
Analysis of the Drinking Behavior of Beef Cattle Using Computer Vision




Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Ethical Considerations
2.2. Experimental Site
2.3. Data Collection and Annotation
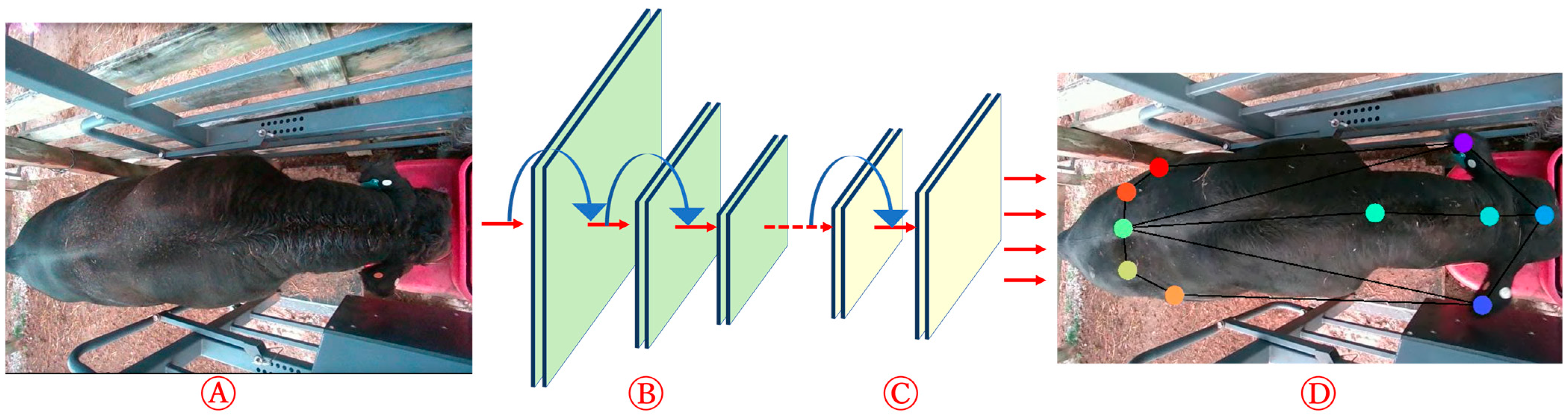
2.4. CNN-Based Pose Recognition
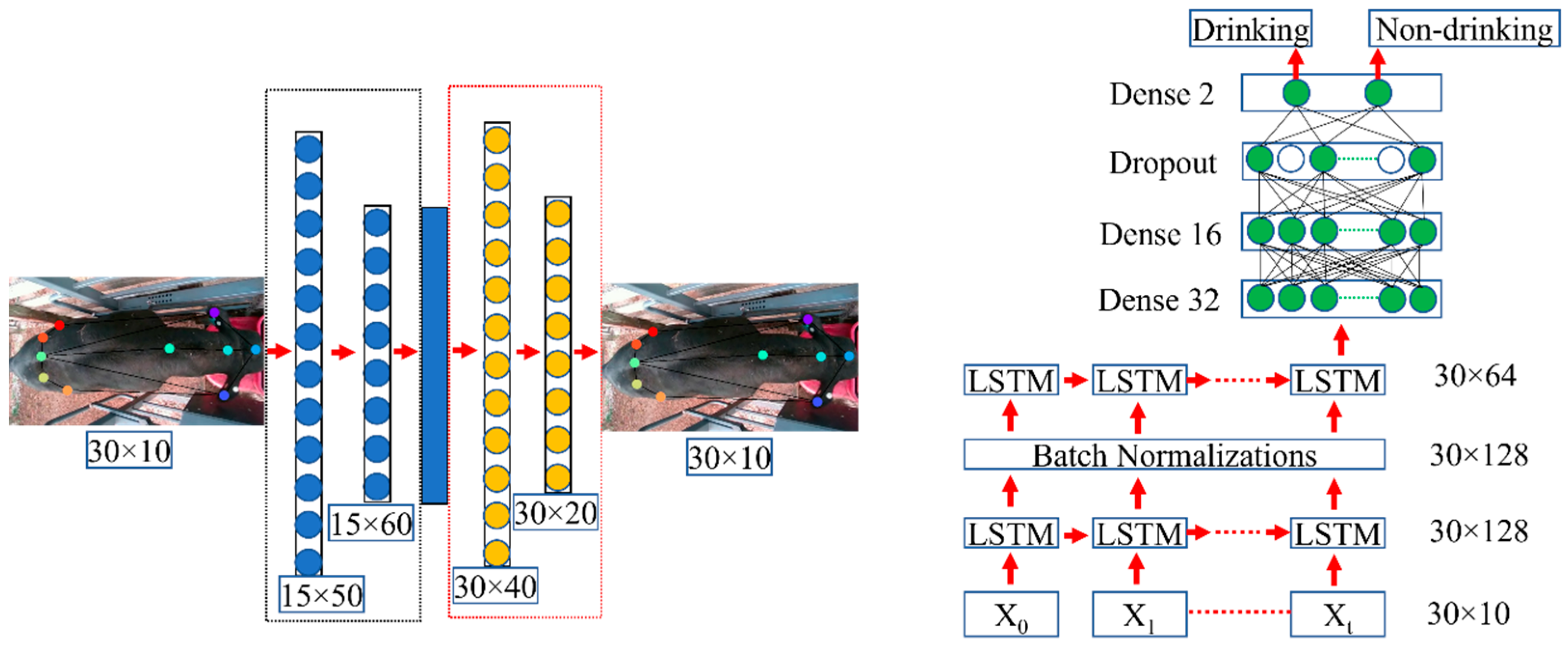
2.5. LSTM-Based Drinking Behavior Estimation
3. Results and Discussion
3.1. Pose Estimation
3.2. Evaluating the AE and LSTM Model Performance
3.3. Comparison of Different Related Studies
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Martinez, C.C.; Maples, J.G.; Benavidez, J. Beef Cattle Markets and COVID-19. Appl. Econ. Perspect. Policy 2021, 43, 304–314. [Google Scholar] [CrossRef]
- USDA. Cattle/Calf Receipts Comprised the Largest Portion of U.S. Animal/Animal Product Receipts in 2022. Available online: https://www.ers.usda.gov/data-products/chart-gallery/gallery/chart-detail/?chartId=76949 (accessed on 11 September 2023).
- Brown-Brandl, T.M. Understanding heat stress in beef cattle. Rev. Bras. Zootec. 2018, 47, e20160414. [Google Scholar] [CrossRef]
- Tuan, S.-A.; Rustia, D.J.A.; Hsu, J.-T.; Lin, T.-T. Frequency modulated continuous wave radar-based system for monitoring dairy cow respiration rate. Comput. Electron. Agric. 2022, 196, 106913. [Google Scholar] [CrossRef]
- González, L.; Bishop-Hurley, G.; Handcock, R.N.; Crossman, C. Behavioral classification of data from collars containing motion sensors in grazing cattle. Comput. Electron. Agric. 2015, 110, 91–102. [Google Scholar] [CrossRef]
- Smith, D.; Rahman, A.; Bishop-Hurley, G.J.; Hills, J.; Shahriar, S.; Henry, D.; Rawnsley, R. Behavior classification of cows fitted with motion collars: Decomposing multi-class classification into a set of binary problems. Comput. Electron. Agric. 2016, 131, 40–50. [Google Scholar] [CrossRef]
- Wang, S.; Li, Q.; Peng, J.; Niu, H. Effects of Long-Term Cold Stress on Growth Performance, Behavior, Physiological Parameters, and Energy Metabolism in Growing Beef Cattle. Animals 2023, 13, 1619. [Google Scholar] [CrossRef]
- Guo, Y.; He, D.; Chai, L. A Machine Vision-Based Method for Monitoring Scene-Interactive Behaviors of Dairy Calf. Animals 2020, 10, 190. [Google Scholar] [CrossRef]
- Jorquera-Chavez, M.; Fuentes, S.; Dunshea, F.R.; Warner, R.D.; Poblete, T.; Jongman, E.C. Modelling and Validation of Computer Vision Techniques to Assess Heart Rate, Eye Temperature, Ear-Base Temperature and Respiration Rate in Cattle. Animals 2019, 9, 1089. [Google Scholar] [CrossRef]
- Li, Z.; Song, L.; Duan, Y.; Wang, Y.; Song, H. Basic motion behaviour recognition of dairy cows based on skeleton and hybrid convolution algorithms. Comput. Electron. Agric. 2022, 196, 106889. [Google Scholar] [CrossRef]
- Gonzalez, L.F.; Montes, G.A.; Puig, E.; Johnson, S.; Mengersen, K.; Gaston, K.J. Unmanned Aerial Vehicles (UAVs) and Artificial Intelligence Revolutionizing Wildlife Monitoring and Conservation. Sensors 2016, 16, 97. [Google Scholar] [CrossRef]
- Tsai, Y.-C.; Hsu, J.-T.; Ding, S.-T.; Rustia, D.J.A.; Lin, T.-T. Assessment of dairy cow heat stress by monitoring drinking behaviour using an embedded imaging system. Biosyst. Eng. 2020, 199, 97–108. [Google Scholar] [CrossRef]
- Wu, D.; Yin, X.; Jiang, B.; Jiang, M.; Li, Z.; Song, H. Detection of the respiratory rate of standing cows by combining the Deeplab V3+ semantic segmentation model with the phase-based video magnification algorithm. Biosyst. Eng. 2020, 192, 72–89. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Mathis, M.W.; Mathis, A. Deep learning tools for the measurement of animal behavior in neuroscience. Curr. Opin. Neurobiol. 2020, 60, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef]
- Mathis, A.; Biasi, T.; Schneider, S.; Yuksekgonul, M.; Rogers, B.; Bethge, M.; Mathis, M.W. Pretraining Boosts Out-of-Domain Robustness for Pose Estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 1859–1868. [Google Scholar]
- Chen, C.; Zhu, W.; Steibel, J.; Siegford, J.; Han, J.; Norton, T. Classification of drinking and drinker-playing in pigs by a video-based deep learning method. Biosyst. Eng. 2020, 196, 1–14. [Google Scholar] [CrossRef]
- Wu, D.; Wang, Y.; Han, M.; Song, L.; Shang, Y.; Zhang, X.; Song, H. Using a CNN-LSTM for basic behaviors detection of a single dairy cow in a complex environment. Comput. Electron. Agric. 2021, 182, 106016. [Google Scholar] [CrossRef]
- Nasiri, A.; Yoder, J.; Zhao, Y.; Hawkins, S.; Prado, M.; Gan, H. Pose estimation-based lameness recognition in broiler using CNN-LSTM network. Comput. Electron. Agric. 2022, 197, 106931. [Google Scholar] [CrossRef]
- Du, L.; Lu, Z.; Li, D. Broodstock breeding behaviour recognition based on Resnet50-LSTM with CBAM attention mechanism. Comput. Electron. Agric. 2022, 202, 107404. [Google Scholar] [CrossRef]
- Sejian, V.; Shashank, C.G.; Silpa, M.V.; Madhusoodan, A.P.; Devaraj, C.; Koenig, S. Non-Invasive Methods of Quantifying Heat Stress Response in Farm Animals with Special Reference to Dairy Cattle. Atmosphere 2022, 13, 1642. [Google Scholar] [CrossRef]
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator (VIA). Available online: https://www.robots.ox.ac.uk/~vgg/software/via/ (accessed on 20 September 2023).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Shu, H.; Bindelle, J.; Guo, L.; Gu, X. Determining the onset of heat stress in a dairy herd based on automated behaviour recognition. Biosyst. Eng. 2023, 226, 238–251. [Google Scholar] [CrossRef]
- Zhang, Y.; Ibrayim, M.; Hamdulla, A. Research on Cow Behavior Recognition Based on Improved SlowFast with 3DCBAM. In Proceedings of the 2023 5th International Conference on Communications, Information System and Computer Engineering (CISCE), Guangzhou, China, 14–16 April 2023; pp. 470–475. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Number | Accuracy (%) | Precision (%) | Recall (%) | Specificity (%) | F1 Score (%) | AUC (%) | Drinking Time (s) | Non-Drinking Time (s) |
|---|---|---|---|---|---|---|---|---|
| 1 | 98.25 | 100.00 | 95.24 | 100.00 | 97.56 | 97.62 | 20 | 37 |
| 2 | 96.49 | 97.50 | 97.50 | 94.12 | 97.50 | 95.81 | 40 | 17 |
| 3 | 94.74 | 100.00 | 90.32 | 100.00 | 94.92 | 95.16 | 28 | 29 |
| 4 | 98.25 | 100.00 | 97.62 | 100.00 | 98.80 | 98.81 | 42 | 15 |
| 5 | 98.28 | 100.00 | 97.30 | 100.00 | 98.63 | 98.65 | 36 | 22 |
| 6 | 98.28 | 100.00 | 94.44 | 100.00 | 97.14 | 97.22 | 17 | 41 |
| 7 | 98.28 | 100.00 | 92.86 | 100.00 | 96.30 | 96.43 | 13 | 45 |
| 8 | 96.56 | 95.12 | 100.00 | 89.48 | 97.50 | 94.74 | 41 | 17 |
| Dataset | Model | Recognition Accuracy (%) | Reference |
|---|---|---|---|
| Dairy cow image | YOLOv3 | 90.00 | [12] |
| Dairy cow video | VGG16 and LSTM | 95.00 | [19] |
| Dairy cow video | YOLOv5 | 97.50 | [25] |
| Dairy cow video | Slowfast | 92.60 | [26] |
| Beef cattle video | DeepLabCut and LSTM | 98.25 | Current study |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.N.; Yoder, J.; Nasiri, A.; Burns, R.T.; Gan, H. Analysis of the Drinking Behavior of Beef Cattle Using Computer Vision. Animals 2023, 13, 2984. https://doi.org/10.3390/ani13182984
Islam MN, Yoder J, Nasiri A, Burns RT, Gan H. Analysis of the Drinking Behavior of Beef Cattle Using Computer Vision. Animals. 2023; 13(18):2984. https://doi.org/10.3390/ani13182984
Chicago/Turabian StyleIslam, Md Nafiul, Jonathan Yoder, Amin Nasiri, Robert T. Burns, and Hao Gan. 2023. "Analysis of the Drinking Behavior of Beef Cattle Using Computer Vision" Animals 13, no. 18: 2984. https://doi.org/10.3390/ani13182984
APA StyleIslam, M. N., Yoder, J., Nasiri, A., Burns, R. T., & Gan, H. (2023). Analysis of the Drinking Behavior of Beef Cattle Using Computer Vision. Animals, 13(18), 2984. https://doi.org/10.3390/ani13182984