

Novel Instance-Based Transfer Learning for Asphalt Pavement Performance Prediction



Abstract
:1. Introduction
2. Literature Review
3. Data Preparation
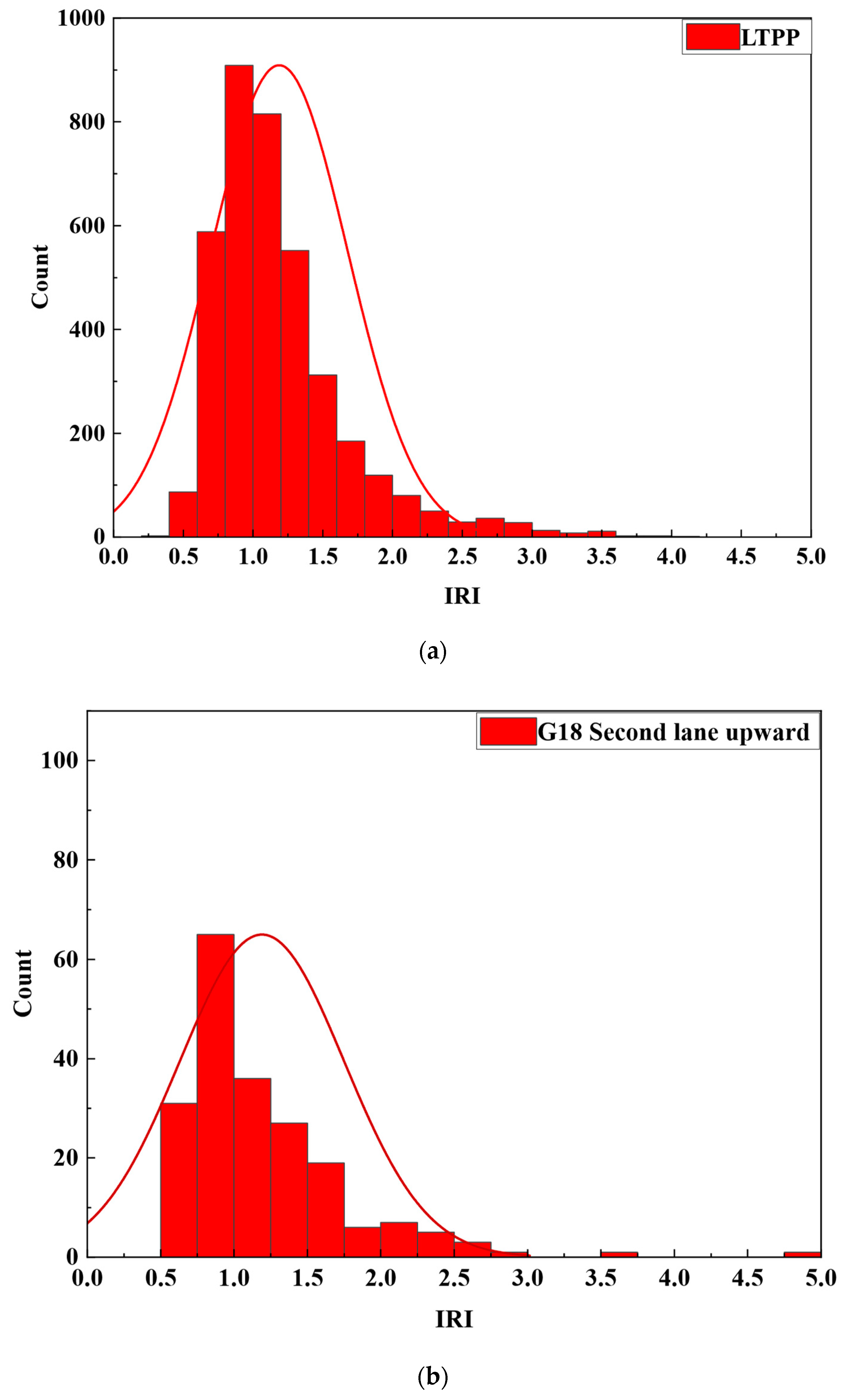
3.1. Long-Term Pavement Performance (LTPP) Program
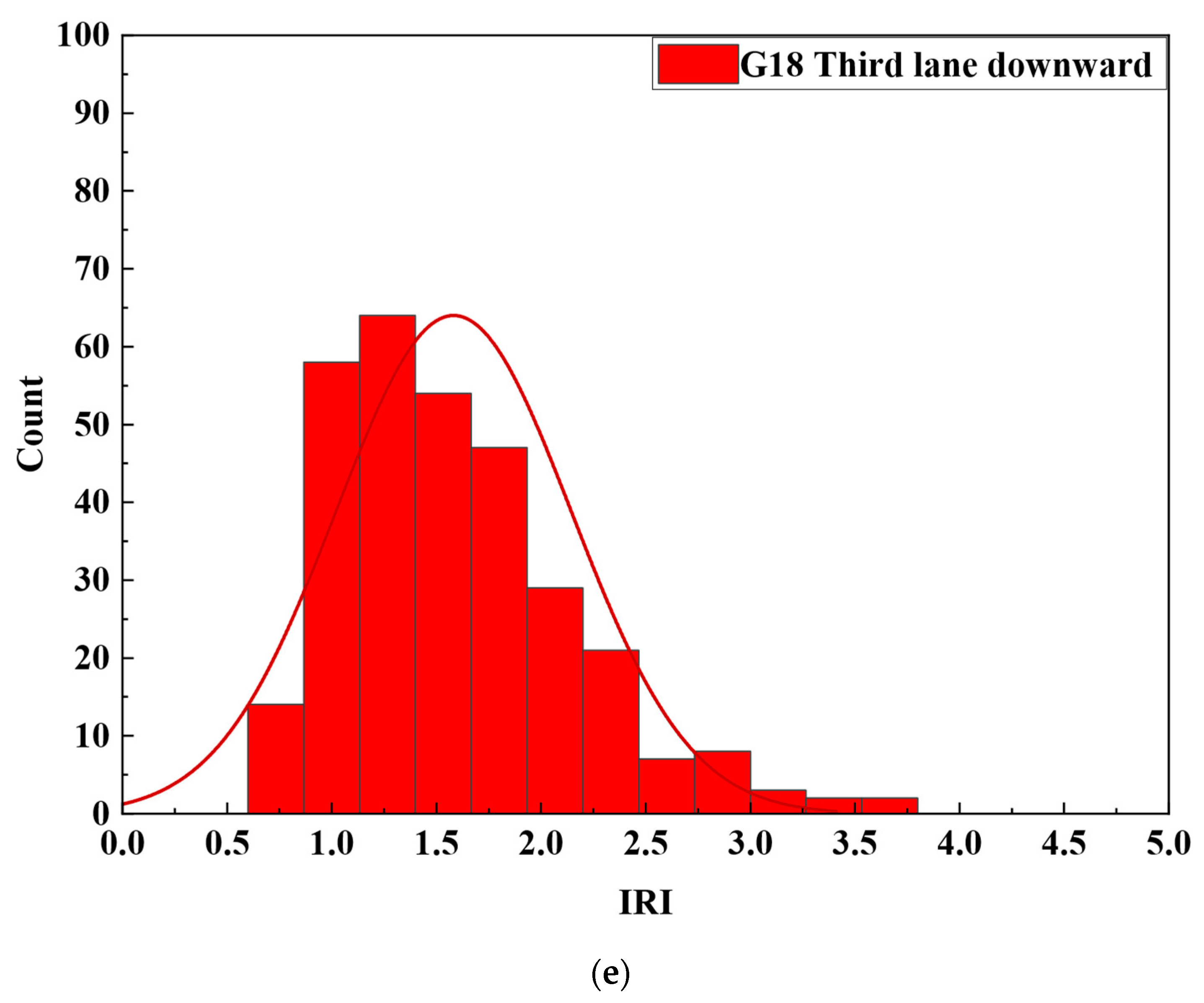
3.2. Target Data Source
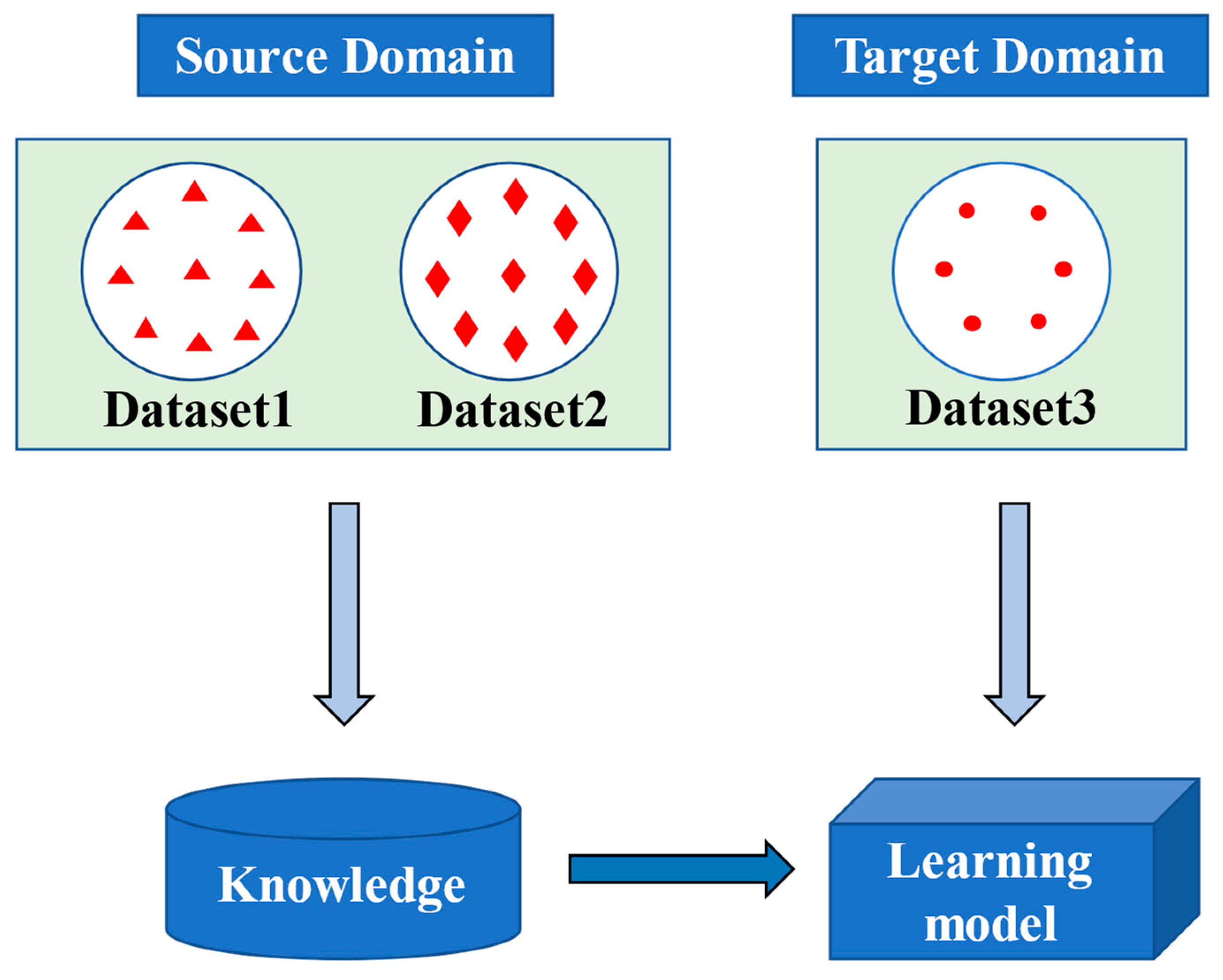
4. Methodology
4.1. AdaBoost.R2
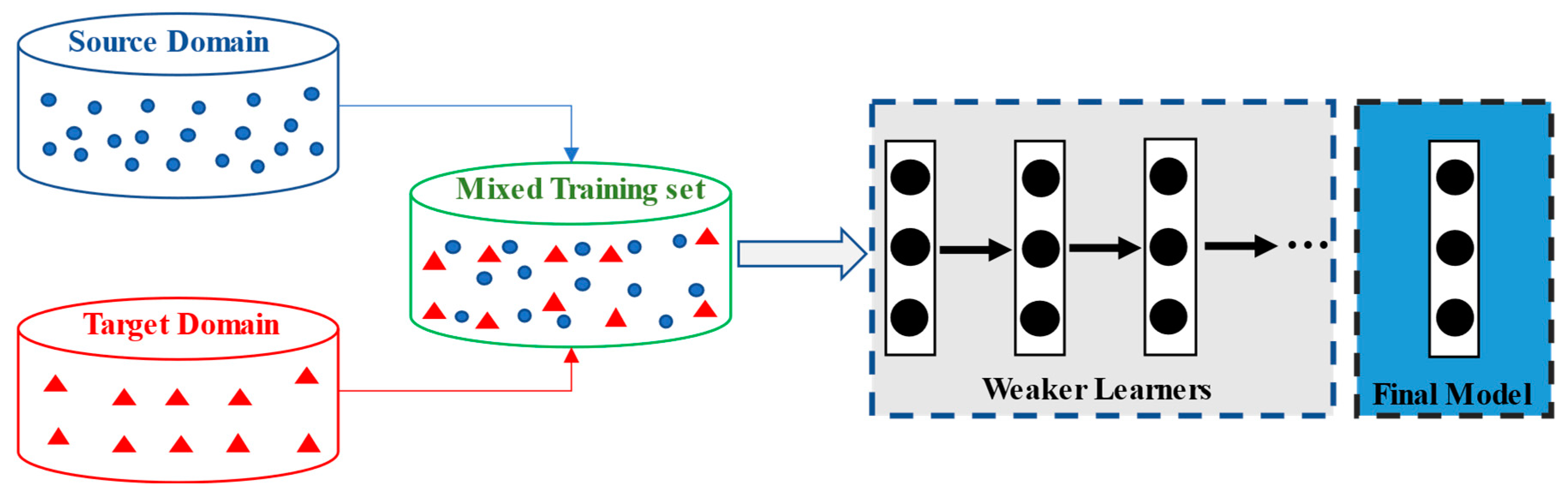
4.2. TrAdaBoost.R2
4.3. Two-Stage TrAdaBoost.R2
- Initialize weights and assign weight distribution D1 to the training dataset, setting the initial weight vector as:where D1 is the weight distribution of the training data, is the weight distribution of each data weight vector under D1, s is the dataset Tsource (of size s), t is the dataset Ttarget (of size t).For n = 1, 2, 3, …, N:
- Call a learner Gn(x) from the training dataset T with the weight distribution Dn.
- Call AdaBoost.R2 with T = Tsource + Ttarget, a base regression estimator G(x), and the weight vector . Tsource stays unchanged. Calculate the errorj of Modelj using F-fold cross-validation.
- Call a learner G(x) with T with the weight distribution Dj.
- Calculate the adjusted error eij of each instance in T using AdaBoost.R2.
- Update the weight vector and the weight distribution.where is the normalizing constant, is the weighting factor to result in a certain total weight for the target instances, selected such that the observed weight of Ttarget is .
- Determine the output of the resulting Modelj:f(x) = Modelj = fj(x), where j = argmini errori
4.4. Decision Tree
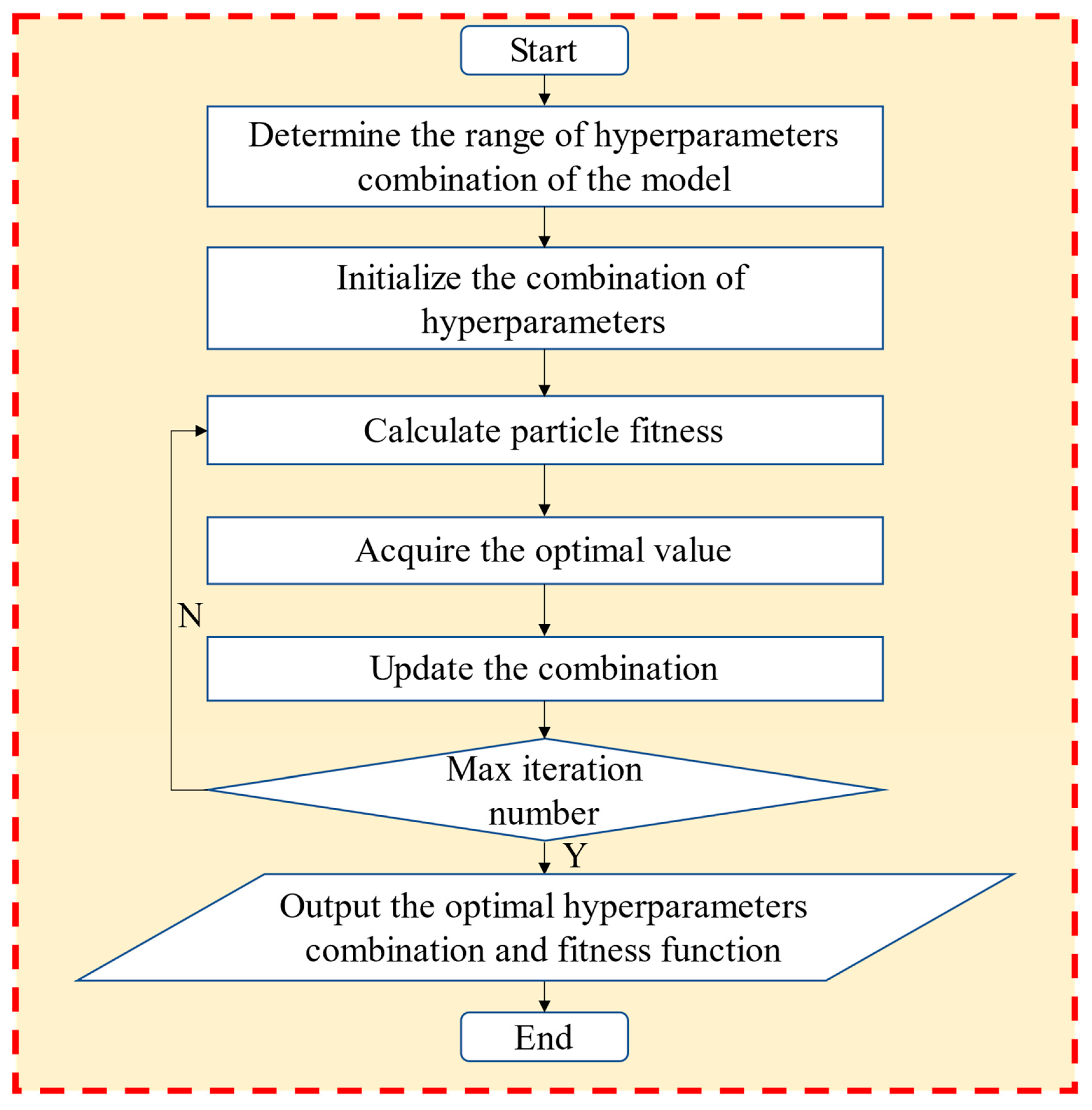
4.5. Particle Swarm Optimization (PSO) Algorithm
4.6. Input and Output Variables
4.7. Data Preprocessing
5. Results
5.1. Model Evaluation Indexes
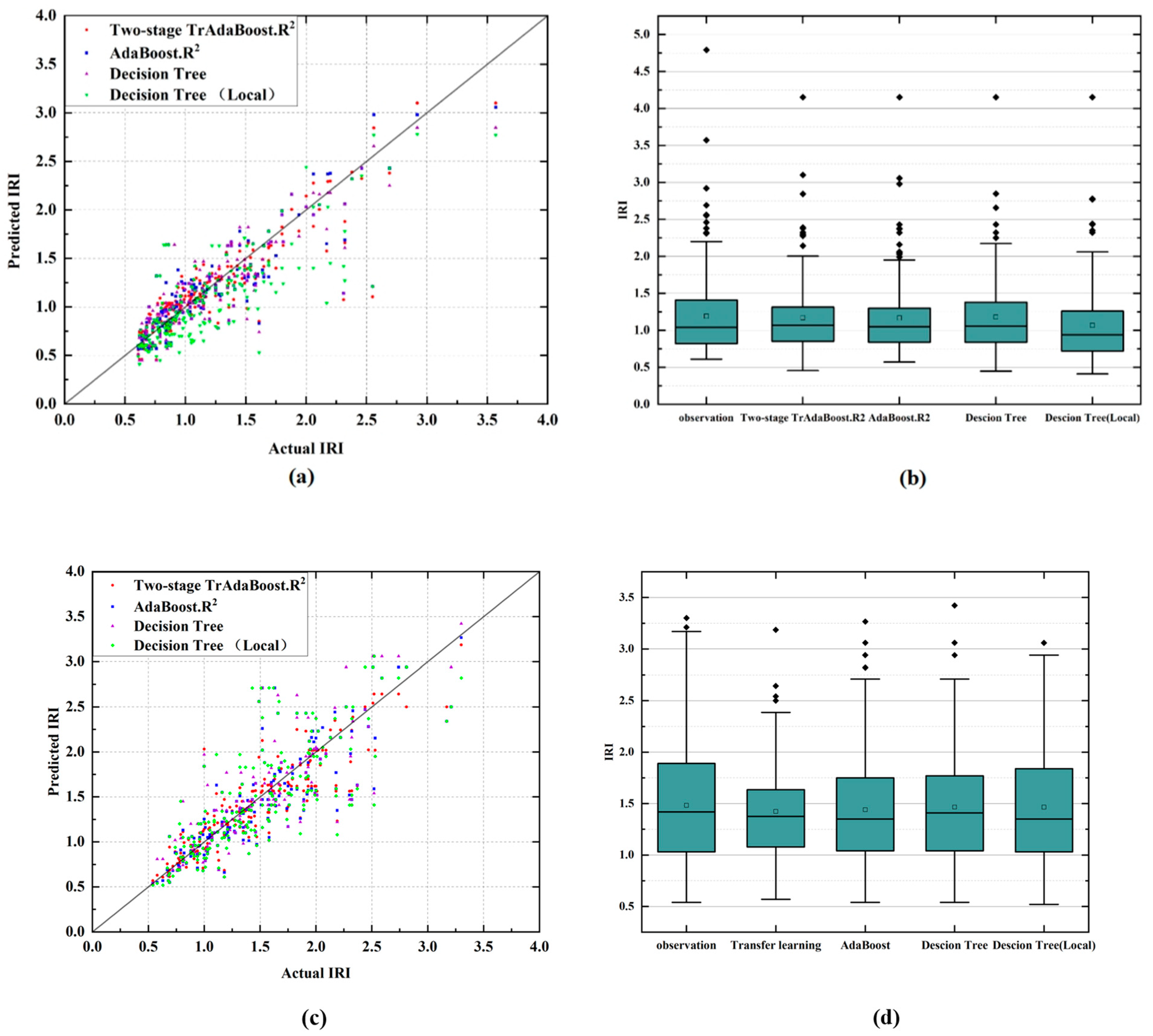
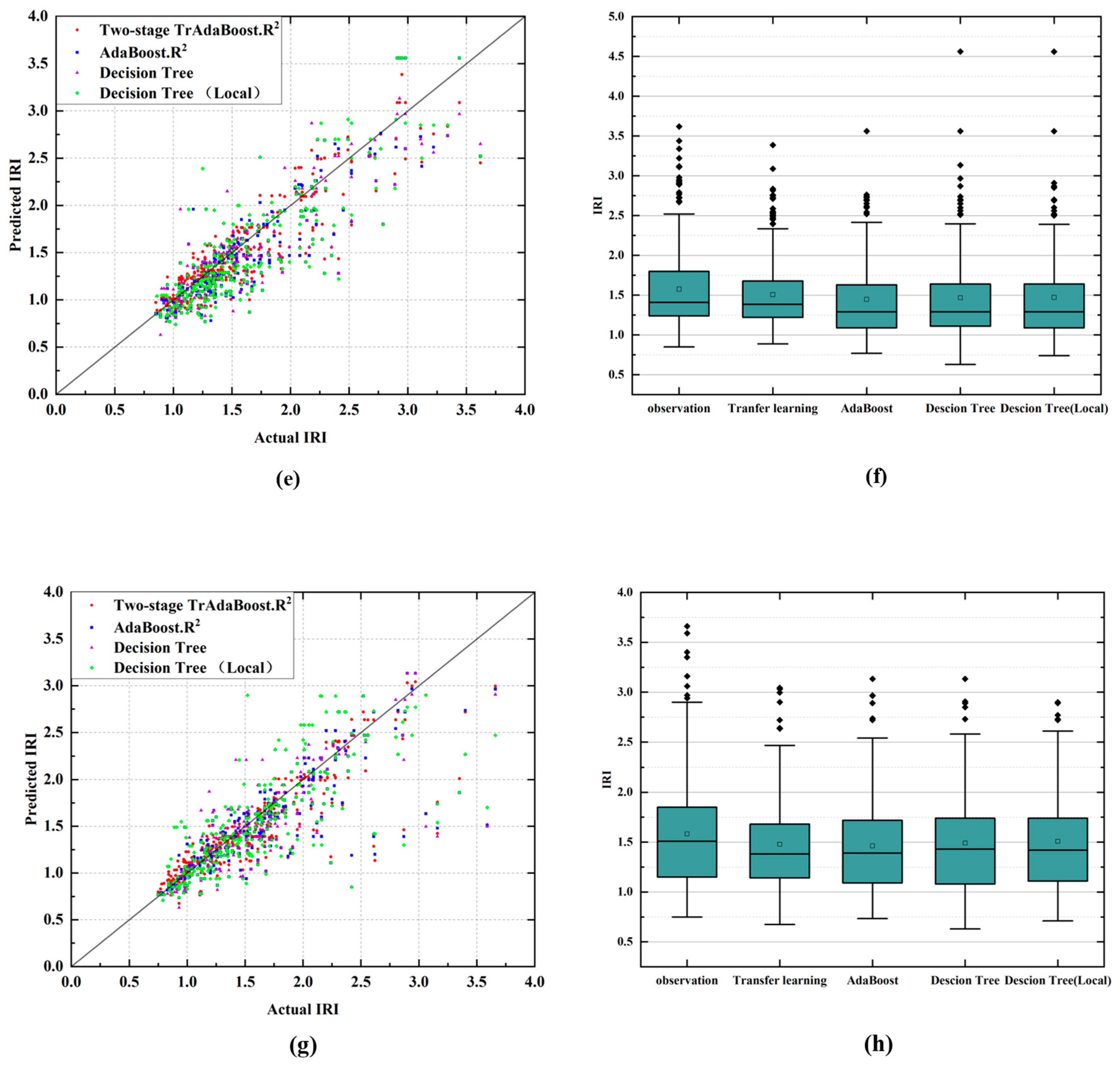
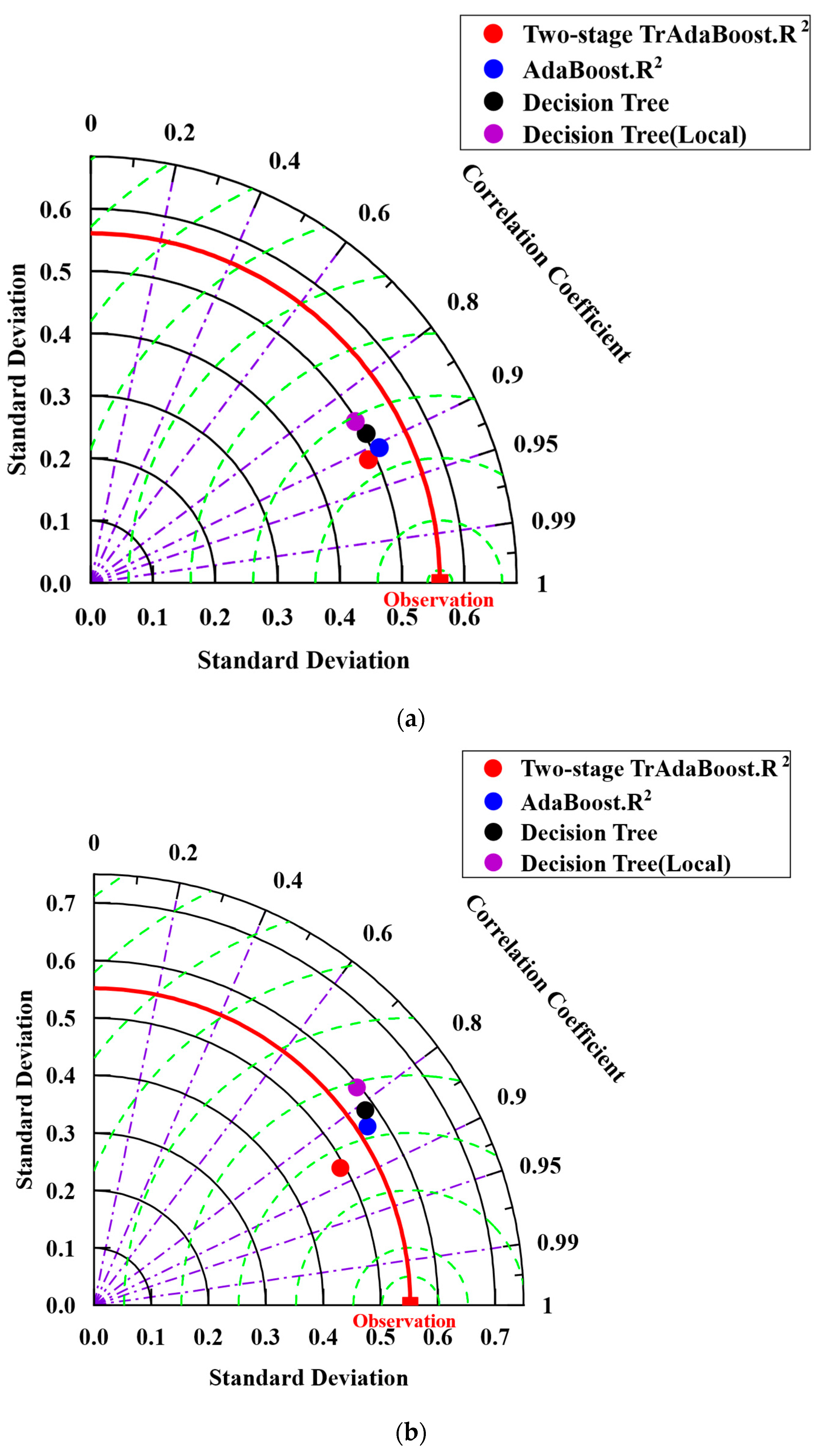
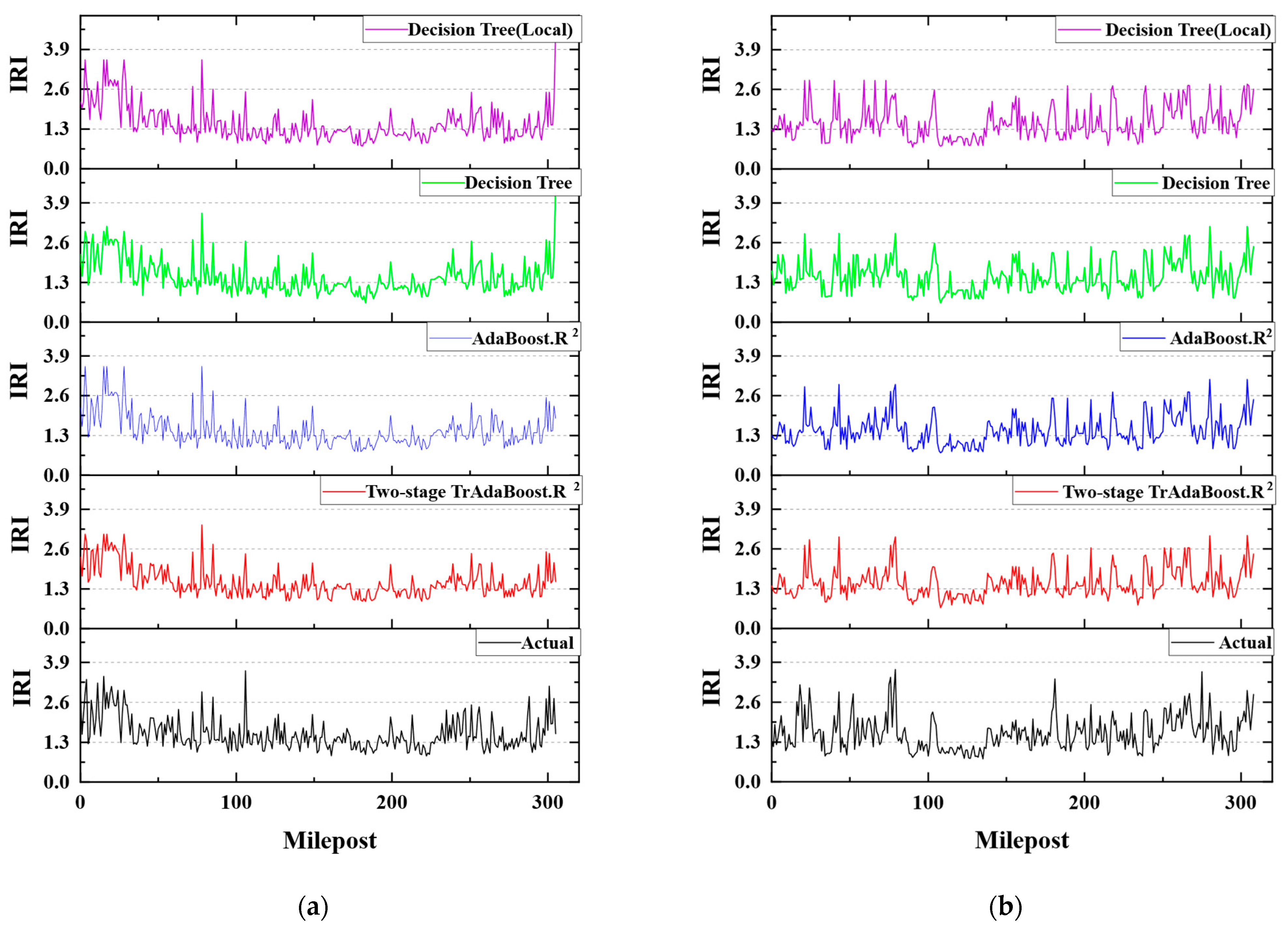
5.2. Prediction Result
5.3. Impact of Training Dataset
6. Conclusions
- (1)
- Four different methods are compared, including the decision tree model trained only on local data, the decision tree model, AdaBoost.R2 model, and the Two-stage TrAdaBoost.R2 model trained using historical data from both local and open-source databases. The prediction results of the decision tree model using local data only and both local data and LTPP data yield R2 values of 0.62 and 0.56, respectively. Although this shows that prediction accuracy could improve by enlarging the database, the prediction results still show low accuracy when using traditional machine learning methods.
- (2)
- The proposed PSO-Two-stage TrAdaBoost.R2 transfer learning method has better performance than the traditional machine learning method in predicting pavement performance. The average R2 of the PSO-Two-stage TrAdaBoost.R2 transfer learning method can reach 0.76 on average for all four lanes, which is 11% better than the AdaBoost.R2 model and 22% better than the decision tree model. The best performance of R2 is 0.83.
- (3)
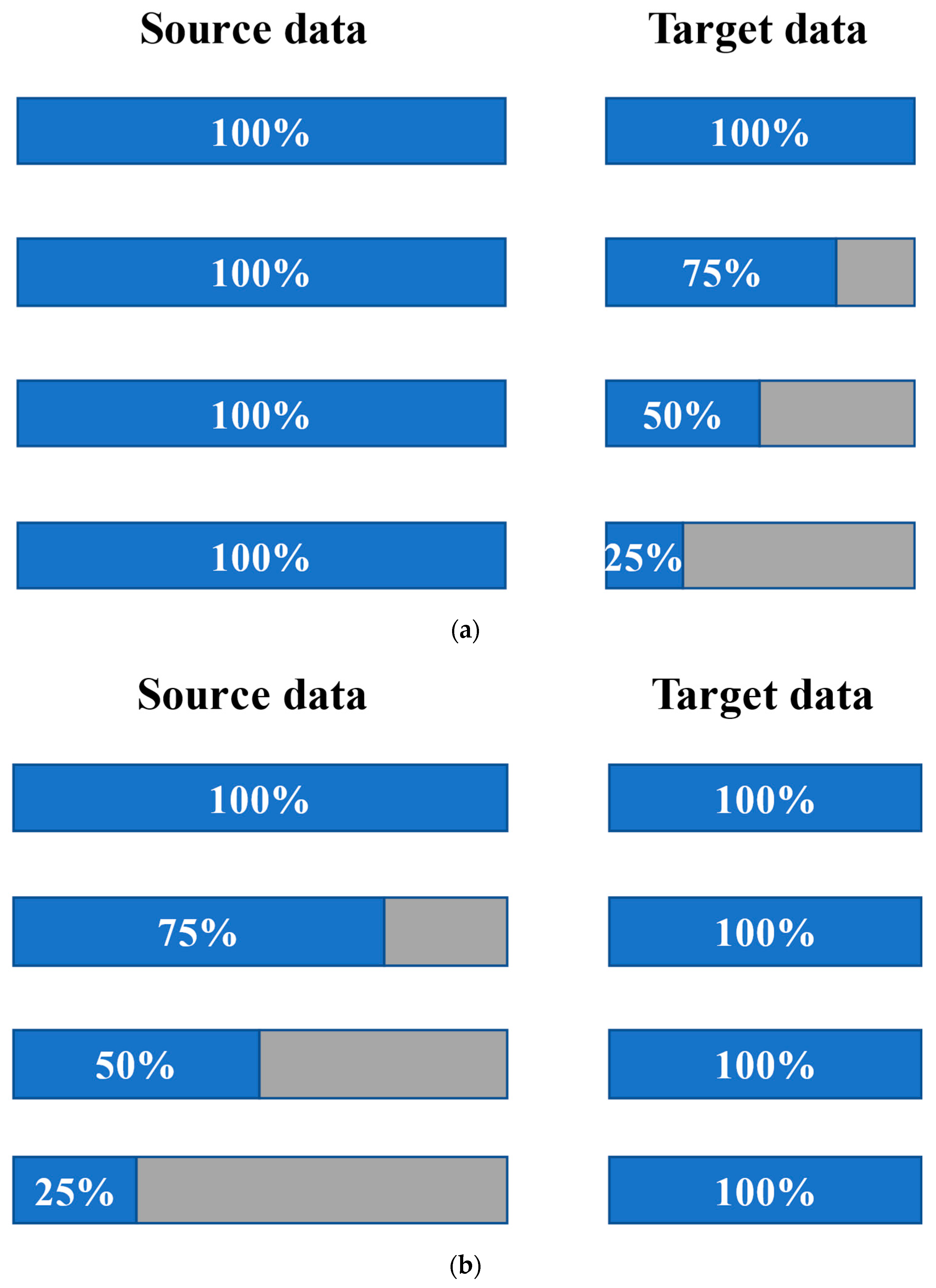
- The effects of the source domain and target domain are also examined in the study. Two groups of combinations are presented, including training the model using 100%, 75%, 50%, and 25% of data in the source domain, using all data in the target domain, and training the model using 100%, 75%, 50%, and 25% of data in the target domain and all data in the source domain. The results show that when predicting the performance of a new road with little dataset availability, it is helpful to use similar available data and transfer learning methods. It also shows that the increasing range of R2 when changing target domain datasets is larger than that when changing source domain datasets.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, J.L.; Zhang, Z.S.; Wang, X.F.; Yan, W.X. Intelligent decision-making model in preventive maintenance of asphalt pavement based on PSO-GRU neural network. Adv. Eng. Inform. 2022, 51, 101525. [Google Scholar] [CrossRef]
- De la Garza, J.M.; Akyildiz, S.; Bish, D.R.; Krueger, D.A. Network-level optimization of pavement maintenance renewal strategies. Adv. Eng. Inform. 2011, 25, 699–712. [Google Scholar] [CrossRef]
- American Society of Civil Engineers. A Comprehensive Assessment of America’s Infrastructure: Infrastructure Report Card for America’s Infrastructure; ASCE: Reston, VA, USA, 2021. [Google Scholar]
- Marcelino, P.; De Lurdes Antunes, M.; Fortunato, E.; Gomes, M.C. Transfer learning for pavement performance prediction. Int. J. Pavement Res. Technol. 2020, 13, 154–167. [Google Scholar] [CrossRef]
- Titus-Glover, L. Reassessment of climate zones for high-level pavement analysis using machine learning algorithms and NASA MERRA-2 data. Adv. Eng. Inform. 2021, 50, 101435. [Google Scholar] [CrossRef]
- Yousaf, M.H.; Azhar, K.; Murtaza, F.; Hussain, F. Visual analysis of asphalt pavement for detection and localization of potholes. Adv. Eng. Inform. 2018, 38, 527–537. [Google Scholar] [CrossRef]
- Ferreira, A.; Picado-Santos, L.D.; Wu, Z.; Flintsch, G. Selection of pavement performance models for use in the Portuguese PMS. Int. J. Pavement Eng. 2011, 12, 87–97. [Google Scholar] [CrossRef]
- Titus-Glover, L. Unsupervised extraction of patterns and trends within highway systems condition attributes data. Adv. Eng. Inform. 2019, 42, 100990. [Google Scholar] [CrossRef]
- Chen, Y.; Saha, S.; Lytton, R.L. Prediction of the pre-erosion stage of faulting in jointed concrete pavement with axle load distribution. Transp. Geotech. 2020, 23, 100343. [Google Scholar] [CrossRef]
- Dong, Q.; Chen, X.Q.; Gong, H.R. Performance evaluation of asphalt pavement resurfacing treatments using structural equation modeling. J. Transp. Eng. 2020, 146, 04019043. [Google Scholar] [CrossRef]
- Abaza, K.A. Back-calculation of transition probabilities for Markovian-based pavement performance prediction models. Int. J. Pavement Eng. 2016, 17, 253–264. [Google Scholar] [CrossRef]
- El-Khawaga, M.; El-Badawy, S.; Gabr, A. Comparison of master sigmoidal curve and Markov chain techniques for pavement performance prediction. Arabian J. Sci. Eng. 2020, 45, 3973–3982. [Google Scholar] [CrossRef]
- Yang, J.D.; Gunaratne, M.; Lu, J.J.; Dietrich, B. Use of recurrent Markov chains for modeling the crack performance of flexible pavements. J. Transp. Eng. 2005, 131, 861–872. [Google Scholar] [CrossRef]
- Abdelaziz, N.; Abd El-Hakim, R.T.; El-Badawy, S.M.; Afify, H.A. International Roughness Index prediction model for flexible pavements. Int. J. Pavement Eng. 2020, 21, 88–99. [Google Scholar] [CrossRef]
- Sollazzo, G.; Fwa, T.; Bosurgi, G. An ANN model to correlate roughness and structural performance in asphalt pavements. Constr. Build. Mater. 2017, 134, 684–693. [Google Scholar] [CrossRef]
- Gong, H.R.; Sun, Y.R.; Hu, W.; Huang, B.S. Neural networks for fatigue cracking prediction using outputs from pavement mechanistic-empirical design. Int. J. Pavement Eng. 2021, 22, 162–172. [Google Scholar] [CrossRef]
- Li, J.L.; Yin, G.H.; Wang, X.F.; Yan, W.X. Automated decision making in highway pavement preventive maintenance based on deep learning. Autom. Constr. 2022, 135, 104111. [Google Scholar] [CrossRef]
- Liu, Z.; Yeoh, J.K.; Gu, X.Y.; Dong, Q.; Chen, Y.H.; Wu, W.X.; Wang, L.T.; Wang, D.Y. Automatic pixel-level detection of vertical cracks in asphalt pavement based on GPR investigation and improved mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Haddad, A.J.; Chehab, G.R.; Saad, G.A. The use of deep neural networks for developing generic pavement rutting predictive models. Int. J. Pavement Eng. 2022, 23, 4260–4276. [Google Scholar] [CrossRef]
- Wang, D.Y.; Liu, Z.; Gu, X.Y.; Wu, W.X. Feature extraction and segmentation of pavement distress using an improved hybrid task cascade network. Int. J. Pavement Eng. 2023, 24, 2266098. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Wang, C.B.; Xu, S.Z.; Yang, J.X. Adaboost Algorithm in Artificial Intelligence for Optimizing the IRI Prediction Accuracy of Asphalt Concrete Pavement. Sensors 2021, 21, 5682. [Google Scholar] [CrossRef]
- Piryonesi, S.M.; El-Diraby, T. Climate change impact on infrastructure: A machine learning solution for predicting pavement condition index. Constr. Build. Mater. 2021, 306, 124905. [Google Scholar] [CrossRef]
- Gong, H.R.; Sun, Y.R.; Shu, X.; Huang, B.S. Use of random forests regression for predicting IRI of asphalt pavements. Constr. Build. Mater. 2018, 189, 890–897. [Google Scholar] [CrossRef]
- Trappey, A.J.; Trappey, C.V.; Lin, E. Intelligent trademark recognition and similarity analysis using a two-stage transfer learning approach. Adv. Eng. Inform. 2022, 52, 101567. [Google Scholar] [CrossRef]
- Li, J.R.; Horiguchi, Y.; Sawaragi, T. Counterfactual inference to predict causal knowledge graph for relational transfer learning by assimilating expert knowledge--Relational feature transfer learning algorithm. Adv. Eng. Inform. 2022, 51, 101516. [Google Scholar] [CrossRef]
- Zhang, K.G.; Cheng, H.; Zhang, B.Y. Unified approach to pavement crack and sealed crack detection using preclassification based on transfer learning. J. Comput. Civ. Eng. 2018, 32, 04018001. [Google Scholar] [CrossRef]
- Jang, K.; Kim, N.; An, Y.-K. Deep learning–based autonomous concrete crack evaluation through hybrid image scanning. Struct. Health Monit. 2019, 18, 1722–1737. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Automated vision-based detection of cracks on concrete surfaces using a deep learning technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef]
- da Silva, W.R.L.; de Lucena, D.S. Concrete cracks detection based on deep learning image classification. Proceedings 2018, 2, 489. [Google Scholar]
- Gopalakrishnan, K.; Gholami, H.; Vidyadharan, A.; Choudhary, A.; Agrawal, A. Crack damage detection in unmanned aerial vehicle images of civil infrastructure using pre-trained deep learning model. Int. J. Traffic Transp. Eng. 2018, 8, 1–14. [Google Scholar]
- Tang, D.J.; Yang, X.H.; Wang, X.S. Improving the transferability of the crash prediction model using the TrAdaBoost. R2 algorithm. Accid. Anal. Prev. 2020, 141, 105551. [Google Scholar] [CrossRef] [PubMed]
- Yehia, A.; Wang, X.S.; Feng, M.J.; Yang, X.H.; Gong, J.; Zhu, Z.X. Applicability of boosting techniques in calibrating safety performance functions for freeways. Accid. Anal. Prev. 2021, 159, 106193. [Google Scholar] [CrossRef] [PubMed]
- Lv, M.Q.; Li, Y.F.; Chen, L.; Chen, T.M. Air quality estimation by exploiting terrain features and multi-view transfer semi-supervised regression. Inf. Sci. 2019, 483, 82–95. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, H.; Jiang, P.; Yu, S.; Lin, G.; Bychkov, I.; Hmelnov, A.; Ruzhnikov, G.; Zhu, N.; Liu, Z. A transfer Learning-Based LSTM strategy for imputing Large-Scale consecutive missing data and its application in a water quality prediction system. J. Hydrol. 2021, 602, 126573. [Google Scholar] [CrossRef]
- Hall, K.T.; Correa, C.E.; Simpson, A.L. Performance of rigid pavement rehabilitation treatments in the long-term pavement performance SPS-6 experiment. Transp. Res. Rec. 2003, 1823, 64–72. [Google Scholar] [CrossRef]
- Labi, S.; Lamptey, G.; Konduri, S.; Sinha, K.C. Analysis of long-term effectiveness of thin hot-mix asphaltic concrete overlay treatments. Transp. Res. Rec. 2005, 1940, 2–12. [Google Scholar] [CrossRef]
- Wang, Y.H. The effects of using reclaimed asphalt pavements (RAP) on the long-term performance of asphalt concrete overlays. Constr. Build. Mater. 2016, 120, 335–348. [Google Scholar] [CrossRef]
- Gong, H.R.; Huang, B.S.; Shu, X. Field performance evaluation of asphalt mixtures containing high percentage of RAP using LTPP data. Constr. Build. Mater. 2018, 176, 118–128. [Google Scholar] [CrossRef]
- Chen, X.Q.; Zhu, H.H.; Dong, Q.; Huang, B.S. Optimal thresholds for pavement preventive maintenance treatments using LTPP data. J. Transp. Eng. 2017, 143, 04017018. [Google Scholar] [CrossRef]
- JTG 5210-2018; Highway Performance Assessment Standards. Minsitry of Transport of the People’s Republic of China: Beijing, China, 2018; pp. 42–45.
- Tan, C.Q.; Sun, F.C.; Kong, T.; Zhang, W.C.; Yang, C.; Liu, C.F. A Survey on Deep Transfer Learning. In Artificial Neural Networks and Machine Learning—ICANN; Springer: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. In International Conference on Machine Learning—ICML; Citeseer: State College, PA, USA, 1996; pp. 148–156. [Google Scholar]
- Drucker, H. Improving Regressors Using Boosting Techniques. In International Conference on Machine Learning—ICML; Citeseer: State College, PA, USA, 1997; pp. 107–115. [Google Scholar]
- Dai, W.Y.; Yang, Q.; Xue, G.-R.; Yu, Y. Boosting for Transfer Learning. In Proceedings of the 24th International Conference on Machine Learning, Association for Computing Machinery, Corvalis, OR, USA, 20–24 June 2007; pp. 193–200. [Google Scholar]
- Pardoe, D.; Stone, P. Boosting for Regression Transfer. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Madison, WI, USA, 21–24 June 2010; pp. 863–870. [Google Scholar]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Song, Y.-Y.; Ying, L. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar] [PubMed]
- Quinlan, J.R. Learning decision tree classifiers. ACM Comput. Surv. 1996, 28, 71–72. [Google Scholar] [CrossRef]
- Hssina, B.; Merbouha, A.; Ezzikouri, H.; Erritali, M. A comparative study of decision tree ID3 and C4. 5. Int. J. Adv. Comput. Sci. Appl. 2014, 4, 13–19. [Google Scholar]
- Jin, C.; De-Lin, L.; Fen-Xiang, M. An Improved ID3 Decision Tree Algorithm. In Proceedings of the 4th International Conference on Computer Science & Education, Nanning, China, 25–28 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 127–130. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Salzberg, S.L. Book Review: C4.5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1994. [Google Scholar]
- Loh, W.Y. Classification and regression trees. Wires. Data. Min. Knowl. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Moisen, G.G. Classification and Regression Trees. In Encyclopedia of Ecology; Jørgensen, S.E., Fath, B.D., Eds.; Elsevier: Oxford, UK, 2008; Volume 1, pp. 582–588. [Google Scholar]
- Speybroeck, N. Classification and regression trees. Int. J. Public Health. 2012, 57, 243–246. [Google Scholar] [CrossRef]
- Timofeev, R. Classification and Regression Trees (CART) Theory and Applications. Master’s Thesis, Humboldt University of Berlin, Berlin, Germany, 2004; p. 8. [Google Scholar]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Wang, X.F.; Dong, X.P.; Zhang, Z.S.; Zhang, J.M.; Ma, G.W.; Yang, X. Compaction quality evaluation of subgrade based on soil characteristics assessment using machine learning. Transp. Geotech. 2022, 32, 100703. [Google Scholar] [CrossRef]
- Ahmed, K.; Al-Khateeb, B.; Mahmood, M. A Multi-Objective Particle Swarm Optimization for Pavement Maintenance with Chaos and Discrete. J. Southwest Jiaotong Univ. 2019, 54, 1–11. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Road Age (Year) | AADT (Vehicle/Day) | Temperature (°C) | Precipitation (mm) | Base Thickness (mm) | Asphalt Layer Thickness (mm) | IRI (m/km) | |
|---|---|---|---|---|---|---|---|
| Mean | 19.78 | 5330.41 | 12.23 | 724.31 | 504.99 | 176.59 | 1.18 |
| Std | 12.31 | 6353.96 | 5.22 | 443.26 | 497.50 | 72.80 | 0.49 |
| Min | 1 | 63.00 | 0.90 | 10.50 | 25.40 | 12.70 | 0.33 |
| 25% quartile | 8 | 1151.00 | 8.00 | 320.39 | 304.80 | 119.40 | 0.85 |
| 50% quartile | 20 | 2829.80 | 10.90 | 696.70 | 416.60 | 162.50 | 1.07 |
| 75% quartile | 30 | 6967.74 | 14.50 | 1052.80 | 604.50 | 213.40 | 1.35 |
| Max | 52 | 45,909.00 | 25.70 | 2447.69 | 2456.00 | 444.60 | 4.11 |
| Road Age (Year) | AADT (Vehicle/Day) | Temperature (°C) | Precipitation (mm) | Base Thickness (mm) | Asphalt Layer Thickness (mm) | IRI (m/km) | |
|---|---|---|---|---|---|---|---|
| Mean | 1.92 | 21,105.38 | 12.97 | 547.58 | 540 | 180 | 1.16 |
| Std | 0.79 | 1736.77 | 0.28 | 167.63 | 0 | 0 | 0.48 |
| Min | 1 | 19,154.37 | 12.54 | 422.66 | 540 | 180 | 0.39 |
| 25% quartile | 1 | 19,286.29 | 12.75 | 422.66 | 540 | 180 | 0.84 |
| 50% quartile | 2 | 22,723.40 | 12.87 | 513.59 | 540 | 180 | 1.05 |
| 75% quartile | 2 | 22,723.40 | 13.17 | 513.59 | 540 | 180 | 1.34 |
| Max | 3 | 22,804.41 | 13.42 | 880.11 | 540 | 180 | 4.79 |
| Two-Stage TrAdaBoost.R2 | AdaBoost.R2 | Decision Tree | Decision Tree (Local) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE | R2 | RMSE | MAPE | R2 | RMSE | MAPE | R2 | RMSE | MAPE | R2 | |
| Second lane upward | 0.227 | 0.1107 | 0.83 | 0.261 | 0.1810 | 0.78 | 0.300 | 0.1551 | 0.71 | 0.316 | 0.1768 | 0.67 |
| Second lane downward | 0.273 | 0.1208 | 0.75 | 0.321 | 0.1449 | 0.65 | 0.347 | 0.164 | 0.60 | 0.389 | 0.1862 | 0.50 |
| Third lane upward | 0.246 | 0.1001 | 0.78 | 0.297 | 0.1286 | 0.68 | 0.340 | 0.1396 | 0.58 | 0.360 | 0.1480 | 0.53 |
| Third lane downward | 0.323 | 0.1037 | 0.67 | 0.344 | 0.1107 | 0.62 | 0.358 | 0.1241 | 0.59 | 0.385 | 0.1465 | 0.52 |
| Lane | RMSE | MAPE | R2 | |
|---|---|---|---|---|
| Second lane upward | 100% | 0.227 | 0.1107 | 0.83 |
| 75% | 0.232 | 0.1144 | 0.82 | |
| 50% | 0.235 | 0.1174 | 0.82 | |
| 25% | 0.265 | 0.1833 | 0.77 | |
| Second lane downward | 100% | 0.273 | 0.1208 | 0.75 |
| 75% | 0.280 | 0.1255 | 0.74 | |
| 50% | 0.282 | 0.1281 | 0.73 | |
| 25% | 0.290 | 0.1305 | 0.72 | |
| Third lane upward | 100% | 0.246 | 0.1001 | 0.78 |
| 75% | 0.252 | 0.1067 | 0.77 | |
| 50% | 0.257 | 0.1061 | 0.76 | |
| 25% | 0.266 | 0.1299 | 0.74 | |
| Third lane downward | 100% | 0.323 | 0.1037 | 0.67 |
| 75% | 0.325 | 0.1045 | 0.66 | |
| 50% | 0.342 | 0.1568 | 0.62 | |
| 25% | 0.353 | 0.1673 | 0.60 |
| Lane | RMSE | MAPE | R2 | |
|---|---|---|---|---|
| Second lane upward | 100% | 0.227 | 0.1107 | 0.83 |
| 75% | 0.239 | 0.1327 | 0.81 | |
| 50% | 0.259 | 0.1122 | 0.78 | |
| 25% | 0.279 | 0.1218 | 0.75 | |
| Second lane downward | 100% | 0.273 | 0.1208 | 0.75 |
| 75% | 0.310 | 0.1429 | 0.68 | |
| 50% | 0.325 | 0.1558 | 0.65 | |
| 25% | 0.352 | 0.1644 | 0.59 | |
| Third lane upward | 100% | 0.246 | 0.1001 | 0.78 |
| 75% | 0.252 | 0.1052 | 0.77 | |
| 50% | 0.261 | 0.1114 | 0.75 | |
| 25% | 0.278 | 0.1219 | 0.72 | |
| Third lane downward | 100% | 0.323 | 0.1037 | 0.67 |
| 75% | 0.332 | 0.1089 | 0.64 | |
| 50% | 0.350 | 0.1337 | 0.61 | |
| 25% | 0.365 | 0.154 | 0.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Guo, J.; Li, B.; Meng, L. Novel Instance-Based Transfer Learning for Asphalt Pavement Performance Prediction. Buildings 2024, 14, 852. https://doi.org/10.3390/buildings14030852
Li J, Guo J, Li B, Meng L. Novel Instance-Based Transfer Learning for Asphalt Pavement Performance Prediction. Buildings. 2024; 14(3):852. https://doi.org/10.3390/buildings14030852
Chicago/Turabian StyleLi, Jiale, Jiayin Guo, Bo Li, and Lingxin Meng. 2024. "Novel Instance-Based Transfer Learning for Asphalt Pavement Performance Prediction" Buildings 14, no. 3: 852. https://doi.org/10.3390/buildings14030852
APA StyleLi, J., Guo, J., Li, B., & Meng, L. (2024). Novel Instance-Based Transfer Learning for Asphalt Pavement Performance Prediction. Buildings, 14(3), 852. https://doi.org/10.3390/buildings14030852