
Interpretation of Machine-Learning-Based (Black-box) Wind Pressure Predictions for Low-Rise Gable-Roofed Buildings Using Shapley Additive Explanations (SHAP)



 ,
, 
Abstract
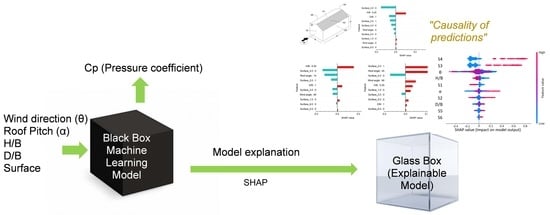
:
1. Introduction
2. Explainable ML
Shapley Additive Explanations (SHAP)
3. Tree-Based ML Algorithms
3.1. Decision Tree Regressor
3.2. XGBoost Regressor
3.3. Extra-Tree Regressor
3.4. LightGBM Regressor
4. Model Performance
Performance Evaluation
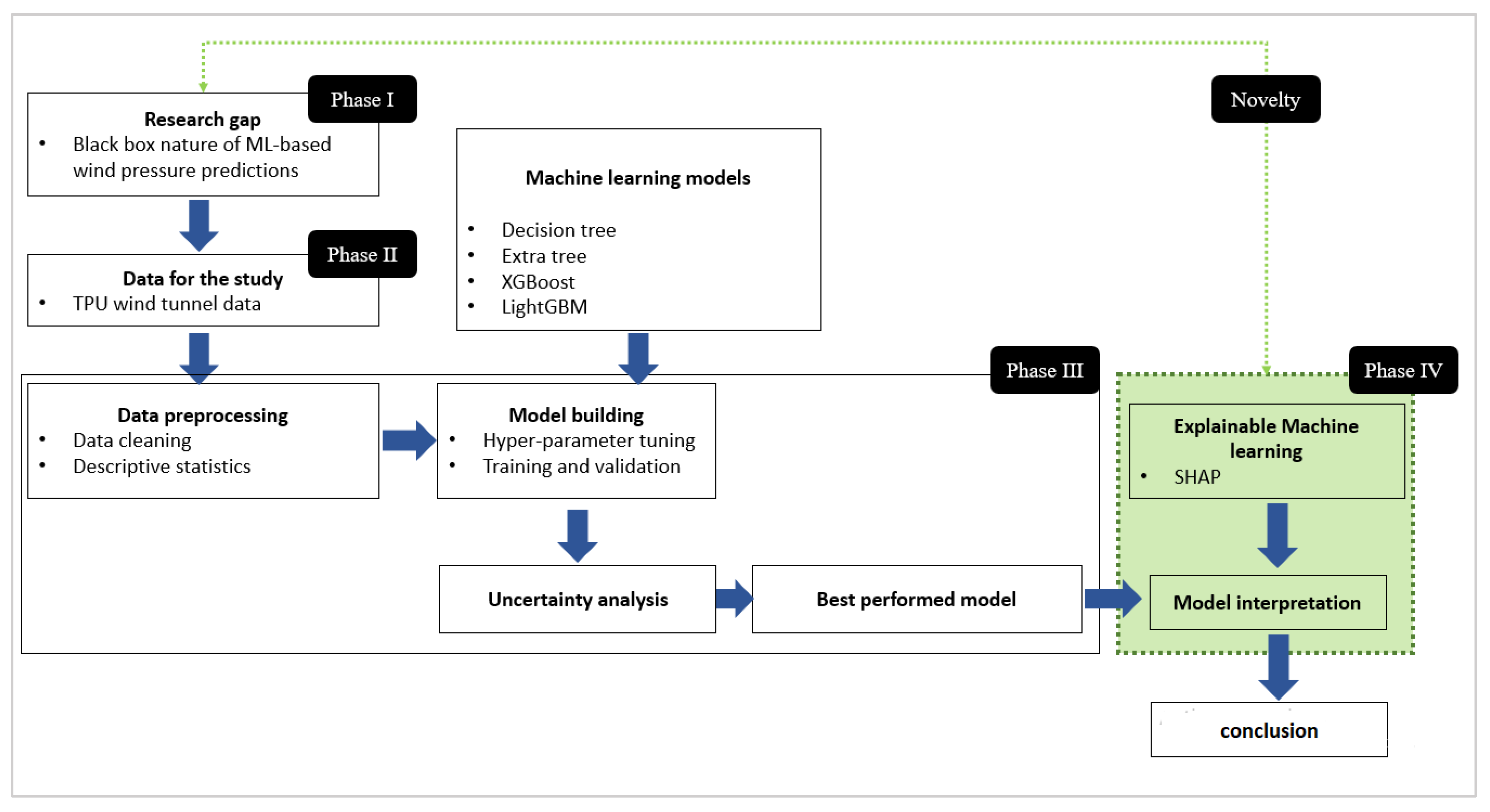
5. Methodology
6. Results and Discussion
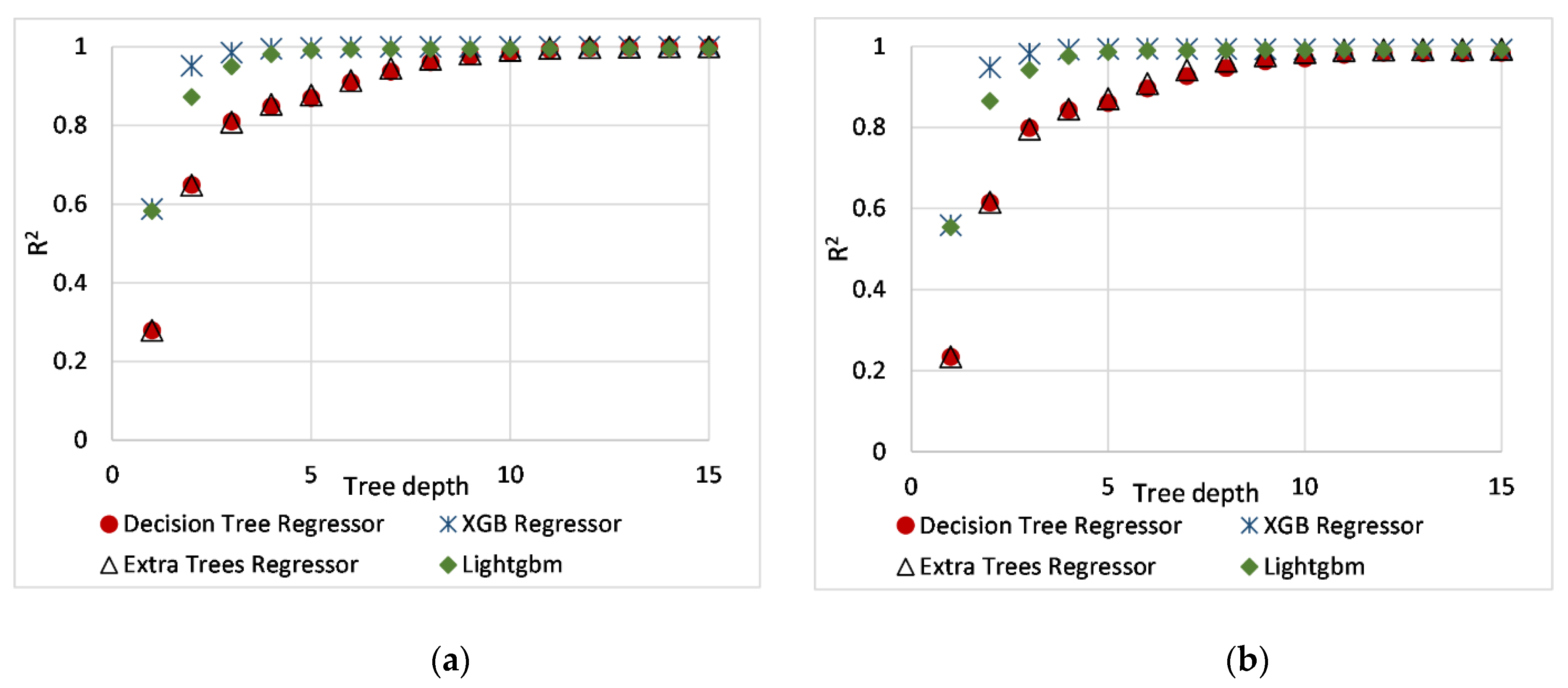
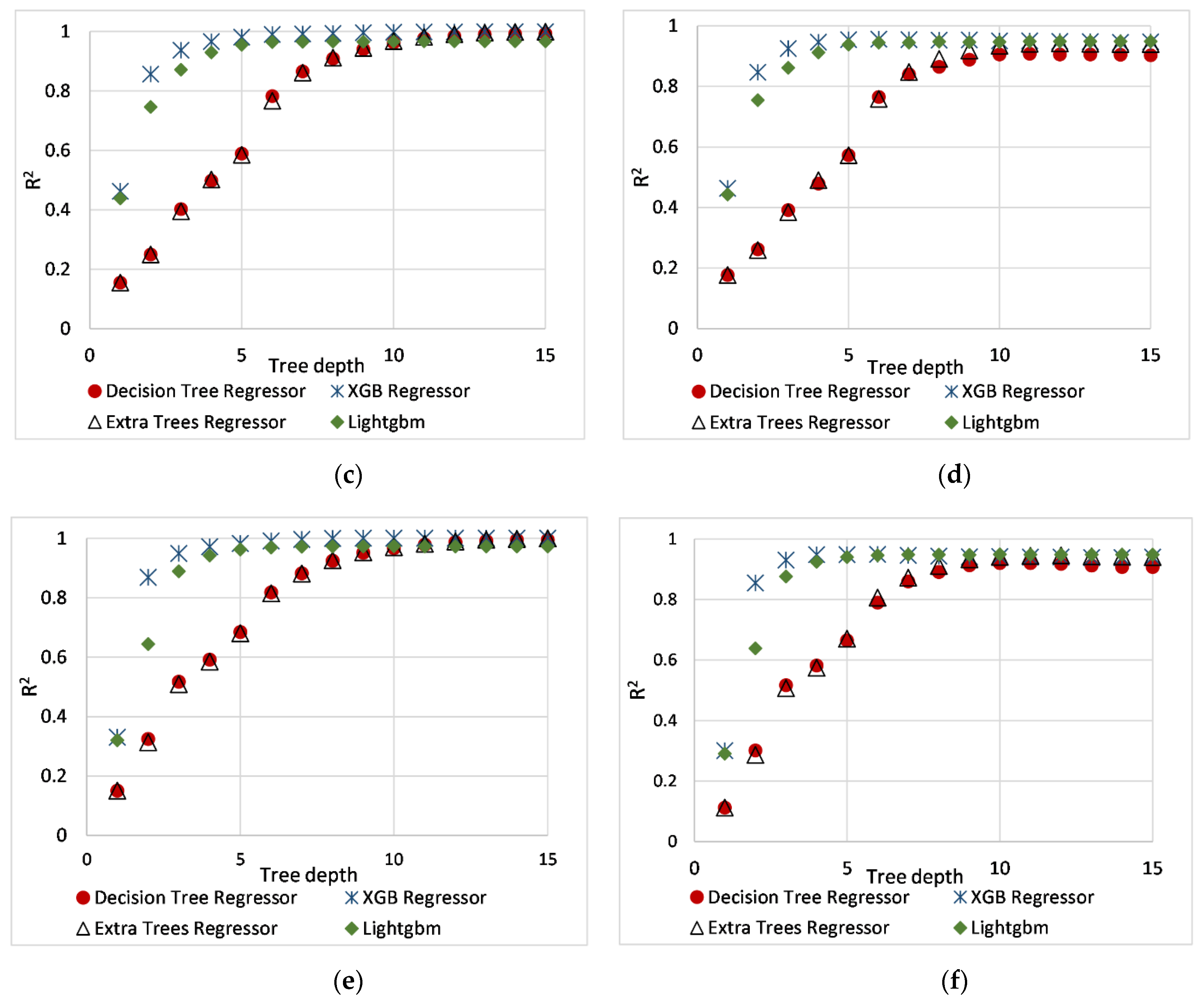
6.1. Hyperparameter Optimization
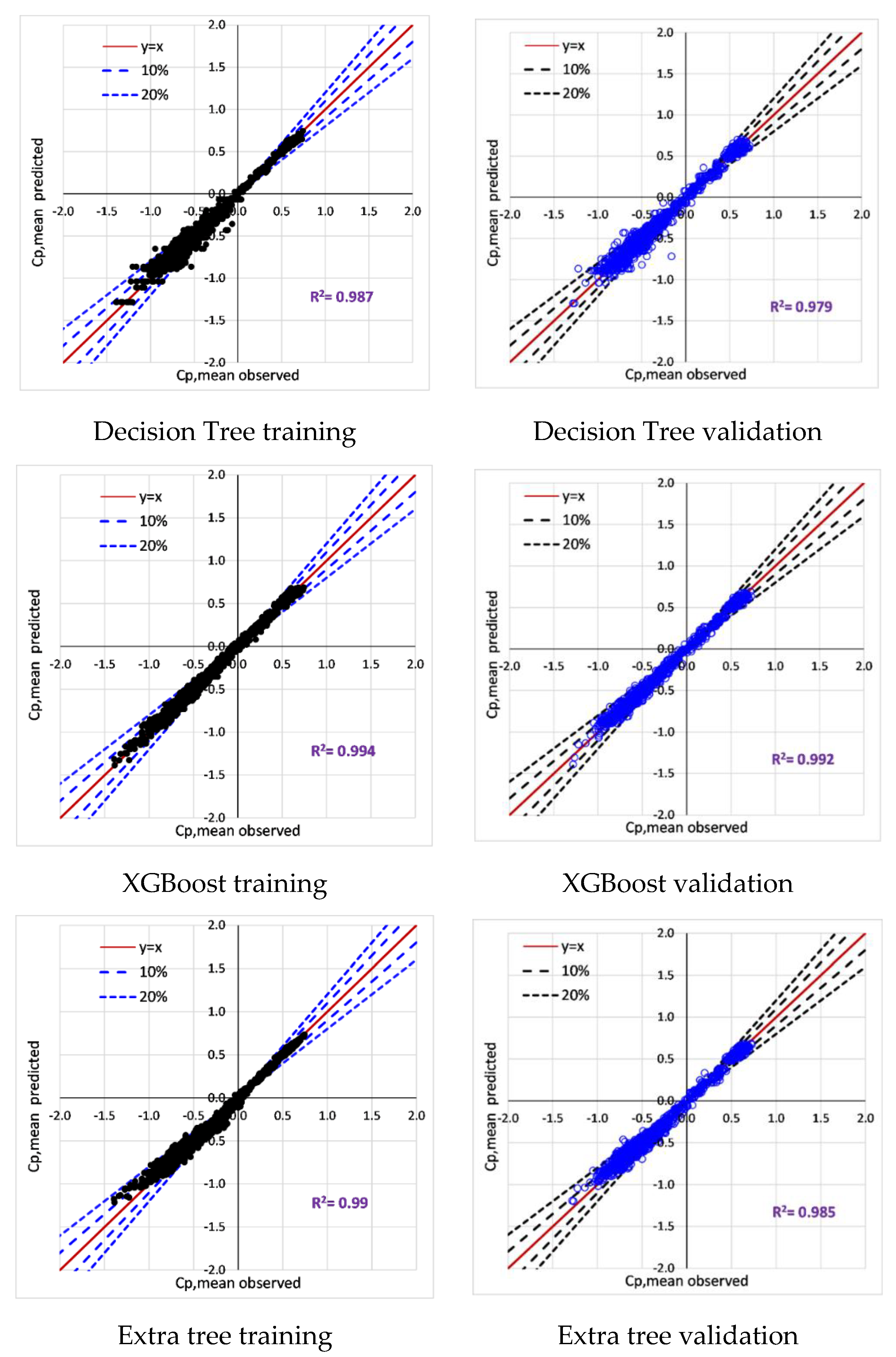
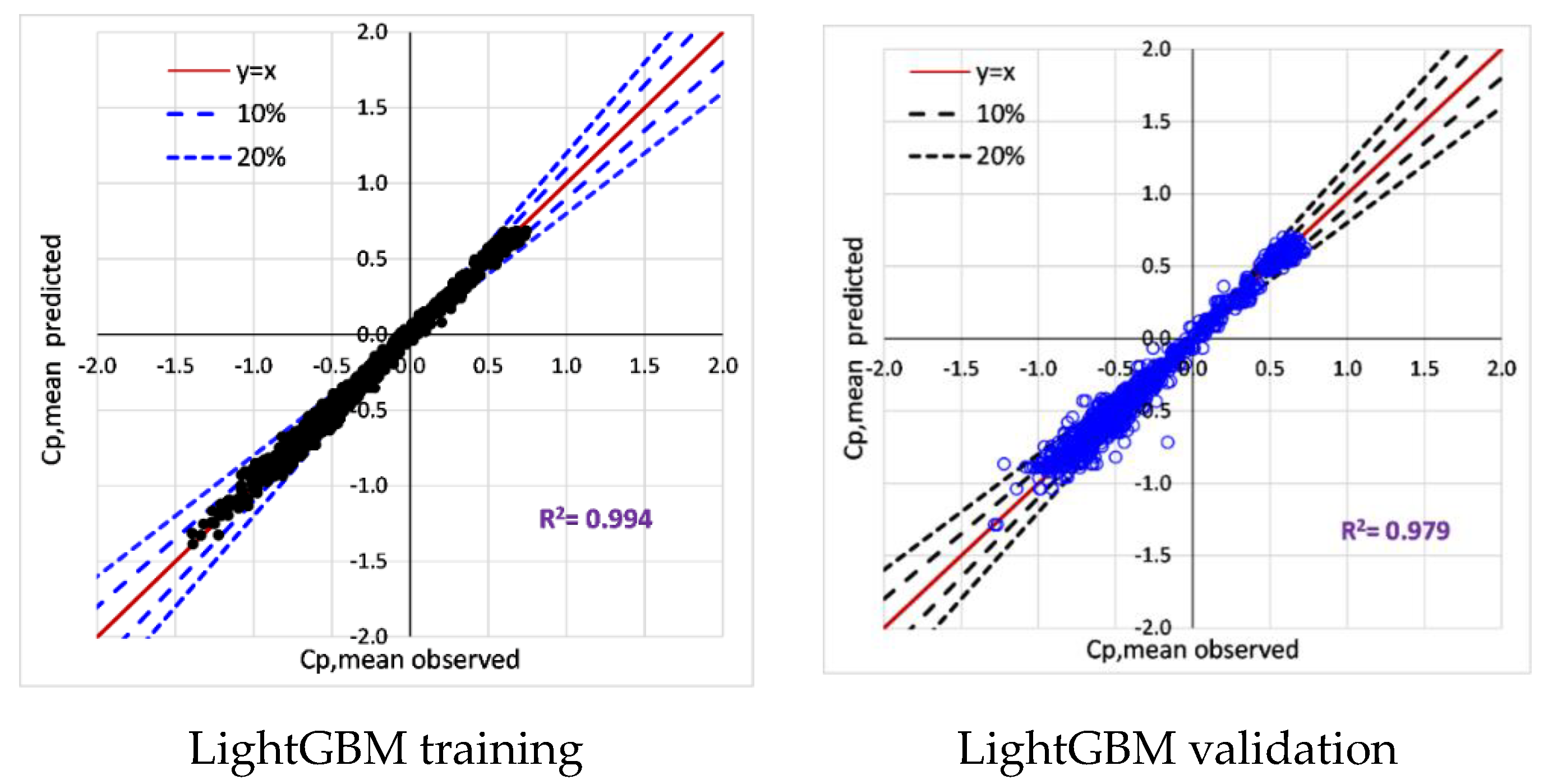
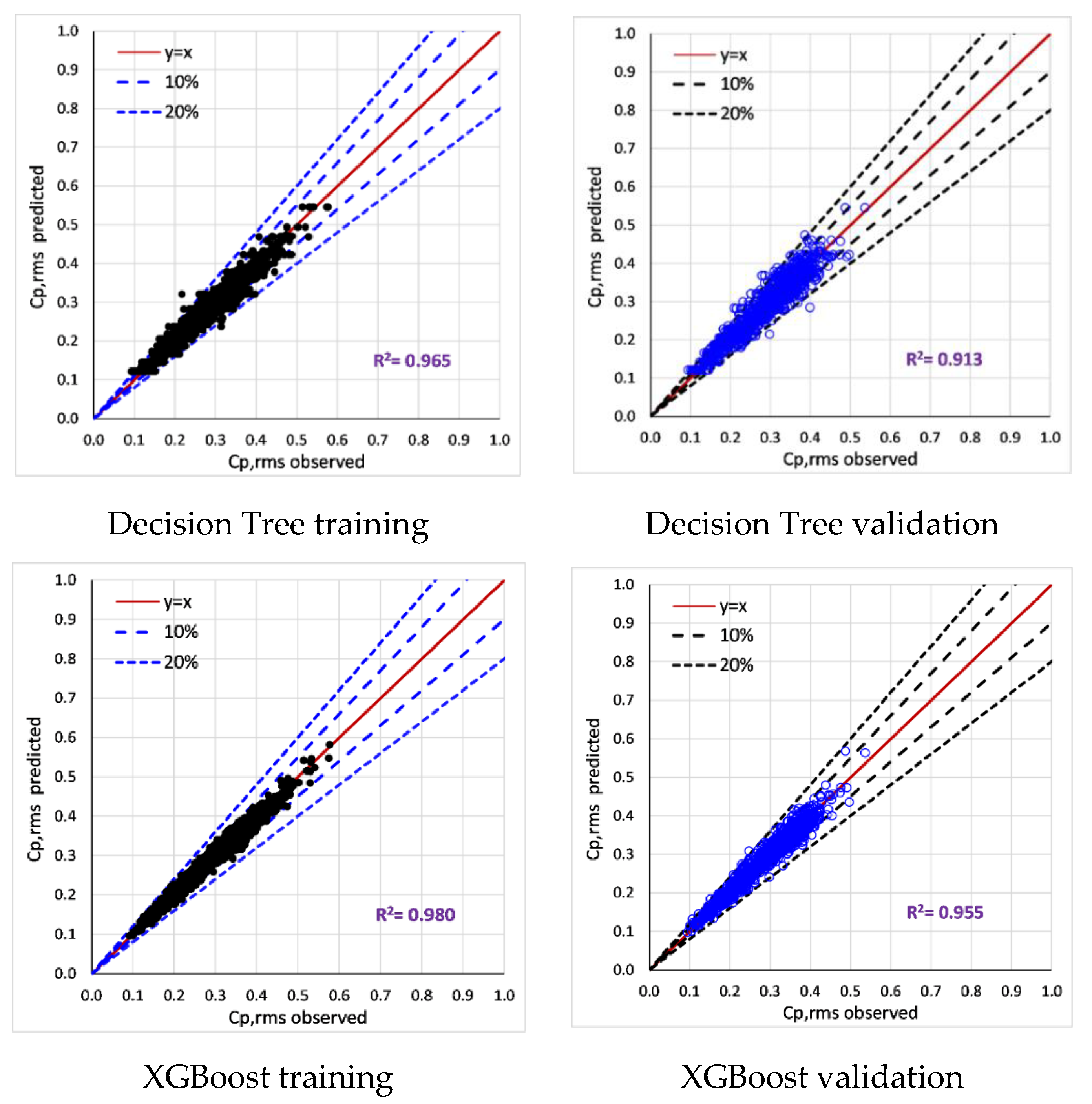
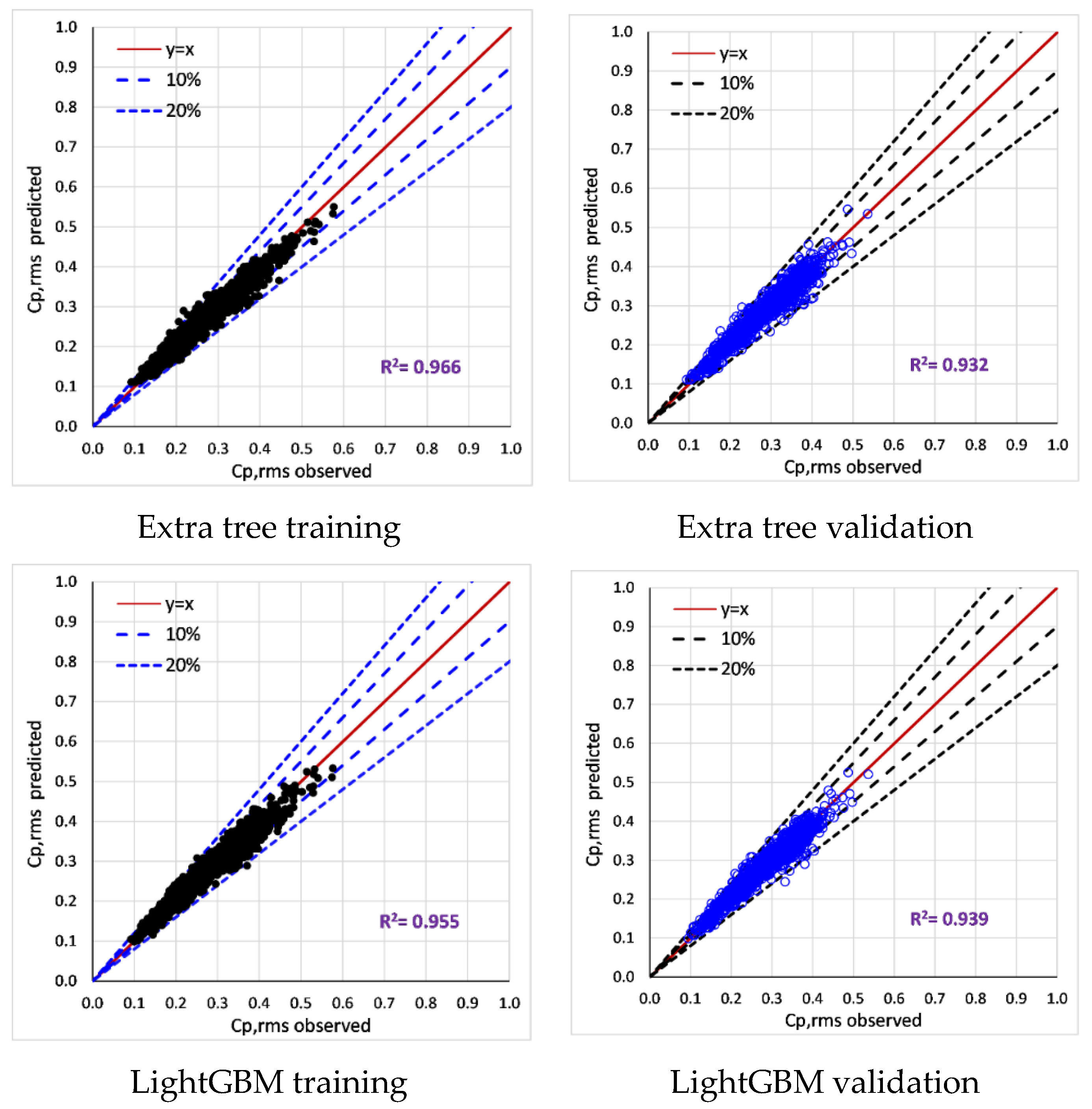
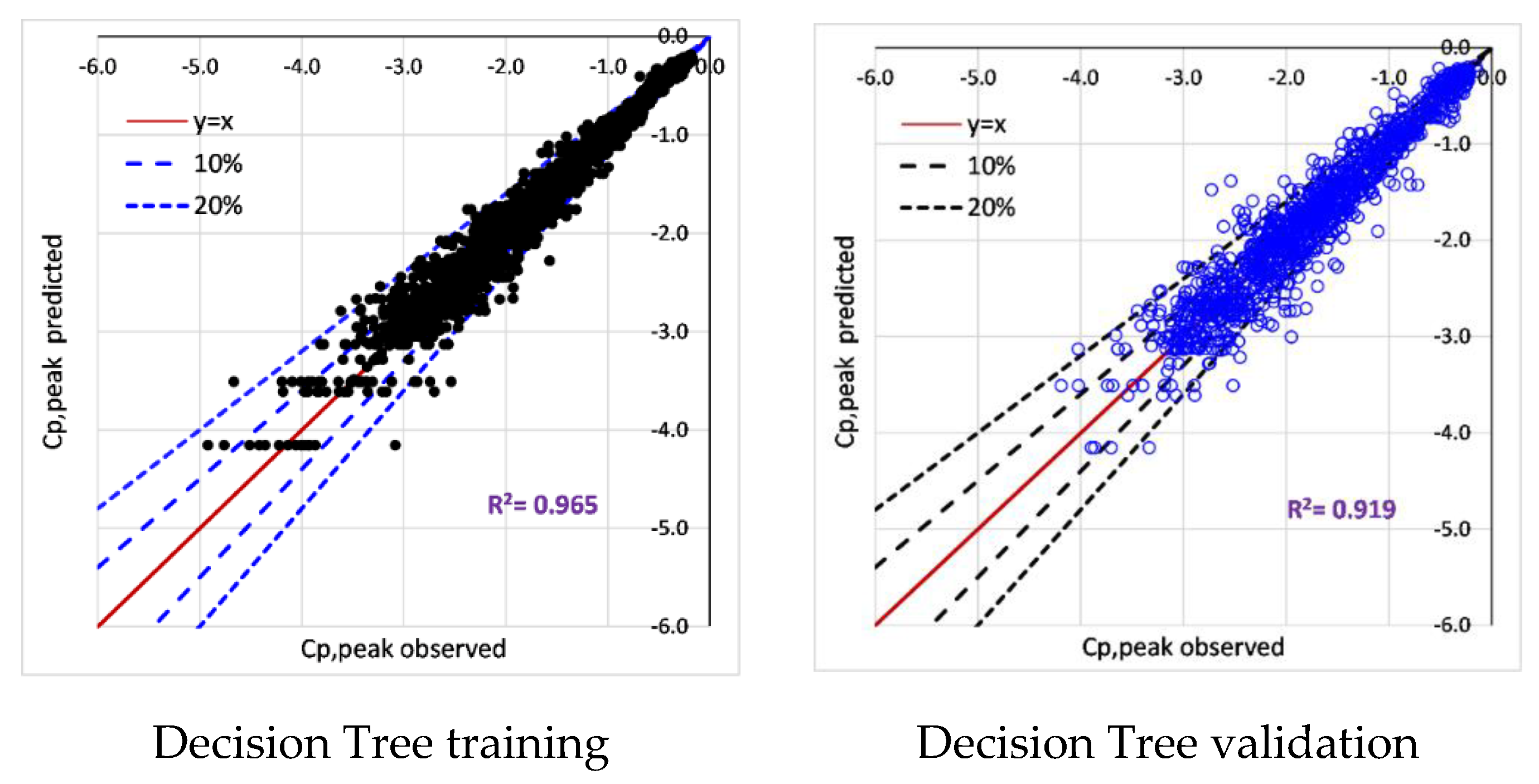
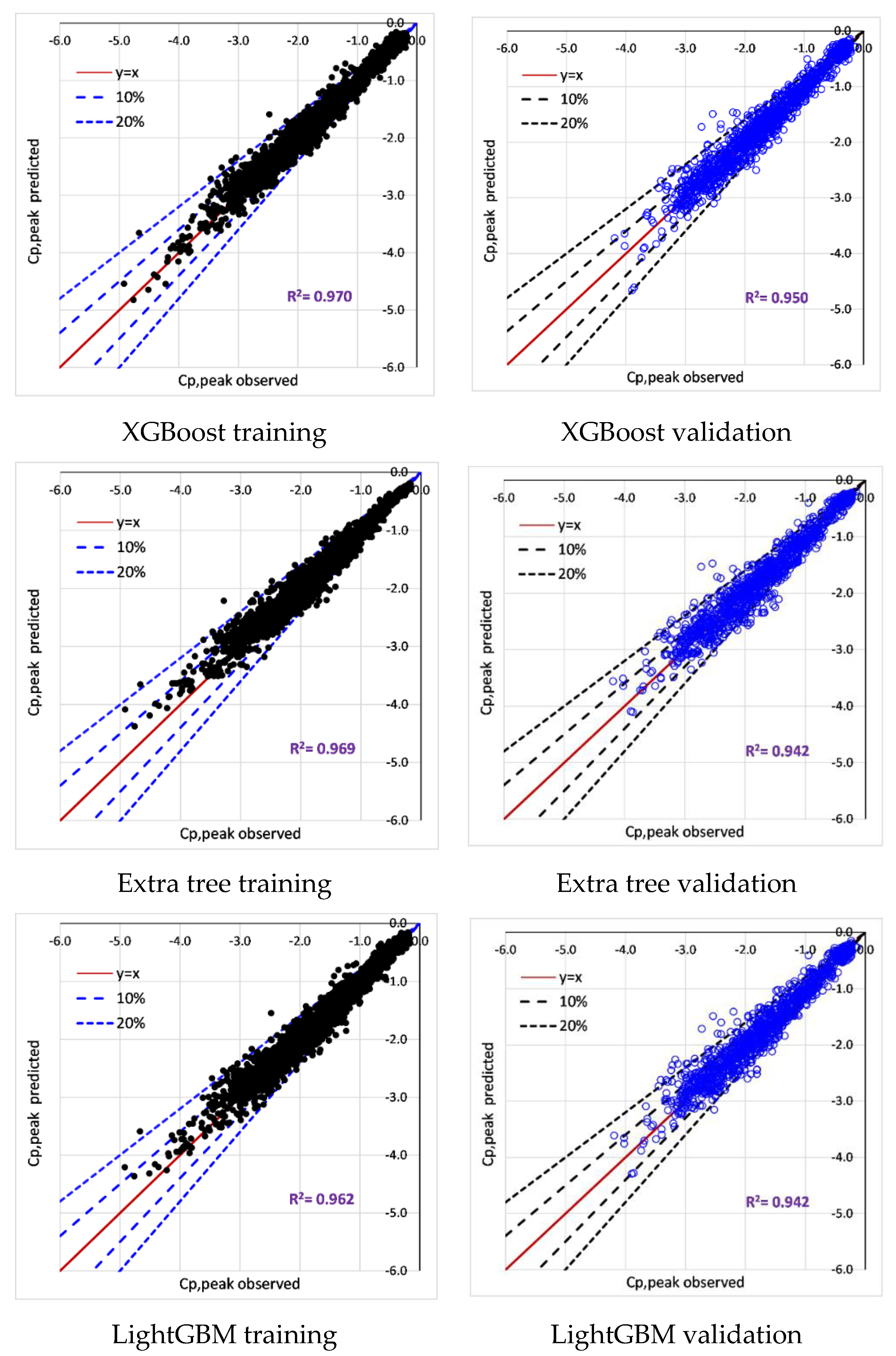
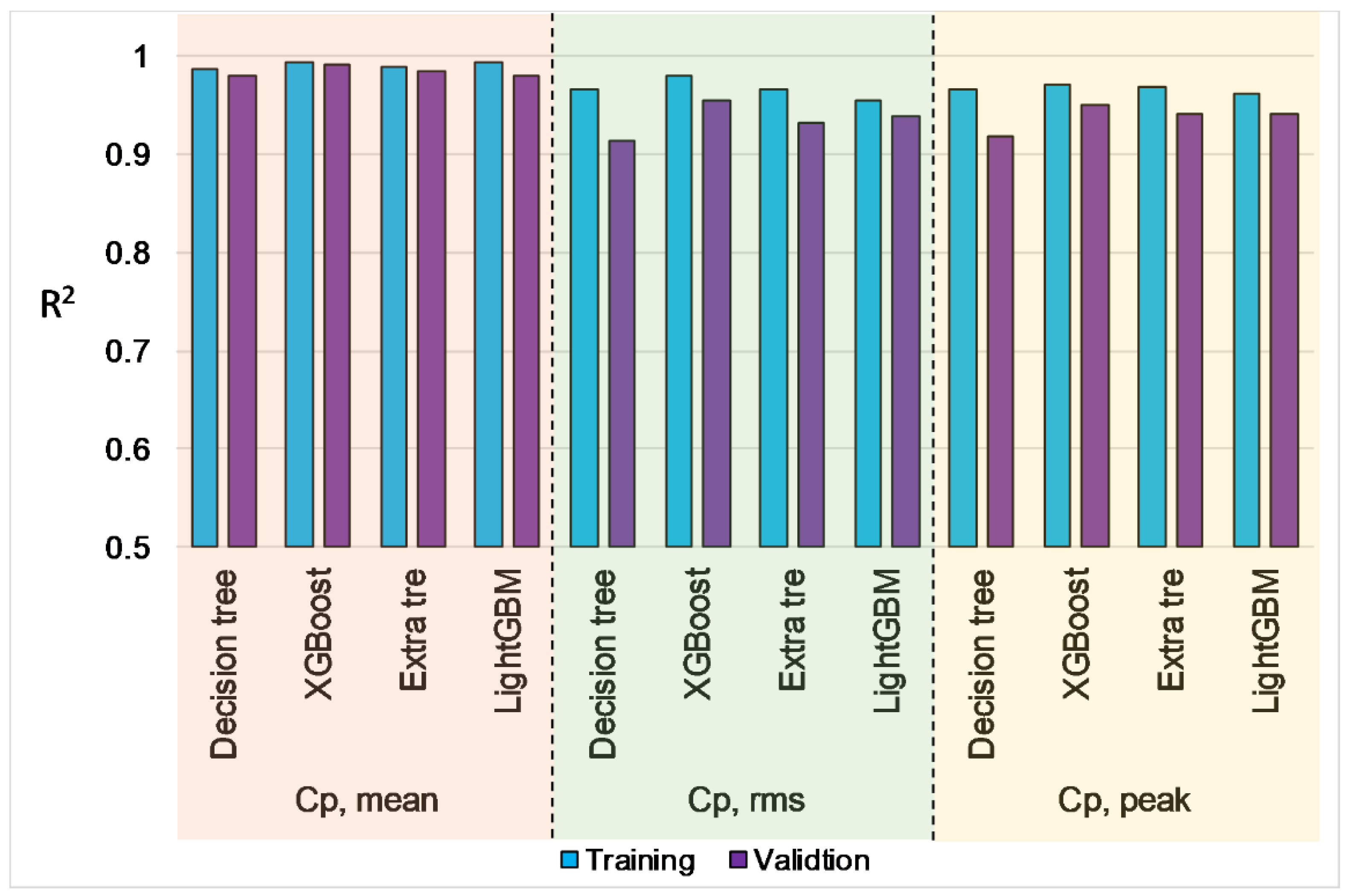
6.2. Training and Validation of Tree-Based Models
6.3. Prediction of Surface-Averaged Pressure Coefficients
6.4. Performance Evaluation of Tree-Based Models
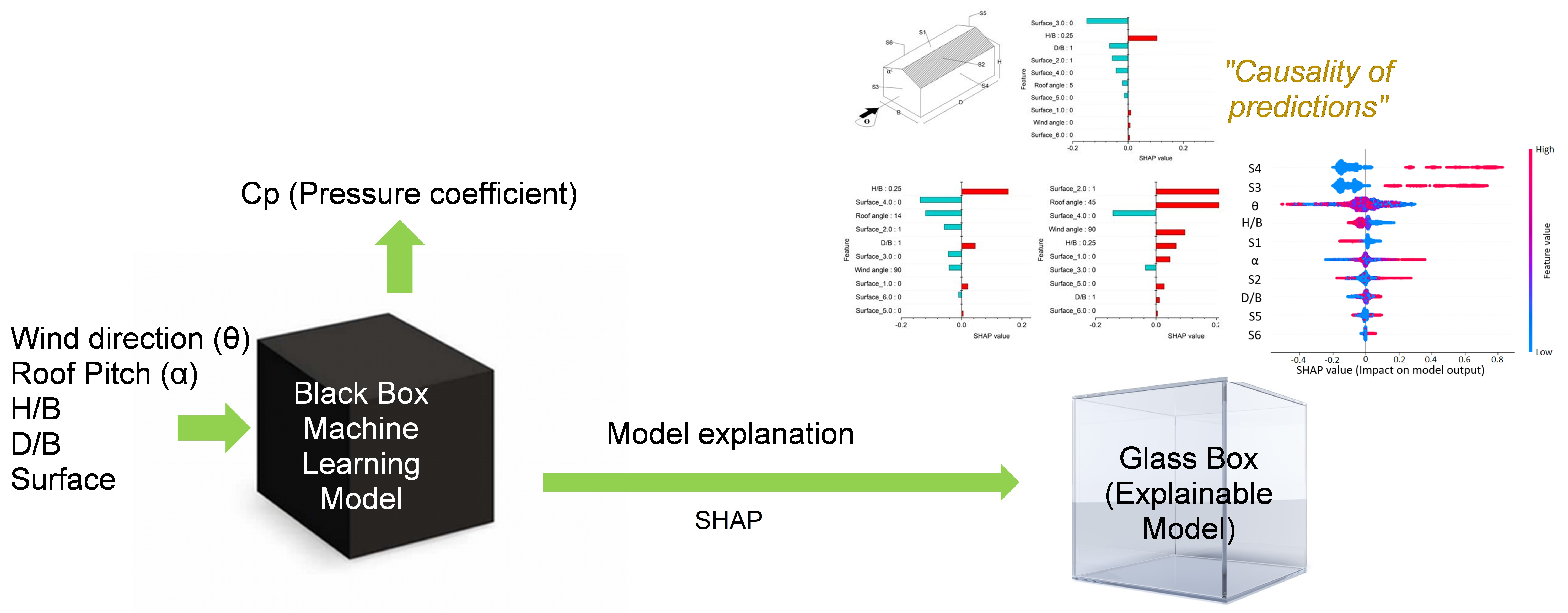
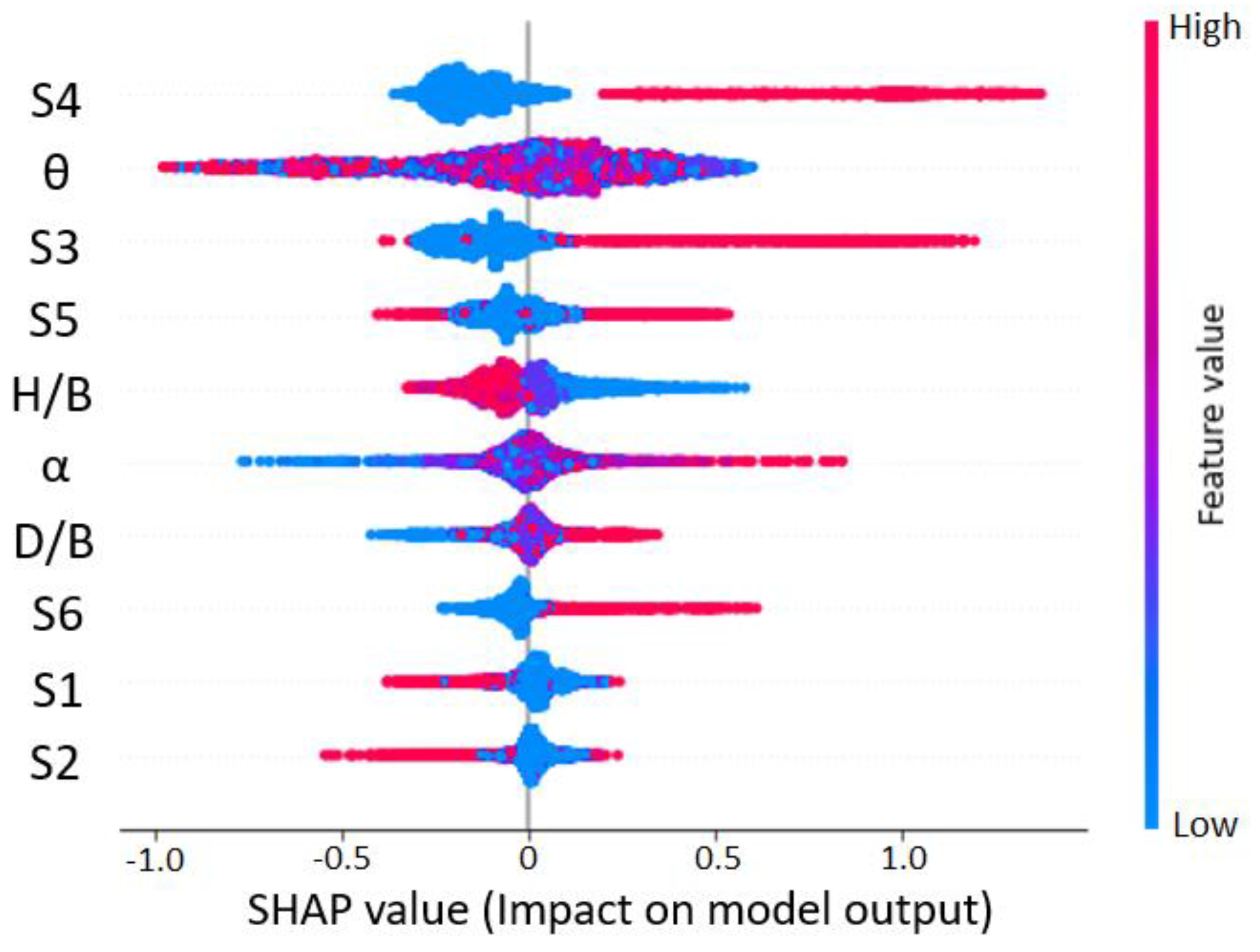
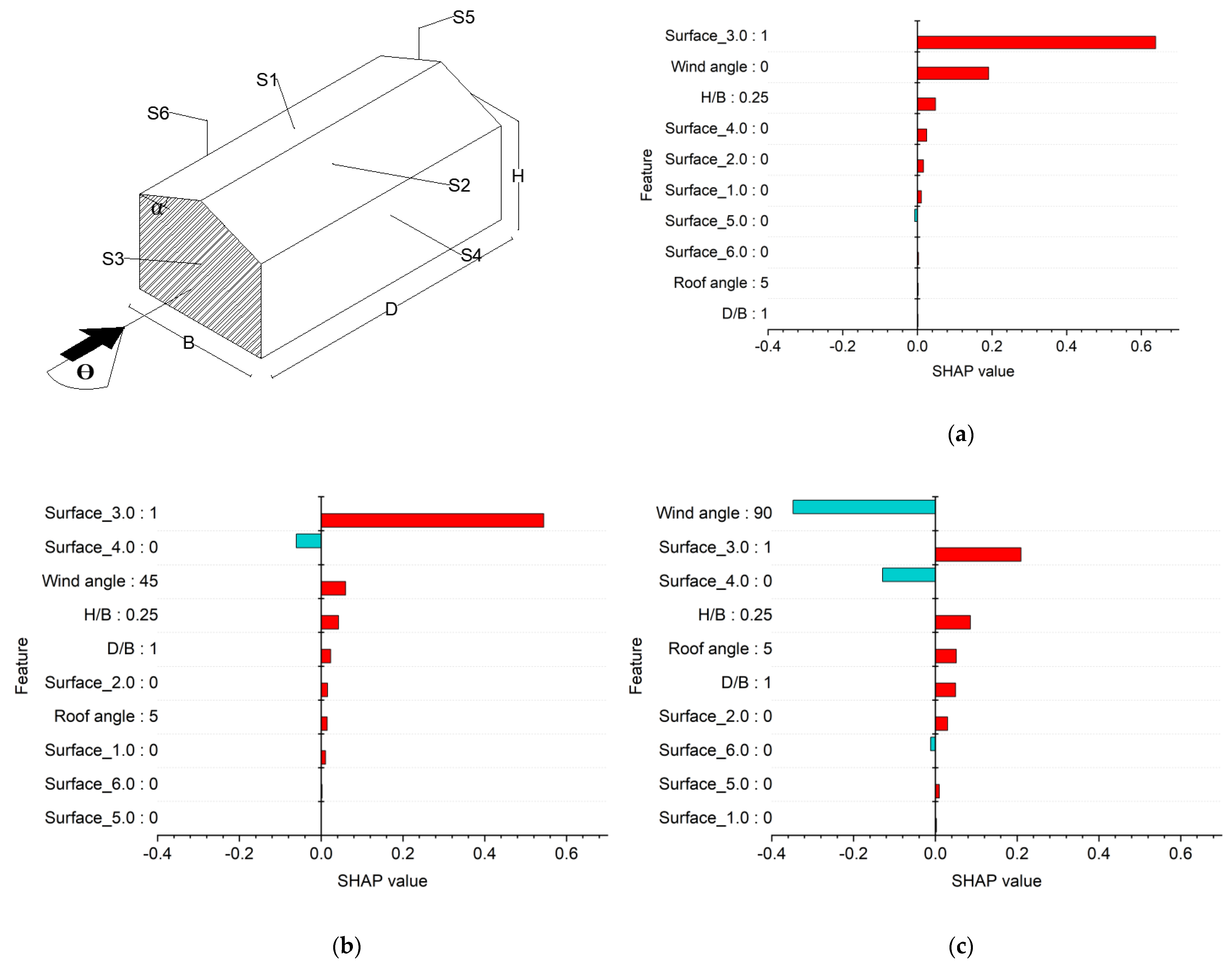
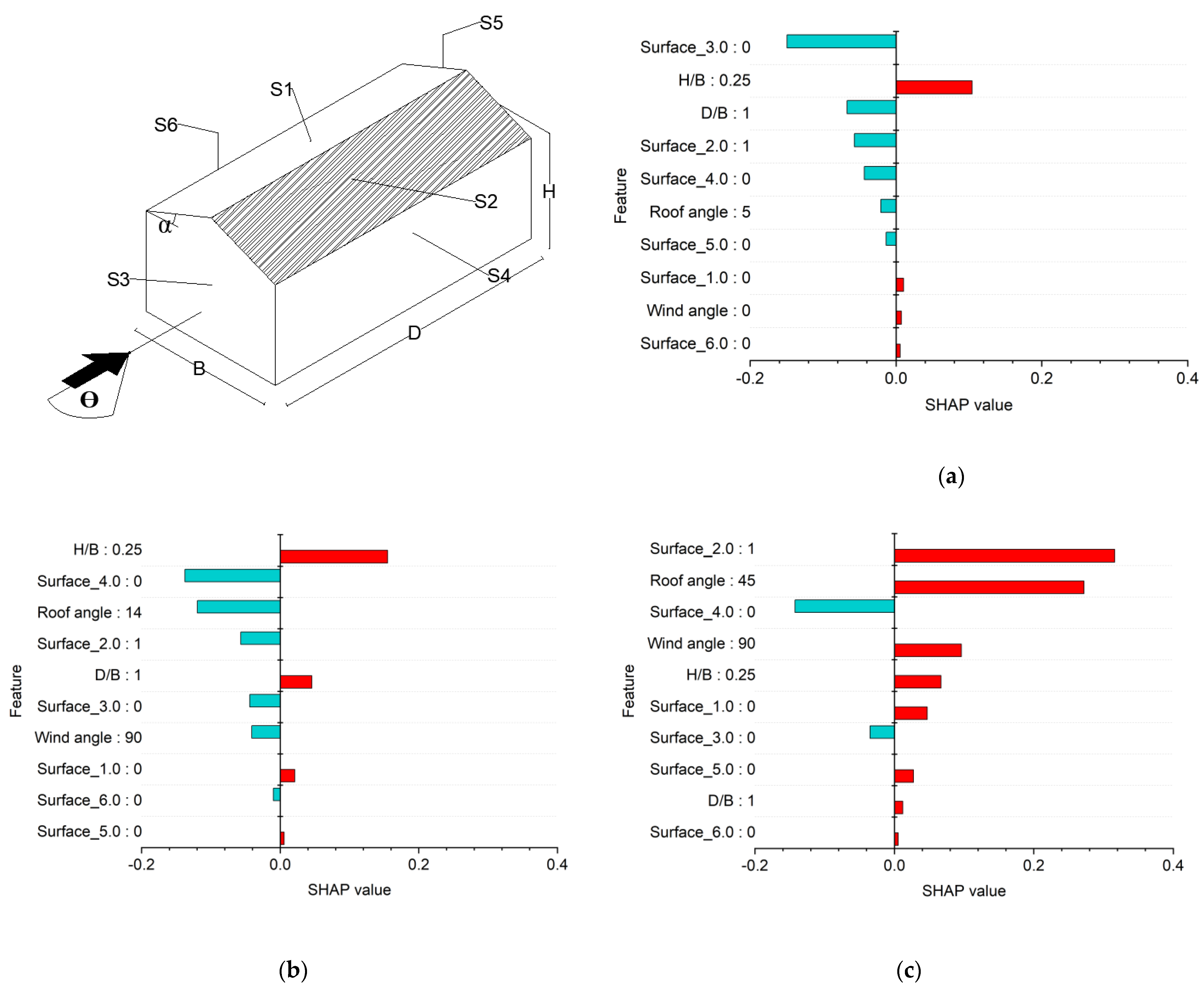
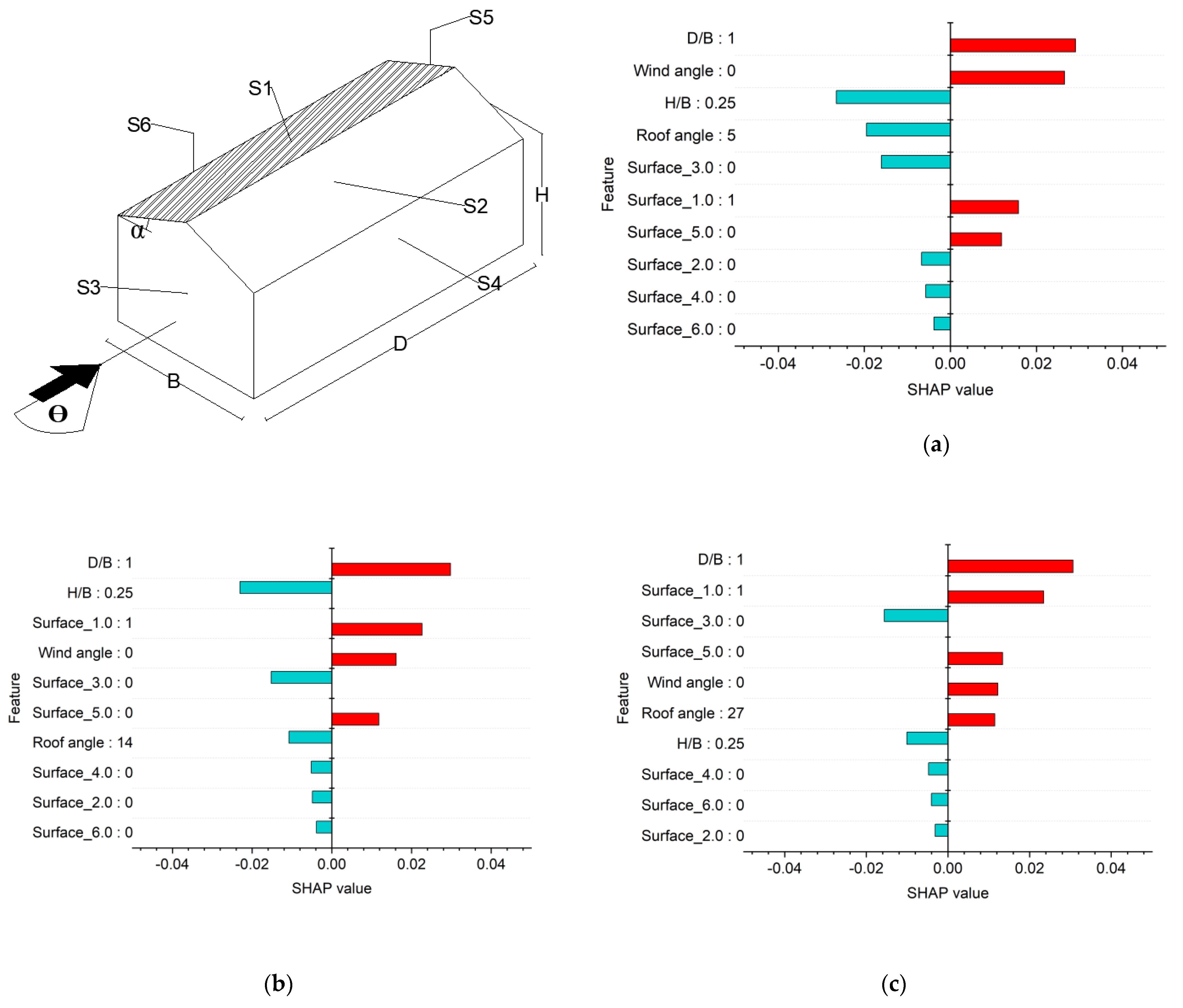
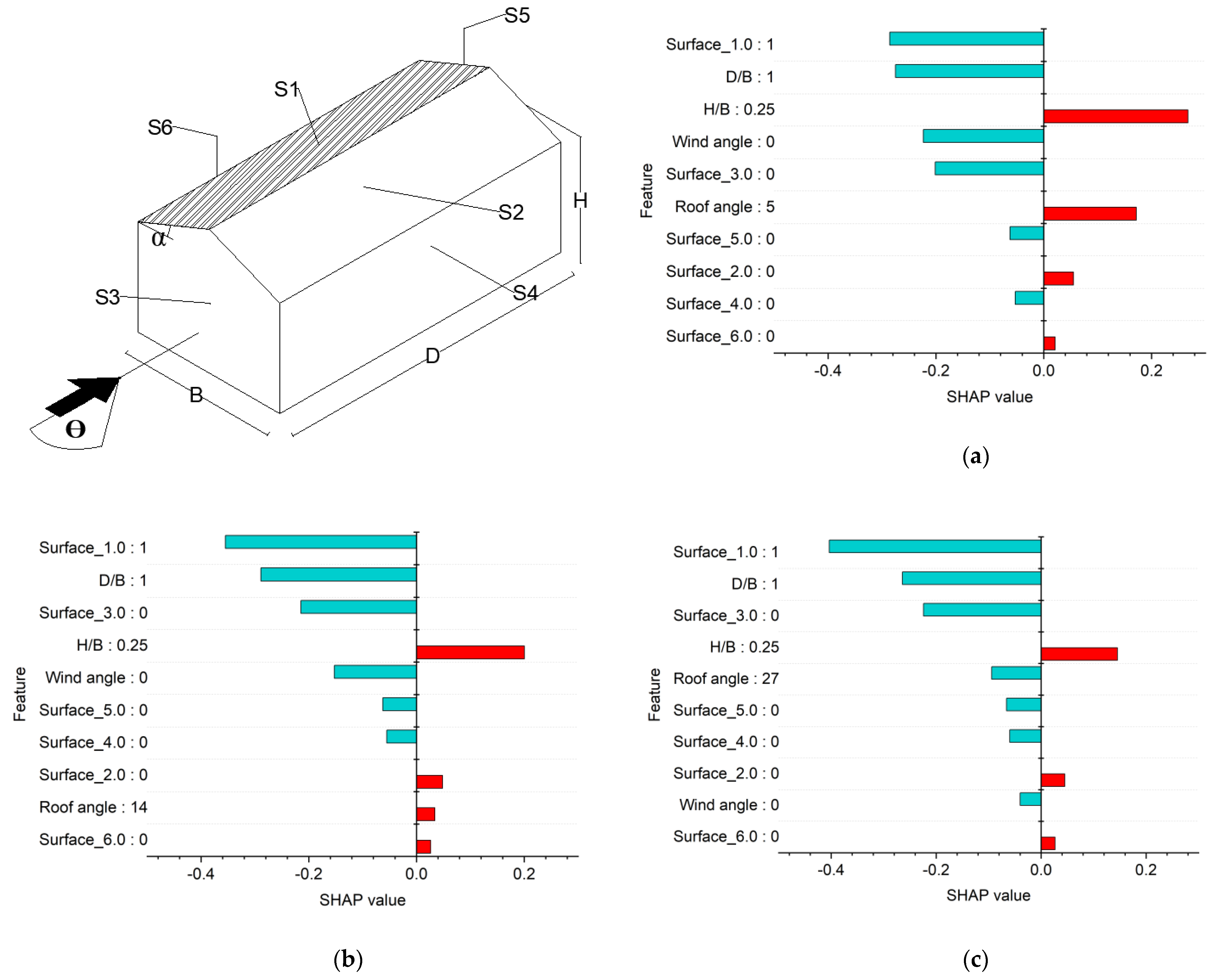
7. Model Explanations
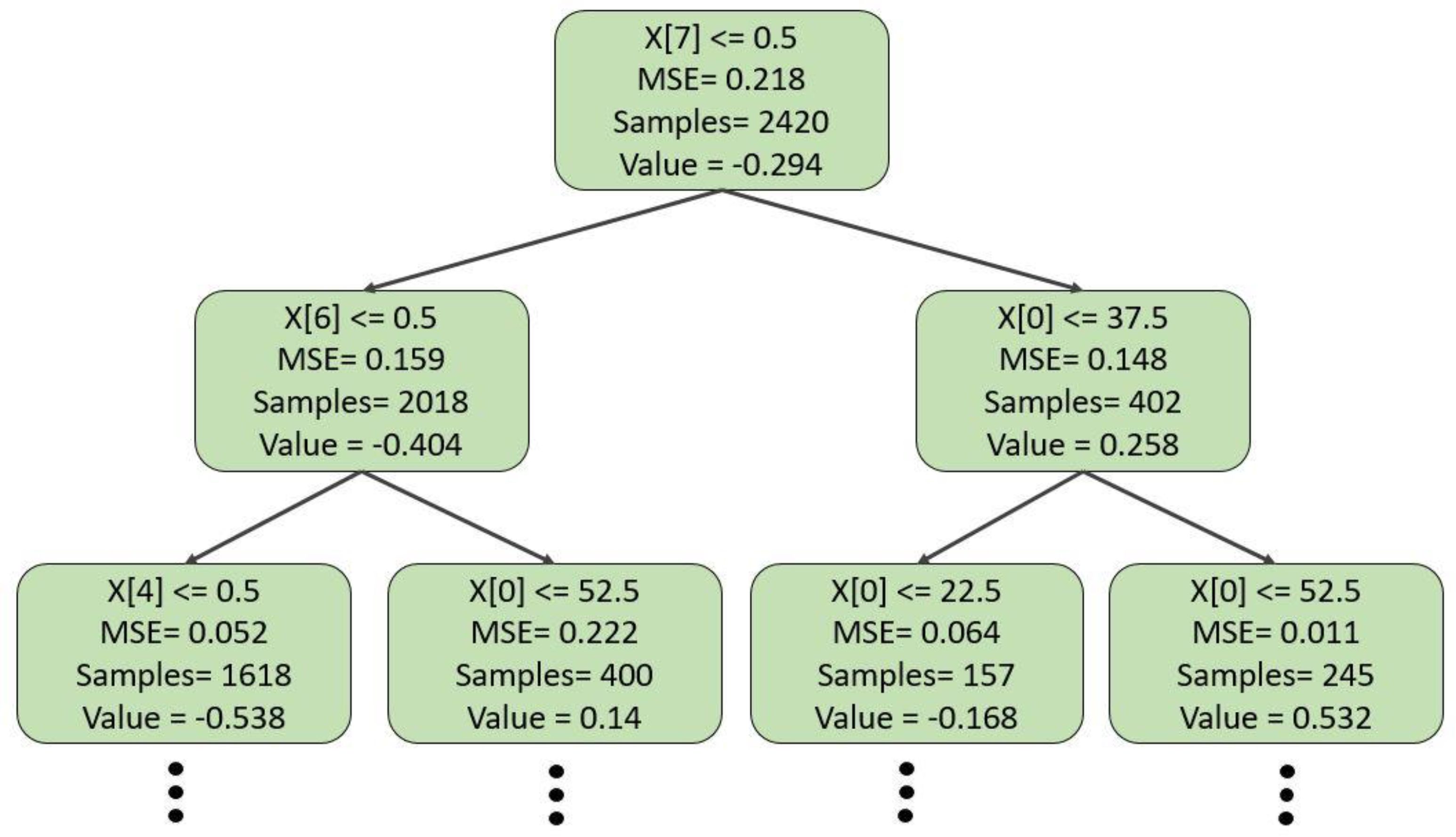
7.1. Model-Based (Intrinsic) Explanations
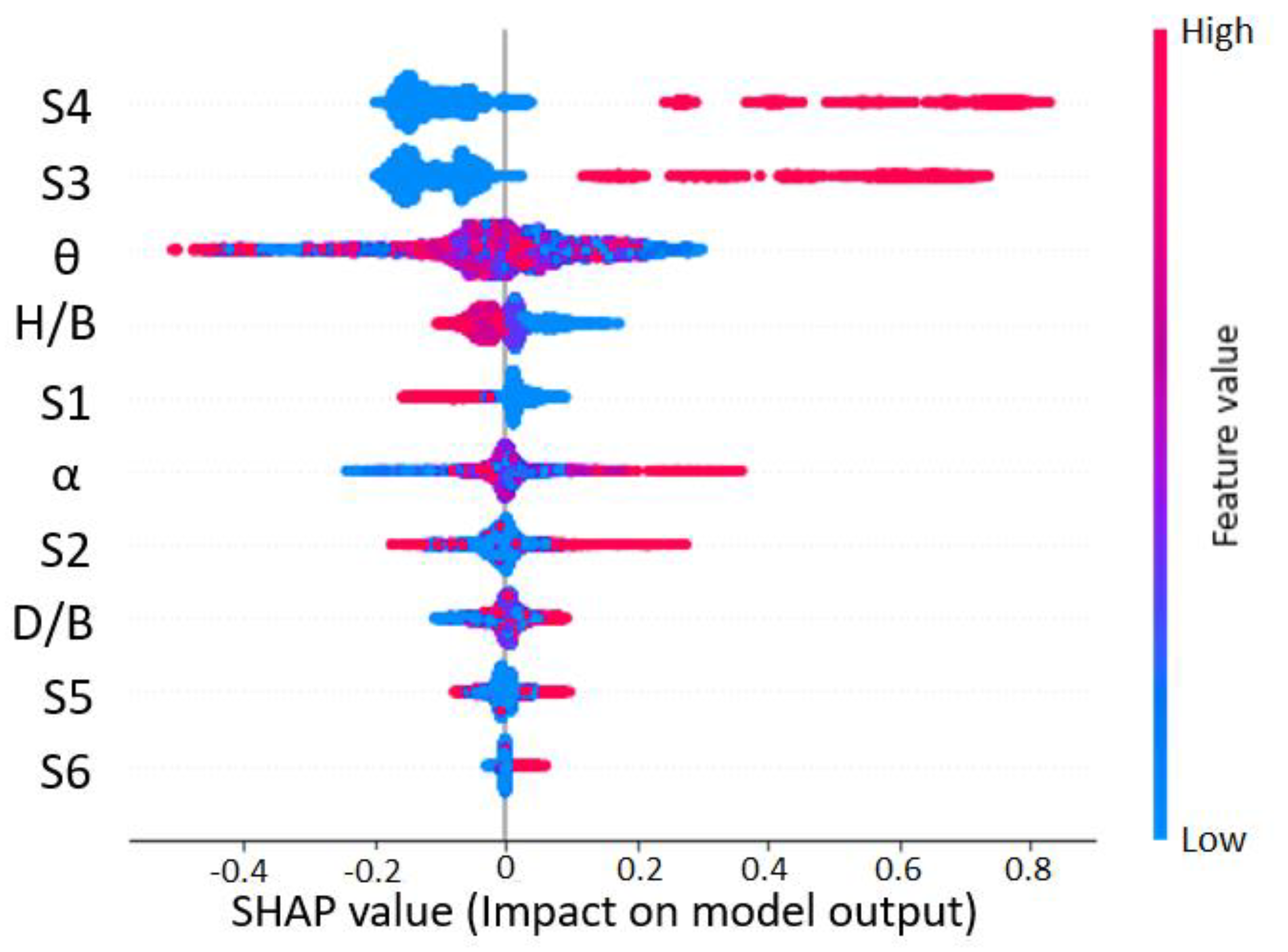
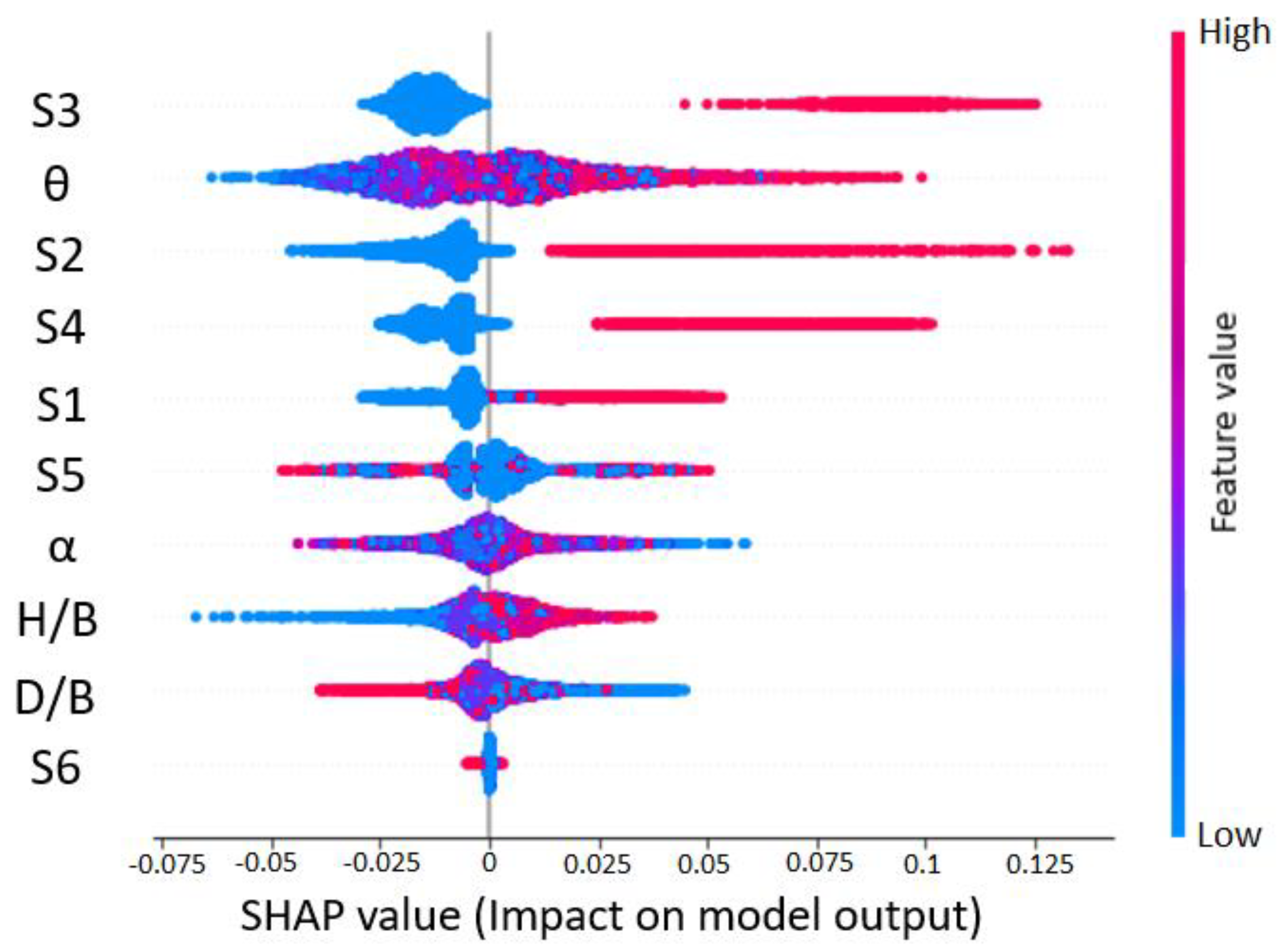
7.2. SHAP Explanations
8. Conclusions
- Ensemble methods such as XGBoost and Extra tree are more accurate in estimating surface averaged pressure coefficients than a Decision Tree and LightGBM model. However, decision tree and extra-tree models require a deeper tree structure to achieve good accuracy. Despite the complexity at higher depths, the decision-tree structure is self-explainable. However, complex tree formations (ensemble method: XGBoost, Extra Tree, LightgGBM) require a post hoc explanation method.
- All tree-based models (Decision Tree, Extra tree, XGBoost, LightGBM) accurately predict surface-averaged wind pressure coefficients (Cp,mean, Cp,rms, Cp,peak). For example, tree-based models reproduce surface averaged mean, fluctuating, and peak pressure coefficients (R > 0.955). XGBoost model achieved the best performance (R > 0.974).
- SHAP explanations convinced predictions to adhere to the elementary flow physics of wind engineering. This provides causality of predictions, the importance of features, and interaction between the features to assist the decision-making process. The knowledge offered by SHAP is highly imperative to optimize the features at the design stage. Further, combining a post hoc explanation with ML provides confidence to its end-user on “how a particular instance is predicted”.
9. Limitations of the Study
- According to the obtained TPU data set, the pressure tap configuration is not uniform for each geometry configuration. Therefore, investigating point pressure predictions is difficult. Further, the data set has a limited number of features. Hence, we suggest a comprehensive study to examine the performance of explainable ML, addressing these drawbacks. Adding more parameters would assist in understanding complex behaviors of external wind pressure around low-rise buildings. For example, the external pressure distribution strongly depends on wind velocity and turbulence intensity [86,87]. Therefore, the authors suggest future studies, incorporating these two parameters.
- We used SHAP explanations for the model interpretations. However, there are many explanatory models available to perform the same task. Each model might result in a unique feature importance value. For example, Moradi and Samweld [62] explained the difference between LIME and SHAP on how those models explain an instance. Therefore, a separate study can be conducted using several interpretable (post hoc) models to evaluate the explanations. In addition, we recommend comparing intrinsic explanations to investigate the effect of model building and the training process of ML models.
- The present study chooses tree-based ordinary and ensemble methods to predict wind pressure coefficients. As highlighted in the introduction section, many authors have employed sophisticated models (Neural Network Architectures: ANN, DNN) to predict wind pressure characteristics. Given their opinion, we suggest combining interpretation methods with such advanced methods to examine the difference between different ML models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ABL | Atmospheric Boundary Layer | LSTM | Long short term memory |
| AI | Artificial Intelligence | ML | Machine learning |
| ANN | Artificial Neural network | MAE | Mean Absolute Error |
| CFD | Computational Fluid Dynamics | MSE | Mean Square Error |
| Cp,mean | Surface-averaged mean pressure coefficient | NIST | National Institute of Standards and Technology |
| Cp,rms | Surface-averaged fluctuation pressure coefficient | R | Coefficient of Correlation |
| Cp,peak | Surface-averaged peak pressure coefficient | R2 | Coefficient of Determination |
| DAD | Database Assist Design | RISE | Real-time Intelligence with Secure Explainable |
| DNN | Deep neural network | RMSE | Root Mean Square Error |
| DeepLIFT | Deep Learning Important FeaTures | SHAP | Shapley Additive explainations |
| GAN | Generative adversarial network | TPU | Tokyo Polytechnic University |
| LIME | Local Interpretable Model-Agnostic Explanations |
Appendix A
- Criterion: The function to measure the quality of a split. Supported criteria are “mse” for the mean squared error.
- Splitter: The strategy used to choose the split at each node. Supported strategies are “best” to choose the best split and “random” to choose the best random split.
- Minimum_samples_split: The minimum number of samples required to split an internal node.
- Minimum sample leaf: The minimum number of samples required to be at a leaf node.
- Random_state: Controls the randomness of the estimator. The features are always randomly permuted at each split, even if “splitter” is set to “best”.
- Maximum_depth: The maximum depth of the tree. If none, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.
- Maximum features: The number of features to consider when looking for the best split.
- Minimum impurity decrease: A node will be split if this split induces a decrease of the impurity greater than or equal to this value.
- CC alpha: Complexity parameter used for Minimal Cost-Complexity Pruning.
- Bootstrap: Whether bootstrap samples are used when building trees. If False, the whole dataset is used to build each tree.
- Number of estimators: The number of trees in the forest.
- Number of jobs: The number of jobs to run in parallel.
- Gamma: Minimum loss reduction required to make a further partition on a leaf node of the tree. The larger gamma is, the more conservative the algorithm will be; range: [0, ∞].
- Reg_Alpha: L1 regularization term on weights. Increasing this value will make model more conservative.
- Learning_rate: Learning rate shrinks the contribution of each tree by “learning rate”.
- Base score: The initial prediction score of all instances, global bias.
References
- Fouad, N.S.; Mahmoud, G.H.; Nasr, N.E. Comparative study of international codes wind loads and CFD results for low rise buildings. Alex. Eng. J. 2018, 57, 3623–3639. [Google Scholar] [CrossRef]
- Franke, J.; Hellsten, A.; Schlunzen, K.H.; Carissimo, B. The COST 732 Best Practice Guideline for CFD simulation of flows in the urban environment: A summary. Int. J. Environ. Pollut. 2011, 44, 419–427. [Google Scholar] [CrossRef]
- Liu, S.; Pan, W.; Zhao, X.; Zhang, H.; Cheng, X.; Long, Z.; Chen, Q. Influence of surrounding buildings on wind flow around a building predicted by CFD simulations. Build. Environ. 2018, 140, 1–10. [Google Scholar] [CrossRef]
- Parente, A.; Longo, R.; Ferrarotti, M. Turbulence model formulation and dispersion modelling for the CFD simulation of flows around obstacles and on complex terrains. In CFD for Atmospheric Flows and Wind Engineering; Von Karman Institute for Fluid Dynamics: Rhode Saint Genèse, Belgium, 2019. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Malkawi, A. Defining the Influence Region in neighborhood-scale CFD simulations for natural ventilation design. Appl. Energy 2016, 182, 625–633. [Google Scholar] [CrossRef]
- Rigato, A.; Chang, P.; Simiu, E. Database-assisted design, standardization and wind direction effects. J. Strucutral Eng. ASCE 2001, 127, 855–860. [Google Scholar] [CrossRef]
- Simiu, E.; Stathopoulos, T. Codification of wind loads on low buildings using bluff body aerodynamics and climatological data base. J. Wind Eng. Ind. Aerodyn. 1997, 69, 497–506. [Google Scholar] [CrossRef]
- Whalen, T.; Simiu, E.; Harris, G.; Lin, J.; Surry, D. The use of aerodynamic databases for the effective estimation of wind effects in main wind-force resisting systems: Application to low buildings. J. Wind. Eng. Ind. Aerodyn. 1998, 77, 685–693. [Google Scholar] [CrossRef]
- Swami, M.V.; Chandra, S. Procedures for Calculating Natural Ventilation Airflow Rates in Buildings. ASHRAE Res. Proj. 1987, 130. Available online: http://www.fsec.ucf.edu/en/publications/pdf/fsec-cr-163-86.pdf (accessed on 1 April 2022).
- Muehleisen, R.T.; Patrizi, S. A new parametric equation for the wind pressure coefficient for low-rise buildings. Energy Build. 2013, 57, 245–249. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Kotsiantis, S.; Zaharakis, I.; Pintelas, P. Supervised Machine Learning: A Review of Classification Techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Sun, H.; Burton, H.V.; Huang, H. Machine learning applications for building structural design and performance assessment: State-of-the-art review. J. Build. Eng. 2021, 33, 101816. [Google Scholar] [CrossRef]
- Fu, J.Y.; Li, Q.S.; Xie, Z.N. Prediction of wind loads on a large flat roof using fuzzy neural networks. Eng. Struct. 2006, 28, 153–161. [Google Scholar] [CrossRef]
- Gong, M.; Wang, J.; Bai, Y.; Li, B.; Zhang, L. Heat load prediction of residential buildings based on discrete wavelet transform and tree-based ensemble learning. J. Build. Eng. 2020, 32, 101455. [Google Scholar] [CrossRef]
- Gupta, A.; Badr, Y.; Negahban, A.; Qiu, R.G. Energy-efficient heating control for smart buildings with deep reinforcement learning. J. Build. Eng. 2021, 34, 101739. [Google Scholar] [CrossRef]
- Huang, H.; Burton, H.V. Classification of in-plane failure modes for reinforced concrete frames with infills using machine learning. J. Build. Eng. 2019, 25, 100767. [Google Scholar] [CrossRef]
- Hwang, S.-H.; Mangalathu, S.; Shin, J.; Jeon, J.-S. Machine learning-based approaches for seismic demand and collapse of ductile reinforced concrete building frames. J. Build. Eng. 2021, 34, 101905. [Google Scholar] [CrossRef]
- Naser, S.S.A.; Lmursheidi, H.A. A Knowledge Based System for Neck Pain Diagnosis. J. Multidiscip. Res. Dev. 2016, 2, 12–18. [Google Scholar]
- Sadhukhan, D.; Peri, S.; Sugunaraj, N.; Biswas, A.; Selvaraj, D.F.; Koiner, K.; Rosener, A.; Dunlevy, M.; Goveas, N.; Flynn, D.; et al. Estimating surface temperature from thermal imagery of buildings for accurate thermal transmittance (U-value): A machine learning perspective. J. Build. Eng. 2020, 32, 101637. [Google Scholar] [CrossRef]
- Sanhudo, L.; Calvetti, D.; Martins, J.P.; Ramos, N.M.; Mêda, P.; Gonçalves, M.C.; Sousa, H. Activity classification using accelerometers and machine learning for complex construction worker activities. J. Build. Eng. 2021, 35, 102001. [Google Scholar] [CrossRef]
- Sargam, Y.; Wang, K.; Cho, I.H. Machine learning based prediction model for thermal conductivity of concrete. J. Build. Eng. 2021, 34, 101956. [Google Scholar] [CrossRef]
- Xuan, Z.; Xuehui, Z.; Liequan, L.; Zubing, F.; Junwei, Y.; Dongmei, P. Forecasting performance comparison of two hybrid machine learning models for cooling load of a large-scale commercial building. J. Build. Eng. 2019, 21, 64–73. [Google Scholar] [CrossRef]
- Yigit, S. A machine-learning-based method for thermal design optimization of residential buildings in highly urbanized areas of Turkey. J. Build. Eng. 2021, 38, 102225. [Google Scholar] [CrossRef]
- Yucel, M.; Bekdaş, G.; Nigdeli, S.M.; Sevgen, S. Estimation of optimum tuned mass damper parameters via machine learning. J. Build. Eng. 2019, 26, 100847. [Google Scholar] [CrossRef]
- Zhou, X.; Ren, J.; An, J.; Yan, D.; Shi, X.; Jin, X. Predicting open-plan office window operating behavior using the random forest algorithm. J. Build. Eng. 2021, 42, 102514. [Google Scholar] [CrossRef]
- Wu, P.-Y.; Sandels, C.; Mjörnell, K.; Mangold, M.; Johansson, T. Predicting the presence of hazardous materials in buildings using machine learning. Build. Environ. 2022, 213, 108894. [Google Scholar] [CrossRef]
- Fan, L.; Ding, Y. Research on risk scorecard of sick building syndrome based on machine learning. Build. Environ. 2022, 211, 108710. [Google Scholar] [CrossRef]
- Ji, S.; Lee, B.; Yi, M.Y. Building life-span prediction for life cycle assessment and life cycle cost using machine learning: A big data approach. Build. Environ. 2021, 205, 108267. [Google Scholar] [CrossRef]
- Yang, L.; Lyu, K.; Li, H.; Liu, Y. Building climate zoning in China using supervised classification-based machine learning. Build. Environ. 2020, 171, 106663. [Google Scholar] [CrossRef]
- Olu-Ajayi, R.; Alaka, H.; Sulaimon, I.; Sunmola, F.; Ajayi, S. Building energy consumption prediction for residential buildings using deep learning and other machine learning techniques. J. Build. Eng. 2022, 45, 103406. [Google Scholar] [CrossRef]
- Kareem, A. Emerging frontiers in wind engineering: Computing, stochastics, machine learning and beyond. J. Wind Eng. Ind. Aerodyn. 2020, 206, 104320. [Google Scholar] [CrossRef]
- Bre, F.; Gimenez, J.M.; Fachinotti, V.D. Prediction of wind pressure coefficients on building surfaces using Artificial Neural Networks. Energy Build. 2018, 158, 1429–1441. [Google Scholar] [CrossRef]
- Chen, Y.; Kopp, G.A.; Surry, D. Interpolation of wind-induced pressure time series with an artificial neural network. J. Wind Eng. Ind. Aerodyn. 2002, 90, 589–615. [Google Scholar] [CrossRef]
- Chen, Y.; Kopp, G.A.; Surry, D. Prediction of pressure coefficients on roofs of low buildings using artificial neural networks. Journal of wind engineering and industrial aerodynamics. J. Wind Eng. Ind. Aerodyn. 2003, 91, 423–441. [Google Scholar] [CrossRef]
- Dongmei, H.; Shiqing, H.; Xuhui, H.; Xue, Z. Prediction of wind loads on high-rise building using a BP neural network combined with POD. J. Wind Eng. Ind. Aerodyn. 2017, 170, 1–17. [Google Scholar] [CrossRef]
- Duan, J.; Zuo, H.; Bai, Y.; Duan, J.; Chang, M.; Chen, B. Short-term wind speed forecasting using recurrent neural networks with error correction. Energy 2021, 217, 119397. [Google Scholar] [CrossRef]
- Fu, J.Y.; Liang, S.G.; Li, Q.S. Prediction of wind-induced pressures on a large gymnasium roof using artificial neural networks. Comput. Struct. 2007, 85, 179–192. [Google Scholar] [CrossRef]
- Gavalda, X.; Ferrer-Gener, J.; Kopp, G.A.; Giralt, F. Interpolation of pressure coefficients for low-rise buildings of different plan dimensions and roof slopes using artificial neural networks. J. Wind Eng. Ind. Aerodyn. 2011, 99, 658–664. [Google Scholar] [CrossRef]
- Hu, G.; Kwok, K.C.S. Predicting wind pressures around circular cylinders using machine learning techniques. J. Wind Eng. Ind. Aerodyn. 2020, 198, 104099. [Google Scholar] [CrossRef]
- Kalogirou, S.; Eftekhari, M.; Marjanovic, L. Predicting the pressure coefficients in a naturally ventilated test room using artificial neural networks. Build. Environ. 2003, 38, 399–407. [Google Scholar] [CrossRef]
- Sang, J.; Pan, X.; Lin, T.; Liang, W.; Liu, G.R. A data-driven artificial neural network model for predicting wind load of buildings using GSM-CFD solver. Eur. J. Mech. Fluids 2021, 87, 24–36. [Google Scholar] [CrossRef]
- Zhang, A.; Zhang, L. RBF neural networks for the prediction of building interference effects. Comput. Struct. 2004, 82, 2333–2339. [Google Scholar] [CrossRef]
- Lamberti, G.; Gorlé, C. A multi-fidelity machine learning framework to predict wind loads on buildings. J. Wind Eng. Ind. Aerodyn. 2021, 214, 104647. [Google Scholar] [CrossRef]
- Lin, P.; Ding, F.; Hu, G.; Li, C.; Xiao, Y.; Tse, K.T.; Kwok, K.C.S.; Kareem, A. Machine learning-enabled estimation of crosswind load effect on tall buildings. J. Wind Eng. Ind. Aerodyn. 2022, 220, 104860. [Google Scholar] [CrossRef]
- Kim, B.; Yuvaraj, N.; Tse, K.T.; Lee, D.-E.; Hu, G. Pressure pattern recognition in buildings using an unsupervised machine-learning algorithm. J. Wind Eng. Ind. Aerodyn. 2021, 214, 104629. [Google Scholar] [CrossRef]
- Hu, G.; Liu, L.; Tao, D.; Song, J.; Tse, K.T.; Kwok, K.C.S. Deep learning-based investigation of wind pressures on tall building under interference effects. J. Wind Eng. Ind. Aerodyn. 2020, 201, 104138. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.-M.; Mao, J.-X.; Wan, H.-P. A probabilistic approach for short-term prediction of wind gust speed using ensemble learning. J. Wind Eng. Ind. Aerodyn. 2020, 202, 104198. [Google Scholar] [CrossRef]
- Tian, J.; Gurley, K.R.; Diaz, M.T.; Fernández-Cabán, P.L.; Masters, F.J.; Fang, R. Low-rise gable roof buildings pressure prediction using deep neural networks. J. Wind Eng. Ind. Aerodyn. 2020, 196, 104026. [Google Scholar] [CrossRef]
- Mallick, M.; Mohanta, A.; Kumar, A.; Patra, K.C. Prediction of Wind-Induced Mean Pressure Coefficients Using GMDH Neural Network. J. Aerosp. Eng. 2020, 33, 04019104. [Google Scholar] [CrossRef]
- Na, B.; Son, S. Prediction of atmospheric motion vectors around typhoons using generative adversarial network. J. Wind Eng. Ind. Aerodyn. 2021, 214, 104643. [Google Scholar] [CrossRef]
- Arul, M.; Kareem, A.; Burlando, M.; Solari, G. Machine learning based automated identification of thunderstorms from anemometric records using shapelet transform. J. Wind Eng. Ind. Aerodyn. 2022, 220, 104856. [Google Scholar] [CrossRef]
- Belle, V.; Papantonis, I. Principles and Practice of Explainable Machine Learning. Front. Big Data 2021, 4, 688969. [Google Scholar] [CrossRef] [PubMed]
- Liang, Y.; Li, S.; Yan, C.; Li, M.; Jiang, C. Explaining the black-box model: A survey of local interpretation methods for deep neural networks. Neurocomputing 2021, 419, 168–182. [Google Scholar] [CrossRef]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable Machine Learning for Scientific Insights and Discoveries. IEEE Access 2020, 8, 42200–42216. [Google Scholar] [CrossRef]
- Xu, F.; Uszkoreit, H.; Du, Y.; Fan, W.; Zhao, D.; Zhu, J. Explainable AI: A Brief Survey on History, Research Areas, Approaches and Challenges. In Natural Language Processing and Chinese Computing; Springer: Cham, Switzerland, 2019; pp. 563–574. [Google Scholar] [CrossRef]
- Meddage, D.P.; Ekanayake, I.U.; Weerasuriya, A.U.; Lewangamage, C.S.; Tse, K.T.; Miyanawala, T.P.; Ramanayaka, C.D. Explainable Machine Learning (XML) to predict external wind pressure of a low-rise building in urban-like settings. J. Wind Eng. Ind. Aerodyn. 2022, 226, 105027. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the 34th International Conference on Machine Learning—Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 3145–3153. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. ‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–16 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Petsiuk, V.; Das, A.; Saenko, K. RISE: Randomized Input Sampling for Explanation of Black-Box Models. Available online: http://arxiv.org/abs/1806.07421 (accessed on 11 April 2021).
- Moradi, M.; Samwald, M. Post-hoc explanation of black-box classifiers using confident itemsets. Expert Syst. Appl. 2021, 165, 113941. [Google Scholar] [CrossRef]
- Yap, M.; Johnston, R.L.; Foley, H.; MacDonald, S.; Kondrashova, O.; Tran, K.A.; Nones, K.; Koufariotis, L.T.; Bean, C.; Pearson, J.V.; et al. Verifying explainability of a deep learning tissue classifier trained on RNA-seq data. Sci. Rep. 2021, 11, 1–2. [Google Scholar] [CrossRef]
- Patel, H.H.; Prajapati, P. Study and Analysis of Decision Tree Based Classification Algorithms. Int. J. Comput. Sci. Eng. 2018, 6, 74–78. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Trees vs Neurons: Comparison between random forest and ANN for high-resolution prediction of building energy consumption. Energy Build. 2017, 147, 77–89. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C.J. Classification and Regression Trees; Routledge: Oxfordshire, UK, 1983. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Watanachaturaporn, P.; Varshney, P.K.; Arora, M.K. Decision tree regression for soft classification of remote sensing data. Remote Sens. Environ. 2005, 97, 322–336. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, D.; Elzarka, H. Early detection of faults in HVAC systems using an XGBoost model with a dynamic threshold. Energy Build. 2019, 185, 326–344. [Google Scholar] [CrossRef]
- Mo, H.; Sun, H.; Liu, J.; Wei, S. Developing window behavior models for residential buildings using XGBoost algorithm. Energy Build. 2019, 205, 109564. [Google Scholar] [CrossRef]
- Xia, Y.; Liu, C.; Li, Y.; Liu, N. A boosted decision tree approach using Bayesian hyper-parameter optimization for credit scoring. Expert Syst. Appl. 2017, 78, 225–241. [Google Scholar] [CrossRef]
- Zięba, M.; Tomczak, S.K.; Tomczak, J.M. Ensemble boosted trees with synthetic features generation in application to bankruptcy prediction. Expert Syst. Appl. 2016, 58, 93–101. [Google Scholar] [CrossRef]
- Maree, R.; Geurts, P.; Piater, J.; Wehenkel, L. A Generic Approach for Image Classification Based On Decision Tree Ensembles And Local Sub-Windows. In Proceedings of the 6th Asian Conference on Computer Vision, Jeju, Korea, 27–30 January 2004; pp. 860–865. [Google Scholar]
- Okoro, E.E.; Obomanu, T.; Sanni, S.E.; Olatunji, D.I.; Igbinedion, P. Application of artificial intelligence in predicting the dynamics of bottom hole pressure for under-balanced drilling: Extra tree compared with feed forward neural network model. Petroleum 2021. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Explainable decision forest: Transforming a decision forest into an interpretable tree. Inf. Fusion 2020, 61, 124–138. [Google Scholar] [CrossRef]
- John, V.; Liu, Z.; Guo, C.; Mita, S.; Kidono, K. Real-Time Lane Estimation Using Deep Features and Extra Trees Regression. In Image and Video Technology; Springer: Cham, Switzerland, 2015; pp. 721–733. [Google Scholar] [CrossRef]
- Seyyedattar, M.; Ghiasi, M.M.; Zendehboudi, S.; Butt, S. Determination of bubble point pressure and oil formation volume factor: Extra trees compared with LSSVM-CSA hybrid and ANFIS models. Fuel 2020, 269, 116834. [Google Scholar] [CrossRef]
- Cai, J.; Li, X.; Tan, Z.; Peng, S. An assembly-level neutronic calculation method based on LightGBM algorithm. Ann. Nucl. Energy 2021, 150, 107871. [Google Scholar] [CrossRef]
- Fan, J.; Ma, X.; Wu, L.; Zhang, F.; Yu, X.; Zeng, W. Light Gradient Boosting Machine: An efficient soft computing model for estimating daily reference evapotranspiration with local and external meteorological data. Agric. Water Manag. 2019, 225, 105758. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Available online: https://www.microsoft.com/en-us/research/publication/lightgbm-a-highly-efficient-gradient-boosting-decision-tree/ (accessed on 11 April 2021).
- Ebtehaj, I.H.; Bonakdari, H.; Zaji, A.H.; Azimi, H.; Khoshbin, F. GMDH-type neural network approach for modeling the discharge coefficient of rectangular sharp-crested side weirs. Int. J. Eng. Sci. Technol. 2015, 18, 746–757. [Google Scholar] [CrossRef] [Green Version]
- NIST Aerodynamic Database. Available online: https://www.nist.gov/el/materials-and-structural-systems-division-73100/nist-aerodynamic-database (accessed on 23 January 2022).
- Tokyo Polytechnic University (TPU). Aerodynamic Database for Low-Rise Buildings. Available online: http://www.wind.arch.t-kougei.ac.jp/info_center/windpressure/lowrise (accessed on 1 April 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Liu, H. Wind Engineering: A Handbook for Structural Engineers; Prentice Hall: Hoboken, NJ, USA, 1991. [Google Scholar]
- Saathoff, P.J.; Melbourne, W.H. Effects of free-stream turbulence on surface pressure fluctuations in a separation bubble. J. Fluid Mech. 1997, 337, 1–24. [Google Scholar] [CrossRef]
- Akon, A.F.; Kopp, G.A. Mean pressure distributions and reattachment lengths for roof-separation bubbles on low-rise buildings. J. Wind Eng. Ind. Aerodyn. 2016, 155, 115–125. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Variable | Details |
|---|---|---|
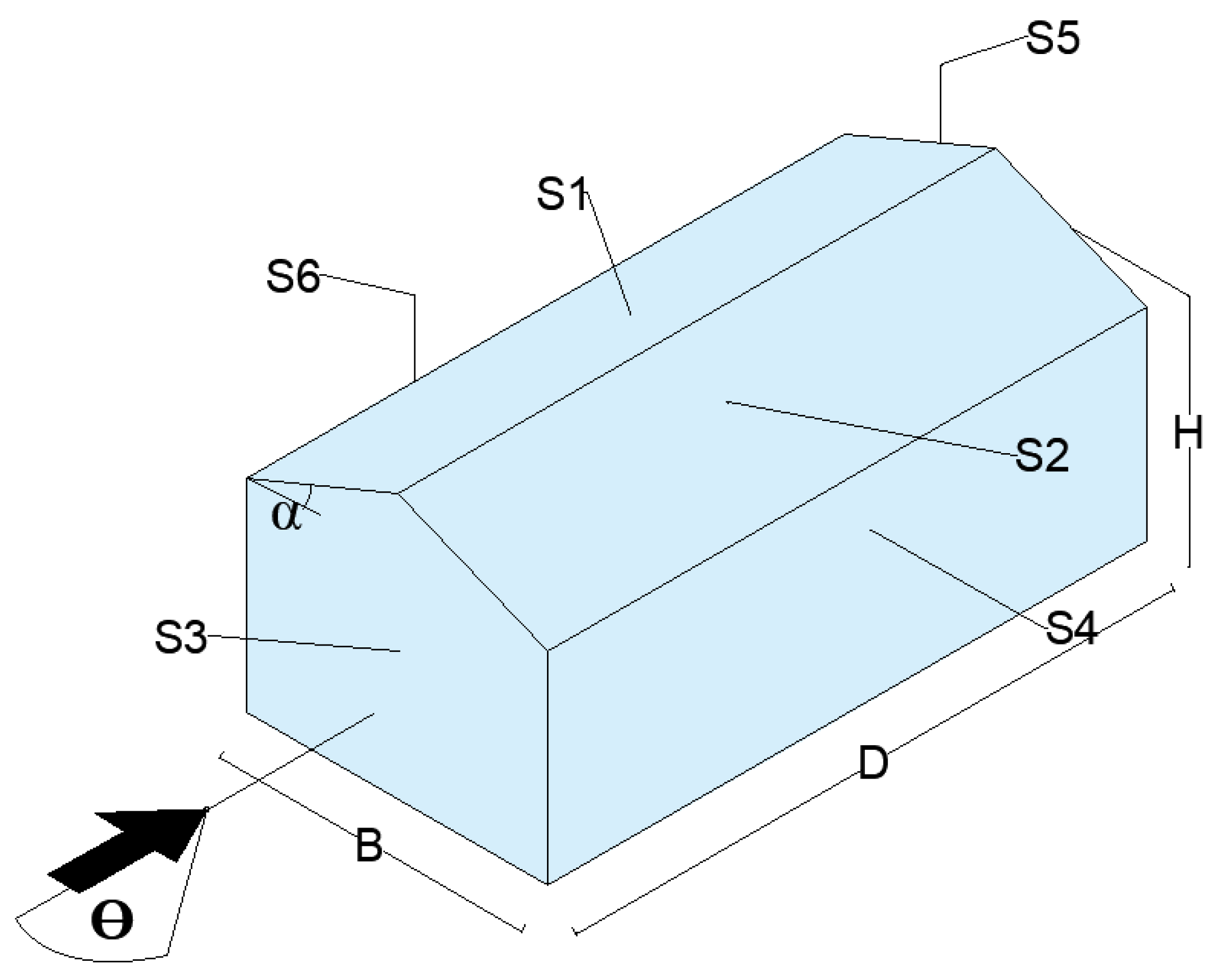
| Independent | Wind direction (θ) | 0°, 15°, 30°, 45°, 60°, 75°, 90° |
| Roof Pitch (α) | 5°, 10°, 14°, 18°, 22°, 27°, 30°, 45° | |
| H/B | 0.25, 0.5, 0.75, 1 | |
| D/B | 1, 1.5, 2.5 | |
| S1 | One-hot encoding is active. A value of “1” is used when a particular surface is referred whereas remaining surfaces hold “0”. | |
| S2 | ||
| S3 | ||
| S4 | ||
| S5 | ||
| S6 | ||
| Dependant | Cp,mean | Ranges from −1.39 to 0.74 |
| Cp,rms | Ranges from 0.09 to 0.57 | |
| Cp,peak [Single worst minimum] | Ranges from −4.91 to −0.13 |
| Decision Tree | Extra Tree | XGBoost | LightGBM | |||||
|---|---|---|---|---|---|---|---|---|
| Hyperparameter | Value | Hyperparameter | Value | Hyperparameter | Value | Hyperparameter | Value | |
| CP,mean | criterion | MSE | criterion | MSE | Maximum depth | 4 | Learning rate | 0.1 |
| splitter | Best | Maximum depth | 10 | Gamma | 0.0002 | Maximum depth | 4 | |
| Maximum depth | 10 | Minimum samples leaf | 2 | Learning rate | 0.3 | Random state | 5464 | |
| Minimum samples leaf | 2 | Minimum sample split | 2 | Number of Estimators | 50 | Number of jobs | none | |
| Minimum sample split | 2 | Number of Estimators | 50 | Random state | 154 | Reg_Alpha | 1 × 10−4 | |
| Maximum Features | 5 | Bootstrap | FALSE | Reg_Alpha | 0.0001 | |||
| Minimum impurity decrease | 0 | Minimum impurity decrease | 0 | Base score | 0.5 | |||
| Random state | 5464 | Random state | 5464 | |||||
| CC alpha | 0 | Number of jobs | none | |||||
| Cp,rms | criterion | MSE | criterion | MSE | Maximum depth | 5 | Learning rate | 0.1 |
| splitter | Best | Maximum depth | 10 | Gamma | 0.0001 | Maximum depth | 5 | |
| Maximum depth | 10 | Minimum samples leaf | 2 | Learning rate | 0.4 | Random state | 5464 | |
| Minimum samples leaf | 2 | Minimum sample split | 2 | Number of Estimators | 400 | Number of jobs | none | |
| Minimum sample split | 2 | Number of Estimators | 100 | Random state | 154 | Reg_Alpha | 1 × 10−4 | |
| Maximum Features | 5 | Bootstrap | True | Reg_Alpha | 0.0001 | |||
| Minimum impurity decrease | 0 | Minimum impurity decrease | 0 | Base score | 0.5 | |||
| Random state | 5464 | Random state | 4745 | |||||
| CC alpha | 0 | Number of jobs | 100 | |||||
| Cp,peak | criterion | MSE | criterion | MSE | Maximum depth | 4 | Learning rate | 0.1 |
| splitter | Best | Maximum depth | 10 | Gamma | 0.0001 | Maximum depth | 5 | |
| Maximum depth | 10 | Minimum samples leaf | 2 | Learning rate | 0.053 | Random state | 5464 | |
| Minimum samples leaf | 2 | Minimum sample split | 2 | Number of Estimators | 400 | Number of jobs | none | |
| Minimum sample split | 2 | Number of Estimators | 100 | Random state | 154 | Reg_Alpha | 1 × 10−4 | |
| Maximum Features | 5 | Bootstrap | True | Reg_Alpha | 0.0001 | |||
| Minimum impurity decrease | 0 | Minimum impurity decrease | 0 | Base score | 0.5 | |||
| Random state | 5464 | Random state | 4745 | |||||
| CC alpha | 0 | Number of jobs | 100 | |||||
| Cp | Performance Indicators | Decision Tree | Extra Tree | LightGBM | XGBoost |
|---|---|---|---|---|---|
| Cp,mean | Correlation (R) | 0.990 | 0.993 | 0.977 | 0.996 |
| MAE | 0.049 | 0.043 | 0.051 | 0.033 | |
| RMSE | 0.067 | 0.055 | 0.07 | 0.043 | |
| Cp,rms | Correlation (R) | 0.955 | 0.966 | 0.969 | 0.977 |
| MAE | 0.018 | 0.016 | 0.015 | 0.013 | |
| RMSE | 0.023 | 0.020 | 0.019 | 0.017 | |
| Cp,peak | Correlation (R) | 0.957 | 0.970 | 0.970 | 0.974 |
| MAE | 0.177 | 0.150 | 0.149 | 0.143 | |
| RMSE | 0.246 | 0.206 | 0.205 | 0.192 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meddage, P.; Ekanayake, I.; Perera, U.S.; Azamathulla, H.M.; Md Said, M.A.; Rathnayake, U. Interpretation of Machine-Learning-Based (Black-box) Wind Pressure Predictions for Low-Rise Gable-Roofed Buildings Using Shapley Additive Explanations (SHAP). Buildings 2022, 12, 734. https://doi.org/10.3390/buildings12060734
Meddage P, Ekanayake I, Perera US, Azamathulla HM, Md Said MA, Rathnayake U. Interpretation of Machine-Learning-Based (Black-box) Wind Pressure Predictions for Low-Rise Gable-Roofed Buildings Using Shapley Additive Explanations (SHAP). Buildings. 2022; 12(6):734. https://doi.org/10.3390/buildings12060734
Chicago/Turabian StyleMeddage, Pasindu, Imesh Ekanayake, Udara Sachinthana Perera, Hazi Md. Azamathulla, Md Azlin Md Said, and Upaka Rathnayake. 2022. "Interpretation of Machine-Learning-Based (Black-box) Wind Pressure Predictions for Low-Rise Gable-Roofed Buildings Using Shapley Additive Explanations (SHAP)" Buildings 12, no. 6: 734. https://doi.org/10.3390/buildings12060734
APA StyleMeddage, P., Ekanayake, I., Perera, U. S., Azamathulla, H. M., Md Said, M. A., & Rathnayake, U. (2022). Interpretation of Machine-Learning-Based (Black-box) Wind Pressure Predictions for Low-Rise Gable-Roofed Buildings Using Shapley Additive Explanations (SHAP). Buildings, 12(6), 734. https://doi.org/10.3390/buildings12060734