
Interoperability between Deep Neural Networks and 3D Architectural Modeling Software: Affordances of Detection and Segmentation

Abstract
:1. Introduction
- Propose a comprehensive post-processing workflow for refining object detection and instance segmentation outputs to generate 3D models.
- Explore and present the considerations involved in choosing between object detection and instance segmentation for recognizing building systems. Additionally, examine instances of object recognition failures and their consequences on interoperability with modeling software.
- Provide possible post-process algorithms to facilitate interoperability between neural networks and 3D modeling software.
- The team’s developing machine learning systems will be able to perform resource allocation more effectively, understanding the tradeoff between data labeling effort and building component recognition capabilities and affordances.
- Inform human-in-the-loop automated modeling quality control checklists.
2. Related Work
2.1. Processing 2D Floor Plans Using Object Detection and Instance Segmentation
2.2. Different Approaches for 3D Model Generation
3. Methodology
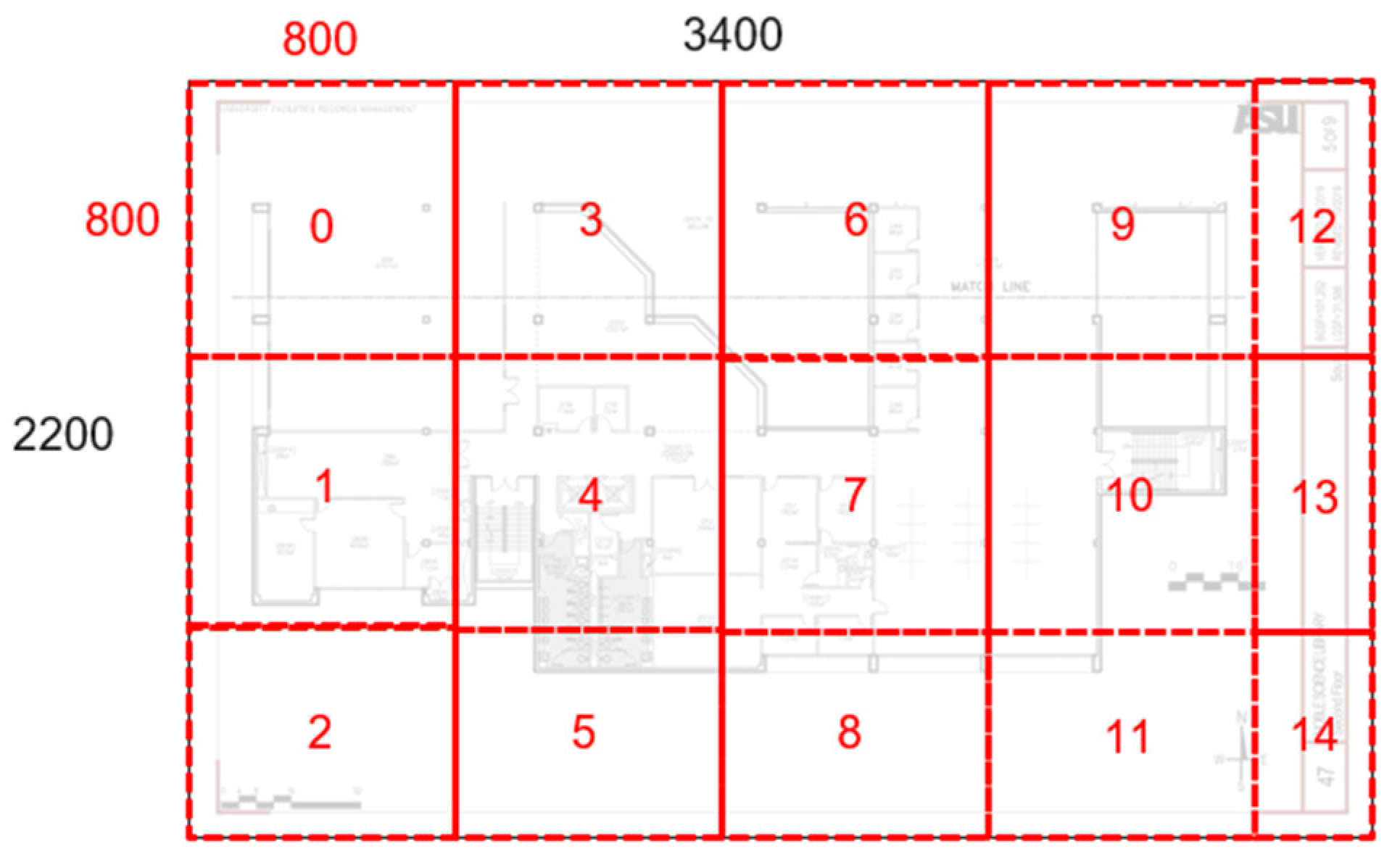
3.1. Data Creation
3.2. Object Detection and Instance Segmentation Model Training
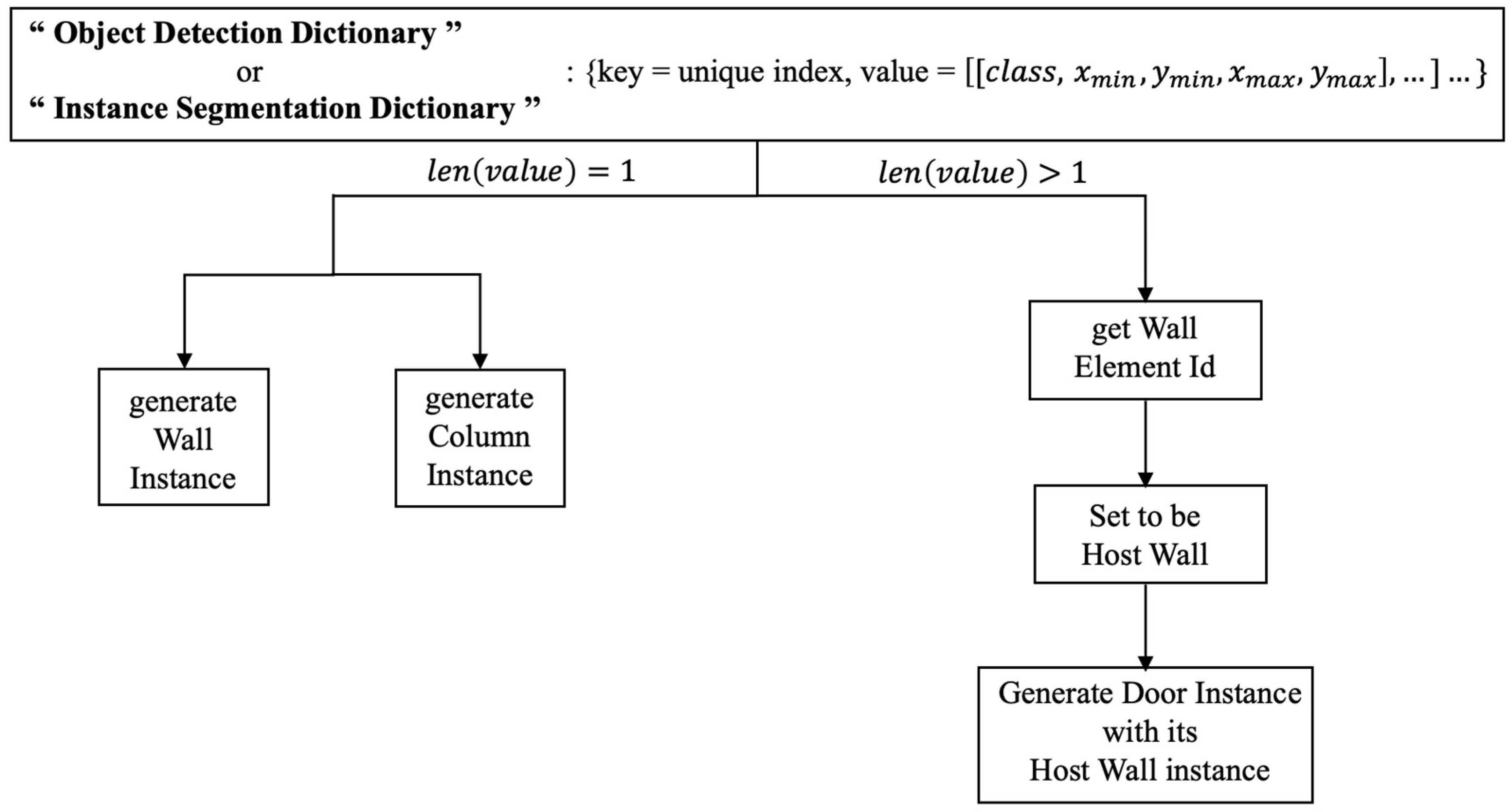
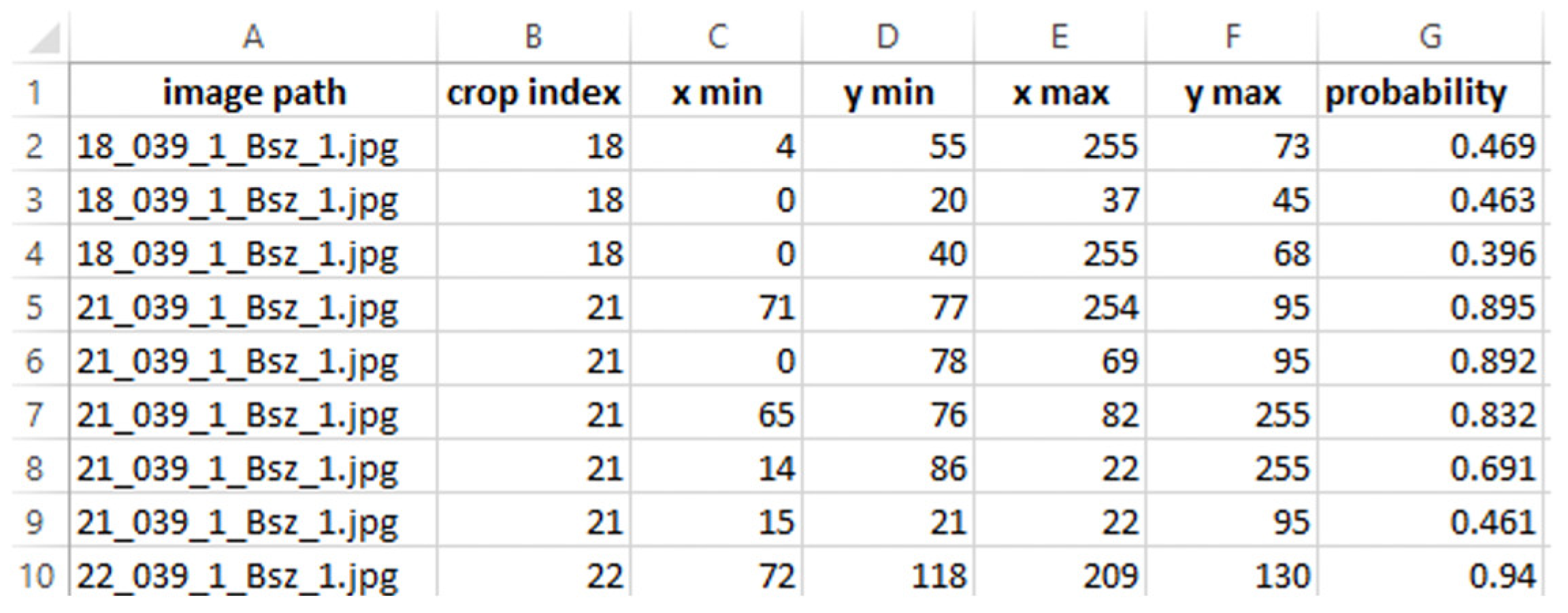
3.3. Object Detection Inference and Post-Processing
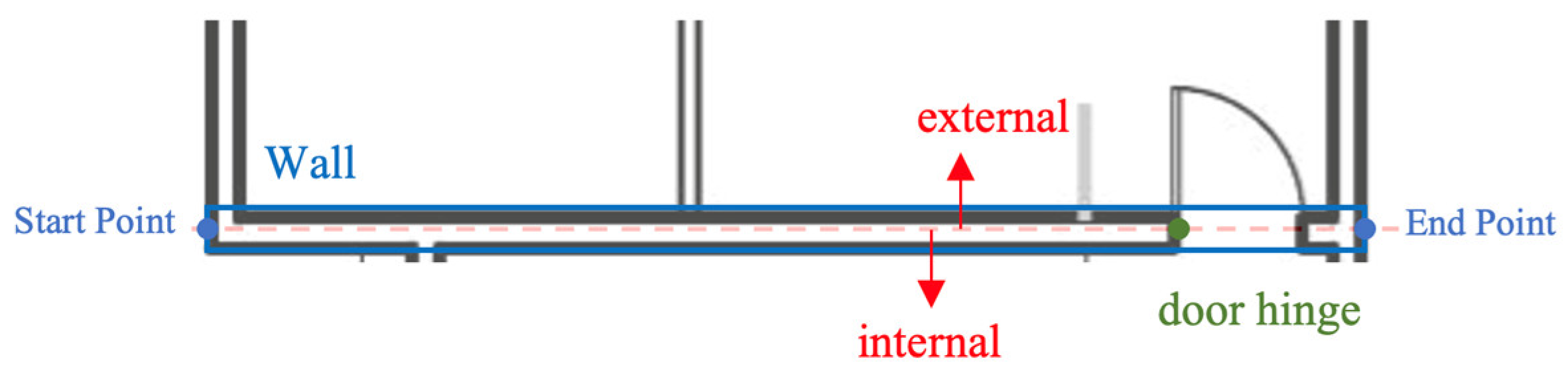
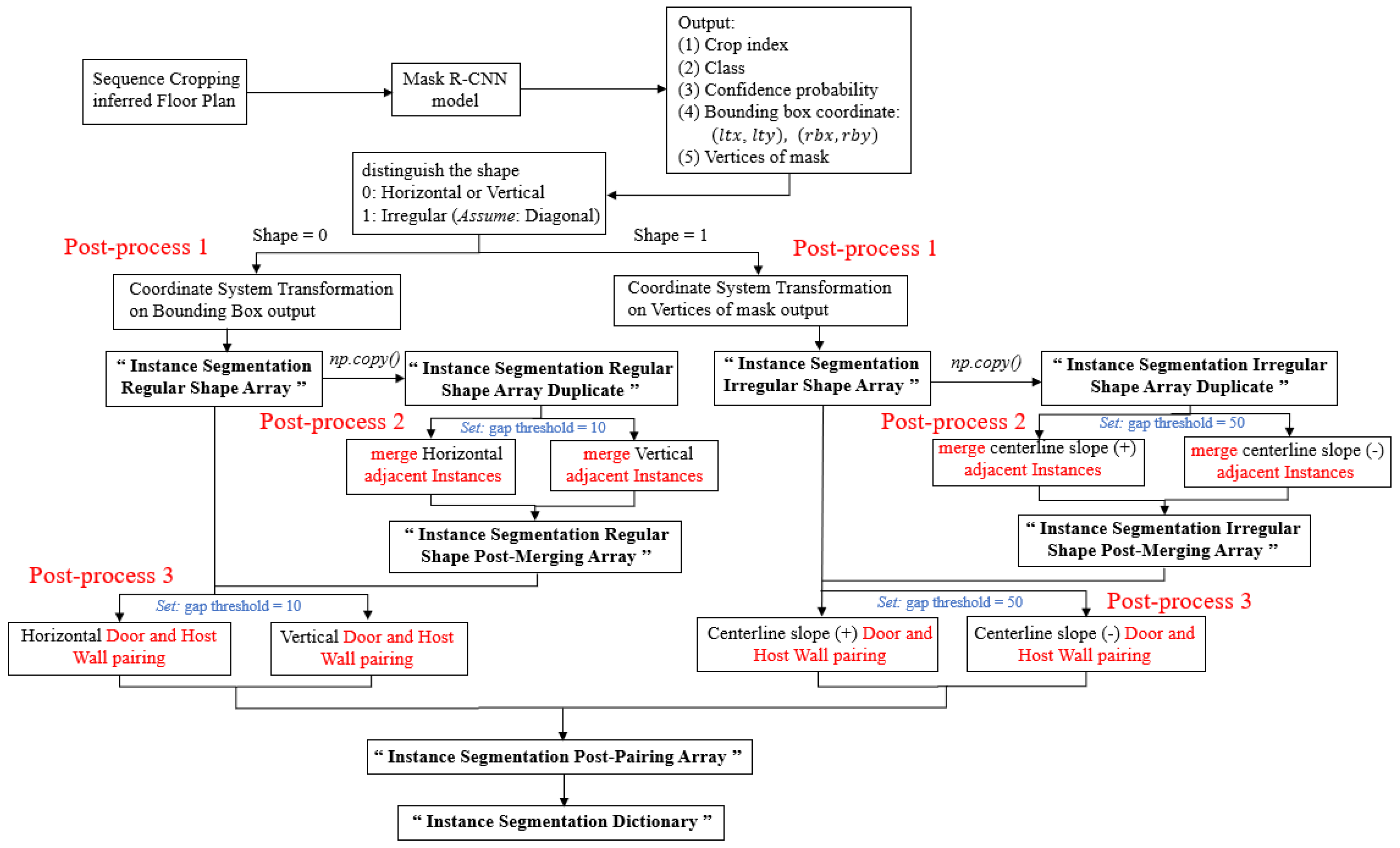
3.3.1. Post-Process 1: Coordination System Transformation
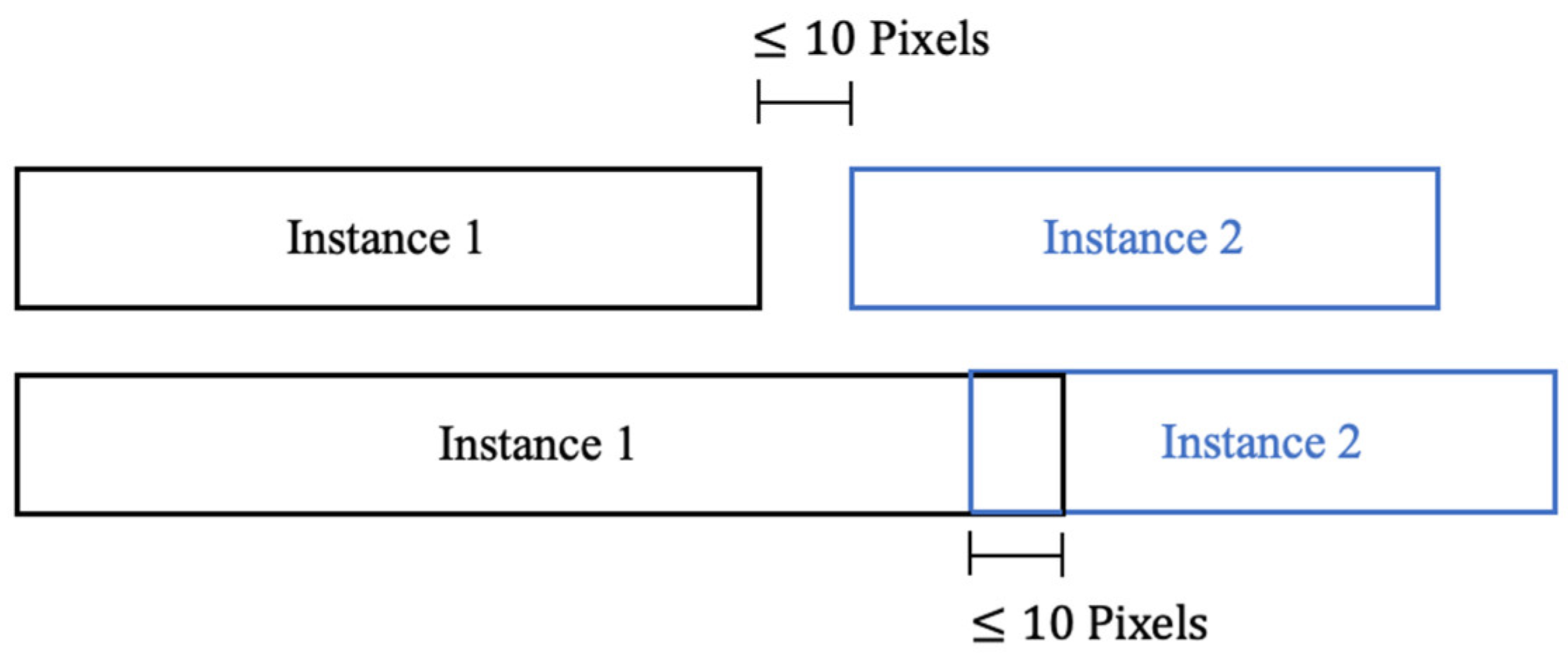
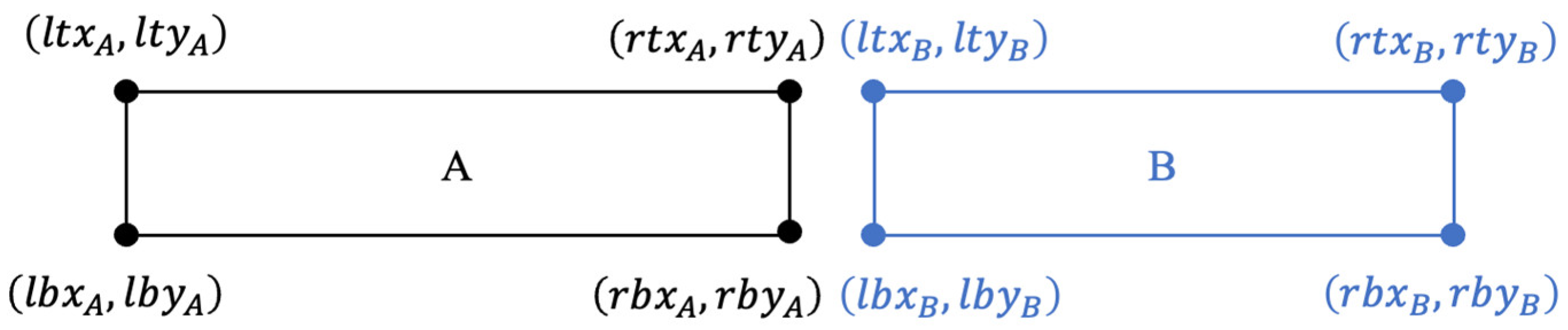
3.3.2. Post-Process 2: Merging Adjacent Instances
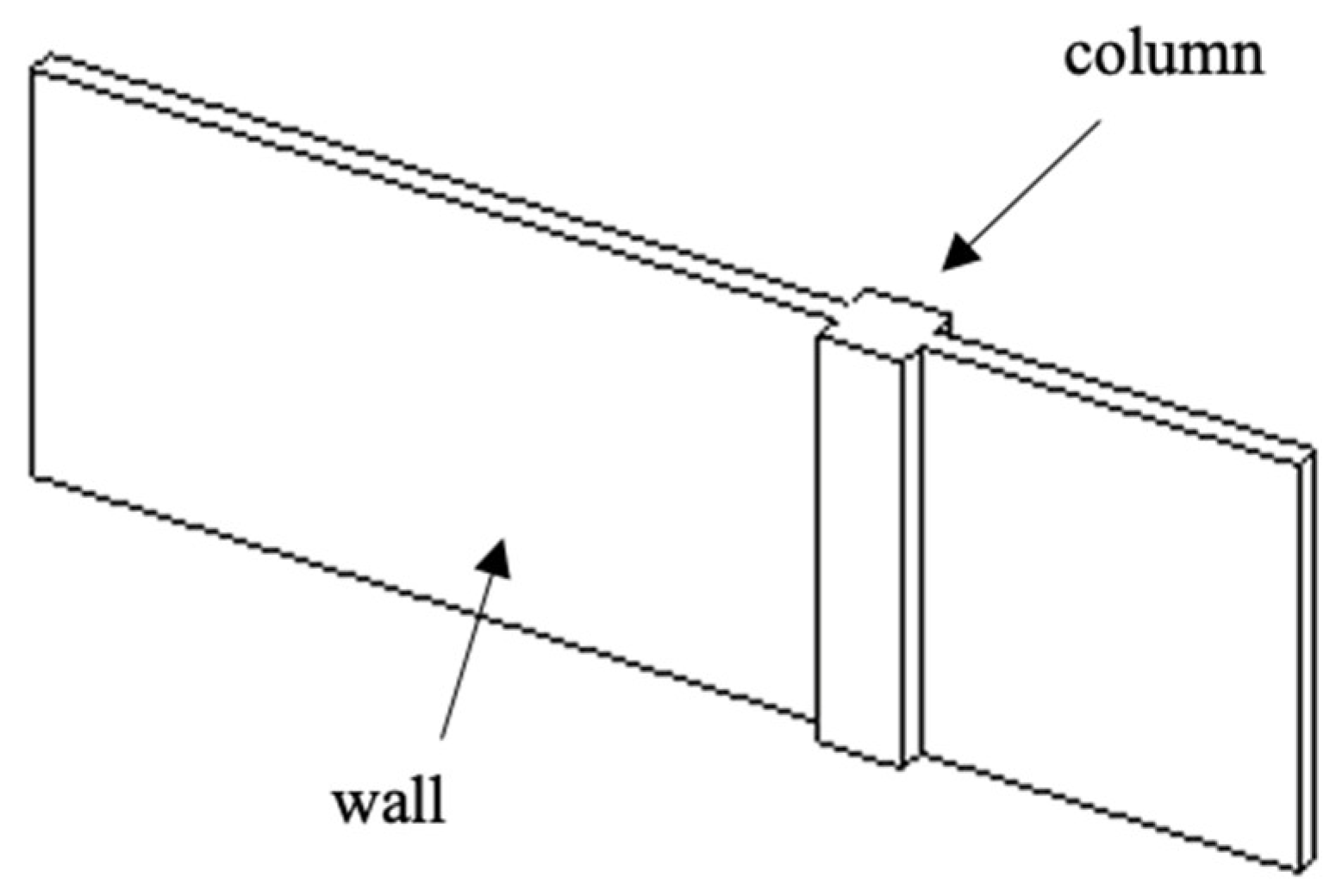
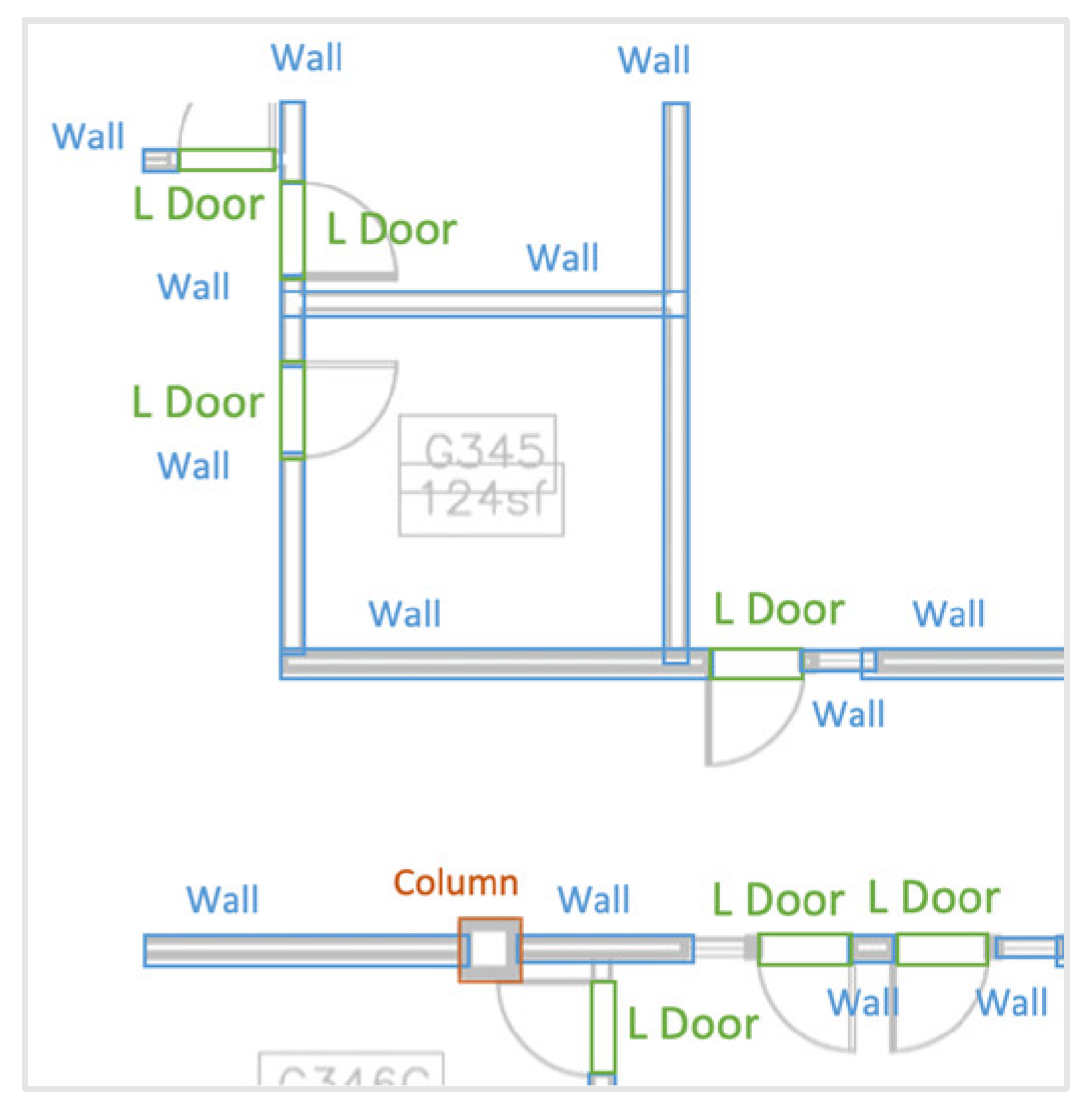
3.3.3. Post-Process 3: Pairing Door and Host Wall Instances
3.4. Instance Segmentation Inference and Post-Processing
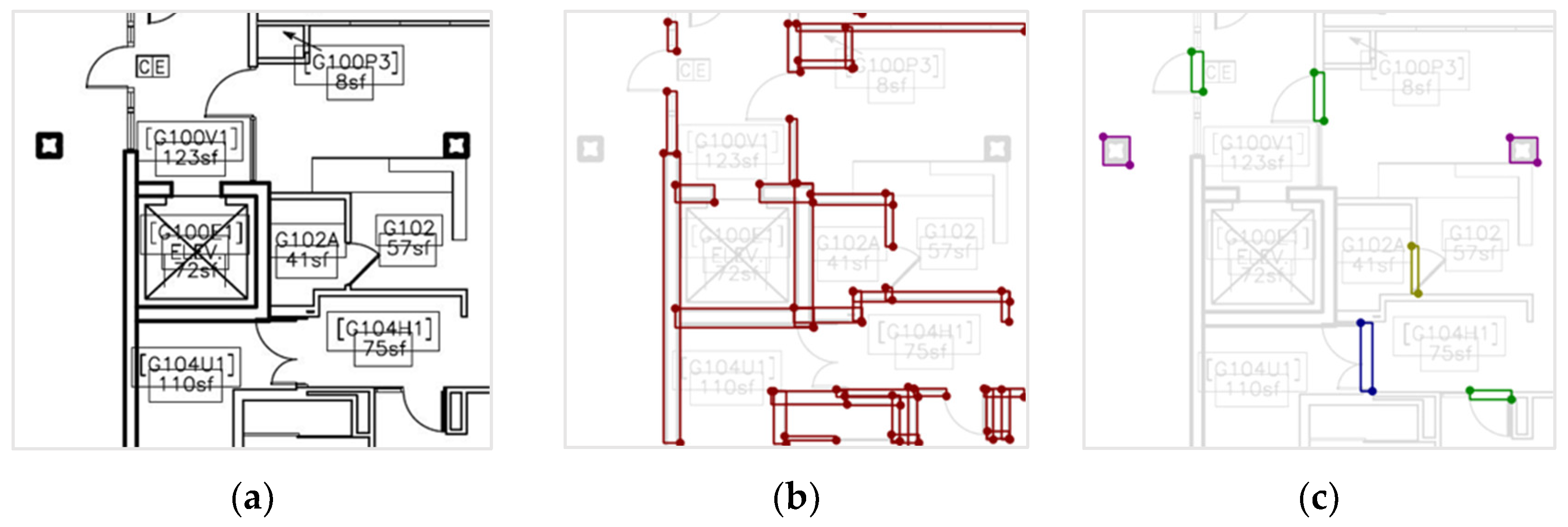
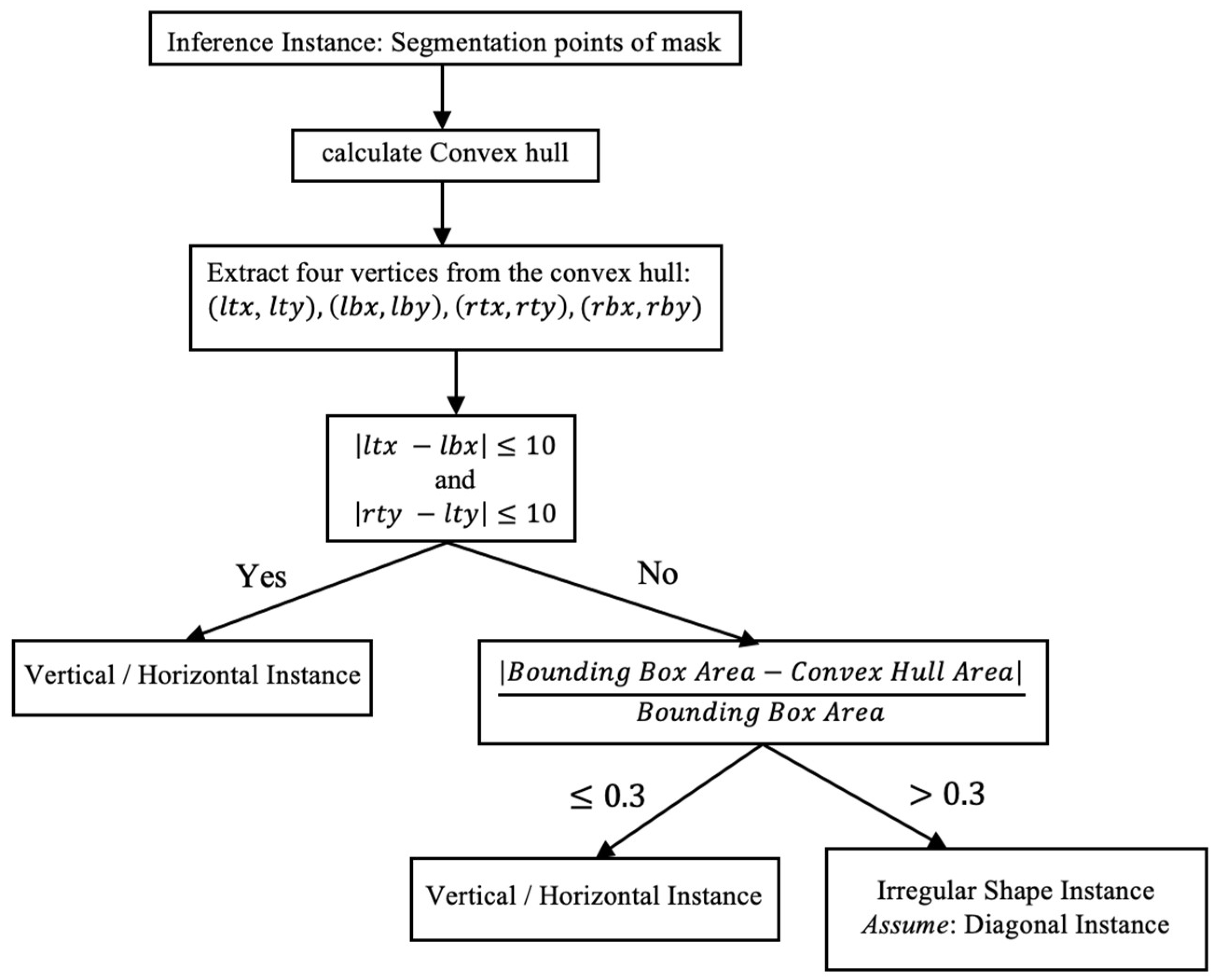
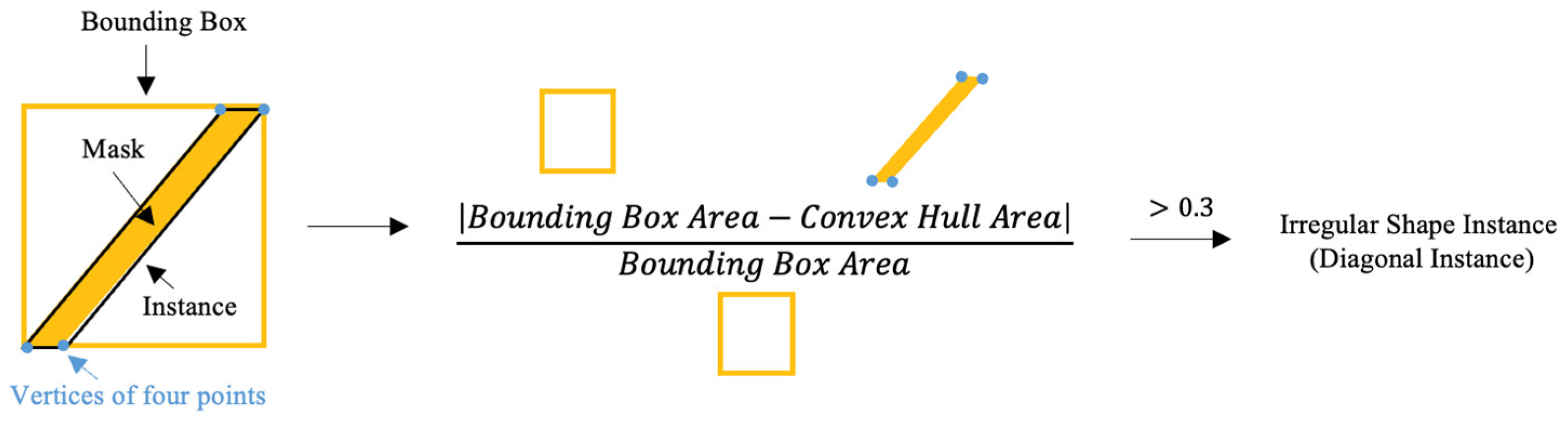
3.4.1. Distinguish the Shape of the Instance
3.4.2. 3 Post-Processing Steps
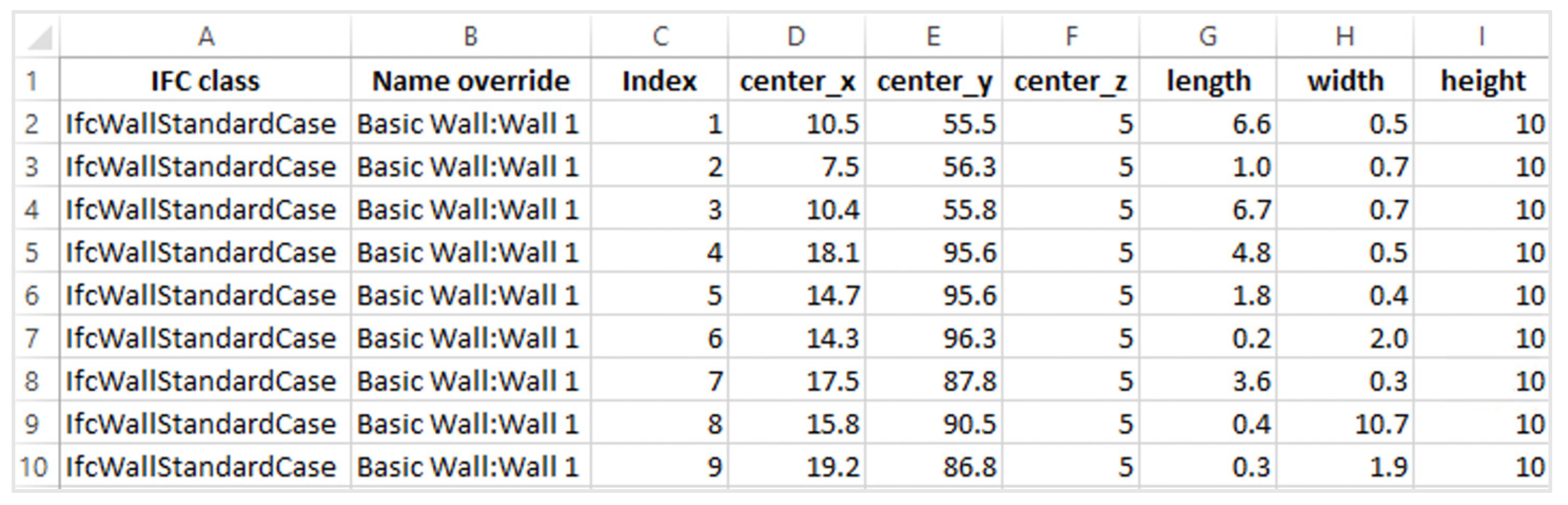
3.5. 3D Model Reconstruction in Revit 2022
4. Results and Discussion
4.1. Quantitative Results of Object Detection and Instance Segmentation Classifiers
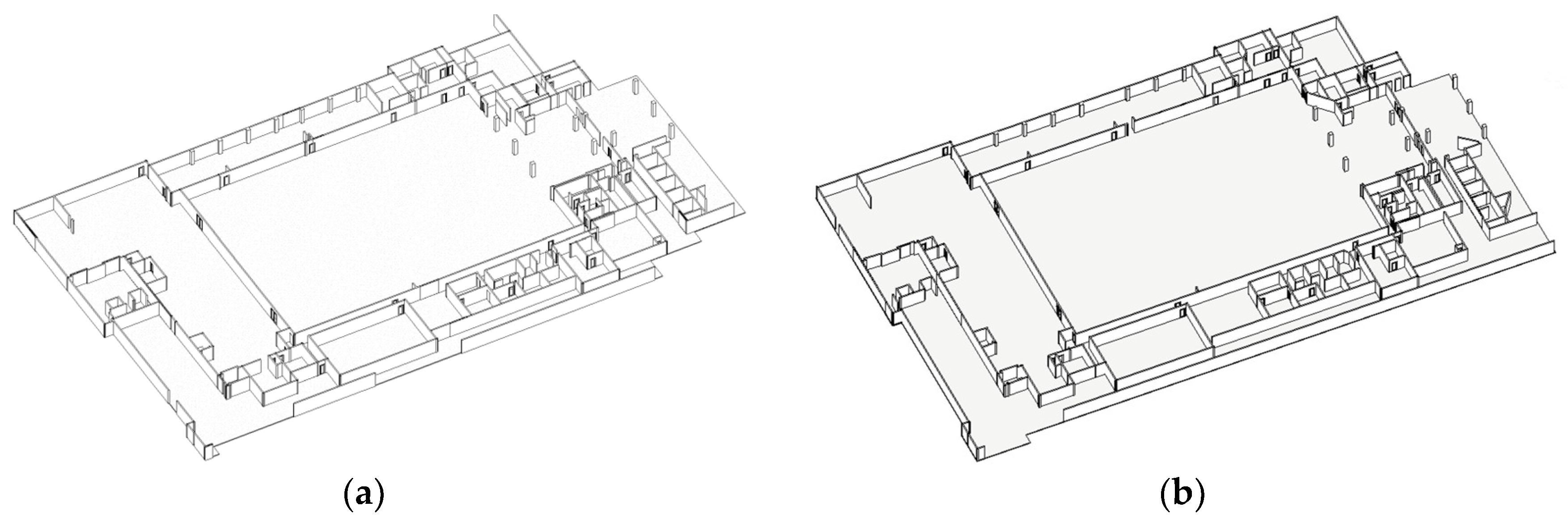
4.2. Inference Results
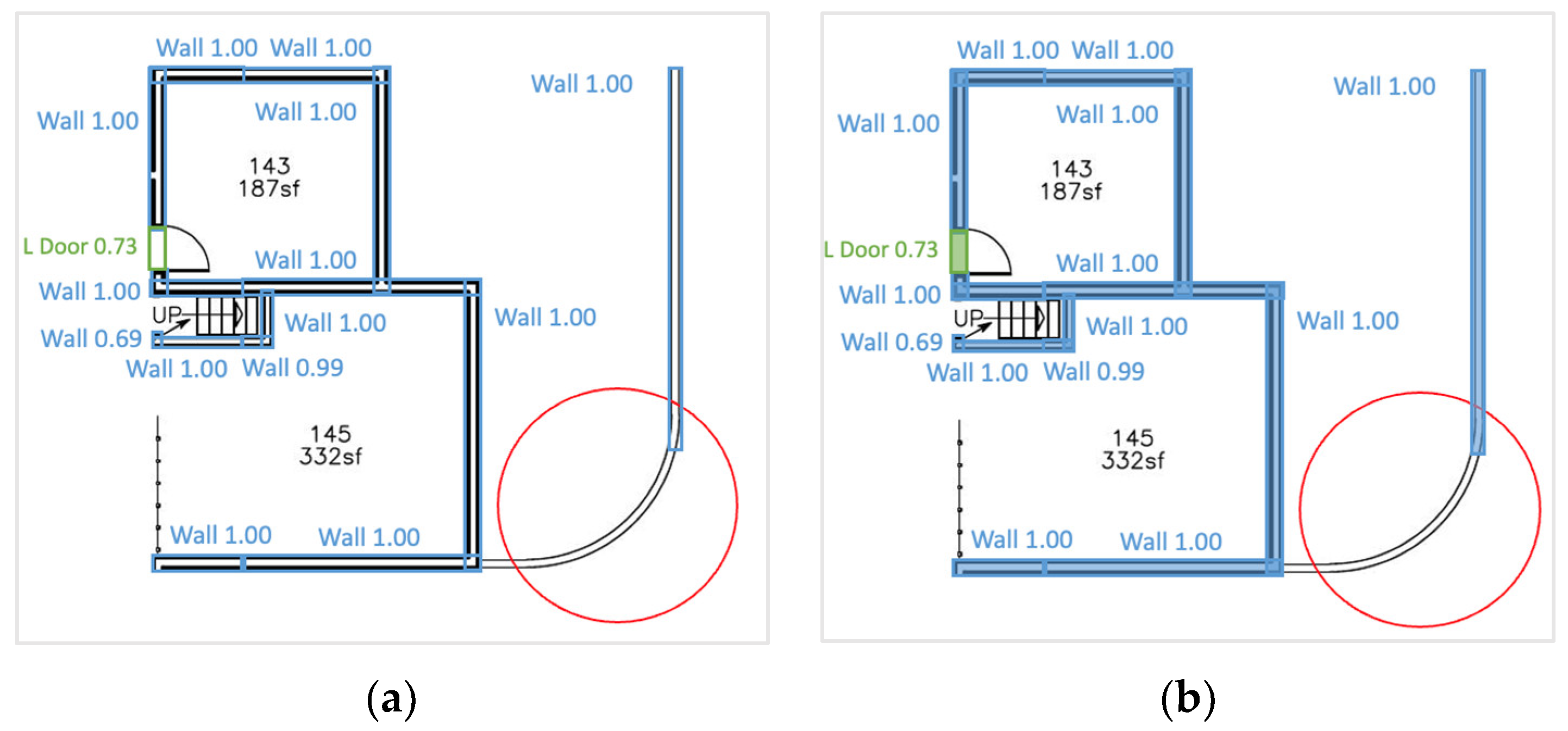
4.3. Observations and Failure Cases on Inference Results
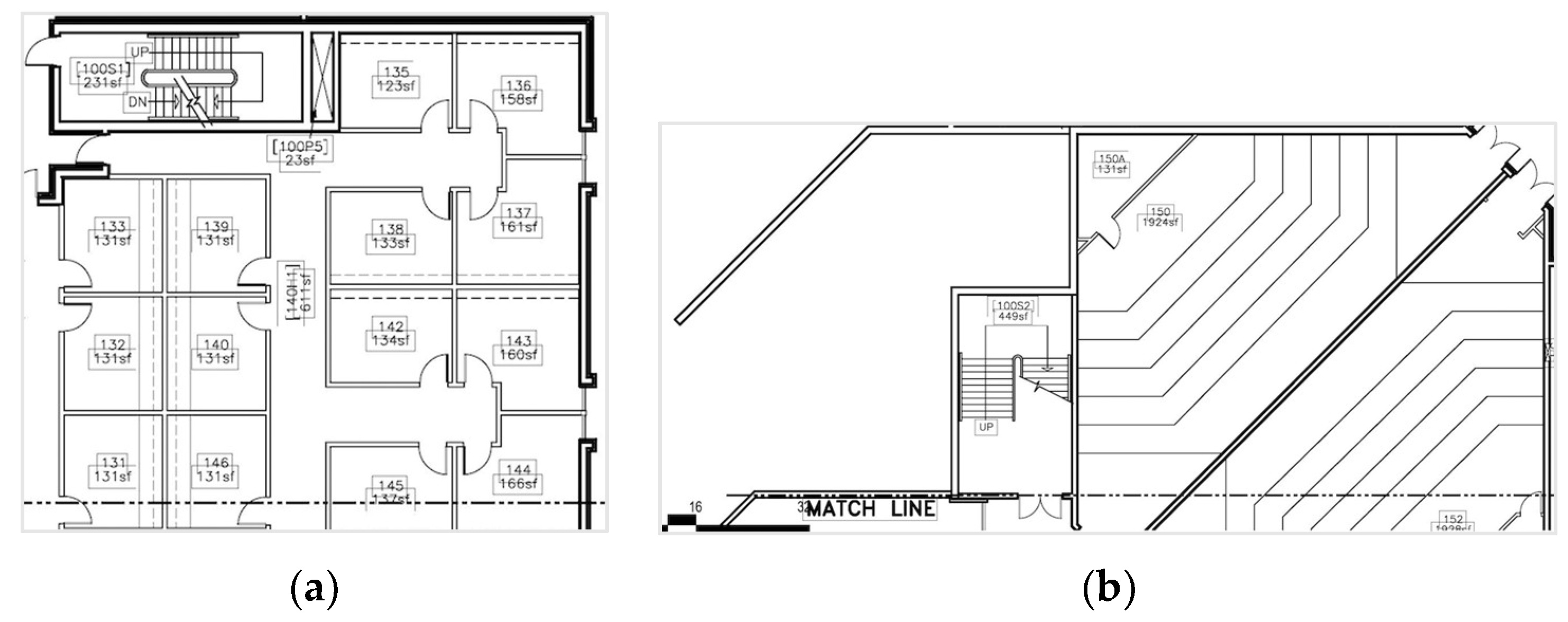
4.3.1. Neural Network Failure Cases
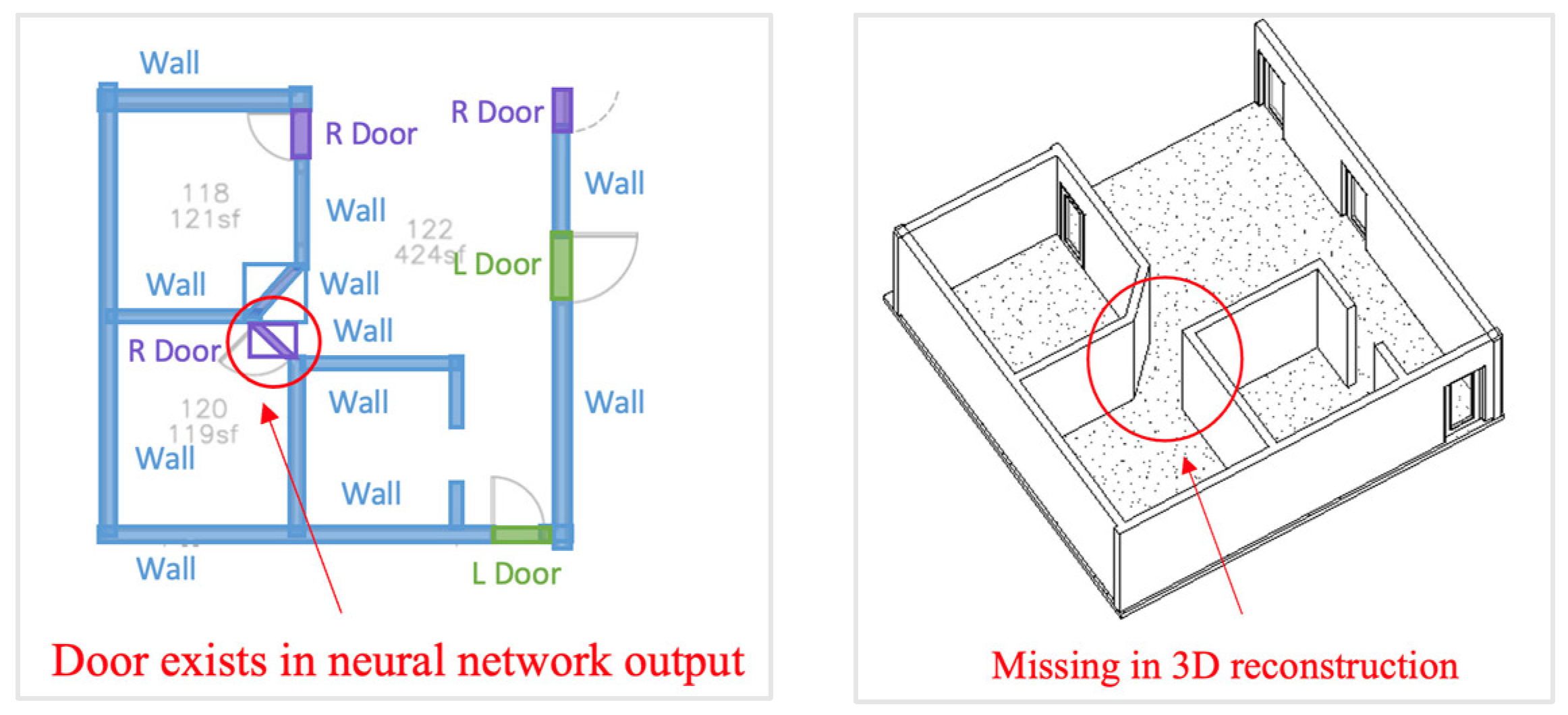
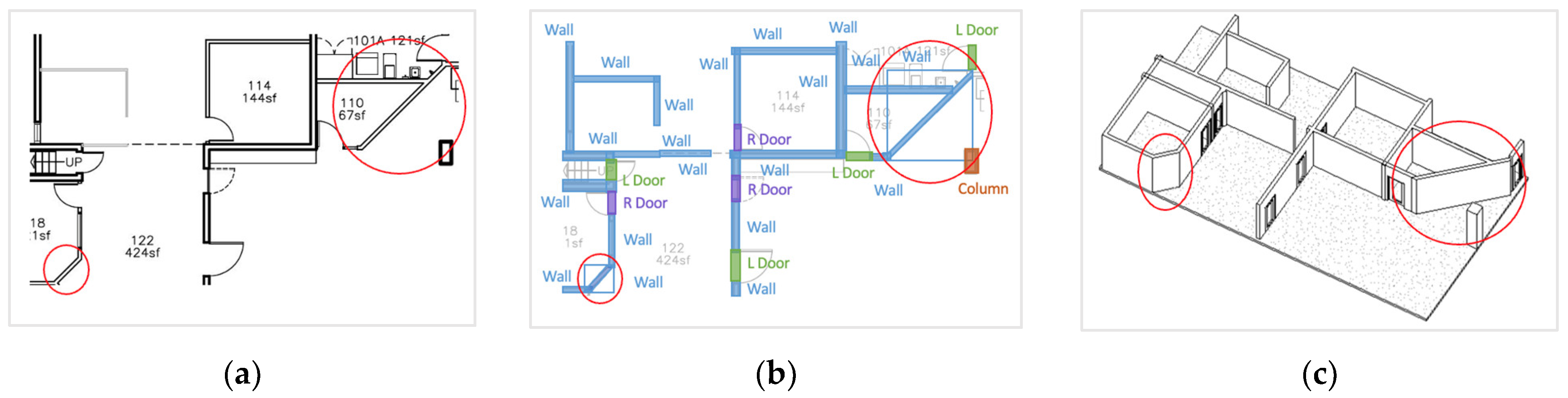
4.3.2. Interoperability Failure Cases
4.4. Comparison of Object Detection and Instance Segmentation Results
4.5. Alternative 3D Modeling Software
4.6. Limitations
- The post-processing pipeline for object detection and instance segmentation outputs cannot accommodate all conditions, such as an isolation door without a host wall.
- Reconstructing irregular shape instances from instance segmentation outputs is limited to diagonal instances.
- The parameters of reconstruction models generated from neural network outputs are limited to length and width.
- This study is limited to the institutional building, which includes bookstore, library, office, classroom, and auditorium.
4.7. Future Works
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A


References
- Ullah, K.; Lill, I.; Witt, E. An Overview of BIM Adoption in the Construction Industry: Benefits and Barriers. In Proceedings of the 10th Nordic Conference on Construction Economics and Organization, Tallinn, Estonia, 7–8 May 2019; Lill, I., Witt, E., Eds.; Emerald Reach Proceedings Series; Emerald Publishing Limited: Bingley, UK, 2019; Volume 2, pp. 297–303. [Google Scholar]
- Park, S.; Kim, H. 3DPlanNet: Generating 3D Models from 2D Floor Plan Images Using Ensemble Methods. Electronics 2021, 10, 2729. [Google Scholar] [CrossRef]
- Mishra, S.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Towards Robust Object Detection in Floor Plan Images: A Data Augmentation Approach. Appl. Sci. 2021, 11, 11174. [Google Scholar] [CrossRef]
- Zhao, Y.; Deng, X.; Lai, H. Reconstructing BIM from 2D structural drawings for existing buildings. Autom. Constr. 2021, 128, 103750. [Google Scholar] [CrossRef]
- Dodge, S.; Xu, J.; Stenger, B. Parsing floor plan images. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 358–361. [Google Scholar]
- Kalervo, A.; Ylioinas, J.; Häikiö, M.; Karhu, A.; Kannala, J. CubiCasa5K: A Dataset and an Improved Multi-task Model for Floorplan Image Analysis. arXiv 2019, arXiv:1904.01920. [Google Scholar]
- Sandelin, F. Semantic and Instance Segmentation of Room Features in Floor Plans Using Mask R-CNN. Master’s Thesis, Uppsala University, Uppsala, Sweden, 2019. [Google Scholar]
- Umapathy, S.G.; Iliev, A.I. Segmentation of Floorplans and Heritage Sites: An Approach to Unbalanced Dataset. J. Digit. Present. Preserv. Cult. Sci. Herit. 2022, 12, 205–216. [Google Scholar]
- Taye, M.M. Understanding of Machine Learning with Deep Learning: Architectures, Workflow, Applications and Future Directions. Computers 2023, 12, 91. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xiao, Y.; Chen, S.; Ikeda, Y.; Hotta, K. Automatic Recognition and Segmentation of Architectural Elements from 2D Drawings by Convolutional Neural Network. In Proceedings of the 25th International Conference of the Association for Computer-Aided Architectural Design Research in Asia (CAADRIA), Bangkok, Thailand, 5–6 August 2020; Volume 1, pp. 843–852. [Google Scholar]
- Jang, H.; Yu, K.; Yang, J. Indoor reconstruction from floorplan images with a deep learning approach. ISPRS Int. J. Geo-Inf. 2020, 9, 65. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Seo, J.; Park, H.; Choo, S. Inference of drawing elements and space usage on architectural drawings using semantic segmentation. Appl. Sci. 2020, 10, 7347. [Google Scholar] [CrossRef]
- Kippers, R.G.; Koeva, M.; Keulen, M.; Elberink, S.J. Automatic 3D building model generation using deep learning methods based on CityJSON and 2D floor plans. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, 46, 49–54. [Google Scholar] [CrossRef]
- Verykokou, S.; Ioannidis, C. An Overview on Image-Based and Scanner-Based 3D Modeling Technologies. Sensors 2023, 23, 596. [Google Scholar] [CrossRef] [PubMed]
- Lu, Q.; Chen, L.; Li, S.; Pitt, M. Semi-Automatic Geometric DFwiigital Twinning for Existing Buildings Based on Images and CAD Drawings. Autom. Constr. 2020, 115, 103183. [Google Scholar] [CrossRef]
- Yang, B.; Liu, B.; Zhu, D.; Zhang, B.; Wang, Z.; Lei, K. Semiautomatic Structural BIM-Model Generation Methodology Using CAD Construction Drawings. J. Comput. Civ. Eng. 2020, 34, 1–17. [Google Scholar] [CrossRef]
- Missing Elements When Importing IFC Model with User IFC Template in Revit. Autodesk. Available online: https://www.autodesk.com/support/technical/article/caas/sfdcarticles/sfdcarticles/Missing-elements-when-importing-IFC-model-with-user-IFC-template-in-Revit.html (accessed on 15 August 2023).
- Some Room Objects are Missing after Import IFC File to Revit. Autodesk. Available online: https://www.autodesk.com/support/technical/article/caas/sfdcarticles/sfdcarticles/Some-Room-objects-are-missing-after-import-IFC-file-to-Revit.html (accessed on 15 August 2023).
- Russell, B.; Torralba, A.; Murphy, K.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. J. Comput. Vis. 2007, 77, 157–173. [Google Scholar] [CrossRef]
- Huyen, C. Designing Machine Learning Systems; O’Reilly Media Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.-Y.; Girshick, R. Detectron2; GitHub: San Francisco, CA, USA, 2019. [Google Scholar]
- Wei, C.; Gupta, M.; Czerniawski, T. Automated Wall Detection in 2D CAD Drawings to Create Digital 3D Models. In Proceedings of the 39th International Symposium on Automation and Robotics in Construction (ISARC), Bogota, Colombia, 12–15 July 2022; pp. 152–158. [Google Scholar]













































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Wall | L Door | R Door | Double Door | Column | mAP |
|---|---|---|---|---|---|---|
| Classifier 1 (Object Detection) | 74.5 | 51.7 | 47.9 | 87.9 | 96.5 | 71.7 |
| Classifier 2 (Instance Segmentation) | 74.4 | 48.6 | 50.0 | 77.1 | 96.8 | 69.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, C.; Gupta, M.; Czerniawski, T. Interoperability between Deep Neural Networks and 3D Architectural Modeling Software: Affordances of Detection and Segmentation. Buildings 2023, 13, 2336. https://doi.org/10.3390/buildings13092336
Wei C, Gupta M, Czerniawski T. Interoperability between Deep Neural Networks and 3D Architectural Modeling Software: Affordances of Detection and Segmentation. Buildings. 2023; 13(9):2336. https://doi.org/10.3390/buildings13092336
Chicago/Turabian StyleWei, Chialing, Mohit Gupta, and Thomas Czerniawski. 2023. "Interoperability between Deep Neural Networks and 3D Architectural Modeling Software: Affordances of Detection and Segmentation" Buildings 13, no. 9: 2336. https://doi.org/10.3390/buildings13092336
APA StyleWei, C., Gupta, M., & Czerniawski, T. (2023). Interoperability between Deep Neural Networks and 3D Architectural Modeling Software: Affordances of Detection and Segmentation. Buildings, 13(9), 2336. https://doi.org/10.3390/buildings13092336