The Influence of Seasonal Meteorology on Vehicle Exhaust PM2.5 in the State of California: A Hybrid Approach Based on Artificial Neural Network and Spatial Analysis


Abstract
:1. Introduction
2. Literature Review
2.1. Classical Regression Models for Particulate Matter
2.2. ANN Models for Particulate Matter
3. Study Area
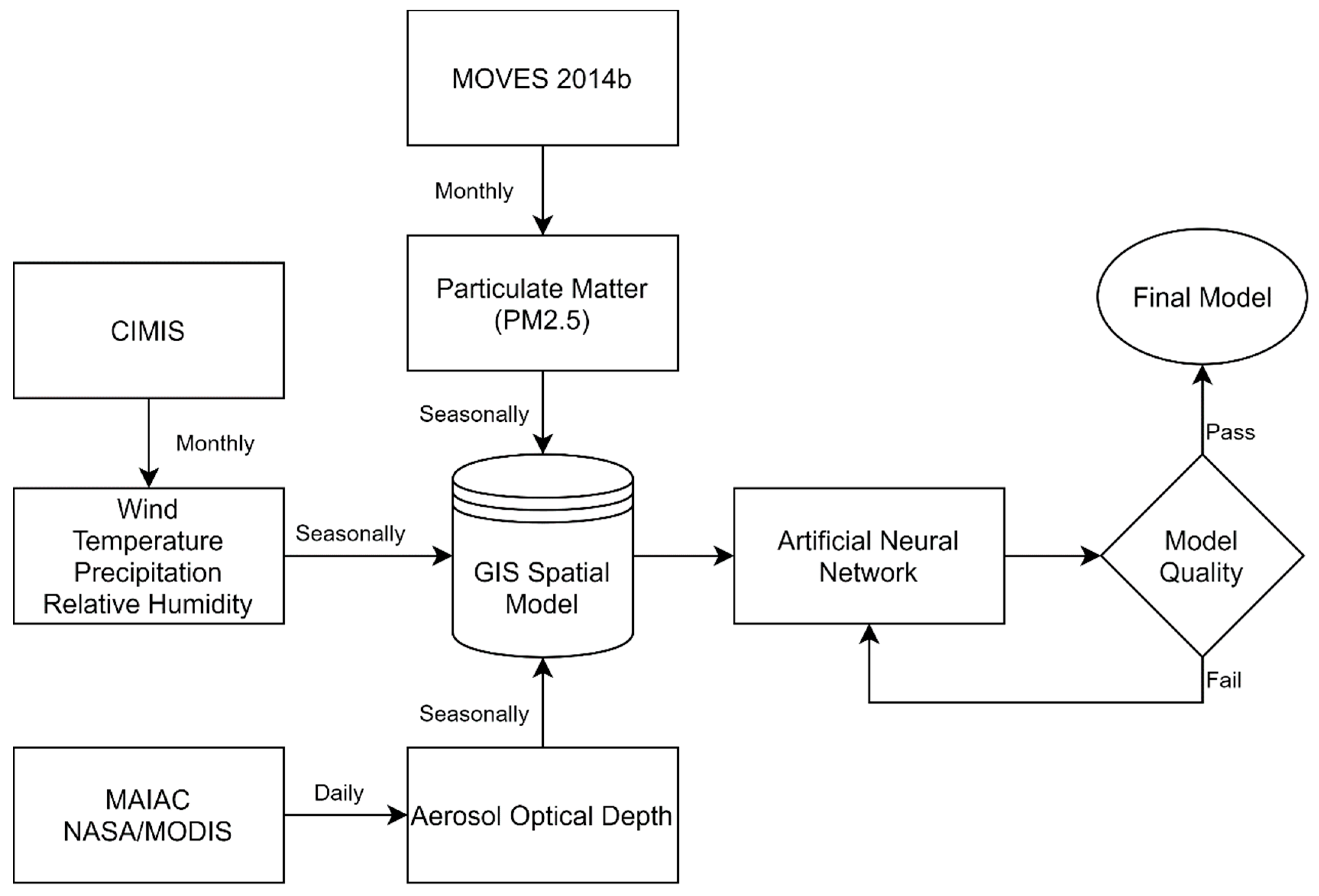
4. Materials and Methods
4.1. Artificial Neural Network (ANN)
4.2. Particulate Matter
4.3. Aerosol Optical Depth (AOD)
4.4. Meteorology
5. Results and Discussion
5.1. Seasonal Pattern of PM2.5
5.2. Seasonal Pattern of AOD
5.3. Seasonal Meteorology
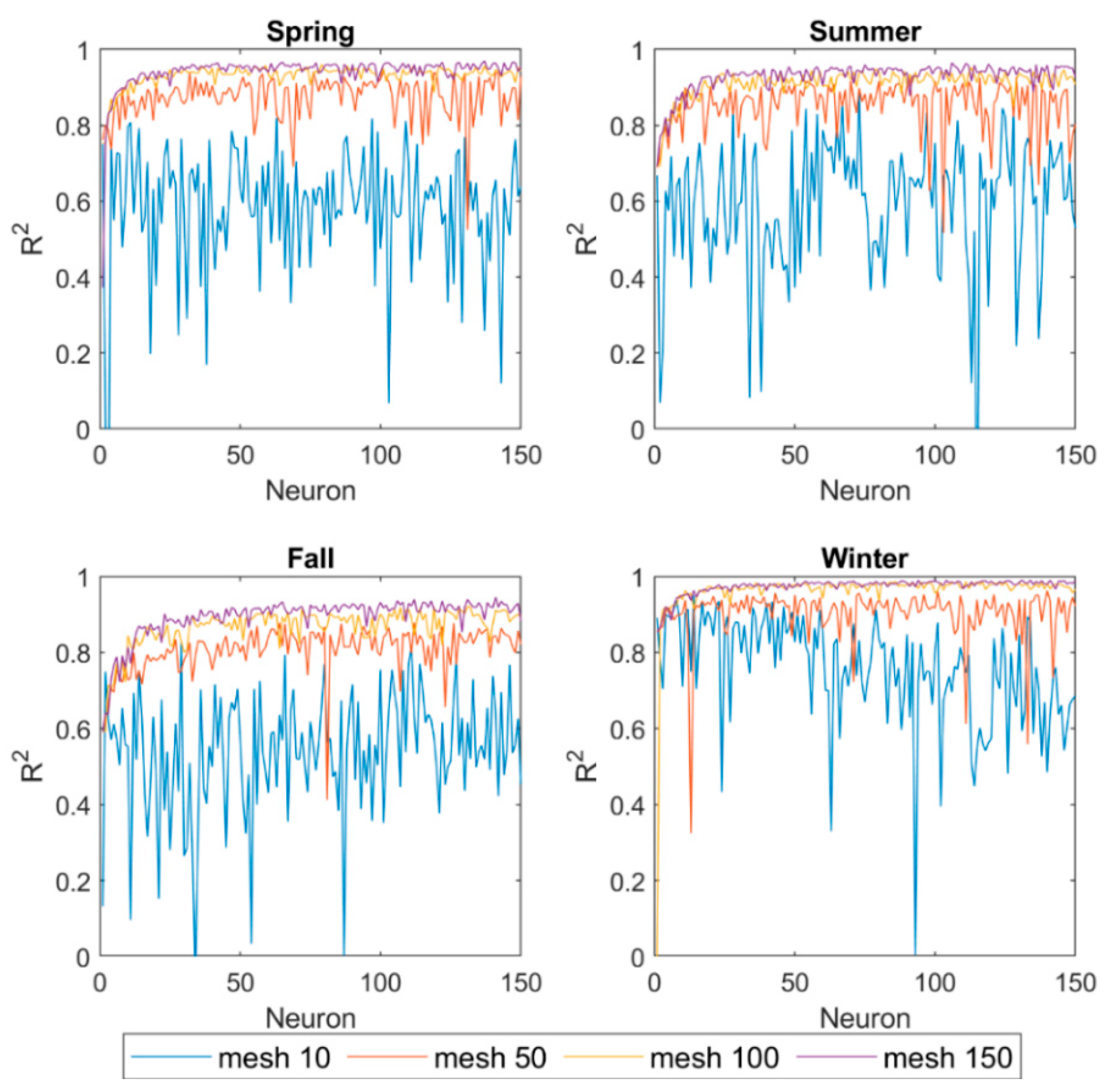
5.4. ANN Model Architecture
5.5. ANN Model Performance
6. Practical Applications
6.1. Prediction
6.2. Best Management Practice
7. Conclusions
- The pre-modeling evaluation indicated that increasing the grid density improved the accuracy of modeling results significantly.
- The Levenberg–Marquardt backpropagation algorithm with 130 neurons in each layer had the best performance.
- The maximum coefficient of determination was 0.991 for the winter of 2010, and the lowest coefficient of determination of 0.899 was for the summer of 2018, demonstrating the ANN model’s capability in PM2.5 predictions.
- Large variability in the dataset (having both very small and very big values) and the presence of some outliers affected the MAPE values.
- Winter had the best MAPE coefficient, where the possible reason was that winter had the most accurate estimate of AOD for vehicle emission particulate matter.
- Based on the sensitivity analysis, the most important variable among the independent variables was determined to be precipitation.
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Roy, S. Prediction of Particulate Matter Concentrations Using Artificial Neural Network. Resour. Environ. 2012, 2, 30–36. [Google Scholar] [CrossRef] [Green Version]
- Mohebbi, A.; Green, G.T.; Akbariyeh, S.; Yu, F.; Russo, B.J.; Smaglik, E.J. Development of Dust Storm Modeling for Use in Freeway Safety and Operations Management: An Arizona Case Study. Transp. Res. Rec. 2019, 2673, 175–187. [Google Scholar] [CrossRef]
- Mohebbi, A.; Yu, F.; Cai, S.; Akbariyeh, S.; Smaglik, E.J. Spatial study of particulate matter distribution, based on climatic indicators during major dust storms in the State of Arizona. Front. Earth Sci. 2020, 1–18. [Google Scholar] [CrossRef]
- Grgurić, S.; Križan, J.; Gašparac, G.; Antonić, O.; Špirić, Z.; Mamouri, R.; Christodoulou, A.; Nisantzi, A.; Agapiou, A.; Themistocleous, K.; et al. Relationship between MODIS based aerosol optical depth and PM10 over Croatia. Open Geosci. 2014, 6, 2–16. [Google Scholar] [CrossRef]
- Mohebbi, A.; Chang, H.I.; Hondula, D. WRF-Chem Model Simulations of Arizona Dust Storms. In Proceedings of the AGU Fall Meeting Abstracts, New Orleans, LA, USA, 11–15 December 2017. [Google Scholar]
- Mohebbi, A.; Akbariyeh, S. Geographically Weighted Regression Analysis of Particulate Matter Levels during Major Dust Storms. In Proceedings of the Association of Environmental Engineering and Science Professors (AEESP), Tempe, AZ, USA, 14–16 May 2019. [Google Scholar]
- Akbariyeh, S.; Patterson, B.M.; Kumar, M.; Li, Y. Quantification of vapor Intrusion pathways: An integration of modeling and site characterization. Vadose Zo. J. 2016, 15. [Google Scholar] [CrossRef]
- Wang, T.; Zhao, B.; Liou, K.N.; Gu, Y.; Jiang, Z.; Song, K.; Su, H.; Jerrett, M.; Zhu, Y. Mortality burdens in California due to air pollution attributable to local and nonlocal emissions. Environ. Int. 2019, 133, 105232. [Google Scholar] [CrossRef] [PubMed]
- Jaffe, D.; Hafner, W.; Chand, D.; Westerling, A.; Spracklen, D. Interannual variations in PM2.5 due to wildfires in the Western United States. Environ. Sci. Technol. 2008, 42, 2812–2818. [Google Scholar] [CrossRef] [PubMed]
- McCarthy, M.C.; Eisinger, D.S.; Hafner, H.R.; Chinkin, L.R.; Roberts, P.T.; Black, K.N.; Clark, N.N.; McMurry, P.H.; Winer, A.M. Particulate matter: A strategic vision for transportation-related research. Environ. Sci. Technol. 2006, 40, 5593–5599. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- USEPA. Environmental Protection Agency. User Guide for MOVES2014. EPA Report; EPA-420-B-14-055; Office of Transportation and Air Quality: Ann Arbor, MI, USA, 2014.
- Pauzi, H.M.; Abdullah, L. Airborne particulate matter research: A review of forecasting methods. J. Sustain. Sci. Manag. 2019, 14, 189–227. [Google Scholar]
- Reid, S.; Bai, S.; Du, Y.; Craig, K.; Erdakos, G.; Baringer, L.; Eisinger, D.; McCarthy, M.; Landsberg, K. Emissions modeling with MOVES and EMFAC to assess the potential for a transportation project to create particulate matter hot spots. Transp. Res. Rec. 2016, 2570, 12–20. [Google Scholar] [CrossRef]
- Gupta, P.; Christopher, S.A. Particulate matter air quality assessment using integrated surface, satellite, and meteorological products: Multiple regression approach. J. Geophys. Res. Atmos. 2009, 114. [Google Scholar] [CrossRef] [Green Version]
- Kamarul Zaman, N.A.F.; Kanniah, K.D.; Kaskaoutis, D.G. Estimating Particulate Matter using satellite based aerosol optical depth and meteorological variables in Malaysia. Atmos. Res. 2017, 193, 142–162. [Google Scholar] [CrossRef] [Green Version]
- Enotoriuwa, R.; Nwachukwu, E.; John, U. Spatial interpolation and land use regression modelling of air. In Proceedings of the 18th International HSE Biennial Conference on the Oil & Gas Industry in Nigeria, Lagos, Nigeria, 26–28 November 2018; pp. 136–148. [Google Scholar]
- Wu, Y.; Guo, J.; Zhang, X.; Tian, X.; Zhang, J.; Wang, Y.; Duan, J.; Li, X. Synergy of satellite and ground based observations in estimation of particulate matter in eastern China. Sci. Total Environ. 2012, 433, 20–30. [Google Scholar] [CrossRef] [PubMed]
- Yi, L.; Mengfan, T.; Kun, Y.; Yu, Z.; Xiaolu, Z.; Miao, Z.; Yan, S. Research on PM2.5 estimation and prediction method and changing characteristics analysis under long temporal and large spatial scale—A case study in China typical regions. Sci. Total Environ. 2019, 696, 133983. [Google Scholar] [CrossRef] [PubMed]
- Memarianfard, M.; Hatami, A.M. Artificial neural network forecast application for fine particulate matter concentration using meteorological data. Glob. J. Environ. Sci. Manag. 2017, 3, 333–340. [Google Scholar]
- Mohebbi, A.; Maruf, M.; Roubik, J.; Akbariyeh, S. Climate Change Impacts on Precipitation in Arid Regions: An Arizona Case Study. In Proceedings of the AGU Fall Meeting Abstracts, Washington, DC, USA, 10–14 December 2018. [Google Scholar]
- Wu, Z.; Fan, J.; Gao, Y.; Shang, H.; Song, H. Study on Prediction Model of Space-Time Distribution of Air Pollutants Based on Artificial Neural Network. Environ. Eng. Manag. J. 2019, 18, 1575–1590. [Google Scholar] [CrossRef]
- Vakili, M.; Sabbagh-Yazdi, S.R.; Khosrojerdi, S.; Kalhor, K. Evaluating the effect of particulate matter pollution on estimation of daily global solar radiation using artificial neural network modeling based on meteorological data. J. Clean. Prod. 2017, 141, 1275–1285. [Google Scholar] [CrossRef]
- Hagan, M.T.; Demuth, H.B.; Beale, M.H. Neural Network Design; PWS Publishing Co.: Boston, MA, USA, 1996. [Google Scholar]
- Beale, M.H.; Hagan, M.T.; Demuth, H.B. Neural network toolbox. User Guid. MathWorks 2010, 2, 13–390. [Google Scholar]
- Allen, J.O.; Mayo, P.R.; Hughes, L.S.; Salmon, L.G.; Cass, G.R. Emissions of size-segregated aerosols from on-road vehicles in the Caldecott Tunnel. Environ. Sci. Technol. 2001, 35, 4189–4197. [Google Scholar] [CrossRef]
- Li, X.; Dallmann, T.R.; May, A.A.; Stanier, C.O.; Grieshop, A.P.; Lipsky, E.M.; Robinson, A.L.; Presto, A.A. Size distribution of vehicle emitted primary particles measured in a traffic tunnel. Atmos. Environ. 2018, 191, 9–18. [Google Scholar] [CrossRef]
- Bishop, G.A. Three decades of on-road mobile source emissions reductions in South Los Angeles. J. Air Waste Manage. Assoc. 2019, 69, 967–976. [Google Scholar] [CrossRef] [PubMed]
- FEAT Fuel Efficiency Automobile Test Data Center. Available online: http://www.feat.biochem.du.edu/light_duty_vehicles.html (accessed on 12 October 2020).
- Vallamsundar, S.; Lin, J. Overview of US EPA new generation emission model: MOVES. Int. J. Transp. Urban Dev. 2011, 1, 39. [Google Scholar]
- Guensler, R.; Liu, H.; Xu, Y.; Akanser, A.; Kim, D.; Hunter, M.P.; Rodgers, M.O. Energy consumption and emissions modeling of individual vehicles. Transp. Res. Rec. 2017, 2627, 93–102. [Google Scholar] [CrossRef]
- EPA. Population and Activity of On-Road Vehicles in MOVES2014; United States Environmental Protection Agency: Washington, DC, USA, 2016.
- NASA Multi-Angle Implementation of Atmospheric Correction. Available online: https://modis-land.gsfc.nasa.gov/MAIAC.html (accessed on 20 January 2020).
- Lyapustin, A.; Wang, Y. MCD19A2 MODIS/Terra+Aqua Land Aerosol Optical Depth Daily L2G Global 1km SIN Grid V006 [Data set]. Available online: https://doi.org/10.5067/MODIS/MCD19A2.006 (accessed on 20 January 2020).
- Wolfe, R.E.; Roy, D.P.; Vermote, E. MODIS land data storage, gridding, and compositing methodology: Level 2 grid. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1324–1338. [Google Scholar] [CrossRef] [Green Version]
- CIMIS California Irrigation Management Information System. Available online: https://cimis.water.ca.gov/ (accessed on 20 January 2020).
- DMV California Department of Motor Vehicle, Estimated Vehicles Registered by County for the Period of January 1 through December 31, 2019. Available online: https://www.dmv.ca.gov/portal/uploads/2020/06/2019-Estimated-Vehicles-Registered-by-County-1.pdf (accessed on 2 September 2020).
- Ramos, É.M.S.; Bergstad, C.J.; Nässén, J. Understanding daily car use: Driving habits, motives, attitudes, and norms across trip purposes. Transp. Res. part F traffic Psychol. Behav. 2020, 68, 306–315. [Google Scholar] [CrossRef]
- Baith, K.; Lindsay, R.; Fu, G.; McClain, C.R. Data analysis system developed for ocean color satellite sensors. Eos, Trans. Am. Geophys. Union 2001, 82, 202. [Google Scholar] [CrossRef]
- Brown, J. Governor Brown Announces Federal Approval of Presidential Major Disaster Declaration for Shasta County. Off. Gov. 2018, 32, 309. [Google Scholar]
- Yang, J.; Hu, M. Filling the missing data gaps of daily MODIS AOD using spatiotemporal interpolation. Sci. Total Environ. 2018, 633, 677–683. [Google Scholar] [CrossRef]
- Skalski, P. Preventing Deep Neural Network from Overfitting. Available online: https://towardsdatascience.com/preventing-deep-neural-network-from-overfitting-953458db800a (accessed on 17 September 2020).
- Vashist, R.; Garg, M.L. Computing the Significance of an Independent Variable Using Rough Set Theory and Neural Network. Int. J. Res. Eng. Appl. Sci. 2013, 3, 122–136. [Google Scholar]
- Ouyang, W.; Guo, B.; Cai, G.; Li, Q.; Han, S.; Liu, B.; Liu, X. The washing effect of precipitation on particulate matter and the pollution dynamics of rainwater in downtown Beijing. Sci. Total Environ. 2015, 505, 306–314. [Google Scholar] [CrossRef]
- Wang, W.; Bruyère, C.; Duda, M.; Dudhia, J.; Gill, D.; Kavulich, M.; Keene, K.; Chen, M.; Lin, H.-C.; Michalakes, J.; et al. User’s Guides for the Advanced Research WRF (ARW) Modeling System Version 3.9; National Center for Atmospheric Research (NCAR): Boulder, CO, USA, 2018. [Google Scholar]
- Grell, G.A.; Peckham, S.E.; Schmitz, R.; McKeen, S.A.; Frost, G.; Skamarock, W.C.; Eder, B. Fully coupled “online” chemistry within the WRF model. Atmos. Environ. 2005, 39, 6957–6975. [Google Scholar] [CrossRef]
- CA.gov Governor Newsom Announces California Will Phase Out Gasoline-Powered Cars & Drastically Reduce Demand for Fossil Fuel in California’s Fight Against Climate Change. Available online: https://www.gov.ca.gov/ (accessed on 28 September 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maximum PM2.5 (kg) | Minimum PM2.5 (kg) | |||||
|---|---|---|---|---|---|---|
| Season/Year | 2010 | 2014 | 2018 | 2010 | 2014 | 2018 |
| Summer | 3.0 × 105 | 2.0 × 105 | 1.6 × 105 | 2.9 × 102 | 1.9 × 102 | 1.6 × 102 |
| Spring | 2.9 × 105 | 1.9 × 105 | 1.5 × 105 | 3.0 × 102 | 2.0 × 102 | 1.6 × 102 |
| Fall | 2.8 × 105 | 1.9 × 105 | 1.5 × 105 | 3.0 × 102 | 1.9 × 102 | 1.5 × 102 |
| Winter | 2.7 × 105 | 1.8 × 105 | 1.4 × 105 | 3.2 × 102 | 2.1 × 102 | 1.6 × 102 |
| File Name | Min Longitude | Max Longitude | Min Latitude | Max Latitude |
|---|---|---|---|---|
| h08v04 | −155.5724 | −117.4758 | 40.0000 | 50.0000 |
| h08v05 | −130.5407 | −103.9134 | 30.0000 | 40.0000 |
| h09v04 | −140.0151 | −104.4217 | 40.0000 | 50.0000 |
| Season | Year | Train | Validation | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE | RMSE | MAPE | RMSE | MAPE | |||||
| Spring | 2010 | 0.948 | 0.048 | 62.96% | 0.941 | 0.052 | 70.88% | 0.949 | 0.047 | 67.31% |
| 2014 | 0.955 | 0.044 | 37.69% | 0.943 | 0.050 | 41.94% | 0.946 | 0.047 | 43.58% | |
| 2018 | 0.952 | 0.046 | 41.99% | 0.939 | 0.051 | 48.94% | 0.938 | 0.053 | 44.29% | |
| Mean | 0.952 | 0.046 | 47.55% | 0.941 | 0.051 | 53.92% | 0.944 | 0.049 | 51.73% | |
| Summer | 2010 | 0.954 | 0.043 | 63.15% | 0.942 | 0.049 | 65.33% | 0.939 | 0.052 | 67.51% |
| 2014 | 0.905 | 0.063 | 72.69% | 0.892 | 0.067 | 78.65% | 0.870 | 0.071 | 79.38% | |
| 2018 | 0.899 | 0.065 | 59.81% | 0.874 | 0.071 | 63.95% | 0.884 | 0.073 | 58.27% | |
| Mean | 0.920 | 0.057 | 65.21% | 0.903 | 0.062 | 69.31% | 0.897 | 0.065 | 68.39% | |
| Fall | 2010 | 0.935 | 0.052 | 55.09% | 0.928 | 0.055 | 57.58% | 0.919 | 0.059 | 66.09% |
| 2014 | 0.947 | 0.047 | 42.77% | 0.945 | 0.047 | 45.12% | 0.930 | 0.053 | 46.15% | |
| 2018 | 0.960 | 0.041 | 34.89% | 0.950 | 0.048 | 35.55% | 0.948 | 0.049 | 40.39% | |
| Mean | 0.947 | 0.047 | 44.25% | 0.941 | 0.050 | 46.08% | 0.932 | 0.054 | 50.88% | |
| Winter | 2010 | 0.991 | 0.021 | 22.65% | 0.981 | 0.032 | 26.20% | 0.985 | 0.024 | 25.46% |
| 2014 | 0.980 | 0.030 | 26.95% | 0.977 | 0.031 | 28.70% | 0.979 | 0.030 | 27.81% | |
| 2018 | 0.980 | 0.030 | 26.34% | 0.963 | 0.042 | 29.34% | 0.967 | 0.039 | 32.03% | |
| Mean | 0.984 | 0.027 | 25.31% | 0.974 | 0.035 | 28.08% | 0.977 | 0.031 | 28.44% | |
| Importance | ||||
|---|---|---|---|---|
| Spring | Summer | Fall | Winter | |
| Aerosol Optical Depth | 0.20 | 0.10 | 0.12 | 0.12 |
| Precipitation | 0.33 * | 0.36 | 0.23 | 0.24 |
| Temperature | 0.09 | 0.15 | 0.29 | 0.16 |
| Relative Humidity | 0.24 | 0.16 | 0.18 | 0.30 |
| Wind | 0.14 | 0.23 | 0.17 | 0.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, F.; Mohebbi, A.; Cai, S.; Akbariyeh, S.; Russo, B.J.; Smaglik, E.J. The Influence of Seasonal Meteorology on Vehicle Exhaust PM2.5 in the State of California: A Hybrid Approach Based on Artificial Neural Network and Spatial Analysis. Environments 2020, 7, 102. https://doi.org/10.3390/environments7110102
Yu F, Mohebbi A, Cai S, Akbariyeh S, Russo BJ, Smaglik EJ. The Influence of Seasonal Meteorology on Vehicle Exhaust PM2.5 in the State of California: A Hybrid Approach Based on Artificial Neural Network and Spatial Analysis. Environments. 2020; 7(11):102. https://doi.org/10.3390/environments7110102
Chicago/Turabian StyleYu, Fan, Amin Mohebbi, Shiqing Cai, Simin Akbariyeh, Brendan J. Russo, and Edward J. Smaglik. 2020. "The Influence of Seasonal Meteorology on Vehicle Exhaust PM2.5 in the State of California: A Hybrid Approach Based on Artificial Neural Network and Spatial Analysis" Environments 7, no. 11: 102. https://doi.org/10.3390/environments7110102
APA StyleYu, F., Mohebbi, A., Cai, S., Akbariyeh, S., Russo, B. J., & Smaglik, E. J. (2020). The Influence of Seasonal Meteorology on Vehicle Exhaust PM2.5 in the State of California: A Hybrid Approach Based on Artificial Neural Network and Spatial Analysis. Environments, 7(11), 102. https://doi.org/10.3390/environments7110102