1. Introduction
To address the uncertain factors in a structure, it is necessary to reasonably select a mathematical model that quantifies the uncertain factors and structural reliability. Many analytical- and simulation-based methods have been developed to calculate the failure probability and reliability index of structures [
1,
2]. Among them, Monte Carlo simulation (MCS) is probably the most widely used high-precision structural reliability analysis method. However, when the probability of structural failure is small, MCS often needs to simulate a large number of samples to obtain accurate probability values, which will increase a lot of computational costs. Some improved methods, such as the subset simulation method [
3], the line sampling method [
4], and the importance sampling method (IS) [
5], still have a high computation when facing complex problems. Analytical methods, such as first-order reliability methods (FORMs) and second-order reliability methods (SORMs), are computationally efficient but are often not stable enough in the face of structures with implicit PFs. For some improved algorithms, such as the directional stability transformation method (DSTM) [
6] and finite-step adaptive length (FAL) [
7], it is difficult to solve the convex set reliability problem [
8]. On the other hand, by the type of random variable in the structures, Cremona [
9] divided structural reliability models into random reliability models, fuzzy reliability models, non-probabilistic reliability models, and mixtures of the three models according to the mechanism of uncertainty factors. Among the various uncertainty models, the most widely used is the probabilistic reliability model based on probability theory and stochastic processes [
10,
11,
12]. However, it is difficult to obtain sufficient statistical sample data in practical engineering structures to construct the probability distribution function of a probabilistic model. Additionally, a small fitting error of the probability distribution function of a random reliability model can lead to a large structural reliability calculation error [
13]. This is especially true when there are few samples with which the model can calculate [
14].
To address the condition of insufficient samples, in 1993, Ben-Haim [
15] and Elishakoff [
16] proposed a non-probabilistic reliability model for structural analysis and applied the maximum uncertainty allowed in the system to evaluate the structural reliability. Non-probabilistic reliability theory uses an artificially defined set model to describe the uncertain variables of the structure. The non-probabilistic reliability model only needs the range of the uncertain variables and then constructs the mapping relationship between the uncertain variables and the corresponding feasible domain of the structure under the combined action of multiple variables. It can be seen from this that it is particularly important to use the non-probabilistic reliability method in the reliability analysis of complex engineering structures. Due to factors such as safety and cost, it is difficult to carry out enough field experiments to obtain enough actual samples to establish reliable probability distribution functions in complex engineering structures [
17]. Furthermore, small deviations in the probability density function due to data noise are likely to lead to large result errors [
13]. However, in the same situation, using a small number of field experiments, the range of random variables can be quickly obtained, and then a structural reliability analysis with high reliability can be constructed through the non-probabilistic reliability method. Then, by comparing the set model and the limit state surface defined by the performance function (PF), the structural reliability index can be evaluated. Subsequently, scholars have conducted many studies that can be summarized into two categories: proposing different non-probabilistic reliability models aimed at better describing multivariable problems and studying how to quantify non-probabilistic reliability indicators according to different models. In 1998, Qiu and Elishakoff [
18] used interval theory to establish an interval model to optimize a six-bar truss. In 2011, Wang et al. [
19,
20] proposed a non-probabilistic reliability model measurement index based on an interval model, where the index was defined by the ratio of the volume of the safety domain of the structure to the total volume of the basic interval variable domain. The interval model can only deal with independent variables [
21]; therefore, scholars further proposed ellipsoid models to deal with dependent variables. In 1998, Pantelides et al. [
22] proposed an ellipsoid model and compared the structural analysis results of different working conditions based on the ellipsoid model. In 2011, Jiang et al. [
23] proposed a modeling method to establish a multidimensional ellipsoid model. To make the dependence of uncertain variables explicit, they introduced a covariance matrix to evaluate the correlations of dependent variables. In 2016, Kang and Zhang [
24] constructed a mathematical formula system to develop a compact ellipsoid model. Recently, to address the problem of including independent and dependent variables, scholars have proposed more general models. In 2015, Jiang et al. [
21] proposed a multidimensional parallelepiped model that can efficiently deal with complex ‘multi-source uncertainty’ problems. Guo et al. [
25] proposed a mixed model composed of a hypercube interval model and a hyper-ellipsoid model. In 2021, Cao et al. [
26] proposed a quantifying strategy for non-probabilistic uncertainties by combining the general polygonal convex set model and cluster polygonal convex set model. However, with the development of non-probabilistic reliability models and quantitative indices of reliability, solving non-probabilistic reliability problems quickly and accurately has become a restriction on related field development.
To address the above problems, scholars have explored many methods. Jiang et al. [
23] applied the first-order reliability method (FORM) to a non-probabilistic convex model based on multidimensional ellipsoids for uncertainty. Wang et al. [
27] proposed an improved second-order reliability method (SORM) for reliability analysis in the presence of both random and interval variables. These methods perform well in reliability analysis with explicit PFs; however, in practical engineering cases, the PF is commonly implicit. Therefore, it is difficult to obtain the exact boundaries of the structural failure domain and the reliable domain. For more complex structures, the reliability can only be calculated by numerical simulation methods such as finite element analysis (FEA), which are very time-consuming in most practical engineering applications. Therefore, the use of an explicit surrogate model of PFs for structural reliability analysis has become mainstream. One of the most commonly used methods is the response surface method (RSM). In 1989, Faravelli [
28] first proposed a quadratic polynomial regression model to approximate a function, and this method is also called the classical RSM. The response surface can quickly and accurately fit an implicit PF and, at the same time, can eliminate the interference caused by sample noise through probabilistic methods. RSMs can be simply divided into two types: regression-based models and interpolation-based models [
29]. Regression-based models, such as Gaussian process regression [
12,
30,
31], use the probabilistic properties of known samples to perform regression analysis to fit functions in the feasible domain. An alternative model is based on general polynomial chaos expansion (gPCE) [
32,
33,
34]. In this surrogate model, the random variables are placed in the random space expanded by orthogonal polynomials. The coefficients of each dimension are multiplied by the corresponding orthogonal polynomials, and then added to obtain the explicit surrogate model of the implicit PF. Interpolation-based models, such as support vector machines [
35,
36] and artificial neural networks [
37,
38,
39], correct the values of the weight parameters of the model by learning the characteristics of the known samples to interpolate the function in the feasible domain. However, the RSMs mentioned above are all aimed at probabilistic reliability, and research on RSMs aimed at non-probabilistic reliability is still very rare.
This paper proposes a grasshopper optimization algorithm (GOA)-based RSM for the non-probabilistic reliability analysis of structures with implicit PFs. In this method, a quadratic polynomial response surface is presented to fit the PF. Notably, for general engineering structures, although the newly proposed RSM has high accuracy, the fitting speed is slow. Additionally, the hyper-parameters in models such as support vector machine (SVM) are difficult to determine without manual parameter adjustment [
40]. In contrast, the application of the quadratic polynomial RSM in the field of probabilistic reliability is very mature [
41] and can be quickly fitted while largely guaranteeing the fitting accuracy in general structures. Then, the proposed method uses a dynamic fitting strategy to find the approximate location of the generalized design point and then performs local fitting of the PF around the generalized design point. To find the globally optimal solution faster in the process of calculating the non-probabilistic reliability index, the GOA is used to search for the reliability index and optimal design point of the structure. This paper is organized as follows:
Section 2 introduces the convex model theory to quantify the non-probabilistic reliability with the reliability index.
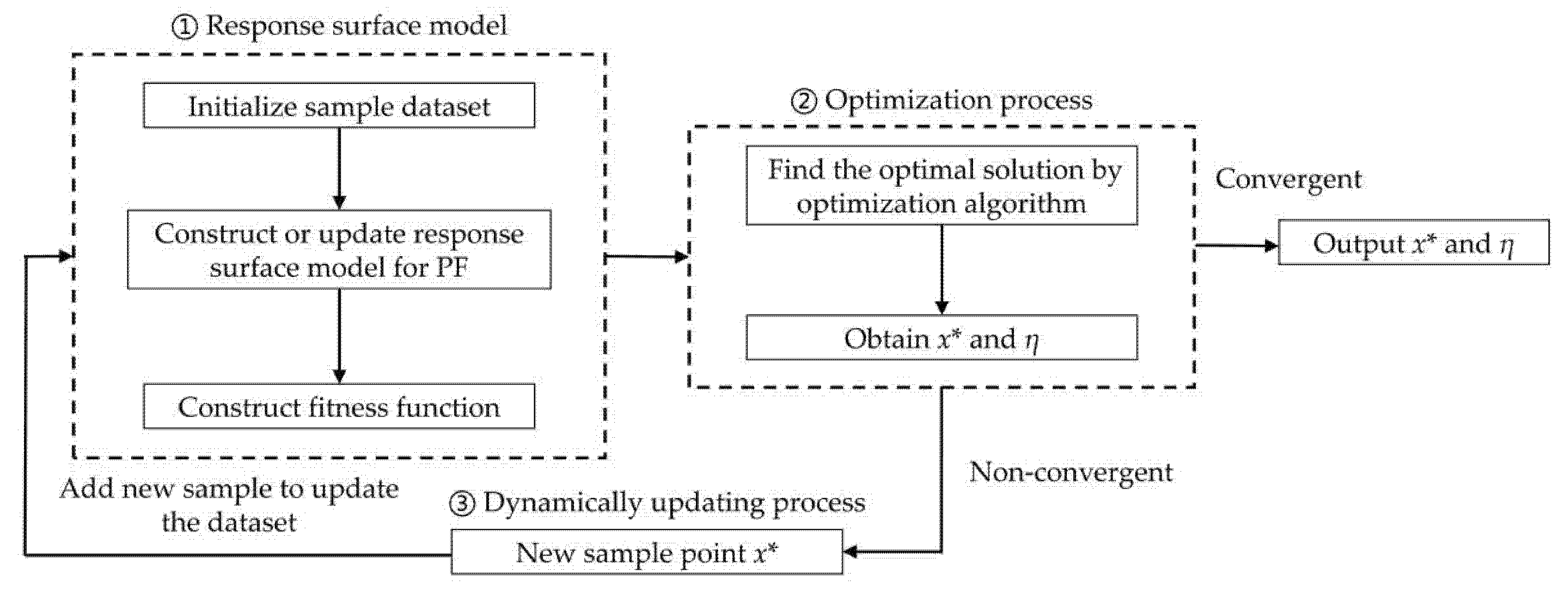
Section 3 presents the framework of the proposed method. According to the framework,
Section 4 introduces the key technologies of the proposed method.
Section 5 introduces the detailed implementation of the proposed method based on the key technologies.
Section 6 gives four examples—two mathematical examples and two engineering structure examples—to verify the feasibility of the proposed method. Finally,
Section 7 summarizes the conclusion for the proposed method according to the examples.
2. Reliability Index of Non-Probabilistic Reliability
A non-probabilistic reliability model is an effective way to deal with structures with insufficient samples. The question arises of how to characterize the safety of structures in a non-probabilistic setting. Many scholars have proposed multiple reliability indices to quantify the non-probabilistic reliability [
42,
43,
44]. The use of a scaling factor for convex sets is one of the most common methods.
According to the properties of the convex model, the total uncertainty of a structure is the intersection set of m convex sets of all uncertainties [
37]. This intersection set can also be considered a feasible domain for the structure to remain stable under the impact of multiple uncertain variables. It can be represented as:
where
is the size parameter of the convex set family of total uncertain variables,
is the position parameter of the convex set family of total uncertain variables, and
represents a subset of uncertain variables with the same convex set. The stability of the structure under a certain working condition can be determined by Equation (1).
The scale factor
can be used to freely scale the intersection set in Equation (1). The scaled intersection set is as follows:
The factor acts on the size parameter of each convex set. When the above intersection set in Equation (2) is increased by the factor
to intersect the failure domain divided by the PF, this indicates that the structure is in a failure state under some combination of uncertain variables. Therefore,
must be reduced until the intersection is tangent to the failure domain. This tangent point represents the generalized design point of the structure on the PF [
45].
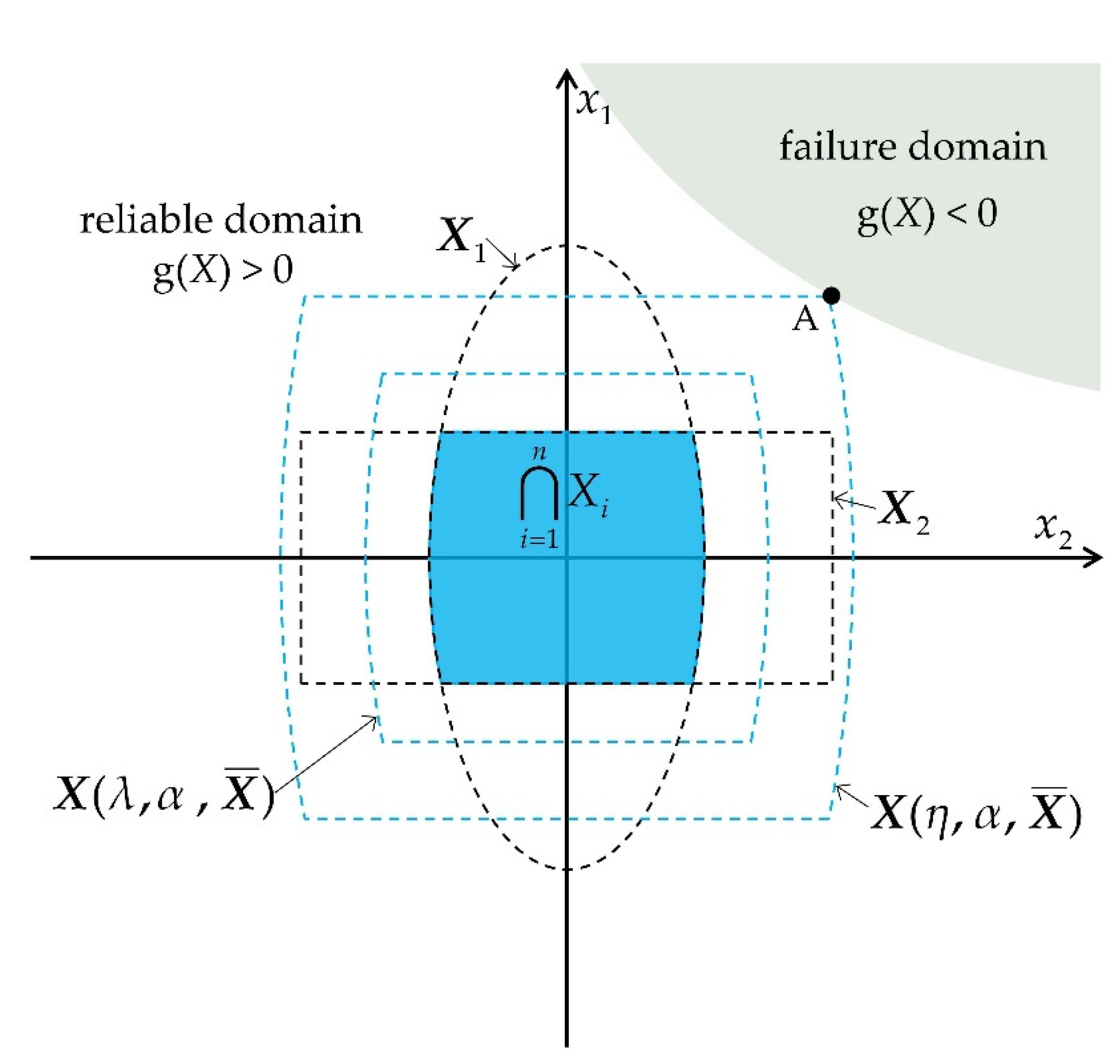
Figure 1 shows the non-probabilistic reliability index of a PF considering two uncertain variables in
x-space. The failure domain is divided by PF
g(
X) = 0, and the blue solid area denotes the normalized convex model. It is defined by the intersection of an ellipsoid convex set
X1 and an interval convex set
X2. When the convex set expands to be tangent to the PF, the value of
is the non-probabilistic reliability index
η, and the tangent point A is the generalized design point.
Therefore, the minimum
value can be defined as the reliability index
η of structural reliability as follows:
The index η can be used to simply measure the degree of non-probabilistic reliability to judge whether the structure is in a safe or failure state. The structural reliability problem is then transformed into the problem of finding the optimal solution of η.
The scaling factor of the convex set is used to obtain the optimization formula of
η. The optimization formula is obtained by transforming Equation (3) into an unconstrained optimization problem through the penalty method:
where
is the functional relation of the convex set model and
P is the penalty coefficient, which is generally a large constant. Finally, the non-probabilistic reliability problem is transformed into the problem of finding the optimal solution of Equation (4), which is based on the convex set model
X and PF
g(
X). In other words, Equation (4) can be considered the fitness function of some optimization algorithm, and the optimal solution can be sought.
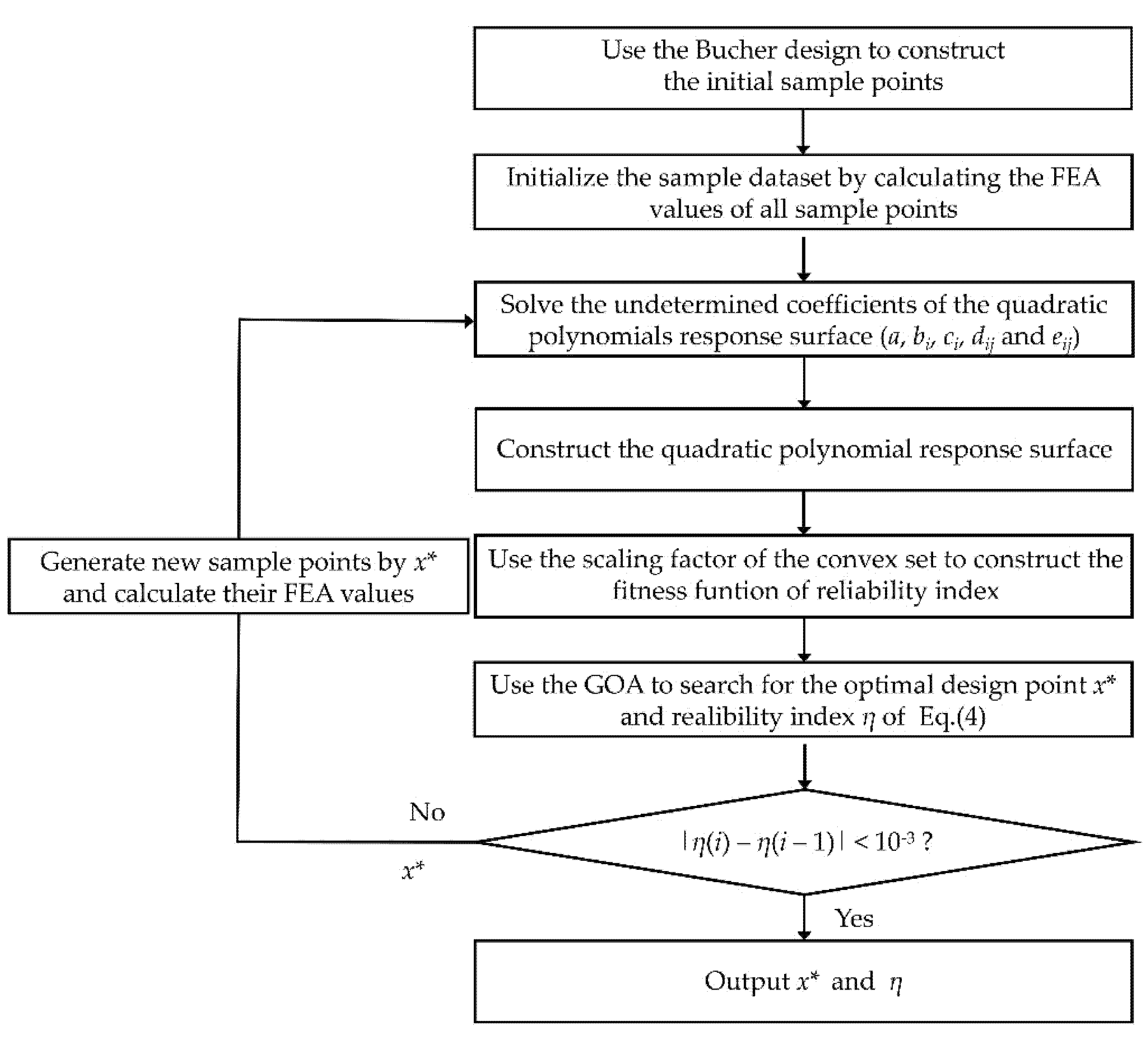
6. Examples and Discussion
To verify the feasibility of this method, four examples—two mathematical examples and two engineering structure examples—are given.
6.1. Example 1
The nonlinear PF of a structure is [
37]:
The variation range of the uncertain variables can be expressed by the following non-probabilistic interval model:
where the position parameters are
and the size parameters are
.
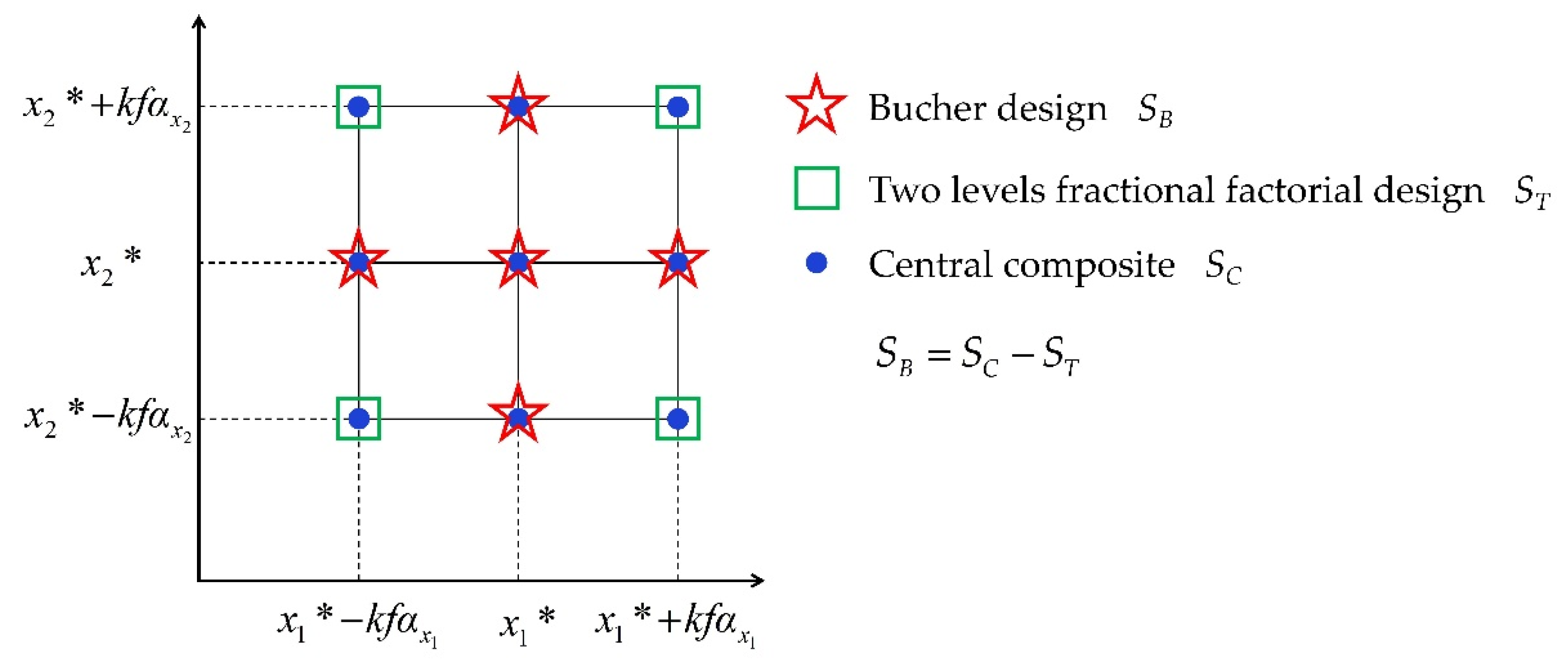
The Bucher experimental design method is used to construct the initial sample points. The position parameter of each variable is taken as the center point. Twice the value of the size parameter is taken as the offset distance of the model.
The parameters of the GOA are set as follows: the dimension is D = 2, the population size is N = 30, the maximum and minimum adaptive shrinkage parameters are cmax = 1 and cmin = 1.0 × 10−5, the number of iterations is t = 1000, the upper and lower bounds of the model space are ul = 10.0 and fl = −10.0, and the search range of the scaling factor λ is [0, 10].
After three calculation steps, the iteration reaches convergence. The explicit expression of the quadratic polynomial response surface at each iteration step is:
where
,
α, and
K in each iteration step are:
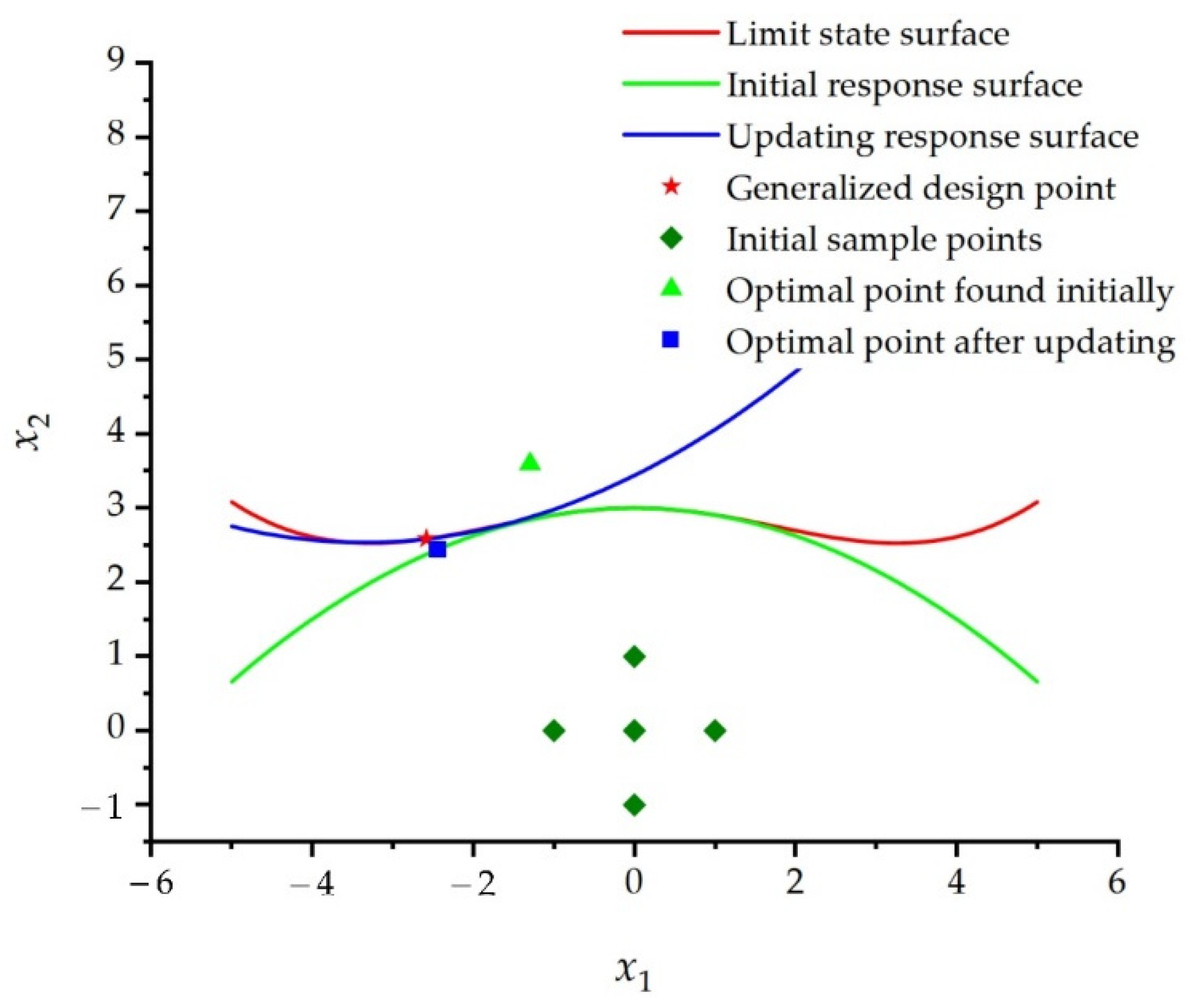
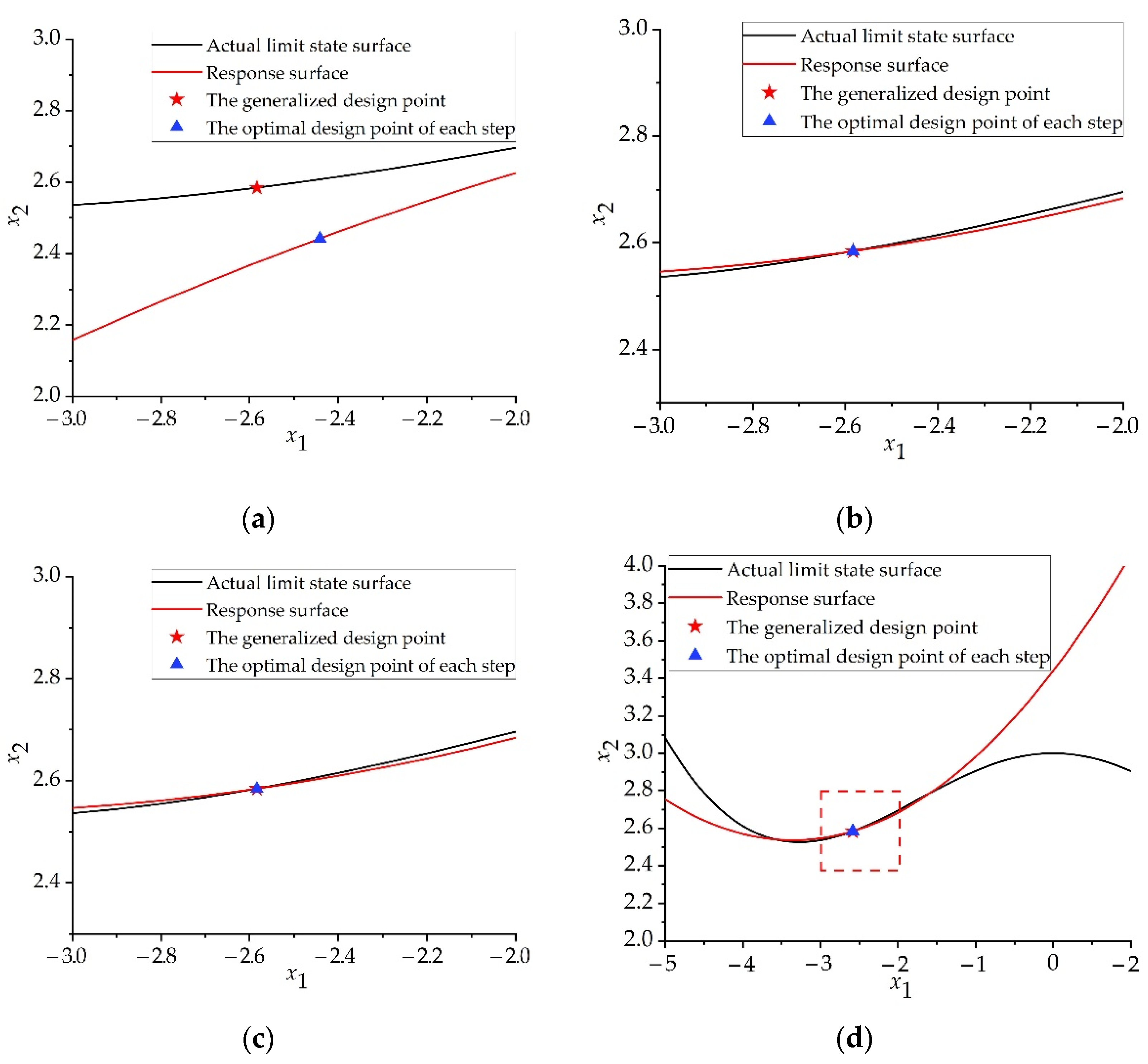
Through the above calculation, the response surface image of each iteration step can be obtained, as shown in
Figure 6. Comparing the response surface with the PF and comparing the optimal design point of each iteration step with the generalized design point, it can be seen that the method in this paper can quickly fit the PF and can quickly find the generalized design point. Notably, image (c) is the part in the red box in image (d). This indicates that the proposed method performs local dynamic fitting to the PF in the vicinity of the domain where the generalized design point is located. The proposed method does not focus too greatly on areas far from the generalized design point. Therefore, the fitting process for the PF can be further accelerated on the premise that the generalized design point can be accurately found.
Table 1 gives the optimal design points and reliability indices searched by the GOA in each iteration step.
Table 2 shows the calculation results of different methods.
In
Table 2, the number of function calls
fc can be calculated from the number of sampling points (2
n + 1) and the number of iteration steps
s. The calculation formula is as follows:
The results of the Monte Carlo simulation (MCS) method with a large number of samples are used as relatively accurate solutions. The result of directly using the GOA to solve the optimization problem of Equation (4) is used as a comparison.
Table 1 and
Table 2 show two valuable pieces of information. First, the GOA method has higher precision, and the relative error is only 0.015%. Second, the relative error of the proposed method is close to that of the GOA method; however, the number of fitness function calls is significantly lower, only 1/34 that of the GOA method. We place tighter constraints on the convergence conditions of dynamic iterations in our method (|
η(
i) −
η(
i − 1)| < 10
−6). The obtained reliability index value is 2.5844, the relative error is reduced to 0.008%, and the number of function calls is 226. It shows that the method in this paper can further increase the accuracy, with a moderate increase in the amount of computation, while still ensuring the computational efficiency. It can be proven that (1) the GOA has a strong optimization capability and can deal with non-probabilistic reliability optimization problems with high precision; (2) the proposed method combines the RSM with the GOA and can improve the efficiency of the solution by reducing the number of calls to the fitness function. The method proposed in this paper has some applicability in solving the non-probabilistic reliability index with the whole interval model of the nonlinear PF of structural reliability.
6.2. Example 2
The PF of a structure is Ref. [
37]:
The variation range of the uncertain variables satisfies the following mixed model, which combines the non-probabilistic interval model and super ellipsoid model:
where the position parameters are
and the size parameters are
.
It is worth noting that GOA has a total of six hyperparameters: the population size N, the maximum number of iterations t, the upper and lower bounds ul and fl of the search, and the maximum and minimum adaptive shrinkage parameters cmax and cmin. The upper and lower search bounds ul and fl represent the search space of the model, which can be reasonably estimated according to the variation range of random variables. The population size N and number of iterations t have similar effects on the operation of the algorithm: when N or t increases, the search operator searches more thoroughly in the entire model space, but if they are too large, it will cause a lot of unnecessary searches, which greatly increases the running time of the algorithm and reduces the efficiency. If N or t is too small, the global optimal solution cannot be searched, which affects the accuracy of the understanding. Therefore, N and the maximum t are two empirical parameters. In general, the more complex the optimization problem to be solved, the greater the N, and the greater the t. The adaptive shrinkage parameter c gradually decreases with the increase in the number of iterations, so that the grasshopper algorithm will not quickly converge to the target. In the early stage of the algorithm, a larger c is set, so that the grasshopper operator is encouraged to perform global optimization, and a small c is set in the later stage of the optimization, so that the grasshopper operator can perform local optimization as much as possible and move toward the target. In addition, the problem dimension D is equal to the number of uncertain variables contained in the optimization problem. Subsequent examples follow the above principles.
The Bucher experimental design method is used to construct the initial sample points. The offset distance of the variables based on the interval model is taken as twice the size parameter value. The offset distance of the variables based on the super ellipsoid model is taken as twice the value, where .
The parameters of the GOA are set as follows: the dimension is D = 3, the population size is N = 30, the maximum and minimum adaptive shrinkage parameters are cmax = 1 and cmin = 1.0 × 10−5, the number of iterations is t = 1000, and the upper and lower bounds of the model space are ul = 100.0 and fl = 0.0. The search range of the scaling factor λ is [0, 10].
The iteration results of Example 2 are shown in
Table 3. The comparison results of using different methods are shown in
Table 4, and
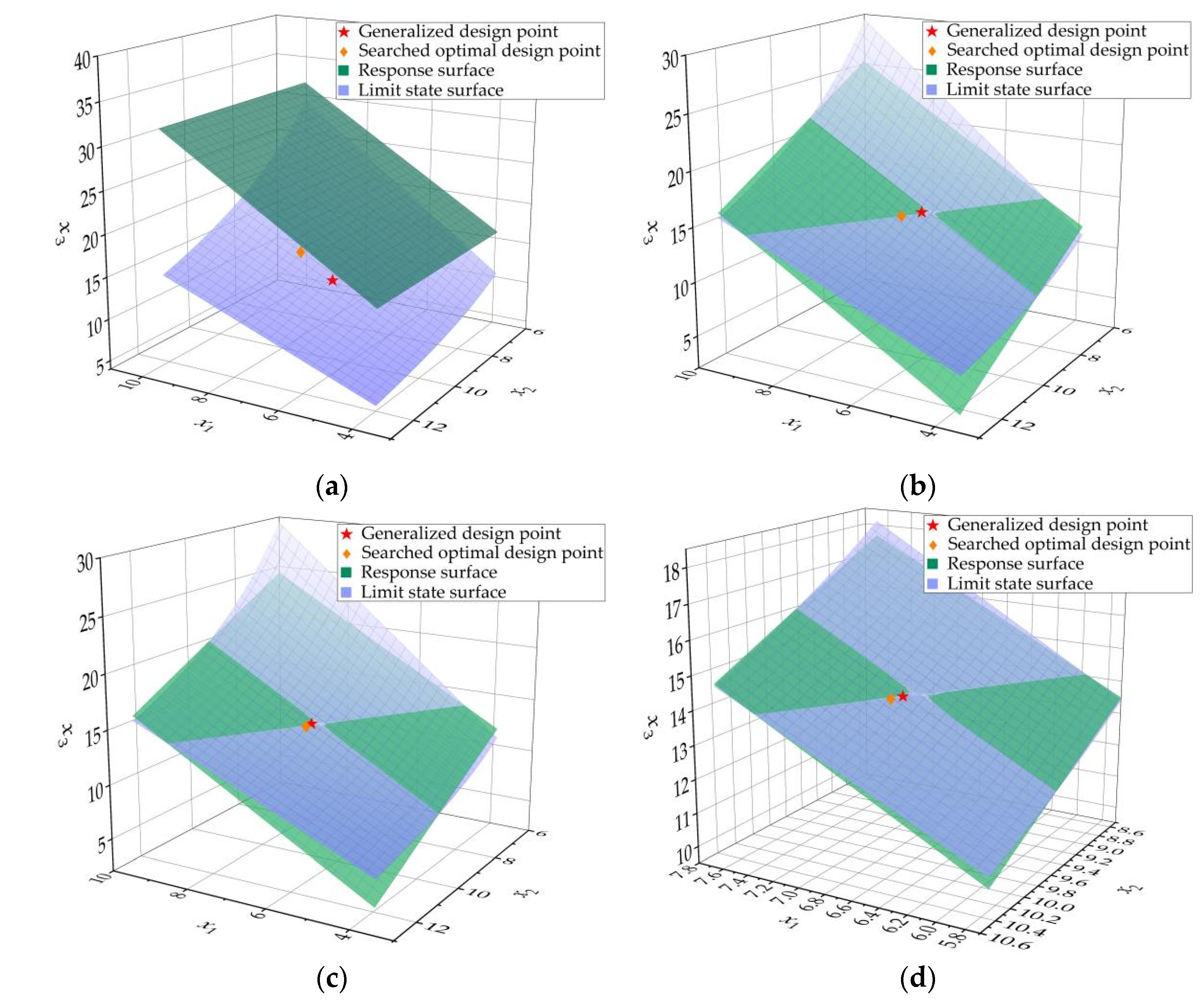
Figure 7 shows the final response surface
and the PF
. The comparison between the final searched optimal point and the generalized design point is also shown.
After four calculation steps, the iteration reaches convergence. In
Table 3, with the increase in the iteration steps, the optimal design points and reliability index values tend to become stable gradually. In
Table 4, the MCS method is used to simulate 10
6 calculation results as a relatively accurate solution, and the result of directly using the GOA to solve the optimization problem of Equation (4) is used as a comparison. The error of the proposed method is only 0.353%, and the calculation accuracy is satisfactory. The calculation accuracy of the proposed method is similar to that of the GOA, and the number of function calls is only 29 while the number of function calls of the GOA is 506. The calculation efficiency of the proposed method is obviously higher. Furthermore,
Figure 7 shows the dynamic fitting process of the response surface model and the optimal design point of each step. Notably, the range shown in the image in step 4 is smaller than those of the other three steps, and the last step shows that this dynamic fitting strategy makes the response surface model fit the PF very well around the generalized design point. The GOA can quickly determine the optimal design point and makes the iteration quickly reach the convergence condition in four steps.
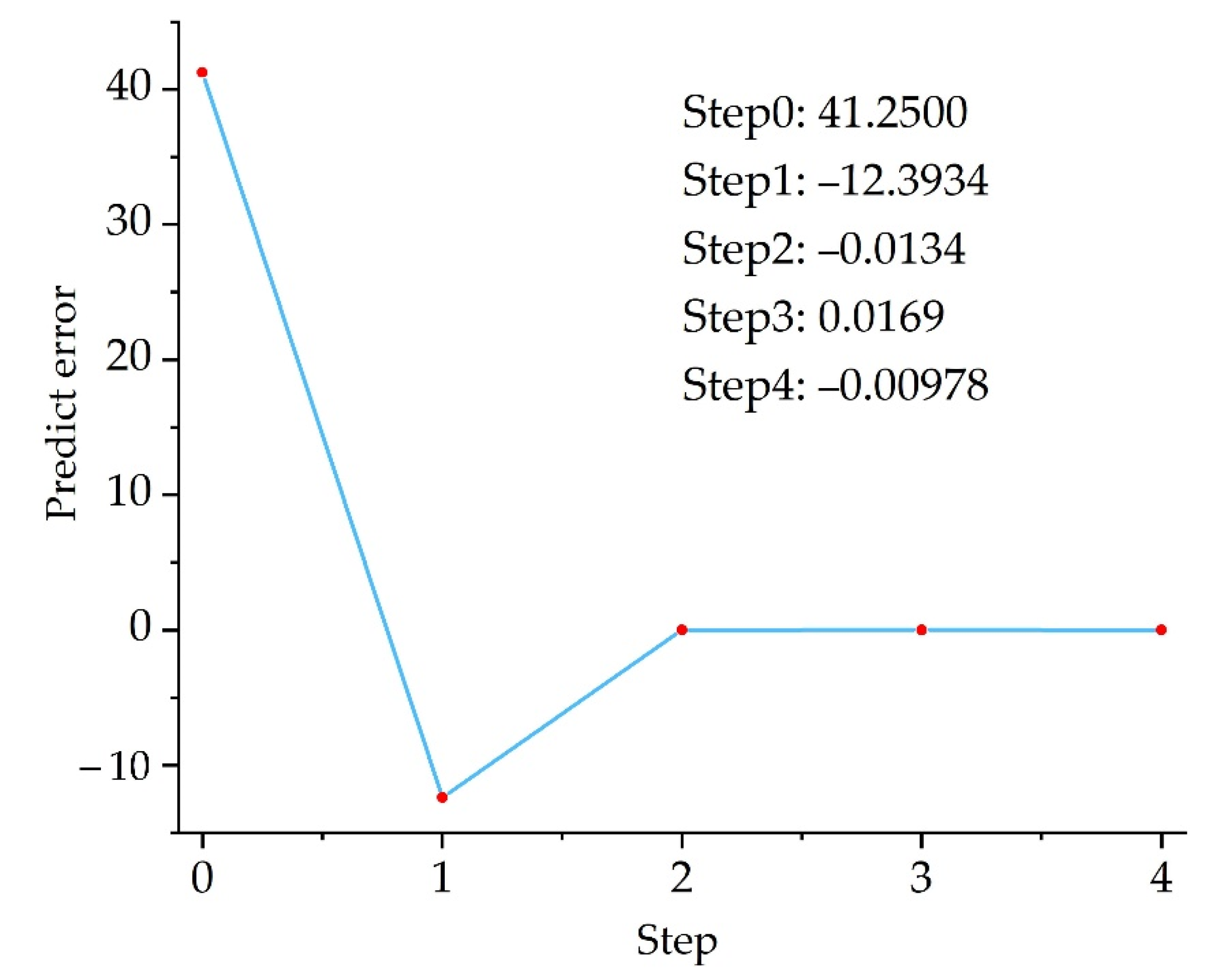
To check the fitting ability of this quadratic polynomial response surface model to the actual PF, after each iteration step, the error between the PF and the response surface model at the optimal design point is calculated (see
Figure 8). It can be seen from
Figure 8 that the sample points set at the beginning have a large error in the positive direction, and then the dynamic fitting strategy of the proposed method quickly adjusts the parameters, and even a negative error occurs; however, the absolute error is reduced. Finally, according to the errors of the first two steps, the fitting error of the response surface is quickly corrected and reduced, which shows that the surrogate model can fit the implicit PF well.
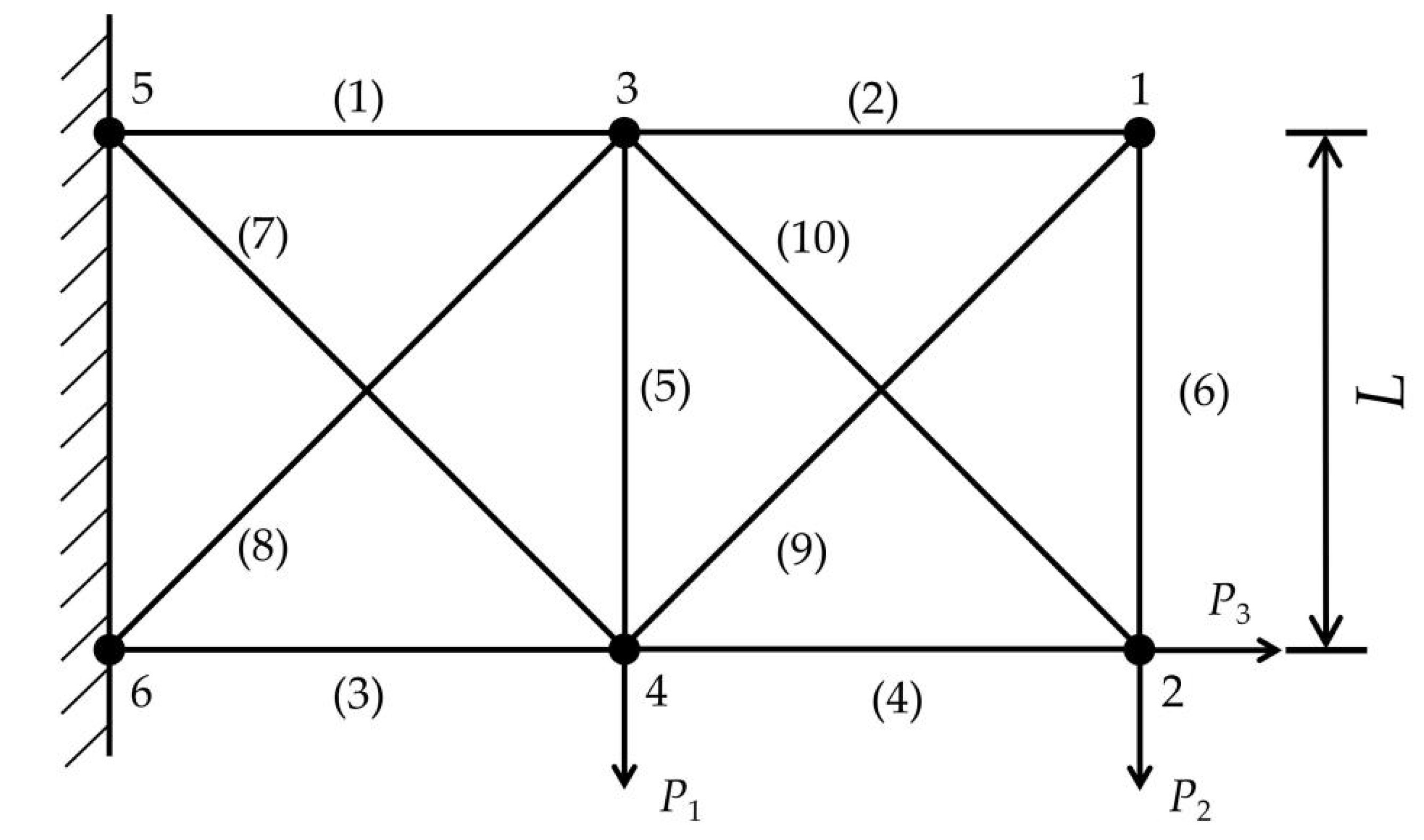
6.3. Example 3: A 10-Truss Girder
Example 3 is a 10-truss girder, as shown in
Figure 9. An interval model is used to solve the reliability index with an implicit PF. The length of the horizontal and vertical bars is
L, the cross-sectional area of each bar is
Ai (
i = 1, 2, …, 10), the elastic modulus is
E, and the acting positions of the external loads
P1,
P2, and
P3 are shown in the figure. Suppose
L,
Ai (
i = 1, 2, …, 10),
E,
P1,
P2, and
P3 are 15 relatively independent interval variables, the position and size parameters of which are shown in
Table 5.
The vertical displacement
D(
x) of node 2 is considered the intuitive stiffness index in this structure. Therefore, a PF can be established, with
D(
x) not exceeding 3% of
L:
The vertical displacement D(x) of node 2 is calculated by the FEA software ANSYS. The parameters of the GOA are set as follows: the dimension is D = 15, the population size is N = 60, the maximum and minimum adaptive shrinkage parameters are cmax = 1 and cmin = 1.0 × 10−5, the number of iterations is t = 5000, the upper and lower bounds of the model space are ul = 10 and fl = 0.0, and the search range of the scaling factor λ is [0, 10].
The calculation results are shown in
Table 6. In the table, the search result of the genetic algorithm is taken as the relatively accurate solution [
37]. The calculation results of the weighted linear RSM [
37] and the ANN [
37] are used as a comparison. The result of the weighted linear RSM is the highest, and the accuracy of the proposed method is similar to that of the ANN. However, the number of function calls of the proposed method is significantly lower than those of the above two methods, indicating that the number of FEA calls used in the calculation process of the proposed method is less, so the calculation speed is higher, and the method is more efficient. In another paper by the author of this paper [
59], the use of SVM to build a response surface model was proposed and applied to the same structural example. Note that the quadratic polynomial requires fewer samples than SVM, the regression effect is more stable, and the support vector fitting effect is too dependent on the hyperparameters.
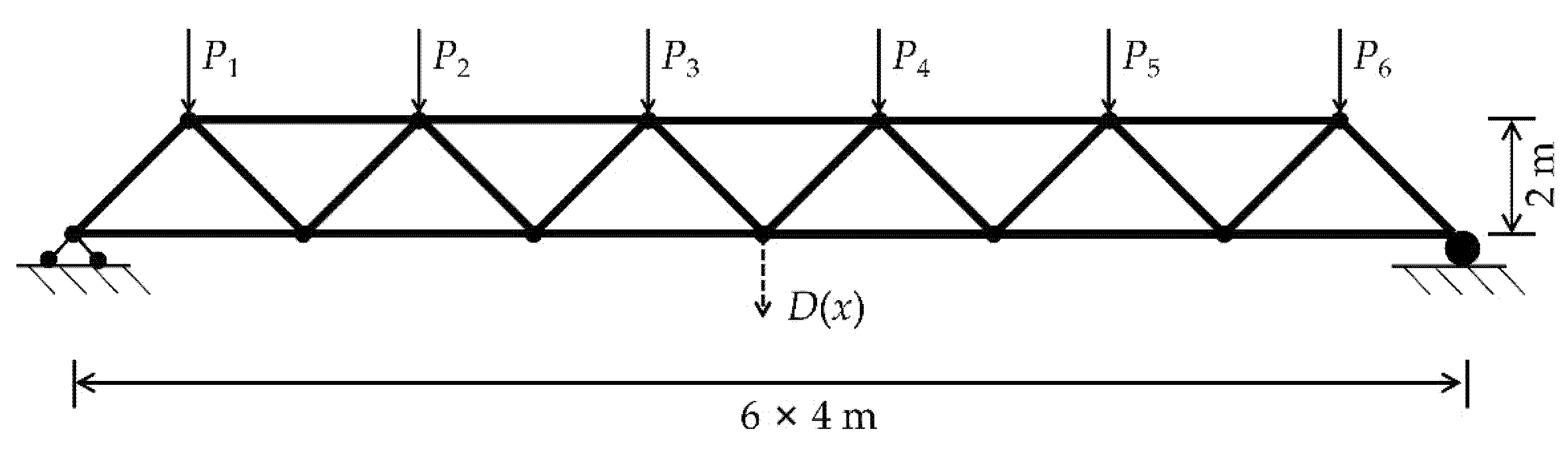
6.4. Example 4: A 23-Truss Girder
Example 4 is a 23-truss girder, as shown in
Figure 10 [
60]. A mixed model is used to solve the reliability index with an implicit PF.
E is the elastic modulus,
A is the cross-sectional area, the load
P is the uncertain variable of the convex model, and the parameter distributions of the uncertain variables are shown in
Table 7.
The vertical displacement
D(
x) of the midpoint is considered the intuitive stiffness index in this structure. Therefore, the performance can be established, with
D(
x) not exceeding 0.15 m:
The vertical displacement D(x) of the midpoint is calculated by the FEA software ANSYS. The parameters of the GOA are set as follows: the dimension is D = 10, the population size is N = 80, the maximum and minimum adaptive shrinkage parameters are cmax = 1 and cmin = 1.0 × 10−5, the number of iterations is t = 6000, the upper and lower bounds of the model space are ul = 20.0 and fl = 0.0, and the search range of the scaling factor λ is [0, 10].
In
Table 8, the MCS method is used to simulate 10
6 calculation results as a relatively accurate solution, and the result of directly using the quadratic polynomial RSM based on sequential quadratic programming (RSM-SQP, implemented using the MATLAB toolbox) to solve the optimization problem of Equation (4) is used as a comparison. It can be seen that in terms of both the number of function calls and the accuracy of the reliability index, the proposed method is better than RSM-SQP.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}