
Automatic Classification and Coding of Prefabricated Components Using IFC and the Random Forest Algorithm



Abstract
:1. Introduction
2. Literature Review
2.1. Intelligent Management of Prefabricated Components
2.2. Information Classification and Coding System
2.3. Random Forest
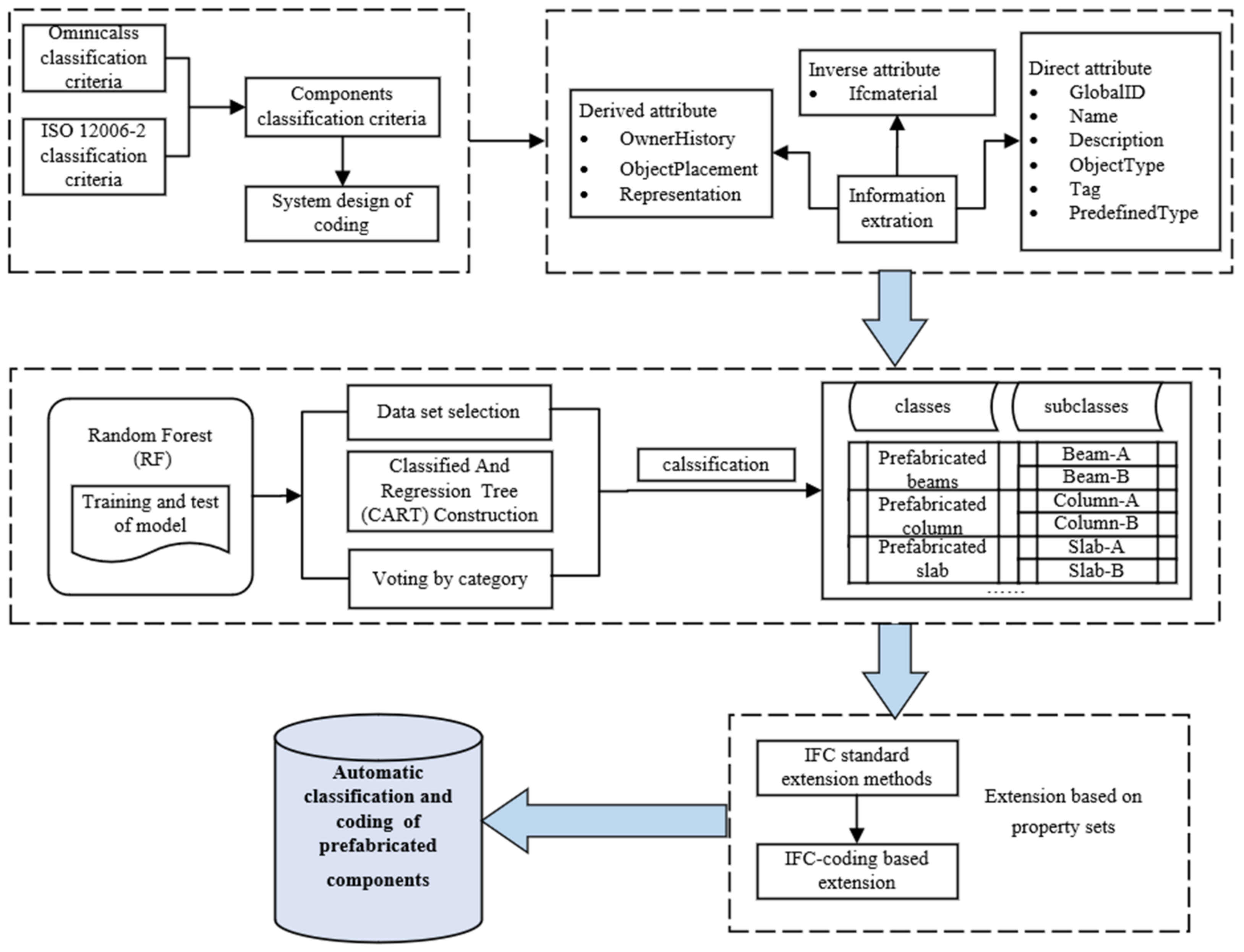
3. Methodology
3.1. Classification Criteria and System Design of Coding for Prefabricated Components
3.1.1. Information Classification of Prefabricated Components
3.1.2. Component Coding System
- (1)
- Beam: The sixth code segment is composed of three numbers. From front to back, the width, height, and length of the section are respectively denoted. The numbers for each segment are connected by “-”.
- (2)
- Slab: The sixth code segment is composed of a number, which is the value of the slab thickness.
- (3)
- Column: The sixth code segment is composed of two numbers. From front to back are, respectively, the values for the cross-section side length of the column and the length of the column, with a “-” connecting each segment of numbers.
- (4)
- Wall: The sixth code segment is composed of a number, which is the wall thickness.
- (5)
- Stair: The sixth code segment is composed of four numbers. The width of the ladder section, the riser height, the tread depth, and the number of risers is sequentially denoted. Each number is connected by “-”.
3.2. Training and Testing of the Machine Learning
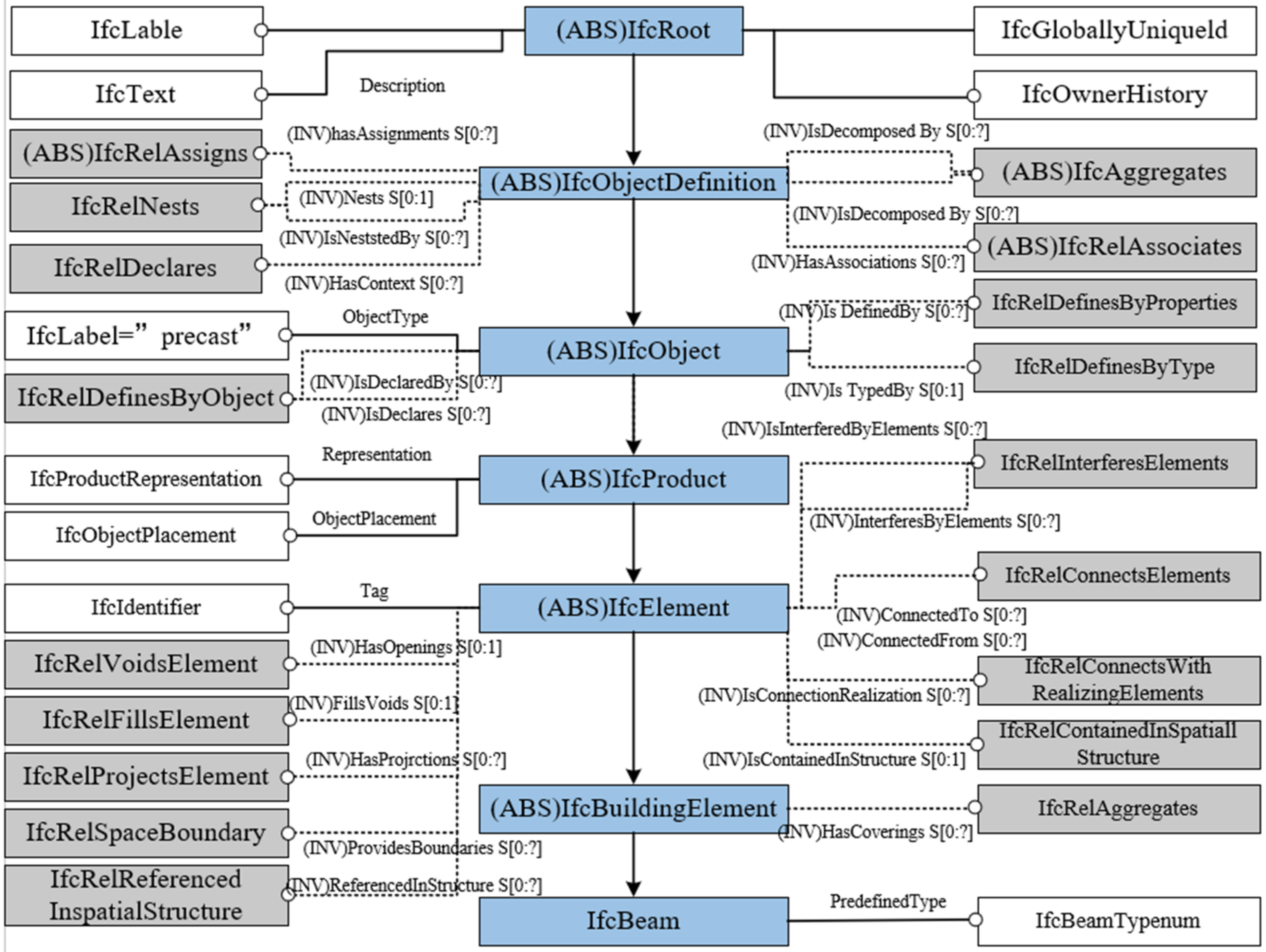
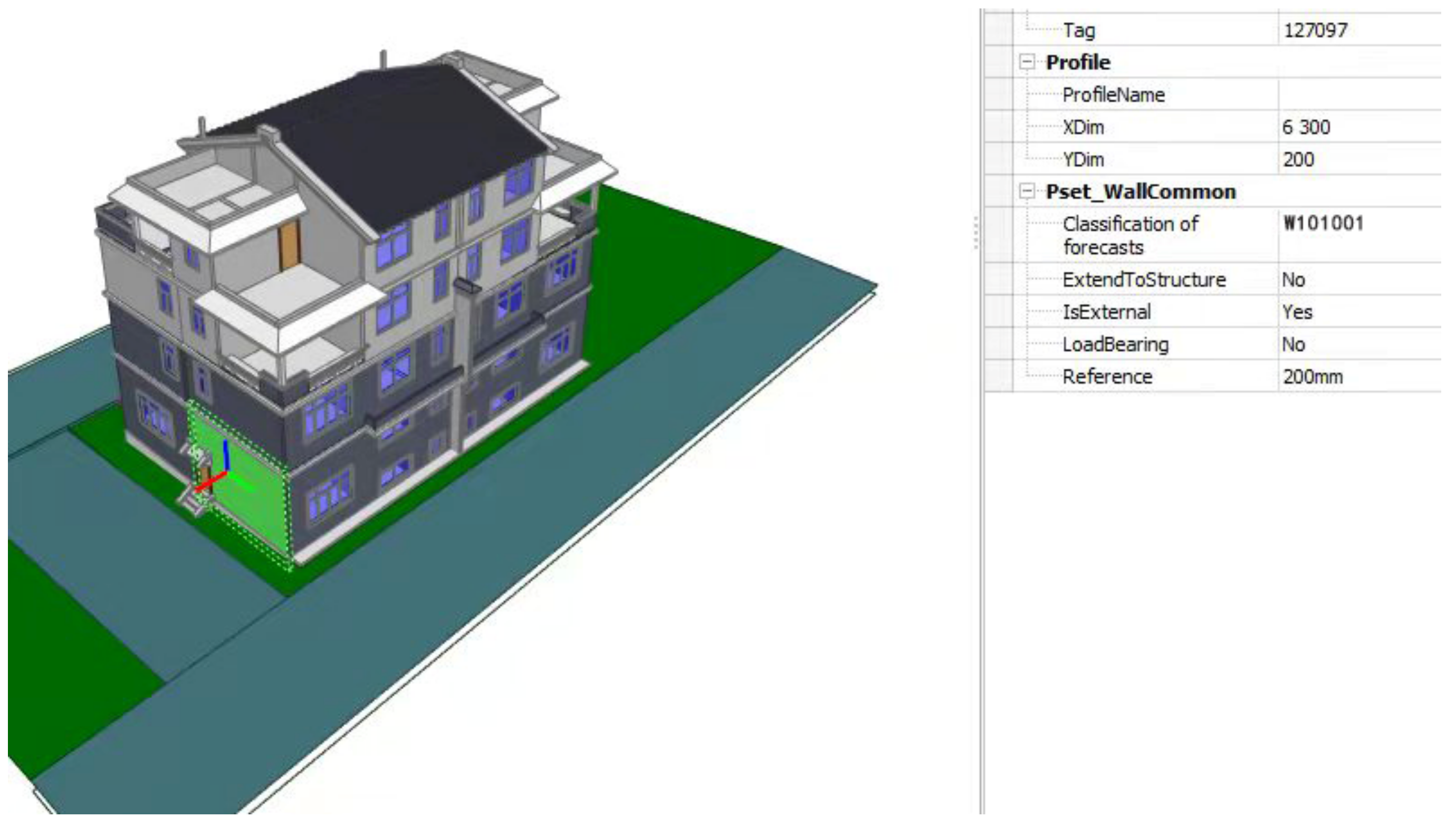
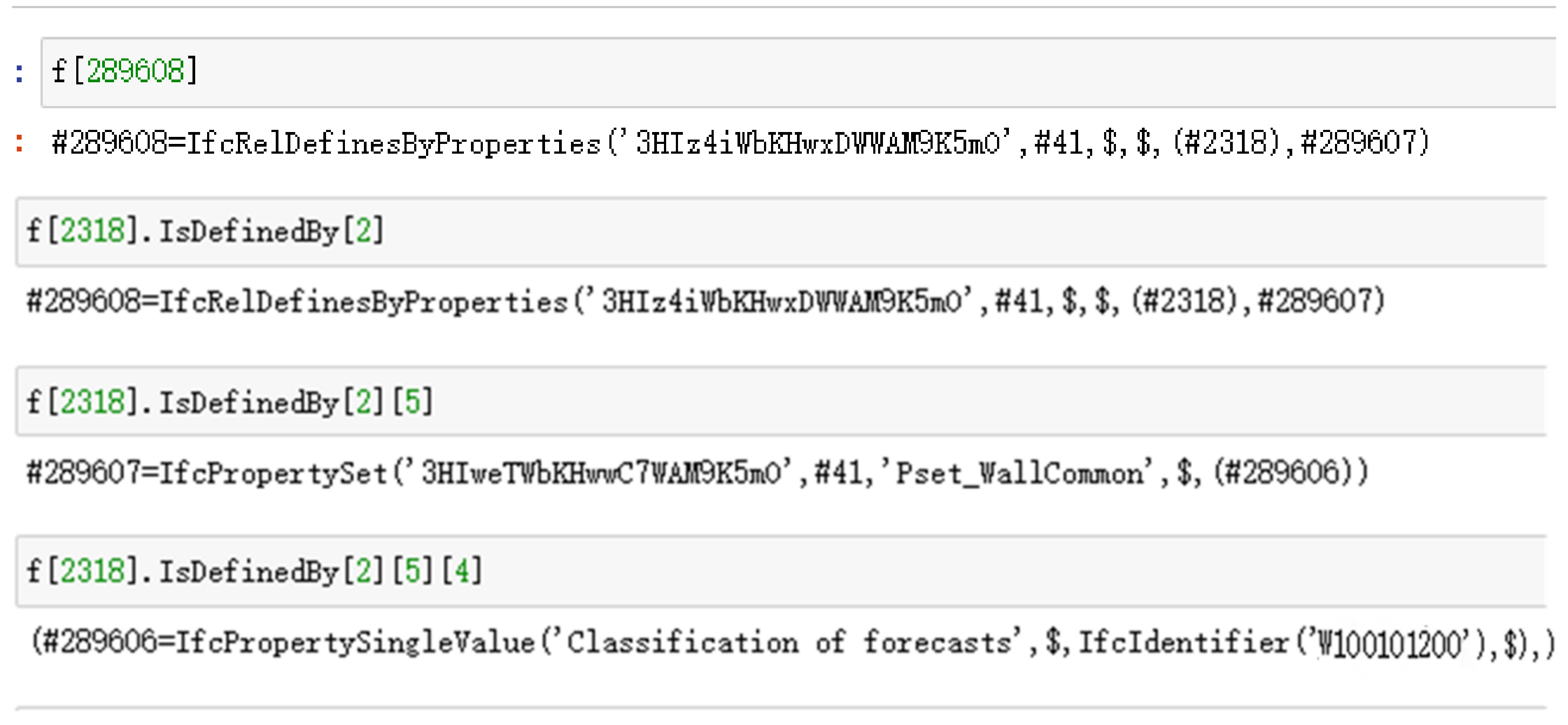
3.2.1. Information Extraction Based on IFC Schema
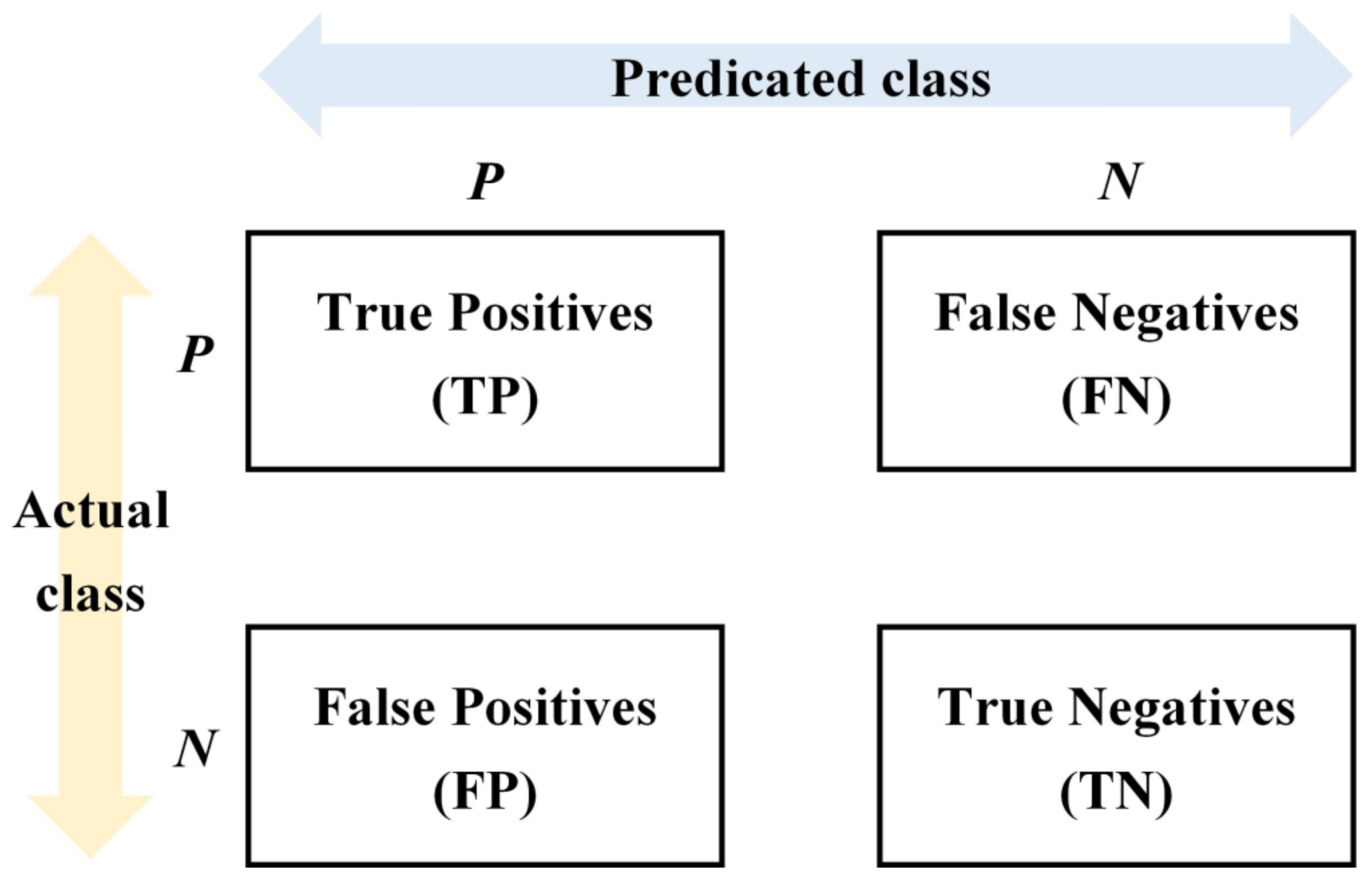
3.2.2. Comparison of Machine Learning
3.2.3. Training and Testing of the Random Forest Models
- Step 1: Randomly Select Datasets
- Step 2: CART Construction Based on Random Component Dataset
- Step 3: Component Classification Result Voting
3.2.4. Component Coding Information Extension Based on IFC
4. Experiment
4.1. Data Collection and Preparation
4.2. Implementation of Automatic Classification and Coding for Prefabricated Building Components
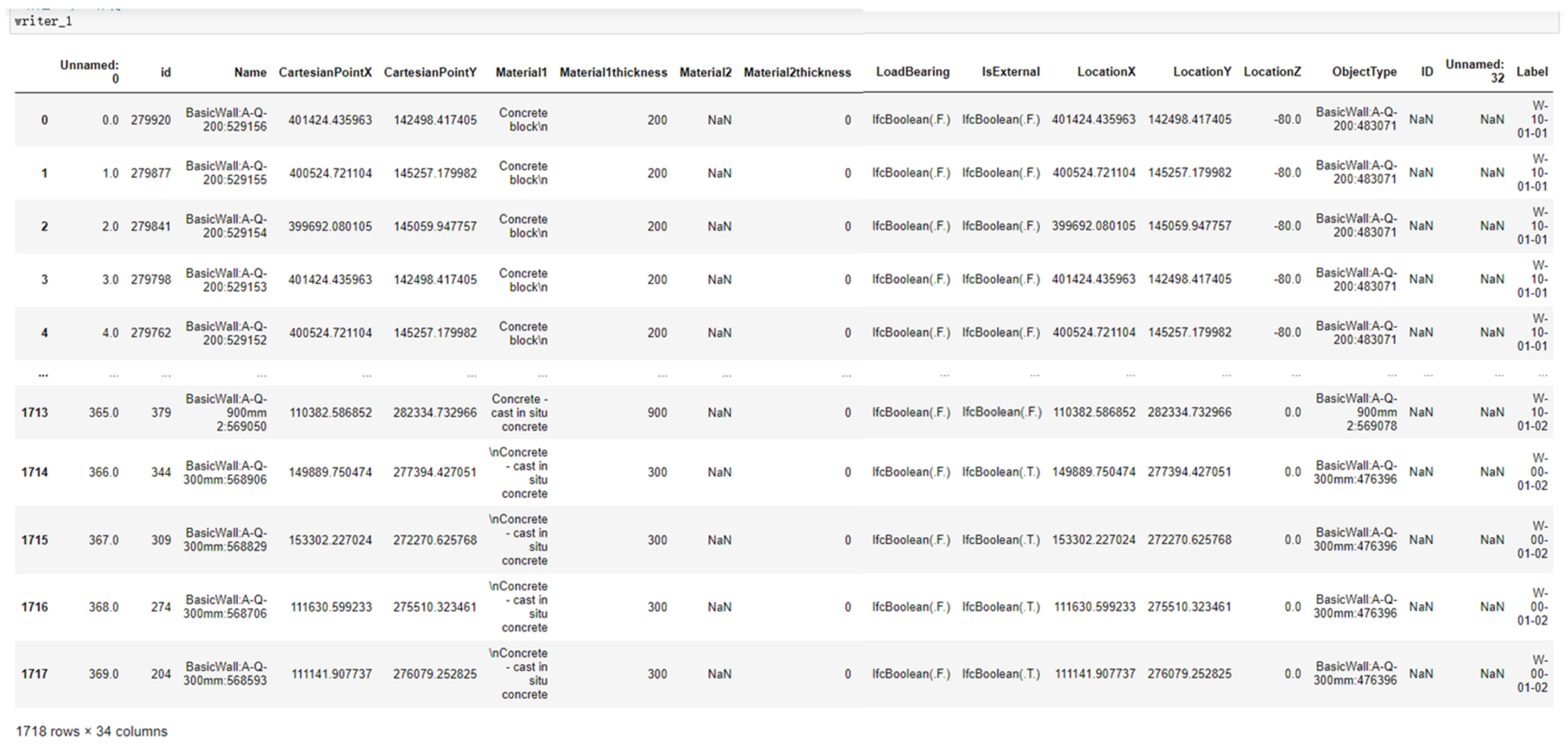
4.2.1. Step 1: Data Extraction and Annotation
| Algorithm 1Extract IFC |
| products = f.by_type('IfcProduct') #Instantiate object for product in products: if(product.is_a() == 'IfcWallStandardCase'): dict = [['null','Name',0,0,'NULL',0,'NULL',0,'NULL',0,'NULL',0,'NULL',0, 'NULL',0,'NULL',0,'NULL',0,'NULL',0,'NULL',0,'T','T',0,0,0,'NULL']] dict[0][0] = product.id() #ID Property dict[0][1] = product.Name #Name Property dict[0][2] = product.ObjectPlacement[1][0][0][0] #CartesianPointX Property dict[0][3] = product.ObjectPlacement[1][0][0][1] #CartesianPointY Property i = 0 #Take out the types and properties of materials 1 ~ 9 in turn for c in product.HasAssociations[0][5][0][0]: dict[0][4+i] = c[0][0] #Material type dict[0][5+i] = c[1] #Material thickness i += 2 for definition in product.IsDefinedBy: if definition.is_a('IfcRelDefinesByProperties'): property_set = definition.RelatingPropertyDefinition if(property_set[2] == ('Pset_WallCommon')): dict[0][24] = property_set[4][1][2] #LoadBearing Property, whether or not to bear weight dict[0][25] = property_set[4][3][2] #IsExternal Property, Whether the representative is outside #LocationX, LocationY, LocationZ dict[0][26] = product.ObjectPlacement.RelativePlacement.Location[0][0] dict[0][27] = product.ObjectPlacement.RelativePlacement.Location[0][1] dict[0][28] = product.ObjectPlacement.RelativePlacement.Location[0][2] #ObjectType dict[0][29] = product.ObjectType frame1 = pd.DataFrame(dict,columns= ('id','Name','CartesianPointX','CartesianPointY','Material1','Material1thickness','Material2', 'Material2thickness','Material3','Material3thickness','Material4','Material4thickness','Material5', 'Material5thickness','Material6','Material6thickness','Material7','Material7thickness','Material8', 'Material8thickness','Material9','Material9thickness','Material10','Material10thickness', 'LoadBearing','IsExternal','LocationX','LocationY','LocationZ','ObjectType')) frame = pd.concat([frame1,frame], axis = 0 ,ignore_index = True) |
4.2.2. Step 2: Training and Testing of the Random Forest Model
| Algorithm 2Random Forest training |
| from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV param_grid = [{‘n_estimators’:range(20,100),’max_depth’:range(2,20)}] forest_clf = RandomForestClassifier() grid_search = GridSearchCV(forest_clf,param_grid,cv=5,scoring=‘accuracy’) grid_search.fit (X,Y) |
4.2.3. Step 3: Component Coding and IFC Extension
| Algorithm 3Extension Ifc |
| writer_1=pd.read_excel(‘C:\\Users\\Administrator\\Desktop\\handson-ml-master\\wow.xlsx’) products = f.by_type(‘IfcProduct’) for product in products: if(product.is_a()==‘IfcWallStandardCase’): id = product.id() tag=writer_1[(writer_1[‘id’] == id)][‘PredClass’].max() #Use Max function to convert the returned information into tag extensionIfcClass(product,tag) |
5. Result and Discussion
5.1. Results
5.1.1. Classification Results
5.1.2. IFC Extension Results
| Algorithm 4Write back IFC file |
| f.write(‘./ifc library/Four story double row villa(Modified).ifc’) |
5.2. Discussion and Limitation
5.2.1. Discussion of Results
5.2.2. Limitations
5.3. Practical Application
6. Conclusions
- (1)
- An information classification and coding system based on BIM technology is proposed. Based on the OmniClass classification system, this paper proposes an information classification method based on the structure and function of the prefabricated components. In addition, it designs a BIM-based coding system for prefabricated components based on this classification method.
- (2)
- Comparing the performance of the Random Forest, SVM, and KNN algorithms in a prefabricated component classification task, we find that the Random Forest algorithm can better deal with the task of component classification of prefabricated components. The intelligent labelling of building component information based on BIM technology is performed. Based on the above information classification and coding rules, an automatic coding program for prefabricated components is also developed. Through the Python-based building information component property, information extraction and Random Forest model training, the unified coding of prefabricated components is automatically carried out, which performs the unique identification of prefabricated components and reduces the workload of designers.
- (3)
- The extension of IFC-based component coding information is proposed. Based on the IFC4 version, the IFC standard format and entity expression methods are analyzed. Based on the IFC physical file, the process of implementing the extension of component coding information is designed to realize the integrity of the BIM-based prefabricated component information description. This provides a data basis for construction management combined with the Internet of Things. In addition, it is more suitable for the concepts of standardizing the design of prefabricated buildings and industrializing the production of components in future developments.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Asadi, S.; Roshan, S.; Kattan, M.W. Random Forest Swarm Optimization-Based for Heart Diseases Diagnosis. J. Biomed. Inform. 2021, 115, 103690. [Google Scholar] [CrossRef] [PubMed]
- Badenko, V.; Fedotov, A.; Zotov, D.; Lytkin, S. Scan-to-BIM methodology adapted for different application. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Bi, W. Research on the Way of Prefabricated Building Information Sharing Based on Computer Software BIM. J. Phys. Conf. Ser. 2021, 1744, 22078. [Google Scholar] [CrossRef]
- Bortolini, R.; Formoso, C.T.; Viana, D.D. Site Logistics Planning and Control for Engineer-To-Order Prefabricated Building Systems Using BIM 4D Modeling. Autom. Constr. 2019, 98, 248–264. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.; Li, X.; Masanet, E.; Zhang, L.; Huang, Z.; Ries, R. Unlocking the Green Opportunity for Prefabricated Buildings and Construction in China. Resour. Conserv. Recycl. 2018, 139, 259–261. [Google Scholar] [CrossRef]
- Čuš-Babič, N.; Rebolj, D.; Nekrep-Perc, M.; Podbreznik, P. Supply-Chain Transparency within Industrialized Construction Projects. Comput. Ind. 2014, 65, 345–353. [Google Scholar] [CrossRef]
- De Santana, F.B.; Borges Neto, W.; Poppi, R.J. Random Forest as One-Class Classifier and Infrared Spectroscopy for Food Adulteration Detection. Food Chem. 2019, 293, 323–332. [Google Scholar] [CrossRef]
- Girardet, A.; Boton, C. A Parametric BIM Approach to Foster Bridge Project Design and Analysis. Autom. Constr. 2021, 126, 103679. [Google Scholar] [CrossRef]
- Hao, J.L.; Cheng, B.; Lu, W.; Xu, J.; Wang, J.; Bu, W.; Guo, Z. Carbon Emission Reduction in Prefabrication Construction During Materialization Stage: A BIM-based Life-Cycle Assessment Approach. Sci. Total Environ. 2020, 723, 137870. [Google Scholar] [CrossRef]
- He, R.; Li, M.; Gan, V.J.L.; Ma, J. BIM-enabled Computerized Design and Digital Fabrication of Industrialized Buildings: A Case Study. J. Clean. Prod. 2021, 278, 123505. [Google Scholar] [CrossRef]
- Isaac, S.; Shimanovich, M. Automated Scheduling and Control of Mechanical and Electrical Works with BIM. Autom. Constr. 2021, 124, 103600. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Eastman, C.M.; Sacks, R.; Kaner, I. Benchmark tests for BIM data exchanges of precast concrete. Autom. Constr. 2009, 18, 469–484. [Google Scholar] [CrossRef]
- Jung, N.; Lee, G. Automated Classification of Building Information Modeling (BIM) Case Studies by BIM Use Based on Natural Language Processing (NLP) and Unsupervised Learning. Adv. Eng. Inform. 2019, 41, 100917. [Google Scholar] [CrossRef]
- Koo, B.; La, S.; Cho, N.; Yu, Y. Using Support Vector Machines to Classify Building Elements for Checking the Semantic Integrity of Building Information Models. Autom. Constr. 2019, 98, 183–194. [Google Scholar] [CrossRef]
- Langroodi, A.K.; Vahdatikhaki, F.; Doree, A. Activity Recognition of Construction Equipment Using Fractional Random Forest. Autom. Constr. 2021, 122, 103465. [Google Scholar] [CrossRef]
- Li, C.Z.; Xue, F.; Li, X.; Hong, J.; Shen, G.Q. An Internet of Things-enabled BIM Platform for On-Site Assembly Services in Prefabricated Construction. Autom. Constr. 2018, 89, 146–161. [Google Scholar] [CrossRef]
- Li, X.T.; Zhang, W.H.; Liu, Z.Z.; Qu, W.Y.; Wu, Z.H.; Wang, L. Application of BIM coding and example modelling for typical asphalt pavement diseases based on Omni Class. J. Phys. Conf. Ser. 2021, 2044, 012153. [Google Scholar] [CrossRef]
- Majrouhi Sardroud, J. Influence of RFID Technology on Automated Management of Construction Materials and Components. Sci. Iran. 2012, 19, 381–392. [Google Scholar] [CrossRef] [Green Version]
- Maritz, T.; Klopper, C.; Siglé, T. Developing a National Standard/Code of Practice for the Classification of Construction Information in South Africa. Build. Environ. 2005, 40, 1003–1009. [Google Scholar] [CrossRef]
- Marmo, R.; Polverino, F.; Nicolella, M.; Tibaut, A. Building Performance and Maintenance Information Model Based on IFC Schema. Autom. Constr. 2020, 118, 103275. [Google Scholar] [CrossRef]
- Mohana, R.M.; Reddy, C.K.K.; Anisha, P.R.; Murthy, B.V.R. Random Forest Algorithms for the Classification of Tree-Based Ensemble. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Montes, C.; Kapelan, Z.; Saldarriaga, J. Predicting Non-Deposition Sediment Transport in Sewer Pipes Using Random Forest. Water Res. 2021, 189, 116639. [Google Scholar] [CrossRef] [PubMed]
- Naranje, V.; Swarnalatha, R. Design of Tracking System for Prefabricated Building Components using RFID Technology and CAD Model. Procedia Manuf. 2019, 32, 928–935. [Google Scholar] [CrossRef]
- Santos, R.; Costa, A.A.; Silvestre, J.D.; Vandenbergh, T.; Pyl, L. BIM-based Life Cycle Assessment and Life Cycle Costing of an Office Building in Western Europe. Build. Environ. 2020, 169, 106568. [Google Scholar] [CrossRef]
- Solihin, W.; Eastman, C.; Lee, Y.; Yang, D. A Simplified Relational Database Schema for Transformation of BIM Data Into a query-efficient and Spatially Enabled Database. Autom. Constr. 2017, 84, 367–383. [Google Scholar] [CrossRef]
- Tan, T.; Chen, K.; Xue, F.; Lu, W. Barriers to Building Information Modeling (BIM) Implementation in China′s Prefabricated Construction: An Interpretive Structural Modeling (ISM) Approach. J. Clean. Prod. 2019, 219, 949–959. [Google Scholar] [CrossRef]
- Yao, F.; Ji, Y.; Tong, W.; Li, H.; Liu, G. Sensing Technology Based Quality Control and Warning Systems for Sleeve Grouting of Prefabricated Buildings. Autom. Constr. 2021, 123, 103537. [Google Scholar] [CrossRef]
- Yuan, L.; Guo, J.J.; Wang, Q. Automatic Classification of Common Building Materials From 3D Terrestrial Laser Scan Data. Autom. Constr. 2020, 110, 103017. [Google Scholar] [CrossRef]
- Zhang, D.; Lou, S. The Application Research of Neural Network and BP Algorithm in Stock Price Pattern Classification and Prediction. Future Gener. Comput. Syst. 2021, 115, 872–879. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, L. Site Layout Planning for Prefabricated Components Subject to Dynamic and Interactive Constraints. Autom. Constr. 2021, 126, 103693. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure Type | Component Category | Component Name | Component Classification | Component Subdivision |
|---|---|---|---|---|
| Assemble integral concrete frame structure | Precast beam | Precast beam | Precast main beam | |
| Precast secondary beam | ||||
| Precast composite beam | Prestressed composite beam | |||
| Ordinary composite beam | ||||
| Precast lintel | ||||
| Precast slab | Precast slab | Prestressed hollow slab | ||
| Prestressed laminated slab | ||||
| Common laminated slab | ||||
| Steel bar truss laminated slab | ||||
| Prestressed grooved slab | ||||
| Common grooved slab | ||||
| Precast balcony | Fully precast balcony | |||
| Precast balcony slab | ||||
| Precast stair | Precast slab stair | |||
| Precast beam stair | ||||
| Precast single run stair | ||||
| Precast double run stair | ||||
| Precast scissor stair | ||||
| Precast clockwise stair | ||||
| Precast counterclockwise stair | ||||
| Prefabricated canopy | Prefabricated aluminum alloy sunshade canopy | |||
| Prefabricated plastic steel canopy | ||||
| Prefabricated French canopy | ||||
| Prefabricated mobile push–pull canopy | ||||
| Prefabricated shrinkage push–pull canopy | ||||
| Prefabricated air conditioning panel | ||||
| Precast column | Precast column | |||
| Precast wall | Precast exterior wall | Precast non-bearing exterior wall | Precast GRC insulation exterior wall panel | |
| Precast sandwich insulation exterior wall panel | ||||
| Precast single exterior wall panel | ||||
| Precast hanging exterior wall panel | ||||
| Precast side connected exterior wall panel | ||||
| Precast wall hanging panel | Precast fiber cement exterior wall hanging panel | |||
| Precast metal wall hanging panel | ||||
| Precast PVC wall hanging panel | ||||
| Precast solid wood wall hanging panel | ||||
| Precast stone wall hanging panel | ||||
| Precast interior wall panel | Precast non-load bearing interior panel | Precast solid interior wall panel | ||
| Precast hollow interior wall panel | ||||
| Precast integrated door and window wall panel | Precast integrated door and window solid wall panel | |||
| Precast integrated door and window laminated wall panel | ||||
| Precast parapet | ||||
| Prefabricated window | Prefabricated bay window | Prefabricated inner bay window | ||
| Prefabricated exterior bay window | ||||
| Ordinary prefabricated window |
| Code Segment Names | Code Segment System | Code Segment Description |
|---|---|---|
| Life Cycle Stages | P | Produce |
| Life Cycle Stages | C | Construct |
| Life Cycle Stages | O | Operate |
| Structure Type | FS | Frame structure |
| Structure Type | SW | Shear wall structure |
| Structure Type | FW | Frame–shear wall structure |
| Structure Type | SS | Steel structure |
| Structure Type | AP | Adapting piece |
| Component Category | BE | Beam |
| Component Category | SL | Slab |
| Component Category | CO | Column |
| Component Category | WA | Wall |
| Component Category | WI | Window |
| Component Name | 01 | Precast beam |
| Component Name | … | … |
| Component Name | 16 | Ordinary prefabricated window |
| Component Classification | 01 | Precast main beam |
| Component Classification | … | … |
| Component Classification | 40 | Ordinary prefabricated window |
| Attribute Set Name | Pset_CodeOfWall |
|---|---|
| Entity | IFCWall |
| Type Value | Wall/UserDefined |
| Description | Description of the IFCWall entity instance coding information |
| Attribute Name | Attribute Type | Attribute Value Type |
|---|---|---|
| Code | IfcPropertySingleValue | IfcIdentifier |
| Machine Learning | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| RF | 0.99 | 0.99 | 0.99 | 98.9% |
| SVM | 0.95 | 0.96 | 0.95 | 95.7% |
| KNN | 0.90 | 0.90 | 0.88 | 89.5% |
| Code | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| W-00-01-01 | 0.98 | 1.00 | 0.99 | 41 |
| W-00-01-02 | 0.98 | 1.00 | 0.99 | 53 |
| W-01-01-02 | 1.00 | 1.00 | 1.00 | 2 |
| W-10-01-01 | 1.00 | 0.99 | 0.99 | 76 |
| W-10-01-02 | 1.00 | 0.99 | 0.99 | 82 |
| W-10-01-04 | 1.00 | 1.00 | 1.00 | 7 |
| W-10-02-01 | 1.00 | 1.00 | 1.00 | 55 |
| W-10-03-02 | 1.00 | 1.00 | 1.00 | 12 |
| W-10-04-01 | 1.00 | 1.00 | 1.00 | 8 |
| W-10-05-01 | 1.00 | 1.00 | 1.00 | 2 |
| W-10-05-03 | 1.00 | 1.00 | 1.00 | 4 |
| W-11-01-02 | 1.00 | 1.00 | 1.00 | 1 |
| W000101 | W000102 | W010102 | W100101 | W100102 | W100104 | W100201 | W100302 | W100401 | W100501 | W100503 | W110102 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| W000101 | 41 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| W000102 | 0 | 53 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| W010102 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| W100101 | 1 | 0 | 0 | 75 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| W100102 | 0 | 1 | 0 | 0 | 81 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| W100104 | 0 | 0 | 0 | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 0 |
| W100201 | 0 | 0 | 0 | 0 | 0 | 0 | 55 | 0 | 0 | 0 | 0 | 0 |
| W100302 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 |
| W100401 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 |
| W100501 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| W100503 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 |
| W110102 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Xie, Z.; Wang, X.; Niu, M. Automatic Classification and Coding of Prefabricated Components Using IFC and the Random Forest Algorithm. Buildings 2022, 12, 688. https://doi.org/10.3390/buildings12050688
Xu Z, Xie Z, Wang X, Niu M. Automatic Classification and Coding of Prefabricated Components Using IFC and the Random Forest Algorithm. Buildings. 2022; 12(5):688. https://doi.org/10.3390/buildings12050688
Chicago/Turabian StyleXu, Zhao, Zheng Xie, Xuerong Wang, and Mi Niu. 2022. "Automatic Classification and Coding of Prefabricated Components Using IFC and the Random Forest Algorithm" Buildings 12, no. 5: 688. https://doi.org/10.3390/buildings12050688
APA StyleXu, Z., Xie, Z., Wang, X., & Niu, M. (2022). Automatic Classification and Coding of Prefabricated Components Using IFC and the Random Forest Algorithm. Buildings, 12(5), 688. https://doi.org/10.3390/buildings12050688