
EfficientNetV2 Based Ensemble Model for Quality Estimation of Diabetic Retinopathy Images from DeepDRiD

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
- The proposed ensemble model is cross-validated and tested on a large publicly available dataset called the Deep Diabetic Retinopathy Image Dataset (DeepDRiD), as the QE of fundus images from this dataset seems challenging [3].
- The ability of the proposed ensemble model for overall QE is further stratified concerning DR disease severity.
Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Method | Dataset | Image Resolution | Performance (%) |
|---|---|---|---|---|
| Yu H et al. [17] | PLS classifier | Private—1884 | 4752 × 3168 | AUC: 95.8 |
| Yu F et al. [21] | SM + AlexNet + SVM | Kaggle—5200 (subset) | Original: 2592 × 1944 Resized: 256 × 256 | Accuracy: 95.4 AUC: 98.2 |
| Yao Z et al. [18] | SVM | Private—3224 | - | Accuracy: 91.4 AUC: 96.2 |
| Welikala RA et al. [20] | SVM | UK Biobank—800 (subset) | 2048 × 1536 | Sensitivity: 95.3 Specificity: 91.1 |
| Wang S et al. [19] | SVM | Private and Public—536 | Private: 2560 × 1960 Public: 570 × 760 and 565 × 584 | AUC: 94.5 Sensitivity: 87.4 Specificity: 91.7 |
| Shao F et al. [22] | DT, SVM and DL | EyePACS at Kaggle—4372 | Multiple resolutions | Accuracy: 93.6 Sensitivity: 94.7 Specificity: 92.3 |
| Sevik U et al. [23] | Several ML classifiers | DRIMDB—216 | 570 × 760 | Accuracy: 98.1 |
| Raj A et al. [27] | Ensemble of CNNs | FIQuA (EyePACS at Kaggle)—1500 | Multiple resolutions | Accuracy: 95.7 (3-class classification) |
| Perez AD et al. [26] | Light-weight CNN | Kaggle—4768 (2-class) Kaggle—28,792 (3-class) | 896 × 896 | Accuracy: 91.1 (2-class) Accuracy: 85.6 (3-class) |
| Liu H et al. [25] | gcforest | DRIMDB—216 (3-class) ACRIMA—705 (2-class) | Multiple resolutions | Accuracy: 88.6 (DRIMDB dataset) Accuracy: 85.1 (ACRIMA dataset) |
| Karlsson RA et al. [24] | Random forest regressor | Private—787 oximetry and 253 RGB DRIMDB—216 (194 were used) | 1600 × 1200 (oximetry) 3192 × 2656 (RGB) 760 × 570 (DRIMDB) | Accuracy: 98.1 (DRIMDB) ICC: 0.85 (oximetry) ICC: 0.91 (RGB) |
| Shi C et al. [28] | Pretrained ResNet50 | Kaggle—2434 (2-class) | Multiple resolutions | Accuracy: 98.6 Sensitivity: 98.0 Specificity: 99.1 |
| Liu R [3] | ISBI 2020 grand challenge | DeepDRiD—2000 (2-class) | Multiple resolutions | Accuracy: 69.81 |
2. Methods
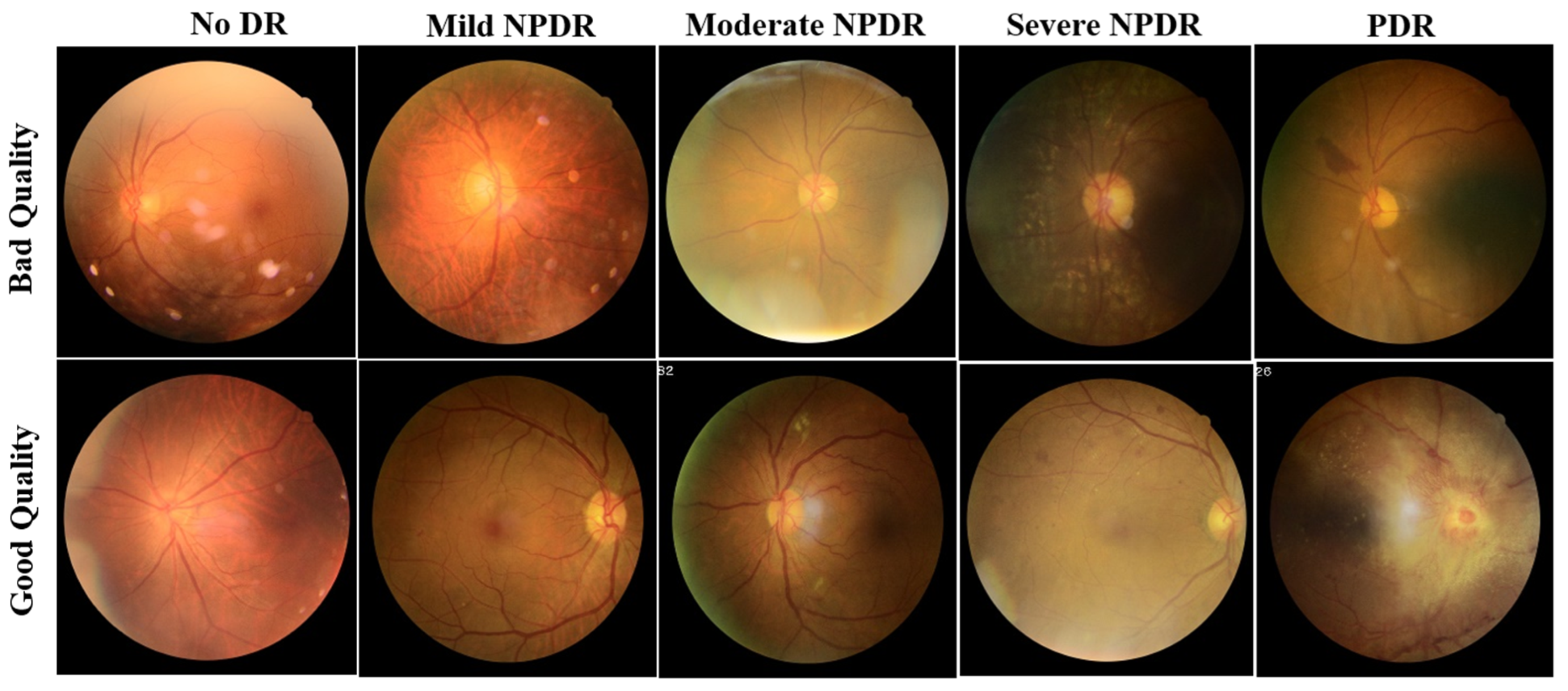
2.1. Dataset
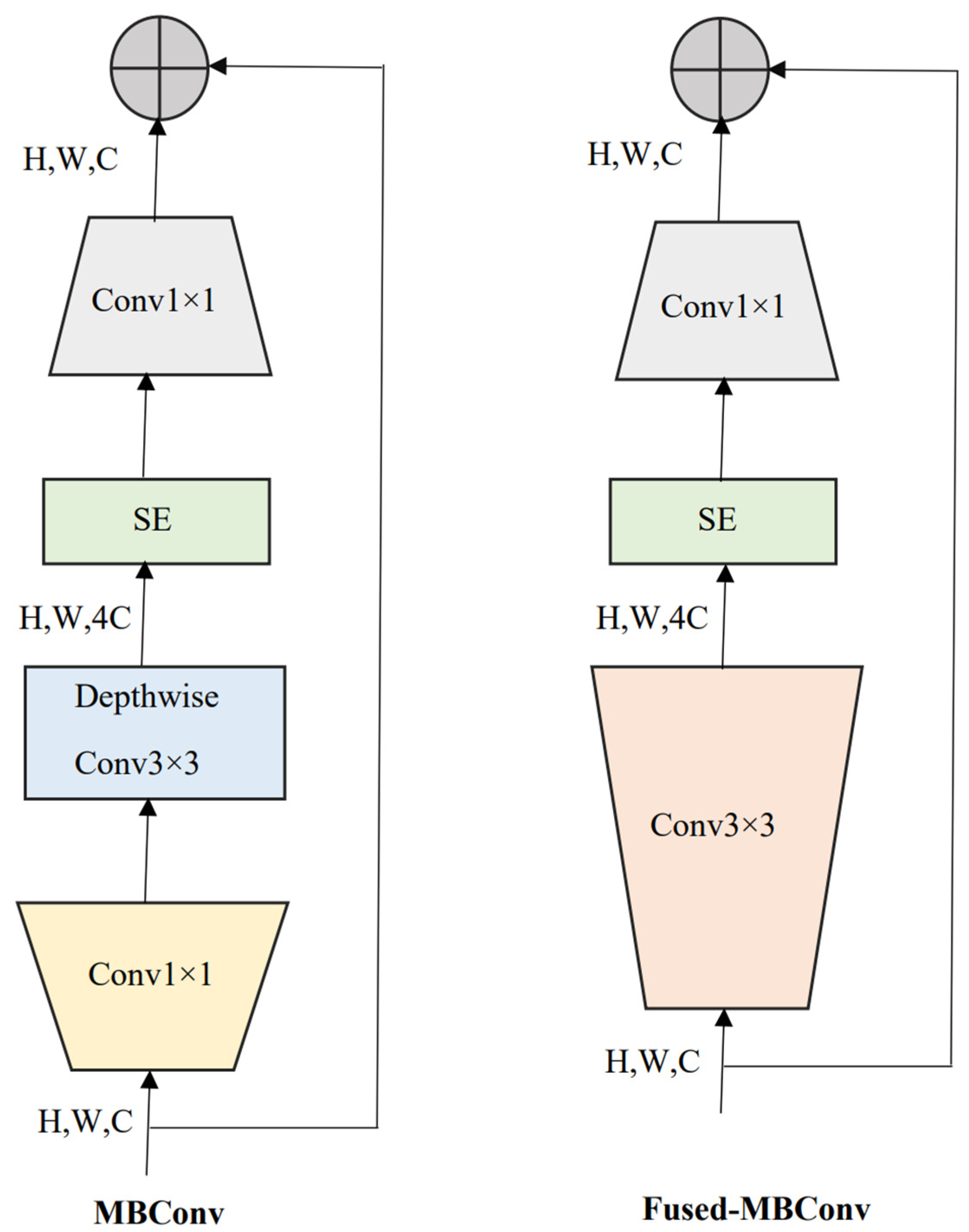
2.2. EfficientNetV2
2.3. Model Training and Validation
2.4. Ensemble Model
2.5. Evaluation Metrics
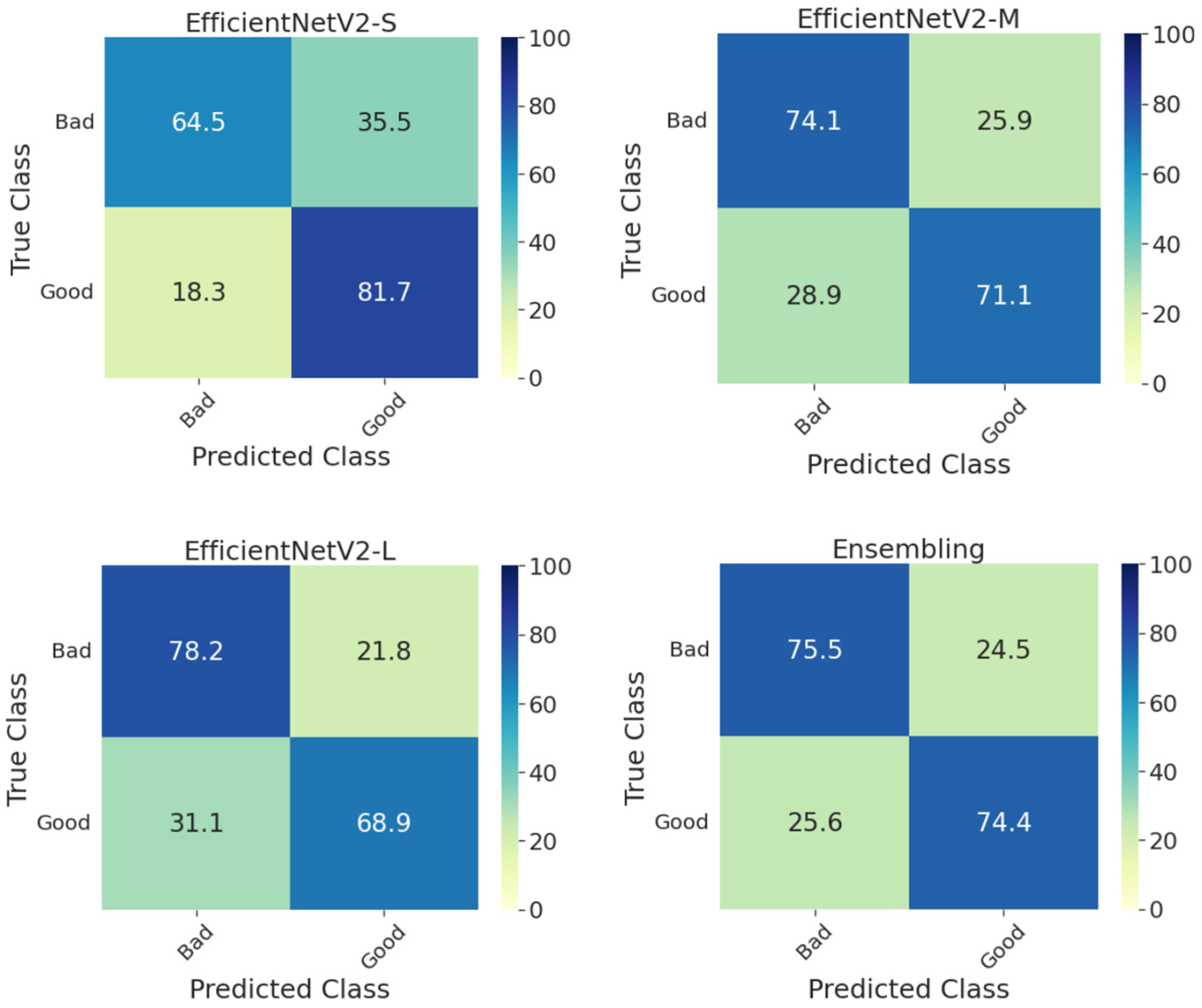
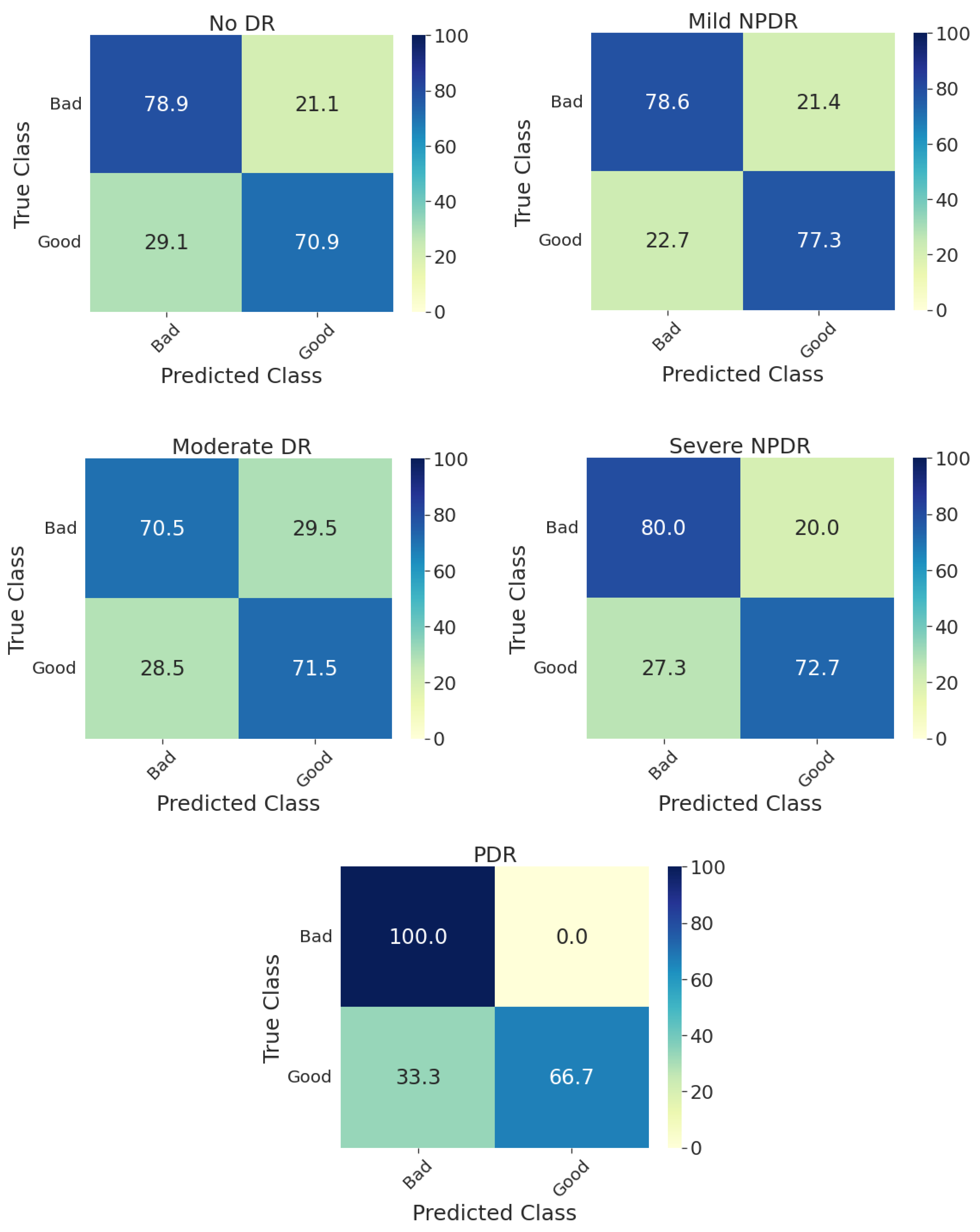
3. Results and Discussion
Limitations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ogurtsova, K.; da Rocha Fernandes, J.D.; Huang, Y.; Linnenkamp, U.; Guariguata, L.; Cho, N.H.; Cavan, D.; Shaw, J.E.; Makaroff, L.E. IDF Diabetes Atlas: Global estimates for the prevalence of diabetes for 2015 and 2040. Diabetes Res. Clin. Pract. 2017, 128, 40–50. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Lo, A.C.Y. Diabetic Retinopathy: Pathophysiology and Treatments. Int. J. Mol. Sci. 2018, 19, 1816. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Wang, X.; Wu, Q.; Dai, L.; Fang, X.; Yan, T.; Son, J.; Tang, S.; Li, J.; Gao, Z.; et al. DeepDRiD: Diabetic Retinopathy-Grading and Image Quality Estimation Challenge. Patterns 2022, 3, 100512. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural. Inf. Process Syst. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 10–15 June 2019; pp. 10691–10700. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Yousef, R.; Gupta, G.; Yousef, N.; Khari, M. A holistic overview of deep learning approach in medical imaging. Multimed. Syst. 2022, 28, 881–914. [Google Scholar] [CrossRef] [PubMed]
- Tummala, S. Deep Learning Framework using Siamese Neural Network for Diagnosis of Autism from Brain Magnetic Resonance Imaging. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Nadeem, M.W.; Goh, H.G.; Hussain, M.; Liew, S.-Y.; Andonovic, I.; Khan, M.A. Deep Learning for Diabetic Retinopathy Analysis: A Review, Research Challenges, and Future Directions. Sensors 2022, 22, 6780. [Google Scholar] [CrossRef] [PubMed]
- Tummala, S.; Kadry, S.; Ahmad, S.; Bukhari, C.; Rauf, H.T. Classification of Brain Tumor from Magnetic Resonance Imaging using Vision Transformers Ensembling. Curr. Oncol. 2022, 29, 7498–7511. [Google Scholar] [CrossRef]
- Tummala, S.; Kim, J.; Kadry, S. BreaST-Net: Multi-Class Classification of Breast Cancer from Histopathological Images Using Ensemble of Swin Transformers. Mathematics 2022, 10, 4109. [Google Scholar] [CrossRef]
- Yu, H.; Agurto, C.; Barriga, S.; Nemeth, S.C.; Soliz, P.; Zamora, G. Automated image quality evaluation of retinal fundus photographs in diabetic retinopathy screening. In Proceedings of the IEEE Southwest Symposium on Image Analysis and Interpretation, Santa Fe, NM, USA, 22–24 April 2012; pp. 125–128. [Google Scholar] [CrossRef]
- Yao, Z.; Zhang, Z.; Xu, L.Q.; Fan, Q.; Xu, L. Generic features for fundus image quality evaluation. In Proceedings of the 2016 IEEE 18th International Conference on e-Health Networking, Applications and Services, Healthcom 2016, Munich, Germany, 14–16 September 2016. [Google Scholar] [CrossRef]
- Wang, S.; Jin, K.; Lu, H.; Cheng, C.; Ye, J.; Qian, D. Human Visual System-Based Fundus Image Quality Assessment of Portable Fundus Camera Photographs. IEEE Trans. Med. Imaging 2016, 35, 1046–1055. [Google Scholar] [CrossRef] [PubMed]
- Welikala, R.A.; Fraz, M.M.; Foster, P.J.; Whincup, P.H.; Rudnicka, A.R.; Owen, C.G.; Strachan, D.P.; Barman, S.A.; on behalf of the UK Biobank Eye and Vision Consortium. Automated retinal image quality assessment on the UK Biobank dataset for epidemiological studies. Comput. Biol. Med. 2016, 71, 67–76. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, F.; Sun, J.; Li, A.; Cheng, J.; Wan, C.; Liu, J. Image quality classification for DR screening using deep learning. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Republic of Korea, 11–15 July 2017; pp. 664–667. [Google Scholar] [CrossRef]
- Shao, F.; Yang, Y.; Jiang, Q.; Jiang, G.; Ho, Y.S. Automated Quality Assessment of Fundus Images via Analysis of Illumination, Naturalness and Structure. IEEE Access 2017, 6, 806–817. [Google Scholar] [CrossRef]
- Sevik, U.; Köse, C.; Berber, T.; Erdöl, H. Identification of suitable fundus images using automated quality assessment methods. J. Biomed. Opt. 2014, 19, 046006. [Google Scholar] [CrossRef]
- Karlsson, R.A.; Jonsson, B.A.; Hardarson, S.H.; Olafsdottir, O.B.; Halldorsson, G.H.; Stefansson, E. Automatic fundus image quality assessment on a continuous scale. Comput. Biol. Med. 2021, 129, 104114. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Zhang, N.; Jin, S.; Xu, D.; Gao, W. Small sample color fundus image quality assessment based on gcforest. Multimed. Tools Appl. 2021, 80, 17441–17459. [Google Scholar] [CrossRef]
- Pérez, A.D.; Perdomo, O.; González, F.A. A lightweight deep learning model for mobile eye fundus image quality assessment. In Proceedings of the 15th International Symposium on Medical Information Processing and Analysis, Medelin, Colombia, 6–8 November 2019. [Google Scholar] [CrossRef]
- Raj, A.; Shah, N.A.; Tiwari, A.K.; Martini, M.G. Multivariate Regression-Based Convolutional Neural Network Model for Fundus Image Quality Assessment. IEEE Access 2020, 8, 57810–57821. [Google Scholar] [CrossRef]
- Shi, C.; Lee, J.; Wang, G.; Dou, X.; Yuan, F.; Zee, B. Assessment of image quality on color fundus retinal images using the automatic retinal image analysis. Sci. Rep. 2022, 12, 10455. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]




| No. of Images | No. of Subjects | Female (%) | Age (Years) | BMI (kg/m2) | |
|---|---|---|---|---|---|
| Set-A (training) | 1200 | 300 | 49.00 | 70.63 ± 7.70 | 25.17 ± 3.13 |
| Set-B (validation) | 400 | 100 | 56.00 | 65.13 ± 1.89 | 24.88 ± 3.21 |
| Set-C (testing) | 400 | 100 | 54.00 | 61.36 ± 7.23 | 25.01 ± 2.6 |
| No DR | Mild NPDR | Moderate NPDR | Severe NPDR | PDR | |
|---|---|---|---|---|---|
| Set-A (Training) | Good: 234 Bad: 306 | Good: 74 Bad: 66 | Good: 126 Bad: 108 | Good: 108 Bad: 106 | Good: 34 Bad: 38 |
| Set-B (Validation) | Good: 62 Bad: 112 | Good: 32 Bad: 14 | Good: 48 Bad: 44 | Good: 30 Bad: 38 | Good: 10 Bad: 10 |
| Set-C (Testing) | Good: 86 Bad: 113 | Good: 22 Bad: 14 | Good: 44 Bad: 28 | Good: 22 Bad: 50 | Good: 6 Bad: 14 |
| EfficientNetV2-S | EfficientNetV2-M | EfficientNetV2-L | Ensemble Model | |
|---|---|---|---|---|
| Accuracy | 72.3 | 72.8 | 74.0 | 75.0 |
| AUC | 73.1 | 72.6 | 73.5 | 74.9 |
| F1-Score | 72.2 | 72.8 | 73.9 | 75.0 |
| BA | 73.1 | 72.6 | 73.5 | 74.9 |
| EfficientNetV2-S | EfficientNetV2-M | EfficientNetV2-L | Ensemble Model | ||
|---|---|---|---|---|---|
| No DR | Accuracy | 71.5 | 73.0 | 72.5 | 75.5 |
| AUC | 72.3 | 72.7 | 71.5 | 74.9 | |
| F1-Score | 71.6 | 73.0 | 72.3 | 75.5 | |
| BA | 72.3 | 72.7 | 71.5 | 74.9 | |
| Mild NPDR | Accuracy | 72.2 | 77.8 | 75.0 | 77.8 |
| AUC | 69.5 | 76.2 | 73.1 | 77.9 | |
| F1-Score | 71.8 | 77.8 | 74.8 | 78.0 | |
| BA | 69.5 | 76.2 | 73.1 | 77.9 | |
| Moderate NPDR | Accuracy | 70.2 | 70.5 | 70.6 | 71.0 |
| AUC | 70.5 | 70.8 | 70.8 | 71.8 | |
| F1-Score | 70.1 | 70.1 | 71.1 | 71.2 | |
| BA | 70.5 | 70.9 | 70.8 | 71.5 | |
| Severe NPDR | Accuracy | 76.4 | 72.2 | 77.8 | 77.8 |
| AUC | 79.2 | 68.5 | 73.8 | 76.4 | |
| F1-Score | 77.3 | 72.5 | 77.8 | 78.2 | |
| BA | 79.2 | 68.5 | 73.8 | 76.4 | |
| PDR | Accuracy | 70.0 | 90.0 | 85.0 | 90.0 |
| AUC | 69.0 | 83.3 | 75.0 | 83.5 | |
| F1-Score | 71.0 | 89.3 | 83.2 | 89.3 | |
| BA | 69.0 | 83.3 | 75.0 | 83.5 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tummala, S.; Thadikemalla, V.S.G.; Kadry, S.; Sharaf, M.; Rauf, H.T. EfficientNetV2 Based Ensemble Model for Quality Estimation of Diabetic Retinopathy Images from DeepDRiD. Diagnostics 2023, 13, 622. https://doi.org/10.3390/diagnostics13040622
Tummala S, Thadikemalla VSG, Kadry S, Sharaf M, Rauf HT. EfficientNetV2 Based Ensemble Model for Quality Estimation of Diabetic Retinopathy Images from DeepDRiD. Diagnostics. 2023; 13(4):622. https://doi.org/10.3390/diagnostics13040622
Chicago/Turabian StyleTummala, Sudhakar, Venkata Sainath Gupta Thadikemalla, Seifedine Kadry, Mohamed Sharaf, and Hafiz Tayyab Rauf. 2023. "EfficientNetV2 Based Ensemble Model for Quality Estimation of Diabetic Retinopathy Images from DeepDRiD" Diagnostics 13, no. 4: 622. https://doi.org/10.3390/diagnostics13040622
APA StyleTummala, S., Thadikemalla, V. S. G., Kadry, S., Sharaf, M., & Rauf, H. T. (2023). EfficientNetV2 Based Ensemble Model for Quality Estimation of Diabetic Retinopathy Images from DeepDRiD. Diagnostics, 13(4), 622. https://doi.org/10.3390/diagnostics13040622