1. Introduction
Concrete is one of the most widely used substances in the word [
1]. This is owing to the widespread usage of concrete in the buildings and civil engineering industries [
2]. It is composed of a variety of elements such as coarse aggregate, fine aggregate, water, and binder, among others [
3]. Its widespread use as a building material may be seen worldwide. The mechanical characteristics of concrete must be evaluated to effectively assess its performance and for use in design methods [
4]. The concrete compressive strength (CCS) is treated as one of the most important parameters in the design and study of concrete structures. Because computation of the compressive strength of concrete takes a long time [
5], needs a lot of material [
6], and requires a lot of effort, artificial intelligence (AI) methods, as dynamic, applicable, accurate and easy-to-use technologies, have been successfully used to get around these issues [
7]. Apart from these issues, AI methods have been highlighted as the main and ultimate solutions for problems in science and engineering [
8,
9].
Ashrafian et al. [
10] used different models, including random forest (RF), M5 rule model tree, M5 prime model tree, and chi-square automatic interaction detection, for the mechanical characteristic prediction of roller-compacted concrete pavement. They concluded that RF outperformed other models. Paji et al. [
11] investigated the impact of fresh and saline water on concrete samples’ compressive strength. To estimate the CCS, two hybrid algorithms, namely neuro-swarm and neuro-imperialism, were presented. Particle swarm optimization and the imperialist competitive algorithms were employed to adjust the weights and biases of the neural network in these two hybrid models, resulting in better prediction accuracy. Naderpour et al. [
12] predicted the compressive strength of the recycled aggregate concrete (RAC) using an artificial neural network (ANN). Shaban et al. [
13] utilized a multi-objective metaheuristic algorithm to create a reliable method for calculation of the compressive strength of the RAC with pozzolanic materials. Mohammed et al. [
14] assessed the ability of neuro-swarm and neuro-imperialism models for the prediction of the compressive strength of concrete modified with fly ash. Li et al. [
15] adopted a back propagation (BP)-ANN model to establish a relationship between the cube compressive strength and the RAC strength. The 30 percent integration rate was indicated as an ideal incorporation rate after examining all parameters, including mechanical strength and replacement ratio, in terms of the maximum usage of recycled aggregates. Imam et al. [
16] computed different concrete properties using ANN, which was trained using three different regularization algorithms, including the scaled conjugate gradient, Levenberg–Marquardt, and Bayesian regularized algorithms. The best results were obtained using an ANN tuned with a Bayesian regularization algorithm. Korouzhdeh et al. [
17] used the ANN with biogeography-based optimization to enhance the prediction accuracy of the different properties of cement mortar exposed to freezing/thawing.
Fly ash has been widely used in the development of fly ash concretes (FACs) in recent years. This concrete has taken the place of traditional concrete without sacrificing strength. For new concrete types, such as FAC and high-performance concrete, since the significant variables are more intricate, and there are even interconnections between many factors, the simple regression model is no longer applicable and often needs a detailed nonlinear law [
18]. Toufigh and Jafaristudied [
19] studied the application of the Bayesian regression algorithm for the calculation of the compressive strength of fly-ash-based concrete. They used a dataset of 162 samples, and the coefficient of determination (
R2) of their model was 0.69. Ahmad et al. [
20] utilized a decision tree with a bagging technique with 270 experimental results for the estimation of the compressive strength of fly-ash-based concrete. Their ensemble model had an
R2 value of 0.91. Farooq et al. [
21] used the ANN, support vector machine, and gene expression programming with 300 experimental results to develop a model for the compressive strength of self-compacting fly-ash-based concrete. The best predictive model was the ANN with an
R2 value of 0.92. The research of Dao et al. [
22] was based on adaptive neuro fuzzy inference (ANFIS). They used ANFIS with a total number of 210 samples and developed a model for the prediction of the compressive strength of FAC. Their results showed that the ANFIS model has an
R2 value of 0.87. Mai et al. [
23] studied the compressive strength of concrete containing fly ash and blast-furnace slag using the ANN and 1274 data samples of experiments. They reported the ANN has an
R2 value of 0.94.
On the other hand, deep neural networks are used in various fields, such as damage detection [
24], strength prediction of concrete [
25,
26], response estimation of concrete building elements [
27], structural reliability analysis [
28], among others, since they are nonlinear approaches that provide more flexibility [
29]. One disadvantage of this flexibility is that they gain knowledge using a stochastic training technique, which implies they are vulnerable to the training data’s peculiarities and may find a different set of weights each time they are trained, resulting in different predictions [
30]. They also suffer from the high variance problem [
29,
31]. This is sometimes known as “high variance neural networks” [
32], and it can be troublesome when seeking to construct a final model to utilize for making predictions. Training many models instead of just a single model and combining the outputs from these models is an effective strategy to reduce the variance of neural network models. This is known as “ensemble learning”, because it can not only minimize forecast variance but also produces results that are superior to any single model. In addition, machine learning (ML) models are still essentially black boxes, despite their ubiquitous use. Explainability is critical in this setting because it is frequently overlooked. In order to describe the predictions of ML models, a unified framework known as the Shapley Additive exPlanations (SHAP) technique was recently established. To the best of the author’s knowledge, no research has been published on the explainability and competence of ML algorithms in predicting the compressive strength of FAC.
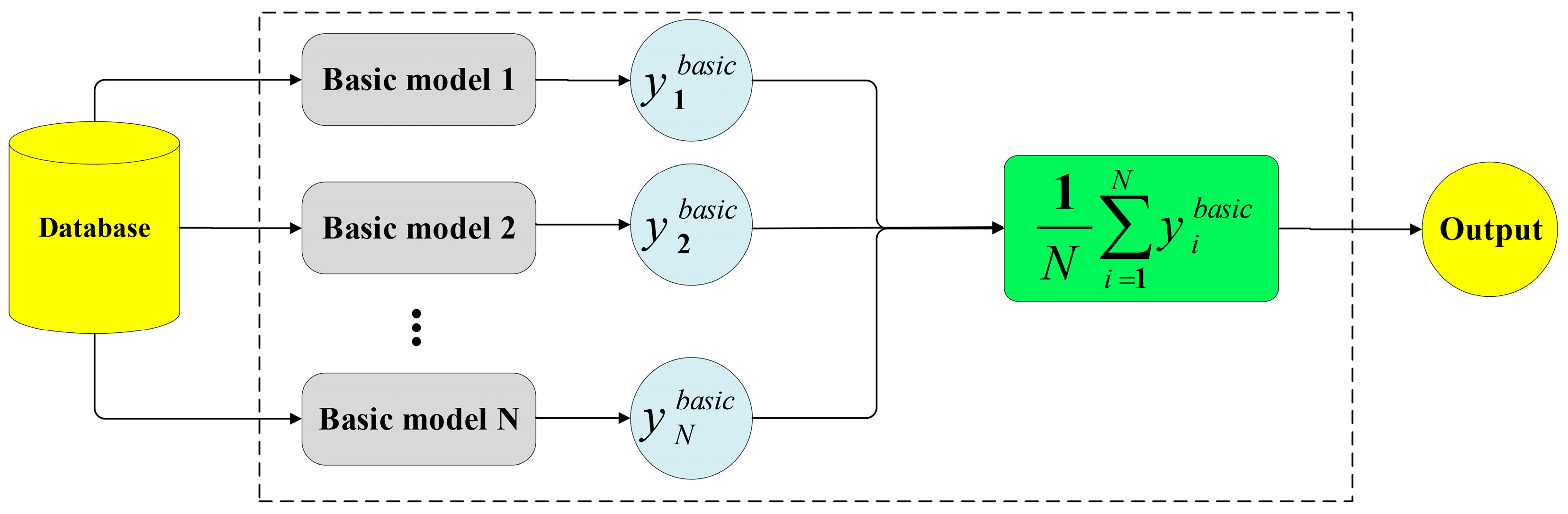
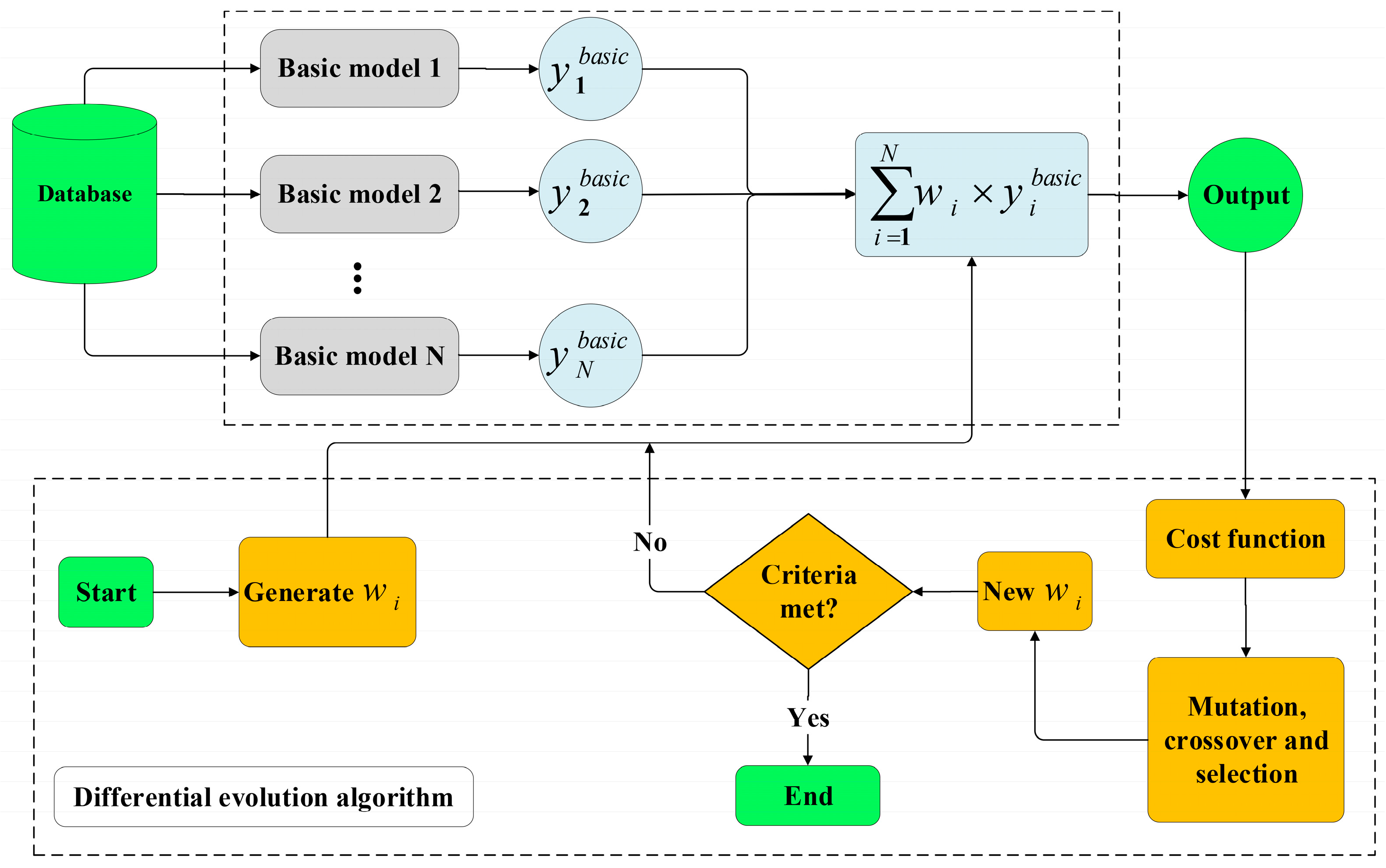
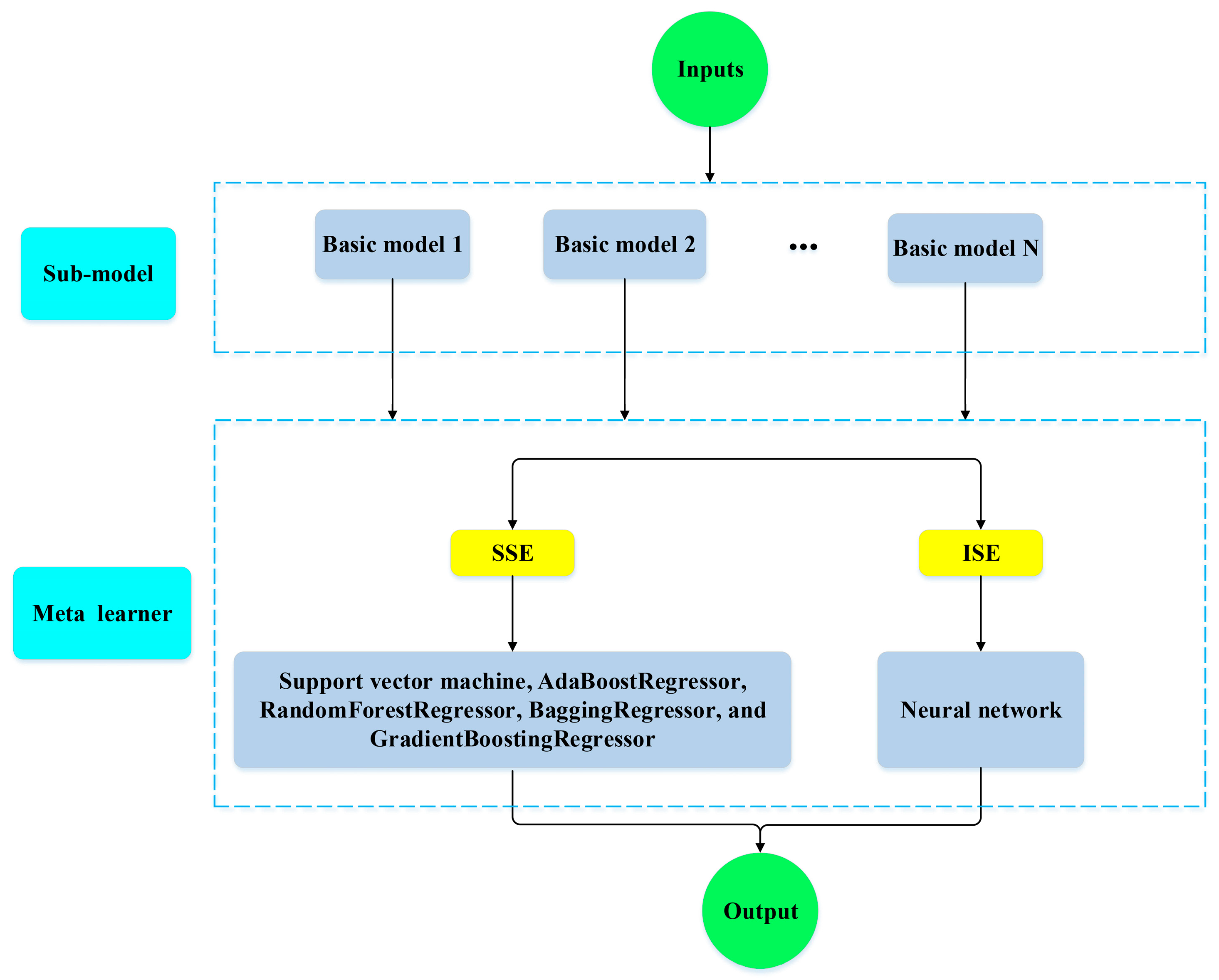
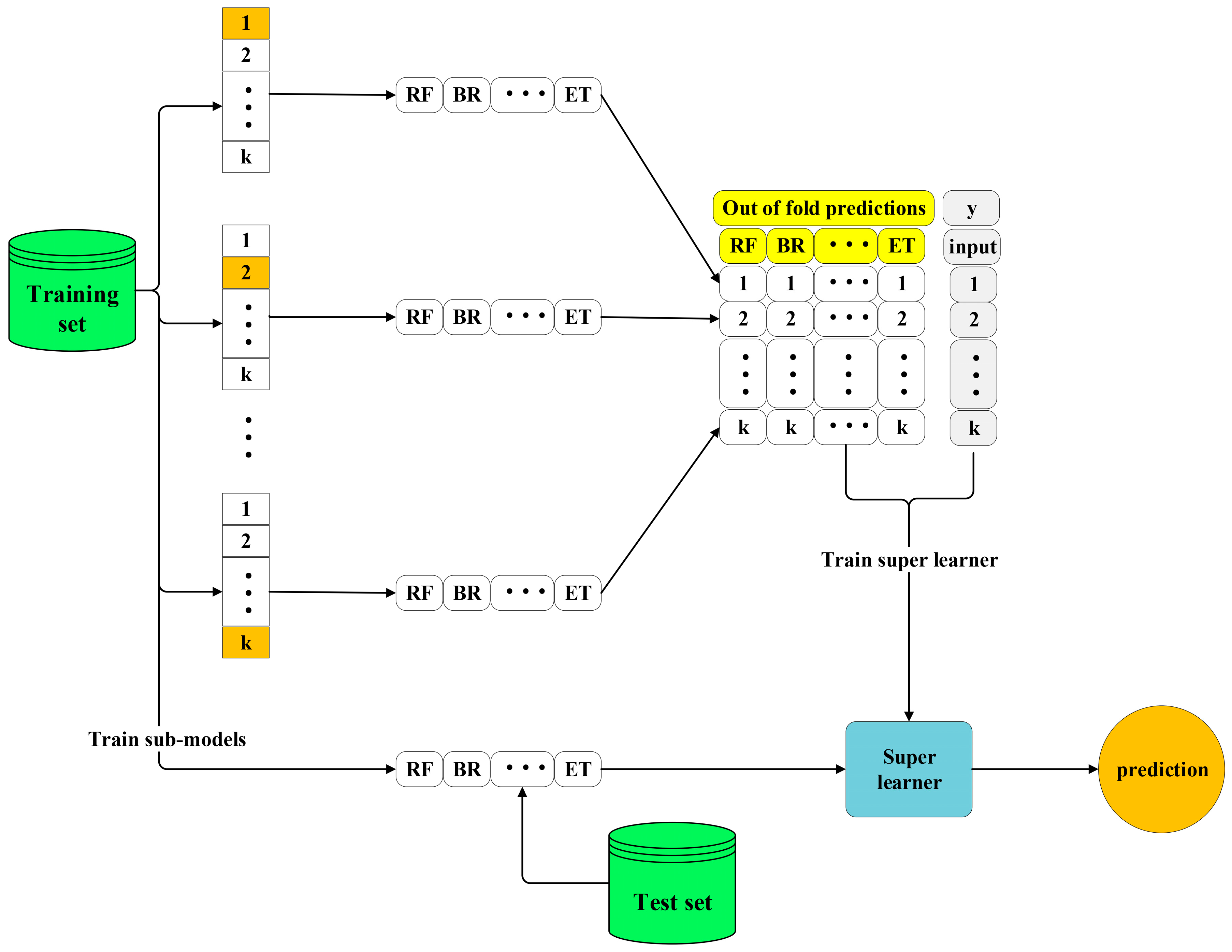
In light of the above discussion, the present study took advantage of ensemble learners and ensemble deep neural networks, including super learner, simple averaging, weighted averaging, integrated stacking, and separate stacking ensemble models, to provide an accurate model for forecasting the compressive strength of FAC. The SHAP technique was utilized to explain the best model’s predictions, rank the input features in order of relevance, and find the most important variables on the prediction of the compressive strength of FAC. This paper is structured as follows. A brief summary of the experimental database is given in
Section 2. Ensemble learning models are presented in
Section 3.
Section 4 provides the predictions obtained with the ensemble learning models. The importance and contribution of the input variables is given in
Section 5. The final section (
Section 6) concludes the paper and discusses the scope for future work.
2. Experimental Database
The collection and preprocessing of the dataset are the first steps in the building of an ML model. Here, the experimental database of FACs (a total of 270 samples) was obtained from the University of California, Irvine (UCI) machine learning repository [
33]. The UCI machine learning repository is a library of databases, domain theories, and data providers that the machine learning community uses to test machine learning algorithms effectively. David Aha and fellow PhD students at UCI launched the archive as an online repository in 1987. Since then, it has been widely employed as a key source of machine learning resources by students, instructors, and researchers worldwide. The parameters of 270 samples include cement, fly ash, water, super plasticizer, coarse aggregate, fine aggregate, days, and water-to- cement ratio, abbreviated as C, FA, W, SP, CA, FAG, D, and WC, respectively.
Table 1 presents characteristics of the dataset and min, max, and STD are the minimum, maximum, and standard deviation of variables, respectively. A split of 20–80% of the data were used for the training and testing of models. The data were also normalized so that all values were within a range of −1 and 1.
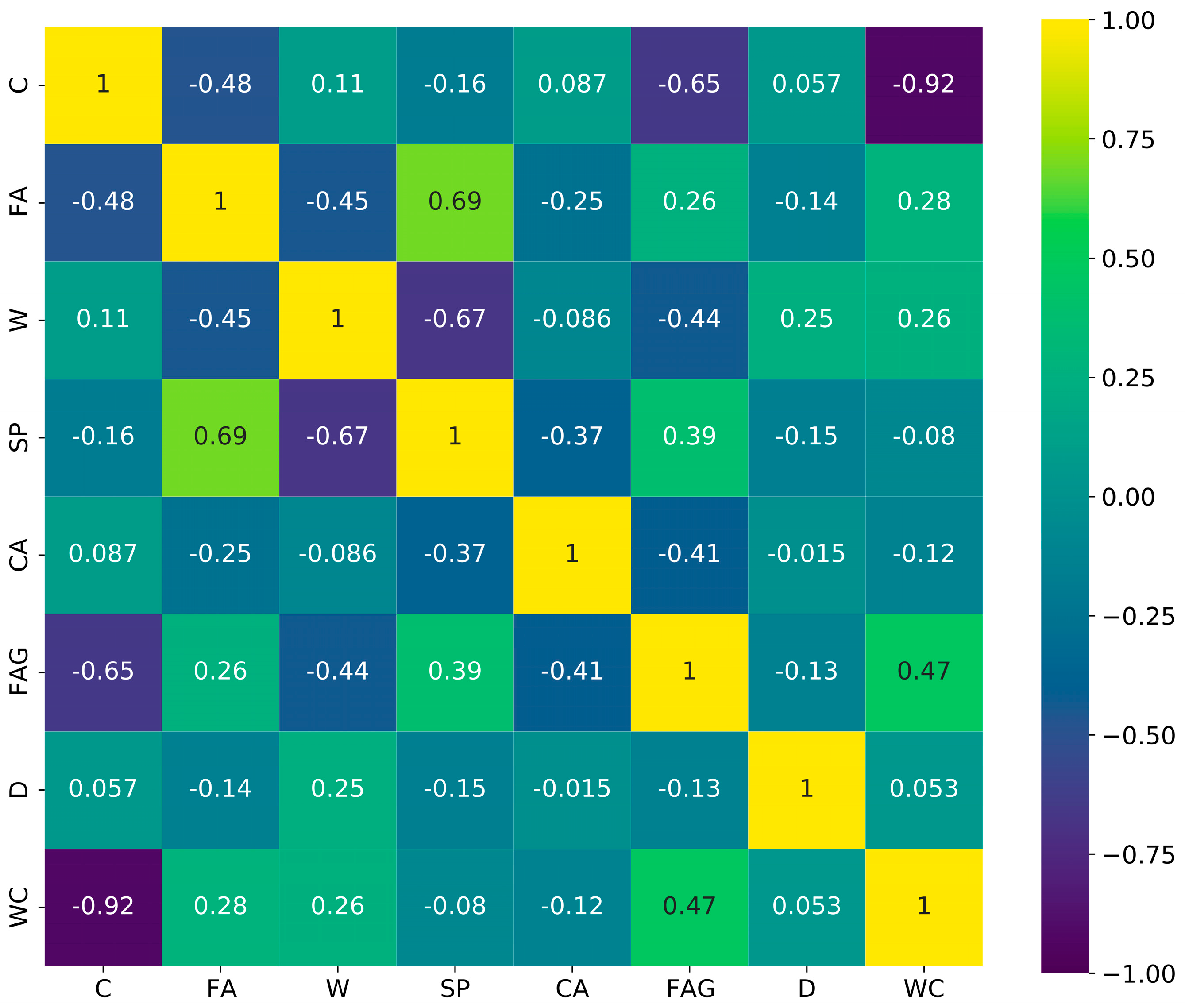
Figure 1 shows a correlation matrix of the inputs. The water-to-cement ratio did seem to correlate with the cement. The cement and fine aggregate also correlated with each other. The cement and fly ash were also correlated. Days did not seem to significantly correlate with other input parameters. Fly ash appeared to correlate well with super plasticizer. Moreover, water also negatively correlated with the super plasticizer.
4. Result and Discussion
One of the most crucial characteristics of the SAE is the range of the number of basic models. For that reason, the impact of expanding the SAE to include more basic models should be explored. Using the first and second basic models (sub-models 1 and 2,
Table 2), an SAE model is created and tested, after which another basic model is appended to the previous set and the model’s performance is re-evaluated.
Figure 6 shows
R2 vs. the number of basic models. It can be seen that when the SAE model includes the basic models 1 and 2 to basic models 1–3, the
R2 value of the SAE models has a slight decrease.
Figure 6 also shows an improvement of the accuracy from 3 to 5 sub-models. It seems the SAE model with six members converges to 0.965 since there is a marginal change in the
R2 value.
The WAE-DE is the second ensemble model. The DE algorithm is used to calculate the weight of the sub-models, as previously stated.
Table 4 summarizes the findings. The results reveal that basic model 5 is given higher weight. Weight values for sub-models 4 and 6 are close. For the testing phase, the
R2 value of the WAE-DE model is 0.973.
In
Table 5, the forecast MSE and
R2 values of the model for testing phase are demonstrated. For the test set, the prediction accuracy with the largest
R2 (0.976) and smallest MSE (0.0041) is obtained using the SSE-RandomForest algorithm among all of the given models. Meanwhile, the SSE-GradientBoosting model gives the best prediction compared to the other models, with the result of MSE and
R2 being 0.005 and 0.997, respectively, for the training phase. The results show that although the coefficient of determination for the SL model is very high in the learning mode, in the test mode, the model has the lowest coefficient of determination among all models. Except for the SL model, the coefficient of determination value of other models is very close, and there is a maximum difference of 1.6% between the lowest and highest value of coefficient of determination. However, in the same case, the difference for MSE reaches 65.8%.
Table 6 shows the mean, standard deviation, COV, and a-20 index of the measured-to-predicted values for all models using test set. It can be seen that the SSE-RandomForest has the lowest COV and highest a-20 index among all models. However, ranking of the developed prediction models is difficult. A simple ranking system is utilized to analyze the efficiency of the developed models for testing datasets using the performance criteria. The total ranking index is utilized to assess the ensemble models. All models are ranked considering each indicator separately. The resulting ranking is then added together.
Table 7 shows the ranking of the various ensemble models. As can be seen in the table, SSE-RandomForest ranks first, SSE-Bagging and ISE rank second, and WAE ranks third. When it came to estimating the compressive strength of FAC, both the SSE-RandomForest and SSE-Bagging algorithms performed well, although SSE-RandomForest outperformed SSE-Bagging in terms of the COV and the a-20 index.
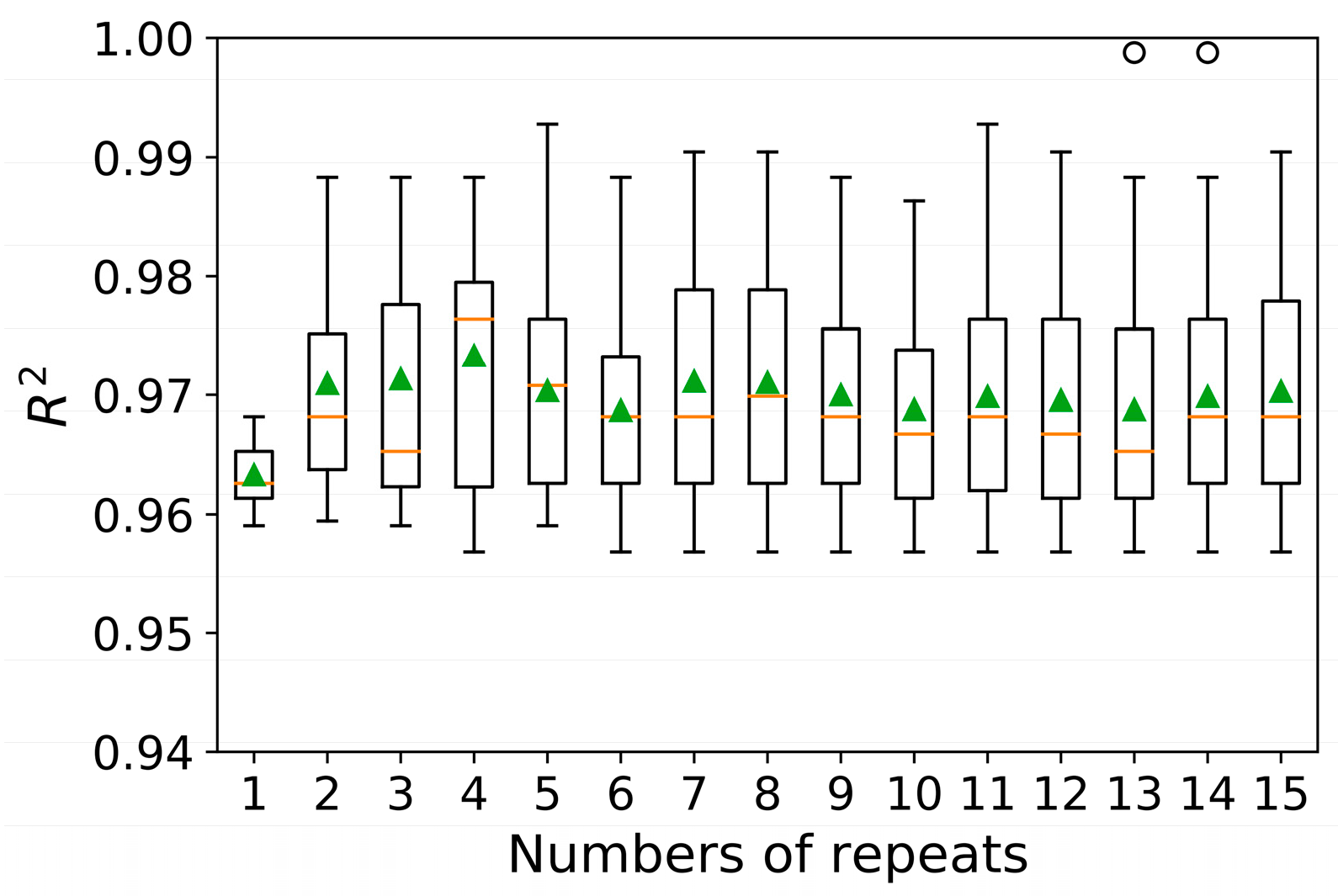
A single- run process may produce a noisy model performance assessment. Different data divisions can produce quite different findings. Repeated k-fold cross-validation is a strategy for better evaluating a machine learning model’s predicted performance. The cross-validation technique is repeated several times and returns the mean value throughout all folds from all runs. This average result should be a more accurate representation of the model’s genuine underlying mean performance on the dataset.
Figure 7 shows plots of
R2 vs. repeats for 10-fold cross-validation. The orange line and the green triangle indicate the median and the arithmetic mean, respectively. The graph illustrates that the average fluctuates slightly around 0.97. It should be noted that for each input, the model predicts a value as an output. If the input is not in the data range, this predicted value may be associated with more error than stated.
5. SHAP (SHapely Additive exPlanations)
The black-box feature of many ML algorithms, like that of other applications, limits their usefulness. As a result, ways to describe ML models are required. In particular, there are two common reasons for describing ML models. One goal is to gain confidence in the model’s decisions. The other option is to use the model’s insights to guide human data analysis. Engineers, on the other hand, want to be directed to elements or combinations of factors that can help them understand and decrease production faults. To meet this demand, we look at the current and new tool, which is the SHAP method [
38,
39]. SHAP helps to understand the effect of each parameter on the prediction using game theory and Shapley values (Equation (5)).
where
M is the players’ number,
is the contribution function,
is coalition size, and
is Shapley value. For a more extensive discussion of the SHAP and the supporting proof, interested readers should refer to [
38,
39].
Here, the predictions of the SSE-RandomForest algorithm are explained.
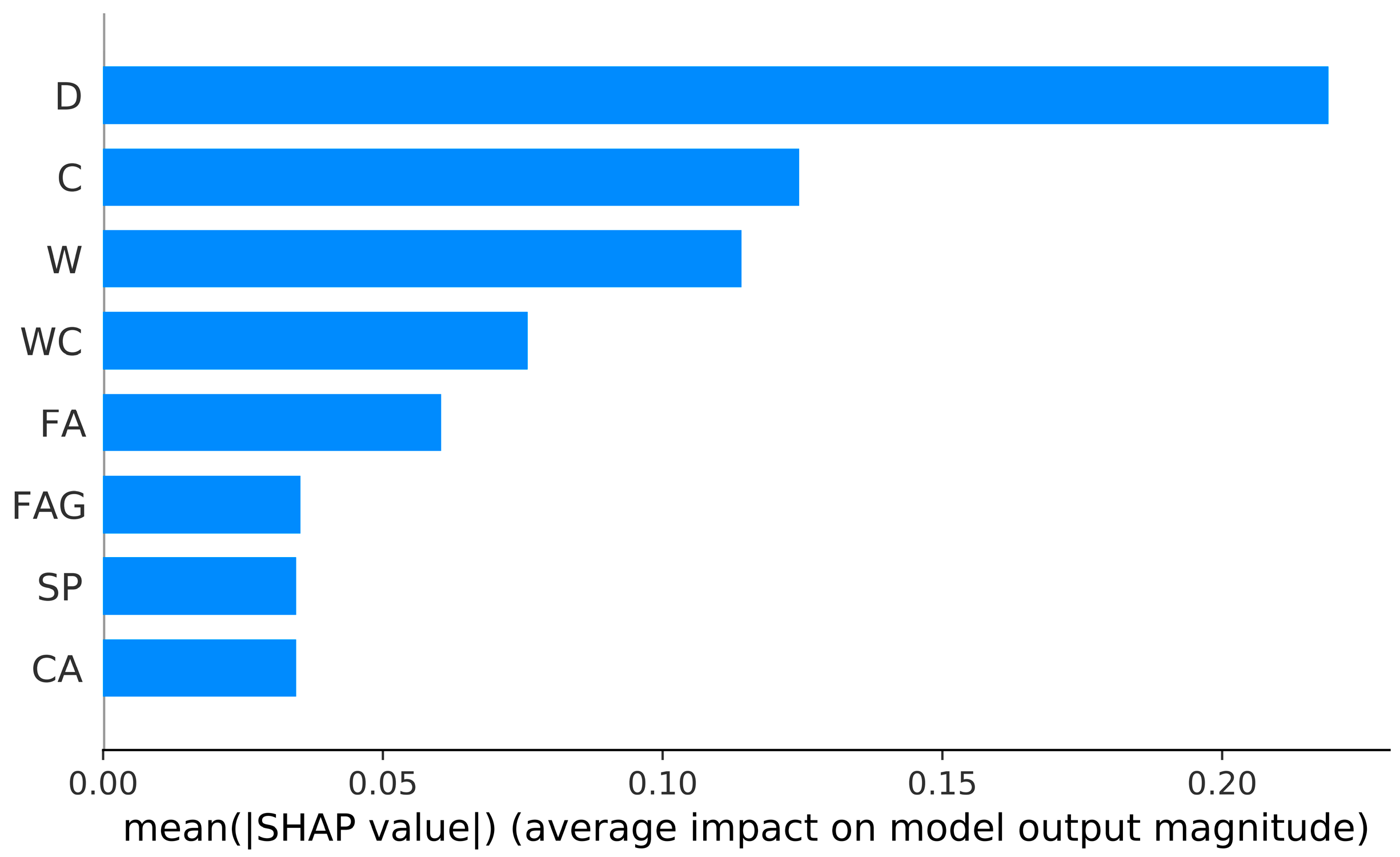
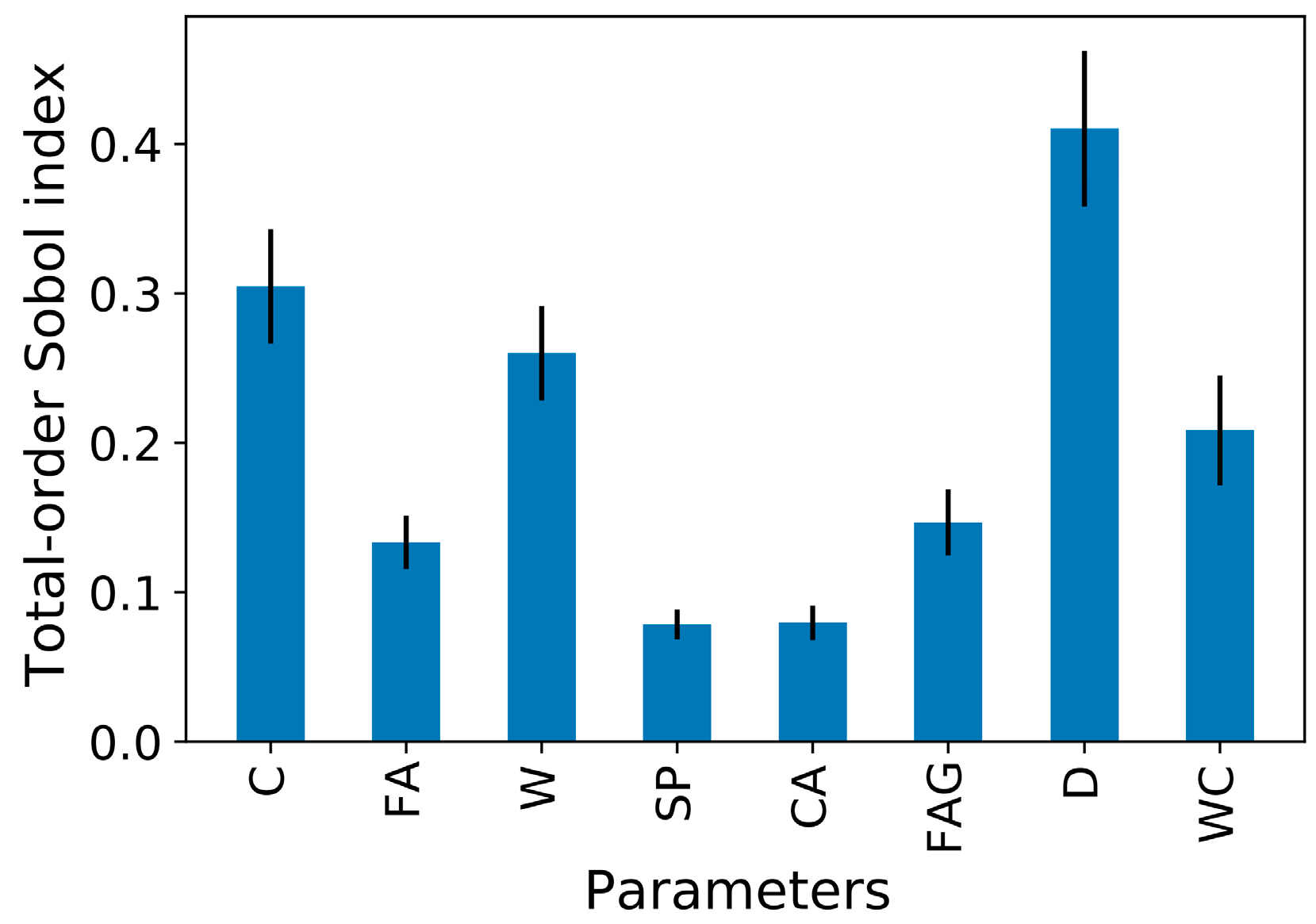
Figure 8 shows the feature importance using mean SHAP values in estimating the compressive strength of FAC. The
y-axis presents input parameters (
Section 2), and
x-axis is mean Shapley values. D has the highest feature importance in the compressive strength prediction of FAC. It can be seen that the mean SHAP value of D is approximately twice the value of the second and third variables (C and W). Interestingly, FAG, SP, and CA have the lowest and almost same feature importance in the compressive strength prediction.
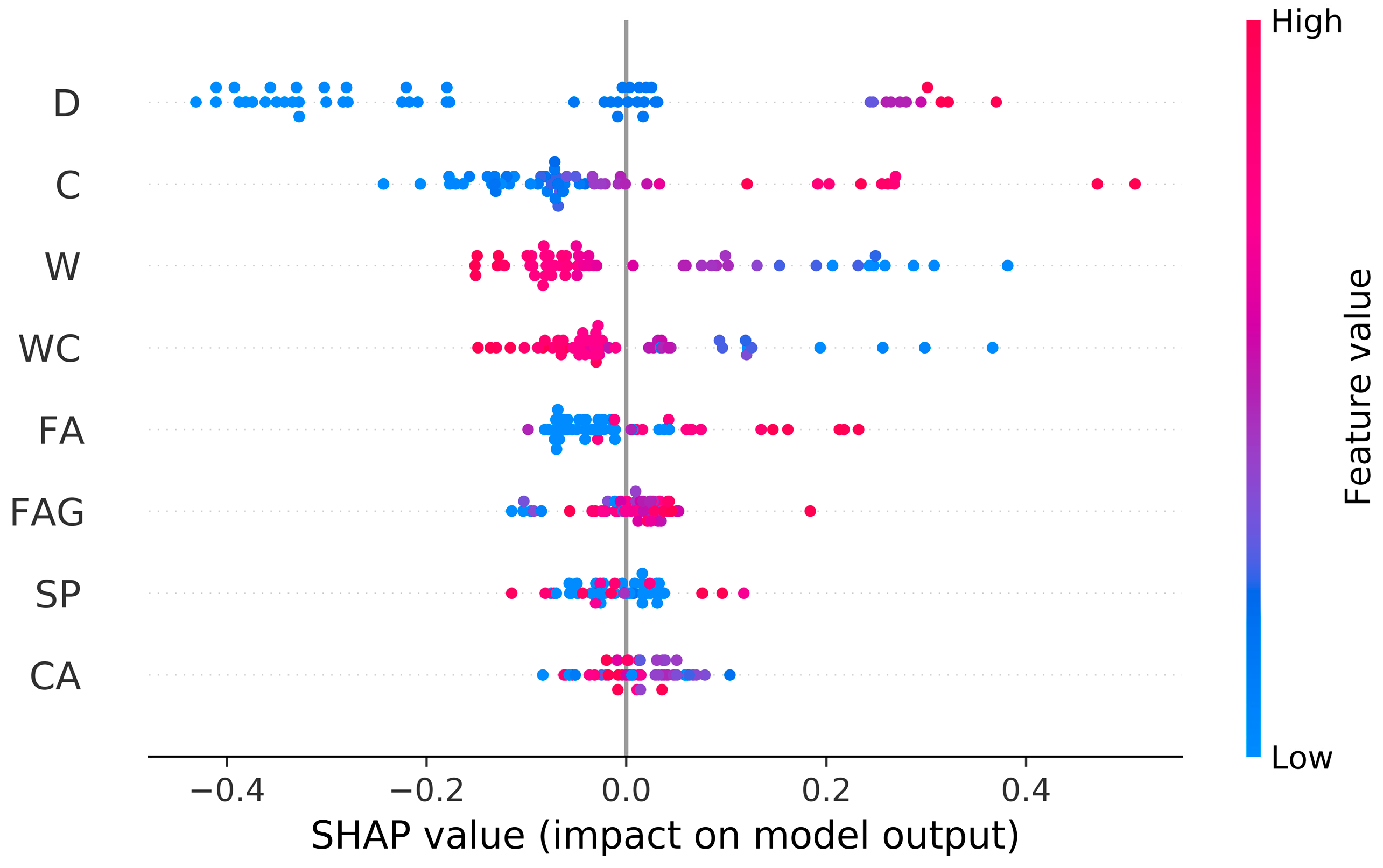
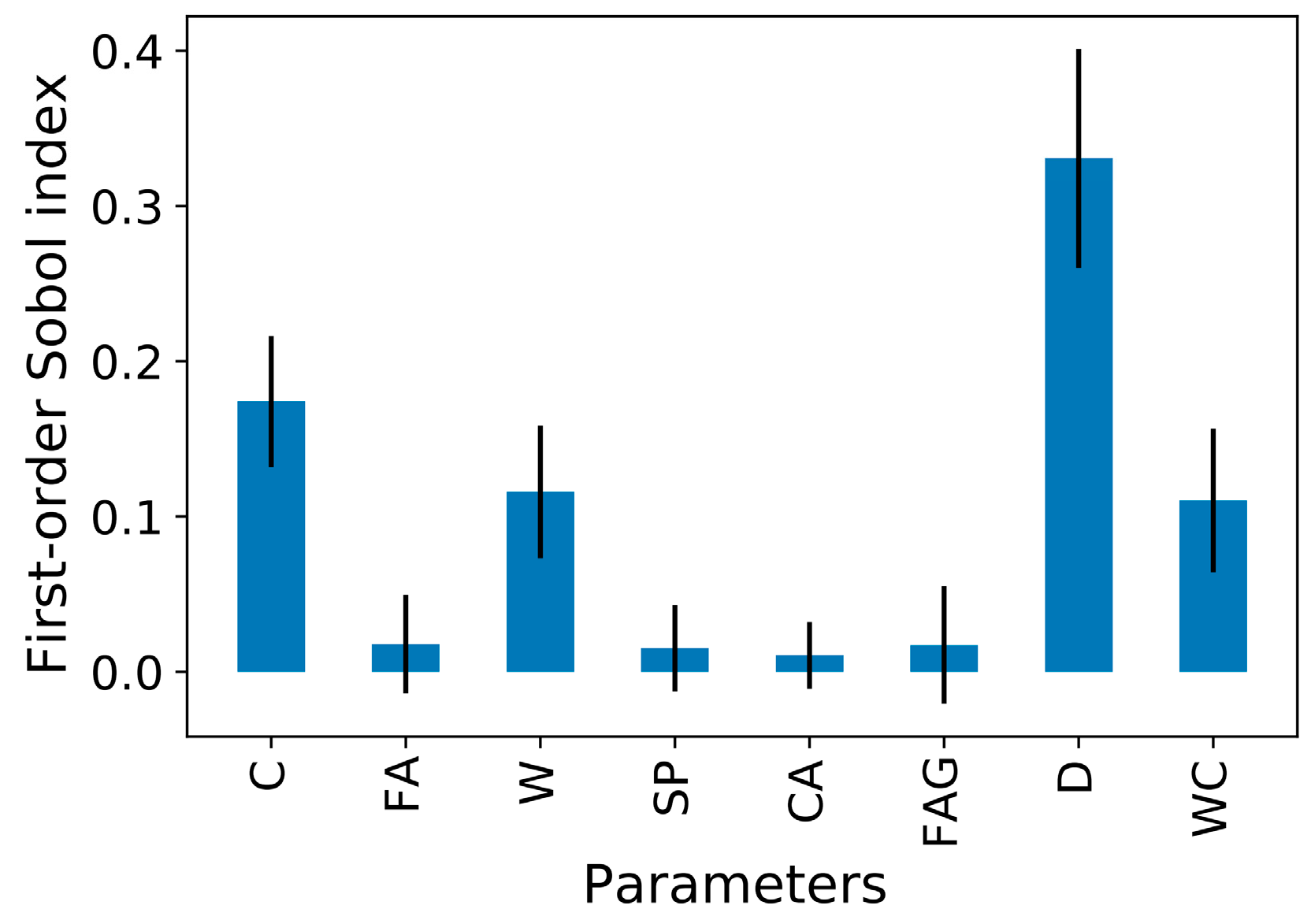
Figure 9 displays the overall SHAP values. A red dot implies a positive effect, while blue represents a negative effect. The term “positive effect” refers to a growth in prediction as the variable value is increased. D and C are prominent parameters with positive influence in the compressive strength prediction. Furthermore, W and WC have negative impacts on the compressive strength of FAC. For CA, SP, and FAG, it is hard to discuss their positive/negative effect since the dots are mixed.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}