
Machine Learning Implementation in Membrane Bioreactor Systems: Progress, Challenges, and Future Perspectives: A Review



Abstract
:1. Introduction
2. Principles of Membrane Bioreactors
2.1. MBR Configurations and Components
2.2. Primary Challenges
2.3. Key Performance Indicators in MBR Processes
- (i)
- The efficiency of pollutant removal: The primary objective of the MBR system is the removal of organic matter, nutrients, and suspended solids. Efficiency is usually estimated by measuring the chemical oxygen demand (COD), biochemical oxygen demand (BOD), total suspended solids (TSS), nitrogen, and phosphorus in the influent and effluent. High efficiency indicates an effective operation of both biological decomposition and physical separation, resulting in high-quality effluent suitable for water reuse or discharge to water bodies.
- (ii)
- Membrane fouling rate: A critical indicator is the rate of membrane fouling, since it directly impacts the membrane lifetime, efficiency, and the cleaning procedure chosen. The fouling rate can be estimated by monitoring the increase in transmembrane pressure (TMP) or the decrease in permeate flux over time [3]. A low fouling rate indicates a stable MBR system with a reduced cleaning frequency. Since MBRs are dynamical systems where the occurrence of unpredicted events of TMP due to fouling is difficult to predict, the use of ML to predict membrane fouling is a very promising strategy.
- (iii)
- Energy consumption: Energy consumption is also a key indicator as it directly affects the viability and environmental footprint of the process. Energy requirements are primarily affected by the aeration system, pumping, and membrane fouling. Different strategies have been proposed to reduce the footprint, including optimization of the aeration rate, the use of more efficient equipment, and the use of more complex and efficient control algorithms to adjust the system parameters according to the observed conditions and the quality of the effluent and influent.
- (iv)
- Sludge production: As in most biological processes, sludge production is a drawback of the biological activity of the microorganisms, and sludge management remains an economic and environmental challenge [2]. In MBRs, sludge production can be quantified through the measurement of MLSS and the estimation of sludge removal. The goal is to achieve lower production rates, as they reduce the associated costs with sludge handling, dewatering, and disposal. MBRs are characterized by longer sludge retention times, and thus, they produce less sludge with higher biomass concentrations than conventional activated sludge systems.
3. Fundamentals of Machine Learning
3.1. Machine Learning Techniques and Algorithms
3.2. Model Evaluation and Validation
3.3. Challenges in Applying Machine Learning to MBR Systems
- (i)
- Data quality and availability: As in most artificial intelligence approaches, the presence of high-quality data is crucial for the accuracy and reliability of the produced ML model. Unfortunately, in the specific case of MBR systems, the quality of data can be significantly affected by issues such as sensor noise, missing values, and biases in data collection. Some well-known techniques, such as preprocessing, data cleaning, and normalization, can improve the data quality to some degree.
- (ii)
- Model interpretability: Although ML models can yield very accurate predictions due to their complex nature, the interpretability of the results and the correlation with the physical systems remain problematic and can limit their adoption by practitioners. The implementation of explainable AI techniques (such as local interpretable model-agnostic explanation (LIME), for example) could bridge the gap between the predictions and the human observer.
- (iii)
- Adaptability to changes in process conditions: As with most systems of environmental engineering and wastewater treatment, MBRs could show significant disturbances and fluctuations in the influent quality. Deviations from the steady state can affect the process efficiency and the quality of the effluent. With this in mind, the ML models must be designed to be able to adapt to these changes and provide reliable simulation results and predictions under a wide range of conditions. Different technologies, such as online learning, can be used to enhance the adaptation of the models in MBR applications.
3.4. Applications of Machine Learning in Membrane Bioreactor Systems
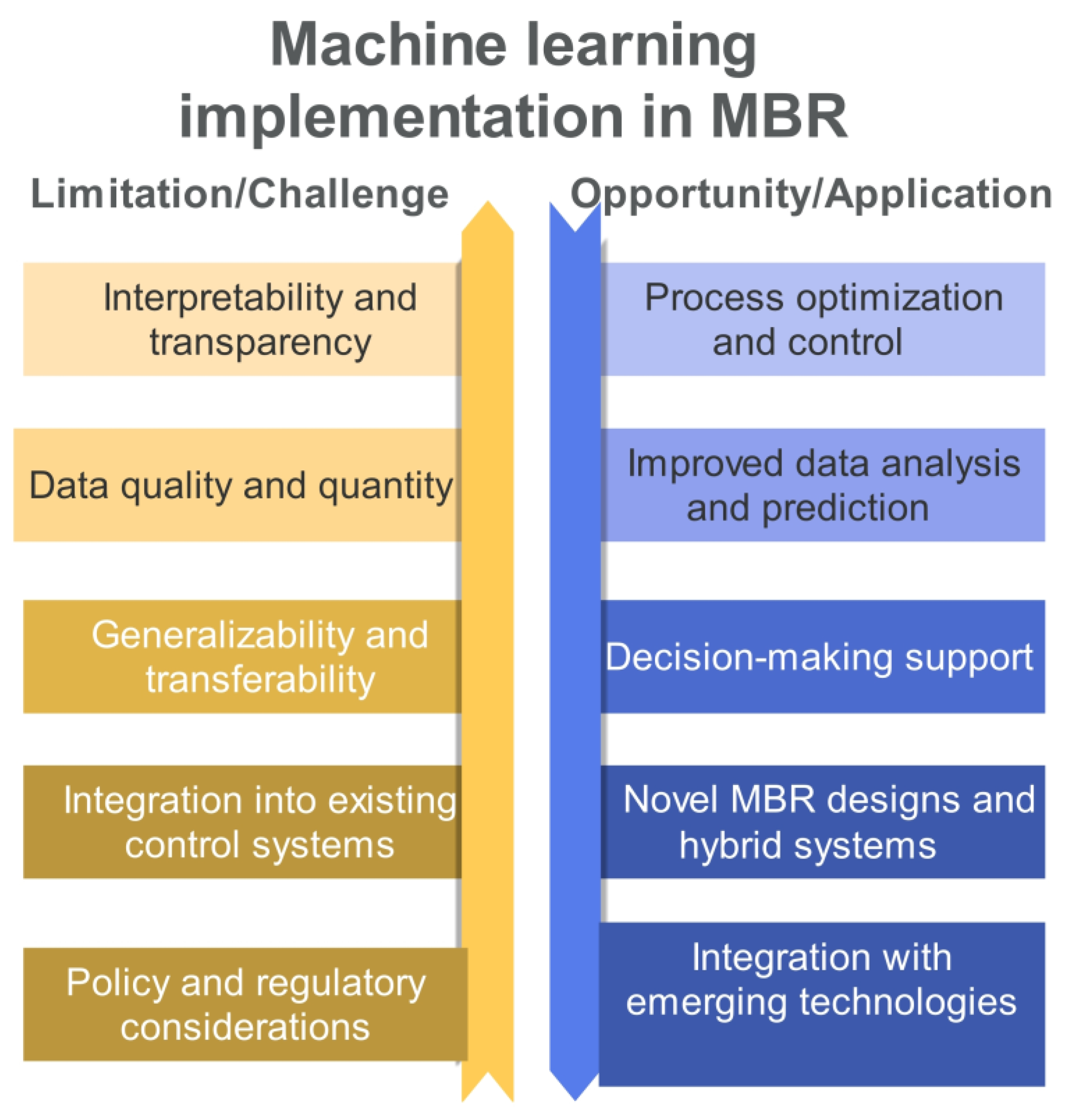
3.5. Challenges and Limitations of ML in MBR Wastewater Treatment
3.6. Integration of ML Models into Existing Control Systems
3.7. Enhancing Membrane Bioreactor Design through Data-Driven Machine Learning for Sustainable Wastewater Treatment and Resource Recovery
3.8. Policy and Regulatory Considerations for ML Implementation in Wastewater Treatment
4. Conclusions and Recommendations for Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Al-Asheh, S.; Bagheri, M.; Aidan, A. Membrane bioreactor for wastewater treatment: A review. Case Stud. Chem. Environ. Eng. 2021, 4, 100109. [Google Scholar] [CrossRef]
- Asante-Sackey, D.; Rathilal, S.; Tetteh, E.K.; Armah, E.K. Membrane Bioreactors for Produced Water Treatment: A Mini-Review. Membranes 2022, 12, 275. [Google Scholar] [CrossRef] [PubMed]
- Krzeminski, P.; Leverette, L.; Malamis, S.; Katsou, E. Membrane bioreactors—A review on recent developments in energy reduction, fouling control, novel configurations, LCA and market prospects. J. Memb. Sci. 2017, 527, 207–227. [Google Scholar] [CrossRef] [Green Version]
- Luo, W.; Hai, F.I.; Price, W.E.; Guo, W.; Ngo, H.H.; Yamamoto, K.; Nghiem, L.D. High retention membrane bioreactors: Challenges and opportunities. Bioresour. Technol. 2014, 167, 539–546. [Google Scholar] [CrossRef]
- Santos, A.; Ma, W.; Judd, S.J. Membrane bioreactors: Two decades of research and implementation. Desalination 2011, 273, 148–154. [Google Scholar] [CrossRef]
- Meng, F.; Chae, S.R.; Drews, A.; Kraume, M.; Shin, H.S.; Yang, F. Recent advances in membrane bioreactors (MBRs): Membrane fouling and membrane material. Water Res. 2009, 43, 1489–1512. [Google Scholar] [CrossRef]
- Goswami, L.; Vinoth Kumar, R.; Borah, S.N.; Arul Manikandan, N.; Pakshirajan, K.; Pugazhenthi, G. Membrane bioreactor and integrated membrane bioreactor systems for micropollutant removal from wastewater: A review. J. Water Process Eng. 2018, 26, 314–328. [Google Scholar] [CrossRef]
- Judd, S. The status of membrane bioreactor technology. Trends Biotechnol. 2008, 26, 109–116. [Google Scholar] [CrossRef]
- Xiao, K.; Liang, S.; Wang, X.; Chen, C.; Huang, X. Current state and challenges of full-scale membrane bioreactor applications: A critical review. Bioresour. Technol. 2019, 271, 473–481. [Google Scholar] [CrossRef]
- Bhattacharyya, A.; Liu, L.; Lee, K.; Miao, J. Review of Biological Processes in a Membrane Bioreactor (MBR): Effects of Wastewater Characteristics and Operational Parameters on Biodegradation Efficiency When Treating Industrial Oily Wastewater. J. Mar. Sci. Eng. 2022, 10, 1229. [Google Scholar] [CrossRef]
- Sahith, J.K.; Lal, B. Artificial Intelligence in Water Treatment Process Optimization. Gas Hydrate Water Treat. Technol. Econ. Ind. Asp. 2022, 139–153. [Google Scholar]
- El-Rawy, M.; Abd-Ellah, M.K.; Fathi, H.; Ahmed, A.K.A. Forecasting effluent and performance of wastewater treatment plant using different machine learning techniques. J. Water Process Eng. 2021, 44, 102380. [Google Scholar] [CrossRef]
- Ramesh, P.; Suganya, K.; Maheswari, T.U.; Sebastian, S.P.; Banu, K.S.P. Relevance of Artificial Intelligence in Wastewater Management. Digit. Agric. Revolut. Innov. Chall. Agric. Through Technol. Disrupt. 2022, 311–332. [Google Scholar]
- Kamali, M.; Appels, L.; Yu, X.; Aminabhavi, T.M.; Dewil, R. Artificial intelligence as a sustainable tool in wastewater treatment using membrane bioreactors. Chem. Eng. J. 2021, 417, 128070. [Google Scholar] [CrossRef]
- Nourani, V.; Asghari, P.; Sharghi, E. Artificial intelligence based ensemble modeling of wastewater treatment plant using jittered data. J. Clean. Prod. 2021, 291, 125772. [Google Scholar] [CrossRef]
- Zhao, L.; Dai, T.; Qiao, Z.; Sun, P.; Hao, J.; Yang, Y. Application of artificial intelligence to wastewater treatment: A bibliometric analysis and systematic review of technology, economy, management, and wastewater reuse. Process Saf. Environ. Prot. 2020, 133, 169–182. [Google Scholar] [CrossRef]
- Malviya, A.; Jaspal, D. Artificial intelligence as an upcoming technology in wastewater treatment: A comprehensive review. Environ. Technol. Rev. 2021, 10, 177–187. [Google Scholar] [CrossRef]
- Nourani, V.; Elkiran, G.; Abba, S.I. Wastewater treatment plant performance analysis using artificial intelligence—An ensemble approach. Water Sci. Technol. 2018, 78, 2064–2076. [Google Scholar] [CrossRef] [Green Version]
- Mamandipoor, B.; Majd, M.; Sheikhalishahi, S.; Modena, C.; Osmani, V. Monitoring and detecting faults in wastewater treatment plants using deep learning. Environ. Monit. Assess. 2020, 192, 148. [Google Scholar] [CrossRef]
- Ray, S. A Quick Review of Machine Learning Algorithms. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 35–39. [Google Scholar]
- Sundui, B.; Ramirez Calderon, O.A.; Abdeldayem, O.M.; Lázaro-Gil, J.; Rene, E.R.; Sambuu, U. Applications of machine learning algorithms for biological wastewater treatment: Updates and perspectives. Clean Technol. Environ. Policy 2021, 23, 127–143. [Google Scholar] [CrossRef]
- Sun, A.Y.; Scanlon, B.R. How can Big Data and machine learning benefit environment and water management: A survey of methods, applications, and future directions. Environ. Res. Lett. 2019, 14, 073001. [Google Scholar] [CrossRef]
- Azrour, M.; Mabrouki, J.; Fattah, G.; Guezzaz, A.; Aziz, F. Machine learning algorithms for efficient water quality prediction. Model. Earth Syst. Environ. 2022, 8, 2793–2801. [Google Scholar] [CrossRef]
- Hino, M.; Benami, E.; Brooks, N. Machine learning for environmental monitoring. Nat. Sustain. 2018, 1, 583–588. [Google Scholar] [CrossRef]
- Zuthi, M.F.R.; Ngo, H.H.; Guo, W.S. Modelling bioprocesses and membrane fouling in membrane bioreactor (MBR): A review towards finding an integrated model framework. Bioresour. Technol. 2012, 122, 119–129. [Google Scholar] [CrossRef] [PubMed]
- Iorhemen, O.T.; Hamza, R.A.; Tay, J.H. Membrane Bioreactor (MBR) Technology for Wastewater Treatment and Reclamation: Membrane Fouling. Membranes 2016, 6, 33. [Google Scholar] [CrossRef] [Green Version]
- Du, X.; Shi, Y.; Jegatheesan, V.; Ul Haq, I. A Review on the Mechanism, Impacts and Control Methods of Membrane Fouling in MBR System. Membranes 2020, 10, 24. [Google Scholar] [CrossRef] [Green Version]
- Meng, F.; Zhang, S.; Oh, Y.; Zhou, Z.; Shin, H.S.; Chae, S.R. Fouling in membrane bioreactors: An updated review. Water Res. 2017, 114, 151–180. [Google Scholar] [CrossRef]
- Dalmau, M.; Atanasova, N.; Gabarrón, S.; Rodriguez-Roda, I.; Comas, J. Comparison of a deterministic and a data driven model to describe MBR fouling. Chem. Eng. J. 2015, 260, 300–308. [Google Scholar] [CrossRef]
- Zhong, H.; Yuan, Y.; Luo, L.; Ye, J.; Chen, M.; Zhong, C. Water quality prediction of MBR based on machine learning: A novel dataset contribution analysis method. J. Water Process Eng. 2022, 50, 103296. [Google Scholar] [CrossRef]
- Li, W.; Li, C.; Wang, T. Application of machine learning algorithms in MBR simulation under big data platform. Water Pract. Technol. 2020, 15, 1238–1247. [Google Scholar] [CrossRef]
- Niu, C.; Li, X.; Dai, R.; Wang, Z. Artificial intelligence-incorporated membrane fouling prediction for membrane-based processes in the past 20 years: A critical review. Water Res. 2022, 216, 118299. [Google Scholar] [CrossRef]
- Zhao, Z.; Lou, Y.; Chen, Y.; Lin, H.; Li, R.; Yu, G. Prediction of interfacial interactions related with membrane fouling in a membrane bioreactor based on radial basis function artificial neural network (ANN). Bioresour. Technol. 2019, 282, 262–268. [Google Scholar] [CrossRef]
- Schmitt, F.; Banu, R.; Yeom, I.T.; Do, K.U. Development of artificial neural networks to predict membrane fouling in an anoxic-aerobic membrane bioreactor treating domestic wastewater. Biochem. Eng. J. 2018, 133, 47–58. [Google Scholar] [CrossRef]
- Wang, Z.; Zeng, J.; Shi, Y.; Ling, G. MBR membrane fouling diagnosis based on improved residual neural network. J. Environ. Chem. Eng. 2023, 11, 109742. [Google Scholar] [CrossRef]
- Jiang, T.; Zhang, H.; Gao, D.; Dong, F.; Gao, J.; Yang, F. Fouling characteristics of a novel rotating tubular membrane bioreactor. Chem. Eng. Process. Process Intensif. 2012, 62, 39–46. [Google Scholar] [CrossRef]
- Kulesha, O.; Maletskyi, Z.; Ratnaweera, H. Multivariate Chemometric Analysis of Membrane Fouling Patterns in Biofilm Ceramic Membrane Bioreactor. Water 2018, 10, 982. [Google Scholar] [CrossRef] [Green Version]
- Giwa, A.; Daer, S.; Ahmed, I.; Marpu, P.R.; Hasan, S.W. Experimental investigation and artificial neural networks ANNs modeling of electrically-enhanced membrane bioreactor for wastewater treatment. J. Water Process Eng. 2016, 11, 88–97. [Google Scholar] [CrossRef]
- Li, G.; Ji, J.; Ni, J.; Wang, S.; Guo, Y.; Hu, Y.; Liu, S.; Huang, S.F.; Li, Y.Y. Application of deep learning for predicting the treatment performance of real municipal wastewater based on one-year operation of two anaerobic membrane bioreactors. Sci. Total Environ. 2022, 813, 151920. [Google Scholar] [CrossRef]
- Kovacs, D.J.; Li, Z.; Baetz, B.W.; Hong, Y.; Donnaz, S.; Zhao, X.; Zhou, P.; Ding, H.; Dong, Q. Membrane fouling prediction and uncertainty analysis using machine learning: A wastewater treatment plant case study. J. Memb. Sci. 2022, 660, 120817. [Google Scholar] [CrossRef]
- Hosseinzadeh, A.; Zhou, J.L.; Altaee, A.; Baziar, M.; Li, X. Modeling water flux in osmotic membrane bioreactor by adaptive network-based fuzzy inference system and artificial neural network. Bioresour. Technol. 2020, 310, 123391. [Google Scholar] [CrossRef]
- Maere, T.; Villez, K.; Marsili-Libelli, S.; Naessens, W.; Nopens, I. Membrane bioreactor fouling behaviour assessment through principal component analysis and fuzzy clustering. Water Res. 2012, 46, 6132–6142. [Google Scholar] [CrossRef]
- Bagheri, M.; Akbari, A.; Mirbagheri, S.A. Advanced control of membrane fouling in filtration systems using artificial intelligence and machine learning techniques: A critical review. Process Saf. Environ. Prot. 2019, 123, 229–252. [Google Scholar] [CrossRef]
- Nam, K.J.; Heo, S.K.; Rhee, G.H.; Kim, M.J.; Yoo, C.K. Dual-objective optimization for energy-saving and fouling mitigation in MBR plants using AI-based influent prediction and an integrated biological-physical model. J. Memb. Sci. 2021, 626, 119208. [Google Scholar] [CrossRef]
- Nam, K.J.; Heo, S.K.; Loy-Benitez, J.; Ifaei, P.; Yoo, C.K. An autonomous operational trajectory searching system for an economic and environmental membrane bioreactor plant using deep reinforcement learning. Water Sci. Technol. 2020, 81, 1578–1587. [Google Scholar] [CrossRef] [PubMed]
- Santos, A.V.; Lin, A.R.A.; Amaral, M.C.S.; Oliveira, S.M.A.C. Improving control of membrane fouling on membrane bioreactors: A data-driven approach. Chem. Eng. J. 2021, 426, 131291. [Google Scholar] [CrossRef]
- Ba-Alawi, A.H.; Nam, K.J.; Heo, S.K.; Woo, T.Y.; Aamer, H.; Yoo, C.K. Explainable multisensor fusion-based automatic reconciliation and imputation of faulty and missing data in membrane bioreactor plants for fouling alleviation and energy saving. Chem. Eng. J. 2023, 452, 139220. [Google Scholar] [CrossRef]
- Zhang, W.; Ma, F.; Ren, M.; Yang, F. Application with Internet of things technology in the municipal industrial wastewater treatment based on membrane bioreactor process. Appl. Water Sci. 2021, 11, 52. [Google Scholar] [CrossRef]
- Lowe, M.; Qin, R.; Mao, X. A Review on Machine Learning, Artificial Intelligence, and Smart Technology in Water Treatment and Monitoring. Water 2022, 14, 1384. [Google Scholar] [CrossRef]
- Tsui, T.H.; Zhang, L.; Zhang, J.; Dai, Y.; Tong, Y.W. Engineering interface between bioenergy recovery and biogas desulfurization: Sustainability interplays of biochar application. Renew. Sustain. Energy Rev. 2022, 157, 112053. [Google Scholar] [CrossRef]
- Tsui, T.H.; van Loosdrecht, M.C.M.; Dai, Y.; Tong, Y.W. Machine learning and circular bioeconomy: Building new resource efficiency from diverse waste streams. Bioresour. Technol. 2023, 369, 128445. [Google Scholar] [CrossRef]


{kind=link}
| Algorithm | Description |
|---|---|
| Artificial neural network (ANN) | Artificial neural network (ANN) is a popular algorithm for predicting, optimizing, and controlling MBRs. ANNs can analyze complex datasets and identify patterns and relationships, thus enabling effective decision-making and control strategies. |
| Support vector machines (SVMs) | Support vector machines (SVMs) are mainly used in MBR systems for classification, regression, and future prediction. SVM models can identify and map nonlinear relationships between variables, enhancing the accuracy and efficiency of MBR control and optimization. |
| Random forest (RF) | Random forest (RF) employs decision trees to improve MBR systems’ accuracy. RF models can handle complex and large datasets and identify and quantify relationships between system input and output variables, leading to precise and effective control strategies. |
| Adaptive network-based fuzzy inference system (ANFIS) | Adaptive network-based fuzzy inference system (ANFIS) is a hybrid ML algorithm that integrates fuzzy logic and neural networks. It is characterized by enhanced prediction and control of MBRs. ANFIS models can capture numerical and linguistic information, thus facilitating effective decision-making and control. |
| Support vector regression (SVR) | Support vector regression (SVR) is a machine learning algorithm used in MBR systems for regression analysis and prediction. SVR models can identify and map nonlinear relationships between different variables, thereby improving the accuracy and effectiveness of MBR control and optimization. |
| Partial least squares regression (PLSR) | PLSR is an algorithm used in MBR systems combining principal component analysis and multiple regression. PLSR can deal with multivariate data that are collinear and reduce the dimensionality of the data, leading to more accurate and effective MBR optimization and control. |
| Deep learning (DL) | Deep learning (DL) is a subfield of machine learning characterized by using ANNs with multiple layers for improved accuracy and effectiveness. DL models can analyze large and complex datasets and identify patterns and relationships between parameters, thereby enabling precise and adaptive control strategies. |
| Technology | Description | Advantages | Limitations | Examples of Applications |
|---|---|---|---|---|
| Conventional control strategies | Control strategies based on fixed rules, heuristics, or manual adjustments by operators. | Simple and familiar for operators. Low cost and minimal equipment requirements. | Limited ability to adapt to changing conditions. Reduced efficiency and effectiveness compared to ML-based control. | Fixed setpoints for flow rates, dissolved oxygen, and other process variables. |
| Rule-based control systems | Control systems utilize logical rules to determine control actions based on sensors data and variables of the system. | Account for complex interrelationships between variables, allowing high customization for specific applications. | Limited ability for learning and adaptation with time. High cost. Complex implementation. | MBR aeration is controlled by fuzzy logic. Sludge removal. |
| ML-based control and optimization | Control and optimization strategies based on machine learning algorithms that learn from data to make decisions and control system variables. | Improved system performance and efficiency. Ability to adapt to changing conditions and learn over time. Decreased energy consumption and reduced chemical use. | High initial investment and equipment requirements. Complex implementation and difficult maintenance. | ML-based control for nutrient removal and MBR fouling control. |
| Hybrid systems combining conventional and ML-based control | Combine the benefits of both conventional and ML-based control strategies, improving system performance. | Very efficient. High customization for specific applications. | Requirement of additional equipment. Complex implementation. | Hybrid rule-based and ML-based, controlling membrane fouling and nutrient removal. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frontistis, Z.; Lykogiannis, G.; Sarmpanis, A. Machine Learning Implementation in Membrane Bioreactor Systems: Progress, Challenges, and Future Perspectives: A Review. Environments 2023, 10, 127. https://doi.org/10.3390/environments10070127
Frontistis Z, Lykogiannis G, Sarmpanis A. Machine Learning Implementation in Membrane Bioreactor Systems: Progress, Challenges, and Future Perspectives: A Review. Environments. 2023; 10(7):127. https://doi.org/10.3390/environments10070127
Chicago/Turabian StyleFrontistis, Zacharias, Grigoris Lykogiannis, and Anastasios Sarmpanis. 2023. "Machine Learning Implementation in Membrane Bioreactor Systems: Progress, Challenges, and Future Perspectives: A Review" Environments 10, no. 7: 127. https://doi.org/10.3390/environments10070127
APA StyleFrontistis, Z., Lykogiannis, G., & Sarmpanis, A. (2023). Machine Learning Implementation in Membrane Bioreactor Systems: Progress, Challenges, and Future Perspectives: A Review. Environments, 10(7), 127. https://doi.org/10.3390/environments10070127