One-Shot Learning with Pseudo-Labeling for Cattle Video Segmentation in Smart Livestock Farming

 ,
,  , ,
, ,  ,
,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Related Work
2.1. One-Shot Learning
2.2. Pseudo Labeling
2.3. Video Segmentation
- Unsupervised segmentation can be achieved by motion analysis, trajectory clustering, or object proposal ranking [34]. Faktor and Irani [35] found motion salient regions by extracting dominant motion for video object segmentation. Xiao and Jae Lee [34] generated a set of spatio-temporal bounding box proposals, and then refined them to obtain pixel-wise segmentation proposals. Recently, Wang et al. [36] proposed unsupervised video object segmentation through visual attention. Li et al. [37] transferred the knowledge encapsulated in image-based instance embedding networks for unsupervised video object segmentation. Although unsupervised approaches do not rely on data labeling, the underlying segmentation hypotheses restricted their applications in high-complexity datasets.
- Semi-supervised segmentation propagates the label information of candidate objects in one or a few key-frames to all video frames [15,38]. Tsai and Huang [39] incorporated motion analysis and image processing techniques in video sequences for the automatic detection of cattle behavior. Liu et al. [40] trained a classifier on low-level hand-crafted features with limited data to process videos for farming automation. Deep learning approaches such as OSMN [13] and FEELVOS [41] began to utilize motion and spatial relationships without fine-tuning. Ventura et al. [42] proposed a Recurrent Neural Network (RNN)-based approach to utilize the temporal correlation between video frames. Feng et al. [43] classified the complex agricultural planting structure with a semi-supervised extreme learning machine framework. Semi-supervised segmentation reduces the need for large labeled datasets but still requires many iterations of optimization for real-world applications.
- Supervised segmentation requires tedious user interaction and iterative human corrections [44], which can attain high-quality boundaries and is more favorable for specific scenarios such as video post-production. Tokmakov et al. [45] combined the outputs of pre-trained appearance and a motion network to generate final segmentation results. Similarly, Xu et al. [46] proposed a sequence-to-sequence model that learns to generate segmentations from sequences of frames. Unfortunately, these performance achievements rely on large amounts of labeled training data, and data labeling is expensive and time-consuming.
3. The Proposed Approach
3.1. Overview of the Proposed Approach
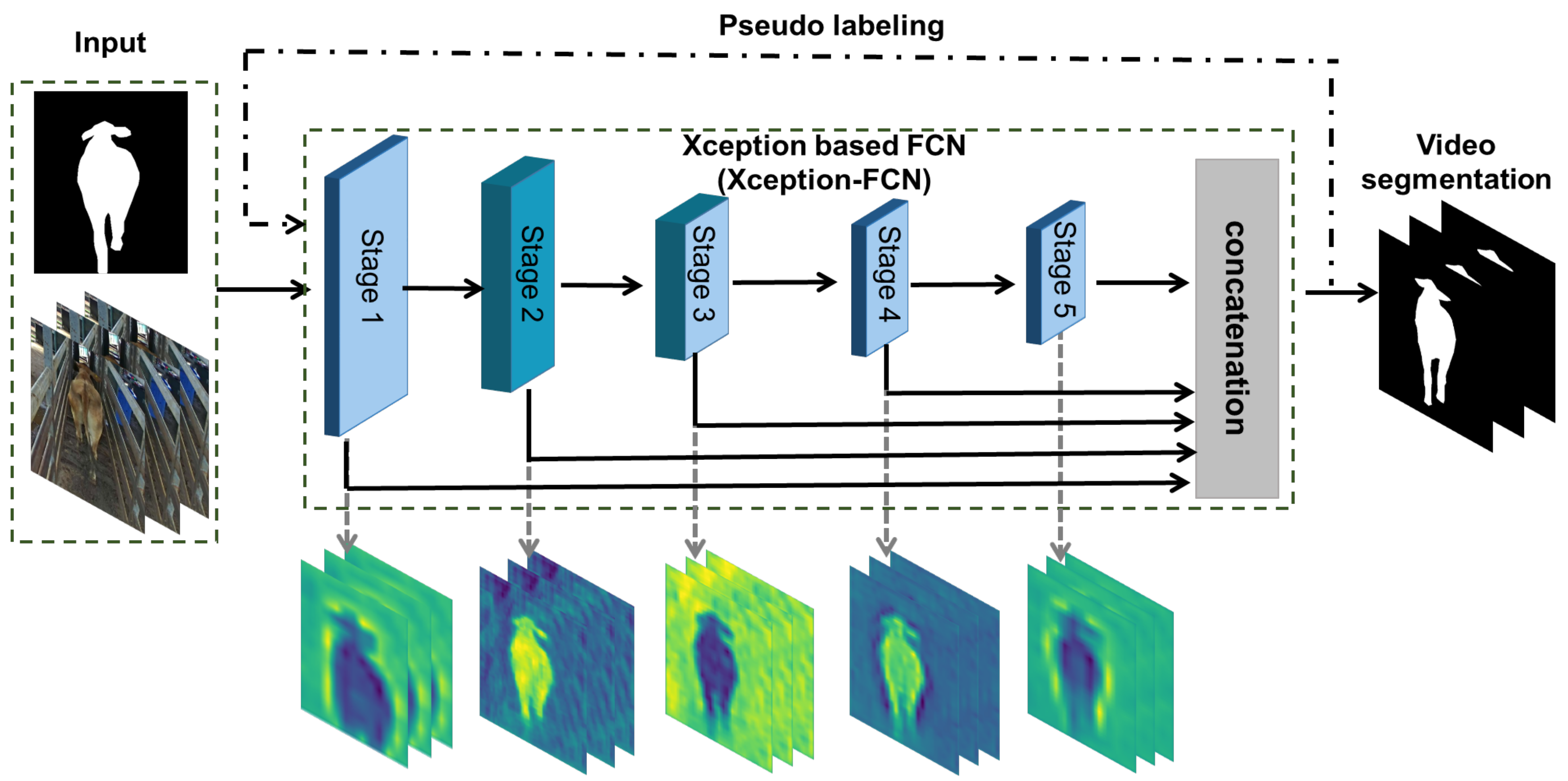
3.2. Xception-FCN Architecture
3.3. Pseudo-Labeling for Cattle Video Segmentation
4. Experimental Setup
4.1. Datasets
4.2. Network Pre-Training and Fine-Tuning Details
- Network pre-training: Several open datasets were used to pre-train the proposed Xception-FCN network, and based on the datasets used, we classified the pre-training process into base and objectness training. For base training, a total of 11,840 images from the PASCAL VOC 2012 dataset [52] and an extended dataset [53] were used. In terms of objectness training, the DAVIS 2016 dataset containing 30 videos (not including cattle videos) was used.For the pre-training, the optimization algorithm used was stochastic gradient descent (SGD) and the whole process had 45,000 iterations (25,000 iterations for base training and 20,000 iterations for objectness training). During the pre-training process, the used learning rate gradually declined from to . With the help of pre-training weights, the optimized Xception-FCN network has the certain capability of segmenting foreground objects (i.e., cattle) from the video.
- Network fine-tuning: After pre-training, the manually labeled one image (first frame) of the testing video was used to fine-tune the proposed Xception-FCN network. To maximize the effectiveness of this one labeled image, some typical data augmentation techniques such as flipping, cropping, brightness, zooming and contrast change were also used. For network fine-tuning, the learning rate was set to . As the light-weight Xception-FCN architecture and separable convolution utilized our approach, the model efficiency of the video segmentation was enhanced. Additionally, based on the experimental comparison, optimized fine-tuning iterations were set to 100 in consideration of the speed and accuracy of the cattle video segmentation.
- Network re-training: for further reducing the segmentation noises and contour errors, pseudo-labels, namely the initial segmentation results generated by Xception-FCN, combined with the one labeled frame, were used to re-train the model. The re-trained epochs were set to 100 and the learning rate was set to . The other parameters were the same as those used in the process of network fine-tuning.
4.3. Performance Evaluation
5. Experimental Results
5.1. Comparison of Different Segmentation Methods
5.2. Qualitative Analysis
5.3. Ablation Study: Effect of PL
5.4. Ablation Study: Effect of Pre-Training
6. Discussion
6.1. Influence of the Cattle Phenotypic Appearances on Video Segmentation
6.2. Analysis of the Influence of Motion on Video Segmentation
6.3. Analysis of the Proposed Approach’s Applicability
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, C.; Zhu, W.; Norton, T. Behaviour recognition of pigs and cattle: Journey from computer vision to deep learning. Comput. Electron. Agric. 2021, 187, 106255. [Google Scholar] [CrossRef]
- Wu, D.; Wang, Y.; Han, M.; Song, L.; Shang, Y.; Zhang, X.; Song, H. Using a CNN-LSTM for basic behaviors detection of a single dairy cow in a complex environment. Comput. Electron. Agric. 2021, 182, 106016. [Google Scholar] [CrossRef]
- Li, G.; Hui, X.; Chen, Z.; Chesser Jr, G.D.; Zhao, Y. Development and evaluation of a method to detect broilers continuously walking around feeder as an indication of restricted feeding behaviors. Comput. Electron. Agric. 2021, 181, 105982. [Google Scholar] [CrossRef]
- Maw, S.Z.; Zin, T.T.; Tin, P.; Kobayashi, I.; Horii, Y. An Absorbing Markov Chain Model to Predict Dairy Cow Calving Time. Sensors 2021, 21, 6490. [Google Scholar] [CrossRef] [PubMed]
- García, R.; Aguilar, J.; Toro, M.; Pinto, A.; Rodríguez, P. A systematic literature review on the use of machine learning in precision livestock farming. Comput. Electron. Agric. 2020, 179, 105826. [Google Scholar] [CrossRef]
- Yin, X.; Wu, D.; Shang, Y.; Jiang, B.; Song, H. Using an EfficientNet-LSTM for the recognition of single Cow’s motion behaviours in a complicated environment. Comput. Electron. Agric. 2020, 177, 105707. [Google Scholar] [CrossRef]
- Qiao, Y.; Kong, H.; Clark, C.; Lomax, S.; Su, D.; Eiffert, S.; Sukkarieh, S. Intelligent Perception-Based Cattle Lameness Detection and Behaviour Recognition: A Review. Animals 2021, 11, 3033. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, J.; Deng, Z.; Qiao, Y. Dynamic multi-scale filters for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3562–3572. [Google Scholar]
- Qiao, Y.; Truman, M.; Sukkarieh, S. Cattle segmentation and contour extraction based on Mask R-CNN for precision livestock farming. Comput. Electron. Agric. 2019, 165, 104958. [Google Scholar] [CrossRef]
- Bahlo, C.; Dahlhaus, P.; Thompson, H.; Trotter, M. The role of interoperable data standards in precision livestock farming in extensive livestock systems: A review. Comput. Electron. Agric. 2019, 156, 459–466. [Google Scholar] [CrossRef]
- Yang, L.; Wang, Y.; Xiong, X.; Yang, J.; Katsaggelos, A.K. Efficient video object segmentation via network modulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6499–6507. [Google Scholar]
- Tokunaga, H.; Iwana, B.K.; Teramoto, Y.; Yoshizawa, A.; Bise, R. Negative pseudo labeling using class proportion for semantic segmentation in pathology. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 430–446. [Google Scholar]
- Caelles, S.; Maninis, K.K.; Pont-Tuset, J.; Leal-Taixé, L.; Cremers, D.; Van Gool, L. One-Shot Video Object Segmentation. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ohkawa, T.; Yagi, T.; Hashimoto, A.; Ushiku, Y.; Sato, Y. Foreground-Aware Stylization and Consensus Pseudo-Labeling for Domain Adaptation of First-Person Hand Segmentation. IEEE Access 2021, 9, 94644–94655. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, Z.; Zhang, H.; Li, C.L.; Bian, X.; Huang, J.B.; Pfister, T. PseudoSeg: Designing Pseudo Labels for Semantic Segmentation. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Chen, Z.; Fu, Y.; Wang, Y.X.; Ma, L.; Liu, W.; Hebert, M. Image deformation meta-networks for one-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8680–8689. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Kwitt, R.; Hegenbart, S.; Niethammer, M. One-shot learning of scene locations via feature trajectory transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–23 June 2016; pp. 78–86. [Google Scholar]
- Douze, M.; Szlam, A.; Hariharan, B.; Jégou, H. Low-shot learning with large-scale diffusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3349–3358. [Google Scholar]
- Wu, Y.; Lin, Y.; Dong, X.; Yan, Y.; Ouyang, W.; Yang, Y. Exploit the unknown gradually: One-shot video-based person re-identification by stepwise learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5177–5186. [Google Scholar]
- Hu, Z.; Li, X.; Tu, C.; Liu, Z.; Sun, M. Few-shot charge prediction with discriminative legal attributes. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 487–498. [Google Scholar]
- Motiian, S.; Jones, Q.; Iranmanesh, S.; Doretto, G. Few-shot adversarial domain adaptation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6670–6680. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3630–3638. [Google Scholar]
- Yoo, D.; Fan, H.; Boddeti, V.N.; Kitani, K.M. Efficient k-shot learning with regularized deep networks. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Wang, Y.X.; Hebert, M. Learning from small sample sets by combining unsupervised meta-training with CNNs. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 244–252. [Google Scholar]
- Pan, Y.; Yao, T.; Li, Y.; Wang, Y.; Ngo, C.W.; Mei, T. Transferrable prototypical networks for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2239–2247. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.E.; McGuinness, K. Pseudo-labeling and confirmation bias in deep semi-supervised learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 16–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Zou, Y.; Yu, Z.; Liu, X.; Kumar, B.; Wang, J. Confidence regularized self-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 5982–5991. [Google Scholar]
- Zheng, Z.; Yang, Y. Rectifying pseudo label learning via uncertainty estimation for domain adaptive semantic segmentation. Int. J. Comput. Vis. 2021, 129, 1106–1120. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. Ha-ccn: Hierarchical attention-based crowd counting network. IEEE Trans. Image Process. 2019, 29, 323–335. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiao, F.; Jae Lee, Y. Track and segment: An iterative unsupervised approach for video object proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–23 June 2016; pp. 933–942. [Google Scholar]
- Faktor, A.; Irani, M. Video Segmentation by Non-Local Consensus voting. BMVC 2014, 2, 8. [Google Scholar]
- Wang, W.; Song, H.; Zhao, S.; Shen, J.; Zhao, S.; Hoi, S.C.; Ling, H. Learning unsupervised video object segmentation through visual attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3064–3074. [Google Scholar]
- Li, S.; Seybold, B.; Vorobyov, A.; Fathi, A.; Huang, Q.; Kuo, C.C.J. Instance embedding transfer to unsupervised video object segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6526–6535. [Google Scholar]
- Xue, T.; Qiao, Y.; Kong, H.; Su, D.; Pan, S.; Rafique, K.; Sukkarieh, S. One-shot Learning-based Animal Video Segmentation. IEEE Trans. Ind. Inform. 2022, 18, 3799–3807. [Google Scholar] [CrossRef]
- Tsai, D.M.; Huang, C.Y. A motion and image analysis method for automatic detection of estrus and mating behavior in cattle. Comput. Electron. Agric. 2014, 104, 25–31. [Google Scholar] [CrossRef]
- Liu, H.; Reibman, A.R.; Ault, A.C.; Krogmeier, J.V. Spatial segmentation for processing videos for farming automation. Comput. Electron. Agric. 2021, 184, 106095. [Google Scholar] [CrossRef]
- Voigtlaender, P.; Chai, Y.; Schroff, F.; Adam, H.; Leibe, B.; Chen, L.C. Feelvos: Fast end-to-end embedding learning for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9481–9490. [Google Scholar]
- Ventura, C.; Bellver, M.; Girbau, A.; Salvador, A.; Marques, F.; Giro-i Nieto, X. RVOS: End-to-End Recurrent Network for Video Object Segmentation. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Feng, Z.; Huang, G.; Chi, D. Classification of the Complex Agricultural Planting Structure with a Semi-Supervised Extreme Learning Machine Framework. Remote Sens. 2020, 12, 3708. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, J.; Li, Y.; Fu, J.; Xu, M.; Lu, H. Hierarchically supervised deconvolutional network for semantic video segmentation. Pattern Recognit. 2017, 64, 437–445. [Google Scholar] [CrossRef]
- Tokmakov, P.; Alahari, K.; Schmid, C. Learning video object segmentation with visual memory. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4481–4490. [Google Scholar]
- Xu, N.; Yang, L.; Fan, Y.; Yang, J.; Yue, D.; Liang, Y.; Price, B.; Cohen, S.; Huang, T. Youtube-vos: Sequence-to-sequence video object segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 585–601. [Google Scholar]
- Milioto, A.; Lottes, P.; Stachniss, C. Real-time semantic segmentation of crop and weed for precision agriculture robots leveraging background knowledge in CNNs. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2229–2235. [Google Scholar]
- Zhang, L.; Dunn, T.; Marshall, J.; Olveczky, B.; Linderman, S. Animal pose estimation from video data with a hierarchical von Mises-Fisher–Gaussian model. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Virtual Event, 13–15 April 2021; pp. 2800–2808. [Google Scholar]
- Liu, H.; Reibman, A.R.; Boerman, J.P. A cow structural model for video analytics of cow health. arXiv 2020, arXiv:2003.05903. [Google Scholar]
- Liu, Y.; Dai, Y.; Doan, A.D.; Liu, L.; Reid, I. In defense of OSVOS. arXiv 2019, arXiv:1908.06692. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–23 June 2016; pp. 724–732. [Google Scholar]
- Xu, B.; Wang, W.; Falzon, G.; Kwan, P.; Guo, L.; Chen, G.; Tait, A.; Schneider, D. Automated cattle counting using Mask R-CNN in quadcopter vision system. Comput. Electron. Agric. 2020, 171, 105300. [Google Scholar] [CrossRef]
- Griffin, B.A.; Corso, J.J. BubbleNets: Learning to Select the Guidance Frame in Video Object Segmentation by Deep Sorting Frames. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8906–8915. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (M)↑ | (R)↑ | (D)↓ | (M)↑ | (R)↑ | (D)↓ | ↓ | Time (s/f) | |
|---|---|---|---|---|---|---|---|---|
| OSMN | 80.0 | 93.4 | 16.6 | 62.1 | 74.6 | 11.3 | 47.4 | 1.21 |
| OSVOS | 84.4 | 97.5 | 13.9 | 75.0 | 89.4 | 14.7 | 46.2 | 0.76 |
| Ours-PL | 87.6 | 98.6 | 10.6 | 79.4 | 96.4 | 12.3 | 48.9 | 0.42 |
| Ours | 88.7 | 99.8 | 9.0 | 80.8 | 97.7 | 10.7 | 45.2 | 0.44 |
| (M)↑ | (R)↑ | (D)↓ | (M)↑ | (R)↑ | (D)↓ | ↓ | |
|---|---|---|---|---|---|---|---|
| Ours | 88.7 | 99.8 | 9.0 | 80.8 | 97.7 | 10.7 | 45.2 |
| Ours-BT | 77.1 | 82.4 | 30.2 | 66.7 | 73.0 | 30.0 | 56.5 |
| Ours-OT | 87.4 | 99.8 | 10.9 | 75.6 | 92.4 | 19.4 | 41.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, Y.; Xue, T.; Kong, H.; Clark, C.; Lomax, S.; Rafique, K.; Sukkarieh, S. One-Shot Learning with Pseudo-Labeling for Cattle Video Segmentation in Smart Livestock Farming. Animals 2022, 12, 558. https://doi.org/10.3390/ani12050558
Qiao Y, Xue T, Kong H, Clark C, Lomax S, Rafique K, Sukkarieh S. One-Shot Learning with Pseudo-Labeling for Cattle Video Segmentation in Smart Livestock Farming. Animals. 2022; 12(5):558. https://doi.org/10.3390/ani12050558
Chicago/Turabian StyleQiao, Yongliang, Tengfei Xue, He Kong, Cameron Clark, Sabrina Lomax, Khalid Rafique, and Salah Sukkarieh. 2022. "One-Shot Learning with Pseudo-Labeling for Cattle Video Segmentation in Smart Livestock Farming" Animals 12, no. 5: 558. https://doi.org/10.3390/ani12050558
APA StyleQiao, Y., Xue, T., Kong, H., Clark, C., Lomax, S., Rafique, K., & Sukkarieh, S. (2022). One-Shot Learning with Pseudo-Labeling for Cattle Video Segmentation in Smart Livestock Farming. Animals, 12(5), 558. https://doi.org/10.3390/ani12050558