




Environment-Aware Worker Trajectory Prediction Using Surveillance Camera in Modular Construction Facilities

_Mei.png)

Abstract
:1. Introduction
- (1)
- A novel formulation of trajectory prediction algorithms is developed in modular construction facilities to fully exploit workplace contextual information, including not only worker-to-worker interactions but also environment-to-worker interactions;
- (2)
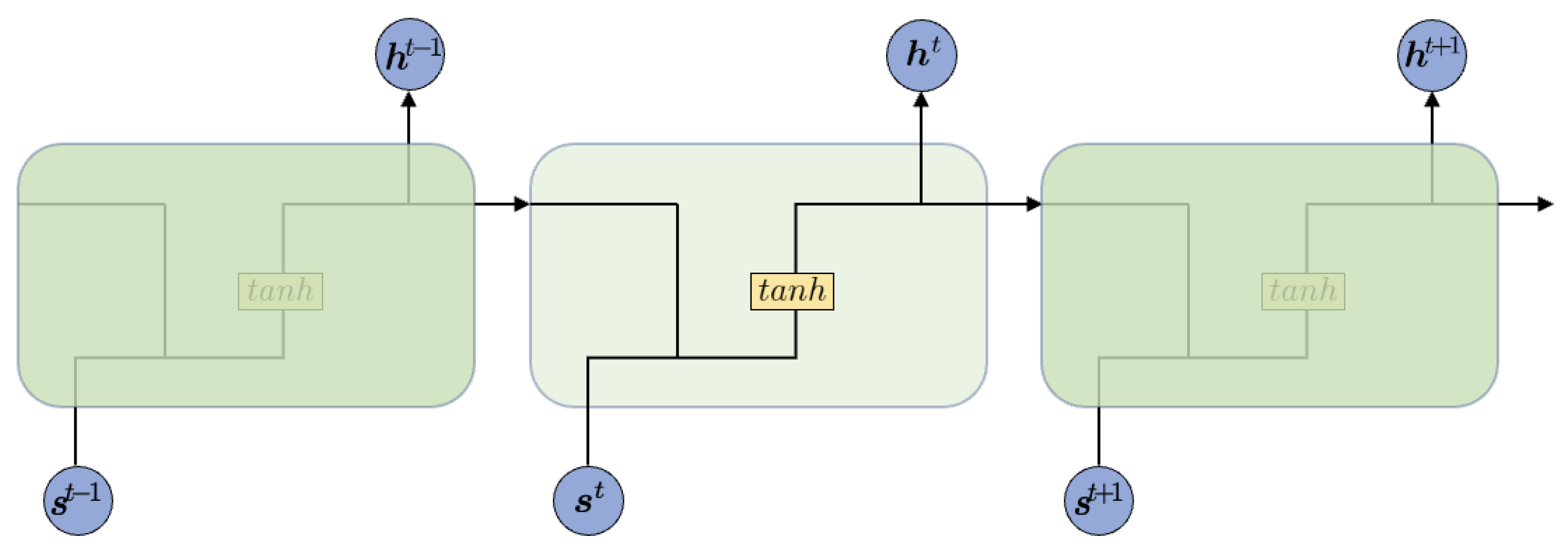
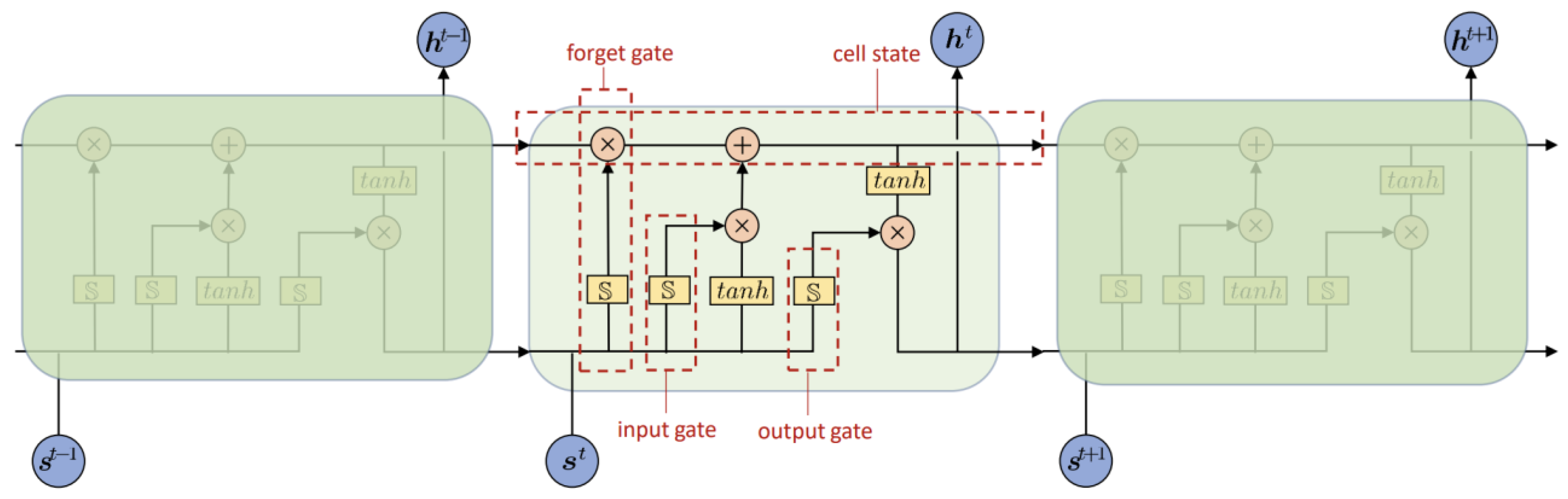
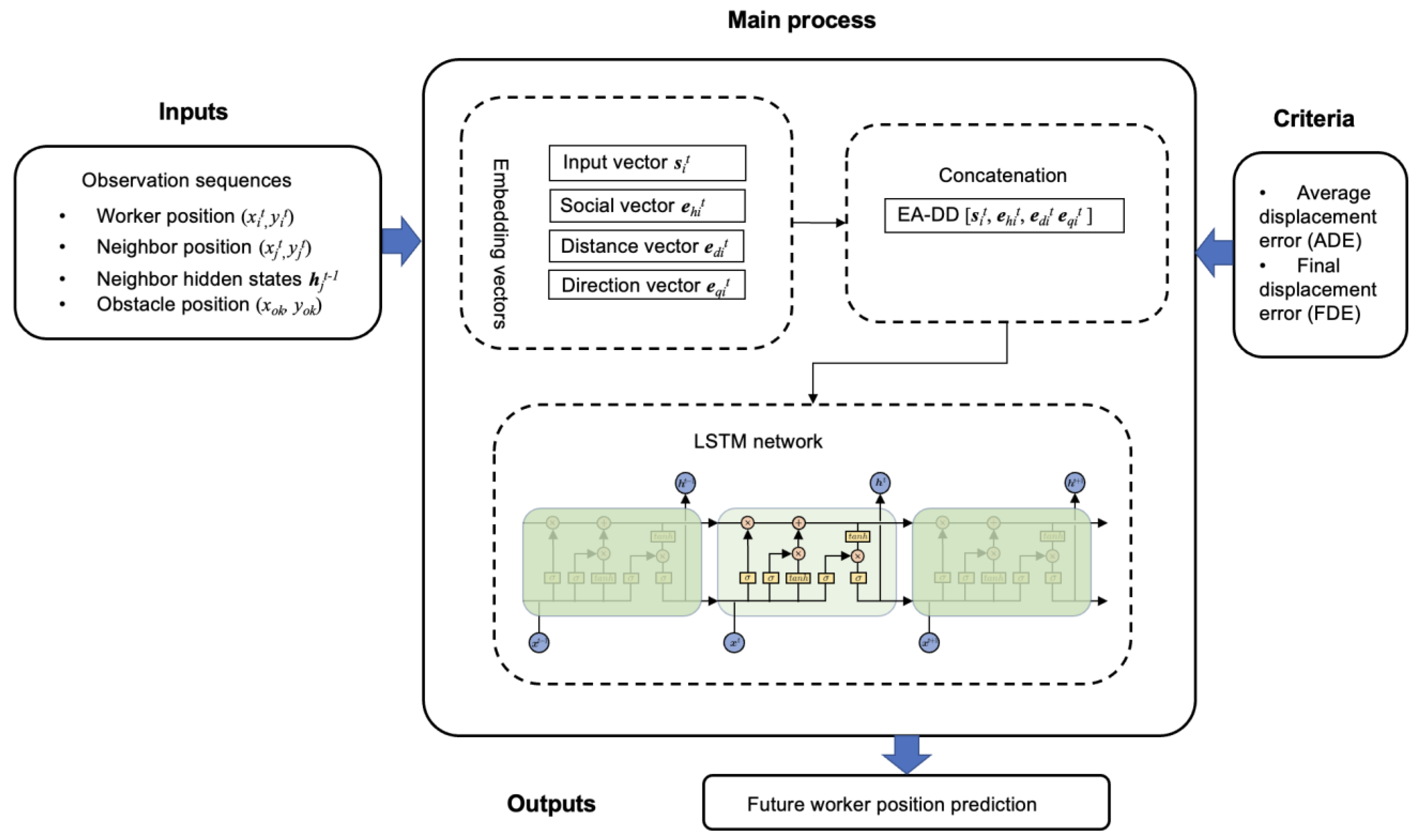
- Every worker path is modeled through an LSTM network with a novel pooling that captures the interactions among workers as well as the relative distance and/or direction with the surrounding static objects;
- (3)
- A systematic and flexible framework is offered to incorporate general environment information into the traditional trajectory prediction model in modular construction facilities.
2. Related Work
3. Method
3.1. Problem Formulation
3.2. Environment-Aware Trajectory Prediction
4. Results
4.1. Implementation Details
4.2. Evaluation Metrics
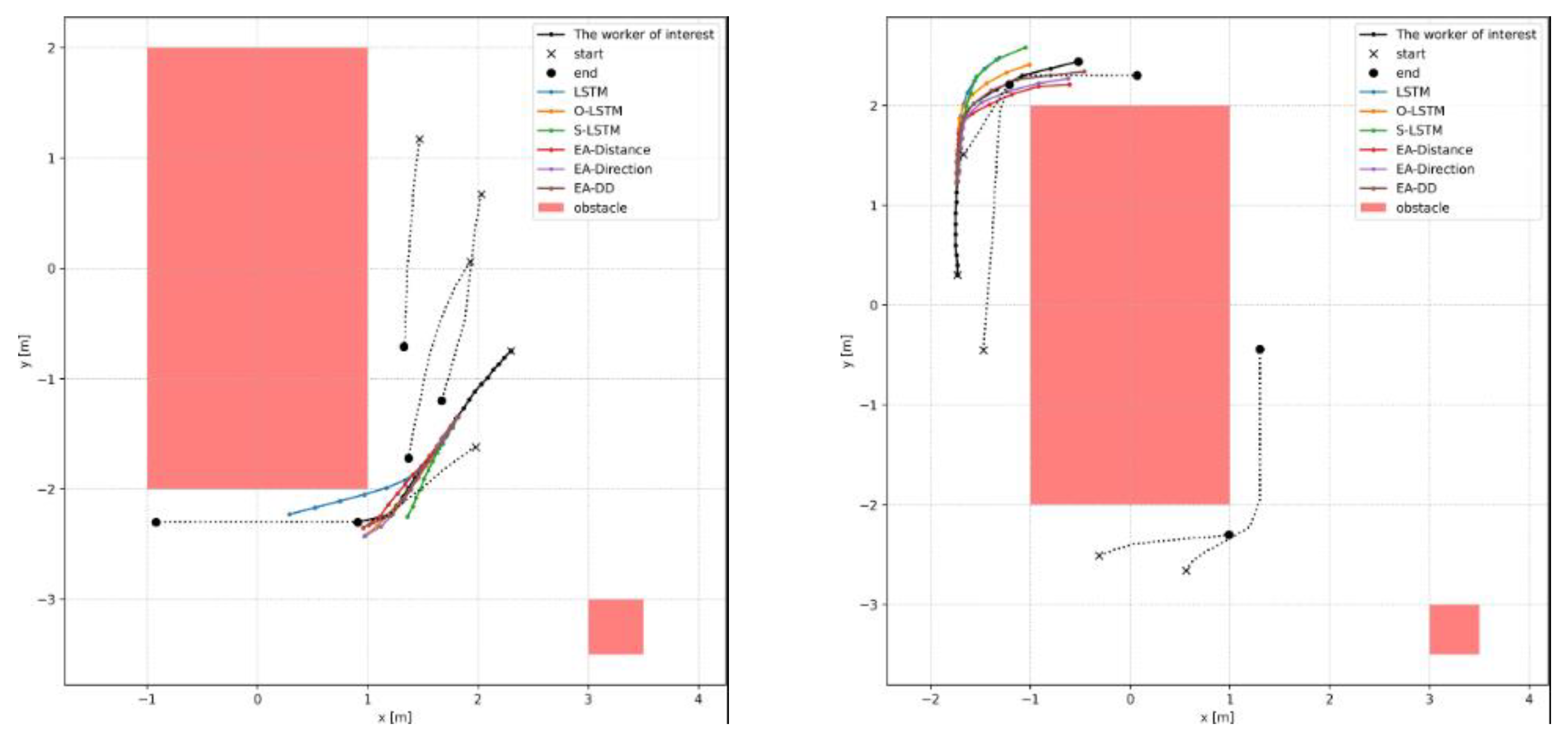
4.3. Synthetic Experiments
4.4. Modular Construction Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social LSTM: Human Trajectory Prediction in Crowded Spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Alazzaz, F.; Whyte, A. Uptake of Off-Site Construction: Benefit and Future Application. Int. J. Civ. Archit. Struct. Constr. Eng. 2014, 8, 5. [Google Scholar]
- Altche, F.; de La Fortelle, A. An LSTM network for highway trajectory prediction. In Proceedings of the 20th IEEE International Conference on Intelligent Transportation Systems, Yokohama, Japan, 16–19 October 2017; pp. 353–359. [Google Scholar] [CrossRef] [Green Version]
- Ballan, L.; Castaldo, F.; Alahi, A.; Palmieri, F.; Savarese, S. Knowledge Transfer for Scene-Specific Motion Prediction. In Computer Vision; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 697–713. [Google Scholar] [CrossRef] [Green Version]
- Bartoli, F.; Lisanti, G.; Ballan, L.; Del Bimbo, A. Context-Aware Trajectory Prediction. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1941–1946. [Google Scholar] [CrossRef] [Green Version]
- Bokhari, S.Z.; Kitani, K.M. Long-Term Activity Forecasting Using First-Person Vision. In Computer Vision; Lai, S.-H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2017; pp. 346–360. [Google Scholar] [CrossRef]
- Bureau of Labor Statistics. Employer-Reported Workplace Injuries and Illnesses—2020; Bureau of Labor Statistics: Washington, DC, USA, 2020; p. 9.
- Cai, J.; Zhang, Y.; Yang, L.; Cai, H.; Li, S. A context-augmented deep learning approach for worker trajectory prediction on unstructured and dynamic construction sites. Adv. Eng. Inform. 2020, 46, 101173. [Google Scholar] [CrossRef]
- Ding, L.; Fang, W.; Luo, H.; Love, P.E.; Zhong, B.; Ouyang, X. A deep hybrid learning model to detect unsafe behavior: Integrating convolution neural networks and long short-term memory. Autom. Constr. 2018, 86, 118–124. [Google Scholar] [CrossRef]
- Dong, C.; Li, H.; Luo, X.; Ding, L.; Siebert, J.; Luo, H. Proactive struck-by risk detection with movement patterns and randomness. Autom. Constr. 2018, 91, 246–255. [Google Scholar] [CrossRef]
- Gupta, A.; Johnson, J.; Fei-Fei, L.; Savarese, S.; Alahi, A. Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2255–2264. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Jeong, G.; Kim, H.; Lee, H.-S.; Park, M.; Hyun, H. Analysis of safety risk factors of modular construction to identify accident trends. J. Asian Arch. Build. Eng. 2021, 21, 1040–1052. [Google Scholar] [CrossRef]
- Karasev, V.; Ayvaci, A.; Heisele, B.; Soatto, S. Intent-Aware Long-Term Prediction of Pedestrian Motion. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2543–2549. [Google Scholar] [CrossRef]
- Kim, D.; Liu, M.; Lee, S.; Kamat, V.R. Trajectory Prediction of Mobile Construction Resources Toward Pro-Active Struck-by Hazard Detection. In International Symposium on Automation and Robotics in Construction; International Association for Automation and Robotics in Construction (IAARC): Banff, AB, Canada, 2019. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. ArXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Kitani, K.M.; Ziebart, B.D.; Bagnell, J.A.; Hebert, M. Activity Forecasting. In Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 201–214. [Google Scholar] [CrossRef]
- Kooij, J.F.P.; Schneider, N.; Flohr, F.; Gavrila, D.M. Context-Based Pedestrian Path Prediction. In Computer Vision; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; pp. 618–633. [Google Scholar] [CrossRef] [Green Version]
- Kothari, P.; Kreiss, S.; Alahi, A. Human Trajectory Forecasting in Crowds: A Deep Learning Perspective. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7386–7400. [Google Scholar] [CrossRef]
- Lasota, P.A.; Fong, T.; Shah, J.A. A Survey of Methods for Safe Human-Robot Interaction. Found. Trends Robot. 2014, 5, 261–349. [Google Scholar] [CrossRef]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.; Chandraker, M. DESIRE: Distant Future Prediction in Dynamic Scenes with Interacting Agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 336–345. [Google Scholar]
- Lerner, A.; Chrysanthou, Y.; Lischinski, D. Crowds by Example. Comput. Graph. Forum 2007, 26, 655–664. [Google Scholar] [CrossRef]
- Luo, H.; Xiong, C.; Fang, W.; Love, P.E.; Zhang, B.; Ouyang, X. Convolutional neural networks: Computer vision-based workforce activity assessment in construction. Autom. Constr. 2018, 94, 282–289. [Google Scholar] [CrossRef]
- Ma, M.; Nikolakopoulos, A.N.; Giannakis, G.B. Hybrid ADMM: A unifying and fast approach to decentralized optimization. EURASIP J. Adv. Signal Process. 2018, 2018, 73. [Google Scholar] [CrossRef]
- Ma, W.C.; Huang, D.A.; Lee, N.; Kitani, K.M. Forecasting Interactive Dynamics of Pedestrians with Fictitious Play. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 774–782. [Google Scholar]
- Mei, Q.; Gül, M. A cost effective solution for pavement crack inspection using cameras and deep neural networks. Constr. Build. Mater. 2020, 256, 119397. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: San Jose, CA, USA, 2019; Volume 32. [Google Scholar]
- Pellegrini, S.; Ess, A.; Schindler, K.; Van Gool, L. You’ll Never Walk Alone: Modeling Social Behavior for Multi-Target Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 261–268. [Google Scholar] [CrossRef] [Green Version]
- Rashid, K.M.; Behzadan, A.H. Risk Behavior-Based Trajectory Prediction for Construction Site Safety Monitoring. J. Constr. Eng. Manag. 2018, 144, 04017106. [Google Scholar] [CrossRef]
- Rashid, K.M.; Louis, J. Activity identification in modular construction using audio signals and machine learning. Autom. Constr. 2020, 119, 103361. [Google Scholar] [CrossRef]
- Rhinehart, N.; Kitani, K.M. First-Person Activity Forecasting with Online Inverse Reinforcement Learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3696–3705. [Google Scholar]
- Rudenko, A.; Palmieri, L.; Herman, M.; Kitani, K.M.; Gavrila, D.M.; O Arras, K. Human motion trajectory prediction: A survey. Int. J. Robot. Res. 2020, 39, 895–935. [Google Scholar] [CrossRef]
- Sadeghi, A.; Wang, G.; Giannakis, G.B. Deep Reinforcement Learning for Adaptive Caching in Hierarchical Content Delivery Networks. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 1024–1033. [Google Scholar] [CrossRef] [Green Version]
- Saleh, K.; Hossny, M.; Nahavandi, S. Intent Prediction of Pedestrians via Motion Trajectories Using Stacked Recurrent Neural Networks. IEEE Trans. Intell. Veh. 2018, 3, 414–424. [Google Scholar] [CrossRef]
- Schneider, N.; Gavrila, D.M. Pedestrian Path Prediction with Recursive Bayesian Filters: A Comparative Study. In Pattern Recognition; Weickert, J., Hein, M., Schiele, B., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 174–183. [Google Scholar] [CrossRef] [Green Version]
- Seo, J.; Han, S.; Lee, S.; Kim, H. Computer vision techniques for construction safety and health monitoring. Adv. Eng. Informatics 2015, 29, 239–251. [Google Scholar] [CrossRef]
- Song, J.; Haas, C.T.; Caldas, C.H. Tracking the Location of Materials on Construction Job Sites. J. Constr. Eng. Manag. 2006, 132, 911–918. [Google Scholar] [CrossRef] [Green Version]
- Teizer, J.; Venugopal, M.; Walia, A. Ultrawideband for Automated Real-Time Three-Dimensional Location Sensing for Workforce, Equipment, and Material Positioning and Tracking. Transp. Res. Rec. J. Transp. Res. Board 2008, 2081, 56–64. [Google Scholar] [CrossRef]
- Berg, J.V.D.; Lin, M.; Manocha, D. Reciprocal Velocity Obstacles for Real-Time Multi-Agent Navigation. In Proceedings of the IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 1928–1935. [Google Scholar] [CrossRef] [Green Version]
- Vemula, A.; Muelling, K.; Oh, J. Social Attention: Modeling Attention in Human Crowds. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; pp. 4601–4607. [Google Scholar] [CrossRef] [Green Version]
- Wells, J. The Construction Industry in Developing Countries: Alternative Strategies for Development; Croom Helm: Beckenham, Kent, UK, 1986.
- Xiao, B.; Xiao, H.; Wang, J.; Chen, Y. Vision-based method for tracking workers by integrating deep learning instance segmentation in off-site construction. Autom. Constr. 2022, 136, 104148. [Google Scholar] [CrossRef]
- Xu, Y.; Piao, Z.; Gao, S. Encoding Crowd Interaction with Deep Neural Network for Pedestrian Trajectory Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5275–5284. [Google Scholar]
- Yang, Q.; Mei, Q.; Fan, C.; Ma, M.; Li, X. Environment-Aware Worker Trajectory Prediction Using Surveillance Camera on Modular Construction Sites. In Proceedings of the Modular and Offsite Construction Summit, Edmonton, AB, Canada, 27–29 July 2022; pp. 1–8. [Google Scholar]
- Yang, Q.; Wang, G.; Sadeghi, A.; Giannakis, G.B.; Sun, J. Two-Timescale Voltage Control in Distribution Grids Using Deep Reinforcement Learning. IEEE Trans. Smart Grid 2019, 11, 2313–2323. [Google Scholar] [CrossRef] [Green Version]
- Yi, S.; Li, H.; Wang, X. Pedestrian Behavior Understanding and Prediction with Deep Neural Networks. In Computer Vision; Springer International Publishing: Cham, Switzerland, 2016; pp. 263–279. [Google Scholar] [CrossRef]
- Yu, Y.; Guo, H.; Ding, Q.; Li, H.; Skitmore, M. An experimental study of real-time identification of construction workers’ unsafe behaviors. Autom. Constr. 2017, 82, 193–206. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Ziebart, B.D.; Ratliff, N.; Gallagher, G.; Mertz, C.; Peterson, K.; Bagnell, J.A.; Hebert, M.; Dey, A.K.; Srinivasa, S. Planning-Based Prediction for Pedestrians. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 3931–3936. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
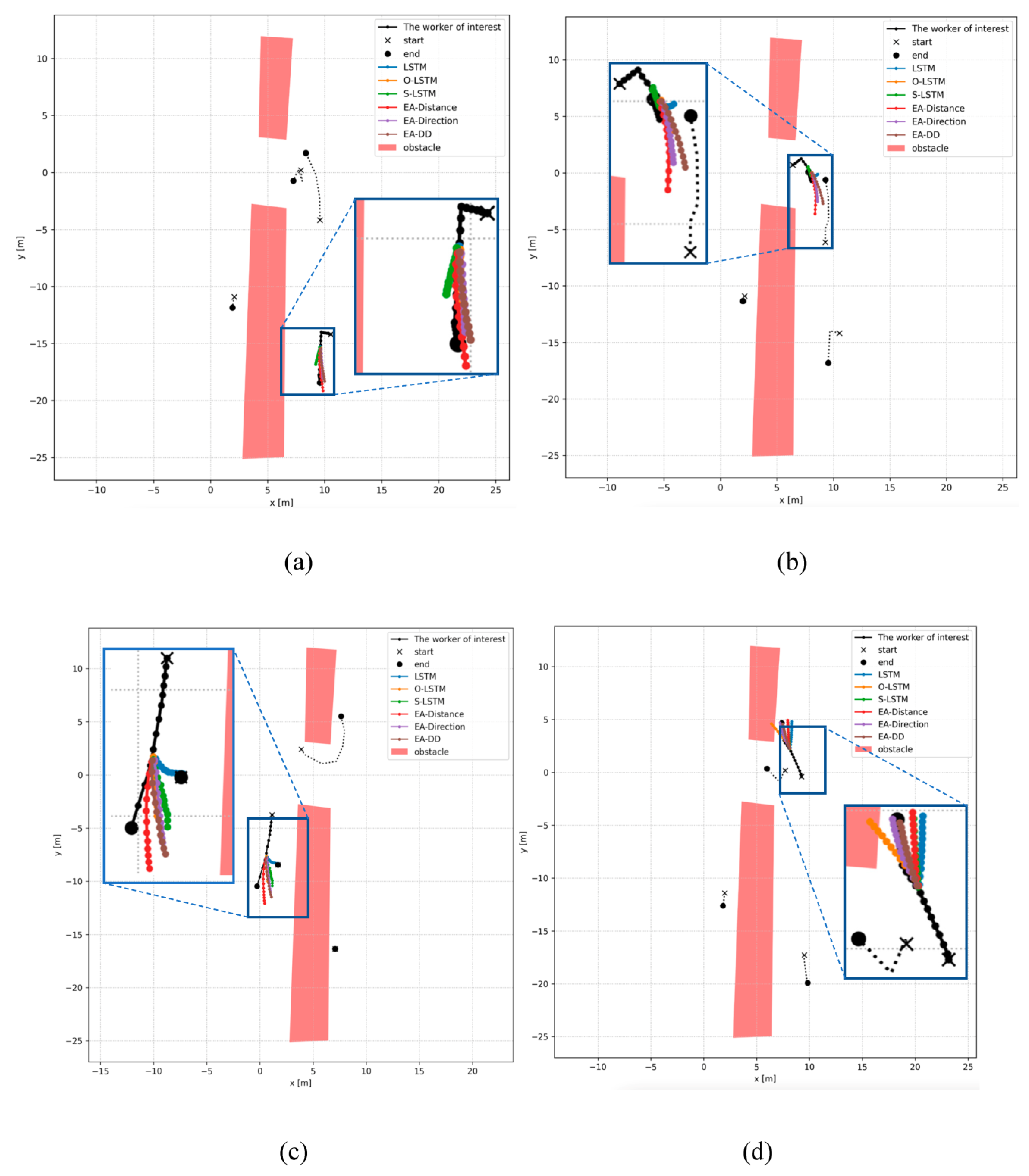{kind=link}
| Category | Method | Input | Reference |
|---|---|---|---|
| Bayesian models | Kalman filter | Coordinate, velocity | [22] |
| Dynamic Bayesian network | Coordinate, head orientation, distance to road | [23,28] | |
| Probabilistic planning | Markov model | Coordinate and moving direction | [24,29] |
| Markov decision process | Environment-aware coordinate | [25,26,30] | |
| Data-driven methods | Convolutional neural network | Coordinate | [31] |
| Inverse reinforcement learning | Coordinate, goal | [32,33,34] | |
| Recurrent neural network | Video | [35] | |
| Social-LSTM | Coordinate, neighbor coordinate | [15] | |
| Encoder-decoder LSTM | Coordinate, neighbor coordinate, group, goal | [17] | |
| Social generative adversarial network | Coordinate, neighbor coordinate | [36,37] |
| Model Name | ADE (m) | FDE (m) | Time (s) |
|---|---|---|---|
| LSTM | 0.36 | 0.89 | 0.16 |
| O-LSTM [15] | 0.31 | 0.74 | 0.39 |
| S-LSTM [15] | 0.28 | 0.67 | 0.82 |
| EA-Distance [45] | 0.30 | 0.69 | 0.93 |
| EA-Direction [45] | 0.24 | 0.55 | 0.95 |
| EA-DD | 0.22 | 0.50 | 1.03 |
| Model Name | ADE (m) | FDE (m) |
|---|---|---|
| LSTM | 1.98 | 3.52 |
| O-LSTM [15] | 1.62 | 2.91 |
| S-LSTM [15] | 1.60 | 2.86 |
| EA-Distance [45] | 1.56 | 2.03 |
| EA-Direction [45] | 1.50 | 1.91 |
| EA-DD | 1.48 | 1.85 |
| Number | Observation (s) | Prediction (s) | ADE (m) | FDE (m) |
|---|---|---|---|---|
| 1 | 2.8 | 4.8 | 0.35 | 0.93 |
| 2 | 3.2 | 4.8 | 0.26 | 0.72 |
| 3 | 3.6 | 4.8 | 0.22 | 0.50 |
| 4 | 4.4 | 4.8 | 0.23 | 0.52 |
| 5 | 4.8 | 4.8 | 0.30 | 0.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Q.; Mei, Q.; Fan, C.; Ma, M.; Li, X. Environment-Aware Worker Trajectory Prediction Using Surveillance Camera in Modular Construction Facilities. Buildings 2023, 13, 1502. https://doi.org/10.3390/buildings13061502
Yang Q, Mei Q, Fan C, Ma M, Li X. Environment-Aware Worker Trajectory Prediction Using Surveillance Camera in Modular Construction Facilities. Buildings. 2023; 13(6):1502. https://doi.org/10.3390/buildings13061502
Chicago/Turabian StyleYang, Qiuling, Qipei Mei, Chao Fan, Meng Ma, and Xinming Li. 2023. "Environment-Aware Worker Trajectory Prediction Using Surveillance Camera in Modular Construction Facilities" Buildings 13, no. 6: 1502. https://doi.org/10.3390/buildings13061502
APA StyleYang, Q., Mei, Q., Fan, C., Ma, M., & Li, X. (2023). Environment-Aware Worker Trajectory Prediction Using Surveillance Camera in Modular Construction Facilities. Buildings, 13(6), 1502. https://doi.org/10.3390/buildings13061502