
Development of the Hypertension Index Model in General Adult Using the Korea National Health and Nutritional Examination Survey and the Korean Genome and Epidemiology Study



Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Definition of Hypertension
2.3. Evaluation of Variables
2.4. Selection of Predictors
2.5. Statistics
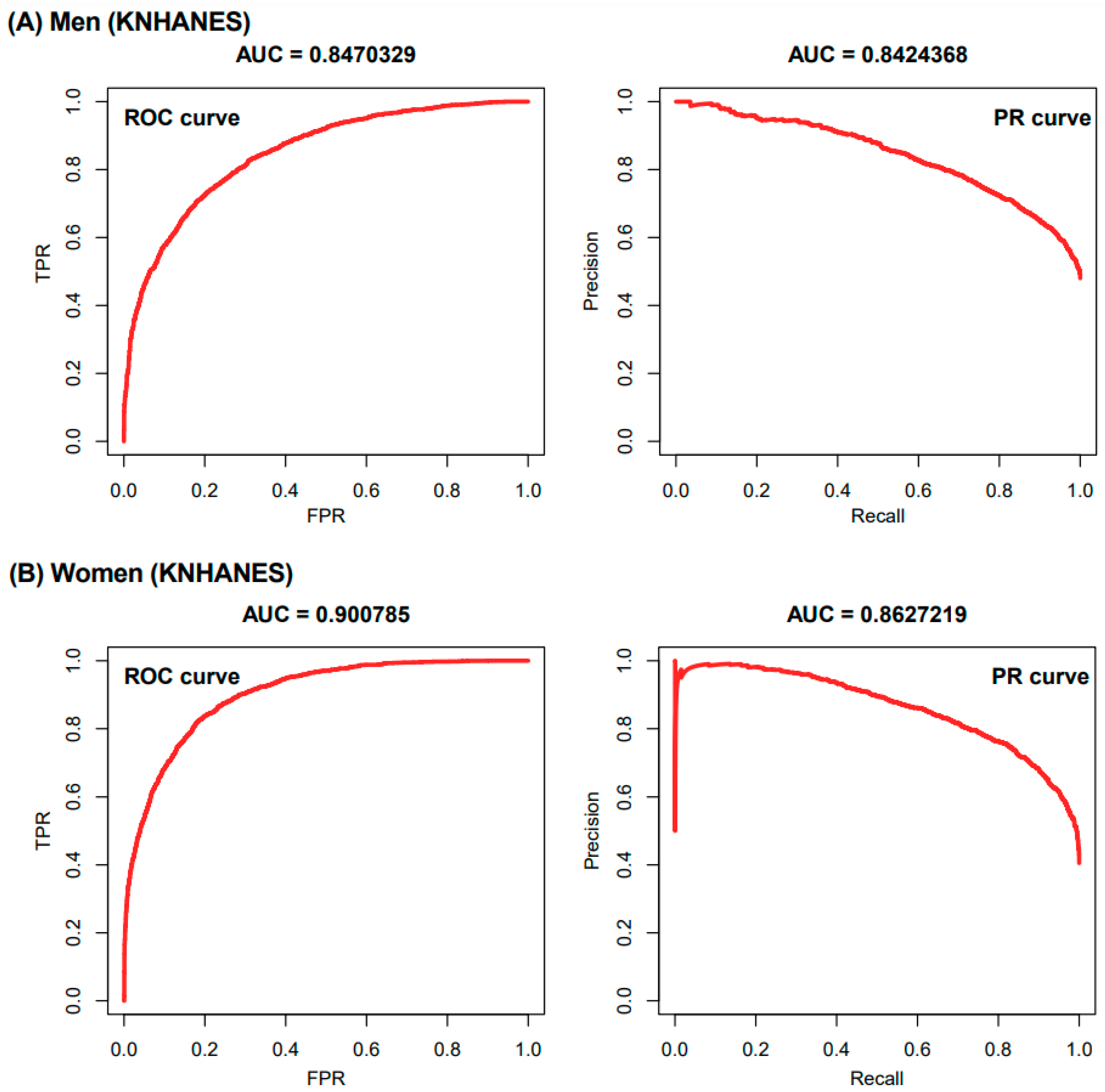
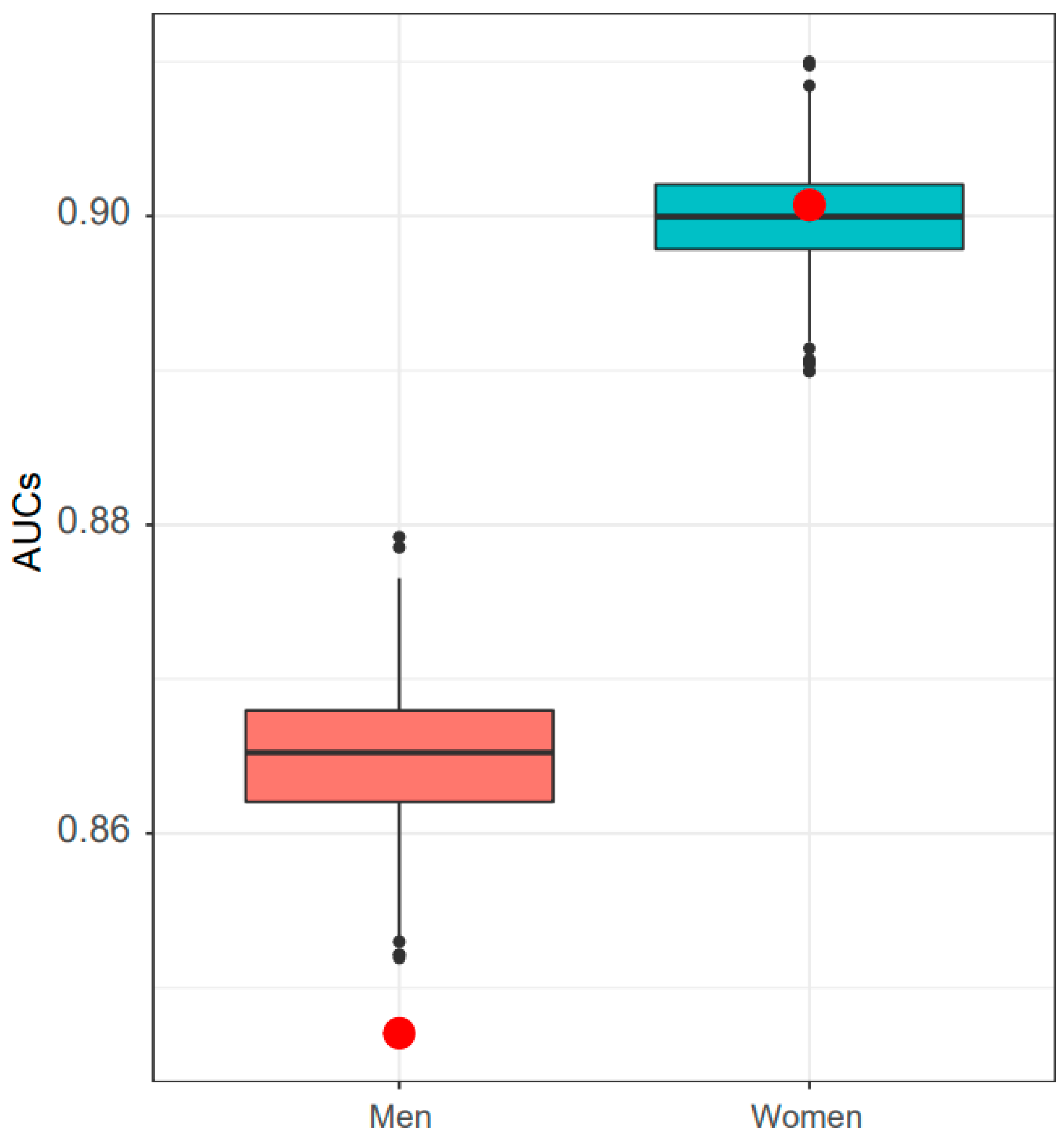
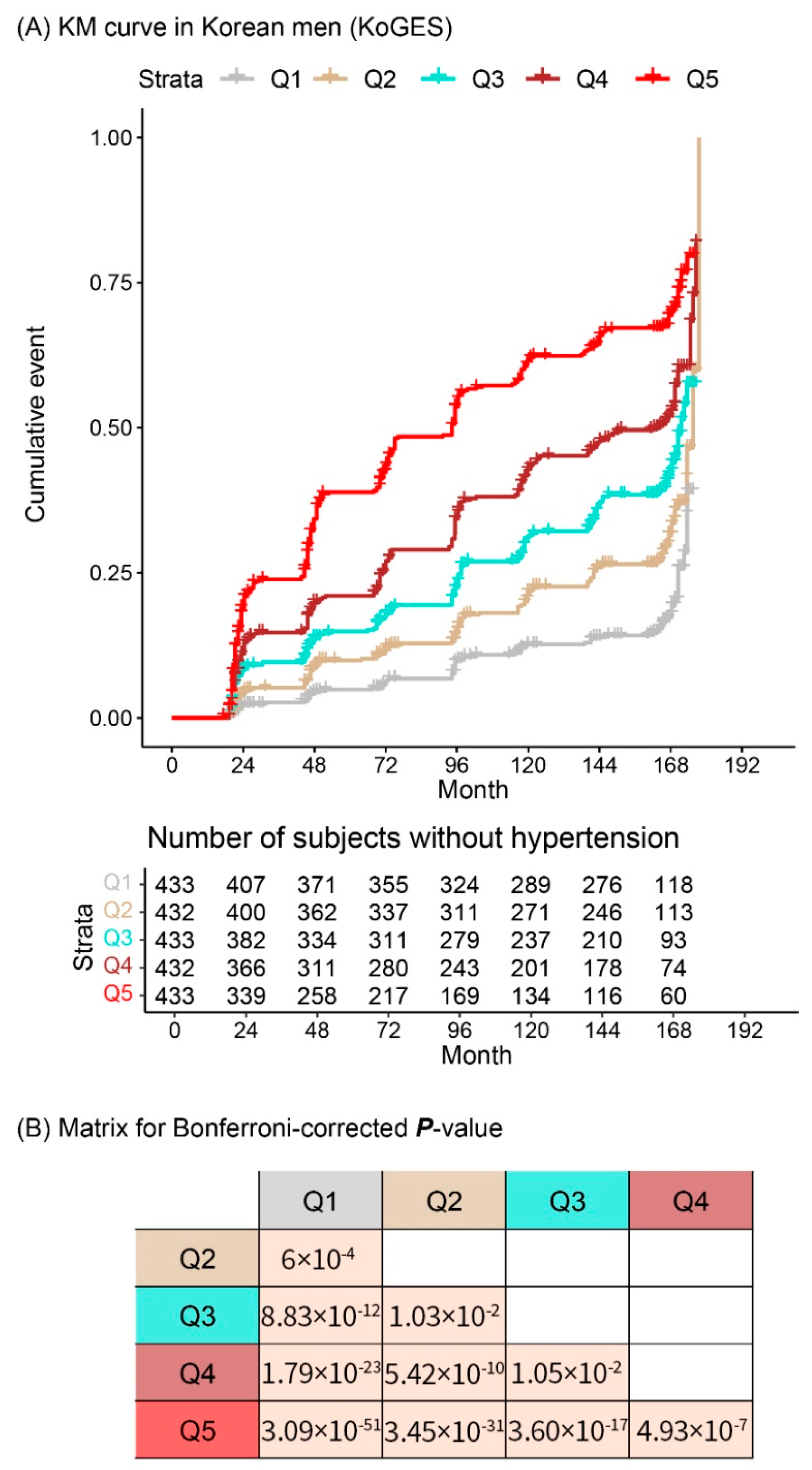
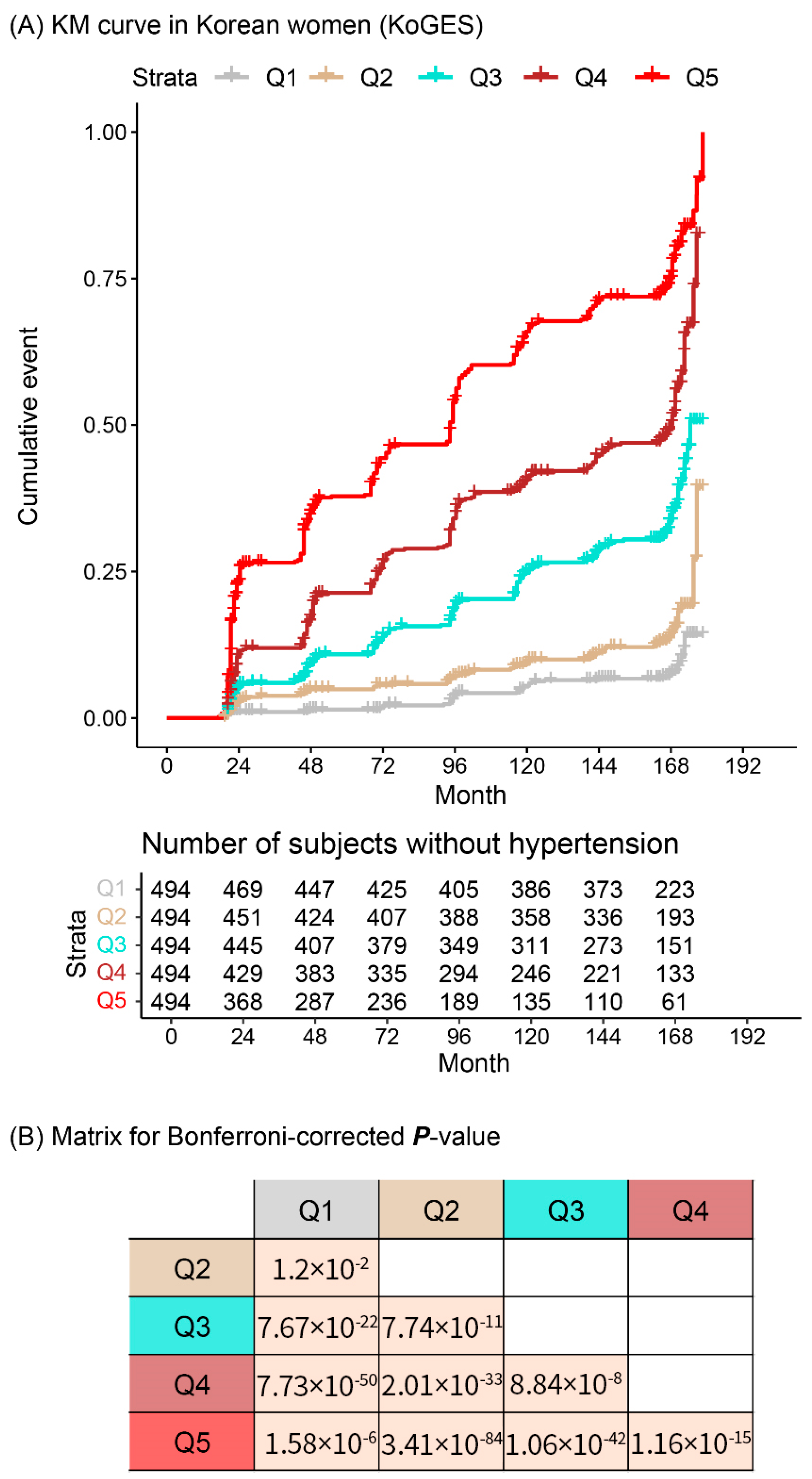
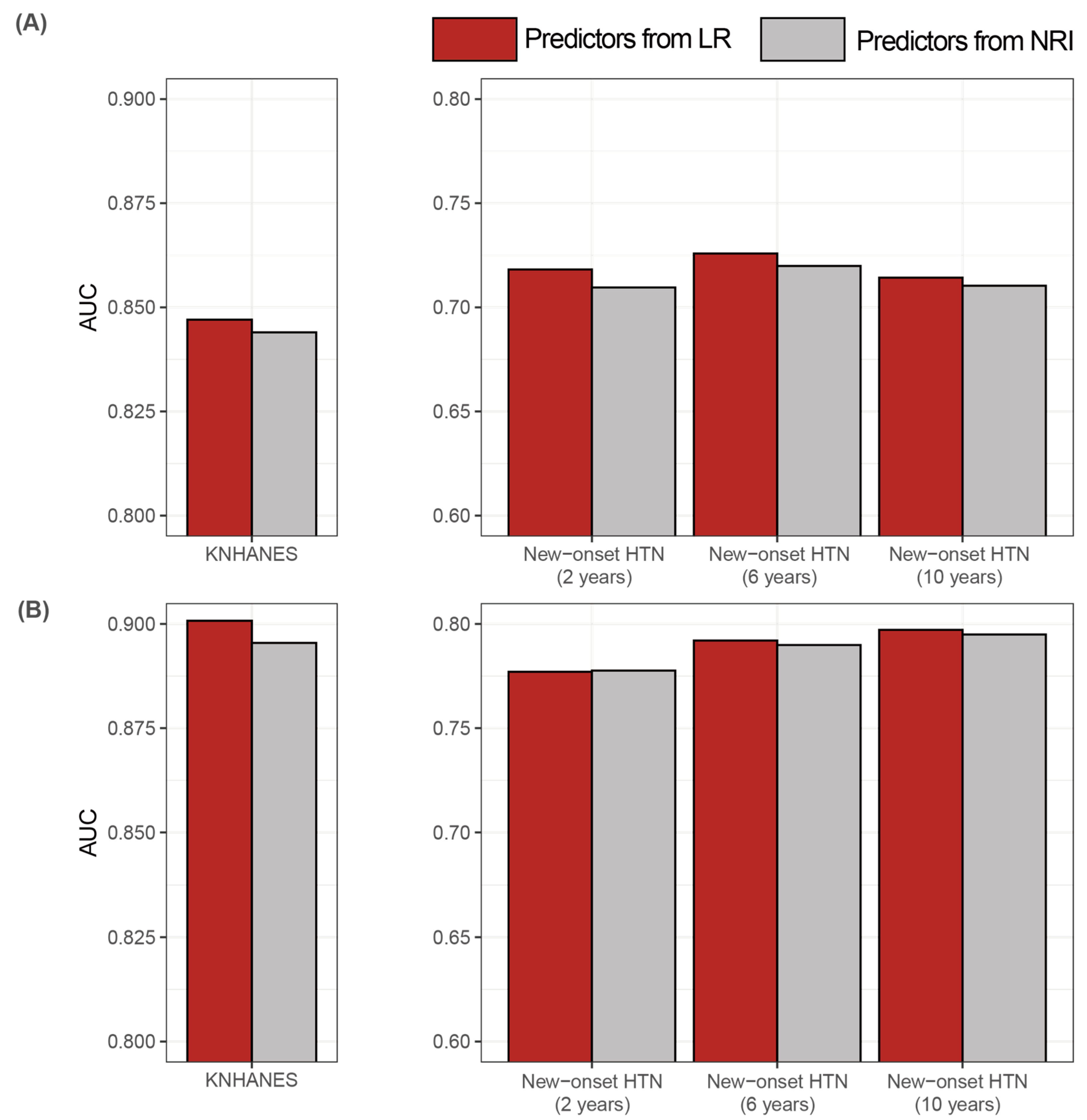
3. Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mills, K.T.; Bundy, J.D.; Kelly, T.N.; Reed, J.E.; Kearney, P.M.; Reynolds, K.; Chen, J.; He, J. Global disparities of hypertension prevalence and control: A systematic analysis of population-based studies from 90 countries. Circulation 2016, 134, 441–450. [Google Scholar] [CrossRef] [PubMed]
- Kang, S.H.; Kim, S.H.; Cho, J.H.; Yoon, C.H.; Hwang, S.S.; Lee, H.Y.; Youn, T.J.; Chae, I.H.; Kim, C.H. Prevalence, awareness, treatment, and control of hypertension in Korea. Sci. Rep. 2019, 9, 10970. [Google Scholar] [CrossRef] [Green Version]
- Kjeldsen, S.E. Hypertension and cardiovascular risk: General aspects. Pharmacol. Res. 2018, 129, 95–99. [Google Scholar] [CrossRef]
- Ku, E.; Lee, B.J.; Wei, J.; Weir, M.R. Hypertension in CKD: Core Curriculum 2019. Am. J. Kidney Dis. 2019, 74, 120–131. [Google Scholar] [CrossRef] [Green Version]
- Zhou, D.; Xi, B.; Zhao, M.; Wang, L.; Veeranki, S.P. Uncontrolled hypertension increases risk of all-cause and cardiovascular disease mortality in US adults: The NHANES III Linked Mortality Study. Sci. Rep. 2018, 8, 9418. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- NCD Risk Factor Collaboration (NCD-RisC). Long-term and recent trends in hypertension awareness, treatment, and control in 12 high-income countries: An analysis of 123 nationally representative surveys. Lancet 2019, 394, 639–651. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.; Shankar, R.; Singh, G.P. Prevalence and associated risk factors of hypertension: A cross-sectional study in urban Varanasi. Int. J. Hypertens. 2017, 2017, 5491838. [Google Scholar] [CrossRef] [Green Version]
- Appel, L.J.; Brands, M.W.; Daniels, S.R.; Karanja, N.; Elmer, P.J.; Sacks, F.M. Dietary approaches to prevent and treat hypertension: A scientific statement from the American Heart Association. Hypertension 2006, 47, 296–308. [Google Scholar] [CrossRef] [Green Version]
- Nakanishi, N.; Yoshida, H.; Nakamura, K.; Suzuki, K.; Tatara, K. Alcohol consumption and risk for hypertension in middle-aged Japanese men. J. Hypertens. 2001, 19, 851–855. [Google Scholar] [CrossRef]
- Parikh, N.I.; Pencina, M.J.; Wang, T.J.; Benjamin, E.J.; Lanier, K.J.; Levy, D.; D’Agostino, R.B.; Kannel, W.B.; Vasan, R.S. A risk score for predicting near-term incidence of hypertension: The Framingham Heart Study. Ann. Intern. Med. 2008, 148, 102–110. [Google Scholar] [CrossRef]
- Kivimaki, M.; Batty, G.D.; Singh-Manoux, A.; Ferrie, J.E.; Tabak, A.G.; Jokela, M.; Marmot, M.G.; Smith, G.D.; Shipley, M.J. Validating the Framingham hypertension risk score: Results from the Whitehall II Study. Hypertension 2009, 54, 496–501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paynter, N.P.; Cook, N.R.; Everett, B.M.; Sesso, H.D.; Buring, J.E.; Ridker, P.M. Prediction of incident hypertension risk in women with currently normal blood pressure. Am. J. Med. 2009, 122, 464–471. [Google Scholar] [CrossRef] [PubMed]
- Beevers, G.; Lip, G.Y.; O’Brien, E. ABC of hypertension: The pathophysiology of hypertension. BMJ 2001, 322, 912–916. [Google Scholar] [CrossRef] [PubMed]
- Kweon, S.; Kim, Y.; Jang, M.J.; Kim, Y.; Kim, K.; Choi, S.; Chun, C.; Khang, Y.H.; Oh, K. Data resource profile: The Korea National Health and Nutrition Examination Survey (KNHANES). Int. J. Epidemiol. 2014, 43, 69–77. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.; Han, B.G. Cohort Profile: The Korean Genome and Epidemiology Study (KoGES) Consortium. Int. J. Epidemiol. 2017, 46, e20. [Google Scholar] [CrossRef] [PubMed]
- Chobanian, A.V.; Bakris, G.L.; Black, H.R.; Cushman, W.C.; Green, L.A.; Izzo, J.L., Jr.; Jones, D.W.; Materson, B.J.; Oparil, S.; Wright, J.T., Jr.; et al. The seventh report of the joint national committee on prevention, detection, evaluation, and treatment of high blood pressure: The JNC 7 report. JAMA 2003, 289, 2560–2572. [Google Scholar] [CrossRef] [PubMed]
- Pippitt, K.; Li, M.; Gurgle, H.E. Diabetes mellitus: Screening and diagnosis. Am. Fam. Physician 2016, 93, 103–109. [Google Scholar] [PubMed]
- Cho, N.H.; Kim, K.M.; Choi, S.H.; Park, K.S.; Jang, H.C.; Kim, S.S.; Sattar, N.; Lim, S. High blood pressure and its association with incident diabetes over 10 years in the Korean Genome and Epidemiology Study (KoGES). Diabetes Care 2015, 38, 1333–1338. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, J.; Jang, H.; Kim, J.; Min, S. Development of a suicide index model in general adolescents using the South Korea 2012-2016 national representative survey data. Sci. Rep. 2019, 9, 1846. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y. The Korea National Health and Nutrition Examination Survey (KNHANES): Current status and challenges. Epidemiol. Health 2014, 36, e2014002. [Google Scholar] [CrossRef] [Green Version]
- Lim, N.K.; Son, K.H.; Lee, K.S.; Park, H.Y.; Cho, M.C. Predicting the risk of incident hypertension in a Korean middle-aged population: Korean genome and epidemiology study. J. Clin. Hypertens. 2013, 15, 344–349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kshirsagar, A.V.; Chiu, Y.L.; Bomback, A.S.; August, P.A.; Viera, A.J.; Colindres, R.E.; Bang, H. A hypertension risk score for middle-aged and older adults. J. Clin. Hypertens. 2010, 12, 800–808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Wang, C.; Liu, Y.; Yuan, Z.; Zhang, W.; Li, X.; Yang, Y.; Sun, X.; Xue, F.; Zhang, C. Incident hypertension and its prediction model in a prospective northern urban Han Chinese cohort study. J. Hum. Hypertens. 2016, 30, 794–800. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Wang, L.; Chen, Y.; Tang, F.; Xue, F.; Zhang, C. Identification of hypertension predictors and application to hypertension prediction in an urban Han Chinese population: A longitudinal study, 2005–2010. Prev. Chronic Dis. 2015, 12, E184. [Google Scholar] [CrossRef] [Green Version]
- Bozorgmanesh, M.; Hadaegh, F.; Mehrabi, Y.; Azizi, F. A point-score system superior to blood pressure measures alone for predicting incident hypertension: Tehran Lipid and Glucose Study. J. Hypertens. 2011, 29, 1486–1493. [Google Scholar] [CrossRef]
- Hajjar, I.; Kotchen, T.A. Trends in prevalence, awareness, treatment, and control of hypertension in the United States, 1988-2000. JAMA 2003, 290, 199–206. [Google Scholar] [CrossRef] [Green Version]
- Di Giosia, P.; Giorgini, P.; Stamerra, C.A.; Petrarca, M.; Ferri, C.; Sahebkar, A. Gender differences in epidemiology, pathophysiology, and treatment of hypertension. Curr. Atheroscler. Rep. 2018, 20, 13. [Google Scholar] [CrossRef] [PubMed]
- Jonas, M.A.; Oates, J.A.; Ockene, J.K.; Hennekens, C.H. Statement on smoking and cardiovascular disease for health care professionals. American Heart Association. Circulation 1992, 86, 1664–1669. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tuomilehto, J.; Elo, J.; Nissinen, A. Smoking among patients with malignant hypertension. Br. Med. J. (Clin. Res. Ed.) 1982, 284, 1086. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Primatesta, P.; Falaschetti, E.; Gupta, S.; Marmot, M.G.; Poulter, N.R. Association between smoking and blood pressure: Evidence from the health survey for England. Hypertension 2001, 37, 187–193. [Google Scholar] [CrossRef] [Green Version]
- Berglund, G.; Wilhelmsen, L. Factors related to blood pressure in a general population sample of Swedish men. Acta Med. Scand. 1975, 198, 291–298. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Derivation Dataset (KNHANES 2011–15) n = 15,395 | ||||||
|---|---|---|---|---|---|---|
| Men | Women | |||||
| Non-Hypertension | Hypertension | p Value | Non-Hypertension | Hypertension | p Value | |
| n = 3472 | n = 2900 | n = 5364 | n = 3659 | |||
| Age, years | 57.5 ± 0.18 | 63 ± 0.19 | <0.001 | 55 ± 0.14 | 64.8 ± 0.16 | <0.001 |
| Income, n | 0.788 | <0.001 | ||||
| 1st quartile | 798 (23) | 690 (23.8) | 1244 (23.2) | 928 (25.4) | ||
| 2nd quartile | 893 (25.7) | 767 (26.4) | 1279 (23.8) | 999 (27.3) | ||
| 3rd quartile | 841 (24.2) | 747 (25.8) | 1380 (25.7) | 891 (24.4) | ||
| 4th quartile | 940 (27.1) | 696 (24) | 1461 (27.2) | 841 (23) | ||
| Education, n | <0.001 | <0.001 | ||||
| Elementary school | 731 (21.1) | 850 (29.3) | 1519 (28.3) | 2206 (60.3) | ||
| Middle school | 510 (14.7) | 486 (16.8) | 757 (14.1) | 534 (14.6) | ||
| High school | 1116 (32.1) | 938 (32.3) | 1934 (36.1) | 681 (18.6) | ||
| University | 1115 (32.1) | 626 (21.6) | 1154 (21.5) | 238 (6.5) | ||
| Diabetes mellitus, n | 462 (13.3) | 743 (25.6) | <0.001 | 365 (6.8) | 823 (22.5) | <0.001 |
| Dyslipidemia, n | 149 (4.3) | 443 (15.3) | <0.001 | 370 (6.9) | 838 (22.9) | <0.001 |
| Cancer, n | 125 (3.6) | 92 (3.2) | 0.385 | 249 (4.6) | 185 (5.1) | 0.394 |
| Smoking, pack-years | 20.4 ± 0.34 | 21.9 ± 0.39 | 0.004 | 0.6 ± 0.05 | 0.8 ± 0.08 | 0.073 |
| Alcohol consumption, g/week | 99.7 ± 2.66 | 122.5 ± 3.16 | <0.001 | 17.2 ± 0.77 | 13.5 ± 0.9 | 0.001 |
| Total energy intake, kcal | 2348.1 ± 16.33 | 2189.6 ± 15.68 | <0.001 | 1725.7 ± 9.26 | 1582.8 ± 10.16 | <0.001 |
| BMI, kg/m2 | 23.6 ± 0.05 | 24.6 ± 0.06 | <0.001 | 23.4 ± 0.04 | 25 ± 0.06 | <0.001 |
| Waist circumference, cm | 84 ± 0.14 | 87.4 ± 0.16 | <0.001 | 78.7 ± 0.12 | 84 ± 0.15 | <0.001 |
| Systolic BP, mmHg | 115.5 ± 0.19 | 133.1 ± 0.31 | <0.001 | 113 ± 0.17 | 134.8 ± 0.28 | <0.001 |
| Diastolic BP, mmHg | 75 ± 0.14 | 80.6 ± 0.23 | 0.001 | 72.5 ± 0.1 | 78.5 ± 0.19 | <0.001 |
| FPG, mg/dL | 102.8 ± 0.42 | 109.3 ± 0.5 | <0.001 | 96.8 ± 0.28 | 105.5 ± 0.42 | <0.001 |
| Creatinine, mg/dL | 0.99 ± 0.0027 | 1.01 ± 0.0098 | <0.001 | 0.7 ± 0.0021 | 0.8 ± 0.0052 | <0.001 |
| Total cholesterol, mg/dL | 190.9 ± 0.59 | 182.9 ± 0.67 | <0.001 | 198 ± 0.48 | 195.5 ± 0.63 | 0.001 |
| Triglyceride, mg/dL | 152.8 ± 2.12 | 165.2 ± 2.33 | 0.762 | 117.7 ± 0.98 | 144 ± 1.49 | <0.001 |
| WBC, thousand/μL | 6.4 ± 0.03 | 6.6 ± 0.03 | <0.001 | 5.6 ± 0.02 | 6.1 ± 0.03 | <0.001 |
| Hb, g/dL | 15.1 ± 0.02 | 14.9 ± 0.03 | <0.001 | 13.1 ± 0.02 | 13.2 ± 0.02 | <0.001 |
| Model 1 (Univariate LR) | Model 2 (Multivariate LR) | |
|---|---|---|
| OR (95% CI) | OR (95% CI) | |
| Age (years) | 1.047 (1.047–1.047) | 1.065 (1.065–1.066) |
| Income status (Ref: Q1) | 0.975 (0.972–0.978) | 0.94 (0.936–0.944) |
| Education status (Ref: Elementary) | 0.782 (0.78–0.784) | 0.961 (0.956–0.965) |
| Diabetes mellitus | 2.237 (2.218–2.257) | 1.494 (1.469–1.519) |
| Dyslipidemia | 4.086 (4.032–4.14) | 4.398 (4.324–4.474) |
| Cancer | 0.937 (0.918–0.957) | 0.633 (0.616–0.651) |
| Smoking (pack-years) | 1.038 (1.037–1.04) | 0.957 (0.955–0.96) |
| Alcohol consumption (g/week) | 1.072 (1.071–1.073) | 1.077 (1.075–1.079) |
| Total energy intake (kcal) | 0.792 (0.788–0.797) | 0.939 (0.931–0.947) |
| BMI (kg/m2) | 1.139 (1.138–1.141) | 1.087 (1.084–1.09) |
| Waist circumference (cm) | 1.052 (1.051–1.052) | 1.013 (1.012–1.014) |
| Systolic BP (mmHg) | 1.117 (1.116–1.117) | 1.091 (1.091–1.092) |
| Diastolic BP (mmHg) | 1.083 (1.083–1.084) | 1.065 (1.065–1.066) |
| FPG (mg/dL) | 2.886 (2.851–2.92) | 0.86 (0.84–0.879) |
| Creatinine (mg/dL) | 4.368 (4.281–4.456) | 6.453 (6.28–6.63) |
| Total cholesterol (mg/dL) | 0.996 (0.995–0.996) | 0.993 (0.993–0.993) |
| Triglyceride (mg/dL) | 1.251 (1.246–1.256) | 1.094 (1.087–1.1) |
| WBC (thousand/μL) | 1.076 (1.074–1.078) | 1.076 (1.073–1.079) |
| Hb (g/dL) | 0.964 (0.961–0.966) | 0.86 (0.856–0.863) |
| Model 1 (Univariate LR) | Model 2 (Multivariate LR) | |
|---|---|---|
| OR (95% CI) | OR (95% CI) | |
| Age (years) | 1.094 (1.093–1.094) | 1.064 (1.063–1.065) |
| Income status (Ref: Q1) | 0.933 (0.93–0.936) | 0.991 (0.987–0.995) |
| Education status (Ref: Elementary) | 0.495 (0.494–0.497) | 0.868 (0.864–0.873) |
| Diabetes mellitus | 4.024 (3.984–4.064) | 1.798 (1.766–1.831) |
| Dyslipidemia | 4.191 (4.149–4.234) | 2.68 (2.643–2.717) |
| Cancer | 1.143 (1.126–1.161) | 0.945 (0.926–0.965) |
| Smoking (pack-years) | 0.997 (0.993–1.001) | - |
| Alcohol consumption (g/week) | 0.914 (0.913–0.915) | 1.019 (1.017–1.021) |
| Total energy intake (kcal) | 0.691 (0.688–0.695) | 0.938 (0.93–0.945) |
| BMI (kg/m2) | 1.165 (1.164–1.166) | 1.104 (1.101–1.107) |
| Waist circumference (cm) | 1.068 (1.068–1.068) | 0.991 (0.99–0.992) |
| Systolic BP (mmHg) | 1.117 (1.117–1.118) | 1.09 (1.09–1.091) |
| Diastolic BP (mmHg) | 1.083 (1.082–1.083) | 1.044 (1.043–1.045) |
| FPG (mg/dL) | 6.414 (6.324–6.505) | 1.192 (1.165–1.22) |
| Creatinine (mg/dL) | 6.207 (6.053–6.365) | 4.679 (4.522–4.842) |
| Total cholesterol (mg/dL) | 0.999 (0.999–0.999) | 0.995 (0.995–0.995) |
| Triglyceride (mg/dL) | 1.734 (1.726–1.741) | 1.109 (1.102–1.116) |
| WBC (thousand/μL) | 1.18 (1.178–1.182) | 1.064 (1.061–1.067) |
| Hb (g/dL) | 1.149 (1.146–1.153) | 1.013 (1.009–1.017) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, M.-J.; Ahn, S.-G.; Lee, Y.-J.; Kim, J.-K. Development of the Hypertension Index Model in General Adult Using the Korea National Health and Nutritional Examination Survey and the Korean Genome and Epidemiology Study. J. Pers. Med. 2021, 11, 968. https://doi.org/10.3390/jpm11100968
Seo M-J, Ahn S-G, Lee Y-J, Kim J-K. Development of the Hypertension Index Model in General Adult Using the Korea National Health and Nutritional Examination Survey and the Korean Genome and Epidemiology Study. Journal of Personalized Medicine. 2021; 11(10):968. https://doi.org/10.3390/jpm11100968
Chicago/Turabian StyleSeo, Myung-Jae, Sung-Gyun Ahn, Yong-Jae Lee, and Jong-Koo Kim. 2021. "Development of the Hypertension Index Model in General Adult Using the Korea National Health and Nutritional Examination Survey and the Korean Genome and Epidemiology Study" Journal of Personalized Medicine 11, no. 10: 968. https://doi.org/10.3390/jpm11100968
APA StyleSeo, M. -J., Ahn, S. -G., Lee, Y. -J., & Kim, J. -K. (2021). Development of the Hypertension Index Model in General Adult Using the Korea National Health and Nutritional Examination Survey and the Korean Genome and Epidemiology Study. Journal of Personalized Medicine, 11(10), 968. https://doi.org/10.3390/jpm11100968