
Research on Chengdu Ma Goat Recognition Based on Computer Vison


Abstract
:Simple Summary
Abstract
1. Introduction
2. Related Work
2.1. Object Detection
2.1.1. YOLO Series Object Detection Algorithms
- (1)
- Backbone: A convolutional neural network is often used here to extract image features.
- (2)
- Neck: A series of network layers that combine and reprocess image features and pass image features to the prediction layer.
- (3)
- Head: It generates bounding boxes and prediction categories with corresponding confidence values. The confidence indicates the precision of the detection under specific conditions.
2.1.2. TPH-YOLOv5
2.2. Self-Supervised Learning
3. Materials and Methods
3.1. Data Acquisition
3.2. Data Preprocessing
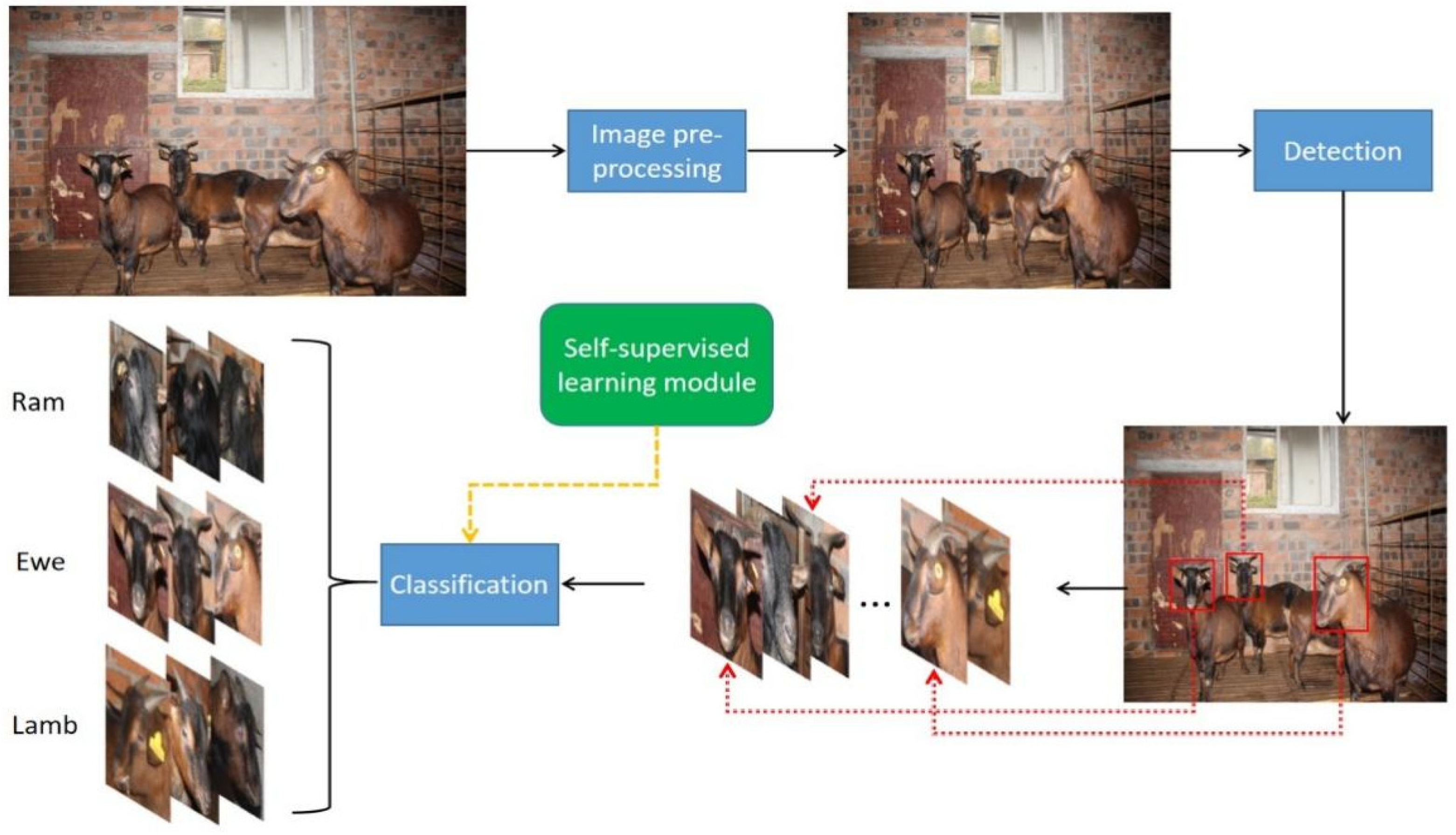
3.3. The Method for Chengdu Ma Goat Recognition
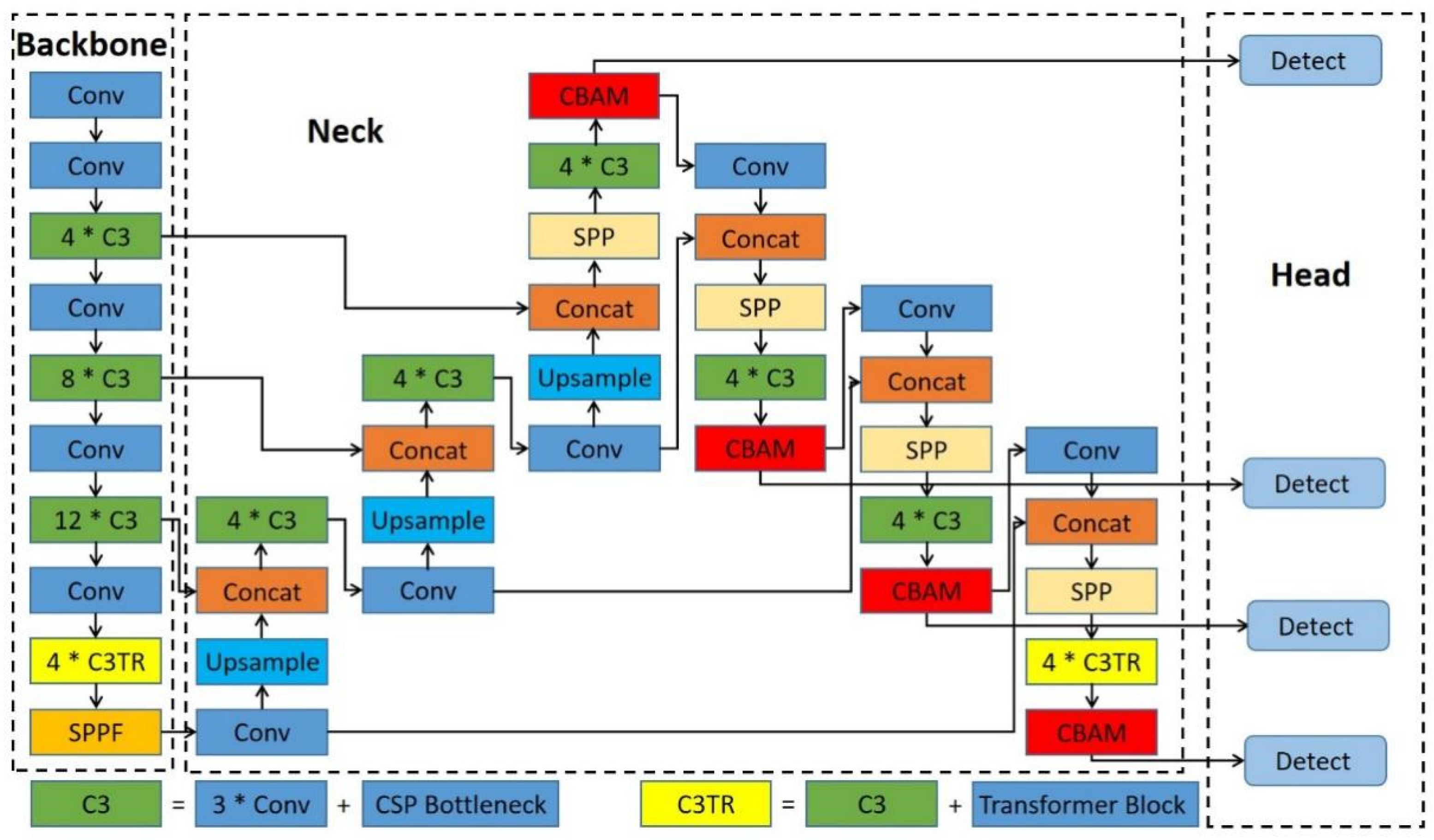
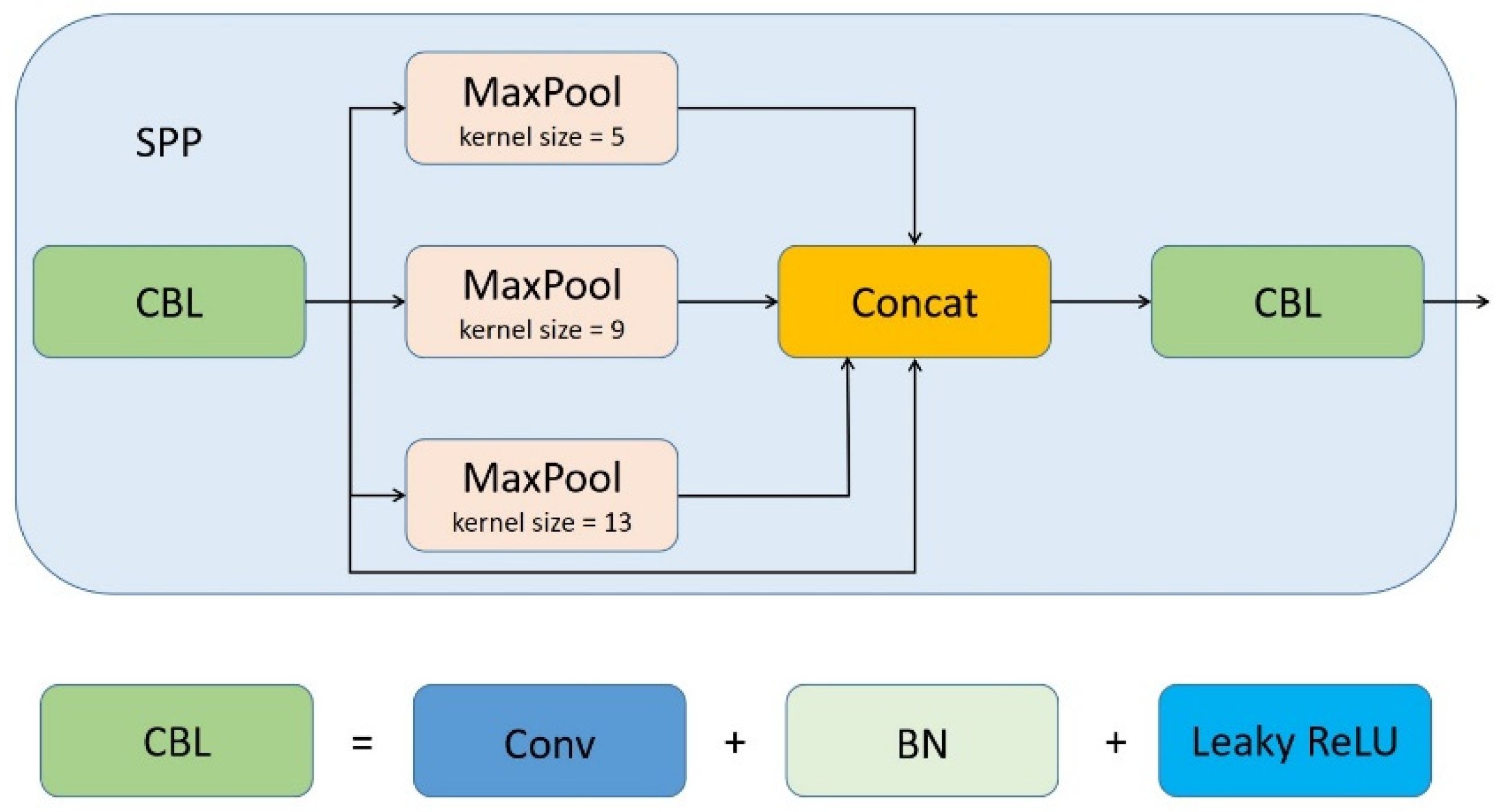
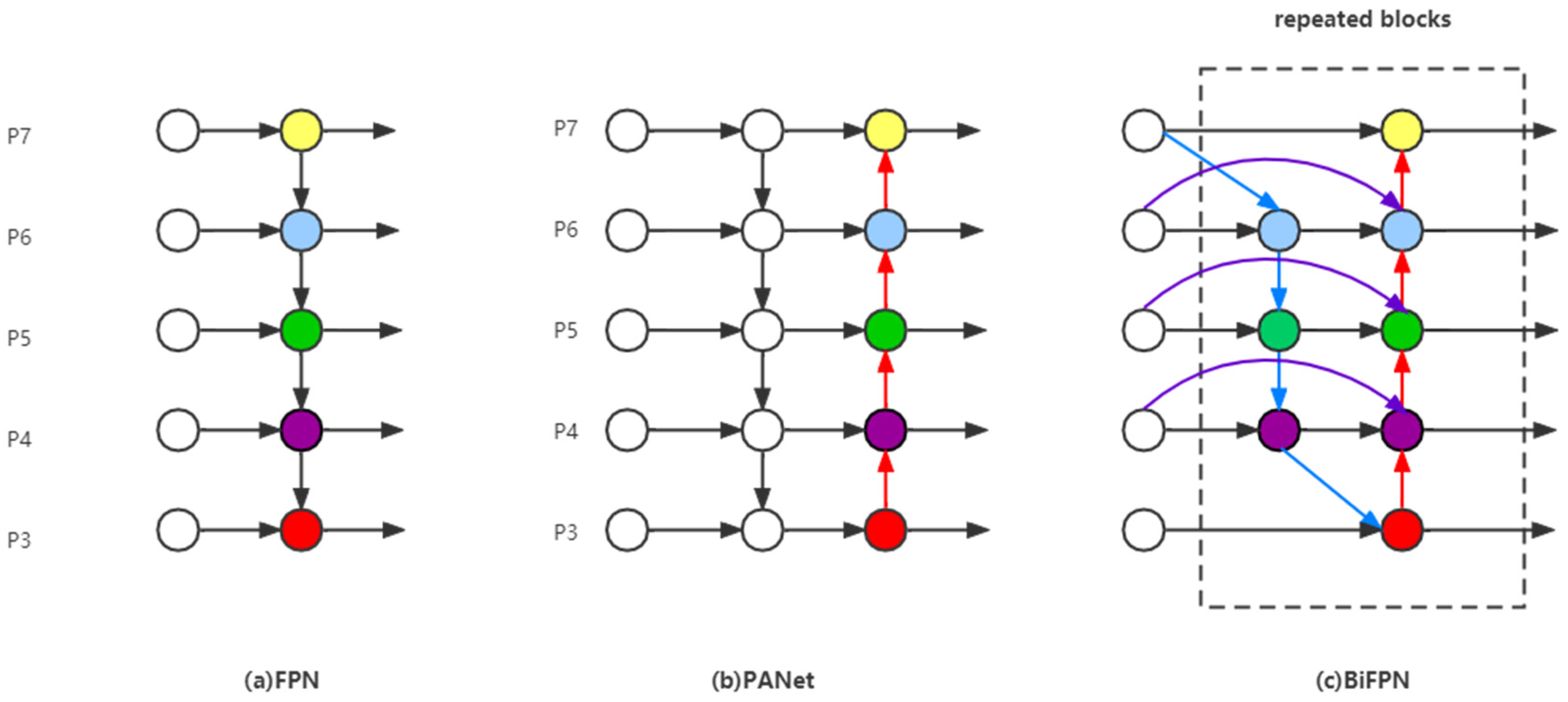
3.3.1. The Improved TPH-YOLOv5
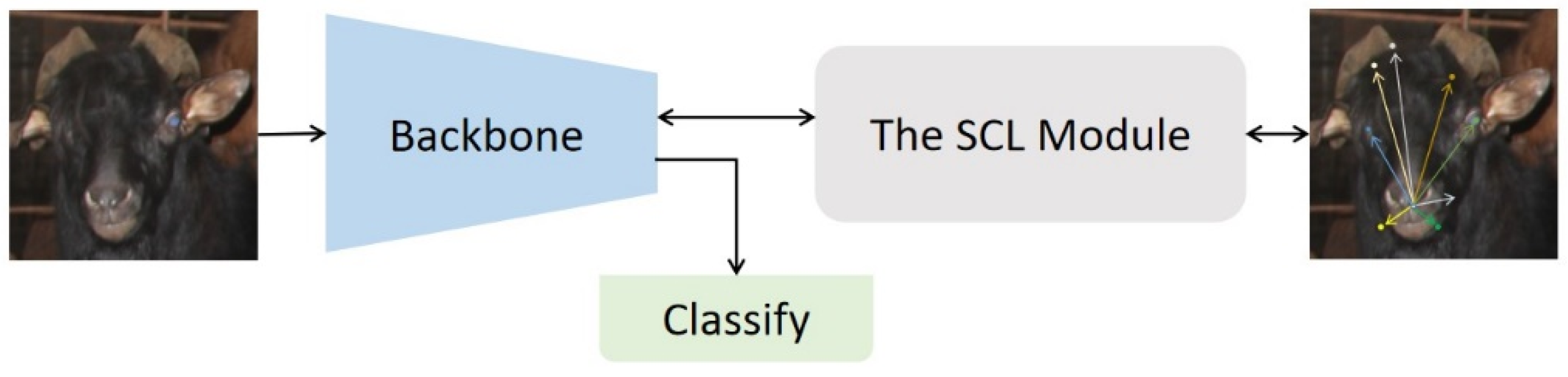
3.3.2. The Classifier Incorporating a Self-Supervised Learning Module
3.3.3. Implementation Details
4. Results
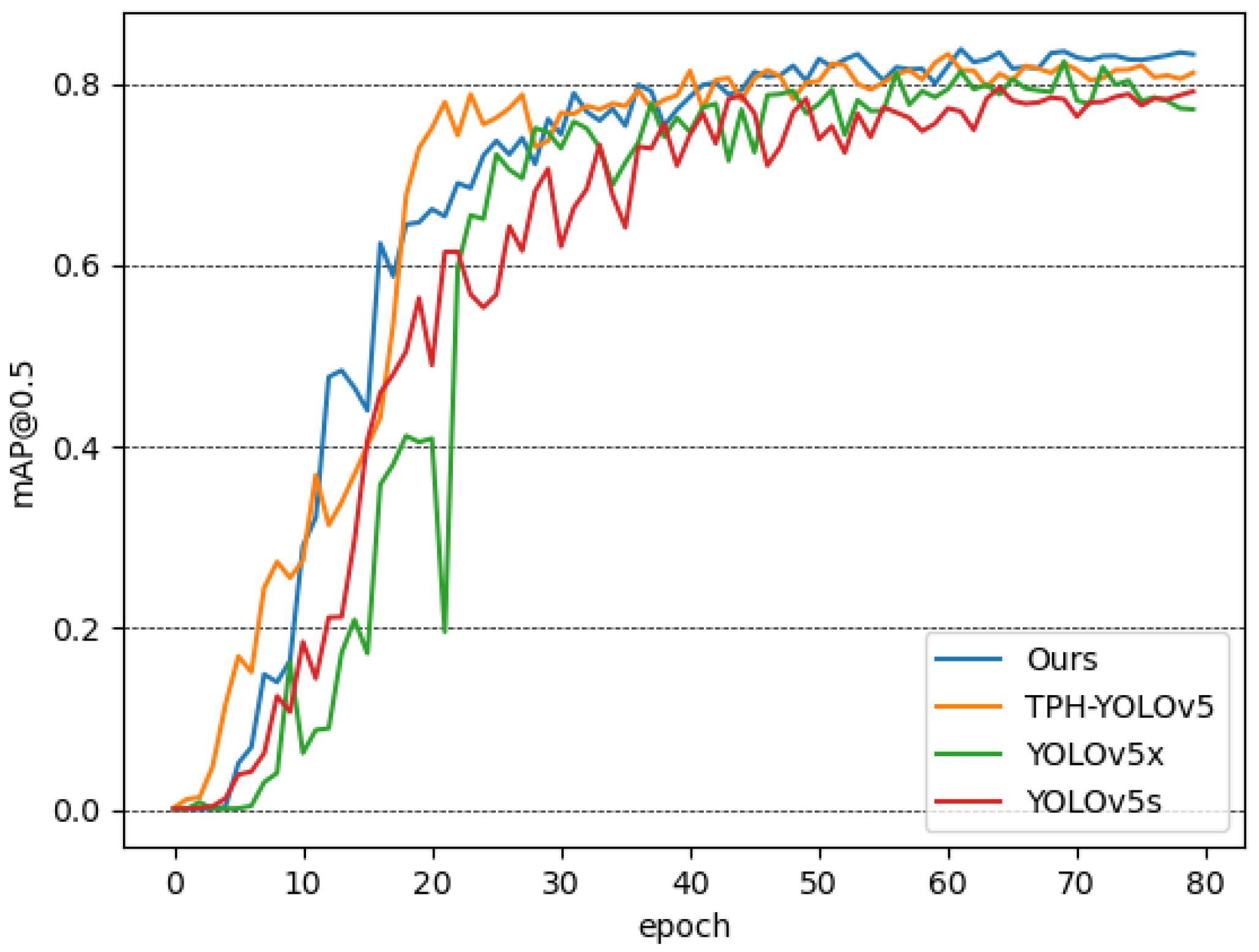
4.1. Detection
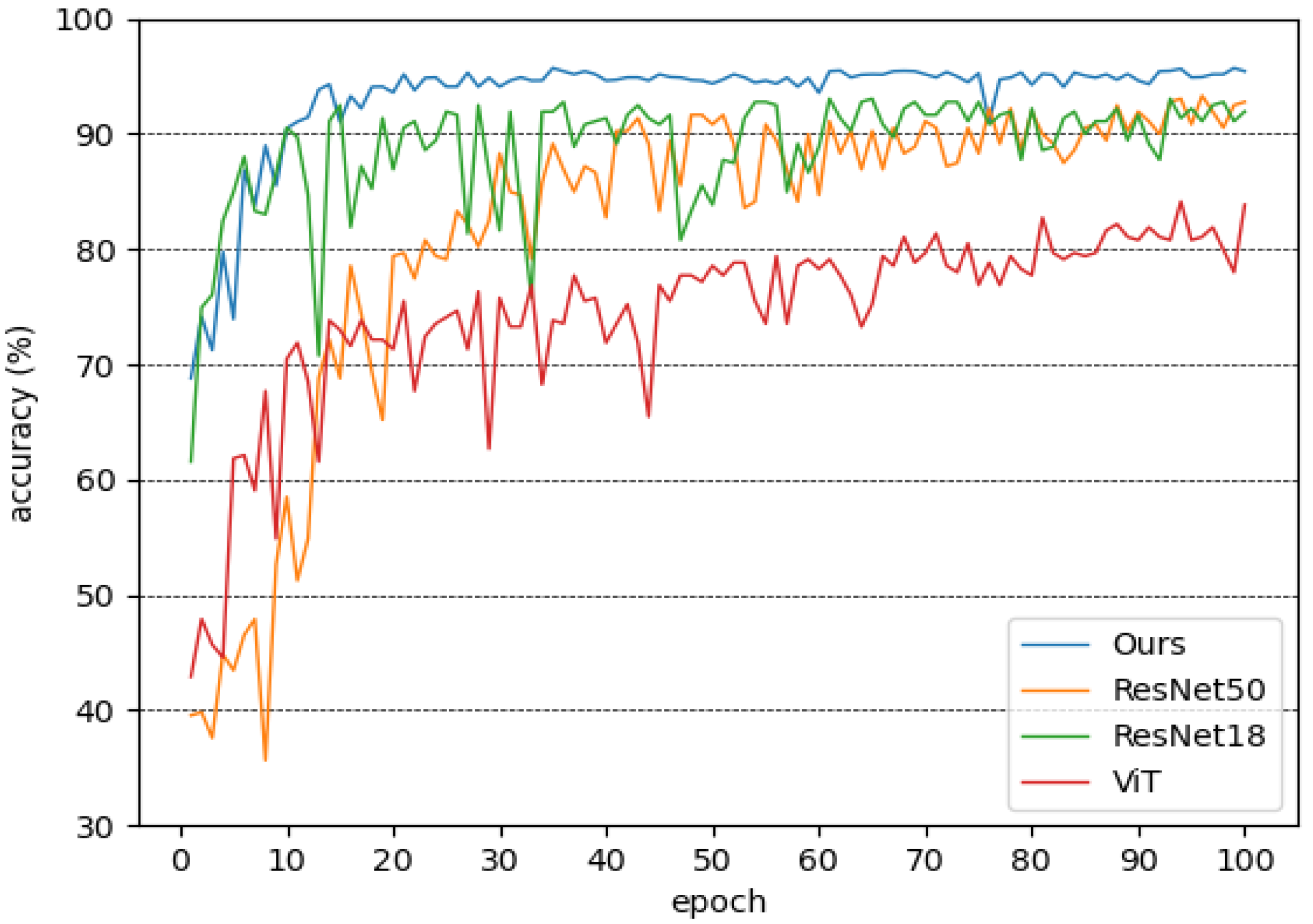
4.2. Classification
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, M. Analysis on the Effect of Breed Conservation and Selection of Chengdu Ma Goat. Master’s Thesis, Sichuan Agricultural University, Ya’an, China, 2019. [Google Scholar]
- Wang, J.; Ouyang, X.; Wang, Y.; Gao, G. Conservation and utilization of Chengdu Ma Goat. J. Southwest Minzu Univ. 2008, 1, 78–82. [Google Scholar]
- Sarwar, F.; Griffin, A.; Periasamy, P.; Portas, K.; Law, J. Detecting and counting sheep with a convolutional neural network. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Jwade, S.A.; Guzzomi, A.; Mian, A. On farm automatic sheep breed classification using deep learning. Comput. Electron. Agric. 2019, 167, 105055. [Google Scholar] [CrossRef]
- Shang, J. Research on Application of Intelligent Ranch Based on Computer Vision. Master’s Thesis, Inner Mongolia University of Science & Technology, Baotou, China, 2020. [Google Scholar]
- Sant’Ana, D.A.; Pache, M.C.B.; Martins, J.; Soares, W.P.; de Melo, S.L.N.; Garcia, V.; Weber, V.A.D.M.; Heimbach, N.D.S.; Mateus, R.G.; Pistori, H. Weighing live sheep using computer vision techniques and regression machine learning. Mach. Learn. Appl. 2021, 5, 100076. [Google Scholar] [CrossRef]
- Sant’Ana, D.A.; Pache, M.C.B.; Martins, J.; Astolfi, G.; Soares, W.P.; de Melo, S.L.N.; Heimbach, N.D.S.; Weber, V.A.D.M.; Mateus, R.G.; Pistori, H. Computer vision system for superpixel classification and segmentation of sheep. Ecol. Inform. 2022, 68, 101551. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Xie, F.; Zhu, D. Overview of Deep Learning Object Detection Methods. Comput. Syst. Appl. 2022, 31, 1–12. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Computer Vision and Pattern Recognition. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. Computer Vision and Pattern Recognition. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.K.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. Computer Vision and Pattern Recognition. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.S.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767, 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Purkait, P.; Zhao, C.; Zach, C. SPP-Net: Deep absolute pose regression with synthetic views. arXiv 2017, arXiv:1712.03452. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Appearance and Performance of Chengdu Ma Goat. Sichuan Agric. Sci. Technol. 1981, 3, 24+39.
- Zhou, M.; Bai, Y.; Zhang, W.; Zhao, T.; Mei, T. Look-into-object: Self-supervised structure modeling for object recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11774–11783. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | The Number of Labeled Goats in the Training Set | The Number of Labeled Goats in the Test Set | Total |
|---|---|---|---|
| Ewe | 1033 | 289 | 1322 |
| Ram | 136 | 38 | 174 |
| Lamb | 896 | 604 | 1500 |
| All | 2065 | 931 | 2996 |
| Methods | [email protected] (%) | GFLOPs | Training Time (Hours) | Inference Time (ms) |
|---|---|---|---|---|
| YOLOv5s | 79.55 | 16.4 | 1.612 | 17.4 |
| YOLOv5x | 81.82 | 217.4 | 2.205 | 23.2 |
| TPH-YOLOv5 | 82.21 | 556.8 | 3.279 | 33.2 |
| Ours | 83.78 | 270.4 | 1.854 | 27.6 |
| Methods | [email protected] (%) | Inference Time (ms) | |
|---|---|---|---|
| TPH-YOLOv5 | 82.21 | 33.2 | |
| TPH-YOLOv5 + SPP | 82.97 | 34.6 | |
| TPH-YOLOv5 + BiFPN | 83.24 | 35.9 | |
| TPH-YOLOv5 + C3TR | 82.12 | 24.1 | |
| TPH-YOLOv5 + C3TR + SPP + BiFPN | 83.78 | 27.6 | |
| Methods | Accuracy (%) |
|---|---|
| ViT | 84.12 |
| ResNet18 | 93.04 |
| ResNet50 | 93.31 |
| Ours | 95.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, J.; Yu, C.; Chen, X.; Zhang, Y.; Yang, X.; Li, J. Research on Chengdu Ma Goat Recognition Based on Computer Vison. Animals 2022, 12, 1746. https://doi.org/10.3390/ani12141746
Pu J, Yu C, Chen X, Zhang Y, Yang X, Li J. Research on Chengdu Ma Goat Recognition Based on Computer Vison. Animals. 2022; 12(14):1746. https://doi.org/10.3390/ani12141746
Chicago/Turabian StylePu, Jingyu, Chengjun Yu, Xiaoyan Chen, Yu Zhang, Xiao Yang, and Jun Li. 2022. "Research on Chengdu Ma Goat Recognition Based on Computer Vison" Animals 12, no. 14: 1746. https://doi.org/10.3390/ani12141746
APA StylePu, J., Yu, C., Chen, X., Zhang, Y., Yang, X., & Li, J. (2022). Research on Chengdu Ma Goat Recognition Based on Computer Vison. Animals, 12(14), 1746. https://doi.org/10.3390/ani12141746