1. Introduction
Urban functional areas are the important spatial carriers of various urban economic and social functions, as well as the specific performance units of natural and socio-economic resources. As rapid urbanization is taking place around the world, various elements are being taken into different spaces of the city, thus forming functional area differentiation at different regional scales. As such, unreasonable urban planning will lead to an array of tangible problems, such as a single-function structure, spatial differentiation, and improper resource allocation in cities. Therefore, accurately identifying the urban spatial and social structures is important to reasonably delineate urban functional areas, thereby functionally coordinating human-land relations, effectively optimizing urban spatial strategies, and improving urban planning [
1,
2,
3,
4,
5,
6].
With accelerated advances in remote sensing technology, we are able to acquire high-resolution satellite and aerial imagery, allowing us obtain more texture detail from high-altitude images than ever before. Traditionally, urban functional zone identification relies on planning maps of land use and field surveys. Nevertheless, the survey-based methodology often consumes significant labor resources and a large amount of time, and even the reliability is presumably influenced by the subjectivity of human perceptions. Moreover, the information obtained from a single data source is not comprehensive enough and is, therefore, limited. There is enormous potential in extracting and analyzing the functions of urban areas from high-resolution spatial remote sensing imagery, which influences the evolution of research regarding urbanization. Further, this technique has proven to be one of the most convenient and effective methods in many applications such as Earth observation and urban structure analysis [
7,
8,
9]. For instance, Pacifici [
10] employed multi-scale texture metrics from very high-resolution panchromatic images to classify urban land use categories. Pacifici’s outcomes demonstrate that, in a multi-scale approach, it is possible to discriminate different asphalt surfaces, such as roads, highways, and parking lots due to the different textural information content. Later, Soe [
11] experimentally verified that the spectral information presented by pixels plays a pivotal role in the process of classification. Zhang [
12] developed a joint deep learning model that fully incorporates a multilayer perceptron (MLP) and convolutional neural network to enhance the spatial and spectral representation, subsequently achieving land refinement classification. Li [
13] completed the urban land classification based on the geometric, morphological, and contextual attributes of the target objects with the corresponding land use indicators. However, most of these studies employ physical features of ground components (e.g., spectral, shape, and textural features) to extract urban land use patterns, which can only be associated with low-level semantic land covered with the information of ground features, and it is difficult to harvest high-level semantic information of urban spatial structures [
14,
15,
16,
17,
18].
It is noteworthy to mention that the fusion of remote sensing images with social perception data is a new, alternative direction [
19]. A series of recent studies have reflected that the exploitation of social sensing data, such as Point of Interest (POI), taxi track data, cell phone data, social media data, and street view data, performs well in identifying functional urban areas [
20,
21,
22,
23,
24,
25]. Take, for example, the case of TU [
26] combining remotely sensed images with cell phone location data, landscape, and activity indicators that are calculated to cluster functional areas. Gong [
27] combined nighttime remote sensing images, satellite images, POI, and cell phone data in order to create a national land use map. Liu [
28] integrates probabilistic thematic models and support vector machines (SVM) to fuse natural physical features from high-resolution images and socio-economic semantic features from multi-source social media data, working to build a lexicon of land use words in a framework to analyze fine-grained urban structures and to monitor urban land use changes. These studies encourage the great potential of multimodal data in revealing the functional zoning of urban areas.
However, remotely sensed and socially sensed data are relatively different in terms of sources and modalities. In general, remotely sensed images cover a study area, where as social sensing data are location-based and are represented as points, dashes, or polygons. In addition, the features of social sensing data may be time-based rather than space-based [
29]. To fuse these two types of multi-source and multi-modal data is not an easy task, especially when mitigating the modal gaps and heterogeneity between them [
30,
31]. Nicolas [
32] exploited the multi-source satellite sensor data through an improved Segnet network, thus providing better performance for urban feature recognition compared to the one that uses fully connected convolutional networks (FCN). Cao [
33] integrated the long short-term memory (LSTM) extraction of user time series feature data with Resnet extraction of remote sensing image features as it seeks to work out functional area identification. Although the extracted modal data features are able to accomplish the classification task, the features independently existed without any interrelationship between them. It is likely that when the deficiency occurred in data collecting, the recognition effect could be influenced by the gap between data forms.
Deep-learning-based fusion methods have great potential for integrating multi-source, multi-modal remote sensing and social remote sensing data. Significant improvements have been made in many domains so far, including hyperspectral image analysis [
34], image scene classification [
35], target detection [
36], and so forth. The main advantage of deep learning methods lies in its capability of learning high-level features from large amounts of data automatically, which is crucial to bridge the gap between different data patterns at the feature level. In particular, the recently emerged attention mechanism [
37] further strengthens the feature representation and advances the functions of multi-source multimodal data in urban functional area identification applications.
In this paper, we propose a deep-learning-based framework where multi-modal data are perfectly fused in urban functional zoning recognition, which consists of three main contributions. First, a multimodal data fusion framework is proposed to reveal the layout of urban functional zones by introducing building footprint and POI data. Second, after feature extraction by deep convolutional neural networks, an attention mechanism is introduced to focus on the main features of multimodal data and enhance the interconnection of different modal data. The results show that using the multimodal network model based on the attention mechanism to extract features can improve the prediction performance. Third, we further compare different fusion methods with different fusion stages to further validate the robustness of the method. Therefore, our method can help to refine the urban land use classification and provide data to support the refinement of urban management.
The paper is organized as follows:
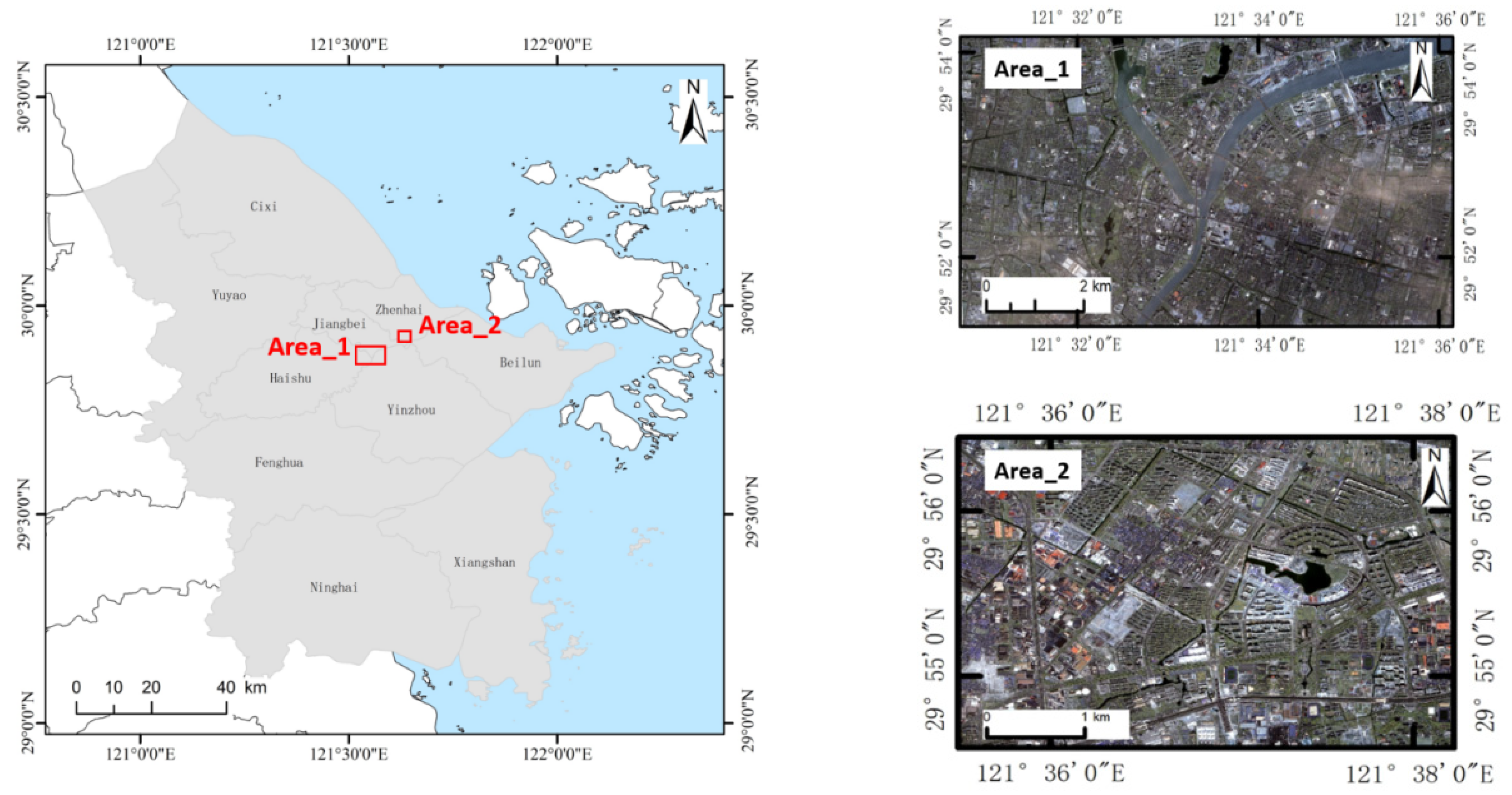
Section 2 brings forward how the dataset was created for the region of Ningbo. In
Section 3, we present the proposed model in detail.
Section 4 illustrates the experimental setup and results, while in
Section 5 the applicability of the method is comprehensively discussed.
Section 6 concludes the paper.
3. Method
The features extracted by traditional methods of identifying urban functional area are independent of each other among the modal data since the features are not interrelated with each other. However, multimodal feature fusion on the basis of deep learning maps all features into a common subspace as well as completes the classification task in the light of the similarity and measurability of data between modalities, somehow marginalizing the main features of the modal data and weakening the feature extraction expression capability of the network. Therefore, this study improves the ability of the convolutional structure in the network to extract each modal data by using the modal data reconstruction loss function. In addition, an attention mechanism is introduced to strengthen the feature expression capability and optimize the network performance by giving more weight to the main features from both spatial and channel dimensions.
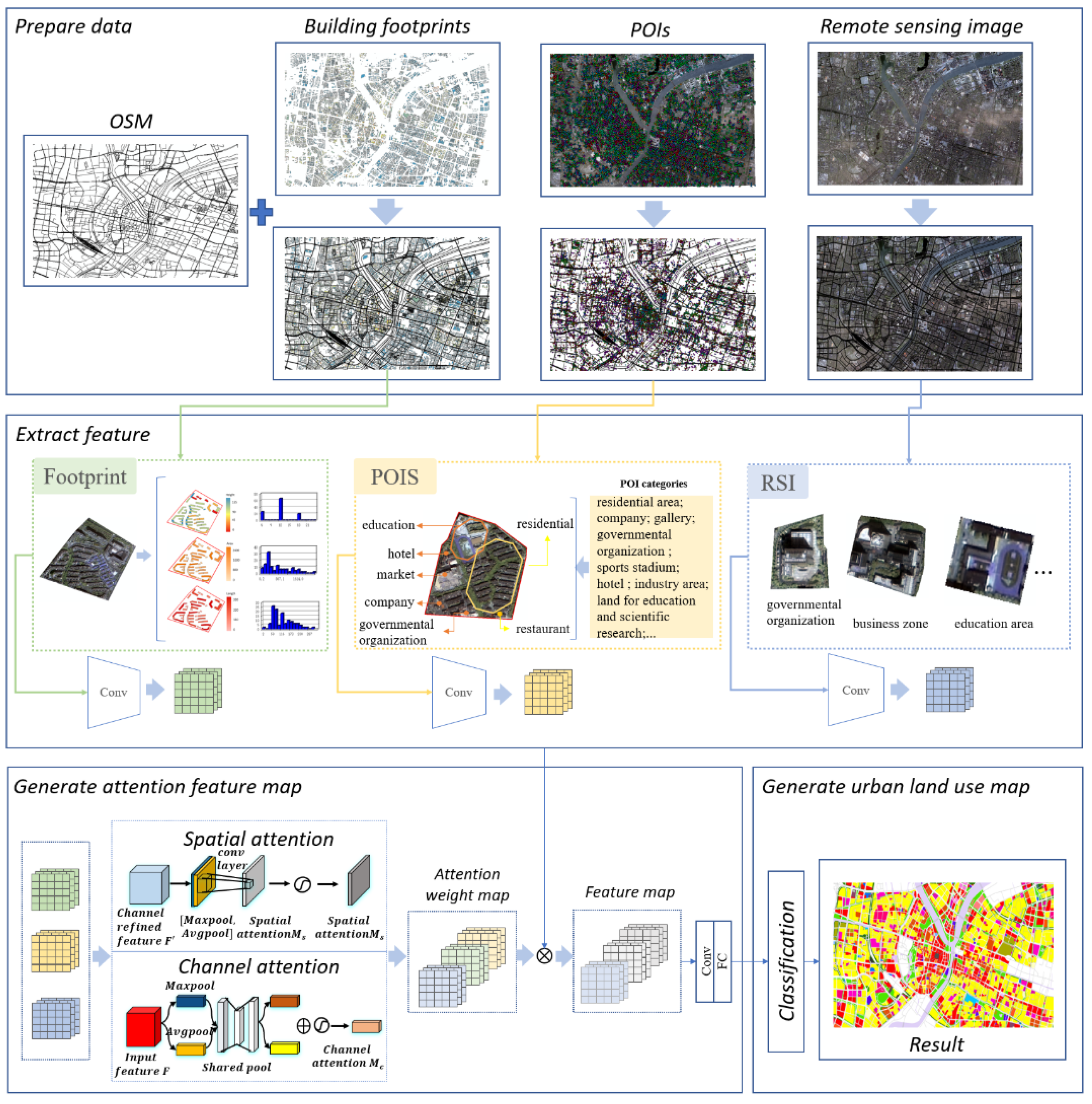
In this paper, the urban functional area identification framework is implemented by a perfect combination of remotely sensed images and socio-economic attribute data, such as points of interest (POI), road networks, and building footprints. As shown in
Figure 4, three major steps are involved in the process of the multi-modal urban functional area identification framework. First, it is clear that the road network segments the preprocessed remote sensing image, POIs, and building footprint data. Next, in the light of the segmented block, the convolution network is applied to further extract the features. Third, the features picked up by step 2 are input into the spatial attention mechanism and channel attention mechanism modules as it looks to fetch the attention weight map. Finally, we multiply the features used in step 1 with the generated feature attention map in step 2 to harvest the final feature map, a key factor to settle city functional area recognition classification mapping.
3.1. Block Generation by Osm
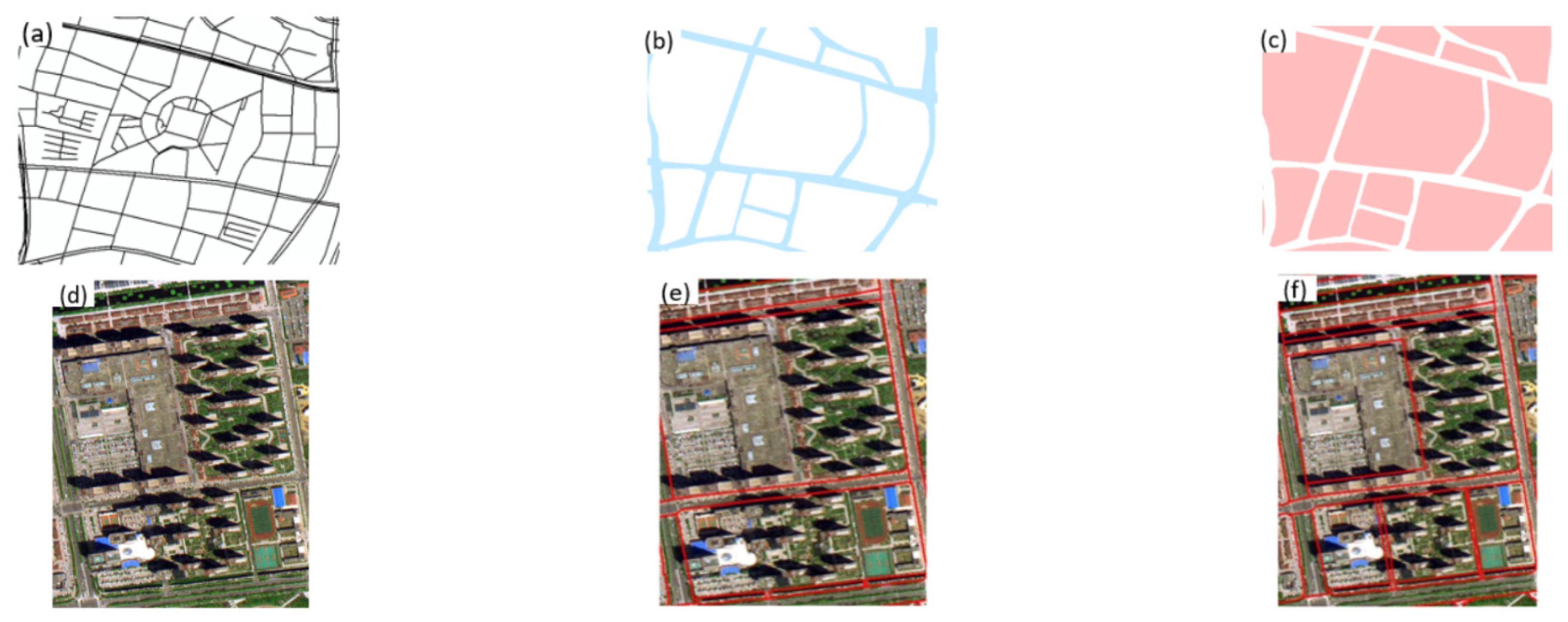
Blocks are the basic units that carry social and economic functions in urban management and urban planning. Long and Liu contend that the land parcel is a polygon surrounded by a road network as the dividing boundary of the urban area [
38]. In this study, we adopted this method, using OSM road network data to form block units. As shown in
Figure 5a–c, first, preprocessing operations such as simplification, merging, and geometric correction are performed on the road network data. Second, it is important to forge a buffer zone hinged on the road network of different levels. Finally, we divide the research area into a string of independent blocks determined from the established buffer zone.
However, in the whole process, few high-purity samples prevail, since the medical and administrative categories are usually mixed with other land uses. Therefore, in order to ensure the integrity and independence of the function blocks, we manually edit the following samples in
Figure 5d,e, seeking to connect original unconnected lines into road sections. These steps help to form an independent unit and to guarantee a purity of each sample that exceeds 90%.
3.2. Generating the Feature Tensor
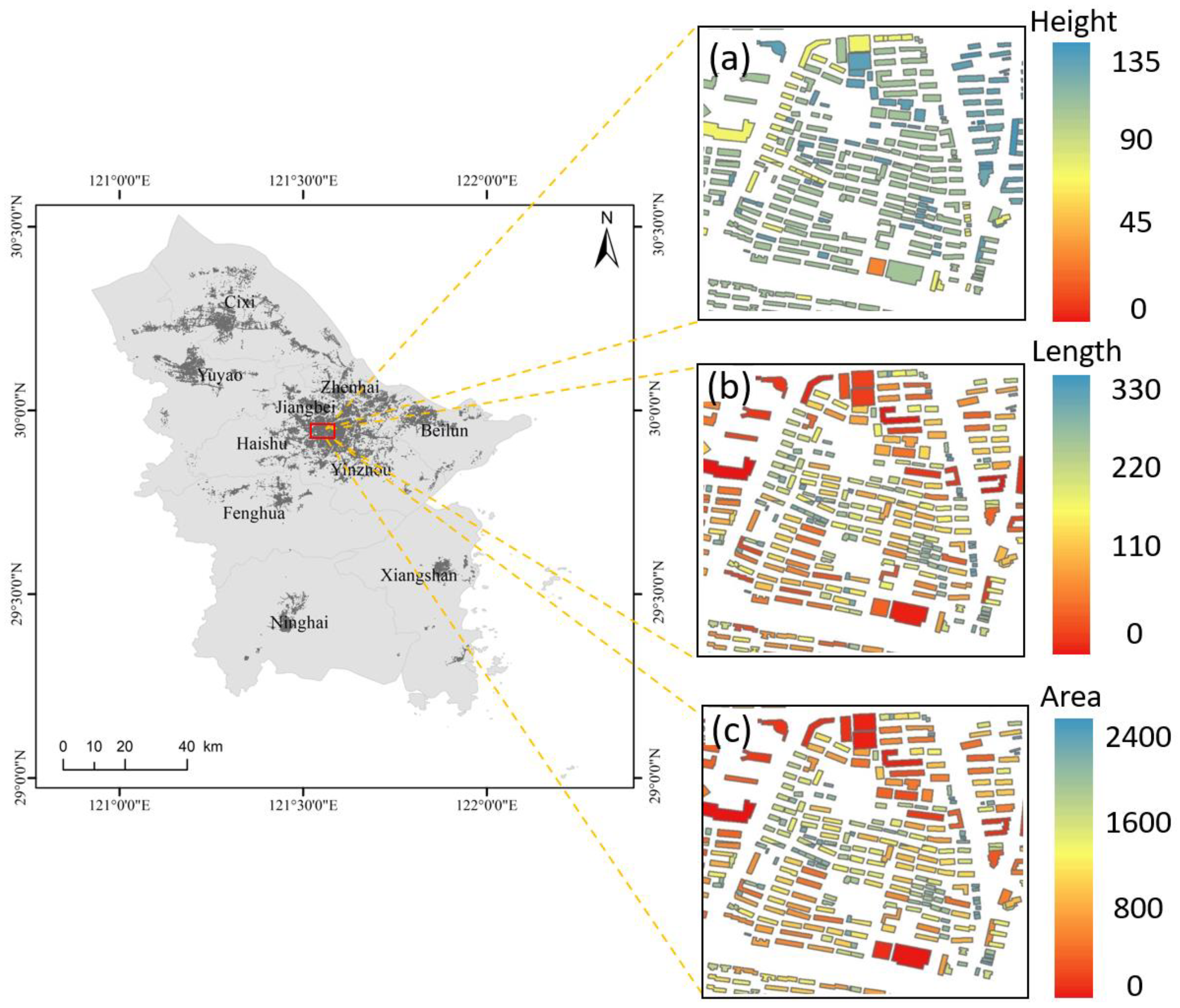
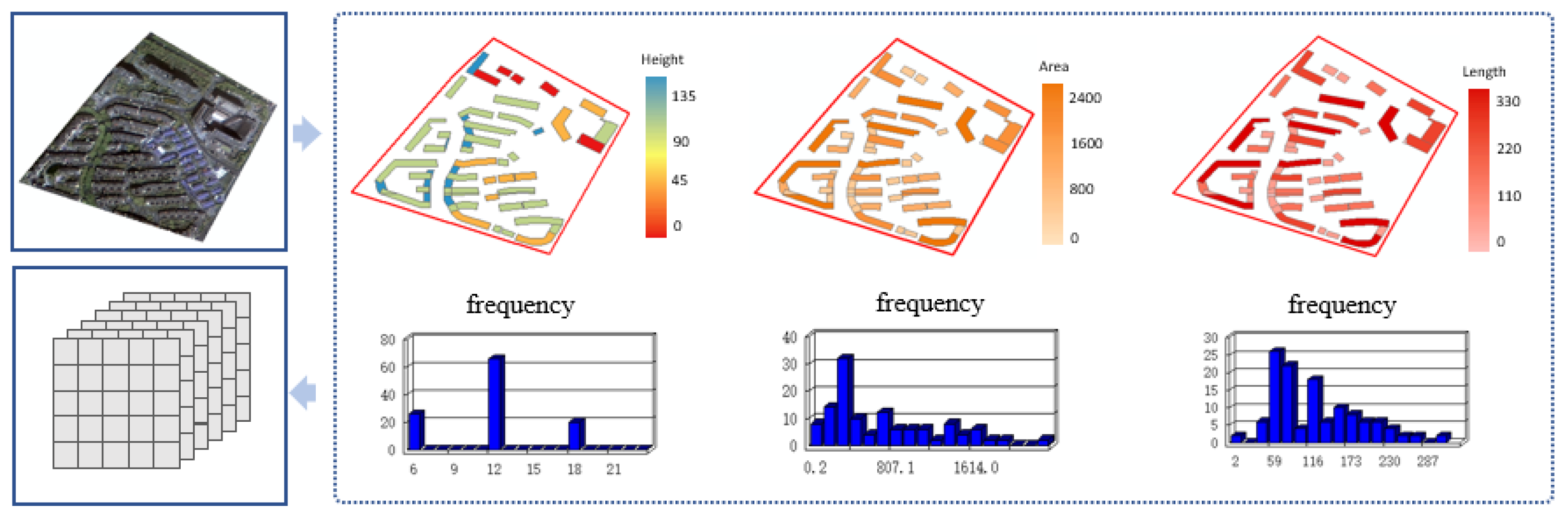
Generation of the footprint feature tensor: As shown in
Figure 6, the spatial connection method of ArcMap10.6 (Environmental Systems Research Institute, Inc., Redlands, CA, USA) is first applied to connect buildings with intersecting parcels while obtaining information of all buildings within a parcel. Next, the metrics are calculated according to the statistical method. Finally, the feature vectors representing the building information are generated.
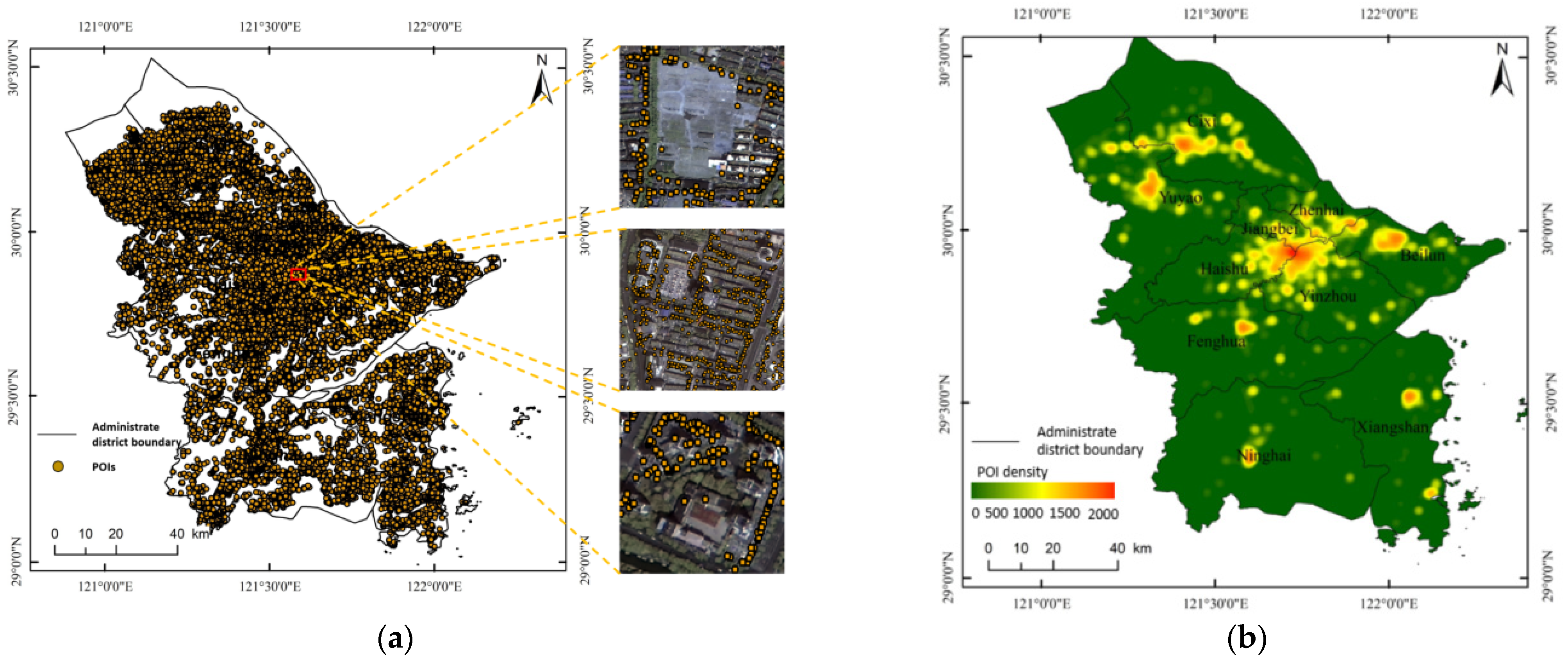
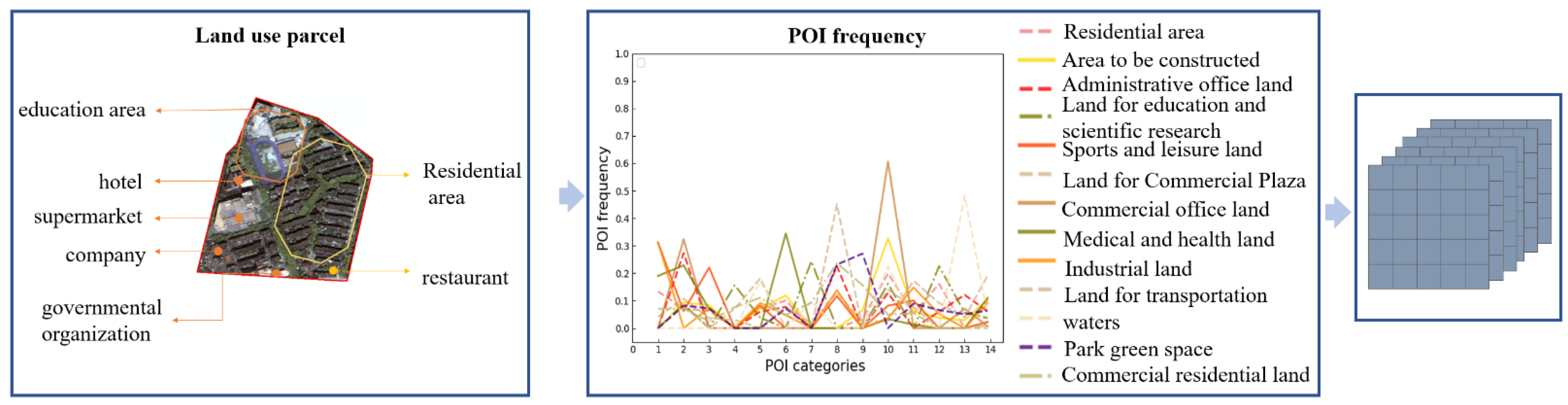
Generation of the POI feature tensor: As shown in
Figure 7, the spatial connectivity method is first implemented in ArcMap10.6 as it seeks to count the number of various POIs in the neighborhood. Second, the type ratio of each unit is calculated on the basis of the formula, and the type ratio value is used as a criterion to judge the functional nature of the neighborhood. Finally, feature vectors are generated to represent building information [
39]. The calculation method is as follows:
where
represents the type of POI,
serves as the number of the
-th type of POI in the block,
stands for the total number of the
-th type of POI,
acts as the frequency density of the
-th type of POI in the total number of POIs of this type, and
represents the ratio of the frequency density of the
-th type of POI to the frequency density of all types of POI in the block.
Generation of the image feature tensor: When extracting the features of high-resolution remote sensing images, instead of separately attaining the low-level semantic features, such as texture, spectrum, and SIFT of the image, we take advantage of CNN to capture high-level semantic features from images. Next, we will continue our research with respect to the items of multi-modal network feature extraction and fusion in greater detail.
3.3. Feature Extraction and Feature Fusion
In this section, our team explores the details of the proposed deep multimodal fusion network, laying a foundation for integrating remote sensing images with social-economic attribute data. This encourages one to better recognize the urban region functions in our study.
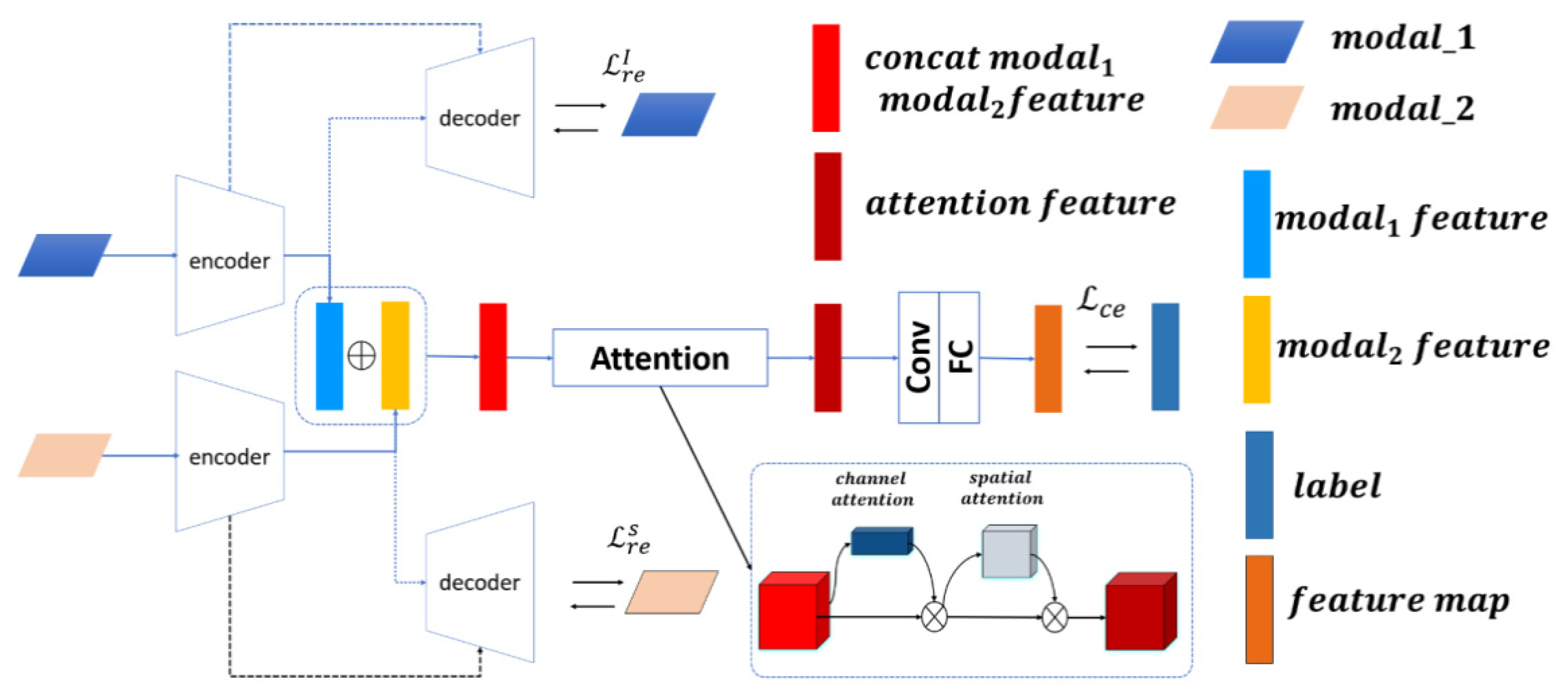
The illustration (
Figure 8) below clearly unveils the overall architecture of the proposed deep multimodal fusion network. The convolution structure has efficient feature extraction and representation capabilities, so two identical convolutional branch structures are employed here to obtain remote sensing image features and socioeconomic attributes, respectively. The network
is composed of three major parts, being the image encoder and socioeconomic attribute encoder, the data fusion module, and the decoder of the image and socioeconomic attributes. The network takes satellite images
and socioeconomic attribute
the inputs. The outputs are demonstrated by the predicted probability distribution
over all the categories, i.e.,
. In particular, it is better to garner the images and socioeconomic attributes data features with the assistance of encoder and decoder structures. Moreover, the extracted features are further fused through the spatial attention mechanism as well as the channel attention mechanism while being classified by introducing the softmax layer after passing through the convolutional layer and being fully connected. The key of the network is to learn a joint embedding space through two attention mechanisms, such that the image and social-economic characteristics are able to be well combined for prediction. Apart from the conventional cross entropy loss for classification task, we propose an auxiliary loss.
3.3.1. Feature Extraction
The network is an encoder–decoder backbone network with a residual network architecture and two convolution branches [
40,
41], i.e., the remote sensing image branch and the socioeconomic attributes data branch. The backbone network, specifically designed for conducting the diversity of remote sensing data and socioeconomic attribute data, aims to integrate complementary information, alleviate the complexity of heterogeneous information, and accomplish the purpose of classification.
Each branch encoder section utilizes a similar structure to the VGG16 [
42]., with four convolution blocks, each of which contains a convolutional layer with a kernel size of 3 × 3 with a rectified linear unit (
Relu) and a batch normalization (
BN). The second and fourth blocks use a max-pooling layer of size of 2 × 2. The features extracted by the encoder are divided into two channels; one is the decoder branch corresponding to the encoder branch for reconstruction and the other is a fusion with the features garnered by other branch networks. The extracted features are transferred to a module with an attention mechanism, working to create an attention feature map for classification. Specifically, two methods need to fuse the extracted features of two different patterns before sending them to the attention module, i.e., concatenation and element summation. For concatenation,
, and
. For the element-wise sum,
, and
. The illustration of the two fusion methods is shown in
Figure 9. Furthermore, the fused feature x is then fed into the attention module to create the attention feature map.
The structure of the decoder part is symmetrical with respect to the encoder part. First, four deconvolution layers with 2 × 2 up-sampling are sequentially added at the end of the encoder section. Second, the final layer is a single 2 × 2 deconvolution layer and the size of the final output is equal to the input. We add these encoders’ features into the decoder features using the skip concatenation function, enabling the decoder network to form finer feature maps. Finally, the reconstructed data is exported.
3.3.2. Feature Fusion
The features obtained after the convolution and pooling operations of the encoder are of equal importance among the features. In addition, the convolutional and the fully connected layer are expected to construct the feature space with the aim of completing the classification of the similarity and measurability between the modal data task. This method has been used previously [
43,
44]. However, for specific extraction and classification tasks, the importance of the features of each channel is not the same, and the feature cannot be fully concentrated on “where” is the most informative part and “what” is the most meaningful input feature map during the interactive fusion. In order to avoid the influence of invalid features on the network model, a channel and spatial attention module is embedded to distribute the weight of spatial information and channel information [
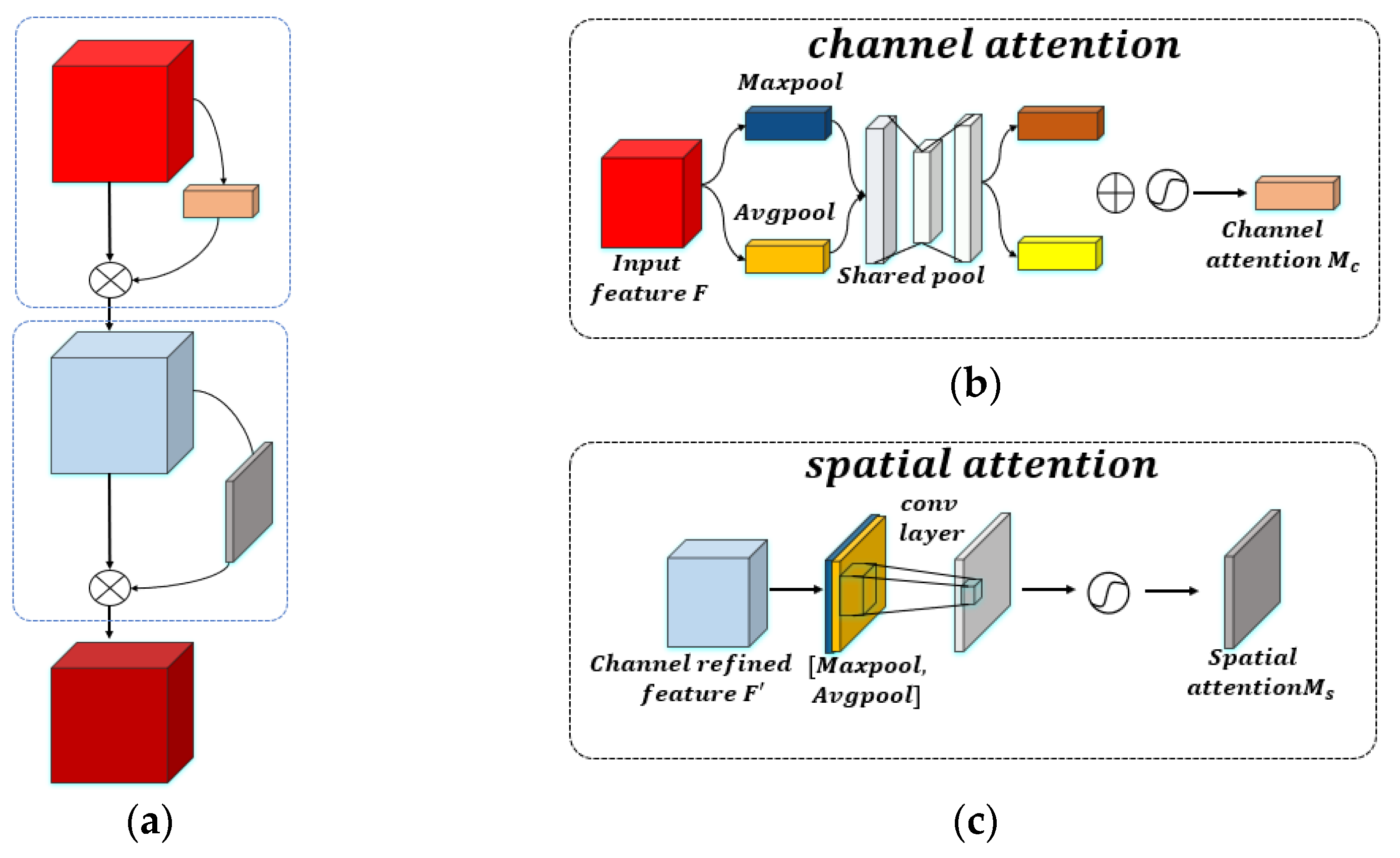
45]. Hence, we adopt the channel and spatial attention module (
Figure 10). Each branch could potentially learn the “what” and “where” in the channel dimension and the spatial dimension separately, thus effectively helping the information flow in the network.
The intermediate feature map
acts as the input to infer the 1D channel attention map
and the 2D spatial attention map
, as illustrated in
Figure 10a. The overall attention process can be summarized as:
where
represents element-wise multiplication and
is the final attention output feature.
Channel attention: As shown in
Figure 10b, the average pooling and maximum pooling operations are first used to aggregate the spatial information of the feature map, bringing about two different spatial context feature descriptions.
,
respectively serve as the average pool feature and the maximum pool feature. Next, these two features go through a shared neural network. The number of neurons in the first layer is
C/r, the activation function is
Relu, and the number of neurons in the second layer is
C, as the neural network parameters of the two layers are shared. After adding the two features gathered through a Sigmoid activation function, the weight coefficient
is grabbed. Finally, the weight coefficient and the original feature
F are multiplied to obtain the scaled new features. The channel attention is calculated as follows:
where
is the sigmoid activation function,
,
is the weight of the fully connected layer, and r is the compression ratio, using the
Relu activation function to process
.
Spatial attention: As shown in
Figure 10c, the average pooling and maximum pooling operations are first used to aggregate the channel information of the feature map as it looks to work out two 2D feature maps
and
. Next, the two feature descriptions to be spliced together are used according to the channel after a 7 × 7 convolutional layer, where the activation function is Sigmoid, and the weight coefficient
is obtained. Finally, multiply the weight coefficient and the feature
to get the attention feature. The spatial attention is calculated as follows:
where
is the sigmoid activation function and
is a convolution operation with a size of 7 × 7.
Eventually, the fused features pass through both the convolutional layer and the fully connected layer for the output classification.
3.4. Loss Function
Aiming to achieve an effective classification and make the network more robust to missing patterns, two losses, the main loss and the auxiliary loss, are introduced to constrain the network training. The major loss is the cross entropy
for the classification task. The auxiliary losses,
, are used to complement the major loss in an attempt to increase the model robustness with missing modalities. The overall loss is formulated as follows:
Widely used in classification tasks, the cross-entropy loss is used to regularize the network to learn from category labels. It can be formulated as follows:
where
and
are the ground truth label and predicted probability value of class
k for the
-th sample, respectively, and
C is the total number of classes.
The auxiliary loss is the mean square error (MSE) loss, which is mainly employed to rein in the extracted features to be more representative through the loss triggered by the reconstruction. It can be formulated as follows:
where
and
denote the remote sensing image and socioeconomic attribute data structure losses, respectively, with
being the reconstructed remote sensing image and socioeconomic attribute data, respectively.
6. Conclusions
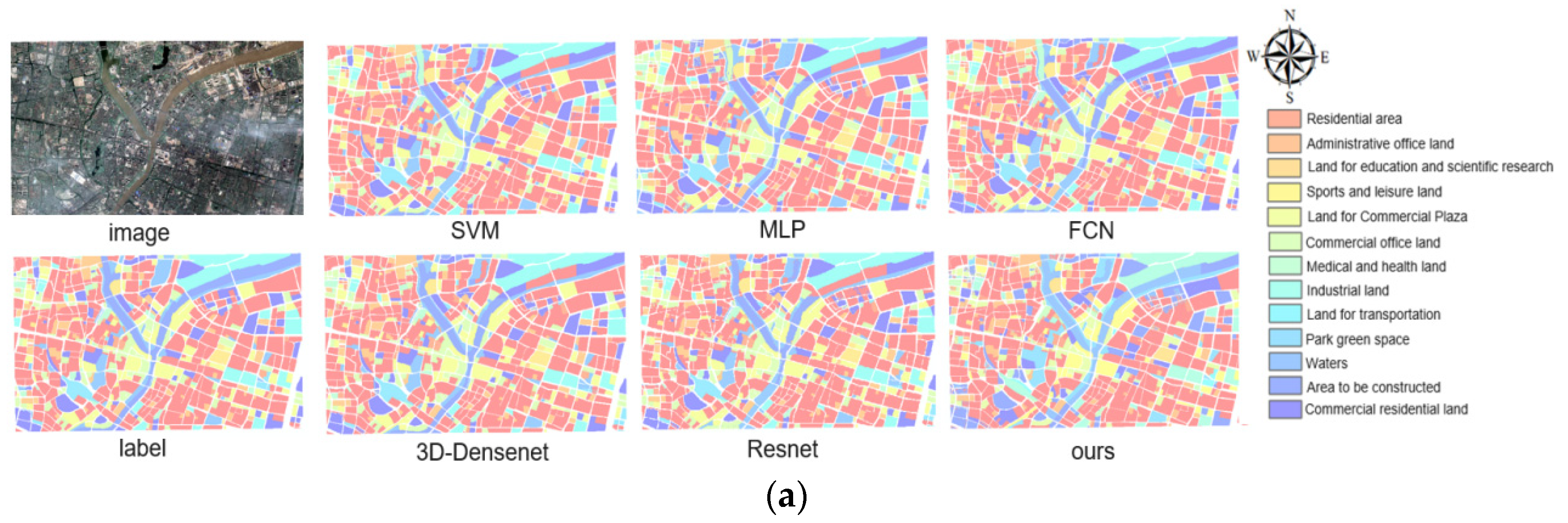
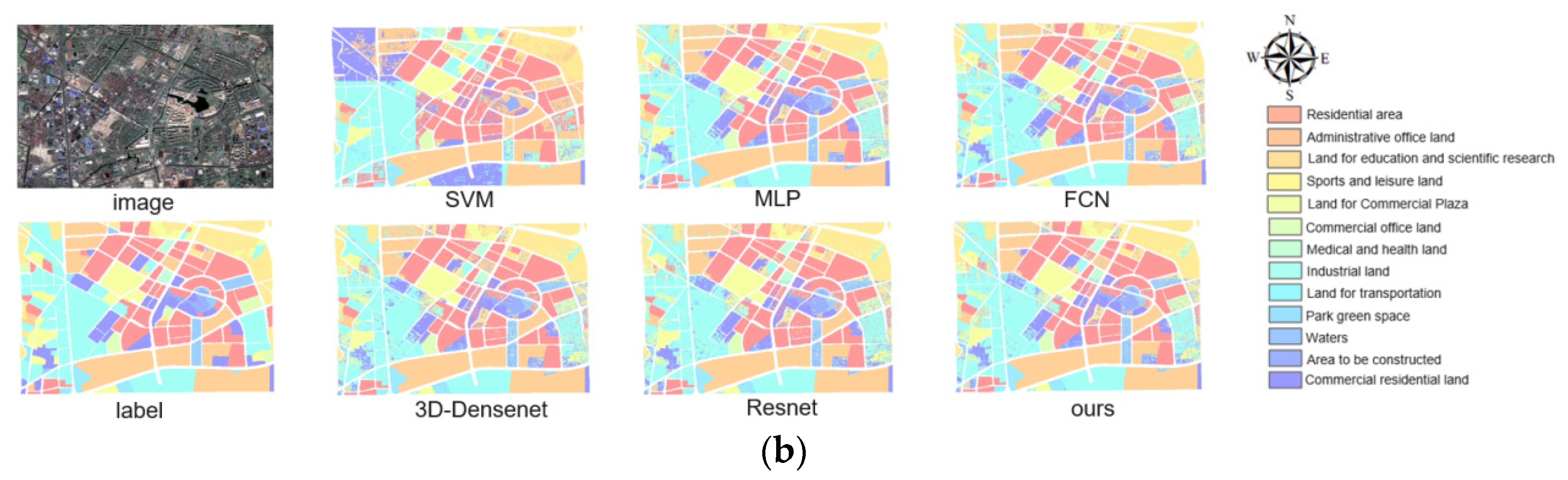
The feature forms and semantic features possessed by remote sensing data and social perception data differ. How to make full use of the low-level semantic information related to remote sensing and high-level semantic information of social perception data is the key to improve the recognition accuracy of urban functional areas. In this paper, based on the advantage of feature extraction and expression of deep convolutional networks, we propose a framework to complete urban identification by fusing satellite images, POI, and building footprint data. This framework, compared with other modeling methods, achieves the feature fusion process by leveraging a multi-branch network structure with an attention mechanism that can focus attention on the most informative part of the most meaningful feature map, such that the semantic attributes of the input features can be fully expressed.
In terms of the method, this paper makes the convolutional structure extract as many features as possible by constructing a loss function, but not all features have the same importance, which may increase the computational burden of the network to some extent. The attention mechanism introduced in this paper strengthens the recognition ability by giving a large weight to the main features during feature fusion, but the attention mechanism may not be fully utilized compared to the network as a whole. The experimental results show that the model recognition ability is greatly improved by adding socially perceptive data. However, some problems that need to be further solved still exist. For example, the recognition effect is not significantly improved after adding building outline data, to some degree, influencing the accurate recognition of some functional areas. Presumably, the main reason for this is that the building footprint data that inherently exhibit is physical attribute features, invoking a data redundancy problem and impacts the recognition performance.
In future work, we will first fully explore the application of social perception data in urban function recognition, such as street view. Second, for the construction of the method, we will take the suitable feature extraction method from the data’s own characteristics as much as possible, as well as make the network simpler and easier to reproduce to the furthest extent. Finally, our method has been proved to be effective for the analysis of Ningbo, but its adaptability to other regions in China and the world needs further validation.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}