
Effects of the Earthquake Nonstationary Characteristics on the Structural Dynamic Response: Base on the BP Neural Networks Modified by the Genetic Algorithm

Abstract
:1. Instruction
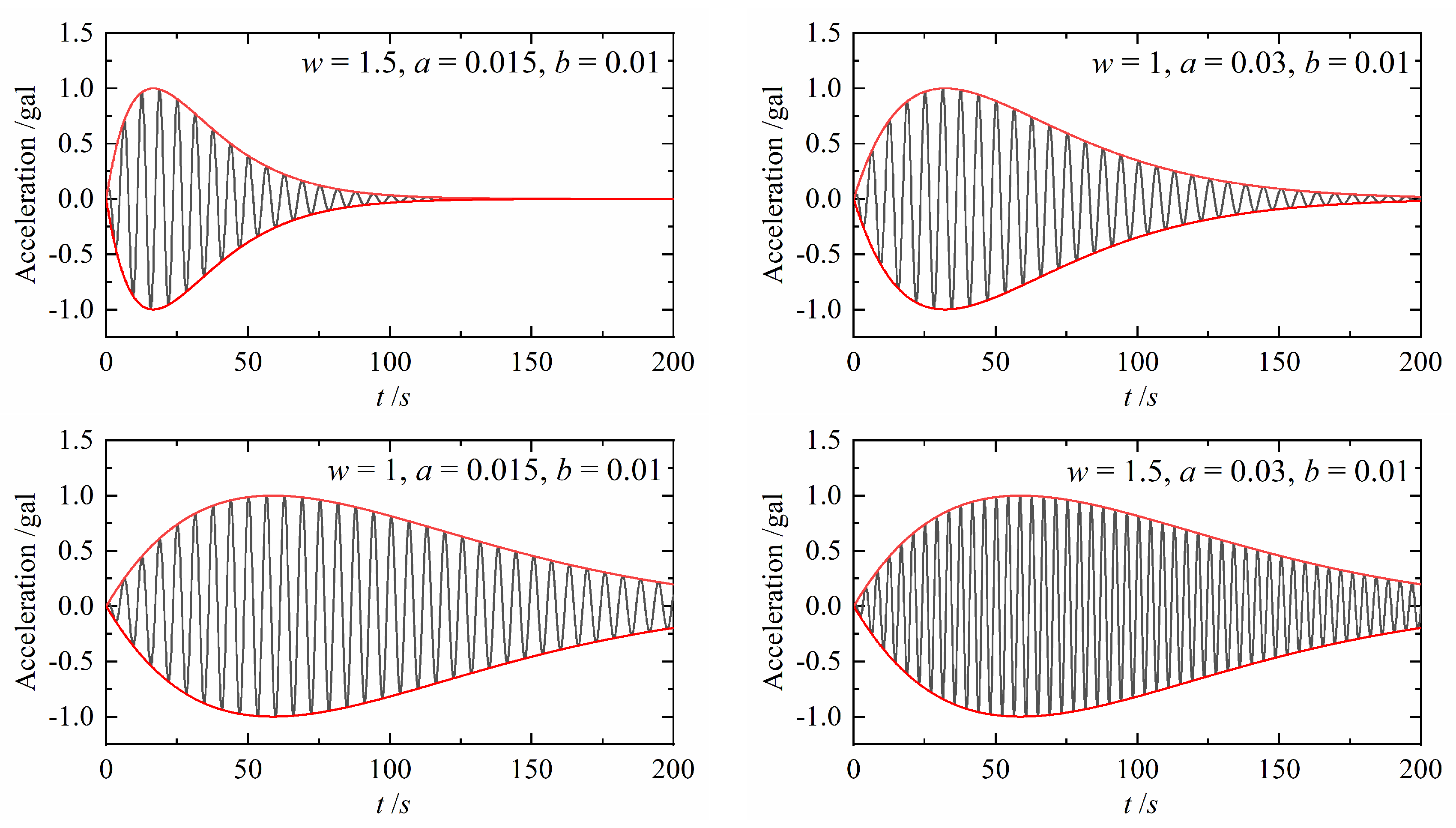
2. The Intensity Non-Stationarity Model Enveloped by the Damped-Sine Function and the Analytical Solution of Its Dynamic Responses
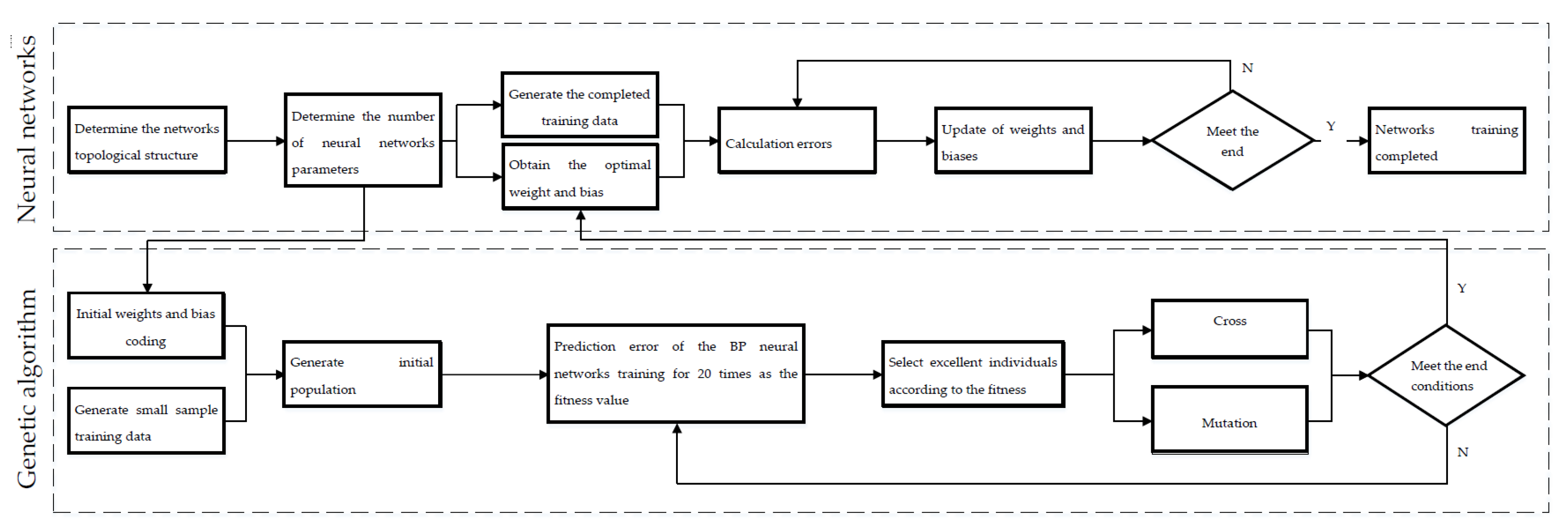
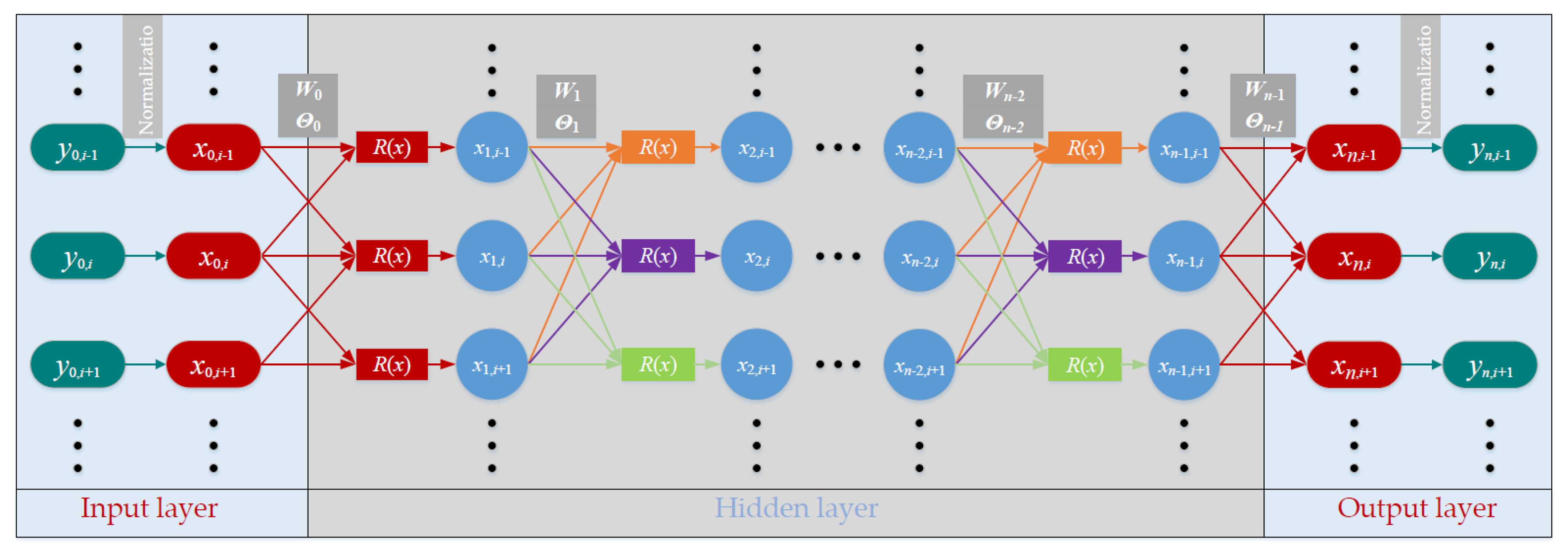
3. Response Prediction Based on the GA-BP Neural Networks
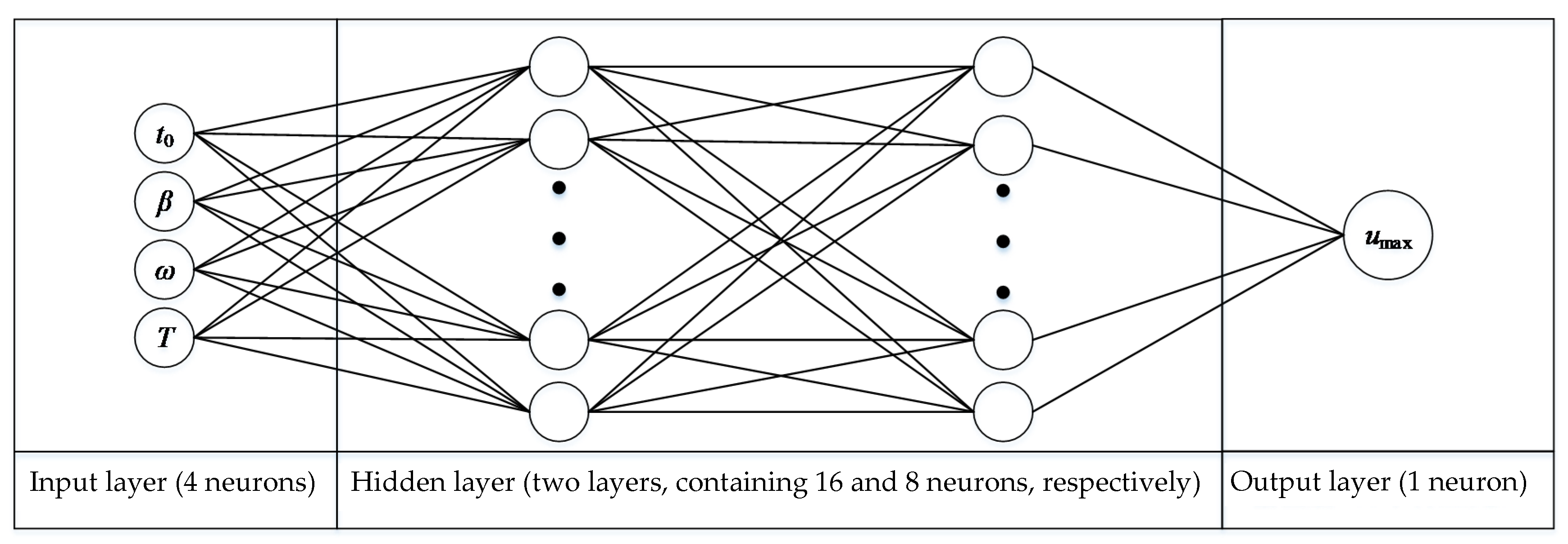
3.1. Hyperparameters of the BP Neural Networks
3.2. Training Dataset
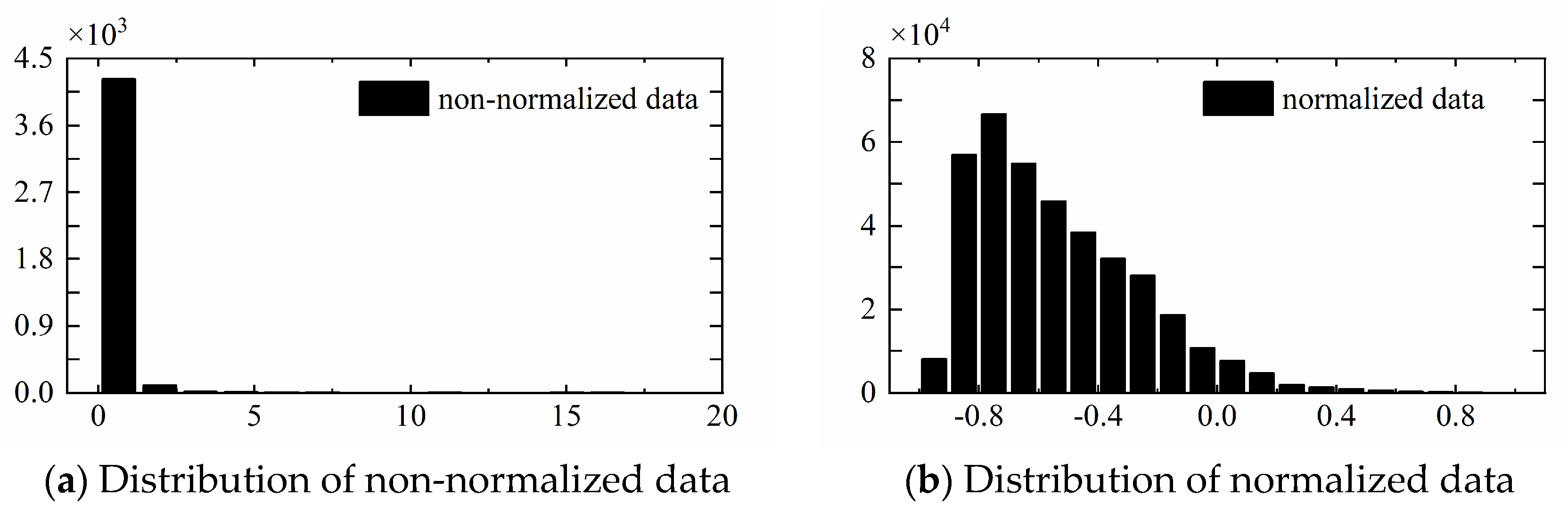
3.3. Data Initialization
3.4. Optimization of Initial Network Parameters Based on the Genetic Algorithm
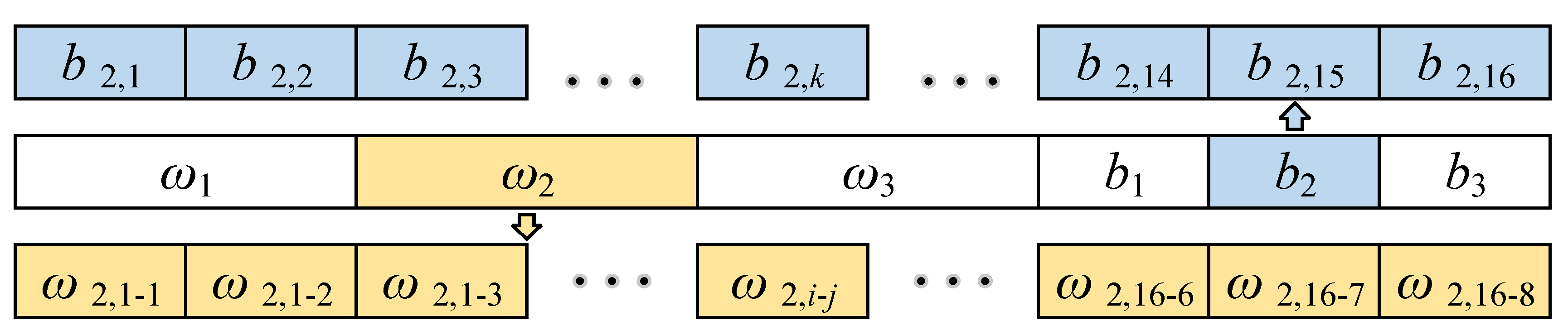
3.4.1. Coding
3.4.2. Fitness Function
3.4.3. Basic Operators of Genetic Algorithm
- (1)
- Section operator
- (2)
- Cross operator
- (3)
- Mutation operator
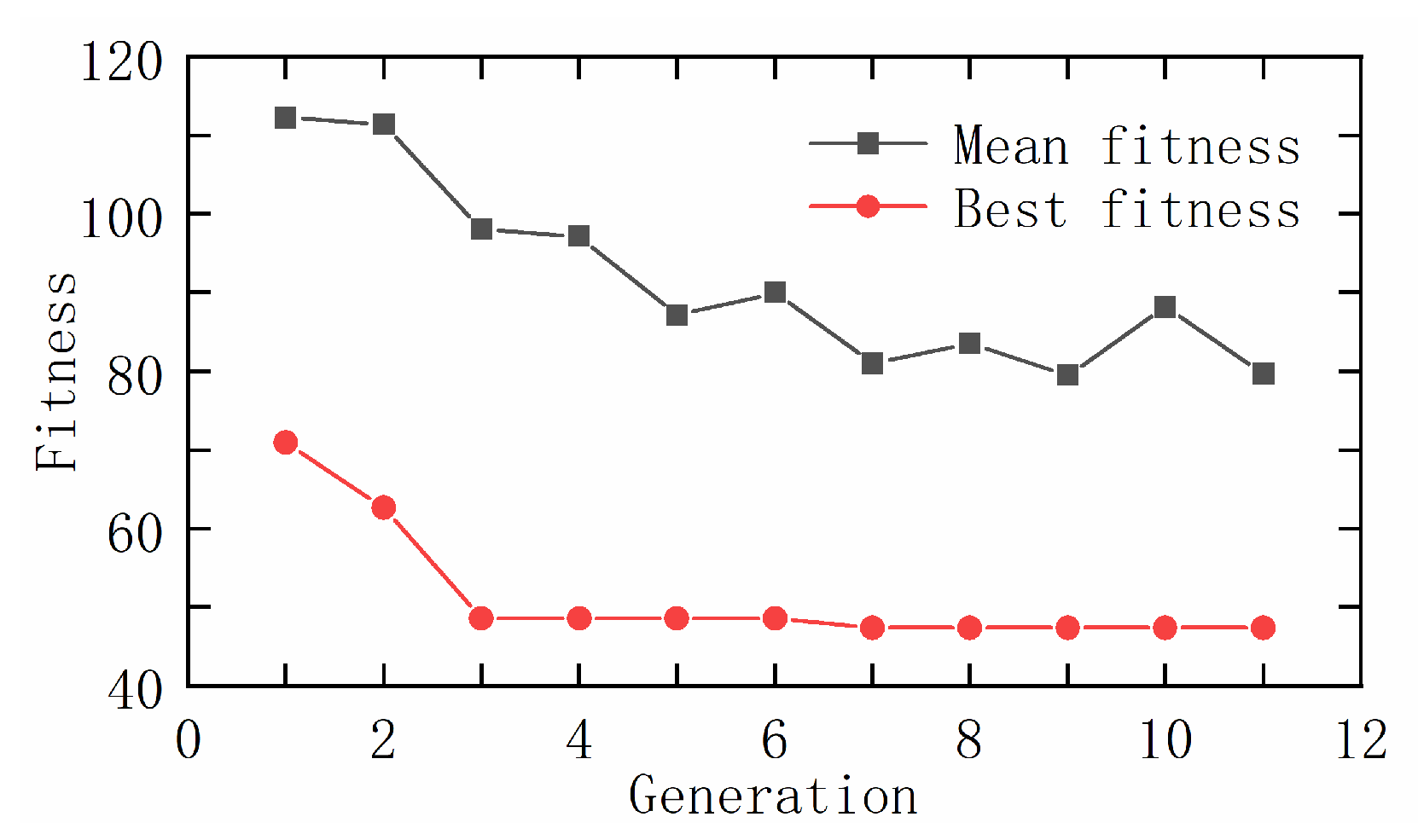
3.5. Genetic Algorithm Optimization Results
4. Validation of the Artificial Neural Networks
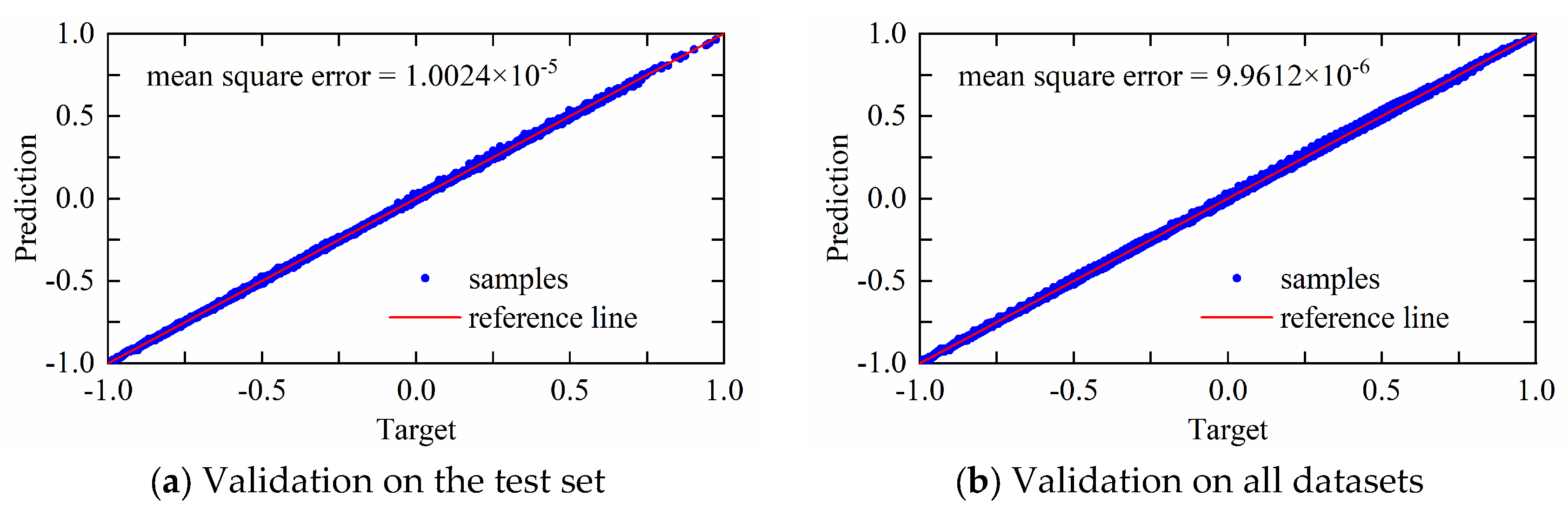
4.1. Validation on the Dataset
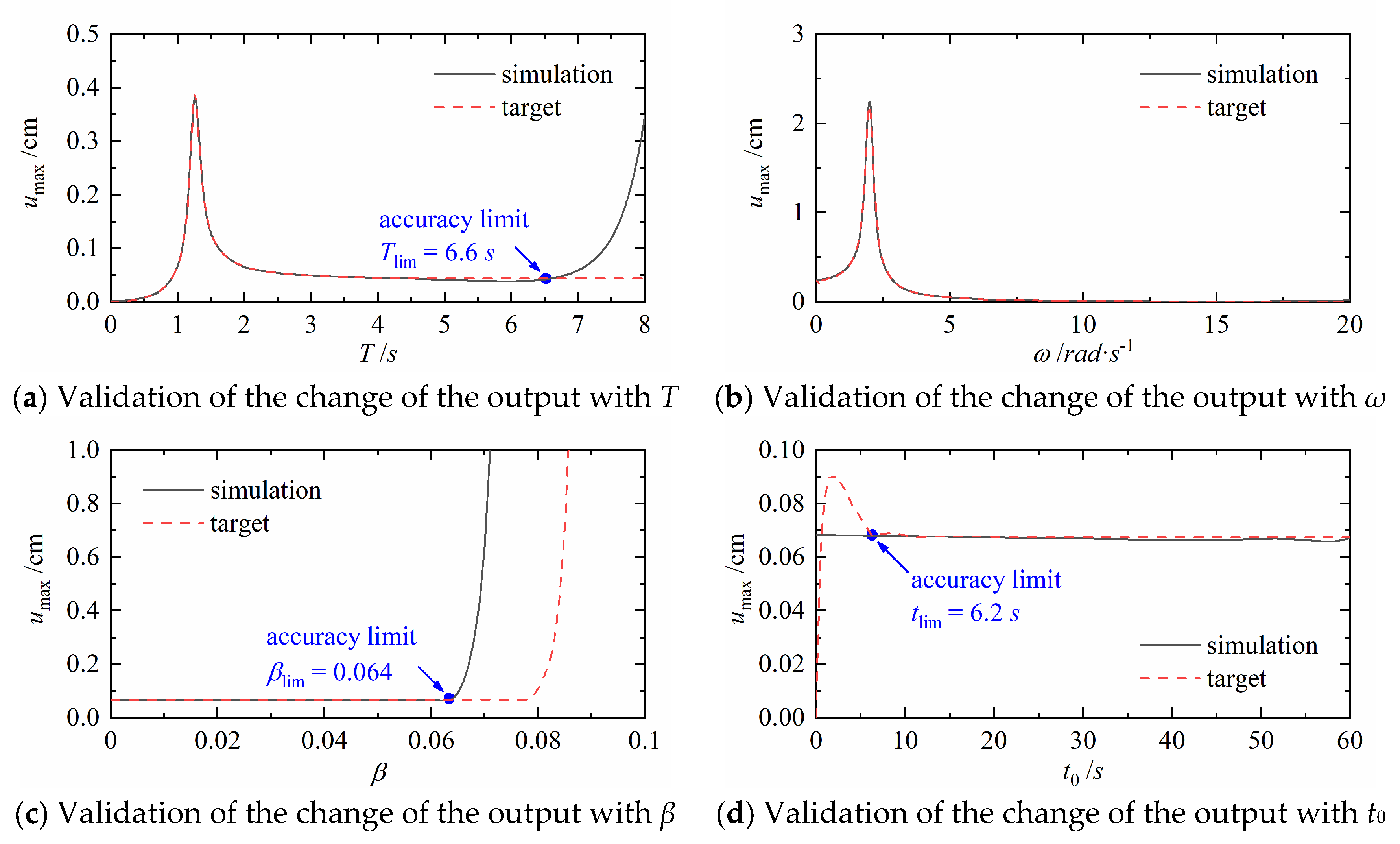
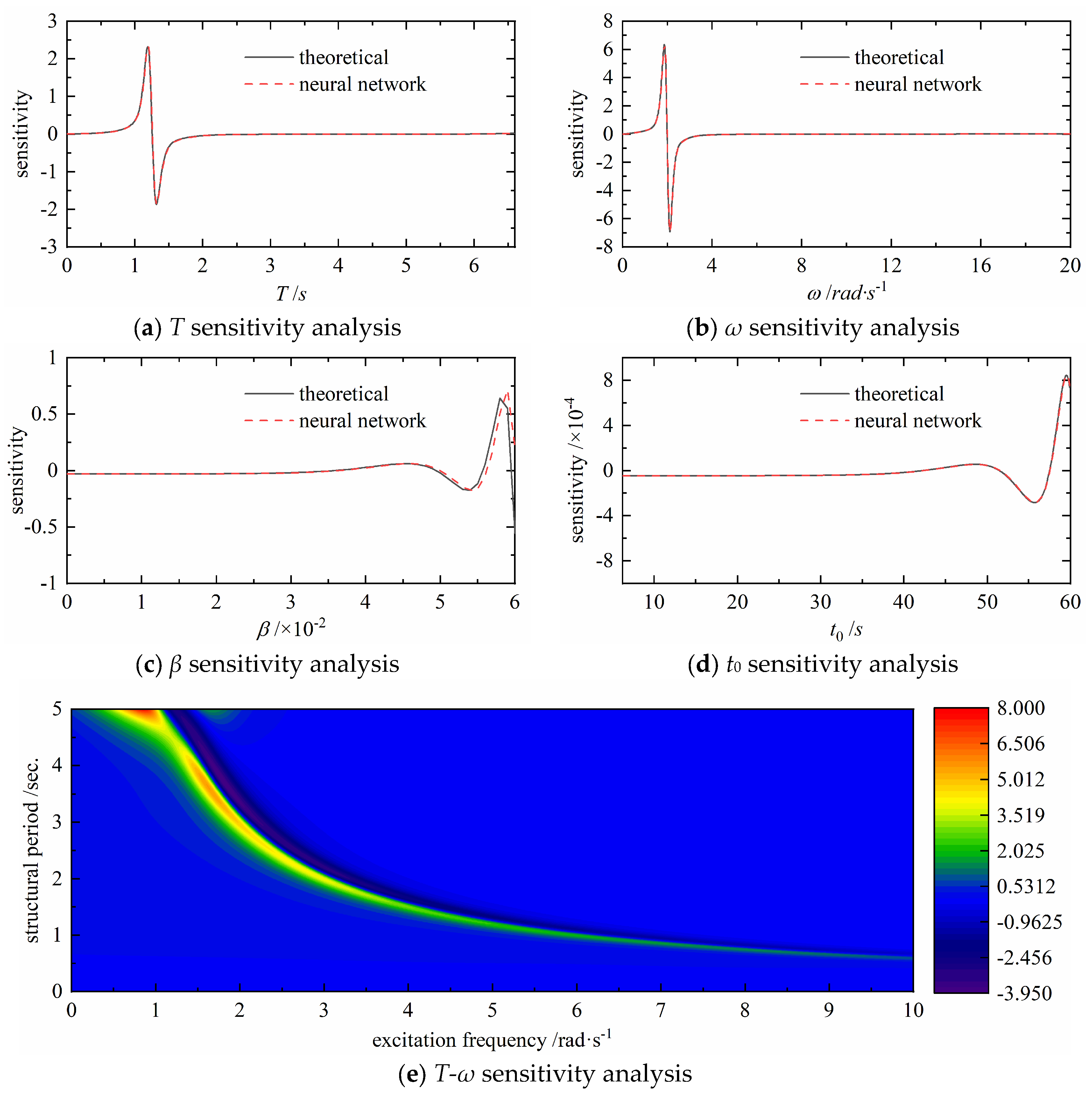
4.2. Validation of the Change Rule of Single Parameter
5. Analysis of Influence of the Intensity Non-Stationarity of Ground Motions
5.1. Sensitivity Analysis of Neutrons at the Adjacent Layers
5.2. Sensitivity Analysis of Neutrons at any Layer
5.3. Analysis of Influence of the Parameters of the Intensity Non-Stationarity Based on Neural Networks
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shinozuka, M.; Sata, Y. Simulation of nonstationary random process. J. Eng. Mech. Div. 1967, 93, 11–40. [Google Scholar] [CrossRef]
- Iyengar, R.N. A non-stationary random process for earthquake. Bull. Seis. Soc. Am. 1969, 59, 1163–1188. [Google Scholar]
- Hu, Y.; Zhou, X. Reactions of Elastic System Under Stationary and Nonstationary Ground Motions: Collection of Earthquake Engineering Research Reports (Episode 1); Science Press: Beijing, China, 1962. [Google Scholar]
- Goto, H.; Toki, K. Structural response to nonstationary random excitation. In Proceedings of the Fourth World Conference on Earthquake Engineering, Santiago, Chile, 13–18 January 1969. [Google Scholar]
- Amin, M.; Ang, A.H.S. Non-stationary stochastic model of earthquake motion. J. Eng. Mech. Div. ASCE 1968, 94, 559–583. [Google Scholar] [CrossRef]
- Huo, J.; Hu, Y.; Feng, Q. Study on envelope function of acceleration time history. Earthq. Eng. Eng. Vib. 1991, 1, 1–12. [Google Scholar]
- Qu, T.; Wang, J.; Wang, Q. Research on the characteristics of intensity envelope function of ground motions on local site. Earthq. Eng. Eng. Vib. 1994, 3, 68–80. [Google Scholar]
- Du, D.; Wang, S.; Kong, C. Research on the three-dimensional earthquake non-stationarity model based on KiK-net strong motion records. China Civil. Eng. J. 2017, 50, 72–80. [Google Scholar]
- Liu, X.; Yu, R. Analysis of approximate quantitative relationship between intensity nonstationary characteristic parameters of ground motions and structural responses. Earthq. Sci. 2016, 38, 924–933. [Google Scholar]
- Jiang, H.; Du, D.; Wang, S.; Li, W. Effects of intensity nonstationary characteristics on structural dynamic responses based on damped-sine function model. J. Nanjing Tech. Univ. 2017, 39, 96–101. [Google Scholar]
- Yao, X. Evolving Artificial Neural Networks. IEEE 1999, 87, 1423–1447. [Google Scholar]
- Kitano, H. Empirical studies on the speed of convergence of neural networks training using genetic algorithms. In Proceedings of the Eighth National Conference on Artificial Intelligence, Boston, MA, USA, 28 July–1 August 1990; pp. 789–795. [Google Scholar]
- Hancock, P. Genetic algorithms and permutation problems: A comparison of Recombination operators for neural net structure specification. In Proceedings of the International Workshop on Combinations of Genetic Algorithms & Neural networks, Baltimore, MD, USA, 6 June 1992. [Google Scholar]
- Montana, D.J.; Davis, L. Training feedforward neural networks using genetic algorithms. In Proceedings of the Eleventh International Joint Conference on Artificial Intelligence, Detroit, MI, USA, 20–25 August 1989. [Google Scholar]
- Peng, J.; Lu, W.L.; Xing, H.; Wu, X. Temperature compensation of humidity sensor based on modified GA-BP neural networks. Instrumentation 2013, 34, 153–160. [Google Scholar]
- Liu, H.; Zhao, C.; Li, X.; Wang, Y.; Guo, C. Research on neural networks optimization algorithm based on modified genetic algorithm. Instrumentation 2016, 37, 1573–1580. [Google Scholar]
- Engelbrecht, A.P.; Cloete, I.; Zurada, J.M. Determining the significance of input parameters using sensitivity analysis. Lect. Notes Comput. Sci. 2006, 930, 382–388. [Google Scholar]
- Zhao, Q.; Ji, L. Finite element-neural networks hybrid method for parameter sensitivity analysis. China Civil. Eng. J. 2004, 37, 60–63. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Activation Function | Number of Weights | Number of Biases | Total Number of Parameters |
|---|---|---|---|---|
| Input layer → Hidden layer 1 | Hyperbolic tangent | 4 × 16 = 64 | 16 | 80 |
| Hidden layer 1 → Hidden layer 2 | Hyperbolic tangent | 16 × 8 = 128 | 8 | 136 |
| Hidden layer 2 → Output layer | Linear transfer | 8 × 1 = 8 | 1 | 9 |
| Total for each layer | - | 200 | 25 | 225 |
| Data Type | Small Sample Data | Whole Data | |
|---|---|---|---|
| t0 | Lower limit | 20 | 20 |
| Upper limit | 40 | 40 | |
| Interval | 2 | 1 | |
| β | Lower limit | 0.01 | 0.01 |
| Upper limit | 0.05 | 0.05 | |
| Interval | 0.01 | 0.01 | |
| ω | Lower limit | 1 | 0.1 |
| Upper limit | 10 | 10 | |
| Interval | 1 | 0.1 | |
| T | Lower limit | 0.5 | 0.5 |
| Upper limit | 4 | 4 | |
| Interval | 0.5 | 0.1 | |
| Total sample | 4400 | 378,000 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Du, D.; Shi, S.; Li, W.; Wang, S. Effects of the Earthquake Nonstationary Characteristics on the Structural Dynamic Response: Base on the BP Neural Networks Modified by the Genetic Algorithm. Buildings 2021, 11, 69. https://doi.org/10.3390/buildings11020069
Zhang Y, Du D, Shi S, Li W, Wang S. Effects of the Earthquake Nonstationary Characteristics on the Structural Dynamic Response: Base on the BP Neural Networks Modified by the Genetic Algorithm. Buildings. 2021; 11(2):69. https://doi.org/10.3390/buildings11020069
Chicago/Turabian StyleZhang, Yunlong, Dongsheng Du, Sheng Shi, Weiwei Li, and Shuguang Wang. 2021. "Effects of the Earthquake Nonstationary Characteristics on the Structural Dynamic Response: Base on the BP Neural Networks Modified by the Genetic Algorithm" Buildings 11, no. 2: 69. https://doi.org/10.3390/buildings11020069
APA StyleZhang, Y., Du, D., Shi, S., Li, W., & Wang, S. (2021). Effects of the Earthquake Nonstationary Characteristics on the Structural Dynamic Response: Base on the BP Neural Networks Modified by the Genetic Algorithm. Buildings, 11(2), 69. https://doi.org/10.3390/buildings11020069