Divergent Copies of a Cryptosporidium parvum-Specific Subtelomeric Gene



Abstract
:1. Introduction
2. Materials and Methods
2.1. Ethics Approval Statement
2.2. Cryptosporidium parvum Isolates
2.3. PCR Analysis of cgd6_5520-5510
2.4. TA Cloning of cgd6_5520-5510 PCR Products
2.5. Sequence Analysis
3. Results
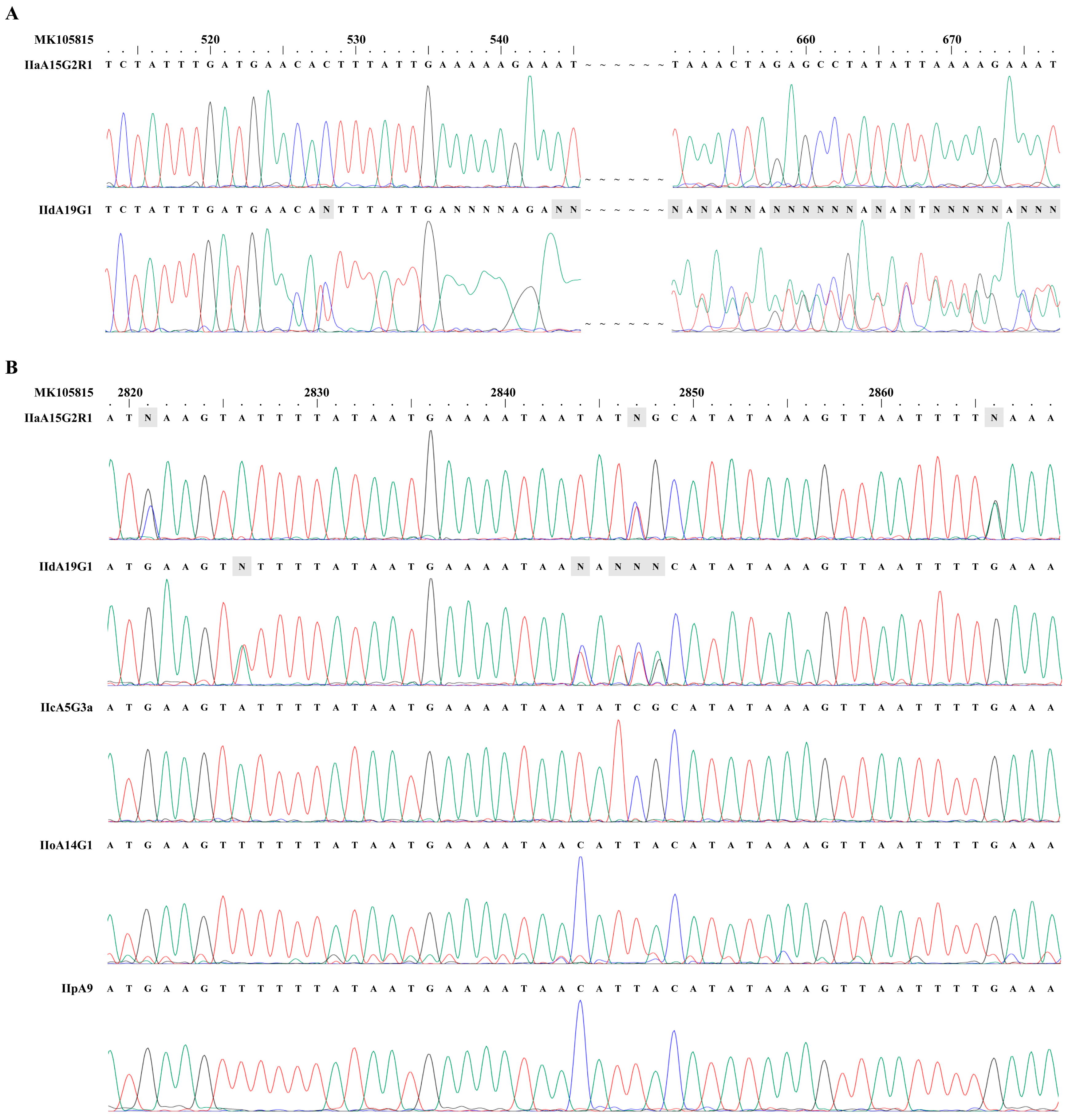
3.1. Presence of Mixed Sequences in cgd6_5520-5510 PCR Products from IIa and IId Subtypes
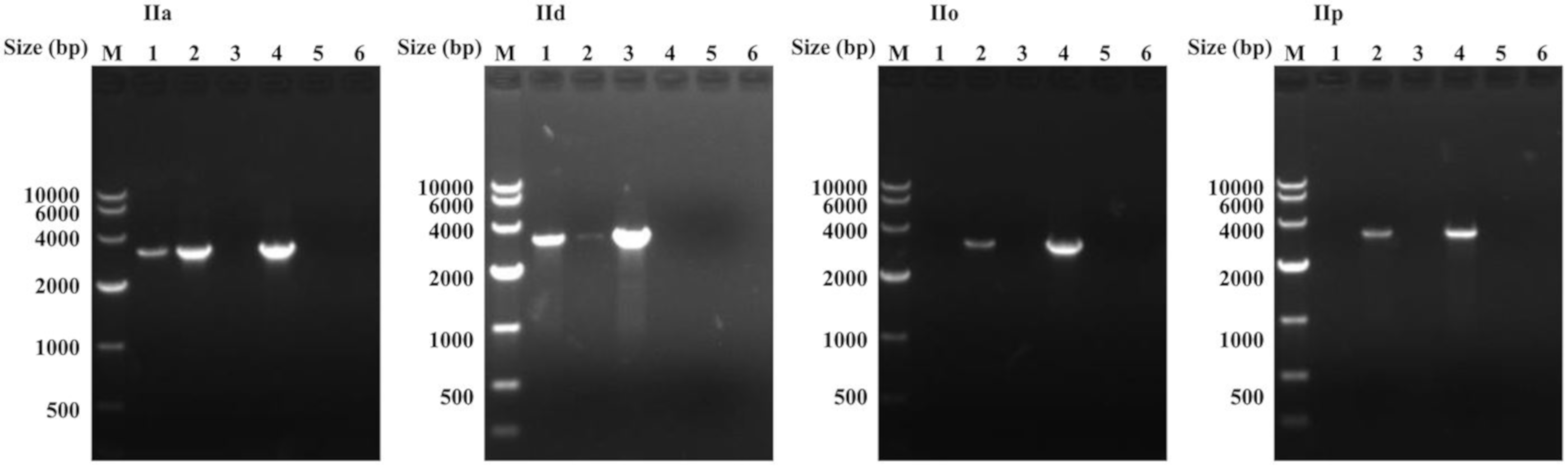
3.2. Two Copies of cgd6_5520-5510 Gene in C. parvum IIa and IId Subtypes
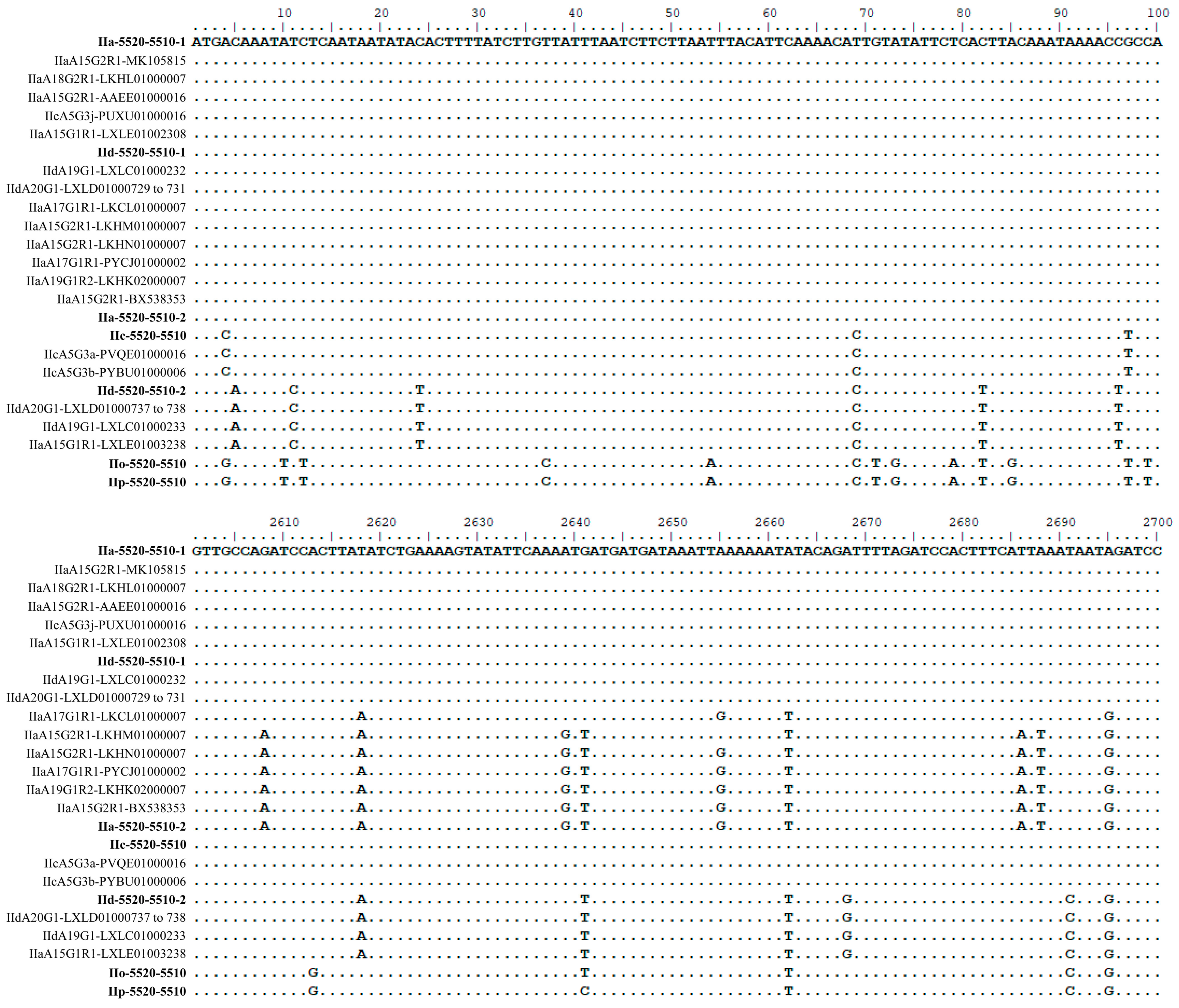
3.3. Sequence Characteristics of cgd6_5520-5510 Gene from Different C. Parvum Subtype Families
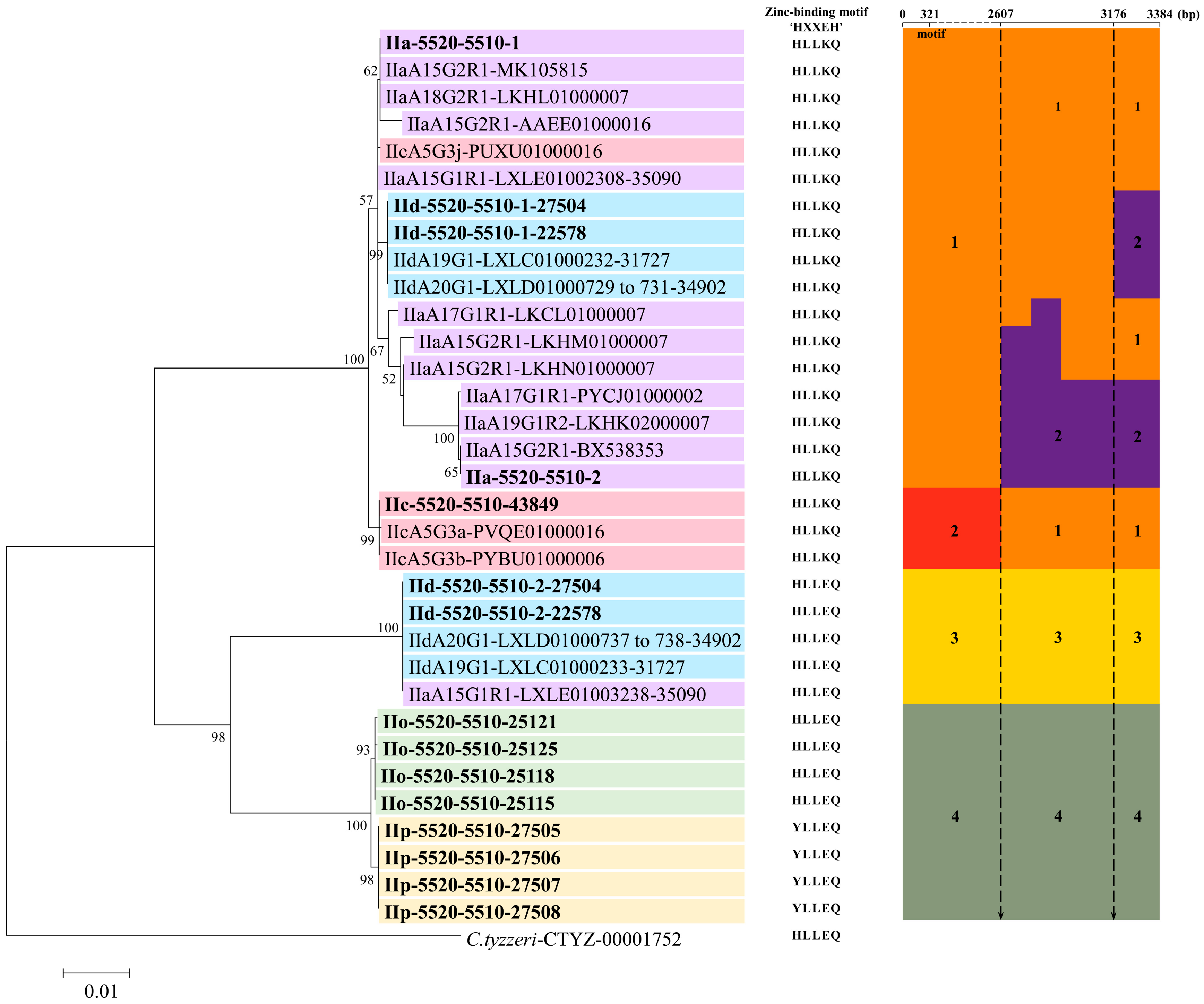
3.4. Phylogenetic Relationship Among cgd6_5520-5510 Gene Sequences
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Checkley, W.; White, A.C.; Jaganath, D.; Arrowood, M.J.; Chalmers, R.M.; Chen, X.M.; Fayer, R.; Griffiths, J.K.; Guerrant, R.L.; Hedstrom, L.; et al. A review of the global burden, novel diagnostics, therapeutics, and vaccine targets for Cryptosporidium. Lancet Infect. Dis. 2015, 15, 85–94. [Google Scholar] [CrossRef]
- Feng, Y.; Ryan, U.M.; Xiao, L. Genetic Diversity and Population Structure of Cryptosporidium. Trends Parasitol. 2018, 34, 997–1011. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Tang, K.; Rowe, L.A.; Li, N.; Roellig, D.M.; Knipe, K.; Frace, M.; Yang, C.; Feng, Y.; Xiao, L. Comparative genomic analysis reveals occurrence of genetic recombination in virulent Cryptosporidium hominis subtypes and telomeric gene duplications in Cryptosporidium parvum. BMC Genom. 2015, 16, 320. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Li, N.; Lysén, C.; Frace, M.; Tang, K.; Sammons, S.; Roellig, D.M.; Feng, Y.; Xiao, L. Isolation and Enrichment of Cryptosporidium DNA and Verification of DNA Purity for Whole-Genome Sequencing. J. Clin. Microbiol. 2015, 53, 641–647. [Google Scholar] [CrossRef] [PubMed]
- Feng, Y.; Xiao, L. Molecular Epidemiology of Cryptosporidiosis in China. Front. Microbiol. 2017, 8. [Google Scholar] [CrossRef] [PubMed]
- Kondrashov, F.A. Gene duplication as a mechanism of genomic adaptation to a changing environment. Proc. R. Soc. B-Biol. Sci. 2012, 279, 5048–5057. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beghain, J.; Langlois, A.C.; Legrand, E.; Grange, L.; Khim, N.; Witkowski, B.; Duru, V.; Ma, L.; Bouchier, C.; Ménard, D.; et al. Plasmodium copy number variation scan: Gene copy numbers evaluation in haploid genomes. Malar. J. 2016, 15, 206. [Google Scholar] [CrossRef] [PubMed]
- Lim, L.S.; Tay, Y.L.; Alias, H.; Wan, K.L.; Dear, P.H. Insights into the genome structure and copy-number variation of Eimeria tenella. BMC Genom. 2012, 13, 389. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Roellig, D.M.; Guo, Y.; Li, N.; Frace, M.A.; Tang, K.; Zhang, L.; Feng, Y.; Xiao, L. Evolution of mitosome metabolism and invasion-related proteins in Cryptosporidium. BMC Genom. 2016, 17, 1006. [Google Scholar] [CrossRef]
- Feng, Y.; Li, N.; Roellig, D.M.; Kelley, A.; Liu, G.; Amer, S.; Tang, K.; Zhang, L.; Xiao, L. Comparative genomic analysis of the IId subtype family of Cryptosporidium parvum. Int. J. Parasit. 2017, 47, 281–290. [Google Scholar] [CrossRef]
- Feng, Y.; Torres, E.; Li, N.; Wang, L.; Bowman, D.; Xiao, L. Population genetic characterisation of dominant Cryptosporidium parvum subtype IIaA15G2R1. Int. J. Parasit. 2013, 43, 1141–1147. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Wang, Y.; Wu, H.; Li, N.; Jiang, J.; Guo, Y.; Feng, Y.; Xiao, L. Characterization of a Species-Specific Insulinase-Like Protease in Cryptosporidium parvum. Front. Microbiol. 2019, 10. [Google Scholar] [CrossRef] [PubMed]
- Alves, M.; Xiao, L.; Sulaiman, I.; Lal, A.A.; Matos, O.; Antunes, F. Subgenotype Analysis of Cryptosporidium Isolates from Humans, Cattle, and Zoo Ruminants in Portugal. J. Clin. Microbiol. 2003, 41, 2744–2747. [Google Scholar] [CrossRef] [PubMed]
- Bankier, A.T.; Spriggs, H.F.; Fartmann, B.; Konfortov, B.A.; Madera, M.; Vogel, C.; Teichmann, S.A.; Ivens, A.; Dear, P.H. Integrated Mapping, Chromosomal Sequencing and Sequence Analysis of Cryptosporidium parvum. Genome Res. 2003, 13, 1787–1799. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhou, X.; Zhong, Z.; Zuo, Z.; Shi, J.; Wang, Y.; Qing, B.; Peng, G. Occurrence of novel and rare subtype families of Cryptosporidium in bamboo rats (Rhizomys sinensis) in China. Vet. Parasitol. 2015, 207, 144–148. [Google Scholar] [CrossRef]
- Cooper, G.M.; Nickerson, D.A.; Eichler, E.E. Mutational and selective effects on copy-number variants in the human genome. Nat. Genet. 2007, 39, S22. [Google Scholar] [CrossRef]
- Freeman, J.L.; Perry, G.H.; Feuk, L.; Redon, R.; McCarroll, S.A.; Altshuler, D.M.; Aburatani, H.; Jones, K.W.; Tyler-Smith, C.; Hurles, M.E.; et al. Copy number variation: New insights in genome diversity. Genome Res. 2006, 16, 949–961. [Google Scholar] [CrossRef] [Green Version]
- Amer, S.; Zidan, S.; Adamu, H.; Ye, J.; Roellig, D.; Xiao, L.; Feng, Y. Prevalence and characterization of Cryptosporidium spp. in dairy cattle in Nile River delta provinces, Egypt. Exp. Parasitol. 2013, 135, 518–523. [Google Scholar] [CrossRef]
- Amer, S.; Zidan, S.; Feng, Y.; Adamu, H.; Li, N.; Xiao, L. Identity and public health potential of Cryptosporidium spp. in water buffalo calves in Egypt. Vet. Parasitol. 2013, 191, 123–127. [Google Scholar] [CrossRef]
- Nader, J.L.; Mathers, T.C.; Ward, B.J.; Pachebat, J.A.; Swain, M.T.; Robinson, G.; Chalmers, R.M.; Hunter, P.R.; van Oosterhout, C.; Tyler, K.M. Evolutionary genomics of anthroponosis in Cryptosporidium. Nat. Microbiol. 2019, 4, 826–836. [Google Scholar] [CrossRef]
- Mauzy, M.J.; Enomoto, S.; Lancto, C.A.; Abrahamsen, M.S.; Rutherford, M.S. The Cryptosporidium parvum transcriptome during in vitro development. PLoS ONE 2012, 7, e31715. [Google Scholar] [CrossRef] [PubMed]
- Orozco, L.D.; Cokus, S.J.; Ghazalpour, A.; Ingram-Drake, L.; Wang, S.; van Nas, A.; Che, N.; Araujo, J.A.; Pellegrini, M.; Lusis, A.J. Copy number variation influences gene expression and metabolic traits in mice. Hum. Mol. Genet. 2009, 18, 4118–4129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mileyko, Y.; Joh, R.I.; Weitz, J.S. Small-scale copy number variation and large-scale changes in gene expression. Proc. Natl. Acad. Sci. USA 2008, 105, 16659–16664. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, K.A.; Bhushan, S.; Ståhl, A.; Hallberg, B.M.; Frohn, A.; Glaser, E.; Eneqvist, T. The closed structure of presequence protease PreP forms a unique 10,000 Å3 chamber for proteolysis. Embo J. 2006, 25, 1977–1986. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Kuo, W.-L.; Yousef, M.; Rosner, M.R.; Tang, W.-J. The C-terminal domain of human insulin degrading enzyme is required for dimerization and substrate recognition. Biochem. Biophys. Res. Commun. 2006, 343, 1032–1037. [Google Scholar] [CrossRef] [PubMed]
- Chesneau, V.; Rosner, M.R. Functional human insulin-degrading enzyme can be expressed in bacteria. Protein Expr. Purif. 2000, 19, 91–98. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subtype Family | Target Region | Name of Primers | Forward Primer (5′ to 3′) | Annealing Temperature | PCR Product (bp) | Usage |
|---|---|---|---|---|---|---|
| Reverse Primer (5′ to 3′) | ||||||
| IIa, IId | 5′ end of the cgd6_5520-5510 gene | IId-F | CTTGTTATTTAATCTTCTTAATTTACATTC | 52 °C | 954–975 | Found mixed sequences |
| IId-R | ATAATAATAAGTTTTTCATTTCCAT | |||||
| 3′ end of the cgd6_5520-5510 gene | IIa-F2 | ACGCAAAAGTGATTAGTAGAATCTTTGATCTAGAC | 52 °C | ~818 | ||
| IIa-R | CTCATCTTTCATGAATTTGAGTTGG | |||||
| IIa-5520-5510-1, IId-5520-5510-1 | IIa-F | ATGACAAATATCTCAATAATATACACTTTTATCTT | 58 °C, 52 °C | ~3165 | Specific reverse primers | |
| Specific-R1 | CTCCATAAATTTTTTAAAGGATGAATC | |||||
| IIa-5520-5510-2, IId-5520-5510-2 | IIa-F | ATGACAAATATCTCAATAATATACACTTTTATCTT | 58 °C, 52 °C | ~3171, ~3192 | ||
| Specific-R2 | CCACTCCATAAATTTATTAAAGGATAATAATTT | |||||
| IIc | IIc-5520-5510 | IIa-F | ATGACAAATATCTCAATAATATACACTTTTATCTT | 58 °C | ~3162 | Specific reverse primers |
| Specific-R1 | CTCCATAAATTTTTTAAAGGATGAATC | |||||
| - | IIa-F | ATGACAAATATCTCAATAATATACACTTTTATCTT | - | - | ||
| Specific-R2 | CCACTCCATAAATTTATTAAAGGATAATAATTT | |||||
| IIo, IIp | The full cgd6_5520-5510 gene | IIa-F 1 | ATGACAAATATCTCAATAATATACACTTTTATCTT | 58 °C | ~3374 | Primary PCR |
| IIa-R-new 1 | TTCATGAATTTGAGTTGGCTATA | |||||
| - | IIo-F2 | AACCTCTAACACGCAAGATTACATA | - | - | Specific reverse primers | |
| Specific-R1 2 | CTCCATAAATTTTTTAAAGGATGAATC | |||||
| IIo-5520-5510, IIp-5520-5510 | IIo-F2 | AACCTCTAACACGCAAGATTACATA | 58 °C | ~3192 | ||
| Specific-R2 2 | CCACTCCATAAATTTATTAAAGGATAATAATTT |
| Subtype Family | Target Region | Name of Primers | Forward Primer (5′ to 3′) | Annealing Temperature | PCR Product (bp) | Usage |
|---|---|---|---|---|---|---|
| Reverse Primer (5′ to 3′) | ||||||
| IIa, IId | IIa-5520-5510-2, IId-5520-5510-1 full gene | IIa-F | ATGACAAATATCTCAATAATATACACTTTTATCTT | 52 °C | ~3360, ~3357 | TA cloning |
| IIa-R | CTCATCTTTCATGAATTTGAGTTGG | |||||
| IIa-5520-5510-1 near full gene | IIa-F | ATGACAAATATCTCAATAATATACACTTTTATCTT | 58 °C | ~3165 | Specific reverse primers | |
| Specific-R1 | CTCCATAAATTTTTTAAAGGATGAATC | |||||
| IId-5520-5510-2 near full gene | IIa-F | ATGACAAATATCTCAATAATATACACTTTTATCTT | 52 °C | ~3192 | Specific reverse primers | |
| Specific-R2 | CCACTCCATAAATTTATTAAAGGATAATAATTT | |||||
| IIc | IIc-5520-5510 full gene | IIa-F | ATGACAAATATCTCAATAATATACACTTTTATCTT | 52 °C | ~3354 | Sequencing directly, TA cloning |
| IIa-R | CTCATCTTTCATGAATTTGAGTTGG | |||||
| IIo, IIp | IIo-5520-5510, IIp-5520-5510 near full gene | IIa-F 1 | ATGACAAATATCTCAATAATATACACTTTTATCTT | 58 °C | ~3374 | Sequencing directly, TA cloning |
| IIa-R-new 1 | TTCATGAATTTGAGTTGGCTATA | |||||
| IIo-F 2 | AACCTCTAACACGCAAGATTACATA | 58 °C | ~3224 | |||
| IIo-R 2 | TTGTATGATCTAACCTTGTAAAG |
| Subtype Family | Subtype | Isolate | Geographic Location | Sequence Name in This Study | GenBank Accession Number | Nucleotide Position |
|---|---|---|---|---|---|---|
| IIa | IIaA15G1R1 | 35090 1 | Egypt: El Beheira | IIaA15G1R1-LXLE01002308 | LXLE01002308.1 | 1 to 2825 |
| IIaA15G1R1-LXLE01003238 | LXLE01003238.1 | 8331 to 11714 | ||||
| IIaA15G2R1 | IOWA 1 | - | IIaA15G2R1-AAEE01000016 | AAEE01000016.1 | 23074 to 26443 | |
| IOWA 1 | - | IIaA15G2R1-BX538353 | BX538353.1 | 271827 to 275189 | ||
| IOWA 1 | - | IIaA15G2R1-MK105815 | MK105815.2 | 1 to 3360 | ||
| UKP4 | United Kingdom: England | IIaA15G2R1-LKHM01000007 | LKHM01000007.1 | 24207 to 27566 | ||
| UKP5 | United Kingdom | IIaA15G2R1-LKHN01000007 | LKHN01000007.1 | 24155 to 27514 | ||
| UKP6 1 | United Kingdom | - | LKCK01000007.1 2 | 19930 to 21805 | ||
| - | LKCK01000011.1 2 | 1196691 to 1198512 | ||||
| IIaA17G1R1 | UKP1 1 | United Kingdom | IIaA17G1R1-PYCJ01000002 | PYCJ01000002.1 | 4407 to 7769 | |
| - | PYCJ01000005.1 2 | 1084332 to 1085232 | ||||
| UKP7 | United Kingdom: England | IIaA17G1R1-LKCL01000007 | LKCL01000007.1 | 23021 to 26687 | ||
| IIaA18G2R1 | UKP3 | United Kingdom: Wales | IIaA18G2R1-LKHL01000007 | LKHL01000007.1 | 25874 to 29233 | |
| IIaA19G1R2 | UKP2 | United Kingdom: England | IIaA19G1R2-LKHK02000007 | LKHK02000007.1 | 16497 to 19859 | |
| IIc | IIcA5G3a | UKP13 | United Kingdom: England | - | PVQD01000016.1 2 | 5597 to 6803 |
| UKP14 | United Kingdom: England | - | PUXT01000016.1 2 | 12896 to 16195 | ||
| UKP15 | United Kingdom: Wales | IIcA5G3a-PVQE01000016 | PVQE01000016.1 | 23118 to 26751 | ||
| IIcA5G3b | TU114 | Uganda | IIcA5G3b-PYBU01000006 | PYBU01000006.1 | 2767 to 6123 | |
| IIcA5G3j | UKP16 | United Kingdom: Wales | IIcA5G3j-PUXU01000016 | PUXU01000016.1 | 26498 to 29857 | |
| IIcA5G3p | UKP12 | United Kingdom: England | - | PUXS01000016.1 2 | 5184 to 5487 | |
| IId | IIdA19G1 | 31727 1 | China: Henan | IIdA19G1-LXLC01000232 | LXLC01000232.1 | 130844 to 134203 |
| IIdA19G1-LXLC01000233 | LXLC01000233.1 | 36841 to 40158 | ||||
| IIdA20G1 | 34902 1 | Egypt: Kafr El Sheikh | IIdA20G1-LXLD01000729 to 731 3 | LXLD01000729.1 | 11759 to 12186 | |
| LXLD01000730.1 | 1 to 699 | |||||
| LXLD01000731.1 | 1 to 2342 | |||||
| IIdA20G1-LXLD01000737 to 738 3 | LXLD01000737.1 | 11998 to 12428 | ||||
| LXLD01000738.1 | 1 to 2363 | |||||
| IIdA22G1 | UKP8 1 | United Kingdom: England | - | LKCJ01000007.1 2 | 27295 to 28283 | |
| - | LKCJ01000010.1 2 | 670660 to 673451 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Chen, L.; Li, F.; Li, N.; Feng, Y.; Xiao, L. Divergent Copies of a Cryptosporidium parvum-Specific Subtelomeric Gene. Microorganisms 2019, 7, 366. https://doi.org/10.3390/microorganisms7090366
Zhang S, Chen L, Li F, Li N, Feng Y, Xiao L. Divergent Copies of a Cryptosporidium parvum-Specific Subtelomeric Gene. Microorganisms. 2019; 7(9):366. https://doi.org/10.3390/microorganisms7090366
Chicago/Turabian StyleZhang, Shijing, Li Chen, Falei Li, Na Li, Yaoyu Feng, and Lihua Xiao. 2019. "Divergent Copies of a Cryptosporidium parvum-Specific Subtelomeric Gene" Microorganisms 7, no. 9: 366. https://doi.org/10.3390/microorganisms7090366
APA StyleZhang, S., Chen, L., Li, F., Li, N., Feng, Y., & Xiao, L. (2019). Divergent Copies of a Cryptosporidium parvum-Specific Subtelomeric Gene. Microorganisms, 7(9), 366. https://doi.org/10.3390/microorganisms7090366