
Guiding Efficient, Effective, and Patient-Oriented Electrolyte Replacement in Critical Care: An Artificial Intelligence Reinforcement Learning Approach

 , ,
, , 

Abstract
:1. Introduction
2. Materials and Methods
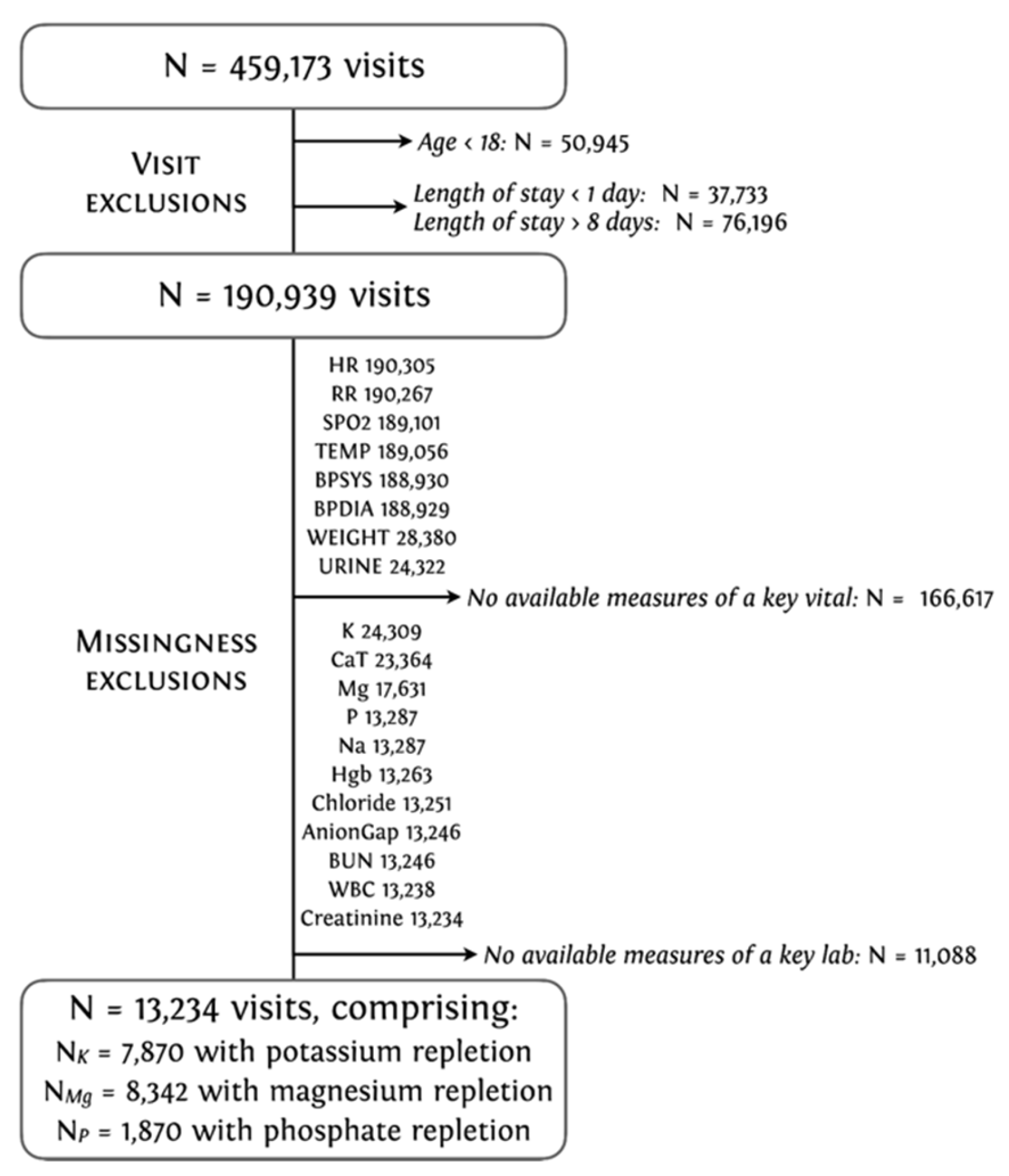
2.1. Dataset and Cohort Selection
2.2. Model Framework
2.3. Model Training
2.4. Validation on MIMIC-IV
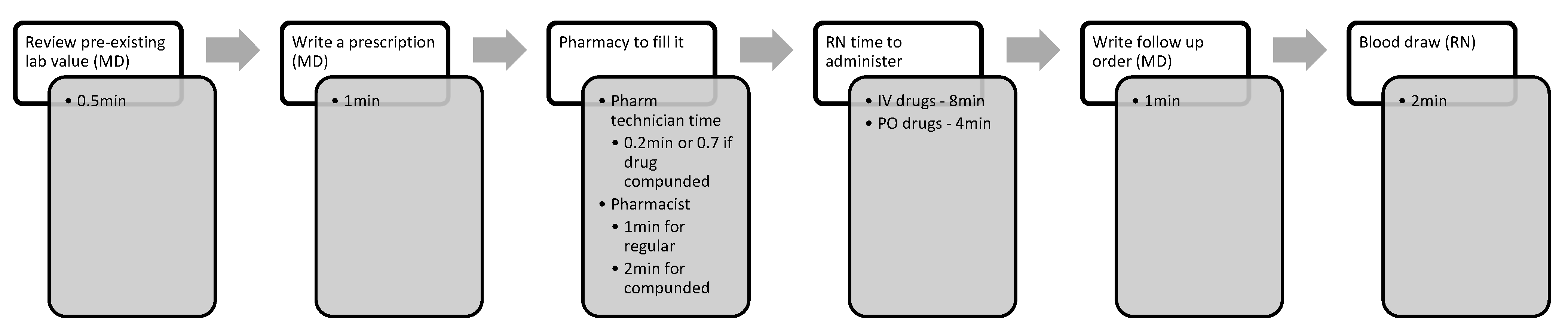
2.5. Financial Modeling
3. Results
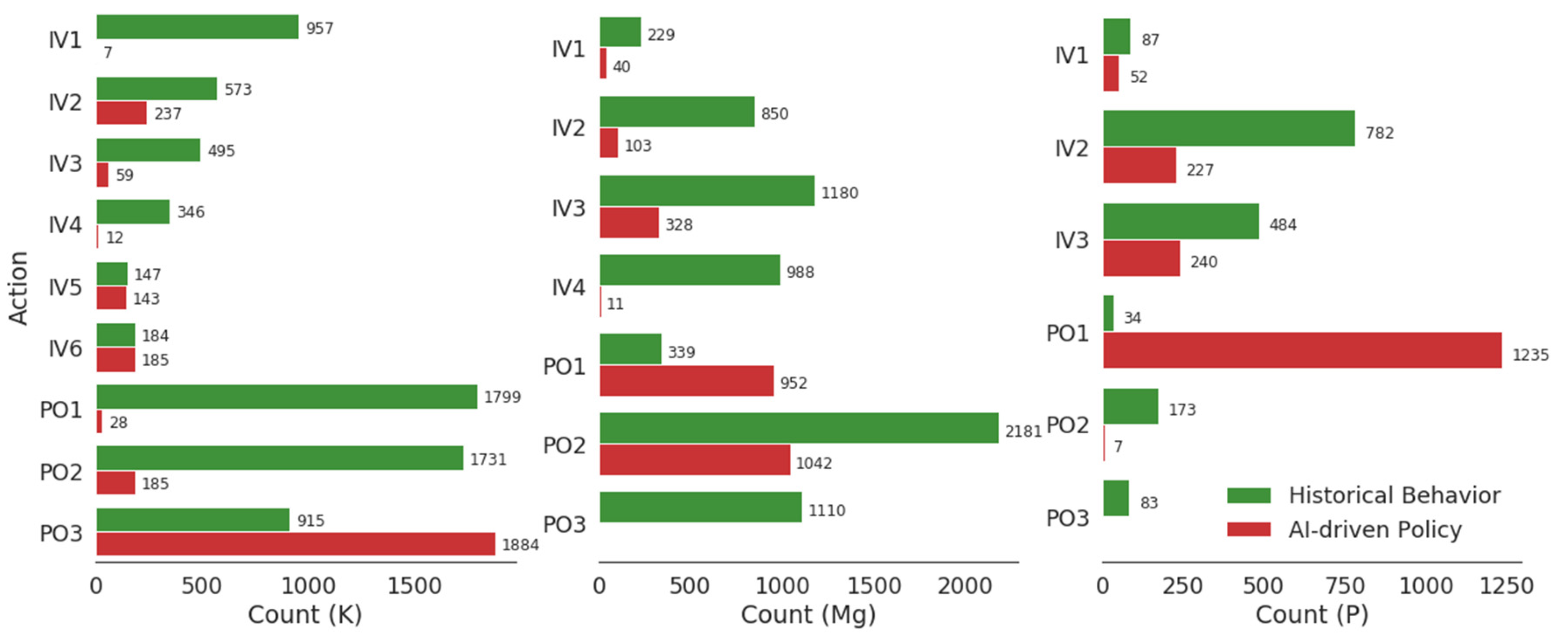
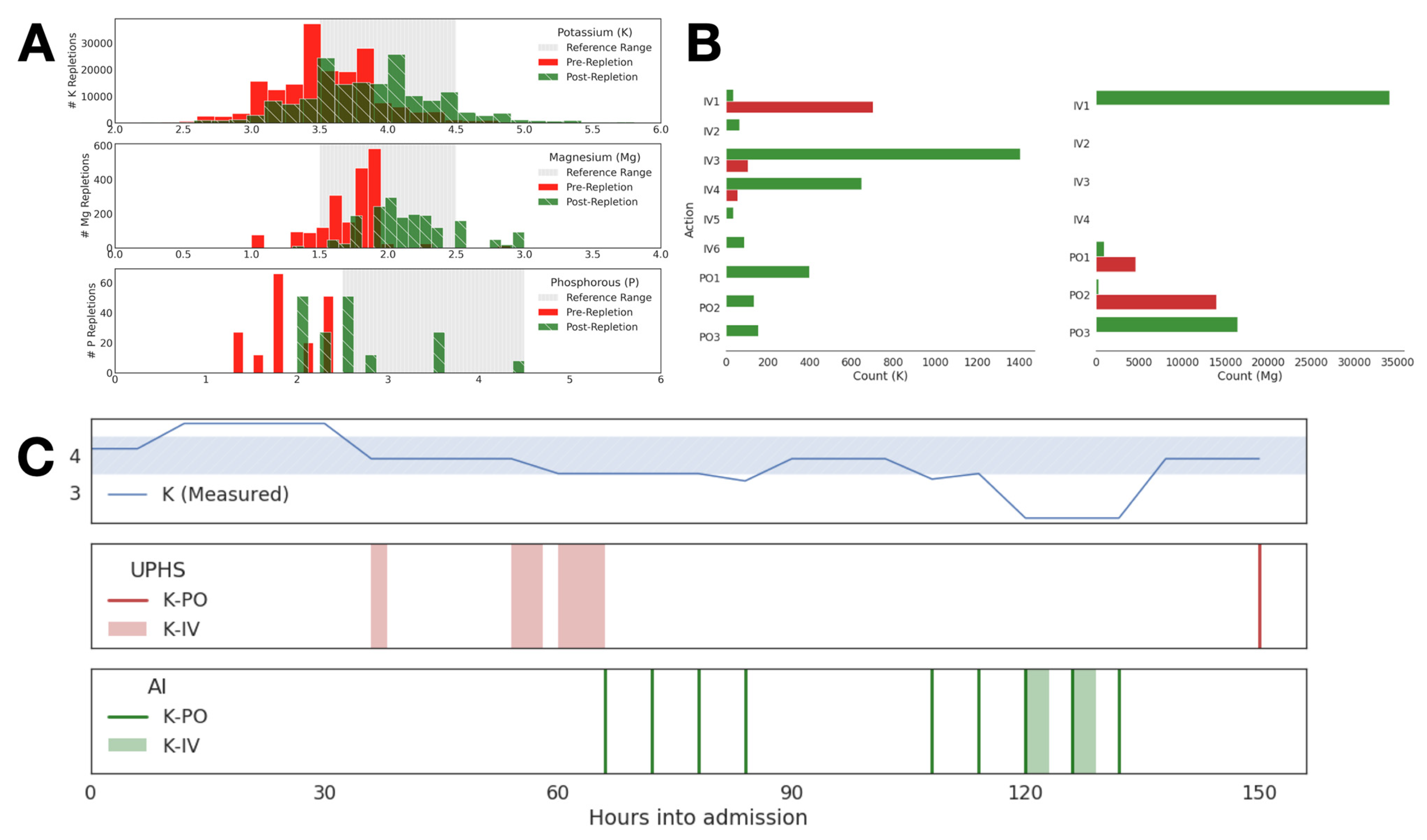
3.1. Patterns in Historical Provider Behavior
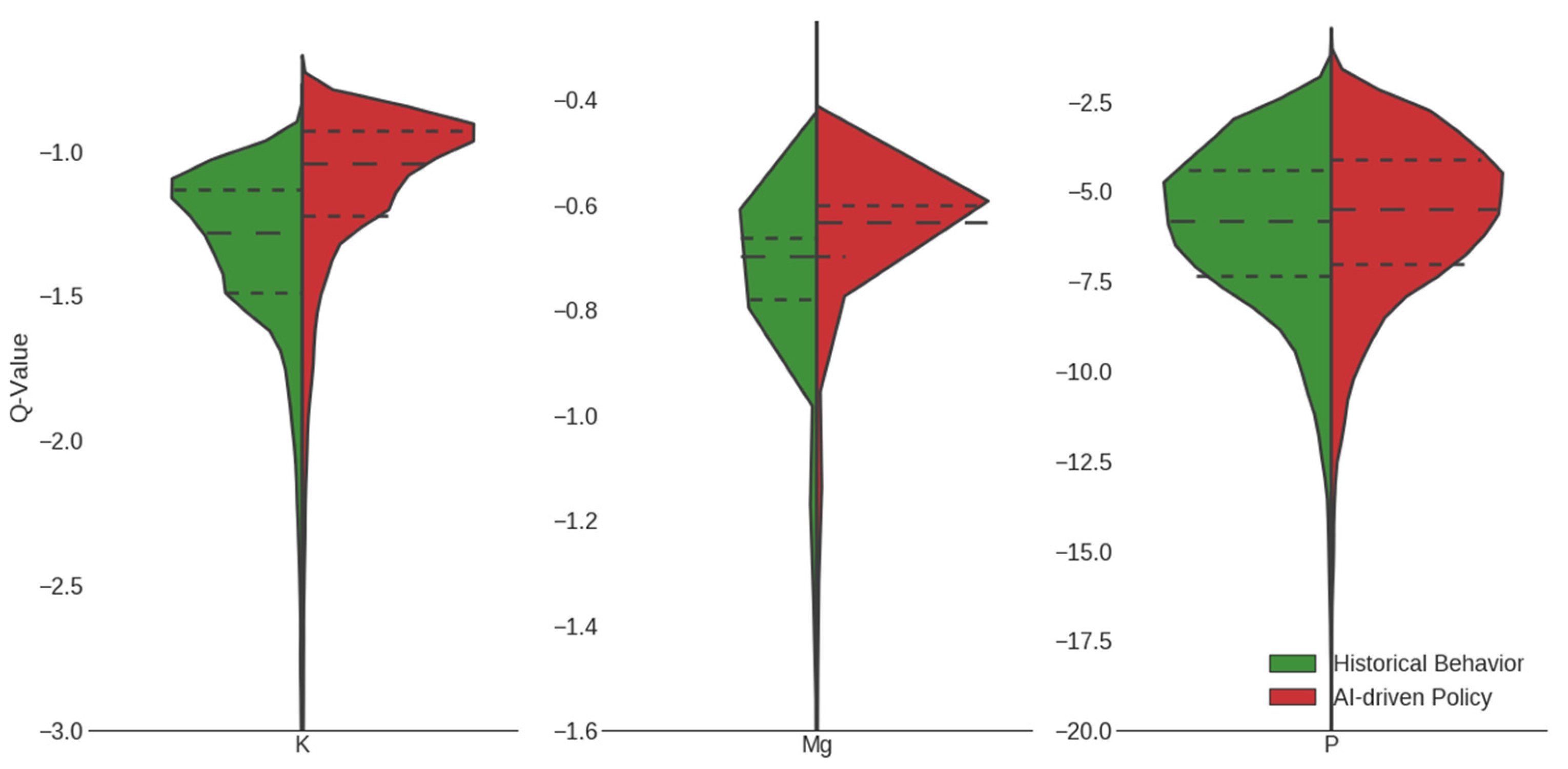
3.2. AI-Driven Repletion Recommendations
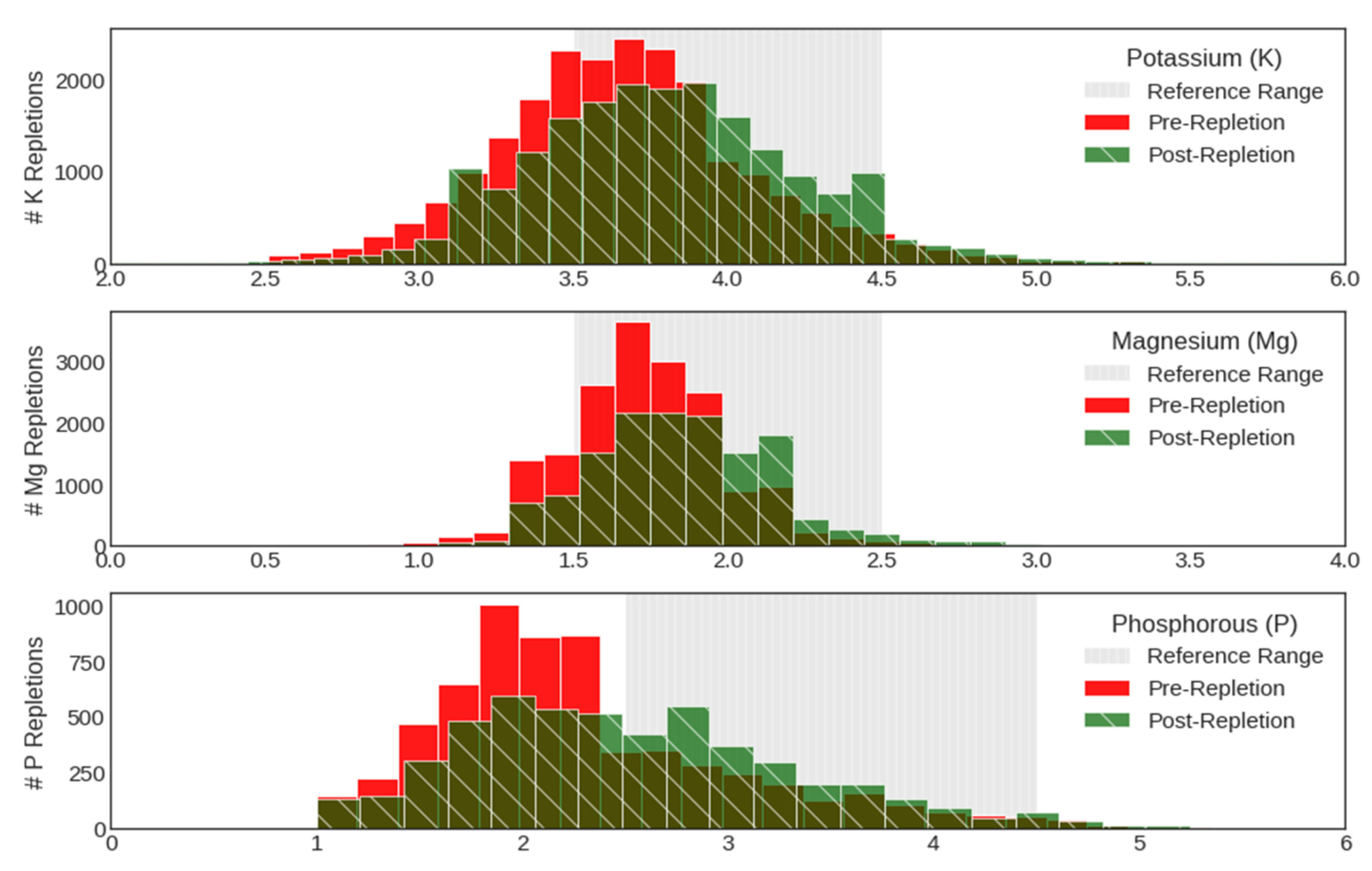
3.3. Expected Outcomes of Implementing AI-Driven Protocol
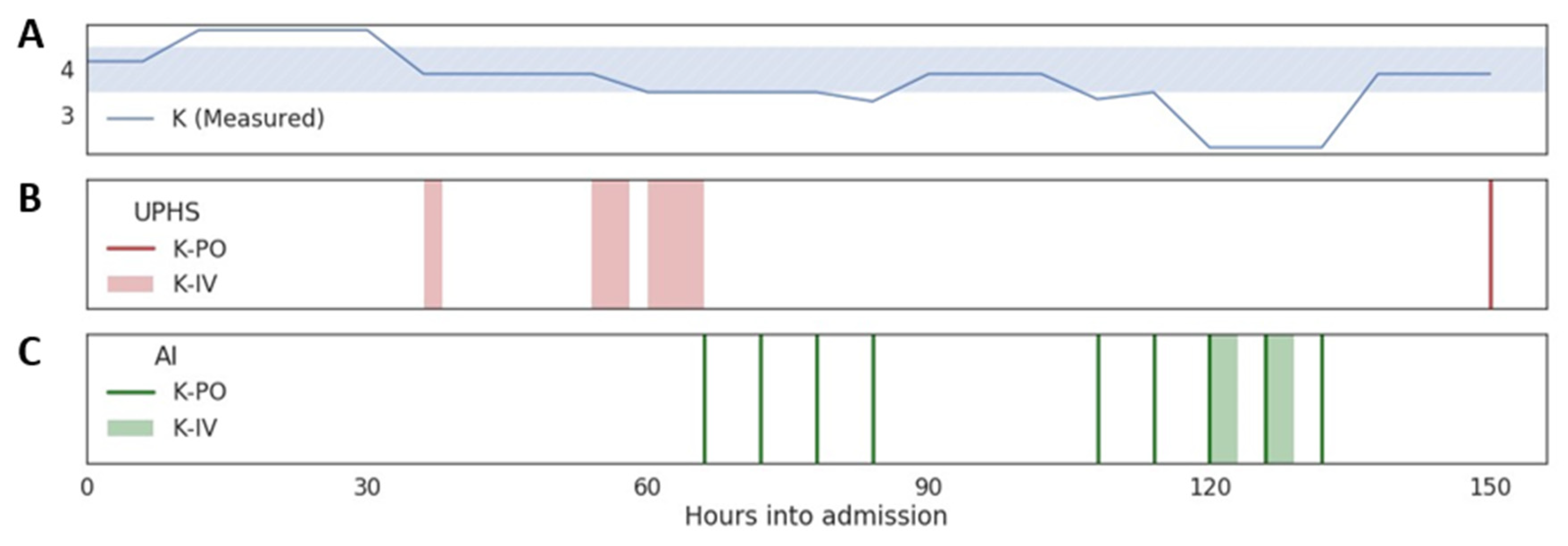
3.4. Validation of the Protocol
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Reward Design
Appendix A.2. Fitted Q Iteration (FQI)
Appendix A.3. Inverse Reinforcement Learning
Appendix B
Expected Clinical Workflow

References
- McKenzie, M.S.; Auriemma, C.L.; Olenik, J.; Cooney, E.; Gabler, N.B.; Halpern, S.D. An Observational Study of Decision Making by Medical Intensivists. Crit. Care Med. 2015, 43, 1660–1668. [Google Scholar] [CrossRef] [PubMed]
- Kuziemsky, C. Decision-making in healthcare as a complex adaptive system. Healthc. Manag. Forum 2016, 29, 4–7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reyna, V.F. A new intuitionism: Meaning, memory, and development in Fuzzy-Trace Theory. Judgm. Decis. Mak. 2012, 7, 332–359. [Google Scholar]
- Corbin, J.C.; Reyna, V.F.; Weldon, R.B.; Brainerd, C.J. How Reasoning, Judgment, and Decision Making are Colored by Gist-based Intuition: A Fuzzy-Trace Theory Approach. J. Appl. Res. Mem. Cogn. 2015, 4, 344–355. [Google Scholar] [CrossRef] [Green Version]
- Croskerry, P.; Nimmo, G.R. Better clinical decision making and reducing diagnostic error. J. R. Coll. Physicians Edinb. 2011, 41, 155–162. [Google Scholar] [CrossRef] [PubMed]
- Saposnik, G.; Redelmeier, D.; Ruff, C.C.; Tobler, P.N. Cognitive biases associated with medical decisions: A systematic review. BMC Med. Inform. Decis. Mak. 2016, 16, 138. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, R. Stress potentiates decision biases: A stress induced deliberation-to-intuition (SIDI) model. Neurobiol. Stress 2016, 3, 83–95. [Google Scholar] [CrossRef] [Green Version]
- Preuschoff, K.; Mohr, P.M.C.; Hsu, M. Decision Making under Uncertainity; Frontiers: Basel, Switzerland, 2015. [Google Scholar]
- Maslove, D.M.; Dubin, J.A.; Shrivats, A.; Lee, J. Errors, Omissions, and Outliers in Hourly Vital Signs Measurements in Intensive Care. Crit. Care Med. 2016, 44, e1021–e1030. [Google Scholar] [CrossRef]
- Djulbegovic, B. Uncertainty and equipoise: At interplay between epistemology, decision making and ethics. Am. J. Med. Sci. 2011, 342, 282–289. [Google Scholar] [CrossRef] [Green Version]
- Buelow, M.T.; Wirth, J.H. Decisions in the face of known risks: Ostracism increases risky decision-making. J. Exp. Soc. Psychol. 2017, 69, 210–217. [Google Scholar] [CrossRef]
- Kanji, Z.; Jung, K. Evaluation of an electrolyte replacement protocol in an adult intensive care unit: A retrospective before and after analysis. Intensive Crit. Care Nurs. 2009, 25, 181–189. [Google Scholar] [CrossRef] [PubMed]
- Hijazi, M.; Al-Ansari, M. Protocol-driven vs. physician-driven electrolyte replacement in adult critically ill patients. Ann. Saudi Med. 2005, 25, 105–110. [Google Scholar] [CrossRef] [PubMed]
- Ament, S.M.; de Groot, J.J.; Maessen, J.M.; Dirksen, C.D.; van der Weijden, T.; Kleijnen, J. Sustainability of professionals’ adherence to clinical practice guidelines in medical care: A systematic review. BMJ Open 2015, 5, e008073. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cohen, J.; Kogan, A.; Sahar, G.; Lev, S.; Vidne, B.; Singer, P. Hypophosphatemia following open heart surgery: Incidence and consequences. Eur. J. Cardiothorac. Surg. 2004, 26, 306–310. [Google Scholar] [CrossRef] [Green Version]
- Couture, J.; Letourneau, A.; Dubuc, A.; Williamson, D. Evaluation of an electrolyte repletion protocol for cardiac surgery intensive care patients. Can. J. Hosp. Pharm. 2013, 66, 96–103. [Google Scholar] [CrossRef] [Green Version]
- Hirsch, I.A.; Tomlinson, D.L.; Slogoff, S.; Keats, A.S. The overstated risk of preoperative hypokalemia. Anesth. Analg. 1988, 67, 131–136. [Google Scholar] [CrossRef]
- Soliman, H.M.; Mercan, D.; Lobo, S.S.; Melot, C.; Vincent, J.L. Development of ionized hypomagnesemia is associated with higher mortality rates. Crit. Care Med. 2003, 31, 1082–1087. [Google Scholar] [CrossRef]
- Udensi, U.K.; Tchounwou, P.B. Potassium Homeostasis, Oxidative Stress, and Human Disease. Int. J. Clin. Exp. Physiol. 2017, 4, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Alfonzo, A.V.; Isles, C.; Geddes, C.; Deighan, C. Potassium disorders—Clinical spectrum and emergency management. Resuscitation 2006, 70, 10–25. [Google Scholar] [CrossRef]
- Lancaster, T.S.; Schill, M.R.; Greenberg, J.W.; Moon, M.R.; Schuessler, R.B.; Damiano, R.J., Jr.; Melby, S.J. Potassium and Magnesium Supplementation Do Not Protect Against Atrial Fibrillation After Cardiac Operation: A Time-Matched Analysis. Ann. Thorac. Surg. 2016, 102, 1181–1188. [Google Scholar] [CrossRef] [Green Version]
- Hammond, D.A.; King, J.; Kathe, N.; Erbach, K.; Stojakovic, J.; Tran, J.; Clem, O.A. Effectiveness and Safety of Potassium Replacement in Critically Ill Patients: A Retrospective Cohort Study. Crit. Care Nurse 2019, 39, e13–e18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hammond, D.A.; Stojakovic, J.; Kathe, N.; Tran, J.; Clem, O.A.; Erbach, K.; King, J. Effectiveness and Safety of Magnesium Replacement in Critically Ill Patients Admitted to the Medical Intensive Care Unit in an Academic Medical Center: A Retrospective, Cohort Study. J. Intensive Care Med. 2019, 34, 967–972. [Google Scholar] [CrossRef] [PubMed]
- Joseph, T.T.; DiMeglio, M.; Huffenberger, A.; Laudanski, K. Behavioural patterns of electrolyte repletion in intensive care units: Lessons from a large electronic dataset. Sci. Rep. 2018, 8, 11915. [Google Scholar] [CrossRef] [PubMed]
- Kindle, R.D.; Badawi, O.; Celi, L.A.; Sturland, S. Intensive Care Unit Telemedicine in the Era of Big Data, Artificial Intelligence, and Computer Clinical Decision Support Systems. Crit. Care Clin. 2019, 35, 483–495. [Google Scholar] [CrossRef]
- Wijnberge, M.; Geerts, B.F.; Hol, L.; Lemmers, N.; Mulder, M.P.; Berge, P.; Schenk, J.; Terwindt, L.E.; Hollmann, M.W.; Vlaar, A.P.; et al. Effect of a Machine Learning–Derived Early Warning System for Intraoperative Hypotension vs Standard Care on Depth and Duration of Intraoperative Hypotension During Elective Noncardiac Surgery: The HYPE Randomized Clinical Trial. JAMA 2020, 323, 1052–1060. [Google Scholar] [CrossRef] [PubMed]
- Barbieri, C.; Cattinelli, I.; Neri, L.; Mari, F.; Ramos, R.; Brancaccio, D.; Canaud, B.; Stuard, S. Development of an Artificial Intelligence Model to Guide the Management of Blood Pressure, Fluid Volume, and Dialysis Dose in End-Stage Kidney Disease Patients: Proof of Concept and First Clinical Assessment. Kidney Dis. 2019, 5, 28–33. [Google Scholar] [CrossRef]
- Nemati, S.; Ghassemi, M.M.; Clifford, G.D. Optimal medication dosing from suboptimal clinical examples: A deep reinforcement learning approach. In Proceedings of the IEEEE 38th Annual International Conference, Orlando, FL, USA, 16–20 August 2016; pp. 2978–2981. [Google Scholar]
- Raghu, A.; Komorowski, M.; Anthony Celi, L.; Szolovits, P.; Ghassemi, M. Continuous state-space models for optimal sepsis treatment: A deep reinforcement learning approach. In Proceedings of the 2nd Machine Learning for Healthcare Conference, MLHC, Boston, MA, USA, 18–19 August 2017; pp. 147–163. [Google Scholar]
- Prasad, N. Methods for Reinforcement Learning in Clinical Decision Support. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 2020. [Google Scholar]
- Sutton, R.S. Reinforcement Learning; An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Ernst, D.; Geurts, P.; Wehenkel, L. Tree-Based Batch Mode Reinforcement Learning. J. Mach. Learn. Res. 2005, 6, 503–556. [Google Scholar]
- Hyland, S.L.; Faltys, M.; Huser, M.; Lyu, X.; Gumbsch, T.; Esteban, C.; Bock, C.; Horn, M.; Moor, M.; Rieck, B.; et al. Early prediction of circulatory failure in the intensive care unit using machine learning. Nat. Med. 2020, 26, 364–373. [Google Scholar] [CrossRef]
- Wong, A.; Young, A.T.; Liang, A.S.; Gonzales, R.; Douglas, V.C.; Hadley, D. Development and Validation of an Electronic Health Record–Based Machine Learning Model to Estimate Delirium Risk in Newly Hospitalized Patients Without Known Cognitive Impairment. JAMA Netw. Open 2018, 1, e181018. [Google Scholar] [CrossRef] [Green Version]
- Hoang, L.M.; Voloshin, C.; Yue, Y. Batch policy learning under constraints. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.W.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [Green Version]
- State Occupational Employment and Wage Estimates Pennsylvania. 2016. Bureau of Labor Statistics, US Department of Labor: May 2016 State Occupational Employment and Wage. Available online: https://www.bls.gov/oes/current/oes_pa.htm#29-0000 (accessed on 20 December 2017).
- Physician Fee Schedule. Center for Medicare & Medicaid Services: Clinical. Available online: https://www.cms.gov/apps/physician-fee-schedule/search/search-criteria.aspx (accessed on 20 December 2017).
- Lexicomp Online®; Lexi-Comp, Inc.: Hudson, OH, USA; Available online: https://www.wolterskluwer.com/en/solutions/lexicomp (accessed on 24 February 2022).
- Clinical Laboratory Fee Schedule. Center for Medicare & Medicaid Services. Available online: https://www.cms.gov/Medicare/Medicare-Fee-for-Service-Payment/ClinicalLabFeeSched (accessed on 20 December 2017).
- Mamdani, M.; Slutsky, A.S. Artificial intelligence in intensive care medicine. Intensive Care Med. 2020, 47, 147–149. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | |
|---|---|
| Static | Age, Gender, Weight, Floor/ICU |
| Vitals | Heart rate, Respiratory rate, Temperature, O2 saturation pulse oximetry (SpO2), Urine output, Non-invasive blood pressure (systolic, diastolic) |
| Labs—Raw | K, Mg, P, Ma, Chloride, Anion gap, Creatinine, Hemoglobin, Glucose, Blood Urea Nitrogen, WBC Count |
| Labs—Indicator | Ca (Ionized), Glucose, CPK, LDH, ALT, AST, PTH |
| Drugs | K-IV, K-PO, Mg-IV, Mg-PO, P-IV, P-PO, Ca-IV, Ca-PO, Loop diuretics, Thiazides, Acetazolamide, Spironolactone, Fluids, Vasopressors, β-blockers, Ca-blockers, Dextrose, Insulin, Kayexalate, TPN, PN, PO nutrition |
| Procedures | Packed-cell transfusion, Dialysis |
| Oral (PO) | Intravenous (IV) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PO1 | PO2 | PO3 | IV1 | IV2 | IV3 | IV4 | IV5 | IV6 | ||
| K | 0 | 20 mg | 40 mg | 60 mg | 20 mEq 2 h | 40 mEq 4 h | 60 mEq 6 h | 20 mEq 1 h | 40 mEq 2 h | 60 mEq 3 h |
| Mg | 0 | 400 mg | 800 mg | 1200 mg | 0.5 g 1 h | 1 g 1 h | 1 g 2 h | 1 g 3 h | ||
| P | 0 | 250 mg | 500 mg | 750 mg | 15 mEq 1 h | 30 mEq 3 h | 45 mEq 6 h | |||
| Historical Policy Drivers | AI Policy Drivers | |
|---|---|---|
| K | (−0.05, −0.08, 0.20, 0.67) | (0.07, 0.04, 0.15, 0.74) |
| Mg | (−0.05, −0.01, 0.33, 0.61) | (0.01, 0.01, 0.48, 0.48) |
| P | (−0.25, 0.11, 0.30, 0.34) | (0.08, 0.07, 0.5, 0.35) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prasad, N.; Mandyam, A.; Chivers, C.; Draugelis, M.; Hanson, C.W., III; Engelhardt, B.E.; Laudanski, K. Guiding Efficient, Effective, and Patient-Oriented Electrolyte Replacement in Critical Care: An Artificial Intelligence Reinforcement Learning Approach. J. Pers. Med. 2022, 12, 661. https://doi.org/10.3390/jpm12050661
Prasad N, Mandyam A, Chivers C, Draugelis M, Hanson CW III, Engelhardt BE, Laudanski K. Guiding Efficient, Effective, and Patient-Oriented Electrolyte Replacement in Critical Care: An Artificial Intelligence Reinforcement Learning Approach. Journal of Personalized Medicine. 2022; 12(5):661. https://doi.org/10.3390/jpm12050661
Chicago/Turabian StylePrasad, Niranjani, Aishwarya Mandyam, Corey Chivers, Michael Draugelis, C. William Hanson, III, Barbara E. Engelhardt, and Krzysztof Laudanski. 2022. "Guiding Efficient, Effective, and Patient-Oriented Electrolyte Replacement in Critical Care: An Artificial Intelligence Reinforcement Learning Approach" Journal of Personalized Medicine 12, no. 5: 661. https://doi.org/10.3390/jpm12050661
APA StylePrasad, N., Mandyam, A., Chivers, C., Draugelis, M., Hanson, C. W., III, Engelhardt, B. E., & Laudanski, K. (2022). Guiding Efficient, Effective, and Patient-Oriented Electrolyte Replacement in Critical Care: An Artificial Intelligence Reinforcement Learning Approach. Journal of Personalized Medicine, 12(5), 661. https://doi.org/10.3390/jpm12050661