1. Introduction
Angus is the most common beef cattle breed currently raised in the United States [
1,
2], the top beef cattle producer in the world [
3]. Longevity was identified by North American beef cattle stakeholders as the utmost priority for further genetic improvement [
4]. Genetic (and genomic) selection for longevity has the potential to reduce the costs associated with the replacement of animals in the herd and, depending on the trait definition assumed for longevity in the breeding program, it can also improve the reproductive potential of mature cows [
5,
6]. Moreover, selecting for improved longevity can contribute to increased genetic progress for other economically important traits, as it can increase the number of animals available for selection (i.e., greater selection intensity for other traits). The potential increase in the number of animals in the herd is mainly due to the fact that less animals are culled due to involuntary reasons, such as disease and structural problems [
7].
Genetic selection for increased longevity can be challenging as this is a trait measured late in life and many cows are still alive at the time of the genetic evaluation [
8], or because their culling might not be recorded or informed to the breeding program [
7]. Thus, the use of censored data is commonly dealt with in the genetic evaluations of longevity. In this context, Hou et al. [
9] showed that merely excluding phenotypes from the genetic analysis can lead to bias, especially for sires that have a high proportion of daughters with censored records. Furthermore, eliminating records from cows that are still alive can contribute to reducing the accuracy of breeding values (EBVs) predicted for them and their parents, which can considerably reduce the genetic gain per unit time because older animals (which tend to have lower genetic merit compared to younger animals in a population under selection) might continue to be selected.
The penalty method [
10] has been considered suitable to treat censored records in the genetic evaluations of fertility related traits, which consists on applying a penalization criterion for animals with censored records. For age at first calving, for example, censored records are replaced by a set of augmented data (i.e., penalized data), which is obtained by adding a constant value of 21 days to the highest value of age at the first calving within each contemporary group [
9,
10,
11]. Specifically for longevity-related traits, penalized data can be obtained by including a culling date for cows without culling information recorded in the dataset. In this context, the last calving information available for each cow can be used to define the penalization criterion for longevity. For instance, the culling data for each cow can be assumed anytime (e.g., one or two years) after its last reported calving. Therefore, the greatest challenge is to defined the optimal threshold to create the penalized data for longevity. Using the augmented data instead the censured records has been shown to increase the prediction accuracy of EBVs for fertility in some studies [
11,
12]. However, to our best knowledge, the use of the penalty method has not yet been investigated for the genetic evaluation of longevity indicator traits, especially when using random regression models (RRM).
Accounting for censored records in the genetic evaluation is simpler when using RRM, because they do not require that all animals have information for all time points [
13,
14]. In addition, the use of RRM usually results in more accurate EBVs compared to other statistical models, and it might allow the identification of the most feasible time periods to perform selection [
13,
15]. Recently, the optimal RRM to perform selection for longevity in North American Angus cattle was defined, while comparing the impact of different longevity indicators in the selection scheme [
6]. However, the impact of censored or penalized data in the selection decisions remains unknown when performing genetic evaluations for longevity using RRM. In this context, we aimed to evaluate the impact of different proportions of censored data (i.e., 0%, 20%, 40%, 60%, and 80%) in the prediction of EBVs, genetic parameters, and computational efficiency for two longevity indicators proposed for North American Angus cattle [
6]: (a) traditional longevity (TL; defined as the time from first calving to culling); and (b) functional longevity (FL; defined as the time period in which the cow was alive and calving after its first calving). Additionally, three different criteria for the penalty method were proposed and extensively compared to the use of censored records.
2. Materials and Methods
2.1. Ethics Statement
All information used in this study was obtained from existing datasets provided by the American Angus Association (Saint Joseph, MO, USA) and the Canadian Angus Association (Rocky View County, AB, Canada). Therefore, no animal care committee approval was necessary.
2.2. Dataset, Quality Control, Designs, Scenarios, and Sub-Scenarios
Only cows with information of natural death (i.e., cows that died due to natural causes or were culled after they were 15 years old) were analyzed in this study. The phenotypic quality control excluded data from cows born before 1990 or that did not have their first calving before 30 months-old, as well as cows with culling age greater than 20 years. Additional details about the original dataset and phenotypic quality control performed can be found in Oliveira et al. [
6].
A total of 100,000 cows were randomly chosen from the 150,229 cows used in Oliveira et al. [
6]. Thereafter, different proportions (i.e., 20%, 40%, 60%, and 80%) of cows were randomly assigned to have their culling information censored, which were used to create the sub-scenarios for censored data evaluated in this study. Cows that had their culling information censored in one sub-scenario were kept as censored in the next sub-scenario, in order to avoid any extra confounding effect. Therefore, an algorithm was created to randomly sample 20% cows and censor their records. Thenceforth, the algorithm would randomly sample 20% cows with uncensored records from each previous sub-scenario, in order to censor their records and create the next sub-scenario (with 40%, 60%, and 80% censored data, respectively). No constraints regarding the number of cows with censored/uncensored records per contemporary group were imposed, because contemporary groups (concatenation of herd-year-season) were assumed as random effects in this study.
The same sub-scenarios evaluated for censored data (in terms of proportion of censored/penalized data and cows sampled) were used to create the sub-scenarios for penalized data (i.e., a penalization criterion was used for cows that had their records previously censored). Three different criteria were proposed for the penalty method [
10] used in this study. The first criterion assumed that all cows with censored records were culled one year after their last reported calving. The second criterion assumed that cows with censored records older than nine years were culled one year after their last reported calving, while censored records were kept for cows younger than nine years. Finally, the third criterion assumed that cows with censored records older than nine years were culled one year after their last reported calving, while cows younger than nine years were culled two years after their last reported calving. The threshold of nine years and the penalization of one or two years were defined based on the average culling age estimated for cows that died due to natural reasons [
6], the number of cows culled per age (
Supplementary Figure S1), and the proportion of reappearance in the dataset after one missing calving (
Supplementary Figure S2).
To facilitate the comparison of results and subsequent discussion, hereafter scenarios based on the complete (i.e., 0% censored or penalized data), censored, and penalized data will be called COM, CEN, and PEN, respectively. The notation of the sub-scenarios is CEN20, CEN40, CEN60, and CEN80 to represent 20%, 40%, 60%, and 80% censored data, respectively. Similarly, the notation of the sub-scenarios used for PEN follows the pattern: PENxmy with x referring to the amount of penalized data and y to the penalty method used. For instance, PEN using 20% penalized data and the first penalty method (which assumes that all cows with censored records were culled one year after their last reported calving) was coded as PEN20m1.
In order to avoid any statistical confounding between the number of animals and the number of censored/uncensored records in the results, two designs were used for each scenario/sub-scenario: (1) always including 55,000 cows with uncensored data; and (2) always including a total of 100,000 cows in the analyses. In this context, the first design considered a total of 55,000; 66,000; 77,000; 88,000; and 99,000 cows (i.e., 55,000 cows with uncensored records plus 0%, 20%, 40%, 60%, and 80% cows with censored or penalized records, respectively), while the second design considered always 100,000 cows, from which 100,000; 80,000; 60,000; 40,000; and 20,000 cows had uncensored data (plus 0; 20,000; 40,000; 60,000; and 80,000 cows with censored or penalized records, respectively). A total of three replicates were performed for each analysis, which differed according to the cows randomly sampled to have their records censored. The initial 100,000 cows were kept the same in all replicates. A scheme of the designs, scenarios and sub-scenarios used in this study is shown in
Figure 1.
2.3. Longevity Indicators and Statistical Analyses
Two different longevity indicators were used to evaluate the impact of censored and penalized data in the prediction of EBVs, genetic parameters, and computational efficiency for the genetic analyses. For the first indicator, longevity was coded as 1 when the cow was alive, and 0 after the cow was culled (i.e., TL). For the second one, longevity was codified as 1 for cows that had calved at the specific age, 0 after the cow was culled, and as missing record when no information of calving was found at the specific age (i.e., FL). Both longevity indicators were evaluated from 2 to 15 years-old, using RRM. The RRM used in this study were defined as follows:
in which
y is the vector of observations, assumed as
;
b is the vector of systematic effects (embryo transfer and coefficients of systematic regressions for year-season of birth), which was assumed as
;
q is the vector of random regression coefficients for the herd-year-season effects, which was assumed as
;
a is the vector of random regression coefficients for the animal additive genetic effects, which was assumed as
;
p is the vector random of regression coefficients for the permanent environmental effects, which was assumed as
and
e is the random vector of residuals, which was assumed as
. Fourth order Legendre orthogonal polynomials [
16] were used for all regressions, as defined in a previous study using the same data [
6].
The X, H, Z, and W are the incidence matrices for b, q, a, and p, respectively. In addition, are the herd-year-season, additive genetic, and permanent environmental variance components matrices, respectively. The matrices A and are the pedigree-based additive relationship and the identity matrices, respectively. The matrix is a diagonal matrix with large variances (1010) to represent vague prior knowledge. The matrices were assumed to follow an inverted Wishart distribution (IW) with small prior knowledge, i.e., , , and . A scaled inverted chi-squared distribution was assumed for .
Gibbs sampler based on the Markov Chain Monte Carlo (MCMC) algorithm was used to estimate the variance components and predict the breeding values for the regression coefficients using the Best Linear Unbiased Prediction (BLUP) method implemented in the gibbs3f90 software [
17]. The MCMC chain length, burn-in, and thin used in this study were 150,000, 50,000, and 10, respectively. Convergence criteria were verified using the Heidelberger and Welch [
18] and Geweke [
19] criteria, both available in the package “
boa—Bayesian Output Analysis” [
20] of the R software [
21].
2.4. Estimation of Heritabilities and EBVs over Time
Heritabilities over time for each scenario/sub-scenario in each replicate were calculated as:
in which
is the heritability estimated for the age j (j = 2, 3, …, 15),
are the additive genetic, herd-year-season, and permanent environmental variances estimated for the age j, respectively, and
is the residual variance. The additive genetic, herd-year-season, and permanent environmental variances were obtained from the jth diagonal of the respective covariance matrices for the ages (i.e.,
,
and
, respectively). The matrices
, and
were calculated using the posterior mean of the variance components estimated for the random regression coefficients of these effects, i.e.,:
where
T is a matrix of independent covariates including all ages associated with the Legendre orthogonal polynomial, and
are the previously mentioned additive genetic, herd-year-season, and permanent environmental variance components matrices for the random regression coefficients, respectively. The heritability estimates reported for each scenario/sub-scenario are the averages (and SE) obtained from three replicates.
The EBVs for all different ages of the animal i, for each scenario/sub-scenario in each replicate, were obtained as:
in which
is the vector of EBVs for animal i that includes all analyzed ages,
is the vector of breeding values for the regression coefficients of animal i, and
T is the previously mentioned matrix of independent covariates associated with the Legendre polynomial.
2.5. Proportion of Commonly Selected Animals, EBV Correlation, and Computational Efficiency
The proportion of commonly selected animals between COM and the sub-scenarios of CEN, or COM and the sub-scenarios of PEN, was calculated for the top 1% and 10% animals of each age. Similarly, the EBV correlation was calculated as the Pearson correlation coefficient between EBVs predicted using COM and the sub-scenarios of CEN (or PEN), but considering all animals and ages together. Additionally, EBV correlations for the age of four years were calculated using either animals with or without censored/penalized records. Proportions and correlations shown in this study are the averages (and SD) obtained from the three replicates.
All analyses were performed using a Unix server available at the American Angus Association [Intel(R) Xeon(R) CPU E5-2697 v4 @ 2.30 GHz](Intel Corporation, Santa Clara, CA, USA), which contains 72 CPUs and considers up to two threads per core. The total computing time for each replicate of each scenario/sub-scenario was estimated as the amount of CPU time spent in user-mode code plus the amount of CPU time spent in the kernel [
22] needed to complete the 150,000 Bayesian iterations. The average (SD) computing time calculated between all three replicates is presented in this study.
2.6. Statistical Significance
Statistically significant (
p-value < 0.05) differences between scenarios, for each longevity indicator, were accessed using paired
t-tests [
23].
4. Discussion
Beef cattle longevity is strongly related to the overall farm profitability [
5]. Due to its importance, several longevity indicators have been proposed over the years [
24,
25,
26,
27]. Recently, Oliveira et al. [
6] contrasted the use of different longevity indicators to genetically evaluate longevity in North American Angus cattle, but without accounting for the presence of censored records in the evaluations. Understanding the impact of censored records and how to account for them in the genetic evaluations of longevity were the main motivations for this study. Therefore, three criteria were proposed for the penalty methods, which differed mainly regarding to the threshold used to create the penalized data. In summary, the first criterion assumed the culling date for each cow as one year after its last reported calving, which can be very stringent for young cows. Thus, the second and third criteria used tried to reduce the possible disadvantage of the first criterion for the young cows, in order to avoid bias and reduction of genetic gain.
Genetic evaluations of longevity usually rely on animal culling records reported by the farmers. However, probably because longevity has not been officially evaluated in North American Angus cattle [
28,
29], a great proportion of cows (~62%) present in the pedigree do not have culling records included in the original dataset [
6]. This proportion is higher than the ones previously reported in the literature for other beef cattle breeds. For instance, Forabosco et al. [
30] reported that about 14% of cows had censored data in longevity analyses of the Chianina beef cattle breed. Brzáková et al. [
26] reported that about 37% of cows from several beef cattle breeds raised in Czech Republic had censored data. Thus, in order to mimic different scenarios for beef cattle, the proportions of cows with censored records in the current study were set to 20%, 40%, 60%, and 80%.
Including all animals with censored records in the genetic evaluation can help to increase the accuracy of EBVs for longevity [
9,
31]. Moreover, the use of more information can also improve the estimation of variance components and genetic parameters [
31]. However, the great challenge is to determine how to best include censored records in the evaluations. Methods described in the literature to account for censored data in the genetic evaluation include the use of augmented data (created using penalization criteria [
12,
32] or replacing censored records by simulated values originated from truncated normal distributions [
12,
32,
33,
34]), and the use of missing values [
12,
27,
32]. Either way, directly removing censored data from the analysis has not been recommended [
9,
32].
Merely excluding censored data from the genetic evaluation of fertility traits was shown to favor sires that have a greater proportion of daughters with censored records, because the average value of their censored records is usually greater than the population mean calculated for the trait [
9]. In this context, Donoghue et al. [
32], evaluating different methods to handle censored records for fertility traits in Australian Angus cattle, concluded that predictions made using augmented data generated by the penalty method and by the simulated values originated from predictive truncated normal distributions were very similar. However, the authors comment that both methods perform better than excluding the censored records from the genetic evaluation. Thus, the use of statistical models that enable analyzing binary traits over time is proposed to keep censored records (assumed as missing or augmented records) in the analysis without mischaracterizing the trait [
12,
32,
35]. In this context, using RRM seems an optimal choice, because it combines the information of all repeated records without requiring all animals having records at all time-points [
13,
14]. Specifically, for longevity related traits, the use of RRM allows to include animals culled at different ages in the same genetic evaluation. This feature excludes the need to evaluate longevity at specific time-points (e.g., six years; [
36]), and assures that EBVs are predicted for all animals within the range of all evaluated ages [
13,
14].
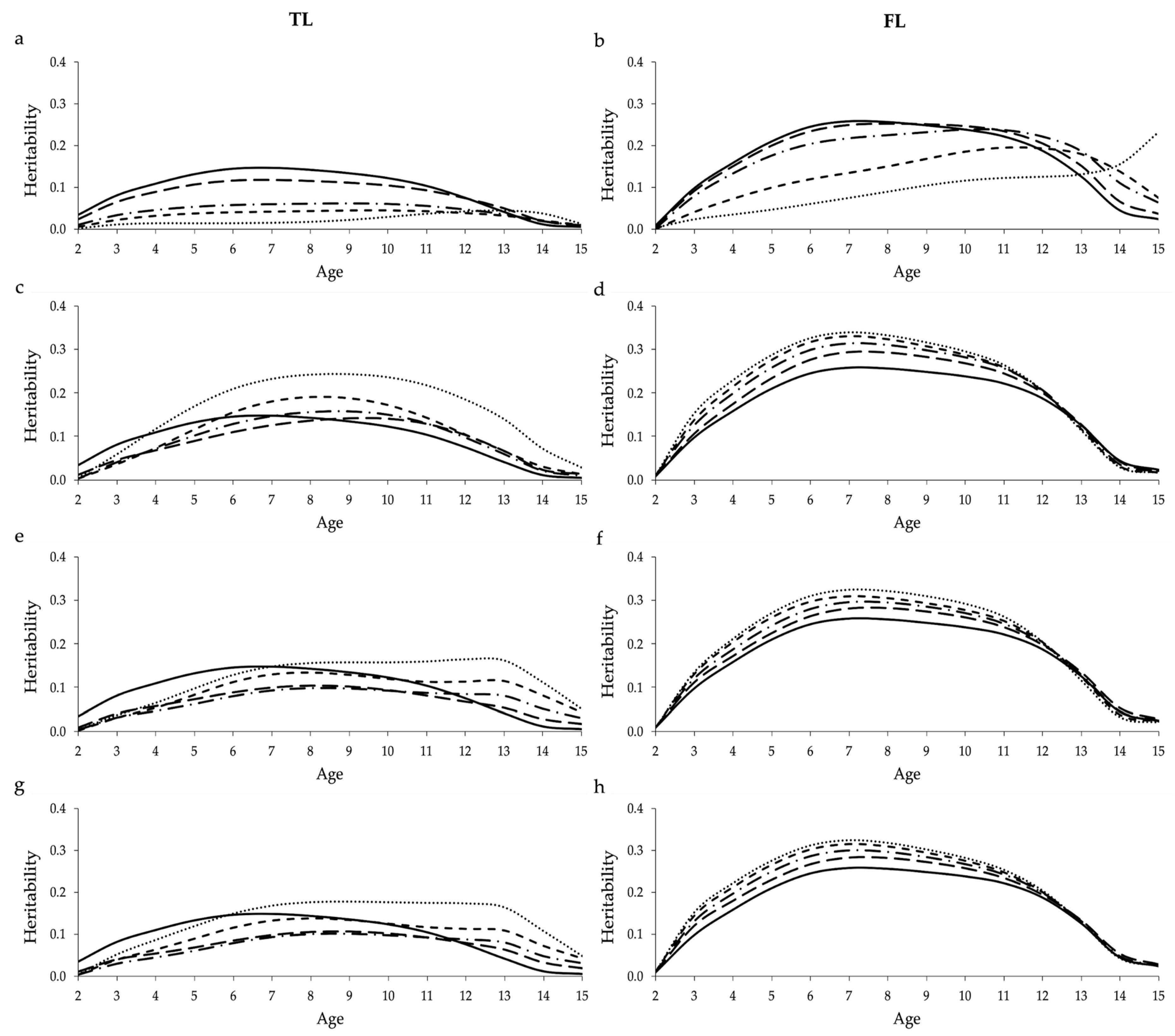
Using missing values to account for censored data in the RRM significantly decreased the average heritabilities estimated for TL and FL across ages, especially when high proportions of censored data where included in the analysis using the design based on 100,000 cows (
Table S1 and
Figure 2). Moreover, a trend of decrease was observed while analyzing the heritabilities estimated over the ages, using both data designs (
Figure 2 and
Figure S3). The lower heritability estimates observed when increasing the proportion of censored data is mainly due to the reduction in the additive genetic variance (
Supplementary Figure S8). These results suggest that including high proportions of censored data may hamper the genetic progress for longevity in North American Angus cattle. However, when small proportions of censored data (20%) were used, the estimated pattern of heritabilities was similar to COM. These results corroborate the ones presented by Donoghue et al. [
35], who reported that genetic parameters estimated using 12% and 20% censored data (treated as missing) were similar to the true values generated in the simulation. On the other hand, Forabosco et al. [
30] reported lower heritability estimates when only uncensored records were used. The different findings of the current study might be justified by the different statistical models used (survival versus RRM). A trend of decrease in the sire variances similar to the one observed for the additive genetic variances estimated in this study was reported by Guo et al. [
37], while studying the influence of censored data on the genetic parameters estimated for performance and prolificacy traits in swine. Among the longevity indicators tested, heritabilities estimated for FL seem to be less impacted by the amount of censored data compared to TL, probably due to the fact that calving information is also included in FL.
Heritabilities estimated for FL in the different sub-scenarios of PEN, based on the design that always included 100,000 cows, tended to be overestimated (
Figure 2 and
Supplementary Table S1). This suggests that the use of penalty method can likely contribute to increasing the genetic variability when the proportion of uncensored cows is reduced in the analysis (
Supplementary Figure S8). However, when the proportion of uncensored cows remains constant (design with 55,000 cows), genetic parameters predicted using PEN are very similar to the real ones (COM). For both designs, similar genetic parameters were estimated using the three penalty criteria. These findings indicate that the criteria proposed in this study for the penalty method might be useful to estimate genetic parameters for FL. On the other hand, the criteria used here do not seem adequate for TL, as heritabilities estimated were mostly biased. A possible explanation for this is that TL (as defined in this study) does not take into account calving information, and the three penalization criteria proposed in this study are based on the information of missing calvings. This result reinforces the importance of using appropriate penalization criteria for the analyzed trait. Donoghue et al. [
32], using data from fertility traits of Australian Angus cattle, found that different methods used to generate augmented data had small impact in the estimation of genetic parameters and additive genetic variance. Moreover, the authors reported that the penalty method does not significantly overestimate the genetic parameters compared to censored records [
32].
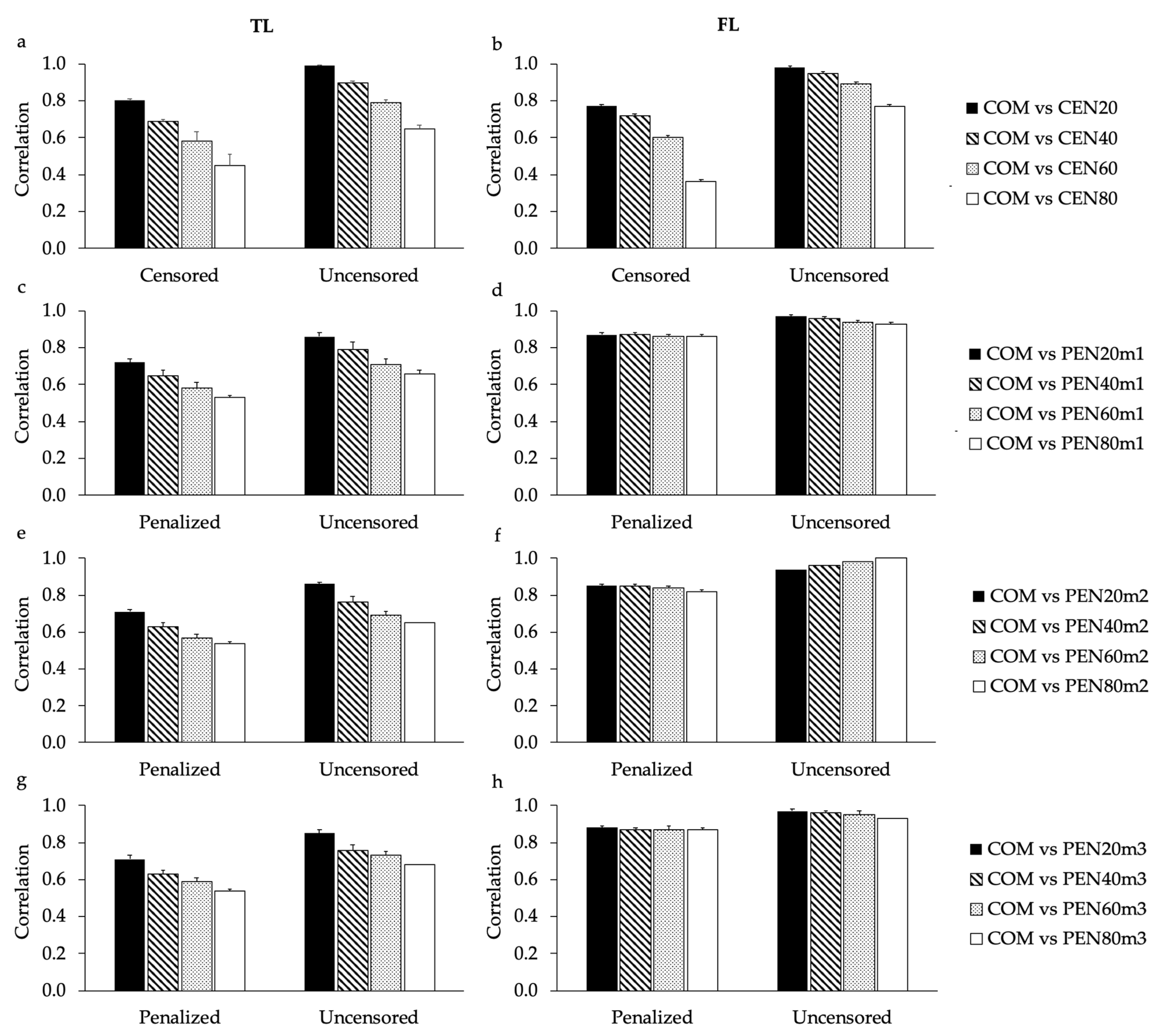
Similar pattern of results was found for the proportion of animals commonly selected using both designs (i.e., always including 55,000 cows with uncensored data, or always including a total of 100,000 cows in the analysis). For both longevity indicators the proportion of animals commonly selected between COM and CEN reduced when the proportion of cows with censored data increased (
Figure 3 and
Supplementary Table S2). These findings corroborate the idea that including great proportions of censored data in the genetic analysis of longevity can have a negative impact in the selection process. Moreover, the proportion of animals commonly selected between COM and PEN support the hypothesis that the penalty methods proposed in this study are appropriate to analyze FL, but not for TL. In this context, the high average proportions (over 78%) of animals selected in common between COM and PEN for FL indicate that similar selection decisions are made when using COM, CEN20, and all sub-scenarios of PEN. However, some re-ranking of animals is expected. These results seem to corroborate in part with the ones reported by Donoghue et al. [
32,
35], as no major re-ranking of sires were reported by the authors when investigating censored data for days to calving in simulated and real beef cattle data, respectively.
Correlations of EBVs estimated in this study considering all animals together (with censored and uncensored records;
Table 1), support the results found for the high proportion of commonly selected animals between COM and CEN20 (for both TL and FL), and COM and all sub-scenarios of PEN (for FL). In order to investigate the impact of censored records in the EBV correlations using only cows that had or not censored/penalized records, the age of four years was used (
Figure 4 and
Supplementary Figure S6). Breeding values predicted for the age of four years were previously recommended for genetic selection of longevity in North American Angus cattle, as they were expected to result in greater selection responses using the longevity indicators analyzed in this study [
6]. As expected, EBV correlations estimated for cows that had their culling information censored tended to be lower than EBV correlations estimated for cows that had only uncensored records. However, it is worth noting that the inclusion of penalized data for cows with previously censored records impacts the EBVs predicted for uncensored animals (
Figure 4 and
Figure S7). This impact is due to the fact that all related animals contribute to the EBVs predicted using the BLUP method [
38], as they are mostly connected through the
A matrix. Moreover, the impact of the amount of censored records in the EBV correlations calculated using the design based on the 55,000 cows with uncensored records was lower than the impact observed using the design based on 100,000 cows (
Figure 4 and
Supplementary Figure S7). These findings might be related to the fact that for the design including the 55,000 cows, the number of informative records were not reduced among sub-scenarios. Setiaji et al. [
39], analyzing different penalty methods to access interval from the first to the last successful insemination in Japanese Black heifers, concluded that EBV correlations decrease at higher levels of censored (missing) records. Using only uncensored data and the conventional linear model was also the most recommended method for the genetic evaluation of age at first calving in Brahman cattle [
11]. However, the authors pointed out that similar EBV correlations were observed using either uncensored or penalized data, which suggests that there was not relevant re-ranking of animals when censored records were used [
11]. Similarly, Costa et al. [
40] also found that the linear-threshold model without censored data showed the best predictive ability (computed based on the EBV correlation estimated between the complete and reduced datasets) for the genetic evaluation of both age at first calving and stayability in Nellore cattle. On the other hand, Veerkamp et al. [
41] showed that RRM were relatively robust to censoring in genetic evaluations of survival in dairy cattle, as similar EBV predictions were made based on uncensored and censored data.
Even though the scheme of the designs, scenarios, and sub-scenarios evaluated in the study tried to mimic real data, it is important to highlight here the need to re-estimate variance components using the complete dataset available for North American Angus. In addition, further studies comparing the use of different approaches (e.g., multiple-trait model without censored/penalized records) are required to simplify the pipeline for the official genetic evaluations. In this regard, it is worth to note that including animals with censored records in the genetic analysis of longevity might not be relevant if genomic information is included, as high prediction accuracies are already expected for young animals using genomic selection [
42,
43,
44]. Thus, especially for selection of candidates at young ages (e.g., when animals are still alive), the increase in accuracy observed in genomic evaluations might enable considerably a reduction in the generation interval. Reduction in the generation interval is highly recommended when analyzing longevity because the productive life of beef cows can be relatively long (i.e., they can easily exceed five years [
30]). Moreover, reducing the generation interval can contribute to significantly increase the genetic gain per unit time. In this regard, Ramos et al. [
25] suggested that genomic information should always be included in the evaluations performed for longevity-related traits, especially when they are evaluated at early ages. However, further studies are needed to evaluate the performance of genomic selection for longevity-related traits in North American Angus cattle.
In order to evaluate the feasibility of the use of censored or penalized data in the genetic evaluation of longevity using RRM, the computational efficiency was also investigated (
Table 2). In summary, for all scenarios/sub-scenarios analyzed in this study, more than eight days were needed to complete the 150,000 iterations. This indicates that further improvements to reduce computational time are required to allow genetic evaluations to be run in a reasonable time frame. However, despite its high computational time, using RRM seems to be suitable to analyze longevity in North American Angus cattle considering COM, CEN, and PEN. Concerns regarding computational time are especially relevant for genomic evaluations, as a recent study showed that incorporating genomic information into genetic evaluations based on RRM increased the computational demand for the evaluation of several traits [
22].





 ), 20% (long dash;
), 20% (long dash;  ), 40% (long dash dot;
), 40% (long dash dot;  ), 60% (short dash;
), 60% (short dash;  ), and 80% (round dot;
), and 80% (round dot;  ) censored data (a,b); penalized data assuming that all cows with censored records were culled one year after their last reported calving (c,d); penalized data assuming that only cows with censored records older than nine years were culled one year after their last reported calving (e,f); and penalized data assuming that cows with censored records older than nine years were culled one year after their last reported calving, while cows younger than nine years were culled two years after their last reported calving (g,h). Heritabilities shown here are average heritabilities obtained from three replicates. The SE ranged from 0.01 to 0.03.
) censored data (a,b); penalized data assuming that all cows with censored records were culled one year after their last reported calving (c,d); penalized data assuming that only cows with censored records older than nine years were culled one year after their last reported calving (e,f); and penalized data assuming that cows with censored records older than nine years were culled one year after their last reported calving, while cows younger than nine years were culled two years after their last reported calving (g,h). Heritabilities shown here are average heritabilities obtained from three replicates. The SE ranged from 0.01 to 0.03.




{kind=link}
{kind=link}
{kind=link}
{kind=link}