Instance Segmentation with Mask R-CNN Applied to Loose-Housed Dairy Cows in a Multi-Camera Setting


Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Hardware and Recording Software
2.2. Data Collection
2.2.1. Camera Installation and Recording
2.2.2. Recorded Cows
Ethical Statement
2.3. Mask R-CNN
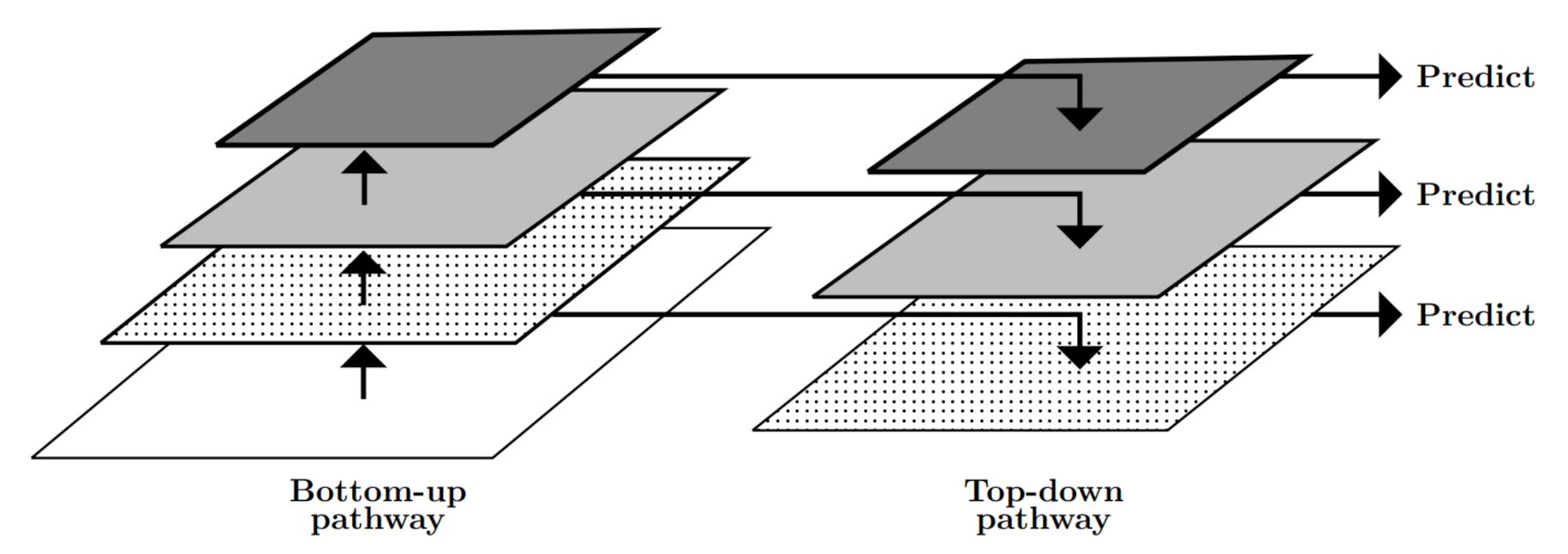
2.3.1. Building Blocks of the Model
Backbone
Region Proposal Network (RPN)
Three Output Branches
- Classifier branch: As the ROIs suggested by the RPN can come with different sizes, a ROI pooling step is carried out to provide a fixed size for the softmax classifier [63]. The classifier is a region-based object detection CNN [64] which gives a confidence score , evaluating how likely the found object was a cow. In a multi class setting, confidence scores for all class labels would be output and a found object would be assigned to the most likely class. Additionally, a background class is generated and respective ROIs are discarded. As confidence threshold 0.9 was set, i.e., at all anchors with confidence score 0.9 or higher a cow was said to be present.
- Bounding box branch: To refine the bounding boxes and to reduce localization errors, an additional regression model is trained to correct the bounding boxes proposed by RPN [64].
- Instance segmentation branch: Masks of size 28 × 28 pixels are generated from the RPN proposals by an additional CNN. The masks hold float numbers, i.e., more information is stored than in binary masks, and they are later scaled to the size of the respective bounding box to receive pixel wise masks for the detected objects.
2.3.2. Implementation and Training of Mask R-CNN
AxisCow
Learning Rate Scheduler and Data Augmentation
- A choice of two out of the following transformations: Identity, horizontal flip, vertical flip and cropping.
- The application of Gaussian blur or Gaussian noise.
- A change of contrast or a change of brightness.
- The application of an affine transformation.
Training
2.4. Training and Validation Data Sets
| “metadata”: { |
| “1_pp7XiE0u”: { |
| “vid”: “1”, |
| “xy”: [7, 1.479, 23.671, 8.877, 11.836, 22.192, 1.479, … |
2.4.1. Training the Model
2.5. Evaluating the Model: ‘Averaged Precision Score’ and ‘Averaged Recall Score’
2.5.1. Intersection over Union
2.5.2. Evaluation Metrics
Averaged Precision Score (AP) and Mean Averaged Precision Score (mAP)
Averaged Recall Score (AR)
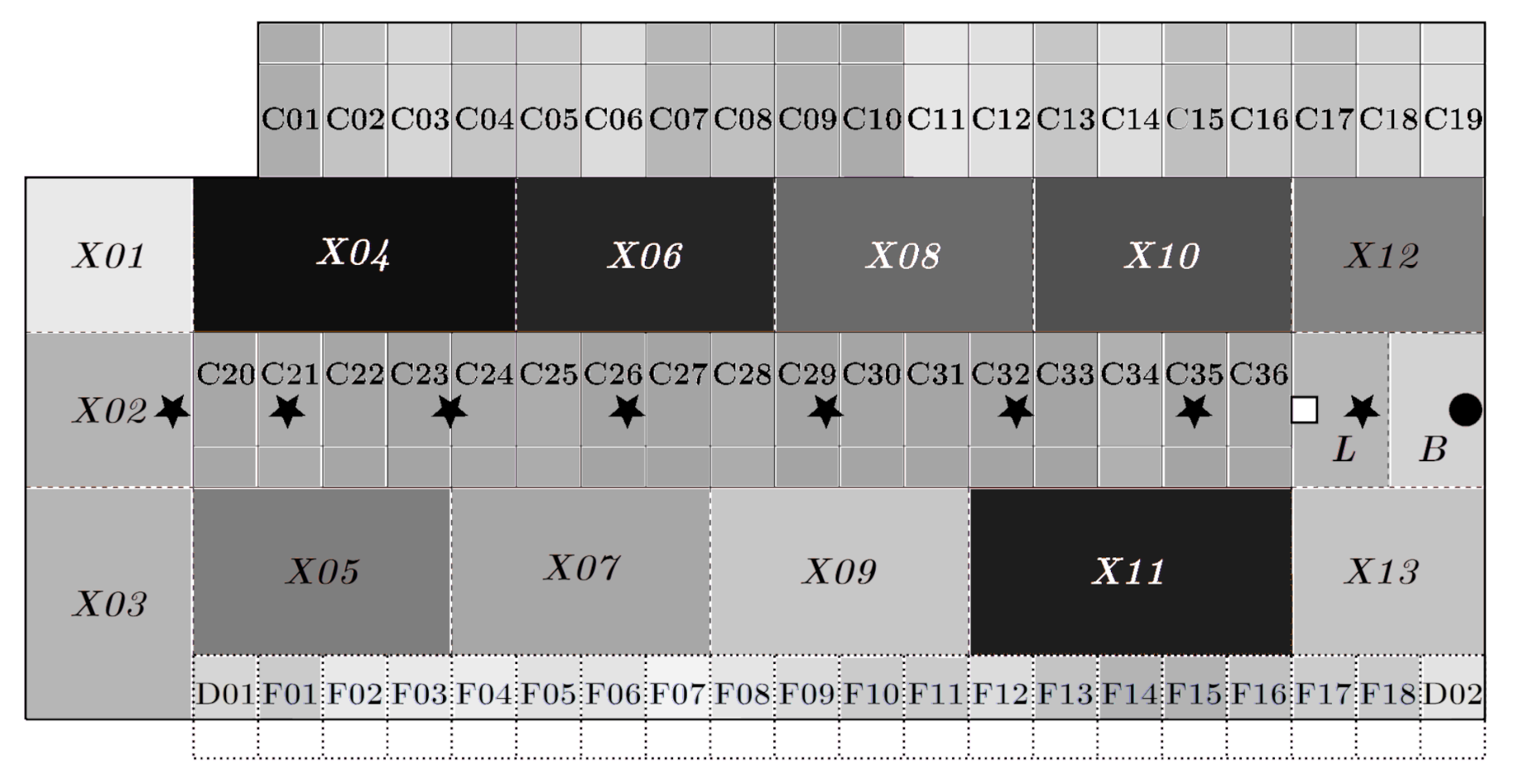
2.6. Exemplary Usage of Barn Space
2.7. Dependency on Size of the Training Data Set
3. Results
3.1. Segmentation of Cows
3.2. Exemplary Usage of Barn Space
3.3. Dependency on the Size of the Training Data Set
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Berckmans, D. Precision livestock farming (PLF). Comput. Electron. Agric. 2008, 62, 1. [Google Scholar] [CrossRef]
- Neethirajan, S. Recent advances in wearable sensors for animal health management. Sens.-Bio-Sens. Res. 2017, 12, 15–29. [Google Scholar] [CrossRef] [Green Version]
- Fournel, S.; Rousseau, A.N.; Laberge, B. Rethinking environment control strategy of confined animal housing systems through precision livestock farming. Biosyst. Eng. 2017, 155, 96–123. [Google Scholar] [CrossRef]
- Van Nuffel, A.; Zwertvaegher, I.; Van Weyenberg, S.; Pastell, M.; Thorup, V.M.; Bahr, C.; Sonck, B.; Saeys, W. Lameness Detection in Dairy Cows: Part 2. Use of Sensors to Automatically Register Changes in Locomotion or Behavior. Animals 2015, 5, 861–885. [Google Scholar] [CrossRef] [Green Version]
- Viazzi, S.; Bahr, C.; Schlageter-Tello, A.; Van Hertem, T.; Romanini, C.E.B.; Pluk, A.; Halachmi, I.; Lokhorst, C.; Berckmans, D. Analysis of individual classification of lameness using automatic measurement of back posture in dairy cattle. J. Dairy Sci. 2013, 96, 257–266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, K.; Bewley, J.; He, D.; Jin, X. Automatic lameness detection in dairy cattle based on leg swing analysis with an image processing technique. Comput. Electron. Agric. 2018, 148, 226–236. [Google Scholar] [CrossRef]
- Zhao, K.; He, D.; Bewley, J. Detection of lameness in dairy cattle using limb motion analysis with automatic image processing. In Precision Dairy Farming 2016; Wageningen Academic Publishers: Leeuwarden, The Netherlands, 2016; pp. 97–104. [Google Scholar]
- Van Hertem, T.; Viazzi, S.; Steensels, M.; Maltz, E.; Antler, A.; Alchanatis, V.; Schlageter-Tello, A.; Lokhorst, K.; Romanini, C.E.B.; Bahr, C.; et al. Automatic lameness detection based on consecutive 3D-video recordings. Biosyst. Eng. 2014, 119, 108–116. [Google Scholar] [CrossRef]
- Jiang, B.; Song, H.; He, D. Lameness detection of dairy cows based on a double normal background statistical model. Comput. Electron. Agric. 2019, 158, 140–149. [Google Scholar] [CrossRef]
- Halachmi, I.; Klopcic, M.; Polak, P.; Roberts, D.J.; Bewley, J.M. Automatic assessment of dairy cattle body condition score using thermal imaging. Comput. Electron. Agric. 2013, 99, 35–40. [Google Scholar] [CrossRef]
- Azzaro, G.; Caccamo, M.; Ferguson, J.; Battiato, S.; Farinella, G.; Guarnera, G.; Puglisi, G.; Petriglieri, R.; Licitra, G. Objective estimation of body condition score by modeling cow body shape from digital images. J. Dairy Sci. 2011, 94, 2126–2137. [Google Scholar] [CrossRef]
- Song, X.; Bokkers, E.; van Mourik, S.; Koerkamp, P.G.; van der Tol, P. Automated body condition scoring of dairy cows using three-dimensional feature extraction from multiple body regions. J. Dairy Sci. 2019, 102, 4294–4308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Imamura, S.; Zin, T.T.; Kobayashi, I.; Horii, Y. Automatic evaluation of Cow’s body-condition-score using 3D camera. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), Nagoya, Japan, 24–27 October 2017; pp. 1–2. [Google Scholar] [CrossRef]
- Spoliansky, R.; Edan, Y.; Parmet, Y.; Halachmi, I. Development of automatic body condition scoring using a low-cost three-dimensional Kinect camera. J. Dairy Sci. 2016, 99, 7714–7725. [Google Scholar] [CrossRef] [PubMed]
- Weber, A.; Salau, J.; Haas, J.H.; Junge, W.; Bauer, U.; Harms, J.; Suhr, O.; Schönrock, K.; Rothfuß, H.; Bieletzki, S.; et al. Estimation of backfat thickness using extracted traits from an automatic 3D optical system in lactating Holstein-Friesian cows. Livest. Sci. 2014, 165, 129–137. [Google Scholar] [CrossRef]
- Guzhva, O.; Ardö, H.; Herlin, A.; Nilsson, M.; Åström, K.; Bergsten, C. Feasibility study for the implementation of an automatic system for the detection of social interactions in the waiting area of automatic milking stations by using a video surveillance system. Comput. Electron. Agric. 2016, 127, 506–509. [Google Scholar] [CrossRef]
- Salau, J.; Haas, J.H.; Junge, W.; Thaller, G. Automated calculation of udder depth and rear leg angle in Holstein-Friesian cows using a multi-Kinect cow scanning system. Biosyst. Eng. 2017, 160, 154–169. [Google Scholar] [CrossRef]
- Thomasen, J.R.; Lassen, J.; Nielsen, G.G.B.; Borggard, C.; Stentebjerg, P.R.B.; Hansen, R.H.; Hansen, N.W.; Borchersen, S. Individual cow identification in a commercial herd using 3D camera technology. In Proceedings of the World Congress on Genetics Applied to Livestock, Auckland, New Zealand, 11–16 February 2018; Technologies—Novel Phenotypes. p. 613. [Google Scholar]
- Tsai, D.M.; Huang, C.Y. A motion and image analysis method for automatic detection of estrus and mating behavior in cattle. Comput. Electron. Agric. 2014, 104, 25–31. [Google Scholar] [CrossRef]
- Salau, J.; Haas, J.H.; Junge, W.; Thaller, G. How does the Behaviour of Dairy Cows during Recording Affect an Image Processing Based Calculation of the Udder Depth? Agric. Sci. 2018, 9. [Google Scholar] [CrossRef] [Green Version]
- Salau, J.; Krieter, J. Analysing the Space-Usage-Pattern of a cow herd using video surveillance and automated motion detection. Biosyst. Eng. 2020, 197, 122–134. [Google Scholar] [CrossRef]
- Reinhardt, V.; Reinhardt, A. Cohesive Relationships in a Cattle Herd (Bos indicus). Behaviour 1981, 77, 121–151. [Google Scholar] [CrossRef]
- Uher, J. Comparative personality research: Methodological approaches. Eur. J. Personal. 2008, 22, 427–455. [Google Scholar] [CrossRef] [Green Version]
- Godde, S.; Humbert, L.; Côté, S.; Réale, D.; Whitehead, H. Correcting for the impact of gregariousness in social network analyses. Anim. Behav. 2013, 85, 553–558. [Google Scholar] [CrossRef]
- Gieseke, D.; Lambertz, C.; Gauly, M. Relationship between herd size and measures of animal welfare on dairy cattle farms with freestall housing in Germany. J. Dairy Sci. 2018, 101, 7397–7411. [Google Scholar] [CrossRef] [PubMed]
- Galindo, F.; Broom, D. The relationships between social behaviour of dairy cows and the occurrence of lameness in three herds. Res. Vet. Sci. 2000, 69, 75–79. [Google Scholar] [CrossRef] [PubMed]
- Hedlund, L.; Løvlie, H. Personality and production: Nervous cows produce less milk. J. Dairy Sci. 2015, 98, 5819–5828. [Google Scholar] [CrossRef]
- Šárová, R.; Špinka, M.; Panamá, J.L.A. Synchronization and leadership in switches between resting and activity in a beef cattle herd—A case study. Appl. Anim. Behav. Sci. 2007, 108, 327–331. [Google Scholar] [CrossRef]
- Nelson, S.; Haadem, C.; Nødtvedt, A.; Hessle, A.; Martin, A. Automated activity monitoring and visual observation of estrus in a herd of loose housed Hereford cattle: Diagnostic accuracy and time to ovulation. Theriogenology 2017, 87, 205–211. [Google Scholar] [CrossRef]
- Davis, J.; Darr, M.; Xin, H.; Harmon, J.; Russell, J. Development of a GPS Herd Activity and Well- Being Kit (GPS HAWK) to Monitor Cattle Behavior and the Effect of Sample Interval on Travel Distance. Appl. Eng. Agric. 2011, 27. [Google Scholar] [CrossRef]
- Rose, T. Real-Time Location System Series 7000 from Ubisense for Behavioural Analysis in Dairy Cows. Ph.D. Thesis, Institute of Animal Breeding and Husbandry, Kiel University, Kiel, Germany, 2015. [Google Scholar]
- Boyland, N.K.; Mlynski, D.T.; James, R.; Brent, L.J.N.; Croft, D.P. The social network structure of a dynamic group of dairy cows: From individual to group level patterns. Appl. Anim. Behav. Sci. 2016, 174, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Will, M.K.; Büttner, K.; Kaufholz, T.; Müller-Graf, C.; Selhorst, T.; Krieter, J. Accuracy of a real-time location system in static positions under practical conditions: Prospects to track group-housed sows. Comput. Electron. Agric. 2017, 142, 473–484. [Google Scholar] [CrossRef]
- Rojas, R. Neural Networks: A Systematic Introduction; Springer: Berlin, Germany, 1996. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K.J. Phoneme recognition using time-delay neural networks. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 328–339. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Oh, K.S.; Jung, K. GPU implementation of neural networks. Pattern Recognit. 2004, 37, 1311–1314. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Kondo, N.; Fujiura, T.; Suzuki, T.; Wulandari; Yoshioka, H.; Itoyama, E. Classification of multiple cattle behavior patterns using a recurrent neural network with long short-term memory and inertial measurement units. Comput. Electron. Agric. 2019, 157, 247–253. [Google Scholar] [CrossRef]
- Alvarez, J.R.; Arroqui, M.; Mangudo, P.; Toloza, J.; Jatip, D.; Rodríguez, J.M.; Teyseyre, A.; Sanz, C.; Zunino, A.; Machado, C.; et al. Body condition estimation on cows from depth images using Convolutional Neural Networks. Comput. Electron. Agric. 2018, 155, 12–22. [Google Scholar] [CrossRef] [Green Version]
- Bonneau, M.; Vayssade, J.A.; Troupe, W.; Arquet, R. Outdoor animal tracking combining neural network and time-lapse cameras. Comput. Electron. Agric. 2020, 168, 105150. [Google Scholar] [CrossRef]
- Porto, S.M.; Arcidiacono, C.; Anguzza, U.; Cascone, G. The automatic detection of dairy cow feeding and standing behaviours in free-stall barns by a computer vision-based system. Biosyst. Eng. 2015, 133, 46–55. [Google Scholar] [CrossRef]
- Guzhva, O.; Ardö, H.; Nilsson, M.; Herlin, A.; Tufvesson, L. Now you see me: Convolutional neural network based tracker for dairy cows. Front. Robot. AI 2018, 5, 107. [Google Scholar] [CrossRef] [Green Version]
- Parikh, R. Garbage in, Garbage Out: How Anomalies Can Wreck Your Data. 2014. Available online: https://heap.io/blog/data-stories/garbage-in-garbage-out-how-anomalies-can-wreck-your-data (accessed on 11 November 2020).
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. Lect. Notes Comput. Sci. 2016, 21–37. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 11 November 2020).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 91–99. [Google Scholar]
- Xu, B.; Wang, W.; Falzon, G.; Kwan, P.; Guo, L.; Chen, G.; Tait, A.; Schneider, D. Automated cattle counting using Mask R-CNN in quadcopter vision system. Comput. Electron. Agric. 2020, 171, 105300. [Google Scholar] [CrossRef]
- Lin, T.Y.; Patterson, G.; Ronchi, M.R.; Cui, Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; et al. COCO 2020 Object Detection Task. 2020. Available online: https://cocodataset.org/#home (accessed on 11 November 2020).
- Salau, J.; Lamp, O.; Krieter, J. Dairy cows’ contact networks derived from videos of eight cameras. Biosyst. Eng. 2019, 188, 106–113. [Google Scholar] [CrossRef]
- Salau, J. Multiple IP Camera Control with Python 3.6. 2019. Available online: https://github.com/jsalau/Multiple-IP-camera-control-with-Python-3.6/tree/3d908191ed99d01486501481934788620e578acd (accessed on 11 December 2018).
- Axis Communications. VAPIX® HTTP API. 2008. Available online: www.axis.com (accessed on 11 December 2018).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 315–323. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Bridle, J.S. Probabilistic Interpretation of Feedforward Classification Network Outputs, with Relationships to Statistical Pattern Recognition. In Neurocomputing; Soulié, F.F., Hérault, J., Eds.; Springer: Berlin/Heidelberg, Germany, 1990; pp. 227–236. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Chollet, F.; Falbel, D.; Allaire, J.J.; Tang, Y.; an Der Bijl, W.; Studer, M.; Keydana, S. Keras. 2015. Available online: https://keras.io/ (accessed on 11 December 2018).
- Van Rossum, G. Python Tutorial; Technical Report CS-R9526; Centrum voor Wiskunde en Informatica (CWI): Amsterdam, The Netherlands, 1995. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; USENIX Association: Berkeley, CA, USA, 2016; pp. 265–283. Available online: tensorflow.org (accessed on 15 March 2020).
- Jung, A.B.; Wada, K.; Crall, J.; Tanaka, S.; Graving, J.; Reinders, C.; Yadav, S.; Banerjee, J.; Vecsei, G.; Kraft, A.; et al. imgaug. 2020. Available online: https://imgaug.readthedocs.io/en/latest/ (accessed on 1 February 2020).
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator (VIA). 2016. Available online: http://www.robots.ox.ac.uk/~vgg/software/via (accessed on 1 February 2020).
- Dutta, A.; Zisserman, A. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar] [CrossRef] [Green Version]
- Salau, J. Instance Segmentation of Loose-Housed Dairy Cows Using Mask R-CNN Modified From the Implementation by Waleed Abdulla (Matterport). 2020. Available online: https://github.com/matterport/Mask_RCNN/blob/master/setup.py (accessed on 11 November 2020).
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Azimi, M.; Eslamlou Dadras, A.; Pekcan, G. Data-Driven Structural Health Monitoring and Damage Detection through Deep Learning: State-of-the-Art Review. Sensors 2020, 20, 2778. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Vázquez Diosdado, J.A.; Barker, Z.E.; Hodges, H.R.; Amory, J.R.; Croft, D.P.; Bell, N.J.; Codling, E.A. Space-use patterns highlight behavioural differences linked to lameness, parity, and days in milk in barn-housed dairy cows. PLoS ONE 2018, 13, e0208424. [Google Scholar] [CrossRef] [PubMed]
- Salau, J.; Krieter, J. Predicting Use of Resources in Dairy Cows Using Time Series. Biosyst. Eng. under review.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Camera | Images for Training | Images for Validation |
|---|---|---|
| CAM 1 | 58 | 11 |
| CAM 2 | 60 | 12 |
| CAM 3 | 59 | 12 |
| CAM 4 | 62 | 12 |
| CAM 5 | 62 | 13 |
| CAM 6 | 61 | 13 |
| CAM 7 | 60 | 12 |
| CAM 8 | 57 | 11 |
| ∑ | 479 | 96 |
| Model Output Compared to Ground Truth | Evaluation | |
|---|---|---|
| T (Cow detected) | IOU (Cow present) | TP |
| IOU (No cow present) | FP | |
| Missed cow: T, but a cow was present at the anchor | FN | |
| Metric | Bounding Box | Segmentation Mask | COCO (Masks) |
|---|---|---|---|
| AP | 0.909 | 0.849 | 0.552 |
| mAP | 0.584 | 0.454 | 0.336 |
| AR | 0.606 | 0.551 | not reported |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salau, J.; Krieter, J. Instance Segmentation with Mask R-CNN Applied to Loose-Housed Dairy Cows in a Multi-Camera Setting. Animals 2020, 10, 2402. https://doi.org/10.3390/ani10122402
Salau J, Krieter J. Instance Segmentation with Mask R-CNN Applied to Loose-Housed Dairy Cows in a Multi-Camera Setting. Animals. 2020; 10(12):2402. https://doi.org/10.3390/ani10122402
Chicago/Turabian StyleSalau, Jennifer, and Joachim Krieter. 2020. "Instance Segmentation with Mask R-CNN Applied to Loose-Housed Dairy Cows in a Multi-Camera Setting" Animals 10, no. 12: 2402. https://doi.org/10.3390/ani10122402
APA StyleSalau, J., & Krieter, J. (2020). Instance Segmentation with Mask R-CNN Applied to Loose-Housed Dairy Cows in a Multi-Camera Setting. Animals, 10(12), 2402. https://doi.org/10.3390/ani10122402