration. Med. Image Anal. 2019, 58, 101539. [Google Scholar] [CrossRef] [PubMed]
- Blendowski, M.; Nickisch, H.; Heinrich, M.P. How to Learn from Unlabeled Volume Data: Self-supervised 3D Context Feature Learning. In Medical Image Computing and Computer-Assisted Intervention; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 649–657. [Google Scholar]
- Chaitanya, K.; Erdil, E.; Karani, N.; Konukoglu, E. Contrastive learning of global and local features for medical image segmentation with limited annotations. arXiv 2020, arXiv:2006.10511. [Google Scholar]
- Hu, J.; Sun, S.; Yang, X.; Zhou, S.; Wang, X.; Fu, Y.; Zhou, J.; Yin, Y.; Cao, K.; Song, Q.; et al. Towards accurate and robust multi-modal medical image registration using contrastive metric learning. IEEE Access 2019, 7, 132816–132827. [Google Scholar] [CrossRef]
- Liu, L.; Aviles-Rivero, A.I.; Schönlieb, C.B. Contrastive Registration for Unsupervised Medical Image Segmentation. arXiv 2020, arXiv:2011.08894. [Google Scholar]
- Kassebaum, N.J.; Smith, A.G.; Bernabé, E.; Fleming, T.D.; Reynolds, A.E.; Vos, T.; Murray, C.; Marcenes, W.; Collaborators, G.O.H. Global, regional, and national prevalence, incidence, and disability-adjusted life years for oral conditions for 195 countries, 1990–2015: A systematic analysis for the global burden of diseases, injuries, and risk factors. J. Dent. Res. 2017, 96, 380–387. [Google Scholar] [CrossRef]
- Schwendicke, F.; Tzschoppe, M.; Paris, S. Radiographic caries detection: A systematic review and meta-analysis. J. Dent. 2015, 43, 924–933. [Google Scholar] [CrossRef]
- Walsh, T.; Macey, R.; Riley, P.; Glenny, A.M.; Schwendicke, F.; Worthington, H.V.; Clarkson, J.E.; Ricketts, D.; Su, T.L.; Sengupta, A. Imaging modalities to inform the detection and diagnosis of early caries. Cochrane Database Syst. Rev. 2021, 3, CD014545. [Google Scholar]
- Bayraktar, Y.; Ayan, E. Diagnosis of interproximal caries lesions with deep convolutional neural network in digital bitewing radiographs. Clin. Oral Investig. 2022, 26, 623–632. [Google Scholar] [CrossRef]
- Cantu, A.G.; Gehrung, S.; Krois, J.; Chaurasia, A.; Rossi, J.G.; Gaudin, R.; Elhennawy, K.; Schwendicke, F. Detecting caries lesions of different radiographic extension on bitewings using deep learning. J. Dent. 2020, 100, 103425. [Google Scholar] [CrossRef]
- Megalan Leo, L.; Kalpalatha Reddy, T. Dental Caries Classification System Using Deep Learning Based Convolutional Neural Network. J. Comput. Theor. Nanosci. 2020, 17, 4660–4665. [Google Scholar] [CrossRef]
- Gianfrancesco, M.A.; Tamang, S.; Yazdany, J.; Schmajuk, G. Potential Biases in Machine Learning Algorithms Using Electronic Health Record Data. JAMA Intern. Med. 2018, 178, 1544–1547. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning Research (PMLR), Virtual, 13–18 July 2020; Volume 119, pp. 1597–1607. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. arXiv 2021, arXiv:2103.03230. [Google Scholar]
- Becker, S.; Hinton, G.E. Self-organizing neural network that discovers surfaces in random-dot stereograms. Nature 1992, 355, 161–163. [Google Scholar] [CrossRef]
- Van den Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Hénaff, O.J.; Srinivas, A.; Fauw, J.D.; Razavi, A.; Doersch, C.; Eslami, S.M.A.; van den Oord, A. Data-Efficient Image Recognition with Contrastive Predictive Coding. arXiv 2019, arXiv:1905.09272. [Google Scholar]
- Gutmann, M.; Hyvärinen, A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Volume 9, pp. 297–304. [Google Scholar]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.Y.; Manmatha, R.; Smola, A.J.; Krahenbuhl, P. Sampling matters in deep embedding learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2840–2848. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2017, arXiv:1608.03983. [Google Scholar]
- Lightly.ai. Lightly. 2021. Available online: https://github.com/lightly-ai/lightly (accessed on 20 November 2021).
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Farahani, A.; Pourshojae, B.; Rasheed, K.; Arabnia, H.R. A concise review of transfer learning. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 16–18 December 2020; pp. 344–351. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Lee, J.H.; Kim, D.H.; Jeong, S.N.; Choi, S.H. Detection and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm. J. Dent. 2018, 77, 106–111. [Google Scholar] [CrossRef] [PubMed]
- Samek, W.; Wiegand, T.; Müller, K.R. Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models. arXiv 2017, arXiv:1708.08296. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Method | Sensitivity | Specificity | ROC-AUC |
|---|---|---|---|
| Baseline | 51.80 | 91.30 | 71.50 |
| SimCLR | 57.20 | 89.30 | 73.30 |
| BYOL | 54.60 | 91.30 | 73.00 |
| Barlow Twins | 57.90 | 88.90 | 73.40 |
| Prev. | #Teeth/#BWRs | SimCLR | BYOL | Barlow Twins | Baseline | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sens. | Spc. | Roc | Sens. | Spc. | Roc | Sens. | Spc. | Roc | Sens. | Spc. | Roc | ||
| ∼20% | 152/18 | 40.02 | 64.27 | 52.15 | 44.78 | 60.45 | 52.61 | 46.28 | 58.43 | 52.35 | 32.87 | 72.10 | 52.49 |
| 305/37 | 50.05 | 55.39 | 52.72 | 48.35 | 56.26 | 52.31 | 41.01 | 62.34 | 51.68 | 41.74 | 63.30 | 52.52 | |
| 1.5K/190 | 46.40 | 63.78 | 55.09 | 60.92 | 51.16 | 56.04 | 45.60 | 63.46 | 54.53 | 42.45 | 64.62 | 53.53 | |
| 3K/380 | 52.99 | 59.79 | 56.39 | 53.88 | 59.61 | 56.75 | 50.08 | 59.29 | 54.69 | 46.61 | 63.86 | 55.23 | |
| 15K/1.9K | 48.96 | 75.28 | 62.12 | 55.32 | 73.44 | 64.38 | 51.34 | 75.40 | 63.37 | 44.78 | 79.00 | 61.89 | |
| 30K/3.8K | 54.80 | 79.42 | 67.11 | 51.18 | 83.98 | 67.58 | 50.88 | 86.85 | 68.87 | 50.19 | 81.57 | 65.88 | |
| 50% | 152/18 | 58.94 | 48.19 | 53.56 | 62.09 | 48.28 | 55.19 | 63.34 | 48.28 | 55.81 | 48.85 | 56.09 | 52.47 |
| 305/37 | 59.62 | 48.24 | 53.93 | 63.29 | 48.83 | 56.06 | 60.07 | 52.89 | 56.48 | 56.00 | 49.69 | 52.84 | |
| 1.5K/190 | 62.59 | 49.85 | 56.22 | 63.58 | 55.93 | 59.75 | 60.92 | 56.44 | 58.68 | 56.24 | 54.80 | 55.52 | |
| 3K/380 | 67.95 | 49.03 | 58.49 | 65.65 | 60.02 | 62.83 | 65.91 | 63.56 | 64.73 | 58.00 | 54.43 | 56.21 | |
| 15K/1.9K | 65.62 | 63.29 | 64.46 | 60.71 | 75.57 | 68.14 | 61.34 | 73.01 | 67.17 | 58.99 | 73.28 | 66.13 | |
| 30K/3.8K | 62.33 | 72.40 | 67.37 | 64.28 | 72.57 | 68.42 | 59.13 | 79.63 | 69.38 | 59.86 | 75.90 | 67.88 | |
| 75% | 152/18 | 64.80 | 42.37 | 53.59 | 70.64 | 38.56 | 54.60 | 79.81 | 30.20 | 55.01 | 57.15 | 48.07 | 52.61 |
| 305/37 | 70.07 | 41.10 | 55.59 | 74.00 | 35.67 | 54.84 | 79.86 | 31.59 | 55.73 | 68.68 | 37.58 | 53.13 | |
| 1.5K/190 | 72.42 | 39.49 | 55.96 | 77.32 | 37.04 | 57.18 | 80.49 | 33.59 | 57.04 | 69.32 | 38.10 | 53.71 | |
| 3K/380 | 75.65 | 40.85 | 58.25 | 78.68 | 41.59 | 60.14 | 81.48 | 42.41 | 61.95 | 71.25 | 39.66 | 55.45 | |
| 15K/1.9K | 78.02 | 51.35 | 64.69 | 81.62 | 51.16 | 66.39 | 79.62 | 55.13 | 67.38 | 74.45 | 55.86 | 65.15 | |
| 30K/3.8K | 79.04 | 54.51 | 66.77 | 81.29 | 54.14 | 67.72 | 78.66 | 61.74 | 70.20 | 76.94 | 58.31 | 67.62 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taleb, A.; Rohrer, C.; Bergner, B.; De Leon, G.; Rodrigues, J.A.; Schwendicke, F.; Lippert, C.; Krois, J. Self-Supervised Learning Methods for Label-Efficient Dental Caries Classification. Diagnostics 2022, 12, 1237. https://doi.org/10.3390/diagnostics12051237
Taleb A, Rohrer C, Bergner B, De Leon G, Rodrigues JA, Schwendicke F, Lippert C, Krois J. Self-Supervised Learning Methods for Label-Efficient Dental Caries Classification. Diagnostics. 2022; 12(5):1237. https://doi.org/10.3390/diagnostics12051237
Chicago/Turabian StyleTaleb, Aiham, Csaba Rohrer, Benjamin Bergner, Guilherme De Leon, Jonas Almeida Rodrigues, Falk Schwendicke, Christoph Lippert, and Joachim Krois. 2022. "Self-Supervised Learning Methods for Label-Efficient Dental Caries Classification" Diagnostics 12, no. 5: 1237. https://doi.org/10.3390/diagnostics12051237
APA StyleTaleb, A., Rohrer, C., Bergner, B., De Leon, G., Rodrigues, J. A., Schwendicke, F., Lippert, C., & Krois, J. (2022). Self-Supervised Learning Methods for Label-Efficient Dental Caries Classification. Diagnostics, 12(5), 1237. https://doi.org/10.3390/diagnostics12051237